
diff --git a/docs/source/en/optimization/fp16.md b/docs/source/en/optimization/fp16.md
index 97a1f5830a..010b721536 100644
--- a/docs/source/en/optimization/fp16.md
+++ b/docs/source/en/optimization/fp16.md
@@ -150,6 +150,24 @@ pipeline(prompt, num_inference_steps=30).images[0]
Compilation is slow the first time, but once compiled, it is significantly faster. Try to only use the compiled pipeline on the same type of inference operations. Calling the compiled pipeline on a different image size retriggers compilation which is slow and inefficient.
+### Regional compilation
+
+[Regional compilation](https://docs.pytorch.org/tutorials/recipes/regional_compilation.html) reduces the cold start compilation time by only compiling a specific repeated region (or block) of the model instead of the entire model. The compiler reuses the cached and compiled code for the other blocks.
+
+[Accelerate](https://huggingface.co/docs/accelerate/index) provides the [compile_regions](https://github.com/huggingface/accelerate/blob/273799c85d849a1954a4f2e65767216eb37fa089/src/accelerate/utils/other.py#L78) method for automatically compiling the repeated blocks of a `nn.Module` sequentially. The rest of the model is compiled separately.
+
+```py
+# pip install -U accelerate
+import torch
+from diffusers import StableDiffusionXLPipeline
+from accelerate.utils import compile regions
+
+pipeline = StableDiffusionXLPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16
+).to("cuda")
+pipeline.unet = compile_regions(pipeline.unet, mode="reduce-overhead", fullgraph=True)
+```
+
### Graph breaks
It is important to specify `fullgraph=True` in torch.compile to ensure there are no graph breaks in the underlying model. This allows you to take advantage of torch.compile without any performance degradation. For the UNet and VAE, this changes how you access the return variables.
@@ -170,6 +188,12 @@ The `step()` function is [called](https://github.com/huggingface/diffusers/blob/
In general, the `sigmas` should [stay on the CPU](https://github.com/huggingface/diffusers/blob/35a969d297cba69110d175ee79c59312b9f49e1e/src/diffusers/schedulers/scheduling_euler_discrete.py#L240) to avoid the communication sync and latency.
+### Benchmarks
+
+Refer to the [diffusers/benchmarks](https://huggingface.co/datasets/diffusers/benchmarks) dataset to see inference latency and memory usage data for compiled pipelines.
+
+The [diffusers-torchao](https://github.com/sayakpaul/diffusers-torchao#benchmarking-results) repository also contains benchmarking results for compiled versions of Flux and CogVideoX.
+
## Dynamic quantization
[Dynamic quantization](https://pytorch.org/tutorials/recipes/recipes/dynamic_quantization.html) improves inference speed by reducing precision to enable faster math operations. This particular type of quantization determines how to scale the activations based on the data at runtime rather than using a fixed scaling factor. As a result, the scaling factor is more accurately aligned with the data.
diff --git a/docs/source/en/optimization/habana.md b/docs/source/en/optimization/habana.md
index 86a0cf0ba0..69964f3244 100644
--- a/docs/source/en/optimization/habana.md
+++ b/docs/source/en/optimization/habana.md
@@ -10,67 +10,22 @@ an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express o
specific language governing permissions and limitations under the License.
-->
-# Habana Gaudi
+# Intel Gaudi
-🤗 Diffusers is compatible with Habana Gaudi through 🤗 [Optimum](https://huggingface.co/docs/optimum/habana/usage_guides/stable_diffusion). Follow the [installation](https://docs.habana.ai/en/latest/Installation_Guide/index.html) guide to install the SynapseAI and Gaudi drivers, and then install Optimum Habana:
+The Intel Gaudi AI accelerator family includes [Intel Gaudi 1](https://habana.ai/products/gaudi/), [Intel Gaudi 2](https://habana.ai/products/gaudi2/), and [Intel Gaudi 3](https://habana.ai/products/gaudi3/). Each server is equipped with 8 devices, known as Habana Processing Units (HPUs), providing 128GB of memory on Gaudi 3, 96GB on Gaudi 2, and 32GB on the first-gen Gaudi. For more details on the underlying hardware architecture, check out the [Gaudi Architecture](https://docs.habana.ai/en/latest/Gaudi_Overview/Gaudi_Architecture.html) overview.
-```bash
-python -m pip install --upgrade-strategy eager optimum[habana]
+Diffusers pipelines can take advantage of HPU acceleration, even if a pipeline hasn't been added to [Optimum for Intel Gaudi](https://huggingface.co/docs/optimum/main/en/habana/index) yet, with the [GPU Migration Toolkit](https://docs.habana.ai/en/latest/PyTorch/PyTorch_Model_Porting/GPU_Migration_Toolkit/GPU_Migration_Toolkit.html).
+
+Call `.to("hpu")` on your pipeline to move it to a HPU device as shown below for Flux:
+```py
+import torch
+from diffusers import DiffusionPipeline
+
+pipeline = DiffusionPipeline.from_pretrained("black-forest-labs/FLUX.1-schnell", torch_dtype=torch.bfloat16)
+pipeline.to("hpu")
+
+image = pipeline("An image of a squirrel in Picasso style").images[0]
```
-To generate images with Stable Diffusion 1 and 2 on Gaudi, you need to instantiate two instances:
-
-- [`~optimum.habana.diffusers.GaudiStableDiffusionPipeline`], a pipeline for text-to-image generation.
-- [`~optimum.habana.diffusers.GaudiDDIMScheduler`], a Gaudi-optimized scheduler.
-
-When you initialize the pipeline, you have to specify `use_habana=True` to deploy it on HPUs and to get the fastest possible generation, you should enable **HPU graphs** with `use_hpu_graphs=True`.
-
-Finally, specify a [`~optimum.habana.GaudiConfig`] which can be downloaded from the [Habana](https://huggingface.co/Habana) organization on the Hub.
-
-```python
-from optimum.habana import GaudiConfig
-from optimum.habana.diffusers import GaudiDDIMScheduler, GaudiStableDiffusionPipeline
-
-model_name = "stabilityai/stable-diffusion-2-base"
-scheduler = GaudiDDIMScheduler.from_pretrained(model_name, subfolder="scheduler")
-pipeline = GaudiStableDiffusionPipeline.from_pretrained(
- model_name,
- scheduler=scheduler,
- use_habana=True,
- use_hpu_graphs=True,
- gaudi_config="Habana/stable-diffusion-2",
-)
-```
-
-Now you can call the pipeline to generate images by batches from one or several prompts:
-
-```python
-outputs = pipeline(
- prompt=[
- "High quality photo of an astronaut riding a horse in space",
- "Face of a yellow cat, high resolution, sitting on a park bench",
- ],
- num_images_per_prompt=10,
- batch_size=4,
-)
-```
-
-For more information, check out 🤗 Optimum Habana's [documentation](https://huggingface.co/docs/optimum/habana/usage_guides/stable_diffusion) and the [example](https://github.com/huggingface/optimum-habana/tree/main/examples/stable-diffusion) provided in the official GitHub repository.
-
-## Benchmark
-
-We benchmarked Habana's first-generation Gaudi and Gaudi2 with the [Habana/stable-diffusion](https://huggingface.co/Habana/stable-diffusion) and [Habana/stable-diffusion-2](https://huggingface.co/Habana/stable-diffusion-2) Gaudi configurations (mixed precision bf16/fp32) to demonstrate their performance.
-
-For [Stable Diffusion v1.5](https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5) on 512x512 images:
-
-| | Latency (batch size = 1) | Throughput |
-| ---------------------- |:------------------------:|:---------------------------:|
-| first-generation Gaudi | 3.80s | 0.308 images/s (batch size = 8) |
-| Gaudi2 | 1.33s | 1.081 images/s (batch size = 8) |
-
-For [Stable Diffusion v2.1](https://huggingface.co/stabilityai/stable-diffusion-2-1) on 768x768 images:
-
-| | Latency (batch size = 1) | Throughput |
-| ---------------------- |:------------------------:|:-------------------------------:|
-| first-generation Gaudi | 10.2s | 0.108 images/s (batch size = 4) |
-| Gaudi2 | 3.17s | 0.379 images/s (batch size = 8) |
+> [!TIP]
+> For Gaudi-optimized diffusion pipeline implementations, we recommend using [Optimum for Intel Gaudi](https://huggingface.co/docs/optimum/main/en/habana/index).
diff --git a/docs/source/en/optimization/memory.md b/docs/source/en/optimization/memory.md
index 5b3bfe650d..6b853a7a08 100644
--- a/docs/source/en/optimization/memory.md
+++ b/docs/source/en/optimization/memory.md
@@ -295,6 +295,13 @@ pipeline.transformer.enable_group_offload(onload_device=onload_device, offload_d
The `low_cpu_mem_usage` parameter can be set to `True` to reduce CPU memory usage when using streams during group offloading. It is best for `leaf_level` offloading and when CPU memory is bottlenecked. Memory is saved by creating pinned tensors on the fly instead of pre-pinning them. However, this may increase overall execution time.
+
+
+The offloading strategies can be combined with [quantization](../quantization/overview.md) to enable further memory savings. For image generation, combining [quantization and model offloading](#model-offloading) can often give the best trade-off between quality, speed, and memory. However, for video generation, as the models are more
+compute-bound, [group-offloading](#group-offloading) tends to be better. Group offloading provides considerable benefits when weight transfers can be overlapped with computation (must use streams). When applying group offloading with quantization on image generation models at typical resolutions (1024x1024, for example), it is usually not possible to *fully* overlap weight transfers if the compute kernel finishes faster, making it communication bound between CPU/GPU (due to device synchronizations).
+
+
+
## Layerwise casting
Layerwise casting stores weights in a smaller data format (for example, `torch.float8_e4m3fn` and `torch.float8_e5m2`) to use less memory and upcasts those weights to a higher precision like `torch.float16` or `torch.bfloat16` for computation. Certain layers (normalization and modulation related weights) are skipped because storing them in fp8 can degrade generation quality.
diff --git a/docs/source/en/optimization/tome.md b/docs/source/en/optimization/tome.md
index 3e574efbfe..f379bc97f4 100644
--- a/docs/source/en/optimization/tome.md
+++ b/docs/source/en/optimization/tome.md
@@ -93,4 +93,4 @@ To reproduce this benchmark, feel free to use this [script](https://gist.github.
| | | 2 | OOM | 13 | 10.78 |
| | | 1 | OOM | 6.66 | 5.54 |
-As seen in the tables above, the speed-up from `tomesd` becomes more pronounced for larger image resolutions. It is also interesting to note that with `tomesd`, it is possible to run the pipeline on a higher resolution like 1024x1024. You may be able to speed-up inference even more with [`torch.compile`](torch2.0).
+As seen in the tables above, the speed-up from `tomesd` becomes more pronounced for larger image resolutions. It is also interesting to note that with `tomesd`, it is possible to run the pipeline on a higher resolution like 1024x1024. You may be able to speed-up inference even more with [`torch.compile`](fp16#torchcompile).
diff --git a/docs/source/en/optimization/torch2.0.md b/docs/source/en/optimization/torch2.0.md
deleted file mode 100644
index 01ea00310a..0000000000
--- a/docs/source/en/optimization/torch2.0.md
+++ /dev/null
@@ -1,421 +0,0 @@
-
-
-# PyTorch 2.0
-
-🤗 Diffusers supports the latest optimizations from [PyTorch 2.0](https://pytorch.org/get-started/pytorch-2.0/) which include:
-
-1. A memory-efficient attention implementation, scaled dot product attention, without requiring any extra dependencies such as xFormers.
-2. [`torch.compile`](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html), a just-in-time (JIT) compiler to provide an extra performance boost when individual models are compiled.
-
-Both of these optimizations require PyTorch 2.0 or later and 🤗 Diffusers > 0.13.0.
-
-```bash
-pip install --upgrade torch diffusers
-```
-
-## Scaled dot product attention
-
-[`torch.nn.functional.scaled_dot_product_attention`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention) (SDPA) is an optimized and memory-efficient attention (similar to xFormers) that automatically enables several other optimizations depending on the model inputs and GPU type. SDPA is enabled by default if you're using PyTorch 2.0 and the latest version of 🤗 Diffusers, so you don't need to add anything to your code.
-
-However, if you want to explicitly enable it, you can set a [`DiffusionPipeline`] to use [`~models.attention_processor.AttnProcessor2_0`]:
-
-```diff
- import torch
- from diffusers import DiffusionPipeline
-+ from diffusers.models.attention_processor import AttnProcessor2_0
-
- pipe = DiffusionPipeline.from_pretrained("stable-diffusion-v1-5/stable-diffusion-v1-5", torch_dtype=torch.float16, use_safetensors=True).to("cuda")
-+ pipe.unet.set_attn_processor(AttnProcessor2_0())
-
- prompt = "a photo of an astronaut riding a horse on mars"
- image = pipe(prompt).images[0]
-```
-
-SDPA should be as fast and memory efficient as `xFormers`; check the [benchmark](#benchmark) for more details.
-
-In some cases - such as making the pipeline more deterministic or converting it to other formats - it may be helpful to use the vanilla attention processor, [`~models.attention_processor.AttnProcessor`]. To revert to [`~models.attention_processor.AttnProcessor`], call the [`~UNet2DConditionModel.set_default_attn_processor`] function on the pipeline:
-
-```diff
- import torch
- from diffusers import DiffusionPipeline
-
- pipe = DiffusionPipeline.from_pretrained("stable-diffusion-v1-5/stable-diffusion-v1-5", torch_dtype=torch.float16, use_safetensors=True).to("cuda")
-+ pipe.unet.set_default_attn_processor()
-
- prompt = "a photo of an astronaut riding a horse on mars"
- image = pipe(prompt).images[0]
-```
-
-## torch.compile
-
-The `torch.compile` function can often provide an additional speed-up to your PyTorch code. In 🤗 Diffusers, it is usually best to wrap the UNet with `torch.compile` because it does most of the heavy lifting in the pipeline.
-
-```python
-from diffusers import DiffusionPipeline
-import torch
-
-pipe = DiffusionPipeline.from_pretrained("stable-diffusion-v1-5/stable-diffusion-v1-5", torch_dtype=torch.float16, use_safetensors=True).to("cuda")
-pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
-images = pipe(prompt, num_inference_steps=steps, num_images_per_prompt=batch_size).images[0]
-```
-
-Depending on GPU type, `torch.compile` can provide an *additional speed-up* of **5-300x** on top of SDPA! If you're using more recent GPU architectures such as Ampere (A100, 3090), Ada (4090), and Hopper (H100), `torch.compile` is able to squeeze even more performance out of these GPUs.
-
-Compilation requires some time to complete, so it is best suited for situations where you prepare your pipeline once and then perform the same type of inference operations multiple times. For example, calling the compiled pipeline on a different image size triggers compilation again which can be expensive.
-
-For more information and different options about `torch.compile`, refer to the [`torch_compile`](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html) tutorial.
-
-> [!TIP]
-> Learn more about other ways PyTorch 2.0 can help optimize your model in the [Accelerate inference of text-to-image diffusion models](../tutorials/fast_diffusion) tutorial.
-
-## Benchmark
-
-We conducted a comprehensive benchmark with PyTorch 2.0's efficient attention implementation and `torch.compile` across different GPUs and batch sizes for five of our most used pipelines. The code is benchmarked on 🤗 Diffusers v0.17.0.dev0 to optimize `torch.compile` usage (see [here](https://github.com/huggingface/diffusers/pull/3313) for more details).
-
-Expand the dropdown below to find the code used to benchmark each pipeline:
-
-
-
-### Stable Diffusion text-to-image
-
-```python
-from diffusers import DiffusionPipeline
-import torch
-
-path = "stable-diffusion-v1-5/stable-diffusion-v1-5"
-
-run_compile = True # Set True / False
-
-pipe = DiffusionPipeline.from_pretrained(path, torch_dtype=torch.float16, use_safetensors=True)
-pipe = pipe.to("cuda")
-pipe.unet.to(memory_format=torch.channels_last)
-
-if run_compile:
- print("Run torch compile")
- pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
-
-prompt = "ghibli style, a fantasy landscape with castles"
-
-for _ in range(3):
- images = pipe(prompt=prompt).images
-```
-
-### Stable Diffusion image-to-image
-
-```python
-from diffusers import StableDiffusionImg2ImgPipeline
-from diffusers.utils import load_image
-import torch
-
-url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
-
-init_image = load_image(url)
-init_image = init_image.resize((512, 512))
-
-path = "stable-diffusion-v1-5/stable-diffusion-v1-5"
-
-run_compile = True # Set True / False
-
-pipe = StableDiffusionImg2ImgPipeline.from_pretrained(path, torch_dtype=torch.float16, use_safetensors=True)
-pipe = pipe.to("cuda")
-pipe.unet.to(memory_format=torch.channels_last)
-
-if run_compile:
- print("Run torch compile")
- pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
-
-prompt = "ghibli style, a fantasy landscape with castles"
-
-for _ in range(3):
- image = pipe(prompt=prompt, image=init_image).images[0]
-```
-
-### Stable Diffusion inpainting
-
-```python
-from diffusers import StableDiffusionInpaintPipeline
-from diffusers.utils import load_image
-import torch
-
-img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
-mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
-
-init_image = load_image(img_url).resize((512, 512))
-mask_image = load_image(mask_url).resize((512, 512))
-
-path = "runwayml/stable-diffusion-inpainting"
-
-run_compile = True # Set True / False
-
-pipe = StableDiffusionInpaintPipeline.from_pretrained(path, torch_dtype=torch.float16, use_safetensors=True)
-pipe = pipe.to("cuda")
-pipe.unet.to(memory_format=torch.channels_last)
-
-if run_compile:
- print("Run torch compile")
- pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
-
-prompt = "ghibli style, a fantasy landscape with castles"
-
-for _ in range(3):
- image = pipe(prompt=prompt, image=init_image, mask_image=mask_image).images[0]
-```
-
-### ControlNet
-
-```python
-from diffusers import StableDiffusionControlNetPipeline, ControlNetModel
-from diffusers.utils import load_image
-import torch
-
-url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
-
-init_image = load_image(url)
-init_image = init_image.resize((512, 512))
-
-path = "stable-diffusion-v1-5/stable-diffusion-v1-5"
-
-run_compile = True # Set True / False
-controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16, use_safetensors=True)
-pipe = StableDiffusionControlNetPipeline.from_pretrained(
- path, controlnet=controlnet, torch_dtype=torch.float16, use_safetensors=True
-)
-
-pipe = pipe.to("cuda")
-pipe.unet.to(memory_format=torch.channels_last)
-pipe.controlnet.to(memory_format=torch.channels_last)
-
-if run_compile:
- print("Run torch compile")
- pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
- pipe.controlnet = torch.compile(pipe.controlnet, mode="reduce-overhead", fullgraph=True)
-
-prompt = "ghibli style, a fantasy landscape with castles"
-
-for _ in range(3):
- image = pipe(prompt=prompt, image=init_image).images[0]
-```
-
-### DeepFloyd IF text-to-image + upscaling
-
-```python
-from diffusers import DiffusionPipeline
-import torch
-
-run_compile = True # Set True / False
-
-pipe_1 = DiffusionPipeline.from_pretrained("DeepFloyd/IF-I-M-v1.0", variant="fp16", text_encoder=None, torch_dtype=torch.float16, use_safetensors=True)
-pipe_1.to("cuda")
-pipe_2 = DiffusionPipeline.from_pretrained("DeepFloyd/IF-II-M-v1.0", variant="fp16", text_encoder=None, torch_dtype=torch.float16, use_safetensors=True)
-pipe_2.to("cuda")
-pipe_3 = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-x4-upscaler", torch_dtype=torch.float16, use_safetensors=True)
-pipe_3.to("cuda")
-
-
-pipe_1.unet.to(memory_format=torch.channels_last)
-pipe_2.unet.to(memory_format=torch.channels_last)
-pipe_3.unet.to(memory_format=torch.channels_last)
-
-if run_compile:
- pipe_1.unet = torch.compile(pipe_1.unet, mode="reduce-overhead", fullgraph=True)
- pipe_2.unet = torch.compile(pipe_2.unet, mode="reduce-overhead", fullgraph=True)
- pipe_3.unet = torch.compile(pipe_3.unet, mode="reduce-overhead", fullgraph=True)
-
-prompt = "the blue hulk"
-
-prompt_embeds = torch.randn((1, 2, 4096), dtype=torch.float16)
-neg_prompt_embeds = torch.randn((1, 2, 4096), dtype=torch.float16)
-
-for _ in range(3):
- image_1 = pipe_1(prompt_embeds=prompt_embeds, negative_prompt_embeds=neg_prompt_embeds, output_type="pt").images
- image_2 = pipe_2(image=image_1, prompt_embeds=prompt_embeds, negative_prompt_embeds=neg_prompt_embeds, output_type="pt").images
- image_3 = pipe_3(prompt=prompt, image=image_1, noise_level=100).images
-```
-
-
-The graph below highlights the relative speed-ups for the [`StableDiffusionPipeline`] across five GPU families with PyTorch 2.0 and `torch.compile` enabled. The benchmarks for the following graphs are measured in *number of iterations/second*.
-
-
-
-To give you an even better idea of how this speed-up holds for the other pipelines, consider the following
-graph for an A100 with PyTorch 2.0 and `torch.compile`:
-
-
-
-In the following tables, we report our findings in terms of the *number of iterations/second*.
-
-### A100 (batch size: 1)
-
-| **Pipeline** | **torch 2.0 -
no compile** | **torch nightly -
no compile** | **torch 2.0 -
compile** | **torch nightly -
compile** |
-|:---:|:---:|:---:|:---:|:---:|
-| SD - txt2img | 21.66 | 23.13 | 44.03 | 49.74 |
-| SD - img2img | 21.81 | 22.40 | 43.92 | 46.32 |
-| SD - inpaint | 22.24 | 23.23 | 43.76 | 49.25 |
-| SD - controlnet | 15.02 | 15.82 | 32.13 | 36.08 |
-| IF | 20.21 /
13.84 /
24.00 | 20.12 /
13.70 /
24.03 | ❌ | 97.34 /
27.23 /
111.66 |
-| SDXL - txt2img | 8.64 | 9.9 | - | - |
-
-### A100 (batch size: 4)
-
-| **Pipeline** | **torch 2.0 -
no compile** | **torch nightly -
no compile** | **torch 2.0 -
compile** | **torch nightly -
compile** |
-|:---:|:---:|:---:|:---:|:---:|
-| SD - txt2img | 11.6 | 13.12 | 14.62 | 17.27 |
-| SD - img2img | 11.47 | 13.06 | 14.66 | 17.25 |
-| SD - inpaint | 11.67 | 13.31 | 14.88 | 17.48 |
-| SD - controlnet | 8.28 | 9.38 | 10.51 | 12.41 |
-| IF | 25.02 | 18.04 | ❌ | 48.47 |
-| SDXL - txt2img | 2.44 | 2.74 | - | - |
-
-### A100 (batch size: 16)
-
-| **Pipeline** | **torch 2.0 -
no compile** | **torch nightly -
no compile** | **torch 2.0 -
compile** | **torch nightly -
compile** |
-|:---:|:---:|:---:|:---:|:---:|
-| SD - txt2img | 3.04 | 3.6 | 3.83 | 4.68 |
-| SD - img2img | 2.98 | 3.58 | 3.83 | 4.67 |
-| SD - inpaint | 3.04 | 3.66 | 3.9 | 4.76 |
-| SD - controlnet | 2.15 | 2.58 | 2.74 | 3.35 |
-| IF | 8.78 | 9.82 | ❌ | 16.77 |
-| SDXL - txt2img | 0.64 | 0.72 | - | - |
-
-### V100 (batch size: 1)
-
-| **Pipeline** | **torch 2.0 -
no compile** | **torch nightly -
no compile** | **torch 2.0 -
compile** | **torch nightly -
compile** |
-|:---:|:---:|:---:|:---:|:---:|
-| SD - txt2img | 18.99 | 19.14 | 20.95 | 22.17 |
-| SD - img2img | 18.56 | 19.18 | 20.95 | 22.11 |
-| SD - inpaint | 19.14 | 19.06 | 21.08 | 22.20 |
-| SD - controlnet | 13.48 | 13.93 | 15.18 | 15.88 |
-| IF | 20.01 /
9.08 /
23.34 | 19.79 /
8.98 /
24.10 | ❌ | 55.75 /
11.57 /
57.67 |
-
-### V100 (batch size: 4)
-
-| **Pipeline** | **torch 2.0 -
no compile** | **torch nightly -
no compile** | **torch 2.0 -
compile** | **torch nightly -
compile** |
-|:---:|:---:|:---:|:---:|:---:|
-| SD - txt2img | 5.96 | 5.89 | 6.83 | 6.86 |
-| SD - img2img | 5.90 | 5.91 | 6.81 | 6.82 |
-| SD - inpaint | 5.99 | 6.03 | 6.93 | 6.95 |
-| SD - controlnet | 4.26 | 4.29 | 4.92 | 4.93 |
-| IF | 15.41 | 14.76 | ❌ | 22.95 |
-
-### V100 (batch size: 16)
-
-| **Pipeline** | **torch 2.0 -
no compile** | **torch nightly -
no compile** | **torch 2.0 -
compile** | **torch nightly -
compile** |
-|:---:|:---:|:---:|:---:|:---:|
-| SD - txt2img | 1.66 | 1.66 | 1.92 | 1.90 |
-| SD - img2img | 1.65 | 1.65 | 1.91 | 1.89 |
-| SD - inpaint | 1.69 | 1.69 | 1.95 | 1.93 |
-| SD - controlnet | 1.19 | 1.19 | OOM after warmup | 1.36 |
-| IF | 5.43 | 5.29 | ❌ | 7.06 |
-
-### T4 (batch size: 1)
-
-| **Pipeline** | **torch 2.0 -
no compile** | **torch nightly -
no compile** | **torch 2.0 -
compile** | **torch nightly -
compile** |
-|:---:|:---:|:---:|:---:|:---:|
-| SD - txt2img | 6.9 | 6.95 | 7.3 | 7.56 |
-| SD - img2img | 6.84 | 6.99 | 7.04 | 7.55 |
-| SD - inpaint | 6.91 | 6.7 | 7.01 | 7.37 |
-| SD - controlnet | 4.89 | 4.86 | 5.35 | 5.48 |
-| IF | 17.42 /
2.47 /
18.52 | 16.96 /
2.45 /
18.69 | ❌ | 24.63 /
2.47 /
23.39 |
-| SDXL - txt2img | 1.15 | 1.16 | - | - |
-
-### T4 (batch size: 4)
-
-| **Pipeline** | **torch 2.0 -
no compile** | **torch nightly -
no compile** | **torch 2.0 -
compile** | **torch nightly -
compile** |
-|:---:|:---:|:---:|:---:|:---:|
-| SD - txt2img | 1.79 | 1.79 | 2.03 | 1.99 |
-| SD - img2img | 1.77 | 1.77 | 2.05 | 2.04 |
-| SD - inpaint | 1.81 | 1.82 | 2.09 | 2.09 |
-| SD - controlnet | 1.34 | 1.27 | 1.47 | 1.46 |
-| IF | 5.79 | 5.61 | ❌ | 7.39 |
-| SDXL - txt2img | 0.288 | 0.289 | - | - |
-
-### T4 (batch size: 16)
-
-| **Pipeline** | **torch 2.0 -
no compile** | **torch nightly -
no compile** | **torch 2.0 -
compile** | **torch nightly -
compile** |
-|:---:|:---:|:---:|:---:|:---:|
-| SD - txt2img | 2.34s | 2.30s | OOM after 2nd iteration | 1.99s |
-| SD - img2img | 2.35s | 2.31s | OOM after warmup | 2.00s |
-| SD - inpaint | 2.30s | 2.26s | OOM after 2nd iteration | 1.95s |
-| SD - controlnet | OOM after 2nd iteration | OOM after 2nd iteration | OOM after warmup | OOM after warmup |
-| IF * | 1.44 | 1.44 | ❌ | 1.94 |
-| SDXL - txt2img | OOM | OOM | - | - |
-
-### RTX 3090 (batch size: 1)
-
-| **Pipeline** | **torch 2.0 -
no compile** | **torch nightly -
no compile** | **torch 2.0 -
compile** | **torch nightly -
compile** |
-|:---:|:---:|:---:|:---:|:---:|
-| SD - txt2img | 22.56 | 22.84 | 23.84 | 25.69 |
-| SD - img2img | 22.25 | 22.61 | 24.1 | 25.83 |
-| SD - inpaint | 22.22 | 22.54 | 24.26 | 26.02 |
-| SD - controlnet | 16.03 | 16.33 | 17.38 | 18.56 |
-| IF | 27.08 /
9.07 /
31.23 | 26.75 /
8.92 /
31.47 | ❌ | 68.08 /
11.16 /
65.29 |
-
-### RTX 3090 (batch size: 4)
-
-| **Pipeline** | **torch 2.0 -
no compile** | **torch nightly -
no compile** | **torch 2.0 -
compile** | **torch nightly -
compile** |
-|:---:|:---:|:---:|:---:|:---:|
-| SD - txt2img | 6.46 | 6.35 | 7.29 | 7.3 |
-| SD - img2img | 6.33 | 6.27 | 7.31 | 7.26 |
-| SD - inpaint | 6.47 | 6.4 | 7.44 | 7.39 |
-| SD - controlnet | 4.59 | 4.54 | 5.27 | 5.26 |
-| IF | 16.81 | 16.62 | ❌ | 21.57 |
-
-### RTX 3090 (batch size: 16)
-
-| **Pipeline** | **torch 2.0 -
no compile** | **torch nightly -
no compile** | **torch 2.0 -
compile** | **torch nightly -
compile** |
-|:---:|:---:|:---:|:---:|:---:|
-| SD - txt2img | 1.7 | 1.69 | 1.93 | 1.91 |
-| SD - img2img | 1.68 | 1.67 | 1.93 | 1.9 |
-| SD - inpaint | 1.72 | 1.71 | 1.97 | 1.94 |
-| SD - controlnet | 1.23 | 1.22 | 1.4 | 1.38 |
-| IF | 5.01 | 5.00 | ❌ | 6.33 |
-
-### RTX 4090 (batch size: 1)
-
-| **Pipeline** | **torch 2.0 -
no compile** | **torch nightly -
no compile** | **torch 2.0 -
compile** | **torch nightly -
compile** |
-|:---:|:---:|:---:|:---:|:---:|
-| SD - txt2img | 40.5 | 41.89 | 44.65 | 49.81 |
-| SD - img2img | 40.39 | 41.95 | 44.46 | 49.8 |
-| SD - inpaint | 40.51 | 41.88 | 44.58 | 49.72 |
-| SD - controlnet | 29.27 | 30.29 | 32.26 | 36.03 |
-| IF | 69.71 /
18.78 /
85.49 | 69.13 /
18.80 /
85.56 | ❌ | 124.60 /
26.37 /
138.79 |
-| SDXL - txt2img | 6.8 | 8.18 | - | - |
-
-### RTX 4090 (batch size: 4)
-
-| **Pipeline** | **torch 2.0 -
no compile** | **torch nightly -
no compile** | **torch 2.0 -
compile** | **torch nightly -
compile** |
-|:---:|:---:|:---:|:---:|:---:|
-| SD - txt2img | 12.62 | 12.84 | 15.32 | 15.59 |
-| SD - img2img | 12.61 | 12,.79 | 15.35 | 15.66 |
-| SD - inpaint | 12.65 | 12.81 | 15.3 | 15.58 |
-| SD - controlnet | 9.1 | 9.25 | 11.03 | 11.22 |
-| IF | 31.88 | 31.14 | ❌ | 43.92 |
-| SDXL - txt2img | 2.19 | 2.35 | - | - |
-
-### RTX 4090 (batch size: 16)
-
-| **Pipeline** | **torch 2.0 -
no compile** | **torch nightly -
no compile** | **torch 2.0 -
compile** | **torch nightly -
compile** |
-|:---:|:---:|:---:|:---:|:---:|
-| SD - txt2img | 3.17 | 3.2 | 3.84 | 3.85 |
-| SD - img2img | 3.16 | 3.2 | 3.84 | 3.85 |
-| SD - inpaint | 3.17 | 3.2 | 3.85 | 3.85 |
-| SD - controlnet | 2.23 | 2.3 | 2.7 | 2.75 |
-| IF | 9.26 | 9.2 | ❌ | 13.31 |
-| SDXL - txt2img | 0.52 | 0.53 | - | - |
-
-## Notes
-
-* Follow this [PR](https://github.com/huggingface/diffusers/pull/3313) for more details on the environment used for conducting the benchmarks.
-* For the DeepFloyd IF pipeline where batch sizes > 1, we only used a batch size of > 1 in the first IF pipeline for text-to-image generation and NOT for upscaling. That means the two upscaling pipelines received a batch size of 1.
-
-*Thanks to [Horace He](https://github.com/Chillee) from the PyTorch team for their support in improving our support of `torch.compile()` in Diffusers.*
diff --git a/docs/source/en/optimization/xdit.md b/docs/source/en/optimization/xdit.md
index 33ff8dc255..ecf4563568 100644
--- a/docs/source/en/optimization/xdit.md
+++ b/docs/source/en/optimization/xdit.md
@@ -2,7 +2,7 @@
[xDiT](https://github.com/xdit-project/xDiT) is an inference engine designed for the large scale parallel deployment of Diffusion Transformers (DiTs). xDiT provides a suite of efficient parallel approaches for Diffusion Models, as well as GPU kernel accelerations.
-There are four parallel methods supported in xDiT, including [Unified Sequence Parallelism](https://arxiv.org/abs/2405.07719), [PipeFusion](https://arxiv.org/abs/2405.14430), CFG parallelism and data parallelism. The four parallel methods in xDiT can be configured in a hybrid manner, optimizing communication patterns to best suit the underlying network hardware.
+There are four parallel methods supported in xDiT, including [Unified Sequence Parallelism](https://huggingface.co/papers/2405.07719), [PipeFusion](https://huggingface.co/papers/2405.14430), CFG parallelism and data parallelism. The four parallel methods in xDiT can be configured in a hybrid manner, optimizing communication patterns to best suit the underlying network hardware.
Optimization orthogonal to parallelization focuses on accelerating single GPU performance. In addition to utilizing well-known Attention optimization libraries, we leverage compilation acceleration technologies such as torch.compile and onediff.
@@ -116,6 +116,6 @@ More detailed performance metric can be found on our [github page](https://githu
[xDiT-project](https://github.com/xdit-project/xDiT)
-[USP: A Unified Sequence Parallelism Approach for Long Context Generative AI](https://arxiv.org/abs/2405.07719)
+[USP: A Unified Sequence Parallelism Approach for Long Context Generative AI](https://huggingface.co/papers/2405.07719)
-[PipeFusion: Displaced Patch Pipeline Parallelism for Inference of Diffusion Transformer Models](https://arxiv.org/abs/2405.14430)
\ No newline at end of file
+[PipeFusion: Displaced Patch Pipeline Parallelism for Inference of Diffusion Transformer Models](https://huggingface.co/papers/2405.14430)
\ No newline at end of file
diff --git a/docs/source/en/quantization/overview.md b/docs/source/en/quantization/overview.md
index 93323f86c7..cc5a7e2891 100644
--- a/docs/source/en/quantization/overview.md
+++ b/docs/source/en/quantization/overview.md
@@ -13,29 +13,120 @@ specific language governing permissions and limitations under the License.
# Quantization
-Quantization techniques focus on representing data with less information while also trying to not lose too much accuracy. This often means converting a data type to represent the same information with fewer bits. For example, if your model weights are stored as 32-bit floating points and they're quantized to 16-bit floating points, this halves the model size which makes it easier to store and reduces memory-usage. Lower precision can also speedup inference because it takes less time to perform calculations with fewer bits.
+Quantization focuses on representing data with fewer bits while also trying to preserve the precision of the original data. This often means converting a data type to represent the same information with fewer bits. For example, if your model weights are stored as 32-bit floating points and they're quantized to 16-bit floating points, this halves the model size which makes it easier to store and reduces memory usage. Lower precision can also speedup inference because it takes less time to perform calculations with fewer bits.
-
+Diffusers supports multiple quantization backends to make large diffusion models like [Flux](../api/pipelines/flux) more accessible. This guide shows how to use the [`~quantizers.PipelineQuantizationConfig`] class to quantize a pipeline during its initialization from a pretrained or non-quantized checkpoint.
-Interested in adding a new quantization method to Diffusers? Refer to the [Contribute new quantization method guide](https://huggingface.co/docs/transformers/main/en/quantization/contribute) to learn more about adding a new quantization method.
+## Pipeline-level quantization
-
+There are two ways you can use [`~quantizers.PipelineQuantizationConfig`] depending on the level of control you want over the quantization specifications of each model in the pipeline.
-
+- for more basic and simple use cases, you only need to define the `quant_backend`, `quant_kwargs`, and `components_to_quantize`
+- for more granular quantization control, provide a `quant_mapping` that provides the quantization specifications for the individual model components
-If you are new to the quantization field, we recommend you to check out these beginner-friendly courses about quantization in collaboration with DeepLearning.AI:
+### Simple quantization
-* [Quantization Fundamentals with Hugging Face](https://www.deeplearning.ai/short-courses/quantization-fundamentals-with-hugging-face/)
-* [Quantization in Depth](https://www.deeplearning.ai/short-courses/quantization-in-depth/)
+Initialize [`~quantizers.PipelineQuantizationConfig`] with the following parameters.
-
+- `quant_backend` specifies which quantization backend to use. Currently supported backends include: `bitsandbytes_4bit`, `bitsandbytes_8bit`, `gguf`, `quanto`, and `torchao`.
+- `quant_kwargs` contains the specific quantization arguments to use.
+- `components_to_quantize` specifies which components of the pipeline to quantize. Typically, you should quantize the most compute intensive components like the transformer. The text encoder is another component to consider quantizing if a pipeline has more than one such as [`FluxPipeline`]. The example below quantizes the T5 text encoder in [`FluxPipeline`] while keeping the CLIP model intact.
-## When to use what?
+```py
+import torch
+from diffusers import DiffusionPipeline
+from diffusers.quantizers import PipelineQuantizationConfig
-Diffusers currently supports the following quantization methods.
-- [BitsandBytes](./bitsandbytes)
-- [TorchAO](./torchao)
-- [GGUF](./gguf)
-- [Quanto](./quanto.md)
+pipeline_quant_config = PipelineQuantizationConfig(
+ quant_backend="bitsandbytes_4bit",
+ quant_kwargs={"load_in_4bit": True, "bnb_4bit_quant_type": "nf4", "bnb_4bit_compute_dtype": torch.bfloat16},
+ components_to_quantize=["transformer", "text_encoder_2"],
+)
+```
-[This resource](https://huggingface.co/docs/transformers/main/en/quantization/overview#when-to-use-what) provides a good overview of the pros and cons of different quantization techniques.
+Pass the `pipeline_quant_config` to [`~DiffusionPipeline.from_pretrained`] to quantize the pipeline.
+
+```py
+pipe = DiffusionPipeline.from_pretrained(
+ "black-forest-labs/FLUX.1-dev",
+ quantization_config=pipeline_quant_config,
+ torch_dtype=torch.bfloat16,
+).to("cuda")
+
+image = pipe("photo of a cute dog").images[0]
+```
+
+### quant_mapping
+
+The `quant_mapping` argument provides more flexible options for how to quantize each individual component in a pipeline, like combining different quantization backends.
+
+Initialize [`~quantizers.PipelineQuantizationConfig`] and pass a `quant_mapping` to it. The `quant_mapping` allows you to specify the quantization options for each component in the pipeline such as the transformer and text encoder.
+
+The example below uses two quantization backends, [`~quantizers.QuantoConfig`] and [`transformers.BitsAndBytesConfig`], for the transformer and text encoder.
+
+```py
+import torch
+from diffusers import DiffusionPipeline
+from diffusers import BitsAndBytesConfig as DiffusersBitsAndBytesConfig
+from diffusers.quantizers.quantization_config import QuantoConfig
+from diffusers.quantizers import PipelineQuantizationConfig
+from transformers import BitsAndBytesConfig as TransformersBitsAndBytesConfig
+
+pipeline_quant_config = PipelineQuantizationConfig(
+ quant_mapping={
+ "transformer": QuantoConfig(weights_dtype="int8"),
+ "text_encoder_2": TransformersBitsAndBytesConfig(
+ load_in_4bit=True, compute_dtype=torch.bfloat16
+ ),
+ }
+)
+```
+
+There is a separate bitsandbytes backend in [Transformers](https://huggingface.co/docs/transformers/main_classes/quantization#transformers.BitsAndBytesConfig). You need to import and use [`transformers.BitsAndBytesConfig`] for components that come from Transformers. For example, `text_encoder_2` in [`FluxPipeline`] is a [`~transformers.T5EncoderModel`] from Transformers so you need to use [`transformers.BitsAndBytesConfig`] instead of [`diffusers.BitsAndBytesConfig`].
+
+> [!TIP]
+> Use the [simple quantization](#simple-quantization) method above if you don't want to manage these distinct imports or aren't sure where each pipeline component comes from.
+
+```py
+import torch
+from diffusers import DiffusionPipeline
+from diffusers import BitsAndBytesConfig as DiffusersBitsAndBytesConfig
+from diffusers.quantizers import PipelineQuantizationConfig
+from transformers import BitsAndBytesConfig as TransformersBitsAndBytesConfig
+
+pipeline_quant_config = PipelineQuantizationConfig(
+ quant_mapping={
+ "transformer": DiffusersBitsAndBytesConfig(load_in_4bit=True, bnb_4bit_compute_dtype=torch.bfloat16),
+ "text_encoder_2": TransformersBitsAndBytesConfig(
+ load_in_4bit=True, compute_dtype=torch.bfloat16
+ ),
+ }
+)
+```
+
+Pass the `pipeline_quant_config` to [`~DiffusionPipeline.from_pretrained`] to quantize the pipeline.
+
+```py
+pipe = DiffusionPipeline.from_pretrained(
+ "black-forest-labs/FLUX.1-dev",
+ quantization_config=pipeline_quant_config,
+ torch_dtype=torch.bfloat16,
+).to("cuda")
+
+image = pipe("photo of a cute dog").images[0]
+```
+
+## Resources
+
+Check out the resources below to learn more about quantization.
+
+- If you are new to quantization, we recommend checking out the following beginner-friendly courses in collaboration with DeepLearning.AI.
+
+ - [Quantization Fundamentals with Hugging Face](https://www.deeplearning.ai/short-courses/quantization-fundamentals-with-hugging-face/)
+ - [Quantization in Depth](https://www.deeplearning.ai/short-courses/quantization-in-depth/)
+
+- Refer to the [Contribute new quantization method guide](https://huggingface.co/docs/transformers/main/en/quantization/contribute) if you're interested in adding a new quantization method.
+
+- The Transformers quantization [Overview](https://huggingface.co/docs/transformers/quantization/overview#when-to-use-what) provides an overview of the pros and cons of different quantization backends.
+
+- Read the [Exploring Quantization Backends in Diffusers](https://huggingface.co/blog/diffusers-quantization) blog post for a brief introduction to each quantization backend, how to choose a backend, and combining quantization with other memory optimizations.
\ No newline at end of file
diff --git a/docs/source/en/quantization/torchao.md b/docs/source/en/quantization/torchao.md
index 3ccca02825..95b30a6e01 100644
--- a/docs/source/en/quantization/torchao.md
+++ b/docs/source/en/quantization/torchao.md
@@ -56,7 +56,7 @@ image = pipe(
image.save("output.png")
```
-TorchAO is fully compatible with [torch.compile](./optimization/torch2.0#torchcompile), setting it apart from other quantization methods. This makes it easy to speed up inference with just one line of code.
+TorchAO is fully compatible with [torch.compile](../optimization/fp16#torchcompile), setting it apart from other quantization methods. This makes it easy to speed up inference with just one line of code.
```python
# In the above code, add the following after initializing the transformer
@@ -91,7 +91,7 @@ The quantization methods supported are as follows:
Some quantization methods are aliases (for example, `int8wo` is the commonly used shorthand for `int8_weight_only`). This allows using the quantization methods described in the torchao docs as-is, while also making it convenient to remember their shorthand notations.
-Refer to the official torchao documentation for a better understanding of the available quantization methods and the exhaustive list of configuration options available.
+Refer to the [official torchao documentation](https://docs.pytorch.org/ao/stable/index.html) for a better understanding of the available quantization methods and the exhaustive list of configuration options available.
## Serializing and Deserializing quantized models
@@ -155,5 +155,5 @@ transformer.load_state_dict(state_dict, strict=True, assign=True)
## Resources
-- [TorchAO Quantization API](https://github.com/pytorch/ao/blob/main/torchao/quantization/README.md)
+- [TorchAO Quantization API](https://docs.pytorch.org/ao/stable/index.html)
- [Diffusers-TorchAO examples](https://github.com/sayakpaul/diffusers-torchao)
diff --git a/docs/source/en/stable_diffusion.md b/docs/source/en/stable_diffusion.md
index fc20d259f5..77610114ec 100644
--- a/docs/source/en/stable_diffusion.md
+++ b/docs/source/en/stable_diffusion.md
@@ -256,6 +256,6 @@ make_image_grid(images, 2, 2)
In this tutorial, you learned how to optimize a [`DiffusionPipeline`] for computational and memory efficiency as well as improving the quality of generated outputs. If you're interested in making your pipeline even faster, take a look at the following resources:
-- Learn how [PyTorch 2.0](./optimization/torch2.0) and [`torch.compile`](https://pytorch.org/docs/stable/generated/torch.compile.html) can yield 5 - 300% faster inference speed. On an A100 GPU, inference can be up to 50% faster!
+- Learn how [PyTorch 2.0](./optimization/fp16) and [`torch.compile`](https://pytorch.org/docs/stable/generated/torch.compile.html) can yield 5 - 300% faster inference speed. On an A100 GPU, inference can be up to 50% faster!
- If you can't use PyTorch 2, we recommend you install [xFormers](./optimization/xformers). Its memory-efficient attention mechanism works great with PyTorch 1.13.1 for faster speed and reduced memory consumption.
- Other optimization techniques, such as model offloading, are covered in [this guide](./optimization/fp16).
diff --git a/docs/source/en/training/ddpo.md b/docs/source/en/training/ddpo.md
index a4538fe070..8ea797f804 100644
--- a/docs/source/en/training/ddpo.md
+++ b/docs/source/en/training/ddpo.md
@@ -12,6 +12,6 @@ specific language governing permissions and limitations under the License.
# Reinforcement learning training with DDPO
-You can fine-tune Stable Diffusion on a reward function via reinforcement learning with the 🤗 TRL library and 🤗 Diffusers. This is done with the Denoising Diffusion Policy Optimization (DDPO) algorithm introduced by Black et al. in [Training Diffusion Models with Reinforcement Learning](https://arxiv.org/abs/2305.13301), which is implemented in 🤗 TRL with the [`~trl.DDPOTrainer`].
+You can fine-tune Stable Diffusion on a reward function via reinforcement learning with the 🤗 TRL library and 🤗 Diffusers. This is done with the Denoising Diffusion Policy Optimization (DDPO) algorithm introduced by Black et al. in [Training Diffusion Models with Reinforcement Learning](https://huggingface.co/papers/2305.13301), which is implemented in 🤗 TRL with the [`~trl.DDPOTrainer`].
For more information, check out the [`~trl.DDPOTrainer`] API reference and the [Finetune Stable Diffusion Models with DDPO via TRL](https://huggingface.co/blog/trl-ddpo) blog post.
\ No newline at end of file
diff --git a/docs/source/en/training/lora.md b/docs/source/en/training/lora.md
index c1f81c48b8..7237879436 100644
--- a/docs/source/en/training/lora.md
+++ b/docs/source/en/training/lora.md
@@ -87,7 +87,7 @@ Lastly, if you want to train a model on your own dataset, take a look at the [Cr
-The following sections highlight parts of the training script that are important for understanding how to modify it, but it doesn't cover every aspect of the script in detail. If you're interested in learning more, feel free to read through the [script](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/text_to_image_lora.py) and let us know if you have any questions or concerns.
+The following sections highlight parts of the training script that are important for understanding how to modify it, but it doesn't cover every aspect of the script in detail. If you're interested in learning more, feel free to read through the [script](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image_lora.py) and let us know if you have any questions or concerns.
diff --git a/docs/source/en/training/overview.md b/docs/source/en/training/overview.md
index 5396afc0b8..bcd855ccb5 100644
--- a/docs/source/en/training/overview.md
+++ b/docs/source/en/training/overview.md
@@ -59,5 +59,5 @@ pip install -r requirements_sdxl.txt
To speedup training and reduce memory-usage, we recommend:
-- using PyTorch 2.0 or higher to automatically use [scaled dot product attention](../optimization/torch2.0#scaled-dot-product-attention) during training (you don't need to make any changes to the training code)
+- using PyTorch 2.0 or higher to automatically use [scaled dot product attention](../optimization/fp16#scaled-dot-product-attention) during training (you don't need to make any changes to the training code)
- installing [xFormers](../optimization/xformers) to enable memory-efficient attention
\ No newline at end of file
diff --git a/docs/source/en/tutorials/fast_diffusion.md b/docs/source/en/tutorials/fast_diffusion.md
deleted file mode 100644
index 0f1133dc2d..0000000000
--- a/docs/source/en/tutorials/fast_diffusion.md
+++ /dev/null
@@ -1,322 +0,0 @@
-
-
-# Accelerate inference of text-to-image diffusion models
-
-Diffusion models are slower than their GAN counterparts because of the iterative and sequential reverse diffusion process. There are several techniques that can address this limitation such as progressive timestep distillation ([LCM LoRA](../using-diffusers/inference_with_lcm_lora)), model compression ([SSD-1B](https://huggingface.co/segmind/SSD-1B)), and reusing adjacent features of the denoiser ([DeepCache](../optimization/deepcache)).
-
-However, you don't necessarily need to use these techniques to speed up inference. With PyTorch 2 alone, you can accelerate the inference latency of text-to-image diffusion pipelines by up to 3x. This tutorial will show you how to progressively apply the optimizations found in PyTorch 2 to reduce inference latency. You'll use the [Stable Diffusion XL (SDXL)](../using-diffusers/sdxl) pipeline in this tutorial, but these techniques are applicable to other text-to-image diffusion pipelines too.
-
-Make sure you're using the latest version of Diffusers:
-
-```bash
-pip install -U diffusers
-```
-
-Then upgrade the other required libraries too:
-
-```bash
-pip install -U transformers accelerate peft
-```
-
-Install [PyTorch nightly](https://pytorch.org/) to benefit from the latest and fastest kernels:
-
-```bash
-pip3 install --pre torch --index-url https://download.pytorch.org/whl/nightly/cu121
-```
-
-> [!TIP]
-> The results reported below are from a 80GB 400W A100 with its clock rate set to the maximum.
-> If you're interested in the full benchmarking code, take a look at [huggingface/diffusion-fast](https://github.com/huggingface/diffusion-fast).
-
-
-## Baseline
-
-Let's start with a baseline. Disable reduced precision and the [`scaled_dot_product_attention` (SDPA)](../optimization/torch2.0#scaled-dot-product-attention) function which is automatically used by Diffusers:
-
-```python
-from diffusers import StableDiffusionXLPipeline
-
-# Load the pipeline in full-precision and place its model components on CUDA.
-pipe = StableDiffusionXLPipeline.from_pretrained(
- "stabilityai/stable-diffusion-xl-base-1.0"
-).to("cuda")
-
-# Run the attention ops without SDPA.
-pipe.unet.set_default_attn_processor()
-pipe.vae.set_default_attn_processor()
-
-prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
-image = pipe(prompt, num_inference_steps=30).images[0]
-```
-
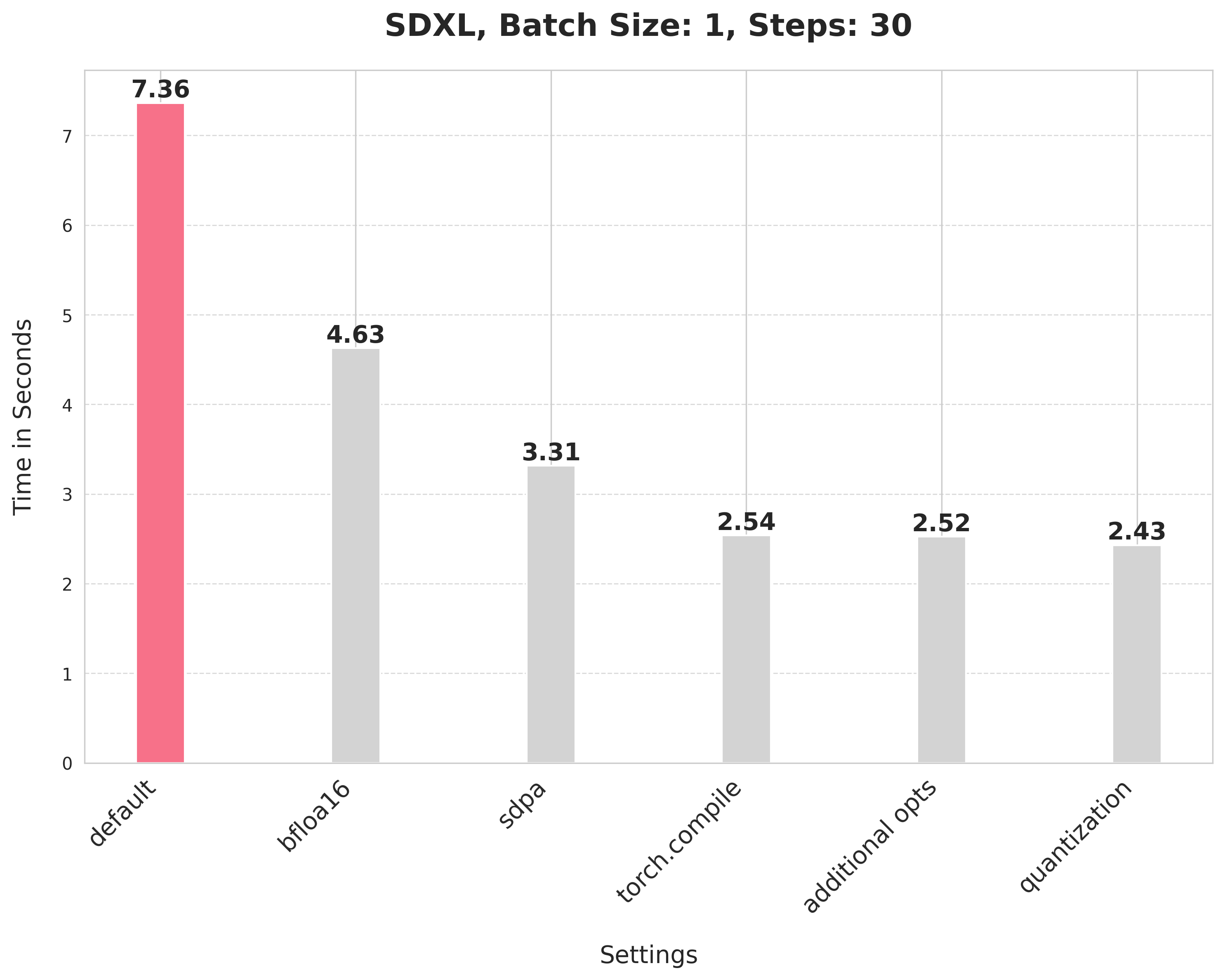
-This default setup takes 7.36 seconds.
-
-
-
-
-
-## bfloat16
-
-Enable the first optimization, reduced precision or more specifically bfloat16. There are several benefits of using reduced precision:
-
-* Using a reduced numerical precision (such as float16 or bfloat16) for inference doesn’t affect the generation quality but significantly improves latency.
-* The benefits of using bfloat16 compared to float16 are hardware dependent, but modern GPUs tend to favor bfloat16.
-* bfloat16 is much more resilient when used with quantization compared to float16, but more recent versions of the quantization library ([torchao](https://github.com/pytorch-labs/ao)) we used don't have numerical issues with float16.
-
-```python
-from diffusers import StableDiffusionXLPipeline
-import torch
-
-pipe = StableDiffusionXLPipeline.from_pretrained(
- "stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.bfloat16
-).to("cuda")
-
-# Run the attention ops without SDPA.
-pipe.unet.set_default_attn_processor()
-pipe.vae.set_default_attn_processor()
-
-prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
-image = pipe(prompt, num_inference_steps=30).images[0]
-```
-
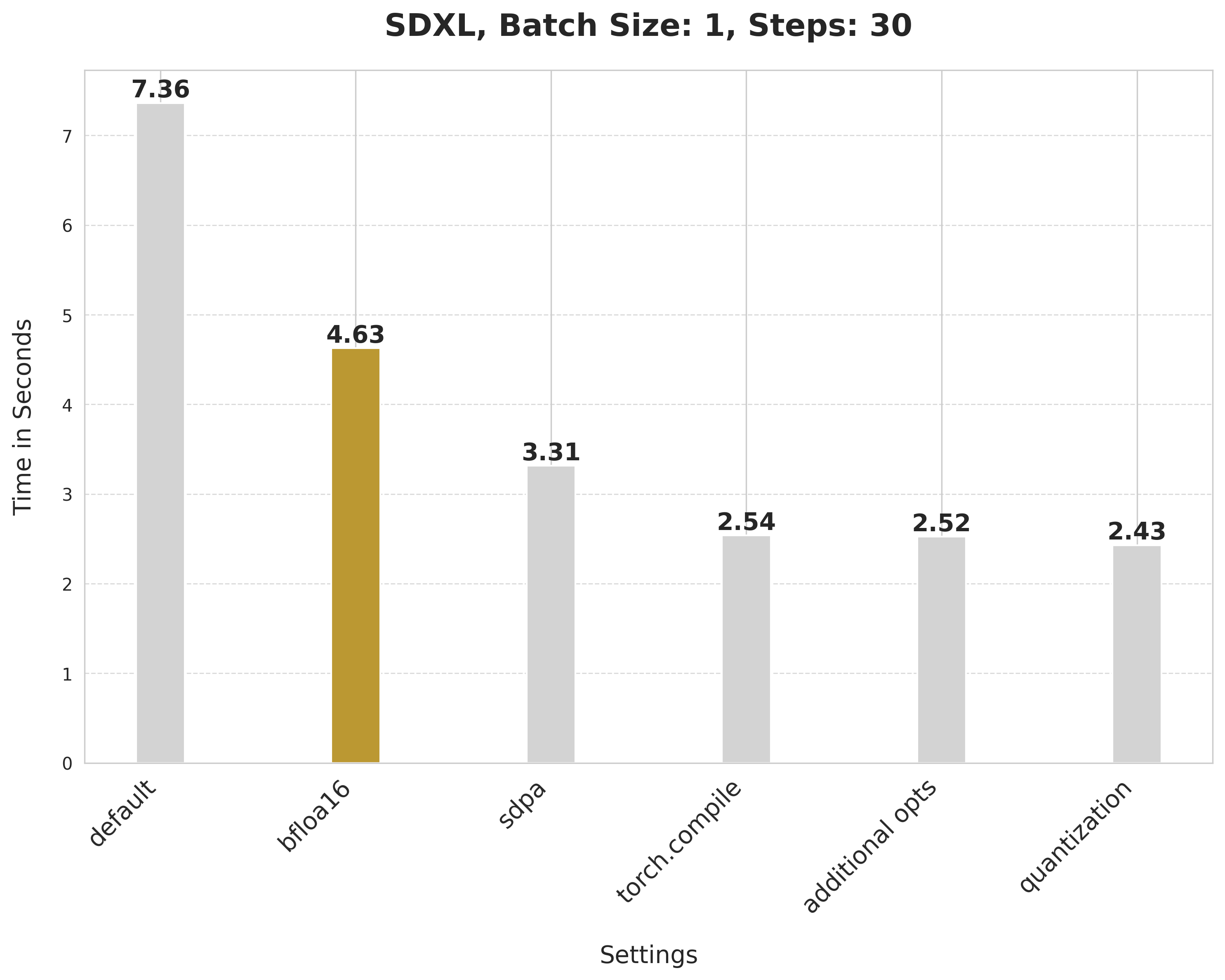
-bfloat16 reduces the latency from 7.36 seconds to 4.63 seconds.
-
-
-
-
-
-
-
-In our later experiments with float16, recent versions of torchao do not incur numerical problems from float16.
-
-
-
-Take a look at the [Speed up inference](../optimization/fp16) guide to learn more about running inference with reduced precision.
-
-## SDPA
-
-Attention blocks are intensive to run. But with PyTorch's [`scaled_dot_product_attention`](../optimization/torch2.0#scaled-dot-product-attention) function, it is a lot more efficient. This function is used by default in Diffusers so you don't need to make any changes to the code.
-
-```python
-from diffusers import StableDiffusionXLPipeline
-import torch
-
-pipe = StableDiffusionXLPipeline.from_pretrained(
- "stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.bfloat16
-).to("cuda")
-
-prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
-image = pipe(prompt, num_inference_steps=30).images[0]
-```
-
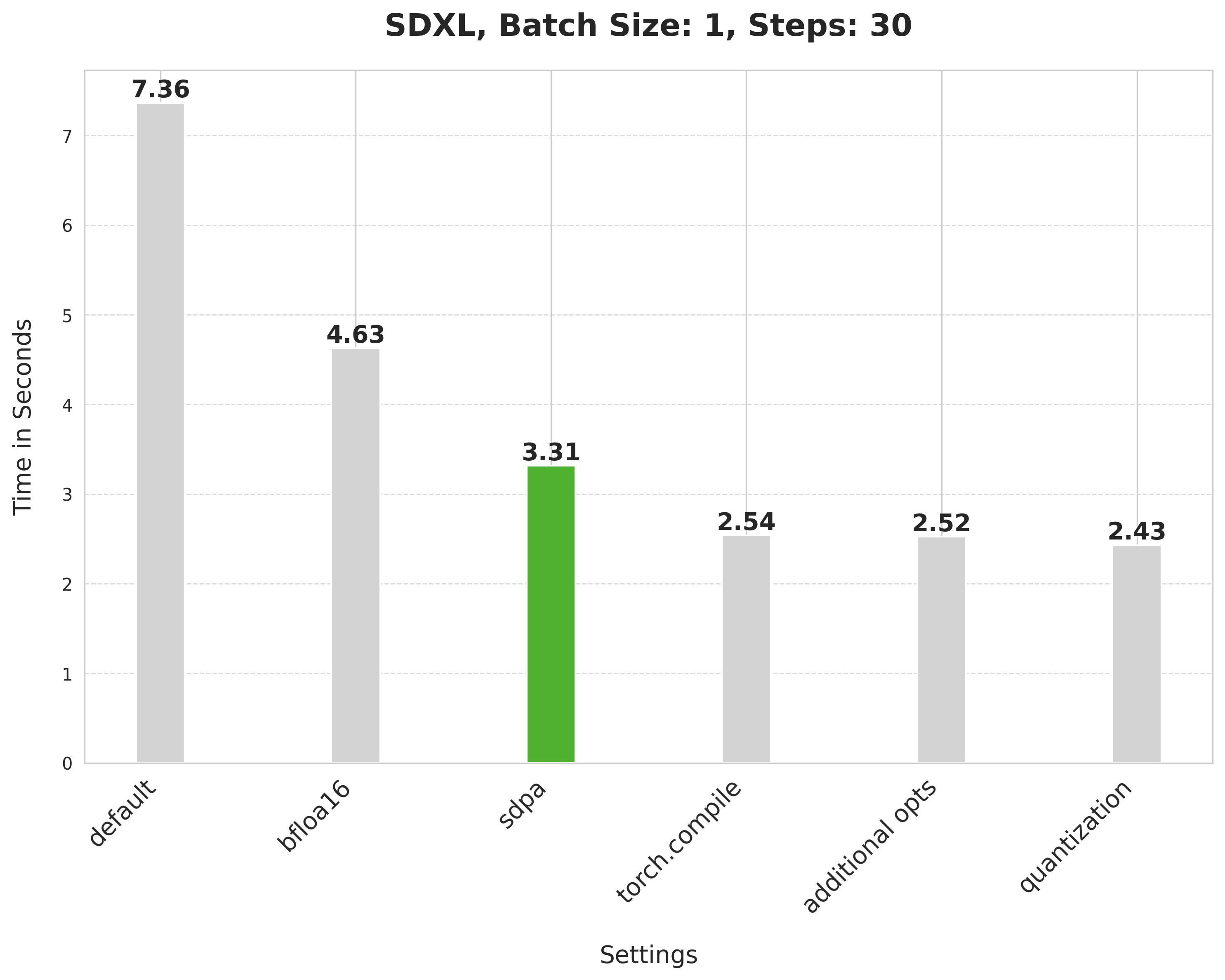
-Scaled dot product attention improves the latency from 4.63 seconds to 3.31 seconds.
-
-
-
-
-
-## torch.compile
-
-PyTorch 2 includes `torch.compile` which uses fast and optimized kernels. In Diffusers, the UNet and VAE are usually compiled because these are the most compute-intensive modules. First, configure a few compiler flags (refer to the [full list](https://github.com/pytorch/pytorch/blob/main/torch/_inductor/config.py) for more options):
-
-```python
-from diffusers import StableDiffusionXLPipeline
-import torch
-
-torch._inductor.config.conv_1x1_as_mm = True
-torch._inductor.config.coordinate_descent_tuning = True
-torch._inductor.config.epilogue_fusion = False
-torch._inductor.config.coordinate_descent_check_all_directions = True
-```
-
-It is also important to change the UNet and VAE's memory layout to "channels_last" when compiling them to ensure maximum speed.
-
-```python
-pipe.unet.to(memory_format=torch.channels_last)
-pipe.vae.to(memory_format=torch.channels_last)
-```
-
-Now compile and perform inference:
-
-```python
-# Compile the UNet and VAE.
-pipe.unet = torch.compile(pipe.unet, mode="max-autotune", fullgraph=True)
-pipe.vae.decode = torch.compile(pipe.vae.decode, mode="max-autotune", fullgraph=True)
-
-prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
-
-# First call to `pipe` is slow, subsequent ones are faster.
-image = pipe(prompt, num_inference_steps=30).images[0]
-```
-
-`torch.compile` offers different backends and modes. For maximum inference speed, use "max-autotune" for the inductor backend. “max-autotune” uses CUDA graphs and optimizes the compilation graph specifically for latency. CUDA graphs greatly reduces the overhead of launching GPU operations by using a mechanism to launch multiple GPU operations through a single CPU operation.
-
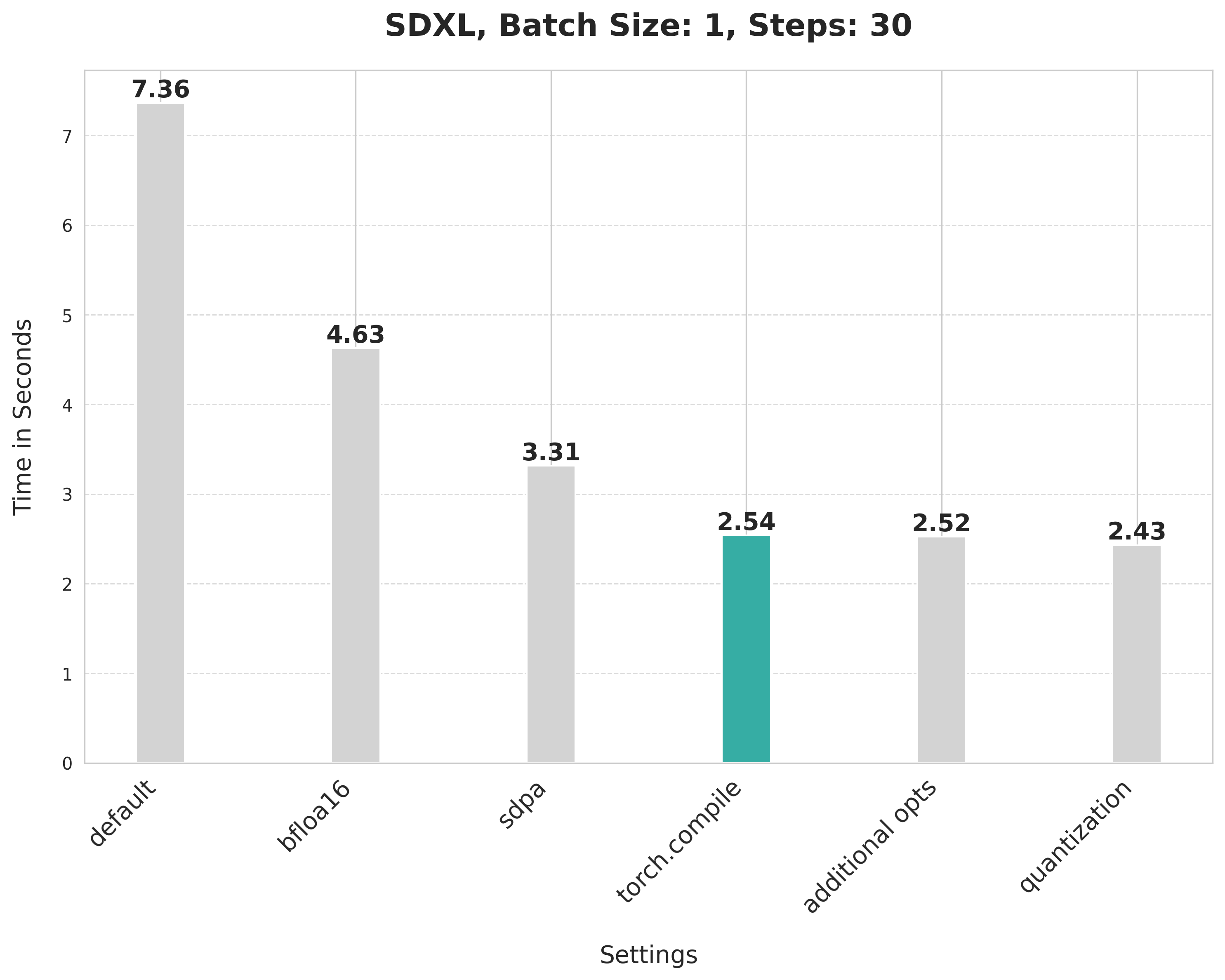
-Using SDPA attention and compiling both the UNet and VAE cuts the latency from 3.31 seconds to 2.54 seconds.
-
-
-
-
-
-> [!TIP]
-> From PyTorch 2.3.1, you can control the caching behavior of `torch.compile()`. This is particularly beneficial for compilation modes like `"max-autotune"` which performs a grid-search over several compilation flags to find the optimal configuration. Learn more in the [Compile Time Caching in torch.compile](https://pytorch.org/tutorials/recipes/torch_compile_caching_tutorial.html) tutorial.
-
-### Prevent graph breaks
-
-Specifying `fullgraph=True` ensures there are no graph breaks in the underlying model to take full advantage of `torch.compile` without any performance degradation. For the UNet and VAE, this means changing how you access the return variables.
-
-```diff
-- latents = unet(
-- latents, timestep=timestep, encoder_hidden_states=prompt_embeds
--).sample
-
-+ latents = unet(
-+ latents, timestep=timestep, encoder_hidden_states=prompt_embeds, return_dict=False
-+)[0]
-```
-
-### Remove GPU sync after compilation
-
-During the iterative reverse diffusion process, the `step()` function is [called](https://github.com/huggingface/diffusers/blob/1d686bac8146037e97f3fd8c56e4063230f71751/src/diffusers/pipelines/stable_diffusion_xl/pipeline_stable_diffusion_xl.py#L1228) on the scheduler each time after the denoiser predicts the less noisy latent embeddings. Inside `step()`, the `sigmas` variable is [indexed](https://github.com/huggingface/diffusers/blob/1d686bac8146037e97f3fd8c56e4063230f71751/src/diffusers/schedulers/scheduling_euler_discrete.py#L476) which when placed on the GPU, causes a communication sync between the CPU and GPU. This introduces latency and it becomes more evident when the denoiser has already been compiled.
-
-But if the `sigmas` array always [stays on the CPU](https://github.com/huggingface/diffusers/blob/35a969d297cba69110d175ee79c59312b9f49e1e/src/diffusers/schedulers/scheduling_euler_discrete.py#L240), the CPU and GPU sync doesn’t occur and you don't get any latency. In general, any CPU and GPU communication sync should be none or be kept to a bare minimum because it can impact inference latency.
-
-## Combine the attention block's projection matrices
-
-The UNet and VAE in SDXL use Transformer-like blocks which consists of attention blocks and feed-forward blocks.
-
-In an attention block, the input is projected into three sub-spaces using three different projection matrices – Q, K, and V. These projections are performed separately on the input. But we can horizontally combine the projection matrices into a single matrix and perform the projection in one step. This increases the size of the matrix multiplications of the input projections and improves the impact of quantization.
-
-You can combine the projection matrices with just a single line of code:
-
-```python
-pipe.fuse_qkv_projections()
-```
-
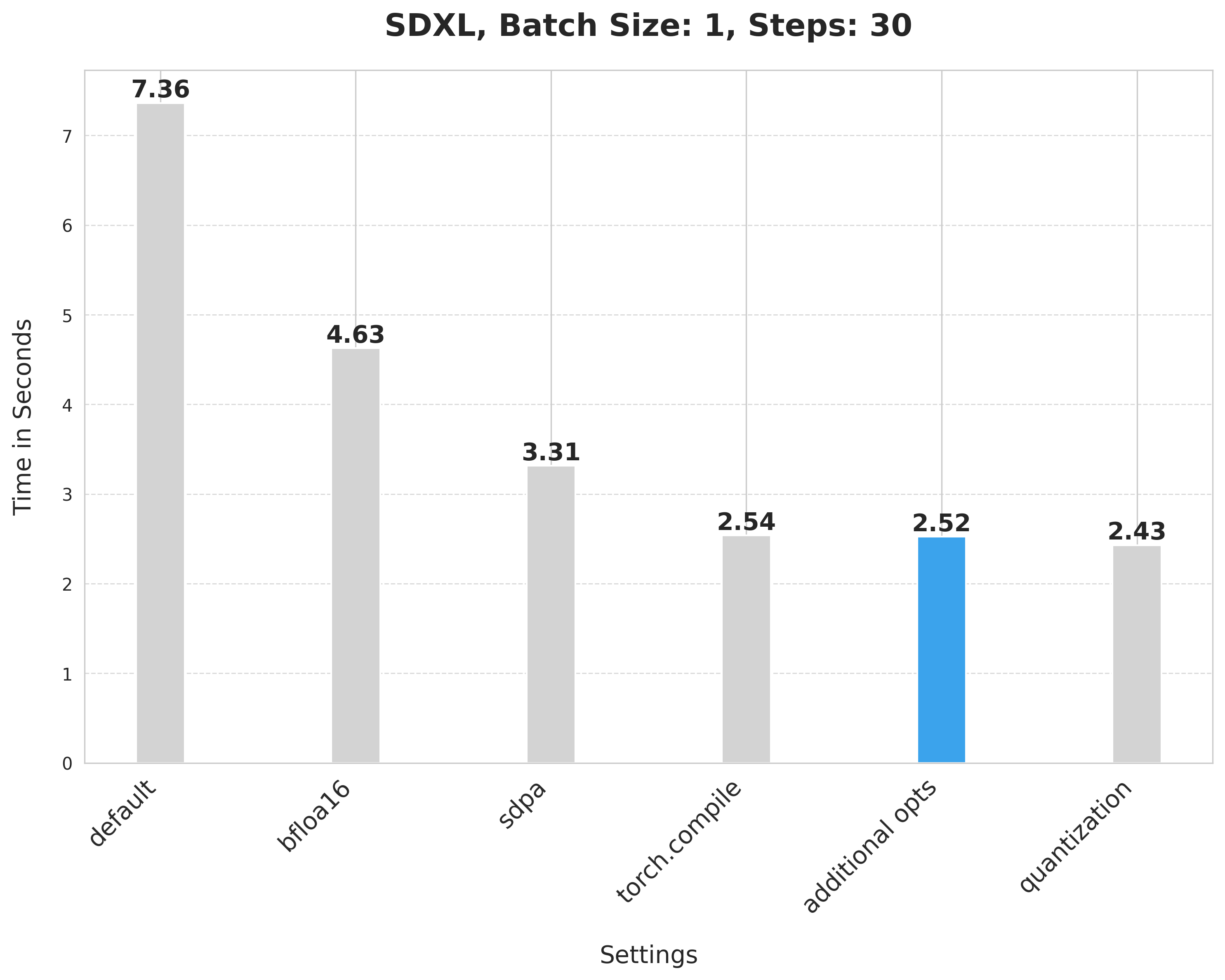
-This provides a minor improvement from 2.54 seconds to 2.52 seconds.
-
-
-
-
-
-
-
-Support for [`~StableDiffusionXLPipeline.fuse_qkv_projections`] is limited and experimental. It's not available for many non-Stable Diffusion pipelines such as [Kandinsky](../using-diffusers/kandinsky). You can refer to this [PR](https://github.com/huggingface/diffusers/pull/6179) to get an idea about how to enable this for the other pipelines.
-
-
-
-## Dynamic quantization
-
-You can also use the ultra-lightweight PyTorch quantization library, [torchao](https://github.com/pytorch-labs/ao) (commit SHA `54bcd5a10d0abbe7b0c045052029257099f83fd9`), to apply [dynamic int8 quantization](https://pytorch.org/tutorials/recipes/recipes/dynamic_quantization.html) to the UNet and VAE. Quantization adds additional conversion overhead to the model that is hopefully made up for by faster matmuls (dynamic quantization). If the matmuls are too small, these techniques may degrade performance.
-
-First, configure all the compiler tags:
-
-```python
-from diffusers import StableDiffusionXLPipeline
-import torch
-
-# Notice the two new flags at the end.
-torch._inductor.config.conv_1x1_as_mm = True
-torch._inductor.config.coordinate_descent_tuning = True
-torch._inductor.config.epilogue_fusion = False
-torch._inductor.config.coordinate_descent_check_all_directions = True
-torch._inductor.config.force_fuse_int_mm_with_mul = True
-torch._inductor.config.use_mixed_mm = True
-```
-
-Certain linear layers in the UNet and VAE don’t benefit from dynamic int8 quantization. You can filter out those layers with the [`dynamic_quant_filter_fn`](https://github.com/huggingface/diffusion-fast/blob/0f169640b1db106fe6a479f78c1ed3bfaeba3386/utils/pipeline_utils.py#L16) shown below.
-
-```python
-def dynamic_quant_filter_fn(mod, *args):
- return (
- isinstance(mod, torch.nn.Linear)
- and mod.in_features > 16
- and (mod.in_features, mod.out_features)
- not in [
- (1280, 640),
- (1920, 1280),
- (1920, 640),
- (2048, 1280),
- (2048, 2560),
- (2560, 1280),
- (256, 128),
- (2816, 1280),
- (320, 640),
- (512, 1536),
- (512, 256),
- (512, 512),
- (640, 1280),
- (640, 1920),
- (640, 320),
- (640, 5120),
- (640, 640),
- (960, 320),
- (960, 640),
- ]
- )
-
-
-def conv_filter_fn(mod, *args):
- return (
- isinstance(mod, torch.nn.Conv2d) and mod.kernel_size == (1, 1) and 128 in [mod.in_channels, mod.out_channels]
- )
-```
-
-Finally, apply all the optimizations discussed so far:
-
-```python
-# SDPA + bfloat16.
-pipe = StableDiffusionXLPipeline.from_pretrained(
- "stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.bfloat16
-).to("cuda")
-
-# Combine attention projection matrices.
-pipe.fuse_qkv_projections()
-
-# Change the memory layout.
-pipe.unet.to(memory_format=torch.channels_last)
-pipe.vae.to(memory_format=torch.channels_last)
-```
-
-Since dynamic quantization is only limited to the linear layers, convert the appropriate pointwise convolution layers into linear layers to maximize its benefit.
