mirror of
https://github.com/huggingface/diffusers.git
synced 2026-01-27 17:22:53 +03:00
Add Kandinsky 2.1 (#3308)
add kandinsky2.1 --------- Co-authored-by: yiyixuxu <yixu310@gmail,com> Co-authored-by: Ayush Mangal <43698245+ayushtues@users.noreply.github.com> Co-authored-by: ayushmangal <ayushmangal@microsoft.com> Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com> Co-authored-by: Sayak Paul <spsayakpaul@gmail.com>
This commit is contained in:
@@ -166,6 +166,8 @@
|
||||
title: DiT
|
||||
- local: api/pipelines/if
|
||||
title: IF
|
||||
- local: api/pipelines/kandinsky
|
||||
title: Kandinsky
|
||||
- local: api/pipelines/latent_diffusion
|
||||
title: Latent Diffusion
|
||||
- local: api/pipelines/paint_by_example
|
||||
|
||||
306
docs/source/en/api/pipelines/kandinsky.mdx
Normal file
306
docs/source/en/api/pipelines/kandinsky.mdx
Normal file
@@ -0,0 +1,306 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Kandinsky
|
||||
|
||||
## Overview
|
||||
|
||||
Kandinsky 2.1 inherits best practices from [DALL-E 2](https://arxiv.org/abs/2204.06125) and [Latent Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/latent_diffusion), while introducing some new ideas.
|
||||
|
||||
It uses [CLIP](https://huggingface.co/docs/transformers/model_doc/clip) for encoding images and text, and a diffusion image prior (mapping) between latent spaces of CLIP modalities. This approach enhances the visual performance of the model and unveils new horizons in blending images and text-guided image manipulation.
|
||||
|
||||
The Kandinsky model is created by [Arseniy Shakhmatov](https://github.com/cene555), [Anton Razzhigaev](https://github.com/razzant), [Aleksandr Nikolich](https://github.com/AlexWortega), [Igor Pavlov](https://github.com/boomb0om), [Andrey Kuznetsov](https://github.com/kuznetsoffandrey) and [Denis Dimitrov](https://github.com/denndimitrov) and the original codebase can be found [here](https://github.com/ai-forever/Kandinsky-2)
|
||||
|
||||
## Available Pipelines:
|
||||
|
||||
| Pipeline | Tasks | Colab
|
||||
|---|---|:---:|
|
||||
| [pipeline_kandinsky.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/kandinsky/pipeline_kandinsky.py) | *Text-to-Image Generation* | - |
|
||||
| [pipeline_kandinsky_inpaint.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/kandinsky/pipeline_kandinsky_inpaint.py) | *Image-Guided Image Generation* | - |
|
||||
| [pipeline_kandinsky_img2img.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/kandinsky/pipeline_kandinsky_img2img.py) | *Image-Guided Image Generation* | - |
|
||||
|
||||
## Usage example
|
||||
|
||||
In the following, we will walk you through some cool examples of using the Kandinsky pipelines to create some visually aesthetic artwork.
|
||||
|
||||
### Text-to-Image Generation
|
||||
|
||||
For text-to-image generation, we need to use both [`KandinskyPriorPipeline`] and [`KandinskyPipeline`]. The first step is to encode text prompts with CLIP and then diffuse the CLIP text embeddings to CLIP image embeddings, as first proposed in [DALL-E 2](https://cdn.openai.com/papers/dall-e-2.pdf). Let's throw a fun prompt at Kandinsky to see what it comes up with :)
|
||||
|
||||
```python
|
||||
prompt = "A alien cheeseburger creature eating itself, claymation, cinematic, moody lighting"
|
||||
negative_prompt = "low quality, bad quality"
|
||||
```
|
||||
|
||||
We will pass both the `prompt` and `negative_prompt` to our prior diffusion pipeline. In contrast to other diffusion pipelines, such as Stable Diffusion, the `prompt` and `negative_prompt` shall be passed separately so that we can retrieve a CLIP image embedding for each prompt input. You can use `guidance_scale`, and `num_inference_steps` arguments to guide this process, just like how you would normally do with all other pipelines in diffusers.
|
||||
|
||||
```python
|
||||
from diffusers import KandinskyPriorPipeline
|
||||
import torch
|
||||
|
||||
# create prior
|
||||
pipe_prior = KandinskyPriorPipeline.from_pretrained(
|
||||
"kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16
|
||||
)
|
||||
pipe_prior.to("cuda")
|
||||
|
||||
generator = torch.Generator(device="cuda").manual_seed(12)
|
||||
image_emb = pipe_prior(
|
||||
prompt, guidance_scale=1.0, num_inference_steps=25, generator=generator, negative_prompt=negative_prompt
|
||||
).images
|
||||
|
||||
zero_image_emb = pipe_prior(
|
||||
negative_prompt, guidance_scale=1.0, num_inference_steps=25, generator=generator, negative_prompt=negative_prompt
|
||||
).images
|
||||
```
|
||||
|
||||
Once we create the image embedding, we can use [`KandinskyPipeline`] to generate images.
|
||||
|
||||
```python
|
||||
from PIL import Image
|
||||
from diffusers import KandinskyPipeline
|
||||
|
||||
|
||||
def image_grid(imgs, rows, cols):
|
||||
assert len(imgs) == rows * cols
|
||||
|
||||
w, h = imgs[0].size
|
||||
grid = Image.new("RGB", size=(cols * w, rows * h))
|
||||
grid_w, grid_h = grid.size
|
||||
|
||||
for i, img in enumerate(imgs):
|
||||
grid.paste(img, box=(i % cols * w, i // cols * h))
|
||||
return grid
|
||||
|
||||
|
||||
# create diffuser pipeline
|
||||
pipe = KandinskyPipeline.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16)
|
||||
pipe.to("cuda")
|
||||
|
||||
images = pipe(
|
||||
prompt,
|
||||
image_embeds=image_emb,
|
||||
negative_image_embeds=zero_image_emb,
|
||||
num_images_per_prompt=2,
|
||||
height=768,
|
||||
width=768,
|
||||
num_inference_steps=100,
|
||||
guidance_scale=4.0,
|
||||
generator=generator,
|
||||
).images
|
||||
```
|
||||
|
||||
One cheeseburger monster coming up! Enjoy!
|
||||
|
||||

|
||||
|
||||
The Kandinsky model works extremely well with creative prompts. Here is some of the amazing art that can be created using the exact same process but with different prompts.
|
||||
|
||||
```python
|
||||
prompt = "bird eye view shot of a full body woman with cyan light orange magenta makeup, digital art, long braided hair her face separated by makeup in the style of yin Yang surrealism, symmetrical face, real image, contrasting tone, pastel gradient background"
|
||||
```
|
||||

|
||||
|
||||
```python
|
||||
prompt = "A car exploding into colorful dust"
|
||||
```
|
||||

|
||||
|
||||
```python
|
||||
prompt = "editorial photography of an organic, almost liquid smoke style armchair"
|
||||
```
|
||||
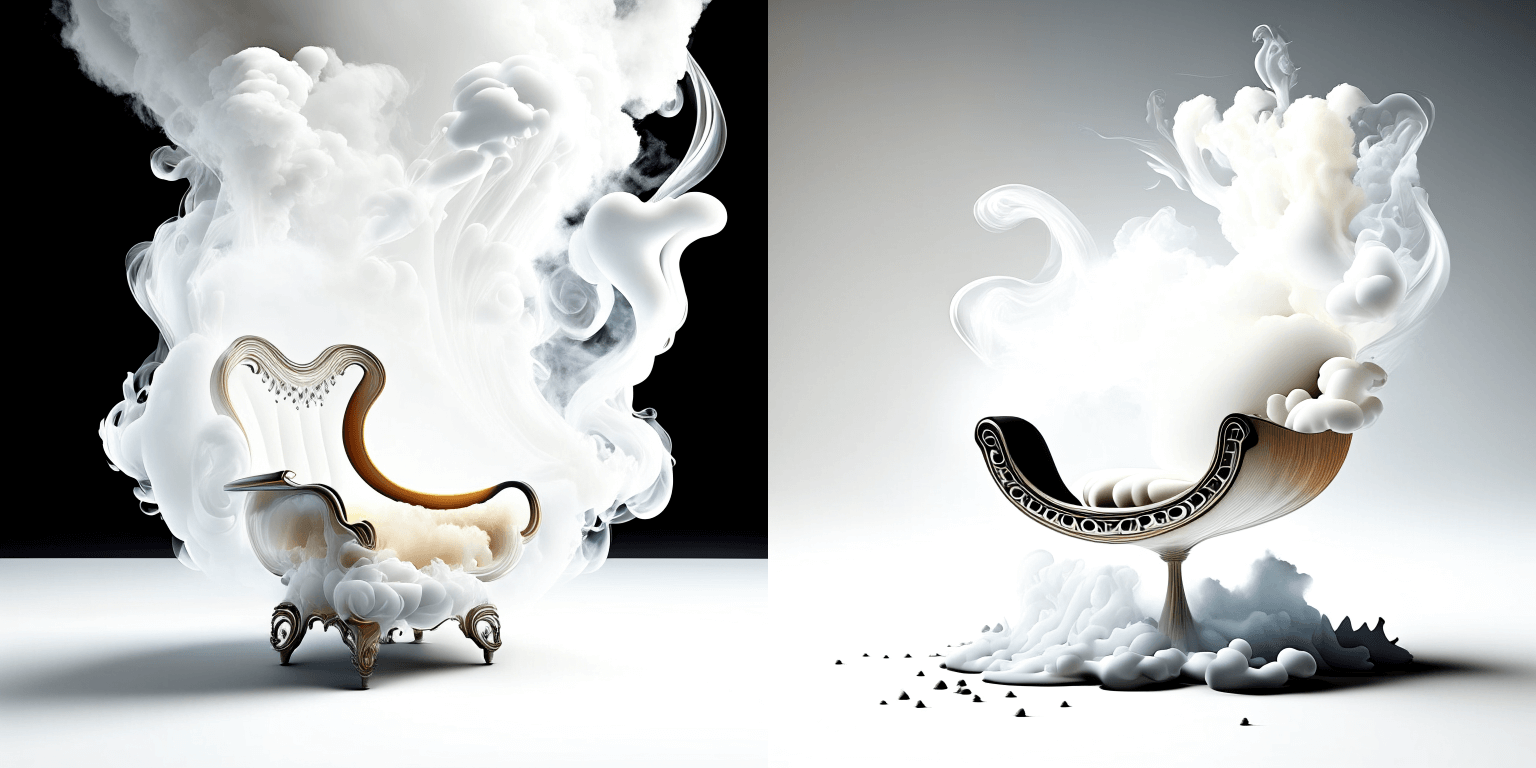
|
||||
|
||||
```python
|
||||
prompt = "birds eye view of a quilted paper style alien planet landscape, vibrant colours, Cinematic lighting"
|
||||
```
|
||||

|
||||
|
||||
|
||||
### Text Guided Image-to-Image Generation
|
||||
|
||||
The same Kandinsky model weights can be used for text-guided image-to-image translation. In this case, just make sure to load the weights using the [`KandinskyImg2ImgPipeline`] pipeline.
|
||||
|
||||
**Note**: You can also directly move the weights of the text-to-image pipelines to the image-to-image pipelines
|
||||
without loading them twice by making use of the [`~DiffusionPipeline.components`] function as explained [here](#converting-between-different-pipelines).
|
||||
|
||||
Let's download an image.
|
||||
|
||||
```python
|
||||
from PIL import Image
|
||||
import requests
|
||||
from io import BytesIO
|
||||
|
||||
# download image
|
||||
url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
|
||||
response = requests.get(url)
|
||||
original_image = Image.open(BytesIO(response.content)).convert("RGB")
|
||||
original_image = original_image.resize((768, 512))
|
||||
```
|
||||
|
||||

|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import KandinskyImg2ImgPipeline, KandinskyPriorPipeline
|
||||
|
||||
# create prior
|
||||
pipe_prior = KandinskyPriorPipeline.from_pretrained(
|
||||
"kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16
|
||||
)
|
||||
pipe_prior.to("cuda")
|
||||
|
||||
# create img2img pipeline
|
||||
pipe = KandinskyImg2ImgPipeline.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16)
|
||||
pipe.to("cuda")
|
||||
|
||||
prompt = "A fantasy landscape, Cinematic lighting"
|
||||
negative_prompt = "low quality, bad quality"
|
||||
|
||||
generator = torch.Generator(device="cuda").manual_seed(30)
|
||||
image_emb = pipe_prior(
|
||||
prompt, guidance_scale=4.0, num_inference_steps=25, generator=generator, negative_prompt=negative_prompt
|
||||
).images
|
||||
|
||||
zero_image_emb = pipe_prior(
|
||||
negative_prompt, guidance_scale=4.0, num_inference_steps=25, generator=generator, negative_prompt=negative_prompt
|
||||
).images
|
||||
|
||||
out = pipe(
|
||||
prompt,
|
||||
image=original_image,
|
||||
image_embeds=image_emb,
|
||||
negative_image_embeds=zero_image_emb,
|
||||
height=768,
|
||||
width=768,
|
||||
num_inference_steps=500,
|
||||
strength=0.3,
|
||||
)
|
||||
|
||||
out.images[0].save("fantasy_land.png")
|
||||
```
|
||||
|
||||

|
||||
|
||||
|
||||
### Text Guided Inpainting Generation
|
||||
|
||||
You can use [`KandinskyInpaintPipeline`] to edit images. In this example, we will add a hat to the portrait of a cat.
|
||||
|
||||
```python
|
||||
from diffusers import KandinskyInpaintPipeline, KandinskyPriorPipeline
|
||||
from diffusers.utils import load_image
|
||||
import torch
|
||||
import numpy as np
|
||||
|
||||
pipe_prior = KandinskyPriorPipeline.from_pretrained(
|
||||
"kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16
|
||||
)
|
||||
pipe_prior.to("cuda")
|
||||
|
||||
prompt = "a hat"
|
||||
image_emb, zero_image_emb = pipe_prior(prompt, return_dict=False)
|
||||
|
||||
pipe = KandinskyInpaintPipeline.from_pretrained("kandinsky-community/kandinsky-2-1-inpaint", torch_dtype=torch.float16)
|
||||
pipe.to("cuda")
|
||||
|
||||
init_image = load_image(
|
||||
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main" "/kandinsky/cat.png"
|
||||
)
|
||||
|
||||
mask = np.ones((768, 768), dtype=np.float32)
|
||||
# Let's mask out an area above the cat's head
|
||||
mask[:250, 250:-250] = 0
|
||||
|
||||
out = pipe(
|
||||
prompt,
|
||||
image=init_image,
|
||||
mask_image=mask,
|
||||
image_embeds=image_emb,
|
||||
negative_image_embeds=zero_image_emb,
|
||||
height=768,
|
||||
width=768,
|
||||
num_inference_steps=150,
|
||||
)
|
||||
|
||||
image = out.images[0]
|
||||
image.save("cat_with_hat.png")
|
||||
```
|
||||

|
||||
|
||||
### Interpolate
|
||||
|
||||
The [`KandinskyPriorPipeline`] also comes with a cool utility function that will allow you to interpolate the latent space of different images and texts super easily. Here is an example of how you can create an Impressionist-style portrait for your pet based on "The Starry Night".
|
||||
|
||||
Note that you can interpolate between texts and images - in the below example, we passed a text prompt "a cat" and two images to the `interplate` function, along with a `weights` variable containing the corresponding weights for each condition we interplate.
|
||||
|
||||
```python
|
||||
from diffusers import KandinskyPriorPipeline, KandinskyPipeline
|
||||
from diffusers.utils import load_image
|
||||
import PIL
|
||||
|
||||
import torch
|
||||
from torchvision import transforms
|
||||
|
||||
pipe_prior = KandinskyPriorPipeline.from_pretrained(
|
||||
"kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16
|
||||
)
|
||||
pipe_prior.to("cuda")
|
||||
|
||||
img1 = load_image(
|
||||
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main" "/kandinsky/cat.png"
|
||||
)
|
||||
|
||||
img2 = load_image(
|
||||
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main" "/kandinsky/starry_night.jpeg"
|
||||
)
|
||||
|
||||
# add all the conditions we want to interpolate, can be either text or image
|
||||
images_texts = ["a cat", img1, img2]
|
||||
# specify the weights for each condition in images_texts
|
||||
weights = [0.3, 0.3, 0.4]
|
||||
image_emb, zero_image_emb = pipe_prior.interpolate(images_texts, weights)
|
||||
|
||||
pipe = KandinskyPipeline.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16)
|
||||
pipe.to("cuda")
|
||||
|
||||
image = pipe(
|
||||
"", image_embeds=image_emb, negative_image_embeds=zero_image_emb, height=768, width=768, num_inference_steps=150
|
||||
).images[0]
|
||||
|
||||
image.save("starry_cat.png")
|
||||
```
|
||||

|
||||
|
||||
|
||||
## KandinskyPriorPipeline
|
||||
|
||||
[[autodoc]] KandinskyPriorPipeline
|
||||
- all
|
||||
- __call__
|
||||
- interpolate
|
||||
|
||||
## KandinskyPipeline
|
||||
|
||||
[[autodoc]] KandinskyPipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## KandinskyInpaintPipeline
|
||||
|
||||
[[autodoc]] KandinskyInpaintPipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## KandinskyImg2ImgPipeline
|
||||
|
||||
[[autodoc]] KandinskyImg2ImgPipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
1400
scripts/convert_kandinsky_to_diffusers.py
Normal file
1400
scripts/convert_kandinsky_to_diffusers.py
Normal file
File diff suppressed because it is too large
Load Diff
@@ -129,6 +129,10 @@ else:
|
||||
IFInpaintingSuperResolutionPipeline,
|
||||
IFPipeline,
|
||||
IFSuperResolutionPipeline,
|
||||
KandinskyImg2ImgPipeline,
|
||||
KandinskyInpaintPipeline,
|
||||
KandinskyPipeline,
|
||||
KandinskyPriorPipeline,
|
||||
LDMTextToImagePipeline,
|
||||
PaintByExamplePipeline,
|
||||
SemanticStableDiffusionPipeline,
|
||||
|
||||
@@ -62,6 +62,7 @@ class Attention(nn.Module):
|
||||
cross_attention_norm_num_groups: int = 32,
|
||||
added_kv_proj_dim: Optional[int] = None,
|
||||
norm_num_groups: Optional[int] = None,
|
||||
spatial_norm_dim: Optional[int] = None,
|
||||
out_bias: bool = True,
|
||||
scale_qk: bool = True,
|
||||
only_cross_attention: bool = False,
|
||||
@@ -105,6 +106,11 @@ class Attention(nn.Module):
|
||||
else:
|
||||
self.group_norm = None
|
||||
|
||||
if spatial_norm_dim is not None:
|
||||
self.spatial_norm = SpatialNorm(f_channels=query_dim, zq_channels=spatial_norm_dim)
|
||||
else:
|
||||
self.spatial_norm = None
|
||||
|
||||
if cross_attention_norm is None:
|
||||
self.norm_cross = None
|
||||
elif cross_attention_norm == "layer_norm":
|
||||
@@ -431,9 +437,13 @@ class AttnProcessor:
|
||||
hidden_states,
|
||||
encoder_hidden_states=None,
|
||||
attention_mask=None,
|
||||
temb=None,
|
||||
):
|
||||
residual = hidden_states
|
||||
|
||||
if attn.spatial_norm is not None:
|
||||
hidden_states = attn.spatial_norm(hidden_states, temb)
|
||||
|
||||
input_ndim = hidden_states.ndim
|
||||
|
||||
if input_ndim == 4:
|
||||
@@ -899,9 +909,19 @@ class AttnProcessor2_0:
|
||||
if not hasattr(F, "scaled_dot_product_attention"):
|
||||
raise ImportError("AttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.")
