From d95b993427234c094d204ef703b154da788df261 Mon Sep 17 00:00:00 2001
From: Steven Liu <59462357+stevhliu@users.noreply.github.com>
Date: Wed, 10 Apr 2024 17:10:41 -0700
Subject: [PATCH] [docs] T2I (#7623)
* refactor t2i
* add code snippets
---
docs/source/en/_toctree.yml | 4 +-
.../api/pipelines/stable_diffusion/adapter.md | 250 ++----------------
docs/source/en/using-diffusers/t2i_adapter.md | 219 +++++++++++++++
3 files changed, 241 insertions(+), 232 deletions(-)
create mode 100644 docs/source/en/using-diffusers/t2i_adapter.md
diff --git a/docs/source/en/_toctree.yml b/docs/source/en/_toctree.yml
index 147386174c..83693485d0 100644
--- a/docs/source/en/_toctree.yml
+++ b/docs/source/en/_toctree.yml
@@ -86,6 +86,8 @@
title: Kandinsky
- local: using-diffusers/controlnet
title: ControlNet
+ - local: using-diffusers/t2i_adapter
+ title: T2I-Adapter
- local: using-diffusers/shap-e
title: Shap-E
- local: using-diffusers/diffedit
@@ -358,7 +360,7 @@
- local: api/pipelines/stable_diffusion/ldm3d_diffusion
title: LDM3D Text-to-(RGB, Depth), Text-to-(RGB-pano, Depth-pano), LDM3D Upscaler
- local: api/pipelines/stable_diffusion/adapter
- title: Stable Diffusion T2I-Adapter
+ title: T2I-Adapter
- local: api/pipelines/stable_diffusion/gligen
title: GLIGEN (Grounded Language-to-Image Generation)
title: Stable Diffusion
diff --git a/docs/source/en/api/pipelines/stable_diffusion/adapter.md b/docs/source/en/api/pipelines/stable_diffusion/adapter.md
index aa38e3d974..ca42fdc839 100644
--- a/docs/source/en/api/pipelines/stable_diffusion/adapter.md
+++ b/docs/source/en/api/pipelines/stable_diffusion/adapter.md
@@ -10,9 +10,7 @@ an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express o
specific language governing permissions and limitations under the License.
-->
-# Text-to-Image Generation with Adapter Conditioning
-
-## Overview
+# T2I-Adapter
[T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models](https://arxiv.org/abs/2302.08453) by Chong Mou, Xintao Wang, Liangbin Xie, Jian Zhang, Zhongang Qi, Ying Shan, Xiaohu Qie.
@@ -24,236 +22,26 @@ The abstract of the paper is the following:
This model was contributed by the community contributor [HimariO](https://github.com/HimariO) ❤️ .
-## Available Pipelines:
-
-| Pipeline | Tasks | Demo
-|---|---|:---:|
-| [StableDiffusionAdapterPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/t2i_adapter/pipeline_stable_diffusion_adapter.py) | *Text-to-Image Generation with T2I-Adapter Conditioning* | -
-| [StableDiffusionXLAdapterPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/t2i_adapter/pipeline_stable_diffusion_xl_adapter.py) | *Text-to-Image Generation with T2I-Adapter Conditioning on StableDiffusion-XL* | -
-
-## Usage example with the base model of StableDiffusion-1.4/1.5
-
-In the following we give a simple example of how to use a *T2I-Adapter* checkpoint with Diffusers for inference based on StableDiffusion-1.4/1.5.
-All adapters use the same pipeline.
-
- 1. Images are first converted into the appropriate *control image* format.
- 2. The *control image* and *prompt* are passed to the [`StableDiffusionAdapterPipeline`].
-
-Let's have a look at a simple example using the [Color Adapter](https://huggingface.co/TencentARC/t2iadapter_color_sd14v1).