-
-```python
-from torchao import swap_conv2d_1x1_to_linear
-
-swap_conv2d_1x1_to_linear(pipe.unet, conv_filter_fn)
-swap_conv2d_1x1_to_linear(pipe.vae, conv_filter_fn)
-```
-
-Apply dynamic quantization:
-
-```python
-from torchao import apply_dynamic_quant
-
-apply_dynamic_quant(pipe.unet, dynamic_quant_filter_fn)
-apply_dynamic_quant(pipe.vae, dynamic_quant_filter_fn)
-```
-
-Finally, compile and perform inference:
-
-```python
-pipe.unet = torch.compile(pipe.unet, mode="max-autotune", fullgraph=True)
-pipe.vae.decode = torch.compile(pipe.vae.decode, mode="max-autotune", fullgraph=True)
-
-prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
-image = pipe(prompt, num_inference_steps=30).images[0]
-```
-
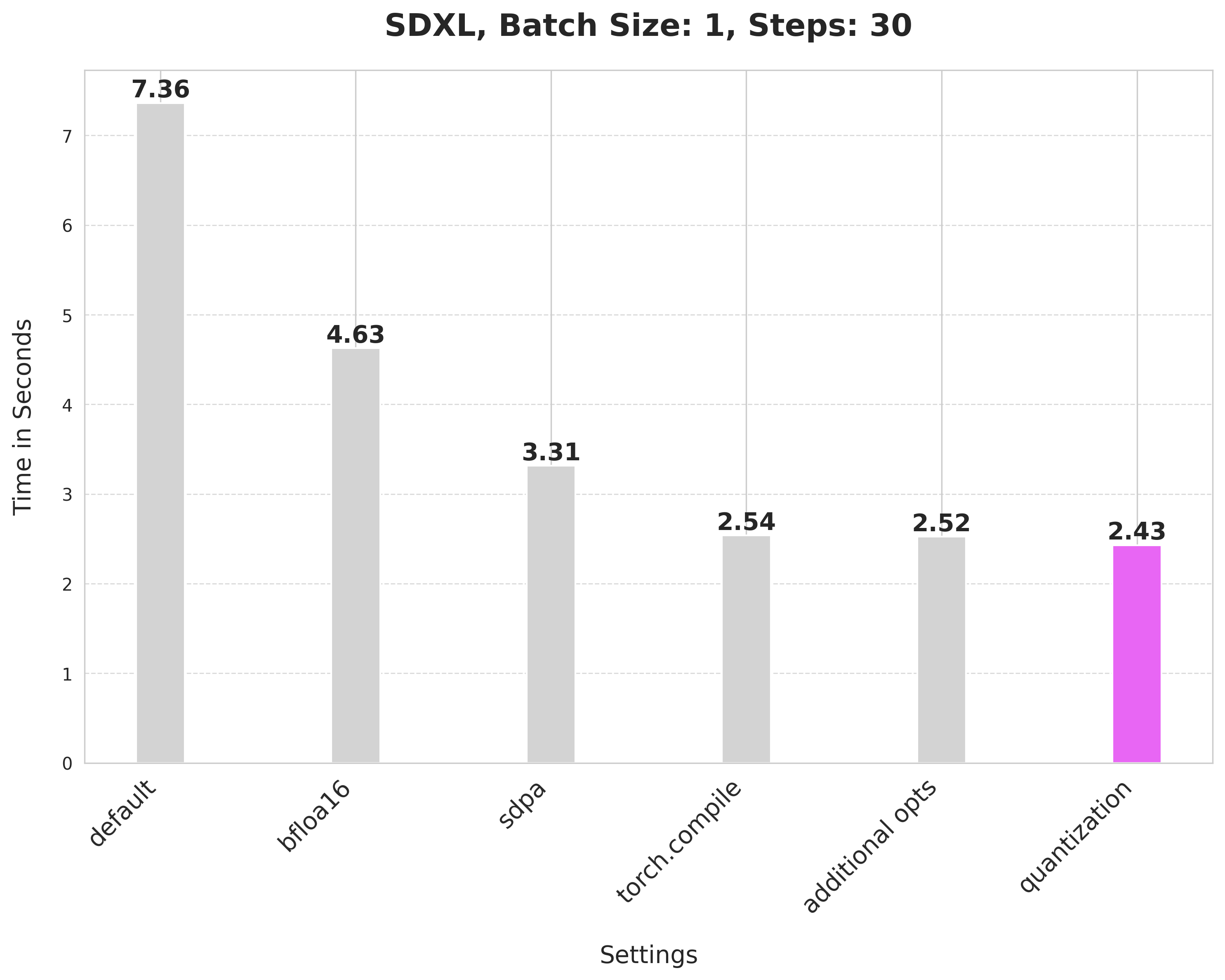
-Applying dynamic quantization improves the latency from 2.52 seconds to 2.43 seconds.
-
-
-
-
diff --git a/docs/source/en/tutorials/using_peft_for_inference.md b/docs/source/en/tutorials/using_peft_for_inference.md
index f17113ecb8..7199361d5e 100644
--- a/docs/source/en/tutorials/using_peft_for_inference.md
+++ b/docs/source/en/tutorials/using_peft_for_inference.md
@@ -103,7 +103,7 @@ pipeline("A cute cnmt eating a slice of pizza, stunning color scheme, masterpiec
## torch.compile
-[torch.compile](../optimization/torch2.0#torchcompile) speeds up inference by compiling the PyTorch model to use optimized kernels. Before compiling, the LoRA weights need to be fused into the base model and unloaded first.
+[torch.compile](../optimization/fp16#torchcompile) speeds up inference by compiling the PyTorch model to use optimized kernels. Before compiling, the LoRA weights need to be fused into the base model and unloaded first.
```py
import torch
diff --git a/docs/source/en/using-diffusers/conditional_image_generation.md b/docs/source/en/using-diffusers/conditional_image_generation.md
index b58b3b74b9..0afbcaabe8 100644
--- a/docs/source/en/using-diffusers/conditional_image_generation.md
+++ b/docs/source/en/using-diffusers/conditional_image_generation.md
@@ -303,7 +303,7 @@ There are many types of conditioning inputs you can use, and 🤗 Diffusers supp
Diffusion models are large, and the iterative nature of denoising an image is computationally expensive and intensive. But this doesn't mean you need access to powerful - or even many - GPUs to use them. There are many optimization techniques for running diffusion models on consumer and free-tier resources. For example, you can load model weights in half-precision to save GPU memory and increase speed or offload the entire model to the GPU to save even more memory.
-PyTorch 2.0 also supports a more memory-efficient attention mechanism called [*scaled dot product attention*](../optimization/torch2.0#scaled-dot-product-attention) that is automatically enabled if you're using PyTorch 2.0. You can combine this with [`torch.compile`](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html) to speed your code up even more:
+PyTorch 2.0 also supports a more memory-efficient attention mechanism called [*scaled dot product attention*](../optimization/fp16#scaled-dot-product-attention) that is automatically enabled if you're using PyTorch 2.0. You can combine this with [`torch.compile`](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html) to speed your code up even more:
```py
from diffusers import AutoPipelineForText2Image
@@ -313,4 +313,4 @@ pipeline = AutoPipelineForText2Image.from_pretrained("stable-diffusion-v1-5/stab
pipeline.unet = torch.compile(pipeline.unet, mode="reduce-overhead", fullgraph=True)
```
-For more tips on how to optimize your code to save memory and speed up inference, read the [Memory and speed](../optimization/fp16) and [Torch 2.0](../optimization/torch2.0) guides.
+For more tips on how to optimize your code to save memory and speed up inference, read the [Accelerate inference](../optimization/fp16) and [Reduce memory usage](../optimization/memory) guides.
diff --git a/docs/source/en/using-diffusers/controlling_generation.md b/docs/source/en/using-diffusers/controlling_generation.md
index c1320dce2a..5d1956ce2c 100644
--- a/docs/source/en/using-diffusers/controlling_generation.md
+++ b/docs/source/en/using-diffusers/controlling_generation.md
@@ -65,14 +65,14 @@ For convenience, we provide a table to denote which methods are inference-only a
| [Fabric](#fabric) | ✅ | ❌ | |
## InstructPix2Pix
-[Paper](https://arxiv.org/abs/2211.09800)
+[Paper](https://huggingface.co/papers/2211.09800)
[InstructPix2Pix](../api/pipelines/pix2pix) is fine-tuned from Stable Diffusion to support editing input images. It takes as inputs an image and a prompt describing an edit, and it outputs the edited image.
InstructPix2Pix has been explicitly trained to work well with [InstructGPT](https://openai.com/blog/instruction-following/)-like prompts.
## Pix2Pix Zero
-[Paper](https://arxiv.org/abs/2302.03027)
+[Paper](https://huggingface.co/papers/2302.03027)
[Pix2Pix Zero](../api/pipelines/pix2pix_zero) allows modifying an image so that one concept or subject is translated to another one while preserving general image semantics.
@@ -104,7 +104,7 @@ apply Pix2Pix Zero to any of the available Stable Diffusion models.
## Attend and Excite
-[Paper](https://arxiv.org/abs/2301.13826)
+[Paper](https://huggingface.co/papers/2301.13826)
[Attend and Excite](../api/pipelines/attend_and_excite) allows subjects in the prompt to be faithfully represented in the final image.
@@ -114,7 +114,7 @@ Like Pix2Pix Zero, Attend and Excite also involves a mini optimization loop (lea
## Semantic Guidance (SEGA)
-[Paper](https://arxiv.org/abs/2301.12247)
+[Paper](https://huggingface.co/papers/2301.12247)
[SEGA](../api/pipelines/semantic_stable_diffusion) allows applying or removing one or more concepts from an image. The strength of the concept can also be controlled. I.e. the smile concept can be used to incrementally increase or decrease the smile of a portrait.
@@ -124,7 +124,7 @@ Unlike Pix2Pix Zero or Attend and Excite, SEGA directly interacts with the diffu
## Self-attention Guidance (SAG)
-[Paper](https://arxiv.org/abs/2210.00939)
+[Paper](https://huggingface.co/papers/2210.00939)
[Self-attention Guidance](../api/pipelines/self_attention_guidance) improves the general quality of images.
@@ -140,7 +140,7 @@ It conditions on a monocular depth estimate of the original image.
## MultiDiffusion Panorama
-[Paper](https://arxiv.org/abs/2302.08113)
+[Paper](https://huggingface.co/papers/2302.08113)
[MultiDiffusion Panorama](../api/pipelines/panorama) defines a new generation process over a pre-trained diffusion model. This process binds together multiple diffusion generation methods that can be readily applied to generate high quality and diverse images. Results adhere to user-provided controls, such as desired aspect ratio (e.g., panorama), and spatial guiding signals, ranging from tight segmentation masks to bounding boxes.
MultiDiffusion Panorama allows to generate high-quality images at arbitrary aspect ratios (e.g., panoramas).
@@ -157,13 +157,13 @@ In addition to pre-trained models, Diffusers has training scripts for fine-tunin
## Textual Inversion
-[Paper](https://arxiv.org/abs/2208.01618)
+[Paper](https://huggingface.co/papers/2208.01618)
[Textual Inversion](../training/text_inversion) fine-tunes a model to teach it about a new concept. I.e. a few pictures of a style of artwork can be used to generate images in that style.
## ControlNet
-[Paper](https://arxiv.org/abs/2302.05543)
+[Paper](https://huggingface.co/papers/2302.05543)
[ControlNet](../api/pipelines/controlnet) is an auxiliary network which adds an extra condition.
There are 8 canonical pre-trained ControlNets trained on different conditionings such as edge detection, scribbles,
@@ -176,7 +176,7 @@ input.
## Custom Diffusion
-[Paper](https://arxiv.org/abs/2212.04488)
+[Paper](https://huggingface.co/papers/2212.04488)
[Custom Diffusion](../training/custom_diffusion) only fine-tunes the cross-attention maps of a pre-trained
text-to-image diffusion model. It also allows for additionally performing Textual Inversion. It supports
@@ -186,7 +186,7 @@ concept(s) of interest.
## Model Editing
-[Paper](https://arxiv.org/abs/2303.08084)
+[Paper](https://huggingface.co/papers/2303.08084)
The [text-to-image model editing pipeline](../api/pipelines/model_editing) helps you mitigate some of the incorrect implicit assumptions a pre-trained text-to-image
diffusion model might make about the subjects present in the input prompt. For example, if you prompt Stable Diffusion to generate images for "A pack of roses", the roses in the generated images
@@ -194,14 +194,14 @@ are more likely to be red. This pipeline helps you change that assumption.
## DiffEdit
-[Paper](https://arxiv.org/abs/2210.11427)
+[Paper](https://huggingface.co/papers/2210.11427)
[DiffEdit](../api/pipelines/diffedit) allows for semantic editing of input images along with
input prompts while preserving the original input images as much as possible.
## T2I-Adapter
-[Paper](https://arxiv.org/abs/2302.08453)
+[Paper](https://huggingface.co/papers/2302.08453)
[T2I-Adapter](../api/pipelines/stable_diffusion/adapter) is an auxiliary network which adds an extra condition.
There are 8 canonical pre-trained adapters trained on different conditionings such as edge detection, sketch,
@@ -209,7 +209,7 @@ depth maps, and semantic segmentations.
## Fabric
-[Paper](https://arxiv.org/abs/2307.10159)
+[Paper](https://huggingface.co/papers/2307.10159)
[Fabric](https://github.com/huggingface/diffusers/tree/442017ccc877279bcf24fbe92f92d3d0def191b6/examples/community#stable-diffusion-fabric-pipeline) is a training-free
approach applicable to a wide range of popular diffusion models, which exploits
diff --git a/docs/source/en/using-diffusers/custom_pipeline_overview.md b/docs/source/en/using-diffusers/custom_pipeline_overview.md
index 11d1173267..c5359fd0bc 100644
--- a/docs/source/en/using-diffusers/custom_pipeline_overview.md
+++ b/docs/source/en/using-diffusers/custom_pipeline_overview.md
@@ -18,7 +18,7 @@ specific language governing permissions and limitations under the License.
> [!TIP] Take a look at GitHub Issue [#841](https://github.com/huggingface/diffusers/issues/841) for more context about why we're adding community pipelines to help everyone easily share their work without being slowed down.
-Community pipelines are any [`DiffusionPipeline`] class that are different from the original paper implementation (for example, the [`StableDiffusionControlNetPipeline`] corresponds to the [Text-to-Image Generation with ControlNet Conditioning](https://arxiv.org/abs/2302.05543) paper). They provide additional functionality or extend the original implementation of a pipeline.
+Community pipelines are any [`DiffusionPipeline`] class that are different from the original paper implementation (for example, the [`StableDiffusionControlNetPipeline`] corresponds to the [Text-to-Image Generation with ControlNet Conditioning](https://huggingface.co/papers/2302.05543) paper). They provide additional functionality or extend the original implementation of a pipeline.
There are many cool community pipelines like [Marigold Depth Estimation](https://github.com/huggingface/diffusers/tree/main/examples/community#marigold-depth-estimation) or [InstantID](https://github.com/huggingface/diffusers/tree/main/examples/community#instantid-pipeline), and you can find all the official community pipelines [here](https://github.com/huggingface/diffusers/tree/main/examples/community).
diff --git a/docs/source/en/using-diffusers/img2img.md b/docs/source/en/using-diffusers/img2img.md
index d9902081fd..3175477f33 100644
--- a/docs/source/en/using-diffusers/img2img.md
+++ b/docs/source/en/using-diffusers/img2img.md
@@ -35,7 +35,7 @@ pipeline.enable_xformers_memory_efficient_attention()
-You'll notice throughout the guide, we use [`~DiffusionPipeline.enable_model_cpu_offload`] and [`~DiffusionPipeline.enable_xformers_memory_efficient_attention`], to save memory and increase inference speed. If you're using PyTorch 2.0, then you don't need to call [`~DiffusionPipeline.enable_xformers_memory_efficient_attention`] on your pipeline because it'll already be using PyTorch 2.0's native [scaled-dot product attention](../optimization/torch2.0#scaled-dot-product-attention).
+You'll notice throughout the guide, we use [`~DiffusionPipeline.enable_model_cpu_offload`] and [`~DiffusionPipeline.enable_xformers_memory_efficient_attention`], to save memory and increase inference speed. If you're using PyTorch 2.0, then you don't need to call [`~DiffusionPipeline.enable_xformers_memory_efficient_attention`] on your pipeline because it'll already be using PyTorch 2.0's native [scaled-dot product attention](../optimization/fp16#scaled-dot-product-attention).
@@ -589,17 +589,17 @@ make_image_grid([init_image, depth_image, image_control_net, image_elden_ring],
## Optimize
-Running diffusion models is computationally expensive and intensive, but with a few optimization tricks, it is entirely possible to run them on consumer and free-tier GPUs. For example, you can use a more memory-efficient form of attention such as PyTorch 2.0's [scaled-dot product attention](../optimization/torch2.0#scaled-dot-product-attention) or [xFormers](../optimization/xformers) (you can use one or the other, but there's no need to use both). You can also offload the model to the GPU while the other pipeline components wait on the CPU.
+Running diffusion models is computationally expensive and intensive, but with a few optimization tricks, it is entirely possible to run them on consumer and free-tier GPUs. For example, you can use a more memory-efficient form of attention such as PyTorch 2.0's [scaled-dot product attention](../optimization/fp16#scaled-dot-product-attention) or [xFormers](../optimization/xformers) (you can use one or the other, but there's no need to use both). You can also offload the model to the GPU while the other pipeline components wait on the CPU.
```diff
+ pipeline.enable_model_cpu_offload()
+ pipeline.enable_xformers_memory_efficient_attention()
```
-With [`torch.compile`](../optimization/torch2.0#torchcompile), you can boost your inference speed even more by wrapping your UNet with it:
+With [`torch.compile`](../optimization/fp16#torchcompile), you can boost your inference speed even more by wrapping your UNet with it:
```py
pipeline.unet = torch.compile(pipeline.unet, mode="reduce-overhead", fullgraph=True)
```
-To learn more, take a look at the [Reduce memory usage](../optimization/memory) and [Torch 2.0](../optimization/torch2.0) guides.
+To learn more, take a look at the [Reduce memory usage](../optimization/memory) and [Accelerate inference](../optimization/fp16) guides.
diff --git a/docs/source/en/using-diffusers/inference_with_tcd_lora.md b/docs/source/en/using-diffusers/inference_with_tcd_lora.md
index 40d909cd4d..d436d2e0ad 100644
--- a/docs/source/en/using-diffusers/inference_with_tcd_lora.md
+++ b/docs/source/en/using-diffusers/inference_with_tcd_lora.md
@@ -25,7 +25,7 @@ The major advantages of TCD are:
- Freely change detail level: During inference, the level of detail in the image can be adjusted with a single hyperparameter, *gamma*.
> [!TIP]
-> For more technical details of TCD, please refer to the [paper](https://arxiv.org/abs/2402.19159) or official [project page](https://mhh0318.github.io/tcd/)).
+> For more technical details of TCD, please refer to the [paper](https://huggingface.co/papers/2402.19159) or official [project page](https://mhh0318.github.io/tcd/).
For large models like SDXL, TCD is trained with [LoRA](https://huggingface.co/docs/peft/conceptual_guides/adapter#low-rank-adaptation-lora) to reduce memory usage. This is also useful because you can reuse LoRAs between different finetuned models, as long as they share the same base model, without further training.
diff --git a/docs/source/en/using-diffusers/inpaint.md b/docs/source/en/using-diffusers/inpaint.md
index 2cf71b6755..e780cc3c4d 100644
--- a/docs/source/en/using-diffusers/inpaint.md
+++ b/docs/source/en/using-diffusers/inpaint.md
@@ -35,7 +35,7 @@ pipeline.enable_xformers_memory_efficient_attention()
-You'll notice throughout the guide, we use [`~DiffusionPipeline.enable_model_cpu_offload`] and [`~DiffusionPipeline.enable_xformers_memory_efficient_attention`], to save memory and increase inference speed. If you're using PyTorch 2.0, it's not necessary to call [`~DiffusionPipeline.enable_xformers_memory_efficient_attention`] on your pipeline because it'll already be using PyTorch 2.0's native [scaled-dot product attention](../optimization/torch2.0#scaled-dot-product-attention).
+You'll notice throughout the guide, we use [`~DiffusionPipeline.enable_model_cpu_offload`] and [`~DiffusionPipeline.enable_xformers_memory_efficient_attention`], to save memory and increase inference speed. If you're using PyTorch 2.0, it's not necessary to call [`~DiffusionPipeline.enable_xformers_memory_efficient_attention`] on your pipeline because it'll already be using PyTorch 2.0's native [scaled-dot product attention](../optimization/fp16#scaled-dot-product-attention).
@@ -363,6 +363,7 @@ device = "cuda"
pipeline = AutoPipelineForInpainting.from_pretrained(
"runwayml/stable-diffusion-inpainting",
torch_dtype=torch.float16,
+ variant="fp16"
)
pipeline = pipeline.to(device)
@@ -787,7 +788,7 @@ make_image_grid([init_image, mask_image, image, image_elden_ring], rows=2, cols=
## Optimize
-It can be difficult and slow to run diffusion models if you're resource constrained, but it doesn't have to be with a few optimization tricks. One of the biggest (and easiest) optimizations you can enable is switching to memory-efficient attention. If you're using PyTorch 2.0, [scaled-dot product attention](../optimization/torch2.0#scaled-dot-product-attention) is automatically enabled and you don't need to do anything else. For non-PyTorch 2.0 users, you can install and use [xFormers](../optimization/xformers)'s implementation of memory-efficient attention. Both options reduce memory usage and accelerate inference.
+It can be difficult and slow to run diffusion models if you're resource constrained, but it doesn't have to be with a few optimization tricks. One of the biggest (and easiest) optimizations you can enable is switching to memory-efficient attention. If you're using PyTorch 2.0, [scaled-dot product attention](../optimization/fp16#scaled-dot-product-attention) is automatically enabled and you don't need to do anything else. For non-PyTorch 2.0 users, you can install and use [xFormers](../optimization/xformers)'s implementation of memory-efficient attention. Both options reduce memory usage and accelerate inference.
You can also offload the model to the CPU to save even more memory:
@@ -796,10 +797,10 @@ You can also offload the model to the CPU to save even more memory:
+ pipeline.enable_model_cpu_offload()
```
-To speed-up your inference code even more, use [`torch_compile`](../optimization/torch2.0#torchcompile). You should wrap `torch.compile` around the most intensive component in the pipeline which is typically the UNet:
+To speed-up your inference code even more, use [`torch_compile`](../optimization/fp16#torchcompile). You should wrap `torch.compile` around the most intensive component in the pipeline which is typically the UNet:
```py
pipeline.unet = torch.compile(pipeline.unet, mode="reduce-overhead", fullgraph=True)
```
-Learn more in the [Reduce memory usage](../optimization/memory) and [Torch 2.0](../optimization/torch2.0) guides.
+Learn more in the [Reduce memory usage](../optimization/memory) and [Accelerate inference](../optimization/fp16) guides.
diff --git a/docs/source/en/using-diffusers/marigold_usage.md b/docs/source/en/using-diffusers/marigold_usage.md
index b8e9a5838e..f66e47bada 100644
--- a/docs/source/en/using-diffusers/marigold_usage.md
+++ b/docs/source/en/using-diffusers/marigold_usage.md
@@ -288,7 +288,7 @@ Speeding them up can be achieved by using a more efficient attention processor:
depth = pipe(image, num_inference_steps=1)
```
-Finally, as suggested in [Optimizations](../optimization/torch2.0#torch.compile), enabling `torch.compile` can further enhance performance depending on
+Finally, as suggested in [Optimizations](../optimization/fp16#torchcompile), enabling `torch.compile` can further enhance performance depending on
the target hardware.
However, compilation incurs a significant overhead during the first pipeline invocation, making it beneficial only when
the same pipeline instance is called repeatedly, such as within a loop.
diff --git a/docs/source/en/using-diffusers/omnigen.md b/docs/source/en/using-diffusers/omnigen.md
index 40a9e81bcd..11b354863a 100644
--- a/docs/source/en/using-diffusers/omnigen.md
+++ b/docs/source/en/using-diffusers/omnigen.md
@@ -15,7 +15,7 @@ OmniGen is an image generation model. Unlike existing text-to-image models, Omni
- Minimalist model architecture, consisting of only a VAE and a transformer module, for joint modeling of text and images.
- Support for multimodal inputs. It can process any text-image mixed data as instructions for image generation, rather than relying solely on text.
-For more information, please refer to the [paper](https://arxiv.org/pdf/2409.11340).
+For more information, please refer to the [paper](https://huggingface.co/papers/2409.11340).
This guide will walk you through using OmniGen for various tasks and use cases.
## Load model checkpoints
diff --git a/docs/source/en/using-diffusers/svd.md b/docs/source/en/using-diffusers/svd.md
index 7852d81fa2..b7fe4df8f7 100644
--- a/docs/source/en/using-diffusers/svd.md
+++ b/docs/source/en/using-diffusers/svd.md
@@ -63,7 +63,7 @@ export_to_video(frames, "generated.mp4", fps=7)
## torch.compile
-You can gain a 20-25% speedup at the expense of slightly increased memory by [compiling](../optimization/torch2.0#torchcompile) the UNet.
+You can gain a 20-25% speedup at the expense of slightly increased memory by [compiling](../optimization/fp16#torchcompile) the UNet.
```diff
- pipe.enable_model_cpu_offload()
diff --git a/docs/source/en/using-diffusers/text-img2vid.md b/docs/source/en/using-diffusers/text-img2vid.md
index 92e740bb57..0098d61cba 100644
--- a/docs/source/en/using-diffusers/text-img2vid.md
+++ b/docs/source/en/using-diffusers/text-img2vid.md
@@ -547,7 +547,7 @@ Video generation requires a lot of memory because you're generating many video f
+ frames = pipeline(image, decode_chunk_size=2, generator=generator, num_frames=25).frames[0]
```
-If memory is not an issue and you want to optimize for speed, try wrapping the UNet with [`torch.compile`](../optimization/torch2.0#torchcompile).
+If memory is not an issue and you want to optimize for speed, try wrapping the UNet with [`torch.compile`](../optimization/fp16#torchcompile).
```diff
- pipeline.enable_model_cpu_offload()
diff --git a/docs/source/ko/_toctree.yml b/docs/source/ko/_toctree.yml
index 05504cbadf..9bd5e8e9e2 100644
--- a/docs/source/ko/_toctree.yml
+++ b/docs/source/ko/_toctree.yml
@@ -175,7 +175,7 @@
- local: optimization/mps
title: Metal Performance Shaders (MPS)
- local: optimization/habana
- title: Habana Gaudi
+ title: Intel Gaudi
title: 최적화된 하드웨어
title: 추론 가속화와 메모리 줄이기
- sections:
diff --git a/docs/source/ko/api/pipelines/stable_diffusion/stable_diffusion_xl.md b/docs/source/ko/api/pipelines/stable_diffusion/stable_diffusion_xl.md
index d708dfa59d..de7c477835 100644
--- a/docs/source/ko/api/pipelines/stable_diffusion/stable_diffusion_xl.md
+++ b/docs/source/ko/api/pipelines/stable_diffusion/stable_diffusion_xl.md
@@ -12,7 +12,7 @@ specific language governing permissions and limitations under the License.
# Stable diffusion XL
-Stable Diffusion XL은 Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, Robin Rombach에 의해 [SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis](https://arxiv.org/abs/2307.01952)에서 제안되었습니다.
+Stable Diffusion XL은 Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, Robin Rombach에 의해 [SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis](https://huggingface.co/papers/2307.01952)에서 제안되었습니다.
논문 초록은 다음을 따릅니다:
@@ -125,7 +125,7 @@ image = pipe(prompt=prompt, image=init_image, mask_image=mask_image, num_inferen
refiner를 사용할 때, 쉽게 사용할 수 있습니다
- 1.) base 모델과 refiner을 사용하는데, 이는 *Denoisers의 앙상블*을 위한 첫 번째 제안된 [eDiff-I](https://research.nvidia.com/labs/dir/eDiff-I/)를 사용하거나
-- 2.) base 모델을 거친 후 [SDEdit](https://arxiv.org/abs/2108.01073) 방법으로 단순하게 refiner를 실행시킬 수 있습니다.
+- 2.) base 모델을 거친 후 [SDEdit](https://huggingface.co/papers/2108.01073) 방법으로 단순하게 refiner를 실행시킬 수 있습니다.
**참고**: SD-XL base와 refiner를 앙상블로 사용하는 아이디어는 커뮤니티 기여자들이 처음으로 제안했으며, 이는 다음과 같은 `diffusers`를 구현하는 데도 도움을 주셨습니다.
- [SytanSD](https://github.com/SytanSD)
diff --git a/docs/source/ko/conceptual/ethical_guidelines.md b/docs/source/ko/conceptual/ethical_guidelines.md
index 5b78525fdb..eef85f22b5 100644
--- a/docs/source/ko/conceptual/ethical_guidelines.md
+++ b/docs/source/ko/conceptual/ethical_guidelines.md
@@ -55,7 +55,7 @@ Diffusers 커뮤니티는 프로젝트의 개발에 다음과 같은 윤리 지
- **배포에서의 안전 유도**
- - [**안전한 Stable Diffusion**](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/stable_diffusion_safe): 이는 필터되지 않은 웹 크롤링 데이터셋으로 훈련된 Stable Diffusion과 같은 모델이 부적절한 변질에 취약한 문제를 완화합니다. 관련 논문: [Safe Latent Diffusion: Mitigating Inappropriate Degeneration in Diffusion Models](https://arxiv.org/abs/2211.05105).
+ - [**안전한 Stable Diffusion**](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/stable_diffusion_safe): 이는 필터되지 않은 웹 크롤링 데이터셋으로 훈련된 Stable Diffusion과 같은 모델이 부적절한 변질에 취약한 문제를 완화합니다. 관련 논문: [Safe Latent Diffusion: Mitigating Inappropriate Degeneration in Diffusion Models](https://huggingface.co/papers/2211.05105).
- [**안전 검사기**](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/safety_checker.py): 이미지가 생성된 후에 이미자가 임베딩 공간에서 일련의 하드코딩된 유해 개념의 클래스일 확률을 확인하고 비교합니다. 유해 개념은 역공학을 방지하기 위해 의도적으로 숨겨져 있습니다.
diff --git a/docs/source/ko/conceptual/evaluation.md b/docs/source/ko/conceptual/evaluation.md
index 144e2b3986..7a6286bafb 100644
--- a/docs/source/ko/conceptual/evaluation.md
+++ b/docs/source/ko/conceptual/evaluation.md
@@ -111,7 +111,7 @@ images = sd_pipeline(sample_prompts, num_images_per_prompt=1, generator=generato
### 텍스트 안내 이미지 생성[[text-guided-image-generation]]
-[CLIP 점수](https://arxiv.org/abs/2104.08718)는 이미지-캡션 쌍의 호환성을 측정합니다. 높은 CLIP 점수는 높은 호환성🔼을 나타냅니다. CLIP 점수는 이미지와 캡션 사이의 의미적 유사성으로 생각할 수도 있습니다. CLIP 점수는 인간 판단과 높은 상관관계를 가지고 있습니다.
+[CLIP 점수](https://huggingface.co/papers/2104.08718)는 이미지-캡션 쌍의 호환성을 측정합니다. 높은 CLIP 점수는 높은 호환성🔼을 나타냅니다. CLIP 점수는 이미지와 캡션 사이의 의미적 유사성으로 생각할 수도 있습니다. CLIP 점수는 인간 판단과 높은 상관관계를 가지고 있습니다.
[`StableDiffusionPipeline`]을 일단 로드해봅시다:
@@ -207,7 +207,7 @@ print(f"CLIP Score with v-1-5: {sd_clip_score_1_5}")

-모델을 평가하는 한 가지 전략은 두 이미지 캡션 간의 변경과([CLIP-Guided Domain Adaptation of Image Generators](https://arxiv.org/abs/2108.00946)에서 보여줍니다) 함께 두 이미지 사이의 변경의 일관성을 측정하는 것입니다 ([CLIP](https://huggingface.co/docs/transformers/model_doc/clip) 공간에서). 이를 "**CLIP 방향성 유사성**"이라고 합니다.
+모델을 평가하는 한 가지 전략은 두 이미지 캡션 간의 변경과([CLIP-Guided Domain Adaptation of Image Generators](https://huggingface.co/papers/2108.00946)에서 보여줍니다) 함께 두 이미지 사이의 변경의 일관성을 측정하는 것입니다 ([CLIP](https://huggingface.co/docs/transformers/model_doc/clip) 공간에서). 이를 "**CLIP 방향성 유사성**"이라고 합니다.
- 캡션 1은 편집할 이미지 (이미지 1)에 해당합니다.
- 캡션 2는 편집된 이미지 (이미지 2)에 해당합니다. 편집 지시를 반영해야 합니다.
@@ -417,7 +417,7 @@ CLIP 점수와 CLIP 방향 유사성 모두 CLIP 모델에 의존하기 때문
### 클래스 조건화 이미지 생성[[class-conditioned-image-generation]]
-클래스 조건화 생성 모델은 일반적으로 [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k)와 같은 클래스 레이블이 지정된 데이터셋에서 사전 훈련됩니다. 이러한 모델을 평가하는 인기있는 지표에는 Fréchet Inception Distance (FID), Kernel Inception Distance (KID) 및 Inception Score (IS)가 있습니다. 이 문서에서는 FID ([Heusel et al.](https://arxiv.org/abs/1706.08500))에 초점을 맞추고 있습니다. [`DiTPipeline`](https://huggingface.co/docs/diffusers/api/pipelines/dit)을 사용하여 FID를 계산하는 방법을 보여줍니다. 이는 내부적으로 [DiT 모델](https://arxiv.org/abs/2212.09748)을 사용합니다.
+클래스 조건화 생성 모델은 일반적으로 [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k)와 같은 클래스 레이블이 지정된 데이터셋에서 사전 훈련됩니다. 이러한 모델을 평가하는 인기있는 지표에는 Fréchet Inception Distance (FID), Kernel Inception Distance (KID) 및 Inception Score (IS)가 있습니다. 이 문서에서는 FID ([Heusel et al.](https://huggingface.co/papers/1706.08500))에 초점을 맞추고 있습니다. [`DiTPipeline`](https://huggingface.co/docs/diffusers/api/pipelines/dit)을 사용하여 FID를 계산하는 방법을 보여줍니다. 이는 내부적으로 [DiT 모델](https://huggingface.co/papers/2212.09748)을 사용합니다.
FID는 두 개의 이미지 데이터셋이 얼마나 유사한지를 측정하는 것을 목표로 합니다. [이 자료](https://mmgeneration.readthedocs.io/en/latest/quick_run.html#fid)에 따르면:
diff --git a/docs/source/ko/optimization/fp16.md b/docs/source/ko/optimization/fp16.md
index ae2bb28a67..62027c8d04 100644
--- a/docs/source/ko/optimization/fp16.md
+++ b/docs/source/ko/optimization/fp16.md
@@ -373,7 +373,7 @@ with torch.inference_mode():
## Memory-efficient attention
어텐션 블록의 대역폭을 최적화하는 최근 작업으로 GPU 메모리 사용량이 크게 향상되고 향상되었습니다.
-@tridao의 가장 최근의 플래시 어텐션: [code](https://github.com/HazyResearch/flash-attention), [paper](https://arxiv.org/pdf/2205.14135.pdf).
+@tridao의 가장 최근의 플래시 어텐션: [code](https://github.com/HazyResearch/flash-attention), [paper](https://huggingface.co/papers/2205.14135).
배치 크기 1(프롬프트 1개)의 512x512 크기로 추론을 실행할 때 몇 가지 Nvidia GPU에서 얻은 속도 향상은 다음과 같습니다:
diff --git a/docs/source/ko/optimization/habana.md b/docs/source/ko/optimization/habana.md
index 917d24d785..b44049569c 100644
--- a/docs/source/ko/optimization/habana.md
+++ b/docs/source/ko/optimization/habana.md
@@ -10,7 +10,7 @@ an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express o
specific language governing permissions and limitations under the License.
-->
-# Habana Gaudi에서 Stable Diffusion을 사용하는 방법
+# Intel Gaudi에서 Stable Diffusion을 사용하는 방법
🤗 Diffusers는 🤗 [Optimum Habana](https://huggingface.co/docs/optimum/habana/usage_guides/stable_diffusion)를 통해서 Habana Gaudi와 호환됩니다.
diff --git a/docs/source/ko/optimization/tome.md b/docs/source/ko/optimization/tome.md
index 7ff96e9290..317cb8a312 100644
--- a/docs/source/ko/optimization/tome.md
+++ b/docs/source/ko/optimization/tome.md
@@ -12,9 +12,9 @@ specific language governing permissions and limitations under the License.
# Token Merging (토큰 병합)
-Token Merging (introduced in [Token Merging: Your ViT But Faster](https://arxiv.org/abs/2210.09461))은 트랜스포머 기반 네트워크의 forward pass에서 중복 토큰이나 패치를 점진적으로 병합하는 방식으로 작동합니다. 이를 통해 기반 네트워크의 추론 지연 시간을 단축할 수 있습니다.
+Token Merging (introduced in [Token Merging: Your ViT But Faster](https://huggingface.co/papers/2210.09461))은 트랜스포머 기반 네트워크의 forward pass에서 중복 토큰이나 패치를 점진적으로 병합하는 방식으로 작동합니다. 이를 통해 기반 네트워크의 추론 지연 시간을 단축할 수 있습니다.
-Token Merging(ToMe)이 출시된 후, 저자들은 [Fast Stable Diffusion을 위한 토큰 병합](https://arxiv.org/abs/2303.17604)을 발표하여 Stable Diffusion과 더 잘 호환되는 ToMe 버전을 소개했습니다. ToMe를 사용하면 [`DiffusionPipeline`]의 추론 지연 시간을 부드럽게 단축할 수 있습니다. 이 문서에서는 ToMe를 [`StableDiffusionPipeline`]에 적용하는 방법, 예상되는 속도 향상, [`StableDiffusionPipeline`]에서 ToMe를 사용할 때의 질적 측면에 대해 설명합니다.
+Token Merging(ToMe)이 출시된 후, 저자들은 [Fast Stable Diffusion을 위한 토큰 병합](https://huggingface.co/papers/2303.17604)을 발표하여 Stable Diffusion과 더 잘 호환되는 ToMe 버전을 소개했습니다. ToMe를 사용하면 [`DiffusionPipeline`]의 추론 지연 시간을 부드럽게 단축할 수 있습니다. 이 문서에서는 ToMe를 [`StableDiffusionPipeline`]에 적용하는 방법, 예상되는 속도 향상, [`StableDiffusionPipeline`]에서 ToMe를 사용할 때의 질적 측면에 대해 설명합니다.
## ToMe 사용하기
@@ -34,7 +34,7 @@ image = pipeline("a photo of an astronaut riding a horse on mars").images[0]
이것이 다입니다!
-`tomesd.apply_patch()`는 파이프라인 추론 속도와 생성된 토큰의 품질 사이의 균형을 맞출 수 있도록 [여러 개의 인자](https://github.com/dbolya/tomesd#usage)를 노출합니다. 이러한 인수 중 가장 중요한 것은 `ratio(비율)`입니다. `ratio`은 forward pass 중에 병합될 토큰의 수를 제어합니다. `tomesd`에 대한 자세한 내용은 해당 리포지토리(https://github.com/dbolya/tomesd) 및 [논문](https://arxiv.org/abs/2303.17604)을 참고하시기 바랍니다.
+`tomesd.apply_patch()`는 파이프라인 추론 속도와 생성된 토큰의 품질 사이의 균형을 맞출 수 있도록 [여러 개의 인자](https://github.com/dbolya/tomesd#usage)를 노출합니다. 이러한 인수 중 가장 중요한 것은 `ratio(비율)`입니다. `ratio`은 forward pass 중에 병합될 토큰의 수를 제어합니다. `tomesd`에 대한 자세한 내용은 해당 리포지토리(https://github.com/dbolya/tomesd) 및 [논문](https://huggingface.co/papers/2303.17604)을 참고하시기 바랍니다.
## `StableDiffusionPipeline`으로 `tomesd` 벤치마킹하기
@@ -102,11 +102,11 @@ We benchmarked the impact of using `tomesd` on [`StableDiffusionPipeline`] along
## 품질
-As reported in [the paper](https://arxiv.org/abs/2303.17604), ToMe can preserve the quality of the generated images to a great extent while speeding up inference. By increasing the `ratio`, it is possible to further speed up inference, but that might come at the cost of a deterioration in the image quality.
+As reported in [the paper](https://huggingface.co/papers/2303.17604), ToMe can preserve the quality of the generated images to a great extent while speeding up inference. By increasing the `ratio`, it is possible to further speed up inference, but that might come at the cost of a deterioration in the image quality.
To test the quality of the generated samples using our setup, we sampled a few prompts from the “Parti Prompts” (introduced in [Parti](https://parti.research.google/)) and performed inference with the [`StableDiffusionPipeline`] in the following settings:
-[논문](https://arxiv.org/abs/2303.17604)에 보고된 바와 같이, ToMe는 생성된 이미지의 품질을 상당 부분 보존하면서 추론 속도를 높일 수 있습니다. `ratio`을 높이면 추론 속도를 더 높일 수 있지만, 이미지 품질이 저하될 수 있습니다.
+[논문](https://huggingface.co/papers/2303.17604)에 보고된 바와 같이, ToMe는 생성된 이미지의 품질을 상당 부분 보존하면서 추론 속도를 높일 수 있습니다. `ratio`을 높이면 추론 속도를 더 높일 수 있지만, 이미지 품질이 저하될 수 있습니다.
해당 설정을 사용하여 생성된 샘플의 품질을 테스트하기 위해, "Parti 프롬프트"([Parti](https://parti.research.google/)에서 소개)에서 몇 가지 프롬프트를 샘플링하고 다음 설정에서 [`StableDiffusionPipeline`]을 사용하여 추론을 수행했습니다:
diff --git a/docs/source/ko/training/controlnet.md b/docs/source/ko/training/controlnet.md
index ce83cab54e..d764418455 100644
--- a/docs/source/ko/training/controlnet.md
+++ b/docs/source/ko/training/controlnet.md
@@ -12,7 +12,7 @@ specific language governing permissions and limitations under the License.
# ControlNet
-[Adding Conditional Control to Text-to-Image Diffusion Models](https://arxiv.org/abs/2302.05543) (ControlNet)은 Lvmin Zhang과 Maneesh Agrawala에 의해 쓰여졌습니다.
+[Adding Conditional Control to Text-to-Image Diffusion Models](https://huggingface.co/papers/2302.05543) (ControlNet)은 Lvmin Zhang과 Maneesh Agrawala에 의해 쓰여졌습니다.
이 예시는 [원본 ControlNet 리포지토리에서 예시 학습하기](https://github.com/lllyasviel/ControlNet/blob/main/docs/train.md)에 기반합니다. ControlNet은 원들을 채우기 위해 [small synthetic dataset](https://huggingface.co/datasets/fusing/fill50k)을 사용해서 학습됩니다.
diff --git a/docs/source/ko/training/custom_diffusion.md b/docs/source/ko/training/custom_diffusion.md
index 5d1fd3dd34..21dd3793aa 100644
--- a/docs/source/ko/training/custom_diffusion.md
+++ b/docs/source/ko/training/custom_diffusion.md
@@ -12,7 +12,7 @@ specific language governing permissions and limitations under the License.
# 커스텀 Diffusion 학습 예제
-[커스텀 Diffusion](https://arxiv.org/abs/2212.04488)은 피사체의 이미지 몇 장(4~5장)만 주어지면 Stable Diffusion처럼 text-to-image 모델을 커스터마이징하는 방법입니다.
+[커스텀 Diffusion](https://huggingface.co/papers/2212.04488)은 피사체의 이미지 몇 장(4~5장)만 주어지면 Stable Diffusion처럼 text-to-image 모델을 커스터마이징하는 방법입니다.
'train_custom_diffusion.py' 스크립트는 학습 과정을 구현하고 이를 Stable Diffusion에 맞게 조정하는 방법을 보여줍니다.
이 교육 사례는 [Nupur Kumari](https://nupurkmr9.github.io/)가 제공하였습니다. (Custom Diffusion의 저자 중 한명).
diff --git a/docs/source/ko/training/dreambooth.md b/docs/source/ko/training/dreambooth.md
index f211f160a3..8222ec516f 100644
--- a/docs/source/ko/training/dreambooth.md
+++ b/docs/source/ko/training/dreambooth.md
@@ -12,7 +12,7 @@ specific language governing permissions and limitations under the License.
# DreamBooth
-[DreamBooth](https://arxiv.org/abs/2208.12242)는 한 주제에 대한 적은 이미지(3~5개)만으로도 stable diffusion과 같이 text-to-image 모델을 개인화할 수 있는 방법입니다. 이를 통해 모델은 다양한 장면, 포즈 및 장면(뷰)에서 피사체에 대해 맥락화(contextualized)된 이미지를 생성할 수 있습니다.
+[DreamBooth](https://huggingface.co/papers/2208.12242)는 한 주제에 대한 적은 이미지(3~5개)만으로도 stable diffusion과 같이 text-to-image 모델을 개인화할 수 있는 방법입니다. 이를 통해 모델은 다양한 장면, 포즈 및 장면(뷰)에서 피사체에 대해 맥락화(contextualized)된 이미지를 생성할 수 있습니다.

에서의 Dreambooth 예시 project's blog.
@@ -118,7 +118,7 @@ python train_dreambooth_flax.py \
### Prior-preserving(사전 보존) loss를 사용한 파인튜닝
-과적합과 language drift를 방지하기 위해 사전 보존이 사용됩니다(관심이 있는 경우 [논문](https://arxiv.org/abs/2208.12242)을 참조하세요). 사전 보존을 위해 동일한 클래스의 다른 이미지를 학습 프로세스의 일부로 사용합니다. 좋은 점은 Stable Diffusion 모델 자체를 사용하여 이러한 이미지를 생성할 수 있다는 것입니다! 학습 스크립트는 생성된 이미지를 우리가 지정한 로컬 경로에 저장합니다.
+과적합과 language drift를 방지하기 위해 사전 보존이 사용됩니다(관심이 있는 경우 [논문](https://huggingface.co/papers/2208.12242)을 참조하세요). 사전 보존을 위해 동일한 클래스의 다른 이미지를 학습 프로세스의 일부로 사용합니다. 좋은 점은 Stable Diffusion 모델 자체를 사용하여 이러한 이미지를 생성할 수 있다는 것입니다! 학습 스크립트는 생성된 이미지를 우리가 지정한 로컬 경로에 저장합니다.
저자들에 따르면 사전 보존을 위해 `num_epochs * num_samples`개의 이미지를 생성하는 것이 좋습니다. 200-300개에서 대부분 잘 작동합니다.
diff --git a/docs/source/ko/training/instructpix2pix.md b/docs/source/ko/training/instructpix2pix.md
index c19ffaf453..494b66a394 100644
--- a/docs/source/ko/training/instructpix2pix.md
+++ b/docs/source/ko/training/instructpix2pix.md
@@ -12,7 +12,7 @@ specific language governing permissions and limitations under the License.
# InstructPix2Pix
-[InstructPix2Pix](https://arxiv.org/abs/2211.09800)는 text-conditioned diffusion 모델이 한 이미지에 편집을 따를 수 있도록 파인튜닝하는 방법입니다. 이 방법을 사용하여 파인튜닝된 모델은 다음을 입력으로 사용합니다:
+[InstructPix2Pix](https://huggingface.co/papers/2211.09800)는 text-conditioned diffusion 모델이 한 이미지에 편집을 따를 수 있도록 파인튜닝하는 방법입니다. 이 방법을 사용하여 파인튜닝된 모델은 다음을 입력으로 사용합니다:
 diff --git a/docs/source/ko/training/lora.md b/docs/source/ko/training/lora.md
index 85ed1dda0b..d0675c72f1 100644
--- a/docs/source/ko/training/lora.md
+++ b/docs/source/ko/training/lora.md
@@ -20,7 +20,7 @@ specific language governing permissions and limitations under the License.
-[LoRA(Low-Rank Adaptation of Large Language Models)](https://arxiv.org/abs/2106.09685)는 메모리를 적게 사용하면서 대규모 모델의 학습을 가속화하는 학습 방법입니다. 이는 rank-decomposition weight 행렬 쌍(**업데이트 행렬**이라고 함)을 추가하고 새로 추가된 가중치**만** 학습합니다. 여기에는 몇 가지 장점이 있습니다.
+[LoRA(Low-Rank Adaptation of Large Language Models)](https://huggingface.co/papers/2106.09685)는 메모리를 적게 사용하면서 대규모 모델의 학습을 가속화하는 학습 방법입니다. 이는 rank-decomposition weight 행렬 쌍(**업데이트 행렬**이라고 함)을 추가하고 새로 추가된 가중치**만** 학습합니다. 여기에는 몇 가지 장점이 있습니다.
- 이전에 미리 학습된 가중치는 고정된 상태로 유지되므로 모델이 [치명적인 망각](https://www.pnas.org/doi/10.1073/pnas.1611835114) 경향이 없습니다.
- Rank-decomposition 행렬은 원래 모델보다 파라메터 수가 훨씬 적으므로 학습된 LoRA 가중치를 쉽게 끼워넣을 수 있습니다.
diff --git a/docs/source/ko/training/text_inversion.md b/docs/source/ko/training/text_inversion.md
index 5c6a96eb41..9cc7b6a255 100644
--- a/docs/source/ko/training/text_inversion.md
+++ b/docs/source/ko/training/text_inversion.md
@@ -16,7 +16,7 @@ specific language governing permissions and limitations under the License.
[[open-in-colab]]
-[textual-inversion](https://arxiv.org/abs/2208.01618)은 소수의 예시 이미지에서 새로운 콘셉트를 포착하는 기법입니다. 이 기술은 원래 [Latent Diffusion](https://github.com/CompVis/latent-diffusion)에서 시연되었지만, 이후 [Stable Diffusion](https://huggingface.co/docs/diffusers/main/en/conceptual/stable_diffusion)과 같은 유사한 다른 모델에도 적용되었습니다. 학습된 콘셉트는 text-to-image 파이프라인에서 생성된 이미지를 더 잘 제어하는 데 사용할 수 있습니다. 이 모델은 텍스트 인코더의 임베딩 공간에서 새로운 '단어'를 학습하여 개인화된 이미지 생성을 위한 텍스트 프롬프트 내에서 사용됩니다.
+[textual-inversion](https://huggingface.co/papers/2208.01618)은 소수의 예시 이미지에서 새로운 콘셉트를 포착하는 기법입니다. 이 기술은 원래 [Latent Diffusion](https://github.com/CompVis/latent-diffusion)에서 시연되었지만, 이후 [Stable Diffusion](https://huggingface.co/docs/diffusers/main/en/conceptual/stable_diffusion)과 같은 유사한 다른 모델에도 적용되었습니다. 학습된 콘셉트는 text-to-image 파이프라인에서 생성된 이미지를 더 잘 제어하는 데 사용할 수 있습니다. 이 모델은 텍스트 인코더의 임베딩 공간에서 새로운 '단어'를 학습하여 개인화된 이미지 생성을 위한 텍스트 프롬프트 내에서 사용됩니다.

By using just 3-5 images you can teach new concepts to a model such as Stable Diffusion for personalized image generation (image source).
diff --git a/docs/source/ko/using-diffusers/controlling_generation.md b/docs/source/ko/using-diffusers/controlling_generation.md
index 41fc52b634..5bbb707eb3 100644
--- a/docs/source/ko/using-diffusers/controlling_generation.md
+++ b/docs/source/ko/using-diffusers/controlling_generation.md
@@ -64,7 +64,7 @@ diffusion 모델 생성을 제어하기 위해 `diffusers`가 지원하는 몇
## Pix2Pix Instruct
-[Paper](https://arxiv.org/abs/2211.09800)
+[Paper](https://huggingface.co/papers/2211.09800)
[Instruct Pix2Pix](../api/pipelines/stable_diffusion/pix2pix) 는 입력 이미지 편집을 지원하기 위해 stable diffusion에서 미세-조정되었습니다. 이미지와 편집을 설명하는 프롬프트를 입력으로 받아 편집된 이미지를 출력합니다.
Instruct Pix2Pix는 [InstructGPT](https://openai.com/blog/instruction-following/)와 같은 프롬프트와 잘 작동하도록 명시적으로 훈련되었습니다.
@@ -73,7 +73,7 @@ Instruct Pix2Pix는 [InstructGPT](https://openai.com/blog/instruction-following/
## Pix2Pix Zero
-[Paper](https://arxiv.org/abs/2302.03027)
+[Paper](https://huggingface.co/papers/2302.03027)
[Pix2Pix Zero](../api/pipelines/stable_diffusion/pix2pix_zero)를 사용하면 일반적인 이미지 의미를 유지하면서 한 개념이나 피사체가 다른 개념이나 피사체로 변환되도록 이미지를 수정할 수 있습니다.
@@ -98,7 +98,7 @@ Pix2Pix Zero는 '제로 샷(zero-shot)' 이미지 편집이 가능한 최초의
## Attend and Excite
-[Paper](https://arxiv.org/abs/2301.13826)
+[Paper](https://huggingface.co/papers/2301.13826)
[Attend and Excite](../api/pipelines/stable_diffusion/attend_and_excite)를 사용하면 프롬프트의 피사체가 최종 이미지에 충실하게 표현되도록 할 수 있습니다.
@@ -110,7 +110,7 @@ Pix2Pix Zero와 마찬가지로 Attend and Excite 역시 파이프라인에 미
## Semantic Guidance (SEGA)
-[Paper](https://arxiv.org/abs/2301.12247)
+[Paper](https://huggingface.co/papers/2301.12247)
의미유도(SEGA)를 사용하면 이미지에서 하나 이상의 컨셉을 적용하거나 제거할 수 있습니다. 컨셉의 강도도 조절할 수 있습니다. 즉, 스마일 컨셉을 사용하여 인물 사진의 스마일을 점진적으로 늘리거나 줄일 수 있습니다.
@@ -122,7 +122,7 @@ Pix2Pix Zero 또는 Attend and Excite와 달리 SEGA는 명시적인 그라데
## Self-attention Guidance (SAG)
-[Paper](https://arxiv.org/abs/2210.00939)
+[Paper](https://huggingface.co/papers/2210.00939)
[자기 주의 안내](../api/pipelines/stable_diffusion/self_attention_guidance)는 이미지의 전반적인 품질을 개선합니다.
@@ -150,7 +150,7 @@ InstructPix2Pix와 Pix2Pix Zero와 같은 방법의 중요한 차이점은 전
## MultiDiffusion Panorama
-[Paper](https://arxiv.org/abs/2302.08113)
+[Paper](https://huggingface.co/papers/2302.08113)
MultiDiffusion은 사전 학습된 diffusion model을 통해 새로운 생성 프로세스를 정의합니다. 이 프로세스는 고품질의 다양한 이미지를 생성하는 데 쉽게 적용할 수 있는 여러 diffusion 생성 방법을 하나로 묶습니다. 결과는 원하는 종횡비(예: 파노라마) 및 타이트한 분할 마스크에서 바운딩 박스에 이르는 공간 안내 신호와 같은 사용자가 제공한 제어를 준수합니다.
[MultiDiffusion 파노라마](../api/pipelines/stable_diffusion/panorama)를 사용하면 임의의 종횡비(예: 파노라마)로 고품질 이미지를 생성할 수 있습니다.
@@ -175,7 +175,7 @@ MultiDiffusion은 사전 학습된 diffusion model을 통해 새로운 생성
## ControlNet
-[Paper](https://arxiv.org/abs/2302.05543)
+[Paper](https://huggingface.co/papers/2302.05543)
[ControlNet](../api/pipelines/stable_diffusion/controlnet)은 추가 조건을 추가하는 보조 네트워크입니다.
가장자리 감지, 낙서, 깊이 맵, 의미적 세그먼트와 같은 다양한 조건에 대해 훈련된 8개의 표준 사전 훈련된 ControlNet이 있습니다,
@@ -200,7 +200,7 @@ DreamBooth 및 Textual Inversion 마찬가지로, 사용자 지정 확산은 사
## Model Editing
-[Paper](https://arxiv.org/abs/2303.08084)
+[Paper](https://huggingface.co/papers/2303.08084)
[텍스트-이미지 모델 편집 파이프라인](../api/pipelines/model_editing)을 사용하면 사전학습된 text-to-image diffusion 모델이 입력 프롬프트에 있는 피사체에 대해 내릴 수 있는 잘못된 암시적 가정을 완화하는 데 도움이 됩니다.
예를 들어, 안정적 확산에 "A pack of roses"에 대한 이미지를 생성하라는 메시지를 표시하면 생성된 이미지의 장미는 빨간색일 가능성이 높습니다. 이 파이프라인은 이러한 가정을 변경하는 데 도움이 됩니다.
@@ -209,7 +209,7 @@ DreamBooth 및 Textual Inversion 마찬가지로, 사용자 지정 확산은 사
## DiffEdit
-[Paper](https://arxiv.org/abs/2210.11427)
+[Paper](https://huggingface.co/papers/2210.11427)
[DiffEdit](../api/pipelines/diffedit)를 사용하면 원본 입력 이미지를 최대한 보존하면서 입력 프롬프트와 함께 입력 이미지의 의미론적 편집이 가능합니다.
@@ -218,7 +218,7 @@ DreamBooth 및 Textual Inversion 마찬가지로, 사용자 지정 확산은 사
## T2I-Adapter
-[Paper](https://arxiv.org/abs/2302.08453)
+[Paper](https://huggingface.co/papers/2302.08453)
[T2I-어댑터](../api/pipelines/stable_diffusion/adapter)는 추가적인 조건을 추가하는 auxiliary 네트워크입니다.
가장자리 감지, 스케치, depth maps, semantic segmentations와 같은 다양한 조건에 대해 훈련된 8개의 표준 사전훈련된 adapter가 있습니다,
diff --git a/docs/source/ko/using-diffusers/custom_pipeline_overview.md b/docs/source/ko/using-diffusers/custom_pipeline_overview.md
index 34cd531047..12d0a5be7b 100644
--- a/docs/source/ko/using-diffusers/custom_pipeline_overview.md
+++ b/docs/source/ko/using-diffusers/custom_pipeline_overview.md
@@ -14,7 +14,7 @@ specific language governing permissions and limitations under the License.
[[open-in-colab]]
-커뮤니티 파이프라인은 논문에 명시된 원래의 구현체와 다른 형태로 구현된 모든 [`DiffusionPipeline`] 클래스를 의미합니다. (예를 들어, [`StableDiffusionControlNetPipeline`]는 ["Text-to-Image Generation with ControlNet Conditioning"](https://arxiv.org/abs/2302.05543) 해당) 이들은 추가 기능을 제공하거나 파이프라인의 원래 구현을 확장합니다.
+커뮤니티 파이프라인은 논문에 명시된 원래의 구현체와 다른 형태로 구현된 모든 [`DiffusionPipeline`] 클래스를 의미합니다. (예를 들어, [`StableDiffusionControlNetPipeline`]는 ["Text-to-Image Generation with ControlNet Conditioning"](https://huggingface.co/papers/2302.05543) 해당) 이들은 추가 기능을 제공하거나 파이프라인의 원래 구현을 확장합니다.
[Speech to Image](https://github.com/huggingface/diffusers/tree/main/examples/community#speech-to-image) 또는 [Composable Stable Diffusion](https://github.com/huggingface/diffusers/tree/main/examples/community#composable-stable-diffusion) 과 같은 멋진 커뮤니티 파이프라인이 많이 있으며 [여기에서](https://github.com/huggingface/diffusers/tree/main/examples/community) 모든 공식 커뮤니티 파이프라인을 찾을 수 있습니다.
diff --git a/docs/source/ko/using-diffusers/unconditional_image_generation.md b/docs/source/ko/using-diffusers/unconditional_image_generation.md
index 9e674d602b..5d5dcdd95e 100644
--- a/docs/source/ko/using-diffusers/unconditional_image_generation.md
+++ b/docs/source/ko/using-diffusers/unconditional_image_generation.md
@@ -27,7 +27,7 @@ Unconditional 이미지 생성은 비교적 간단한 작업입니다. 모델이
-이 가이드에서는 unconditional 이미지 생성에 ['DiffusionPipeline']과 [DDPM](https://arxiv.org/abs/2006.11239)을 사용합니다:
+이 가이드에서는 unconditional 이미지 생성에 ['DiffusionPipeline']과 [DDPM](https://huggingface.co/papers/2006.11239)을 사용합니다:
```python
>>> from diffusers import DiffusionPipeline
diff --git a/docs/source/zh/index.md b/docs/source/zh/index.md
index 92c52bc1c1..133864e406 100644
--- a/docs/source/zh/index.md
+++ b/docs/source/zh/index.md
@@ -56,32 +56,32 @@ specific language governing permissions and limitations under the License.
| 管道 | 论文/仓库 | 任务 |
|---|---|:---:|
-| [alt_diffusion](./api/pipelines/alt_diffusion) | [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679) | Image-to-Image Text-Guided Generation |
+| [alt_diffusion](./api/pipelines/alt_diffusion) | [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://huggingface.co/papers/2211.06679) | Image-to-Image Text-Guided Generation |
| [audio_diffusion](./api/pipelines/audio_diffusion) | [Audio Diffusion](https://github.com/teticio/audio-diffusion.git) | Unconditional Audio Generation |
-| [controlnet](./api/pipelines/stable_diffusion/controlnet) | [Adding Conditional Control to Text-to-Image Diffusion Models](https://arxiv.org/abs/2302.05543) | Image-to-Image Text-Guided Generation |
-| [cycle_diffusion](./api/pipelines/cycle_diffusion) | [Unifying Diffusion Models' Latent Space, with Applications to CycleDiffusion and Guidance](https://arxiv.org/abs/2210.05559) | Image-to-Image Text-Guided Generation |
+| [controlnet](./api/pipelines/stable_diffusion/controlnet) | [Adding Conditional Control to Text-to-Image Diffusion Models](https://huggingface.co/papers/2302.05543) | Image-to-Image Text-Guided Generation |
+| [cycle_diffusion](./api/pipelines/cycle_diffusion) | [Unifying Diffusion Models' Latent Space, with Applications to CycleDiffusion and Guidance](https://huggingface.co/papers/2210.05559) | Image-to-Image Text-Guided Generation |
| [dance_diffusion](./api/pipelines/dance_diffusion) | [Dance Diffusion](https://github.com/williamberman/diffusers.git) | Unconditional Audio Generation |
-| [ddpm](./api/pipelines/ddpm) | [Denoising Diffusion Probabilistic Models](https://arxiv.org/abs/2006.11239) | Unconditional Image Generation |
-| [ddim](./api/pipelines/ddim) | [Denoising Diffusion Implicit Models](https://arxiv.org/abs/2010.02502) | Unconditional Image Generation |
+| [ddpm](./api/pipelines/ddpm) | [Denoising Diffusion Probabilistic Models](https://huggingface.co/papers/2006.11239) | Unconditional Image Generation |
+| [ddim](./api/pipelines/ddim) | [Denoising Diffusion Implicit Models](https://huggingface.co/papers/2010.02502) | Unconditional Image Generation |
| [if](./if) | [**IF**](./api/pipelines/if) | Image Generation |
| [if_img2img](./if) | [**IF**](./api/pipelines/if) | Image-to-Image Generation |
| [if_inpainting](./if) | [**IF**](./api/pipelines/if) | Image-to-Image Generation |
-| [latent_diffusion](./api/pipelines/latent_diffusion) | [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752)| Text-to-Image Generation |
-| [latent_diffusion](./api/pipelines/latent_diffusion) | [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752)| Super Resolution Image-to-Image |
-| [latent_diffusion_uncond](./api/pipelines/latent_diffusion_uncond) | [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752) | Unconditional Image Generation |
-| [paint_by_example](./api/pipelines/paint_by_example) | [Paint by Example: Exemplar-based Image Editing with Diffusion Models](https://arxiv.org/abs/2211.13227) | Image-Guided Image Inpainting |
-| [pndm](./api/pipelines/pndm) | [Pseudo Numerical Methods for Diffusion Models on Manifolds](https://arxiv.org/abs/2202.09778) | Unconditional Image Generation |
+| [latent_diffusion](./api/pipelines/latent_diffusion) | [High-Resolution Image Synthesis with Latent Diffusion Models](https://huggingface.co/papers/2112.10752)| Text-to-Image Generation |
+| [latent_diffusion](./api/pipelines/latent_diffusion) | [High-Resolution Image Synthesis with Latent Diffusion Models](https://huggingface.co/papers/2112.10752)| Super Resolution Image-to-Image |
+| [latent_diffusion_uncond](./api/pipelines/latent_diffusion_uncond) | [High-Resolution Image Synthesis with Latent Diffusion Models](https://huggingface.co/papers/2112.10752) | Unconditional Image Generation |
+| [paint_by_example](./api/pipelines/paint_by_example) | [Paint by Example: Exemplar-based Image Editing with Diffusion Models](https://huggingface.co/papers/2211.13227) | Image-Guided Image Inpainting |
+| [pndm](./api/pipelines/pndm) | [Pseudo Numerical Methods for Diffusion Models on Manifolds](https://huggingface.co/papers/2202.09778) | Unconditional Image Generation |
| [score_sde_ve](./api/pipelines/score_sde_ve) | [Score-Based Generative Modeling through Stochastic Differential Equations](https://openreview.net/forum?id=PxTIG12RRHS) | Unconditional Image Generation |
| [score_sde_vp](./api/pipelines/score_sde_vp) | [Score-Based Generative Modeling through Stochastic Differential Equations](https://openreview.net/forum?id=PxTIG12RRHS) | Unconditional Image Generation |
-| [semantic_stable_diffusion](./api/pipelines/semantic_stable_diffusion) | [Semantic Guidance](https://arxiv.org/abs/2301.12247) | Text-Guided Generation |
+| [semantic_stable_diffusion](./api/pipelines/semantic_stable_diffusion) | [Semantic Guidance](https://huggingface.co/papers/2301.12247) | Text-Guided Generation |
| [stable_diffusion_text2img](./api/pipelines/stable_diffusion/text2img) | [Stable Diffusion](https://stability.ai/blog/stable-diffusion-public-release) | Text-to-Image Generation |
| [stable_diffusion_img2img](./api/pipelines/stable_diffusion/img2img) | [Stable Diffusion](https://stability.ai/blog/stable-diffusion-public-release) | Image-to-Image Text-Guided Generation |
| [stable_diffusion_inpaint](./api/pipelines/stable_diffusion/inpaint) | [Stable Diffusion](https://stability.ai/blog/stable-diffusion-public-release) | Text-Guided Image Inpainting |
| [stable_diffusion_panorama](./api/pipelines/stable_diffusion/panorama) | [MultiDiffusion](https://multidiffusion.github.io/) | Text-to-Panorama Generation |
-| [stable_diffusion_pix2pix](./api/pipelines/stable_diffusion/pix2pix) | [InstructPix2Pix: Learning to Follow Image Editing Instructions](https://arxiv.org/abs/2211.09800) | Text-Guided Image Editing|
+| [stable_diffusion_pix2pix](./api/pipelines/stable_diffusion/pix2pix) | [InstructPix2Pix: Learning to Follow Image Editing Instructions](https://huggingface.co/papers/2211.09800) | Text-Guided Image Editing|
| [stable_diffusion_pix2pix_zero](./api/pipelines/stable_diffusion/pix2pix_zero) | [Zero-shot Image-to-Image Translation](https://pix2pixzero.github.io/) | Text-Guided Image Editing |
-| [stable_diffusion_attend_and_excite](./api/pipelines/stable_diffusion/attend_and_excite) | [Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models](https://arxiv.org/abs/2301.13826) | Text-to-Image Generation |
-| [stable_diffusion_self_attention_guidance](./api/pipelines/stable_diffusion/self_attention_guidance) | [Improving Sample Quality of Diffusion Models Using Self-Attention Guidance](https://arxiv.org/abs/2210.00939) | Text-to-Image Generation Unconditional Image Generation |
+| [stable_diffusion_attend_and_excite](./api/pipelines/stable_diffusion/attend_and_excite) | [Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models](https://huggingface.co/papers/2301.13826) | Text-to-Image Generation |
+| [stable_diffusion_self_attention_guidance](./api/pipelines/stable_diffusion/self_attention_guidance) | [Improving Sample Quality of Diffusion Models Using Self-Attention Guidance](https://huggingface.co/papers/2210.00939) | Text-to-Image Generation Unconditional Image Generation |
| [stable_diffusion_image_variation](./stable_diffusion/image_variation) | [Stable Diffusion Image Variations](https://github.com/LambdaLabsML/lambda-diffusers#stable-diffusion-image-variations) | Image-to-Image Generation |
| [stable_diffusion_latent_upscale](./stable_diffusion/latent_upscale) | [Stable Diffusion Latent Upscaler](https://twitter.com/StabilityAI/status/1590531958815064065) | Text-Guided Super Resolution Image-to-Image |
| [stable_diffusion_model_editing](./api/pipelines/stable_diffusion/model_editing) | [Editing Implicit Assumptions in Text-to-Image Diffusion Models](https://time-diffusion.github.io/) | Text-to-Image Model Editing |
@@ -89,13 +89,13 @@ specific language governing permissions and limitations under the License.
| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [Stable Diffusion 2](https://stability.ai/blog/stable-diffusion-v2-release) | Text-Guided Image Inpainting |
| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [Depth-Conditional Stable Diffusion](https://github.com/Stability-AI/stablediffusion#depth-conditional-stable-diffusion) | Depth-to-Image Generation |
| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [Stable Diffusion 2](https://stability.ai/blog/stable-diffusion-v2-release) | Text-Guided Super Resolution Image-to-Image |
-| [stable_diffusion_safe](./api/pipelines/stable_diffusion_safe) | [Safe Stable Diffusion](https://arxiv.org/abs/2211.05105) | Text-Guided Generation |
+| [stable_diffusion_safe](./api/pipelines/stable_diffusion_safe) | [Safe Stable Diffusion](https://huggingface.co/papers/2211.05105) | Text-Guided Generation |
| [stable_unclip](./stable_unclip) | Stable unCLIP | Text-to-Image Generation |
| [stable_unclip](./stable_unclip) | Stable unCLIP | Image-to-Image Text-Guided Generation |
-| [stochastic_karras_ve](./api/pipelines/stochastic_karras_ve) | [Elucidating the Design Space of Diffusion-Based Generative Models](https://arxiv.org/abs/2206.00364) | Unconditional Image Generation |
+| [stochastic_karras_ve](./api/pipelines/stochastic_karras_ve) | [Elucidating the Design Space of Diffusion-Based Generative Models](https://huggingface.co/papers/2206.00364) | Unconditional Image Generation |
| [text_to_video_sd](./api/pipelines/text_to_video) | [Modelscope's Text-to-video-synthesis Model in Open Domain](https://modelscope.cn/models/damo/text-to-video-synthesis/summary) | Text-to-Video Generation |
-| [unclip](./api/pipelines/unclip) | [Hierarchical Text-Conditional Image Generation with CLIP Latents](https://arxiv.org/abs/2204.06125)(implementation by [kakaobrain](https://github.com/kakaobrain/karlo)) | Text-to-Image Generation |
-| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Text-to-Image Generation |
-| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Image Variations Generation |
-| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Dual Image and Text Guided Generation |
-| [vq_diffusion](./api/pipelines/vq_diffusion) | [Vector Quantized Diffusion Model for Text-to-Image Synthesis](https://arxiv.org/abs/2111.14822) | Text-to-Image Generation |
+| [unclip](./api/pipelines/unclip) | [Hierarchical Text-Conditional Image Generation with CLIP Latents](https://huggingface.co/papers/2204.06125)(implementation by [kakaobrain](https://github.com/kakaobrain/karlo)) | Text-to-Image Generation |
+| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://huggingface.co/papers/2211.08332) | Text-to-Image Generation |
+| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://huggingface.co/papers/2211.08332) | Image Variations Generation |
+| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://huggingface.co/papers/2211.08332) | Dual Image and Text Guided Generation |
+| [vq_diffusion](./api/pipelines/vq_diffusion) | [Vector Quantized Diffusion Model for Text-to-Image Synthesis](https://huggingface.co/papers/2111.14822) | Text-to-Image Generation |
diff --git a/examples/advanced_diffusion_training/README.md b/examples/advanced_diffusion_training/README.md
index f30f8c83a1..eedb1c96e4 100644
--- a/examples/advanced_diffusion_training/README.md
+++ b/examples/advanced_diffusion_training/README.md
@@ -4,9 +4,9 @@
> [!TIP]
> 💡 This example follows the techniques and recommended practices covered in the blog post: [LoRA training scripts of the world, unite!](https://huggingface.co/blog/sdxl_lora_advanced_script). Make sure to check it out before starting 🤗
-[DreamBooth](https://arxiv.org/abs/2208.12242) is a method to personalize text2image models like stable diffusion given just a few(3~5) images of a subject.
+[DreamBooth](https://huggingface.co/papers/2208.12242) is a method to personalize text2image models like stable diffusion given just a few(3~5) images of a subject.
-LoRA - Low-Rank Adaption of Large Language Models, was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*
+LoRA - Low-Rank Adaption of Large Language Models, was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://huggingface.co/papers/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*
In a nutshell, LoRA allows to adapt pretrained models by adding pairs of rank-decomposition matrices to existing weights and **only** training those newly added weights. This has a couple of advantages:
- Previous pretrained weights are kept frozen so that the model is not prone to [catastrophic forgetting](https://www.pnas.org/doi/10.1073/pnas.1611835114)
- Rank-decomposition matrices have significantly fewer parameters than the original model, which means that trained LoRA weights are easily portable.
@@ -15,7 +15,7 @@ In a nutshell, LoRA allows to adapt pretrained models by adding pairs of rank-de
the popular [lora](https://github.com/cloneofsimo/lora) GitHub repository.
The `train_dreambooth_lora_sdxl_advanced.py` script shows how to implement dreambooth-LoRA, combining the training process shown in `train_dreambooth_lora_sdxl.py`, with
-advanced features and techniques, inspired and built upon contributions by [Nataniel Ruiz](https://twitter.com/natanielruizg): [Dreambooth](https://dreambooth.github.io), [Rinon Gal](https://twitter.com/RinonGal): [Textual Inversion](https://textual-inversion.github.io), [Ron Mokady](https://twitter.com/MokadyRon): [Pivotal Tuning](https://arxiv.org/abs/2106.05744), [Simo Ryu](https://twitter.com/cloneofsimo): [cog-sdxl](https://github.com/replicate/cog-sdxl),
+advanced features and techniques, inspired and built upon contributions by [Nataniel Ruiz](https://twitter.com/natanielruizg): [Dreambooth](https://dreambooth.github.io), [Rinon Gal](https://twitter.com/RinonGal): [Textual Inversion](https://textual-inversion.github.io), [Ron Mokady](https://twitter.com/MokadyRon): [Pivotal Tuning](https://huggingface.co/papers/2106.05744), [Simo Ryu](https://twitter.com/cloneofsimo): [cog-sdxl](https://github.com/replicate/cog-sdxl),
[Kohya](https://twitter.com/kohya_tech/): [sd-scripts](https://github.com/kohya-ss/sd-scripts), [The Last Ben](https://twitter.com/__TheBen): [fast-stable-diffusion](https://github.com/TheLastBen/fast-stable-diffusion) ❤️
> [!NOTE]
@@ -128,6 +128,7 @@ You can also load a dataset straight from by specifying it's name in `dataset_na
Look [here](https://huggingface.co/blog/sdxl_lora_advanced_script#custom-captioning) for more info on creating/loading your own caption dataset.
- **optimizer**: for this example, we'll use [prodigy](https://huggingface.co/blog/sdxl_lora_advanced_script#adaptive-optimizers) - an adaptive optimizer
+ - To use Prodigy, please make sure to install the prodigyopt library: `pip install prodigyopt`
- **pivotal tuning**
- **min SNR gamma**
@@ -246,7 +247,7 @@ SDXL's VAE is known to suffer from numerical instability issues. This is why we
### DoRA training
The advanced script supports DoRA training too!
-> Proposed in [DoRA: Weight-Decomposed Low-Rank Adaptation](https://arxiv.org/abs/2402.09353),
+> Proposed in [DoRA: Weight-Decomposed Low-Rank Adaptation](https://huggingface.co/papers/2402.09353),
**DoRA** is very similar to LoRA, except it decomposes the pre-trained weight into two components, **magnitude** and **direction** and employs LoRA for _directional_ updates to efficiently minimize the number of trainable parameters.
The authors found that by using DoRA, both the learning capacity and training stability of LoRA are enhanced without any additional overhead during inference.
@@ -272,7 +273,7 @@ The inference is the same as if you train a regular LoRA 🤗
## Conducting EDM-style training
-It's now possible to perform EDM-style training as proposed in [Elucidating the Design Space of Diffusion-Based Generative Models](https://arxiv.org/abs/2206.00364).
+It's now possible to perform EDM-style training as proposed in [Elucidating the Design Space of Diffusion-Based Generative Models](https://huggingface.co/papers/2206.00364).
simply set:
@@ -317,7 +318,7 @@ accelerate launch train_dreambooth_lora_sdxl_advanced.py \
### B-LoRA training
The advanced script now supports B-LoRA training too!
-> Proposed in [Implicit Style-Content Separation using B-LoRA](https://arxiv.org/abs/2403.14572),
+> Proposed in [Implicit Style-Content Separation using B-LoRA](https://huggingface.co/papers/2403.14572),
B-LoRA is a method that leverages LoRA to implicitly separate the style and content components of a **single** image.
It was shown that learning the LoRA weights of two specific blocks (referred to as B-LoRAs)
achieves style-content separation that cannot be achieved by training each B-LoRA independently.
diff --git a/examples/advanced_diffusion_training/README_flux.md b/examples/advanced_diffusion_training/README_flux.md
index ded6f11314..c05fa26cf9 100644
--- a/examples/advanced_diffusion_training/README_flux.md
+++ b/examples/advanced_diffusion_training/README_flux.md
@@ -5,9 +5,9 @@
> 💡 This example follows some of the techniques and recommended practices covered in the community derived guide we made for SDXL training: [LoRA training scripts of the world, unite!](https://huggingface.co/blog/sdxl_lora_advanced_script).
> As many of these are architecture agnostic & generally relevant to fine-tuning of diffusion models we suggest to take a look 🤗
-[DreamBooth](https://arxiv.org/abs/2208.12242) is a method to personalize text-to-image models like flux, stable diffusion given just a few(3~5) images of a subject.
+[DreamBooth](https://huggingface.co/papers/2208.12242) is a method to personalize text-to-image models like flux, stable diffusion given just a few(3~5) images of a subject.
-LoRA - Low-Rank Adaption of Large Language Models, was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*
+LoRA - Low-Rank Adaption of Large Language Models, was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://huggingface.co/papers/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*
In a nutshell, LoRA allows to adapt pretrained models by adding pairs of rank-decomposition matrices to existing weights and **only** training those newly added weights. This has a couple of advantages:
- Previous pretrained weights are kept frozen so that the model is not prone to [catastrophic forgetting](https://www.pnas.org/doi/10.1073/pnas.1611835114)
- Rank-decomposition matrices have significantly fewer parameters than the original model, which means that trained LoRA weights are easily portable.
@@ -16,7 +16,7 @@ In a nutshell, LoRA allows to adapt pretrained models by adding pairs of rank-de
the popular [lora](https://github.com/cloneofsimo/lora) GitHub repository.
The `train_dreambooth_lora_flux_advanced.py` script shows how to implement dreambooth-LoRA, combining the training process shown in `train_dreambooth_lora_flux.py`, with
-advanced features and techniques, inspired and built upon contributions by [Nataniel Ruiz](https://twitter.com/natanielruizg): [Dreambooth](https://dreambooth.github.io), [Rinon Gal](https://twitter.com/RinonGal): [Textual Inversion](https://textual-inversion.github.io), [Ron Mokady](https://twitter.com/MokadyRon): [Pivotal Tuning](https://arxiv.org/abs/2106.05744), [Simo Ryu](https://twitter.com/cloneofsimo): [cog-sdxl](https://github.com/replicate/cog-sdxl),
+advanced features and techniques, inspired and built upon contributions by [Nataniel Ruiz](https://twitter.com/natanielruizg): [Dreambooth](https://dreambooth.github.io), [Rinon Gal](https://twitter.com/RinonGal): [Textual Inversion](https://textual-inversion.github.io), [Ron Mokady](https://twitter.com/MokadyRon): [Pivotal Tuning](https://huggingface.co/papers/2106.05744), [Simo Ryu](https://twitter.com/cloneofsimo): [cog-sdxl](https://github.com/replicate/cog-sdxl),
[ostris](https://x.com/ostrisai):[ai-toolkit](https://github.com/ostris/ai-toolkit), [bghira](https://github.com/bghira):[SimpleTuner](https://github.com/bghira/SimpleTuner), [Kohya](https://twitter.com/kohya_tech/): [sd-scripts](https://github.com/kohya-ss/sd-scripts), [The Last Ben](https://twitter.com/__TheBen): [fast-stable-diffusion](https://github.com/TheLastBen/fast-stable-diffusion) ❤️
> [!NOTE]
@@ -143,7 +143,8 @@ Now we'll simply specify the name of the dataset and caption column (in this cas
You can also load a dataset straight from by specifying it's name in `dataset_name`.
Look [here](https://huggingface.co/blog/sdxl_lora_advanced_script#custom-captioning) for more info on creating/loading your own caption dataset.
-- **optimizer**: for this example, we'll use [prodigy](https://huggingface.co/blog/sdxl_lora_advanced_script#adaptive-optimizers) - an adaptive optimizer
+- **optimizer**: for this example, we'll use [prodigy](https://huggingface.co/blog/sdxl_lora_advanced_script#adaptive-optimizers) - an adaptive optimizer
+ - To use Prodigy, please make sure to install the prodigyopt library: `pip install prodigyopt`
- **pivotal tuning**
### Example #1: Pivotal tuning
diff --git a/examples/advanced_diffusion_training/train_dreambooth_lora_sd15_advanced.py b/examples/advanced_diffusion_training/train_dreambooth_lora_sd15_advanced.py
index 770f9b92f9..52aee07e81 100644
--- a/examples/advanced_diffusion_training/train_dreambooth_lora_sd15_advanced.py
+++ b/examples/advanced_diffusion_training/train_dreambooth_lora_sd15_advanced.py
@@ -498,7 +498,7 @@ def parse_args(input_args=None):
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
- "More details here: https://arxiv.org/abs/2303.09556.",
+ "More details here: https://huggingface.co/papers/2303.09556.",
)
parser.add_argument(
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
@@ -665,7 +665,7 @@ def parse_args(input_args=None):
action="store_true",
default=False,
help=(
- "Whether to train a DoRA as proposed in- DoRA: Weight-Decomposed Low-Rank Adaptation https://arxiv.org/abs/2402.09353. "
+ "Whether to train a DoRA as proposed in- DoRA: Weight-Decomposed Low-Rank Adaptation https://huggingface.co/papers/2402.09353. "
"Note: to use DoRA you need to install peft from main, `pip install git+https://github.com/huggingface/peft.git`"
),
)
@@ -1771,7 +1771,7 @@ def main(args):
if args.snr_gamma is None:
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
else:
- # Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
+ # Compute loss-weights as per Section 3.4 of https://huggingface.co/papers/2303.09556.