|
||||
|
||||
def __call__(self, attn: Attention, hidden_states, encoder_hidden_states=None, attention_mask=None):
|
||||
def __call__(
|
||||
self,
|
||||
attn: Attention,
|
||||
hidden_states,
|
||||
encoder_hidden_states=None,
|
||||
attention_mask=None,
|
||||
temb=None,
|
||||
):
|
||||
residual = hidden_states
|
||||
|
||||
if attn.spatial_norm is not None:
|
||||
hidden_states = attn.spatial_norm(hidden_states, temb)
|
||||
|
||||
input_ndim = hidden_states.ndim
|
||||
|
||||
if input_ndim == 4:
|
||||
@@ -1271,3 +1291,26 @@ AttentionProcessor = Union[
|
||||
CustomDiffusionAttnProcessor,
|
||||
CustomDiffusionXFormersAttnProcessor,
|
||||
]
|
||||
|
||||
|
||||
class SpatialNorm(nn.Module):
|
||||
"""
|
||||
Spatially conditioned normalization as defined in https://arxiv.org/abs/2209.09002
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
f_channels,
|
||||
zq_channels,
|
||||
):
|
||||
super().__init__()
|
||||
self.norm_layer = nn.GroupNorm(num_channels=f_channels, num_groups=32, eps=1e-6, affine=True)
|
||||
self.conv_y = nn.Conv2d(zq_channels, f_channels, kernel_size=1, stride=1, padding=0)
|
||||
self.conv_b = nn.Conv2d(zq_channels, f_channels, kernel_size=1, stride=1, padding=0)
|
||||
|
||||
def forward(self, f, zq):
|
||||
f_size = f.shape[-2:]
|
||||
zq = F.interpolate(zq, size=f_size, mode="nearest")
|
||||
norm_f = self.norm_layer(f)
|
||||
new_f = norm_f * self.conv_y(zq) + self.conv_b(zq)
|
||||
return new_f
|
||||
|
||||
@@ -360,6 +360,33 @@ class LabelEmbedding(nn.Module):
|
||||
return embeddings
|
||||
|
||||
|
||||
class TextImageProjection(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
text_embed_dim: int = 1024,
|
||||
image_embed_dim: int = 768,
|
||||
cross_attention_dim: int = 768,
|
||||
num_image_text_embeds: int = 10,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
self.num_image_text_embeds = num_image_text_embeds
|
||||
self.image_embeds = nn.Linear(image_embed_dim, self.num_image_text_embeds * cross_attention_dim)
|
||||
self.text_proj = nn.Linear(text_embed_dim, cross_attention_dim)
|
||||
|
||||
def forward(self, text_embeds: torch.FloatTensor, image_embeds: torch.FloatTensor):
|
||||
batch_size = text_embeds.shape[0]
|
||||
|
||||
# image
|
||||
image_text_embeds = self.image_embeds(image_embeds)
|
||||
image_text_embeds = image_text_embeds.reshape(batch_size, self.num_image_text_embeds, -1)
|
||||
|
||||
# text
|
||||
text_embeds = self.text_proj(text_embeds)
|
||||
|
||||
return torch.cat([image_text_embeds, text_embeds], dim=1)
|
||||
|
||||
|
||||
class CombinedTimestepLabelEmbeddings(nn.Module):
|
||||
def __init__(self, num_classes, embedding_dim, class_dropout_prob=0.1):
|
||||
super().__init__()
|
||||
@@ -395,6 +422,24 @@ class TextTimeEmbedding(nn.Module):
|
||||
return hidden_states
|
||||
|
||||
|
||||
class TextImageTimeEmbedding(nn.Module):
|
||||
def __init__(self, text_embed_dim: int = 768, image_embed_dim: int = 768, time_embed_dim: int = 1536):
|
||||
super().__init__()
|
||||
self.text_proj = nn.Linear(text_embed_dim, time_embed_dim)
|
||||
self.text_norm = nn.LayerNorm(time_embed_dim)
|
||||
self.image_proj = nn.Linear(image_embed_dim, time_embed_dim)
|
||||
|
||||
def forward(self, text_embeds: torch.FloatTensor, image_embeds: torch.FloatTensor):
|
||||
# text
|
||||
time_text_embeds = self.text_proj(text_embeds)
|
||||
time_text_embeds = self.text_norm(time_text_embeds)
|
||||
|
||||
# image
|
||||
time_image_embeds = self.image_proj(image_embeds)
|
||||
|
||||
return time_image_embeds + time_text_embeds
|
||||
|
||||
|
||||
class AttentionPooling(nn.Module):
|
||||
# Copied from https://github.com/deep-floyd/IF/blob/2f91391f27dd3c468bf174be5805b4cc92980c0b/deepfloyd_if/model/nn.py#L54
|
||||
|
||||
|
||||
@@ -21,6 +21,7 @@ import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
|
||||
from .attention import AdaGroupNorm
|
||||
from .attention_processor import SpatialNorm
|
||||
|
||||
|
||||
class Upsample1D(nn.Module):
|
||||
@@ -500,7 +501,7 @@ class ResnetBlock2D(nn.Module):
|
||||
eps=1e-6,
|
||||
non_linearity="swish",
|
||||
skip_time_act=False,
|
||||
time_embedding_norm="default", # default, scale_shift, ada_group
|
||||
time_embedding_norm="default", # default, scale_shift, ada_group, spatial
|
||||
kernel=None,
|
||||
output_scale_factor=1.0,
|
||||
use_in_shortcut=None,
|
||||
@@ -527,6 +528,8 @@ class ResnetBlock2D(nn.Module):
|
||||
|
||||
if self.time_embedding_norm == "ada_group":
|
||||
self.norm1 = AdaGroupNorm(temb_channels, in_channels, groups, eps=eps)
|
||||
elif self.time_embedding_norm == "spatial":
|
||||
self.norm1 = SpatialNorm(in_channels, temb_channels)
|
||||
else:
|
||||
self.norm1 = torch.nn.GroupNorm(num_groups=groups, num_channels=in_channels, eps=eps, affine=True)
|
||||
|
||||
@@ -537,7 +540,7 @@ class ResnetBlock2D(nn.Module):
|
||||
self.time_emb_proj = torch.nn.Linear(temb_channels, out_channels)
|
||||
elif self.time_embedding_norm == "scale_shift":
|
||||
self.time_emb_proj = torch.nn.Linear(temb_channels, 2 * out_channels)
|
||||
elif self.time_embedding_norm == "ada_group":
|
||||
elif self.time_embedding_norm == "ada_group" or self.time_embedding_norm == "spatial":
|
||||
self.time_emb_proj = None
|
||||
else:
|
||||
raise ValueError(f"unknown time_embedding_norm : {self.time_embedding_norm} ")
|
||||
@@ -546,6 +549,8 @@ class ResnetBlock2D(nn.Module):
|
||||
|
||||
if self.time_embedding_norm == "ada_group":
|
||||
self.norm2 = AdaGroupNorm(temb_channels, out_channels, groups_out, eps=eps)
|
||||
elif self.time_embedding_norm == "spatial":
|
||||
self.norm2 = SpatialNorm(out_channels, temb_channels)
|
||||
else:
|
||||
self.norm2 = torch.nn.GroupNorm(num_groups=groups_out, num_channels=out_channels, eps=eps, affine=True)
|
||||
|
||||
@@ -591,7 +596,7 @@ class ResnetBlock2D(nn.Module):
|
||||
def forward(self, input_tensor, temb):
|
||||
hidden_states = input_tensor
|
||||
|
||||
if self.time_embedding_norm == "ada_group":
|
||||
if self.time_embedding_norm == "ada_group" or self.time_embedding_norm == "spatial":
|
||||
hidden_states = self.norm1(hidden_states, temb)
|
||||
else:
|
||||
hidden_states = self.norm1(hidden_states)
|
||||
@@ -619,7 +624,7 @@ class ResnetBlock2D(nn.Module):
|
||||
if temb is not None and self.time_embedding_norm == "default":
|
||||
hidden_states = hidden_states + temb
|
||||
|
||||
if self.time_embedding_norm == "ada_group":
|
||||
if self.time_embedding_norm == "ada_group" or self.time_embedding_norm == "spatial":
|
||||
hidden_states = self.norm2(hidden_states, temb)
|
||||
else:
|
||||
hidden_states = self.norm2(hidden_states)
|
||||
|
||||
@@ -349,6 +349,7 @@ def get_up_block(
|
||||
resnet_act_fn=resnet_act_fn,
|
||||
resnet_groups=resnet_groups,
|
||||
resnet_time_scale_shift=resnet_time_scale_shift,
|
||||
temb_channels=temb_channels,
|
||||
)
|
||||
elif up_block_type == "AttnUpDecoderBlock2D":
|
||||
return AttnUpDecoderBlock2D(
|
||||
@@ -361,6 +362,7 @@ def get_up_block(
|
||||
resnet_groups=resnet_groups,
|
||||
attn_num_head_channels=attn_num_head_channels,
|
||||
resnet_time_scale_shift=resnet_time_scale_shift,
|
||||
temb_channels=temb_channels,
|
||||
)
|
||||
elif up_block_type == "KUpBlock2D":
|
||||
return KUpBlock2D(
|
||||
@@ -396,7 +398,7 @@ class UNetMidBlock2D(nn.Module):
|
||||
dropout: float = 0.0,
|
||||
num_layers: int = 1,
|
||||
resnet_eps: float = 1e-6,
|
||||
resnet_time_scale_shift: str = "default",
|
||||
resnet_time_scale_shift: str = "default", # default, spatial
|
||||
resnet_act_fn: str = "swish",
|
||||
resnet_groups: int = 32,
|
||||
resnet_pre_norm: bool = True,
|
||||
@@ -434,7 +436,8 @@ class UNetMidBlock2D(nn.Module):
|
||||
dim_head=attn_num_head_channels if attn_num_head_channels is not None else in_channels,
|
||||
rescale_output_factor=output_scale_factor,
|
||||
eps=resnet_eps,
|
||||
norm_num_groups=resnet_groups,
|
||||
norm_num_groups=resnet_groups if resnet_time_scale_shift == "default" else None,
|
||||
spatial_norm_dim=temb_channels if resnet_time_scale_shift == "spatial" else None,
|
||||
residual_connection=True,
|
||||
bias=True,
|
||||
upcast_softmax=True,
|
||||
@@ -466,7 +469,7 @@ class UNetMidBlock2D(nn.Module):
|
||||
hidden_states = self.resnets[0](hidden_states, temb)
|
||||
for attn, resnet in zip(self.attentions, self.resnets[1:]):
|
||||
if attn is not None:
|
||||
hidden_states = attn(hidden_states)
|
||||
hidden_states = attn(hidden_states, temb=temb)
|
||||
hidden_states = resnet(hidden_states, temb)
|
||||
|
||||
return hidden_states
|
||||
@@ -2116,12 +2119,13 @@ class UpDecoderBlock2D(nn.Module):
|
||||
dropout: float = 0.0,
|
||||
num_layers: int = 1,
|
||||
resnet_eps: float = 1e-6,
|
||||
resnet_time_scale_shift: str = "default",
|
||||
resnet_time_scale_shift: str = "default", # default, spatial
|
||||
resnet_act_fn: str = "swish",
|
||||
resnet_groups: int = 32,
|
||||
resnet_pre_norm: bool = True,
|
||||
output_scale_factor=1.0,
|
||||
add_upsample=True,
|
||||
temb_channels=None,
|
||||
):
|
||||
super().__init__()
|
||||
resnets = []
|
||||
@@ -2133,7 +2137,7 @@ class UpDecoderBlock2D(nn.Module):
|
||||
ResnetBlock2D(
|
||||
in_channels=input_channels,
|
||||
out_channels=out_channels,
|
||||
temb_channels=None,
|
||||
temb_channels=temb_channels,
|
||||
eps=resnet_eps,
|
||||
groups=resnet_groups,
|
||||
dropout=dropout,
|
||||
@@ -2151,9 +2155,9 @@ class UpDecoderBlock2D(nn.Module):
|
||||
else:
|
||||
self.upsamplers = None
|
||||
|
||||
def forward(self, hidden_states):
|
||||
def forward(self, hidden_states, temb=None):
|
||||
for resnet in self.resnets:
|
||||
hidden_states = resnet(hidden_states, temb=None)
|
||||
hidden_states = resnet(hidden_states, temb=temb)
|
||||
|
||||
if self.upsamplers is not None:
|
||||
for upsampler in self.upsamplers:
|
||||
@@ -2177,6 +2181,7 @@ class AttnUpDecoderBlock2D(nn.Module):
|
||||
attn_num_head_channels=1,
|
||||
output_scale_factor=1.0,
|
||||
add_upsample=True,
|
||||
temb_channels=None,
|
||||
):
|
||||
super().__init__()
|
||||
resnets = []
|
||||
@@ -2189,7 +2194,7 @@ class AttnUpDecoderBlock2D(nn.Module):
|
||||
ResnetBlock2D(
|
||||
in_channels=input_channels,
|
||||
out_channels=out_channels,
|
||||
temb_channels=None,
|
||||
temb_channels=temb_channels,
|
||||
eps=resnet_eps,
|
||||
groups=resnet_groups,
|
||||
dropout=dropout,
|
||||
@@ -2206,7 +2211,8 @@ class AttnUpDecoderBlock2D(nn.Module):
|
||||
dim_head=attn_num_head_channels if attn_num_head_channels is not None else out_channels,
|
||||
rescale_output_factor=output_scale_factor,
|
||||
eps=resnet_eps,
|
||||
norm_num_groups=resnet_groups,
|
||||
norm_num_groups=resnet_groups if resnet_time_scale_shift == "default" else None,
|
||||
spatial_norm_dim=temb_channels if resnet_time_scale_shift == "spatial" else None,
|
||||
residual_connection=True,
|
||||
bias=True,
|
||||
upcast_softmax=True,
|
||||
@@ -2222,10 +2228,10 @@ class AttnUpDecoderBlock2D(nn.Module):
|
||||
else:
|
||||
self.upsamplers = None
|
||||
|
||||
def forward(self, hidden_states):
|
||||
def forward(self, hidden_states, temb=None):
|
||||
for resnet, attn in zip(self.resnets, self.attentions):
|
||||
hidden_states = resnet(hidden_states, temb=None)
|
||||
hidden_states = attn(hidden_states)
|
||||
hidden_states = resnet(hidden_states, temb=temb)
|
||||
hidden_states = attn(hidden_states, temb=temb)
|
||||
|
||||
if self.upsamplers is not None:
|
||||
for upsampler in self.upsamplers:
|
||||
|
||||
@@ -23,7 +23,14 @@ from ..configuration_utils import ConfigMixin, register_to_config
|
||||
from ..loaders import UNet2DConditionLoadersMixin
|
||||
from ..utils import BaseOutput, logging
|
||||
from .attention_processor import AttentionProcessor, AttnProcessor
|
||||
from .embeddings import GaussianFourierProjection, TextTimeEmbedding, TimestepEmbedding, Timesteps
|
||||
from .embeddings import (
|
||||
GaussianFourierProjection,
|
||||
TextImageProjection,
|
||||
TextImageTimeEmbedding,
|
||||
TextTimeEmbedding,
|
||||
TimestepEmbedding,
|
||||
Timesteps,
|
||||
)
|
||||
from .modeling_utils import ModelMixin
|
||||
from .unet_2d_blocks import (
|
||||
CrossAttnDownBlock2D,
|
||||
@@ -90,7 +97,11 @@ class UNet2DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin)
|
||||
cross_attention_dim (`int` or `Tuple[int]`, *optional*, defaults to 1280):
|
||||
The dimension of the cross attention features.
|
||||
encoder_hid_dim (`int`, *optional*, defaults to None):
|
||||
If given, `encoder_hidden_states` will be projected from this dimension to `cross_attention_dim`.
|
||||
If `encoder_hid_dim_type` is defined, `encoder_hidden_states` will be projected from `encoder_hid_dim`
|
||||
dimension to `cross_attention_dim`.
|
||||
encoder_hid_dim_type (`str`, *optional*, defaults to None):
|
||||
If given, the `encoder_hidden_states` and potentially other embeddings will be down-projected to text
|
||||
embeddings of dimension `cross_attention` according to `encoder_hid_dim_type`.
|
||||
attention_head_dim (`int`, *optional*, defaults to 8): The dimension of the attention heads.
|
||||
resnet_time_scale_shift (`str`, *optional*, defaults to `"default"`): Time scale shift config
|
||||
for resnet blocks, see [`~models.resnet.ResnetBlock2D`]. Choose from `default` or `scale_shift`.
|
||||
@@ -156,6 +167,7 @@ class UNet2DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin)
|
||||
norm_eps: float = 1e-5,
|
||||
cross_attention_dim: Union[int, Tuple[int]] = 1280,
|
||||
encoder_hid_dim: Optional[int] = None,
|
||||
encoder_hid_dim_type: Optional[str] = None,
|
||||
attention_head_dim: Union[int, Tuple[int]] = 8,
|
||||
dual_cross_attention: bool = False,
|
||||
use_linear_projection: bool = False,
|
||||
@@ -247,8 +259,31 @@ class UNet2DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin)
|
||||
cond_proj_dim=time_cond_proj_dim,
|
||||
)
|
||||
|
||||
if encoder_hid_dim is not None:
|
||||
if encoder_hid_dim_type is None and encoder_hid_dim is not None:
|
||||
encoder_hid_dim_type = "text_proj"
|
||||
logger.info("encoder_hid_dim_type defaults to 'text_proj' as `encoder_hid_dim` is defined.")
|
||||
|
||||
if encoder_hid_dim is None and encoder_hid_dim_type is not None:
|
||||
raise ValueError(
|
||||
f"`encoder_hid_dim` has to be defined when `encoder_hid_dim_type` is set to {encoder_hid_dim_type}."
|
||||
)
|
||||
|
||||
if encoder_hid_dim_type == "text_proj":
|
||||
self.encoder_hid_proj = nn.Linear(encoder_hid_dim, cross_attention_dim)
|
||||
elif encoder_hid_dim_type == "text_image_proj":
|
||||
# image_embed_dim DOESN'T have to be `cross_attention_dim`. To not clutter the __init__ too much
|
||||
# they are set to `cross_attention_dim` here as this is exactly the required dimension for the currently only use
|
||||
# case when `addition_embed_type == "text_image_proj"` (Kadinsky 2.1)`
|
||||
self.encoder_hid_proj = TextImageProjection(
|
||||
text_embed_dim=encoder_hid_dim,
|
||||
image_embed_dim=cross_attention_dim,
|
||||
cross_attention_dim=cross_attention_dim,
|
||||
)
|
||||
|
||||
elif encoder_hid_dim_type is not None:
|
||||
raise ValueError(
|
||||
f"encoder_hid_dim_type: {encoder_hid_dim_type} must be None, 'text_proj' or 'text_image_proj'."
|
||||
)
|
||||
else:
|
||||
self.encoder_hid_proj = None
|
||||
|
||||
@@ -290,8 +325,15 @@ class UNet2DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin)
|
||||
self.add_embedding = TextTimeEmbedding(
|
||||
text_time_embedding_from_dim, time_embed_dim, num_heads=addition_embed_type_num_heads
|
||||
)
|
||||
elif addition_embed_type == "text_image":
|
||||
# text_embed_dim and image_embed_dim DON'T have to be `cross_attention_dim`. To not clutter the __init__ too much
|
||||
# they are set to `cross_attention_dim` here as this is exactly the required dimension for the currently only use
|
||||
# case when `addition_embed_type == "text_image"` (Kadinsky 2.1)`
|
||||
self.add_embedding = TextImageTimeEmbedding(
|
||||
text_embed_dim=cross_attention_dim, image_embed_dim=cross_attention_dim, time_embed_dim=time_embed_dim
|
||||
)
|
||||
elif addition_embed_type is not None:
|
||||
raise ValueError(f"addition_embed_type: {addition_embed_type} must be None or 'text'.")
|
||||
raise ValueError(f"addition_embed_type: {addition_embed_type} must be None, 'text' or 'text_image'.")
|
||||
|
||||
if time_embedding_act_fn is None:
|
||||
self.time_embed_act = None
|
||||
@@ -616,6 +658,7 @@ class UNet2DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin)
|
||||
timestep_cond: Optional[torch.Tensor] = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
||||
added_cond_kwargs: Optional[Dict[str, torch.Tensor]] = None,
|
||||
down_block_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
|
||||
mid_block_additional_residual: Optional[torch.Tensor] = None,
|
||||
encoder_attention_mask: Optional[torch.Tensor] = None,
|
||||
@@ -636,6 +679,10 @@ class UNet2DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin)
|
||||
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
|
||||
`self.processor` in
|
||||
[diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
|
||||
added_cond_kwargs (`dict`, *optional*):
|
||||
A kwargs dictionary that if specified includes additonal conditions that can be used for additonal time
|
||||
embeddings or encoder hidden states projections. See the configurations `encoder_hid_dim_type` and
|
||||
`addition_embed_type` for more information.
|
||||
|
||||
Returns:
|
||||
[`~models.unet_2d_condition.UNet2DConditionOutput`] or `tuple`:
|
||||
@@ -728,12 +775,33 @@ class UNet2DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin)
|
||||
if self.config.addition_embed_type == "text":
|
||||
aug_emb = self.add_embedding(encoder_hidden_states)
|
||||
emb = emb + aug_emb
|
||||
elif self.config.addition_embed_type == "text_image":
|
||||
# Kadinsky 2.1 - style
|
||||
if "image_embeds" not in added_cond_kwargs:
|
||||
raise ValueError(
|
||||
f"{self.__class__} has the config param `addition_embed_type` set to 'text_image' which requires the keyword argument `image_embeds` to be passed in `added_cond_kwargs`"
|
||||
)
|
||||
|
||||
image_embs = added_cond_kwargs.get("image_embeds")
|
||||
text_embs = added_cond_kwargs.get("text_embeds", encoder_hidden_states)
|
||||
|
||||
aug_emb = self.add_embedding(text_embs, image_embs)
|
||||
emb = emb + aug_emb
|
||||
|
||||
if self.time_embed_act is not None:
|
||||
emb = self.time_embed_act(emb)
|
||||
|
||||
if self.encoder_hid_proj is not None:
|
||||
if self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "text_proj":
|
||||
encoder_hidden_states = self.encoder_hid_proj(encoder_hidden_states)
|
||||
elif self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "text_image_proj":
|
||||
# Kadinsky 2.1 - style
|
||||
if "image_embeds" not in added_cond_kwargs:
|
||||
raise ValueError(
|
||||
f"{self.__class__} has the config param `encoder_hid_dim_type` set to 'text_image_proj' which requires the keyword argument `image_embeds` to be passed in `added_conditions`"
|
||||
)
|
||||
|
||||
image_embeds = added_cond_kwargs.get("image_embeds")
|
||||
encoder_hidden_states = self.encoder_hid_proj(encoder_hidden_states, image_embeds)
|
||||
|
||||
# 2. pre-process
|
||||
sample = self.conv_in(sample)
|
||||
|
||||
@@ -19,6 +19,7 @@ import torch
|
||||
import torch.nn as nn
|
||||
|
||||
from ..utils import BaseOutput, is_torch_version, randn_tensor
|
||||
from .attention_processor import SpatialNorm
|
||||
from .unet_2d_blocks import UNetMidBlock2D, get_down_block, get_up_block
|
||||
|
||||
|
||||
@@ -158,6 +159,7 @@ class Decoder(nn.Module):
|
||||
layers_per_block=2,
|
||||
norm_num_groups=32,
|
||||
act_fn="silu",
|
||||
norm_type="group", # group, spatial
|
||||
):
|
||||
super().__init__()
|
||||
self.layers_per_block = layers_per_block
|
||||
@@ -173,16 +175,18 @@ class Decoder(nn.Module):
|
||||
self.mid_block = None
|
||||
self.up_blocks = nn.ModuleList([])
|
||||
|
||||
temb_channels = in_channels if norm_type == "spatial" else None
|
||||
|
||||
# mid
|
||||
self.mid_block = UNetMidBlock2D(
|
||||
in_channels=block_out_channels[-1],
|
||||
resnet_eps=1e-6,
|
||||
resnet_act_fn=act_fn,
|
||||
output_scale_factor=1,
|
||||
resnet_time_scale_shift="default",
|
||||
resnet_time_scale_shift="default" if norm_type == "group" else norm_type,
|
||||
attn_num_head_channels=None,
|
||||
resnet_groups=norm_num_groups,
|
||||
temb_channels=None,
|
||||
temb_channels=temb_channels,
|
||||
)
|
||||
|
||||
# up
|
||||
@@ -205,19 +209,23 @@ class Decoder(nn.Module):
|
||||
resnet_act_fn=act_fn,
|
||||
resnet_groups=norm_num_groups,
|
||||
attn_num_head_channels=None,
|
||||
temb_channels=None,
|
||||
temb_channels=temb_channels,
|
||||
resnet_time_scale_shift=norm_type,
|
||||
)
|
||||
self.up_blocks.append(up_block)
|
||||
prev_output_channel = output_channel
|
||||
|
||||
# out
|
||||
self.conv_norm_out = nn.GroupNorm(num_channels=block_out_channels[0], num_groups=norm_num_groups, eps=1e-6)
|
||||
if norm_type == "spatial":
|
||||
self.conv_norm_out = SpatialNorm(block_out_channels[0], temb_channels)
|
||||
else:
|
||||
self.conv_norm_out = nn.GroupNorm(num_channels=block_out_channels[0], num_groups=norm_num_groups, eps=1e-6)
|
||||
self.conv_act = nn.SiLU()
|
||||
self.conv_out = nn.Conv2d(block_out_channels[0], out_channels, 3, padding=1)
|
||||
|
||||
self.gradient_checkpointing = False
|
||||
|
||||
def forward(self, z):
|
||||
def forward(self, z, latent_embeds=None):
|
||||
sample = z
|
||||
sample = self.conv_in(sample)
|
||||
|
||||
@@ -233,34 +241,39 @@ class Decoder(nn.Module):
|
||||
if is_torch_version(">=", "1.11.0"):
|
||||
# middle
|
||||
sample = torch.utils.checkpoint.checkpoint(
|
||||
create_custom_forward(self.mid_block), sample, use_reentrant=False
|
||||
create_custom_forward(self.mid_block), sample, latent_embeds, use_reentrant=False
|
||||
)
|
||||
sample = sample.to(upscale_dtype)
|
||||
|
||||
# up
|
||||
for up_block in self.up_blocks:
|
||||
sample = torch.utils.checkpoint.checkpoint(
|
||||
create_custom_forward(up_block), sample, use_reentrant=False
|
||||
create_custom_forward(up_block), sample, latent_embeds, use_reentrant=False
|
||||
)
|
||||
else:
|
||||
# middle
|
||||
sample = torch.utils.checkpoint.checkpoint(create_custom_forward(self.mid_block), sample)
|
||||
sample = torch.utils.checkpoint.checkpoint(
|
||||
create_custom_forward(self.mid_block), sample, latent_embeds
|
||||
)
|
||||
sample = sample.to(upscale_dtype)
|
||||
|
||||
# up
|
||||
for up_block in self.up_blocks:
|
||||
sample = torch.utils.checkpoint.checkpoint(create_custom_forward(up_block), sample)
|
||||
sample = torch.utils.checkpoint.checkpoint(create_custom_forward(up_block), sample, latent_embeds)
|
||||
else:
|
||||
# middle
|
||||
sample = self.mid_block(sample)
|
||||
sample = self.mid_block(sample, latent_embeds)
|
||||
sample = sample.to(upscale_dtype)
|
||||
|
||||
# up
|
||||
for up_block in self.up_blocks:
|
||||
sample = up_block(sample)
|
||||
sample = up_block(sample, latent_embeds)
|
||||
|
||||
# post-process
|
||||
sample = self.conv_norm_out(sample)
|
||||
if latent_embeds is None:
|
||||
sample = self.conv_norm_out(sample)
|
||||
else:
|
||||
sample = self.conv_norm_out(sample, latent_embeds)
|
||||
sample = self.conv_act(sample)
|
||||
sample = self.conv_out(sample)
|
||||
|
||||
|
||||
@@ -82,6 +82,7 @@ class VQModel(ModelMixin, ConfigMixin):
|
||||
norm_num_groups: int = 32,
|
||||
vq_embed_dim: Optional[int] = None,
|
||||
scaling_factor: float = 0.18215,
|
||||
norm_type: str = "group", # group, spatial
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
@@ -112,6 +113,7 @@ class VQModel(ModelMixin, ConfigMixin):
|
||||
layers_per_block=layers_per_block,
|
||||
act_fn=act_fn,
|
||||
norm_num_groups=norm_num_groups,
|
||||
norm_type=norm_type,
|
||||
)
|
||||
|
||||
def encode(self, x: torch.FloatTensor, return_dict: bool = True) -> VQEncoderOutput:
|
||||
@@ -131,8 +133,8 @@ class VQModel(ModelMixin, ConfigMixin):
|
||||
quant, emb_loss, info = self.quantize(h)
|
||||
else:
|
||||
quant = h
|
||||
quant = self.post_quant_conv(quant)
|
||||
dec = self.decoder(quant)
|
||||
quant2 = self.post_quant_conv(quant)
|
||||
dec = self.decoder(quant2, quant if self.config.norm_type == "spatial" else None)
|
||||
|
||||
if not return_dict:
|
||||
return (dec,)
|
||||
|
||||
@@ -57,6 +57,12 @@ else:
|
||||
IFPipeline,
|
||||
IFSuperResolutionPipeline,
|
||||
)
|
||||
from .kandinsky import (
|
||||
KandinskyImg2ImgPipeline,
|
||||
KandinskyInpaintPipeline,
|
||||
KandinskyPipeline,
|
||||
KandinskyPriorPipeline,
|
||||
)
|
||||
from .latent_diffusion import LDMTextToImagePipeline
|
||||
from .paint_by_example import PaintByExamplePipeline
|
||||
from .semantic_stable_diffusion import SemanticStableDiffusionPipeline
|
||||
|
||||
19
src/diffusers/pipelines/kandinsky/__init__.py
Normal file
19
src/diffusers/pipelines/kandinsky/__init__.py
Normal file
@@ -0,0 +1,19 @@
|
||||
from ...utils import (
|
||||
OptionalDependencyNotAvailable,
|
||||
is_torch_available,
|
||||
is_transformers_available,
|
||||
is_transformers_version,
|
||||
)
|
||||
|
||||
|
||||
try:
|
||||
if not (is_transformers_available() and is_torch_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ...utils.dummy_torch_and_transformers_objects import KandinskyPipeline, KandinskyPriorPipeline
|
||||
else:
|
||||
from .pipeline_kandinsky import KandinskyPipeline
|
||||
from .pipeline_kandinsky_img2img import KandinskyImg2ImgPipeline
|
||||
from .pipeline_kandinsky_inpaint import KandinskyInpaintPipeline
|
||||
from .pipeline_kandinsky_prior import KandinskyPriorPipeline
|
||||
from .text_encoder import MultilingualCLIP
|
||||
463
src/diffusers/pipelines/kandinsky/pipeline_kandinsky.py
Normal file
463
src/diffusers/pipelines/kandinsky/pipeline_kandinsky.py
Normal file
@@ -0,0 +1,463 @@
|
||||
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from typing import List, Optional, Union
|
||||
|
||||
import torch
|
||||
from transformers import (
|
||||
XLMRobertaTokenizer,
|
||||
)
|
||||
|
||||
from ...models import UNet2DConditionModel, VQModel
|
||||
from ...pipelines import DiffusionPipeline
|
||||
from ...pipelines.pipeline_utils import ImagePipelineOutput
|
||||
from ...schedulers import DDIMScheduler
|
||||
from ...utils import (
|
||||
is_accelerate_available,
|
||||
is_accelerate_version,
|
||||
logging,
|
||||
randn_tensor,
|
||||
replace_example_docstring,
|
||||
)
|
||||
from .text_encoder import MultilingualCLIP
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
|
||||
EXAMPLE_DOC_STRING = """
|
||||
Examples:
|
||||
```py
|
||||
>>> from diffusers import KandinskyPipeline, KandinskyPriorPipeline
|
||||
>>> import torch
|
||||
|
||||
>>> pipe_prior = KandinskyPriorPipeline.from_pretrained("kandinsky-community/Kandinsky-prior")
|
||||
>>> pipe_prior.to("cuda")
|
||||
|
||||
>>> prompt = "red cat, 4k photo"
|
||||
>>> out = pipe_prior(prompt)
|
||||
>>> image_emb = out.images
|
||||
>>> zero_image_emb = out.zero_embeds
|
||||
|
||||
>>> pipe = KandinskyPipeline.from_pretrained("kandinsky-community/kandinsky-2-1")
|
||||
>>> pipe.to("cuda")
|
||||
|
||||
>>> image = pipe(
|
||||
... prompt,
|
||||
... image_embeds=image_emb,
|
||||
... negative_image_embeds=zero_image_emb,
|
||||
... height=768,
|
||||
... width=768,
|
||||
... num_inference_steps=100,
|
||||
... ).images
|
||||
|
||||
>>> image[0].save("cat.png")
|
||||
```
|
||||
"""
|
||||
|
||||
|
||||
def get_new_h_w(h, w, scale_factor=8):
|
||||
new_h = h // scale_factor**2
|
||||
if h % scale_factor**2 != 0:
|
||||
new_h += 1
|
||||
new_w = w // scale_factor**2
|
||||
if w % scale_factor**2 != 0:
|
||||
new_w += 1
|
||||
return new_h * scale_factor, new_w * scale_factor
|
||||
|
||||
|
||||
class KandinskyPipeline(DiffusionPipeline):
|
||||
"""
|
||||
Pipeline for text-to-image generation using Kandinsky
|
||||
|
||||
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
|
||||
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
|
||||
|
||||
Args:
|
||||
text_encoder ([`MultilingualCLIP`]):
|
||||
Frozen text-encoder.