-
-```python
-from diffusers.utils import load_image, make_image_grid
-
-image = load_image("https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/color_ref.png")
-```
-
-
-
-
-Then we can create our color palette by simply resizing it to 8 by 8 pixels and then scaling it back to original size.
-
-```python
-from PIL import Image
-
-color_palette = image.resize((8, 8))
-color_palette = color_palette.resize((512, 512), resample=Image.Resampling.NEAREST)
-```
-
-Let's take a look at the processed image.
-
-
-
-
-Next, create the adapter pipeline
-
-```py
-import torch
-from diffusers import StableDiffusionAdapterPipeline, T2IAdapter
-
-adapter = T2IAdapter.from_pretrained("TencentARC/t2iadapter_color_sd14v1", torch_dtype=torch.float16)
-pipe = StableDiffusionAdapterPipeline.from_pretrained(
- "CompVis/stable-diffusion-v1-4",
- adapter=adapter,
- torch_dtype=torch.float16,
-)
-pipe.to("cuda")
-```
-
-Finally, pass the prompt and control image to the pipeline
-
-```py
-# fix the random seed, so you will get the same result as the example
-generator = torch.Generator("cuda").manual_seed(7)
-
-out_image = pipe(
- "At night, glowing cubes in front of the beach",
- image=color_palette,
- generator=generator,
-).images[0]
-make_image_grid([image, color_palette, out_image], rows=1, cols=3)
-```
-
-
-
-## Usage example with the base model of StableDiffusion-XL
-
-In the following we give a simple example of how to use a *T2I-Adapter* checkpoint with Diffusers for inference based on StableDiffusion-XL.
-All adapters use the same pipeline.
-
- 1. Images are first downloaded into the appropriate *control image* format.
- 2. The *control image* and *prompt* are passed to the [`StableDiffusionXLAdapterPipeline`].
-
-Let's have a look at a simple example using the [Sketch Adapter](https://huggingface.co/Adapter/t2iadapter/tree/main/sketch_sdxl_1.0).
-
-```python
-from diffusers.utils import load_image, make_image_grid
-
-sketch_image = load_image("https://huggingface.co/Adapter/t2iadapter/resolve/main/sketch.png").convert("L")
-```
-
-
-
-Then, create the adapter pipeline
-
-```py
-import torch
-from diffusers import (
- T2IAdapter,
- StableDiffusionXLAdapterPipeline,
- DDPMScheduler
-)
-
-model_id = "stabilityai/stable-diffusion-xl-base-1.0"
-adapter = T2IAdapter.from_pretrained("Adapter/t2iadapter", subfolder="sketch_sdxl_1.0", torch_dtype=torch.float16, adapter_type="full_adapter_xl")
-scheduler = DDPMScheduler.from_pretrained(model_id, subfolder="scheduler")
-
-pipe = StableDiffusionXLAdapterPipeline.from_pretrained(
- model_id, adapter=adapter, safety_checker=None, torch_dtype=torch.float16, variant="fp16", scheduler=scheduler
-)
-
-pipe.to("cuda")
-```
-
-Finally, pass the prompt and control image to the pipeline
-
-```py
-# fix the random seed, so you will get the same result as the example
-generator = torch.Generator().manual_seed(42)
-
-sketch_image_out = pipe(
- prompt="a photo of a dog in real world, high quality",
- negative_prompt="extra digit, fewer digits, cropped, worst quality, low quality",
- image=sketch_image,
- generator=generator,
- guidance_scale=7.5
-).images[0]
-make_image_grid([sketch_image, sketch_image_out], rows=1, cols=2)
-```
-
-
-
-## Available checkpoints
-
-Non-diffusers checkpoints can be found under [TencentARC/T2I-Adapter](https://huggingface.co/TencentARC/T2I-Adapter/tree/main/models).