# Since we predict the noise instead of x_0, the original formulation is slightly changed.
# This is discussed in Section 4.2 of the same paper.
diff --git a/examples/advanced_diffusion_training/train_dreambooth_lora_sdxl_advanced.py b/examples/advanced_diffusion_training/train_dreambooth_lora_sdxl_advanced.py
index 29d454ba8e..911102c049 100644
--- a/examples/advanced_diffusion_training/train_dreambooth_lora_sdxl_advanced.py
+++ b/examples/advanced_diffusion_training/train_dreambooth_lora_sdxl_advanced.py
@@ -464,7 +464,7 @@ def parse_args(input_args=None):
"--do_edm_style_training",
default=False,
action="store_true",
- help="Flag to conduct training using the EDM formulation as introduced in https://arxiv.org/abs/2206.00364.",
+ help="Flag to conduct training using the EDM formulation as introduced in https://huggingface.co/papers/2206.00364.",
)
parser.add_argument(
"--with_prior_preservation",
@@ -607,7 +607,7 @@ def parse_args(input_args=None):
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
- "More details here: https://arxiv.org/abs/2303.09556.",
+ "More details here: https://huggingface.co/papers/2303.09556.",
)
parser.add_argument(
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
@@ -775,7 +775,7 @@ def parse_args(input_args=None):
action="store_true",
default=False,
help=(
- "Whether to train a DoRA as proposed in- DoRA: Weight-Decomposed Low-Rank Adaptation https://arxiv.org/abs/2402.09353. "
+ "Whether to train a DoRA as proposed in- DoRA: Weight-Decomposed Low-Rank Adaptation https://huggingface.co/papers/2402.09353. "
"Note: to use DoRA you need to install peft from main, `pip install git+https://github.com/huggingface/peft.git`"
),
)
@@ -793,7 +793,7 @@ def parse_args(input_args=None):
"--use_blora",
action="store_true",
help=(
- "Whether to train a B-LoRA as proposed in- Implicit Style-Content Separation using B-LoRA https://arxiv.org/abs/2403.14572. "
+ "Whether to train a B-LoRA as proposed in- Implicit Style-Content Separation using B-LoRA https://huggingface.co/papers/2403.14572. "
),
)
parser.add_argument(
@@ -2131,7 +2131,7 @@ def main(args):
noisy_model_input = noise_scheduler.add_noise(model_input, noise, timesteps)
# For EDM-style training, we first obtain the sigmas based on the continuous timesteps.
# We then precondition the final model inputs based on these sigmas instead of the timesteps.
- # Follow: Section 5 of https://arxiv.org/abs/2206.00364.
+ # Follow: Section 5 of https://huggingface.co/papers/2206.00364.
if args.do_edm_style_training:
sigmas = get_sigmas(timesteps, len(noisy_model_input.shape), noisy_model_input.dtype)
if "EDM" in scheduler_type:
@@ -2193,7 +2193,7 @@ def main(args):
if args.do_edm_style_training:
# Similar to the input preconditioning, the model predictions are also preconditioned
# on noised model inputs (before preconditioning) and the sigmas.
- # Follow: Section 5 of https://arxiv.org/abs/2206.00364.
+ # Follow: Section 5 of https://huggingface.co/papers/2206.00364.
if "EDM" in scheduler_type:
model_pred = noise_scheduler.precondition_outputs(noisy_model_input, model_pred, sigmas)
else:
@@ -2251,7 +2251,7 @@ def main(args):
else:
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
else:
- # Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
+ # Compute loss-weights as per Section 3.4 of https://huggingface.co/papers/2303.09556.
# Since we predict the noise instead of x_0, the original formulation is slightly changed.
# This is discussed in Section 4.2 of the same paper.
diff --git a/examples/amused/README.md b/examples/amused/README.md
index 9d5ae17ef5..e7916eafcc 100644
--- a/examples/amused/README.md
+++ b/examples/amused/README.md
@@ -250,7 +250,7 @@ accelerate launch train_amused.py \
### Styledrop
-[Styledrop](https://arxiv.org/abs/2306.00983) is an efficient finetuning method for learning a new style from just one or very few images. It has an optional first stage to generate human picked additional training samples. The additional training samples can be used to augment the initial images. Our examples exclude the optional additional image selection stage and instead we just finetune on a single image.
+[Styledrop](https://huggingface.co/papers/2306.00983) is an efficient finetuning method for learning a new style from just one or very few images. It has an optional first stage to generate human picked additional training samples. The additional training samples can be used to augment the initial images. Our examples exclude the optional additional image selection stage and instead we just finetune on a single image.
This is our example style image:

diff --git a/examples/cogvideo/README.md b/examples/cogvideo/README.md
index 6cb0a51e9f..dc74690983 100644
--- a/examples/cogvideo/README.md
+++ b/examples/cogvideo/README.md
@@ -1,6 +1,6 @@
# LoRA finetuning example for CogVideoX
-Low-Rank Adaption of Large Language Models was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*.
+Low-Rank Adaption of Large Language Models was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://huggingface.co/papers/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*.
In a nutshell, LoRA allows adapting pretrained models by adding pairs of rank-decomposition matrices to existing weights and **only** training those newly added weights. This has a couple of advantages:
diff --git a/examples/cogvideo/train_cogvideox_image_to_video_lora.py b/examples/cogvideo/train_cogvideox_image_to_video_lora.py
index 642aecabf7..809911c279 100644
--- a/examples/cogvideo/train_cogvideox_image_to_video_lora.py
+++ b/examples/cogvideo/train_cogvideox_image_to_video_lora.py
@@ -555,7 +555,7 @@ class VideoDataset(Dataset):
if any(not path.is_file() for path in instance_videos):
raise ValueError(
- "Expected '--video_column' to be a path to a file in `--instance_data_root` containing line-separated paths to video data but found atleast one path that is not a valid file."
+ "Expected '--video_column' to be a path to a file in `--instance_data_root` containing line-separated paths to video data but found at least one path that is not a valid file."
)
return instance_prompts, instance_videos
diff --git a/examples/cogvideo/train_cogvideox_lora.py b/examples/cogvideo/train_cogvideox_lora.py
index e737ce7624..acd593c2af 100644
--- a/examples/cogvideo/train_cogvideox_lora.py
+++ b/examples/cogvideo/train_cogvideox_lora.py
@@ -539,7 +539,7 @@ class VideoDataset(Dataset):
if any(not path.is_file() for path in instance_videos):
raise ValueError(
- "Expected '--video_column' to be a path to a file in `--instance_data_root` containing line-separated paths to video data but found atleast one path that is not a valid file."
+ "Expected '--video_column' to be a path to a file in `--instance_data_root` containing line-separated paths to video data but found at least one path that is not a valid file."
)
return instance_prompts, instance_videos
diff --git a/examples/community/README.md b/examples/community/README.md
index 3117070b20..225a25fac7 100644
--- a/examples/community/README.md
+++ b/examples/community/README.md
@@ -10,7 +10,7 @@ Please also check out our [Community Scripts](https://github.com/huggingface/dif
| Example | Description | Code Example | Colab | Author |
|:--------------------------------------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:------------------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------:|
-|Spatiotemporal Skip Guidance (STG)|[Spatiotemporal Skip Guidance for Enhanced Video Diffusion Sampling](https://arxiv.org/abs/2411.18664) (CVPR 2025) enhances video diffusion models by generating a weaker model through layer skipping and using it as guidance, improving fidelity in models like HunyuanVideo, LTXVideo, and Mochi.|[Spatiotemporal Skip Guidance](#spatiotemporal-skip-guidance)|-|[Junha Hyung](https://junhahyung.github.io/), [Kinam Kim](https://kinam0252.github.io/), and [Ednaordinary](https://github.com/Ednaordinary)|
+|Spatiotemporal Skip Guidance (STG)|[Spatiotemporal Skip Guidance for Enhanced Video Diffusion Sampling](https://huggingface.co/papers/2411.18664) (CVPR 2025) enhances video diffusion models by generating a weaker model through layer skipping and using it as guidance, improving fidelity in models like HunyuanVideo, LTXVideo, and Mochi.|[Spatiotemporal Skip Guidance](#spatiotemporal-skip-guidance)|-|[Junha Hyung](https://junhahyung.github.io/), [Kinam Kim](https://kinam0252.github.io/), and [Ednaordinary](https://github.com/Ednaordinary)|
|Adaptive Mask Inpainting|Adaptive Mask Inpainting algorithm from [Beyond the Contact: Discovering Comprehensive Affordance for 3D Objects from Pre-trained 2D Diffusion Models](https://github.com/snuvclab/coma) (ECCV '24, Oral) provides a way to insert human inside the scene image without altering the background, by inpainting with adapting mask.|[Adaptive Mask Inpainting](#adaptive-mask-inpainting)|-|[Hyeonwoo Kim](https://sshowbiz.xyz),[Sookwan Han](https://jellyheadandrew.github.io)|
|Flux with CFG|[Flux with CFG](https://github.com/ToTheBeginning/PuLID/blob/main/docs/pulid_for_flux.md) provides an implementation of using CFG in [Flux](https://blackforestlabs.ai/announcing-black-forest-labs/).|[Flux with CFG](#flux-with-cfg)|[Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/flux_with_cfg.ipynb)|[Linoy Tsaban](https://github.com/linoytsaban), [Apolinário](https://github.com/apolinario), and [Sayak Paul](https://github.com/sayakpaul)|
|Differential Diffusion|[Differential Diffusion](https://github.com/exx8/differential-diffusion) modifies an image according to a text prompt, and according to a map that specifies the amount of change in each region.|[Differential Diffusion](#differential-diffusion)|[](https://huggingface.co/spaces/exx8/differential-diffusion) [](https://colab.research.google.com/github/exx8/differential-diffusion/blob/main/examples/SD2.ipynb)|[Eran Levin](https://github.com/exx8) and [Ohad Fried](https://www.ohadf.com/)|
@@ -39,17 +39,17 @@ Please also check out our [Community Scripts](https://github.com/huggingface/dif
| Stable UnCLIP | Diffusion Pipeline for combining prior model (generate clip image embedding from text, UnCLIPPipeline `"kakaobrain/karlo-v1-alpha"`) and decoder pipeline (decode clip image embedding to image, StableDiffusionImageVariationPipeline `"lambdalabs/sd-image-variations-diffusers"` ). | [Stable UnCLIP](#stable-unclip) | [Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/stable_unclip.ipynb) | [Ray Wang](https://wrong.wang) |
| UnCLIP Text Interpolation Pipeline | Diffusion Pipeline that allows passing two prompts and produces images while interpolating between the text-embeddings of the two prompts | [UnCLIP Text Interpolation Pipeline](#unclip-text-interpolation-pipeline) | [Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/unclip_text_interpolation.ipynb)| [Naga Sai Abhinay Devarinti](https://github.com/Abhinay1997/) |
| UnCLIP Image Interpolation Pipeline | Diffusion Pipeline that allows passing two images/image_embeddings and produces images while interpolating between their image-embeddings | [UnCLIP Image Interpolation Pipeline](#unclip-image-interpolation-pipeline) | [Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/unclip_image_interpolation.ipynb)| [Naga Sai Abhinay Devarinti](https://github.com/Abhinay1997/) |
-| DDIM Noise Comparative Analysis Pipeline | Investigating how the diffusion models learn visual concepts from each noise level (which is a contribution of [P2 weighting (CVPR 2022)](https://arxiv.org/abs/2204.00227)) | [DDIM Noise Comparative Analysis Pipeline](#ddim-noise-comparative-analysis-pipeline) | [Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/ddim_noise_comparative_analysis.ipynb)| [Aengus (Duc-Anh)](https://github.com/aengusng8) |
+| DDIM Noise Comparative Analysis Pipeline | Investigating how the diffusion models learn visual concepts from each noise level (which is a contribution of [P2 weighting (CVPR 2022)](https://huggingface.co/papers/2204.00227)) | [DDIM Noise Comparative Analysis Pipeline](#ddim-noise-comparative-analysis-pipeline) | [Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/ddim_noise_comparative_analysis.ipynb)| [Aengus (Duc-Anh)](https://github.com/aengusng8) |
| CLIP Guided Img2Img Stable Diffusion Pipeline | Doing CLIP guidance for image to image generation with Stable Diffusion | [CLIP Guided Img2Img Stable Diffusion](#clip-guided-img2img-stable-diffusion) | [Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/clip_guided_img2img_stable_diffusion.ipynb) | [Nipun Jindal](https://github.com/nipunjindal/) |
| TensorRT Stable Diffusion Text to Image Pipeline | Accelerates the Stable Diffusion Text2Image Pipeline using TensorRT | [TensorRT Stable Diffusion Text to Image Pipeline](#tensorrt-text2image-stable-diffusion-pipeline) | [Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/tensorrt_text2image_stable_diffusion_pipeline.ipynb) | [Asfiya Baig](https://github.com/asfiyab-nvidia) |
| EDICT Image Editing Pipeline | Diffusion pipeline for text-guided image editing | [EDICT Image Editing Pipeline](#edict-image-editing-pipeline) | [Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/edict_image_pipeline.ipynb) | [Joqsan Azocar](https://github.com/Joqsan) |
-| Stable Diffusion RePaint | Stable Diffusion pipeline using [RePaint](https://arxiv.org/abs/2201.09865) for inpainting. | [Stable Diffusion RePaint](#stable-diffusion-repaint )|[Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/stable_diffusion_repaint.ipynb)| [Markus Pobitzer](https://github.com/Markus-Pobitzer) |
+| Stable Diffusion RePaint | Stable Diffusion pipeline using [RePaint](https://huggingface.co/papers/2201.09865) for inpainting. | [Stable Diffusion RePaint](#stable-diffusion-repaint )|[Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/stable_diffusion_repaint.ipynb)| [Markus Pobitzer](https://github.com/Markus-Pobitzer) |
| TensorRT Stable Diffusion Image to Image Pipeline | Accelerates the Stable Diffusion Image2Image Pipeline using TensorRT | [TensorRT Stable Diffusion Image to Image Pipeline](#tensorrt-image2image-stable-diffusion-pipeline) | - | [Asfiya Baig](https://github.com/asfiyab-nvidia) |
| Stable Diffusion IPEX Pipeline | Accelerate Stable Diffusion inference pipeline with BF16/FP32 precision on Intel Xeon CPUs with [IPEX](https://github.com/intel/intel-extension-for-pytorch) | [Stable Diffusion on IPEX](#stable-diffusion-on-ipex) | - | [Yingjie Han](https://github.com/yingjie-han/) |
| CLIP Guided Images Mixing Stable Diffusion Pipeline | Сombine images using usual diffusion models. | [CLIP Guided Images Mixing Using Stable Diffusion](#clip-guided-images-mixing-with-stable-diffusion) | [Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/clip_guided_images_mixing_with_stable_diffusion.ipynb) | [Karachev Denis](https://github.com/TheDenk) |
| TensorRT Stable Diffusion Inpainting Pipeline | Accelerates the Stable Diffusion Inpainting Pipeline using TensorRT | [TensorRT Stable Diffusion Inpainting Pipeline](#tensorrt-inpainting-stable-diffusion-pipeline) | - | [Asfiya Baig](https://github.com/asfiyab-nvidia) |
-| IADB Pipeline | Implementation of [Iterative α-(de)Blending: a Minimalist Deterministic Diffusion Model](https://arxiv.org/abs/2305.03486) | [IADB Pipeline](#iadb-pipeline) | - | [Thomas Chambon](https://github.com/tchambon)
-| Zero1to3 Pipeline | Implementation of [Zero-1-to-3: Zero-shot One Image to 3D Object](https://arxiv.org/abs/2303.11328) | [Zero1to3 Pipeline](#zero1to3-pipeline) | - | [Xin Kong](https://github.com/kxhit) |
+| IADB Pipeline | Implementation of [Iterative α-(de)Blending: a Minimalist Deterministic Diffusion Model](https://huggingface.co/papers/2305.03486) | [IADB Pipeline](#iadb-pipeline) | - | [Thomas Chambon](https://github.com/tchambon)
+| Zero1to3 Pipeline | Implementation of [Zero-1-to-3: Zero-shot One Image to 3D Object](https://huggingface.co/papers/2303.11328) | [Zero1to3 Pipeline](#zero1to3-pipeline) | - | [Xin Kong](https://github.com/kxhit) |
| Stable Diffusion XL Long Weighted Prompt Pipeline | A pipeline support unlimited length of prompt and negative prompt, use A1111 style of prompt weighting | [Stable Diffusion XL Long Weighted Prompt Pipeline](#stable-diffusion-xl-long-weighted-prompt-pipeline) | [](https://colab.research.google.com/drive/1LsqilswLR40XLLcp6XFOl5nKb_wOe26W?usp=sharing) | [Andrew Zhu](https://xhinker.medium.com/) |
| Stable Diffusion Mixture Tiling Pipeline SD 1.5 | A pipeline generates cohesive images by integrating multiple diffusion processes, each focused on a specific image region and considering boundary effects for smooth blending | [Stable Diffusion Mixture Tiling Pipeline SD 1.5](#stable-diffusion-mixture-tiling-pipeline-sd-15) | [](https://huggingface.co/spaces/albarji/mixture-of-diffusers) | [Álvaro B Jiménez](https://github.com/albarji/) |
| Stable Diffusion Mixture Canvas Pipeline SD 1.5 | A pipeline generates cohesive images by integrating multiple diffusion processes, each focused on a specific image region and considering boundary effects for smooth blending. Works by defining a list of Text2Image region objects that detail the region of influence of each diffuser. | [Stable Diffusion Mixture Canvas Pipeline SD 1.5](#stable-diffusion-mixture-canvas-pipeline-sd-15) | [](https://huggingface.co/spaces/albarji/mixture-of-diffusers) | [Álvaro B Jiménez](https://github.com/albarji/) |
@@ -59,25 +59,25 @@ Please also check out our [Community Scripts](https://github.com/huggingface/dif
| sketch inpaint - Inpainting with non-inpaint Stable Diffusion | sketch inpaint much like in automatic1111 | [Masked Im2Im Stable Diffusion Pipeline](#stable-diffusion-masked-im2im) | - | [Anatoly Belikov](https://github.com/noskill) |
| sketch inpaint xl - Inpainting with non-inpaint Stable Diffusion | sketch inpaint much like in automatic1111 | [Masked Im2Im Stable Diffusion XL Pipeline](#stable-diffusion-xl-masked-im2im) | - | [Anatoly Belikov](https://github.com/noskill) |
| prompt-to-prompt | change parts of a prompt and retain image structure (see [paper page](https://prompt-to-prompt.github.io/)) | [Prompt2Prompt Pipeline](#prompt2prompt-pipeline) | [Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/prompt_2_prompt_pipeline.ipynb) | [Umer H. Adil](https://twitter.com/UmerHAdil) |
-| Latent Consistency Pipeline | Implementation of [Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference](https://arxiv.org/abs/2310.04378) | [Latent Consistency Pipeline](#latent-consistency-pipeline) | - | [Simian Luo](https://github.com/luosiallen) |
+| Latent Consistency Pipeline | Implementation of [Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference](https://huggingface.co/papers/2310.04378) | [Latent Consistency Pipeline](#latent-consistency-pipeline) | - | [Simian Luo](https://github.com/luosiallen) |
| Latent Consistency Img2img Pipeline | Img2img pipeline for Latent Consistency Models | [Latent Consistency Img2Img Pipeline](#latent-consistency-img2img-pipeline) | - | [Logan Zoellner](https://github.com/nagolinc) |
| Latent Consistency Interpolation Pipeline | Interpolate the latent space of Latent Consistency Models with multiple prompts | [Latent Consistency Interpolation Pipeline](#latent-consistency-interpolation-pipeline) | [](https://colab.research.google.com/drive/1pK3NrLWJSiJsBynLns1K1-IDTW9zbPvl?usp=sharing) | [Aryan V S](https://github.com/a-r-r-o-w) |
| SDE Drag Pipeline | The pipeline supports drag editing of images using stochastic differential equations | [SDE Drag Pipeline](#sde-drag-pipeline) | [Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/sde_drag.ipynb) | [NieShen](https://github.com/NieShenRuc) [Fengqi Zhu](https://github.com/Monohydroxides) |
| Regional Prompting Pipeline | Assign multiple prompts for different regions | [Regional Prompting Pipeline](#regional-prompting-pipeline) | - | [hako-mikan](https://github.com/hako-mikan) |
| LDM3D-sr (LDM3D upscaler) | Upscale low resolution RGB and depth inputs to high resolution | [StableDiffusionUpscaleLDM3D Pipeline](https://github.com/estelleafl/diffusers/tree/ldm3d_upscaler_community/examples/community#stablediffusionupscaleldm3d-pipeline) | - | [Estelle Aflalo](https://github.com/estelleafl) |
| AnimateDiff ControlNet Pipeline | Combines AnimateDiff with precise motion control using ControlNets | [AnimateDiff ControlNet Pipeline](#animatediff-controlnet-pipeline) | [](https://colab.research.google.com/drive/1SKboYeGjEQmQPWoFC0aLYpBlYdHXkvAu?usp=sharing) | [Aryan V S](https://github.com/a-r-r-o-w) and [Edoardo Botta](https://github.com/EdoardoBotta) |
-| DemoFusion Pipeline | Implementation of [DemoFusion: Democratising High-Resolution Image Generation With No $$$](https://arxiv.org/abs/2311.16973) | [DemoFusion Pipeline](#demofusion) | [Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/demo_fusion.ipynb) | [Ruoyi Du](https://github.com/RuoyiDu) |
-| Instaflow Pipeline | Implementation of [InstaFlow! One-Step Stable Diffusion with Rectified Flow](https://arxiv.org/abs/2309.06380) | [Instaflow Pipeline](#instaflow-pipeline) | [Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/insta_flow.ipynb) | [Ayush Mangal](https://github.com/ayushtues) |
-| Null-Text Inversion Pipeline | Implement [Null-text Inversion for Editing Real Images using Guided Diffusion Models](https://arxiv.org/abs/2211.09794) as a pipeline. | [Null-Text Inversion](https://github.com/google/prompt-to-prompt/) | - | [Junsheng Luan](https://github.com/Junsheng121) |
-| Rerender A Video Pipeline | Implementation of [[SIGGRAPH Asia 2023] Rerender A Video: Zero-Shot Text-Guided Video-to-Video Translation](https://arxiv.org/abs/2306.07954) | [Rerender A Video Pipeline](#rerender-a-video) | - | [Yifan Zhou](https://github.com/SingleZombie) |
-| StyleAligned Pipeline | Implementation of [Style Aligned Image Generation via Shared Attention](https://arxiv.org/abs/2312.02133) | [StyleAligned Pipeline](#stylealigned-pipeline) | [](https://drive.google.com/file/d/15X2E0jFPTajUIjS0FzX50OaHsCbP2lQ0/view?usp=sharing) | [Aryan V S](https://github.com/a-r-r-o-w) |
+| DemoFusion Pipeline | Implementation of [DemoFusion: Democratising High-Resolution Image Generation With No $$$](https://huggingface.co/papers/2311.16973) | [DemoFusion Pipeline](#demofusion) | [Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/demo_fusion.ipynb) | [Ruoyi Du](https://github.com/RuoyiDu) |
+| Instaflow Pipeline | Implementation of [InstaFlow! One-Step Stable Diffusion with Rectified Flow](https://huggingface.co/papers/2309.06380) | [Instaflow Pipeline](#instaflow-pipeline) | [Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/insta_flow.ipynb) | [Ayush Mangal](https://github.com/ayushtues) |
+| Null-Text Inversion Pipeline | Implement [Null-text Inversion for Editing Real Images using Guided Diffusion Models](https://huggingface.co/papers/2211.09794) as a pipeline. | [Null-Text Inversion](https://github.com/google/prompt-to-prompt/) | - | [Junsheng Luan](https://github.com/Junsheng121) |
+| Rerender A Video Pipeline | Implementation of [[SIGGRAPH Asia 2023] Rerender A Video: Zero-Shot Text-Guided Video-to-Video Translation](https://huggingface.co/papers/2306.07954) | [Rerender A Video Pipeline](#rerender-a-video) | - | [Yifan Zhou](https://github.com/SingleZombie) |
+| StyleAligned Pipeline | Implementation of [Style Aligned Image Generation via Shared Attention](https://huggingface.co/papers/2312.02133) | [StyleAligned Pipeline](#stylealigned-pipeline) | [](https://drive.google.com/file/d/15X2E0jFPTajUIjS0FzX50OaHsCbP2lQ0/view?usp=sharing) | [Aryan V S](https://github.com/a-r-r-o-w) |
| AnimateDiff Image-To-Video Pipeline | Experimental Image-To-Video support for AnimateDiff (open to improvements) | [AnimateDiff Image To Video Pipeline](#animatediff-image-to-video-pipeline) | [](https://drive.google.com/file/d/1TvzCDPHhfFtdcJZe4RLloAwyoLKuttWK/view?usp=sharing) | [Aryan V S](https://github.com/a-r-r-o-w) |
| IP Adapter FaceID Stable Diffusion | Stable Diffusion Pipeline that supports IP Adapter Face ID | [IP Adapter Face ID](#ip-adapter-face-id) |[Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/ip_adapter_face_id.ipynb)| [Fabio Rigano](https://github.com/fabiorigano) |
| InstantID Pipeline | Stable Diffusion XL Pipeline that supports InstantID | [InstantID Pipeline](#instantid-pipeline) | [](https://huggingface.co/spaces/InstantX/InstantID) | [Haofan Wang](https://github.com/haofanwang) |
| UFOGen Scheduler | Scheduler for UFOGen Model (compatible with Stable Diffusion pipelines) | [UFOGen Scheduler](#ufogen-scheduler) | - | [dg845](https://github.com/dg845) |
| Stable Diffusion XL IPEX Pipeline | Accelerate Stable Diffusion XL inference pipeline with BF16/FP32 precision on Intel Xeon CPUs with [IPEX](https://github.com/intel/intel-extension-for-pytorch) | [Stable Diffusion XL on IPEX](#stable-diffusion-xl-on-ipex) | - | [Dan Li](https://github.com/ustcuna/) |
| Stable Diffusion BoxDiff Pipeline | Training-free controlled generation with bounding boxes using [BoxDiff](https://github.com/showlab/BoxDiff) | [Stable Diffusion BoxDiff Pipeline](#stable-diffusion-boxdiff) | - | [Jingyang Zhang](https://github.com/zjysteven/) |
-| FRESCO V2V Pipeline | Implementation of [[CVPR 2024] FRESCO: Spatial-Temporal Correspondence for Zero-Shot Video Translation](https://arxiv.org/abs/2403.12962) | [FRESCO V2V Pipeline](#fresco) | - | [Yifan Zhou](https://github.com/SingleZombie) |
+| FRESCO V2V Pipeline | Implementation of [[CVPR 2024] FRESCO: Spatial-Temporal Correspondence for Zero-Shot Video Translation](https://huggingface.co/papers/2403.12962) | [FRESCO V2V Pipeline](#fresco) | - | [Yifan Zhou](https://github.com/SingleZombie) |
| AnimateDiff IPEX Pipeline | Accelerate AnimateDiff inference pipeline with BF16/FP32 precision on Intel Xeon CPUs with [IPEX](https://github.com/intel/intel-extension-for-pytorch) | [AnimateDiff on IPEX](#animatediff-on-ipex) | - | [Dan Li](https://github.com/ustcuna/) |
PIXART-α Controlnet pipeline | Implementation of the controlnet model for pixart alpha and its diffusers pipeline | [PIXART-α Controlnet pipeline](#pixart-α-controlnet-pipeline) | - | [Raul Ciotescu](https://github.com/raulc0399/) |
| HunyuanDiT Differential Diffusion Pipeline | Applies [Differential Diffusion](https://github.com/exx8/differential-diffusion) to [HunyuanDiT](https://github.com/huggingface/diffusers/pull/8240). | [HunyuanDiT with Differential Diffusion](#hunyuandit-with-differential-diffusion) | [](https://colab.research.google.com/drive/1v44a5fpzyr4Ffr4v2XBQ7BajzG874N4P?usp=sharing) | [Monjoy Choudhury](https://github.com/MnCSSJ4x) |
@@ -85,7 +85,7 @@ PIXART-α Controlnet pipeline | Implementation of the controlnet model for pixar
| Stable Diffusion XL Attentive Eraser Pipeline |[[AAAI2025 Oral] Attentive Eraser](https://github.com/Anonym0u3/AttentiveEraser) is a novel tuning-free method that enhances object removal capabilities in pre-trained diffusion models.|[Stable Diffusion XL Attentive Eraser Pipeline](#stable-diffusion-xl-attentive-eraser-pipeline)|-|[Wenhao Sun](https://github.com/Anonym0u3) and [Benlei Cui](https://github.com/Benny079)|
| Perturbed-Attention Guidance |StableDiffusionPAGPipeline is a modification of StableDiffusionPipeline to support Perturbed-Attention Guidance (PAG).|[Perturbed-Attention Guidance](#perturbed-attention-guidance)|[Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/perturbed_attention_guidance.ipynb)|[Hyoungwon Cho](https://github.com/HyoungwonCho)|
| CogVideoX DDIM Inversion Pipeline | Implementation of DDIM inversion and guided attention-based editing denoising process on CogVideoX. | [CogVideoX DDIM Inversion Pipeline](#cogvideox-ddim-inversion-pipeline) | - | [LittleNyima](https://github.com/LittleNyima) |
-| FaithDiff Stable Diffusion XL Pipeline | Implementation of [(CVPR 2025) FaithDiff: Unleashing Diffusion Priors for Faithful Image Super-resolutionUnleashing Diffusion Priors for Faithful Image Super-resolution](https://arxiv.org/abs/2411.18824) - FaithDiff is a faithful image super-resolution method that leverages latent diffusion models by actively adapting the diffusion prior and jointly fine-tuning its components (encoder and diffusion model) with an alignment module to ensure high fidelity and structural consistency. | [FaithDiff Stable Diffusion XL Pipeline](#faithdiff-stable-diffusion-xl-pipeline) | [](https://huggingface.co/jychen9811/FaithDiff) | [Junyang Chen, Jinshan Pan, Jiangxin Dong, IMAG Lab, (Adapted by Eliseu Silva)](https://github.com/JyChen9811/FaithDiff) |
+| FaithDiff Stable Diffusion XL Pipeline | Implementation of [(CVPR 2025) FaithDiff: Unleashing Diffusion Priors for Faithful Image Super-resolutionUnleashing Diffusion Priors for Faithful Image Super-resolution](https://huggingface.co/papers/2411.18824) - FaithDiff is a faithful image super-resolution method that leverages latent diffusion models by actively adapting the diffusion prior and jointly fine-tuning its components (encoder and diffusion model) with an alignment module to ensure high fidelity and structural consistency. | [FaithDiff Stable Diffusion XL Pipeline](#faithdiff-stable-diffusion-xl-pipeline) | [](https://huggingface.co/jychen9811/FaithDiff) | [Junyang Chen, Jinshan Pan, Jiangxin Dong, IMAG Lab, (Adapted by Eliseu Silva)](https://github.com/JyChen9811/FaithDiff) |
| Stable Diffusion 3 InstructPix2Pix Pipeline | Implementation of Stable Diffusion 3 InstructPix2Pix Pipeline | [Stable Diffusion 3 InstructPix2Pix Pipeline](#stable-diffusion-3-instructpix2pix-pipeline) | [](https://huggingface.co/BleachNick/SD3_UltraEdit_freeform) [](https://huggingface.co/CaptainZZZ/sd3-instructpix2pix) | [Jiayu Zhang](https://github.com/xduzhangjiayu) and [Haozhe Zhao](https://github.com/HaozheZhao)|
To load a custom pipeline you just need to pass the `custom_pipeline` argument to `DiffusionPipeline`, as one of the files in `diffusers/examples/community`. Feel free to send a PR with your own pipelines, we will merge them quickly.
@@ -101,7 +101,7 @@ pipe = DiffusionPipeline.from_pretrained("stable-diffusion-v1-5/stable-diffusion
**KAIST AI, University of Washington**
-[*Spatiotemporal Skip Guidance (STG) for Enhanced Video Diffusion Sampling*](https://arxiv.org/abs/2411.18664) (CVPR 2025) is a simple training-free sampling guidance method for enhancing transformer-based video diffusion models. STG employs an implicit weak model via self-perturbation, avoiding the need for external models or additional training. By selectively skipping spatiotemporal layers, STG produces an aligned, degraded version of the original model to boost sample quality without compromising diversity or dynamic degree.
+[*Spatiotemporal Skip Guidance (STG) for Enhanced Video Diffusion Sampling*](https://huggingface.co/papers/2411.18664) (CVPR 2025) is a simple training-free sampling guidance method for enhancing transformer-based video diffusion models. STG employs an implicit weak model via self-perturbation, avoiding the need for external models or additional training. By selectively skipping spatiotemporal layers, STG produces an aligned, degraded version of the original model to boost sample quality without compromising diversity or dynamic degree.
Following is the example video of STG applied to Mochi.
@@ -161,7 +161,7 @@ Here is the demonstration of Adaptive Mask Inpainting:

-You can find additional information about Adaptive Mask Inpainting in the [paper](https://arxiv.org/pdf/2401.12978) or in the [project website](https://snuvclab.github.io/coma).
+You can find additional information about Adaptive Mask Inpainting in the [paper](https://huggingface.co/papers/2401.12978) or in the [project website](https://snuvclab.github.io/coma).
#### Usage example
First, clone the diffusers github repository, and run the following command to set environment.
@@ -413,7 +413,7 @@ image.save("result.png")
### HD-Painter
-Implementation of [HD-Painter: High-Resolution and Prompt-Faithful Text-Guided Image Inpainting with Diffusion Models](https://arxiv.org/abs/2312.14091).
+Implementation of [HD-Painter: High-Resolution and Prompt-Faithful Text-Guided Image Inpainting with Diffusion Models](https://huggingface.co/papers/2312.14091).

@@ -428,7 +428,7 @@ Moreover, HD-Painter allows extension to larger scales by introducing a speciali
Our experiments demonstrate that HD-Painter surpasses existing state-of-the-art approaches qualitatively and quantitatively, achieving an impressive generation accuracy improvement of **61.4** vs **51.9**.
We will make the codes publicly available.
-You can find additional information about Text2Video-Zero in the [paper](https://arxiv.org/abs/2312.14091) or the [original codebase](https://github.com/Picsart-AI-Research/HD-Painter).
+You can find additional information about Text2Video-Zero in the [paper](https://huggingface.co/papers/2312.14091) or the [original codebase](https://github.com/Picsart-AI-Research/HD-Painter).
#### Usage example
@@ -1362,7 +1362,7 @@ print("Inpainting completed. Image saved as 'inpainting_output.png'.")
### Bit Diffusion
-Based , this is used for diffusion on discrete data - eg, discrete image data, DNA sequence data. An unconditional discrete image can be generated like this:
+Based , this is used for diffusion on discrete data - eg, discrete image data, DNA sequence data. An unconditional discrete image can be generated like this:
```python
from diffusers import DiffusionPipeline
@@ -1523,7 +1523,7 @@ As a result, you can look at a grid of all 4 generated images being shown togeth
### Magic Mix
-Implementation of the [MagicMix: Semantic Mixing with Diffusion Models](https://arxiv.org/abs/2210.16056) paper. This is a Diffusion Pipeline for semantic mixing of an image and a text prompt to create a new concept while preserving the spatial layout and geometry of the subject in the image. The pipeline takes an image that provides the layout semantics and a prompt that provides the content semantics for the mixing process.
+Implementation of the [MagicMix: Semantic Mixing with Diffusion Models](https://huggingface.co/papers/2210.16056) paper. This is a Diffusion Pipeline for semantic mixing of an image and a text prompt to create a new concept while preserving the spatial layout and geometry of the subject in the image. The pipeline takes an image that provides the layout semantics and a prompt that provides the content semantics for the mixing process.
There are 3 parameters for the method-
@@ -1754,7 +1754,7 @@ The resulting images in order:-
#### **Research question: What visual concepts do the diffusion models learn from each noise level during training?**
-The [P2 weighting (CVPR 2022)](https://arxiv.org/abs/2204.00227) paper proposed an approach to answer the above question, which is their second contribution.
+The [P2 weighting (CVPR 2022)](https://huggingface.co/papers/2204.00227) paper proposed an approach to answer the above question, which is their second contribution.
The approach consists of the following steps:
1. The input is an image x0.
@@ -1896,7 +1896,7 @@ image.save('tensorrt_mt_fuji.png')
### EDICT Image Editing Pipeline
-This pipeline implements the text-guided image editing approach from the paper [EDICT: Exact Diffusion Inversion via Coupled Transformations](https://arxiv.org/abs/2211.12446). You have to pass:
+This pipeline implements the text-guided image editing approach from the paper [EDICT: Exact Diffusion Inversion via Coupled Transformations](https://huggingface.co/papers/2211.12446). You have to pass:
- (`PIL`) `image` you want to edit.
- `base_prompt`: the text prompt describing the current image (before editing).
@@ -1981,7 +1981,7 @@ Output Image
### Stable Diffusion RePaint
-This pipeline uses the [RePaint](https://arxiv.org/abs/2201.09865) logic on the latent space of stable diffusion. It can
+This pipeline uses the [RePaint](https://huggingface.co/papers/2201.09865) logic on the latent space of stable diffusion. It can
be used similarly to other image inpainting pipelines but does not rely on a specific inpainting model. This means you can use
models that are not specifically created for inpainting.
@@ -2576,7 +2576,7 @@ For more results, checkout [PR #6114](https://github.com/huggingface/diffusers/p
### Stable Diffusion Mixture Tiling Pipeline SD 1.5
-This pipeline uses the Mixture. Refer to the [Mixture](https://arxiv.org/abs/2302.02412) paper for more details.
+This pipeline uses the Mixture. Refer to the [Mixture](https://huggingface.co/papers/2302.02412) paper for more details.
```python
from diffusers import LMSDiscreteScheduler, DiffusionPipeline
@@ -2607,7 +2607,7 @@ image = pipeline(
### Stable Diffusion Mixture Canvas Pipeline SD 1.5
-This pipeline uses the Mixture. Refer to the [Mixture](https://arxiv.org/abs/2302.02412) paper for more details.
+This pipeline uses the Mixture. Refer to the [Mixture](https://huggingface.co/papers/2302.02412) paper for more details.
```python
from PIL import Image
@@ -2642,7 +2642,7 @@ output = pipeline(
### Stable Diffusion Mixture Tiling Pipeline SDXL
-This pipeline uses the Mixture. Refer to the [Mixture](https://arxiv.org/abs/2302.02412) paper for more details.
+This pipeline uses the Mixture. Refer to the [Mixture](https://huggingface.co/papers/2302.02412) paper for more details.
```python
import torch
@@ -2696,7 +2696,7 @@ image = pipe(
### Stable Diffusion MoD ControlNet Tile SR Pipeline SDXL
-This pipeline implements the [MoD (Mixture-of-Diffusers)]("https://arxiv.org/pdf/2408.06072") tiled diffusion technique and combines it with SDXL's ControlNet Tile process to generate SR images.
+This pipeline implements the [MoD (Mixture-of-Diffusers)](https://huggingface.co/papers/2408.06072) tiled diffusion technique and combines it with SDXL's ControlNet Tile process to generate SR images.
This works better with 4x scales, but you can try adjusts parameters to higher scales.
@@ -2835,7 +2835,7 @@ image.save('tensorrt_inpaint_mecha_robot.png')
### IADB pipeline
-This pipeline is the implementation of the [α-(de)Blending: a Minimalist Deterministic Diffusion Model](https://arxiv.org/abs/2305.03486) paper.
+This pipeline is the implementation of the [α-(de)Blending: a Minimalist Deterministic Diffusion Model](https://huggingface.co/papers/2305.03486) paper.
It is a simple and minimalist diffusion model.
The following code shows how to use the IADB pipeline to generate images using a pretrained celebahq-256 model.
@@ -2888,7 +2888,7 @@ while True:
### Zero1to3 pipeline
-This pipeline is the implementation of the [Zero-1-to-3: Zero-shot One Image to 3D Object](https://arxiv.org/abs/2303.11328) paper.
+This pipeline is the implementation of the [Zero-1-to-3: Zero-shot One Image to 3D Object](https://huggingface.co/papers/2303.11328) paper.
The original pytorch-lightning [repo](https://github.com/cvlab-columbia/zero123) and a diffusers [repo](https://github.com/kxhit/zero123-hf).
The following code shows how to use the Zero1to3 pipeline to generate novel view synthesis images using a pretrained stable diffusion model.
@@ -3356,7 +3356,7 @@ Side note: See [this GitHub gist](https://gist.github.com/UmerHA/b65bb5fb9626c9c
### Latent Consistency Pipeline
-Latent Consistency Models was proposed in [Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference](https://arxiv.org/abs/2310.04378) by _Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, Hang Zhao_ from Tsinghua University.
+Latent Consistency Models was proposed in [Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference](https://huggingface.co/papers/2310.04378) by _Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, Hang Zhao_ from Tsinghua University.
The abstract of the paper reads as follows:
@@ -3468,7 +3468,7 @@ assert len(images) == (len(prompts) - 1) * num_interpolation_steps
### StableDiffusionUpscaleLDM3D Pipeline
-[LDM3D-VR](https://arxiv.org/pdf/2311.03226.pdf) is an extended version of LDM3D.
+[LDM3D-VR](https://huggingface.co/papers/2311.03226) is an extended version of LDM3D.
The abstract from the paper is:
*Latent diffusion models have proven to be state-of-the-art in the creation and manipulation of visual outputs. However, as far as we know, the generation of depth maps jointly with RGB is still limited. We introduce LDM3D-VR, a suite of diffusion models targeting virtual reality development that includes LDM3D-pano and LDM3D-SR. These models enable the generation of panoramic RGBD based on textual prompts and the upscaling of low-resolution inputs to high-resolution RGBD, respectively. Our models are fine-tuned from existing pretrained models on datasets containing panoramic/high-resolution RGB images, depth maps and captions. Both models are evaluated in comparison to existing related methods*
@@ -4165,7 +4165,7 @@ export_to_gif(result.frames[0], "result.gif")
### DemoFusion
-This pipeline is the official implementation of [DemoFusion: Democratising High-Resolution Image Generation With No $$$](https://arxiv.org/abs/2311.16973).
+This pipeline is the official implementation of [DemoFusion: Democratising High-Resolution Image Generation With No $$$](https://huggingface.co/papers/2311.16973).
The original repo can be found at [repo](https://github.com/PRIS-CV/DemoFusion).
- `view_batch_size` (`int`, defaults to 16):
@@ -4259,7 +4259,7 @@ This pipeline provides drag-and-drop image editing using stochastic differential

-See [paper](https://arxiv.org/abs/2311.01410), [paper page](https://ml-gsai.github.io/SDE-Drag-demo/), [original repo](https://github.com/ML-GSAI/SDE-Drag) for more information.
+See [paper](https://huggingface.co/papers/2311.01410), [paper page](https://ml-gsai.github.io/SDE-Drag-demo/), [original repo](https://github.com/ML-GSAI/SDE-Drag) for more information.
```py
import torch
@@ -4515,7 +4515,7 @@ export_to_video(
### StyleAligned Pipeline
-This pipeline is the implementation of [Style Aligned Image Generation via Shared Attention](https://arxiv.org/abs/2312.02133). You can find more results [here](https://github.com/huggingface/diffusers/pull/6489#issuecomment-1881209354).
+This pipeline is the implementation of [Style Aligned Image Generation via Shared Attention](https://huggingface.co/papers/2312.02133). You can find more results [here](https://github.com/huggingface/diffusers/pull/6489#issuecomment-1881209354).
> Large-scale Text-to-Image (T2I) models have rapidly gained prominence across creative fields, generating visually compelling outputs from textual prompts. However, controlling these models to ensure consistent style remains challenging, with existing methods necessitating fine-tuning and manual intervention to disentangle content and style. In this paper, we introduce StyleAligned, a novel technique designed to establish style alignment among a series of generated images. By employing minimal `attention sharing' during the diffusion process, our method maintains style consistency across images within T2I models. This approach allows for the creation of style-consistent images using a reference style through a straightforward inversion operation. Our method's evaluation across diverse styles and text prompts demonstrates high-quality synthesis and fidelity, underscoring its efficacy in achieving consistent style across various inputs.
@@ -4729,7 +4729,7 @@ image = pipe(
### UFOGen Scheduler
-[UFOGen](https://arxiv.org/abs/2311.09257) is a generative model designed for fast one-step text-to-image generation, trained via adversarial training starting from an initial pretrained diffusion model such as Stable Diffusion. `scheduling_ufogen.py` implements a onestep and multistep sampling algorithm for UFOGen models compatible with pipelines like `StableDiffusionPipeline`. A usage example is as follows:
+[UFOGen](https://huggingface.co/papers/2311.09257) is a generative model designed for fast one-step text-to-image generation, trained via adversarial training starting from an initial pretrained diffusion model such as Stable Diffusion. `scheduling_ufogen.py` implements a onestep and multistep sampling algorithm for UFOGen models compatible with pipelines like `StableDiffusionPipeline`. A usage example is as follows:
```py
import torch
@@ -5047,7 +5047,7 @@ make_image_grid(image, rows=1, cols=len(image))
### Stable Diffusion XL Attentive Eraser Pipeline
diff --git a/docs/source/ko/training/lora.md b/docs/source/ko/training/lora.md
index 85ed1dda0b..d0675c72f1 100644
--- a/docs/source/ko/training/lora.md
+++ b/docs/source/ko/training/lora.md
@@ -20,7 +20,7 @@ specific language governing permissions and limitations under the License.
-[LoRA(Low-Rank Adaptation of Large Language Models)](https://arxiv.org/abs/2106.09685)는 메모리를 적게 사용하면서 대규모 모델의 학습을 가속화하는 학습 방법입니다. 이는 rank-decomposition weight 행렬 쌍(**업데이트 행렬**이라고 함)을 추가하고 새로 추가된 가중치**만** 학습합니다. 여기에는 몇 가지 장점이 있습니다.
+[LoRA(Low-Rank Adaptation of Large Language Models)](https://huggingface.co/papers/2106.09685)는 메모리를 적게 사용하면서 대규모 모델의 학습을 가속화하는 학습 방법입니다. 이는 rank-decomposition weight 행렬 쌍(**업데이트 행렬**이라고 함)을 추가하고 새로 추가된 가중치**만** 학습합니다. 여기에는 몇 가지 장점이 있습니다.
- 이전에 미리 학습된 가중치는 고정된 상태로 유지되므로 모델이 [치명적인 망각](https://www.pnas.org/doi/10.1073/pnas.1611835114) 경향이 없습니다.
- Rank-decomposition 행렬은 원래 모델보다 파라메터 수가 훨씬 적으므로 학습된 LoRA 가중치를 쉽게 끼워넣을 수 있습니다.
diff --git a/docs/source/ko/training/text_inversion.md b/docs/source/ko/training/text_inversion.md
index 5c6a96eb41..9cc7b6a255 100644
--- a/docs/source/ko/training/text_inversion.md
+++ b/docs/source/ko/training/text_inversion.md
@@ -16,7 +16,7 @@ specific language governing permissions and limitations under the License.
[[open-in-colab]]
-[textual-inversion](https://arxiv.org/abs/2208.01618)은 소수의 예시 이미지에서 새로운 콘셉트를 포착하는 기법입니다. 이 기술은 원래 [Latent Diffusion](https://github.com/CompVis/latent-diffusion)에서 시연되었지만, 이후 [Stable Diffusion](https://huggingface.co/docs/diffusers/main/en/conceptual/stable_diffusion)과 같은 유사한 다른 모델에도 적용되었습니다. 학습된 콘셉트는 text-to-image 파이프라인에서 생성된 이미지를 더 잘 제어하는 데 사용할 수 있습니다. 이 모델은 텍스트 인코더의 임베딩 공간에서 새로운 '단어'를 학습하여 개인화된 이미지 생성을 위한 텍스트 프롬프트 내에서 사용됩니다.
+[textual-inversion](https://huggingface.co/papers/2208.01618)은 소수의 예시 이미지에서 새로운 콘셉트를 포착하는 기법입니다. 이 기술은 원래 [Latent Diffusion](https://github.com/CompVis/latent-diffusion)에서 시연되었지만, 이후 [Stable Diffusion](https://huggingface.co/docs/diffusers/main/en/conceptual/stable_diffusion)과 같은 유사한 다른 모델에도 적용되었습니다. 학습된 콘셉트는 text-to-image 파이프라인에서 생성된 이미지를 더 잘 제어하는 데 사용할 수 있습니다. 이 모델은 텍스트 인코더의 임베딩 공간에서 새로운 '단어'를 학습하여 개인화된 이미지 생성을 위한 텍스트 프롬프트 내에서 사용됩니다.

By using just 3-5 images you can teach new concepts to a model such as Stable Diffusion for personalized image generation (image source).
diff --git a/docs/source/ko/using-diffusers/controlling_generation.md b/docs/source/ko/using-diffusers/controlling_generation.md
index 41fc52b634..5bbb707eb3 100644
--- a/docs/source/ko/using-diffusers/controlling_generation.md
+++ b/docs/source/ko/using-diffusers/controlling_generation.md
@@ -64,7 +64,7 @@ diffusion 모델 생성을 제어하기 위해 `diffusers`가 지원하는 몇
## Pix2Pix Instruct
-[Paper](https://arxiv.org/abs/2211.09800)
+[Paper](https://huggingface.co/papers/2211.09800)
[Instruct Pix2Pix](../api/pipelines/stable_diffusion/pix2pix) 는 입력 이미지 편집을 지원하기 위해 stable diffusion에서 미세-조정되었습니다. 이미지와 편집을 설명하는 프롬프트를 입력으로 받아 편집된 이미지를 출력합니다.
Instruct Pix2Pix는 [InstructGPT](https://openai.com/blog/instruction-following/)와 같은 프롬프트와 잘 작동하도록 명시적으로 훈련되었습니다.
@@ -73,7 +73,7 @@ Instruct Pix2Pix는 [InstructGPT](https://openai.com/blog/instruction-following/
## Pix2Pix Zero
-[Paper](https://arxiv.org/abs/2302.03027)
+[Paper](https://huggingface.co/papers/2302.03027)
[Pix2Pix Zero](../api/pipelines/stable_diffusion/pix2pix_zero)를 사용하면 일반적인 이미지 의미를 유지하면서 한 개념이나 피사체가 다른 개념이나 피사체로 변환되도록 이미지를 수정할 수 있습니다.
@@ -98,7 +98,7 @@ Pix2Pix Zero는 '제로 샷(zero-shot)' 이미지 편집이 가능한 최초의
## Attend and Excite
-[Paper](https://arxiv.org/abs/2301.13826)
+[Paper](https://huggingface.co/papers/2301.13826)
[Attend and Excite](../api/pipelines/stable_diffusion/attend_and_excite)를 사용하면 프롬프트의 피사체가 최종 이미지에 충실하게 표현되도록 할 수 있습니다.
@@ -110,7 +110,7 @@ Pix2Pix Zero와 마찬가지로 Attend and Excite 역시 파이프라인에 미
## Semantic Guidance (SEGA)
-[Paper](https://arxiv.org/abs/2301.12247)
+[Paper](https://huggingface.co/papers/2301.12247)
의미유도(SEGA)를 사용하면 이미지에서 하나 이상의 컨셉을 적용하거나 제거할 수 있습니다. 컨셉의 강도도 조절할 수 있습니다. 즉, 스마일 컨셉을 사용하여 인물 사진의 스마일을 점진적으로 늘리거나 줄일 수 있습니다.
@@ -122,7 +122,7 @@ Pix2Pix Zero 또는 Attend and Excite와 달리 SEGA는 명시적인 그라데
## Self-attention Guidance (SAG)
-[Paper](https://arxiv.org/abs/2210.00939)
+[Paper](https://huggingface.co/papers/2210.00939)
[자기 주의 안내](../api/pipelines/stable_diffusion/self_attention_guidance)는 이미지의 전반적인 품질을 개선합니다.
@@ -150,7 +150,7 @@ InstructPix2Pix와 Pix2Pix Zero와 같은 방법의 중요한 차이점은 전
## MultiDiffusion Panorama
-[Paper](https://arxiv.org/abs/2302.08113)
+[Paper](https://huggingface.co/papers/2302.08113)
MultiDiffusion은 사전 학습된 diffusion model을 통해 새로운 생성 프로세스를 정의합니다. 이 프로세스는 고품질의 다양한 이미지를 생성하는 데 쉽게 적용할 수 있는 여러 diffusion 생성 방법을 하나로 묶습니다. 결과는 원하는 종횡비(예: 파노라마) 및 타이트한 분할 마스크에서 바운딩 박스에 이르는 공간 안내 신호와 같은 사용자가 제공한 제어를 준수합니다.
[MultiDiffusion 파노라마](../api/pipelines/stable_diffusion/panorama)를 사용하면 임의의 종횡비(예: 파노라마)로 고품질 이미지를 생성할 수 있습니다.
@@ -175,7 +175,7 @@ MultiDiffusion은 사전 학습된 diffusion model을 통해 새로운 생성
## ControlNet
-[Paper](https://arxiv.org/abs/2302.05543)
+[Paper](https://huggingface.co/papers/2302.05543)
[ControlNet](../api/pipelines/stable_diffusion/controlnet)은 추가 조건을 추가하는 보조 네트워크입니다.
가장자리 감지, 낙서, 깊이 맵, 의미적 세그먼트와 같은 다양한 조건에 대해 훈련된 8개의 표준 사전 훈련된 ControlNet이 있습니다,
@@ -200,7 +200,7 @@ DreamBooth 및 Textual Inversion 마찬가지로, 사용자 지정 확산은 사
## Model Editing
-[Paper](https://arxiv.org/abs/2303.08084)
+[Paper](https://huggingface.co/papers/2303.08084)
[텍스트-이미지 모델 편집 파이프라인](../api/pipelines/model_editing)을 사용하면 사전학습된 text-to-image diffusion 모델이 입력 프롬프트에 있는 피사체에 대해 내릴 수 있는 잘못된 암시적 가정을 완화하는 데 도움이 됩니다.
예를 들어, 안정적 확산에 "A pack of roses"에 대한 이미지를 생성하라는 메시지를 표시하면 생성된 이미지의 장미는 빨간색일 가능성이 높습니다. 이 파이프라인은 이러한 가정을 변경하는 데 도움이 됩니다.
@@ -209,7 +209,7 @@ DreamBooth 및 Textual Inversion 마찬가지로, 사용자 지정 확산은 사
## DiffEdit
-[Paper](https://arxiv.org/abs/2210.11427)
+[Paper](https://huggingface.co/papers/2210.11427)
[DiffEdit](../api/pipelines/diffedit)를 사용하면 원본 입력 이미지를 최대한 보존하면서 입력 프롬프트와 함께 입력 이미지의 의미론적 편집이 가능합니다.
@@ -218,7 +218,7 @@ DreamBooth 및 Textual Inversion 마찬가지로, 사용자 지정 확산은 사
## T2I-Adapter
-[Paper](https://arxiv.org/abs/2302.08453)
+[Paper](https://huggingface.co/papers/2302.08453)
[T2I-어댑터](../api/pipelines/stable_diffusion/adapter)는 추가적인 조건을 추가하는 auxiliary 네트워크입니다.
가장자리 감지, 스케치, depth maps, semantic segmentations와 같은 다양한 조건에 대해 훈련된 8개의 표준 사전훈련된 adapter가 있습니다,
diff --git a/docs/source/ko/using-diffusers/custom_pipeline_overview.md b/docs/source/ko/using-diffusers/custom_pipeline_overview.md
index 34cd531047..12d0a5be7b 100644
--- a/docs/source/ko/using-diffusers/custom_pipeline_overview.md
+++ b/docs/source/ko/using-diffusers/custom_pipeline_overview.md
@@ -14,7 +14,7 @@ specific language governing permissions and limitations under the License.
[[open-in-colab]]
-커뮤니티 파이프라인은 논문에 명시된 원래의 구현체와 다른 형태로 구현된 모든 [`DiffusionPipeline`] 클래스를 의미합니다. (예를 들어, [`StableDiffusionControlNetPipeline`]는 ["Text-to-Image Generation with ControlNet Conditioning"](https://arxiv.org/abs/2302.05543) 해당) 이들은 추가 기능을 제공하거나 파이프라인의 원래 구현을 확장합니다.
+커뮤니티 파이프라인은 논문에 명시된 원래의 구현체와 다른 형태로 구현된 모든 [`DiffusionPipeline`] 클래스를 의미합니다. (예를 들어, [`StableDiffusionControlNetPipeline`]는 ["Text-to-Image Generation with ControlNet Conditioning"](https://huggingface.co/papers/2302.05543) 해당) 이들은 추가 기능을 제공하거나 파이프라인의 원래 구현을 확장합니다.
[Speech to Image](https://github.com/huggingface/diffusers/tree/main/examples/community#speech-to-image) 또는 [Composable Stable Diffusion](https://github.com/huggingface/diffusers/tree/main/examples/community#composable-stable-diffusion) 과 같은 멋진 커뮤니티 파이프라인이 많이 있으며 [여기에서](https://github.com/huggingface/diffusers/tree/main/examples/community) 모든 공식 커뮤니티 파이프라인을 찾을 수 있습니다.
diff --git a/docs/source/ko/using-diffusers/unconditional_image_generation.md b/docs/source/ko/using-diffusers/unconditional_image_generation.md
index 9e674d602b..5d5dcdd95e 100644
--- a/docs/source/ko/using-diffusers/unconditional_image_generation.md
+++ b/docs/source/ko/using-diffusers/unconditional_image_generation.md
@@ -27,7 +27,7 @@ Unconditional 이미지 생성은 비교적 간단한 작업입니다. 모델이
-이 가이드에서는 unconditional 이미지 생성에 ['DiffusionPipeline']과 [DDPM](https://arxiv.org/abs/2006.11239)을 사용합니다:
+이 가이드에서는 unconditional 이미지 생성에 ['DiffusionPipeline']과 [DDPM](https://huggingface.co/papers/2006.11239)을 사용합니다:
```python
>>> from diffusers import DiffusionPipeline
diff --git a/docs/source/zh/index.md b/docs/source/zh/index.md
index 92c52bc1c1..133864e406 100644
--- a/docs/source/zh/index.md
+++ b/docs/source/zh/index.md
@@ -56,32 +56,32 @@ specific language governing permissions and limitations under the License.
| 管道 | 论文/仓库 | 任务 |
|---|---|:---:|
-| [alt_diffusion](./api/pipelines/alt_diffusion) | [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679) | Image-to-Image Text-Guided Generation |
+| [alt_diffusion](./api/pipelines/alt_diffusion) | [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://huggingface.co/papers/2211.06679) | Image-to-Image Text-Guided Generation |
| [audio_diffusion](./api/pipelines/audio_diffusion) | [Audio Diffusion](https://github.com/teticio/audio-diffusion.git) | Unconditional Audio Generation |
-| [controlnet](./api/pipelines/stable_diffusion/controlnet) | [Adding Conditional Control to Text-to-Image Diffusion Models](https://arxiv.org/abs/2302.05543) | Image-to-Image Text-Guided Generation |
-| [cycle_diffusion](./api/pipelines/cycle_diffusion) | [Unifying Diffusion Models' Latent Space, with Applications to CycleDiffusion and Guidance](https://arxiv.org/abs/2210.05559) | Image-to-Image Text-Guided Generation |
+| [controlnet](./api/pipelines/stable_diffusion/controlnet) | [Adding Conditional Control to Text-to-Image Diffusion Models](https://huggingface.co/papers/2302.05543) | Image-to-Image Text-Guided Generation |
+| [cycle_diffusion](./api/pipelines/cycle_diffusion) | [Unifying Diffusion Models' Latent Space, with Applications to CycleDiffusion and Guidance](https://huggingface.co/papers/2210.05559) | Image-to-Image Text-Guided Generation |
| [dance_diffusion](./api/pipelines/dance_diffusion) | [Dance Diffusion](https://github.com/williamberman/diffusers.git) | Unconditional Audio Generation |
-| [ddpm](./api/pipelines/ddpm) | [Denoising Diffusion Probabilistic Models](https://arxiv.org/abs/2006.11239) | Unconditional Image Generation |
-| [ddim](./api/pipelines/ddim) | [Denoising Diffusion Implicit Models](https://arxiv.org/abs/2010.02502) | Unconditional Image Generation |
+| [ddpm](./api/pipelines/ddpm) | [Denoising Diffusion Probabilistic Models](https://huggingface.co/papers/2006.11239) | Unconditional Image Generation |
+| [ddim](./api/pipelines/ddim) | [Denoising Diffusion Implicit Models](https://huggingface.co/papers/2010.02502) | Unconditional Image Generation |
| [if](./if) | [**IF**](./api/pipelines/if) | Image Generation |
| [if_img2img](./if) | [**IF**](./api/pipelines/if) | Image-to-Image Generation |
| [if_inpainting](./if) | [**IF**](./api/pipelines/if) | Image-to-Image Generation |
-| [latent_diffusion](./api/pipelines/latent_diffusion) | [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752)| Text-to-Image Generation |
-| [latent_diffusion](./api/pipelines/latent_diffusion) | [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752)| Super Resolution Image-to-Image |
-| [latent_diffusion_uncond](./api/pipelines/latent_diffusion_uncond) | [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752) | Unconditional Image Generation |
-| [paint_by_example](./api/pipelines/paint_by_example) | [Paint by Example: Exemplar-based Image Editing with Diffusion Models](https://arxiv.org/abs/2211.13227) | Image-Guided Image Inpainting |
-| [pndm](./api/pipelines/pndm) | [Pseudo Numerical Methods for Diffusion Models on Manifolds](https://arxiv.org/abs/2202.09778) | Unconditional Image Generation |
+| [latent_diffusion](./api/pipelines/latent_diffusion) | [High-Resolution Image Synthesis with Latent Diffusion Models](https://huggingface.co/papers/2112.10752)| Text-to-Image Generation |
+| [latent_diffusion](./api/pipelines/latent_diffusion) | [High-Resolution Image Synthesis with Latent Diffusion Models](https://huggingface.co/papers/2112.10752)| Super Resolution Image-to-Image |
+| [latent_diffusion_uncond](./api/pipelines/latent_diffusion_uncond) | [High-Resolution Image Synthesis with Latent Diffusion Models](https://huggingface.co/papers/2112.10752) | Unconditional Image Generation |
+| [paint_by_example](./api/pipelines/paint_by_example) | [Paint by Example: Exemplar-based Image Editing with Diffusion Models](https://huggingface.co/papers/2211.13227) | Image-Guided Image Inpainting |
+| [pndm](./api/pipelines/pndm) | [Pseudo Numerical Methods for Diffusion Models on Manifolds](https://huggingface.co/papers/2202.09778) | Unconditional Image Generation |
| [score_sde_ve](./api/pipelines/score_sde_ve) | [Score-Based Generative Modeling through Stochastic Differential Equations](https://openreview.net/forum?id=PxTIG12RRHS) | Unconditional Image Generation |
| [score_sde_vp](./api/pipelines/score_sde_vp) | [Score-Based Generative Modeling through Stochastic Differential Equations](https://openreview.net/forum?id=PxTIG12RRHS) | Unconditional Image Generation |
-| [semantic_stable_diffusion](./api/pipelines/semantic_stable_diffusion) | [Semantic Guidance](https://arxiv.org/abs/2301.12247) | Text-Guided Generation |
+| [semantic_stable_diffusion](./api/pipelines/semantic_stable_diffusion) | [Semantic Guidance](https://huggingface.co/papers/2301.12247) | Text-Guided Generation |
| [stable_diffusion_text2img](./api/pipelines/stable_diffusion/text2img) | [Stable Diffusion](https://stability.ai/blog/stable-diffusion-public-release) | Text-to-Image Generation |
| [stable_diffusion_img2img](./api/pipelines/stable_diffusion/img2img) | [Stable Diffusion](https://stability.ai/blog/stable-diffusion-public-release) | Image-to-Image Text-Guided Generation |
| [stable_diffusion_inpaint](./api/pipelines/stable_diffusion/inpaint) | [Stable Diffusion](https://stability.ai/blog/stable-diffusion-public-release) | Text-Guided Image Inpainting |
| [stable_diffusion_panorama](./api/pipelines/stable_diffusion/panorama) | [MultiDiffusion](https://multidiffusion.github.io/) | Text-to-Panorama Generation |
-| [stable_diffusion_pix2pix](./api/pipelines/stable_diffusion/pix2pix) | [InstructPix2Pix: Learning to Follow Image Editing Instructions](https://arxiv.org/abs/2211.09800) | Text-Guided Image Editing|
+| [stable_diffusion_pix2pix](./api/pipelines/stable_diffusion/pix2pix) | [InstructPix2Pix: Learning to Follow Image Editing Instructions](https://huggingface.co/papers/2211.09800) | Text-Guided Image Editing|
| [stable_diffusion_pix2pix_zero](./api/pipelines/stable_diffusion/pix2pix_zero) | [Zero-shot Image-to-Image Translation](https://pix2pixzero.github.io/) | Text-Guided Image Editing |
-| [stable_diffusion_attend_and_excite](./api/pipelines/stable_diffusion/attend_and_excite) | [Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models](https://arxiv.org/abs/2301.13826) | Text-to-Image Generation |
-| [stable_diffusion_self_attention_guidance](./api/pipelines/stable_diffusion/self_attention_guidance) | [Improving Sample Quality of Diffusion Models Using Self-Attention Guidance](https://arxiv.org/abs/2210.00939) | Text-to-Image Generation Unconditional Image Generation |
+| [stable_diffusion_attend_and_excite](./api/pipelines/stable_diffusion/attend_and_excite) | [Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models](https://huggingface.co/papers/2301.13826) | Text-to-Image Generation |
+| [stable_diffusion_self_attention_guidance](./api/pipelines/stable_diffusion/self_attention_guidance) | [Improving Sample Quality of Diffusion Models Using Self-Attention Guidance](https://huggingface.co/papers/2210.00939) | Text-to-Image Generation Unconditional Image Generation |
| [stable_diffusion_image_variation](./stable_diffusion/image_variation) | [Stable Diffusion Image Variations](https://github.com/LambdaLabsML/lambda-diffusers#stable-diffusion-image-variations) | Image-to-Image Generation |
| [stable_diffusion_latent_upscale](./stable_diffusion/latent_upscale) | [Stable Diffusion Latent Upscaler](https://twitter.com/StabilityAI/status/1590531958815064065) | Text-Guided Super Resolution Image-to-Image |
| [stable_diffusion_model_editing](./api/pipelines/stable_diffusion/model_editing) | [Editing Implicit Assumptions in Text-to-Image Diffusion Models](https://time-diffusion.github.io/) | Text-to-Image Model Editing |
@@ -89,13 +89,13 @@ specific language governing permissions and limitations under the License.
| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [Stable Diffusion 2](https://stability.ai/blog/stable-diffusion-v2-release) | Text-Guided Image Inpainting |
| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [Depth-Conditional Stable Diffusion](https://github.com/Stability-AI/stablediffusion#depth-conditional-stable-diffusion) | Depth-to-Image Generation |
| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [Stable Diffusion 2](https://stability.ai/blog/stable-diffusion-v2-release) | Text-Guided Super Resolution Image-to-Image |
-| [stable_diffusion_safe](./api/pipelines/stable_diffusion_safe) | [Safe Stable Diffusion](https://arxiv.org/abs/2211.05105) | Text-Guided Generation |
+| [stable_diffusion_safe](./api/pipelines/stable_diffusion_safe) | [Safe Stable Diffusion](https://huggingface.co/papers/2211.05105) | Text-Guided Generation |
| [stable_unclip](./stable_unclip) | Stable unCLIP | Text-to-Image Generation |
| [stable_unclip](./stable_unclip) | Stable unCLIP | Image-to-Image Text-Guided Generation |
-| [stochastic_karras_ve](./api/pipelines/stochastic_karras_ve) | [Elucidating the Design Space of Diffusion-Based Generative Models](https://arxiv.org/abs/2206.00364) | Unconditional Image Generation |
+| [stochastic_karras_ve](./api/pipelines/stochastic_karras_ve) | [Elucidating the Design Space of Diffusion-Based Generative Models](https://huggingface.co/papers/2206.00364) | Unconditional Image Generation |
| [text_to_video_sd](./api/pipelines/text_to_video) | [Modelscope's Text-to-video-synthesis Model in Open Domain](https://modelscope.cn/models/damo/text-to-video-synthesis/summary) | Text-to-Video Generation |
-| [unclip](./api/pipelines/unclip) | [Hierarchical Text-Conditional Image Generation with CLIP Latents](https://arxiv.org/abs/2204.06125)(implementation by [kakaobrain](https://github.com/kakaobrain/karlo)) | Text-to-Image Generation |
-| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Text-to-Image Generation |
-| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Image Variations Generation |
-| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Dual Image and Text Guided Generation |
-| [vq_diffusion](./api/pipelines/vq_diffusion) | [Vector Quantized Diffusion Model for Text-to-Image Synthesis](https://arxiv.org/abs/2111.14822) | Text-to-Image Generation |
+| [unclip](./api/pipelines/unclip) | [Hierarchical Text-Conditional Image Generation with CLIP Latents](https://huggingface.co/papers/2204.06125)(implementation by [kakaobrain](https://github.com/kakaobrain/karlo)) | Text-to-Image Generation |
+| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://huggingface.co/papers/2211.08332) | Text-to-Image Generation |
+| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://huggingface.co/papers/2211.08332) | Image Variations Generation |
+| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://huggingface.co/papers/2211.08332) | Dual Image and Text Guided Generation |
+| [vq_diffusion](./api/pipelines/vq_diffusion) | [Vector Quantized Diffusion Model for Text-to-Image Synthesis](https://huggingface.co/papers/2111.14822) | Text-to-Image Generation |
diff --git a/examples/advanced_diffusion_training/README.md b/examples/advanced_diffusion_training/README.md
index f30f8c83a1..eedb1c96e4 100644
--- a/examples/advanced_diffusion_training/README.md
+++ b/examples/advanced_diffusion_training/README.md
@@ -4,9 +4,9 @@
> [!TIP]
> 💡 This example follows the techniques and recommended practices covered in the blog post: [LoRA training scripts of the world, unite!](https://huggingface.co/blog/sdxl_lora_advanced_script). Make sure to check it out before starting 🤗
-[DreamBooth](https://arxiv.org/abs/2208.12242) is a method to personalize text2image models like stable diffusion given just a few(3~5) images of a subject.
+[DreamBooth](https://huggingface.co/papers/2208.12242) is a method to personalize text2image models like stable diffusion given just a few(3~5) images of a subject.
-LoRA - Low-Rank Adaption of Large Language Models, was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*
+LoRA - Low-Rank Adaption of Large Language Models, was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://huggingface.co/papers/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*
In a nutshell, LoRA allows to adapt pretrained models by adding pairs of rank-decomposition matrices to existing weights and **only** training those newly added weights. This has a couple of advantages:
- Previous pretrained weights are kept frozen so that the model is not prone to [catastrophic forgetting](https://www.pnas.org/doi/10.1073/pnas.1611835114)
- Rank-decomposition matrices have significantly fewer parameters than the original model, which means that trained LoRA weights are easily portable.
@@ -15,7 +15,7 @@ In a nutshell, LoRA allows to adapt pretrained models by adding pairs of rank-de
the popular [lora](https://github.com/cloneofsimo/lora) GitHub repository.
The `train_dreambooth_lora_sdxl_advanced.py` script shows how to implement dreambooth-LoRA, combining the training process shown in `train_dreambooth_lora_sdxl.py`, with
-advanced features and techniques, inspired and built upon contributions by [Nataniel Ruiz](https://twitter.com/natanielruizg): [Dreambooth](https://dreambooth.github.io), [Rinon Gal](https://twitter.com/RinonGal): [Textual Inversion](https://textual-inversion.github.io), [Ron Mokady](https://twitter.com/MokadyRon): [Pivotal Tuning](https://arxiv.org/abs/2106.05744), [Simo Ryu](https://twitter.com/cloneofsimo): [cog-sdxl](https://github.com/replicate/cog-sdxl),
+advanced features and techniques, inspired and built upon contributions by [Nataniel Ruiz](https://twitter.com/natanielruizg): [Dreambooth](https://dreambooth.github.io), [Rinon Gal](https://twitter.com/RinonGal): [Textual Inversion](https://textual-inversion.github.io), [Ron Mokady](https://twitter.com/MokadyRon): [Pivotal Tuning](https://huggingface.co/papers/2106.05744), [Simo Ryu](https://twitter.com/cloneofsimo): [cog-sdxl](https://github.com/replicate/cog-sdxl),
[Kohya](https://twitter.com/kohya_tech/): [sd-scripts](https://github.com/kohya-ss/sd-scripts), [The Last Ben](https://twitter.com/__TheBen): [fast-stable-diffusion](https://github.com/TheLastBen/fast-stable-diffusion) ❤️
> [!NOTE]
@@ -128,6 +128,7 @@ You can also load a dataset straight from by specifying it's name in `dataset_na
Look [here](https://huggingface.co/blog/sdxl_lora_advanced_script#custom-captioning) for more info on creating/loading your own caption dataset.
- **optimizer**: for this example, we'll use [prodigy](https://huggingface.co/blog/sdxl_lora_advanced_script#adaptive-optimizers) - an adaptive optimizer
+ - To use Prodigy, please make sure to install the prodigyopt library: `pip install prodigyopt`
- **pivotal tuning**
- **min SNR gamma**
@@ -246,7 +247,7 @@ SDXL's VAE is known to suffer from numerical instability issues. This is why we
### DoRA training
The advanced script supports DoRA training too!
-> Proposed in [DoRA: Weight-Decomposed Low-Rank Adaptation](https://arxiv.org/abs/2402.09353),
+> Proposed in [DoRA: Weight-Decomposed Low-Rank Adaptation](https://huggingface.co/papers/2402.09353),
**DoRA** is very similar to LoRA, except it decomposes the pre-trained weight into two components, **magnitude** and **direction** and employs LoRA for _directional_ updates to efficiently minimize the number of trainable parameters.
The authors found that by using DoRA, both the learning capacity and training stability of LoRA are enhanced without any additional overhead during inference.
@@ -272,7 +273,7 @@ The inference is the same as if you train a regular LoRA 🤗
## Conducting EDM-style training
-It's now possible to perform EDM-style training as proposed in [Elucidating the Design Space of Diffusion-Based Generative Models](https://arxiv.org/abs/2206.00364).
+It's now possible to perform EDM-style training as proposed in [Elucidating the Design Space of Diffusion-Based Generative Models](https://huggingface.co/papers/2206.00364).
simply set:
@@ -317,7 +318,7 @@ accelerate launch train_dreambooth_lora_sdxl_advanced.py \
### B-LoRA training
The advanced script now supports B-LoRA training too!
-> Proposed in [Implicit Style-Content Separation using B-LoRA](https://arxiv.org/abs/2403.14572),
+> Proposed in [Implicit Style-Content Separation using B-LoRA](https://huggingface.co/papers/2403.14572),
B-LoRA is a method that leverages LoRA to implicitly separate the style and content components of a **single** image.
It was shown that learning the LoRA weights of two specific blocks (referred to as B-LoRAs)
achieves style-content separation that cannot be achieved by training each B-LoRA independently.
diff --git a/examples/advanced_diffusion_training/README_flux.md b/examples/advanced_diffusion_training/README_flux.md
index ded6f11314..c05fa26cf9 100644
--- a/examples/advanced_diffusion_training/README_flux.md
+++ b/examples/advanced_diffusion_training/README_flux.md
@@ -5,9 +5,9 @@
> 💡 This example follows some of the techniques and recommended practices covered in the community derived guide we made for SDXL training: [LoRA training scripts of the world, unite!](https://huggingface.co/blog/sdxl_lora_advanced_script).
> As many of these are architecture agnostic & generally relevant to fine-tuning of diffusion models we suggest to take a look 🤗
-[DreamBooth](https://arxiv.org/abs/2208.12242) is a method to personalize text-to-image models like flux, stable diffusion given just a few(3~5) images of a subject.
+[DreamBooth](https://huggingface.co/papers/2208.12242) is a method to personalize text-to-image models like flux, stable diffusion given just a few(3~5) images of a subject.
-LoRA - Low-Rank Adaption of Large Language Models, was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*
+LoRA - Low-Rank Adaption of Large Language Models, was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://huggingface.co/papers/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*
In a nutshell, LoRA allows to adapt pretrained models by adding pairs of rank-decomposition matrices to existing weights and **only** training those newly added weights. This has a couple of advantages:
- Previous pretrained weights are kept frozen so that the model is not prone to [catastrophic forgetting](https://www.pnas.org/doi/10.1073/pnas.1611835114)
- Rank-decomposition matrices have significantly fewer parameters than the original model, which means that trained LoRA weights are easily portable.
@@ -16,7 +16,7 @@ In a nutshell, LoRA allows to adapt pretrained models by adding pairs of rank-de
the popular [lora](https://github.com/cloneofsimo/lora) GitHub repository.
The `train_dreambooth_lora_flux_advanced.py` script shows how to implement dreambooth-LoRA, combining the training process shown in `train_dreambooth_lora_flux.py`, with
-advanced features and techniques, inspired and built upon contributions by [Nataniel Ruiz](https://twitter.com/natanielruizg): [Dreambooth](https://dreambooth.github.io), [Rinon Gal](https://twitter.com/RinonGal): [Textual Inversion](https://textual-inversion.github.io), [Ron Mokady](https://twitter.com/MokadyRon): [Pivotal Tuning](https://arxiv.org/abs/2106.05744), [Simo Ryu](https://twitter.com/cloneofsimo): [cog-sdxl](https://github.com/replicate/cog-sdxl),
+advanced features and techniques, inspired and built upon contributions by [Nataniel Ruiz](https://twitter.com/natanielruizg): [Dreambooth](https://dreambooth.github.io), [Rinon Gal](https://twitter.com/RinonGal): [Textual Inversion](https://textual-inversion.github.io), [Ron Mokady](https://twitter.com/MokadyRon): [Pivotal Tuning](https://huggingface.co/papers/2106.05744), [Simo Ryu](https://twitter.com/cloneofsimo): [cog-sdxl](https://github.com/replicate/cog-sdxl),
[ostris](https://x.com/ostrisai):[ai-toolkit](https://github.com/ostris/ai-toolkit), [bghira](https://github.com/bghira):[SimpleTuner](https://github.com/bghira/SimpleTuner), [Kohya](https://twitter.com/kohya_tech/): [sd-scripts](https://github.com/kohya-ss/sd-scripts), [The Last Ben](https://twitter.com/__TheBen): [fast-stable-diffusion](https://github.com/TheLastBen/fast-stable-diffusion) ❤️
> [!NOTE]
@@ -143,7 +143,8 @@ Now we'll simply specify the name of the dataset and caption column (in this cas
You can also load a dataset straight from by specifying it's name in `dataset_name`.
Look [here](https://huggingface.co/blog/sdxl_lora_advanced_script#custom-captioning) for more info on creating/loading your own caption dataset.
-- **optimizer**: for this example, we'll use [prodigy](https://huggingface.co/blog/sdxl_lora_advanced_script#adaptive-optimizers) - an adaptive optimizer
+- **optimizer**: for this example, we'll use [prodigy](https://huggingface.co/blog/sdxl_lora_advanced_script#adaptive-optimizers) - an adaptive optimizer
+ - To use Prodigy, please make sure to install the prodigyopt library: `pip install prodigyopt`
- **pivotal tuning**
### Example #1: Pivotal tuning
diff --git a/examples/advanced_diffusion_training/train_dreambooth_lora_sd15_advanced.py b/examples/advanced_diffusion_training/train_dreambooth_lora_sd15_advanced.py
index 770f9b92f9..52aee07e81 100644
--- a/examples/advanced_diffusion_training/train_dreambooth_lora_sd15_advanced.py
+++ b/examples/advanced_diffusion_training/train_dreambooth_lora_sd15_advanced.py
@@ -498,7 +498,7 @@ def parse_args(input_args=None):
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
- "More details here: https://arxiv.org/abs/2303.09556.",
+ "More details here: https://huggingface.co/papers/2303.09556.",
)
parser.add_argument(
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
@@ -665,7 +665,7 @@ def parse_args(input_args=None):
action="store_true",
default=False,
help=(
- "Whether to train a DoRA as proposed in- DoRA: Weight-Decomposed Low-Rank Adaptation https://arxiv.org/abs/2402.09353. "
+ "Whether to train a DoRA as proposed in- DoRA: Weight-Decomposed Low-Rank Adaptation https://huggingface.co/papers/2402.09353. "
"Note: to use DoRA you need to install peft from main, `pip install git+https://github.com/huggingface/peft.git`"
),
)
@@ -1771,7 +1771,7 @@ def main(args):
if args.snr_gamma is None:
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
else:
- # Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
+ # Compute loss-weights as per Section 3.4 of https://huggingface.co/papers/2303.09556.