|
||||
tokenizer ([`XLMRobertaTokenizer`]):
|
||||
Tokenizer of class
|
||||
scheduler ([`DDIMScheduler`]):
|
||||
A scheduler to be used in combination with `unet` to generate image latents.
|
||||
unet ([`UNet2DConditionModel`]):
|
||||
Conditional U-Net architecture to denoise the image embedding.
|
||||
movq ([`VQModel`]):
|
||||
MoVQ Decoder to generate the image from the latents.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
text_encoder: MultilingualCLIP,
|
||||
tokenizer: XLMRobertaTokenizer,
|
||||
unet: UNet2DConditionModel,
|
||||
scheduler: DDIMScheduler,
|
||||
movq: VQModel,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
self.register_modules(
|
||||
text_encoder=text_encoder,
|
||||
tokenizer=tokenizer,
|
||||
unet=unet,
|
||||
scheduler=scheduler,
|
||||
movq=movq,
|
||||
)
|
||||
self.movq_scale_factor = 2 ** (len(self.movq.config.block_out_channels) - 1)
|
||||
|
||||
def prepare_latents(self, shape, dtype, device, generator, latents, scheduler):
|
||||
if latents is None:
|
||||
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
|
||||
else:
|
||||
if latents.shape != shape:
|
||||
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {shape}")
|
||||
latents = latents.to(device)
|
||||
|
||||
latents = latents * scheduler.init_noise_sigma
|
||||
return latents
|
||||
|
||||
def _encode_prompt(
|
||||
self,
|
||||
prompt,
|
||||
device,
|
||||
num_images_per_prompt,
|
||||
do_classifier_free_guidance,
|
||||
negative_prompt=None,
|
||||
):
|
||||
batch_size = len(prompt) if isinstance(prompt, list) else 1
|
||||
# get prompt text embeddings
|
||||
text_inputs = self.tokenizer(
|
||||
prompt,
|
||||
padding="max_length",
|
||||
truncation=True,
|
||||
max_length=77,
|
||||
return_attention_mask=True,
|
||||
add_special_tokens=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
|
||||
text_input_ids = text_inputs.input_ids
|
||||
untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
|
||||
|
||||
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(text_input_ids, untruncated_ids):
|
||||
removed_text = self.tokenizer.batch_decode(untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1])
|
||||
logger.warning(
|
||||
"The following part of your input was truncated because CLIP can only handle sequences up to"
|
||||
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
|
||||
)
|
||||
|
||||
text_input_ids = text_input_ids.to(device)
|
||||
text_mask = text_inputs.attention_mask.to(device)
|
||||
|
||||
prompt_embeds, text_encoder_hidden_states = self.text_encoder(
|
||||
input_ids=text_input_ids, attention_mask=text_mask
|
||||
)
|
||||
|
||||
prompt_embeds = prompt_embeds.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
text_encoder_hidden_states = text_encoder_hidden_states.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
text_mask = text_mask.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
|
||||
if do_classifier_free_guidance:
|
||||
uncond_tokens: List[str]
|
||||
if negative_prompt is None:
|
||||
uncond_tokens = [""] * batch_size
|
||||
elif type(prompt) is not type(negative_prompt):
|
||||
raise TypeError(
|
||||
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
|
||||
f" {type(prompt)}."
|
||||
)
|
||||
elif isinstance(negative_prompt, str):
|
||||
uncond_tokens = [negative_prompt]
|
||||
elif batch_size != len(negative_prompt):
|
||||
raise ValueError(
|
||||
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
|
||||
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
|
||||
" the batch size of `prompt`."
|
||||
)
|
||||
else:
|
||||
uncond_tokens = negative_prompt
|
||||
|
||||
uncond_input = self.tokenizer(
|
||||
uncond_tokens,
|
||||
padding="max_length",
|
||||
max_length=77,
|
||||
truncation=True,
|
||||
return_attention_mask=True,
|
||||
add_special_tokens=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
uncond_text_input_ids = uncond_input.input_ids.to(device)
|
||||
uncond_text_mask = uncond_input.attention_mask.to(device)
|
||||
|
||||
negative_prompt_embeds, uncond_text_encoder_hidden_states = self.text_encoder(
|
||||
input_ids=uncond_text_input_ids, attention_mask=uncond_text_mask
|
||||
)
|
||||
|
||||
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
|
||||
|
||||
seq_len = negative_prompt_embeds.shape[1]
|
||||
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt)
|
||||
negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len)
|
||||
|
||||
seq_len = uncond_text_encoder_hidden_states.shape[1]
|
||||
uncond_text_encoder_hidden_states = uncond_text_encoder_hidden_states.repeat(1, num_images_per_prompt, 1)
|
||||
uncond_text_encoder_hidden_states = uncond_text_encoder_hidden_states.view(
|
||||
batch_size * num_images_per_prompt, seq_len, -1
|
||||
)
|
||||
uncond_text_mask = uncond_text_mask.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
|
||||
# done duplicates
|
||||
|
||||
# For classifier free guidance, we need to do two forward passes.
|
||||
# Here we concatenate the unconditional and text embeddings into a single batch
|
||||
# to avoid doing two forward passes
|
||||
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
|
||||
text_encoder_hidden_states = torch.cat([uncond_text_encoder_hidden_states, text_encoder_hidden_states])
|
||||
|
||||
text_mask = torch.cat([uncond_text_mask, text_mask])
|
||||
|
||||
return prompt_embeds, text_encoder_hidden_states, text_mask
|
||||
|
||||
def enable_sequential_cpu_offload(self, gpu_id=0):
|
||||
r"""
|
||||
Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, the pipeline's
|
||||
models have their state dicts saved to CPU and then are moved to a `torch.device('meta') and loaded to GPU only
|
||||
when their specific submodule has its `forward` method called.
|
||||
"""
|
||||
if is_accelerate_available():
|
||||
from accelerate import cpu_offload
|
||||
else:
|
||||
raise ImportError("Please install accelerate via `pip install accelerate`")
|
||||
|
||||
device = torch.device(f"cuda:{gpu_id}")
|
||||
|
||||
models = [
|
||||
self.unet,
|
||||
self.text_encoder,
|
||||
self.movq,
|
||||
]
|
||||
for cpu_offloaded_model in models:
|
||||
if cpu_offloaded_model is not None:
|
||||
cpu_offload(cpu_offloaded_model, device)
|
||||
|
||||
def enable_model_cpu_offload(self, gpu_id=0):
|
||||
r"""
|
||||
Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
|
||||
to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
|
||||
method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
|
||||
`enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
|
||||
"""
|
||||
if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
|
||||
from accelerate import cpu_offload_with_hook
|
||||
else:
|
||||
raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
|
||||
|
||||
device = torch.device(f"cuda:{gpu_id}")
|
||||
|
||||
if self.device.type != "cpu":
|
||||
self.to("cpu", silence_dtype_warnings=True)
|
||||
torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
|
||||
|
||||
hook = None
|
||||
for cpu_offloaded_model in [self.text_encoder, self.unet, self.movq]:
|
||||
_, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
|
||||
|
||||
if self.safety_checker is not None:
|
||||
_, hook = cpu_offload_with_hook(self.safety_checker, device, prev_module_hook=hook)
|
||||
|
||||
# We'll offload the last model manually.
|
||||
self.final_offload_hook = hook
|
||||
|
||||
@property
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
|
||||
def _execution_device(self):
|
||||
r"""
|
||||
Returns the device on which the pipeline's models will be executed. After calling
|
||||
`pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
|
||||
hooks.
|
||||
"""
|
||||
if not hasattr(self.unet, "_hf_hook"):
|
||||
return self.device
|
||||
for module in self.unet.modules():
|
||||
if (
|
||||
hasattr(module, "_hf_hook")
|
||||
and hasattr(module._hf_hook, "execution_device")
|
||||
and module._hf_hook.execution_device is not None
|
||||
):
|
||||
return torch.device(module._hf_hook.execution_device)
|
||||
return self.device
|
||||
|
||||
@torch.no_grad()
|
||||
@replace_example_docstring(EXAMPLE_DOC_STRING)
|
||||
def __call__(
|
||||
self,
|
||||
prompt: Union[str, List[str]],
|
||||
image_embeds: Union[torch.FloatTensor, List[torch.FloatTensor]],
|
||||
negative_image_embeds: Union[torch.FloatTensor, List[torch.FloatTensor]],
|
||||
height: int = 512,
|
||||
width: int = 512,
|
||||
num_inference_steps: int = 100,
|
||||
guidance_scale: float = 4.0,
|
||||
num_images_per_prompt: int = 1,
|
||||
negative_prompt: Optional[Union[str, List[str]]] = None,
|
||||
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
|
||||
latents: Optional[torch.FloatTensor] = None,
|
||||
output_type: Optional[str] = "pil",
|
||||
return_dict: bool = True,
|
||||
):
|
||||
"""
|
||||
Function invoked when calling the pipeline for generation.
|
||||
|
||||
Args:
|
||||
prompt (`str` or `List[str]`):
|
||||
The prompt or prompts to guide the image generation.
|
||||
image_embeds (`torch.FloatTensor` or `List[torch.FloatTensor]`):
|
||||
The clip image embeddings for text prompt, that will be used to condition the image generation.
|
||||
negative_image_embeds (`torch.FloatTensor` or `List[torch.FloatTensor]`):
|
||||
The clip image embeddings for negative text prompt, will be used to condition the image generation.
|
||||
height (`int`, *optional*, defaults to 512):
|
||||
The height in pixels of the generated image.
|
||||
width (`int`, *optional*, defaults to 512):
|
||||
The width in pixels of the generated image.
|
||||
num_inference_steps (`int`, *optional*, defaults to 100):
|
||||
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
|
||||
expense of slower inference.
|
||||
guidance_scale (`float`, *optional*, defaults to 4.0):
|
||||
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
|
||||
`guidance_scale` is defined as `w` of equation 2. of [Imagen
|
||||
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
|
||||
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
|
||||
usually at the expense of lower image quality.
|
||||
num_images_per_prompt (`int`, *optional*, defaults to 1):
|
||||
The number of images to generate per prompt.
|
||||
negative_prompt (`str` or `List[str]`, *optional*):
|
||||
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
|
||||
if `guidance_scale` is less than `1`).
|
||||
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
|
||||
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
|
||||
to make generation deterministic.
|
||||
latents (`torch.FloatTensor`, *optional*):
|
||||
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
|
||||
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
|
||||
tensor will ge generated by sampling using the supplied random `generator`.
|
||||
output_type (`str`, *optional*, defaults to `"pil"`):
|
||||
The output format of the generate image. Choose between: `"pil"` (`PIL.Image.Image`), `"np"`
|
||||
(`np.array`) or `"pt"` (`torch.Tensor`).
|
||||
return_dict (`bool`, *optional*, defaults to `True`):
|
||||
Whether or not to return a [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
|
||||
|
||||
Examples:
|
||||
|
||||
Returns:
|
||||
[`~pipelines.ImagePipelineOutput`] or `tuple`
|
||||
"""
|
||||
|
||||
if isinstance(prompt, str):
|
||||
batch_size = 1
|
||||
elif isinstance(prompt, list):
|
||||
batch_size = len(prompt)
|
||||
else:
|
||||
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
|
||||
|
||||
device = self._execution_device
|
||||
|
||||
batch_size = batch_size * num_images_per_prompt
|
||||
do_classifier_free_guidance = guidance_scale > 1.0
|
||||
|
||||
prompt_embeds, text_encoder_hidden_states, _ = self._encode_prompt(
|
||||
prompt, device, num_images_per_prompt, do_classifier_free_guidance, negative_prompt
|
||||
)
|
||||
|
||||
if isinstance(image_embeds, list):
|
||||
image_embeds = torch.cat(image_embeds, dim=0)
|
||||
if isinstance(negative_image_embeds, list):
|
||||
negative_image_embeds = torch.cat(negative_image_embeds, dim=0)
|
||||
|
||||
if do_classifier_free_guidance:
|
||||
image_embeds = image_embeds.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
negative_image_embeds = negative_image_embeds.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
|
||||
image_embeds = torch.cat([negative_image_embeds, image_embeds], dim=0).to(
|
||||
dtype=prompt_embeds.dtype, device=device
|
||||
)
|
||||
|
||||
self.scheduler.set_timesteps(num_inference_steps, device=device)
|
||||
timesteps_tensor = self.scheduler.timesteps
|
||||
|
||||
num_channels_latents = self.unet.config.in_channels
|
||||
|
||||
height, width = get_new_h_w(height, width, self.movq_scale_factor)
|
||||
|
||||
# create initial latent
|
||||
latents = self.prepare_latents(
|
||||
(batch_size, num_channels_latents, height, width),
|
||||
text_encoder_hidden_states.dtype,
|
||||
device,
|
||||
generator,
|
||||
latents,
|
||||
self.scheduler,
|
||||
)
|
||||
|
||||
for i, t in enumerate(self.progress_bar(timesteps_tensor)):
|
||||
# expand the latents if we are doing classifier free guidance
|
||||
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
|
||||
|
||||
added_cond_kwargs = {"text_embeds": prompt_embeds, "image_embeds": image_embeds}
|
||||
noise_pred = self.unet(
|
||||
sample=latent_model_input,
|
||||
timestep=t,
|
||||
encoder_hidden_states=text_encoder_hidden_states,
|
||||
added_cond_kwargs=added_cond_kwargs,
|
||||
).sample
|
||||
|
||||
if do_classifier_free_guidance:
|
||||
noise_pred, variance_pred = noise_pred.split(latents.shape[1], dim=1)
|
||||
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
|
||||
_, variance_pred_text = variance_pred.chunk(2)
|
||||
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
|
||||
noise_pred = torch.cat([noise_pred, variance_pred_text], dim=1)
|
||||
|
||||
if not (
|
||||
hasattr(self.scheduler.config, "variance_type")
|
||||
and self.scheduler.config.variance_type in ["learned", "learned_range"]
|
||||
):
|
||||
noise_pred, _ = noise_pred.split(latents.shape[1], dim=1)
|
||||
|
||||
# compute the previous noisy sample x_t -> x_t-1
|
||||
latents = self.scheduler.step(
|
||||
noise_pred,
|
||||
t,
|
||||
latents,
|
||||
# YiYi notes: only reason this pipeline can't work with unclip scheduler is that can't pass down this argument
|
||||
# need to use DDPM scheduler instead
|
||||
# prev_timestep=prev_timestep,
|
||||
generator=generator,
|
||||
).prev_sample
|
||||
# post-processing
|
||||
image = self.movq.decode(latents, force_not_quantize=True)["sample"]
|
||||
|
||||
if output_type not in ["pt", "np", "pil"]:
|
||||
raise ValueError(f"Only the output types `pt`, `pil` and `np` are supported not output_type={output_type}")
|
||||
|
||||
if output_type in ["np", "pil"]:
|
||||
image = image * 0.5 + 0.5
|
||||
image = image.clamp(0, 1)
|
||||
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
|
||||
|
||||
if output_type == "pil":
|
||||
image = self.numpy_to_pil(image)
|
||||
|
||||
if not return_dict:
|
||||
return (image,)
|
||||
|
||||
return ImagePipelineOutput(images=image)
|
||||
547
src/diffusers/pipelines/kandinsky/pipeline_kandinsky_img2img.py
Normal file
547
src/diffusers/pipelines/kandinsky/pipeline_kandinsky_img2img.py
Normal file
@@ -0,0 +1,547 @@
|
||||
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from typing import List, Optional, Union
|
||||
|
||||
import numpy as np
|
||||
import PIL
|
||||
import torch
|
||||
from PIL import Image
|
||||
from transformers import (
|
||||
XLMRobertaTokenizer,
|
||||
)
|
||||
|
||||
from ...models import UNet2DConditionModel, VQModel
|
||||
from ...pipelines import DiffusionPipeline
|
||||
from ...pipelines.pipeline_utils import ImagePipelineOutput
|
||||
from ...schedulers import DDIMScheduler
|
||||
from ...utils import (
|
||||
is_accelerate_available,
|
||||
is_accelerate_version,
|
||||
logging,
|
||||
randn_tensor,
|
||||
replace_example_docstring,
|
||||
)
|
||||
from .text_encoder import MultilingualCLIP
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
|
||||
EXAMPLE_DOC_STRING = """
|
||||
Examples:
|
||||
```py
|
||||
>>> from diffusers import KandinskyImg2ImgPipeline, KandinskyPriorPipeline
|
||||
>>> from diffusers.utils import load_image
|
||||
>>> import torch
|
||||
|
||||
>>> pipe_prior = KandinskyPriorPipeline.from_pretrained(
|
||||
... "kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16
|
||||
... )
|
||||
>>> pipe_prior.to("cuda")
|
||||
|
||||
>>> prompt = "A red cartoon frog, 4k"
|
||||
>>> image_emb, zero_image_emb = pipe_prior(prompt, return_dict=False)
|
||||
|
||||
>>> pipe = KandinskyImg2ImgPipeline.from_pretrained(
|
||||
... "kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16
|
||||
... )
|
||||
>>> pipe.to("cuda")
|
||||
|
||||
>>> init_image = load_image(
|
||||
... "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
|
||||
... "/kandinsky/frog.png"
|
||||
... )
|
||||
|
||||
>>> image = pipe(
|
||||
... prompt,
|
||||
... image=init_image,
|
||||
... image_embeds=image_emb,
|
||||
... negative_image_embeds=zero_image_emb,
|
||||
... height=768,
|
||||
... width=768,
|
||||
... num_inference_steps=100,
|
||||
... strength=0.2,
|
||||
... ).images
|
||||
|
||||
>>> image[0].save("red_frog.png")
|
||||
```
|
||||
"""
|
||||
|
||||
|
||||
def get_new_h_w(h, w, scale_factor=8):
|
||||
new_h = h // scale_factor**2
|
||||
if h % scale_factor**2 != 0:
|
||||
new_h += 1
|
||||
new_w = w // scale_factor**2
|
||||
if w % scale_factor**2 != 0:
|
||||
new_w += 1
|
||||
return new_h * scale_factor, new_w * scale_factor
|
||||
|
||||
|
||||
def prepare_image(pil_image, w=512, h=512):
|
||||
pil_image = pil_image.resize((w, h), resample=Image.BICUBIC, reducing_gap=1)
|
||||
arr = np.array(pil_image.convert("RGB"))
|
||||
arr = arr.astype(np.float32) / 127.5 - 1
|
||||
arr = np.transpose(arr, [2, 0, 1])
|
||||
image = torch.from_numpy(arr).unsqueeze(0)
|
||||
return image
|
||||
|
||||
|
||||
class KandinskyImg2ImgPipeline(DiffusionPipeline):
|
||||
"""
|
||||
Pipeline for image-to-image generation using Kandinsky
|
||||
|
||||
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
|
||||
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
|
||||
|
||||
Args:
|
||||
text_encoder ([`MultilingualCLIP`]):
|
||||
Frozen text-encoder.
|
||||
tokenizer ([`XLMRobertaTokenizer`]):
|
||||
Tokenizer of class
|
||||
scheduler ([`DDIMScheduler`]):
|
||||
A scheduler to be used in combination with `unet` to generate image latents.
|
||||
unet ([`UNet2DConditionModel`]):
|
||||
Conditional U-Net architecture to denoise the image embedding.