-
-### T2I-Adapter with Stable Diffusion 1.4
-
-| Model Name | Control Image Overview| Control Image Example | Generated Image Example |
-|---|---|---|---|
-|[TencentARC/t2iadapter_color_sd14v1](https://huggingface.co/TencentARC/t2iadapter_color_sd14v1)
*Trained with spatial color palette* | An image with 8x8 color palette.| |
| |
-|[TencentARC/t2iadapter_canny_sd14v1](https://huggingface.co/TencentARC/t2iadapter_canny_sd14v1)
|
-|[TencentARC/t2iadapter_canny_sd14v1](https://huggingface.co/TencentARC/t2iadapter_canny_sd14v1)
*Trained with canny edge detection* | A monochrome image with white edges on a black background.| |
| |
-|[TencentARC/t2iadapter_sketch_sd14v1](https://huggingface.co/TencentARC/t2iadapter_sketch_sd14v1)
|
-|[TencentARC/t2iadapter_sketch_sd14v1](https://huggingface.co/TencentARC/t2iadapter_sketch_sd14v1)
*Trained with [PidiNet](https://github.com/zhuoinoulu/pidinet) edge detection* | A hand-drawn monochrome image with white outlines on a black background.| |
| |
-|[TencentARC/t2iadapter_depth_sd14v1](https://huggingface.co/TencentARC/t2iadapter_depth_sd14v1)
|
-|[TencentARC/t2iadapter_depth_sd14v1](https://huggingface.co/TencentARC/t2iadapter_depth_sd14v1)
*Trained with Midas depth estimation* | A grayscale image with black representing deep areas and white representing shallow areas.| |
| |
-|[TencentARC/t2iadapter_openpose_sd14v1](https://huggingface.co/TencentARC/t2iadapter_openpose_sd14v1)
|
-|[TencentARC/t2iadapter_openpose_sd14v1](https://huggingface.co/TencentARC/t2iadapter_openpose_sd14v1)
*Trained with OpenPose bone image* | A [OpenPose bone](https://github.com/CMU-Perceptual-Computing-Lab/openpose) image.|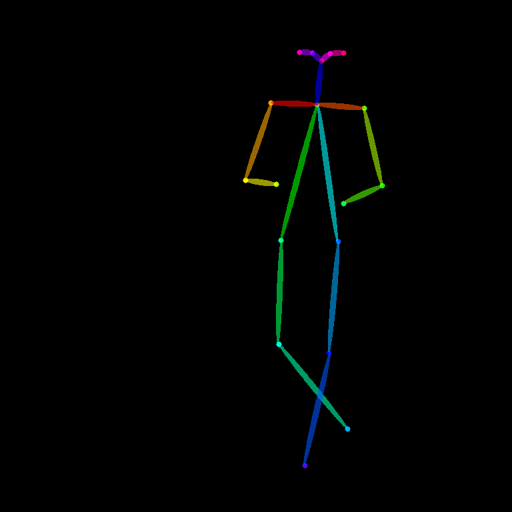 |
| |
-|[TencentARC/t2iadapter_keypose_sd14v1](https://huggingface.co/TencentARC/t2iadapter_keypose_sd14v1)
|
-|[TencentARC/t2iadapter_keypose_sd14v1](https://huggingface.co/TencentARC/t2iadapter_keypose_sd14v1)
*Trained with mmpose skeleton image* | A [mmpose skeleton](https://github.com/open-mmlab/mmpose) image.| |
| |
-|[TencentARC/t2iadapter_seg_sd14v1](https://huggingface.co/TencentARC/t2iadapter_seg_sd14v1)
|
-|[TencentARC/t2iadapter_seg_sd14v1](https://huggingface.co/TencentARC/t2iadapter_seg_sd14v1)
*Trained with semantic segmentation* | An [custom](https://github.com/TencentARC/T2I-Adapter/discussions/25) segmentation protocol image.| |
| |
-|[TencentARC/t2iadapter_canny_sd15v2](https://huggingface.co/TencentARC/t2iadapter_canny_sd15v2)||
-|[TencentARC/t2iadapter_depth_sd15v2](https://huggingface.co/TencentARC/t2iadapter_depth_sd15v2)||
-|[TencentARC/t2iadapter_sketch_sd15v2](https://huggingface.co/TencentARC/t2iadapter_sketch_sd15v2)||
-|[TencentARC/t2iadapter_zoedepth_sd15v1](https://huggingface.co/TencentARC/t2iadapter_zoedepth_sd15v1)||
-|[Adapter/t2iadapter, subfolder='sketch_sdxl_1.0'](https://huggingface.co/Adapter/t2iadapter/tree/main/sketch_sdxl_1.0)||
-|[Adapter/t2iadapter, subfolder='canny_sdxl_1.0'](https://huggingface.co/Adapter/t2iadapter/tree/main/canny_sdxl_1.0)||
-|[Adapter/t2iadapter, subfolder='openpose_sdxl_1.0'](https://huggingface.co/Adapter/t2iadapter/tree/main/openpose_sdxl_1.0)||
-
-## Combining multiple adapters
-
-[`MultiAdapter`] can be used for applying multiple conditionings at once.