# Since we predict the noise instead of x_0, the original formulation is slightly changed.
# This is discussed in Section 4.2 of the same paper.
diff --git a/examples/advanced_diffusion_training/train_dreambooth_lora_sdxl_advanced.py b/examples/advanced_diffusion_training/train_dreambooth_lora_sdxl_advanced.py
index 29d454ba8e..911102c049 100644
--- a/examples/advanced_diffusion_training/train_dreambooth_lora_sdxl_advanced.py
+++ b/examples/advanced_diffusion_training/train_dreambooth_lora_sdxl_advanced.py
@@ -464,7 +464,7 @@ def parse_args(input_args=None):
"--do_edm_style_training",
default=False,
action="store_true",
- help="Flag to conduct training using the EDM formulation as introduced in https://arxiv.org/abs/2206.00364.",
+ help="Flag to conduct training using the EDM formulation as introduced in https://huggingface.co/papers/2206.00364.",
)
parser.add_argument(
"--with_prior_preservation",
@@ -607,7 +607,7 @@ def parse_args(input_args=None):
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
- "More details here: https://arxiv.org/abs/2303.09556.",
+ "More details here: https://huggingface.co/papers/2303.09556.",
)
parser.add_argument(
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
@@ -775,7 +775,7 @@ def parse_args(input_args=None):
action="store_true",
default=False,
help=(
- "Whether to train a DoRA as proposed in- DoRA: Weight-Decomposed Low-Rank Adaptation https://arxiv.org/abs/2402.09353. "
+ "Whether to train a DoRA as proposed in- DoRA: Weight-Decomposed Low-Rank Adaptation https://huggingface.co/papers/2402.09353. "
"Note: to use DoRA you need to install peft from main, `pip install git+https://github.com/huggingface/peft.git`"
),
)
@@ -793,7 +793,7 @@ def parse_args(input_args=None):
"--use_blora",
action="store_true",
help=(
- "Whether to train a B-LoRA as proposed in- Implicit Style-Content Separation using B-LoRA https://arxiv.org/abs/2403.14572. "
+ "Whether to train a B-LoRA as proposed in- Implicit Style-Content Separation using B-LoRA https://huggingface.co/papers/2403.14572. "
),
)
parser.add_argument(
@@ -2131,7 +2131,7 @@ def main(args):
noisy_model_input = noise_scheduler.add_noise(model_input, noise, timesteps)
# For EDM-style training, we first obtain the sigmas based on the continuous timesteps.
# We then precondition the final model inputs based on these sigmas instead of the timesteps.
- # Follow: Section 5 of https://arxiv.org/abs/2206.00364.
+ # Follow: Section 5 of https://huggingface.co/papers/2206.00364.
if args.do_edm_style_training:
sigmas = get_sigmas(timesteps, len(noisy_model_input.shape), noisy_model_input.dtype)
if "EDM" in scheduler_type:
@@ -2193,7 +2193,7 @@ def main(args):
if args.do_edm_style_training:
# Similar to the input preconditioning, the model predictions are also preconditioned
# on noised model inputs (before preconditioning) and the sigmas.
- # Follow: Section 5 of https://arxiv.org/abs/2206.00364.
+ # Follow: Section 5 of https://huggingface.co/papers/2206.00364.
if "EDM" in scheduler_type:
model_pred = noise_scheduler.precondition_outputs(noisy_model_input, model_pred, sigmas)
else:
@@ -2251,7 +2251,7 @@ def main(args):
else:
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
else:
- # Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
+ # Compute loss-weights as per Section 3.4 of https://huggingface.co/papers/2303.09556.
# Since we predict the noise instead of x_0, the original formulation is slightly changed.
# This is discussed in Section 4.2 of the same paper.
diff --git a/examples/amused/README.md b/examples/amused/README.md
index 9d5ae17ef5..e7916eafcc 100644
--- a/examples/amused/README.md
+++ b/examples/amused/README.md
@@ -250,7 +250,7 @@ accelerate launch train_amused.py \
### Styledrop
-[Styledrop](https://arxiv.org/abs/2306.00983) is an efficient finetuning method for learning a new style from just one or very few images. It has an optional first stage to generate human picked additional training samples. The additional training samples can be used to augment the initial images. Our examples exclude the optional additional image selection stage and instead we just finetune on a single image.
+[Styledrop](https://huggingface.co/papers/2306.00983) is an efficient finetuning method for learning a new style from just one or very few images. It has an optional first stage to generate human picked additional training samples. The additional training samples can be used to augment the initial images. Our examples exclude the optional additional image selection stage and instead we just finetune on a single image.
This is our example style image:

diff --git a/examples/cogvideo/README.md b/examples/cogvideo/README.md
index 6cb0a51e9f..dc74690983 100644
--- a/examples/cogvideo/README.md
+++ b/examples/cogvideo/README.md
@@ -1,6 +1,6 @@
# LoRA finetuning example for CogVideoX
-Low-Rank Adaption of Large Language Models was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*.
+Low-Rank Adaption of Large Language Models was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://huggingface.co/papers/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*.
In a nutshell, LoRA allows adapting pretrained models by adding pairs of rank-decomposition matrices to existing weights and **only** training those newly added weights. This has a couple of advantages:
diff --git a/examples/cogvideo/train_cogvideox_image_to_video_lora.py b/examples/cogvideo/train_cogvideox_image_to_video_lora.py
index 642aecabf7..809911c279 100644
--- a/examples/cogvideo/train_cogvideox_image_to_video_lora.py
+++ b/examples/cogvideo/train_cogvideox_image_to_video_lora.py
@@ -555,7 +555,7 @@ class VideoDataset(Dataset):
if any(not path.is_file() for path in instance_videos):
raise ValueError(
- "Expected '--video_column' to be a path to a file in `--instance_data_root` containing line-separated paths to video data but found atleast one path that is not a valid file."
+ "Expected '--video_column' to be a path to a file in `--instance_data_root` containing line-separated paths to video data but found at least one path that is not a valid file."
)
return instance_prompts, instance_videos
diff --git a/examples/cogvideo/train_cogvideox_lora.py b/examples/cogvideo/train_cogvideox_lora.py
index e737ce7624..acd593c2af 100644
--- a/examples/cogvideo/train_cogvideox_lora.py
+++ b/examples/cogvideo/train_cogvideox_lora.py
@@ -539,7 +539,7 @@ class VideoDataset(Dataset):
if any(not path.is_file() for path in instance_videos):
raise ValueError(
- "Expected '--video_column' to be a path to a file in `--instance_data_root` containing line-separated paths to video data but found atleast one path that is not a valid file."
+ "Expected '--video_column' to be a path to a file in `--instance_data_root` containing line-separated paths to video data but found at least one path that is not a valid file."
)
return instance_prompts, instance_videos
diff --git a/examples/community/README.md b/examples/community/README.md
index 3117070b20..225a25fac7 100644
--- a/examples/community/README.md
+++ b/examples/community/README.md
@@ -10,7 +10,7 @@ Please also check out our [Community Scripts](https://github.com/huggingface/dif
| Example | Description | Code Example | Colab | Author |
|:--------------------------------------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:------------------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------:|
-|Spatiotemporal Skip Guidance (STG)|[Spatiotemporal Skip Guidance for Enhanced Video Diffusion Sampling](https://arxiv.org/abs/2411.18664) (CVPR 2025) enhances video diffusion models by generating a weaker model through layer skipping and using it as guidance, improving fidelity in models like HunyuanVideo, LTXVideo, and Mochi.|[Spatiotemporal Skip Guidance](#spatiotemporal-skip-guidance)|-|[Junha Hyung](https://junhahyung.github.io/), [Kinam Kim](https://kinam0252.github.io/), and [Ednaordinary](https://github.com/Ednaordinary)|
+|Spatiotemporal Skip Guidance (STG)|[Spatiotemporal Skip Guidance for Enhanced Video Diffusion Sampling](https://huggingface.co/papers/2411.18664) (CVPR 2025) enhances video diffusion models by generating a weaker model through layer skipping and using it as guidance, improving fidelity in models like HunyuanVideo, LTXVideo, and Mochi.|[Spatiotemporal Skip Guidance](#spatiotemporal-skip-guidance)|-|[Junha Hyung](https://junhahyung.github.io/), [Kinam Kim](https://kinam0252.github.io/), and [Ednaordinary](https://github.com/Ednaordinary)|
|Adaptive Mask Inpainting|Adaptive Mask Inpainting algorithm from [Beyond the Contact: Discovering Comprehensive Affordance for 3D Objects from Pre-trained 2D Diffusion Models](https://github.com/snuvclab/coma) (ECCV '24, Oral) provides a way to insert human inside the scene image without altering the background, by inpainting with adapting mask.|[Adaptive Mask Inpainting](#adaptive-mask-inpainting)|-|[Hyeonwoo Kim](https://sshowbiz.xyz),[Sookwan Han](https://jellyheadandrew.github.io)|
|Flux with CFG|[Flux with CFG](https://github.com/ToTheBeginning/PuLID/blob/main/docs/pulid_for_flux.md) provides an implementation of using CFG in [Flux](https://blackforestlabs.ai/announcing-black-forest-labs/).|[Flux with CFG](#flux-with-cfg)|[Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/flux_with_cfg.ipynb)|[Linoy Tsaban](https://github.com/linoytsaban), [Apolinário](https://github.com/apolinario), and [Sayak Paul](https://github.com/sayakpaul)|
|Differential Diffusion|[Differential Diffusion](https://github.com/exx8/differential-diffusion) modifies an image according to a text prompt, and according to a map that specifies the amount of change in each region.|[Differential Diffusion](#differential-diffusion)|[](https://huggingface.co/spaces/exx8/differential-diffusion) [](https://colab.research.google.com/github/exx8/differential-diffusion/blob/main/examples/SD2.ipynb)|[Eran Levin](https://github.com/exx8) and [Ohad Fried](https://www.ohadf.com/)|
@@ -39,17 +39,17 @@ Please also check out our [Community Scripts](https://github.com/huggingface/dif
| Stable UnCLIP | Diffusion Pipeline for combining prior model (generate clip image embedding from text, UnCLIPPipeline `"kakaobrain/karlo-v1-alpha"`) and decoder pipeline (decode clip image embedding to image, StableDiffusionImageVariationPipeline `"lambdalabs/sd-image-variations-diffusers"` ). | [Stable UnCLIP](#stable-unclip) | [Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/stable_unclip.ipynb) | [Ray Wang](https://wrong.wang) |
| UnCLIP Text Interpolation Pipeline | Diffusion Pipeline that allows passing two prompts and produces images while interpolating between the text-embeddings of the two prompts | [UnCLIP Text Interpolation Pipeline](#unclip-text-interpolation-pipeline) | [Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/unclip_text_interpolation.ipynb)| [Naga Sai Abhinay Devarinti](https://github.com/Abhinay1997/) |
| UnCLIP Image Interpolation Pipeline | Diffusion Pipeline that allows passing two images/image_embeddings and produces images while interpolating between their image-embeddings | [UnCLIP Image Interpolation Pipeline](#unclip-image-interpolation-pipeline) | [Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/unclip_image_interpolation.ipynb)| [Naga Sai Abhinay Devarinti](https://github.com/Abhinay1997/) |
-| DDIM Noise Comparative Analysis Pipeline | Investigating how the diffusion models learn visual concepts from each noise level (which is a contribution of [P2 weighting (CVPR 2022)](https://arxiv.org/abs/2204.00227)) | [DDIM Noise Comparative Analysis Pipeline](#ddim-noise-comparative-analysis-pipeline) | [Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/ddim_noise_comparative_analysis.ipynb)| [Aengus (Duc-Anh)](https://github.com/aengusng8) |
+| DDIM Noise Comparative Analysis Pipeline | Investigating how the diffusion models learn visual concepts from each noise level (which is a contribution of [P2 weighting (CVPR 2022)](https://huggingface.co/papers/2204.00227)) | [DDIM Noise Comparative Analysis Pipeline](#ddim-noise-comparative-analysis-pipeline) | [Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/ddim_noise_comparative_analysis.ipynb)| [Aengus (Duc-Anh)](https://github.com/aengusng8) |
| CLIP Guided Img2Img Stable Diffusion Pipeline | Doing CLIP guidance for image to image generation with Stable Diffusion | [CLIP Guided Img2Img Stable Diffusion](#clip-guided-img2img-stable-diffusion) | [Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/clip_guided_img2img_stable_diffusion.ipynb) | [Nipun Jindal](https://github.com/nipunjindal/) |
| TensorRT Stable Diffusion Text to Image Pipeline | Accelerates the Stable Diffusion Text2Image Pipeline using TensorRT | [TensorRT Stable Diffusion Text to Image Pipeline](#tensorrt-text2image-stable-diffusion-pipeline) | [Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/tensorrt_text2image_stable_diffusion_pipeline.ipynb) | [Asfiya Baig](https://github.com/asfiyab-nvidia) |
| EDICT Image Editing Pipeline | Diffusion pipeline for text-guided image editing | [EDICT Image Editing Pipeline](#edict-image-editing-pipeline) | [Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/edict_image_pipeline.ipynb) | [Joqsan Azocar](https://github.com/Joqsan) |
-| Stable Diffusion RePaint | Stable Diffusion pipeline using [RePaint](https://arxiv.org/abs/2201.09865) for inpainting. | [Stable Diffusion RePaint](#stable-diffusion-repaint )|[Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/stable_diffusion_repaint.ipynb)| [Markus Pobitzer](https://github.com/Markus-Pobitzer) |
+| Stable Diffusion RePaint | Stable Diffusion pipeline using [RePaint](https://huggingface.co/papers/2201.09865) for inpainting. | [Stable Diffusion RePaint](#stable-diffusion-repaint )|[Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/stable_diffusion_repaint.ipynb)| [Markus Pobitzer](https://github.com/Markus-Pobitzer) |
| TensorRT Stable Diffusion Image to Image Pipeline | Accelerates the Stable Diffusion Image2Image Pipeline using TensorRT | [TensorRT Stable Diffusion Image to Image Pipeline](#tensorrt-image2image-stable-diffusion-pipeline) | - | [Asfiya Baig](https://github.com/asfiyab-nvidia) |
| Stable Diffusion IPEX Pipeline | Accelerate Stable Diffusion inference pipeline with BF16/FP32 precision on Intel Xeon CPUs with [IPEX](https://github.com/intel/intel-extension-for-pytorch) | [Stable Diffusion on IPEX](#stable-diffusion-on-ipex) | - | [Yingjie Han](https://github.com/yingjie-han/) |
| CLIP Guided Images Mixing Stable Diffusion Pipeline | Сombine images using usual diffusion models. | [CLIP Guided Images Mixing Using Stable Diffusion](#clip-guided-images-mixing-with-stable-diffusion) | [Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/clip_guided_images_mixing_with_stable_diffusion.ipynb) | [Karachev Denis](https://github.com/TheDenk) |
| TensorRT Stable Diffusion Inpainting Pipeline | Accelerates the Stable Diffusion Inpainting Pipeline using TensorRT | [TensorRT Stable Diffusion Inpainting Pipeline](#tensorrt-inpainting-stable-diffusion-pipeline) | - | [Asfiya Baig](https://github.com/asfiyab-nvidia) |
-| IADB Pipeline | Implementation of [Iterative α-(de)Blending: a Minimalist Deterministic Diffusion Model](https://arxiv.org/abs/2305.03486) | [IADB Pipeline](#iadb-pipeline) | - | [Thomas Chambon](https://github.com/tchambon)
-| Zero1to3 Pipeline | Implementation of [Zero-1-to-3: Zero-shot One Image to 3D Object](https://arxiv.org/abs/2303.11328) | [Zero1to3 Pipeline](#zero1to3-pipeline) | - | [Xin Kong](https://github.com/kxhit) |
+| IADB Pipeline | Implementation of [Iterative α-(de)Blending: a Minimalist Deterministic Diffusion Model](https://huggingface.co/papers/2305.03486) | [IADB Pipeline](#iadb-pipeline) | - | [Thomas Chambon](https://github.com/tchambon)
+| Zero1to3 Pipeline | Implementation of [Zero-1-to-3: Zero-shot One Image to 3D Object](https://huggingface.co/papers/2303.11328) | [Zero1to3 Pipeline](#zero1to3-pipeline) | - | [Xin Kong](https://github.com/kxhit) |
| Stable Diffusion XL Long Weighted Prompt Pipeline | A pipeline support unlimited length of prompt and negative prompt, use A1111 style of prompt weighting | [Stable Diffusion XL Long Weighted Prompt Pipeline](#stable-diffusion-xl-long-weighted-prompt-pipeline) | [](https://colab.research.google.com/drive/1LsqilswLR40XLLcp6XFOl5nKb_wOe26W?usp=sharing) | [Andrew Zhu](https://xhinker.medium.com/) |
| Stable Diffusion Mixture Tiling Pipeline SD 1.5 | A pipeline generates cohesive images by integrating multiple diffusion processes, each focused on a specific image region and considering boundary effects for smooth blending | [Stable Diffusion Mixture Tiling Pipeline SD 1.5](#stable-diffusion-mixture-tiling-pipeline-sd-15) | [](https://huggingface.co/spaces/albarji/mixture-of-diffusers) | [Álvaro B Jiménez](https://github.com/albarji/) |
| Stable Diffusion Mixture Canvas Pipeline SD 1.5 | A pipeline generates cohesive images by integrating multiple diffusion processes, each focused on a specific image region and considering boundary effects for smooth blending. Works by defining a list of Text2Image region objects that detail the region of influence of each diffuser. | [Stable Diffusion Mixture Canvas Pipeline SD 1.5](#stable-diffusion-mixture-canvas-pipeline-sd-15) | [](https://huggingface.co/spaces/albarji/mixture-of-diffusers) | [Álvaro B Jiménez](https://github.com/albarji/) |
@@ -59,25 +59,25 @@ Please also check out our [Community Scripts](https://github.com/huggingface/dif
| sketch inpaint - Inpainting with non-inpaint Stable Diffusion | sketch inpaint much like in automatic1111 | [Masked Im2Im Stable Diffusion Pipeline](#stable-diffusion-masked-im2im) | - | [Anatoly Belikov](https://github.com/noskill) |
| sketch inpaint xl - Inpainting with non-inpaint Stable Diffusion | sketch inpaint much like in automatic1111 | [Masked Im2Im Stable Diffusion XL Pipeline](#stable-diffusion-xl-masked-im2im) | - | [Anatoly Belikov](https://github.com/noskill) |
| prompt-to-prompt | change parts of a prompt and retain image structure (see [paper page](https://prompt-to-prompt.github.io/)) | [Prompt2Prompt Pipeline](#prompt2prompt-pipeline) | [Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/prompt_2_prompt_pipeline.ipynb) | [Umer H. Adil](https://twitter.com/UmerHAdil) |
-| Latent Consistency Pipeline | Implementation of [Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference](https://arxiv.org/abs/2310.04378) | [Latent Consistency Pipeline](#latent-consistency-pipeline) | - | [Simian Luo](https://github.com/luosiallen) |
+| Latent Consistency Pipeline | Implementation of [Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference](https://huggingface.co/papers/2310.04378) | [Latent Consistency Pipeline](#latent-consistency-pipeline) | - | [Simian Luo](https://github.com/luosiallen) |
| Latent Consistency Img2img Pipeline | Img2img pipeline for Latent Consistency Models | [Latent Consistency Img2Img Pipeline](#latent-consistency-img2img-pipeline) | - | [Logan Zoellner](https://github.com/nagolinc) |
| Latent Consistency Interpolation Pipeline | Interpolate the latent space of Latent Consistency Models with multiple prompts | [Latent Consistency Interpolation Pipeline](#latent-consistency-interpolation-pipeline) | [](https://colab.research.google.com/drive/1pK3NrLWJSiJsBynLns1K1-IDTW9zbPvl?usp=sharing) | [Aryan V S](https://github.com/a-r-r-o-w) |
| SDE Drag Pipeline | The pipeline supports drag editing of images using stochastic differential equations | [SDE Drag Pipeline](#sde-drag-pipeline) | [Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/sde_drag.ipynb) | [NieShen](https://github.com/NieShenRuc) [Fengqi Zhu](https://github.com/Monohydroxides) |
| Regional Prompting Pipeline | Assign multiple prompts for different regions | [Regional Prompting Pipeline](#regional-prompting-pipeline) | - | [hako-mikan](https://github.com/hako-mikan) |
| LDM3D-sr (LDM3D upscaler) | Upscale low resolution RGB and depth inputs to high resolution | [StableDiffusionUpscaleLDM3D Pipeline](https://github.com/estelleafl/diffusers/tree/ldm3d_upscaler_community/examples/community#stablediffusionupscaleldm3d-pipeline) | - | [Estelle Aflalo](https://github.com/estelleafl) |
| AnimateDiff ControlNet Pipeline | Combines AnimateDiff with precise motion control using ControlNets | [AnimateDiff ControlNet Pipeline](#animatediff-controlnet-pipeline) | [](https://colab.research.google.com/drive/1SKboYeGjEQmQPWoFC0aLYpBlYdHXkvAu?usp=sharing) | [Aryan V S](https://github.com/a-r-r-o-w) and [Edoardo Botta](https://github.com/EdoardoBotta) |
-| DemoFusion Pipeline | Implementation of [DemoFusion: Democratising High-Resolution Image Generation With No $$$](https://arxiv.org/abs/2311.16973) | [DemoFusion Pipeline](#demofusion) | [Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/demo_fusion.ipynb) | [Ruoyi Du](https://github.com/RuoyiDu) |
-| Instaflow Pipeline | Implementation of [InstaFlow! One-Step Stable Diffusion with Rectified Flow](https://arxiv.org/abs/2309.06380) | [Instaflow Pipeline](#instaflow-pipeline) | [Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/insta_flow.ipynb) | [Ayush Mangal](https://github.com/ayushtues) |
-| Null-Text Inversion Pipeline | Implement [Null-text Inversion for Editing Real Images using Guided Diffusion Models](https://arxiv.org/abs/2211.09794) as a pipeline. | [Null-Text Inversion](https://github.com/google/prompt-to-prompt/) | - | [Junsheng Luan](https://github.com/Junsheng121) |
-| Rerender A Video Pipeline | Implementation of [[SIGGRAPH Asia 2023] Rerender A Video: Zero-Shot Text-Guided Video-to-Video Translation](https://arxiv.org/abs/2306.07954) | [Rerender A Video Pipeline](#rerender-a-video) | - | [Yifan Zhou](https://github.com/SingleZombie) |
-| StyleAligned Pipeline | Implementation of [Style Aligned Image Generation via Shared Attention](https://arxiv.org/abs/2312.02133) | [StyleAligned Pipeline](#stylealigned-pipeline) | [](https://drive.google.com/file/d/15X2E0jFPTajUIjS0FzX50OaHsCbP2lQ0/view?usp=sharing) | [Aryan V S](https://github.com/a-r-r-o-w) |
+| DemoFusion Pipeline | Implementation of [DemoFusion: Democratising High-Resolution Image Generation With No $$$](https://huggingface.co/papers/2311.16973) | [DemoFusion Pipeline](#demofusion) | [Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/demo_fusion.ipynb) | [Ruoyi Du](https://github.com/RuoyiDu) |
+| Instaflow Pipeline | Implementation of [InstaFlow! One-Step Stable Diffusion with Rectified Flow](https://huggingface.co/papers/2309.06380) | [Instaflow Pipeline](#instaflow-pipeline) | [Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/insta_flow.ipynb) | [Ayush Mangal](https://github.com/ayushtues) |
+| Null-Text Inversion Pipeline | Implement [Null-text Inversion for Editing Real Images using Guided Diffusion Models](https://huggingface.co/papers/2211.09794) as a pipeline. | [Null-Text Inversion](https://github.com/google/prompt-to-prompt/) | - | [Junsheng Luan](https://github.com/Junsheng121) |
+| Rerender A Video Pipeline | Implementation of [[SIGGRAPH Asia 2023] Rerender A Video: Zero-Shot Text-Guided Video-to-Video Translation](https://huggingface.co/papers/2306.07954) | [Rerender A Video Pipeline](#rerender-a-video) | - | [Yifan Zhou](https://github.com/SingleZombie) |
+| StyleAligned Pipeline | Implementation of [Style Aligned Image Generation via Shared Attention](https://huggingface.co/papers/2312.02133) | [StyleAligned Pipeline](#stylealigned-pipeline) | [](https://drive.google.com/file/d/15X2E0jFPTajUIjS0FzX50OaHsCbP2lQ0/view?usp=sharing) | [Aryan V S](https://github.com/a-r-r-o-w) |
| AnimateDiff Image-To-Video Pipeline | Experimental Image-To-Video support for AnimateDiff (open to improvements) | [AnimateDiff Image To Video Pipeline](#animatediff-image-to-video-pipeline) | [](https://drive.google.com/file/d/1TvzCDPHhfFtdcJZe4RLloAwyoLKuttWK/view?usp=sharing) | [Aryan V S](https://github.com/a-r-r-o-w) |
| IP Adapter FaceID Stable Diffusion | Stable Diffusion Pipeline that supports IP Adapter Face ID | [IP Adapter Face ID](#ip-adapter-face-id) |[Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/ip_adapter_face_id.ipynb)| [Fabio Rigano](https://github.com/fabiorigano) |
| InstantID Pipeline | Stable Diffusion XL Pipeline that supports InstantID | [InstantID Pipeline](#instantid-pipeline) | [](https://huggingface.co/spaces/InstantX/InstantID) | [Haofan Wang](https://github.com/haofanwang) |
| UFOGen Scheduler | Scheduler for UFOGen Model (compatible with Stable Diffusion pipelines) | [UFOGen Scheduler](#ufogen-scheduler) | - | [dg845](https://github.com/dg845) |
| Stable Diffusion XL IPEX Pipeline | Accelerate Stable Diffusion XL inference pipeline with BF16/FP32 precision on Intel Xeon CPUs with [IPEX](https://github.com/intel/intel-extension-for-pytorch) | [Stable Diffusion XL on IPEX](#stable-diffusion-xl-on-ipex) | - | [Dan Li](https://github.com/ustcuna/) |
| Stable Diffusion BoxDiff Pipeline | Training-free controlled generation with bounding boxes using [BoxDiff](https://github.com/showlab/BoxDiff) | [Stable Diffusion BoxDiff Pipeline](#stable-diffusion-boxdiff) | - | [Jingyang Zhang](https://github.com/zjysteven/) |
-| FRESCO V2V Pipeline | Implementation of [[CVPR 2024] FRESCO: Spatial-Temporal Correspondence for Zero-Shot Video Translation](https://arxiv.org/abs/2403.12962) | [FRESCO V2V Pipeline](#fresco) | - | [Yifan Zhou](https://github.com/SingleZombie) |
+| FRESCO V2V Pipeline | Implementation of [[CVPR 2024] FRESCO: Spatial-Temporal Correspondence for Zero-Shot Video Translation](https://huggingface.co/papers/2403.12962) | [FRESCO V2V Pipeline](#fresco) | - | [Yifan Zhou](https://github.com/SingleZombie) |
| AnimateDiff IPEX Pipeline | Accelerate AnimateDiff inference pipeline with BF16/FP32 precision on Intel Xeon CPUs with [IPEX](https://github.com/intel/intel-extension-for-pytorch) | [AnimateDiff on IPEX](#animatediff-on-ipex) | - | [Dan Li](https://github.com/ustcuna/) |
PIXART-α Controlnet pipeline | Implementation of the controlnet model for pixart alpha and its diffusers pipeline | [PIXART-α Controlnet pipeline](#pixart-α-controlnet-pipeline) | - | [Raul Ciotescu](https://github.com/raulc0399/) |
| HunyuanDiT Differential Diffusion Pipeline | Applies [Differential Diffusion](https://github.com/exx8/differential-diffusion) to [HunyuanDiT](https://github.com/huggingface/diffusers/pull/8240). | [HunyuanDiT with Differential Diffusion](#hunyuandit-with-differential-diffusion) | [](https://colab.research.google.com/drive/1v44a5fpzyr4Ffr4v2XBQ7BajzG874N4P?usp=sharing) | [Monjoy Choudhury](https://github.com/MnCSSJ4x) |
@@ -85,7 +85,7 @@ PIXART-α Controlnet pipeline | Implementation of the controlnet model for pixar
| Stable Diffusion XL Attentive Eraser Pipeline |[[AAAI2025 Oral] Attentive Eraser](https://github.com/Anonym0u3/AttentiveEraser) is a novel tuning-free method that enhances object removal capabilities in pre-trained diffusion models.|[Stable Diffusion XL Attentive Eraser Pipeline](#stable-diffusion-xl-attentive-eraser-pipeline)|-|[Wenhao Sun](https://github.com/Anonym0u3) and [Benlei Cui](https://github.com/Benny079)|
| Perturbed-Attention Guidance |StableDiffusionPAGPipeline is a modification of StableDiffusionPipeline to support Perturbed-Attention Guidance (PAG).|[Perturbed-Attention Guidance](#perturbed-attention-guidance)|[Notebook](https://github.com/huggingface/notebooks/blob/main/diffusers/perturbed_attention_guidance.ipynb)|[Hyoungwon Cho](https://github.com/HyoungwonCho)|
| CogVideoX DDIM Inversion Pipeline | Implementation of DDIM inversion and guided attention-based editing denoising process on CogVideoX. | [CogVideoX DDIM Inversion Pipeline](#cogvideox-ddim-inversion-pipeline) | - | [LittleNyima](https://github.com/LittleNyima) |
-| FaithDiff Stable Diffusion XL Pipeline | Implementation of [(CVPR 2025) FaithDiff: Unleashing Diffusion Priors for Faithful Image Super-resolutionUnleashing Diffusion Priors for Faithful Image Super-resolution](https://arxiv.org/abs/2411.18824) - FaithDiff is a faithful image super-resolution method that leverages latent diffusion models by actively adapting the diffusion prior and jointly fine-tuning its components (encoder and diffusion model) with an alignment module to ensure high fidelity and structural consistency. | [FaithDiff Stable Diffusion XL Pipeline](#faithdiff-stable-diffusion-xl-pipeline) | [](https://huggingface.co/jychen9811/FaithDiff) | [Junyang Chen, Jinshan Pan, Jiangxin Dong, IMAG Lab, (Adapted by Eliseu Silva)](https://github.com/JyChen9811/FaithDiff) |
+| FaithDiff Stable Diffusion XL Pipeline | Implementation of [(CVPR 2025) FaithDiff: Unleashing Diffusion Priors for Faithful Image Super-resolutionUnleashing Diffusion Priors for Faithful Image Super-resolution](https://huggingface.co/papers/2411.18824) - FaithDiff is a faithful image super-resolution method that leverages latent diffusion models by actively adapting the diffusion prior and jointly fine-tuning its components (encoder and diffusion model) with an alignment module to ensure high fidelity and structural consistency. | [FaithDiff Stable Diffusion XL Pipeline](#faithdiff-stable-diffusion-xl-pipeline) | [](https://huggingface.co/jychen9811/FaithDiff) | [Junyang Chen, Jinshan Pan, Jiangxin Dong, IMAG Lab, (Adapted by Eliseu Silva)](https://github.com/JyChen9811/FaithDiff) |
| Stable Diffusion 3 InstructPix2Pix Pipeline | Implementation of Stable Diffusion 3 InstructPix2Pix Pipeline | [Stable Diffusion 3 InstructPix2Pix Pipeline](#stable-diffusion-3-instructpix2pix-pipeline) | [](https://huggingface.co/BleachNick/SD3_UltraEdit_freeform) [](https://huggingface.co/CaptainZZZ/sd3-instructpix2pix) | [Jiayu Zhang](https://github.com/xduzhangjiayu) and [Haozhe Zhao](https://github.com/HaozheZhao)|
To load a custom pipeline you just need to pass the `custom_pipeline` argument to `DiffusionPipeline`, as one of the files in `diffusers/examples/community`. Feel free to send a PR with your own pipelines, we will merge them quickly.
@@ -101,7 +101,7 @@ pipe = DiffusionPipeline.from_pretrained("stable-diffusion-v1-5/stable-diffusion
**KAIST AI, University of Washington**
-[*Spatiotemporal Skip Guidance (STG) for Enhanced Video Diffusion Sampling*](https://arxiv.org/abs/2411.18664) (CVPR 2025) is a simple training-free sampling guidance method for enhancing transformer-based video diffusion models. STG employs an implicit weak model via self-perturbation, avoiding the need for external models or additional training. By selectively skipping spatiotemporal layers, STG produces an aligned, degraded version of the original model to boost sample quality without compromising diversity or dynamic degree.
+[*Spatiotemporal Skip Guidance (STG) for Enhanced Video Diffusion Sampling*](https://huggingface.co/papers/2411.18664) (CVPR 2025) is a simple training-free sampling guidance method for enhancing transformer-based video diffusion models. STG employs an implicit weak model via self-perturbation, avoiding the need for external models or additional training. By selectively skipping spatiotemporal layers, STG produces an aligned, degraded version of the original model to boost sample quality without compromising diversity or dynamic degree.
Following is the example video of STG applied to Mochi.
@@ -161,7 +161,7 @@ Here is the demonstration of Adaptive Mask Inpainting:

-You can find additional information about Adaptive Mask Inpainting in the [paper](https://arxiv.org/pdf/2401.12978) or in the [project website](https://snuvclab.github.io/coma).
+You can find additional information about Adaptive Mask Inpainting in the [paper](https://huggingface.co/papers/2401.12978) or in the [project website](https://snuvclab.github.io/coma).
#### Usage example
First, clone the diffusers github repository, and run the following command to set environment.
@@ -413,7 +413,7 @@ image.save("result.png")
### HD-Painter
-Implementation of [HD-Painter: High-Resolution and Prompt-Faithful Text-Guided Image Inpainting with Diffusion Models](https://arxiv.org/abs/2312.14091).
+Implementation of [HD-Painter: High-Resolution and Prompt-Faithful Text-Guided Image Inpainting with Diffusion Models](https://huggingface.co/papers/2312.14091).

@@ -428,7 +428,7 @@ Moreover, HD-Painter allows extension to larger scales by introducing a speciali
Our experiments demonstrate that HD-Painter surpasses existing state-of-the-art approaches qualitatively and quantitatively, achieving an impressive generation accuracy improvement of **61.4** vs **51.9**.
We will make the codes publicly available.
-You can find additional information about Text2Video-Zero in the [paper](https://arxiv.org/abs/2312.14091) or the [original codebase](https://github.com/Picsart-AI-Research/HD-Painter).
+You can find additional information about Text2Video-Zero in the [paper](https://huggingface.co/papers/2312.14091) or the [original codebase](https://github.com/Picsart-AI-Research/HD-Painter).
#### Usage example
@@ -1362,7 +1362,7 @@ print("Inpainting completed. Image saved as 'inpainting_output.png'.")
### Bit Diffusion
-Based , this is used for diffusion on discrete data - eg, discrete image data, DNA sequence data. An unconditional discrete image can be generated like this:
+Based , this is used for diffusion on discrete data - eg, discrete image data, DNA sequence data. An unconditional discrete image can be generated like this:
```python
from diffusers import DiffusionPipeline
@@ -1523,7 +1523,7 @@ As a result, you can look at a grid of all 4 generated images being shown togeth
### Magic Mix
-Implementation of the [MagicMix: Semantic Mixing with Diffusion Models](https://arxiv.org/abs/2210.16056) paper. This is a Diffusion Pipeline for semantic mixing of an image and a text prompt to create a new concept while preserving the spatial layout and geometry of the subject in the image. The pipeline takes an image that provides the layout semantics and a prompt that provides the content semantics for the mixing process.
+Implementation of the [MagicMix: Semantic Mixing with Diffusion Models](https://huggingface.co/papers/2210.16056) paper. This is a Diffusion Pipeline for semantic mixing of an image and a text prompt to create a new concept while preserving the spatial layout and geometry of the subject in the image. The pipeline takes an image that provides the layout semantics and a prompt that provides the content semantics for the mixing process.
There are 3 parameters for the method-
@@ -1754,7 +1754,7 @@ The resulting images in order:-
#### **Research question: What visual concepts do the diffusion models learn from each noise level during training?**
-The [P2 weighting (CVPR 2022)](https://arxiv.org/abs/2204.00227) paper proposed an approach to answer the above question, which is their second contribution.
+The [P2 weighting (CVPR 2022)](https://huggingface.co/papers/2204.00227) paper proposed an approach to answer the above question, which is their second contribution.
The approach consists of the following steps:
1. The input is an image x0.
@@ -1896,7 +1896,7 @@ image.save('tensorrt_mt_fuji.png')
### EDICT Image Editing Pipeline
-This pipeline implements the text-guided image editing approach from the paper [EDICT: Exact Diffusion Inversion via Coupled Transformations](https://arxiv.org/abs/2211.12446). You have to pass:
+This pipeline implements the text-guided image editing approach from the paper [EDICT: Exact Diffusion Inversion via Coupled Transformations](https://huggingface.co/papers/2211.12446). You have to pass:
- (`PIL`) `image` you want to edit.
- `base_prompt`: the text prompt describing the current image (before editing).
@@ -1981,7 +1981,7 @@ Output Image
### Stable Diffusion RePaint
-This pipeline uses the [RePaint](https://arxiv.org/abs/2201.09865) logic on the latent space of stable diffusion. It can
+This pipeline uses the [RePaint](https://huggingface.co/papers/2201.09865) logic on the latent space of stable diffusion. It can
be used similarly to other image inpainting pipelines but does not rely on a specific inpainting model. This means you can use
models that are not specifically created for inpainting.
@@ -2576,7 +2576,7 @@ For more results, checkout [PR #6114](https://github.com/huggingface/diffusers/p
### Stable Diffusion Mixture Tiling Pipeline SD 1.5
-This pipeline uses the Mixture. Refer to the [Mixture](https://arxiv.org/abs/2302.02412) paper for more details.
+This pipeline uses the Mixture. Refer to the [Mixture](https://huggingface.co/papers/2302.02412) paper for more details.
```python
from diffusers import LMSDiscreteScheduler, DiffusionPipeline
@@ -2607,7 +2607,7 @@ image = pipeline(
### Stable Diffusion Mixture Canvas Pipeline SD 1.5
-This pipeline uses the Mixture. Refer to the [Mixture](https://arxiv.org/abs/2302.02412) paper for more details.
+This pipeline uses the Mixture. Refer to the [Mixture](https://huggingface.co/papers/2302.02412) paper for more details.
```python
from PIL import Image
@@ -2642,7 +2642,7 @@ output = pipeline(
### Stable Diffusion Mixture Tiling Pipeline SDXL
-This pipeline uses the Mixture. Refer to the [Mixture](https://arxiv.org/abs/2302.02412) paper for more details.
+This pipeline uses the Mixture. Refer to the [Mixture](https://huggingface.co/papers/2302.02412) paper for more details.
```python
import torch
@@ -2696,7 +2696,7 @@ image = pipe(
### Stable Diffusion MoD ControlNet Tile SR Pipeline SDXL
-This pipeline implements the [MoD (Mixture-of-Diffusers)]("https://arxiv.org/pdf/2408.06072") tiled diffusion technique and combines it with SDXL's ControlNet Tile process to generate SR images.
+This pipeline implements the [MoD (Mixture-of-Diffusers)](https://huggingface.co/papers/2408.06072) tiled diffusion technique and combines it with SDXL's ControlNet Tile process to generate SR images.
This works better with 4x scales, but you can try adjusts parameters to higher scales.
@@ -2835,7 +2835,7 @@ image.save('tensorrt_inpaint_mecha_robot.png')
### IADB pipeline
-This pipeline is the implementation of the [α-(de)Blending: a Minimalist Deterministic Diffusion Model](https://arxiv.org/abs/2305.03486) paper.
+This pipeline is the implementation of the [α-(de)Blending: a Minimalist Deterministic Diffusion Model](https://huggingface.co/papers/2305.03486) paper.
It is a simple and minimalist diffusion model.
The following code shows how to use the IADB pipeline to generate images using a pretrained celebahq-256 model.
@@ -2888,7 +2888,7 @@ while True:
### Zero1to3 pipeline
-This pipeline is the implementation of the [Zero-1-to-3: Zero-shot One Image to 3D Object](https://arxiv.org/abs/2303.11328) paper.
+This pipeline is the implementation of the [Zero-1-to-3: Zero-shot One Image to 3D Object](https://huggingface.co/papers/2303.11328) paper.
The original pytorch-lightning [repo](https://github.com/cvlab-columbia/zero123) and a diffusers [repo](https://github.com/kxhit/zero123-hf).
The following code shows how to use the Zero1to3 pipeline to generate novel view synthesis images using a pretrained stable diffusion model.
@@ -3356,7 +3356,7 @@ Side note: See [this GitHub gist](https://gist.github.com/UmerHA/b65bb5fb9626c9c
### Latent Consistency Pipeline
-Latent Consistency Models was proposed in [Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference](https://arxiv.org/abs/2310.04378) by _Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, Hang Zhao_ from Tsinghua University.
+Latent Consistency Models was proposed in [Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference](https://huggingface.co/papers/2310.04378) by _Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, Hang Zhao_ from Tsinghua University.
The abstract of the paper reads as follows:
@@ -3468,7 +3468,7 @@ assert len(images) == (len(prompts) - 1) * num_interpolation_steps
### StableDiffusionUpscaleLDM3D Pipeline
-[LDM3D-VR](https://arxiv.org/pdf/2311.03226.pdf) is an extended version of LDM3D.
+[LDM3D-VR](https://huggingface.co/papers/2311.03226) is an extended version of LDM3D.
The abstract from the paper is:
*Latent diffusion models have proven to be state-of-the-art in the creation and manipulation of visual outputs. However, as far as we know, the generation of depth maps jointly with RGB is still limited. We introduce LDM3D-VR, a suite of diffusion models targeting virtual reality development that includes LDM3D-pano and LDM3D-SR. These models enable the generation of panoramic RGBD based on textual prompts and the upscaling of low-resolution inputs to high-resolution RGBD, respectively. Our models are fine-tuned from existing pretrained models on datasets containing panoramic/high-resolution RGB images, depth maps and captions. Both models are evaluated in comparison to existing related methods*
@@ -4165,7 +4165,7 @@ export_to_gif(result.frames[0], "result.gif")
### DemoFusion
-This pipeline is the official implementation of [DemoFusion: Democratising High-Resolution Image Generation With No $$$](https://arxiv.org/abs/2311.16973).
+This pipeline is the official implementation of [DemoFusion: Democratising High-Resolution Image Generation With No $$$](https://huggingface.co/papers/2311.16973).
The original repo can be found at [repo](https://github.com/PRIS-CV/DemoFusion).
- `view_batch_size` (`int`, defaults to 16):
@@ -4259,7 +4259,7 @@ This pipeline provides drag-and-drop image editing using stochastic differential

-See [paper](https://arxiv.org/abs/2311.01410), [paper page](https://ml-gsai.github.io/SDE-Drag-demo/), [original repo](https://github.com/ML-GSAI/SDE-Drag) for more information.
+See [paper](https://huggingface.co/papers/2311.01410), [paper page](https://ml-gsai.github.io/SDE-Drag-demo/), [original repo](https://github.com/ML-GSAI/SDE-Drag) for more information.
```py
import torch
@@ -4515,7 +4515,7 @@ export_to_video(
### StyleAligned Pipeline
-This pipeline is the implementation of [Style Aligned Image Generation via Shared Attention](https://arxiv.org/abs/2312.02133). You can find more results [here](https://github.com/huggingface/diffusers/pull/6489#issuecomment-1881209354).
+This pipeline is the implementation of [Style Aligned Image Generation via Shared Attention](https://huggingface.co/papers/2312.02133). You can find more results [here](https://github.com/huggingface/diffusers/pull/6489#issuecomment-1881209354).
> Large-scale Text-to-Image (T2I) models have rapidly gained prominence across creative fields, generating visually compelling outputs from textual prompts. However, controlling these models to ensure consistent style remains challenging, with existing methods necessitating fine-tuning and manual intervention to disentangle content and style. In this paper, we introduce StyleAligned, a novel technique designed to establish style alignment among a series of generated images. By employing minimal `attention sharing' during the diffusion process, our method maintains style consistency across images within T2I models. This approach allows for the creation of style-consistent images using a reference style through a straightforward inversion operation. Our method's evaluation across diverse styles and text prompts demonstrates high-quality synthesis and fidelity, underscoring its efficacy in achieving consistent style across various inputs.
@@ -4729,7 +4729,7 @@ image = pipe(
### UFOGen Scheduler
-[UFOGen](https://arxiv.org/abs/2311.09257) is a generative model designed for fast one-step text-to-image generation, trained via adversarial training starting from an initial pretrained diffusion model such as Stable Diffusion. `scheduling_ufogen.py` implements a onestep and multistep sampling algorithm for UFOGen models compatible with pipelines like `StableDiffusionPipeline`. A usage example is as follows:
+[UFOGen](https://huggingface.co/papers/2311.09257) is a generative model designed for fast one-step text-to-image generation, trained via adversarial training starting from an initial pretrained diffusion model such as Stable Diffusion. `scheduling_ufogen.py` implements a onestep and multistep sampling algorithm for UFOGen models compatible with pipelines like `StableDiffusionPipeline`. A usage example is as follows:
```py
import torch
@@ -5047,7 +5047,7 @@ make_image_grid(image, rows=1, cols=len(image))
### Stable Diffusion XL Attentive Eraser Pipeline
 -**Stable Diffusion XL Attentive Eraser Pipeline** is an advanced object removal pipeline that leverages SDXL for precise content suppression and seamless region completion. This pipeline uses **self-attention redirection guidance** to modify the model’s self-attention mechanism, allowing for effective removal and inpainting across various levels of mask precision, including semantic segmentation masks, bounding boxes, and hand-drawn masks. If you are interested in more detailed information and have any questions, please refer to the [paper](https://arxiv.org/abs/2412.12974) and [official implementation](https://github.com/Anonym0u3/AttentiveEraser).
+**Stable Diffusion XL Attentive Eraser Pipeline** is an advanced object removal pipeline that leverages SDXL for precise content suppression and seamless region completion. This pipeline uses **self-attention redirection guidance** to modify the model’s self-attention mechanism, allowing for effective removal and inpainting across various levels of mask precision, including semantic segmentation masks, bounding boxes, and hand-drawn masks. If you are interested in more detailed information and have any questions, please refer to the [paper](https://huggingface.co/papers/2412.12974) and [official implementation](https://github.com/Anonym0u3/AttentiveEraser).
#### Key features
@@ -5133,7 +5133,7 @@ print("Object removal completed")
# Perturbed-Attention Guidance
-[Project](https://ku-cvlab.github.io/Perturbed-Attention-Guidance/) / [arXiv](https://arxiv.org/abs/2403.17377) / [GitHub](https://github.com/KU-CVLAB/Perturbed-Attention-Guidance)
+[Project](https://ku-cvlab.github.io/Perturbed-Attention-Guidance/) / [arXiv](https://huggingface.co/papers/2403.17377) / [GitHub](https://github.com/KU-CVLAB/Perturbed-Attention-Guidance)
This implementation is based on [Diffusers](https://huggingface.co/docs/diffusers/index). `StableDiffusionPAGPipeline` is a modification of `StableDiffusionPipeline` to support Perturbed-Attention Guidance (PAG).
diff --git a/examples/community/adaptive_mask_inpainting.py b/examples/community/adaptive_mask_inpainting.py
index 81f9527b47..aac460cb46 100644
--- a/examples/community/adaptive_mask_inpainting.py
+++ b/examples/community/adaptive_mask_inpainting.py
@@ -670,7 +670,7 @@ class AdaptiveMaskInpaintPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -917,7 +917,7 @@ class AdaptiveMaskInpaintPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
@@ -1012,7 +1012,7 @@ class AdaptiveMaskInpaintPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/bit_diffusion.py b/examples/community/bit_diffusion.py
index 71d8f31163..67f4cd3fe1 100644
--- a/examples/community/bit_diffusion.py
+++ b/examples/community/bit_diffusion.py
@@ -74,7 +74,7 @@ def ddim_bit_scheduler_step(
"Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
)
- # See formulas (12) and (16) of DDIM paper https://arxiv.org/pdf/2010.02502.pdf
+ # See formulas (12) and (16) of DDIM paper https://huggingface.co/papers/2010.02502
# Ideally, read DDIM paper in-detail understanding
# Notation ( ->
@@ -95,7 +95,7 @@ def ddim_bit_scheduler_step(
beta_prod_t = 1 - alpha_prod_t
# 3. compute predicted original sample from predicted noise also called
- # "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # "predicted x_0" of formula (12) from https://huggingface.co/papers/2010.02502
pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
# 4. Clip "predicted x_0"
@@ -112,10 +112,10 @@ def ddim_bit_scheduler_step(
# the model_output is always re-derived from the clipped x_0 in Glide
model_output = (sample - alpha_prod_t ** (0.5) * pred_original_sample) / beta_prod_t ** (0.5)
- # 6. compute "direction pointing to x_t" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # 6. compute "direction pointing to x_t" of formula (12) from https://huggingface.co/papers/2010.02502
pred_sample_direction = (1 - alpha_prod_t_prev - std_dev_t**2) ** (0.5) * model_output
- # 7. compute x_t without "random noise" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # 7. compute x_t without "random noise" of formula (12) from https://huggingface.co/papers/2010.02502
prev_sample = alpha_prod_t_prev ** (0.5) * pred_original_sample + pred_sample_direction
if eta > 0:
@@ -172,7 +172,7 @@ def ddpm_bit_scheduler_step(
beta_prod_t_prev = 1 - alpha_prod_t_prev
# 2. compute predicted original sample from predicted noise also called
- # "predicted x_0" of formula (15) from https://arxiv.org/pdf/2006.11239.pdf
+ # "predicted x_0" of formula (15) from https://huggingface.co/papers/2006.11239
if prediction_type == "epsilon":
pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
elif prediction_type == "sample":
@@ -186,12 +186,12 @@ def ddpm_bit_scheduler_step(
pred_original_sample = torch.clamp(pred_original_sample, -scale, scale)
# 4. Compute coefficients for pred_original_sample x_0 and current sample x_t
- # See formula (7) from https://arxiv.org/pdf/2006.11239.pdf
+ # See formula (7) from https://huggingface.co/papers/2006.11239
pred_original_sample_coeff = (alpha_prod_t_prev ** (0.5) * self.betas[t]) / beta_prod_t
current_sample_coeff = self.alphas[t] ** (0.5) * beta_prod_t_prev / beta_prod_t
# 5. Compute predicted previous sample µ_t
- # See formula (7) from https://arxiv.org/pdf/2006.11239.pdf
+ # See formula (7) from https://huggingface.co/papers/2006.11239
pred_prev_sample = pred_original_sample_coeff * pred_original_sample + current_sample_coeff * sample
# 6. Add noise
diff --git a/examples/community/clip_guided_images_mixing_stable_diffusion.py b/examples/community/clip_guided_images_mixing_stable_diffusion.py
index f9a4b12ad2..2cd3daf68c 100644
--- a/examples/community/clip_guided_images_mixing_stable_diffusion.py
+++ b/examples/community/clip_guided_images_mixing_stable_diffusion.py
@@ -197,7 +197,7 @@ class CLIPGuidedImagesMixingStableDiffusion(DiffusionPipeline, StableDiffusionMi
alpha_prod_t = self.scheduler.alphas_cumprod[timestep]
beta_prod_t = 1 - alpha_prod_t
# compute predicted original sample from predicted noise also called
- # "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # "predicted x_0" of formula (12) from https://huggingface.co/papers/2010.02502
pred_original_sample = (latents - beta_prod_t ** (0.5) * noise_pred) / alpha_prod_t ** (0.5)
fac = torch.sqrt(beta_prod_t)
@@ -343,7 +343,7 @@ class CLIPGuidedImagesMixingStableDiffusion(DiffusionPipeline, StableDiffusionMi
)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
@@ -384,7 +384,7 @@ class CLIPGuidedImagesMixingStableDiffusion(DiffusionPipeline, StableDiffusionMi
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
diff --git a/examples/community/clip_guided_stable_diffusion.py b/examples/community/clip_guided_stable_diffusion.py
index 1350650113..bfd0858d24 100644
--- a/examples/community/clip_guided_stable_diffusion.py
+++ b/examples/community/clip_guided_stable_diffusion.py
@@ -125,7 +125,7 @@ class CLIPGuidedStableDiffusion(DiffusionPipeline, StableDiffusionMixin):
alpha_prod_t = self.scheduler.alphas_cumprod[timestep]
beta_prod_t = 1 - alpha_prod_t
# compute predicted original sample from predicted noise also called
- # "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # "predicted x_0" of formula (12) from https://huggingface.co/papers/2010.02502
pred_original_sample = (latents - beta_prod_t ** (0.5) * noise_pred) / alpha_prod_t ** (0.5)
fac = torch.sqrt(beta_prod_t)
@@ -223,7 +223,7 @@ class CLIPGuidedStableDiffusion(DiffusionPipeline, StableDiffusionMixin):
text_embeddings_clip = text_embeddings_clip.repeat_interleave(num_images_per_prompt, dim=0)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
@@ -276,7 +276,7 @@ class CLIPGuidedStableDiffusion(DiffusionPipeline, StableDiffusionMixin):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
diff --git a/examples/community/clip_guided_stable_diffusion_img2img.py b/examples/community/clip_guided_stable_diffusion_img2img.py
index 91c74b9ffa..f3dd4903f8 100644
--- a/examples/community/clip_guided_stable_diffusion_img2img.py
+++ b/examples/community/clip_guided_stable_diffusion_img2img.py
@@ -260,7 +260,7 @@ class CLIPGuidedStableDiffusion(DiffusionPipeline, StableDiffusionMixin):
alpha_prod_t = self.scheduler.alphas_cumprod[timestep]
beta_prod_t = 1 - alpha_prod_t
# compute predicted original sample from predicted noise also called
- # "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # "predicted x_0" of formula (12) from https://huggingface.co/papers/2010.02502
pred_original_sample = (latents - beta_prod_t ** (0.5) * noise_pred) / alpha_prod_t ** (0.5)
fac = torch.sqrt(beta_prod_t)
@@ -387,7 +387,7 @@ class CLIPGuidedStableDiffusion(DiffusionPipeline, StableDiffusionMixin):
text_embeddings_clip = text_embeddings_clip.repeat_interleave(num_images_per_prompt, dim=0)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
@@ -428,7 +428,7 @@ class CLIPGuidedStableDiffusion(DiffusionPipeline, StableDiffusionMixin):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
diff --git a/examples/community/cogvideox_ddim_inversion.py b/examples/community/cogvideox_ddim_inversion.py
index e9d1746d2d..36d95901c6 100644
--- a/examples/community/cogvideox_ddim_inversion.py
+++ b/examples/community/cogvideox_ddim_inversion.py
@@ -462,7 +462,7 @@ class CogVideoXPipelineForDDIMInversion(CogVideoXPipeline):
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/composable_stable_diffusion.py b/examples/community/composable_stable_diffusion.py
index 024818daf1..14a4c7e1d0 100644
--- a/examples/community/composable_stable_diffusion.py
+++ b/examples/community/composable_stable_diffusion.py
@@ -295,7 +295,7 @@ class ComposableStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin)
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -379,9 +379,9 @@ class ComposableStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin)
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -390,7 +390,7 @@ class ComposableStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin)
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
@@ -430,7 +430,7 @@ class ComposableStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin)
batch_size = 1 if isinstance(prompt, str) else len(prompt)
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/fresco_v2v.py b/examples/community/fresco_v2v.py
index 052130cd93..fe7cdae7bd 100644
--- a/examples/community/fresco_v2v.py
+++ b/examples/community/fresco_v2v.py
@@ -124,7 +124,7 @@ def flow_warp(feature, flow, mask=False, mode="bilinear", padding_mode="zeros"):
def forward_backward_consistency_check(fwd_flow, bwd_flow, alpha=0.01, beta=0.5):
# fwd_flow, bwd_flow: [B, 2, H, W]
# alpha and beta values are following UnFlow
- # (https://arxiv.org/abs/1711.07837)
+ # (https://huggingface.co/papers/1711.07837)
assert fwd_flow.dim() == 4 and bwd_flow.dim() == 4
assert fwd_flow.size(1) == 2 and bwd_flow.size(1) == 2
flow_mag = torch.norm(fwd_flow, dim=1) + torch.norm(bwd_flow, dim=1) # [B, H, W]
@@ -1703,7 +1703,7 @@ class FrescoV2VPipeline(StableDiffusionControlNetImg2ImgPipeline):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -2030,7 +2030,7 @@ class FrescoV2VPipeline(StableDiffusionControlNetImg2ImgPipeline):
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -2109,7 +2109,7 @@ class FrescoV2VPipeline(StableDiffusionControlNetImg2ImgPipeline):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
diff --git a/examples/community/gluegen.py b/examples/community/gluegen.py
index 54cc562d55..86813b63ec 100644
--- a/examples/community/gluegen.py
+++ b/examples/community/gluegen.py
@@ -139,7 +139,7 @@ class TranslatorNoLN(nn.Module):
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -447,7 +447,7 @@ class GlueGenStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin, St
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -563,7 +563,7 @@ class GlueGenStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin, St
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -630,7 +630,7 @@ class GlueGenStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin, St
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
@@ -656,7 +656,7 @@ class GlueGenStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin, St
[`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf). Guidance rescale factor should fix overexposure when
+ Flawed](https://huggingface.co/papers/2305.08891). Guidance rescale factor should fix overexposure when
using zero terminal SNR.
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
@@ -781,7 +781,7 @@ class GlueGenStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin, St
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/examples/community/iadb.py b/examples/community/iadb.py
index 81e9e8d89d..6262c3cb15 100644
--- a/examples/community/iadb.py
+++ b/examples/community/iadb.py
@@ -12,7 +12,7 @@ class IADBScheduler(SchedulerMixin, ConfigMixin):
"""
IADBScheduler is a scheduler for the Iterative α-(de)Blending denoising method. It is simple and minimalist.
- For more details, see the original paper: https://arxiv.org/abs/2305.03486 and the blog post: https://ggx-research.github.io/publication/2023/05/10/publication-iadb.html
+ For more details, see the original paper: https://huggingface.co/papers/2305.03486 and the blog post: https://ggx-research.github.io/publication/2023/05/10/publication-iadb.html
"""
def step(
diff --git a/examples/community/imagic_stable_diffusion.py b/examples/community/imagic_stable_diffusion.py
index cea55dd383..a2561c9198 100644
--- a/examples/community/imagic_stable_diffusion.py
+++ b/examples/community/imagic_stable_diffusion.py
@@ -61,7 +61,7 @@ def preprocess(image):
class ImagicStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
r"""
Pipeline for imagic image editing.
- See paper here: https://arxiv.org/pdf/2210.09276.pdf
+ See paper here: https://huggingface.co/papers/2210.09276
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
@@ -133,13 +133,13 @@ class ImagicStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
@@ -334,9 +334,9 @@ class ImagicStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
generator (`torch.Generator`, *optional*):
@@ -349,7 +349,7 @@ class ImagicStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
@@ -368,7 +368,7 @@ class ImagicStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
text_embeddings = alpha * self.text_embeddings_orig + (1 - alpha) * self.text_embeddings
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
@@ -420,7 +420,7 @@ class ImagicStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
diff --git a/examples/community/img2img_inpainting.py b/examples/community/img2img_inpainting.py
index c6de027897..7b9bd043d0 100644
--- a/examples/community/img2img_inpainting.py
+++ b/examples/community/img2img_inpainting.py
@@ -178,9 +178,9 @@ class ImageToImageInpaintingPipeline(DiffusionPipeline):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -189,7 +189,7 @@ class ImageToImageInpaintingPipeline(DiffusionPipeline):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
@@ -266,7 +266,7 @@ class ImageToImageInpaintingPipeline(DiffusionPipeline):
text_embeddings = text_embeddings.view(bs_embed * num_images_per_prompt, seq_len, -1)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
@@ -378,7 +378,7 @@ class ImageToImageInpaintingPipeline(DiffusionPipeline):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
diff --git a/examples/community/instaflow_one_step.py b/examples/community/instaflow_one_step.py
index e726b42756..59687e979c 100644
--- a/examples/community/instaflow_one_step.py
+++ b/examples/community/instaflow_one_step.py
@@ -41,7 +41,7 @@ logger = logging.get_logger(__name__) # pylint: disable=invalid-name
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -414,7 +414,7 @@ class InstaFlowPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -541,7 +541,7 @@ class InstaFlowPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
@@ -572,7 +572,7 @@ class InstaFlowPipeline(
[`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.7):
Guidance rescale factor from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf). Guidance rescale factor should fix overexposure when
+ Flawed](https://huggingface.co/papers/2305.08891). Guidance rescale factor should fix overexposure when
using zero terminal SNR.
Examples:
@@ -603,7 +603,7 @@ class InstaFlowPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/interpolate_stable_diffusion.py b/examples/community/interpolate_stable_diffusion.py
index 99614635ee..460bb464f3 100644
--- a/examples/community/interpolate_stable_diffusion.py
+++ b/examples/community/interpolate_stable_diffusion.py
@@ -154,9 +154,9 @@ class StableDiffusionWalkPipeline(DiffusionPipeline, StableDiffusionMixin):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -165,7 +165,7 @@ class StableDiffusionWalkPipeline(DiffusionPipeline, StableDiffusionMixin):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
@@ -244,7 +244,7 @@ class StableDiffusionWalkPipeline(DiffusionPipeline, StableDiffusionMixin):
text_embeddings = text_embeddings.view(bs_embed * num_images_per_prompt, seq_len, -1)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
@@ -320,7 +320,7 @@ class StableDiffusionWalkPipeline(DiffusionPipeline, StableDiffusionMixin):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
@@ -432,16 +432,16 @@ class StableDiffusionWalkPipeline(DiffusionPipeline, StableDiffusionMixin):
width (`int`, *optional*, defaults to 512):
Width of the generated images.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
Returns:
diff --git a/examples/community/ip_adapter_face_id.py b/examples/community/ip_adapter_face_id.py
index 648bf29331..203be1d4c8 100644
--- a/examples/community/ip_adapter_face_id.py
+++ b/examples/community/ip_adapter_face_id.py
@@ -76,7 +76,7 @@ class IPAdapterFullImageProjection(nn.Module):
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -693,7 +693,7 @@ class IPAdapterFaceIDStableDiffusionPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -823,7 +823,7 @@ class IPAdapterFaceIDStableDiffusionPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -893,7 +893,7 @@ class IPAdapterFaceIDStableDiffusionPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
@@ -920,7 +920,7 @@ class IPAdapterFaceIDStableDiffusionPipeline(
[`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf). Guidance rescale factor should fix overexposure when
+ Flawed](https://huggingface.co/papers/2305.08891). Guidance rescale factor should fix overexposure when
using zero terminal SNR.
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
@@ -1084,7 +1084,7 @@ class IPAdapterFaceIDStableDiffusionPipeline(
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/examples/community/latent_consistency_img2img.py b/examples/community/latent_consistency_img2img.py
index 01abf861b8..ae98ff0d1e 100644
--- a/examples/community/latent_consistency_img2img.py
+++ b/examples/community/latent_consistency_img2img.py
@@ -450,7 +450,7 @@ def betas_for_alpha_bar(
def rescale_zero_terminal_snr(betas):
"""
- Rescales betas to have zero terminal SNR Based on https://arxiv.org/pdf/2305.08891.pdf (Algorithm 1)
+ Rescales betas to have zero terminal SNR Based on https://huggingface.co/papers/2305.08891 (Algorithm 1)
Args:
betas (`torch.Tensor`):
the betas that the scheduler is being initialized with.
@@ -620,7 +620,7 @@ class LCMSchedulerWithTimestamp(SchedulerMixin, ConfigMixin):
s. Dynamic thresholding pushes saturated pixels (those near -1 and 1) inwards, thereby actively preventing
pixels from saturation at each step. We find that dynamic thresholding results in significantly better
photorealism as well as better image-text alignment, especially when using very large guidance weights."
- https://arxiv.org/abs/2205.11487
+ https://huggingface.co/papers/2205.11487
"""
dtype = sample.dtype
batch_size, channels, height, width = sample.shape
diff --git a/examples/community/latent_consistency_interpolate.py b/examples/community/latent_consistency_interpolate.py
index 34cdb0fec7..9fc4233682 100644
--- a/examples/community/latent_consistency_interpolate.py
+++ b/examples/community/latent_consistency_interpolate.py
@@ -529,7 +529,7 @@ class LatentConsistencyModelWalkPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
diff --git a/examples/community/latent_consistency_txt2img.py b/examples/community/latent_consistency_txt2img.py
index 7b60f5bb87..83515b6bae 100755
--- a/examples/community/latent_consistency_txt2img.py
+++ b/examples/community/latent_consistency_txt2img.py
@@ -365,7 +365,7 @@ def betas_for_alpha_bar(
def rescale_zero_terminal_snr(betas):
"""
- Rescales betas to have zero terminal SNR Based on https://arxiv.org/pdf/2305.08891.pdf (Algorithm 1)
+ Rescales betas to have zero terminal SNR Based on https://huggingface.co/papers/2305.08891 (Algorithm 1)
Args:
betas (`torch.Tensor`):
the betas that the scheduler is being initialized with.
@@ -532,7 +532,7 @@ class LCMScheduler(SchedulerMixin, ConfigMixin):
s. Dynamic thresholding pushes saturated pixels (those near -1 and 1) inwards, thereby actively preventing
pixels from saturation at each step. We find that dynamic thresholding results in significantly better
photorealism as well as better image-text alignment, especially when using very large guidance weights."
- https://arxiv.org/abs/2205.11487
+ https://huggingface.co/papers/2205.11487
"""
dtype = sample.dtype
batch_size, channels, height, width = sample.shape
diff --git a/examples/community/llm_grounded_diffusion.py b/examples/community/llm_grounded_diffusion.py
index 814694f1e3..72b99983f2 100644
--- a/examples/community/llm_grounded_diffusion.py
+++ b/examples/community/llm_grounded_diffusion.py
@@ -281,7 +281,7 @@ class LLMGroundedDiffusionPipeline(
FromSingleFileMixin,
):
r"""
- Pipeline for layout-grounded text-to-image generation using LLM-grounded Diffusion (LMD+): https://arxiv.org/pdf/2305.13655.pdf.
+ Pipeline for layout-grounded text-to-image generation using LLM-grounded Diffusion (LMD+): https://huggingface.co/papers/2305.13655.
This model inherits from [`StableDiffusionPipeline`] and aims at implementing the pipeline with minimal modifications. Check the superclass documentation for the generic methods
implemented for all pipelines (downloading, saving, running on a particular device, etc.).
@@ -803,7 +803,7 @@ class LLMGroundedDiffusionPipeline(
`List[float]` of 4 elements `[xmin, ymin, xmax, ymax]` where each value is between [0,1].
gligen_scheduled_sampling_beta (`float`, defaults to 0.3):
Scheduled Sampling factor from [GLIGEN: Open-Set Grounded Text-to-Image
- Generation](https://arxiv.org/pdf/2301.07093.pdf). Scheduled Sampling factor is only varied for
+ Generation](https://huggingface.co/papers/2301.07093). Scheduled Sampling factor is only varied for
scheduled sampling during inference for improved quality and controllability.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide what to not include in image generation. If not defined, you need to
@@ -811,7 +811,7 @@ class LLMGroundedDiffusionPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
@@ -843,7 +843,7 @@ class LLMGroundedDiffusionPipeline(
[`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf). Guidance rescale factor should fix overexposure when
+ Flawed](https://huggingface.co/papers/2305.08891). Guidance rescale factor should fix overexposure when
using zero terminal SNR.
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
@@ -901,7 +901,7 @@ class LLMGroundedDiffusionPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
@@ -1171,8 +1171,8 @@ class LLMGroundedDiffusionPipeline(
# Scaling with classifier guidance
alpha_prod_t = scheduler.alphas_cumprod[t]
- # Classifier guidance: https://arxiv.org/pdf/2105.05233.pdf
- # DDIM: https://arxiv.org/pdf/2010.02502.pdf
+ # Classifier guidance: https://huggingface.co/papers/2105.05233
+ # DDIM: https://huggingface.co/papers/2010.02502
scale = (1 - alpha_prod_t) ** (0.5)
latents = latents - scale * grad_cond
@@ -1457,7 +1457,7 @@ class LLMGroundedDiffusionPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -1549,7 +1549,7 @@ class LLMGroundedDiffusionPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.do_classifier_free_guidance
diff --git a/examples/community/lpw_stable_diffusion.py b/examples/community/lpw_stable_diffusion.py
index 32baf500d4..ccb17a51e6 100644
--- a/examples/community/lpw_stable_diffusion.py
+++ b/examples/community/lpw_stable_diffusion.py
@@ -744,7 +744,7 @@ class StableDiffusionLongPromptWeightingPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -863,9 +863,9 @@ class StableDiffusionLongPromptWeightingPipeline(
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
strength (`float`, *optional*, defaults to 0.8):
@@ -880,7 +880,7 @@ class StableDiffusionLongPromptWeightingPipeline(
Use predicted noise instead of random noise when constructing noisy versions of the original image in
the reverse diffusion process
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -948,7 +948,7 @@ class StableDiffusionLongPromptWeightingPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
lora_scale = cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None
@@ -1115,15 +1115,15 @@ class StableDiffusionLongPromptWeightingPipeline(
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -1237,15 +1237,15 @@ class StableDiffusionLongPromptWeightingPipeline(
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference. This parameter will be modulated by `strength`.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -1355,9 +1355,9 @@ class StableDiffusionLongPromptWeightingPipeline(
The reference number of denoising steps. More denoising steps usually lead to a higher quality image at
the expense of slower inference. This parameter will be modulated by `strength`, as explained above.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
@@ -1366,7 +1366,7 @@ class StableDiffusionLongPromptWeightingPipeline(
Use predicted noise instead of random noise when constructing noisy versions of the original image in
the reverse diffusion process
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
diff --git a/examples/community/lpw_stable_diffusion_onnx.py b/examples/community/lpw_stable_diffusion_onnx.py
index 87c2944dbc..ab1462b81b 100644
--- a/examples/community/lpw_stable_diffusion_onnx.py
+++ b/examples/community/lpw_stable_diffusion_onnx.py
@@ -604,7 +604,7 @@ class OnnxStableDiffusionLongPromptWeightingPipeline(OnnxStableDiffusionPipeline
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -699,9 +699,9 @@ class OnnxStableDiffusionLongPromptWeightingPipeline(OnnxStableDiffusionPipeline
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
strength (`float`, *optional*, defaults to 0.8):
@@ -713,7 +713,7 @@ class OnnxStableDiffusionLongPromptWeightingPipeline(OnnxStableDiffusionPipeline
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
@@ -758,7 +758,7 @@ class OnnxStableDiffusionLongPromptWeightingPipeline(OnnxStableDiffusionPipeline
# 2. Define call parameters
batch_size = 1 if isinstance(prompt, str) else len(prompt)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
@@ -902,15 +902,15 @@ class OnnxStableDiffusionLongPromptWeightingPipeline(OnnxStableDiffusionPipeline
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
@@ -998,15 +998,15 @@ class OnnxStableDiffusionLongPromptWeightingPipeline(OnnxStableDiffusionPipeline
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference. This parameter will be modulated by `strength`.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
@@ -1094,15 +1094,15 @@ class OnnxStableDiffusionLongPromptWeightingPipeline(OnnxStableDiffusionPipeline
The reference number of denoising steps. More denoising steps usually lead to a higher quality image at
the expense of slower inference. This parameter will be modulated by `strength`, as explained above.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
diff --git a/examples/community/lpw_stable_diffusion_xl.py b/examples/community/lpw_stable_diffusion_xl.py
index 4d9683b73f..ea67738ab7 100644
--- a/examples/community/lpw_stable_diffusion_xl.py
+++ b/examples/community/lpw_stable_diffusion_xl.py
@@ -507,7 +507,7 @@ EXAMPLE_DOC_STRING = """
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -945,7 +945,7 @@ class SDXLLongPromptWeightingPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -1383,7 +1383,7 @@ class SDXLLongPromptWeightingPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1496,9 +1496,9 @@ class SDXLLongPromptWeightingPipeline(
forms a part of a "Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refine Image
Quality**](https://huggingface.co/docs/diffusers/using-diffusers/sdxl#refine-image-quality).
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str`):
@@ -1511,7 +1511,7 @@ class SDXLLongPromptWeightingPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -1548,8 +1548,8 @@ class SDXLLongPromptWeightingPipeline(
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
- [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://huggingface.co/papers/2305.08891).
Guidance rescale factor should fix overexposure when using zero terminal SNR.
original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
@@ -1872,7 +1872,7 @@ class SDXLLongPromptWeightingPipeline(
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/examples/community/masked_stable_diffusion_img2img.py b/examples/community/masked_stable_diffusion_img2img.py
index a210c167a2..570bd0963e 100644
--- a/examples/community/masked_stable_diffusion_img2img.py
+++ b/examples/community/masked_stable_diffusion_img2img.py
@@ -73,7 +73,7 @@ class MaskedStableDiffusionImg2ImgPipeline(StableDiffusionImg2ImgPipeline):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
@@ -123,7 +123,7 @@ class MaskedStableDiffusionImg2ImgPipeline(StableDiffusionImg2ImgPipeline):
batch_size = prompt_embeds.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/masked_stable_diffusion_xl_img2img.py b/examples/community/masked_stable_diffusion_xl_img2img.py
index c6b0ced527..14d8c7c2da 100644
--- a/examples/community/masked_stable_diffusion_xl_img2img.py
+++ b/examples/community/masked_stable_diffusion_xl_img2img.py
@@ -115,7 +115,7 @@ class MaskedStableDiffusionXLImg2ImgPipeline(StableDiffusionXLImg2ImgPipeline):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
@@ -438,7 +438,7 @@ class MaskedStableDiffusionXLImg2ImgPipeline(StableDiffusionXLImg2ImgPipeline):
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/examples/community/matryoshka.py b/examples/community/matryoshka.py
index 4895bd1501..2d5d0dd7c4 100644
--- a/examples/community/matryoshka.py
+++ b/examples/community/matryoshka.py
@@ -125,7 +125,7 @@ EXAMPLE_DOC_STRING = """
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -278,7 +278,7 @@ def betas_for_alpha_bar(
# Copied from diffusers.schedulers.scheduling_ddim.rescale_zero_terminal_snr
def rescale_zero_terminal_snr(betas):
"""
- Rescales betas to have zero terminal SNR Based on https://arxiv.org/pdf/2305.08891.pdf (Algorithm 1)
+ Rescales betas to have zero terminal SNR Based on https://huggingface.co/papers/2305.08891 (Algorithm 1)
Args:
@@ -458,7 +458,7 @@ class MatryoshkaDDIMScheduler(SchedulerMixin, ConfigMixin):
pixels from saturation at each step. We find that dynamic thresholding results in significantly better
photorealism as well as better image-text alignment, especially when using very large guidance weights."
- https://arxiv.org/abs/2205.11487
+ https://huggingface.co/papers/2205.11487
"""
dtype = sample.dtype
batch_size, channels, *remaining_dims = sample.shape
@@ -501,7 +501,7 @@ class MatryoshkaDDIMScheduler(SchedulerMixin, ConfigMixin):
self.num_inference_steps = num_inference_steps
- # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://arxiv.org/abs/2305.08891
+ # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://huggingface.co/papers/2305.08891
if self.config.timestep_spacing == "linspace":
timesteps = (
np.linspace(0, self.config.num_train_timesteps - 1, num_inference_steps)
@@ -587,7 +587,7 @@ class MatryoshkaDDIMScheduler(SchedulerMixin, ConfigMixin):
"Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
)
- # See formulas (12) and (16) of DDIM paper https://arxiv.org/pdf/2010.02502.pdf
+ # See formulas (12) and (16) of DDIM paper https://huggingface.co/papers/2010.02502
# Ideally, read DDIM paper in-detail understanding
# Notation ( ->
@@ -615,7 +615,7 @@ class MatryoshkaDDIMScheduler(SchedulerMixin, ConfigMixin):
beta_prod_t = 1 - alpha_prod_t
# 3. compute predicted original sample from predicted noise also called
- # "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # "predicted x_0" of formula (12) from https://huggingface.co/papers/2010.02502
if self.config.prediction_type == "epsilon":
pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
pred_epsilon = model_output
@@ -669,7 +669,7 @@ class MatryoshkaDDIMScheduler(SchedulerMixin, ConfigMixin):
else:
pred_epsilon = (sample - alpha_prod_t ** (0.5) * pred_original_sample) / beta_prod_t ** (0.5)
- # 6. compute "direction pointing to x_t" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # 6. compute "direction pointing to x_t" of formula (12) from https://huggingface.co/papers/2010.02502
if len(model_output) > 1:
pred_sample_direction = []
for p_e, a_p_t_p in zip(pred_epsilon, alpha_prod_t_prev):
@@ -677,7 +677,7 @@ class MatryoshkaDDIMScheduler(SchedulerMixin, ConfigMixin):
else:
pred_sample_direction = (1 - alpha_prod_t_prev - std_dev_t**2) ** (0.5) * pred_epsilon
- # 7. compute x_t without "random noise" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # 7. compute x_t without "random noise" of formula (12) from https://huggingface.co/papers/2010.02502
if len(model_output) > 1:
prev_sample = []
for p_o_s, p_s_d, a_p_t_p in zip(pred_original_sample, pred_sample_direction, alpha_prod_t_prev):
@@ -2660,7 +2660,7 @@ class MatryoshkaUNet2DConditionModel(
fn_recursive_set_attention_slice(module, reversed_slice_size)
def enable_freeu(self, s1: float, s2: float, b1: float, b2: float):
- r"""Enables the FreeU mechanism from https://arxiv.org/abs/2309.11497.
+ r"""Enables the FreeU mechanism from https://huggingface.co/papers/2309.11497.
The suffixes after the scaling factors represent the stage blocks where they are being applied.
@@ -4065,7 +4065,7 @@ class MatryoshkaPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -4230,7 +4230,7 @@ class MatryoshkaPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -4309,7 +4309,7 @@ class MatryoshkaPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
@@ -4340,7 +4340,7 @@ class MatryoshkaPipeline(
[`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf). Guidance rescale factor should fix overexposure when
+ Flawed](https://huggingface.co/papers/2305.08891). Guidance rescale factor should fix overexposure when
using zero terminal SNR.
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
@@ -4538,7 +4538,7 @@ class MatryoshkaPipeline(
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/examples/community/mixture_tiling.py b/examples/community/mixture_tiling.py
index 3feed5c88d..3f5affc4f4 100644
--- a/examples/community/mixture_tiling.py
+++ b/examples/community/mixture_tiling.py
@@ -298,7 +298,7 @@ class StableDiffusionTilingPipeline(DiffusionPipeline, StableDiffusionExtrasMixi
text_embeddings = [[self.text_encoder(col.input_ids.to(self.device))[0] for col in row] for row in text_input]
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0 # TODO: also active if any tile has guidance scale
# get unconditional embeddings for classifier free guidance
@@ -318,7 +318,7 @@ class StableDiffusionTilingPipeline(DiffusionPipeline, StableDiffusionExtrasMixi
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
diff --git a/examples/community/mixture_tiling_sdxl.py b/examples/community/mixture_tiling_sdxl.py
index bd56ddb3d6..66c338b5b2 100644
--- a/examples/community/mixture_tiling_sdxl.py
+++ b/examples/community/mixture_tiling_sdxl.py
@@ -201,7 +201,7 @@ def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
r"""
Rescales `noise_cfg` tensor based on `guidance_rescale` to improve image quality and fix overexposure. Based on
Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891).
Args:
noise_cfg (`torch.Tensor`):
@@ -631,7 +631,7 @@ class StableDiffusionXLTilingPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -767,7 +767,7 @@ class StableDiffusionXLTilingPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -839,9 +839,9 @@ class StableDiffusionXLTilingPipeline(
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -851,7 +851,7 @@ class StableDiffusionXLTilingPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
diff --git a/examples/community/mod_controlnet_tile_sr_sdxl.py b/examples/community/mod_controlnet_tile_sr_sdxl.py
index 3db2645a78..27249ce3fb 100644
--- a/examples/community/mod_controlnet_tile_sr_sdxl.py
+++ b/examples/community/mod_controlnet_tile_sr_sdxl.py
@@ -637,7 +637,7 @@ class StableDiffusionXLControlNetTileSRPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -1247,7 +1247,7 @@ class StableDiffusionXLControlNetTileSRPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1335,8 +1335,8 @@ class StableDiffusionXLControlNetTileSRPipeline(
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen Paper](https://arxiv.org/pdf/2205.11487.pdf).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen Paper](https://huggingface.co/papers/2205.11487).