|
||||
movq ([`VQModel`]):
|
||||
MoVQ image encoder and decoder
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
text_encoder: MultilingualCLIP,
|
||||
movq: VQModel,
|
||||
tokenizer: XLMRobertaTokenizer,
|
||||
unet: UNet2DConditionModel,
|
||||
scheduler: DDIMScheduler,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
self.register_modules(
|
||||
text_encoder=text_encoder,
|
||||
tokenizer=tokenizer,
|
||||
unet=unet,
|
||||
scheduler=scheduler,
|
||||
movq=movq,
|
||||
)
|
||||
self.movq_scale_factor = 2 ** (len(self.movq.config.block_out_channels) - 1)
|
||||
|
||||
def get_timesteps(self, num_inference_steps, strength, device):
|
||||
# get the original timestep using init_timestep
|
||||
init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
|
||||
|
||||
t_start = max(num_inference_steps - init_timestep, 0)
|
||||
timesteps = self.scheduler.timesteps[t_start:]
|
||||
|
||||
return timesteps, num_inference_steps - t_start
|
||||
|
||||
def prepare_latents(self, latents, latent_timestep, shape, dtype, device, generator, scheduler):
|
||||
if latents is None:
|
||||
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
|
||||
else:
|
||||
if latents.shape != shape:
|
||||
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {shape}")
|
||||
latents = latents.to(device)
|
||||
|
||||
latents = latents * scheduler.init_noise_sigma
|
||||
|
||||
shape = latents.shape
|
||||
noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
|
||||
|
||||
latents = self.add_noise(latents, noise, latent_timestep)
|
||||
return latents
|
||||
|
||||
def _encode_prompt(
|
||||
self,
|
||||
prompt,
|
||||
device,
|
||||
num_images_per_prompt,
|
||||
do_classifier_free_guidance,
|
||||
negative_prompt=None,
|
||||
):
|
||||
batch_size = len(prompt) if isinstance(prompt, list) else 1
|
||||
# get prompt text embeddings
|
||||
text_inputs = self.tokenizer(
|
||||
prompt,
|
||||
padding="max_length",
|
||||
max_length=77,
|
||||
truncation=True,
|
||||
return_attention_mask=True,
|
||||
add_special_tokens=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
|
||||
text_input_ids = text_inputs.input_ids
|
||||
untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
|
||||
|
||||
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(text_input_ids, untruncated_ids):
|
||||
removed_text = self.tokenizer.batch_decode(untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1])
|
||||
logger.warning(
|
||||
"The following part of your input was truncated because CLIP can only handle sequences up to"
|
||||
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
|
||||
)
|
||||
|
||||
text_input_ids = text_input_ids.to(device)
|
||||
text_mask = text_inputs.attention_mask.to(device)
|
||||
|
||||
prompt_embeds, text_encoder_hidden_states = self.text_encoder(
|
||||
input_ids=text_input_ids, attention_mask=text_mask
|
||||
)
|
||||
|
||||
prompt_embeds = prompt_embeds.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
text_encoder_hidden_states = text_encoder_hidden_states.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
text_mask = text_mask.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
|
||||
if do_classifier_free_guidance:
|
||||
uncond_tokens: List[str]
|
||||
if negative_prompt is None:
|
||||
uncond_tokens = [""] * batch_size
|
||||
elif type(prompt) is not type(negative_prompt):
|
||||
raise TypeError(
|
||||
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
|
||||
f" {type(prompt)}."
|
||||
)
|
||||
elif isinstance(negative_prompt, str):
|
||||
uncond_tokens = [negative_prompt]
|
||||
elif batch_size != len(negative_prompt):
|
||||
raise ValueError(
|
||||
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
|
||||
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
|
||||
" the batch size of `prompt`."
|
||||
)
|
||||
else:
|
||||
uncond_tokens = negative_prompt
|
||||
|
||||
uncond_input = self.tokenizer(
|
||||
uncond_tokens,
|
||||
padding="max_length",
|
||||
max_length=77,
|
||||
truncation=True,
|
||||
return_attention_mask=True,
|
||||
add_special_tokens=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
uncond_text_input_ids = uncond_input.input_ids.to(device)
|
||||
uncond_text_mask = uncond_input.attention_mask.to(device)
|
||||
|
||||
negative_prompt_embeds, uncond_text_encoder_hidden_states = self.text_encoder(
|
||||
input_ids=uncond_text_input_ids, attention_mask=uncond_text_mask
|
||||
)
|
||||
|
||||
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
|
||||
|
||||
seq_len = negative_prompt_embeds.shape[1]
|
||||
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt)
|
||||
negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len)
|
||||
|
||||
seq_len = uncond_text_encoder_hidden_states.shape[1]
|
||||
uncond_text_encoder_hidden_states = uncond_text_encoder_hidden_states.repeat(1, num_images_per_prompt, 1)
|
||||
uncond_text_encoder_hidden_states = uncond_text_encoder_hidden_states.view(
|
||||
batch_size * num_images_per_prompt, seq_len, -1
|
||||
)
|
||||
uncond_text_mask = uncond_text_mask.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
|
||||
# done duplicates
|
||||
|
||||
# For classifier free guidance, we need to do two forward passes.
|
||||
# Here we concatenate the unconditional and text embeddings into a single batch
|
||||
# to avoid doing two forward passes
|
||||
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
|
||||
text_encoder_hidden_states = torch.cat([uncond_text_encoder_hidden_states, text_encoder_hidden_states])
|
||||
|
||||
text_mask = torch.cat([uncond_text_mask, text_mask])
|
||||
|
||||
return prompt_embeds, text_encoder_hidden_states, text_mask
|
||||
|
||||
def enable_sequential_cpu_offload(self, gpu_id=0):
|
||||
r"""
|
||||
Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, the pipeline's
|
||||
models have their state dicts saved to CPU and then are moved to a `torch.device('meta') and loaded to GPU only
|
||||
when their specific submodule has its `forward` method called.
|
||||
"""
|
||||
if is_accelerate_available():
|
||||
from accelerate import cpu_offload
|
||||
else:
|
||||
raise ImportError("Please install accelerate via `pip install accelerate`")
|
||||
|
||||
device = torch.device(f"cuda:{gpu_id}")
|
||||
|
||||
models = [
|
||||
self.unet,
|
||||
self.text_encoder,
|
||||
self.movq,
|
||||
]
|
||||
for cpu_offloaded_model in models:
|
||||
if cpu_offloaded_model is not None:
|
||||
cpu_offload(cpu_offloaded_model, device)
|
||||
|
||||
def enable_model_cpu_offload(self, gpu_id=0):
|
||||
r"""
|
||||
Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
|
||||
to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
|
||||
method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
|
||||
`enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
|
||||
"""
|
||||
if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
|
||||
from accelerate import cpu_offload_with_hook
|
||||
else:
|
||||
raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
|
||||
|
||||
device = torch.device(f"cuda:{gpu_id}")
|
||||
|
||||
if self.device.type != "cpu":
|
||||
self.to("cpu", silence_dtype_warnings=True)
|
||||
torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
|
||||
|
||||
hook = None
|
||||
for cpu_offloaded_model in [self.text_encoder, self.unet, self.movq]:
|
||||
_, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
|
||||
|
||||
if self.safety_checker is not None:
|
||||
_, hook = cpu_offload_with_hook(self.safety_checker, device, prev_module_hook=hook)
|
||||
|
||||
# We'll offload the last model manually.
|
||||
self.final_offload_hook = hook
|
||||
|
||||
@property
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
|
||||
def _execution_device(self):
|
||||
r"""
|
||||
Returns the device on which the pipeline's models will be executed. After calling
|
||||
`pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
|
||||
hooks.
|
||||
"""
|
||||
if not hasattr(self.unet, "_hf_hook"):
|
||||
return self.device
|
||||
for module in self.unet.modules():
|
||||
if (
|
||||
hasattr(module, "_hf_hook")
|
||||
and hasattr(module._hf_hook, "execution_device")
|
||||
and module._hf_hook.execution_device is not None
|
||||
):
|
||||
return torch.device(module._hf_hook.execution_device)
|
||||
return self.device
|
||||
|
||||
# add_noise method to overwrite the one in schedule because it use a different beta schedule for adding noise vs sampling
|
||||
def add_noise(
|
||||
self,
|
||||
original_samples: torch.FloatTensor,
|
||||
noise: torch.FloatTensor,
|
||||
timesteps: torch.IntTensor,
|
||||
) -> torch.FloatTensor:
|
||||
betas = torch.linspace(0.0001, 0.02, 1000, dtype=torch.float32)
|
||||
alphas = 1.0 - betas
|
||||
alphas_cumprod = torch.cumprod(alphas, dim=0)
|
||||
alphas_cumprod = alphas_cumprod.to(device=original_samples.device, dtype=original_samples.dtype)
|
||||
timesteps = timesteps.to(original_samples.device)
|
||||
|
||||
sqrt_alpha_prod = alphas_cumprod[timesteps] ** 0.5
|
||||
sqrt_alpha_prod = sqrt_alpha_prod.flatten()
|
||||
while len(sqrt_alpha_prod.shape) < len(original_samples.shape):
|
||||
sqrt_alpha_prod = sqrt_alpha_prod.unsqueeze(-1)
|
||||
|
||||
sqrt_one_minus_alpha_prod = (1 - alphas_cumprod[timesteps]) ** 0.5
|
||||
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten()
|
||||
while len(sqrt_one_minus_alpha_prod.shape) < len(original_samples.shape):
|
||||
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.unsqueeze(-1)
|
||||
|
||||
noisy_samples = sqrt_alpha_prod * original_samples + sqrt_one_minus_alpha_prod * noise
|
||||
|
||||
return noisy_samples
|
||||
|
||||
@torch.no_grad()
|
||||
@replace_example_docstring(EXAMPLE_DOC_STRING)
|
||||
def __call__(
|
||||
self,
|
||||
prompt: Union[str, List[str]],
|
||||
image: Union[torch.FloatTensor, PIL.Image.Image, List[torch.FloatTensor], List[PIL.Image.Image]],
|
||||
image_embeds: torch.FloatTensor,
|
||||
negative_image_embeds: torch.FloatTensor,
|
||||
height: int = 512,
|
||||
width: int = 512,
|
||||
num_inference_steps: int = 100,
|
||||
strength: float = 0.3,
|
||||
guidance_scale: float = 7.0,
|
||||
num_images_per_prompt: int = 1,
|
||||
negative_prompt: Optional[Union[str, List[str]]] = None,
|
||||
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
|
||||
output_type: Optional[str] = "pil",
|
||||
return_dict: bool = True,
|
||||
):
|
||||
"""
|
||||
Function invoked when calling the pipeline for generation.
|
||||
|
||||
Args:
|
||||
prompt (`str` or `List[str]`):
|
||||
The prompt or prompts to guide the image generation.
|
||||
image (`torch.FloatTensor`, `PIL.Image.Image`):
|
||||
`Image`, or tensor representing an image batch, that will be used as the starting point for the
|
||||
process.
|
||||
image_embeds (`torch.FloatTensor` or `List[torch.FloatTensor]`):
|
||||
The clip image embeddings for text prompt, that will be used to condition the image generation.
|
||||
negative_image_embeds (`torch.FloatTensor` or `List[torch.FloatTensor]`):
|
||||
The clip image embeddings for negative text prompt, will be used to condition the image generation.
|
||||
height (`int`, *optional*, defaults to 512):
|
||||
The height in pixels of the generated image.
|
||||
width (`int`, *optional*, defaults to 512):
|
||||
The width in pixels of the generated image.
|
||||
num_inference_steps (`int`, *optional*, defaults to 100):
|
||||
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
|
||||
expense of slower inference.
|
||||
strength (`float`, *optional*, defaults to 0.3):
|
||||
Conceptually, indicates how much to transform the reference `image`. Must be between 0 and 1. `image`
|
||||
will be used as a starting point, adding more noise to it the larger the `strength`. The number of
|
||||
denoising steps depends on the amount of noise initially added. When `strength` is 1, added noise will
|
||||
be maximum and the denoising process will run for the full number of iterations specified in
|
||||
`num_inference_steps`. A value of 1, therefore, essentially ignores `image`.
|
||||
guidance_scale (`float`, *optional*, defaults to 4.0):
|
||||
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
|
||||
`guidance_scale` is defined as `w` of equation 2. of [Imagen
|
||||
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
|
||||
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
|
||||
usually at the expense of lower image quality.
|
||||
num_images_per_prompt (`int`, *optional*, defaults to 1):
|
||||
The number of images to generate per prompt.
|
||||
negative_prompt (`str` or `List[str]`, *optional*):
|
||||
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
|
||||
if `guidance_scale` is less than `1`).
|
||||
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
|
||||
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
|
||||
to make generation deterministic.
|
||||
output_type (`str`, *optional*, defaults to `"pil"`):
|
||||
The output format of the generate image. Choose between: `"pil"` (`PIL.Image.Image`), `"np"`
|
||||
(`np.array`) or `"pt"` (`torch.Tensor`).
|
||||
return_dict (`bool`, *optional*, defaults to `True`):
|
||||
Whether or not to return a [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
|
||||
|
||||
Examples:
|
||||
|
||||
Returns:
|
||||
[`~pipelines.ImagePipelineOutput`] or `tuple`
|
||||
"""
|
||||
# 1. Define call parameters
|
||||
if isinstance(prompt, str):
|
||||
batch_size = 1
|
||||
elif isinstance(prompt, list):
|
||||
batch_size = len(prompt)
|
||||
else:
|
||||
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
|
||||
|
||||
device = self._execution_device
|
||||
|
||||
batch_size = batch_size * num_images_per_prompt
|
||||
|
||||
do_classifier_free_guidance = guidance_scale > 1.0
|
||||
|
||||
# 2. get text and image embeddings
|
||||
prompt_embeds, text_encoder_hidden_states, _ = self._encode_prompt(
|
||||
prompt, device, num_images_per_prompt, do_classifier_free_guidance, negative_prompt
|
||||
)
|
||||
|
||||
if isinstance(image_embeds, list):
|
||||
image_embeds = torch.cat(image_embeds, dim=0)
|
||||
if isinstance(negative_image_embeds, list):
|
||||
negative_image_embeds = torch.cat(negative_image_embeds, dim=0)
|
||||
|
||||
if do_classifier_free_guidance:
|
||||
image_embeds = image_embeds.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
negative_image_embeds = negative_image_embeds.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
|
||||
image_embeds = torch.cat([negative_image_embeds, image_embeds], dim=0).to(
|
||||
dtype=prompt_embeds.dtype, device=device
|
||||
)
|
||||
|
||||
# 3. pre-processing initial image
|
||||
if not isinstance(image, list):
|
||||
image = [image]
|
||||
if not all(isinstance(i, (PIL.Image.Image, torch.Tensor)) for i in image):
|
||||
raise ValueError(
|
||||
f"Input is in incorrect format: {[type(i) for i in image]}. Currently, we only support PIL image and pytorch tensor"
|
||||
)
|
||||
|
||||
image = torch.cat([prepare_image(i, width, height) for i in image], dim=0)
|
||||
image = image.to(dtype=prompt_embeds.dtype, device=device)
|
||||
|
||||
latents = self.movq.encode(image)["latents"]
|
||||
latents = latents.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
|
||||
# 4. set timesteps
|
||||
self.scheduler.set_timesteps(num_inference_steps, device=device)
|
||||
|
||||
timesteps_tensor, num_inference_steps = self.get_timesteps(num_inference_steps, strength, device)
|
||||
|
||||
# the formular to calculate timestep for add_noise is taken from the original kandinsky repo
|
||||
latent_timestep = int(self.scheduler.config.num_train_timesteps * strength) - 2
|
||||
|
||||
latent_timestep = torch.tensor([latent_timestep] * batch_size, dtype=timesteps_tensor.dtype, device=device)
|
||||
|
||||
num_channels_latents = self.unet.config.in_channels
|
||||
|
||||
height, width = get_new_h_w(height, width, self.movq_scale_factor)
|
||||
|
||||
# 5. Create initial latent
|
||||
latents = self.prepare_latents(
|
||||
latents,
|
||||
latent_timestep,
|
||||
(batch_size, num_channels_latents, height, width),
|
||||
text_encoder_hidden_states.dtype,
|
||||
device,
|
||||
generator,
|
||||
self.scheduler,
|
||||
)
|
||||
|
||||
# 6. Denoising loop
|
||||
for i, t in enumerate(self.progress_bar(timesteps_tensor)):
|
||||
# expand the latents if we are doing classifier free guidance
|
||||
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
|
||||
|
||||
added_cond_kwargs = {"text_embeds": prompt_embeds, "image_embeds": image_embeds}
|
||||
noise_pred = self.unet(
|
||||
sample=latent_model_input,
|
||||
timestep=t,
|
||||
encoder_hidden_states=text_encoder_hidden_states,
|
||||
added_cond_kwargs=added_cond_kwargs,
|
||||
).sample
|
||||
|
||||
if do_classifier_free_guidance:
|
||||
noise_pred, _ = noise_pred.split(latents.shape[1], dim=1)
|
||||
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
|
||||
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
|
||||
|
||||
# compute the previous noisy sample x_t -> x_t-1
|
||||
latents = self.scheduler.step(
|
||||
noise_pred,
|
||||
t,
|
||||
latents,
|
||||
generator=generator,
|
||||
).prev_sample
|
||||
|
||||
# 7. post-processing
|
||||
image = self.movq.decode(latents, force_not_quantize=True)["sample"]
|
||||
|
||||
if output_type not in ["pt", "np", "pil"]:
|
||||
raise ValueError(f"Only the output types `pt`, `pil` and `np` are supported not output_type={output_type}")
|
||||
|
||||
if output_type in ["np", "pil"]:
|
||||
image = image * 0.5 + 0.5
|
||||
image = image.clamp(0, 1)
|
||||
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
|
||||
|
||||
if output_type == "pil":
|
||||
image = self.numpy_to_pil(image)
|
||||
|
||||
if not return_dict:
|
||||
return (image,)
|
||||
|
||||
return ImagePipelineOutput(images=image)
|
||||
672
src/diffusers/pipelines/kandinsky/pipeline_kandinsky_inpaint.py
Normal file
672
src/diffusers/pipelines/kandinsky/pipeline_kandinsky_inpaint.py
Normal file
@@ -0,0 +1,672 @@
|
||||
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from copy import deepcopy
|
||||
from typing import List, Optional, Union
|
||||
|
||||
import numpy as np
|
||||
import PIL
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
from PIL import Image
|
||||
from transformers import (
|
||||
XLMRobertaTokenizer,
|
||||
)
|
||||
|
||||
from ...models import UNet2DConditionModel, VQModel
|
||||
from ...pipelines import DiffusionPipeline
|
||||
from ...pipelines.pipeline_utils import ImagePipelineOutput
|
||||
from ...schedulers import DDIMScheduler
|
||||
from ...utils import (
|
||||
is_accelerate_available,
|
||||
is_accelerate_version,
|
||||
logging,
|
||||
randn_tensor,
|
||||
replace_example_docstring,
|
||||
)
|
||||
from .text_encoder import MultilingualCLIP
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
|
||||
EXAMPLE_DOC_STRING = """
|
||||
Examples:
|
||||
```py
|
||||
>>> from diffusers import KandinskyInpaintPipeline, KandinskyPriorPipeline
|
||||
>>> from diffusers.utils import load_image
|
||||
>>> import torch
|
||||
>>> import numpy as np
|
||||
|
||||
>>> pipe_prior = KandinskyPriorPipeline.from_pretrained(
|
||||
... "kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16
|
||||
... )
|
||||
>>> pipe_prior.to("cuda")
|
||||
|
||||
>>> prompt = "a hat"
|
||||
>>> image_emb, zero_image_emb = pipe_prior(prompt, return_dict=False)
|
||||
|
||||
>>> pipe = KandinskyInpaintPipeline.from_pretrained(
|
||||
... "kandinsky-community/kandinsky-2-1-inpaint", torch_dtype=torch.float16
|
||||
... )
|
||||
>>> pipe.to("cuda")
|
||||
|
||||
>>> init_image = load_image(
|
||||
... "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
|
||||
... "/kandinsky/cat.png"
|
||||
... )
|
||||
|
||||
>>> mask = np.ones((768, 768), dtype=np.float32)
|
||||
>>> mask[:250, 250:-250] = 0
|
||||
|
||||
>>> out = pipe(
|
||||
... prompt,
|
||||
... image=init_image,
|
||||
... mask_image=mask,
|
||||
... image_embeds=image_emb,
|
||||
... negative_image_embeds=zero_image_emb,
|
||||
... height=768,
|
||||
... width=768,
|
||||
... num_inference_steps=50,
|
||||
... )
|
||||
|
||||
>>> image = out.images[0]
|
||||
>>> image.save("cat_with_hat.png")
|
||||
```
|
||||
"""
|
||||
|
||||
|
||||
def get_new_h_w(h, w, scale_factor=8):
|
||||
new_h = h // scale_factor**2
|
||||
if h % scale_factor**2 != 0:
|
||||
new_h += 1
|
||||
new_w = w // scale_factor**2
|
||||
if w % scale_factor**2 != 0:
|
||||
new_w += 1
|
||||
return new_h * scale_factor, new_w * scale_factor
|
||||
|
||||
|
||||
def prepare_mask(masks):
|
||||
prepared_masks = []
|
||||
for mask in masks:
|
||||
old_mask = deepcopy(mask)
|
||||
for i in range(mask.shape[1]):
|
||||
for j in range(mask.shape[2]):
|
||||
if old_mask[0][i][j] == 1:
|
||||
continue
|
||||
if i != 0:
|
||||
mask[:, i - 1, j] = 0
|
||||
if j != 0:
|
||||
mask[:, i, j - 1] = 0
|
||||
if i != 0 and j != 0:
|
||||
mask[:, i - 1, j - 1] = 0
|
||||
if i != mask.shape[1] - 1:
|
||||
mask[:, i + 1, j] = 0
|
||||
if j != mask.shape[2] - 1:
|
||||
mask[:, i, j + 1] = 0
|
||||
if i != mask.shape[1] - 1 and j != mask.shape[2] - 1:
|
||||
mask[:, i + 1, j + 1] = 0
|
||||
prepared_masks.append(mask)
|
||||
return torch.stack(prepared_masks, dim=0)
|
||||
|
||||
|
||||
def prepare_mask_and_masked_image(image, mask, height, width):
|
||||
r"""
|
||||
Prepares a pair (mask, image) to be consumed by the Kandinsky inpaint pipeline. This means that those inputs will
|
||||
be converted to ``torch.Tensor`` with shapes ``batch x channels x height x width`` where ``channels`` is ``3`` for
|
||||
the ``image`` and ``1`` for the ``mask``.
|
||||
|
||||
The ``image`` will be converted to ``torch.float32`` and normalized to be in ``[-1, 1]``. The ``mask`` will be
|
||||
binarized (``mask > 0.5``) and cast to ``torch.float32`` too.
|
||||
|
||||
Args:
|
||||
image (Union[np.array, PIL.Image, torch.Tensor]): The image to inpaint.
|
||||
It can be a ``PIL.Image``, or a ``height x width x 3`` ``np.array`` or a ``channels x height x width``
|
||||
``torch.Tensor`` or a ``batch x channels x height x width`` ``torch.Tensor``.
|
||||
mask (_type_): The mask to apply to the image, i.e. regions to inpaint.
|
||||
It can be a ``PIL.Image``, or a ``height x width`` ``np.array`` or a ``1 x height x width``
|
||||
``torch.Tensor`` or a ``batch x 1 x height x width`` ``torch.Tensor``.
|
||||
height (`int`, *optional*, defaults to 512):
|
||||
The height in pixels of the generated image.
|
||||
width (`int`, *optional*, defaults to 512):
|
||||
The width in pixels of the generated image.
|
||||
|
||||
|
||||
Raises:
|
||||
ValueError: ``torch.Tensor`` images should be in the ``[-1, 1]`` range. ValueError: ``torch.Tensor`` mask
|
||||
should be in the ``[0, 1]`` range. ValueError: ``mask`` and ``image`` should have the same spatial dimensions.
|
||||
TypeError: ``mask`` is a ``torch.Tensor`` but ``image`` is not
|
||||
(ot the other way around).
|
||||
|
||||
Returns:
|
||||
tuple[torch.Tensor]: The pair (mask, image) as ``torch.Tensor`` with 4
|
||||
dimensions: ``batch x channels x height x width``.
|
||||
"""
|
||||
|
||||
if image is None:
|
||||
raise ValueError("`image` input cannot be undefined.")
|
||||
|
||||
if mask is None:
|
||||
raise ValueError("`mask_image` input cannot be undefined.")
