mirror of
https://github.com/huggingface/diffusers.git
synced 2026-01-29 07:22:12 +03:00
* initial TokenEncoder and ContinuousEncoder * initial modules * added ContinuousContextTransformer * fix copy paste error * use numpy for get_sequence_length * initial terminal relative positional encodings * fix weights keys * fix assert * cross attend style: concat encodings * make style * concat once * fix formatting * Initial SpectrogramPipeline * fix input_tokens * make style * added mel output * ignore weights for config * move mel to numpy * import pipeline * fix class names and import * moved models to models folder * import ContinuousContextTransformer and SpectrogramDiffusionPipeline * initial spec diffusion converstion script * renamed config to t5config * added weight loading * use arguments instead of t5config * broadcast noise time to batch dim * fix call * added scale_to_features * fix weights * transpose laynorm weight * scale is a vector * scale the query outputs * added comment * undo scaling * undo depth_scaling * inital get_extended_attention_mask * attention_mask is none in self-attention * cleanup * manually invert attention * nn.linear need bias=False * added T5LayerFFCond * remove to fix conflict * make style and dummy * remove unsed variables * remove predict_epsilon * Move accelerate to a soft-dependency (#1134) * finish * finish * Update src/diffusers/modeling_utils.py * Update src/diffusers/pipeline_utils.py Co-authored-by: Anton Lozhkov <anton@huggingface.co> * more fixes * fix Co-authored-by: Anton Lozhkov <anton@huggingface.co> * fix order * added initial midi to note token data pipeline * added int to int tokenizer * remove duplicate * added logic for segments * add melgan to pipeline * move autoregressive gen into pipeline * added note_representation_processor_chain * fix dtypes * remove immutabledict req * initial doc * use np.where * require note_seq * fix typo * update dependency * added note-seq to test * added is_note_seq_available * fix import * added toc * added example usage * undo for now * moved docs * fix merge * fix imports * predict first segment * avoid un-needed copy to and from cpu * make style * Copyright * fix style * add test and fix inference steps * remove bogus files * reorder models * up * remove transformers dependency * make work with diffusers cross attention * clean more * remove @ * improve further * up * uP * Apply suggestions from code review * Update tests/pipelines/spectrogram_diffusion/test_spectrogram_diffusion.py * loop over all tokens * make style * Added a section on the model * fix formatting * grammer * formatting * make fix-copies * Update src/diffusers/pipelines/__init__.py Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com> * Update src/diffusers/pipelines/spectrogram_diffusion/pipeline_spectrogram_diffusion.py Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com> * added callback ad optional ionnx * do not squeeze batch dim * clean up more * upload * convert jax to nnumpy * make style * fix warning * make fix-copies * fix warning * add initial fast tests * add initial pipeline_params * eval mode due to dropout * skip batch tests as pipeline runs on a single file * make style * fix relative path * fix doc tests * Update src/diffusers/models/t5_film_transformer.py Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com> * Update src/diffusers/models/t5_film_transformer.py Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com> * Update docs/source/en/api/pipelines/spectrogram_diffusion.mdx Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com> * Update tests/pipelines/spectrogram_diffusion/test_spectrogram_diffusion.py Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com> * Update tests/pipelines/spectrogram_diffusion/test_spectrogram_diffusion.py Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com> * Update tests/pipelines/spectrogram_diffusion/test_spectrogram_diffusion.py Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com> * Update tests/pipelines/spectrogram_diffusion/test_spectrogram_diffusion.py Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com> * add MidiProcessor * format * fix org * Apply suggestions from code review * Update tests/pipelines/spectrogram_diffusion/test_spectrogram_diffusion.py * make style * pin protobuf to <4 * fix formatting * white space * tensorboard needs protobuf --------- Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com> Co-authored-by: Anton Lozhkov <anton@huggingface.co>
55 lines
4.0 KiB
Plaintext
55 lines
4.0 KiB
Plaintext
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
|
|
|
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
|
the License. You may obtain a copy of the License at
|
|
|
|
http://www.apache.org/licenses/LICENSE-2.0
|
|
|
|
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
|
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
|
specific language governing permissions and limitations under the License.
|
|
-->
|
|
|
|
# Multi-instrument Music Synthesis with Spectrogram Diffusion
|
|
|
|
## Overview
|
|
|
|
[Spectrogram Diffusion](https://arxiv.org/abs/2206.05408) by Curtis Hawthorne, Ian Simon, Adam Roberts, Neil Zeghidour, Josh Gardner, Ethan Manilow, and Jesse Engel.
|
|
|
|
An ideal music synthesizer should be both interactive and expressive, generating high-fidelity audio in realtime for arbitrary combinations of instruments and notes. Recent neural synthesizers have exhibited a tradeoff between domain-specific models that offer detailed control of only specific instruments, or raw waveform models that can train on any music but with minimal control and slow generation. In this work, we focus on a middle ground of neural synthesizers that can generate audio from MIDI sequences with arbitrary combinations of instruments in realtime. This enables training on a wide range of transcription datasets with a single model, which in turn offers note-level control of composition and instrumentation across a wide range of instruments. We use a simple two-stage process: MIDI to spectrograms with an encoder-decoder Transformer, then spectrograms to audio with a generative adversarial network (GAN) spectrogram inverter. We compare training the decoder as an autoregressive model and as a Denoising Diffusion Probabilistic Model (DDPM) and find that the DDPM approach is superior both qualitatively and as measured by audio reconstruction and Fréchet distance metrics. Given the interactivity and generality of this approach, we find this to be a promising first step towards interactive and expressive neural synthesis for arbitrary combinations of instruments and notes.
|
|
|
|
The original codebase of this implementation can be found at [magenta/music-spectrogram-diffusion](https://github.com/magenta/music-spectrogram-diffusion).