Guidance scale is enabled by setting `guidance_scale > 1`. Higher guidance scale encourages generating
images closely linked to the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -1346,7 +1346,7 @@ class StableDiffusionXLControlNetTileSRPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
diff --git a/examples/community/multilingual_stable_diffusion.py b/examples/community/multilingual_stable_diffusion.py
index 5dcc75c9e2..5e7453ed12 100644
--- a/examples/community/multilingual_stable_diffusion.py
+++ b/examples/community/multilingual_stable_diffusion.py
@@ -168,9 +168,9 @@ class MultilingualStableDiffusion(DiffusionPipeline, StableDiffusionMixin):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -179,7 +179,7 @@ class MultilingualStableDiffusion(DiffusionPipeline, StableDiffusionMixin):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
@@ -263,7 +263,7 @@ class MultilingualStableDiffusion(DiffusionPipeline, StableDiffusionMixin):
text_embeddings = text_embeddings.view(bs_embed * num_images_per_prompt, seq_len, -1)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
@@ -355,7 +355,7 @@ class MultilingualStableDiffusion(DiffusionPipeline, StableDiffusionMixin):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
diff --git a/examples/community/pipeline_animatediff_controlnet.py b/examples/community/pipeline_animatediff_controlnet.py
index 9f99ad248b..cd168cf419 100644
--- a/examples/community/pipeline_animatediff_controlnet.py
+++ b/examples/community/pipeline_animatediff_controlnet.py
@@ -464,7 +464,7 @@ class AnimateDiffControlNetPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -729,7 +729,7 @@ class AnimateDiffControlNetPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -797,7 +797,7 @@ class AnimateDiffControlNetPipeline(
The prompt or prompts to guide what to not include in image generation. If not defined, you need to
pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
diff --git a/examples/community/pipeline_animatediff_img2video.py b/examples/community/pipeline_animatediff_img2video.py
index f7f0cf31c5..ec0c340666 100644
--- a/examples/community/pipeline_animatediff_img2video.py
+++ b/examples/community/pipeline_animatediff_img2video.py
@@ -581,7 +581,7 @@ class AnimateDiffImgToVideoPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -790,7 +790,7 @@ class AnimateDiffImgToVideoPipeline(
The prompt or prompts to guide what to not include in image generation. If not defined, you need to
pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
@@ -870,7 +870,7 @@ class AnimateDiffImgToVideoPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/pipeline_animatediff_ipex.py b/examples/community/pipeline_animatediff_ipex.py
index 06508f217c..7c76aac090 100644
--- a/examples/community/pipeline_animatediff_ipex.py
+++ b/examples/community/pipeline_animatediff_ipex.py
@@ -442,7 +442,7 @@ class AnimateDiffPipelineIpex(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -555,7 +555,7 @@ class AnimateDiffPipelineIpex(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -618,7 +618,7 @@ class AnimateDiffPipelineIpex(
The prompt or prompts to guide what to not include in image generation. If not defined, you need to
pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
diff --git a/examples/community/pipeline_controlnet_xl_kolors.py b/examples/community/pipeline_controlnet_xl_kolors.py
index 5b0576fbcd..e4e05ca11c 100644
--- a/examples/community/pipeline_controlnet_xl_kolors.py
+++ b/examples/community/pipeline_controlnet_xl_kolors.py
@@ -462,7 +462,7 @@ class KolorsControlNetPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -781,7 +781,7 @@ class KolorsControlNetPipeline(
return self._guidance_scale
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -868,9 +868,9 @@ class KolorsControlNetPipeline(
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -880,7 +880,7 @@ class KolorsControlNetPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
diff --git a/examples/community/pipeline_controlnet_xl_kolors_img2img.py b/examples/community/pipeline_controlnet_xl_kolors_img2img.py
index 44c866e826..310372593a 100644
--- a/examples/community/pipeline_controlnet_xl_kolors_img2img.py
+++ b/examples/community/pipeline_controlnet_xl_kolors_img2img.py
@@ -505,7 +505,7 @@ class KolorsControlNetImg2ImgPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for others.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -951,7 +951,7 @@ class KolorsControlNetImg2ImgPipeline(
return self._guidance_scale
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1046,9 +1046,9 @@ class KolorsControlNetImg2ImgPipeline(
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -1058,7 +1058,7 @@ class KolorsControlNetImg2ImgPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
diff --git a/examples/community/pipeline_controlnet_xl_kolors_inpaint.py b/examples/community/pipeline_controlnet_xl_kolors_inpaint.py
index 09d4b0241e..05e58c0fff 100644
--- a/examples/community/pipeline_controlnet_xl_kolors_inpaint.py
+++ b/examples/community/pipeline_controlnet_xl_kolors_inpaint.py
@@ -556,7 +556,7 @@ class KolorsControlNetInpaintPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -1035,7 +1035,7 @@ class KolorsControlNetInpaintPipeline(
return self._guidance_scale
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1255,9 +1255,9 @@ class KolorsControlNetInpaintPipeline(
forms a part of a "Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output).
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -1290,7 +1290,7 @@ class KolorsControlNetInpaintPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
diff --git a/examples/community/pipeline_demofusion_sdxl.py b/examples/community/pipeline_demofusion_sdxl.py
index 624b2bd1ed..c9b57a6ece 100644
--- a/examples/community/pipeline_demofusion_sdxl.py
+++ b/examples/community/pipeline_demofusion_sdxl.py
@@ -77,7 +77,7 @@ def gaussian_filter(latents, kernel_size=3, sigma=1.0):
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -383,7 +383,7 @@ class DemoFusionSDXLPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -701,9 +701,9 @@ class DemoFusionSDXLPipeline(
"Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output)
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -716,7 +716,7 @@ class DemoFusionSDXLPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -757,8 +757,8 @@ class DemoFusionSDXLPipeline(
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.7):
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
- [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://huggingface.co/papers/2305.08891).
Guidance rescale factor should fix overexposure when using zero terminal SNR.
original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
@@ -860,7 +860,7 @@ class DemoFusionSDXLPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
@@ -977,7 +977,7 @@ class DemoFusionSDXLPipeline(
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if do_classifier_free_guidance and guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
@@ -1119,7 +1119,7 @@ class DemoFusionSDXLPipeline(
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if do_classifier_free_guidance and guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(
noise_pred, noise_pred_text, guidance_rescale=guidance_rescale
)
@@ -1215,7 +1215,7 @@ class DemoFusionSDXLPipeline(
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if do_classifier_free_guidance and guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(
noise_pred, noise_pred_text, guidance_rescale=guidance_rescale
)
diff --git a/examples/community/pipeline_faithdiff_stable_diffusion_xl.py b/examples/community/pipeline_faithdiff_stable_diffusion_xl.py
index 749f0322d0..43ef55d32c 100644
--- a/examples/community/pipeline_faithdiff_stable_diffusion_xl.py
+++ b/examples/community/pipeline_faithdiff_stable_diffusion_xl.py
@@ -1077,7 +1077,7 @@ class LocalAttention:
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
Args:
noise_cfg (torch.Tensor): Noise configuration tensor.
@@ -1504,7 +1504,7 @@ class FaithDiffStableDiffusionXLPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -1729,7 +1729,7 @@ class FaithDiffStableDiffusionXLPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1883,9 +1883,9 @@ class FaithDiffStableDiffusionXLPipeline(
Overlap factor for local attention tiling (between 0.0 and 1.0). Controls the overlap between adjacent
grid patches during processing. Defaults to 0.5.
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -1898,7 +1898,7 @@ class FaithDiffStableDiffusionXLPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -1933,8 +1933,8 @@ class FaithDiffStableDiffusionXLPipeline(
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
- [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://huggingface.co/papers/2305.08891).
Guidance rescale factor should fix overexposure when using zero terminal SNR.
original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
@@ -2173,7 +2173,7 @@ class FaithDiffStableDiffusionXLPipeline(
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(
noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale
)
diff --git a/examples/community/pipeline_flux_differential_img2img.py b/examples/community/pipeline_flux_differential_img2img.py
index 5dc321ea98..940cbd7976 100644
--- a/examples/community/pipeline_flux_differential_img2img.py
+++ b/examples/community/pipeline_flux_differential_img2img.py
@@ -756,9 +756,9 @@ class FluxDifferentialImg2ImgPipeline(DiffusionPipeline, FluxLoraLoaderMixin):
in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
passed will be used. Must be in descending order.
guidance_scale (`float`, *optional*, defaults to 7.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
diff --git a/examples/community/pipeline_flux_rf_inversion.py b/examples/community/pipeline_flux_rf_inversion.py
index 572856a047..5a5b76adcf 100644
--- a/examples/community/pipeline_flux_rf_inversion.py
+++ b/examples/community/pipeline_flux_rf_inversion.py
@@ -698,9 +698,9 @@ class RFInversionFluxPipeline(
in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
passed will be used. Must be in descending order.
guidance_scale (`float`, *optional*, defaults to 7.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
@@ -849,7 +849,7 @@ class RFInversionFluxPipeline(
if do_rf_inversion:
y_0 = image_latents.clone()
- # 6. Denoising loop / Controlled Reverse ODE, Algorithm 2 from: https://arxiv.org/pdf/2410.10792
+ # 6. Denoising loop / Controlled Reverse ODE, Algorithm 2 from: https://huggingface.co/papers/2410.10792
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
if do_rf_inversion:
@@ -884,7 +884,7 @@ class RFInversionFluxPipeline(
eta_t = eta_t * (1 - i / num_inference_steps) ** eta_decay_power # Decay eta over the loop
v_hat_t = v_t + eta_t * (v_t_cond - v_t)
- # SDE Eq: 17 from https://arxiv.org/pdf/2410.10792
+ # SDE Eq: 17 from https://huggingface.co/papers/2410.10792
latents = latents + v_hat_t * (sigmas[i] - sigmas[i + 1])
else:
# compute the previous noisy sample x_t -> x_t-1
@@ -944,7 +944,7 @@ class RFInversionFluxPipeline(
joint_attention_kwargs: Optional[Dict[str, Any]] = None,
):
r"""
- Performs Algorithm 1: Controlled Forward ODE from https://arxiv.org/pdf/2410.10792
+ Performs Algorithm 1: Controlled Forward ODE from https://huggingface.co/papers/2410.10792
Args:
image (`PipelineImageInput`):
Input for the image(s) that are to be edited. Multiple input images have to default to the same aspect
@@ -953,9 +953,9 @@ class RFInversionFluxPipeline(
The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
instead.
source_guidance_scale (`float`, *optional*, defaults to 0.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). For this algorithm, it's better to keep it 0.
+ Paper](https://huggingface.co/papers/2205.11487). For this algorithm, it's better to keep it 0.
num_inversion_steps (`int`, *optional*, defaults to 28):
The number of discretization steps.
height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
diff --git a/examples/community/pipeline_flux_semantic_guidance.py b/examples/community/pipeline_flux_semantic_guidance.py
index 919e0ad46b..fd801420c3 100644
--- a/examples/community/pipeline_flux_semantic_guidance.py
+++ b/examples/community/pipeline_flux_semantic_guidance.py
@@ -840,9 +840,9 @@ class FluxSemanticGuidancePipeline(
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, *optional*, defaults to 7.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
diff --git a/examples/community/pipeline_flux_with_cfg.py b/examples/community/pipeline_flux_with_cfg.py
index f55f73620f..fbe50a0b0e 100644
--- a/examples/community/pipeline_flux_with_cfg.py
+++ b/examples/community/pipeline_flux_with_cfg.py
@@ -626,9 +626,9 @@ class FluxCFGPipeline(DiffusionPipeline, FluxLoraLoaderMixin, FromSingleFileMixi
in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
passed will be used. Must be in descending order.
guidance_scale (`float`, *optional*, defaults to 7.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
diff --git a/examples/community/pipeline_hunyuandit_differential_img2img.py b/examples/community/pipeline_hunyuandit_differential_img2img.py
index a294ff7824..f2d31a7419 100644
--- a/examples/community/pipeline_hunyuandit_differential_img2img.py
+++ b/examples/community/pipeline_hunyuandit_differential_img2img.py
@@ -150,7 +150,7 @@ def get_resize_crop_region_for_grid(src, tgt_size):
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -531,7 +531,7 @@ class HunyuanDiTDifferentialImg2ImgPipeline(DiffusionPipeline):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -709,7 +709,7 @@ class HunyuanDiTDifferentialImg2ImgPipeline(DiffusionPipeline):
return self._guidance_rescale
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -809,7 +809,7 @@ class HunyuanDiTDifferentialImg2ImgPipeline(DiffusionPipeline):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
@@ -846,7 +846,7 @@ class HunyuanDiTDifferentialImg2ImgPipeline(DiffusionPipeline):
inputs will be passed.
guidance_rescale (`float`, *optional*, defaults to 0.0):
Rescale the noise_cfg according to `guidance_rescale`. Based on findings of [Common Diffusion Noise
- Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Schedules and Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
original_size (`Tuple[int, int]`, *optional*, defaults to `(1024, 1024)`):
The original size of the image. Used to calculate the time ids.
target_size (`Tuple[int, int]`, *optional*):
@@ -1095,7 +1095,7 @@ class HunyuanDiTDifferentialImg2ImgPipeline(DiffusionPipeline):
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/examples/community/pipeline_kolors_differential_img2img.py b/examples/community/pipeline_kolors_differential_img2img.py
index dfef872d1c..c2cab10e07 100644
--- a/examples/community/pipeline_kolors_differential_img2img.py
+++ b/examples/community/pipeline_kolors_differential_img2img.py
@@ -462,7 +462,7 @@ class KolorsDifferentialImg2ImgPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -764,7 +764,7 @@ class KolorsDifferentialImg2ImgPipeline(
return self._guidance_scale
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -884,9 +884,9 @@ class KolorsDifferentialImg2ImgPipeline(
"Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output)
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -896,7 +896,7 @@ class KolorsDifferentialImg2ImgPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
diff --git a/examples/community/pipeline_kolors_inpainting.py b/examples/community/pipeline_kolors_inpainting.py
index 43a3957c82..f550299f9a 100644
--- a/examples/community/pipeline_kolors_inpainting.py
+++ b/examples/community/pipeline_kolors_inpainting.py
@@ -98,7 +98,7 @@ EXAMPLE_DOC_STRING = """
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -673,7 +673,7 @@ class KolorsInpaintPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -1066,7 +1066,7 @@ class KolorsInpaintPipeline(
return self._guidance_rescale
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1206,9 +1206,9 @@ class KolorsInpaintPipeline(
forms a part of a "Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output).
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -1238,7 +1238,7 @@ class KolorsInpaintPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -1621,7 +1621,7 @@ class KolorsInpaintPipeline(
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/examples/community/pipeline_prompt2prompt.py b/examples/community/pipeline_prompt2prompt.py
index b9985542cc..3a7b4b69d7 100644
--- a/examples/community/pipeline_prompt2prompt.py
+++ b/examples/community/pipeline_prompt2prompt.py
@@ -61,7 +61,7 @@ logger = logging.get_logger(__name__)
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -449,7 +449,7 @@ class Prompt2PromptPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -592,9 +592,9 @@ class Prompt2PromptPipeline(
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -603,7 +603,7 @@ class Prompt2PromptPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -641,7 +641,7 @@ class Prompt2PromptPipeline(
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf). Guidance rescale factor should fix overexposure when
+ Flawed](https://huggingface.co/papers/2305.08891). Guidance rescale factor should fix overexposure when
using zero terminal SNR.
Returns:
@@ -678,7 +678,7 @@ class Prompt2PromptPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
@@ -734,7 +734,7 @@ class Prompt2PromptPipeline(
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if do_classifier_free_guidance and guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/examples/community/pipeline_sdxl_style_aligned.py b/examples/community/pipeline_sdxl_style_aligned.py
index 6aebb6c18d..1af5fc3e88 100644
--- a/examples/community/pipeline_sdxl_style_aligned.py
+++ b/examples/community/pipeline_sdxl_style_aligned.py
@@ -12,7 +12,7 @@
# See the License for the specific language governing permissions and
# limitations under the License.
#
-# Based on [Style Aligned Image Generation via Shared Attention](https://arxiv.org/abs/2312.02133).
+# Based on [Style Aligned Image Generation via Shared Attention](https://huggingface.co/papers/2312.02133).
# Authors: Amir Hertz, Andrey Voynov, Shlomi Fruchter, Daniel Cohen-Or
# Project Page: https://style-aligned-gen.github.io/
# Code: https://github.com/google/style-aligned
@@ -315,7 +315,7 @@ class SharedAttentionProcessor(AttnProcessor2_0):
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -396,7 +396,7 @@ class StyleAlignedSDXLPipeline(
r"""
Pipeline for text-to-image generation using Stable Diffusion XL.
- This pipeline also adds experimental support for [StyleAligned](https://arxiv.org/abs/2312.02133). It can
+ This pipeline also adds experimental support for [StyleAligned](https://huggingface.co/papers/2312.02133). It can
be enabled/disabled using `.enable_style_aligned()` or `.disable_style_aligned()` respectively.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
@@ -773,7 +773,7 @@ class StyleAlignedSDXLPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -1272,7 +1272,7 @@ class StyleAlignedSDXLPipeline(
only_self_level: float = 0.0,
):
r"""
- Enables the StyleAligned mechanism as in https://arxiv.org/abs/2312.02133.
+ Enables the StyleAligned mechanism as in https://huggingface.co/papers/2312.02133.
Args:
share_group_norm (`bool`, defaults to `True`):
@@ -1356,7 +1356,7 @@ class StyleAlignedSDXLPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1457,9 +1457,9 @@ class StyleAlignedSDXLPipeline(
"Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output)
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -1472,7 +1472,7 @@ class StyleAlignedSDXLPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -1509,8 +1509,8 @@ class StyleAlignedSDXLPipeline(
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
- [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://huggingface.co/papers/2305.08891).
Guidance rescale factor should fix overexposure when using zero terminal SNR.
original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
@@ -1840,7 +1840,7 @@ class StyleAlignedSDXLPipeline(
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/examples/community/pipeline_stable_diffusion_3_differential_img2img.py b/examples/community/pipeline_stable_diffusion_3_differential_img2img.py
index 50952304fc..081fcda6d6 100644
--- a/examples/community/pipeline_stable_diffusion_3_differential_img2img.py
+++ b/examples/community/pipeline_stable_diffusion_3_differential_img2img.py
@@ -654,7 +654,7 @@ class StableDiffusion3DifferentialImg2ImgPipeline(DiffusionPipeline):
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -725,9 +725,9 @@ class StableDiffusion3DifferentialImg2ImgPipeline(DiffusionPipeline):
in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
passed will be used. Must be in descending order.
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
diff --git a/examples/community/pipeline_stable_diffusion_3_instruct_pix2pix.py b/examples/community/pipeline_stable_diffusion_3_instruct_pix2pix.py
index 97491a8597..54e0c4b5bc 100644
--- a/examples/community/pipeline_stable_diffusion_3_instruct_pix2pix.py
+++ b/examples/community/pipeline_stable_diffusion_3_instruct_pix2pix.py
@@ -759,7 +759,7 @@ class StableDiffusion3InstructPix2PixPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -918,9 +918,9 @@ class StableDiffusion3InstructPix2PixPipeline(
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, *optional*, defaults to 7.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
image_guidance_scale (`float`, *optional*, defaults to 1.5):
diff --git a/examples/community/pipeline_stable_diffusion_boxdiff.py b/examples/community/pipeline_stable_diffusion_boxdiff.py
index 7c7f7e8a18..f0e19aba62 100644
--- a/examples/community/pipeline_stable_diffusion_boxdiff.py
+++ b/examples/community/pipeline_stable_diffusion_boxdiff.py
@@ -307,7 +307,7 @@ def register_attention_control(model, controller):
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -793,7 +793,7 @@ class StableDiffusionBoxDiffPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -893,7 +893,7 @@ class StableDiffusionBoxDiffPipeline(
return latents
def enable_freeu(self, s1: float, s2: float, b1: float, b2: float):
- r"""Enables the FreeU mechanism as in https://arxiv.org/abs/2309.11497.
+ r"""Enables the FreeU mechanism as in https://huggingface.co/papers/2309.11497.
The suffixes after the scaling factors represent the stages where they are being applied.
@@ -1021,7 +1021,7 @@ class StableDiffusionBoxDiffPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1365,7 +1365,7 @@ class StableDiffusionBoxDiffPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
@@ -1391,7 +1391,7 @@ class StableDiffusionBoxDiffPipeline(
[`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf). Guidance rescale factor should fix overexposure when
+ Flawed](https://huggingface.co/papers/2305.08891). Guidance rescale factor should fix overexposure when
using zero terminal SNR.
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
@@ -1661,7 +1661,7 @@ class StableDiffusionBoxDiffPipeline(
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/examples/community/pipeline_stable_diffusion_pag.py b/examples/community/pipeline_stable_diffusion_pag.py
index 874303e0ad..69a0059d98 100644
--- a/examples/community/pipeline_stable_diffusion_pag.py
+++ b/examples/community/pipeline_stable_diffusion_pag.py
@@ -279,7 +279,7 @@ class PAGCFGIdentitySelfAttnProcessor:
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -793,7 +793,7 @@ class StableDiffusionPAGPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -889,7 +889,7 @@ class StableDiffusionPAGPipeline(
return latents
def enable_freeu(self, s1: float, s2: float, b1: float, b2: float):
- r"""Enables the FreeU mechanism as in https://arxiv.org/abs/2309.11497.
+ r"""Enables the FreeU mechanism as in https://huggingface.co/papers/2309.11497.
The suffixes after the scaling factors represent the stages where they are being applied.
Please refer to the [official repository](https://github.com/ChenyangSi/FreeU) for combinations of the values
that are known to work well for different pipelines such as Stable Diffusion v1, v2, and Stable Diffusion XL.
@@ -1032,7 +1032,7 @@ class StableDiffusionPAGPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1126,7 +1126,7 @@ class StableDiffusionPAGPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
@@ -1155,7 +1155,7 @@ class StableDiffusionPAGPipeline(
[`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf). Guidance rescale factor should fix overexposure when
+ Flawed](https://huggingface.co/papers/2305.08891). Guidance rescale factor should fix overexposure when
using zero terminal SNR.
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
@@ -1414,7 +1414,7 @@ class StableDiffusionPAGPipeline(
)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/examples/community/pipeline_stable_diffusion_upscale_ldm3d.py b/examples/community/pipeline_stable_diffusion_upscale_ldm3d.py
index 6c63f53e81..0ca3083e63 100644
--- a/examples/community/pipeline_stable_diffusion_upscale_ldm3d.py
+++ b/examples/community/pipeline_stable_diffusion_upscale_ldm3d.py
@@ -390,7 +390,7 @@ class StableDiffusionUpscaleLDM3DPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -565,7 +565,7 @@ class StableDiffusionUpscaleLDM3DPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
@@ -624,7 +624,7 @@ class StableDiffusionUpscaleLDM3DPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/pipeline_stable_diffusion_xl_attentive_eraser.py b/examples/community/pipeline_stable_diffusion_xl_attentive_eraser.py
index 73f52736f4..fa87c1db2a 100644
--- a/examples/community/pipeline_stable_diffusion_xl_attentive_eraser.py
+++ b/examples/community/pipeline_stable_diffusion_xl_attentive_eraser.py
@@ -301,7 +301,7 @@ class AAS_XL(AttentionBase):
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -935,7 +935,7 @@ class StableDiffusionXL_AE_Pipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -1346,7 +1346,7 @@ class StableDiffusionXL_AE_Pipeline(
return self._rm_guidance_scale > 1 and self._AAS
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1743,9 +1743,9 @@ class StableDiffusionXL_AE_Pipeline(
forms a part of a "Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output).
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -1778,7 +1778,7 @@ class StableDiffusionXL_AE_Pipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -2219,7 +2219,7 @@ class StableDiffusionXL_AE_Pipeline(
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/examples/community/pipeline_stable_diffusion_xl_controlnet_adapter.py b/examples/community/pipeline_stable_diffusion_xl_controlnet_adapter.py
index de5887c6de..d473064e29 100644
--- a/examples/community/pipeline_stable_diffusion_xl_controlnet_adapter.py
+++ b/examples/community/pipeline_stable_diffusion_xl_controlnet_adapter.py
@@ -141,7 +141,7 @@ def _preprocess_adapter_image(image, height, width):
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -161,7 +161,7 @@ class StableDiffusionXLControlNetAdapterPipeline(
):
r"""
Pipeline for text-to-image generation using Stable Diffusion augmented with T2I-Adapter
- https://arxiv.org/abs/2302.08453
+ https://huggingface.co/papers/2302.08453
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
@@ -479,7 +479,7 @@ class StableDiffusionXLControlNetAdapterPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -950,9 +950,9 @@ class StableDiffusionXLControlNetAdapterPipeline(
"Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output)
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -965,7 +965,7 @@ class StableDiffusionXLControlNetAdapterPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -1006,8 +1006,8 @@ class StableDiffusionXLControlNetAdapterPipeline(
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
- [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://huggingface.co/papers/2305.08891).
Guidance rescale factor should fix overexposure when using zero terminal SNR.
original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
@@ -1137,7 +1137,7 @@ class StableDiffusionXLControlNetAdapterPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
@@ -1367,7 +1367,7 @@ class StableDiffusionXLControlNetAdapterPipeline(
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if do_classifier_free_guidance and guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/examples/community/pipeline_stable_diffusion_xl_controlnet_adapter_inpaint.py b/examples/community/pipeline_stable_diffusion_xl_controlnet_adapter_inpaint.py
index c5f8ec3dfa..003397f062 100644
--- a/examples/community/pipeline_stable_diffusion_xl_controlnet_adapter_inpaint.py
+++ b/examples/community/pipeline_stable_diffusion_xl_controlnet_adapter_inpaint.py
@@ -287,7 +287,7 @@ def prepare_mask_and_masked_image(image, mask, height, width, return_image: bool
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -303,7 +303,7 @@ class StableDiffusionXLControlNetAdapterInpaintPipeline(
):
r"""
Pipeline for text-to-image generation using Stable Diffusion augmented with T2I-Adapter
- https://arxiv.org/abs/2302.08453
+ https://huggingface.co/papers/2302.08453
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
@@ -626,7 +626,7 @@ class StableDiffusionXLControlNetAdapterInpaintPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -1306,9 +1306,9 @@ class StableDiffusionXLControlNetAdapterInpaintPipeline(
"Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output)
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -1321,7 +1321,7 @@ class StableDiffusionXLControlNetAdapterInpaintPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -1362,8 +1362,8 @@ class StableDiffusionXLControlNetAdapterInpaintPipeline(
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.7):
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
- [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://huggingface.co/papers/2305.08891).
Guidance rescale factor should fix overexposure when using zero terminal SNR.
original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
@@ -1475,7 +1475,7 @@ class StableDiffusionXLControlNetAdapterInpaintPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
@@ -1784,7 +1784,7 @@ class StableDiffusionXLControlNetAdapterInpaintPipeline(
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if do_classifier_free_guidance and guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(
noise_pred,
noise_pred_text,
diff --git a/examples/community/pipeline_stable_diffusion_xl_differential_img2img.py b/examples/community/pipeline_stable_diffusion_xl_differential_img2img.py
index e74ea26301..143f2b5ffc 100644
--- a/examples/community/pipeline_stable_diffusion_xl_differential_img2img.py
+++ b/examples/community/pipeline_stable_diffusion_xl_differential_img2img.py
@@ -92,7 +92,7 @@ EXAMPLE_DOC_STRING = """
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -510,7 +510,7 @@ class StableDiffusionXLDifferentialImg2ImgPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -908,7 +908,7 @@ class StableDiffusionXLDifferentialImg2ImgPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1030,9 +1030,9 @@ class StableDiffusionXLDifferentialImg2ImgPipeline(
forms a part of a "Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output).
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -1045,7 +1045,7 @@ class StableDiffusionXLDifferentialImg2ImgPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -1092,8 +1092,8 @@ class StableDiffusionXLDifferentialImg2ImgPipeline(
[diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
guidance_rescale (`float`, *optional*, defaults to 0.7):
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
- [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://huggingface.co/papers/2305.08891).
Guidance rescale factor should fix overexposure when using zero terminal SNR.
original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
@@ -1375,7 +1375,7 @@ class StableDiffusionXLDifferentialImg2ImgPipeline(
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/examples/community/pipeline_stable_diffusion_xl_instandid_img2img.py b/examples/community/pipeline_stable_diffusion_xl_instandid_img2img.py
index 7aeba79ae9..8c1b67fddd 100644
--- a/examples/community/pipeline_stable_diffusion_xl_instandid_img2img.py
+++ b/examples/community/pipeline_stable_diffusion_xl_instandid_img2img.py
@@ -627,7 +627,7 @@ class StableDiffusionXLInstantIDImg2ImgPipeline(StableDiffusionXLControlNetImg2I
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
diff --git a/examples/community/pipeline_stable_diffusion_xl_instantid.py b/examples/community/pipeline_stable_diffusion_xl_instantid.py
index 2eead8861e..5a944cf1bf 100644
--- a/examples/community/pipeline_stable_diffusion_xl_instantid.py
+++ b/examples/community/pipeline_stable_diffusion_xl_instantid.py
@@ -623,7 +623,7 @@ class StableDiffusionXLInstantIDPipeline(StableDiffusionXLControlNetPipeline):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
diff --git a/examples/community/pipeline_stable_diffusion_xl_ipex.py b/examples/community/pipeline_stable_diffusion_xl_ipex.py
index f43726b1b5..eda6089f59 100644
--- a/examples/community/pipeline_stable_diffusion_xl_ipex.py
+++ b/examples/community/pipeline_stable_diffusion_xl_ipex.py
@@ -102,7 +102,7 @@ EXAMPLE_DOC_STRING = """
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -524,7 +524,7 @@ class StableDiffusionXLPipelineIpex(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -718,7 +718,7 @@ class StableDiffusionXLPipelineIpex(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -809,9 +809,9 @@ class StableDiffusionXLPipelineIpex(
"Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output)
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -824,7 +824,7 @@ class StableDiffusionXLPipelineIpex(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -860,8 +860,8 @@ class StableDiffusionXLPipelineIpex(
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
- [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://huggingface.co/papers/2305.08891).
Guidance rescale factor should fix overexposure when using zero terminal SNR.
original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
@@ -1113,7 +1113,7 @@ class StableDiffusionXLPipelineIpex(
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/examples/community/pipeline_stg_cogvideox.py b/examples/community/pipeline_stg_cogvideox.py
index 2e7f7906a3..0fe9778a47 100644
--- a/examples/community/pipeline_stg_cogvideox.py
+++ b/examples/community/pipeline_stg_cogvideox.py
@@ -413,7 +413,7 @@ class CogVideoXSTGPipeline(DiffusionPipeline, CogVideoXLoraLoaderMixin):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -619,9 +619,9 @@ class CogVideoXSTGPipeline(DiffusionPipeline, CogVideoXLoraLoaderMixin):
in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
passed will be used. Must be in descending order.
guidance_scale (`float`, *optional*, defaults to 7.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_videos_per_prompt (`int`, *optional*, defaults to 1):
@@ -713,7 +713,7 @@ class CogVideoXSTGPipeline(DiffusionPipeline, CogVideoXLoraLoaderMixin):
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/pipeline_stg_hunyuan_video.py b/examples/community/pipeline_stg_hunyuan_video.py
index e41f99e13a..88cc60d164 100644
--- a/examples/community/pipeline_stg_hunyuan_video.py
+++ b/examples/community/pipeline_stg_hunyuan_video.py
@@ -583,9 +583,9 @@ class HunyuanVideoSTGPipeline(DiffusionPipeline, HunyuanVideoLoraLoaderMixin):
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, defaults to `6.0`):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality. Note that the only available HunyuanVideo model is
CFG-distilled, which means that traditional guidance between unconditional and conditional latent is
diff --git a/examples/community/pipeline_stg_ltx.py b/examples/community/pipeline_stg_ltx.py
index 4a257a0a92..fbc2f17659 100644
--- a/examples/community/pipeline_stg_ltx.py
+++ b/examples/community/pipeline_stg_ltx.py
@@ -607,9 +607,9 @@ class LTXSTGPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLoraLoaderM
in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
passed will be used. Must be in descending order.
guidance_scale (`float`, defaults to `3 `):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_videos_per_prompt (`int`, *optional*, defaults to 1):
diff --git a/examples/community/pipeline_stg_ltx_image2video.py b/examples/community/pipeline_stg_ltx_image2video.py
index 5a3c3c5304..2c1f38d7db 100644
--- a/examples/community/pipeline_stg_ltx_image2video.py
+++ b/examples/community/pipeline_stg_ltx_image2video.py
@@ -669,9 +669,9 @@ class LTXImageToVideoSTGPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVide
in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
passed will be used. Must be in descending order.
guidance_scale (`float`, defaults to `3 `):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_videos_per_prompt (`int`, *optional*, defaults to 1):
diff --git a/examples/community/pipeline_stg_mochi.py b/examples/community/pipeline_stg_mochi.py
index 97b7293d0a..19ad347b95 100644
--- a/examples/community/pipeline_stg_mochi.py
+++ b/examples/community/pipeline_stg_mochi.py
@@ -590,9 +590,9 @@ class MochiSTGPipeline(DiffusionPipeline, Mochi1LoraLoaderMixin):
in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
passed will be used. Must be in descending order.
guidance_scale (`float`, defaults to `4.5`):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_videos_per_prompt (`int`, *optional*, defaults to 1):
diff --git a/examples/community/pipeline_stg_wan.py b/examples/community/pipeline_stg_wan.py
index 31cdd0efca..39f208bad7 100644
--- a/examples/community/pipeline_stg_wan.py
+++ b/examples/community/pipeline_stg_wan.py
@@ -451,9 +451,9 @@ class WanSTGPipeline(DiffusionPipeline, WanLoraLoaderMixin):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, defaults to `5.0`):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_videos_per_prompt (`int`, *optional*, defaults to 1):
diff --git a/examples/community/pipeline_zero1to3.py b/examples/community/pipeline_zero1to3.py
index 9a34f91bf8..0db543b169 100644
--- a/examples/community/pipeline_zero1to3.py
+++ b/examples/community/pipeline_zero1to3.py
@@ -464,7 +464,7 @@ class Zero1to3StableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -637,9 +637,9 @@ class Zero1to3StableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -649,7 +649,7 @@ class Zero1to3StableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -708,7 +708,7 @@ class Zero1to3StableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
batch_size = input_imgs.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/regional_prompting_stable_diffusion.py b/examples/community/regional_prompting_stable_diffusion.py
index 25923a6503..bca67e3959 100644
--- a/examples/community/regional_prompting_stable_diffusion.py
+++ b/examples/community/regional_prompting_stable_diffusion.py
@@ -1,14 +1,43 @@
+import inspect
import math
-from typing import Dict, Optional
+from typing import Any, Callable, Dict, List, Optional, Union
import torch
import torchvision.transforms.functional as FF
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer, CLIPVisionModelWithProjection
-from diffusers import StableDiffusionPipeline
+from diffusers.callbacks import MultiPipelineCallbacks, PipelineCallback
+from diffusers.image_processor import PipelineImageInput, VaeImageProcessor
+from diffusers.loaders import StableDiffusionLoraLoaderMixin
+from diffusers.loaders.ip_adapter import IPAdapterMixin
+from diffusers.loaders.lora_pipeline import LoraLoaderMixin
+from diffusers.loaders.single_file import FromSingleFileMixin
+from diffusers.loaders.textual_inversion import TextualInversionLoaderMixin
from diffusers.models import AutoencoderKL, UNet2DConditionModel
+from diffusers.models.lora import adjust_lora_scale_text_encoder
+from diffusers.pipelines.pipeline_utils import DiffusionPipeline
+from diffusers.pipelines.stable_diffusion.pipeline_output import StableDiffusionPipelineOutput
from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
from diffusers.schedulers import KarrasDiffusionSchedulers
+from diffusers.utils import (
+ USE_PEFT_BACKEND,
+ deprecate,
+ is_torch_xla_available,
+ logging,
+ scale_lora_layers,
+ unscale_lora_layers,
+)
+from diffusers.utils.torch_utils import randn_tensor
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+if is_torch_xla_available():
+ import torch_xla.core.xla_model as xm
+
+ XLA_AVAILABLE = True
+else:
+ XLA_AVAILABLE = False
try:
@@ -21,7 +50,14 @@ KCOMM = "ADDCOMM"
KBRK = "BREAK"
-class RegionalPromptingStableDiffusionPipeline(StableDiffusionPipeline):
+class RegionalPromptingStableDiffusionPipeline(
+ DiffusionPipeline,
+ TextualInversionLoaderMixin,
+ LoraLoaderMixin,
+ IPAdapterMixin,
+ FromSingleFileMixin,
+ StableDiffusionLoraLoaderMixin,
+):
r"""
Args for Regional Prompting Pipeline:
rp_args:dict
@@ -78,17 +114,7 @@ class RegionalPromptingStableDiffusionPipeline(StableDiffusionPipeline):
image_encoder: CLIPVisionModelWithProjection = None,
requires_safety_checker: bool = True,
):
- super().__init__(
- vae,
- text_encoder,
- tokenizer,
- unet,
- scheduler,
- safety_checker,
- feature_extractor,
- image_encoder,
- requires_safety_checker,
- )
+ super().__init__()
self.register_modules(
vae=vae,
text_encoder=text_encoder,
@@ -99,6 +125,17 @@ class RegionalPromptingStableDiffusionPipeline(StableDiffusionPipeline):
feature_extractor=feature_extractor,
image_encoder=image_encoder,
)
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1) if getattr(self, "vae", None) else 8
+ self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
+ self.register_to_config(requires_safety_checker=requires_safety_checker)
+
+ # Initialize additional properties needed for DiffusionPipeline
+ self._num_timesteps = None
+ self._interrupt = False
+ self._guidance_scale = 7.5
+ self._guidance_rescale = 0.0
+ self._clip_skip = None
+ self._cross_attention_kwargs = None
@torch.no_grad()
def __call__(
@@ -413,7 +450,7 @@ class RegionalPromptingStableDiffusionPipeline(StableDiffusionPipeline):
hook_forwards(self.unet)
- output = StableDiffusionPipeline(**self.components)(
+ output = self.stable_diffusion_call(
prompt=prompt,
prompt_embeds=embs,
negative_prompt=negative_prompt,
@@ -449,6 +486,909 @@ class RegionalPromptingStableDiffusionPipeline(StableDiffusionPipeline):
return output
+ # copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ # copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion
+ def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
+ shape = (
+ batch_size,
+ num_channels_latents,
+ int(height) // self.vae_scale_factor,
+ int(width) // self.vae_scale_factor,
+ )
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ # copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion
+ def encode_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt=None,
+ prompt_embeds: Optional[torch.Tensor] = None,
+ negative_prompt_embeds: Optional[torch.Tensor] = None,
+ lora_scale: Optional[float] = None,
+ clip_skip: Optional[int] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ lora_scale (`float`, *optional*):
+ A LoRA scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
+ clip_skip (`int`, *optional*):
+ Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
+ the output of the pre-final layer will be used for computing the prompt embeddings.
+ """
+ # set lora scale so that monkey patched LoRA
+ # function of text encoder can correctly access it
+ if lora_scale is not None and isinstance(self, StableDiffusionLoraLoaderMixin):
+ self._lora_scale = lora_scale
+
+ # dynamically adjust the LoRA scale
+ if not USE_PEFT_BACKEND:
+ adjust_lora_scale_text_encoder(self.text_encoder, lora_scale)
+ else:
+ scale_lora_layers(self.text_encoder, lora_scale)
+
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if prompt_embeds is None:
+ # textual inversion: process multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = self.tokenizer.batch_decode(
+ untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = text_inputs.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ if clip_skip is None:
+ prompt_embeds = self.text_encoder(text_input_ids.to(device), attention_mask=attention_mask)
+ prompt_embeds = prompt_embeds[0]
+ else:
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device), attention_mask=attention_mask, output_hidden_states=True
+ )
+ # Access the `hidden_states` first, that contains a tuple of
+ # all the hidden states from the encoder layers. Then index into
+ # the tuple to access the hidden states from the desired layer.
+ prompt_embeds = prompt_embeds[-1][-(clip_skip + 1)]
+ # We also need to apply the final LayerNorm here to not mess with the
+ # representations. The `last_hidden_states` that we typically use for
+ # obtaining the final prompt representations passes through the LayerNorm
+ # layer.
+ prompt_embeds = self.text_encoder.text_model.final_layer_norm(prompt_embeds)
+
+ if self.text_encoder is not None:
+ prompt_embeds_dtype = self.text_encoder.dtype
+ elif self.unet is not None:
+ prompt_embeds_dtype = self.unet.dtype
+ else:
+ prompt_embeds_dtype = prompt_embeds.dtype
+
+ prompt_embeds = prompt_embeds.to(dtype=prompt_embeds_dtype, device=device)
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance and negative_prompt_embeds is None:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif prompt is not None and type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ # textual inversion: process multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = uncond_input.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input.input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = negative_prompt_embeds[0]
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=prompt_embeds_dtype, device=device)
+
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ if self.text_encoder is not None:
+ if isinstance(self, StableDiffusionLoraLoaderMixin) and USE_PEFT_BACKEND:
+ # Retrieve the original scale by scaling back the LoRA layers
+ unscale_lora_layers(self.text_encoder, lora_scale)
+
+ return prompt_embeds, negative_prompt_embeds
+
+ # copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion
+ def check_inputs(
+ self,
+ prompt,
+ height,
+ width,
+ callback_steps,
+ negative_prompt=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ ip_adapter_image=None,
+ ip_adapter_image_embeds=None,
+ callback_on_step_end_tensor_inputs=None,
+ ):
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+ if callback_on_step_end_tensor_inputs is not None and not all(
+ k in self._callback_tensor_inputs for k in callback_on_step_end_tensor_inputs
+ ):
+ raise ValueError(
+ f"`callback_on_step_end_tensor_inputs` has to be in {self._callback_tensor_inputs}, but found {[k for k in callback_on_step_end_tensor_inputs if k not in self._callback_tensor_inputs]}"
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ if ip_adapter_image is not None and ip_adapter_image_embeds is not None:
+ raise ValueError(
+ "Provide either `ip_adapter_image` or `ip_adapter_image_embeds`. Cannot leave both `ip_adapter_image` and `ip_adapter_image_embeds` defined."
+ )
+
+ if ip_adapter_image_embeds is not None:
+ if not isinstance(ip_adapter_image_embeds, list):
+ raise ValueError(
+ f"`ip_adapter_image_embeds` has to be of type `list` but is {type(ip_adapter_image_embeds)}"
+ )
+ elif ip_adapter_image_embeds[0].ndim not in [3, 4]:
+ raise ValueError(
+ f"`ip_adapter_image_embeds` has to be a list of 3D or 4D tensors but is {ip_adapter_image_embeds[0].ndim}D"
+ )
+
+ # copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion
+ @torch.no_grad()
+ def stable_diffusion_call(
+ self,
+ prompt: Union[str, List[str]] = None,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ timesteps: List[int] = None,
+ sigmas: List[float] = None,
+ guidance_scale: float = 7.5,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.Tensor] = None,
+ prompt_embeds: Optional[torch.Tensor] = None,
+ negative_prompt_embeds: Optional[torch.Tensor] = None,
+ ip_adapter_image: Optional[PipelineImageInput] = None,
+ ip_adapter_image_embeds: Optional[List[torch.Tensor]] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ guidance_rescale: float = 0.0,
+ clip_skip: Optional[int] = None,
+ callback_on_step_end: Optional[
+ Union[Callable[[int, int, Dict], None], PipelineCallback, MultiPipelineCallbacks]
+ ] = None,
+ callback_on_step_end_tensor_inputs: List[str] = ["latents"],
+ **kwargs,
+ ):
+ r"""
+ The call function to the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide image generation. If not defined, you need to pass `prompt_embeds`.
+ height (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ timesteps (`List[int]`, *optional*):
+ Custom timesteps to use for the denoising process with schedulers which support a `timesteps` argument
+ in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
+ passed will be used. Must be in descending order.
+ sigmas (`List[float]`, *optional*):
+ Custom sigmas to use for the denoising process with schedulers which support a `sigmas` argument in
+ their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
+ will be used.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ A higher guidance scale value encourages the model to generate images closely linked to the text
+ `prompt` at the expense of lower image quality. Guidance scale is enabled when `guidance_scale > 1`.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide what to not include in image generation. If not defined, you need to
+ pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
+ generation deterministic.
+ latents (`torch.Tensor`, *optional*):
+ Pre-generated noisy latents sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor is generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs (prompt weighting). If not
+ provided, text embeddings are generated from the `prompt` input argument.
+ negative_prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs (prompt weighting). If
+ not provided, `negative_prompt_embeds` are generated from the `negative_prompt` input argument.
+ ip_adapter_image: (`PipelineImageInput`, *optional*): Optional image input to work with IP Adapters.
+ ip_adapter_image_embeds (`List[torch.Tensor]`, *optional*):
+ Pre-generated image embeddings for IP-Adapter. It should be a list of length same as number of
+ IP-adapters. Each element should be a tensor of shape `(batch_size, num_images, emb_dim)`. It should
+ contain the negative image embedding if `do_classifier_free_guidance` is set to `True`. If not
+ provided, embeddings are computed from the `ip_adapter_image` input argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generated image. Choose between `PIL.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the [`AttentionProcessor`] as defined in
+ [`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
+ guidance_rescale (`float`, *optional*, defaults to 0.0):
+ Guidance rescale factor from [Common Diffusion Noise Schedules and Sample Steps are
+ Flawed](https://arxiv.org/pdf/2305.08891.pdf). Guidance rescale factor should fix overexposure when
+ using zero terminal SNR.
+ clip_skip (`int`, *optional*):
+ Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
+ the output of the pre-final layer will be used for computing the prompt embeddings.
+ callback_on_step_end (`Callable`, `PipelineCallback`, `MultiPipelineCallbacks`, *optional*):
+ A function or a subclass of `PipelineCallback` or `MultiPipelineCallbacks` that is called at the end of
+ each denoising step during the inference. with the following arguments: `callback_on_step_end(self:
+ DiffusionPipeline, step: int, timestep: int, callback_kwargs: Dict)`. `callback_kwargs` will include a
+ list of all tensors as specified by `callback_on_step_end_tensor_inputs`.
+ callback_on_step_end_tensor_inputs (`List`, *optional*):
+ The list of tensor inputs for the `callback_on_step_end` function. The tensors specified in the list
+ will be passed as `callback_kwargs` argument. You will only be able to include variables listed in the
+ `._callback_tensor_inputs` attribute of your pipeline class.
+
+ Examples:
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ If `return_dict` is `True`, [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] is returned,
+ otherwise a `tuple` is returned where the first element is a list with the generated images and the
+ second element is a list of `bool`s indicating whether the corresponding generated image contains
+ "not-safe-for-work" (nsfw) content.
+ """
+
+ callback = kwargs.pop("callback", None)
+ callback_steps = kwargs.pop("callback_steps", None)
+ self.model_cpu_offload_seq = "text_encoder->image_encoder->unet->vae"
+ self._optional_components = ["safety_checker", "feature_extractor", "image_encoder"]
+ self._exclude_from_cpu_offload = ["safety_checker"]
+ self._callback_tensor_inputs = ["latents", "prompt_embeds", "negative_prompt_embeds"]
+
+ if callback is not None:
+ deprecate(
+ "callback",
+ "1.0.0",
+ "Passing `callback` as an input argument to `__call__` is deprecated, consider using `callback_on_step_end`",
+ )
+ if callback_steps is not None:
+ deprecate(
+ "callback_steps",
+ "1.0.0",
+ "Passing `callback_steps` as an input argument to `__call__` is deprecated, consider using `callback_on_step_end`",
+ )
+
+ if isinstance(callback_on_step_end, (PipelineCallback, MultiPipelineCallbacks)):
+ callback_on_step_end_tensor_inputs = callback_on_step_end.tensor_inputs
+
+ # 0. Default height and width to unet
+ if not height or not width:
+ height = (
+ self.unet.config.sample_size
+ if self._is_unet_config_sample_size_int
+ else self.unet.config.sample_size[0]
+ )
+ width = (
+ self.unet.config.sample_size
+ if self._is_unet_config_sample_size_int
+ else self.unet.config.sample_size[1]
+ )
+ height, width = height * self.vae_scale_factor, width * self.vae_scale_factor
+ # to deal with lora scaling and other possible forward hooks
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ prompt,
+ height,
+ width,
+ callback_steps,
+ negative_prompt,
+ prompt_embeds,
+ negative_prompt_embeds,
+ ip_adapter_image,
+ ip_adapter_image_embeds,
+ callback_on_step_end_tensor_inputs,
+ )
+
+ self._guidance_scale = guidance_scale
+ self._guidance_rescale = guidance_rescale
+ self._clip_skip = clip_skip
+ self._cross_attention_kwargs = cross_attention_kwargs
+ self._interrupt = False
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+
+ # 3. Encode input prompt
+ lora_scale = (
+ self.cross_attention_kwargs.get("scale", None) if self.cross_attention_kwargs is not None else None
+ )
+
+ prompt_embeds, negative_prompt_embeds = self.encode_prompt(
+ prompt,
+ device,
+ num_images_per_prompt,
+ self.do_classifier_free_guidance,
+ negative_prompt,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ lora_scale=lora_scale,
+ clip_skip=self.clip_skip,
+ )
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ if self.do_classifier_free_guidance:
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ if ip_adapter_image is not None or ip_adapter_image_embeds is not None:
+ image_embeds = self.prepare_ip_adapter_image_embeds(
+ ip_adapter_image,
+ ip_adapter_image_embeds,
+ device,
+ batch_size * num_images_per_prompt,
+ self.do_classifier_free_guidance,
+ )
+
+ # 4. Prepare timesteps
+ timesteps, num_inference_steps = retrieve_timesteps(
+ self.scheduler, num_inference_steps, device, timesteps, sigmas
+ )
+
+ # 5. Prepare latent variables
+ num_channels_latents = self.unet.config.in_channels
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ height,
+ width,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 6.1 Add image embeds for IP-Adapter
+ added_cond_kwargs = (
+ {"image_embeds": image_embeds}
+ if (ip_adapter_image is not None or ip_adapter_image_embeds is not None)
+ else None
+ )
+
+ # 6.2 Optionally get Guidance Scale Embedding
+ timestep_cond = None
+ if self.unet.config.time_cond_proj_dim is not None:
+ guidance_scale_tensor = torch.tensor(self.guidance_scale - 1).repeat(batch_size * num_images_per_prompt)
+ timestep_cond = self.get_guidance_scale_embedding(
+ guidance_scale_tensor, embedding_dim=self.unet.config.time_cond_proj_dim
+ ).to(device=device, dtype=latents.dtype)
+
+ # 7. Denoising loop
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+ self._num_timesteps = len(timesteps)
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ if self.interrupt:
+ continue
+
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if self.do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # predict the noise residual
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ timestep_cond=timestep_cond,
+ cross_attention_kwargs=self.cross_attention_kwargs,
+ added_cond_kwargs=added_cond_kwargs,
+ return_dict=False,
+ )[0]
+
+ # perform guidance
+ if self.do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
+ # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
+
+ if callback_on_step_end is not None:
+ callback_kwargs = {}
+ for k in callback_on_step_end_tensor_inputs:
+ callback_kwargs[k] = locals()[k]
+ callback_outputs = callback_on_step_end(self, i, t, callback_kwargs)
+
+ latents = callback_outputs.pop("latents", latents)
+ prompt_embeds = callback_outputs.pop("prompt_embeds", prompt_embeds)
+ negative_prompt_embeds = callback_outputs.pop("negative_prompt_embeds", negative_prompt_embeds)
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ step_idx = i // getattr(self.scheduler, "order", 1)
+ callback(step_idx, t, latents)
+
+ if XLA_AVAILABLE:
+ xm.mark_step()
+
+ if not output_type == "latent":
+ image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False, generator=generator)[
+ 0
+ ]
+ image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
+ else:
+ image = latents
+ has_nsfw_concept = None
+
+ if has_nsfw_concept is None:
+ do_denormalize = [True] * image.shape[0]
+ else:
+ do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
+ image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
+
+ # Offload all models
+ self.maybe_free_model_hooks()
+
+ if not return_dict:
+ return (image, has_nsfw_concept)
+
+ return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
+
+ # copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion
+ def _encode_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt=None,
+ prompt_embeds: Optional[torch.Tensor] = None,
+ negative_prompt_embeds: Optional[torch.Tensor] = None,
+ lora_scale: Optional[float] = None,
+ **kwargs,
+ ):
+ r"""Encodes the prompt into text encoder hidden states."""
+ batch_size = len(prompt) if isinstance(prompt, list) else 1
+
+ # get prompt text embeddings
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(text_input_ids, untruncated_ids):
+ removed_text = self.tokenizer.batch_decode(untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1])
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = text_inputs.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ if isinstance(self, StableDiffusionLoraLoaderMixin) and USE_PEFT_BACKEND:
+ # cast text_encoder.dtype to prevent overflow when using bf16
+ text_input_ids = text_input_ids.to(device=device, dtype=self.text_encoder.dtype)
+ prompt_embeds = self.text_encoder(
+ text_input_ids,
+ attention_mask=attention_mask,
+ )
+ prompt_embeds = prompt_embeds[0]
+ else:
+ text_encoder_lora_scale = None
+ if lora_scale is not None and isinstance(self, StableDiffusionLoraLoaderMixin):
+ text_encoder_lora_scale = lora_scale
+ if text_encoder_lora_scale is not None and isinstance(self, StableDiffusionLoraLoaderMixin):
+ # dynamically adjust the LoRA scale
+ adjust_lora_scale_text_encoder(self.text_encoder, lora_scale)
+
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ prompt_embeds = prompt_embeds[0]
+
+ # duplicate text embeddings for each generation per prompt
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance and negative_prompt_embeds is None:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""]
+ elif type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ # textual inversion: process multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = uncond_input.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input.input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = negative_prompt_embeds[0]
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt
+ seq_len = negative_prompt_embeds.shape[1]
+
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ if isinstance(self, StableDiffusionLoraLoaderMixin) and USE_PEFT_BACKEND:
+ # Unscale LoRA weights to avoid overfitting. This is a hack
+ unscale_lora_layers(self.text_encoder, lora_scale)
+
+ return prompt_embeds, negative_prompt_embeds
+
+ def encode_image(self, image, device, num_images_per_prompt, output_hidden_states=None):
+ """Encodes the image into image encoder hidden states."""
+ dtype = next(self.image_encoder.parameters()).dtype
+
+ if not isinstance(image, torch.Tensor):
+ image = self.feature_extractor(image, return_tensors="pt").pixel_values
+
+ image = image.to(device=device, dtype=dtype)
+ if output_hidden_states:
+ image_enc_hidden_states = self.image_encoder(image, output_hidden_states=True).hidden_states[-2]
+ image_enc_hidden_states = image_enc_hidden_states.repeat_interleave(num_images_per_prompt, dim=0)
+ uncond_image_enc_hidden_states = self.image_encoder(
+ torch.zeros_like(image), output_hidden_states=True
+ ).hidden_states[-2]
+ uncond_image_enc_hidden_states = uncond_image_enc_hidden_states.repeat_interleave(
+ num_images_per_prompt, dim=0
+ )
+ return image_enc_hidden_states, uncond_image_enc_hidden_states
+ else:
+ image_embeds = self.image_encoder(image).image_embeds
+ image_embeds = image_embeds.repeat_interleave(num_images_per_prompt, dim=0)
+ uncond_image_embeds = torch.zeros_like(image_embeds)
+
+ return image_embeds, uncond_image_embeds
+
+ def prepare_ip_adapter_image_embeds(
+ self, ip_adapter_image, ip_adapter_image_embeds, device, num_images_per_prompt, do_classifier_free_guidance
+ ):
+ """Prepares and processes IP-Adapter image embeddings."""
+ image_embeds = []
+ if do_classifier_free_guidance:
+ negative_image_embeds = []
+ if ip_adapter_image_embeds is None:
+ for image in ip_adapter_image:
+ if not isinstance(image, torch.Tensor):
+ image = self.image_processor.preprocess(image)
+ image = image.to(device=device)
+ if len(image.shape) == 3:
+ image = image.unsqueeze(0)
+ image_emb, neg_image_emb = self.encode_image(image, device, num_images_per_prompt, True)
+ image_embeds.append(image_emb)
+ if do_classifier_free_guidance:
+ negative_image_embeds.append(neg_image_emb)
+
+ if len(image_embeds) == 1:
+ image_embeds = image_embeds[0]
+ if do_classifier_free_guidance:
+ negative_image_embeds = negative_image_embeds[0]
+ else:
+ image_embeds = torch.cat(image_embeds, dim=0)
+ if do_classifier_free_guidance:
+ negative_image_embeds = torch.cat(negative_image_embeds, dim=0)
+ else:
+ repeat_dim = 2 if do_classifier_free_guidance else 1
+ image_embeds = ip_adapter_image_embeds.repeat_interleave(repeat_dim, dim=0)
+ if do_classifier_free_guidance:
+ negative_image_embeds = torch.zeros_like(image_embeds)
+
+ if do_classifier_free_guidance:
+ image_embeds = torch.cat([negative_image_embeds, image_embeds])
+
+ return image_embeds
+
+ def run_safety_checker(self, image, device, dtype):
+ """Runs the safety checker on the generated image."""
+ if self.safety_checker is None:
+ has_nsfw_concept = None
+ return image, has_nsfw_concept
+
+ if isinstance(self.safety_checker, StableDiffusionSafetyChecker):
+ safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(device)
+ image, has_nsfw_concept = self.safety_checker(
+ images=image,
+ clip_input=safety_checker_input.pixel_values.to(dtype),
+ )
+ else:
+ images_np = self.numpy_to_pil(image)
+ safety_checker_input = self.safety_checker.feature_extractor(images_np, return_tensors="pt").to(device)
+ has_nsfw_concept = self.safety_checker(
+ images=image,
+ clip_input=safety_checker_input.pixel_values.to(dtype),
+ )[1]
+
+ return image, has_nsfw_concept
+
+ # copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion
+ def decode_latents(self, latents):
+ """Decodes the latents to images."""
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents, return_dict=False)[0]
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ @property
+ def guidance_scale(self):
+ return self._guidance_scale
+
+ @property
+ def guidance_rescale(self):
+ return self._guidance_rescale
+
+ # copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion
+ def get_guidance_scale_embedding(
+ self, w: torch.Tensor, embedding_dim: int = 512, dtype: torch.dtype = torch.float32
+ ):
+ """Gets the guidance scale embedding for classifier free guidance conditioning.
+ See https://github.com/google-research/vdm/blob/dc27b98a554f65cdc654b800da5aa1846545d41b/model_vdm.py#L298
+
+ Args:
+ w (`torch.Tensor`):
+ The guidance scale tensor used for classifier free guidance conditioning.
+ embedding_dim (`int`, defaults to 512):
+ The dimensionality of the guidance scale embedding.
+ dtype (`torch.dtype`, defaults to torch.float32):
+ The dtype of the embedding.
+
+ Returns:
+ `torch.Tensor`: Embedding vectors with shape `(len(w), embedding_dim)`.
+ """
+ assert len(w.shape) == 1
+ w = w * 1000.0
+
+ half_dim = embedding_dim // 2
+ emb = torch.log(torch.tensor(10000.0)) / (half_dim - 1)
+ emb = torch.exp(torch.arange(half_dim, dtype=dtype) * -emb)
+ emb = w.to(dtype)[:, None] * emb[None, :]
+ emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=1)
+ if embedding_dim % 2 == 1: # zero pad
+ emb = torch.nn.functional.pad(emb, (0, 1))
+ assert emb.shape == (w.shape[0], embedding_dim)
+ return emb
+
+ @property
+ def clip_skip(self):
+ return self._clip_skip
+
+ @property
+ def num_timesteps(self):
+ return self._num_timesteps
+
+ @property
+ def interrupt(self):
+ return self._interrupt
+
+ @property
+ def cross_attention_kwargs(self):
+ return self._cross_attention_kwargs
+
+ @property
+ def do_classifier_free_guidance(self):
+ return self._guidance_scale > 1 and self.unet.config.time_cond_proj_dim is None
+
### Make prompt list for each regions
def promptsmaker(prompts, batch):
@@ -663,3 +1603,88 @@ def scaled_dot_product_attention(
get_attn_maps(self, attn_weight)
attn_weight = torch.dropout(attn_weight, dropout_p, train=True)
return attn_weight @ value
+
+
+def retrieve_timesteps(
+ scheduler,
+ num_inference_steps: Optional[int] = None,
+ device: Optional[Union[str, torch.device]] = None,
+ timesteps: Optional[List[int]] = None,
+ sigmas: Optional[List[float]] = None,
+ **kwargs,
+):
+ r"""
+ Calls the scheduler's `set_timesteps` method and retrieves timesteps from the scheduler after the call. Handles
+ custom timesteps. Any kwargs will be supplied to `scheduler.set_timesteps`.
+
+ Args:
+ scheduler (`SchedulerMixin`):
+ The scheduler to get timesteps from.
+ num_inference_steps (`int`):
+ The number of diffusion steps used when generating samples with a pre-trained model. If used, `timesteps`
+ must be `None`.
+ device (`str` or `torch.device`, *optional*):
+ The device to which the timesteps should be moved to. If `None`, the timesteps are not moved.
+ timesteps (`List[int]`, *optional*):
+ Custom timesteps used to override the timestep spacing strategy of the scheduler. If `timesteps` is passed,
+ `num_inference_steps` and `sigmas` must be `None`.
+ sigmas (`List[float]`, *optional*):
+ Custom sigmas used to override the timestep spacing strategy of the scheduler. If `sigmas` is passed,
+ `num_inference_steps` and `timesteps` must be `None`.
+
+ Returns:
+ `Tuple[torch.Tensor, int]`: A tuple where the first element is the timestep schedule from the scheduler and the
+ second element is the number of inference steps.
+ """
+ if timesteps is not None and sigmas is not None:
+ raise ValueError("Only one of `timesteps` or `sigmas` can be passed. Please choose one to set custom values")
+ if timesteps is not None:
+ accepts_timesteps = "timesteps" in set(inspect.signature(scheduler.set_timesteps).parameters.keys())
+ if not accepts_timesteps:
+ raise ValueError(
+ f"The current scheduler class {scheduler.__class__}'s `set_timesteps` does not support custom"
+ f" timestep schedules. Please check whether you are using the correct scheduler."
+ )
+ scheduler.set_timesteps(timesteps=timesteps, device=device, **kwargs)
+ timesteps = scheduler.timesteps
+ num_inference_steps = len(timesteps)
+ elif sigmas is not None:
+ accept_sigmas = "sigmas" in set(inspect.signature(scheduler.set_timesteps).parameters.keys())
+ if not accept_sigmas:
+ raise ValueError(
+ f"The current scheduler class {scheduler.__class__}'s `set_timesteps` does not support custom"
+ f" sigmas schedules. Please check whether you are using the correct scheduler."
+ )
+ scheduler.set_timesteps(sigmas=sigmas, device=device, **kwargs)
+ timesteps = scheduler.timesteps
+ num_inference_steps = len(timesteps)
+ else:
+ scheduler.set_timesteps(num_inference_steps, device=device, **kwargs)
+ timesteps = scheduler.timesteps
+ return timesteps, num_inference_steps
+
+
+def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
+ r"""
+ Rescales `noise_cfg` tensor based on `guidance_rescale` to improve image quality and fix overexposure. Based on
+ Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
+ Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+
+ Args:
+ noise_cfg (`torch.Tensor`):
+ The predicted noise tensor for the guided diffusion process.
+ noise_pred_text (`torch.Tensor`):
+ The predicted noise tensor for the text-guided diffusion process.
+ guidance_rescale (`float`, *optional*, defaults to 0.0):
+ A rescale factor applied to the noise predictions.
+
+ Returns:
+ noise_cfg (`torch.Tensor`): The rescaled noise prediction tensor.
+ """
+ std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
+ std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
+ # rescale the results from guidance (fixes overexposure)
+ noise_pred_rescaled = noise_cfg * (std_text / std_cfg)
+ # mix with the original results from guidance by factor guidance_rescale to avoid "plain looking" images
+ noise_cfg = guidance_rescale * noise_pred_rescaled + (1 - guidance_rescale) * noise_cfg
+ return noise_cfg
diff --git a/examples/community/rerender_a_video.py b/examples/community/rerender_a_video.py
index 7e66bff51d..521dc975a2 100644
--- a/examples/community/rerender_a_video.py
+++ b/examples/community/rerender_a_video.py
@@ -99,7 +99,7 @@ def flow_warp(feature, flow, mask=False, mode="bilinear", padding_mode="zeros"):
def forward_backward_consistency_check(fwd_flow, bwd_flow, alpha=0.01, beta=0.5):
# fwd_flow, bwd_flow: [B, 2, H, W]
# alpha and beta values are following UnFlow
- # (https://arxiv.org/abs/1711.07837)
+ # (https://huggingface.co/papers/1711.07837)
assert fwd_flow.dim() == 4 and bwd_flow.dim() == 4
assert fwd_flow.size(1) == 2 and bwd_flow.size(1) == 2
flow_mag = torch.norm(fwd_flow, dim=1) + torch.norm(bwd_flow, dim=1) # [B, H, W]
@@ -638,9 +638,9 @@ class RerenderAVideoPipeline(StableDiffusionControlNetImg2ImgPipeline):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -648,7 +648,7 @@ class RerenderAVideoPipeline(StableDiffusionControlNetImg2ImgPipeline):
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
less than `1`).
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -747,7 +747,7 @@ class RerenderAVideoPipeline(StableDiffusionControlNetImg2ImgPipeline):
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/run_onnx_controlnet.py b/examples/community/run_onnx_controlnet.py
index af2672c17e..2221fc09db 100644
--- a/examples/community/run_onnx_controlnet.py
+++ b/examples/community/run_onnx_controlnet.py
@@ -252,7 +252,7 @@ class OnnxStableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -571,9 +571,9 @@ class OnnxStableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -583,7 +583,7 @@ class OnnxStableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -680,7 +680,7 @@ class OnnxStableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline):
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/run_tensorrt_controlnet.py b/examples/community/run_tensorrt_controlnet.py
index 873195fa31..b9e71724c0 100644
--- a/examples/community/run_tensorrt_controlnet.py
+++ b/examples/community/run_tensorrt_controlnet.py
@@ -356,7 +356,7 @@ class TensorRTStableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -675,9 +675,9 @@ class TensorRTStableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -687,7 +687,7 @@ class TensorRTStableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -784,7 +784,7 @@ class TensorRTStableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline):
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/scheduling_ufogen.py b/examples/community/scheduling_ufogen.py
index 0b832394cf..a3b9640c95 100644
--- a/examples/community/scheduling_ufogen.py
+++ b/examples/community/scheduling_ufogen.py
@@ -94,7 +94,7 @@ def betas_for_alpha_bar(
# Copied from diffusers.schedulers.scheduling_ddim.rescale_zero_terminal_snr
def rescale_zero_terminal_snr(betas):
"""
- Rescales betas to have zero terminal SNR Based on https://arxiv.org/pdf/2305.08891.pdf (Algorithm 1)
+ Rescales betas to have zero terminal SNR Based on https://huggingface.co/papers/2305.08891 (Algorithm 1)
Args:
@@ -131,7 +131,7 @@ def rescale_zero_terminal_snr(betas):
class UFOGenScheduler(SchedulerMixin, ConfigMixin):
"""
`UFOGenScheduler` implements multistep and onestep sampling for a UFOGen model, introduced in
- [UFOGen: You Forward Once Large Scale Text-to-Image Generation via Diffusion GANs](https://arxiv.org/abs/2311.09257)
+ [UFOGen: You Forward Once Large Scale Text-to-Image Generation via Diffusion GANs](https://huggingface.co/papers/2311.09257)
by Yanwu Xu, Yang Zhao, Zhisheng Xiao, and Tingbo Hou. UFOGen is a varianet of the denoising diffusion GAN (DDGAN)
model designed for one-step sampling.
@@ -311,7 +311,7 @@ class UFOGenScheduler(SchedulerMixin, ConfigMixin):
timesteps = np.array([self.config.num_train_timesteps - 1], dtype=np.int64)
else:
# TODO: For now, retain the DDPM timestep spacing logic
- # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://arxiv.org/abs/2305.08891
+ # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://huggingface.co/papers/2305.08891
if self.config.timestep_spacing == "linspace":
timesteps = (
np.linspace(0, self.config.num_train_timesteps - 1, num_inference_steps)
@@ -347,7 +347,7 @@ class UFOGenScheduler(SchedulerMixin, ConfigMixin):
pixels from saturation at each step. We find that dynamic thresholding results in significantly better
photorealism as well as better image-text alignment, especially when using very large guidance weights."
- https://arxiv.org/abs/2205.11487
+ https://huggingface.co/papers/2205.11487
"""
dtype = sample.dtype
batch_size, channels, *remaining_dims = sample.shape
@@ -415,7 +415,7 @@ class UFOGenScheduler(SchedulerMixin, ConfigMixin):
# current_beta_t = 1 - current_alpha_t
# 2. compute predicted original sample from predicted noise also called
- # "predicted x_0" of formula (15) from https://arxiv.org/pdf/2006.11239.pdf
+ # "predicted x_0" of formula (15) from https://huggingface.co/papers/2006.11239
if self.config.prediction_type == "epsilon":
pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
elif self.config.prediction_type == "sample":
diff --git a/examples/community/sd_text2img_k_diffusion.py b/examples/community/sd_text2img_k_diffusion.py
index 9f83973aba..598207850e 100755
--- a/examples/community/sd_text2img_k_diffusion.py
+++ b/examples/community/sd_text2img_k_diffusion.py
@@ -307,9 +307,9 @@ class StableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -318,7 +318,7 @@ class StableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
@@ -355,7 +355,7 @@ class StableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
batch_size = 1 if isinstance(prompt, str) else len(prompt)
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = True
if guidance_scale <= 1.0:
diff --git a/examples/community/sde_drag.py b/examples/community/sde_drag.py
index 3ded8c247c..f408ee64db 100644
--- a/examples/community/sde_drag.py
+++ b/examples/community/sde_drag.py
@@ -25,7 +25,7 @@ from diffusers.optimization import get_scheduler
class SdeDragPipeline(DiffusionPipeline):
r"""
- Pipeline for image drag-and-drop editing using stochastic differential equations: https://arxiv.org/abs/2311.01410.
+ Pipeline for image drag-and-drop editing using stochastic differential equations: https://huggingface.co/papers/2311.01410.
Please refer to the [official repository](https://github.com/ML-GSAI/SDE-Drag) for more information.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
diff --git a/examples/community/seed_resize_stable_diffusion.py b/examples/community/seed_resize_stable_diffusion.py
index ae2d8a53b2..3c823012c1 100644
--- a/examples/community/seed_resize_stable_diffusion.py
+++ b/examples/community/seed_resize_stable_diffusion.py
@@ -103,9 +103,9 @@ class SeedResizeStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin)
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -114,7 +114,7 @@ class SeedResizeStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin)
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
@@ -188,7 +188,7 @@ class SeedResizeStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin)
text_embeddings = text_embeddings.view(bs_embed * num_images_per_prompt, seq_len, -1)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
@@ -287,7 +287,7 @@ class SeedResizeStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin)
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
diff --git a/examples/community/speech_to_image_diffusion.py b/examples/community/speech_to_image_diffusion.py
index 9cb5a2a8c7..a8ec1620a2 100644
--- a/examples/community/speech_to_image_diffusion.py
+++ b/examples/community/speech_to_image_diffusion.py
@@ -134,7 +134,7 @@ class SpeechToImagePipeline(DiffusionPipeline, StableDiffusionMixin):
text_embeddings = text_embeddings.view(bs_embed * num_images_per_prompt, seq_len, -1)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
@@ -210,7 +210,7 @@ class SpeechToImagePipeline(DiffusionPipeline, StableDiffusionMixin):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
diff --git a/examples/community/stable_diffusion_comparison.py b/examples/community/stable_diffusion_comparison.py
index 2b510a64f8..36e7dba2de 100644
--- a/examples/community/stable_diffusion_comparison.py
+++ b/examples/community/stable_diffusion_comparison.py
@@ -265,13 +265,13 @@ class StableDiffusionComparisonPipeline(DiffusionPipeline, StableDiffusionMixin)
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, optional, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
eta (`float`, optional, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, optional):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
diff --git a/examples/community/stable_diffusion_controlnet_img2img.py b/examples/community/stable_diffusion_controlnet_img2img.py
index 6aa4067d69..877464454a 100644
--- a/examples/community/stable_diffusion_controlnet_img2img.py
+++ b/examples/community/stable_diffusion_controlnet_img2img.py
@@ -340,7 +340,7 @@ class StableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline, StableDiffusio
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -651,9 +651,9 @@ class StableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline, StableDiffusio
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -662,7 +662,7 @@ class StableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline, StableDiffusio
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -742,7 +742,7 @@ class StableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline, StableDiffusio
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/stable_diffusion_controlnet_inpaint.py b/examples/community/stable_diffusion_controlnet_inpaint.py
index 2d19e26b42..175c47d015 100644
--- a/examples/community/stable_diffusion_controlnet_inpaint.py
+++ b/examples/community/stable_diffusion_controlnet_inpaint.py
@@ -439,7 +439,7 @@ class StableDiffusionControlNetInpaintPipeline(DiffusionPipeline, StableDiffusio
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -791,9 +791,9 @@ class StableDiffusionControlNetInpaintPipeline(DiffusionPipeline, StableDiffusio
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -802,7 +802,7 @@ class StableDiffusionControlNetInpaintPipeline(DiffusionPipeline, StableDiffusio
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -875,7 +875,7 @@ class StableDiffusionControlNetInpaintPipeline(DiffusionPipeline, StableDiffusio
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/stable_diffusion_controlnet_inpaint_img2img.py b/examples/community/stable_diffusion_controlnet_inpaint_img2img.py
index 4363a2294b..51e7ac38dd 100644
--- a/examples/community/stable_diffusion_controlnet_inpaint_img2img.py
+++ b/examples/community/stable_diffusion_controlnet_inpaint_img2img.py
@@ -424,7 +424,7 @@ class StableDiffusionControlNetInpaintImg2ImgPipeline(DiffusionPipeline, StableD
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -785,9 +785,9 @@ class StableDiffusionControlNetInpaintImg2ImgPipeline(DiffusionPipeline, StableD
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -796,7 +796,7 @@ class StableDiffusionControlNetInpaintImg2ImgPipeline(DiffusionPipeline, StableD
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -869,7 +869,7 @@ class StableDiffusionControlNetInpaintImg2ImgPipeline(DiffusionPipeline, StableD
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/stable_diffusion_controlnet_reference.py b/examples/community/stable_diffusion_controlnet_reference.py
index 577c7712e7..aa9ab1b242 100644
--- a/examples/community/stable_diffusion_controlnet_reference.py
+++ b/examples/community/stable_diffusion_controlnet_reference.py
@@ -159,9 +159,9 @@ class StableDiffusionControlNetReferencePipeline(StableDiffusionControlNetPipeli
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -171,7 +171,7 @@ class StableDiffusionControlNetReferencePipeline(StableDiffusionControlNetPipeli
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -255,7 +255,7 @@ class StableDiffusionControlNetReferencePipeline(StableDiffusionControlNetPipeli
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/stable_diffusion_ipex.py b/examples/community/stable_diffusion_ipex.py
index b2d4541797..137b72de64 100644
--- a/examples/community/stable_diffusion_ipex.py
+++ b/examples/community/stable_diffusion_ipex.py
@@ -210,7 +210,7 @@ class StableDiffusionIPEXPipeline(
device = "cpu"
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
@@ -475,7 +475,7 @@ class StableDiffusionIPEXPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -595,9 +595,9 @@ class StableDiffusionIPEXPipeline(
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -607,7 +607,7 @@ class StableDiffusionIPEXPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -668,7 +668,7 @@ class StableDiffusionIPEXPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/stable_diffusion_reference.py b/examples/community/stable_diffusion_reference.py
index 9ef95a5205..69fa0722cf 100644
--- a/examples/community/stable_diffusion_reference.py
+++ b/examples/community/stable_diffusion_reference.py
@@ -655,7 +655,7 @@ class StableDiffusionReferencePipeline(
"""
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -865,9 +865,9 @@ class StableDiffusionReferencePipeline(
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -877,7 +877,7 @@ class StableDiffusionReferencePipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -911,8 +911,8 @@ class StableDiffusionReferencePipeline(
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
- [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://huggingface.co/papers/2305.08891).
Guidance rescale factor should fix overexposure when using zero terminal SNR.
attention_auto_machine_weight (`float`):
Weight of using reference query for self attention's context.
@@ -956,7 +956,7 @@ class StableDiffusionReferencePipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
@@ -1432,7 +1432,7 @@ class StableDiffusionReferencePipeline(
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if do_classifier_free_guidance and guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/examples/community/stable_diffusion_repaint.py b/examples/community/stable_diffusion_repaint.py
index 0bc28eca15..1245a89702 100644
--- a/examples/community/stable_diffusion_repaint.py
+++ b/examples/community/stable_diffusion_repaint.py
@@ -442,7 +442,7 @@ class StableDiffusionRepaintPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -653,14 +653,14 @@ class StableDiffusionRepaintPipeline(
expense of slower inference.
jump_length (`int`, *optional*, defaults to 10):
The number of steps taken forward in time before going backward in time for a single jump ("j" in
- RePaint paper). Take a look at Figure 9 and 10 in https://arxiv.org/pdf/2201.09865.pdf.
+ RePaint paper). Take a look at Figure 9 and 10 in https://huggingface.co/papers/2201.09865.
jump_n_sample (`int`, *optional*, defaults to 10):
The number of times we will make forward time jump for a given chosen time sample. Take a look at
- Figure 9 and 10 in https://arxiv.org/pdf/2201.09865.pdf.
+ Figure 9 and 10 in https://huggingface.co/papers/2201.09865.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -670,7 +670,7 @@ class StableDiffusionRepaintPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -759,7 +759,7 @@ class StableDiffusionRepaintPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/stable_diffusion_tensorrt_img2img.py b/examples/community/stable_diffusion_tensorrt_img2img.py
index f2d184bb73..dc11703b6a 100755
--- a/examples/community/stable_diffusion_tensorrt_img2img.py
+++ b/examples/community/stable_diffusion_tensorrt_img2img.py
@@ -1059,9 +1059,9 @@ class TensorRTStableDiffusionImg2ImgPipeline(DiffusionPipeline):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
diff --git a/examples/community/stable_diffusion_tensorrt_inpaint.py b/examples/community/stable_diffusion_tensorrt_inpaint.py
index 8da37d37ac..fff7309e9c 100755
--- a/examples/community/stable_diffusion_tensorrt_inpaint.py
+++ b/examples/community/stable_diffusion_tensorrt_inpaint.py
@@ -1148,9 +1148,9 @@ class TensorRTStableDiffusionInpaintPipeline(DiffusionPipeline):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
diff --git a/examples/community/stable_diffusion_tensorrt_txt2img.py b/examples/community/stable_diffusion_tensorrt_txt2img.py
index a3f9aae371..15a6e69c41 100755
--- a/examples/community/stable_diffusion_tensorrt_txt2img.py
+++ b/examples/community/stable_diffusion_tensorrt_txt2img.py
@@ -982,9 +982,9 @@ class TensorRTStableDiffusionPipeline(DiffusionPipeline):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
diff --git a/examples/community/stable_diffusion_xl_controlnet_reference.py b/examples/community/stable_diffusion_xl_controlnet_reference.py
index 2c9bef311b..421e67f5bb 100644
--- a/examples/community/stable_diffusion_xl_controlnet_reference.py
+++ b/examples/community/stable_diffusion_xl_controlnet_reference.py
@@ -431,7 +431,7 @@ class StableDiffusionXLControlNetReferencePipeline(StableDiffusionXLControlNetPi
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
diff --git a/examples/community/stable_diffusion_xl_reference.py b/examples/community/stable_diffusion_xl_reference.py
index e01eac970b..11926a5d9a 100644
--- a/examples/community/stable_diffusion_xl_reference.py
+++ b/examples/community/stable_diffusion_xl_reference.py
@@ -65,7 +65,7 @@ def torch_dfs(model: torch.nn.Module):
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -357,9 +357,9 @@ class StableDiffusionXLReferencePipeline(StableDiffusionXLPipeline):
"Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output)
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -372,7 +372,7 @@ class StableDiffusionXLReferencePipeline(StableDiffusionXLPipeline):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -413,8 +413,8 @@ class StableDiffusionXLReferencePipeline(StableDiffusionXLPipeline):
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
- [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://huggingface.co/papers/2305.08891).
Guidance rescale factor should fix overexposure when using zero terminal SNR.
original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
@@ -1114,7 +1114,7 @@ class StableDiffusionXLReferencePipeline(StableDiffusionXLPipeline):
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/examples/community/text_inpainting.py b/examples/community/text_inpainting.py
index d73082b6cf..2908388029 100644
--- a/examples/community/text_inpainting.py
+++ b/examples/community/text_inpainting.py
@@ -161,9 +161,9 @@ class TextInpainting(DiffusionPipeline, StableDiffusionMixin):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -172,7 +172,7 @@ class TextInpainting(DiffusionPipeline, StableDiffusionMixin):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
diff --git a/examples/community/tiled_upscaling.py b/examples/community/tiled_upscaling.py
index 3fe7399c8a..7e9abe55bb 100644
--- a/examples/community/tiled_upscaling.py
+++ b/examples/community/tiled_upscaling.py
@@ -212,9 +212,9 @@ class StableDiffusionTiledUpscalePipeline(StableDiffusionUpscalePipeline):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -223,7 +223,7 @@ class StableDiffusionTiledUpscalePipeline(StableDiffusionUpscalePipeline):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
diff --git a/examples/community/unclip_image_interpolation.py b/examples/community/unclip_image_interpolation.py
index 413c103cef..65b5257860 100644
--- a/examples/community/unclip_image_interpolation.py
+++ b/examples/community/unclip_image_interpolation.py
@@ -247,9 +247,9 @@ class UnCLIPImageInterpolationPipeline(DiffusionPipeline):
super_res_latents (`torch.Tensor` of shape (batch size, channels, super res height, super res width), *optional*):
Pre-generated noisy latents to be used as inputs for the decoder.
decoder_guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
output_type (`str`, *optional*, defaults to `"pil"`):
diff --git a/examples/community/unclip_text_interpolation.py b/examples/community/unclip_text_interpolation.py
index 84f1c5a21f..6fd4f348f4 100644
--- a/examples/community/unclip_text_interpolation.py
+++ b/examples/community/unclip_text_interpolation.py
@@ -252,15 +252,15 @@ class UnCLIPTextInterpolationPipeline(DiffusionPipeline):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
prior_guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
decoder_guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
output_type (`str`, *optional*, defaults to `"pil"`):
diff --git a/examples/community/wildcard_stable_diffusion.py b/examples/community/wildcard_stable_diffusion.py
index 3c42c54f71..c750610ca3 100644
--- a/examples/community/wildcard_stable_diffusion.py
+++ b/examples/community/wildcard_stable_diffusion.py
@@ -190,9 +190,9 @@ class WildcardStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -201,7 +201,7 @@ class WildcardStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
@@ -288,7 +288,7 @@ class WildcardStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
text_embeddings = text_embeddings.view(bs_embed * num_images_per_prompt, seq_len, -1)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
@@ -364,7 +364,7 @@ class WildcardStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
diff --git a/examples/consistency_distillation/README.md b/examples/consistency_distillation/README.md
index f5cb72fa86..d5cf45444d 100644
--- a/examples/consistency_distillation/README.md
+++ b/examples/consistency_distillation/README.md
@@ -1,6 +1,6 @@
# Latent Consistency Distillation Example:
-[Latent Consistency Models (LCMs)](https://arxiv.org/abs/2310.04378) is a method to distill a latent diffusion model to enable swift inference with minimal steps. This example demonstrates how to use latent consistency distillation to distill stable-diffusion-v1.5 for inference with few timesteps.