|
||||
|
||||
if isinstance(image, torch.Tensor):
|
||||
if not isinstance(mask, torch.Tensor):
|
||||
raise TypeError(f"`image` is a torch.Tensor but `mask` (type: {type(mask)} is not")
|
||||
|
||||
# Batch single image
|
||||
if image.ndim == 3:
|
||||
assert image.shape[0] == 3, "Image outside a batch should be of shape (3, H, W)"
|
||||
image = image.unsqueeze(0)
|
||||
|
||||
# Batch and add channel dim for single mask
|
||||
if mask.ndim == 2:
|
||||
mask = mask.unsqueeze(0).unsqueeze(0)
|
||||
|
||||
# Batch single mask or add channel dim
|
||||
if mask.ndim == 3:
|
||||
# Single batched mask, no channel dim or single mask not batched but channel dim
|
||||
if mask.shape[0] == 1:
|
||||
mask = mask.unsqueeze(0)
|
||||
|
||||
# Batched masks no channel dim
|
||||
else:
|
||||
mask = mask.unsqueeze(1)
|
||||
|
||||
assert image.ndim == 4 and mask.ndim == 4, "Image and Mask must have 4 dimensions"
|
||||
assert image.shape[-2:] == mask.shape[-2:], "Image and Mask must have the same spatial dimensions"
|
||||
assert image.shape[0] == mask.shape[0], "Image and Mask must have the same batch size"
|
||||
|
||||
# Check image is in [-1, 1]
|
||||
if image.min() < -1 or image.max() > 1:
|
||||
raise ValueError("Image should be in [-1, 1] range")
|
||||
|
||||
# Check mask is in [0, 1]
|
||||
if mask.min() < 0 or mask.max() > 1:
|
||||
raise ValueError("Mask should be in [0, 1] range")
|
||||
|
||||
# Binarize mask
|
||||
mask[mask < 0.5] = 0
|
||||
mask[mask >= 0.5] = 1
|
||||
|
||||
# Image as float32
|
||||
image = image.to(dtype=torch.float32)
|
||||
elif isinstance(mask, torch.Tensor):
|
||||
raise TypeError(f"`mask` is a torch.Tensor but `image` (type: {type(image)} is not")
|
||||
else:
|
||||
# preprocess image
|
||||
if isinstance(image, (PIL.Image.Image, np.ndarray)):
|
||||
image = [image]
|
||||
|
||||
if isinstance(image, list) and isinstance(image[0], PIL.Image.Image):
|
||||
# resize all images w.r.t passed height an width
|
||||
image = [i.resize((width, height), resample=Image.BICUBIC, reducing_gap=1) for i in image]
|
||||
image = [np.array(i.convert("RGB"))[None, :] for i in image]
|
||||
image = np.concatenate(image, axis=0)
|
||||
elif isinstance(image, list) and isinstance(image[0], np.ndarray):
|
||||
image = np.concatenate([i[None, :] for i in image], axis=0)
|
||||
|
||||
image = image.transpose(0, 3, 1, 2)
|
||||
image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0
|
||||
|
||||
# preprocess mask
|
||||
if isinstance(mask, (PIL.Image.Image, np.ndarray)):
|
||||
mask = [mask]
|
||||
|
||||
if isinstance(mask, list) and isinstance(mask[0], PIL.Image.Image):
|
||||
mask = [i.resize((width, height), resample=PIL.Image.LANCZOS) for i in mask]
|
||||
mask = np.concatenate([np.array(m.convert("L"))[None, None, :] for m in mask], axis=0)
|
||||
mask = mask.astype(np.float32) / 255.0
|
||||
elif isinstance(mask, list) and isinstance(mask[0], np.ndarray):
|
||||
mask = np.concatenate([m[None, None, :] for m in mask], axis=0)
|
||||
|
||||
mask[mask < 0.5] = 0
|
||||
mask[mask >= 0.5] = 1
|
||||
mask = torch.from_numpy(mask)
|
||||
|
||||
return mask, image
|
||||
|
||||
|
||||
class KandinskyInpaintPipeline(DiffusionPipeline):
|
||||
"""
|
||||
Pipeline for text-guided image inpainting using Kandinsky2.1
|
||||
|
||||
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
|
||||
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
|
||||
|
||||
Args:
|
||||
text_encoder ([`MultilingualCLIP`]):
|
||||
Frozen text-encoder.
|
||||
tokenizer ([`XLMRobertaTokenizer`]):
|
||||
Tokenizer of class
|
||||
scheduler ([`DDIMScheduler`]):
|
||||
A scheduler to be used in combination with `unet` to generate image latents.
|
||||
unet ([`UNet2DConditionModel`]):
|
||||
Conditional U-Net architecture to denoise the image embedding.
|
||||
movq ([`VQModel`]):
|
||||
MoVQ image encoder and decoder
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
text_encoder: MultilingualCLIP,
|
||||
movq: VQModel,
|
||||
tokenizer: XLMRobertaTokenizer,
|
||||
unet: UNet2DConditionModel,
|
||||
scheduler: DDIMScheduler,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
self.register_modules(
|
||||
text_encoder=text_encoder,
|
||||
movq=movq,
|
||||
tokenizer=tokenizer,
|
||||
unet=unet,
|
||||
scheduler=scheduler,
|
||||
)
|
||||
self.movq_scale_factor = 2 ** (len(self.movq.config.block_out_channels) - 1)
|
||||
|
||||
def prepare_latents(self, shape, dtype, device, generator, latents, scheduler):
|
||||
if latents is None:
|
||||
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
|
||||
else:
|
||||
if latents.shape != shape:
|
||||
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {shape}")
|
||||
latents = latents.to(device)
|
||||
|
||||
latents = latents * scheduler.init_noise_sigma
|
||||
return latents
|
||||
|
||||
def _encode_prompt(
|
||||
self,
|
||||
prompt,
|
||||
device,
|
||||
num_images_per_prompt,
|
||||
do_classifier_free_guidance,
|
||||
negative_prompt=None,
|
||||
):
|
||||
batch_size = len(prompt) if isinstance(prompt, list) else 1
|
||||
# get prompt text embeddings
|
||||
text_inputs = self.tokenizer(
|
||||
prompt,
|
||||
padding="max_length",
|
||||
max_length=77,
|
||||
truncation=True,
|
||||
return_attention_mask=True,
|
||||
add_special_tokens=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
|
||||
text_input_ids = text_inputs.input_ids
|
||||
untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
|
||||
|
||||
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(text_input_ids, untruncated_ids):
|
||||
removed_text = self.tokenizer.batch_decode(untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1])
|
||||
logger.warning(
|
||||
"The following part of your input was truncated because CLIP can only handle sequences up to"
|
||||
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
|
||||
)
|
||||
|
||||
text_input_ids = text_input_ids.to(device)
|
||||
text_mask = text_inputs.attention_mask.to(device)
|
||||
|
||||
prompt_embeds, text_encoder_hidden_states = self.text_encoder(
|
||||
input_ids=text_input_ids, attention_mask=text_mask
|
||||
)
|
||||
|
||||
prompt_embeds = prompt_embeds.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
text_encoder_hidden_states = text_encoder_hidden_states.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
text_mask = text_mask.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
|
||||
if do_classifier_free_guidance:
|
||||
uncond_tokens: List[str]
|
||||
if negative_prompt is None:
|
||||
uncond_tokens = [""] * batch_size
|
||||
elif type(prompt) is not type(negative_prompt):
|
||||
raise TypeError(
|
||||
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
|
||||
f" {type(prompt)}."
|
||||
)
|
||||
elif isinstance(negative_prompt, str):
|
||||
uncond_tokens = [negative_prompt]
|
||||
elif batch_size != len(negative_prompt):
|
||||
raise ValueError(
|
||||
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
|
||||
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
|
||||
" the batch size of `prompt`."
|
||||
)
|
||||
else:
|
||||
uncond_tokens = negative_prompt
|
||||
|
||||
uncond_input = self.tokenizer(
|
||||
uncond_tokens,
|
||||
padding="max_length",
|
||||
max_length=77,
|
||||
truncation=True,
|
||||
return_attention_mask=True,
|
||||
add_special_tokens=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
uncond_text_input_ids = uncond_input.input_ids.to(device)
|
||||
uncond_text_mask = uncond_input.attention_mask.to(device)
|
||||
|
||||
negative_prompt_embeds, uncond_text_encoder_hidden_states = self.text_encoder(
|
||||
input_ids=uncond_text_input_ids, attention_mask=uncond_text_mask
|
||||
)
|
||||
|
||||
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
|
||||
|
||||
seq_len = negative_prompt_embeds.shape[1]
|
||||
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt)
|
||||
negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len)
|
||||
|
||||
seq_len = uncond_text_encoder_hidden_states.shape[1]
|
||||
uncond_text_encoder_hidden_states = uncond_text_encoder_hidden_states.repeat(1, num_images_per_prompt, 1)
|
||||
uncond_text_encoder_hidden_states = uncond_text_encoder_hidden_states.view(
|
||||
batch_size * num_images_per_prompt, seq_len, -1
|
||||
)
|
||||
uncond_text_mask = uncond_text_mask.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
|
||||
# done duplicates
|
||||
|
||||
# For classifier free guidance, we need to do two forward passes.
|
||||
# Here we concatenate the unconditional and text embeddings into a single batch
|
||||
# to avoid doing two forward passes
|
||||
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
|
||||
text_encoder_hidden_states = torch.cat([uncond_text_encoder_hidden_states, text_encoder_hidden_states])
|
||||
|
||||
text_mask = torch.cat([uncond_text_mask, text_mask])
|
||||
|
||||
return prompt_embeds, text_encoder_hidden_states, text_mask
|
||||
|
||||
def enable_sequential_cpu_offload(self, gpu_id=0):
|
||||
r"""
|
||||
Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, the pipeline's
|
||||
models have their state dicts saved to CPU and then are moved to a `torch.device('meta') and loaded to GPU only
|
||||
when their specific submodule has its `forward` method called.
|
||||
"""
|
||||
if is_accelerate_available():
|
||||
from accelerate import cpu_offload
|
||||
else:
|
||||
raise ImportError("Please install accelerate via `pip install accelerate`")
|
||||
|
||||
device = torch.device(f"cuda:{gpu_id}")
|
||||
|
||||
models = [
|
||||
self.unet,
|
||||
self.text_encoder,
|
||||
self.movq,
|
||||
]
|
||||
for cpu_offloaded_model in models:
|
||||
if cpu_offloaded_model is not None:
|
||||
cpu_offload(cpu_offloaded_model, device)
|
||||
|
||||
def enable_model_cpu_offload(self, gpu_id=0):
|
||||
r"""
|
||||
Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
|
||||
to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
|
||||
method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
|
||||
`enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
|
||||
"""
|
||||
if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
|
||||
from accelerate import cpu_offload_with_hook
|
||||
else:
|
||||
raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
|
||||
|
||||
device = torch.device(f"cuda:{gpu_id}")
|
||||
|
||||
if self.device.type != "cpu":
|
||||
self.to("cpu", silence_dtype_warnings=True)
|
||||
torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
|
||||
|
||||
hook = None
|
||||
for cpu_offloaded_model in [self.text_encoder, self.unet, self.movq]:
|
||||
_, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
|
||||
|
||||
if self.safety_checker is not None:
|
||||
_, hook = cpu_offload_with_hook(self.safety_checker, device, prev_module_hook=hook)
|
||||
|
||||
# We'll offload the last model manually.
|
||||
self.final_offload_hook = hook
|
||||
|
||||
@property
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
|
||||
def _execution_device(self):
|
||||
r"""
|
||||
Returns the device on which the pipeline's models will be executed. After calling
|
||||
`pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
|
||||
hooks.
|
||||
"""
|
||||
if not hasattr(self.unet, "_hf_hook"):
|
||||
return self.device
|
||||
for module in self.unet.modules():
|
||||
if (
|
||||
hasattr(module, "_hf_hook")
|
||||
and hasattr(module._hf_hook, "execution_device")
|
||||
and module._hf_hook.execution_device is not None
|
||||
):
|
||||
return torch.device(module._hf_hook.execution_device)
|
||||
return self.device
|
||||
|
||||
@torch.no_grad()
|
||||
@replace_example_docstring(EXAMPLE_DOC_STRING)
|
||||
def __call__(
|
||||
self,
|
||||
prompt: Union[str, List[str]],
|
||||
image: Union[torch.FloatTensor, PIL.Image.Image],
|
||||
mask_image: Union[torch.FloatTensor, PIL.Image.Image, np.ndarray],
|
||||
image_embeds: torch.FloatTensor,
|
||||
negative_image_embeds: torch.FloatTensor,
|
||||
height: int = 512,
|
||||
width: int = 512,
|
||||
num_inference_steps: int = 100,
|
||||
guidance_scale: float = 4.0,
|
||||
num_images_per_prompt: int = 1,
|
||||
negative_prompt: Optional[Union[str, List[str]]] = None,
|
||||
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
|
||||
latents: Optional[torch.FloatTensor] = None,
|
||||
output_type: Optional[str] = "pil",
|
||||
return_dict: bool = True,
|
||||
):
|
||||
"""
|
||||
Function invoked when calling the pipeline for generation.
|
||||
|
||||
Args:
|
||||
prompt (`str` or `List[str]`):
|
||||
The prompt or prompts to guide the image generation.
|
||||
image (`torch.FloatTensor`, `PIL.Image.Image` or `np.ndarray`):
|
||||
`Image`, or tensor representing an image batch, that will be used as the starting point for the
|
||||
process.
|
||||
mask_image (`PIL.Image.Image`,`torch.FloatTensor` or `np.ndarray`):
|
||||
`Image`, or a tensor representing an image batch, to mask `image`. White pixels in the mask will be
|
||||
repainted, while black pixels will be preserved. You can pass a pytorch tensor as mask only if the
|
||||
image you passed is a pytorch tensor, and it should contain one color channel (L) instead of 3, so the
|
||||
expected shape would be either `(B, 1, H, W,)`, `(B, H, W)`, `(1, H, W)` or `(H, W)` If image is an PIL
|
||||
image or numpy array, mask should also be a either PIL image or numpy array. If it is a PIL image, it
|
||||
will be converted to a single channel (luminance) before use. If it is a nummpy array, the expected
|
||||
shape is `(H, W)`.
|
||||
image_embeds (`torch.FloatTensor` or `List[torch.FloatTensor]`):
|
||||
The clip image embeddings for text prompt, that will be used to condition the image generation.
|
||||
negative_image_embeds (`torch.FloatTensor` or `List[torch.FloatTensor]`):
|
||||
The clip image embeddings for negative text prompt, will be used to condition the image generation.
|
||||
height (`int`, *optional*, defaults to 512):
|
||||
The height in pixels of the generated image.
|
||||
width (`int`, *optional*, defaults to 512):
|
||||
The width in pixels of the generated image.
|
||||
num_inference_steps (`int`, *optional*, defaults to 100):
|
||||
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
|
||||
expense of slower inference.
|
||||
guidance_scale (`float`, *optional*, defaults to 4.0):
|
||||
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
|
||||
`guidance_scale` is defined as `w` of equation 2. of [Imagen
|
||||
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
|
||||
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
|
||||
usually at the expense of lower image quality.
|
||||
num_images_per_prompt (`int`, *optional*, defaults to 1):
|
||||
The number of images to generate per prompt.
|
||||
negative_prompt (`str` or `List[str]`, *optional*):
|
||||
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
|
||||
if `guidance_scale` is less than `1`).
|
||||
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
|
||||
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
|
||||
to make generation deterministic.
|
||||
latents (`torch.FloatTensor`, *optional*):
|
||||
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
|
||||
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
|
||||
tensor will ge generated by sampling using the supplied random `generator`.
|
||||
output_type (`str`, *optional*, defaults to `"pil"`):
|
||||
The output format of the generate image. Choose between: `"pil"` (`PIL.Image.Image`), `"np"`
|
||||
(`np.array`) or `"pt"` (`torch.Tensor`).
|
||||
return_dict (`bool`, *optional*, defaults to `True`):
|
||||
Whether or not to return a [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
|
||||
|
||||
Examples:
|
||||
|
||||
Returns:
|
||||
[`~pipelines.ImagePipelineOutput`] or `tuple`
|
||||
"""
|
||||
|
||||
# Define call parameters
|
||||
if isinstance(prompt, str):
|
||||
batch_size = 1
|
||||
elif isinstance(prompt, list):
|
||||
batch_size = len(prompt)
|
||||
else:
|
||||
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
|
||||
|
||||
device = self._execution_device
|
||||
|
||||
batch_size = batch_size * num_images_per_prompt
|
||||
do_classifier_free_guidance = guidance_scale > 1.0
|
||||
|
||||
prompt_embeds, text_encoder_hidden_states, _ = self._encode_prompt(
|
||||
prompt, device, num_images_per_prompt, do_classifier_free_guidance, negative_prompt
|
||||
)
|
||||
|
||||
if isinstance(image_embeds, list):
|
||||
image_embeds = torch.cat(image_embeds, dim=0)
|
||||
if isinstance(negative_image_embeds, list):
|
||||
negative_image_embeds = torch.cat(negative_image_embeds, dim=0)
|
||||
|
||||
if do_classifier_free_guidance:
|
||||
image_embeds = image_embeds.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
negative_image_embeds = negative_image_embeds.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
|
||||
image_embeds = torch.cat([negative_image_embeds, image_embeds], dim=0).to(
|
||||
dtype=prompt_embeds.dtype, device=device
|
||||
)
|
||||
|
||||
# preprocess image and mask
|
||||
mask_image, image = prepare_mask_and_masked_image(image, mask_image, height, width)
|
||||
|
||||
image = image.to(dtype=prompt_embeds.dtype, device=device)
|
||||
image = self.movq.encode(image)["latents"]
|
||||
|
||||
mask_image = mask_image.to(dtype=prompt_embeds.dtype, device=device)
|
||||
|
||||
image_shape = tuple(image.shape[-2:])
|
||||
mask_image = F.interpolate(
|
||||
mask_image,
|
||||
image_shape,
|
||||
mode="nearest",
|
||||
)
|
||||
mask_image = prepare_mask(mask_image)
|
||||
masked_image = image * mask_image
|
||||
|
||||
mask_image = mask_image.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
masked_image = masked_image.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
if do_classifier_free_guidance:
|
||||
mask_image = mask_image.repeat(2, 1, 1, 1)
|
||||
masked_image = masked_image.repeat(2, 1, 1, 1)
|
||||
|
||||
self.scheduler.set_timesteps(num_inference_steps, device=device)
|
||||
timesteps_tensor = self.scheduler.timesteps
|
||||
|
||||
num_channels_latents = self.movq.config.latent_channels
|
||||
|
||||
# get h, w for latents
|
||||
sample_height, sample_width = get_new_h_w(height, width, self.movq_scale_factor)
|
||||
|
||||
# create initial latent
|
||||
latents = self.prepare_latents(
|
||||
(batch_size, num_channels_latents, sample_height, sample_width),
|
||||
text_encoder_hidden_states.dtype,
|
||||
device,
|
||||
generator,
|
||||
latents,
|
||||
self.scheduler,
|
||||
)
|
||||
|
||||
# Check that sizes of mask, masked image and latents match with expected
|
||||
num_channels_mask = mask_image.shape[1]
|
||||
num_channels_masked_image = masked_image.shape[1]
|
||||
if num_channels_latents + num_channels_mask + num_channels_masked_image != self.unet.config.in_channels:
|
||||
raise ValueError(
|
||||
f"Incorrect configuration settings! The config of `pipeline.unet`: {self.unet.config} expects"
|
||||
f" {self.unet.config.in_channels} but received `num_channels_latents`: {num_channels_latents} +"
|
||||
f" `num_channels_mask`: {num_channels_mask} + `num_channels_masked_image`: {num_channels_masked_image}"
|
||||
f" = {num_channels_latents+num_channels_masked_image+num_channels_mask}. Please verify the config of"
|
||||
" `pipeline.unet` or your `mask_image` or `image` input."
|
||||
)
|
||||
|
||||
for i, t in enumerate(self.progress_bar(timesteps_tensor)):
|
||||
# expand the latents if we are doing classifier free guidance
|
||||
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
|
||||
latent_model_input = torch.cat([latent_model_input, masked_image, mask_image], dim=1)
|
||||
|
||||
added_cond_kwargs = {"text_embeds": prompt_embeds, "image_embeds": image_embeds}
|
||||
noise_pred = self.unet(
|
||||
sample=latent_model_input,
|
||||
timestep=t,
|
||||
encoder_hidden_states=text_encoder_hidden_states,
|
||||
added_cond_kwargs=added_cond_kwargs,
|
||||
).sample
|
||||
|
||||
if do_classifier_free_guidance:
|
||||
noise_pred, variance_pred = noise_pred.split(latents.shape[1], dim=1)
|
||||
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
|
||||
_, variance_pred_text = variance_pred.chunk(2)
|
||||
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
|
||||
noise_pred = torch.cat([noise_pred, variance_pred_text], dim=1)
|
||||
|
||||
if not (
|
||||
hasattr(self.scheduler.config, "variance_type")
|
||||
and self.scheduler.config.variance_type in ["learned", "learned_range"]
|
||||
):
|
||||
noise_pred, _ = noise_pred.split(latents.shape[1], dim=1)
|
||||
|
||||
# compute the previous noisy sample x_t -> x_t-1
|
||||
latents = self.scheduler.step(
|
||||
noise_pred,
|
||||
t,
|
||||
latents,
|
||||
generator=generator,
|
||||
).prev_sample
|
||||
|
||||
# post-processing
|
||||
image = self.movq.decode(latents, force_not_quantize=True)["sample"]
|
||||
|
||||
if output_type not in ["pt", "np", "pil"]:
|
||||
raise ValueError(f"Only the output types `pt`, `pil` and `np` are supported not output_type={output_type}")
|
||||
|
||||
if output_type in ["np", "pil"]:
|
||||
image = image * 0.5 + 0.5
|
||||
image = image.clamp(0, 1)
|
||||
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
|
||||
|
||||
if output_type == "pil":
|
||||
image = self.numpy_to_pil(image)
|
||||
|
||||
if not return_dict:
|
||||
return (image,)
|
||||
|
||||
return ImagePipelineOutput(images=image)
|
||||
563
src/diffusers/pipelines/kandinsky/pipeline_kandinsky_prior.py
Normal file
563
src/diffusers/pipelines/kandinsky/pipeline_kandinsky_prior.py
Normal file
@@ -0,0 +1,563 @@
|
||||
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from dataclasses import dataclass
|
||||
from typing import List, Optional, Union
|
||||
|
||||
import numpy as np
|
||||
import PIL
|
||||
import torch
|
||||
from transformers import CLIPImageProcessor, CLIPTextModelWithProjection, CLIPTokenizer, CLIPVisionModelWithProjection
|
||||
|
||||
from ...models import PriorTransformer
|
||||
from ...pipelines import DiffusionPipeline
|
||||
from ...schedulers import UnCLIPScheduler
|
||||
from ...utils import (
|
||||
BaseOutput,
|
||||
is_accelerate_available,
|
||||
logging,
|
||||
randn_tensor,
|
||||
replace_example_docstring,
|
||||
)
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
|
||||
EXAMPLE_DOC_STRING = """
|
||||
Examples:
|
||||
```py
|
||||
>>> from diffusers import KandinskyPipeline, KandinskyPriorPipeline
|
||||
>>> import torch
|
||||
|
||||
>>> pipe_prior = KandinskyPriorPipeline.from_pretrained("kandinsky-community/kandinsky-2-1-prior")
|
||||
>>> pipe_prior.to("cuda")
|
||||
|
||||
>>> prompt = "red cat, 4k photo"
|
||||
>>> out = pipe_prior(prompt)
|
||||
>>> image_emb = out.images
|
||||
>>> zero_image_emb = out.zero_embeds
|
||||
|
||||
>>> pipe = KandinskyPipeline.from_pretrained("kandinsky-community/kandinsky-2-1")
|
||||
>>> pipe.to("cuda")
|
||||
|
||||
>>> image = pipe(
|
||||
... prompt,
|
||||
... image_embeds=image_emb,
|
||||
... negative_image_embeds=zero_image_emb,
|
||||
... height=768,
|
||||
... width=768,
|
||||
... num_inference_steps=100,
|
||||
... ).images
|
||||
|
||||
>>> image[0].save("cat.png")
|
||||
```
|
||||
"""
|
||||
|
||||
EXAMPLE_INTERPOLATE_DOC_STRING = """
|
||||
Examples:
|
||||
```py
|
||||
>>> from diffusers import KandinskyPriorPipeline, KandinskyPipeline
|
||||
>>> from diffusers.utils import load_image
|
||||
>>> import PIL
|
||||
|
||||
>>> import torch
|
||||
>>> from torchvision import transforms
|
||||
|
||||
>>> pipe_prior = KandinskyPriorPipeline.from_pretrained(
|
||||
... "kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16
|
||||
... )
|
||||
>>> pipe_prior.to("cuda")
|
||||
|
||||
>>> img1 = load_image(
|
||||
... "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
|
||||
... "/kandinsky/cat.png"
|
||||
... )
|
||||
|
||||
>>> img2 = load_image(
|
||||
... "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
|
||||
... "/kandinsky/starry_night.jpeg"
|
||||
... )
|
||||
|
||||
>>> images_texts = ["a cat", img1, img2]
|
||||
>>> weights = [0.3, 0.3, 0.4]
|
||||
>>> image_emb, zero_image_emb = pipe_prior.interpolate(images_texts, weights)
|
||||
|
||||
>>> pipe = KandinskyPipeline.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16)
|
||||
>>> pipe.to("cuda")
|
||||
|
||||
>>> image = pipe(
|
||||
... "",
|
||||
... image_embeds=image_emb,
|
||||
... negative_image_embeds=zero_image_emb,
|
||||
... height=768,
|
||||
... width=768,
|
||||
... num_inference_steps=150,
|
||||
... ).images[0]
|
||||
|
||||
>>> image.save("starry_cat.png")
|
||||
```
|
||||
"""
|
||||
|
||||
|
||||
@dataclass
|
||||
class KandinskyPriorPipelineOutput(BaseOutput):
|
||||
"""
|
||||
Output class for KandinskyPriorPipeline.
