mirror of
https://github.com/huggingface/diffusers.git
synced 2026-01-27 17:22:53 +03:00
Add LLM-grounded Diffusion (LMD+) pipeline (#5634)
* Add LLM-grounded Diffusion (LMD+) pipeline * Update the formatting * Applied formatting
This commit is contained in:
@@ -8,6 +8,7 @@ If a community doesn't work as expected, please open an issue and ping the autho
|
||||
|
||||
| Example | Description | Code Example | Colab | Author |
|
||||
|:--------------------------------------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:------------------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------:|
|
||||
| LLM-grounded Diffusion (LMD+) | LMD greatly improves the prompt following ability of text-to-image generation models by introducing an LLM as a front-end prompt parser and layout planner. [Project page.](https://llm-grounded-diffusion.github.io/) [See our full codebase (also with diffusers).](https://github.com/TonyLianLong/LLM-groundedDiffusion) | [LLM-grounded Diffusion (LMD+)](#llm-grounded-diffusion) | [Huggingface Demo](https://huggingface.co/spaces/longlian/llm-grounded-diffusion) | [Long (Tony) Lian](https://tonylian.com/) |
|
||||
| CLIP Guided Stable Diffusion | Doing CLIP guidance for text to image generation with Stable Diffusion | [CLIP Guided Stable Diffusion](#clip-guided-stable-diffusion) | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/CLIP_Guided_Stable_diffusion_with_diffusers.ipynb) | [Suraj Patil](https://github.com/patil-suraj/) |
|
||||
| One Step U-Net (Dummy) | Example showcasing of how to use Community Pipelines (see https://github.com/huggingface/diffusers/issues/841) | [One Step U-Net](#one-step-unet) | - | [Patrick von Platen](https://github.com/patrickvonplaten/) |
|
||||
| Stable Diffusion Interpolation | Interpolate the latent space of Stable Diffusion between different prompts/seeds | [Stable Diffusion Interpolation](#stable-diffusion-interpolation) | - | [Nate Raw](https://github.com/nateraw/) |
|
||||
@@ -55,6 +56,82 @@ pipe = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", custo
|
||||
|
||||
## Example usages
|
||||
|
||||
### LLM-grounded Diffusion
|
||||
|
||||
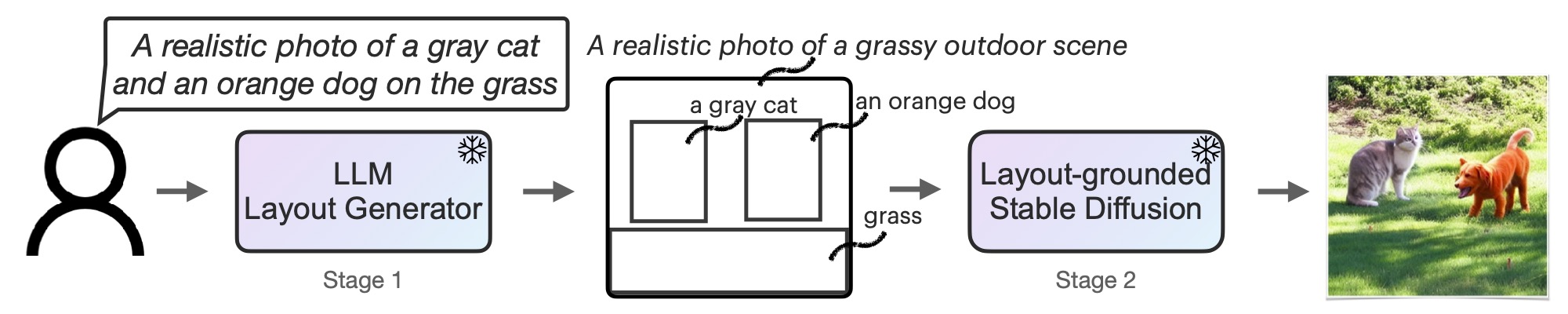
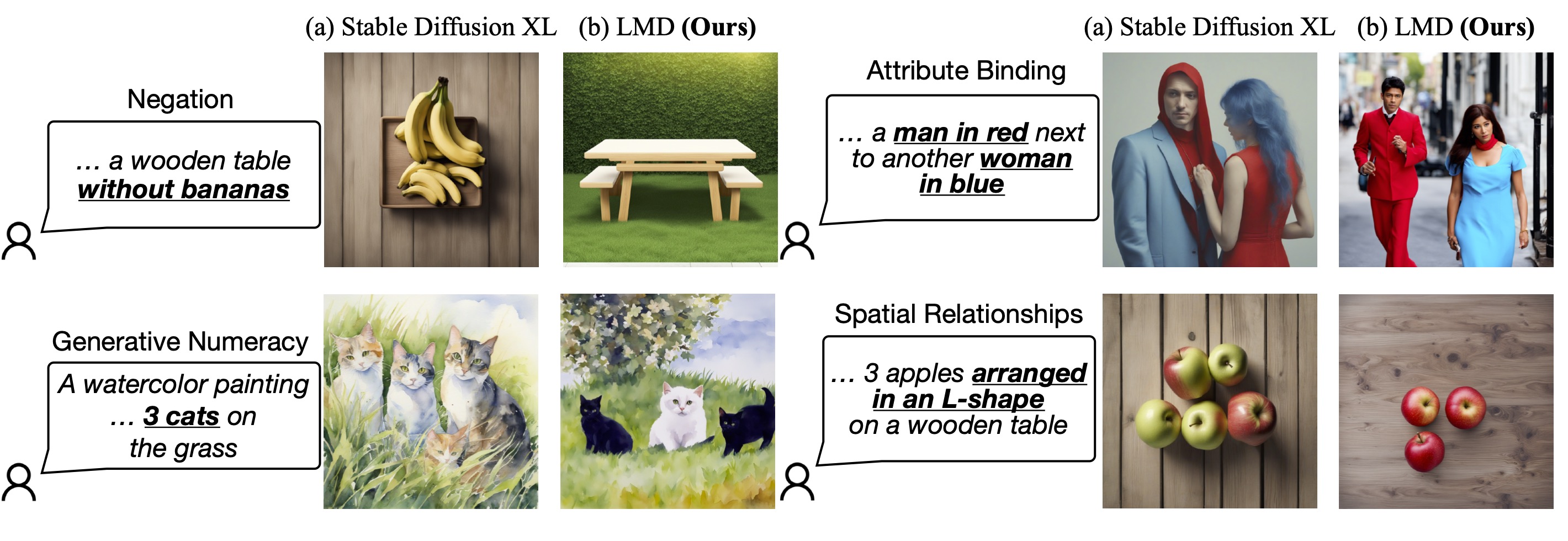
LMD and LMD+ greatly improves the prompt understanding ability of text-to-image generation models by introducing an LLM as a front-end prompt parser and layout planner. It improves spatial reasoning, the understanding of negation, attribute binding, generative numeracy, etc. in a unified manner without explicitly aiming for each. LMD is completely training-free (i.e., uses SD model off-the-shelf). LMD+ takes in additional adapters for better control. This is a reproduction of LMD+ model used in our work. [Project page.](https://llm-grounded-diffusion.github.io/) [See our full codebase (also with diffusers).](https://github.com/TonyLianLong/LLM-groundedDiffusion)
|
||||
|
||||
|
||||
|
||||
|
||||