+[Latent Consistency Models (LCMs)](https://huggingface.co/papers/2310.04378) is a method to distill a latent diffusion model to enable swift inference with minimal steps. This example demonstrates how to use latent consistency distillation to distill stable-diffusion-v1.5 for inference with few timesteps.
## Full model distillation
diff --git a/examples/consistency_distillation/README_sdxl.md b/examples/consistency_distillation/README_sdxl.md
index edb4bd57f2..ba6c61d9fa 100644
--- a/examples/consistency_distillation/README_sdxl.md
+++ b/examples/consistency_distillation/README_sdxl.md
@@ -1,6 +1,6 @@
# Latent Consistency Distillation Example:
-[Latent Consistency Models (LCMs)](https://arxiv.org/abs/2310.04378) is a method to distill a latent diffusion model to enable swift inference with minimal steps. This example demonstrates how to use latent consistency distillation to distill SDXL for inference with few timesteps.
+[Latent Consistency Models (LCMs)](https://huggingface.co/papers/2310.04378) is a method to distill a latent diffusion model to enable swift inference with minimal steps. This example demonstrates how to use latent consistency distillation to distill SDXL for inference with few timesteps.
## Full model distillation
diff --git a/examples/controlnet/README.md b/examples/controlnet/README.md
index 0555857b77..3b223c8c46 100644
--- a/examples/controlnet/README.md
+++ b/examples/controlnet/README.md
@@ -1,6 +1,6 @@
# ControlNet training example
-[Adding Conditional Control to Text-to-Image Diffusion Models](https://arxiv.org/abs/2302.05543) by Lvmin Zhang and Maneesh Agrawala.
+[Adding Conditional Control to Text-to-Image Diffusion Models](https://huggingface.co/papers/2302.05543) by Lvmin Zhang and Maneesh Agrawala.
This example is based on the [training example in the original ControlNet repository](https://github.com/lllyasviel/ControlNet/blob/main/docs/train.md). It trains a ControlNet to fill circles using a [small synthetic dataset](https://huggingface.co/datasets/fusing/fill50k).
@@ -437,7 +437,7 @@ You can then start your training from this saved checkpoint with
--controlnet_model_name_or_path="./control_out/500"
```
-We support training with the Min-SNR weighting strategy proposed in [Efficient Diffusion Training via Min-SNR Weighting Strategy](https://arxiv.org/abs/2303.09556) which helps to achieve faster convergence by rebalancing the loss. To use it, one needs to set the `--snr_gamma` argument. The recommended value when using it is `5.0`.
+We support training with the Min-SNR weighting strategy proposed in [Efficient Diffusion Training via Min-SNR Weighting Strategy](https://huggingface.co/papers/2303.09556) which helps to achieve faster convergence by rebalancing the loss. To use it, one needs to set the `--snr_gamma` argument. The recommended value when using it is `5.0`.
We also support gradient accumulation - it is a technique that lets you use a bigger batch size than your machine would normally be able to fit into memory. You can use `gradient_accumulation_steps` argument to set gradient accumulation steps. The ControlNet author recommends using gradient accumulation to achieve better convergence. Read more [here](https://github.com/lllyasviel/ControlNet/blob/main/docs/train.md#more-consideration-sudden-converge-phenomenon-and-gradient-accumulation).
diff --git a/examples/controlnet/README_sd3.md b/examples/controlnet/README_sd3.md
index c95f34e32f..b62e33362d 100644
--- a/examples/controlnet/README_sd3.md
+++ b/examples/controlnet/README_sd3.md
@@ -1,6 +1,6 @@
# ControlNet training example for Stable Diffusion 3/3.5 (SD3/3.5)
-The `train_controlnet_sd3.py` script shows how to implement the ControlNet training procedure and adapt it for [Stable Diffusion 3](https://arxiv.org/abs/2403.03206) and [Stable Diffusion 3.5](https://stability.ai/news/introducing-stable-diffusion-3-5).
+The `train_controlnet_sd3.py` script shows how to implement the ControlNet training procedure and adapt it for [Stable Diffusion 3](https://huggingface.co/papers/2403.03206) and [Stable Diffusion 3.5](https://stability.ai/news/introducing-stable-diffusion-3-5).
## Running locally with PyTorch
diff --git a/examples/controlnet/train_controlnet.py b/examples/controlnet/train_controlnet.py
index 2097fd398f..69bd39944a 100644
--- a/examples/controlnet/train_controlnet.py
+++ b/examples/controlnet/train_controlnet.py
@@ -178,11 +178,11 @@ def log_validation(
else:
logger.warning(f"image logging not implemented for {tracker.name}")
- del pipeline
- gc.collect()
- torch.cuda.empty_cache()
+ del pipeline
+ gc.collect()
+ torch.cuda.empty_cache()
- return image_logs
+ return image_logs
def import_model_class_from_model_name_or_path(pretrained_model_name_or_path: str, revision: str):
diff --git a/examples/controlnet/train_controlnet_flax.py b/examples/controlnet/train_controlnet_flax.py
index 477732c299..5561710d6f 100644
--- a/examples/controlnet/train_controlnet_flax.py
+++ b/examples/controlnet/train_controlnet_flax.py
@@ -305,7 +305,7 @@ def parse_args():
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
- "More details here: https://arxiv.org/abs/2303.09556.",
+ "More details here: https://huggingface.co/papers/2303.09556.",
)
parser.add_argument(
"--dataloader_num_workers",
diff --git a/examples/controlnet/train_controlnet_flux.py b/examples/controlnet/train_controlnet_flux.py
index 232d3da8e8..94f030fe01 100644
--- a/examples/controlnet/train_controlnet_flux.py
+++ b/examples/controlnet/train_controlnet_flux.py
@@ -192,9 +192,9 @@ def log_validation(
else:
logger.warning(f"image logging not implemented for {tracker.name}")
- del pipeline
- free_memory()
- return image_logs
+ del pipeline
+ free_memory()
+ return image_logs
def save_model_card(repo_id: str, image_logs=None, base_model=str, repo_folder=None):
diff --git a/examples/controlnet/train_controlnet_sd3.py b/examples/controlnet/train_controlnet_sd3.py
index d6efc7dabb..ecd7572ca3 100644
--- a/examples/controlnet/train_controlnet_sd3.py
+++ b/examples/controlnet/train_controlnet_sd3.py
@@ -199,13 +199,13 @@ def log_validation(controlnet, args, accelerator, weight_dtype, step, is_final_v
else:
logger.warning(f"image logging not implemented for {tracker.name}")
- del pipeline
- free_memory()
+ del pipeline
+ free_memory()
- if not is_final_validation:
- controlnet.to(accelerator.device)
+ if not is_final_validation:
+ controlnet.to(accelerator.device)
- return image_logs
+ return image_logs
# Copied from dreambooth sd3 example
@@ -1352,7 +1352,7 @@ def main(args):
return_dict=False,
)[0]
- # Follow: Section 5 of https://arxiv.org/abs/2206.00364.
+ # Follow: Section 5 of https://huggingface.co/papers/2206.00364.
# Preconditioning of the model outputs.
if args.precondition_outputs:
model_pred = model_pred * (-sigmas) + noisy_model_input
diff --git a/examples/controlnet/train_controlnet_sdxl.py b/examples/controlnet/train_controlnet_sdxl.py
index 3368db1ec0..76d232da1c 100644
--- a/examples/controlnet/train_controlnet_sdxl.py
+++ b/examples/controlnet/train_controlnet_sdxl.py
@@ -201,11 +201,11 @@ def log_validation(vae, unet, controlnet, args, accelerator, weight_dtype, step,
else:
logger.warning(f"image logging not implemented for {tracker.name}")
- del pipeline
- gc.collect()
- torch.cuda.empty_cache()
+ del pipeline
+ gc.collect()
+ torch.cuda.empty_cache()
- return image_logs
+ return image_logs
def import_model_class_from_model_name_or_path(
diff --git a/examples/custom_diffusion/README.md b/examples/custom_diffusion/README.md
index 9b0b52e5ae..8dcba85622 100644
--- a/examples/custom_diffusion/README.md
+++ b/examples/custom_diffusion/README.md
@@ -1,6 +1,6 @@
# Custom Diffusion training example
-[Custom Diffusion](https://arxiv.org/abs/2212.04488) is a method to customize text-to-image models like Stable Diffusion given just a few (4~5) images of a subject.
+[Custom Diffusion](https://huggingface.co/papers/2212.04488) is a method to customize text-to-image models like Stable Diffusion given just a few (4~5) images of a subject.
The `train_custom_diffusion.py` script shows how to implement the training procedure and adapt it for stable diffusion.
## Running locally with PyTorch
diff --git a/examples/dreambooth/README.md b/examples/dreambooth/README.md
index eed0575c32..f0697609b3 100644
--- a/examples/dreambooth/README.md
+++ b/examples/dreambooth/README.md
@@ -1,6 +1,6 @@
# DreamBooth training example
-[DreamBooth](https://arxiv.org/abs/2208.12242) is a method to personalize text2image models like stable diffusion given just a few(3~5) images of a subject.
+[DreamBooth](https://huggingface.co/papers/2208.12242) is a method to personalize text2image models like stable diffusion given just a few(3~5) images of a subject.
The `train_dreambooth.py` script shows how to implement the training procedure and adapt it for stable diffusion.
@@ -296,7 +296,7 @@ You can also perform inference from one of the checkpoints saved during the trai
## Training with Low-Rank Adaptation of Large Language Models (LoRA)
-Low-Rank Adaption of Large Language Models was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*
+Low-Rank Adaption of Large Language Models was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://huggingface.co/papers/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*
In a nutshell, LoRA allows to adapt pretrained models by adding pairs of rank-decomposition matrices to existing weights and **only** training those newly added weights. This has a couple of advantages:
- Previous pretrained weights are kept frozen so that the model is not prone to [catastrophic forgetting](https://www.pnas.org/doi/10.1073/pnas.1611835114)
diff --git a/examples/dreambooth/README_flux.md b/examples/dreambooth/README_flux.md
index 3a6f7905e6..aa43b00faf 100644
--- a/examples/dreambooth/README_flux.md
+++ b/examples/dreambooth/README_flux.md
@@ -1,6 +1,6 @@
# DreamBooth training example for FLUX.1 [dev]
-[DreamBooth](https://arxiv.org/abs/2208.12242) is a method to personalize text2image models like stable diffusion given just a few (3~5) images of a subject.
+[DreamBooth](https://huggingface.co/papers/2208.12242) is a method to personalize text2image models like stable diffusion given just a few (3~5) images of a subject.
The `train_dreambooth_flux.py` script shows how to implement the training procedure and adapt it for [FLUX.1 [dev]](https://blackforestlabs.ai/announcing-black-forest-labs/). We also provide a LoRA implementation in the `train_dreambooth_lora_flux.py` script.
> [!NOTE]
@@ -134,7 +134,7 @@ Note also that we use PEFT library as backend for LoRA training, make sure to ha
Prodigy is an adaptive optimizer that dynamically adjusts the learning rate learned parameters based on past gradients, allowing for more efficient convergence.
By using prodigy we can "eliminate" the need for manual learning rate tuning. read more [here](https://huggingface.co/blog/sdxl_lora_advanced_script#adaptive-optimizers).
-to use prodigy, specify
+to use prodigy, first make sure to install the prodigyopt library: `pip install prodigyopt`, and then specify -
```bash
--optimizer="prodigy"
```
diff --git a/examples/dreambooth/README_hidream.md b/examples/dreambooth/README_hidream.md
index 6e4fd2510f..2c6b68f3f6 100644
--- a/examples/dreambooth/README_hidream.md
+++ b/examples/dreambooth/README_hidream.md
@@ -1,6 +1,6 @@
# DreamBooth training example for HiDream Image
-[DreamBooth](https://arxiv.org/abs/2208.12242) is a method to personalize text2image models like stable diffusion given just a few (3~5) images of a subject.
+[DreamBooth](https://huggingface.co/papers/2208.12242) is a method to personalize text2image models like stable diffusion given just a few (3~5) images of a subject.
The `train_dreambooth_lora_hidream.py` script shows how to implement the training procedure with [LoRA](https://huggingface.co/docs/peft/conceptual_guides/adapter#low-rank-adaptation-lora) and adapt it for [HiDream Image](https://huggingface.co/docs/diffusers/main/en/api/pipelines/).
diff --git a/examples/dreambooth/README_lumina2.md b/examples/dreambooth/README_lumina2.md
index fe2907092c..f691acd266 100644
--- a/examples/dreambooth/README_lumina2.md
+++ b/examples/dreambooth/README_lumina2.md
@@ -1,6 +1,6 @@
# DreamBooth training example for Lumina2
-[DreamBooth](https://arxiv.org/abs/2208.12242) is a method to personalize text2image models like stable diffusion given just a few (3~5) images of a subject.
+[DreamBooth](https://huggingface.co/papers/2208.12242) is a method to personalize text2image models like stable diffusion given just a few (3~5) images of a subject.
The `train_dreambooth_lora_lumina2.py` script shows how to implement the training procedure with [LoRA](https://huggingface.co/docs/peft/conceptual_guides/adapter#low-rank-adaptation-lora) and adapt it for [Lumina2](https://huggingface.co/docs/diffusers/main/en/api/pipelines/lumina2).
diff --git a/examples/dreambooth/README_sana.md b/examples/dreambooth/README_sana.md
index 6136bfcc16..1cc189149b 100644
--- a/examples/dreambooth/README_sana.md
+++ b/examples/dreambooth/README_sana.md
@@ -1,8 +1,8 @@
# DreamBooth training example for SANA
-[DreamBooth](https://arxiv.org/abs/2208.12242) is a method to personalize text2image models like stable diffusion given just a few (3~5) images of a subject.
+[DreamBooth](https://huggingface.co/papers/2208.12242) is a method to personalize text2image models like stable diffusion given just a few (3~5) images of a subject.
-The `train_dreambooth_lora_sana.py` script shows how to implement the training procedure with [LoRA](https://huggingface.co/docs/peft/conceptual_guides/adapter#low-rank-adaptation-lora) and adapt it for [SANA](https://arxiv.org/abs/2410.10629).
+The `train_dreambooth_lora_sana.py` script shows how to implement the training procedure with [LoRA](https://huggingface.co/docs/peft/conceptual_guides/adapter#low-rank-adaptation-lora) and adapt it for [SANA](https://huggingface.co/papers/2410.10629).
This will also allow us to push the trained model parameters to the Hugging Face Hub platform.
diff --git a/examples/dreambooth/README_sd3.md b/examples/dreambooth/README_sd3.md
index 2ac7bf7101..5b706930e9 100644
--- a/examples/dreambooth/README_sd3.md
+++ b/examples/dreambooth/README_sd3.md
@@ -1,6 +1,6 @@
# DreamBooth training example for Stable Diffusion 3 (SD3)
-[DreamBooth](https://arxiv.org/abs/2208.12242) is a method to personalize text2image models like stable diffusion given just a few (3~5) images of a subject.
+[DreamBooth](https://huggingface.co/papers/2208.12242) is a method to personalize text2image models like stable diffusion given just a few (3~5) images of a subject.
The `train_dreambooth_sd3.py` script shows how to implement the training procedure and adapt it for [Stable Diffusion 3](https://huggingface.co/papers/2403.03206). We also provide a LoRA implementation in the `train_dreambooth_lora_sd3.py` script.
diff --git a/examples/dreambooth/README_sdxl.md b/examples/dreambooth/README_sdxl.md
index 565ff9a5dd..c033d1e641 100644
--- a/examples/dreambooth/README_sdxl.md
+++ b/examples/dreambooth/README_sdxl.md
@@ -1,10 +1,10 @@
# DreamBooth training example for Stable Diffusion XL (SDXL)
-[DreamBooth](https://arxiv.org/abs/2208.12242) is a method to personalize text2image models like stable diffusion given just a few (3~5) images of a subject.
+[DreamBooth](https://huggingface.co/papers/2208.12242) is a method to personalize text2image models like stable diffusion given just a few (3~5) images of a subject.
The `train_dreambooth_lora_sdxl.py` script shows how to implement the training procedure and adapt it for [Stable Diffusion XL](https://huggingface.co/papers/2307.01952).
-> 💡 **Note**: For now, we only allow DreamBooth fine-tuning of the SDXL UNet via LoRA. LoRA is a parameter-efficient fine-tuning technique introduced in [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*.
+> 💡 **Note**: For now, we only allow DreamBooth fine-tuning of the SDXL UNet via LoRA. LoRA is a parameter-efficient fine-tuning technique introduced in [LoRA: Low-Rank Adaptation of Large Language Models](https://huggingface.co/papers/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*.
## Running locally with PyTorch
@@ -209,7 +209,7 @@ Check out [this notebook](https://colab.research.google.com/github/huggingface/n
## Conducting EDM-style training
-It's now possible to perform EDM-style training as proposed in [Elucidating the Design Space of Diffusion-Based Generative Models](https://arxiv.org/abs/2206.00364).
+It's now possible to perform EDM-style training as proposed in [Elucidating the Design Space of Diffusion-Based Generative Models](https://huggingface.co/papers/2206.00364).
For the SDXL model, simple set:
@@ -246,7 +246,7 @@ accelerate launch train_dreambooth_lora_sdxl.py \
### DoRA training
The script now supports DoRA training too!
-> Proposed in [DoRA: Weight-Decomposed Low-Rank Adaptation](https://arxiv.org/abs/2402.09353),
+> Proposed in [DoRA: Weight-Decomposed Low-Rank Adaptation](https://huggingface.co/papers/2402.09353),
**DoRA** is very similar to LoRA, except it decomposes the pre-trained weight into two components, **magnitude** and **direction** and employs LoRA for _directional_ updates to efficiently minimize the number of trainable parameters.
The authors found that by using DoRA, both the learning capacity and training stability of LoRA are enhanced without any additional overhead during inference.
diff --git a/examples/dreambooth/train_dreambooth.py b/examples/dreambooth/train_dreambooth.py
index aa5c069d29..ec0cc686b0 100644
--- a/examples/dreambooth/train_dreambooth.py
+++ b/examples/dreambooth/train_dreambooth.py
@@ -536,7 +536,7 @@ def parse_args(input_args=None):
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
- "More details here: https://arxiv.org/abs/2303.09556.",
+ "More details here: https://huggingface.co/papers/2303.09556.",
)
parser.add_argument(
"--pre_compute_text_embeddings",
@@ -1114,17 +1114,22 @@ def main(args):
)
# Scheduler and math around the number of training steps.
- overrode_max_train_steps = False
- num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ # Check the PR https://github.com/huggingface/diffusers/pull/8312 for detailed explanation.
+ num_warmup_steps_for_scheduler = args.lr_warmup_steps * accelerator.num_processes
if args.max_train_steps is None:
- args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
- overrode_max_train_steps = True
+ len_train_dataloader_after_sharding = math.ceil(len(train_dataloader) / accelerator.num_processes)
+ num_update_steps_per_epoch = math.ceil(len_train_dataloader_after_sharding / args.gradient_accumulation_steps)
+ num_training_steps_for_scheduler = (
+ args.num_train_epochs * accelerator.num_processes * num_update_steps_per_epoch
+ )
+ else:
+ num_training_steps_for_scheduler = args.max_train_steps * accelerator.num_processes
lr_scheduler = get_scheduler(
args.lr_scheduler,
optimizer=optimizer,
- num_warmup_steps=args.lr_warmup_steps * accelerator.num_processes,
- num_training_steps=args.max_train_steps * accelerator.num_processes,
+ num_warmup_steps=num_warmup_steps_for_scheduler,
+ num_training_steps=num_training_steps_for_scheduler,
num_cycles=args.lr_num_cycles,
power=args.lr_power,
)
@@ -1156,8 +1161,14 @@ def main(args):
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
- if overrode_max_train_steps:
+ if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ if num_training_steps_for_scheduler != args.max_train_steps:
+ logger.warning(
+ f"The length of the 'train_dataloader' after 'accelerator.prepare' ({len(train_dataloader)}) does not match "
+ f"the expected length ({len_train_dataloader_after_sharding}) when the learning rate scheduler was created. "
+ f"This inconsistency may result in the learning rate scheduler not functioning properly."
+ )
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
@@ -1296,7 +1307,7 @@ def main(args):
if args.snr_gamma is None:
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
else:
- # Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
+ # Compute loss-weights as per Section 3.4 of https://huggingface.co/papers/2303.09556.
# Since we predict the noise instead of x_0, the original formulation is slightly changed.
# This is discussed in Section 4.2 of the same paper.
snr = compute_snr(noise_scheduler, timesteps)
diff --git a/examples/dreambooth/train_dreambooth_lora_sd3.py b/examples/dreambooth/train_dreambooth_lora_sd3.py
index d00d2fafe8..05dfe6301f 100644
--- a/examples/dreambooth/train_dreambooth_lora_sd3.py
+++ b/examples/dreambooth/train_dreambooth_lora_sd3.py
@@ -1795,7 +1795,7 @@ def main(args):
return_dict=False,
)[0]
- # Follow: Section 5 of https://arxiv.org/abs/2206.00364.
+ # Follow: Section 5 of https://huggingface.co/papers/2206.00364.
# Preconditioning of the model outputs.
if args.precondition_outputs:
model_pred = model_pred * (-sigmas) + noisy_model_input
diff --git a/examples/dreambooth/train_dreambooth_lora_sdxl.py b/examples/dreambooth/train_dreambooth_lora_sdxl.py
index 364c0da8d5..c3dfc923f0 100644
--- a/examples/dreambooth/train_dreambooth_lora_sdxl.py
+++ b/examples/dreambooth/train_dreambooth_lora_sdxl.py
@@ -379,7 +379,7 @@ def parse_args(input_args=None):
"--do_edm_style_training",
default=False,
action="store_true",
- help="Flag to conduct training using the EDM formulation as introduced in https://arxiv.org/abs/2206.00364.",
+ help="Flag to conduct training using the EDM formulation as introduced in https://huggingface.co/papers/2206.00364.",
)
parser.add_argument(
"--with_prior_preservation",
@@ -520,7 +520,7 @@ def parse_args(input_args=None):
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
- "More details here: https://arxiv.org/abs/2303.09556.",
+ "More details here: https://huggingface.co/papers/2303.09556.",
)
parser.add_argument(
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
@@ -667,7 +667,7 @@ def parse_args(input_args=None):
action="store_true",
default=False,
help=(
- "Whether to train a DoRA as proposed in- DoRA: Weight-Decomposed Low-Rank Adaptation https://arxiv.org/abs/2402.09353. "
+ "Whether to train a DoRA as proposed in- DoRA: Weight-Decomposed Low-Rank Adaptation https://huggingface.co/papers/2402.09353. "
"Note: to use DoRA you need to install peft from main, `pip install git+https://github.com/huggingface/peft.git`"
),
)
@@ -1713,7 +1713,7 @@ def main(args):
noisy_model_input = noise_scheduler.add_noise(model_input, noise, timesteps)
# For EDM-style training, we first obtain the sigmas based on the continuous timesteps.
# We then precondition the final model inputs based on these sigmas instead of the timesteps.
- # Follow: Section 5 of https://arxiv.org/abs/2206.00364.
+ # Follow: Section 5 of https://huggingface.co/papers/2206.00364.
if args.do_edm_style_training:
sigmas = get_sigmas(timesteps, len(noisy_model_input.shape), noisy_model_input.dtype)
if "EDM" in scheduler_type:
@@ -1773,7 +1773,7 @@ def main(args):
if args.do_edm_style_training:
# Similar to the input preconditioning, the model predictions are also preconditioned
# on noised model inputs (before preconditioning) and the sigmas.
- # Follow: Section 5 of https://arxiv.org/abs/2206.00364.
+ # Follow: Section 5 of https://huggingface.co/papers/2206.00364.
if "EDM" in scheduler_type:
model_pred = noise_scheduler.precondition_outputs(noisy_model_input, model_pred, sigmas)
else:
@@ -1831,7 +1831,7 @@ def main(args):
else:
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
else:
- # Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
+ # Compute loss-weights as per Section 3.4 of https://huggingface.co/papers/2303.09556.
# Since we predict the noise instead of x_0, the original formulation is slightly changed.
# This is discussed in Section 4.2 of the same paper.
snr = compute_snr(noise_scheduler, timesteps)
diff --git a/examples/dreambooth/train_dreambooth_sd3.py b/examples/dreambooth/train_dreambooth_sd3.py
index 656eee031a..8d5dee0188 100644
--- a/examples/dreambooth/train_dreambooth_sd3.py
+++ b/examples/dreambooth/train_dreambooth_sd3.py
@@ -1615,7 +1615,7 @@ def main(args):
return_dict=False,
)[0]
- # Follow: Section 5 of https://arxiv.org/abs/2206.00364.
+ # Follow: Section 5 of https://huggingface.co/papers/2206.00364.
# Preconditioning of the model outputs.
if args.precondition_outputs:
model_pred = model_pred * (-sigmas) + noisy_model_input
diff --git a/examples/instruct_pix2pix/README.md b/examples/instruct_pix2pix/README.md
index a5e91a5356..9df6b46ee9 100644
--- a/examples/instruct_pix2pix/README.md
+++ b/examples/instruct_pix2pix/README.md
@@ -1,6 +1,6 @@
# InstructPix2Pix training example
-[InstructPix2Pix](https://arxiv.org/abs/2211.09800) is a method to fine-tune text-conditioned diffusion models such that they can follow an edit instruction for an input image. Models fine-tuned using this method take the following as inputs:
+[InstructPix2Pix](https://huggingface.co/papers/2211.09800) is a method to fine-tune text-conditioned diffusion models such that they can follow an edit instruction for an input image. Models fine-tuned using this method take the following as inputs:
-**Stable Diffusion XL Attentive Eraser Pipeline** is an advanced object removal pipeline that leverages SDXL for precise content suppression and seamless region completion. This pipeline uses **self-attention redirection guidance** to modify the model’s self-attention mechanism, allowing for effective removal and inpainting across various levels of mask precision, including semantic segmentation masks, bounding boxes, and hand-drawn masks. If you are interested in more detailed information and have any questions, please refer to the [paper](https://arxiv.org/abs/2412.12974) and [official implementation](https://github.com/Anonym0u3/AttentiveEraser).
+**Stable Diffusion XL Attentive Eraser Pipeline** is an advanced object removal pipeline that leverages SDXL for precise content suppression and seamless region completion. This pipeline uses **self-attention redirection guidance** to modify the model’s self-attention mechanism, allowing for effective removal and inpainting across various levels of mask precision, including semantic segmentation masks, bounding boxes, and hand-drawn masks. If you are interested in more detailed information and have any questions, please refer to the [paper](https://huggingface.co/papers/2412.12974) and [official implementation](https://github.com/Anonym0u3/AttentiveEraser).
#### Key features
@@ -5133,7 +5133,7 @@ print("Object removal completed")
# Perturbed-Attention Guidance
-[Project](https://ku-cvlab.github.io/Perturbed-Attention-Guidance/) / [arXiv](https://arxiv.org/abs/2403.17377) / [GitHub](https://github.com/KU-CVLAB/Perturbed-Attention-Guidance)
+[Project](https://ku-cvlab.github.io/Perturbed-Attention-Guidance/) / [arXiv](https://huggingface.co/papers/2403.17377) / [GitHub](https://github.com/KU-CVLAB/Perturbed-Attention-Guidance)
This implementation is based on [Diffusers](https://huggingface.co/docs/diffusers/index). `StableDiffusionPAGPipeline` is a modification of `StableDiffusionPipeline` to support Perturbed-Attention Guidance (PAG).
diff --git a/examples/community/adaptive_mask_inpainting.py b/examples/community/adaptive_mask_inpainting.py
index 81f9527b47..aac460cb46 100644
--- a/examples/community/adaptive_mask_inpainting.py
+++ b/examples/community/adaptive_mask_inpainting.py
@@ -670,7 +670,7 @@ class AdaptiveMaskInpaintPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -917,7 +917,7 @@ class AdaptiveMaskInpaintPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
@@ -1012,7 +1012,7 @@ class AdaptiveMaskInpaintPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/bit_diffusion.py b/examples/community/bit_diffusion.py
index 71d8f31163..67f4cd3fe1 100644
--- a/examples/community/bit_diffusion.py
+++ b/examples/community/bit_diffusion.py
@@ -74,7 +74,7 @@ def ddim_bit_scheduler_step(
"Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
)
- # See formulas (12) and (16) of DDIM paper https://arxiv.org/pdf/2010.02502.pdf
+ # See formulas (12) and (16) of DDIM paper https://huggingface.co/papers/2010.02502
# Ideally, read DDIM paper in-detail understanding
# Notation ( ->
@@ -95,7 +95,7 @@ def ddim_bit_scheduler_step(
beta_prod_t = 1 - alpha_prod_t
# 3. compute predicted original sample from predicted noise also called
- # "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # "predicted x_0" of formula (12) from https://huggingface.co/papers/2010.02502
pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
# 4. Clip "predicted x_0"
@@ -112,10 +112,10 @@ def ddim_bit_scheduler_step(
# the model_output is always re-derived from the clipped x_0 in Glide
model_output = (sample - alpha_prod_t ** (0.5) * pred_original_sample) / beta_prod_t ** (0.5)
- # 6. compute "direction pointing to x_t" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # 6. compute "direction pointing to x_t" of formula (12) from https://huggingface.co/papers/2010.02502
pred_sample_direction = (1 - alpha_prod_t_prev - std_dev_t**2) ** (0.5) * model_output
- # 7. compute x_t without "random noise" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # 7. compute x_t without "random noise" of formula (12) from https://huggingface.co/papers/2010.02502
prev_sample = alpha_prod_t_prev ** (0.5) * pred_original_sample + pred_sample_direction
if eta > 0:
@@ -172,7 +172,7 @@ def ddpm_bit_scheduler_step(
beta_prod_t_prev = 1 - alpha_prod_t_prev
# 2. compute predicted original sample from predicted noise also called
- # "predicted x_0" of formula (15) from https://arxiv.org/pdf/2006.11239.pdf
+ # "predicted x_0" of formula (15) from https://huggingface.co/papers/2006.11239
if prediction_type == "epsilon":
pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
elif prediction_type == "sample":
@@ -186,12 +186,12 @@ def ddpm_bit_scheduler_step(
pred_original_sample = torch.clamp(pred_original_sample, -scale, scale)
# 4. Compute coefficients for pred_original_sample x_0 and current sample x_t
- # See formula (7) from https://arxiv.org/pdf/2006.11239.pdf
+ # See formula (7) from https://huggingface.co/papers/2006.11239
pred_original_sample_coeff = (alpha_prod_t_prev ** (0.5) * self.betas[t]) / beta_prod_t
current_sample_coeff = self.alphas[t] ** (0.5) * beta_prod_t_prev / beta_prod_t
# 5. Compute predicted previous sample µ_t
- # See formula (7) from https://arxiv.org/pdf/2006.11239.pdf
+ # See formula (7) from https://huggingface.co/papers/2006.11239
pred_prev_sample = pred_original_sample_coeff * pred_original_sample + current_sample_coeff * sample
# 6. Add noise
diff --git a/examples/community/clip_guided_images_mixing_stable_diffusion.py b/examples/community/clip_guided_images_mixing_stable_diffusion.py
index f9a4b12ad2..2cd3daf68c 100644
--- a/examples/community/clip_guided_images_mixing_stable_diffusion.py
+++ b/examples/community/clip_guided_images_mixing_stable_diffusion.py
@@ -197,7 +197,7 @@ class CLIPGuidedImagesMixingStableDiffusion(DiffusionPipeline, StableDiffusionMi
alpha_prod_t = self.scheduler.alphas_cumprod[timestep]
beta_prod_t = 1 - alpha_prod_t
# compute predicted original sample from predicted noise also called
- # "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # "predicted x_0" of formula (12) from https://huggingface.co/papers/2010.02502
pred_original_sample = (latents - beta_prod_t ** (0.5) * noise_pred) / alpha_prod_t ** (0.5)
fac = torch.sqrt(beta_prod_t)
@@ -343,7 +343,7 @@ class CLIPGuidedImagesMixingStableDiffusion(DiffusionPipeline, StableDiffusionMi
)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
@@ -384,7 +384,7 @@ class CLIPGuidedImagesMixingStableDiffusion(DiffusionPipeline, StableDiffusionMi
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
diff --git a/examples/community/clip_guided_stable_diffusion.py b/examples/community/clip_guided_stable_diffusion.py
index 1350650113..bfd0858d24 100644
--- a/examples/community/clip_guided_stable_diffusion.py
+++ b/examples/community/clip_guided_stable_diffusion.py
@@ -125,7 +125,7 @@ class CLIPGuidedStableDiffusion(DiffusionPipeline, StableDiffusionMixin):
alpha_prod_t = self.scheduler.alphas_cumprod[timestep]
beta_prod_t = 1 - alpha_prod_t
# compute predicted original sample from predicted noise also called
- # "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # "predicted x_0" of formula (12) from https://huggingface.co/papers/2010.02502
pred_original_sample = (latents - beta_prod_t ** (0.5) * noise_pred) / alpha_prod_t ** (0.5)
fac = torch.sqrt(beta_prod_t)
@@ -223,7 +223,7 @@ class CLIPGuidedStableDiffusion(DiffusionPipeline, StableDiffusionMixin):
text_embeddings_clip = text_embeddings_clip.repeat_interleave(num_images_per_prompt, dim=0)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
@@ -276,7 +276,7 @@ class CLIPGuidedStableDiffusion(DiffusionPipeline, StableDiffusionMixin):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
diff --git a/examples/community/clip_guided_stable_diffusion_img2img.py b/examples/community/clip_guided_stable_diffusion_img2img.py
index 91c74b9ffa..f3dd4903f8 100644
--- a/examples/community/clip_guided_stable_diffusion_img2img.py
+++ b/examples/community/clip_guided_stable_diffusion_img2img.py
@@ -260,7 +260,7 @@ class CLIPGuidedStableDiffusion(DiffusionPipeline, StableDiffusionMixin):
alpha_prod_t = self.scheduler.alphas_cumprod[timestep]
beta_prod_t = 1 - alpha_prod_t
# compute predicted original sample from predicted noise also called
- # "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # "predicted x_0" of formula (12) from https://huggingface.co/papers/2010.02502
pred_original_sample = (latents - beta_prod_t ** (0.5) * noise_pred) / alpha_prod_t ** (0.5)
fac = torch.sqrt(beta_prod_t)
@@ -387,7 +387,7 @@ class CLIPGuidedStableDiffusion(DiffusionPipeline, StableDiffusionMixin):
text_embeddings_clip = text_embeddings_clip.repeat_interleave(num_images_per_prompt, dim=0)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
@@ -428,7 +428,7 @@ class CLIPGuidedStableDiffusion(DiffusionPipeline, StableDiffusionMixin):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
diff --git a/examples/community/cogvideox_ddim_inversion.py b/examples/community/cogvideox_ddim_inversion.py
index e9d1746d2d..36d95901c6 100644
--- a/examples/community/cogvideox_ddim_inversion.py
+++ b/examples/community/cogvideox_ddim_inversion.py
@@ -462,7 +462,7 @@ class CogVideoXPipelineForDDIMInversion(CogVideoXPipeline):
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/composable_stable_diffusion.py b/examples/community/composable_stable_diffusion.py
index 024818daf1..14a4c7e1d0 100644
--- a/examples/community/composable_stable_diffusion.py
+++ b/examples/community/composable_stable_diffusion.py
@@ -295,7 +295,7 @@ class ComposableStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin)
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -379,9 +379,9 @@ class ComposableStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin)
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -390,7 +390,7 @@ class ComposableStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin)
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
@@ -430,7 +430,7 @@ class ComposableStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin)
batch_size = 1 if isinstance(prompt, str) else len(prompt)
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/fresco_v2v.py b/examples/community/fresco_v2v.py
index 052130cd93..fe7cdae7bd 100644
--- a/examples/community/fresco_v2v.py
+++ b/examples/community/fresco_v2v.py
@@ -124,7 +124,7 @@ def flow_warp(feature, flow, mask=False, mode="bilinear", padding_mode="zeros"):
def forward_backward_consistency_check(fwd_flow, bwd_flow, alpha=0.01, beta=0.5):
# fwd_flow, bwd_flow: [B, 2, H, W]
# alpha and beta values are following UnFlow
- # (https://arxiv.org/abs/1711.07837)
+ # (https://huggingface.co/papers/1711.07837)
assert fwd_flow.dim() == 4 and bwd_flow.dim() == 4
assert fwd_flow.size(1) == 2 and bwd_flow.size(1) == 2
flow_mag = torch.norm(fwd_flow, dim=1) + torch.norm(bwd_flow, dim=1) # [B, H, W]
@@ -1703,7 +1703,7 @@ class FrescoV2VPipeline(StableDiffusionControlNetImg2ImgPipeline):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -2030,7 +2030,7 @@ class FrescoV2VPipeline(StableDiffusionControlNetImg2ImgPipeline):
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -2109,7 +2109,7 @@ class FrescoV2VPipeline(StableDiffusionControlNetImg2ImgPipeline):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
diff --git a/examples/community/gluegen.py b/examples/community/gluegen.py
index 54cc562d55..86813b63ec 100644
--- a/examples/community/gluegen.py
+++ b/examples/community/gluegen.py
@@ -139,7 +139,7 @@ class TranslatorNoLN(nn.Module):
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -447,7 +447,7 @@ class GlueGenStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin, St
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -563,7 +563,7 @@ class GlueGenStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin, St
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -630,7 +630,7 @@ class GlueGenStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin, St
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
@@ -656,7 +656,7 @@ class GlueGenStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin, St
[`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf). Guidance rescale factor should fix overexposure when
+ Flawed](https://huggingface.co/papers/2305.08891). Guidance rescale factor should fix overexposure when
using zero terminal SNR.
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
@@ -781,7 +781,7 @@ class GlueGenStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin, St
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/examples/community/iadb.py b/examples/community/iadb.py
index 81e9e8d89d..6262c3cb15 100644
--- a/examples/community/iadb.py
+++ b/examples/community/iadb.py
@@ -12,7 +12,7 @@ class IADBScheduler(SchedulerMixin, ConfigMixin):
"""
IADBScheduler is a scheduler for the Iterative α-(de)Blending denoising method. It is simple and minimalist.
- For more details, see the original paper: https://arxiv.org/abs/2305.03486 and the blog post: https://ggx-research.github.io/publication/2023/05/10/publication-iadb.html
+ For more details, see the original paper: https://huggingface.co/papers/2305.03486 and the blog post: https://ggx-research.github.io/publication/2023/05/10/publication-iadb.html
"""
def step(
diff --git a/examples/community/imagic_stable_diffusion.py b/examples/community/imagic_stable_diffusion.py
index cea55dd383..a2561c9198 100644
--- a/examples/community/imagic_stable_diffusion.py
+++ b/examples/community/imagic_stable_diffusion.py
@@ -61,7 +61,7 @@ def preprocess(image):
class ImagicStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
r"""
Pipeline for imagic image editing.
- See paper here: https://arxiv.org/pdf/2210.09276.pdf
+ See paper here: https://huggingface.co/papers/2210.09276
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
@@ -133,13 +133,13 @@ class ImagicStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
@@ -334,9 +334,9 @@ class ImagicStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
generator (`torch.Generator`, *optional*):
@@ -349,7 +349,7 @@ class ImagicStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
@@ -368,7 +368,7 @@ class ImagicStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
text_embeddings = alpha * self.text_embeddings_orig + (1 - alpha) * self.text_embeddings
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
@@ -420,7 +420,7 @@ class ImagicStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
diff --git a/examples/community/img2img_inpainting.py b/examples/community/img2img_inpainting.py
index c6de027897..7b9bd043d0 100644
--- a/examples/community/img2img_inpainting.py
+++ b/examples/community/img2img_inpainting.py
@@ -178,9 +178,9 @@ class ImageToImageInpaintingPipeline(DiffusionPipeline):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -189,7 +189,7 @@ class ImageToImageInpaintingPipeline(DiffusionPipeline):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
@@ -266,7 +266,7 @@ class ImageToImageInpaintingPipeline(DiffusionPipeline):
text_embeddings = text_embeddings.view(bs_embed * num_images_per_prompt, seq_len, -1)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
@@ -378,7 +378,7 @@ class ImageToImageInpaintingPipeline(DiffusionPipeline):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
diff --git a/examples/community/instaflow_one_step.py b/examples/community/instaflow_one_step.py
index e726b42756..59687e979c 100644
--- a/examples/community/instaflow_one_step.py
+++ b/examples/community/instaflow_one_step.py
@@ -41,7 +41,7 @@ logger = logging.get_logger(__name__) # pylint: disable=invalid-name
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -414,7 +414,7 @@ class InstaFlowPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -541,7 +541,7 @@ class InstaFlowPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
@@ -572,7 +572,7 @@ class InstaFlowPipeline(
[`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.7):
Guidance rescale factor from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf). Guidance rescale factor should fix overexposure when
+ Flawed](https://huggingface.co/papers/2305.08891). Guidance rescale factor should fix overexposure when
using zero terminal SNR.
Examples:
@@ -603,7 +603,7 @@ class InstaFlowPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/interpolate_stable_diffusion.py b/examples/community/interpolate_stable_diffusion.py
index 99614635ee..460bb464f3 100644
--- a/examples/community/interpolate_stable_diffusion.py
+++ b/examples/community/interpolate_stable_diffusion.py
@@ -154,9 +154,9 @@ class StableDiffusionWalkPipeline(DiffusionPipeline, StableDiffusionMixin):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -165,7 +165,7 @@ class StableDiffusionWalkPipeline(DiffusionPipeline, StableDiffusionMixin):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
@@ -244,7 +244,7 @@ class StableDiffusionWalkPipeline(DiffusionPipeline, StableDiffusionMixin):
text_embeddings = text_embeddings.view(bs_embed * num_images_per_prompt, seq_len, -1)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
@@ -320,7 +320,7 @@ class StableDiffusionWalkPipeline(DiffusionPipeline, StableDiffusionMixin):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
@@ -432,16 +432,16 @@ class StableDiffusionWalkPipeline(DiffusionPipeline, StableDiffusionMixin):
width (`int`, *optional*, defaults to 512):
Width of the generated images.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
Returns:
diff --git a/examples/community/ip_adapter_face_id.py b/examples/community/ip_adapter_face_id.py
index 648bf29331..203be1d4c8 100644
--- a/examples/community/ip_adapter_face_id.py
+++ b/examples/community/ip_adapter_face_id.py
@@ -76,7 +76,7 @@ class IPAdapterFullImageProjection(nn.Module):
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -693,7 +693,7 @@ class IPAdapterFaceIDStableDiffusionPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -823,7 +823,7 @@ class IPAdapterFaceIDStableDiffusionPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -893,7 +893,7 @@ class IPAdapterFaceIDStableDiffusionPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
@@ -920,7 +920,7 @@ class IPAdapterFaceIDStableDiffusionPipeline(
[`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf). Guidance rescale factor should fix overexposure when
+ Flawed](https://huggingface.co/papers/2305.08891). Guidance rescale factor should fix overexposure when
using zero terminal SNR.
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
@@ -1084,7 +1084,7 @@ class IPAdapterFaceIDStableDiffusionPipeline(
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/examples/community/latent_consistency_img2img.py b/examples/community/latent_consistency_img2img.py
index 01abf861b8..ae98ff0d1e 100644
--- a/examples/community/latent_consistency_img2img.py
+++ b/examples/community/latent_consistency_img2img.py
@@ -450,7 +450,7 @@ def betas_for_alpha_bar(
def rescale_zero_terminal_snr(betas):
"""
- Rescales betas to have zero terminal SNR Based on https://arxiv.org/pdf/2305.08891.pdf (Algorithm 1)
+ Rescales betas to have zero terminal SNR Based on https://huggingface.co/papers/2305.08891 (Algorithm 1)
Args:
betas (`torch.Tensor`):
the betas that the scheduler is being initialized with.
@@ -620,7 +620,7 @@ class LCMSchedulerWithTimestamp(SchedulerMixin, ConfigMixin):
s. Dynamic thresholding pushes saturated pixels (those near -1 and 1) inwards, thereby actively preventing
pixels from saturation at each step. We find that dynamic thresholding results in significantly better
photorealism as well as better image-text alignment, especially when using very large guidance weights."
- https://arxiv.org/abs/2205.11487
+ https://huggingface.co/papers/2205.11487
"""
dtype = sample.dtype
batch_size, channels, height, width = sample.shape
diff --git a/examples/community/latent_consistency_interpolate.py b/examples/community/latent_consistency_interpolate.py
index 34cdb0fec7..9fc4233682 100644
--- a/examples/community/latent_consistency_interpolate.py
+++ b/examples/community/latent_consistency_interpolate.py
@@ -529,7 +529,7 @@ class LatentConsistencyModelWalkPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
diff --git a/examples/community/latent_consistency_txt2img.py b/examples/community/latent_consistency_txt2img.py
index 7b60f5bb87..83515b6bae 100755
--- a/examples/community/latent_consistency_txt2img.py
+++ b/examples/community/latent_consistency_txt2img.py
@@ -365,7 +365,7 @@ def betas_for_alpha_bar(
def rescale_zero_terminal_snr(betas):
"""
- Rescales betas to have zero terminal SNR Based on https://arxiv.org/pdf/2305.08891.pdf (Algorithm 1)
+ Rescales betas to have zero terminal SNR Based on https://huggingface.co/papers/2305.08891 (Algorithm 1)
Args:
betas (`torch.Tensor`):
the betas that the scheduler is being initialized with.
@@ -532,7 +532,7 @@ class LCMScheduler(SchedulerMixin, ConfigMixin):
s. Dynamic thresholding pushes saturated pixels (those near -1 and 1) inwards, thereby actively preventing
pixels from saturation at each step. We find that dynamic thresholding results in significantly better
photorealism as well as better image-text alignment, especially when using very large guidance weights."
- https://arxiv.org/abs/2205.11487
+ https://huggingface.co/papers/2205.11487
"""
dtype = sample.dtype
batch_size, channels, height, width = sample.shape
diff --git a/examples/community/llm_grounded_diffusion.py b/examples/community/llm_grounded_diffusion.py
index 814694f1e3..72b99983f2 100644
--- a/examples/community/llm_grounded_diffusion.py
+++ b/examples/community/llm_grounded_diffusion.py
@@ -281,7 +281,7 @@ class LLMGroundedDiffusionPipeline(
FromSingleFileMixin,
):
r"""
- Pipeline for layout-grounded text-to-image generation using LLM-grounded Diffusion (LMD+): https://arxiv.org/pdf/2305.13655.pdf.
+ Pipeline for layout-grounded text-to-image generation using LLM-grounded Diffusion (LMD+): https://huggingface.co/papers/2305.13655.
This model inherits from [`StableDiffusionPipeline`] and aims at implementing the pipeline with minimal modifications. Check the superclass documentation for the generic methods
implemented for all pipelines (downloading, saving, running on a particular device, etc.).
@@ -803,7 +803,7 @@ class LLMGroundedDiffusionPipeline(
`List[float]` of 4 elements `[xmin, ymin, xmax, ymax]` where each value is between [0,1].
gligen_scheduled_sampling_beta (`float`, defaults to 0.3):
Scheduled Sampling factor from [GLIGEN: Open-Set Grounded Text-to-Image
- Generation](https://arxiv.org/pdf/2301.07093.pdf). Scheduled Sampling factor is only varied for
+ Generation](https://huggingface.co/papers/2301.07093). Scheduled Sampling factor is only varied for
scheduled sampling during inference for improved quality and controllability.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide what to not include in image generation. If not defined, you need to
@@ -811,7 +811,7 @@ class LLMGroundedDiffusionPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
@@ -843,7 +843,7 @@ class LLMGroundedDiffusionPipeline(
[`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf). Guidance rescale factor should fix overexposure when
+ Flawed](https://huggingface.co/papers/2305.08891). Guidance rescale factor should fix overexposure when
using zero terminal SNR.
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
@@ -901,7 +901,7 @@ class LLMGroundedDiffusionPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
@@ -1171,8 +1171,8 @@ class LLMGroundedDiffusionPipeline(
# Scaling with classifier guidance
alpha_prod_t = scheduler.alphas_cumprod[t]
- # Classifier guidance: https://arxiv.org/pdf/2105.05233.pdf
- # DDIM: https://arxiv.org/pdf/2010.02502.pdf
+ # Classifier guidance: https://huggingface.co/papers/2105.05233
+ # DDIM: https://huggingface.co/papers/2010.02502
scale = (1 - alpha_prod_t) ** (0.5)
latents = latents - scale * grad_cond
@@ -1457,7 +1457,7 @@ class LLMGroundedDiffusionPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -1549,7 +1549,7 @@ class LLMGroundedDiffusionPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.do_classifier_free_guidance
diff --git a/examples/community/lpw_stable_diffusion.py b/examples/community/lpw_stable_diffusion.py
index 32baf500d4..ccb17a51e6 100644
--- a/examples/community/lpw_stable_diffusion.py
+++ b/examples/community/lpw_stable_diffusion.py
@@ -744,7 +744,7 @@ class StableDiffusionLongPromptWeightingPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -863,9 +863,9 @@ class StableDiffusionLongPromptWeightingPipeline(
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
strength (`float`, *optional*, defaults to 0.8):
@@ -880,7 +880,7 @@ class StableDiffusionLongPromptWeightingPipeline(
Use predicted noise instead of random noise when constructing noisy versions of the original image in
the reverse diffusion process
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -948,7 +948,7 @@ class StableDiffusionLongPromptWeightingPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
lora_scale = cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None
@@ -1115,15 +1115,15 @@ class StableDiffusionLongPromptWeightingPipeline(
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -1237,15 +1237,15 @@ class StableDiffusionLongPromptWeightingPipeline(
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference. This parameter will be modulated by `strength`.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -1355,9 +1355,9 @@ class StableDiffusionLongPromptWeightingPipeline(
The reference number of denoising steps. More denoising steps usually lead to a higher quality image at
the expense of slower inference. This parameter will be modulated by `strength`, as explained above.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
@@ -1366,7 +1366,7 @@ class StableDiffusionLongPromptWeightingPipeline(
Use predicted noise instead of random noise when constructing noisy versions of the original image in
the reverse diffusion process
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
diff --git a/examples/community/lpw_stable_diffusion_onnx.py b/examples/community/lpw_stable_diffusion_onnx.py
index 87c2944dbc..ab1462b81b 100644
--- a/examples/community/lpw_stable_diffusion_onnx.py
+++ b/examples/community/lpw_stable_diffusion_onnx.py
@@ -604,7 +604,7 @@ class OnnxStableDiffusionLongPromptWeightingPipeline(OnnxStableDiffusionPipeline
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -699,9 +699,9 @@ class OnnxStableDiffusionLongPromptWeightingPipeline(OnnxStableDiffusionPipeline
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
strength (`float`, *optional*, defaults to 0.8):
@@ -713,7 +713,7 @@ class OnnxStableDiffusionLongPromptWeightingPipeline(OnnxStableDiffusionPipeline
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
@@ -758,7 +758,7 @@ class OnnxStableDiffusionLongPromptWeightingPipeline(OnnxStableDiffusionPipeline
# 2. Define call parameters
batch_size = 1 if isinstance(prompt, str) else len(prompt)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
@@ -902,15 +902,15 @@ class OnnxStableDiffusionLongPromptWeightingPipeline(OnnxStableDiffusionPipeline
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
@@ -998,15 +998,15 @@ class OnnxStableDiffusionLongPromptWeightingPipeline(OnnxStableDiffusionPipeline
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference. This parameter will be modulated by `strength`.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
@@ -1094,15 +1094,15 @@ class OnnxStableDiffusionLongPromptWeightingPipeline(OnnxStableDiffusionPipeline
The reference number of denoising steps. More denoising steps usually lead to a higher quality image at
the expense of slower inference. This parameter will be modulated by `strength`, as explained above.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
diff --git a/examples/community/lpw_stable_diffusion_xl.py b/examples/community/lpw_stable_diffusion_xl.py
index 4d9683b73f..ea67738ab7 100644
--- a/examples/community/lpw_stable_diffusion_xl.py
+++ b/examples/community/lpw_stable_diffusion_xl.py
@@ -507,7 +507,7 @@ EXAMPLE_DOC_STRING = """
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -945,7 +945,7 @@ class SDXLLongPromptWeightingPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -1383,7 +1383,7 @@ class SDXLLongPromptWeightingPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1496,9 +1496,9 @@ class SDXLLongPromptWeightingPipeline(
forms a part of a "Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refine Image
Quality**](https://huggingface.co/docs/diffusers/using-diffusers/sdxl#refine-image-quality).
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str`):
@@ -1511,7 +1511,7 @@ class SDXLLongPromptWeightingPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -1548,8 +1548,8 @@ class SDXLLongPromptWeightingPipeline(
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
- [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://huggingface.co/papers/2305.08891).
Guidance rescale factor should fix overexposure when using zero terminal SNR.
original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
@@ -1872,7 +1872,7 @@ class SDXLLongPromptWeightingPipeline(
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/examples/community/masked_stable_diffusion_img2img.py b/examples/community/masked_stable_diffusion_img2img.py
index a210c167a2..570bd0963e 100644
--- a/examples/community/masked_stable_diffusion_img2img.py
+++ b/examples/community/masked_stable_diffusion_img2img.py
@@ -73,7 +73,7 @@ class MaskedStableDiffusionImg2ImgPipeline(StableDiffusionImg2ImgPipeline):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
@@ -123,7 +123,7 @@ class MaskedStableDiffusionImg2ImgPipeline(StableDiffusionImg2ImgPipeline):
batch_size = prompt_embeds.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/masked_stable_diffusion_xl_img2img.py b/examples/community/masked_stable_diffusion_xl_img2img.py
index c6b0ced527..14d8c7c2da 100644
--- a/examples/community/masked_stable_diffusion_xl_img2img.py
+++ b/examples/community/masked_stable_diffusion_xl_img2img.py
@@ -115,7 +115,7 @@ class MaskedStableDiffusionXLImg2ImgPipeline(StableDiffusionXLImg2ImgPipeline):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
@@ -438,7 +438,7 @@ class MaskedStableDiffusionXLImg2ImgPipeline(StableDiffusionXLImg2ImgPipeline):
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/examples/community/matryoshka.py b/examples/community/matryoshka.py
index 4895bd1501..2d5d0dd7c4 100644
--- a/examples/community/matryoshka.py
+++ b/examples/community/matryoshka.py
@@ -125,7 +125,7 @@ EXAMPLE_DOC_STRING = """
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -278,7 +278,7 @@ def betas_for_alpha_bar(
# Copied from diffusers.schedulers.scheduling_ddim.rescale_zero_terminal_snr
def rescale_zero_terminal_snr(betas):
"""
- Rescales betas to have zero terminal SNR Based on https://arxiv.org/pdf/2305.08891.pdf (Algorithm 1)
+ Rescales betas to have zero terminal SNR Based on https://huggingface.co/papers/2305.08891 (Algorithm 1)
Args:
@@ -458,7 +458,7 @@ class MatryoshkaDDIMScheduler(SchedulerMixin, ConfigMixin):
pixels from saturation at each step. We find that dynamic thresholding results in significantly better
photorealism as well as better image-text alignment, especially when using very large guidance weights."
- https://arxiv.org/abs/2205.11487
+ https://huggingface.co/papers/2205.11487
"""
dtype = sample.dtype
batch_size, channels, *remaining_dims = sample.shape
@@ -501,7 +501,7 @@ class MatryoshkaDDIMScheduler(SchedulerMixin, ConfigMixin):
self.num_inference_steps = num_inference_steps
- # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://arxiv.org/abs/2305.08891
+ # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://huggingface.co/papers/2305.08891
if self.config.timestep_spacing == "linspace":
timesteps = (
np.linspace(0, self.config.num_train_timesteps - 1, num_inference_steps)
@@ -587,7 +587,7 @@ class MatryoshkaDDIMScheduler(SchedulerMixin, ConfigMixin):
"Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
)
- # See formulas (12) and (16) of DDIM paper https://arxiv.org/pdf/2010.02502.pdf
+ # See formulas (12) and (16) of DDIM paper https://huggingface.co/papers/2010.02502
# Ideally, read DDIM paper in-detail understanding
# Notation ( ->
@@ -615,7 +615,7 @@ class MatryoshkaDDIMScheduler(SchedulerMixin, ConfigMixin):
beta_prod_t = 1 - alpha_prod_t
# 3. compute predicted original sample from predicted noise also called
- # "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # "predicted x_0" of formula (12) from https://huggingface.co/papers/2010.02502
if self.config.prediction_type == "epsilon":
pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
pred_epsilon = model_output
@@ -669,7 +669,7 @@ class MatryoshkaDDIMScheduler(SchedulerMixin, ConfigMixin):
else:
pred_epsilon = (sample - alpha_prod_t ** (0.5) * pred_original_sample) / beta_prod_t ** (0.5)
- # 6. compute "direction pointing to x_t" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # 6. compute "direction pointing to x_t" of formula (12) from https://huggingface.co/papers/2010.02502
if len(model_output) > 1:
pred_sample_direction = []
for p_e, a_p_t_p in zip(pred_epsilon, alpha_prod_t_prev):
@@ -677,7 +677,7 @@ class MatryoshkaDDIMScheduler(SchedulerMixin, ConfigMixin):
else:
pred_sample_direction = (1 - alpha_prod_t_prev - std_dev_t**2) ** (0.5) * pred_epsilon
- # 7. compute x_t without "random noise" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # 7. compute x_t without "random noise" of formula (12) from https://huggingface.co/papers/2010.02502
if len(model_output) > 1:
prev_sample = []
for p_o_s, p_s_d, a_p_t_p in zip(pred_original_sample, pred_sample_direction, alpha_prod_t_prev):
@@ -2660,7 +2660,7 @@ class MatryoshkaUNet2DConditionModel(
fn_recursive_set_attention_slice(module, reversed_slice_size)
def enable_freeu(self, s1: float, s2: float, b1: float, b2: float):
- r"""Enables the FreeU mechanism from https://arxiv.org/abs/2309.11497.
+ r"""Enables the FreeU mechanism from https://huggingface.co/papers/2309.11497.
The suffixes after the scaling factors represent the stage blocks where they are being applied.
@@ -4065,7 +4065,7 @@ class MatryoshkaPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -4230,7 +4230,7 @@ class MatryoshkaPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -4309,7 +4309,7 @@ class MatryoshkaPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
@@ -4340,7 +4340,7 @@ class MatryoshkaPipeline(
[`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf). Guidance rescale factor should fix overexposure when
+ Flawed](https://huggingface.co/papers/2305.08891). Guidance rescale factor should fix overexposure when
using zero terminal SNR.
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
@@ -4538,7 +4538,7 @@ class MatryoshkaPipeline(
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/examples/community/mixture_tiling.py b/examples/community/mixture_tiling.py
index 3feed5c88d..3f5affc4f4 100644
--- a/examples/community/mixture_tiling.py
+++ b/examples/community/mixture_tiling.py
@@ -298,7 +298,7 @@ class StableDiffusionTilingPipeline(DiffusionPipeline, StableDiffusionExtrasMixi
text_embeddings = [[self.text_encoder(col.input_ids.to(self.device))[0] for col in row] for row in text_input]
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0 # TODO: also active if any tile has guidance scale
# get unconditional embeddings for classifier free guidance
@@ -318,7 +318,7 @@ class StableDiffusionTilingPipeline(DiffusionPipeline, StableDiffusionExtrasMixi
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
diff --git a/examples/community/mixture_tiling_sdxl.py b/examples/community/mixture_tiling_sdxl.py
index bd56ddb3d6..66c338b5b2 100644
--- a/examples/community/mixture_tiling_sdxl.py
+++ b/examples/community/mixture_tiling_sdxl.py
@@ -201,7 +201,7 @@ def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
r"""
Rescales `noise_cfg` tensor based on `guidance_rescale` to improve image quality and fix overexposure. Based on
Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891).
Args:
noise_cfg (`torch.Tensor`):
@@ -631,7 +631,7 @@ class StableDiffusionXLTilingPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -767,7 +767,7 @@ class StableDiffusionXLTilingPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -839,9 +839,9 @@ class StableDiffusionXLTilingPipeline(
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -851,7 +851,7 @@ class StableDiffusionXLTilingPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
diff --git a/examples/community/mod_controlnet_tile_sr_sdxl.py b/examples/community/mod_controlnet_tile_sr_sdxl.py
index 3db2645a78..27249ce3fb 100644
--- a/examples/community/mod_controlnet_tile_sr_sdxl.py
+++ b/examples/community/mod_controlnet_tile_sr_sdxl.py
@@ -637,7 +637,7 @@ class StableDiffusionXLControlNetTileSRPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -1247,7 +1247,7 @@ class StableDiffusionXLControlNetTileSRPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1335,8 +1335,8 @@ class StableDiffusionXLControlNetTileSRPipeline(
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen Paper](https://arxiv.org/pdf/2205.11487.pdf).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen Paper](https://huggingface.co/papers/2205.11487).
Guidance scale is enabled by setting `guidance_scale > 1`. Higher guidance scale encourages generating
images closely linked to the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -1346,7 +1346,7 @@ class StableDiffusionXLControlNetTileSRPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
diff --git a/examples/community/multilingual_stable_diffusion.py b/examples/community/multilingual_stable_diffusion.py
index 5dcc75c9e2..5e7453ed12 100644
--- a/examples/community/multilingual_stable_diffusion.py
+++ b/examples/community/multilingual_stable_diffusion.py
@@ -168,9 +168,9 @@ class MultilingualStableDiffusion(DiffusionPipeline, StableDiffusionMixin):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -179,7 +179,7 @@ class MultilingualStableDiffusion(DiffusionPipeline, StableDiffusionMixin):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
@@ -263,7 +263,7 @@ class MultilingualStableDiffusion(DiffusionPipeline, StableDiffusionMixin):
text_embeddings = text_embeddings.view(bs_embed * num_images_per_prompt, seq_len, -1)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
@@ -355,7 +355,7 @@ class MultilingualStableDiffusion(DiffusionPipeline, StableDiffusionMixin):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
diff --git a/examples/community/pipeline_animatediff_controlnet.py b/examples/community/pipeline_animatediff_controlnet.py
index 9f99ad248b..cd168cf419 100644
--- a/examples/community/pipeline_animatediff_controlnet.py
+++ b/examples/community/pipeline_animatediff_controlnet.py
@@ -464,7 +464,7 @@ class AnimateDiffControlNetPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -729,7 +729,7 @@ class AnimateDiffControlNetPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -797,7 +797,7 @@ class AnimateDiffControlNetPipeline(
The prompt or prompts to guide what to not include in image generation. If not defined, you need to
pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
diff --git a/examples/community/pipeline_animatediff_img2video.py b/examples/community/pipeline_animatediff_img2video.py
index f7f0cf31c5..ec0c340666 100644
--- a/examples/community/pipeline_animatediff_img2video.py
+++ b/examples/community/pipeline_animatediff_img2video.py
@@ -581,7 +581,7 @@ class AnimateDiffImgToVideoPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -790,7 +790,7 @@ class AnimateDiffImgToVideoPipeline(
The prompt or prompts to guide what to not include in image generation. If not defined, you need to
pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
@@ -870,7 +870,7 @@ class AnimateDiffImgToVideoPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/pipeline_animatediff_ipex.py b/examples/community/pipeline_animatediff_ipex.py
index 06508f217c..7c76aac090 100644
--- a/examples/community/pipeline_animatediff_ipex.py
+++ b/examples/community/pipeline_animatediff_ipex.py
@@ -442,7 +442,7 @@ class AnimateDiffPipelineIpex(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -555,7 +555,7 @@ class AnimateDiffPipelineIpex(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -618,7 +618,7 @@ class AnimateDiffPipelineIpex(
The prompt or prompts to guide what to not include in image generation. If not defined, you need to
pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
diff --git a/examples/community/pipeline_controlnet_xl_kolors.py b/examples/community/pipeline_controlnet_xl_kolors.py
index 5b0576fbcd..e4e05ca11c 100644
--- a/examples/community/pipeline_controlnet_xl_kolors.py
+++ b/examples/community/pipeline_controlnet_xl_kolors.py
@@ -462,7 +462,7 @@ class KolorsControlNetPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -781,7 +781,7 @@ class KolorsControlNetPipeline(
return self._guidance_scale
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -868,9 +868,9 @@ class KolorsControlNetPipeline(
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -880,7 +880,7 @@ class KolorsControlNetPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
diff --git a/examples/community/pipeline_controlnet_xl_kolors_img2img.py b/examples/community/pipeline_controlnet_xl_kolors_img2img.py
index 44c866e826..310372593a 100644
--- a/examples/community/pipeline_controlnet_xl_kolors_img2img.py
+++ b/examples/community/pipeline_controlnet_xl_kolors_img2img.py
@@ -505,7 +505,7 @@ class KolorsControlNetImg2ImgPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for others.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -951,7 +951,7 @@ class KolorsControlNetImg2ImgPipeline(
return self._guidance_scale
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1046,9 +1046,9 @@ class KolorsControlNetImg2ImgPipeline(
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -1058,7 +1058,7 @@ class KolorsControlNetImg2ImgPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
diff --git a/examples/community/pipeline_controlnet_xl_kolors_inpaint.py b/examples/community/pipeline_controlnet_xl_kolors_inpaint.py
index 09d4b0241e..05e58c0fff 100644
--- a/examples/community/pipeline_controlnet_xl_kolors_inpaint.py
+++ b/examples/community/pipeline_controlnet_xl_kolors_inpaint.py
@@ -556,7 +556,7 @@ class KolorsControlNetInpaintPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -1035,7 +1035,7 @@ class KolorsControlNetInpaintPipeline(
return self._guidance_scale
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1255,9 +1255,9 @@ class KolorsControlNetInpaintPipeline(
forms a part of a "Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output).
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -1290,7 +1290,7 @@ class KolorsControlNetInpaintPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
diff --git a/examples/community/pipeline_demofusion_sdxl.py b/examples/community/pipeline_demofusion_sdxl.py
index 624b2bd1ed..c9b57a6ece 100644
--- a/examples/community/pipeline_demofusion_sdxl.py
+++ b/examples/community/pipeline_demofusion_sdxl.py
@@ -77,7 +77,7 @@ def gaussian_filter(latents, kernel_size=3, sigma=1.0):
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -383,7 +383,7 @@ class DemoFusionSDXLPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -701,9 +701,9 @@ class DemoFusionSDXLPipeline(
"Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output)
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -716,7 +716,7 @@ class DemoFusionSDXLPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -757,8 +757,8 @@ class DemoFusionSDXLPipeline(
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.7):
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
- [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://huggingface.co/papers/2305.08891).
Guidance rescale factor should fix overexposure when using zero terminal SNR.
original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
@@ -860,7 +860,7 @@ class DemoFusionSDXLPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
@@ -977,7 +977,7 @@ class DemoFusionSDXLPipeline(
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if do_classifier_free_guidance and guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
@@ -1119,7 +1119,7 @@ class DemoFusionSDXLPipeline(
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if do_classifier_free_guidance and guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(
noise_pred, noise_pred_text, guidance_rescale=guidance_rescale
)
@@ -1215,7 +1215,7 @@ class DemoFusionSDXLPipeline(
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if do_classifier_free_guidance and guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(
noise_pred, noise_pred_text, guidance_rescale=guidance_rescale
)
diff --git a/examples/community/pipeline_faithdiff_stable_diffusion_xl.py b/examples/community/pipeline_faithdiff_stable_diffusion_xl.py
index 749f0322d0..43ef55d32c 100644
--- a/examples/community/pipeline_faithdiff_stable_diffusion_xl.py
+++ b/examples/community/pipeline_faithdiff_stable_diffusion_xl.py
@@ -1077,7 +1077,7 @@ class LocalAttention:
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
Args:
noise_cfg (torch.Tensor): Noise configuration tensor.
@@ -1504,7 +1504,7 @@ class FaithDiffStableDiffusionXLPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -1729,7 +1729,7 @@ class FaithDiffStableDiffusionXLPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1883,9 +1883,9 @@ class FaithDiffStableDiffusionXLPipeline(
Overlap factor for local attention tiling (between 0.0 and 1.0). Controls the overlap between adjacent
grid patches during processing. Defaults to 0.5.
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -1898,7 +1898,7 @@ class FaithDiffStableDiffusionXLPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -1933,8 +1933,8 @@ class FaithDiffStableDiffusionXLPipeline(
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
- [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://huggingface.co/papers/2305.08891).
Guidance rescale factor should fix overexposure when using zero terminal SNR.
original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
@@ -2173,7 +2173,7 @@ class FaithDiffStableDiffusionXLPipeline(
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(
noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale
)
diff --git a/examples/community/pipeline_flux_differential_img2img.py b/examples/community/pipeline_flux_differential_img2img.py
index 5dc321ea98..940cbd7976 100644
--- a/examples/community/pipeline_flux_differential_img2img.py
+++ b/examples/community/pipeline_flux_differential_img2img.py
@@ -756,9 +756,9 @@ class FluxDifferentialImg2ImgPipeline(DiffusionPipeline, FluxLoraLoaderMixin):
in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
passed will be used. Must be in descending order.
guidance_scale (`float`, *optional*, defaults to 7.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
diff --git a/examples/community/pipeline_flux_rf_inversion.py b/examples/community/pipeline_flux_rf_inversion.py
index 572856a047..5a5b76adcf 100644
--- a/examples/community/pipeline_flux_rf_inversion.py
+++ b/examples/community/pipeline_flux_rf_inversion.py
@@ -698,9 +698,9 @@ class RFInversionFluxPipeline(
in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
passed will be used. Must be in descending order.
guidance_scale (`float`, *optional*, defaults to 7.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
@@ -849,7 +849,7 @@ class RFInversionFluxPipeline(
if do_rf_inversion:
y_0 = image_latents.clone()
- # 6. Denoising loop / Controlled Reverse ODE, Algorithm 2 from: https://arxiv.org/pdf/2410.10792
+ # 6. Denoising loop / Controlled Reverse ODE, Algorithm 2 from: https://huggingface.co/papers/2410.10792
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
if do_rf_inversion:
@@ -884,7 +884,7 @@ class RFInversionFluxPipeline(
eta_t = eta_t * (1 - i / num_inference_steps) ** eta_decay_power # Decay eta over the loop
v_hat_t = v_t + eta_t * (v_t_cond - v_t)
- # SDE Eq: 17 from https://arxiv.org/pdf/2410.10792
+ # SDE Eq: 17 from https://huggingface.co/papers/2410.10792
latents = latents + v_hat_t * (sigmas[i] - sigmas[i + 1])
else:
# compute the previous noisy sample x_t -> x_t-1
@@ -944,7 +944,7 @@ class RFInversionFluxPipeline(
joint_attention_kwargs: Optional[Dict[str, Any]] = None,
):
r"""
- Performs Algorithm 1: Controlled Forward ODE from https://arxiv.org/pdf/2410.10792
+ Performs Algorithm 1: Controlled Forward ODE from https://huggingface.co/papers/2410.10792
Args:
image (`PipelineImageInput`):
Input for the image(s) that are to be edited. Multiple input images have to default to the same aspect
@@ -953,9 +953,9 @@ class RFInversionFluxPipeline(
The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
instead.
source_guidance_scale (`float`, *optional*, defaults to 0.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). For this algorithm, it's better to keep it 0.
+ Paper](https://huggingface.co/papers/2205.11487). For this algorithm, it's better to keep it 0.
num_inversion_steps (`int`, *optional*, defaults to 28):
The number of discretization steps.
height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
diff --git a/examples/community/pipeline_flux_semantic_guidance.py b/examples/community/pipeline_flux_semantic_guidance.py
index 919e0ad46b..fd801420c3 100644
--- a/examples/community/pipeline_flux_semantic_guidance.py
+++ b/examples/community/pipeline_flux_semantic_guidance.py
@@ -840,9 +840,9 @@ class FluxSemanticGuidancePipeline(
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, *optional*, defaults to 7.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
diff --git a/examples/community/pipeline_flux_with_cfg.py b/examples/community/pipeline_flux_with_cfg.py
index f55f73620f..fbe50a0b0e 100644
--- a/examples/community/pipeline_flux_with_cfg.py
+++ b/examples/community/pipeline_flux_with_cfg.py
@@ -626,9 +626,9 @@ class FluxCFGPipeline(DiffusionPipeline, FluxLoraLoaderMixin, FromSingleFileMixi
in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
passed will be used. Must be in descending order.
guidance_scale (`float`, *optional*, defaults to 7.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
diff --git a/examples/community/pipeline_hunyuandit_differential_img2img.py b/examples/community/pipeline_hunyuandit_differential_img2img.py
index a294ff7824..f2d31a7419 100644
--- a/examples/community/pipeline_hunyuandit_differential_img2img.py
+++ b/examples/community/pipeline_hunyuandit_differential_img2img.py
@@ -150,7 +150,7 @@ def get_resize_crop_region_for_grid(src, tgt_size):
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -531,7 +531,7 @@ class HunyuanDiTDifferentialImg2ImgPipeline(DiffusionPipeline):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -709,7 +709,7 @@ class HunyuanDiTDifferentialImg2ImgPipeline(DiffusionPipeline):
return self._guidance_rescale
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -809,7 +809,7 @@ class HunyuanDiTDifferentialImg2ImgPipeline(DiffusionPipeline):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
@@ -846,7 +846,7 @@ class HunyuanDiTDifferentialImg2ImgPipeline(DiffusionPipeline):
inputs will be passed.
guidance_rescale (`float`, *optional*, defaults to 0.0):
Rescale the noise_cfg according to `guidance_rescale`. Based on findings of [Common Diffusion Noise
- Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Schedules and Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
original_size (`Tuple[int, int]`, *optional*, defaults to `(1024, 1024)`):
The original size of the image. Used to calculate the time ids.
target_size (`Tuple[int, int]`, *optional*):
@@ -1095,7 +1095,7 @@ class HunyuanDiTDifferentialImg2ImgPipeline(DiffusionPipeline):
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/examples/community/pipeline_kolors_differential_img2img.py b/examples/community/pipeline_kolors_differential_img2img.py
index dfef872d1c..c2cab10e07 100644
--- a/examples/community/pipeline_kolors_differential_img2img.py
+++ b/examples/community/pipeline_kolors_differential_img2img.py
@@ -462,7 +462,7 @@ class KolorsDifferentialImg2ImgPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -764,7 +764,7 @@ class KolorsDifferentialImg2ImgPipeline(
return self._guidance_scale
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -884,9 +884,9 @@ class KolorsDifferentialImg2ImgPipeline(
"Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output)
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -896,7 +896,7 @@ class KolorsDifferentialImg2ImgPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
diff --git a/examples/community/pipeline_kolors_inpainting.py b/examples/community/pipeline_kolors_inpainting.py
index 43a3957c82..f550299f9a 100644
--- a/examples/community/pipeline_kolors_inpainting.py
+++ b/examples/community/pipeline_kolors_inpainting.py
@@ -98,7 +98,7 @@ EXAMPLE_DOC_STRING = """
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -673,7 +673,7 @@ class KolorsInpaintPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -1066,7 +1066,7 @@ class KolorsInpaintPipeline(
return self._guidance_rescale
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1206,9 +1206,9 @@ class KolorsInpaintPipeline(
forms a part of a "Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output).
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -1238,7 +1238,7 @@ class KolorsInpaintPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -1621,7 +1621,7 @@ class KolorsInpaintPipeline(
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/examples/community/pipeline_prompt2prompt.py b/examples/community/pipeline_prompt2prompt.py
index b9985542cc..3a7b4b69d7 100644
--- a/examples/community/pipeline_prompt2prompt.py
+++ b/examples/community/pipeline_prompt2prompt.py
@@ -61,7 +61,7 @@ logger = logging.get_logger(__name__)
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -449,7 +449,7 @@ class Prompt2PromptPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -592,9 +592,9 @@ class Prompt2PromptPipeline(
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -603,7 +603,7 @@ class Prompt2PromptPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -641,7 +641,7 @@ class Prompt2PromptPipeline(
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf). Guidance rescale factor should fix overexposure when
+ Flawed](https://huggingface.co/papers/2305.08891). Guidance rescale factor should fix overexposure when
using zero terminal SNR.
Returns:
@@ -678,7 +678,7 @@ class Prompt2PromptPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
@@ -734,7 +734,7 @@ class Prompt2PromptPipeline(
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if do_classifier_free_guidance and guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/examples/community/pipeline_sdxl_style_aligned.py b/examples/community/pipeline_sdxl_style_aligned.py
index 6aebb6c18d..1af5fc3e88 100644
--- a/examples/community/pipeline_sdxl_style_aligned.py
+++ b/examples/community/pipeline_sdxl_style_aligned.py
@@ -12,7 +12,7 @@
# See the License for the specific language governing permissions and
# limitations under the License.
#
-# Based on [Style Aligned Image Generation via Shared Attention](https://arxiv.org/abs/2312.02133).
+# Based on [Style Aligned Image Generation via Shared Attention](https://huggingface.co/papers/2312.02133).
# Authors: Amir Hertz, Andrey Voynov, Shlomi Fruchter, Daniel Cohen-Or
# Project Page: https://style-aligned-gen.github.io/
# Code: https://github.com/google/style-aligned
@@ -315,7 +315,7 @@ class SharedAttentionProcessor(AttnProcessor2_0):
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -396,7 +396,7 @@ class StyleAlignedSDXLPipeline(
r"""
Pipeline for text-to-image generation using Stable Diffusion XL.
- This pipeline also adds experimental support for [StyleAligned](https://arxiv.org/abs/2312.02133). It can
+ This pipeline also adds experimental support for [StyleAligned](https://huggingface.co/papers/2312.02133). It can
be enabled/disabled using `.enable_style_aligned()` or `.disable_style_aligned()` respectively.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
@@ -773,7 +773,7 @@ class StyleAlignedSDXLPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -1272,7 +1272,7 @@ class StyleAlignedSDXLPipeline(
only_self_level: float = 0.0,
):
r"""
- Enables the StyleAligned mechanism as in https://arxiv.org/abs/2312.02133.
+ Enables the StyleAligned mechanism as in https://huggingface.co/papers/2312.02133.
Args:
share_group_norm (`bool`, defaults to `True`):
@@ -1356,7 +1356,7 @@ class StyleAlignedSDXLPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1457,9 +1457,9 @@ class StyleAlignedSDXLPipeline(
"Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output)
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -1472,7 +1472,7 @@ class StyleAlignedSDXLPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -1509,8 +1509,8 @@ class StyleAlignedSDXLPipeline(
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
- [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://huggingface.co/papers/2305.08891).
Guidance rescale factor should fix overexposure when using zero terminal SNR.
original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
@@ -1840,7 +1840,7 @@ class StyleAlignedSDXLPipeline(
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/examples/community/pipeline_stable_diffusion_3_differential_img2img.py b/examples/community/pipeline_stable_diffusion_3_differential_img2img.py
index 50952304fc..081fcda6d6 100644
--- a/examples/community/pipeline_stable_diffusion_3_differential_img2img.py
+++ b/examples/community/pipeline_stable_diffusion_3_differential_img2img.py
@@ -654,7 +654,7 @@ class StableDiffusion3DifferentialImg2ImgPipeline(DiffusionPipeline):
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -725,9 +725,9 @@ class StableDiffusion3DifferentialImg2ImgPipeline(DiffusionPipeline):
in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
passed will be used. Must be in descending order.
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
diff --git a/examples/community/pipeline_stable_diffusion_3_instruct_pix2pix.py b/examples/community/pipeline_stable_diffusion_3_instruct_pix2pix.py
index 97491a8597..54e0c4b5bc 100644
--- a/examples/community/pipeline_stable_diffusion_3_instruct_pix2pix.py
+++ b/examples/community/pipeline_stable_diffusion_3_instruct_pix2pix.py
@@ -759,7 +759,7 @@ class StableDiffusion3InstructPix2PixPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -918,9 +918,9 @@ class StableDiffusion3InstructPix2PixPipeline(
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, *optional*, defaults to 7.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
image_guidance_scale (`float`, *optional*, defaults to 1.5):
diff --git a/examples/community/pipeline_stable_diffusion_boxdiff.py b/examples/community/pipeline_stable_diffusion_boxdiff.py
index 7c7f7e8a18..f0e19aba62 100644
--- a/examples/community/pipeline_stable_diffusion_boxdiff.py
+++ b/examples/community/pipeline_stable_diffusion_boxdiff.py
@@ -307,7 +307,7 @@ def register_attention_control(model, controller):
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -793,7 +793,7 @@ class StableDiffusionBoxDiffPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -893,7 +893,7 @@ class StableDiffusionBoxDiffPipeline(
return latents
def enable_freeu(self, s1: float, s2: float, b1: float, b2: float):
- r"""Enables the FreeU mechanism as in https://arxiv.org/abs/2309.11497.
+ r"""Enables the FreeU mechanism as in https://huggingface.co/papers/2309.11497.
The suffixes after the scaling factors represent the stages where they are being applied.
@@ -1021,7 +1021,7 @@ class StableDiffusionBoxDiffPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1365,7 +1365,7 @@ class StableDiffusionBoxDiffPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
@@ -1391,7 +1391,7 @@ class StableDiffusionBoxDiffPipeline(
[`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf). Guidance rescale factor should fix overexposure when
+ Flawed](https://huggingface.co/papers/2305.08891). Guidance rescale factor should fix overexposure when
using zero terminal SNR.