|
||||
|
||||
Args:
|
||||
images (`torch.FloatTensor`)
|
||||
clip image embeddings for text prompt
|
||||
zero_embeds (`List[PIL.Image.Image]` or `np.ndarray`)
|
||||
clip image embeddings for unconditional tokens
|
||||
"""
|
||||
|
||||
images: Union[torch.FloatTensor, np.ndarray]
|
||||
zero_embeds: Union[torch.FloatTensor, np.ndarray]
|
||||
|
||||
|
||||
class KandinskyPriorPipeline(DiffusionPipeline):
|
||||
"""
|
||||
Pipeline for generating image prior for Kandinsky
|
||||
|
||||
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
|
||||
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
|
||||
|
||||
Args:
|
||||
prior ([`PriorTransformer`]):
|
||||
The canonincal unCLIP prior to approximate the image embedding from the text embedding.
|
||||
image_encoder ([`CLIPVisionModelWithProjection`]):
|
||||
Frozen image-encoder.
|
||||
text_encoder ([`CLIPTextModelWithProjection`]):
|
||||
Frozen text-encoder.
|
||||
tokenizer (`CLIPTokenizer`):
|
||||
Tokenizer of class
|
||||
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
|
||||
scheduler ([`UnCLIPScheduler`]):
|
||||
A scheduler to be used in combination with `prior` to generate image embedding.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
prior: PriorTransformer,
|
||||
image_encoder: CLIPVisionModelWithProjection,
|
||||
text_encoder: CLIPTextModelWithProjection,
|
||||
tokenizer: CLIPTokenizer,
|
||||
scheduler: UnCLIPScheduler,
|
||||
image_processor: CLIPImageProcessor,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
self.register_modules(
|
||||
prior=prior,
|
||||
text_encoder=text_encoder,
|
||||
tokenizer=tokenizer,
|
||||
scheduler=scheduler,
|
||||
image_encoder=image_encoder,
|
||||
image_processor=image_processor,
|
||||
)
|
||||
|
||||
@torch.no_grad()
|
||||
@replace_example_docstring(EXAMPLE_INTERPOLATE_DOC_STRING)
|
||||
def interpolate(
|
||||
self,
|
||||
images_and_prompts: List[Union[str, PIL.Image.Image, torch.FloatTensor]],
|
||||
weights: List[float],
|
||||
num_images_per_prompt: int = 1,
|
||||
num_inference_steps: int = 25,
|
||||
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
|
||||
latents: Optional[torch.FloatTensor] = None,
|
||||
negative_prior_prompt: Optional[str] = None,
|
||||
negative_prompt: Union[str] = "",
|
||||
guidance_scale: float = 4.0,
|
||||
device=None,
|
||||
):
|
||||
"""
|
||||
Function invoked when using the prior pipeline for interpolation.
|
||||
|
||||
Args:
|
||||
images_and_prompts (`List[Union[str, PIL.Image.Image, torch.FloatTensor]]`):
|
||||
list of prompts and images to guide the image generation.
|
||||
weights: (`List[float]`):
|
||||
list of weights for each condition in `images_and_prompts`
|
||||
num_images_per_prompt (`int`, *optional*, defaults to 1):
|
||||
The number of images to generate per prompt.
|
||||
num_inference_steps (`int`, *optional*, defaults to 100):
|
||||
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
|
||||
expense of slower inference.
|
||||
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
|
||||
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
|
||||
to make generation deterministic.
|
||||
latents (`torch.FloatTensor`, *optional*):
|
||||
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
|
||||
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
|
||||
tensor will ge generated by sampling using the supplied random `generator`.
|
||||
negative_prior_prompt (`str`, *optional*):
|
||||
The prompt not to guide the prior diffusion process. Ignored when not using guidance (i.e., ignored if
|
||||
`guidance_scale` is less than `1`).
|
||||
negative_prompt (`str` or `List[str]`, *optional*):
|
||||
The prompt not to guide the image generation. Ignored when not using guidance (i.e., ignored if
|
||||
`guidance_scale` is less than `1`).
|
||||
guidance_scale (`float`, *optional*, defaults to 4.0):
|
||||
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
|
||||
`guidance_scale` is defined as `w` of equation 2. of [Imagen
|
||||
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
|
||||
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
|
||||
usually at the expense of lower image quality.
|
||||
|
||||
Examples:
|
||||
|
||||
Returns:
|
||||
[`KandinskyPriorPipelineOutput`] or `tuple`
|
||||
"""
|
||||
|
||||
device = device or self.device
|
||||
|
||||
if len(images_and_prompts) != len(weights):
|
||||
raise ValueError(
|
||||
f"`images_and_prompts` contains {len(images_and_prompts)} items and `weights` contains {len(weights)} items - they should be lists of same length"
|
||||
)
|
||||
|
||||
image_embeddings = []
|
||||
for cond, weight in zip(images_and_prompts, weights):
|
||||
if isinstance(cond, str):
|
||||
image_emb = self.__call__(
|
||||
cond,
|
||||
num_inference_steps=num_inference_steps,
|
||||
num_images_per_prompt=num_images_per_prompt,
|
||||
generator=generator,
|
||||
latents=latents,
|
||||
negative_prompt=negative_prior_prompt,
|
||||
guidance_scale=guidance_scale,
|
||||
).images
|
||||
|
||||
elif isinstance(cond, (PIL.Image.Image, torch.Tensor)):
|
||||
if isinstance(cond, PIL.Image.Image):
|
||||
cond = (
|
||||
self.image_processor(cond, return_tensors="pt")
|
||||
.pixel_values[0]
|
||||
.unsqueeze(0)
|
||||
.to(dtype=self.image_encoder.dtype, device=device)
|
||||
)
|
||||
|
||||
image_emb = self.image_encoder(cond)["image_embeds"]
|
||||
|
||||
else:
|
||||
raise ValueError(
|
||||
f"`images_and_prompts` can only contains elements to be of type `str`, `PIL.Image.Image` or `torch.Tensor` but is {type(cond)}"
|
||||
)
|
||||
|
||||
image_embeddings.append(image_emb * weight)
|
||||
|
||||
image_emb = torch.cat(image_embeddings).sum(dim=0, keepdim=True)
|
||||
|
||||
out_zero = self.__call__(
|
||||
negative_prompt,
|
||||
num_inference_steps=num_inference_steps,
|
||||
num_images_per_prompt=num_images_per_prompt,
|
||||
generator=generator,
|
||||
latents=latents,
|
||||
negative_prompt=negative_prior_prompt,
|
||||
guidance_scale=guidance_scale,
|
||||
)
|
||||
zero_image_emb = out_zero.zero_embeds if negative_prompt == "" else out_zero.images
|
||||
|
||||
return image_emb, zero_image_emb
|
||||
|
||||
def prepare_latents(self, shape, dtype, device, generator, latents, scheduler):
|
||||
if latents is None:
|
||||
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
|
||||
else:
|
||||
if latents.shape != shape:
|
||||
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {shape}")
|
||||
latents = latents.to(device)
|
||||
|
||||
latents = latents * scheduler.init_noise_sigma
|
||||
return latents
|
||||
|
||||
def get_zero_embed(self, batch_size=1, device=None):
|
||||
device = device or self.device
|
||||
zero_img = torch.zeros(1, 3, self.image_encoder.config.image_size, self.image_encoder.config.image_size).to(
|
||||
device=device, dtype=self.image_encoder.dtype
|
||||
)
|
||||
zero_image_emb = self.image_encoder(zero_img)["image_embeds"]
|
||||
zero_image_emb = zero_image_emb.repeat(batch_size, 1)
|
||||
return zero_image_emb
|
||||
|
||||
def enable_sequential_cpu_offload(self, gpu_id=0):
|
||||
r"""
|
||||
Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, the pipeline's
|
||||
models have their state dicts saved to CPU and then are moved to a `torch.device('meta') and loaded to GPU only
|
||||
when their specific submodule has its `forward` method called.
|
||||
"""
|
||||
if is_accelerate_available():
|
||||
from accelerate import cpu_offload
|
||||
else:
|
||||
raise ImportError("Please install accelerate via `pip install accelerate`")
|
||||
|
||||
device = torch.device(f"cuda:{gpu_id}")
|
||||
|
||||
models = [
|
||||
self.image_encoder,
|
||||
self.text_encoder,
|
||||
]
|
||||
for cpu_offloaded_model in models:
|
||||
if cpu_offloaded_model is not None:
|
||||
cpu_offload(cpu_offloaded_model, device)
|
||||
|
||||
@property
|
||||
def _execution_device(self):
|
||||
r"""
|
||||
Returns the device on which the pipeline's models will be executed. After calling
|
||||
`pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
|
||||
hooks.
|
||||
"""
|
||||
if self.device != torch.device("meta") or not hasattr(self.text_encoder, "_hf_hook"):
|
||||
return self.device
|
||||
for module in self.text_encoder.modules():
|
||||
if (
|
||||
hasattr(module, "_hf_hook")
|
||||
and hasattr(module._hf_hook, "execution_device")
|
||||
and module._hf_hook.execution_device is not None
|
||||
):
|
||||
return torch.device(module._hf_hook.execution_device)
|
||||
return self.device
|
||||
|
||||
def _encode_prompt(
|
||||
self,
|
||||
prompt,
|
||||
device,
|
||||
num_images_per_prompt,
|
||||
do_classifier_free_guidance,
|
||||
negative_prompt=None,
|
||||
):
|
||||
batch_size = len(prompt) if isinstance(prompt, list) else 1
|
||||
# get prompt text embeddings
|
||||
text_inputs = self.tokenizer(
|
||||
prompt,
|
||||
padding="max_length",
|
||||
max_length=self.tokenizer.model_max_length,
|
||||
truncation=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
text_input_ids = text_inputs.input_ids
|
||||
text_mask = text_inputs.attention_mask.bool().to(device)
|
||||
|
||||
untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
|
||||
|
||||
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(text_input_ids, untruncated_ids):
|
||||
removed_text = self.tokenizer.batch_decode(untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1])
|
||||
logger.warning(
|
||||
"The following part of your input was truncated because CLIP can only handle sequences up to"
|
||||
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
|
||||
)
|
||||
text_input_ids = text_input_ids[:, : self.tokenizer.model_max_length]
|
||||
|
||||
text_encoder_output = self.text_encoder(text_input_ids.to(device))
|
||||
|
||||
prompt_embeds = text_encoder_output.text_embeds
|
||||
text_encoder_hidden_states = text_encoder_output.last_hidden_state
|
||||
|
||||
prompt_embeds = prompt_embeds.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
text_encoder_hidden_states = text_encoder_hidden_states.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
text_mask = text_mask.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
|
||||
if do_classifier_free_guidance:
|
||||
uncond_tokens: List[str]
|
||||
if negative_prompt is None:
|
||||
uncond_tokens = [""] * batch_size
|
||||
elif type(prompt) is not type(negative_prompt):
|
||||
raise TypeError(
|
||||
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
|
||||
f" {type(prompt)}."
|
||||
)
|
||||
elif isinstance(negative_prompt, str):
|
||||
uncond_tokens = [negative_prompt]
|
||||
elif batch_size != len(negative_prompt):
|
||||
raise ValueError(
|
||||
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
|
||||
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
|
||||
" the batch size of `prompt`."
|
||||
)
|
||||
else:
|
||||
uncond_tokens = negative_prompt
|
||||
|
||||
uncond_input = self.tokenizer(
|
||||
uncond_tokens,
|
||||
padding="max_length",
|
||||
max_length=self.tokenizer.model_max_length,
|
||||
truncation=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
uncond_text_mask = uncond_input.attention_mask.bool().to(device)
|
||||
negative_prompt_embeds_text_encoder_output = self.text_encoder(uncond_input.input_ids.to(device))
|
||||
|
||||
negative_prompt_embeds = negative_prompt_embeds_text_encoder_output.text_embeds
|
||||
uncond_text_encoder_hidden_states = negative_prompt_embeds_text_encoder_output.last_hidden_state
|
||||
|
||||
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
|
||||
|
||||
seq_len = negative_prompt_embeds.shape[1]
|
||||
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt)
|
||||
negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len)
|
||||
|
||||
seq_len = uncond_text_encoder_hidden_states.shape[1]
|
||||
uncond_text_encoder_hidden_states = uncond_text_encoder_hidden_states.repeat(1, num_images_per_prompt, 1)
|
||||
uncond_text_encoder_hidden_states = uncond_text_encoder_hidden_states.view(
|
||||
batch_size * num_images_per_prompt, seq_len, -1
|
||||
)
|
||||
uncond_text_mask = uncond_text_mask.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
|
||||
# done duplicates
|
||||
|
||||
# For classifier free guidance, we need to do two forward passes.
|
||||
# Here we concatenate the unconditional and text embeddings into a single batch
|
||||
# to avoid doing two forward passes
|
||||
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
|
||||
text_encoder_hidden_states = torch.cat([uncond_text_encoder_hidden_states, text_encoder_hidden_states])
|
||||
|
||||
text_mask = torch.cat([uncond_text_mask, text_mask])
|
||||
|
||||
return prompt_embeds, text_encoder_hidden_states, text_mask
|
||||
|
||||
@torch.no_grad()
|
||||
@replace_example_docstring(EXAMPLE_DOC_STRING)
|
||||
def __call__(
|
||||
self,
|
||||
prompt: Union[str, List[str]],
|
||||
num_images_per_prompt: int = 1,
|
||||
num_inference_steps: int = 25,
|
||||
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
|
||||
latents: Optional[torch.FloatTensor] = None,
|
||||
negative_prompt: Optional[Union[str, List[str]]] = None,
|
||||
guidance_scale: float = 4.0,
|
||||
output_type: Optional[str] = "pt", # pt only
|
||||
return_dict: bool = True,
|
||||
):
|
||||
"""
|
||||
Function invoked when calling the pipeline for generation.
|
||||
|
||||
Args:
|
||||
prompt (`str` or `List[str]`):
|
||||
The prompt or prompts to guide the image generation.
|
||||
num_images_per_prompt (`int`, *optional*, defaults to 1):
|
||||
The number of images to generate per prompt.
|
||||
num_inference_steps (`int`, *optional*, defaults to 100):
|
||||
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
|
||||
expense of slower inference.
|
||||
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
|
||||
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
|
||||
to make generation deterministic.
|
||||
latents (`torch.FloatTensor`, *optional*):
|
||||
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
|
||||
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
|
||||
tensor will ge generated by sampling using the supplied random `generator`.
|
||||
negative_prompt (`str` or `List[str]`, *optional*):
|
||||
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
|
||||
if `guidance_scale` is less than `1`).
|
||||
guidance_scale (`float`, *optional*, defaults to 4.0):
|
||||
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
|
||||
`guidance_scale` is defined as `w` of equation 2. of [Imagen
|
||||
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
|
||||
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
|
||||
usually at the expense of lower image quality.
|
||||
output_type (`str`, *optional*, defaults to `"pt"`):
|
||||
The output format of the generate image. Choose between: `"np"` (`np.array`) or `"pt"`
|
||||
(`torch.Tensor`).
|
||||
return_dict (`bool`, *optional*, defaults to `True`):
|
||||
Whether or not to return a [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
|
||||
|
||||
Examples:
|
||||
|
||||
Returns:
|
||||
[`KandinskyPriorPipelineOutput`] or `tuple`
|
||||
"""
|
||||
|
||||
if isinstance(prompt, str):
|
||||
batch_size = 1
|
||||
elif isinstance(prompt, list):
|
||||
batch_size = len(prompt)
|
||||
else:
|
||||
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
|
||||
|
||||
device = self._execution_device
|
||||
|
||||
batch_size = batch_size * num_images_per_prompt
|
||||
|
||||
do_classifier_free_guidance = guidance_scale > 1.0
|
||||
prompt_embeds, text_encoder_hidden_states, text_mask = self._encode_prompt(
|
||||
prompt, device, num_images_per_prompt, do_classifier_free_guidance, negative_prompt
|
||||
)
|
||||
|
||||
# prior
|
||||
self.scheduler.set_timesteps(num_inference_steps, device=device)
|
||||
prior_timesteps_tensor = self.scheduler.timesteps
|
||||
|
||||
embedding_dim = self.prior.config.embedding_dim
|
||||
|
||||
latents = self.prepare_latents(
|
||||
(batch_size, embedding_dim),
|
||||
prompt_embeds.dtype,
|
||||
device,
|
||||
generator,
|
||||
latents,
|
||||
self.scheduler,
|
||||
)
|
||||
|
||||
for i, t in enumerate(self.progress_bar(prior_timesteps_tensor)):
|
||||
# expand the latents if we are doing classifier free guidance
|
||||
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
|
||||
|
||||
predicted_image_embedding = self.prior(
|
||||
latent_model_input,
|
||||
timestep=t,
|
||||
proj_embedding=prompt_embeds,
|
||||
encoder_hidden_states=text_encoder_hidden_states,
|
||||
attention_mask=text_mask,
|
||||
).predicted_image_embedding
|
||||
|
||||
if do_classifier_free_guidance:
|
||||
predicted_image_embedding_uncond, predicted_image_embedding_text = predicted_image_embedding.chunk(2)
|
||||
predicted_image_embedding = predicted_image_embedding_uncond + guidance_scale * (
|
||||
predicted_image_embedding_text - predicted_image_embedding_uncond
|
||||
)
|
||||
|
||||
if i + 1 == prior_timesteps_tensor.shape[0]:
|
||||
prev_timestep = None
|
||||
else:
|
||||
prev_timestep = prior_timesteps_tensor[i + 1]
|
||||
|
||||
latents = self.scheduler.step(
|
||||
predicted_image_embedding,
|
||||
timestep=t,
|
||||
sample=latents,
|
||||
generator=generator,
|
||||
prev_timestep=prev_timestep,
|
||||
).prev_sample
|
||||
|
||||
latents = self.prior.post_process_latents(latents)
|
||||
|
||||
image_embeddings = latents
|
||||
zero_embeds = self.get_zero_embed(latents.shape[0], device=latents.device)
|
||||
|
||||
if output_type not in ["pt", "np"]:
|
||||
raise ValueError(f"Only the output types `pt` and `np` are supported not output_type={output_type}")
|
||||
|
||||
if output_type == "np":
|
||||
image_embeddings = image_embeddings.cpu().numpy()
|
||||
zero_embeds = zero_embeds.cpu().numpy()
|
||||
|
||||
if not return_dict:
|
||||
return (image_embeddings, zero_embeds)
|
||||
|
||||
return KandinskyPriorPipelineOutput(images=image_embeddings, zero_embeds=zero_embeds)
|
||||
27
src/diffusers/pipelines/kandinsky/text_encoder.py
Normal file
27
src/diffusers/pipelines/kandinsky/text_encoder.py
Normal file
@@ -0,0 +1,27 @@
|
||||
import torch
|
||||
from transformers import PreTrainedModel, XLMRobertaConfig, XLMRobertaModel
|
||||
|
||||
|
||||
class MCLIPConfig(XLMRobertaConfig):
|
||||
model_type = "M-CLIP"
|
||||
|
||||
def __init__(self, transformerDimSize=1024, imageDimSize=768, **kwargs):
|
||||
self.transformerDimensions = transformerDimSize
|
||||
self.numDims = imageDimSize
|
||||
super().__init__(**kwargs)
|
||||
|
||||
|
||||
class MultilingualCLIP(PreTrainedModel):
|
||||
config_class = MCLIPConfig
|
||||
|
||||
def __init__(self, config, *args, **kwargs):
|
||||
super().__init__(config, *args, **kwargs)
|
||||
self.transformer = XLMRobertaModel(config)
|
||||
self.LinearTransformation = torch.nn.Linear(
|
||||
in_features=config.transformerDimensions, out_features=config.numDims
|
||||
)
|
||||
|
||||
def forward(self, input_ids, attention_mask):
|
||||
embs = self.transformer(input_ids=input_ids, attention_mask=attention_mask)[0]
|
||||
embs2 = (embs * attention_mask.unsqueeze(2)).sum(dim=1) / attention_mask.sum(dim=1)[:, None]
|
||||
return self.LinearTransformation(embs2), embs
|
||||
@@ -15,7 +15,14 @@ from ...models.attention_processor import (
|
||||
AttnProcessor,
|
||||
)
|
||||
from ...models.dual_transformer_2d import DualTransformer2DModel
|
||||
from ...models.embeddings import GaussianFourierProjection, TextTimeEmbedding, TimestepEmbedding, Timesteps
|
||||
from ...models.embeddings import (
|
||||
GaussianFourierProjection,
|
||||
TextImageProjection,
|
||||
TextImageTimeEmbedding,
|
||||
TextTimeEmbedding,
|
||||
TimestepEmbedding,
|
||||
Timesteps,
|
||||
)
|
||||
from ...models.transformer_2d import Transformer2DModel
|
||||
from ...models.unet_2d_condition import UNet2DConditionOutput
|
||||
from ...utils import is_torch_version, logging
|
||||
@@ -182,7 +189,11 @@ class UNetFlatConditionModel(ModelMixin, ConfigMixin):
|
||||
cross_attention_dim (`int` or `Tuple[int]`, *optional*, defaults to 1280):
|
||||
The dimension of the cross attention features.
|
||||
encoder_hid_dim (`int`, *optional*, defaults to None):
|
||||
If given, `encoder_hidden_states` will be projected from this dimension to `cross_attention_dim`.
|
||||
If `encoder_hid_dim_type` is defined, `encoder_hidden_states` will be projected from `encoder_hid_dim`
|
||||
dimension to `cross_attention_dim`.
|
||||
encoder_hid_dim_type (`str`, *optional*, defaults to None):
|
||||
If given, the `encoder_hidden_states` and potentially other embeddings will be down-projected to text
|
||||
embeddings of dimension `cross_attention` according to `encoder_hid_dim_type`.
|
||||
attention_head_dim (`int`, *optional*, defaults to 8): The dimension of the attention heads.
|
||||
resnet_time_scale_shift (`str`, *optional*, defaults to `"default"`): Time scale shift config
|
||||
for resnet blocks, see [`~models.resnet.ResnetBlockFlat`]. Choose from `default` or `scale_shift`.
|
||||
@@ -253,6 +264,7 @@ class UNetFlatConditionModel(ModelMixin, ConfigMixin):
|
||||
norm_eps: float = 1e-5,
|
||||
cross_attention_dim: Union[int, Tuple[int]] = 1280,
|
||||
encoder_hid_dim: Optional[int] = None,
|
||||
encoder_hid_dim_type: Optional[str] = None,
|
||||
attention_head_dim: Union[int, Tuple[int]] = 8,
|
||||
dual_cross_attention: bool = False,
|
||||
use_linear_projection: bool = False,
|
||||
@@ -350,8 +362,31 @@ class UNetFlatConditionModel(ModelMixin, ConfigMixin):
|
||||
cond_proj_dim=time_cond_proj_dim,
|
||||
)
|
||||
|
||||
if encoder_hid_dim is not None:
|
||||
if encoder_hid_dim_type is None and encoder_hid_dim is not None:
|
||||
encoder_hid_dim_type = "text_proj"
|
||||
logger.info("encoder_hid_dim_type defaults to 'text_proj' as `encoder_hid_dim` is defined.")
|
||||
|
||||
if encoder_hid_dim is None and encoder_hid_dim_type is not None:
|
||||
raise ValueError(
|
||||
f"`encoder_hid_dim` has to be defined when `encoder_hid_dim_type` is set to {encoder_hid_dim_type}."
|
||||
)
|
||||
|
||||
if encoder_hid_dim_type == "text_proj":
|
||||
self.encoder_hid_proj = nn.Linear(encoder_hid_dim, cross_attention_dim)
|
||||
elif encoder_hid_dim_type == "text_image_proj":
|
||||
# image_embed_dim DOESN'T have to be `cross_attention_dim`. To not clutter the __init__ too much
|
||||
# they are set to `cross_attention_dim` here as this is exactly the required dimension for the currently only use
|
||||
# case when `addition_embed_type == "text_image_proj"` (Kadinsky 2.1)`
|
||||
self.encoder_hid_proj = TextImageProjection(
|
||||
text_embed_dim=encoder_hid_dim,
|
||||
image_embed_dim=cross_attention_dim,
|
||||
cross_attention_dim=cross_attention_dim,
|
||||
)
|
||||
|
||||
elif encoder_hid_dim_type is not None:
|
||||
raise ValueError(
|
||||
f"encoder_hid_dim_type: {encoder_hid_dim_type} must be None, 'text_proj' or 'text_image_proj'."