|
|
|
|
## Model
|
|
|
|
|
|
|
|
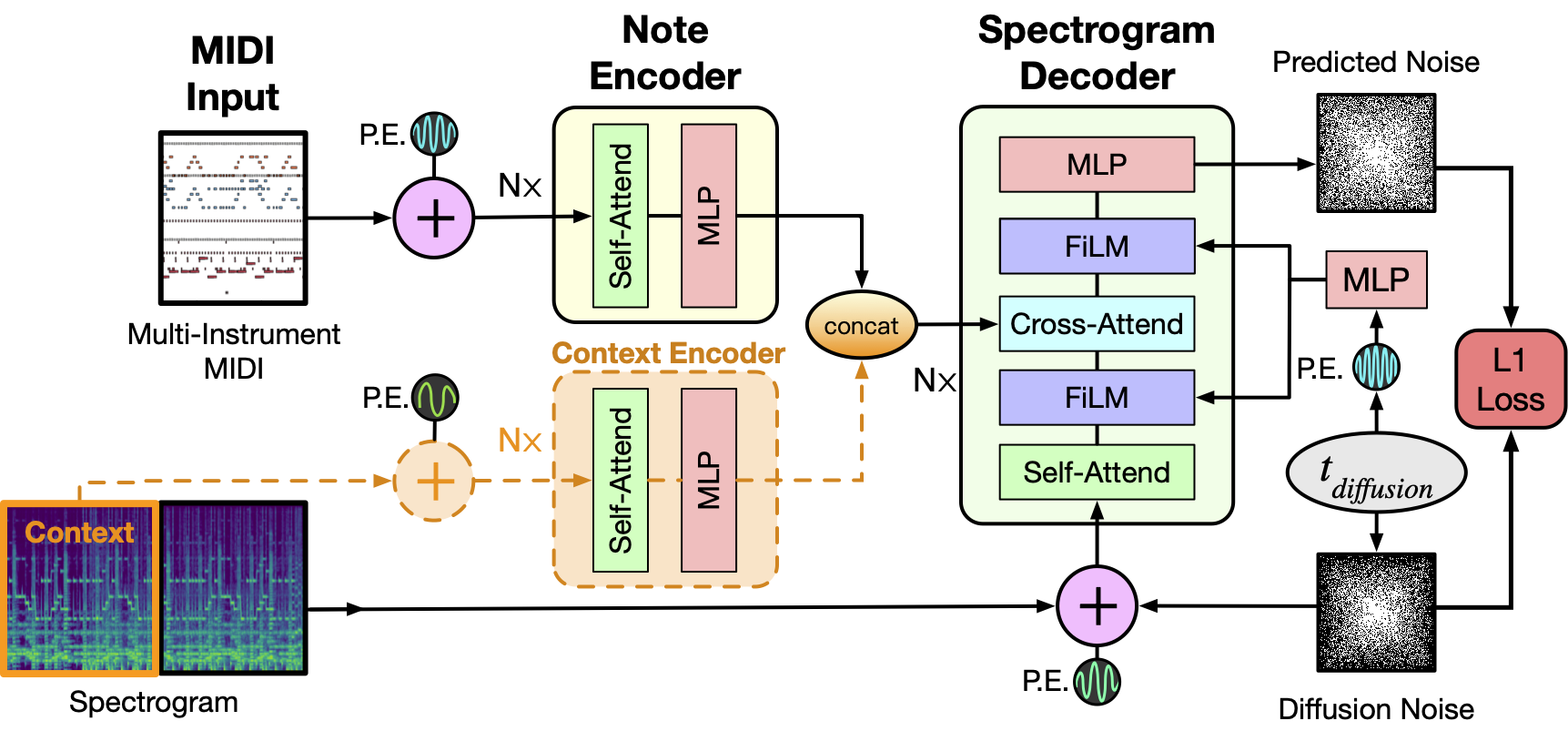
As depicted above the model takes as input a MIDI file and tokenizes it into a sequence of 5 second intervals. Each tokenized interval then together with positional encodings is passed through the Note Encoder and its representation is concatenated with the previous window's generated spectrogram representation obtained via the Context Encoder. For the initial 5 second window this is set to zero. The resulting context is then used as conditioning to sample the denoised Spectrogram from the MIDI window and we concatenate this spectrogram to the final output as well as use it for the context of the next MIDI window. The process repeats till we have gone over all the MIDI inputs. Finally a MelGAN decoder converts the potentially long spectrogram to audio which is the final result of this pipeline.
|
|
|
|
## Available Pipelines:
|
|
|
|
| Pipeline | Tasks | Colab
|
|
|---|---|:---:|
|
|
| [pipeline_spectrogram_diffusion.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/spectrogram_diffusion/pipeline_spectrogram_diffusion) | *Unconditional Audio Generation* | - |
|
|
|
|
|
|
## Example usage
|
|
|
|
```python
|
|
from diffusers import SpectrogramDiffusionPipeline, MidiProcessor
|
|
|
|
pipe = SpectrogramDiffusionPipeline.from_pretrained("google/music-spectrogram-diffusion")
|
|
pipe = pipe.to("cuda")
|
|
processor = MidiProcessor()
|
|
|
|
# Download MIDI from: wget http://www.piano-midi.de/midis/beethoven/beethoven_hammerklavier_2.mid
|
|
output = pipe(processor("beethoven_hammerklavier_2.mid"))
|
|
|
|
audio = output.audios[0]
|
|
```
|
|
|
|
## SpectrogramDiffusionPipeline
|
|
[[autodoc]] SpectrogramDiffusionPipeline
|
|
- all
|
|
- __call__
|