This pipeline can be used with an LLM or on its own. We provide a parser that parses LLM outputs to the layouts. You can obtain the prompt to input to the LLM for layout generation [here](https://github.com/TonyLianLong/LLM-groundedDiffusion/blob/main/prompt.py). After feeding the prompt to an LLM (e.g., GPT-4 on ChatGPT website), you can feed the LLM response into our pipeline.
|
||||
|
||||
The following code has been tested on 1x RTX 4090, but it should also support GPUs with lower GPU memory.
|
||||
|
||||
#### Use this pipeline with an LLM
|
||||
```python
|
||||
import torch
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
pipe = DiffusionPipeline.from_pretrained(
|
||||
"longlian/lmd_plus",
|
||||
custom_pipeline="llm-grounded-diffusion",
|
||||
variant="fp16", torch_dtype=torch.float16
|
||||
)
|
||||
pipe.enable_model_cpu_offload()
|
||||
|
||||
# Generate directly from a text prompt and an LLM response
|
||||
prompt = "a waterfall and a modern high speed train in a beautiful forest with fall foliage"
|
||||
phrases, boxes, bg_prompt, neg_prompt = pipe.parse_llm_response("""
|
||||
[('a waterfall', [71, 105, 148, 258]), ('a modern high speed train', [255, 223, 181, 149])]
|
||||
Background prompt: A beautiful forest with fall foliage
|
||||
Negative prompt:
|
||||
""")
|
||||
|
||||
images = pipe(
|
||||
prompt=prompt,
|
||||
negative_prompt=neg_prompt,
|
||||
phrases=phrases,
|
||||
boxes=boxes,
|
||||
gligen_scheduled_sampling_beta=0.4,
|
||||
output_type="pil",
|
||||
num_inference_steps=50,
|
||||
lmd_guidance_kwargs={}
|
||||
).images
|
||||
|
||||
images[0].save("./lmd_plus_generation.jpg")
|
||||
```
|
||||
|
||||
#### Use this pipeline on its own for layout generation
|
||||
```python
|
||||
import torch
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
pipe = DiffusionPipeline.from_pretrained(
|
||||
"longlian/lmd_plus",
|
||||
custom_pipeline="llm-grounded-diffusion",
|
||||
variant="fp16", torch_dtype=torch.float16
|
||||
)
|
||||
pipe.enable_model_cpu_offload()
|
||||
|
||||
# Generate an image described by the prompt and
|
||||
# insert objects described by text at the region defined by bounding boxes
|
||||
prompt = "a waterfall and a modern high speed train in a beautiful forest with fall foliage"
|
||||
boxes = [[0.1387, 0.2051, 0.4277, 0.7090], [0.4980, 0.4355, 0.8516, 0.7266]]
|
||||
phrases = ["a waterfall", "a modern high speed train"]
|
||||
|
||||
images = pipe(
|
||||
prompt=prompt,
|
||||
phrases=phrases,
|
||||
boxes=boxes,
|
||||
gligen_scheduled_sampling_beta=0.4,
|
||||
output_type="pil",
|
||||
num_inference_steps=50,
|
||||
lmd_guidance_kwargs={}
|
||||
).images
|
||||
|
||||
images[0].save("./lmd_plus_generation.jpg")
|
||||
```
|
||||
|
||||
### CLIP Guided Stable Diffusion
|
||||
|
||||
CLIP guided stable diffusion can help to generate more realistic images
|
||||
|
||||
1015
examples/community/llm_grounded_diffusion.py
Normal file
1015
examples/community/llm_grounded_diffusion.py
Normal file
File diff suppressed because it is too large
Load Diff
Reference in New Issue
Block a user