-
-Here we use the keypose adapter for the character posture and the depth adapter for creating the scene.
-
-```py
-from diffusers.utils import load_image, make_image_grid
-
-cond_keypose = load_image(
- "https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/keypose_sample_input.png"
-)
-cond_depth = load_image(
- "https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/depth_sample_input.png"
-)
-cond = [cond_keypose, cond_depth]
-
-prompt = ["A man walking in an office room with a nice view"]
-```
-
-The two control images look as such:
-
-
-
-
-
-`MultiAdapter` combines keypose and depth adapters.
-
-`adapter_conditioning_scale` balances the relative influence of the different adapters.
-
-```py
-import torch
-from diffusers import StableDiffusionAdapterPipeline, MultiAdapter, T2IAdapter
-
-adapters = MultiAdapter(
- [
- T2IAdapter.from_pretrained("TencentARC/t2iadapter_keypose_sd14v1"),
- T2IAdapter.from_pretrained("TencentARC/t2iadapter_depth_sd14v1"),
- ]
-)
-adapters = adapters.to(torch.float16)
-
-pipe = StableDiffusionAdapterPipeline.from_pretrained(
- "CompVis/stable-diffusion-v1-4",
- torch_dtype=torch.float16,
- adapter=adapters,
-).to("cuda")
-
-image = pipe(prompt, cond, adapter_conditioning_scale=[0.8, 0.8]).images[0]
-make_image_grid([cond_keypose, cond_depth, image], rows=1, cols=3)
-```
-
-
-
-
-## T2I-Adapter vs ControlNet
-
-T2I-Adapter is similar to [ControlNet](https://huggingface.co/docs/diffusers/main/en/api/pipelines/controlnet).
-T2I-Adapter uses a smaller auxiliary network which is only run once for the entire diffusion process.
-However, T2I-Adapter performs slightly worse than ControlNet.
-
## StableDiffusionAdapterPipeline
+
[[autodoc]] StableDiffusionAdapterPipeline
- - all
- - __call__
- - enable_attention_slicing
- - disable_attention_slicing
- - enable_vae_slicing
- - disable_vae_slicing
- - enable_xformers_memory_efficient_attention
- - disable_xformers_memory_efficient_attention
+ - all
+ - __call__
+ - enable_attention_slicing
+ - disable_attention_slicing
+ - enable_vae_slicing
+ - disable_vae_slicing
+ - enable_xformers_memory_efficient_attention
+ - disable_xformers_memory_efficient_attention
## StableDiffusionXLAdapterPipeline
+
[[autodoc]] StableDiffusionXLAdapterPipeline
- - all
- - __call__
- - enable_attention_slicing
- - disable_attention_slicing
- - enable_vae_slicing
- - disable_vae_slicing
- - enable_xformers_memory_efficient_attention
- - disable_xformers_memory_efficient_attention
+ - all
+ - __call__
+ - enable_attention_slicing
+ - disable_attention_slicing
+ - enable_vae_slicing
+ - disable_vae_slicing
+ - enable_xformers_memory_efficient_attention
+ - disable_xformers_memory_efficient_attention
diff --git a/docs/source/en/using-diffusers/t2i_adapter.md b/docs/source/en/using-diffusers/t2i_adapter.md
new file mode 100644
index 0000000000..5e150312e1
--- /dev/null
+++ b/docs/source/en/using-diffusers/t2i_adapter.md
@@ -0,0 +1,219 @@
+
+
+# T2I-Adapter
+
+[T2I-Adapter](https://hf.co/papers/2302.08453) is a lightweight adapter for controlling and providing more accurate
+structure guidance for text-to-image models. It works by learning an alignment between the internal knowledge of the
+text-to-image model and an external control signal, such as edge detection or depth estimation.