|
||||
)
|
||||
else:
|
||||
self.encoder_hid_proj = None
|
||||
|
||||
@@ -393,8 +428,15 @@ class UNetFlatConditionModel(ModelMixin, ConfigMixin):
|
||||
self.add_embedding = TextTimeEmbedding(
|
||||
text_time_embedding_from_dim, time_embed_dim, num_heads=addition_embed_type_num_heads
|
||||
)
|
||||
elif addition_embed_type == "text_image":
|
||||
# text_embed_dim and image_embed_dim DON'T have to be `cross_attention_dim`. To not clutter the __init__ too much
|
||||
# they are set to `cross_attention_dim` here as this is exactly the required dimension for the currently only use
|
||||
# case when `addition_embed_type == "text_image"` (Kadinsky 2.1)`
|
||||
self.add_embedding = TextImageTimeEmbedding(
|
||||
text_embed_dim=cross_attention_dim, image_embed_dim=cross_attention_dim, time_embed_dim=time_embed_dim
|
||||
)
|
||||
elif addition_embed_type is not None:
|
||||
raise ValueError(f"addition_embed_type: {addition_embed_type} must be None or 'text'.")
|
||||
raise ValueError(f"addition_embed_type: {addition_embed_type} must be None, 'text' or 'text_image'.")
|
||||
|
||||
if time_embedding_act_fn is None:
|
||||
self.time_embed_act = None
|
||||
@@ -719,6 +761,7 @@ class UNetFlatConditionModel(ModelMixin, ConfigMixin):
|
||||
timestep_cond: Optional[torch.Tensor] = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
||||
added_cond_kwargs: Optional[Dict[str, torch.Tensor]] = None,
|
||||
down_block_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
|
||||
mid_block_additional_residual: Optional[torch.Tensor] = None,
|
||||
encoder_attention_mask: Optional[torch.Tensor] = None,
|
||||
@@ -739,6 +782,10 @@ class UNetFlatConditionModel(ModelMixin, ConfigMixin):
|
||||
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
|
||||
`self.processor` in
|
||||
[diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
|
||||
added_cond_kwargs (`dict`, *optional*):
|
||||
A kwargs dictionary that if specified includes additonal conditions that can be used for additonal time
|
||||
embeddings or encoder hidden states projections. See the configurations `encoder_hid_dim_type` and
|
||||
`addition_embed_type` for more information.
|
||||
|
||||
Returns:
|
||||
[`~models.unet_2d_condition.UNet2DConditionOutput`] or `tuple`:
|
||||
@@ -831,12 +878,35 @@ class UNetFlatConditionModel(ModelMixin, ConfigMixin):
|
||||
if self.config.addition_embed_type == "text":
|
||||
aug_emb = self.add_embedding(encoder_hidden_states)
|
||||
emb = emb + aug_emb
|
||||
elif self.config.addition_embed_type == "text_image":
|
||||
# Kadinsky 2.1 - style
|
||||
if "image_embeds" not in added_cond_kwargs:
|
||||
raise ValueError(
|
||||
f"{self.__class__} has the config param `addition_embed_type` set to 'text_image' which requires"
|
||||
" the keyword argument `image_embeds` to be passed in `added_cond_kwargs`"
|
||||
)
|
||||
|
||||
image_embs = added_cond_kwargs.get("image_embeds")
|
||||
text_embs = added_cond_kwargs.get("text_embeds", encoder_hidden_states)
|
||||
|
||||
aug_emb = self.add_embedding(text_embs, image_embs)
|
||||
emb = emb + aug_emb
|
||||
|
||||
if self.time_embed_act is not None:
|
||||
emb = self.time_embed_act(emb)
|
||||
|
||||
if self.encoder_hid_proj is not None:
|
||||
if self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "text_proj":
|
||||
encoder_hidden_states = self.encoder_hid_proj(encoder_hidden_states)
|
||||
elif self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "text_image_proj":
|
||||
# Kadinsky 2.1 - style
|
||||
if "image_embeds" not in added_cond_kwargs:
|
||||
raise ValueError(
|
||||
f"{self.__class__} has the config param `encoder_hid_dim_type` set to 'text_image_proj' which"
|
||||
" requires the keyword argument `image_embeds` to be passed in `added_conditions`"
|
||||
)
|
||||
|
||||
image_embeds = added_cond_kwargs.get("image_embeds")
|
||||
encoder_hidden_states = self.encoder_hid_proj(encoder_hidden_states, image_embeds)
|
||||
|
||||
# 2. pre-process
|
||||
sample = self.conv_in(sample)
|
||||
|
||||
@@ -152,6 +152,66 @@ class IFSuperResolutionPipeline(metaclass=DummyObject):
|
||||
requires_backends(cls, ["torch", "transformers"])
|
||||
|
||||
|
||||
class KandinskyImg2ImgPipeline(metaclass=DummyObject):
|
||||
_backends = ["torch", "transformers"]
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
requires_backends(self, ["torch", "transformers"])
|
||||
|
||||
@classmethod
|
||||
def from_config(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch", "transformers"])
|
||||
|
||||
@classmethod
|
||||
def from_pretrained(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch", "transformers"])
|
||||
|
||||
|
||||
class KandinskyInpaintPipeline(metaclass=DummyObject):
|
||||
_backends = ["torch", "transformers"]
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
requires_backends(self, ["torch", "transformers"])
|
||||
|
||||
@classmethod
|
||||
def from_config(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch", "transformers"])
|
||||
|
||||
@classmethod
|
||||
def from_pretrained(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch", "transformers"])
|
||||
|
||||
|
||||
class KandinskyPipeline(metaclass=DummyObject):
|
||||
_backends = ["torch", "transformers"]
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
requires_backends(self, ["torch", "transformers"])
|
||||
|
||||
@classmethod
|
||||
def from_config(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch", "transformers"])
|
||||
|
||||
@classmethod
|
||||
def from_pretrained(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch", "transformers"])
|
||||
|
||||
|
||||
class KandinskyPriorPipeline(metaclass=DummyObject):
|
||||
_backends = ["torch", "transformers"]
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
requires_backends(self, ["torch", "transformers"])
|
||||
|
||||
@classmethod
|
||||
def from_config(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch", "transformers"])
|
||||
|
||||
@classmethod
|
||||
def from_pretrained(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch", "transformers"])
|
||||
|
||||
|
||||
class LDMTextToImagePipeline(metaclass=DummyObject):
|
||||
_backends = ["torch", "transformers"]
|
||||
|
||||
|
||||
0
tests/pipelines/kandinsky/__init__.py
Normal file
0
tests/pipelines/kandinsky/__init__.py
Normal file
282
tests/pipelines/kandinsky/test_kandinsky.py
Normal file
282
tests/pipelines/kandinsky/test_kandinsky.py
Normal file
@@ -0,0 +1,282 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2023 HuggingFace Inc.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import gc
|
||||
import random
|
||||
import unittest
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
from transformers import XLMRobertaTokenizerFast
|
||||
|
||||
from diffusers import DDIMScheduler, KandinskyPipeline, KandinskyPriorPipeline, UNet2DConditionModel, VQModel
|
||||
from diffusers.pipelines.kandinsky.text_encoder import MCLIPConfig, MultilingualCLIP
|
||||
from diffusers.utils import floats_tensor, load_numpy, slow, torch_device
|
||||
from diffusers.utils.testing_utils import enable_full_determinism, require_torch_gpu
|
||||
|
||||
from ..test_pipelines_common import PipelineTesterMixin, assert_mean_pixel_difference
|
||||
|
||||
|
||||
enable_full_determinism()
|
||||
|
||||
|
||||
class KandinskyPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
|
||||
pipeline_class = KandinskyPipeline
|
||||
params = [
|
||||
"prompt",
|
||||
"image_embeds",
|
||||
"negative_image_embeds",
|
||||
]
|
||||
batch_params = ["prompt", "negative_prompt", "image_embeds", "negative_image_embeds"]
|
||||
required_optional_params = [
|
||||
"generator",
|
||||
"height",
|
||||
"width",
|
||||
"latents",
|
||||
"guidance_scale",
|
||||
"negative_prompt",
|
||||
"num_inference_steps",
|
||||
"return_dict",
|
||||
"guidance_scale",
|
||||
"num_images_per_prompt",
|
||||
"output_type",
|
||||
"return_dict",
|
||||
]
|
||||
test_xformers_attention = False
|
||||
|
||||
@property
|
||||
def text_embedder_hidden_size(self):
|
||||
return 32
|
||||
|
||||
@property
|
||||
def time_input_dim(self):
|
||||
return 32
|
||||
|
||||
@property
|
||||
def block_out_channels_0(self):
|
||||
return self.time_input_dim
|
||||
|
||||
@property
|
||||
def time_embed_dim(self):
|
||||
return self.time_input_dim * 4
|
||||
|
||||
@property
|
||||
def cross_attention_dim(self):
|
||||
return 100
|
||||
|
||||
@property
|
||||
def dummy_tokenizer(self):
|
||||
tokenizer = XLMRobertaTokenizerFast.from_pretrained("YiYiXu/tiny-random-mclip-base")
|
||||
return tokenizer
|
||||
|
||||
@property
|
||||
def dummy_text_encoder(self):
|
||||
torch.manual_seed(0)
|
||||
config = MCLIPConfig(
|
||||
numDims=self.cross_attention_dim,
|
||||
transformerDimensions=self.text_embedder_hidden_size,
|
||||
hidden_size=self.text_embedder_hidden_size,
|
||||
intermediate_size=37,
|
||||
num_attention_heads=4,
|
||||
num_hidden_layers=5,
|
||||
vocab_size=1005,
|
||||
)
|
||||
|
||||
text_encoder = MultilingualCLIP(config)
|
||||
text_encoder = text_encoder.eval()
|
||||
|
||||
return text_encoder
|
||||
|
||||
@property
|
||||
def dummy_unet(self):
|
||||
torch.manual_seed(0)
|
||||
|
||||
model_kwargs = {
|
||||
"in_channels": 4,
|
||||
# Out channels is double in channels because predicts mean and variance
|
||||
"out_channels": 8,
|
||||
"addition_embed_type": "text_image",
|
||||
"down_block_types": ("ResnetDownsampleBlock2D", "SimpleCrossAttnDownBlock2D"),
|
||||
"up_block_types": ("SimpleCrossAttnUpBlock2D", "ResnetUpsampleBlock2D"),
|
||||
"mid_block_type": "UNetMidBlock2DSimpleCrossAttn",
|
||||
"block_out_channels": (self.block_out_channels_0, self.block_out_channels_0 * 2),
|
||||
"layers_per_block": 1,
|
||||
"encoder_hid_dim": self.text_embedder_hidden_size,
|
||||
"encoder_hid_dim_type": "text_image_proj",
|
||||
"cross_attention_dim": self.cross_attention_dim,
|
||||
"attention_head_dim": 4,
|
||||
"resnet_time_scale_shift": "scale_shift",
|
||||
"class_embed_type": None,
|
||||
}
|
||||
|
||||
model = UNet2DConditionModel(**model_kwargs)
|
||||
return model
|
||||
|
||||
@property
|
||||
def dummy_movq_kwargs(self):
|
||||
return {
|
||||
"block_out_channels": [32, 64],
|
||||
"down_block_types": ["DownEncoderBlock2D", "AttnDownEncoderBlock2D"],
|
||||
"in_channels": 3,
|
||||
"latent_channels": 4,
|
||||
"layers_per_block": 1,
|
||||
"norm_num_groups": 8,
|
||||
"norm_type": "spatial",
|
||||
"num_vq_embeddings": 12,
|
||||
"out_channels": 3,
|
||||
"up_block_types": [
|
||||
"AttnUpDecoderBlock2D",
|
||||
"UpDecoderBlock2D",
|
||||
],
|
||||
"vq_embed_dim": 4,
|
||||
}
|
||||
|
||||
@property
|
||||
def dummy_movq(self):
|
||||
torch.manual_seed(0)
|
||||
model = VQModel(**self.dummy_movq_kwargs)
|
||||
return model
|
||||
|
||||
def get_dummy_components(self):
|
||||
text_encoder = self.dummy_text_encoder
|
||||
tokenizer = self.dummy_tokenizer
|
||||
unet = self.dummy_unet
|
||||
movq = self.dummy_movq
|
||||
|
||||
scheduler = DDIMScheduler(
|
||||
num_train_timesteps=1000,
|
||||
beta_schedule="linear",
|
||||
beta_start=0.00085,
|
||||
beta_end=0.012,
|
||||
clip_sample=False,
|
||||
set_alpha_to_one=False,
|
||||
steps_offset=1,
|
||||
prediction_type="epsilon",
|
||||
thresholding=False,
|
||||
)
|
||||
|
||||
components = {
|
||||
"text_encoder": text_encoder,
|
||||
"tokenizer": tokenizer,
|
||||
"unet": unet,
|
||||
"scheduler": scheduler,
|
||||
"movq": movq,
|
||||
}
|
||||
return components
|
||||
|
||||
def get_dummy_inputs(self, device, seed=0):
|
||||
image_embeds = floats_tensor((1, self.cross_attention_dim), rng=random.Random(seed)).to(device)
|
||||
negative_image_embeds = floats_tensor((1, self.cross_attention_dim), rng=random.Random(seed + 1)).to(device)
|
||||
if str(device).startswith("mps"):
|
||||
generator = torch.manual_seed(seed)
|
||||
else:
|
||||
generator = torch.Generator(device=device).manual_seed(seed)
|
||||
inputs = {
|
||||
"prompt": "horse",
|
||||
"image_embeds": image_embeds,
|
||||
"negative_image_embeds": negative_image_embeds,
|
||||
"generator": generator,
|
||||
"height": 64,
|
||||
"width": 64,
|
||||
"guidance_scale": 4.0,
|
||||
"num_inference_steps": 2,
|
||||
"output_type": "np",
|
||||
}
|
||||
return inputs
|
||||
|
||||
def test_kandinsky(self):
|
||||
device = "cpu"
|
||||
|
||||
components = self.get_dummy_components()
|
||||
|
||||
pipe = self.pipeline_class(**components)
|
||||
pipe = pipe.to(device)
|
||||
|
||||
pipe.set_progress_bar_config(disable=None)
|
||||
|
||||
output = pipe(**self.get_dummy_inputs(device))
|
||||
image = output.images
|
||||
|
||||
image_from_tuple = pipe(
|
||||
**self.get_dummy_inputs(device),
|
||||
return_dict=False,
|
||||
)[0]
|
||||
|
||||
image_slice = image[0, -3:, -3:, -1]
|
||||
image_from_tuple_slice = image_from_tuple[0, -3:, -3:, -1]
|
||||
|
||||
assert image.shape == (1, 64, 64, 3)
|
||||
|
||||
expected_slice = np.array(
|
||||
[0.328663, 1.0, 0.23216873, 1.0, 0.92717564, 0.4639046, 0.96894777, 0.31713378, 0.6293953]
|
||||
)
|
||||
|
||||
assert (
|
||||
np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
|
||||
), f" expected_slice {expected_slice}, but got {image_slice.flatten()}"
|
||||
assert (
|
||||
np.abs(image_from_tuple_slice.flatten() - expected_slice).max() < 1e-2
|
||||
), f" expected_slice {expected_slice}, but got {image_from_tuple_slice.flatten()}"
|
||||
|
||||
|
||||
@slow
|
||||
@require_torch_gpu
|
||||
class KandinskyPipelineIntegrationTests(unittest.TestCase):
|
||||
def tearDown(self):
|
||||
# clean up the VRAM after each test
|
||||
super().tearDown()
|
||||
gc.collect()
|
||||
torch.cuda.empty_cache()
|
||||
|
||||
def test_kandinsky_text2img(self):
|
||||
expected_image = load_numpy(
|
||||
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
|
||||
"/kandinsky/kandinsky_text2img_cat_fp16.npy"
|
||||
)
|
||||
|
||||
pipe_prior = KandinskyPriorPipeline.from_pretrained(
|
||||
"kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16
|
||||
)
|
||||
pipe_prior.to(torch_device)
|
||||
|
||||
pipeline = KandinskyPipeline.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16)
|
||||
pipeline = pipeline.to(torch_device)
|
||||
pipeline.set_progress_bar_config(disable=None)
|
||||
|
||||
prompt = "red cat, 4k photo"
|
||||
|
||||
generator = torch.Generator(device="cuda").manual_seed(0)
|
||||
image_emb = pipe_prior(
|
||||
prompt,
|
||||
generator=generator,
|
||||
num_inference_steps=5,
|
||||
).images
|
||||
zero_image_emb = pipe_prior("", num_inference_steps=5).images
|
||||
|
||||
generator = torch.Generator(device="cuda").manual_seed(0)
|
||||
output = pipeline(
|
||||
prompt,
|
||||
image_embeds=image_emb,
|
||||
negative_image_embeds=zero_image_emb,
|
||||
generator=generator,
|
||||
num_inference_steps=100,
|
||||
output_type="np",
|
||||
)
|
||||
|
||||
image = output.images[0]
|
||||
|
||||
assert image.shape == (512, 512, 3)
|
||||
|
||||
assert_mean_pixel_difference(image, expected_image)
|
||||
303
tests/pipelines/kandinsky/test_kandinsky_img2img.py
Normal file
303
tests/pipelines/kandinsky/test_kandinsky_img2img.py
Normal file
@@ -0,0 +1,303 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2023 HuggingFace Inc.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import gc
|
||||
import random
|
||||
import unittest
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
from PIL import Image
|
||||
from transformers import XLMRobertaTokenizerFast
|
||||
|
||||
from diffusers import DDIMScheduler, KandinskyImg2ImgPipeline, KandinskyPriorPipeline, UNet2DConditionModel, VQModel
|
||||
from diffusers.pipelines.kandinsky.text_encoder import MCLIPConfig, MultilingualCLIP
|
||||
from diffusers.utils import floats_tensor, load_image, load_numpy, slow, torch_device
|
||||
from diffusers.utils.testing_utils import enable_full_determinism, require_torch_gpu
|
||||
|
||||
from ..test_pipelines_common import PipelineTesterMixin, assert_mean_pixel_difference
|
||||
|
||||
|
||||
enable_full_determinism()
|
||||
|
||||
|
||||
class KandinskyImg2ImgPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
|
||||
pipeline_class = KandinskyImg2ImgPipeline
|
||||
params = ["prompt", "image_embeds", "negative_image_embeds", "image"]
|
||||
batch_params = [
|
||||
"prompt",
|
||||
"negative_prompt",
|
||||
"image_embeds",
|
||||
"negative_image_embeds",
|
||||
"image",
|
||||
]
|
||||
required_optional_params = [
|
||||
"generator",
|
||||
"height",
|
||||
"width",
|
||||
"strength",
|
||||
"guidance_scale",
|
||||
"negative_prompt",
|
||||
"num_inference_steps",
|
||||
"return_dict",
|
||||
"guidance_scale",
|
||||
"num_images_per_prompt",
|
||||
"output_type",
|
||||
"return_dict",
|
||||
]
|
||||
test_xformers_attention = False
|
||||
|
||||
@property
|
||||
def text_embedder_hidden_size(self):
|
||||
return 32
|
||||
|
||||
@property
|
||||
def time_input_dim(self):
|
||||
return 32
|
||||
|
||||
@property
|
||||
def block_out_channels_0(self):
|
||||
return self.time_input_dim
|
||||
|
||||
@property
|
||||
def time_embed_dim(self):
|
||||
return self.time_input_dim * 4
|
||||
|
||||
@property
|
||||
def cross_attention_dim(self):
|
||||
return 100
|
||||
|
||||
@property
|
||||
def dummy_tokenizer(self):
|
||||
tokenizer = XLMRobertaTokenizerFast.from_pretrained("YiYiXu/tiny-random-mclip-base")
|
||||
return tokenizer
|
||||
|
||||
@property
|
||||
def dummy_text_encoder(self):
|
||||
torch.manual_seed(0)
|
||||
config = MCLIPConfig(
|
||||
numDims=self.cross_attention_dim,
|
||||
transformerDimensions=self.text_embedder_hidden_size,
|
||||
hidden_size=self.text_embedder_hidden_size,
|
||||
intermediate_size=37,
|
||||
num_attention_heads=4,
|
||||
num_hidden_layers=5,
|
||||
vocab_size=1005,
|
||||
)
|
||||
|
||||
text_encoder = MultilingualCLIP(config)
|
||||
text_encoder = text_encoder.eval()
|
||||
|
||||
return text_encoder
|
||||
|
||||
@property
|
||||
def dummy_unet(self):
|
||||
torch.manual_seed(0)
|
||||
|
||||
model_kwargs = {
|
||||
"in_channels": 4,
|
||||
# Out channels is double in channels because predicts mean and variance
|
||||
"out_channels": 8,
|
||||
"addition_embed_type": "text_image",
|
||||
"down_block_types": ("ResnetDownsampleBlock2D", "SimpleCrossAttnDownBlock2D"),
|
||||
"up_block_types": ("SimpleCrossAttnUpBlock2D", "ResnetUpsampleBlock2D"),
|
||||
"mid_block_type": "UNetMidBlock2DSimpleCrossAttn",
|
||||
"block_out_channels": (self.block_out_channels_0, self.block_out_channels_0 * 2),
|
||||
"layers_per_block": 1,
|
||||
"encoder_hid_dim": self.text_embedder_hidden_size,
|
||||
"encoder_hid_dim_type": "text_image_proj",
|
||||
"cross_attention_dim": self.cross_attention_dim,
|
||||
"attention_head_dim": 4,
|
||||
"resnet_time_scale_shift": "scale_shift",
|
||||
"class_embed_type": None,
|
||||
}
|
||||
|
||||
model = UNet2DConditionModel(**model_kwargs)
|
||||
return model
|
||||
|
||||
@property
|
||||
def dummy_movq_kwargs(self):
|
||||
return {
|
||||
"block_out_channels": [32, 64],
|
||||
"down_block_types": ["DownEncoderBlock2D", "AttnDownEncoderBlock2D"],
|
||||
"in_channels": 3,
|
||||
"latent_channels": 4,
|
||||
"layers_per_block": 1,
|
||||
"norm_num_groups": 8,
|
||||
"norm_type": "spatial",
|
||||
"num_vq_embeddings": 12,
|
||||
"out_channels": 3,
|
||||
"up_block_types": [
|
||||
"AttnUpDecoderBlock2D",
|
||||
"UpDecoderBlock2D",
|
||||
],
|
||||
"vq_embed_dim": 4,
|
||||
}
|
||||
|
||||
@property
|
||||
def dummy_movq(self):
|
||||
torch.manual_seed(0)
|
||||
model = VQModel(**self.dummy_movq_kwargs)
|
||||
return model
|
||||
|
||||
def get_dummy_components(self):
|
||||
text_encoder = self.dummy_text_encoder
|
||||
tokenizer = self.dummy_tokenizer
|
||||
unet = self.dummy_unet
|
||||
movq = self.dummy_movq
|
||||
|
||||
ddim_config = {
|
||||
"num_train_timesteps": 1000,
|
||||
"beta_schedule": "linear",
|
||||
"beta_start": 0.00085,
|
||||
"beta_end": 0.012,
|
||||
"clip_sample": False,
|
||||
"set_alpha_to_one": False,
|
||||
"steps_offset": 0,
|
||||
"prediction_type": "epsilon",
|
||||
"thresholding": False,
|
||||
}
|
||||
|
||||
scheduler = DDIMScheduler(**ddim_config)
|
||||
|
||||
components = {
|
||||
"text_encoder": text_encoder,
|
||||
"tokenizer": tokenizer,
|
||||
"unet": unet,
|
||||
"scheduler": scheduler,
|
||||
"movq": movq,
|
||||
}
|
||||
|
||||
return components
|
||||
|
||||
def get_dummy_inputs(self, device, seed=0):
|
||||
image_embeds = floats_tensor((1, self.cross_attention_dim), rng=random.Random(seed)).to(device)
|
||||
negative_image_embeds = floats_tensor((1, self.cross_attention_dim), rng=random.Random(seed + 1)).to(device)
|
||||
# create init_image
|
||||