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
@@ -1661,7 +1661,7 @@ class StableDiffusionBoxDiffPipeline(
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/examples/community/pipeline_stable_diffusion_pag.py b/examples/community/pipeline_stable_diffusion_pag.py
index 874303e0ad..69a0059d98 100644
--- a/examples/community/pipeline_stable_diffusion_pag.py
+++ b/examples/community/pipeline_stable_diffusion_pag.py
@@ -279,7 +279,7 @@ class PAGCFGIdentitySelfAttnProcessor:
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -793,7 +793,7 @@ class StableDiffusionPAGPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -889,7 +889,7 @@ class StableDiffusionPAGPipeline(
return latents
def enable_freeu(self, s1: float, s2: float, b1: float, b2: float):
- r"""Enables the FreeU mechanism as in https://arxiv.org/abs/2309.11497.
+ r"""Enables the FreeU mechanism as in https://huggingface.co/papers/2309.11497.
The suffixes after the scaling factors represent the stages where they are being applied.
Please refer to the [official repository](https://github.com/ChenyangSi/FreeU) for combinations of the values
that are known to work well for different pipelines such as Stable Diffusion v1, v2, and Stable Diffusion XL.
@@ -1032,7 +1032,7 @@ class StableDiffusionPAGPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1126,7 +1126,7 @@ class StableDiffusionPAGPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
@@ -1155,7 +1155,7 @@ class StableDiffusionPAGPipeline(
[`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf). Guidance rescale factor should fix overexposure when
+ Flawed](https://huggingface.co/papers/2305.08891). Guidance rescale factor should fix overexposure when
using zero terminal SNR.
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
@@ -1414,7 +1414,7 @@ class StableDiffusionPAGPipeline(
)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/examples/community/pipeline_stable_diffusion_upscale_ldm3d.py b/examples/community/pipeline_stable_diffusion_upscale_ldm3d.py
index 6c63f53e81..0ca3083e63 100644
--- a/examples/community/pipeline_stable_diffusion_upscale_ldm3d.py
+++ b/examples/community/pipeline_stable_diffusion_upscale_ldm3d.py
@@ -390,7 +390,7 @@ class StableDiffusionUpscaleLDM3DPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -565,7 +565,7 @@ class StableDiffusionUpscaleLDM3DPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
@@ -624,7 +624,7 @@ class StableDiffusionUpscaleLDM3DPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/pipeline_stable_diffusion_xl_attentive_eraser.py b/examples/community/pipeline_stable_diffusion_xl_attentive_eraser.py
index 73f52736f4..fa87c1db2a 100644
--- a/examples/community/pipeline_stable_diffusion_xl_attentive_eraser.py
+++ b/examples/community/pipeline_stable_diffusion_xl_attentive_eraser.py
@@ -301,7 +301,7 @@ class AAS_XL(AttentionBase):
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -935,7 +935,7 @@ class StableDiffusionXL_AE_Pipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -1346,7 +1346,7 @@ class StableDiffusionXL_AE_Pipeline(
return self._rm_guidance_scale > 1 and self._AAS
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1743,9 +1743,9 @@ class StableDiffusionXL_AE_Pipeline(
forms a part of a "Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output).
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -1778,7 +1778,7 @@ class StableDiffusionXL_AE_Pipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -2219,7 +2219,7 @@ class StableDiffusionXL_AE_Pipeline(
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/examples/community/pipeline_stable_diffusion_xl_controlnet_adapter.py b/examples/community/pipeline_stable_diffusion_xl_controlnet_adapter.py
index de5887c6de..d473064e29 100644
--- a/examples/community/pipeline_stable_diffusion_xl_controlnet_adapter.py
+++ b/examples/community/pipeline_stable_diffusion_xl_controlnet_adapter.py
@@ -141,7 +141,7 @@ def _preprocess_adapter_image(image, height, width):
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -161,7 +161,7 @@ class StableDiffusionXLControlNetAdapterPipeline(
):
r"""
Pipeline for text-to-image generation using Stable Diffusion augmented with T2I-Adapter
- https://arxiv.org/abs/2302.08453
+ https://huggingface.co/papers/2302.08453
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
@@ -479,7 +479,7 @@ class StableDiffusionXLControlNetAdapterPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -950,9 +950,9 @@ class StableDiffusionXLControlNetAdapterPipeline(
"Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output)
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -965,7 +965,7 @@ class StableDiffusionXLControlNetAdapterPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -1006,8 +1006,8 @@ class StableDiffusionXLControlNetAdapterPipeline(
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
- [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://huggingface.co/papers/2305.08891).
Guidance rescale factor should fix overexposure when using zero terminal SNR.
original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
@@ -1137,7 +1137,7 @@ class StableDiffusionXLControlNetAdapterPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
@@ -1367,7 +1367,7 @@ class StableDiffusionXLControlNetAdapterPipeline(
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if do_classifier_free_guidance and guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/examples/community/pipeline_stable_diffusion_xl_controlnet_adapter_inpaint.py b/examples/community/pipeline_stable_diffusion_xl_controlnet_adapter_inpaint.py
index c5f8ec3dfa..003397f062 100644
--- a/examples/community/pipeline_stable_diffusion_xl_controlnet_adapter_inpaint.py
+++ b/examples/community/pipeline_stable_diffusion_xl_controlnet_adapter_inpaint.py
@@ -287,7 +287,7 @@ def prepare_mask_and_masked_image(image, mask, height, width, return_image: bool
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -303,7 +303,7 @@ class StableDiffusionXLControlNetAdapterInpaintPipeline(
):
r"""
Pipeline for text-to-image generation using Stable Diffusion augmented with T2I-Adapter
- https://arxiv.org/abs/2302.08453
+ https://huggingface.co/papers/2302.08453
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
@@ -626,7 +626,7 @@ class StableDiffusionXLControlNetAdapterInpaintPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -1306,9 +1306,9 @@ class StableDiffusionXLControlNetAdapterInpaintPipeline(
"Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output)
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -1321,7 +1321,7 @@ class StableDiffusionXLControlNetAdapterInpaintPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -1362,8 +1362,8 @@ class StableDiffusionXLControlNetAdapterInpaintPipeline(
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.7):
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
- [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://huggingface.co/papers/2305.08891).
Guidance rescale factor should fix overexposure when using zero terminal SNR.
original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
@@ -1475,7 +1475,7 @@ class StableDiffusionXLControlNetAdapterInpaintPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
@@ -1784,7 +1784,7 @@ class StableDiffusionXLControlNetAdapterInpaintPipeline(
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if do_classifier_free_guidance and guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(
noise_pred,
noise_pred_text,
diff --git a/examples/community/pipeline_stable_diffusion_xl_differential_img2img.py b/examples/community/pipeline_stable_diffusion_xl_differential_img2img.py
index e74ea26301..143f2b5ffc 100644
--- a/examples/community/pipeline_stable_diffusion_xl_differential_img2img.py
+++ b/examples/community/pipeline_stable_diffusion_xl_differential_img2img.py
@@ -92,7 +92,7 @@ EXAMPLE_DOC_STRING = """
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -510,7 +510,7 @@ class StableDiffusionXLDifferentialImg2ImgPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -908,7 +908,7 @@ class StableDiffusionXLDifferentialImg2ImgPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1030,9 +1030,9 @@ class StableDiffusionXLDifferentialImg2ImgPipeline(
forms a part of a "Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output).
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -1045,7 +1045,7 @@ class StableDiffusionXLDifferentialImg2ImgPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -1092,8 +1092,8 @@ class StableDiffusionXLDifferentialImg2ImgPipeline(
[diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
guidance_rescale (`float`, *optional*, defaults to 0.7):
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
- [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://huggingface.co/papers/2305.08891).
Guidance rescale factor should fix overexposure when using zero terminal SNR.
original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
@@ -1375,7 +1375,7 @@ class StableDiffusionXLDifferentialImg2ImgPipeline(
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/examples/community/pipeline_stable_diffusion_xl_instandid_img2img.py b/examples/community/pipeline_stable_diffusion_xl_instandid_img2img.py
index 7aeba79ae9..8c1b67fddd 100644
--- a/examples/community/pipeline_stable_diffusion_xl_instandid_img2img.py
+++ b/examples/community/pipeline_stable_diffusion_xl_instandid_img2img.py
@@ -627,7 +627,7 @@ class StableDiffusionXLInstantIDImg2ImgPipeline(StableDiffusionXLControlNetImg2I
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
diff --git a/examples/community/pipeline_stable_diffusion_xl_instantid.py b/examples/community/pipeline_stable_diffusion_xl_instantid.py
index 2eead8861e..5a944cf1bf 100644
--- a/examples/community/pipeline_stable_diffusion_xl_instantid.py
+++ b/examples/community/pipeline_stable_diffusion_xl_instantid.py
@@ -623,7 +623,7 @@ class StableDiffusionXLInstantIDPipeline(StableDiffusionXLControlNetPipeline):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
diff --git a/examples/community/pipeline_stable_diffusion_xl_ipex.py b/examples/community/pipeline_stable_diffusion_xl_ipex.py
index f43726b1b5..eda6089f59 100644
--- a/examples/community/pipeline_stable_diffusion_xl_ipex.py
+++ b/examples/community/pipeline_stable_diffusion_xl_ipex.py
@@ -102,7 +102,7 @@ EXAMPLE_DOC_STRING = """
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -524,7 +524,7 @@ class StableDiffusionXLPipelineIpex(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -718,7 +718,7 @@ class StableDiffusionXLPipelineIpex(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -809,9 +809,9 @@ class StableDiffusionXLPipelineIpex(
"Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output)
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -824,7 +824,7 @@ class StableDiffusionXLPipelineIpex(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -860,8 +860,8 @@ class StableDiffusionXLPipelineIpex(
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
- [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://huggingface.co/papers/2305.08891).
Guidance rescale factor should fix overexposure when using zero terminal SNR.
original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
@@ -1113,7 +1113,7 @@ class StableDiffusionXLPipelineIpex(
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/examples/community/pipeline_stg_cogvideox.py b/examples/community/pipeline_stg_cogvideox.py
index 2e7f7906a3..0fe9778a47 100644
--- a/examples/community/pipeline_stg_cogvideox.py
+++ b/examples/community/pipeline_stg_cogvideox.py
@@ -413,7 +413,7 @@ class CogVideoXSTGPipeline(DiffusionPipeline, CogVideoXLoraLoaderMixin):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -619,9 +619,9 @@ class CogVideoXSTGPipeline(DiffusionPipeline, CogVideoXLoraLoaderMixin):
in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
passed will be used. Must be in descending order.
guidance_scale (`float`, *optional*, defaults to 7.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_videos_per_prompt (`int`, *optional*, defaults to 1):
@@ -713,7 +713,7 @@ class CogVideoXSTGPipeline(DiffusionPipeline, CogVideoXLoraLoaderMixin):
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/pipeline_stg_hunyuan_video.py b/examples/community/pipeline_stg_hunyuan_video.py
index e41f99e13a..88cc60d164 100644
--- a/examples/community/pipeline_stg_hunyuan_video.py
+++ b/examples/community/pipeline_stg_hunyuan_video.py
@@ -583,9 +583,9 @@ class HunyuanVideoSTGPipeline(DiffusionPipeline, HunyuanVideoLoraLoaderMixin):
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, defaults to `6.0`):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality. Note that the only available HunyuanVideo model is
CFG-distilled, which means that traditional guidance between unconditional and conditional latent is
diff --git a/examples/community/pipeline_stg_ltx.py b/examples/community/pipeline_stg_ltx.py
index 4a257a0a92..fbc2f17659 100644
--- a/examples/community/pipeline_stg_ltx.py
+++ b/examples/community/pipeline_stg_ltx.py
@@ -607,9 +607,9 @@ class LTXSTGPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLoraLoaderM
in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
passed will be used. Must be in descending order.
guidance_scale (`float`, defaults to `3 `):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_videos_per_prompt (`int`, *optional*, defaults to 1):
diff --git a/examples/community/pipeline_stg_ltx_image2video.py b/examples/community/pipeline_stg_ltx_image2video.py
index 5a3c3c5304..2c1f38d7db 100644
--- a/examples/community/pipeline_stg_ltx_image2video.py
+++ b/examples/community/pipeline_stg_ltx_image2video.py
@@ -669,9 +669,9 @@ class LTXImageToVideoSTGPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVide
in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
passed will be used. Must be in descending order.
guidance_scale (`float`, defaults to `3 `):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_videos_per_prompt (`int`, *optional*, defaults to 1):
diff --git a/examples/community/pipeline_stg_mochi.py b/examples/community/pipeline_stg_mochi.py
index 97b7293d0a..19ad347b95 100644
--- a/examples/community/pipeline_stg_mochi.py
+++ b/examples/community/pipeline_stg_mochi.py
@@ -590,9 +590,9 @@ class MochiSTGPipeline(DiffusionPipeline, Mochi1LoraLoaderMixin):
in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
passed will be used. Must be in descending order.
guidance_scale (`float`, defaults to `4.5`):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_videos_per_prompt (`int`, *optional*, defaults to 1):
diff --git a/examples/community/pipeline_stg_wan.py b/examples/community/pipeline_stg_wan.py
index 31cdd0efca..39f208bad7 100644
--- a/examples/community/pipeline_stg_wan.py
+++ b/examples/community/pipeline_stg_wan.py
@@ -451,9 +451,9 @@ class WanSTGPipeline(DiffusionPipeline, WanLoraLoaderMixin):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, defaults to `5.0`):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_videos_per_prompt (`int`, *optional*, defaults to 1):
diff --git a/examples/community/pipeline_zero1to3.py b/examples/community/pipeline_zero1to3.py
index 9a34f91bf8..0db543b169 100644
--- a/examples/community/pipeline_zero1to3.py
+++ b/examples/community/pipeline_zero1to3.py
@@ -464,7 +464,7 @@ class Zero1to3StableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -637,9 +637,9 @@ class Zero1to3StableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -649,7 +649,7 @@ class Zero1to3StableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -708,7 +708,7 @@ class Zero1to3StableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
batch_size = input_imgs.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/regional_prompting_stable_diffusion.py b/examples/community/regional_prompting_stable_diffusion.py
index 25923a6503..bca67e3959 100644
--- a/examples/community/regional_prompting_stable_diffusion.py
+++ b/examples/community/regional_prompting_stable_diffusion.py
@@ -1,14 +1,43 @@
+import inspect
import math
-from typing import Dict, Optional
+from typing import Any, Callable, Dict, List, Optional, Union
import torch
import torchvision.transforms.functional as FF
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer, CLIPVisionModelWithProjection
-from diffusers import StableDiffusionPipeline
+from diffusers.callbacks import MultiPipelineCallbacks, PipelineCallback
+from diffusers.image_processor import PipelineImageInput, VaeImageProcessor
+from diffusers.loaders import StableDiffusionLoraLoaderMixin
+from diffusers.loaders.ip_adapter import IPAdapterMixin
+from diffusers.loaders.lora_pipeline import LoraLoaderMixin
+from diffusers.loaders.single_file import FromSingleFileMixin
+from diffusers.loaders.textual_inversion import TextualInversionLoaderMixin
from diffusers.models import AutoencoderKL, UNet2DConditionModel
+from diffusers.models.lora import adjust_lora_scale_text_encoder
+from diffusers.pipelines.pipeline_utils import DiffusionPipeline
+from diffusers.pipelines.stable_diffusion.pipeline_output import StableDiffusionPipelineOutput
from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
from diffusers.schedulers import KarrasDiffusionSchedulers
+from diffusers.utils import (
+ USE_PEFT_BACKEND,
+ deprecate,
+ is_torch_xla_available,
+ logging,
+ scale_lora_layers,
+ unscale_lora_layers,
+)
+from diffusers.utils.torch_utils import randn_tensor
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+if is_torch_xla_available():
+ import torch_xla.core.xla_model as xm
+
+ XLA_AVAILABLE = True
+else:
+ XLA_AVAILABLE = False
try:
@@ -21,7 +50,14 @@ KCOMM = "ADDCOMM"
KBRK = "BREAK"
-class RegionalPromptingStableDiffusionPipeline(StableDiffusionPipeline):
+class RegionalPromptingStableDiffusionPipeline(
+ DiffusionPipeline,
+ TextualInversionLoaderMixin,
+ LoraLoaderMixin,
+ IPAdapterMixin,
+ FromSingleFileMixin,
+ StableDiffusionLoraLoaderMixin,
+):
r"""
Args for Regional Prompting Pipeline:
rp_args:dict
@@ -78,17 +114,7 @@ class RegionalPromptingStableDiffusionPipeline(StableDiffusionPipeline):
image_encoder: CLIPVisionModelWithProjection = None,
requires_safety_checker: bool = True,
):
- super().__init__(
- vae,
- text_encoder,
- tokenizer,
- unet,
- scheduler,
- safety_checker,
- feature_extractor,
- image_encoder,
- requires_safety_checker,
- )
+ super().__init__()
self.register_modules(
vae=vae,
text_encoder=text_encoder,
@@ -99,6 +125,17 @@ class RegionalPromptingStableDiffusionPipeline(StableDiffusionPipeline):
feature_extractor=feature_extractor,
image_encoder=image_encoder,
)
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1) if getattr(self, "vae", None) else 8
+ self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
+ self.register_to_config(requires_safety_checker=requires_safety_checker)
+
+ # Initialize additional properties needed for DiffusionPipeline
+ self._num_timesteps = None
+ self._interrupt = False
+ self._guidance_scale = 7.5
+ self._guidance_rescale = 0.0
+ self._clip_skip = None
+ self._cross_attention_kwargs = None
@torch.no_grad()
def __call__(
@@ -413,7 +450,7 @@ class RegionalPromptingStableDiffusionPipeline(StableDiffusionPipeline):
hook_forwards(self.unet)
- output = StableDiffusionPipeline(**self.components)(
+ output = self.stable_diffusion_call(
prompt=prompt,
prompt_embeds=embs,
negative_prompt=negative_prompt,
@@ -449,6 +486,909 @@ class RegionalPromptingStableDiffusionPipeline(StableDiffusionPipeline):
return output
+ # copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ # copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion
+ def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
+ shape = (
+ batch_size,
+ num_channels_latents,
+ int(height) // self.vae_scale_factor,
+ int(width) // self.vae_scale_factor,
+ )
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ # copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion
+ def encode_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt=None,
+ prompt_embeds: Optional[torch.Tensor] = None,
+ negative_prompt_embeds: Optional[torch.Tensor] = None,
+ lora_scale: Optional[float] = None,
+ clip_skip: Optional[int] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ lora_scale (`float`, *optional*):
+ A LoRA scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
+ clip_skip (`int`, *optional*):
+ Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
+ the output of the pre-final layer will be used for computing the prompt embeddings.
+ """
+ # set lora scale so that monkey patched LoRA
+ # function of text encoder can correctly access it
+ if lora_scale is not None and isinstance(self, StableDiffusionLoraLoaderMixin):
+ self._lora_scale = lora_scale
+
+ # dynamically adjust the LoRA scale
+ if not USE_PEFT_BACKEND:
+ adjust_lora_scale_text_encoder(self.text_encoder, lora_scale)
+ else:
+ scale_lora_layers(self.text_encoder, lora_scale)
+
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if prompt_embeds is None:
+ # textual inversion: process multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = self.tokenizer.batch_decode(
+ untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = text_inputs.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ if clip_skip is None:
+ prompt_embeds = self.text_encoder(text_input_ids.to(device), attention_mask=attention_mask)
+ prompt_embeds = prompt_embeds[0]
+ else:
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device), attention_mask=attention_mask, output_hidden_states=True
+ )
+ # Access the `hidden_states` first, that contains a tuple of
+ # all the hidden states from the encoder layers. Then index into
+ # the tuple to access the hidden states from the desired layer.
+ prompt_embeds = prompt_embeds[-1][-(clip_skip + 1)]
+ # We also need to apply the final LayerNorm here to not mess with the
+ # representations. The `last_hidden_states` that we typically use for
+ # obtaining the final prompt representations passes through the LayerNorm
+ # layer.
+ prompt_embeds = self.text_encoder.text_model.final_layer_norm(prompt_embeds)
+
+ if self.text_encoder is not None:
+ prompt_embeds_dtype = self.text_encoder.dtype
+ elif self.unet is not None:
+ prompt_embeds_dtype = self.unet.dtype
+ else:
+ prompt_embeds_dtype = prompt_embeds.dtype
+
+ prompt_embeds = prompt_embeds.to(dtype=prompt_embeds_dtype, device=device)
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance and negative_prompt_embeds is None:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif prompt is not None and type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ # textual inversion: process multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = uncond_input.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input.input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = negative_prompt_embeds[0]
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=prompt_embeds_dtype, device=device)
+
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ if self.text_encoder is not None:
+ if isinstance(self, StableDiffusionLoraLoaderMixin) and USE_PEFT_BACKEND:
+ # Retrieve the original scale by scaling back the LoRA layers
+ unscale_lora_layers(self.text_encoder, lora_scale)
+
+ return prompt_embeds, negative_prompt_embeds
+
+ # copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion
+ def check_inputs(
+ self,
+ prompt,
+ height,
+ width,
+ callback_steps,
+ negative_prompt=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ ip_adapter_image=None,
+ ip_adapter_image_embeds=None,
+ callback_on_step_end_tensor_inputs=None,
+ ):
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+ if callback_on_step_end_tensor_inputs is not None and not all(
+ k in self._callback_tensor_inputs for k in callback_on_step_end_tensor_inputs
+ ):
+ raise ValueError(
+ f"`callback_on_step_end_tensor_inputs` has to be in {self._callback_tensor_inputs}, but found {[k for k in callback_on_step_end_tensor_inputs if k not in self._callback_tensor_inputs]}"
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ if ip_adapter_image is not None and ip_adapter_image_embeds is not None:
+ raise ValueError(
+ "Provide either `ip_adapter_image` or `ip_adapter_image_embeds`. Cannot leave both `ip_adapter_image` and `ip_adapter_image_embeds` defined."
+ )
+
+ if ip_adapter_image_embeds is not None:
+ if not isinstance(ip_adapter_image_embeds, list):
+ raise ValueError(
+ f"`ip_adapter_image_embeds` has to be of type `list` but is {type(ip_adapter_image_embeds)}"
+ )
+ elif ip_adapter_image_embeds[0].ndim not in [3, 4]:
+ raise ValueError(
+ f"`ip_adapter_image_embeds` has to be a list of 3D or 4D tensors but is {ip_adapter_image_embeds[0].ndim}D"
+ )
+
+ # copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion
+ @torch.no_grad()
+ def stable_diffusion_call(
+ self,
+ prompt: Union[str, List[str]] = None,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ timesteps: List[int] = None,
+ sigmas: List[float] = None,
+ guidance_scale: float = 7.5,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.Tensor] = None,
+ prompt_embeds: Optional[torch.Tensor] = None,
+ negative_prompt_embeds: Optional[torch.Tensor] = None,
+ ip_adapter_image: Optional[PipelineImageInput] = None,
+ ip_adapter_image_embeds: Optional[List[torch.Tensor]] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ guidance_rescale: float = 0.0,
+ clip_skip: Optional[int] = None,
+ callback_on_step_end: Optional[
+ Union[Callable[[int, int, Dict], None], PipelineCallback, MultiPipelineCallbacks]
+ ] = None,
+ callback_on_step_end_tensor_inputs: List[str] = ["latents"],
+ **kwargs,
+ ):
+ r"""
+ The call function to the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide image generation. If not defined, you need to pass `prompt_embeds`.
+ height (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ timesteps (`List[int]`, *optional*):
+ Custom timesteps to use for the denoising process with schedulers which support a `timesteps` argument
+ in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
+ passed will be used. Must be in descending order.
+ sigmas (`List[float]`, *optional*):
+ Custom sigmas to use for the denoising process with schedulers which support a `sigmas` argument in
+ their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
+ will be used.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ A higher guidance scale value encourages the model to generate images closely linked to the text
+ `prompt` at the expense of lower image quality. Guidance scale is enabled when `guidance_scale > 1`.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide what to not include in image generation. If not defined, you need to
+ pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
+ generation deterministic.
+ latents (`torch.Tensor`, *optional*):
+ Pre-generated noisy latents sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor is generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs (prompt weighting). If not
+ provided, text embeddings are generated from the `prompt` input argument.
+ negative_prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs (prompt weighting). If
+ not provided, `negative_prompt_embeds` are generated from the `negative_prompt` input argument.
+ ip_adapter_image: (`PipelineImageInput`, *optional*): Optional image input to work with IP Adapters.
+ ip_adapter_image_embeds (`List[torch.Tensor]`, *optional*):
+ Pre-generated image embeddings for IP-Adapter. It should be a list of length same as number of
+ IP-adapters. Each element should be a tensor of shape `(batch_size, num_images, emb_dim)`. It should
+ contain the negative image embedding if `do_classifier_free_guidance` is set to `True`. If not
+ provided, embeddings are computed from the `ip_adapter_image` input argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generated image. Choose between `PIL.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the [`AttentionProcessor`] as defined in
+ [`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
+ guidance_rescale (`float`, *optional*, defaults to 0.0):
+ Guidance rescale factor from [Common Diffusion Noise Schedules and Sample Steps are
+ Flawed](https://arxiv.org/pdf/2305.08891.pdf). Guidance rescale factor should fix overexposure when
+ using zero terminal SNR.
+ clip_skip (`int`, *optional*):
+ Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
+ the output of the pre-final layer will be used for computing the prompt embeddings.
+ callback_on_step_end (`Callable`, `PipelineCallback`, `MultiPipelineCallbacks`, *optional*):
+ A function or a subclass of `PipelineCallback` or `MultiPipelineCallbacks` that is called at the end of
+ each denoising step during the inference. with the following arguments: `callback_on_step_end(self:
+ DiffusionPipeline, step: int, timestep: int, callback_kwargs: Dict)`. `callback_kwargs` will include a
+ list of all tensors as specified by `callback_on_step_end_tensor_inputs`.
+ callback_on_step_end_tensor_inputs (`List`, *optional*):
+ The list of tensor inputs for the `callback_on_step_end` function. The tensors specified in the list
+ will be passed as `callback_kwargs` argument. You will only be able to include variables listed in the
+ `._callback_tensor_inputs` attribute of your pipeline class.
+
+ Examples:
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ If `return_dict` is `True`, [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] is returned,
+ otherwise a `tuple` is returned where the first element is a list with the generated images and the
+ second element is a list of `bool`s indicating whether the corresponding generated image contains
+ "not-safe-for-work" (nsfw) content.
+ """
+
+ callback = kwargs.pop("callback", None)
+ callback_steps = kwargs.pop("callback_steps", None)
+ self.model_cpu_offload_seq = "text_encoder->image_encoder->unet->vae"
+ self._optional_components = ["safety_checker", "feature_extractor", "image_encoder"]
+ self._exclude_from_cpu_offload = ["safety_checker"]
+ self._callback_tensor_inputs = ["latents", "prompt_embeds", "negative_prompt_embeds"]
+
+ if callback is not None:
+ deprecate(
+ "callback",
+ "1.0.0",
+ "Passing `callback` as an input argument to `__call__` is deprecated, consider using `callback_on_step_end`",
+ )
+ if callback_steps is not None:
+ deprecate(
+ "callback_steps",
+ "1.0.0",
+ "Passing `callback_steps` as an input argument to `__call__` is deprecated, consider using `callback_on_step_end`",
+ )
+
+ if isinstance(callback_on_step_end, (PipelineCallback, MultiPipelineCallbacks)):
+ callback_on_step_end_tensor_inputs = callback_on_step_end.tensor_inputs
+
+ # 0. Default height and width to unet
+ if not height or not width:
+ height = (
+ self.unet.config.sample_size
+ if self._is_unet_config_sample_size_int
+ else self.unet.config.sample_size[0]
+ )
+ width = (
+ self.unet.config.sample_size
+ if self._is_unet_config_sample_size_int
+ else self.unet.config.sample_size[1]
+ )
+ height, width = height * self.vae_scale_factor, width * self.vae_scale_factor
+ # to deal with lora scaling and other possible forward hooks
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ prompt,
+ height,
+ width,
+ callback_steps,
+ negative_prompt,
+ prompt_embeds,
+ negative_prompt_embeds,
+ ip_adapter_image,
+ ip_adapter_image_embeds,
+ callback_on_step_end_tensor_inputs,
+ )
+
+ self._guidance_scale = guidance_scale
+ self._guidance_rescale = guidance_rescale
+ self._clip_skip = clip_skip
+ self._cross_attention_kwargs = cross_attention_kwargs
+ self._interrupt = False
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+
+ # 3. Encode input prompt
+ lora_scale = (
+ self.cross_attention_kwargs.get("scale", None) if self.cross_attention_kwargs is not None else None
+ )
+
+ prompt_embeds, negative_prompt_embeds = self.encode_prompt(
+ prompt,
+ device,
+ num_images_per_prompt,
+ self.do_classifier_free_guidance,
+ negative_prompt,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ lora_scale=lora_scale,
+ clip_skip=self.clip_skip,
+ )
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ if self.do_classifier_free_guidance:
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ if ip_adapter_image is not None or ip_adapter_image_embeds is not None:
+ image_embeds = self.prepare_ip_adapter_image_embeds(
+ ip_adapter_image,
+ ip_adapter_image_embeds,
+ device,
+ batch_size * num_images_per_prompt,
+ self.do_classifier_free_guidance,
+ )
+
+ # 4. Prepare timesteps
+ timesteps, num_inference_steps = retrieve_timesteps(
+ self.scheduler, num_inference_steps, device, timesteps, sigmas
+ )
+
+ # 5. Prepare latent variables
+ num_channels_latents = self.unet.config.in_channels
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ height,
+ width,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 6.1 Add image embeds for IP-Adapter
+ added_cond_kwargs = (
+ {"image_embeds": image_embeds}
+ if (ip_adapter_image is not None or ip_adapter_image_embeds is not None)
+ else None
+ )
+
+ # 6.2 Optionally get Guidance Scale Embedding
+ timestep_cond = None
+ if self.unet.config.time_cond_proj_dim is not None:
+ guidance_scale_tensor = torch.tensor(self.guidance_scale - 1).repeat(batch_size * num_images_per_prompt)
+ timestep_cond = self.get_guidance_scale_embedding(
+ guidance_scale_tensor, embedding_dim=self.unet.config.time_cond_proj_dim
+ ).to(device=device, dtype=latents.dtype)
+
+ # 7. Denoising loop
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+ self._num_timesteps = len(timesteps)
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ if self.interrupt:
+ continue
+
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if self.do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # predict the noise residual
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ timestep_cond=timestep_cond,
+ cross_attention_kwargs=self.cross_attention_kwargs,
+ added_cond_kwargs=added_cond_kwargs,
+ return_dict=False,
+ )[0]
+
+ # perform guidance
+ if self.do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
+ # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
+
+ if callback_on_step_end is not None:
+ callback_kwargs = {}
+ for k in callback_on_step_end_tensor_inputs:
+ callback_kwargs[k] = locals()[k]
+ callback_outputs = callback_on_step_end(self, i, t, callback_kwargs)
+
+ latents = callback_outputs.pop("latents", latents)
+ prompt_embeds = callback_outputs.pop("prompt_embeds", prompt_embeds)
+ negative_prompt_embeds = callback_outputs.pop("negative_prompt_embeds", negative_prompt_embeds)
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ step_idx = i // getattr(self.scheduler, "order", 1)
+ callback(step_idx, t, latents)
+
+ if XLA_AVAILABLE:
+ xm.mark_step()
+
+ if not output_type == "latent":
+ image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False, generator=generator)[
+ 0
+ ]
+ image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
+ else:
+ image = latents
+ has_nsfw_concept = None
+
+ if has_nsfw_concept is None:
+ do_denormalize = [True] * image.shape[0]
+ else:
+ do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
+ image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
+
+ # Offload all models
+ self.maybe_free_model_hooks()
+
+ if not return_dict:
+ return (image, has_nsfw_concept)
+
+ return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
+
+ # copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion
+ def _encode_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt=None,
+ prompt_embeds: Optional[torch.Tensor] = None,
+ negative_prompt_embeds: Optional[torch.Tensor] = None,
+ lora_scale: Optional[float] = None,
+ **kwargs,
+ ):
+ r"""Encodes the prompt into text encoder hidden states."""
+ batch_size = len(prompt) if isinstance(prompt, list) else 1
+
+ # get prompt text embeddings
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(text_input_ids, untruncated_ids):
+ removed_text = self.tokenizer.batch_decode(untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1])
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = text_inputs.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ if isinstance(self, StableDiffusionLoraLoaderMixin) and USE_PEFT_BACKEND:
+ # cast text_encoder.dtype to prevent overflow when using bf16
+ text_input_ids = text_input_ids.to(device=device, dtype=self.text_encoder.dtype)
+ prompt_embeds = self.text_encoder(
+ text_input_ids,
+ attention_mask=attention_mask,
+ )
+ prompt_embeds = prompt_embeds[0]
+ else:
+ text_encoder_lora_scale = None
+ if lora_scale is not None and isinstance(self, StableDiffusionLoraLoaderMixin):
+ text_encoder_lora_scale = lora_scale
+ if text_encoder_lora_scale is not None and isinstance(self, StableDiffusionLoraLoaderMixin):
+ # dynamically adjust the LoRA scale
+ adjust_lora_scale_text_encoder(self.text_encoder, lora_scale)
+
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ prompt_embeds = prompt_embeds[0]
+
+ # duplicate text embeddings for each generation per prompt
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance and negative_prompt_embeds is None:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""]
+ elif type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ # textual inversion: process multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = uncond_input.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input.input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = negative_prompt_embeds[0]
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt
+ seq_len = negative_prompt_embeds.shape[1]
+
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ if isinstance(self, StableDiffusionLoraLoaderMixin) and USE_PEFT_BACKEND:
+ # Unscale LoRA weights to avoid overfitting. This is a hack
+ unscale_lora_layers(self.text_encoder, lora_scale)
+
+ return prompt_embeds, negative_prompt_embeds
+
+ def encode_image(self, image, device, num_images_per_prompt, output_hidden_states=None):
+ """Encodes the image into image encoder hidden states."""
+ dtype = next(self.image_encoder.parameters()).dtype
+
+ if not isinstance(image, torch.Tensor):
+ image = self.feature_extractor(image, return_tensors="pt").pixel_values
+
+ image = image.to(device=device, dtype=dtype)
+ if output_hidden_states:
+ image_enc_hidden_states = self.image_encoder(image, output_hidden_states=True).hidden_states[-2]
+ image_enc_hidden_states = image_enc_hidden_states.repeat_interleave(num_images_per_prompt, dim=0)
+ uncond_image_enc_hidden_states = self.image_encoder(
+ torch.zeros_like(image), output_hidden_states=True
+ ).hidden_states[-2]
+ uncond_image_enc_hidden_states = uncond_image_enc_hidden_states.repeat_interleave(
+ num_images_per_prompt, dim=0
+ )
+ return image_enc_hidden_states, uncond_image_enc_hidden_states
+ else:
+ image_embeds = self.image_encoder(image).image_embeds
+ image_embeds = image_embeds.repeat_interleave(num_images_per_prompt, dim=0)
+ uncond_image_embeds = torch.zeros_like(image_embeds)
+
+ return image_embeds, uncond_image_embeds
+
+ def prepare_ip_adapter_image_embeds(
+ self, ip_adapter_image, ip_adapter_image_embeds, device, num_images_per_prompt, do_classifier_free_guidance
+ ):
+ """Prepares and processes IP-Adapter image embeddings."""
+ image_embeds = []
+ if do_classifier_free_guidance:
+ negative_image_embeds = []
+ if ip_adapter_image_embeds is None:
+ for image in ip_adapter_image:
+ if not isinstance(image, torch.Tensor):
+ image = self.image_processor.preprocess(image)
+ image = image.to(device=device)
+ if len(image.shape) == 3:
+ image = image.unsqueeze(0)
+ image_emb, neg_image_emb = self.encode_image(image, device, num_images_per_prompt, True)
+ image_embeds.append(image_emb)
+ if do_classifier_free_guidance:
+ negative_image_embeds.append(neg_image_emb)
+
+ if len(image_embeds) == 1:
+ image_embeds = image_embeds[0]
+ if do_classifier_free_guidance:
+ negative_image_embeds = negative_image_embeds[0]
+ else:
+ image_embeds = torch.cat(image_embeds, dim=0)
+ if do_classifier_free_guidance:
+ negative_image_embeds = torch.cat(negative_image_embeds, dim=0)
+ else:
+ repeat_dim = 2 if do_classifier_free_guidance else 1
+ image_embeds = ip_adapter_image_embeds.repeat_interleave(repeat_dim, dim=0)
+ if do_classifier_free_guidance:
+ negative_image_embeds = torch.zeros_like(image_embeds)
+
+ if do_classifier_free_guidance:
+ image_embeds = torch.cat([negative_image_embeds, image_embeds])
+
+ return image_embeds
+
+ def run_safety_checker(self, image, device, dtype):
+ """Runs the safety checker on the generated image."""
+ if self.safety_checker is None:
+ has_nsfw_concept = None
+ return image, has_nsfw_concept
+
+ if isinstance(self.safety_checker, StableDiffusionSafetyChecker):
+ safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(device)
+ image, has_nsfw_concept = self.safety_checker(
+ images=image,
+ clip_input=safety_checker_input.pixel_values.to(dtype),
+ )
+ else:
+ images_np = self.numpy_to_pil(image)
+ safety_checker_input = self.safety_checker.feature_extractor(images_np, return_tensors="pt").to(device)
+ has_nsfw_concept = self.safety_checker(
+ images=image,
+ clip_input=safety_checker_input.pixel_values.to(dtype),
+ )[1]
+
+ return image, has_nsfw_concept
+
+ # copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion
+ def decode_latents(self, latents):
+ """Decodes the latents to images."""
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents, return_dict=False)[0]
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ @property
+ def guidance_scale(self):
+ return self._guidance_scale
+
+ @property
+ def guidance_rescale(self):
+ return self._guidance_rescale
+
+ # copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion
+ def get_guidance_scale_embedding(
+ self, w: torch.Tensor, embedding_dim: int = 512, dtype: torch.dtype = torch.float32
+ ):
+ """Gets the guidance scale embedding for classifier free guidance conditioning.
+ See https://github.com/google-research/vdm/blob/dc27b98a554f65cdc654b800da5aa1846545d41b/model_vdm.py#L298
+
+ Args:
+ w (`torch.Tensor`):
+ The guidance scale tensor used for classifier free guidance conditioning.
+ embedding_dim (`int`, defaults to 512):
+ The dimensionality of the guidance scale embedding.
+ dtype (`torch.dtype`, defaults to torch.float32):
+ The dtype of the embedding.
+
+ Returns:
+ `torch.Tensor`: Embedding vectors with shape `(len(w), embedding_dim)`.
+ """
+ assert len(w.shape) == 1
+ w = w * 1000.0
+
+ half_dim = embedding_dim // 2
+ emb = torch.log(torch.tensor(10000.0)) / (half_dim - 1)
+ emb = torch.exp(torch.arange(half_dim, dtype=dtype) * -emb)
+ emb = w.to(dtype)[:, None] * emb[None, :]
+ emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=1)
+ if embedding_dim % 2 == 1: # zero pad
+ emb = torch.nn.functional.pad(emb, (0, 1))
+ assert emb.shape == (w.shape[0], embedding_dim)
+ return emb
+
+ @property
+ def clip_skip(self):
+ return self._clip_skip
+
+ @property
+ def num_timesteps(self):
+ return self._num_timesteps
+
+ @property
+ def interrupt(self):
+ return self._interrupt
+
+ @property
+ def cross_attention_kwargs(self):
+ return self._cross_attention_kwargs
+
+ @property
+ def do_classifier_free_guidance(self):
+ return self._guidance_scale > 1 and self.unet.config.time_cond_proj_dim is None
+
### Make prompt list for each regions
def promptsmaker(prompts, batch):
@@ -663,3 +1603,88 @@ def scaled_dot_product_attention(
get_attn_maps(self, attn_weight)
attn_weight = torch.dropout(attn_weight, dropout_p, train=True)
return attn_weight @ value
+
+
+def retrieve_timesteps(
+ scheduler,
+ num_inference_steps: Optional[int] = None,
+ device: Optional[Union[str, torch.device]] = None,
+ timesteps: Optional[List[int]] = None,
+ sigmas: Optional[List[float]] = None,
+ **kwargs,
+):
+ r"""
+ Calls the scheduler's `set_timesteps` method and retrieves timesteps from the scheduler after the call. Handles
+ custom timesteps. Any kwargs will be supplied to `scheduler.set_timesteps`.
+
+ Args:
+ scheduler (`SchedulerMixin`):
+ The scheduler to get timesteps from.
+ num_inference_steps (`int`):
+ The number of diffusion steps used when generating samples with a pre-trained model. If used, `timesteps`
+ must be `None`.
+ device (`str` or `torch.device`, *optional*):
+ The device to which the timesteps should be moved to. If `None`, the timesteps are not moved.
+ timesteps (`List[int]`, *optional*):
+ Custom timesteps used to override the timestep spacing strategy of the scheduler. If `timesteps` is passed,
+ `num_inference_steps` and `sigmas` must be `None`.
+ sigmas (`List[float]`, *optional*):
+ Custom sigmas used to override the timestep spacing strategy of the scheduler. If `sigmas` is passed,
+ `num_inference_steps` and `timesteps` must be `None`.
+
+ Returns:
+ `Tuple[torch.Tensor, int]`: A tuple where the first element is the timestep schedule from the scheduler and the
+ second element is the number of inference steps.
+ """
+ if timesteps is not None and sigmas is not None:
+ raise ValueError("Only one of `timesteps` or `sigmas` can be passed. Please choose one to set custom values")
+ if timesteps is not None:
+ accepts_timesteps = "timesteps" in set(inspect.signature(scheduler.set_timesteps).parameters.keys())
+ if not accepts_timesteps:
+ raise ValueError(
+ f"The current scheduler class {scheduler.__class__}'s `set_timesteps` does not support custom"
+ f" timestep schedules. Please check whether you are using the correct scheduler."
+ )
+ scheduler.set_timesteps(timesteps=timesteps, device=device, **kwargs)
+ timesteps = scheduler.timesteps
+ num_inference_steps = len(timesteps)
+ elif sigmas is not None:
+ accept_sigmas = "sigmas" in set(inspect.signature(scheduler.set_timesteps).parameters.keys())
+ if not accept_sigmas:
+ raise ValueError(
+ f"The current scheduler class {scheduler.__class__}'s `set_timesteps` does not support custom"
+ f" sigmas schedules. Please check whether you are using the correct scheduler."
+ )
+ scheduler.set_timesteps(sigmas=sigmas, device=device, **kwargs)
+ timesteps = scheduler.timesteps
+ num_inference_steps = len(timesteps)
+ else:
+ scheduler.set_timesteps(num_inference_steps, device=device, **kwargs)
+ timesteps = scheduler.timesteps
+ return timesteps, num_inference_steps
+
+
+def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
+ r"""
+ Rescales `noise_cfg` tensor based on `guidance_rescale` to improve image quality and fix overexposure. Based on
+ Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
+ Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+
+ Args:
+ noise_cfg (`torch.Tensor`):
+ The predicted noise tensor for the guided diffusion process.
+ noise_pred_text (`torch.Tensor`):
+ The predicted noise tensor for the text-guided diffusion process.
+ guidance_rescale (`float`, *optional*, defaults to 0.0):
+ A rescale factor applied to the noise predictions.
+
+ Returns:
+ noise_cfg (`torch.Tensor`): The rescaled noise prediction tensor.
+ """
+ std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
+ std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
+ # rescale the results from guidance (fixes overexposure)
+ noise_pred_rescaled = noise_cfg * (std_text / std_cfg)
+ # mix with the original results from guidance by factor guidance_rescale to avoid "plain looking" images
+ noise_cfg = guidance_rescale * noise_pred_rescaled + (1 - guidance_rescale) * noise_cfg
+ return noise_cfg
diff --git a/examples/community/rerender_a_video.py b/examples/community/rerender_a_video.py
index 7e66bff51d..521dc975a2 100644
--- a/examples/community/rerender_a_video.py
+++ b/examples/community/rerender_a_video.py
@@ -99,7 +99,7 @@ def flow_warp(feature, flow, mask=False, mode="bilinear", padding_mode="zeros"):
def forward_backward_consistency_check(fwd_flow, bwd_flow, alpha=0.01, beta=0.5):
# fwd_flow, bwd_flow: [B, 2, H, W]
# alpha and beta values are following UnFlow
- # (https://arxiv.org/abs/1711.07837)
+ # (https://huggingface.co/papers/1711.07837)
assert fwd_flow.dim() == 4 and bwd_flow.dim() == 4
assert fwd_flow.size(1) == 2 and bwd_flow.size(1) == 2
flow_mag = torch.norm(fwd_flow, dim=1) + torch.norm(bwd_flow, dim=1) # [B, H, W]
@@ -638,9 +638,9 @@ class RerenderAVideoPipeline(StableDiffusionControlNetImg2ImgPipeline):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -648,7 +648,7 @@ class RerenderAVideoPipeline(StableDiffusionControlNetImg2ImgPipeline):
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
less than `1`).
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -747,7 +747,7 @@ class RerenderAVideoPipeline(StableDiffusionControlNetImg2ImgPipeline):
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/run_onnx_controlnet.py b/examples/community/run_onnx_controlnet.py
index af2672c17e..2221fc09db 100644
--- a/examples/community/run_onnx_controlnet.py
+++ b/examples/community/run_onnx_controlnet.py
@@ -252,7 +252,7 @@ class OnnxStableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -571,9 +571,9 @@ class OnnxStableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -583,7 +583,7 @@ class OnnxStableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -680,7 +680,7 @@ class OnnxStableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline):
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/run_tensorrt_controlnet.py b/examples/community/run_tensorrt_controlnet.py
index 873195fa31..b9e71724c0 100644
--- a/examples/community/run_tensorrt_controlnet.py
+++ b/examples/community/run_tensorrt_controlnet.py
@@ -356,7 +356,7 @@ class TensorRTStableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -675,9 +675,9 @@ class TensorRTStableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -687,7 +687,7 @@ class TensorRTStableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -784,7 +784,7 @@ class TensorRTStableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline):
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/scheduling_ufogen.py b/examples/community/scheduling_ufogen.py
index 0b832394cf..a3b9640c95 100644
--- a/examples/community/scheduling_ufogen.py
+++ b/examples/community/scheduling_ufogen.py
@@ -94,7 +94,7 @@ def betas_for_alpha_bar(
# Copied from diffusers.schedulers.scheduling_ddim.rescale_zero_terminal_snr
def rescale_zero_terminal_snr(betas):
"""
- Rescales betas to have zero terminal SNR Based on https://arxiv.org/pdf/2305.08891.pdf (Algorithm 1)
+ Rescales betas to have zero terminal SNR Based on https://huggingface.co/papers/2305.08891 (Algorithm 1)
Args:
@@ -131,7 +131,7 @@ def rescale_zero_terminal_snr(betas):
class UFOGenScheduler(SchedulerMixin, ConfigMixin):
"""
`UFOGenScheduler` implements multistep and onestep sampling for a UFOGen model, introduced in
- [UFOGen: You Forward Once Large Scale Text-to-Image Generation via Diffusion GANs](https://arxiv.org/abs/2311.09257)
+ [UFOGen: You Forward Once Large Scale Text-to-Image Generation via Diffusion GANs](https://huggingface.co/papers/2311.09257)
by Yanwu Xu, Yang Zhao, Zhisheng Xiao, and Tingbo Hou. UFOGen is a varianet of the denoising diffusion GAN (DDGAN)
model designed for one-step sampling.
@@ -311,7 +311,7 @@ class UFOGenScheduler(SchedulerMixin, ConfigMixin):
timesteps = np.array([self.config.num_train_timesteps - 1], dtype=np.int64)
else:
# TODO: For now, retain the DDPM timestep spacing logic
- # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://arxiv.org/abs/2305.08891
+ # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://huggingface.co/papers/2305.08891
if self.config.timestep_spacing == "linspace":
timesteps = (
np.linspace(0, self.config.num_train_timesteps - 1, num_inference_steps)
@@ -347,7 +347,7 @@ class UFOGenScheduler(SchedulerMixin, ConfigMixin):
pixels from saturation at each step. We find that dynamic thresholding results in significantly better
photorealism as well as better image-text alignment, especially when using very large guidance weights."
- https://arxiv.org/abs/2205.11487
+ https://huggingface.co/papers/2205.11487
"""
dtype = sample.dtype
batch_size, channels, *remaining_dims = sample.shape
@@ -415,7 +415,7 @@ class UFOGenScheduler(SchedulerMixin, ConfigMixin):
# current_beta_t = 1 - current_alpha_t
# 2. compute predicted original sample from predicted noise also called
- # "predicted x_0" of formula (15) from https://arxiv.org/pdf/2006.11239.pdf
+ # "predicted x_0" of formula (15) from https://huggingface.co/papers/2006.11239
if self.config.prediction_type == "epsilon":
pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
elif self.config.prediction_type == "sample":
diff --git a/examples/community/sd_text2img_k_diffusion.py b/examples/community/sd_text2img_k_diffusion.py
index 9f83973aba..598207850e 100755
--- a/examples/community/sd_text2img_k_diffusion.py
+++ b/examples/community/sd_text2img_k_diffusion.py
@@ -307,9 +307,9 @@ class StableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -318,7 +318,7 @@ class StableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
@@ -355,7 +355,7 @@ class StableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
batch_size = 1 if isinstance(prompt, str) else len(prompt)
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = True
if guidance_scale <= 1.0:
diff --git a/examples/community/sde_drag.py b/examples/community/sde_drag.py
index 3ded8c247c..f408ee64db 100644
--- a/examples/community/sde_drag.py
+++ b/examples/community/sde_drag.py
@@ -25,7 +25,7 @@ from diffusers.optimization import get_scheduler
class SdeDragPipeline(DiffusionPipeline):
r"""
- Pipeline for image drag-and-drop editing using stochastic differential equations: https://arxiv.org/abs/2311.01410.
+ Pipeline for image drag-and-drop editing using stochastic differential equations: https://huggingface.co/papers/2311.01410.
Please refer to the [official repository](https://github.com/ML-GSAI/SDE-Drag) for more information.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
diff --git a/examples/community/seed_resize_stable_diffusion.py b/examples/community/seed_resize_stable_diffusion.py
index ae2d8a53b2..3c823012c1 100644
--- a/examples/community/seed_resize_stable_diffusion.py
+++ b/examples/community/seed_resize_stable_diffusion.py
@@ -103,9 +103,9 @@ class SeedResizeStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin)
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -114,7 +114,7 @@ class SeedResizeStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin)
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
@@ -188,7 +188,7 @@ class SeedResizeStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin)
text_embeddings = text_embeddings.view(bs_embed * num_images_per_prompt, seq_len, -1)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
@@ -287,7 +287,7 @@ class SeedResizeStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin)
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
diff --git a/examples/community/speech_to_image_diffusion.py b/examples/community/speech_to_image_diffusion.py
index 9cb5a2a8c7..a8ec1620a2 100644
--- a/examples/community/speech_to_image_diffusion.py
+++ b/examples/community/speech_to_image_diffusion.py
@@ -134,7 +134,7 @@ class SpeechToImagePipeline(DiffusionPipeline, StableDiffusionMixin):
text_embeddings = text_embeddings.view(bs_embed * num_images_per_prompt, seq_len, -1)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
@@ -210,7 +210,7 @@ class SpeechToImagePipeline(DiffusionPipeline, StableDiffusionMixin):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
diff --git a/examples/community/stable_diffusion_comparison.py b/examples/community/stable_diffusion_comparison.py
index 2b510a64f8..36e7dba2de 100644
--- a/examples/community/stable_diffusion_comparison.py
+++ b/examples/community/stable_diffusion_comparison.py
@@ -265,13 +265,13 @@ class StableDiffusionComparisonPipeline(DiffusionPipeline, StableDiffusionMixin)
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, optional, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
eta (`float`, optional, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, optional):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
diff --git a/examples/community/stable_diffusion_controlnet_img2img.py b/examples/community/stable_diffusion_controlnet_img2img.py
index 6aa4067d69..877464454a 100644
--- a/examples/community/stable_diffusion_controlnet_img2img.py
+++ b/examples/community/stable_diffusion_controlnet_img2img.py
@@ -340,7 +340,7 @@ class StableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline, StableDiffusio
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -651,9 +651,9 @@ class StableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline, StableDiffusio
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -662,7 +662,7 @@ class StableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline, StableDiffusio
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -742,7 +742,7 @@ class StableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline, StableDiffusio
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/stable_diffusion_controlnet_inpaint.py b/examples/community/stable_diffusion_controlnet_inpaint.py
index 2d19e26b42..175c47d015 100644
--- a/examples/community/stable_diffusion_controlnet_inpaint.py
+++ b/examples/community/stable_diffusion_controlnet_inpaint.py
@@ -439,7 +439,7 @@ class StableDiffusionControlNetInpaintPipeline(DiffusionPipeline, StableDiffusio
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -791,9 +791,9 @@ class StableDiffusionControlNetInpaintPipeline(DiffusionPipeline, StableDiffusio
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -802,7 +802,7 @@ class StableDiffusionControlNetInpaintPipeline(DiffusionPipeline, StableDiffusio
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -875,7 +875,7 @@ class StableDiffusionControlNetInpaintPipeline(DiffusionPipeline, StableDiffusio
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/stable_diffusion_controlnet_inpaint_img2img.py b/examples/community/stable_diffusion_controlnet_inpaint_img2img.py
index 4363a2294b..51e7ac38dd 100644
--- a/examples/community/stable_diffusion_controlnet_inpaint_img2img.py
+++ b/examples/community/stable_diffusion_controlnet_inpaint_img2img.py
@@ -424,7 +424,7 @@ class StableDiffusionControlNetInpaintImg2ImgPipeline(DiffusionPipeline, StableD
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -785,9 +785,9 @@ class StableDiffusionControlNetInpaintImg2ImgPipeline(DiffusionPipeline, StableD
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -796,7 +796,7 @@ class StableDiffusionControlNetInpaintImg2ImgPipeline(DiffusionPipeline, StableD
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -869,7 +869,7 @@ class StableDiffusionControlNetInpaintImg2ImgPipeline(DiffusionPipeline, StableD
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/stable_diffusion_controlnet_reference.py b/examples/community/stable_diffusion_controlnet_reference.py
index 577c7712e7..aa9ab1b242 100644
--- a/examples/community/stable_diffusion_controlnet_reference.py
+++ b/examples/community/stable_diffusion_controlnet_reference.py
@@ -159,9 +159,9 @@ class StableDiffusionControlNetReferencePipeline(StableDiffusionControlNetPipeli
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -171,7 +171,7 @@ class StableDiffusionControlNetReferencePipeline(StableDiffusionControlNetPipeli
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -255,7 +255,7 @@ class StableDiffusionControlNetReferencePipeline(StableDiffusionControlNetPipeli
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/stable_diffusion_ipex.py b/examples/community/stable_diffusion_ipex.py
index b2d4541797..137b72de64 100644
--- a/examples/community/stable_diffusion_ipex.py
+++ b/examples/community/stable_diffusion_ipex.py
@@ -210,7 +210,7 @@ class StableDiffusionIPEXPipeline(
device = "cpu"
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
@@ -475,7 +475,7 @@ class StableDiffusionIPEXPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -595,9 +595,9 @@ class StableDiffusionIPEXPipeline(
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -607,7 +607,7 @@ class StableDiffusionIPEXPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -668,7 +668,7 @@ class StableDiffusionIPEXPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/stable_diffusion_reference.py b/examples/community/stable_diffusion_reference.py
index 9ef95a5205..69fa0722cf 100644
--- a/examples/community/stable_diffusion_reference.py
+++ b/examples/community/stable_diffusion_reference.py
@@ -655,7 +655,7 @@ class StableDiffusionReferencePipeline(
"""
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -865,9 +865,9 @@ class StableDiffusionReferencePipeline(
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -877,7 +877,7 @@ class StableDiffusionReferencePipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -911,8 +911,8 @@ class StableDiffusionReferencePipeline(
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
- [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://huggingface.co/papers/2305.08891).
Guidance rescale factor should fix overexposure when using zero terminal SNR.
attention_auto_machine_weight (`float`):
Weight of using reference query for self attention's context.
@@ -956,7 +956,7 @@ class StableDiffusionReferencePipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
@@ -1432,7 +1432,7 @@ class StableDiffusionReferencePipeline(
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if do_classifier_free_guidance and guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/examples/community/stable_diffusion_repaint.py b/examples/community/stable_diffusion_repaint.py
index 0bc28eca15..1245a89702 100644
--- a/examples/community/stable_diffusion_repaint.py
+++ b/examples/community/stable_diffusion_repaint.py
@@ -442,7 +442,7 @@ class StableDiffusionRepaintPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -653,14 +653,14 @@ class StableDiffusionRepaintPipeline(
expense of slower inference.
jump_length (`int`, *optional*, defaults to 10):
The number of steps taken forward in time before going backward in time for a single jump ("j" in
- RePaint paper). Take a look at Figure 9 and 10 in https://arxiv.org/pdf/2201.09865.pdf.
+ RePaint paper). Take a look at Figure 9 and 10 in https://huggingface.co/papers/2201.09865.
jump_n_sample (`int`, *optional*, defaults to 10):
The number of times we will make forward time jump for a given chosen time sample. Take a look at
- Figure 9 and 10 in https://arxiv.org/pdf/2201.09865.pdf.
+ Figure 9 and 10 in https://huggingface.co/papers/2201.09865.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -670,7 +670,7 @@ class StableDiffusionRepaintPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -759,7 +759,7 @@ class StableDiffusionRepaintPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/examples/community/stable_diffusion_tensorrt_img2img.py b/examples/community/stable_diffusion_tensorrt_img2img.py
index f2d184bb73..dc11703b6a 100755
--- a/examples/community/stable_diffusion_tensorrt_img2img.py
+++ b/examples/community/stable_diffusion_tensorrt_img2img.py
@@ -1059,9 +1059,9 @@ class TensorRTStableDiffusionImg2ImgPipeline(DiffusionPipeline):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
diff --git a/examples/community/stable_diffusion_tensorrt_inpaint.py b/examples/community/stable_diffusion_tensorrt_inpaint.py
index 8da37d37ac..fff7309e9c 100755
--- a/examples/community/stable_diffusion_tensorrt_inpaint.py
+++ b/examples/community/stable_diffusion_tensorrt_inpaint.py
@@ -1148,9 +1148,9 @@ class TensorRTStableDiffusionInpaintPipeline(DiffusionPipeline):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
diff --git a/examples/community/stable_diffusion_tensorrt_txt2img.py b/examples/community/stable_diffusion_tensorrt_txt2img.py
index a3f9aae371..15a6e69c41 100755
--- a/examples/community/stable_diffusion_tensorrt_txt2img.py
+++ b/examples/community/stable_diffusion_tensorrt_txt2img.py
@@ -982,9 +982,9 @@ class TensorRTStableDiffusionPipeline(DiffusionPipeline):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
diff --git a/examples/community/stable_diffusion_xl_controlnet_reference.py b/examples/community/stable_diffusion_xl_controlnet_reference.py
index 2c9bef311b..421e67f5bb 100644
--- a/examples/community/stable_diffusion_xl_controlnet_reference.py
+++ b/examples/community/stable_diffusion_xl_controlnet_reference.py
@@ -431,7 +431,7 @@ class StableDiffusionXLControlNetReferencePipeline(StableDiffusionXLControlNetPi
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
diff --git a/examples/community/stable_diffusion_xl_reference.py b/examples/community/stable_diffusion_xl_reference.py
index e01eac970b..11926a5d9a 100644
--- a/examples/community/stable_diffusion_xl_reference.py
+++ b/examples/community/stable_diffusion_xl_reference.py
@@ -65,7 +65,7 @@ def torch_dfs(model: torch.nn.Module):
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -357,9 +357,9 @@ class StableDiffusionXLReferencePipeline(StableDiffusionXLPipeline):
"Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output)
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -372,7 +372,7 @@ class StableDiffusionXLReferencePipeline(StableDiffusionXLPipeline):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -413,8 +413,8 @@ class StableDiffusionXLReferencePipeline(StableDiffusionXLPipeline):
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
- [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://huggingface.co/papers/2305.08891).
Guidance rescale factor should fix overexposure when using zero terminal SNR.
original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
@@ -1114,7 +1114,7 @@ class StableDiffusionXLReferencePipeline(StableDiffusionXLPipeline):
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/examples/community/text_inpainting.py b/examples/community/text_inpainting.py
index d73082b6cf..2908388029 100644
--- a/examples/community/text_inpainting.py
+++ b/examples/community/text_inpainting.py
@@ -161,9 +161,9 @@ class TextInpainting(DiffusionPipeline, StableDiffusionMixin):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -172,7 +172,7 @@ class TextInpainting(DiffusionPipeline, StableDiffusionMixin):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
diff --git a/examples/community/tiled_upscaling.py b/examples/community/tiled_upscaling.py
index 3fe7399c8a..7e9abe55bb 100644
--- a/examples/community/tiled_upscaling.py
+++ b/examples/community/tiled_upscaling.py
@@ -212,9 +212,9 @@ class StableDiffusionTiledUpscalePipeline(StableDiffusionUpscalePipeline):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -223,7 +223,7 @@ class StableDiffusionTiledUpscalePipeline(StableDiffusionUpscalePipeline):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
diff --git a/examples/community/unclip_image_interpolation.py b/examples/community/unclip_image_interpolation.py
index 413c103cef..65b5257860 100644
--- a/examples/community/unclip_image_interpolation.py
+++ b/examples/community/unclip_image_interpolation.py
@@ -247,9 +247,9 @@ class UnCLIPImageInterpolationPipeline(DiffusionPipeline):
super_res_latents (`torch.Tensor` of shape (batch size, channels, super res height, super res width), *optional*):
Pre-generated noisy latents to be used as inputs for the decoder.
decoder_guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
output_type (`str`, *optional*, defaults to `"pil"`):
diff --git a/examples/community/unclip_text_interpolation.py b/examples/community/unclip_text_interpolation.py
index 84f1c5a21f..6fd4f348f4 100644
--- a/examples/community/unclip_text_interpolation.py
+++ b/examples/community/unclip_text_interpolation.py
@@ -252,15 +252,15 @@ class UnCLIPTextInterpolationPipeline(DiffusionPipeline):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
prior_guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
decoder_guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
output_type (`str`, *optional*, defaults to `"pil"`):
diff --git a/examples/community/wildcard_stable_diffusion.py b/examples/community/wildcard_stable_diffusion.py
index 3c42c54f71..c750610ca3 100644
--- a/examples/community/wildcard_stable_diffusion.py
+++ b/examples/community/wildcard_stable_diffusion.py
@@ -190,9 +190,9 @@ class WildcardStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -201,7 +201,7 @@ class WildcardStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
@@ -288,7 +288,7 @@ class WildcardStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
text_embeddings = text_embeddings.view(bs_embed * num_images_per_prompt, seq_len, -1)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
@@ -364,7 +364,7 @@ class WildcardStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
diff --git a/examples/consistency_distillation/README.md b/examples/consistency_distillation/README.md
index f5cb72fa86..d5cf45444d 100644
--- a/examples/consistency_distillation/README.md
+++ b/examples/consistency_distillation/README.md
@@ -1,6 +1,6 @@
# Latent Consistency Distillation Example:
-[Latent Consistency Models (LCMs)](https://arxiv.org/abs/2310.04378) is a method to distill a latent diffusion model to enable swift inference with minimal steps. This example demonstrates how to use latent consistency distillation to distill stable-diffusion-v1.5 for inference with few timesteps.
+[Latent Consistency Models (LCMs)](https://huggingface.co/papers/2310.04378) is a method to distill a latent diffusion model to enable swift inference with minimal steps. This example demonstrates how to use latent consistency distillation to distill stable-diffusion-v1.5 for inference with few timesteps.
## Full model distillation
diff --git a/examples/consistency_distillation/README_sdxl.md b/examples/consistency_distillation/README_sdxl.md
index edb4bd57f2..ba6c61d9fa 100644
--- a/examples/consistency_distillation/README_sdxl.md
+++ b/examples/consistency_distillation/README_sdxl.md
@@ -1,6 +1,6 @@
# Latent Consistency Distillation Example:
-[Latent Consistency Models (LCMs)](https://arxiv.org/abs/2310.04378) is a method to distill a latent diffusion model to enable swift inference with minimal steps. This example demonstrates how to use latent consistency distillation to distill SDXL for inference with few timesteps.
+[Latent Consistency Models (LCMs)](https://huggingface.co/papers/2310.04378) is a method to distill a latent diffusion model to enable swift inference with minimal steps. This example demonstrates how to use latent consistency distillation to distill SDXL for inference with few timesteps.
## Full model distillation
diff --git a/examples/controlnet/README.md b/examples/controlnet/README.md
index 0555857b77..3b223c8c46 100644
--- a/examples/controlnet/README.md
+++ b/examples/controlnet/README.md
@@ -1,6 +1,6 @@
# ControlNet training example
-[Adding Conditional Control to Text-to-Image Diffusion Models](https://arxiv.org/abs/2302.05543) by Lvmin Zhang and Maneesh Agrawala.
+[Adding Conditional Control to Text-to-Image Diffusion Models](https://huggingface.co/papers/2302.05543) by Lvmin Zhang and Maneesh Agrawala.
This example is based on the [training example in the original ControlNet repository](https://github.com/lllyasviel/ControlNet/blob/main/docs/train.md). It trains a ControlNet to fill circles using a [small synthetic dataset](https://huggingface.co/datasets/fusing/fill50k).
@@ -437,7 +437,7 @@ You can then start your training from this saved checkpoint with
--controlnet_model_name_or_path="./control_out/500"
```
-We support training with the Min-SNR weighting strategy proposed in [Efficient Diffusion Training via Min-SNR Weighting Strategy](https://arxiv.org/abs/2303.09556) which helps to achieve faster convergence by rebalancing the loss. To use it, one needs to set the `--snr_gamma` argument. The recommended value when using it is `5.0`.
+We support training with the Min-SNR weighting strategy proposed in [Efficient Diffusion Training via Min-SNR Weighting Strategy](https://huggingface.co/papers/2303.09556) which helps to achieve faster convergence by rebalancing the loss. To use it, one needs to set the `--snr_gamma` argument. The recommended value when using it is `5.0`.
We also support gradient accumulation - it is a technique that lets you use a bigger batch size than your machine would normally be able to fit into memory. You can use `gradient_accumulation_steps` argument to set gradient accumulation steps. The ControlNet author recommends using gradient accumulation to achieve better convergence. Read more [here](https://github.com/lllyasviel/ControlNet/blob/main/docs/train.md#more-consideration-sudden-converge-phenomenon-and-gradient-accumulation).
diff --git a/examples/controlnet/README_sd3.md b/examples/controlnet/README_sd3.md
index c95f34e32f..b62e33362d 100644
--- a/examples/controlnet/README_sd3.md
+++ b/examples/controlnet/README_sd3.md
@@ -1,6 +1,6 @@
# ControlNet training example for Stable Diffusion 3/3.5 (SD3/3.5)
-The `train_controlnet_sd3.py` script shows how to implement the ControlNet training procedure and adapt it for [Stable Diffusion 3](https://arxiv.org/abs/2403.03206) and [Stable Diffusion 3.5](https://stability.ai/news/introducing-stable-diffusion-3-5).
+The `train_controlnet_sd3.py` script shows how to implement the ControlNet training procedure and adapt it for [Stable Diffusion 3](https://huggingface.co/papers/2403.03206) and [Stable Diffusion 3.5](https://stability.ai/news/introducing-stable-diffusion-3-5).
## Running locally with PyTorch
diff --git a/examples/controlnet/train_controlnet.py b/examples/controlnet/train_controlnet.py
index 2097fd398f..69bd39944a 100644
--- a/examples/controlnet/train_controlnet.py
+++ b/examples/controlnet/train_controlnet.py
@@ -178,11 +178,11 @@ def log_validation(
else:
logger.warning(f"image logging not implemented for {tracker.name}")
- del pipeline
- gc.collect()
- torch.cuda.empty_cache()
+ del pipeline
+ gc.collect()
+ torch.cuda.empty_cache()
- return image_logs
+ return image_logs
def import_model_class_from_model_name_or_path(pretrained_model_name_or_path: str, revision: str):
diff --git a/examples/controlnet/train_controlnet_flax.py b/examples/controlnet/train_controlnet_flax.py
index 477732c299..5561710d6f 100644
--- a/examples/controlnet/train_controlnet_flax.py
+++ b/examples/controlnet/train_controlnet_flax.py
@@ -305,7 +305,7 @@ def parse_args():
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
- "More details here: https://arxiv.org/abs/2303.09556.",
+ "More details here: https://huggingface.co/papers/2303.09556.",
)
parser.add_argument(
"--dataloader_num_workers",
diff --git a/examples/controlnet/train_controlnet_flux.py b/examples/controlnet/train_controlnet_flux.py
index 232d3da8e8..94f030fe01 100644
--- a/examples/controlnet/train_controlnet_flux.py
+++ b/examples/controlnet/train_controlnet_flux.py
@@ -192,9 +192,9 @@ def log_validation(
else:
logger.warning(f"image logging not implemented for {tracker.name}")
- del pipeline
- free_memory()
- return image_logs
+ del pipeline
+ free_memory()
+ return image_logs
def save_model_card(repo_id: str, image_logs=None, base_model=str, repo_folder=None):
diff --git a/examples/controlnet/train_controlnet_sd3.py b/examples/controlnet/train_controlnet_sd3.py
index d6efc7dabb..ecd7572ca3 100644
--- a/examples/controlnet/train_controlnet_sd3.py
+++ b/examples/controlnet/train_controlnet_sd3.py
@@ -199,13 +199,13 @@ def log_validation(controlnet, args, accelerator, weight_dtype, step, is_final_v
else:
logger.warning(f"image logging not implemented for {tracker.name}")
- del pipeline
- free_memory()
+ del pipeline
+ free_memory()
- if not is_final_validation:
- controlnet.to(accelerator.device)
+ if not is_final_validation:
+ controlnet.to(accelerator.device)
- return image_logs
+ return image_logs
# Copied from dreambooth sd3 example
@@ -1352,7 +1352,7 @@ def main(args):
return_dict=False,
)[0]
- # Follow: Section 5 of https://arxiv.org/abs/2206.00364.
+ # Follow: Section 5 of https://huggingface.co/papers/2206.00364.
# Preconditioning of the model outputs.
if args.precondition_outputs:
model_pred = model_pred * (-sigmas) + noisy_model_input
diff --git a/examples/controlnet/train_controlnet_sdxl.py b/examples/controlnet/train_controlnet_sdxl.py
index 3368db1ec0..76d232da1c 100644
--- a/examples/controlnet/train_controlnet_sdxl.py
+++ b/examples/controlnet/train_controlnet_sdxl.py
@@ -201,11 +201,11 @@ def log_validation(vae, unet, controlnet, args, accelerator, weight_dtype, step,
else:
logger.warning(f"image logging not implemented for {tracker.name}")
- del pipeline
- gc.collect()
- torch.cuda.empty_cache()
+ del pipeline
+ gc.collect()
+ torch.cuda.empty_cache()
- return image_logs
+ return image_logs
def import_model_class_from_model_name_or_path(
diff --git a/examples/custom_diffusion/README.md b/examples/custom_diffusion/README.md
index 9b0b52e5ae..8dcba85622 100644
--- a/examples/custom_diffusion/README.md
+++ b/examples/custom_diffusion/README.md
@@ -1,6 +1,6 @@
# Custom Diffusion training example
-[Custom Diffusion](https://arxiv.org/abs/2212.04488) is a method to customize text-to-image models like Stable Diffusion given just a few (4~5) images of a subject.
+[Custom Diffusion](https://huggingface.co/papers/2212.04488) is a method to customize text-to-image models like Stable Diffusion given just a few (4~5) images of a subject.
The `train_custom_diffusion.py` script shows how to implement the training procedure and adapt it for stable diffusion.
## Running locally with PyTorch
diff --git a/examples/dreambooth/README.md b/examples/dreambooth/README.md
index eed0575c32..f0697609b3 100644
--- a/examples/dreambooth/README.md
+++ b/examples/dreambooth/README.md
@@ -1,6 +1,6 @@
# DreamBooth training example
-[DreamBooth](https://arxiv.org/abs/2208.12242) is a method to personalize text2image models like stable diffusion given just a few(3~5) images of a subject.
+[DreamBooth](https://huggingface.co/papers/2208.12242) is a method to personalize text2image models like stable diffusion given just a few(3~5) images of a subject.
The `train_dreambooth.py` script shows how to implement the training procedure and adapt it for stable diffusion.
@@ -296,7 +296,7 @@ You can also perform inference from one of the checkpoints saved during the trai
## Training with Low-Rank Adaptation of Large Language Models (LoRA)
-Low-Rank Adaption of Large Language Models was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*
+Low-Rank Adaption of Large Language Models was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://huggingface.co/papers/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*
In a nutshell, LoRA allows to adapt pretrained models by adding pairs of rank-decomposition matrices to existing weights and **only** training those newly added weights. This has a couple of advantages:
- Previous pretrained weights are kept frozen so that the model is not prone to [catastrophic forgetting](https://www.pnas.org/doi/10.1073/pnas.1611835114)
diff --git a/examples/dreambooth/README_flux.md b/examples/dreambooth/README_flux.md
index 3a6f7905e6..aa43b00faf 100644
--- a/examples/dreambooth/README_flux.md
+++ b/examples/dreambooth/README_flux.md
@@ -1,6 +1,6 @@
# DreamBooth training example for FLUX.1 [dev]
-[DreamBooth](https://arxiv.org/abs/2208.12242) is a method to personalize text2image models like stable diffusion given just a few (3~5) images of a subject.
+[DreamBooth](https://huggingface.co/papers/2208.12242) is a method to personalize text2image models like stable diffusion given just a few (3~5) images of a subject.
The `train_dreambooth_flux.py` script shows how to implement the training procedure and adapt it for [FLUX.1 [dev]](https://blackforestlabs.ai/announcing-black-forest-labs/). We also provide a LoRA implementation in the `train_dreambooth_lora_flux.py` script.
> [!NOTE]
@@ -134,7 +134,7 @@ Note also that we use PEFT library as backend for LoRA training, make sure to ha
Prodigy is an adaptive optimizer that dynamically adjusts the learning rate learned parameters based on past gradients, allowing for more efficient convergence.
By using prodigy we can "eliminate" the need for manual learning rate tuning. read more [here](https://huggingface.co/blog/sdxl_lora_advanced_script#adaptive-optimizers).
-to use prodigy, specify
+to use prodigy, first make sure to install the prodigyopt library: `pip install prodigyopt`, and then specify -
```bash
--optimizer="prodigy"
```
diff --git a/examples/dreambooth/README_hidream.md b/examples/dreambooth/README_hidream.md
index 6e4fd2510f..2c6b68f3f6 100644
--- a/examples/dreambooth/README_hidream.md
+++ b/examples/dreambooth/README_hidream.md
@@ -1,6 +1,6 @@
# DreamBooth training example for HiDream Image
-[DreamBooth](https://arxiv.org/abs/2208.12242) is a method to personalize text2image models like stable diffusion given just a few (3~5) images of a subject.
+[DreamBooth](https://huggingface.co/papers/2208.12242) is a method to personalize text2image models like stable diffusion given just a few (3~5) images of a subject.
The `train_dreambooth_lora_hidream.py` script shows how to implement the training procedure with [LoRA](https://huggingface.co/docs/peft/conceptual_guides/adapter#low-rank-adaptation-lora) and adapt it for [HiDream Image](https://huggingface.co/docs/diffusers/main/en/api/pipelines/).
diff --git a/examples/dreambooth/README_lumina2.md b/examples/dreambooth/README_lumina2.md
index fe2907092c..f691acd266 100644
--- a/examples/dreambooth/README_lumina2.md
+++ b/examples/dreambooth/README_lumina2.md
@@ -1,6 +1,6 @@
# DreamBooth training example for Lumina2
-[DreamBooth](https://arxiv.org/abs/2208.12242) is a method to personalize text2image models like stable diffusion given just a few (3~5) images of a subject.
+[DreamBooth](https://huggingface.co/papers/2208.12242) is a method to personalize text2image models like stable diffusion given just a few (3~5) images of a subject.
The `train_dreambooth_lora_lumina2.py` script shows how to implement the training procedure with [LoRA](https://huggingface.co/docs/peft/conceptual_guides/adapter#low-rank-adaptation-lora) and adapt it for [Lumina2](https://huggingface.co/docs/diffusers/main/en/api/pipelines/lumina2).
diff --git a/examples/dreambooth/README_sana.md b/examples/dreambooth/README_sana.md
index 6136bfcc16..1cc189149b 100644
--- a/examples/dreambooth/README_sana.md
+++ b/examples/dreambooth/README_sana.md
@@ -1,8 +1,8 @@
# DreamBooth training example for SANA
-[DreamBooth](https://arxiv.org/abs/2208.12242) is a method to personalize text2image models like stable diffusion given just a few (3~5) images of a subject.
+[DreamBooth](https://huggingface.co/papers/2208.12242) is a method to personalize text2image models like stable diffusion given just a few (3~5) images of a subject.
-The `train_dreambooth_lora_sana.py` script shows how to implement the training procedure with [LoRA](https://huggingface.co/docs/peft/conceptual_guides/adapter#low-rank-adaptation-lora) and adapt it for [SANA](https://arxiv.org/abs/2410.10629).
+The `train_dreambooth_lora_sana.py` script shows how to implement the training procedure with [LoRA](https://huggingface.co/docs/peft/conceptual_guides/adapter#low-rank-adaptation-lora) and adapt it for [SANA](https://huggingface.co/papers/2410.10629).
This will also allow us to push the trained model parameters to the Hugging Face Hub platform.
diff --git a/examples/dreambooth/README_sd3.md b/examples/dreambooth/README_sd3.md
index 2ac7bf7101..5b706930e9 100644
--- a/examples/dreambooth/README_sd3.md
+++ b/examples/dreambooth/README_sd3.md
@@ -1,6 +1,6 @@
# DreamBooth training example for Stable Diffusion 3 (SD3)
-[DreamBooth](https://arxiv.org/abs/2208.12242) is a method to personalize text2image models like stable diffusion given just a few (3~5) images of a subject.
+[DreamBooth](https://huggingface.co/papers/2208.12242) is a method to personalize text2image models like stable diffusion given just a few (3~5) images of a subject.
The `train_dreambooth_sd3.py` script shows how to implement the training procedure and adapt it for [Stable Diffusion 3](https://huggingface.co/papers/2403.03206). We also provide a LoRA implementation in the `train_dreambooth_lora_sd3.py` script.
diff --git a/examples/dreambooth/README_sdxl.md b/examples/dreambooth/README_sdxl.md
index 565ff9a5dd..c033d1e641 100644
--- a/examples/dreambooth/README_sdxl.md
+++ b/examples/dreambooth/README_sdxl.md
@@ -1,10 +1,10 @@
# DreamBooth training example for Stable Diffusion XL (SDXL)
-[DreamBooth](https://arxiv.org/abs/2208.12242) is a method to personalize text2image models like stable diffusion given just a few (3~5) images of a subject.
+[DreamBooth](https://huggingface.co/papers/2208.12242) is a method to personalize text2image models like stable diffusion given just a few (3~5) images of a subject.
The `train_dreambooth_lora_sdxl.py` script shows how to implement the training procedure and adapt it for [Stable Diffusion XL](https://huggingface.co/papers/2307.01952).
-> 💡 **Note**: For now, we only allow DreamBooth fine-tuning of the SDXL UNet via LoRA. LoRA is a parameter-efficient fine-tuning technique introduced in [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*.
+> 💡 **Note**: For now, we only allow DreamBooth fine-tuning of the SDXL UNet via LoRA. LoRA is a parameter-efficient fine-tuning technique introduced in [LoRA: Low-Rank Adaptation of Large Language Models](https://huggingface.co/papers/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*.
## Running locally with PyTorch
@@ -209,7 +209,7 @@ Check out [this notebook](https://colab.research.google.com/github/huggingface/n
## Conducting EDM-style training
-It's now possible to perform EDM-style training as proposed in [Elucidating the Design Space of Diffusion-Based Generative Models](https://arxiv.org/abs/2206.00364).
+It's now possible to perform EDM-style training as proposed in [Elucidating the Design Space of Diffusion-Based Generative Models](https://huggingface.co/papers/2206.00364).
For the SDXL model, simple set:
@@ -246,7 +246,7 @@ accelerate launch train_dreambooth_lora_sdxl.py \
### DoRA training
The script now supports DoRA training too!
-> Proposed in [DoRA: Weight-Decomposed Low-Rank Adaptation](https://arxiv.org/abs/2402.09353),
+> Proposed in [DoRA: Weight-Decomposed Low-Rank Adaptation](https://huggingface.co/papers/2402.09353),
**DoRA** is very similar to LoRA, except it decomposes the pre-trained weight into two components, **magnitude** and **direction** and employs LoRA for _directional_ updates to efficiently minimize the number of trainable parameters.
The authors found that by using DoRA, both the learning capacity and training stability of LoRA are enhanced without any additional overhead during inference.
diff --git a/examples/dreambooth/train_dreambooth.py b/examples/dreambooth/train_dreambooth.py
index aa5c069d29..ec0cc686b0 100644
--- a/examples/dreambooth/train_dreambooth.py
+++ b/examples/dreambooth/train_dreambooth.py
@@ -536,7 +536,7 @@ def parse_args(input_args=None):
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
- "More details here: https://arxiv.org/abs/2303.09556.",
+ "More details here: https://huggingface.co/papers/2303.09556.",
)
parser.add_argument(
"--pre_compute_text_embeddings",
@@ -1114,17 +1114,22 @@ def main(args):
)
# Scheduler and math around the number of training steps.
- overrode_max_train_steps = False
- num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ # Check the PR https://github.com/huggingface/diffusers/pull/8312 for detailed explanation.