+
+The T2I-Adapter design is simple, the condition is passed to four feature extraction blocks and three downsample
+blocks. This makes it fast and easy to train different adapters for different conditions which can be plugged into the
+text-to-image model. T2I-Adapter is similar to [ControlNet](controlnet) except it is smaller (~77M parameters) and
+faster because it only runs once during the diffusion process. The downside is that performance may be slightly worse
+than ControlNet.
+
+This guide will show you how to use T2I-Adapter with different Stable Diffusion models and how you can compose multiple
+T2I-Adapters to impose more than one condition.
+
+> [!TIP]
+> There are several T2I-Adapters available for different conditions, such as color palette, depth, sketch, pose, and
+> segmentation. Check out the [TencentARC](https://hf.co/TencentARC) repository to try them out!
+
+Before you begin, make sure you have the following libraries installed.
+
+```py
+# uncomment to install the necessary libraries in Colab
+#!pip install -q diffusers accelerate controlnet-aux==0.0.7
+```
+
+## Text-to-image
+
+Text-to-image models rely on a prompt to generate an image, but sometimes, text alone may not be enough to provide more
+accurate structural guidance. T2I-Adapter allows you to provide an additional control image to guide the generation
+process. For example, you can provide a canny image (a white outline of an image on a black background) to guide the
+model to generate an image with a similar structure.
+
+
+
+
+Create a canny image with the [opencv-library](https://github.com/opencv/opencv-python).
+
+```py
+import cv2
+import numpy as np
+from PIL import Image
+from diffusers.utils import load_image
+
+image = load_image("https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/hf-logo.png")
+image = np.array(image)
+
+low_threshold = 100
+high_threshold = 200
+
+image = cv2.Canny(image, low_threshold, high_threshold)
+image = Image.fromarray(image)
+```
+
+Now load a T2I-Adapter conditioned on [canny images](https://hf.co/TencentARC/t2iadapter_canny_sd15v2) and pass it to
+the [`StableDiffusionAdapterPipeline`].
+
+```py
+import torch
+from diffusers import StableDiffusionAdapterPipeline, T2IAdapter
+
+adapter = T2IAdapter.from_pretrained("TencentARC/t2iadapter_canny_sd15v2", torch_dtype=torch.float16)
+pipeline = StableDiffusionAdapterPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5",
+ adapter=adapter,
+ torch_dtype=torch.float16,
+)
+pipeline.to("cuda")
+```
+
+Finally, pass your prompt and control image to the pipeline.