image = floats_tensor((1, 3, 64, 64), rng=random.Random(seed)).to(device)
|
||||
image = image.cpu().permute(0, 2, 3, 1)[0]
|
||||
init_image = Image.fromarray(np.uint8(image)).convert("RGB").resize((256, 256))
|
||||
|
||||
if str(device).startswith("mps"):
|
||||
generator = torch.manual_seed(seed)
|
||||
else:
|
||||
generator = torch.Generator(device=device).manual_seed(seed)
|
||||
inputs = {
|
||||
"prompt": "horse",
|
||||
"image": init_image,
|
||||
"image_embeds": image_embeds,
|
||||
"negative_image_embeds": negative_image_embeds,
|
||||
"generator": generator,
|
||||
"height": 64,
|
||||
"width": 64,
|
||||
"num_inference_steps": 10,
|
||||
"guidance_scale": 7.0,
|
||||
"strength": 0.2,
|
||||
"output_type": "np",
|
||||
}
|
||||
return inputs
|
||||
|
||||
def test_kandinsky_img2img(self):
|
||||
device = "cpu"
|
||||
|
||||
components = self.get_dummy_components()
|
||||
|
||||
pipe = self.pipeline_class(**components)
|
||||
pipe = pipe.to(device)
|
||||
|
||||
pipe.set_progress_bar_config(disable=None)
|
||||
|
||||
output = pipe(**self.get_dummy_inputs(device))
|
||||
image = output.images
|
||||
|
||||
image_from_tuple = pipe(
|
||||
**self.get_dummy_inputs(device),
|
||||
return_dict=False,
|
||||
)[0]
|
||||
|
||||
image_slice = image[0, -3:, -3:, -1]
|
||||
image_from_tuple_slice = image_from_tuple[0, -3:, -3:, -1]
|
||||
|
||||
assert image.shape == (1, 64, 64, 3)
|
||||
|
||||
expected_slice = np.array(
|
||||
[0.61474943, 0.6073539, 0.43308544, 0.5928269, 0.47493595, 0.46755973, 0.4613838, 0.45368797, 0.50119233]
|
||||
)
|
||||
assert (
|
||||
np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
|
||||
), f" expected_slice {expected_slice}, but got {image_slice.flatten()}"
|
||||
assert (
|
||||
np.abs(image_from_tuple_slice.flatten() - expected_slice).max() < 1e-2
|
||||
), f" expected_slice {expected_slice}, but got {image_from_tuple_slice.flatten()}"
|
||||
|
||||
|
||||
@slow
|
||||
@require_torch_gpu
|
||||
class KandinskyImg2ImgPipelineIntegrationTests(unittest.TestCase):
|
||||
def tearDown(self):
|
||||
# clean up the VRAM after each test
|
||||
super().tearDown()
|
||||
gc.collect()
|
||||
torch.cuda.empty_cache()
|
||||
|
||||
def test_kandinsky_img2img(self):
|
||||
expected_image = load_numpy(
|
||||
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
|
||||
"/kandinsky/kandinsky_img2img_frog.npy"
|
||||
)
|
||||
|
||||
init_image = load_image(
|
||||
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main" "/kandinsky/cat.png"
|
||||
)
|
||||
prompt = "A red cartoon frog, 4k"
|
||||
|
||||
pipe_prior = KandinskyPriorPipeline.from_pretrained(
|
||||
"kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16
|
||||
)
|
||||
pipe_prior.to(torch_device)
|
||||
|
||||
pipeline = KandinskyImg2ImgPipeline.from_pretrained(
|
||||
"kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16
|
||||
)
|
||||
pipeline = pipeline.to(torch_device)
|
||||
|
||||
pipeline.set_progress_bar_config(disable=None)
|
||||
|
||||
generator = torch.Generator(device="cpu").manual_seed(0)
|
||||
image_emb = pipe_prior(
|
||||
prompt,
|
||||
generator=generator,
|
||||
num_inference_steps=5,
|
||||
).images
|
||||
zero_image_emb = pipe_prior("", num_inference_steps=5).images
|
||||
|
||||
output = pipeline(
|
||||
prompt,
|
||||
image=init_image,
|
||||
image_embeds=image_emb,
|
||||
negative_image_embeds=zero_image_emb,
|
||||
generator=generator,
|
||||
num_inference_steps=100,
|
||||
height=768,
|
||||
width=768,
|
||||
strength=0.2,
|
||||
output_type="np",
|
||||
)
|
||||
|
||||
image = output.images[0]
|
||||
|
||||
assert image.shape == (768, 768, 3)
|
||||
|
||||
assert_mean_pixel_difference(image, expected_image)
|
||||
313
tests/pipelines/kandinsky/test_kandinsky_inpaint.py
Normal file
313
tests/pipelines/kandinsky/test_kandinsky_inpaint.py
Normal file
@@ -0,0 +1,313 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2023 HuggingFace Inc.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import gc
|
||||
import random
|
||||
import unittest
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
from PIL import Image
|
||||
from transformers import XLMRobertaTokenizerFast
|
||||
|
||||
from diffusers import DDIMScheduler, KandinskyInpaintPipeline, KandinskyPriorPipeline, UNet2DConditionModel, VQModel
|
||||
from diffusers.pipelines.kandinsky.text_encoder import MCLIPConfig, MultilingualCLIP
|
||||
from diffusers.utils import floats_tensor, load_image, load_numpy, slow, torch_device
|
||||
from diffusers.utils.testing_utils import enable_full_determinism, require_torch_gpu
|
||||
|
||||
from ..test_pipelines_common import PipelineTesterMixin, assert_mean_pixel_difference
|
||||
|
||||
|
||||
enable_full_determinism()
|
||||
|
||||
|
||||
class KandinskyInpaintPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
|
||||
pipeline_class = KandinskyInpaintPipeline
|
||||
params = ["prompt", "image_embeds", "negative_image_embeds", "image", "mask_image"]
|
||||
batch_params = [
|
||||
"prompt",
|
||||
"negative_prompt",
|
||||
"image_embeds",
|
||||
"negative_image_embeds",
|
||||
"image",
|
||||
"mask_image",
|
||||
]
|
||||
required_optional_params = [
|
||||
"generator",
|
||||
"height",
|
||||
"width",
|
||||
"latents",
|
||||
"guidance_scale",
|
||||
"negative_prompt",
|
||||
"num_inference_steps",
|
||||
"return_dict",
|
||||
"guidance_scale",
|
||||
"num_images_per_prompt",
|
||||
"output_type",
|
||||
"return_dict",
|
||||
]
|
||||
test_xformers_attention = False
|
||||
|
||||
@property
|
||||
def text_embedder_hidden_size(self):
|
||||
return 32
|
||||
|
||||
@property
|
||||
def time_input_dim(self):
|
||||
return 32
|
||||
|
||||
@property
|
||||
def block_out_channels_0(self):
|
||||
return self.time_input_dim
|
||||
|
||||
@property
|
||||
def time_embed_dim(self):
|
||||
return self.time_input_dim * 4
|
||||
|
||||
@property
|
||||
def cross_attention_dim(self):
|
||||
return 100
|
||||
|
||||
@property
|
||||
def dummy_tokenizer(self):
|
||||
tokenizer = XLMRobertaTokenizerFast.from_pretrained("YiYiXu/tiny-random-mclip-base")
|
||||
return tokenizer
|
||||
|
||||
@property
|
||||
def dummy_text_encoder(self):
|
||||
torch.manual_seed(0)
|
||||
config = MCLIPConfig(
|
||||
numDims=self.cross_attention_dim,
|
||||
transformerDimensions=self.text_embedder_hidden_size,
|
||||
hidden_size=self.text_embedder_hidden_size,
|
||||
intermediate_size=37,
|
||||
num_attention_heads=4,
|
||||
num_hidden_layers=5,
|
||||
vocab_size=1005,
|
||||
)
|
||||
|
||||
text_encoder = MultilingualCLIP(config)
|
||||
text_encoder = text_encoder.eval()
|
||||
|
||||
return text_encoder
|
||||
|
||||
@property
|
||||
def dummy_unet(self):
|
||||
torch.manual_seed(0)
|
||||
|
||||
model_kwargs = {
|
||||
"in_channels": 9,
|
||||
# Out channels is double in channels because predicts mean and variance
|
||||
"out_channels": 8,
|
||||
"addition_embed_type": "text_image",
|
||||
"down_block_types": ("ResnetDownsampleBlock2D", "SimpleCrossAttnDownBlock2D"),
|
||||
"up_block_types": ("SimpleCrossAttnUpBlock2D", "ResnetUpsampleBlock2D"),
|
||||
"mid_block_type": "UNetMidBlock2DSimpleCrossAttn",
|
||||
"block_out_channels": (self.block_out_channels_0, self.block_out_channels_0 * 2),
|
||||
"layers_per_block": 1,
|
||||
"encoder_hid_dim": self.text_embedder_hidden_size,
|
||||
"encoder_hid_dim_type": "text_image_proj",
|
||||
"cross_attention_dim": self.cross_attention_dim,
|
||||
"attention_head_dim": 4,
|
||||
"resnet_time_scale_shift": "scale_shift",
|
||||
"class_embed_type": None,
|
||||
}
|
||||
|
||||
model = UNet2DConditionModel(**model_kwargs)
|
||||
return model
|
||||
|
||||
@property
|
||||
def dummy_movq_kwargs(self):
|
||||
return {
|
||||
"block_out_channels": [32, 64],
|
||||
"down_block_types": ["DownEncoderBlock2D", "AttnDownEncoderBlock2D"],
|
||||
"in_channels": 3,
|
||||
"latent_channels": 4,
|
||||
"layers_per_block": 1,
|
||||
"norm_num_groups": 8,
|
||||
"norm_type": "spatial",
|
||||
"num_vq_embeddings": 12,
|
||||
"out_channels": 3,
|
||||
"up_block_types": [
|
||||
"AttnUpDecoderBlock2D",
|
||||
"UpDecoderBlock2D",
|
||||
],
|
||||
"vq_embed_dim": 4,
|
||||
}
|
||||
|
||||
@property
|
||||
def dummy_movq(self):
|
||||
torch.manual_seed(0)
|
||||
model = VQModel(**self.dummy_movq_kwargs)
|
||||
return model
|
||||
|
||||
def get_dummy_components(self):
|
||||
text_encoder = self.dummy_text_encoder
|
||||
tokenizer = self.dummy_tokenizer
|
||||
unet = self.dummy_unet
|
||||
movq = self.dummy_movq
|
||||
|
||||
scheduler = DDIMScheduler(
|
||||
num_train_timesteps=1000,
|
||||
beta_schedule="linear",
|
||||
beta_start=0.00085,
|
||||
beta_end=0.012,
|
||||
clip_sample=False,
|
||||
set_alpha_to_one=False,
|
||||
steps_offset=1,
|
||||
prediction_type="epsilon",
|
||||
thresholding=False,
|
||||
)
|
||||
|
||||
components = {
|
||||
"text_encoder": text_encoder,
|
||||
"tokenizer": tokenizer,
|
||||
"unet": unet,
|
||||
"scheduler": scheduler,
|
||||
"movq": movq,
|
||||
}
|
||||
|
||||
return components
|
||||
|
||||
def get_dummy_inputs(self, device, seed=0):
|
||||
image_embeds = floats_tensor((1, self.cross_attention_dim), rng=random.Random(seed)).to(device)
|
||||
negative_image_embeds = floats_tensor((1, self.cross_attention_dim), rng=random.Random(seed + 1)).to(device)
|
||||
# create init_image
|
||||
image = floats_tensor((1, 3, 64, 64), rng=random.Random(seed)).to(device)
|
||||
image = image.cpu().permute(0, 2, 3, 1)[0]
|
||||
init_image = Image.fromarray(np.uint8(image)).convert("RGB").resize((256, 256))
|
||||
# create mask
|
||||
mask = np.ones((64, 64), dtype=np.float32)
|
||||
mask[:32, :32] = 0
|
||||
|
||||
if str(device).startswith("mps"):
|
||||
generator = torch.manual_seed(seed)
|
||||
else:
|
||||
generator = torch.Generator(device=device).manual_seed(seed)
|
||||
inputs = {
|
||||
"prompt": "horse",
|
||||
"image": init_image,
|
||||
"mask_image": mask,
|
||||
"image_embeds": image_embeds,
|
||||
"negative_image_embeds": negative_image_embeds,
|
||||
"generator": generator,
|
||||
"height": 64,
|
||||
"width": 64,
|
||||
"num_inference_steps": 2,
|
||||
"guidance_scale": 4.0,
|
||||
"output_type": "np",
|
||||
}
|
||||
return inputs
|
||||
|
||||
def test_kandinsky_inpaint(self):
|
||||
device = "cpu"
|
||||
|
||||
components = self.get_dummy_components()
|
||||
|
||||
pipe = self.pipeline_class(**components)
|
||||
pipe = pipe.to(device)
|
||||
|
||||
pipe.set_progress_bar_config(disable=None)
|
||||
|
||||
output = pipe(**self.get_dummy_inputs(device))
|
||||
image = output.images
|
||||
|
||||
image_from_tuple = pipe(
|
||||
**self.get_dummy_inputs(device),
|
||||
return_dict=False,
|
||||
)[0]
|
||||
|
||||
image_slice = image[0, -3:, -3:, -1]
|
||||
image_from_tuple_slice = image_from_tuple[0, -3:, -3:, -1]
|
||||
|
||||
print(f"image.shape {image.shape}")
|
||||
|
||||
assert image.shape == (1, 64, 64, 3)
|
||||
|
||||
expected_slice = np.array(
|
||||
[0.8326919, 0.73790467, 0.20918581, 0.9309612, 0.5511791, 0.43713328, 0.5513321, 0.49922934, 0.59497786]
|
||||
)
|
||||
|
||||
assert (
|
||||
np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
|
||||
), f" expected_slice {expected_slice}, but got {image_slice.flatten()}"
|
||||
assert (
|
||||
np.abs(image_from_tuple_slice.flatten() - expected_slice).max() < 1e-2
|
||||
), f" expected_slice {expected_slice}, but got {image_from_tuple_slice.flatten()}"
|
||||
|
||||
def test_inference_batch_single_identical(self):
|
||||
super().test_inference_batch_single_identical(expected_max_diff=3e-3)
|
||||
|
||||
|
||||
@slow
|
||||
@require_torch_gpu
|
||||
class KandinskyInpaintPipelineIntegrationTests(unittest.TestCase):
|
||||
def tearDown(self):
|
||||
# clean up the VRAM after each test
|
||||
super().tearDown()
|
||||
gc.collect()
|
||||
torch.cuda.empty_cache()
|
||||
|
||||
def test_kandinsky_inpaint(self):
|
||||
expected_image = load_numpy(
|
||||
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
|
||||
"/kandinsky/kandinsky_inpaint_cat_with_hat_fp16.npy"
|
||||
)
|
||||
|
||||
init_image = load_image(
|
||||
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main" "/kandinsky/cat.png"
|
||||
)
|
||||
mask = np.ones((768, 768), dtype=np.float32)
|
||||
mask[:250, 250:-250] = 0
|
||||
|
||||
prompt = "a hat"
|
||||
|
||||
pipe_prior = KandinskyPriorPipeline.from_pretrained(
|
||||
"kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16
|
||||
)
|
||||
pipe_prior.to(torch_device)
|
||||
|
||||
pipeline = KandinskyInpaintPipeline.from_pretrained(
|
||||
"kandinsky-community/kandinsky-2-1-inpaint", torch_dtype=torch.float16
|
||||
)
|
||||
pipeline = pipeline.to(torch_device)
|
||||
pipeline.set_progress_bar_config(disable=None)
|
||||
|
||||
generator = torch.Generator(device="cpu").manual_seed(0)
|
||||
image_emb = pipe_prior(
|
||||
prompt,
|
||||
generator=generator,
|
||||
num_inference_steps=5,
|
||||
).images
|
||||
zero_image_emb = pipe_prior("").images
|
||||
|
||||
output = pipeline(
|
||||
prompt,
|
||||
image=init_image,
|
||||
mask_image=mask,
|
||||
image_embeds=image_emb,
|
||||
negative_image_embeds=zero_image_emb,
|
||||
generator=generator,
|
||||
num_inference_steps=100,
|
||||
height=768,
|
||||
width=768,
|
||||
output_type="np",
|
||||
)
|
||||
|
||||
image = output.images[0]
|
||||
|
||||
assert image.shape == (768, 768, 3)
|
||||
|
||||
assert_mean_pixel_difference(image, expected_image)
|
||||
236
tests/pipelines/kandinsky/test_kandinsky_prior.py
Normal file
236
tests/pipelines/kandinsky/test_kandinsky_prior.py
Normal file
@@ -0,0 +1,236 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2023 HuggingFace Inc.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import unittest
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
from torch import nn
|
||||
from transformers import (
|
||||
CLIPImageProcessor,
|
||||
CLIPTextConfig,
|
||||
CLIPTextModelWithProjection,
|
||||
CLIPTokenizer,
|
||||
CLIPVisionConfig,
|
||||
CLIPVisionModelWithProjection,
|
||||
)
|
||||
|
||||
from diffusers import KandinskyPriorPipeline, PriorTransformer, UnCLIPScheduler
|
||||
from diffusers.utils import torch_device
|
||||
from diffusers.utils.testing_utils import enable_full_determinism, skip_mps
|
||||
|
||||
from ..test_pipelines_common import PipelineTesterMixin
|
||||
|
||||
|
||||
enable_full_determinism()
|
||||
|
||||
|
||||
class KandinskyPriorPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
|
||||
pipeline_class = KandinskyPriorPipeline
|
||||
params = ["prompt"]
|
||||
batch_params = ["prompt", "negative_prompt"]
|
||||
required_optional_params = [
|
||||
"num_images_per_prompt",
|
||||
"generator",
|
||||
"num_inference_steps",
|
||||
"latents",
|
||||
"negative_prompt",
|
||||
"guidance_scale",
|
||||
"output_type",
|
||||
"return_dict",
|
||||
]
|
||||
test_xformers_attention = False
|
||||
|
||||
@property
|
||||
def text_embedder_hidden_size(self):
|
||||
return 32
|
||||
|
||||
@property
|
||||
def time_input_dim(self):
|
||||
return 32
|
||||
|
||||
@property
|
||||
def block_out_channels_0(self):
|
||||
return self.time_input_dim
|
||||
|
||||
@property
|
||||
def time_embed_dim(self):
|
||||
return self.time_input_dim * 4
|
||||
|
||||
@property
|
||||
def cross_attention_dim(self):
|
||||
return 100
|
||||
|
||||
@property
|
||||
def dummy_tokenizer(self):
|
||||
tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
|
||||
return tokenizer
|
||||
|
||||
@property
|
||||
def dummy_text_encoder(self):
|
||||
torch.manual_seed(0)
|
||||
config = CLIPTextConfig(
|
||||
bos_token_id=0,
|
||||
eos_token_id=2,
|
||||
hidden_size=self.text_embedder_hidden_size,
|
||||
projection_dim=self.text_embedder_hidden_size,
|
||||
intermediate_size=37,
|
||||
layer_norm_eps=1e-05,
|
||||
num_attention_heads=4,
|
||||
num_hidden_layers=5,
|
||||
pad_token_id=1,
|
||||
vocab_size=1000,
|
||||
)
|
||||
return CLIPTextModelWithProjection(config)
|
||||
|
||||
@property
|
||||
def dummy_prior(self):
|
||||
torch.manual_seed(0)
|
||||
|
||||
model_kwargs = {
|
||||
"num_attention_heads": 2,
|
||||
"attention_head_dim": 12,
|
||||
"embedding_dim": self.text_embedder_hidden_size,
|
||||
"num_layers": 1,
|
||||
}
|
||||
|
||||
model = PriorTransformer(**model_kwargs)
|
||||
# clip_std and clip_mean is initialized to be 0 so PriorTransformer.post_process_latents will always return 0 - set clip_std to be 1 so it won't return 0
|
||||
model.clip_std = nn.Parameter(torch.ones(model.clip_std.shape))
|
||||
return model
|
||||
|
||||
@property
|
||||
def dummy_image_encoder(self):
|
||||
torch.manual_seed(0)
|
||||
config = CLIPVisionConfig(
|
||||
hidden_size=self.text_embedder_hidden_size,
|
||||
image_size=224,
|
||||
projection_dim=self.text_embedder_hidden_size,
|
||||
intermediate_size=37,
|
||||
num_attention_heads=4,
|
||||
num_channels=3,
|
||||
num_hidden_layers=5,
|
||||
patch_size=14,
|
||||
)
|
||||
|
||||
model = CLIPVisionModelWithProjection(config)
|
||||
return model
|
||||
|
||||
@property
|
||||
def dummy_image_processor(self):
|
||||
image_processor = CLIPImageProcessor(
|
||||
crop_size=224,
|
||||
do_center_crop=True,
|
||||
do_normalize=True,
|
||||
do_resize=True,
|
||||
image_mean=[0.48145466, 0.4578275, 0.40821073],
|
||||
image_std=[0.26862954, 0.26130258, 0.27577711],
|
||||
resample=3,
|
||||
size=224,
|
||||
)
|
||||
|
||||
return image_processor
|
||||
|
||||
def get_dummy_components(self):
|
||||
prior = self.dummy_prior
|
||||
image_encoder = self.dummy_image_encoder
|
||||
text_encoder = self.dummy_text_encoder
|
||||
tokenizer = self.dummy_tokenizer
|
||||
image_processor = self.dummy_image_processor
|
||||
|
||||
scheduler = UnCLIPScheduler(
|
||||
variance_type="fixed_small_log",
|
||||
prediction_type="sample",
|
||||
num_train_timesteps=1000,
|
||||
clip_sample=True,
|
||||
clip_sample_range=10.0,
|
||||
)
|
||||
|
||||
components = {
|
||||
"prior": prior,
|
||||
"image_encoder": image_encoder,
|
||||
"text_encoder": text_encoder,
|
||||
"tokenizer": tokenizer,
|
||||
"scheduler": scheduler,
|
||||
"image_processor": image_processor,
|
||||
}
|
||||
|
||||
return components
|
||||
|
||||
def get_dummy_inputs(self, device, seed=0):
|
||||
if str(device).startswith("mps"):
|
||||
generator = torch.manual_seed(seed)
|
||||
else:
|
||||
generator = torch.Generator(device=device).manual_seed(seed)
|
||||
inputs = {
|
||||
"prompt": "horse",
|
||||
"generator": generator,
|
||||
"guidance_scale": 4.0,
|
||||
"num_inference_steps": 2,
|
||||
"output_type": "np",
|
||||
}
|
||||
return inputs
|
||||
|
||||
def test_kandinsky_prior(self):
|
||||
device = "cpu"
|
||||
|
||||
components = self.get_dummy_components()
|
||||
|
||||
pipe = self.pipeline_class(**components)
|
||||
pipe = pipe.to(device)
|
||||
|
||||
pipe.set_progress_bar_config(disable=None)
|
||||
|
||||
output = pipe(**self.get_dummy_inputs(device))
|
||||
image = output.images
|
||||
|
||||
image_from_tuple = pipe(
|
||||
**self.get_dummy_inputs(device),
|
||||
return_dict=False,
|
||||
)[0]
|
||||
|
||||
image_slice = image[0, -10:]
|
||||
image_from_tuple_slice = image_from_tuple[0, -10:]
|
||||
|
||||
assert image.shape == (1, 32)
|
||||
|
||||
expected_slice = np.array(
|
||||
[-0.0532, 1.7120, 0.3656, -1.0852, -0.8946, -1.1756, 0.4348, 0.2482, 0.5146, -0.1156]
|
||||
)
|
||||
|
||||
assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
|
||||
assert np.abs(image_from_tuple_slice.flatten() - expected_slice).max() < 1e-2
|
||||
|
||||
@skip_mps
|
||||
def test_inference_batch_single_identical(self):
|
||||
test_max_difference = torch_device == "cpu"
|
||||
relax_max_difference = True
|
||||
test_mean_pixel_difference = False
|
||||
|
||||
self._test_inference_batch_single_identical(
|
||||
test_max_difference=test_max_difference,
|
||||
relax_max_difference=relax_max_difference,
|
||||
test_mean_pixel_difference=test_mean_pixel_difference,
|
||||
)
|
||||
|
||||
@skip_mps
|
||||
def test_attention_slicing_forward_pass(self):
|
||||
test_max_difference = torch_device == "cpu"
|
||||
test_mean_pixel_difference = False
|
||||
|
||||
self._test_attention_slicing_forward_pass(
|
||||
test_max_difference=test_max_difference,
|
||||
test_mean_pixel_difference=test_mean_pixel_difference,
|
||||
)
|
||||
@@ -287,7 +287,7 @@ class PipelineTesterMixin:
|
||||
for arg in additional_params_copy_to_batched_inputs:
|
||||
batched_inputs[arg] = inputs[arg]
|
||||
|
||||
batched_inputs["output_type"] = None
|
||||
batched_inputs["output_type"] = "np"
|
||||
|
||||
if self.pipeline_class.__name__ == "DanceDiffusionPipeline":
|
||||
batched_inputs.pop("output_type")
|
||||
|
||||
Reference in New Issue
Block a user