mirror of
https://github.com/huggingface/diffusers.git
synced 2026-01-27 17:22:53 +03:00
improve readme
This commit is contained in:
48
README.md
48
README.md
@@ -1,23 +1,57 @@
|
||||
# Diffusers
|
||||
<p align="center">
|
||||
<br>
|
||||
<img src="https://raw.githubusercontent.com/huggingface/diffusers/master/docs/source/imgs/diffusers_library.jpg" width="400"/>
|
||||
<br>
|
||||
<p>
|
||||
<p align="center">
|
||||
<a href="https://github.com/huggingface/diffusers/blob/master/LICENSE">
|
||||
<img alt="GitHub" src="https://img.shields.io/github/license/huggingface/datasets.svg?color=blue">
|
||||
</a>
|
||||
<a href="https://github.com/huggingface/diffusers/releases">
|
||||
<img alt="GitHub release" src="https://img.shields.io/github/release/huggingface/datasets.svg">
|
||||
</a>
|
||||
<a href="CODE_OF_CONDUCT.md">
|
||||
<img alt="Contributor Covenant" src="https://img.shields.io/badge/Contributor%20Covenant-2.0-4baaaa.svg">
|
||||
</a>
|
||||
<a href="https://zenodo.org/badge/latestdoi/250213286"><img src="https://zenodo.org/badge/250213286.svg" alt="DOI"></a>
|
||||
</p>
|
||||
|
||||
🤗 Diffusers provides pretrained diffusion models across multiple modalities, such as vision and audio, and serves
|
||||
as a modular toolbox for inference and training of diffusion models.
|
||||
|
||||
More precisely, 🤗 Diffusers offers:
|
||||
|
||||
- State-of-the-art diffusion pipelines that can be run in inference with just a couple of lines of code (see [src/diffusers/pipelines](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines)).
|
||||
- Various noise schedulers that can be used interchangeably for the prefered speed vs. quality trade-off in inference (see [src/diffusers/schedulers](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers)).
|
||||
- Multiple types of diffusion models, such as UNet, that can be used as building blocks in an end-to-end diffusion system (see [src/diffusers/models](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models)).
|
||||
- Training examples to show how to train the most popular diffusion models (see [examples](https://github.com/huggingface/diffusers/tree/main/examples))
|
||||
|
||||
## Definitions
|
||||
|
||||
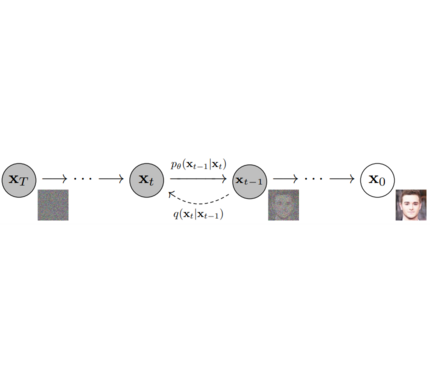
**Models**: Single neural network that models p_θ(x_t-1|x_t) and is trained to “denoise” to image
|
||||
*Examples: UNet, Conditioned UNet, 3D UNet, Transformer UNet*
|
||||
**Models**: Neural network that models **p_θ(x_t-1|x_t)** (see image below) and is trained end-to-end to *denoise* a noisy input to an image.
|
||||
*Examples*: UNet, Conditioned UNet, 3D UNet, Transformer UNet
|
||||
|
||||
|
||||
|
||||
**Schedulers**: Algorithm to compute previous image according to alpha, beta schedule and to sample noise. Should be used for both *training* and *inference*.
|
||||
*Example: Gaussian DDPM, DDIM, PMLS, DEIN*
|
||||
**Schedulers**: Algorithm class for both **inference** and **training**.
|
||||
The class provides functionality to compute previous image according to alpha, beta schedule as well as predict noise for training.
|
||||
*Examples*: [DDPM](https://arxiv.org/abs/2006.11239), [DDIM](https://arxiv.org/abs/2010.02502), [PNDM](https://arxiv.org/abs/2202.09778), [DEIS](https://arxiv.org/abs/2204.13902)
|
||||
|
||||

|
||||

|
||||
|
||||
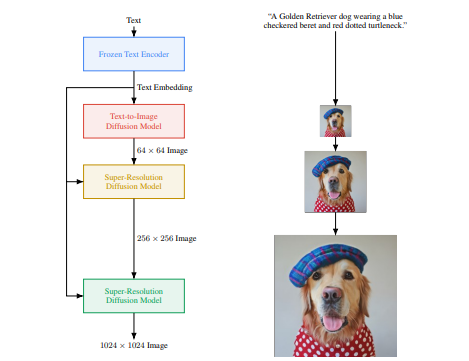
**Diffusion Pipeline**: End-to-end pipeline that includes multiple diffusion models, possible text encoders, CLIP
|
||||
*Example: GLIDE,CompVis/Latent-Diffusion, Imagen, DALL-E*
|
||||
**Diffusion Pipeline**: End-to-end pipeline that includes multiple diffusion models, possible text encoders, ...
|
||||
*Examples*: GLIDE, Latent-Diffusion, Imagen, DALL-E 2
|
||||
|
||||
|
||||
|
||||
|
||||
## Philosophy
|
||||
|
||||
- Readability and clarity is prefered over highly optimized code. A strong importance is put on providing readable, intuitive and elementary code desgin. *E.g.*, the provided [schedulers](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers) are separated from the provided [models](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models) and provide well-commented code that can be read alongside the original paper.
|
||||
- Diffusers is **modality independent** and focusses on providing pretrained models and tools to build systems that generate **continous outputs**, *e.g.* vision and audio.
|
||||
- Diffusion models and schedulers are provided as consise, elementary building blocks whereas diffusion pipelines are a collection of end-to-end diffusion systems that can be used out-of-the-box, should stay as close as possible to their original implementation and can include components of other library, such as text-encoders. Examples for diffusion pipelines are [Glide](https://github.com/openai/glide-text2im) and [Latent Diffusion](https://github.com/CompVis/latent-diffusion).
|
||||
|
||||
## Quickstart
|
||||
|
||||
```
|
||||
|
||||
BIN
docs/source/imgs/diffusers_library.jpg
Normal file
BIN
docs/source/imgs/diffusers_library.jpg
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 14 KiB |
Reference in New Issue
Block a user