+
+```py
+generator = torch.Generator("cuda").manual_seed(0)
+
+image = pipeline(
+ prompt="cinematic photo of a plush and soft midcentury style rug on a wooden floor, 35mm photograph, film, professional, 4k, highly detailed",
+ image=image,
+ generator=generator,
+).images[0]
+image
+```
+
+
|
-|[TencentARC/t2iadapter_canny_sd15v2](https://huggingface.co/TencentARC/t2iadapter_canny_sd15v2)||
-|[TencentARC/t2iadapter_depth_sd15v2](https://huggingface.co/TencentARC/t2iadapter_depth_sd15v2)||
-|[TencentARC/t2iadapter_sketch_sd15v2](https://huggingface.co/TencentARC/t2iadapter_sketch_sd15v2)||
-|[TencentARC/t2iadapter_zoedepth_sd15v1](https://huggingface.co/TencentARC/t2iadapter_zoedepth_sd15v1)||
-|[Adapter/t2iadapter, subfolder='sketch_sdxl_1.0'](https://huggingface.co/Adapter/t2iadapter/tree/main/sketch_sdxl_1.0)||
-|[Adapter/t2iadapter, subfolder='canny_sdxl_1.0'](https://huggingface.co/Adapter/t2iadapter/tree/main/canny_sdxl_1.0)||
-|[Adapter/t2iadapter, subfolder='openpose_sdxl_1.0'](https://huggingface.co/Adapter/t2iadapter/tree/main/openpose_sdxl_1.0)||
-
-## Combining multiple adapters
-
-[`MultiAdapter`] can be used for applying multiple conditionings at once.
-
-Here we use the keypose adapter for the character posture and the depth adapter for creating the scene.
-
-```py
-from diffusers.utils import load_image, make_image_grid
-
-cond_keypose = load_image(
- "https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/keypose_sample_input.png"
-)
-cond_depth = load_image(
- "https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/depth_sample_input.png"
-)
-cond = [cond_keypose, cond_depth]
-
-prompt = ["A man walking in an office room with a nice view"]
-```
-
-The two control images look as such:
-
-
-
-
-
-`MultiAdapter` combines keypose and depth adapters.
-
-`adapter_conditioning_scale` balances the relative influence of the different adapters.
-
-```py
-import torch
-from diffusers import StableDiffusionAdapterPipeline, MultiAdapter, T2IAdapter
-
-adapters = MultiAdapter(
- [
- T2IAdapter.from_pretrained("TencentARC/t2iadapter_keypose_sd14v1"),
- T2IAdapter.from_pretrained("TencentARC/t2iadapter_depth_sd14v1"),
- ]
-)
-adapters = adapters.to(torch.float16)
-
-pipe = StableDiffusionAdapterPipeline.from_pretrained(
- "CompVis/stable-diffusion-v1-4",
- torch_dtype=torch.float16,
- adapter=adapters,
-).to("cuda")
-
-image = pipe(prompt, cond, adapter_conditioning_scale=[0.8, 0.8]).images[0]
-make_image_grid([cond_keypose, cond_depth, image], rows=1, cols=3)
-```
-
-
-
-
-## T2I-Adapter vs ControlNet
-
-T2I-Adapter is similar to [ControlNet](https://huggingface.co/docs/diffusers/main/en/api/pipelines/controlnet).
-T2I-Adapter uses a smaller auxiliary network which is only run once for the entire diffusion process.
-However, T2I-Adapter performs slightly worse than ControlNet.
-
## StableDiffusionAdapterPipeline
+
[[autodoc]] StableDiffusionAdapterPipeline
- - all
- - __call__
- - enable_attention_slicing
- - disable_attention_slicing
- - enable_vae_slicing
- - disable_vae_slicing
- - enable_xformers_memory_efficient_attention
- - disable_xformers_memory_efficient_attention
+ - all
+ - __call__
+ - enable_attention_slicing
+ - disable_attention_slicing
+ - enable_vae_slicing
+ - disable_vae_slicing
+ - enable_xformers_memory_efficient_attention
+ - disable_xformers_memory_efficient_attention
## StableDiffusionXLAdapterPipeline
+
[[autodoc]] StableDiffusionXLAdapterPipeline
- - all
- - __call__
- - enable_attention_slicing
- - disable_attention_slicing
- - enable_vae_slicing
- - disable_vae_slicing
- - enable_xformers_memory_efficient_attention
- - disable_xformers_memory_efficient_attention
+ - all
+ - __call__
+ - enable_attention_slicing
+ - disable_attention_slicing
+ - enable_vae_slicing
+ - disable_vae_slicing
+ - enable_xformers_memory_efficient_attention
+ - disable_xformers_memory_efficient_attention
diff --git a/docs/source/en/using-diffusers/t2i_adapter.md b/docs/source/en/using-diffusers/t2i_adapter.md
new file mode 100644
index 0000000000..5e150312e1
--- /dev/null
+++ b/docs/source/en/using-diffusers/t2i_adapter.md
@@ -0,0 +1,219 @@
+
+
+# T2I-Adapter
+
+[T2I-Adapter](https://hf.co/papers/2302.08453) is a lightweight adapter for controlling and providing more accurate
+structure guidance for text-to-image models. It works by learning an alignment between the internal knowledge of the
+text-to-image model and an external control signal, such as edge detection or depth estimation.
+
+The T2I-Adapter design is simple, the condition is passed to four feature extraction blocks and three downsample
+blocks. This makes it fast and easy to train different adapters for different conditions which can be plugged into the
+text-to-image model. T2I-Adapter is similar to [ControlNet](controlnet) except it is smaller (~77M parameters) and
+faster because it only runs once during the diffusion process. The downside is that performance may be slightly worse
+than ControlNet.
+
+This guide will show you how to use T2I-Adapter with different Stable Diffusion models and how you can compose multiple
+T2I-Adapters to impose more than one condition.
+
+> [!TIP]
+> There are several T2I-Adapters available for different conditions, such as color palette, depth, sketch, pose, and
+> segmentation. Check out the [TencentARC](https://hf.co/TencentARC) repository to try them out!
+
+Before you begin, make sure you have the following libraries installed.
+
+```py
+# uncomment to install the necessary libraries in Colab
+#!pip install -q diffusers accelerate controlnet-aux==0.0.7
+```
+
+## Text-to-image
+
+Text-to-image models rely on a prompt to generate an image, but sometimes, text alone may not be enough to provide more
+accurate structural guidance. T2I-Adapter allows you to provide an additional control image to guide the generation
+process. For example, you can provide a canny image (a white outline of an image on a black background) to guide the
+model to generate an image with a similar structure.
+
+
+
+
+Create a canny image with the [opencv-library](https://github.com/opencv/opencv-python).
+
+```py
+import cv2
+import numpy as np
+from PIL import Image
+from diffusers.utils import load_image
+
+image = load_image("https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/hf-logo.png")
+image = np.array(image)
+
+low_threshold = 100
+high_threshold = 200
+
+image = cv2.Canny(image, low_threshold, high_threshold)
+image = Image.fromarray(image)
+```
+
+Now load a T2I-Adapter conditioned on [canny images](https://hf.co/TencentARC/t2iadapter_canny_sd15v2) and pass it to
+the [`StableDiffusionAdapterPipeline`].
+
+```py
+import torch
+from diffusers import StableDiffusionAdapterPipeline, T2IAdapter
+
+adapter = T2IAdapter.from_pretrained("TencentARC/t2iadapter_canny_sd15v2", torch_dtype=torch.float16)
+pipeline = StableDiffusionAdapterPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5",
+ adapter=adapter,
+ torch_dtype=torch.float16,
+)
+pipeline.to("cuda")
+```
+
+Finally, pass your prompt and control image to the pipeline.
+
+```py
+generator = torch.Generator("cuda").manual_seed(0)
+
+image = pipeline(
+ prompt="cinematic photo of a plush and soft midcentury style rug on a wooden floor, 35mm photograph, film, professional, 4k, highly detailed",
+ image=image,
+ generator=generator,
+).images[0]
+image
+```
+
+
+

+
+

+
+
+
+
depth image
+
+
+
+
pose image
+
+
+

+