+ num_warmup_steps_for_scheduler = args.lr_warmup_steps * accelerator.num_processes
if args.max_train_steps is None:
- args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
- overrode_max_train_steps = True
+ len_train_dataloader_after_sharding = math.ceil(len(train_dataloader) / accelerator.num_processes)
+ num_update_steps_per_epoch = math.ceil(len_train_dataloader_after_sharding / args.gradient_accumulation_steps)
+ num_training_steps_for_scheduler = (
+ args.num_train_epochs * accelerator.num_processes * num_update_steps_per_epoch
+ )
+ else:
+ num_training_steps_for_scheduler = args.max_train_steps * accelerator.num_processes
lr_scheduler = get_scheduler(
args.lr_scheduler,
optimizer=optimizer,
- num_warmup_steps=args.lr_warmup_steps * accelerator.num_processes,
- num_training_steps=args.max_train_steps * accelerator.num_processes,
+ num_warmup_steps=num_warmup_steps_for_scheduler,
+ num_training_steps=num_training_steps_for_scheduler,
num_cycles=args.lr_num_cycles,
power=args.lr_power,
)
@@ -1156,8 +1161,14 @@ def main(args):
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
- if overrode_max_train_steps:
+ if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ if num_training_steps_for_scheduler != args.max_train_steps:
+ logger.warning(
+ f"The length of the 'train_dataloader' after 'accelerator.prepare' ({len(train_dataloader)}) does not match "
+ f"the expected length ({len_train_dataloader_after_sharding}) when the learning rate scheduler was created. "
+ f"This inconsistency may result in the learning rate scheduler not functioning properly."
+ )
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
@@ -1296,7 +1307,7 @@ def main(args):
if args.snr_gamma is None:
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
else:
- # Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
+ # Compute loss-weights as per Section 3.4 of https://huggingface.co/papers/2303.09556.
# Since we predict the noise instead of x_0, the original formulation is slightly changed.
# This is discussed in Section 4.2 of the same paper.
snr = compute_snr(noise_scheduler, timesteps)
diff --git a/examples/dreambooth/train_dreambooth_lora_sd3.py b/examples/dreambooth/train_dreambooth_lora_sd3.py
index d00d2fafe8..05dfe6301f 100644
--- a/examples/dreambooth/train_dreambooth_lora_sd3.py
+++ b/examples/dreambooth/train_dreambooth_lora_sd3.py
@@ -1795,7 +1795,7 @@ def main(args):
return_dict=False,
)[0]
- # Follow: Section 5 of https://arxiv.org/abs/2206.00364.
+ # Follow: Section 5 of https://huggingface.co/papers/2206.00364.
# Preconditioning of the model outputs.
if args.precondition_outputs:
model_pred = model_pred * (-sigmas) + noisy_model_input
diff --git a/examples/dreambooth/train_dreambooth_lora_sdxl.py b/examples/dreambooth/train_dreambooth_lora_sdxl.py
index 364c0da8d5..c3dfc923f0 100644
--- a/examples/dreambooth/train_dreambooth_lora_sdxl.py
+++ b/examples/dreambooth/train_dreambooth_lora_sdxl.py
@@ -379,7 +379,7 @@ def parse_args(input_args=None):
"--do_edm_style_training",
default=False,
action="store_true",
- help="Flag to conduct training using the EDM formulation as introduced in https://arxiv.org/abs/2206.00364.",
+ help="Flag to conduct training using the EDM formulation as introduced in https://huggingface.co/papers/2206.00364.",
)
parser.add_argument(
"--with_prior_preservation",
@@ -520,7 +520,7 @@ def parse_args(input_args=None):
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
- "More details here: https://arxiv.org/abs/2303.09556.",
+ "More details here: https://huggingface.co/papers/2303.09556.",
)
parser.add_argument(
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
@@ -667,7 +667,7 @@ def parse_args(input_args=None):
action="store_true",
default=False,
help=(
- "Whether to train a DoRA as proposed in- DoRA: Weight-Decomposed Low-Rank Adaptation https://arxiv.org/abs/2402.09353. "
+ "Whether to train a DoRA as proposed in- DoRA: Weight-Decomposed Low-Rank Adaptation https://huggingface.co/papers/2402.09353. "
"Note: to use DoRA you need to install peft from main, `pip install git+https://github.com/huggingface/peft.git`"
),
)
@@ -1713,7 +1713,7 @@ def main(args):
noisy_model_input = noise_scheduler.add_noise(model_input, noise, timesteps)
# For EDM-style training, we first obtain the sigmas based on the continuous timesteps.
# We then precondition the final model inputs based on these sigmas instead of the timesteps.
- # Follow: Section 5 of https://arxiv.org/abs/2206.00364.
+ # Follow: Section 5 of https://huggingface.co/papers/2206.00364.
if args.do_edm_style_training:
sigmas = get_sigmas(timesteps, len(noisy_model_input.shape), noisy_model_input.dtype)
if "EDM" in scheduler_type:
@@ -1773,7 +1773,7 @@ def main(args):
if args.do_edm_style_training:
# Similar to the input preconditioning, the model predictions are also preconditioned
# on noised model inputs (before preconditioning) and the sigmas.
- # Follow: Section 5 of https://arxiv.org/abs/2206.00364.
+ # Follow: Section 5 of https://huggingface.co/papers/2206.00364.
if "EDM" in scheduler_type:
model_pred = noise_scheduler.precondition_outputs(noisy_model_input, model_pred, sigmas)
else:
@@ -1831,7 +1831,7 @@ def main(args):
else:
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
else:
- # Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
+ # Compute loss-weights as per Section 3.4 of https://huggingface.co/papers/2303.09556.
# Since we predict the noise instead of x_0, the original formulation is slightly changed.
# This is discussed in Section 4.2 of the same paper.
snr = compute_snr(noise_scheduler, timesteps)
diff --git a/examples/dreambooth/train_dreambooth_sd3.py b/examples/dreambooth/train_dreambooth_sd3.py
index 656eee031a..8d5dee0188 100644
--- a/examples/dreambooth/train_dreambooth_sd3.py
+++ b/examples/dreambooth/train_dreambooth_sd3.py
@@ -1615,7 +1615,7 @@ def main(args):
return_dict=False,
)[0]
- # Follow: Section 5 of https://arxiv.org/abs/2206.00364.
+ # Follow: Section 5 of https://huggingface.co/papers/2206.00364.
# Preconditioning of the model outputs.
if args.precondition_outputs:
model_pred = model_pred * (-sigmas) + noisy_model_input
diff --git a/examples/instruct_pix2pix/README.md b/examples/instruct_pix2pix/README.md
index a5e91a5356..9df6b46ee9 100644
--- a/examples/instruct_pix2pix/README.md
+++ b/examples/instruct_pix2pix/README.md
@@ -1,6 +1,6 @@
# InstructPix2Pix training example
-[InstructPix2Pix](https://arxiv.org/abs/2211.09800) is a method to fine-tune text-conditioned diffusion models such that they can follow an edit instruction for an input image. Models fine-tuned using this method take the following as inputs:
+[InstructPix2Pix](https://huggingface.co/papers/2211.09800) is a method to fine-tune text-conditioned diffusion models such that they can follow an edit instruction for an input image. Models fine-tuned using this method take the following as inputs:
diff --git a/examples/instruct_pix2pix/train_instruct_pix2pix.py b/examples/instruct_pix2pix/train_instruct_pix2pix.py
index c691464a7d..9f536139ab 100644
--- a/examples/instruct_pix2pix/train_instruct_pix2pix.py
+++ b/examples/instruct_pix2pix/train_instruct_pix2pix.py
@@ -294,7 +294,7 @@ def parse_args():
"--conditioning_dropout_prob",
type=float,
default=None,
- help="Conditioning dropout probability. Drops out the conditionings (image and edit prompt) used in training InstructPix2Pix. See section 3.2.1 in the paper: https://arxiv.org/abs/2211.09800.",
+ help="Conditioning dropout probability. Drops out the conditionings (image and edit prompt) used in training InstructPix2Pix. See section 3.2.1 in the paper: https://huggingface.co/papers/2211.09800.",
)
parser.add_argument(
"--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
@@ -882,7 +882,7 @@ def main():
original_image_embeds = vae.encode(batch["original_pixel_values"].to(weight_dtype)).latent_dist.mode()
# Conditioning dropout to support classifier-free guidance during inference. For more details
- # check out the section 3.2.1 of the original paper https://arxiv.org/abs/2211.09800.
+ # check out the section 3.2.1 of the original paper https://huggingface.co/papers/2211.09800.
if args.conditioning_dropout_prob is not None:
random_p = torch.rand(bsz, device=latents.device, generator=generator)
# Sample masks for the edit prompts.
diff --git a/examples/instruct_pix2pix/train_instruct_pix2pix_sdxl.py b/examples/instruct_pix2pix/train_instruct_pix2pix_sdxl.py
index 6298fe2340..622cf69b2f 100644
--- a/examples/instruct_pix2pix/train_instruct_pix2pix_sdxl.py
+++ b/examples/instruct_pix2pix/train_instruct_pix2pix_sdxl.py
@@ -351,7 +351,7 @@ def parse_args():
"--conditioning_dropout_prob",
type=float,
default=None,
- help="Conditioning dropout probability. Drops out the conditionings (image and edit prompt) used in training InstructPix2Pix. See section 3.2.1 in the paper: https://arxiv.org/abs/2211.09800.",
+ help="Conditioning dropout probability. Drops out the conditionings (image and edit prompt) used in training InstructPix2Pix. See section 3.2.1 in the paper: https://huggingface.co/papers/2211.09800.",
)
parser.add_argument(
"--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
@@ -1081,7 +1081,7 @@ def main():
original_image_embeds = original_image_embeds.to(weight_dtype)
# Conditioning dropout to support classifier-free guidance during inference. For more details
- # check out the section 3.2.1 of the original paper https://arxiv.org/abs/2211.09800.
+ # check out the section 3.2.1 of the original paper https://huggingface.co/papers/2211.09800.
if args.conditioning_dropout_prob is not None:
random_p = torch.rand(bsz, device=latents.device, generator=generator)
# Sample masks for the edit prompts.
diff --git a/examples/kandinsky2_2/text_to_image/README.md b/examples/kandinsky2_2/text_to_image/README.md
index 6daf06dcb8..c14e02f6d0 100644
--- a/examples/kandinsky2_2/text_to_image/README.md
+++ b/examples/kandinsky2_2/text_to_image/README.md
@@ -205,14 +205,14 @@ accelerate launch --mixed_precision="fp16" --multi_gpu train_text_to_image_deco
#### Training with Min-SNR weighting
-We support training with the Min-SNR weighting strategy proposed in [Efficient Diffusion Training via Min-SNR Weighting Strategy](https://arxiv.org/abs/2303.09556) which helps achieve faster convergence
+We support training with the Min-SNR weighting strategy proposed in [Efficient Diffusion Training via Min-SNR Weighting Strategy](https://huggingface.co/papers/2303.09556) which helps achieve faster convergence
by rebalancing the loss. Enable the `--snr_gamma` argument and set it to the recommended
value of 5.0.
## Training with LoRA
-Low-Rank Adaption of Large Language Models was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*.
+Low-Rank Adaption of Large Language Models was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://huggingface.co/papers/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*.
In a nutshell, LoRA allows adapting pretrained models by adding pairs of rank-decomposition matrices to existing weights and **only** training those newly added weights. This has a couple of advantages:
diff --git a/examples/kandinsky2_2/text_to_image/train_text_to_image_decoder.py b/examples/kandinsky2_2/text_to_image/train_text_to_image_decoder.py
index e03118415a..f2c5047d75 100644
--- a/examples/kandinsky2_2/text_to_image/train_text_to_image_decoder.py
+++ b/examples/kandinsky2_2/text_to_image/train_text_to_image_decoder.py
@@ -312,7 +312,7 @@ def parse_args():
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
- "More details here: https://arxiv.org/abs/2303.09556.",
+ "More details here: https://huggingface.co/papers/2303.09556.",
)
parser.add_argument(
"--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
@@ -789,7 +789,7 @@ def main():
if args.snr_gamma is None:
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
else:
- # Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
+ # Compute loss-weights as per Section 3.4 of https://huggingface.co/papers/2303.09556.
# Since we predict the noise instead of x_0, the original formulation is slightly changed.
# This is discussed in Section 4.2 of the same paper.
snr = compute_snr(noise_scheduler, timesteps)
diff --git a/examples/kandinsky2_2/text_to_image/train_text_to_image_lora_decoder.py b/examples/kandinsky2_2/text_to_image/train_text_to_image_lora_decoder.py
index f96a4c4f98..5b39c25901 100644
--- a/examples/kandinsky2_2/text_to_image/train_text_to_image_lora_decoder.py
+++ b/examples/kandinsky2_2/text_to_image/train_text_to_image_lora_decoder.py
@@ -217,7 +217,7 @@ def parse_args():
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
- "More details here: https://arxiv.org/abs/2303.09556.",
+ "More details here: https://huggingface.co/papers/2303.09556.",
)
parser.add_argument(
"--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
@@ -640,7 +640,7 @@ def main():
if args.snr_gamma is None:
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
else:
- # Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
+ # Compute loss-weights as per Section 3.4 of https://huggingface.co/papers/2303.09556.
# Since we predict the noise instead of x_0, the original formulation is slightly changed.
# This is discussed in Section 4.2 of the same paper.
snr = compute_snr(noise_scheduler, timesteps)
diff --git a/examples/kandinsky2_2/text_to_image/train_text_to_image_lora_prior.py b/examples/kandinsky2_2/text_to_image/train_text_to_image_lora_prior.py
index 4d49e7b0b0..8c31f8f03b 100644
--- a/examples/kandinsky2_2/text_to_image/train_text_to_image_lora_prior.py
+++ b/examples/kandinsky2_2/text_to_image/train_text_to_image_lora_prior.py
@@ -218,7 +218,7 @@ def parse_args():
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
- "More details here: https://arxiv.org/abs/2303.09556.",
+ "More details here: https://huggingface.co/papers/2303.09556.",
)
parser.add_argument(
"--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
@@ -673,7 +673,7 @@ def main():
if args.snr_gamma is None:
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
else:
- # Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
+ # Compute loss-weights as per Section 3.4 of https://huggingface.co/papers/2303.09556.
# Since we predict the noise instead of x_0, the original formulation is slightly changed.
# This is discussed in Section 4.2 of the same paper.
snr = compute_snr(noise_scheduler, timesteps)
diff --git a/examples/kandinsky2_2/text_to_image/train_text_to_image_prior.py b/examples/kandinsky2_2/text_to_image/train_text_to_image_prior.py
index 88f3e64dc8..1f16c2d21a 100644
--- a/examples/kandinsky2_2/text_to_image/train_text_to_image_prior.py
+++ b/examples/kandinsky2_2/text_to_image/train_text_to_image_prior.py
@@ -316,7 +316,7 @@ def parse_args():
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
- "More details here: https://arxiv.org/abs/2303.09556.",
+ "More details here: https://huggingface.co/papers/2303.09556.",
)
parser.add_argument(
"--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
@@ -819,7 +819,7 @@ def main():
if args.snr_gamma is None:
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
else:
- # Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
+ # Compute loss-weights as per Section 3.4 of https://huggingface.co/papers/2303.09556.
# Since we predict the noise instead of x_0, the original formulation is slightly changed.
# This is discussed in Section 4.2 of the same paper.
snr = compute_snr(noise_scheduler, timesteps)
diff --git a/examples/reinforcement_learning/README.md b/examples/reinforcement_learning/README.md
index 30d3b5bb1d..777113f556 100644
--- a/examples/reinforcement_learning/README.md
+++ b/examples/reinforcement_learning/README.md
@@ -9,7 +9,7 @@ To execute the script, run `diffusion_policy.py`
## Diffuser Locomotion
-These examples show how to run [Diffuser](https://arxiv.org/abs/2205.09991) in Diffusers.
+These examples show how to run [Diffuser](https://huggingface.co/papers/2205.09991) in Diffusers.
There are two ways to use the script, `run_diffuser_locomotion.py`.
The key option is a change of the variable `n_guide_steps`.
diff --git a/examples/research_projects/anytext/README.md b/examples/research_projects/anytext/README.md
index 3a67efd8b2..ddd2f7c6f4 100644
--- a/examples/research_projects/anytext/README.md
+++ b/examples/research_projects/anytext/README.md
@@ -6,7 +6,7 @@ Project page: https://aigcdesigngroup.github.io/homepage_anytext
> **Note:** Each text line that needs to be generated should be enclosed in double quotes.
-For any usage questions, please refer to the [paper](https://arxiv.org/abs/2311.03054).
+For any usage questions, please refer to the [paper](https://huggingface.co/papers/2311.03054).
[](https://colab.research.google.com/gist/tolgacangoz/b87ec9d2f265b448dd947c9d4a0da389/anytext.ipynb)
diff --git a/examples/research_projects/anytext/anytext.py b/examples/research_projects/anytext/anytext.py
index 2e96014c41..6f9b033fe6 100644
--- a/examples/research_projects/anytext/anytext.py
+++ b/examples/research_projects/anytext/anytext.py
@@ -1641,7 +1641,7 @@ class AnyTextPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -1916,7 +1916,7 @@ class AnyTextPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -2007,7 +2007,7 @@ class AnyTextPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
diff --git a/examples/research_projects/anytext/anytext_controlnet.py b/examples/research_projects/anytext/anytext_controlnet.py
index 5965ceed13..879d48fc84 100644
--- a/examples/research_projects/anytext/anytext_controlnet.py
+++ b/examples/research_projects/anytext/anytext_controlnet.py
@@ -37,7 +37,7 @@ logger = logging.get_logger(__name__) # pylint: disable=invalid-name
class AnyTextControlNetConditioningEmbedding(nn.Module):
"""
- Quoting from https://arxiv.org/abs/2302.05543: "Stable Diffusion uses a pre-processing method similar to VQ-GAN
+ Quoting from https://huggingface.co/papers/2302.05543: "Stable Diffusion uses a pre-processing method similar to VQ-GAN
[11] to convert the entire dataset of 512 × 512 images into smaller 64 × 64 “latent images” for stabilized
training. This requires ControlNets to convert image-based conditions to 64 × 64 feature space to match the
convolution size. We use a tiny network E(·) of four convolution layers with 4 × 4 kernels and 2 × 2 strides
diff --git a/examples/research_projects/colossalai/README.md b/examples/research_projects/colossalai/README.md
index be94950b77..bae223ec29 100644
--- a/examples/research_projects/colossalai/README.md
+++ b/examples/research_projects/colossalai/README.md
@@ -1,6 +1,6 @@
# [DreamBooth](https://github.com/huggingface/diffusers/tree/main/examples/dreambooth) by [colossalai](https://github.com/hpcaitech/ColossalAI.git)
-[DreamBooth](https://arxiv.org/abs/2208.12242) is a method to personalize text2image models like stable diffusion given just a few(3~5) images of a subject.
+[DreamBooth](https://huggingface.co/papers/2208.12242) is a method to personalize text2image models like stable diffusion given just a few(3~5) images of a subject.
The `train_dreambooth_colossalai.py` script shows how to implement the training procedure and adapt it for stable diffusion.
By accommodating model data in CPU and GPU and moving the data to the computing device when necessary, [Gemini](https://www.colossalai.org/docs/advanced_tutorials/meet_gemini), the Heterogeneous Memory Manager of [Colossal-AI](https://github.com/hpcaitech/ColossalAI) can breakthrough the GPU memory wall by using GPU and CPU memory (composed of CPU DRAM or nvme SSD memory) together at the same time. Moreover, the model scale can be further improved by combining heterogeneous training with the other parallel approaches, such as data parallel, tensor parallel and pipeline parallel.
diff --git a/examples/research_projects/consistency_training/README.md b/examples/research_projects/consistency_training/README.md
index 67eb835141..dbf43de0b4 100644
--- a/examples/research_projects/consistency_training/README.md
+++ b/examples/research_projects/consistency_training/README.md
@@ -1,6 +1,6 @@
# Consistency Training
-`train_cm_ct_unconditional.py` trains a consistency model (CM) from scratch following the consistency training (CT) algorithm introduced in [Consistency Models](https://arxiv.org/abs/2303.01469) and refined in [Improved Techniques for Training Consistency Models](https://arxiv.org/abs/2310.14189). Both unconditional and class-conditional training are supported.
+`train_cm_ct_unconditional.py` trains a consistency model (CM) from scratch following the consistency training (CT) algorithm introduced in [Consistency Models](https://huggingface.co/papers/2303.01469) and refined in [Improved Techniques for Training Consistency Models](https://huggingface.co/papers/2310.14189). Both unconditional and class-conditional training are supported.
A usage example is as follows:
diff --git a/examples/research_projects/diffusion_dpo/README.md b/examples/research_projects/diffusion_dpo/README.md
index 32704b6f77..3b99870315 100644
--- a/examples/research_projects/diffusion_dpo/README.md
+++ b/examples/research_projects/diffusion_dpo/README.md
@@ -1,6 +1,6 @@
# Diffusion Model Alignment Using Direct Preference Optimization
-This directory provides LoRA implementations of Diffusion DPO proposed in [DiffusionModel Alignment Using Direct Preference Optimization](https://arxiv.org/abs/2311.12908) by Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik.
+This directory provides LoRA implementations of Diffusion DPO proposed in [DiffusionModel Alignment Using Direct Preference Optimization](https://huggingface.co/papers/2311.12908) by Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik.
We provide implementations for both Stable Diffusion (SD) and Stable Diffusion XL (SDXL). The original checkpoints are available at the URLs below:
diff --git a/examples/research_projects/diffusion_dpo/train_diffusion_dpo_sdxl.py b/examples/research_projects/diffusion_dpo/train_diffusion_dpo_sdxl.py
index f0afa12e9c..42c91a423b 100644
--- a/examples/research_projects/diffusion_dpo/train_diffusion_dpo_sdxl.py
+++ b/examples/research_projects/diffusion_dpo/train_diffusion_dpo_sdxl.py
@@ -585,7 +585,7 @@ def main(args):
def enforce_zero_terminal_snr(scheduler):
# Modified from https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_ddpm.py#L93
- # Original implementation https://arxiv.org/pdf/2305.08891.pdf
+ # Original implementation https://huggingface.co/papers/2305.08891
# Turbo needs zero terminal SNR
# Turbo: https://static1.squarespace.com/static/6213c340453c3f502425776e/t/65663480a92fba51d0e1023f/1701197769659/adversarial_diffusion_distillation.pdf
# Convert betas to alphas_bar_sqrt
diff --git a/examples/research_projects/diffusion_orpo/train_diffusion_orpo_sdxl_lora_wds.py b/examples/research_projects/diffusion_orpo/train_diffusion_orpo_sdxl_lora_wds.py
index a5d89f77d6..9f96ef944a 100644
--- a/examples/research_projects/diffusion_orpo/train_diffusion_orpo_sdxl_lora_wds.py
+++ b/examples/research_projects/diffusion_orpo/train_diffusion_orpo_sdxl_lora_wds.py
@@ -812,7 +812,7 @@ def main(args):
if args.scale_lr:
args.learning_rate = (
- args.learning_rat * args.gradient_accumulation_steps * args.per_gpu_batch_size * accelerator.num_processes
+ args.learning_rate * args.gradient_accumulation_steps * args.per_gpu_batch_size * accelerator.num_processes
)
# Use 8-bit Adam for lower memory usage or to fine-tune the model in 16GB GPUs
diff --git a/examples/research_projects/flux_lora_quantization/README.md b/examples/research_projects/flux_lora_quantization/README.md
index 840d02fce7..c0d76ac9bc 100644
--- a/examples/research_projects/flux_lora_quantization/README.md
+++ b/examples/research_projects/flux_lora_quantization/README.md
@@ -10,7 +10,7 @@ This example shows how to fine-tune [Flux.1 Dev](https://huggingface.co/black-fo
* `train_dreambooth_lora_flux_miniature.py` takes care of training:
* Since we already precomputed the text embeddings, we don't load the text encoders.
* We load the VAE and use it to precompute the image latents and we then delete it.
- * Load the Flux transformer, quantize it with the [NF4 datatype](https://arxiv.org/abs/2305.14314) through `bitsandbytes`, prepare it for 4bit training.
+ * Load the Flux transformer, quantize it with the [NF4 datatype](https://huggingface.co/papers/2305.14314) through `bitsandbytes`, prepare it for 4bit training.
* Add LoRA adapter layers to it and then ensure they are kept in FP32 precision.
* Train!
diff --git a/examples/research_projects/geodiff/geodiff_molecule_conformation.ipynb b/examples/research_projects/geodiff/geodiff_molecule_conformation.ipynb
index aa5951723a..a39bcc5eea 100644
--- a/examples/research_projects/geodiff/geodiff_molecule_conformation.ipynb
+++ b/examples/research_projects/geodiff/geodiff_molecule_conformation.ipynb
@@ -886,7 +886,7 @@
"class GINEConv(MessagePassing):\n",
" \"\"\"\n",
" Custom class of the graph isomorphism operator from the \"How Powerful are Graph Neural Networks?\n",
- " https://arxiv.org/abs/1810.00826 paper. Note that this implementation has the added option of a custom activation.\n",
+ " https://huggingface.co/papers/1810.00826 paper. Note that this implementation has the added option of a custom activation.\n",
" \"\"\"\n",
"\n",
" def __init__(self, mlp: Callable, eps: float = 0.0, train_eps: bool = False, activation=\"softplus\", **kwargs):\n",
@@ -1157,7 +1157,7 @@
"def graph_field_network(score_d, pos, edge_index, edge_length):\n",
" \"\"\"\n",
" Transformation to make the epsilon predicted from the diffusion model roto-translational equivariant. See equations\n",
- " 5-7 of the GeoDiff Paper https://arxiv.org/pdf/2203.02923.pdf\n",
+ " 5-7 of the GeoDiff Paper https://huggingface.co/papers/2203.02923\n",
" \"\"\"\n",
" N = pos.size(0)\n",
" dd_dr = (1.0 / edge_length) * (pos[edge_index[0]] - pos[edge_index[1]]) # (E, 3)\n",
diff --git a/examples/research_projects/instructpix2pix_lora/train_instruct_pix2pix_lora.py b/examples/research_projects/instructpix2pix_lora/train_instruct_pix2pix_lora.py
index f94b1dd6b5..ac754dc9c5 100644
--- a/examples/research_projects/instructpix2pix_lora/train_instruct_pix2pix_lora.py
+++ b/examples/research_projects/instructpix2pix_lora/train_instruct_pix2pix_lora.py
@@ -345,7 +345,7 @@ def parse_args():
"--conditioning_dropout_prob",
type=float,
default=None,
- help="Conditioning dropout probability. Drops out the conditionings (image and edit prompt) used in training InstructPix2Pix. See section 3.2.1 in the paper: https://arxiv.org/abs/2211.09800.",
+ help="Conditioning dropout probability. Drops out the conditionings (image and edit prompt) used in training InstructPix2Pix. See section 3.2.1 in the paper: https://huggingface.co/papers/2211.09800.",
)
parser.add_argument(
"--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
@@ -974,7 +974,7 @@ def main():
original_image_embeds = vae.encode(batch["original_pixel_values"].to(weight_dtype)).latent_dist.mode()
# Conditioning dropout to support classifier-free guidance during inference. For more details
- # check out the section 3.2.1 of the original paper https://arxiv.org/abs/2211.09800.
+ # check out the section 3.2.1 of the original paper https://huggingface.co/papers/2211.09800.
if args.conditioning_dropout_prob is not None:
random_p = torch.rand(bsz, device=latents.device, generator=generator)
# Sample masks for the edit prompts.
diff --git a/examples/research_projects/intel_opts/textual_inversion/README.md b/examples/research_projects/intel_opts/textual_inversion/README.md
index 3339b8e2cb..8efb14b47f 100644
--- a/examples/research_projects/intel_opts/textual_inversion/README.md
+++ b/examples/research_projects/intel_opts/textual_inversion/README.md
@@ -1,6 +1,6 @@
## Textual Inversion fine-tuning example
-[Textual inversion](https://arxiv.org/abs/2208.01618) is a method to personalize text2image models like stable diffusion on your own images using just 3-5 examples.
+[Textual inversion](https://huggingface.co/papers/2208.01618) is a method to personalize text2image models like stable diffusion on your own images using just 3-5 examples.
The `textual_inversion.py` script shows how to implement the training procedure and adapt it for stable diffusion.
## Training with Intel Extension for PyTorch
diff --git a/examples/research_projects/intel_opts/textual_inversion_dfq/README.md b/examples/research_projects/intel_opts/textual_inversion_dfq/README.md
index 184a64ec76..844227ed87 100644
--- a/examples/research_projects/intel_opts/textual_inversion_dfq/README.md
+++ b/examples/research_projects/intel_opts/textual_inversion_dfq/README.md
@@ -1,6 +1,6 @@
# Distillation for quantization on Textual Inversion models to personalize text2image
-[Textual inversion](https://arxiv.org/abs/2208.01618) is a method to personalize text2image models like stable diffusion on your own images._By using just 3-5 images new concepts can be taught to Stable Diffusion and the model personalized on your own images_
+[Textual inversion](https://huggingface.co/papers/2208.01618) is a method to personalize text2image models like stable diffusion on your own images._By using just 3-5 images new concepts can be taught to Stable Diffusion and the model personalized on your own images_
The `textual_inversion.py` script shows how to implement the training procedure and adapt it for stable diffusion.
We have enabled distillation for quantization in `textual_inversion.py` to do quantization aware training as well as distillation on the model generated by Textual Inversion method.
diff --git a/examples/research_projects/ip_adapter/README.md b/examples/research_projects/ip_adapter/README.md
index 04a6c86e53..3df9644ddf 100644
--- a/examples/research_projects/ip_adapter/README.md
+++ b/examples/research_projects/ip_adapter/README.md
@@ -1,6 +1,6 @@
# IP Adapter Training Example
-[IP Adapter](https://arxiv.org/abs/2308.06721) is a novel approach designed to enhance text-to-image models such as Stable Diffusion by enabling them to generate images based on image prompts rather than text prompts alone. Unlike traditional methods that rely solely on complex text prompts, IP Adapter introduces the concept of using image prompts, leveraging the idea that "an image is worth a thousand words." By decoupling cross-attention layers for text and image features, IP Adapter effectively integrates image prompts into the generation process without the need for extensive fine-tuning or large computing resources.
+[IP Adapter](https://huggingface.co/papers/2308.06721) is a novel approach designed to enhance text-to-image models such as Stable Diffusion by enabling them to generate images based on image prompts rather than text prompts alone. Unlike traditional methods that rely solely on complex text prompts, IP Adapter introduces the concept of using image prompts, leveraging the idea that "an image is worth a thousand words." By decoupling cross-attention layers for text and image features, IP Adapter effectively integrates image prompts into the generation process without the need for extensive fine-tuning or large computing resources.
## Training locally with PyTorch
diff --git a/examples/research_projects/lora/README.md b/examples/research_projects/lora/README.md
index 643f664ce1..589d3e9c0f 100644
--- a/examples/research_projects/lora/README.md
+++ b/examples/research_projects/lora/README.md
@@ -4,7 +4,7 @@ This is an experimental LoRA extension of [this example](https://github.com/hugg
## Training with LoRA
-Low-Rank Adaption of Large Language Models was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*.
+Low-Rank Adaption of Large Language Models was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://huggingface.co/papers/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*.
In a nutshell, LoRA allows adapting pretrained models by adding pairs of rank-decomposition matrices to existing weights and **only** training those newly added weights. This has a couple of advantages:
diff --git a/examples/research_projects/multi_subject_dreambooth/README.md b/examples/research_projects/multi_subject_dreambooth/README.md
index 7c2e6f4009..3415a63c10 100644
--- a/examples/research_projects/multi_subject_dreambooth/README.md
+++ b/examples/research_projects/multi_subject_dreambooth/README.md
@@ -1,6 +1,6 @@
# Multi Subject DreamBooth training
-[DreamBooth](https://arxiv.org/abs/2208.12242) is a method to personalize text2image models like stable diffusion given just a few(3~5) images of a subject.
+[DreamBooth](https://huggingface.co/papers/2208.12242) is a method to personalize text2image models like stable diffusion given just a few(3~5) images of a subject.
This `train_multi_subject_dreambooth.py` script shows how to implement the training procedure for one or more subjects and adapt it for stable diffusion. Note that this code is based off of the `examples/dreambooth/train_dreambooth.py` script as of 01/06/2022.
This script was added by @kopsahlong, and is not actively maintained. However, if you come across anything that could use fixing, feel free to open an issue and tag @kopsahlong.
diff --git a/examples/research_projects/multi_subject_dreambooth_inpainting/README.md b/examples/research_projects/multi_subject_dreambooth_inpainting/README.md
index ffd8e304ef..32c375efea 100644
--- a/examples/research_projects/multi_subject_dreambooth_inpainting/README.md
+++ b/examples/research_projects/multi_subject_dreambooth_inpainting/README.md
@@ -2,7 +2,7 @@
Please note that this project is not actively maintained. However, you can open an issue and tag @gzguevara.
-[DreamBooth](https://arxiv.org/abs/2208.12242) is a method to personalize text2image models like stable diffusion given just a few(3~5) images of a subject. This project consists of **two parts**. Training Stable Diffusion for inpainting requieres prompt-image-mask pairs. The Unet of inpainiting models have 5 additional input channels (4 for the encoded masked-image and 1 for the mask itself).
+[DreamBooth](https://huggingface.co/papers/2208.12242) is a method to personalize text2image models like stable diffusion given just a few(3~5) images of a subject. This project consists of **two parts**. Training Stable Diffusion for inpainting requieres prompt-image-mask pairs. The Unet of inpainiting models have 5 additional input channels (4 for the encoded masked-image and 1 for the mask itself).
**The first part**, the `multi_inpaint_dataset.ipynb` notebook, demonstrates how make a 🤗 dataset of prompt-image-mask pairs. You can, however, skip the first part and move straight to the second part with the example datasets in this project. ([cat toy dataset masked](https://huggingface.co/datasets/gzguevara/cat_toy_masked), [mr. potato head dataset masked](https://huggingface.co/datasets/gzguevara/mr_potato_head_masked))
@@ -73,7 +73,7 @@ accelerate launch train_multi_subject_dreambooth_inpaint.py \
## 3. Results
-A [](https://wandb.ai/gzguevara/uncategorized/reports/Multi-Subject-Dreambooth-for-Inpainting--Vmlldzo2MzY5NDQ4?accessToken=y0nya2d7baguhbryxaikbfr1203amvn1jsmyl07vk122mrs7tnph037u1nqgse8t) is provided showing the training progress by every 50 steps. Note, the reported weights & baises run was performed on a A100 GPU with the following stetting:
+A [](https://wandb.ai/gzguevara/uncategorized/reports/Multi-Subject-Dreambooth-for-Inpainting--Vmlldzo2MzY5NDQ4?accessToken=y0nya2d7baguhbryxaikbfr1203amvn1jsmyl07vk122mrs7tnph037u1nqgse8t) is provided showing the training progress by every 50 steps. Note, the reported weights & biases run was performed on a A100 GPU with the following stetting:
```bash
accelerate launch train_multi_subject_dreambooth_inpaint.py \
diff --git a/examples/research_projects/multi_token_textual_inversion/README.md b/examples/research_projects/multi_token_textual_inversion/README.md
index 5e0aaf2c05..16847c2cce 100644
--- a/examples/research_projects/multi_token_textual_inversion/README.md
+++ b/examples/research_projects/multi_token_textual_inversion/README.md
@@ -14,7 +14,7 @@ Feel free to add these options to your training! In practice num_vec_per_token a
## Textual Inversion fine-tuning example
-[Textual inversion](https://arxiv.org/abs/2208.01618) is a method to personalize text2image models like stable diffusion on your own images using just 3-5 examples.
+[Textual inversion](https://huggingface.co/papers/2208.01618) is a method to personalize text2image models like stable diffusion on your own images using just 3-5 examples.
The `textual_inversion.py` script shows how to implement the training procedure and adapt it for stable diffusion.
## Running on Colab
diff --git a/examples/research_projects/onnxruntime/text_to_image/train_text_to_image.py b/examples/research_projects/onnxruntime/text_to_image/train_text_to_image.py
index a886f9ab27..ef910fab40 100644
--- a/examples/research_projects/onnxruntime/text_to_image/train_text_to_image.py
+++ b/examples/research_projects/onnxruntime/text_to_image/train_text_to_image.py
@@ -270,7 +270,7 @@ def parse_args():
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
- "More details here: https://arxiv.org/abs/2303.09556.",
+ "More details here: https://huggingface.co/papers/2303.09556.",
)
parser.add_argument(
"--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
@@ -854,7 +854,7 @@ def main():
if args.snr_gamma is None:
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
else:
- # Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
+ # Compute loss-weights as per Section 3.4 of https://huggingface.co/papers/2303.09556.
# Since we predict the noise instead of x_0, the original formulation is slightly changed.
# This is discussed in Section 4.2 of the same paper.
snr = compute_snr(noise_scheduler, timesteps)
diff --git a/examples/research_projects/onnxruntime/textual_inversion/README.md b/examples/research_projects/onnxruntime/textual_inversion/README.md
index 0f6ec7f511..a0ca4f954b 100644
--- a/examples/research_projects/onnxruntime/textual_inversion/README.md
+++ b/examples/research_projects/onnxruntime/textual_inversion/README.md
@@ -1,6 +1,6 @@
## Textual Inversion fine-tuning example
-[Textual inversion](https://arxiv.org/abs/2208.01618) is a method to personalize text2image models like stable diffusion on your own images using just 3-5 examples.
+[Textual inversion](https://huggingface.co/papers/2208.01618) is a method to personalize text2image models like stable diffusion on your own images using just 3-5 examples.
The `textual_inversion.py` script shows how to implement the training procedure and adapt it for stable diffusion.
## Running on Colab
diff --git a/examples/research_projects/pixart/pipeline_pixart_alpha_controlnet.py b/examples/research_projects/pixart/pipeline_pixart_alpha_controlnet.py
index 5a555c45a1..cbecd24f08 100644
--- a/examples/research_projects/pixart/pipeline_pixart_alpha_controlnet.py
+++ b/examples/research_projects/pixart/pipeline_pixart_alpha_controlnet.py
@@ -461,7 +461,7 @@ class PixArtAlphaControlnetPipeline(DiffusionPipeline):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -840,9 +840,9 @@ class PixArtAlphaControlnetPipeline(DiffusionPipeline):
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, *optional*, defaults to 4.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
@@ -852,7 +852,7 @@ class PixArtAlphaControlnetPipeline(DiffusionPipeline):
width (`int`, *optional*, defaults to self.unet.config.sample_size):
The width in pixels of the generated image.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
@@ -940,7 +940,7 @@ class PixArtAlphaControlnetPipeline(DiffusionPipeline):
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
@@ -1067,7 +1067,7 @@ class PixArtAlphaControlnetPipeline(DiffusionPipeline):
# compute previous image: x_t -> x_t-1
if num_inference_steps == 1:
- # For DMD one step sampling: https://arxiv.org/abs/2311.18828
+ # For DMD one step sampling: https://huggingface.co/papers/2311.18828
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).pred_original_sample
else:
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
diff --git a/examples/research_projects/pixart/train_pixart_controlnet_hf.py b/examples/research_projects/pixart/train_pixart_controlnet_hf.py
index 98329c6cd4..ec954505c2 100644
--- a/examples/research_projects/pixart/train_pixart_controlnet_hf.py
+++ b/examples/research_projects/pixart/train_pixart_controlnet_hf.py
@@ -429,7 +429,7 @@ def parse_args():
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
- "More details here: https://arxiv.org/abs/2303.09556.",
+ "More details here: https://huggingface.co/papers/2303.09556.",
)
parser.add_argument(
"--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
@@ -1047,7 +1047,7 @@ def main():
if args.snr_gamma is None:
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
else:
- # Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
+ # Compute loss-weights as per Section 3.4 of https://huggingface.co/papers/2303.09556.
# Since we predict the noise instead of x_0, the original formulation is slightly changed.
# This is discussed in Section 4.2 of the same paper.
snr = compute_snr(noise_scheduler, timesteps)
diff --git a/examples/research_projects/promptdiffusion/README.md b/examples/research_projects/promptdiffusion/README.md
index 33ffec3125..3df04eb7a3 100644
--- a/examples/research_projects/promptdiffusion/README.md
+++ b/examples/research_projects/promptdiffusion/README.md
@@ -4,7 +4,7 @@ From the project [page](https://zhendong-wang.github.io/prompt-diffusion.github.
"With a prompt consisting of a task-specific example pair of images and text guidance, and a new query image, Prompt Diffusion can comprehend the desired task and generate the corresponding output image on both seen (trained) and unseen (new) task types."
-For any usage questions, please refer to the [paper](https://arxiv.org/abs/2305.01115).
+For any usage questions, please refer to the [paper](https://huggingface.co/papers/2305.01115).
Prepare models by converting them from the [checkpoint](https://huggingface.co/zhendongw/prompt-diffusion)
diff --git a/examples/research_projects/promptdiffusion/pipeline_prompt_diffusion.py b/examples/research_projects/promptdiffusion/pipeline_prompt_diffusion.py
index 51668a61cd..7dfbc8b3e5 100644
--- a/examples/research_projects/promptdiffusion/pipeline_prompt_diffusion.py
+++ b/examples/research_projects/promptdiffusion/pipeline_prompt_diffusion.py
@@ -12,7 +12,7 @@
# See the License for the specific language governing permissions and
# limitations under the License.
#
-# Based on [In-Context Learning Unlocked for Diffusion Models](https://arxiv.org/abs/2305.01115)
+# Based on [In-Context Learning Unlocked for Diffusion Models](https://huggingface.co/papers/2305.01115)
# Authors: Zhendong Wang, Yifan Jiang, Yadong Lu, Yelong Shen, Pengcheng He, Weizhu Chen, Zhangyang Wang, Mingyuan Zhou
# Project Page: https://zhendong-wang.github.io/prompt-diffusion.github.io/
# Code: https://github.com/Zhendong-Wang/Prompt-Diffusion
@@ -148,7 +148,7 @@ class PromptDiffusionPipeline(
r"""
Pipeline for text-to-image generation using Stable Diffusion with ControlNet guidance.
- This pipeline also adds experimental support for [Prompt Diffusion](https://arxiv.org/abs/2305.01115).
+ This pipeline also adds experimental support for [Prompt Diffusion](https://huggingface.co/papers/2305.01115).
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods
implemented for all pipelines (downloading, saving, running on a particular device, etc.).
@@ -544,7 +544,7 @@ class PromptDiffusionPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -813,7 +813,7 @@ class PromptDiffusionPipeline(
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_freeu
def enable_freeu(self, s1: float, s2: float, b1: float, b2: float):
- r"""Enables the FreeU mechanism as in https://arxiv.org/abs/2309.11497.
+ r"""Enables the FreeU mechanism as in https://huggingface.co/papers/2309.11497.
The suffixes after the scaling factors represent the stages where they are being applied.
@@ -877,7 +877,7 @@ class PromptDiffusionPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -959,7 +959,7 @@ class PromptDiffusionPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
diff --git a/examples/research_projects/pytorch_xla/training/text_to_image/train_text_to_image_xla.py b/examples/research_projects/pytorch_xla/training/text_to_image/train_text_to_image_xla.py
index 6ae1a9a6c6..021b732ad4 100644
--- a/examples/research_projects/pytorch_xla/training/text_to_image/train_text_to_image_xla.py
+++ b/examples/research_projects/pytorch_xla/training/text_to_image/train_text_to_image_xla.py
@@ -214,7 +214,7 @@ class TrainSD:
if self.args.snr_gamma is None:
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
else:
- # Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
+ # Compute loss-weights as per Section 3.4 of https://huggingface.co/papers/2303.09556.
# Since we predict the noise instead of x_0, the original formulation is slightly changed.
# This is discussed in Section 4.2 of the same paper.
snr = compute_snr(self.noise_scheduler, timesteps)
@@ -342,7 +342,7 @@ def parse_args():
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
- "More details here: https://arxiv.org/abs/2303.09556.",
+ "More details here: https://huggingface.co/papers/2303.09556.",
)
parser.add_argument(
"--non_ema_revision",
diff --git a/examples/research_projects/rdm/pipeline_rdm.py b/examples/research_projects/rdm/pipeline_rdm.py
index e84568786f..7e2095b724 100644
--- a/examples/research_projects/rdm/pipeline_rdm.py
+++ b/examples/research_projects/rdm/pipeline_rdm.py
@@ -186,15 +186,15 @@ class RDMPipeline(DiffusionPipeline, StableDiffusionMixin):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://huggingface.co/papers/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
@@ -260,7 +260,7 @@ class RDMPipeline(DiffusionPipeline, StableDiffusionMixin):
prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
@@ -293,7 +293,7 @@ class RDMPipeline(DiffusionPipeline, StableDiffusionMixin):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
diff --git a/examples/research_projects/realfill/README.md b/examples/research_projects/realfill/README.md
index 91821031d2..bca5495297 100644
--- a/examples/research_projects/realfill/README.md
+++ b/examples/research_projects/realfill/README.md
@@ -1,6 +1,6 @@
# RealFill
-[RealFill](https://arxiv.org/abs/2309.16668) is a method to personalize text2image inpainting models like stable diffusion inpainting given just a few(1~5) images of a scene.
+[RealFill](https://huggingface.co/papers/2309.16668) is a method to personalize text2image inpainting models like stable diffusion inpainting given just a few(1~5) images of a scene.
The `train_realfill.py` script shows how to implement the training procedure for stable diffusion inpainting.
diff --git a/examples/research_projects/sana/README.md b/examples/research_projects/sana/README.md
index 1dbae667c8..ae80d11df4 100644
--- a/examples/research_projects/sana/README.md
+++ b/examples/research_projects/sana/README.md
@@ -1,6 +1,6 @@
# Training SANA Sprint Diffuser
-This README explains how to use the provided bash script commands to download a pre-trained teacher diffuser model and train it on a specific dataset, following the [SANA Sprint methodology](https://arxiv.org/abs/2503.09641).
+This README explains how to use the provided bash script commands to download a pre-trained teacher diffuser model and train it on a specific dataset, following the [SANA Sprint methodology](https://huggingface.co/papers/2503.09641).
## Setup
diff --git a/examples/research_projects/scheduled_huber_loss_training/README.md b/examples/research_projects/scheduled_huber_loss_training/README.md
index 239f94ba10..a587b07666 100644
--- a/examples/research_projects/scheduled_huber_loss_training/README.md
+++ b/examples/research_projects/scheduled_huber_loss_training/README.md
@@ -1,6 +1,6 @@
# Scheduled Pseudo-Huber Loss for Diffusers
-These are the modifications of to include the possibility of training text2image models with Scheduled Pseudo Huber loss, introduced in https://arxiv.org/abs/2403.16728. (https://github.com/kabachuha/SPHL-for-stable-diffusion)
+These are the modifications of to include the possibility of training text2image models with Scheduled Pseudo Huber loss, introduced in https://huggingface.co/papers/2403.16728. (https://github.com/kabachuha/SPHL-for-stable-diffusion)
## Why this might be useful?
diff --git a/examples/research_projects/scheduled_huber_loss_training/dreambooth/train_dreambooth.py b/examples/research_projects/scheduled_huber_loss_training/dreambooth/train_dreambooth.py
index 043f913893..fd5b83a66e 100644
--- a/examples/research_projects/scheduled_huber_loss_training/dreambooth/train_dreambooth.py
+++ b/examples/research_projects/scheduled_huber_loss_training/dreambooth/train_dreambooth.py
@@ -536,7 +536,7 @@ def parse_args(input_args=None):
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
- "More details here: https://arxiv.org/abs/2303.09556.",
+ "More details here: https://huggingface.co/papers/2303.09556.",
)
parser.add_argument(
"--pre_compute_text_embeddings",
@@ -1369,7 +1369,7 @@ def main(args):
model_pred.float(), target.float(), reduction="mean", loss_type=args.loss_type, huber_c=huber_c
)
else:
- # Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
+ # Compute loss-weights as per Section 3.4 of https://huggingface.co/papers/2303.09556.
# Since we predict the noise instead of x_0, the original formulation is slightly changed.
# This is discussed in Section 4.2 of the same paper.
snr = compute_snr(noise_scheduler, timesteps)
diff --git a/examples/research_projects/scheduled_huber_loss_training/dreambooth/train_dreambooth_lora_sdxl.py b/examples/research_projects/scheduled_huber_loss_training/dreambooth/train_dreambooth_lora_sdxl.py
index 402265bde1..f011871c25 100644
--- a/examples/research_projects/scheduled_huber_loss_training/dreambooth/train_dreambooth_lora_sdxl.py
+++ b/examples/research_projects/scheduled_huber_loss_training/dreambooth/train_dreambooth_lora_sdxl.py
@@ -376,7 +376,7 @@ def parse_args(input_args=None):
"--do_edm_style_training",
default=False,
action="store_true",
- help="Flag to conduct training using the EDM formulation as introduced in https://arxiv.org/abs/2206.00364.",
+ help="Flag to conduct training using the EDM formulation as introduced in https://huggingface.co/papers/2206.00364.",
)
parser.add_argument(
"--with_prior_preservation",
@@ -517,7 +517,7 @@ def parse_args(input_args=None):
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
- "More details here: https://arxiv.org/abs/2303.09556.",
+ "More details here: https://huggingface.co/papers/2303.09556.",
)
parser.add_argument(
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
@@ -661,7 +661,7 @@ def parse_args(input_args=None):
action="store_true",
default=False,
help=(
- "Whether to train a DoRA as proposed in- DoRA: Weight-Decomposed Low-Rank Adaptation https://arxiv.org/abs/2402.09353. "
+ "Whether to train a DoRA as proposed in- DoRA: Weight-Decomposed Low-Rank Adaptation https://huggingface.co/papers/2402.09353. "
"Note: to use DoRA you need to install peft from main, `pip install git+https://github.com/huggingface/peft.git`"
),
)
@@ -1759,7 +1759,7 @@ def main(args):
noisy_model_input = noise_scheduler.add_noise(model_input, noise, timesteps)
# For EDM-style training, we first obtain the sigmas based on the continuous timesteps.
# We then precondition the final model inputs based on these sigmas instead of the timesteps.
- # Follow: Section 5 of https://arxiv.org/abs/2206.00364.
+ # Follow: Section 5 of https://huggingface.co/papers/2206.00364.
if args.do_edm_style_training:
sigmas = get_sigmas(timesteps, len(noisy_model_input.shape), noisy_model_input.dtype)
if "EDM" in scheduler_type:
@@ -1819,7 +1819,7 @@ def main(args):
if args.do_edm_style_training:
# Similar to the input preconditioning, the model predictions are also preconditioned
# on noised model inputs (before preconditioning) and the sigmas.
- # Follow: Section 5 of https://arxiv.org/abs/2206.00364.
+ # Follow: Section 5 of https://huggingface.co/papers/2206.00364.
if "EDM" in scheduler_type:
model_pred = noise_scheduler.precondition_outputs(noisy_model_input, model_pred, sigmas)
else:
@@ -1873,7 +1873,7 @@ def main(args):
weighting=weighting,
)
else:
- # Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
+ # Compute loss-weights as per Section 3.4 of https://huggingface.co/papers/2303.09556.
# Since we predict the noise instead of x_0, the original formulation is slightly changed.
# This is discussed in Section 4.2 of the same paper.
snr = compute_snr(noise_scheduler, timesteps)
diff --git a/examples/research_projects/scheduled_huber_loss_training/text_to_image/train_text_to_image.py b/examples/research_projects/scheduled_huber_loss_training/text_to_image/train_text_to_image.py
index 2ca555889c..d867a5dd6a 100644
--- a/examples/research_projects/scheduled_huber_loss_training/text_to_image/train_text_to_image.py
+++ b/examples/research_projects/scheduled_huber_loss_training/text_to_image/train_text_to_image.py
@@ -353,7 +353,7 @@ def parse_args():
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
- "More details here: https://arxiv.org/abs/2303.09556.",
+ "More details here: https://huggingface.co/papers/2303.09556.",
)
parser.add_argument(
"--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
@@ -1017,7 +1017,7 @@ def main():
model_pred.float(), target.float(), reduction="mean", loss_type=args.loss_type, huber_c=huber_c
)
else:
- # Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
+ # Compute loss-weights as per Section 3.4 of https://huggingface.co/papers/2303.09556.
# Since we predict the noise instead of x_0, the original formulation is slightly changed.
# This is discussed in Section 4.2 of the same paper.
snr = compute_snr(noise_scheduler, timesteps)
diff --git a/examples/research_projects/scheduled_huber_loss_training/text_to_image/train_text_to_image_lora.py b/examples/research_projects/scheduled_huber_loss_training/text_to_image/train_text_to_image_lora.py
index 3e6199a09a..d01d5838f2 100644
--- a/examples/research_projects/scheduled_huber_loss_training/text_to_image/train_text_to_image_lora.py
+++ b/examples/research_projects/scheduled_huber_loss_training/text_to_image/train_text_to_image_lora.py
@@ -268,7 +268,7 @@ def parse_args():
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
- "More details here: https://arxiv.org/abs/2303.09556.",
+ "More details here: https://huggingface.co/papers/2303.09556.",
)
parser.add_argument(
"--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
@@ -849,7 +849,7 @@ def main():
model_pred.float(), target.float(), reduction="mean", loss_type=args.loss_type, huber_c=huber_c
)
else:
- # Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
+ # Compute loss-weights as per Section 3.4 of https://huggingface.co/papers/2303.09556.
# Since we predict the noise instead of x_0, the original formulation is slightly changed.
# This is discussed in Section 4.2 of the same paper.
snr = compute_snr(noise_scheduler, timesteps)
diff --git a/examples/research_projects/scheduled_huber_loss_training/text_to_image/train_text_to_image_lora_sdxl.py b/examples/research_projects/scheduled_huber_loss_training/text_to_image/train_text_to_image_lora_sdxl.py
index c87f50e272..d9efca5ba5 100644
--- a/examples/research_projects/scheduled_huber_loss_training/text_to_image/train_text_to_image_lora_sdxl.py
+++ b/examples/research_projects/scheduled_huber_loss_training/text_to_image/train_text_to_image_lora_sdxl.py
@@ -345,7 +345,7 @@ def parse_args(input_args=None):
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
- "More details here: https://arxiv.org/abs/2303.09556.",
+ "More details here: https://huggingface.co/papers/2303.09556.",
)
parser.add_argument(
"--allow_tf32",
@@ -1170,7 +1170,7 @@ def main(args):
model_pred.float(), target.float(), reduction="mean", loss_type=args.loss_type, huber_c=huber_c
)
else:
- # Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
+ # Compute loss-weights as per Section 3.4 of https://huggingface.co/papers/2303.09556.
# Since we predict the noise instead of x_0, the original formulation is slightly changed.
# This is discussed in Section 4.2 of the same paper.
snr = compute_snr(noise_scheduler, timesteps)
diff --git a/examples/research_projects/scheduled_huber_loss_training/text_to_image/train_text_to_image_sdxl.py b/examples/research_projects/scheduled_huber_loss_training/text_to_image/train_text_to_image_sdxl.py
index 4738e39e83..88880f5669 100644
--- a/examples/research_projects/scheduled_huber_loss_training/text_to_image/train_text_to_image_sdxl.py
+++ b/examples/research_projects/scheduled_huber_loss_training/text_to_image/train_text_to_image_sdxl.py
@@ -388,7 +388,7 @@ def parse_args(input_args=None):
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
- "More details here: https://arxiv.org/abs/2303.09556.",
+ "More details here: https://huggingface.co/papers/2303.09556.",
)
parser.add_argument("--use_ema", action="store_true", help="Whether to use EMA model.")
parser.add_argument(
@@ -1185,7 +1185,7 @@ def main(args):
model_pred.float(), target.float(), reduction="mean", loss_type=args.loss_type, huber_c=huber_c
)
else:
- # Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
+ # Compute loss-weights as per Section 3.4 of https://huggingface.co/papers/2303.09556.
# Since we predict the noise instead of x_0, the original formulation is slightly changed.
# This is discussed in Section 4.2 of the same paper.
snr = compute_snr(noise_scheduler, timesteps)
diff --git a/examples/research_projects/sd3_lora_colab/README.md b/examples/research_projects/sd3_lora_colab/README.md
index b7d7eedfb5..33fc7030de 100644
--- a/examples/research_projects/sd3_lora_colab/README.md
+++ b/examples/research_projects/sd3_lora_colab/README.md
@@ -17,7 +17,7 @@ For setup, inference code, and details on how to run the code, please follow the
We make use of several techniques to make this possible:
-* Compute the embeddings from the instance prompt and serialize them for later reuse. This is implemented in the [`compute_embeddings.py`](./compute_embeddings.py) script. We use an 8bit (as introduced in [`LLM.int8()`](https://arxiv.org/abs/2208.07339)) T5 to reduce memory requirements to ~10.5GB.
+* Compute the embeddings from the instance prompt and serialize them for later reuse. This is implemented in the [`compute_embeddings.py`](./compute_embeddings.py) script. We use an 8bit (as introduced in [`LLM.int8()`](https://huggingface.co/papers/2208.07339)) T5 to reduce memory requirements to ~10.5GB.
* In the `train_dreambooth_sd3_lora_miniature.py` script, we make use of:
* 8bit Adam for optimization through the `bitsandbytes` library.
* Gradient checkpointing and gradient accumulation.
diff --git a/examples/research_projects/sd3_lora_colab/train_dreambooth_lora_sd3_miniature.py b/examples/research_projects/sd3_lora_colab/train_dreambooth_lora_sd3_miniature.py
index ebb9b129db..21eb57ddc2 100644
--- a/examples/research_projects/sd3_lora_colab/train_dreambooth_lora_sd3_miniature.py
+++ b/examples/research_projects/sd3_lora_colab/train_dreambooth_lora_sd3_miniature.py
@@ -1001,7 +1001,7 @@ def main(args):
return_dict=False,
)[0]
- # Follow: Section 5 of https://arxiv.org/abs/2206.00364.
+ # Follow: Section 5 of https://huggingface.co/papers/2206.00364.
# Preconditioning of the model outputs.
model_pred = model_pred * (-sigmas) + noisy_model_input
diff --git a/examples/research_projects/wuerstchen/text_to_image/README.md b/examples/research_projects/wuerstchen/text_to_image/README.md
index a6ec4698b6..118c5e0cf9 100644
--- a/examples/research_projects/wuerstchen/text_to_image/README.md
+++ b/examples/research_projects/wuerstchen/text_to_image/README.md
@@ -61,7 +61,7 @@ accelerate launch train_text_to_image_prior.py \
## Training with LoRA
-Low-Rank Adaption of Large Language Models (or LoRA) was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*.
+Low-Rank Adaption of Large Language Models (or LoRA) was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://huggingface.co/papers/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*.
In a nutshell, LoRA allows adapting pretrained models by adding pairs of rank-decomposition matrices to existing weights and **only** training those newly added weights. This has a couple of advantages:
diff --git a/examples/t2i_adapter/train_t2i_adapter_sdxl.py b/examples/t2i_adapter/train_t2i_adapter_sdxl.py
index 83584c5924..cb8fade444 100644
--- a/examples/t2i_adapter/train_t2i_adapter_sdxl.py
+++ b/examples/t2i_adapter/train_t2i_adapter_sdxl.py
@@ -1190,7 +1190,7 @@ def main(args):
bsz = latents.shape[0]
# Cubic sampling to sample a random timestep for each image.
- # For more details about why cubic sampling is used, refer to section 3.4 of https://arxiv.org/abs/2302.08453
+ # For more details about why cubic sampling is used, refer to section 3.4 of https://huggingface.co/papers/2302.08453
timesteps = torch.rand((bsz,), device=latents.device)
timesteps = (1 - timesteps**3) * noise_scheduler.config.num_train_timesteps
timesteps = timesteps.long().to(noise_scheduler.timesteps.dtype)
diff --git a/examples/text_to_image/README.md b/examples/text_to_image/README.md
index 0bdf02f804..940d40c7b2 100644
--- a/examples/text_to_image/README.md
+++ b/examples/text_to_image/README.md
@@ -156,7 +156,7 @@ accelerate launch --mixed_precision="fp16" --multi_gpu train_text_to_image.py \
#### Training with Min-SNR weighting
-We support training with the Min-SNR weighting strategy proposed in [Efficient Diffusion Training via Min-SNR Weighting Strategy](https://arxiv.org/abs/2303.09556) which helps to achieve faster convergence
+We support training with the Min-SNR weighting strategy proposed in [Efficient Diffusion Training via Min-SNR Weighting Strategy](https://huggingface.co/papers/2303.09556) which helps to achieve faster convergence
by rebalancing the loss. In order to use it, one needs to set the `--snr_gamma` argument. The recommended
value when using it is 5.0.
@@ -179,13 +179,13 @@ EMA weights require an additional full-precision copy of the model parameters to
#### Training with DREAM
-We support training epsilon (noise) prediction models using the [DREAM (Diffusion Rectification and Estimation-Adaptive Models) strategy](https://arxiv.org/abs/2312.00210). DREAM claims to increase model fidelity for the performance cost of an extra grad-less unet `forward` step in the training loop. You can turn on DREAM training by using the `--dream_training` argument. The `--dream_detail_preservation` argument controls the detail preservation variable p and is the default of 1 from the paper.
+We support training epsilon (noise) prediction models using the [DREAM (Diffusion Rectification and Estimation-Adaptive Models) strategy](https://huggingface.co/papers/2312.00210). DREAM claims to increase model fidelity for the performance cost of an extra grad-less unet `forward` step in the training loop. You can turn on DREAM training by using the `--dream_training` argument. The `--dream_detail_preservation` argument controls the detail preservation variable p and is the default of 1 from the paper.
## Training with LoRA
-Low-Rank Adaption of Large Language Models was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*.
+Low-Rank Adaption of Large Language Models was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://huggingface.co/papers/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*.
In a nutshell, LoRA allows adapting pretrained models by adding pairs of rank-decomposition matrices to existing weights and **only** training those newly added weights. This has a couple of advantages:
diff --git a/examples/text_to_image/README_sdxl.md b/examples/text_to_image/README_sdxl.md
index 08d82ac133..c0b7840f10 100644
--- a/examples/text_to_image/README_sdxl.md
+++ b/examples/text_to_image/README_sdxl.md
@@ -127,7 +127,7 @@ boost.
## LoRA training example for Stable Diffusion XL (SDXL)
-Low-Rank Adaption of Large Language Models was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*.
+Low-Rank Adaption of Large Language Models was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://huggingface.co/papers/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*.
In a nutshell, LoRA allows adapting pretrained models by adding pairs of rank-decomposition matrices to existing weights and **only** training those newly added weights. This has a couple of advantages:
diff --git a/examples/text_to_image/train_text_to_image.py b/examples/text_to_image/train_text_to_image.py
index 324891dc79..17f5dc852b 100644
--- a/examples/text_to_image/train_text_to_image.py
+++ b/examples/text_to_image/train_text_to_image.py
@@ -359,14 +359,14 @@ def parse_args():
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
- "More details here: https://arxiv.org/abs/2303.09556.",
+ "More details here: https://huggingface.co/papers/2303.09556.",
)
parser.add_argument(
"--dream_training",
action="store_true",
help=(
"Use the DREAM training method, which makes training more efficient and accurate at the "
- "expense of doing an extra forward pass. See: https://arxiv.org/abs/2312.00210"
+ "expense of doing an extra forward pass. See: https://huggingface.co/papers/2312.00210"
),
)
parser.add_argument(
@@ -1022,7 +1022,7 @@ def main():
if args.snr_gamma is None:
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
else:
- # Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
+ # Compute loss-weights as per Section 3.4 of https://huggingface.co/papers/2303.09556.
# Since we predict the noise instead of x_0, the original formulation is slightly changed.
# This is discussed in Section 4.2 of the same paper.
snr = compute_snr(noise_scheduler, timesteps)
diff --git a/examples/text_to_image/train_text_to_image_lora.py b/examples/text_to_image/train_text_to_image_lora.py
index 480f4b36df..89f867b5ba 100644
--- a/examples/text_to_image/train_text_to_image_lora.py
+++ b/examples/text_to_image/train_text_to_image_lora.py
@@ -314,7 +314,7 @@ def parse_args():
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
- "More details here: https://arxiv.org/abs/2303.09556.",
+ "More details here: https://huggingface.co/papers/2303.09556.",
)
parser.add_argument(
"--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
@@ -845,7 +845,7 @@ def main():
if args.snr_gamma is None:
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
else:
- # Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
+ # Compute loss-weights as per Section 3.4 of https://huggingface.co/papers/2303.09556.
# Since we predict the noise instead of x_0, the original formulation is slightly changed.
# This is discussed in Section 4.2 of the same paper.
snr = compute_snr(noise_scheduler, timesteps)
diff --git a/examples/text_to_image/train_text_to_image_lora_sdxl.py b/examples/text_to_image/train_text_to_image_lora_sdxl.py
index a5c72c1e97..12afb72b9a 100644
--- a/examples/text_to_image/train_text_to_image_lora_sdxl.py
+++ b/examples/text_to_image/train_text_to_image_lora_sdxl.py
@@ -392,7 +392,7 @@ def parse_args(input_args=None):
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
- "More details here: https://arxiv.org/abs/2303.09556.",
+ "More details here: https://huggingface.co/papers/2303.09556.",
)
parser.add_argument(
"--allow_tf32",
@@ -1178,7 +1178,7 @@ def main(args):
if args.snr_gamma is None:
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
else:
- # Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
+ # Compute loss-weights as per Section 3.4 of https://huggingface.co/papers/2303.09556.
# Since we predict the noise instead of x_0, the original formulation is slightly changed.
# This is discussed in Section 4.2 of the same paper.
snr = compute_snr(noise_scheduler, timesteps)
diff --git a/examples/text_to_image/train_text_to_image_sdxl.py b/examples/text_to_image/train_text_to_image_sdxl.py
index ba059fd6fa..65a6131e66 100644
--- a/examples/text_to_image/train_text_to_image_sdxl.py
+++ b/examples/text_to_image/train_text_to_image_sdxl.py
@@ -392,7 +392,7 @@ def parse_args(input_args=None):
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
- "More details here: https://arxiv.org/abs/2303.09556.",
+ "More details here: https://huggingface.co/papers/2303.09556.",
)
parser.add_argument("--use_ema", action="store_true", help="Whether to use EMA model.")
parser.add_argument(
@@ -1148,7 +1148,7 @@ def main(args):
if args.snr_gamma is None:
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
else:
- # Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
+ # Compute loss-weights as per Section 3.4 of https://huggingface.co/papers/2303.09556.
# Since we predict the noise instead of x_0, the original formulation is slightly changed.
# This is discussed in Section 4.2 of the same paper.
snr = compute_snr(noise_scheduler, timesteps)
diff --git a/examples/textual_inversion/README.md b/examples/textual_inversion/README.md
index e869bb38d2..2f79107edb 100644
--- a/examples/textual_inversion/README.md
+++ b/examples/textual_inversion/README.md
@@ -1,6 +1,6 @@
## Textual Inversion fine-tuning example
-[Textual inversion](https://arxiv.org/abs/2208.01618) is a method to personalize text2image models like stable diffusion on your own images using just 3-5 examples.
+[Textual inversion](https://huggingface.co/papers/2208.01618) is a method to personalize text2image models like stable diffusion on your own images using just 3-5 examples.
The `textual_inversion.py` script shows how to implement the training procedure and adapt it for stable diffusion.
## Running on Colab
@@ -86,7 +86,7 @@ accelerate launch textual_inversion.py \
A full training run takes ~1 hour on one V100 GPU.
-**Note**: As described in [the official paper](https://arxiv.org/abs/2208.01618)
+**Note**: As described in [the official paper](https://huggingface.co/papers/2208.01618)
only one embedding vector is used for the placeholder token, *e.g.* `""`.
However, one can also add multiple embedding vectors for the placeholder token
to increase the number of fine-tuneable parameters. This can help the model to learn
diff --git a/examples/textual_inversion/textual_inversion_sdxl.py b/examples/textual_inversion/textual_inversion_sdxl.py
index ecbc7a185b..add15a8583 100644
--- a/examples/textual_inversion/textual_inversion_sdxl.py
+++ b/examples/textual_inversion/textual_inversion_sdxl.py
@@ -793,17 +793,22 @@ def main():
)
# Scheduler and math around the number of training steps.
- overrode_max_train_steps = False
- num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ # Check the PR https://github.com/huggingface/diffusers/pull/8312 for detailed explanation.
+ num_warmup_steps_for_scheduler = args.lr_warmup_steps * accelerator.num_processes
if args.max_train_steps is None:
- args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
- overrode_max_train_steps = True
+ len_train_dataloader_after_sharding = math.ceil(len(train_dataloader) / accelerator.num_processes)
+ num_update_steps_per_epoch = math.ceil(len_train_dataloader_after_sharding / args.gradient_accumulation_steps)
+ num_training_steps_for_scheduler = (
+ args.num_train_epochs * num_update_steps_per_epoch * accelerator.num_processes
+ )
+ else:
+ num_training_steps_for_scheduler = args.max_train_steps * accelerator.num_processes
lr_scheduler = get_scheduler(
args.lr_scheduler,
optimizer=optimizer,
- num_warmup_steps=args.lr_warmup_steps * accelerator.num_processes,
- num_training_steps=args.max_train_steps * accelerator.num_processes,
+ num_warmup_steps=num_warmup_steps_for_scheduler,
+ num_training_steps=num_training_steps_for_scheduler,
num_cycles=args.lr_num_cycles,
)
@@ -829,8 +834,14 @@ def main():
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
- if overrode_max_train_steps:
+ if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ if num_training_steps_for_scheduler != args.max_train_steps * accelerator.num_processes:
+ logger.warning(
+ f"The length of the 'train_dataloader' after 'accelerator.prepare' ({len(train_dataloader)}) does not match "
+ f"the expected length ({len_train_dataloader_after_sharding}) when the learning rate scheduler was created. "
+ f"This inconsistency may result in the learning rate scheduler not functioning properly."
+ )
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
diff --git a/examples/vqgan/README.md b/examples/vqgan/README.md
index 056bbcaf67..65bb044ea5 100644
--- a/examples/vqgan/README.md
+++ b/examples/vqgan/README.md
@@ -1,5 +1,5 @@
## Training an VQGAN VAE
-VQVAEs were first introduced in [Neural Discrete Representation Learning](https://arxiv.org/abs/1711.00937) and was combined with a GAN in the paper [Taming Transformers for High-Resolution Image Synthesis](https://arxiv.org/abs/2012.09841). The basic idea of a VQVAE is it's a type of a variational auto encoder with tokens as the latent space similar to tokens for LLMs. This script was adapted from a [pr to huggingface's open-muse project](https://github.com/huggingface/open-muse/pull/52) with general code following [lucidrian's implementation of the vqgan training script](https://github.com/lucidrains/muse-maskgit-pytorch/blob/main/muse_maskgit_pytorch/trainers.py) but both of these implementation follow from the [taming transformer repo](https://github.com/CompVis/taming-transformers?tab=readme-ov-file).
+VQVAEs were first introduced in [Neural Discrete Representation Learning](https://huggingface.co/papers/1711.00937) and was combined with a GAN in the paper [Taming Transformers for High-Resolution Image Synthesis](https://huggingface.co/papers/2012.09841). The basic idea of a VQVAE is it's a type of a variational auto encoder with tokens as the latent space similar to tokens for LLMs. This script was adapted from a [pr to huggingface's open-muse project](https://github.com/huggingface/open-muse/pull/52) with general code following [lucidrian's implementation of the vqgan training script](https://github.com/lucidrains/muse-maskgit-pytorch/blob/main/muse_maskgit_pytorch/trainers.py) but both of these implementation follow from the [taming transformer repo](https://github.com/CompVis/taming-transformers?tab=readme-ov-file).
Creating a training image set is [described in a different document](https://huggingface.co/docs/datasets/image_process#image-datasets).
diff --git a/scripts/convert_ltx_to_diffusers.py b/scripts/convert_ltx_to_diffusers.py
index 2e966d5d11..256312cc72 100644
--- a/scripts/convert_ltx_to_diffusers.py
+++ b/scripts/convert_ltx_to_diffusers.py
@@ -7,7 +7,15 @@ from accelerate import init_empty_weights
from safetensors.torch import load_file
from transformers import T5EncoderModel, T5Tokenizer
-from diffusers import AutoencoderKLLTXVideo, FlowMatchEulerDiscreteScheduler, LTXPipeline, LTXVideoTransformer3DModel
+from diffusers import (
+ AutoencoderKLLTXVideo,
+ FlowMatchEulerDiscreteScheduler,
+ LTXConditionPipeline,
+ LTXLatentUpsamplePipeline,
+ LTXPipeline,
+ LTXVideoTransformer3DModel,
+)
+from diffusers.pipelines.ltx.modeling_latent_upsampler import LTXLatentUpsamplerModel
def remove_keys_(key: str, state_dict: Dict[str, Any]):
@@ -123,17 +131,10 @@ def update_state_dict_inplace(state_dict: Dict[str, Any], old_key: str, new_key:
state_dict[new_key] = state_dict.pop(old_key)
-def convert_transformer(
- ckpt_path: str,
- dtype: torch.dtype,
- version: str = "0.9.0",
-):
+def convert_transformer(ckpt_path: str, config, dtype: torch.dtype):
PREFIX_KEY = "model.diffusion_model."
original_state_dict = get_state_dict(load_file(ckpt_path))
- config = {}
- if version == "0.9.5":
- config["_use_causal_rope_fix"] = True
with init_empty_weights():
transformer = LTXVideoTransformer3DModel(**config)
@@ -180,8 +181,59 @@ def convert_vae(ckpt_path: str, config, dtype: torch.dtype):
return vae
+def convert_spatial_latent_upsampler(ckpt_path: str, config, dtype: torch.dtype):
+ original_state_dict = get_state_dict(load_file(ckpt_path))
+
+ with init_empty_weights():
+ latent_upsampler = LTXLatentUpsamplerModel(**config)
+
+ latent_upsampler.load_state_dict(original_state_dict, strict=True, assign=True)
+ latent_upsampler.to(dtype)
+ return latent_upsampler
+
+
+def get_transformer_config(version: str) -> Dict[str, Any]:
+ if version == "0.9.7":
+ config = {
+ "in_channels": 128,
+ "out_channels": 128,
+ "patch_size": 1,
+ "patch_size_t": 1,
+ "num_attention_heads": 32,
+ "attention_head_dim": 128,
+ "cross_attention_dim": 4096,
+ "num_layers": 48,
+ "activation_fn": "gelu-approximate",
+ "qk_norm": "rms_norm_across_heads",
+ "norm_elementwise_affine": False,
+ "norm_eps": 1e-6,
+ "caption_channels": 4096,
+ "attention_bias": True,
+ "attention_out_bias": True,
+ }
+ else:
+ config = {
+ "in_channels": 128,
+ "out_channels": 128,
+ "patch_size": 1,
+ "patch_size_t": 1,
+ "num_attention_heads": 32,
+ "attention_head_dim": 64,
+ "cross_attention_dim": 2048,
+ "num_layers": 28,
+ "activation_fn": "gelu-approximate",
+ "qk_norm": "rms_norm_across_heads",
+ "norm_elementwise_affine": False,
+ "norm_eps": 1e-6,
+ "caption_channels": 4096,
+ "attention_bias": True,
+ "attention_out_bias": True,
+ }
+ return config
+
+
def get_vae_config(version: str) -> Dict[str, Any]:
- if version == "0.9.0":
+ if version in ["0.9.0"]:
config = {
"in_channels": 3,
"out_channels": 3,
@@ -210,7 +262,7 @@ def get_vae_config(version: str) -> Dict[str, Any]:
"decoder_causal": False,
"timestep_conditioning": False,
}
- elif version == "0.9.1":
+ elif version in ["0.9.1"]:
config = {
"in_channels": 3,
"out_channels": 3,
@@ -240,7 +292,39 @@ def get_vae_config(version: str) -> Dict[str, Any]:
"decoder_causal": False,
}
VAE_KEYS_RENAME_DICT.update(VAE_091_RENAME_DICT)
- elif version == "0.9.5":
+ elif version in ["0.9.5"]:
+ config = {
+ "in_channels": 3,
+ "out_channels": 3,
+ "latent_channels": 128,
+ "block_out_channels": (128, 256, 512, 1024, 2048),
+ "down_block_types": (
+ "LTXVideo095DownBlock3D",
+ "LTXVideo095DownBlock3D",
+ "LTXVideo095DownBlock3D",
+ "LTXVideo095DownBlock3D",
+ ),
+ "decoder_block_out_channels": (256, 512, 1024),
+ "layers_per_block": (4, 6, 6, 2, 2),
+ "decoder_layers_per_block": (5, 5, 5, 5),
+ "spatio_temporal_scaling": (True, True, True, True),
+ "decoder_spatio_temporal_scaling": (True, True, True),
+ "decoder_inject_noise": (False, False, False, False),
+ "downsample_type": ("spatial", "temporal", "spatiotemporal", "spatiotemporal"),
+ "upsample_residual": (True, True, True),
+ "upsample_factor": (2, 2, 2),
+ "timestep_conditioning": True,
+ "patch_size": 4,
+ "patch_size_t": 1,
+ "resnet_norm_eps": 1e-6,
+ "scaling_factor": 1.0,
+ "encoder_causal": True,
+ "decoder_causal": False,
+ "spatial_compression_ratio": 32,
+ "temporal_compression_ratio": 8,
+ }
+ VAE_KEYS_RENAME_DICT.update(VAE_095_RENAME_DICT)
+ elif version in ["0.9.7"]:
config = {
"in_channels": 3,
"out_channels": 3,
@@ -275,12 +359,33 @@ def get_vae_config(version: str) -> Dict[str, Any]:
return config
+def get_spatial_latent_upsampler_config(version: str) -> Dict[str, Any]:
+ if version == "0.9.7":
+ config = {
+ "in_channels": 128,
+ "mid_channels": 512,
+ "num_blocks_per_stage": 4,
+ "dims": 3,
+ "spatial_upsample": True,
+ "temporal_upsample": False,
+ }
+ else:
+ raise ValueError(f"Unsupported version: {version}")
+ return config
+
+
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument(
"--transformer_ckpt_path", type=str, default=None, help="Path to original transformer checkpoint"
)
parser.add_argument("--vae_ckpt_path", type=str, default=None, help="Path to original vae checkpoint")
+ parser.add_argument(
+ "--spatial_latent_upsampler_path",
+ type=str,
+ default=None,
+ help="Path to original spatial latent upsampler checkpoint",
+ )
parser.add_argument(
"--text_encoder_cache_dir", type=str, default=None, help="Path to text encoder cache directory"
)
@@ -294,7 +399,11 @@ def get_args():
parser.add_argument("--output_path", type=str, required=True, help="Path where converted model should be saved")
parser.add_argument("--dtype", default="fp32", help="Torch dtype to save the model in.")
parser.add_argument(
- "--version", type=str, default="0.9.0", choices=["0.9.0", "0.9.1", "0.9.5"], help="Version of the LTX model"
+ "--version",
+ type=str,
+ default="0.9.0",
+ choices=["0.9.0", "0.9.1", "0.9.5", "0.9.7"],
+ help="Version of the LTX model",
)
return parser.parse_args()
@@ -320,11 +429,9 @@ if __name__ == "__main__":
variant = VARIANT_MAPPING[args.dtype]
output_path = Path(args.output_path)
- if args.save_pipeline:
- assert args.transformer_ckpt_path is not None and args.vae_ckpt_path is not None
-
if args.transformer_ckpt_path is not None:
- transformer: LTXVideoTransformer3DModel = convert_transformer(args.transformer_ckpt_path, dtype)
+ config = get_transformer_config(args.version)
+ transformer: LTXVideoTransformer3DModel = convert_transformer(args.transformer_ckpt_path, config, dtype)
if not args.save_pipeline:
transformer.save_pretrained(
output_path / "transformer", safe_serialization=True, max_shard_size="5GB", variant=variant
@@ -336,6 +443,16 @@ if __name__ == "__main__":
if not args.save_pipeline:
vae.save_pretrained(output_path / "vae", safe_serialization=True, max_shard_size="5GB", variant=variant)
+ if args.spatial_latent_upsampler_path is not None:
+ config = get_spatial_latent_upsampler_config(args.version)
+ latent_upsampler: LTXLatentUpsamplerModel = convert_spatial_latent_upsampler(
+ args.spatial_latent_upsampler_path, config, dtype
+ )
+ if not args.save_pipeline:
+ latent_upsampler.save_pretrained(
+ output_path / "latent_upsampler", safe_serialization=True, max_shard_size="5GB", variant=variant
+ )
+
if args.save_pipeline:
text_encoder_id = "google/t5-v1_1-xxl"
tokenizer = T5Tokenizer.from_pretrained(text_encoder_id, model_max_length=TOKENIZER_MAX_LENGTH)
@@ -348,7 +465,7 @@ if __name__ == "__main__":
for param in text_encoder.parameters():
param.data = param.data.contiguous()
- if args.version == "0.9.5":
+ if args.version in ["0.9.5", "0.9.7"]:
scheduler = FlowMatchEulerDiscreteScheduler(use_dynamic_shifting=False)
else:
scheduler = FlowMatchEulerDiscreteScheduler(
@@ -360,12 +477,40 @@ if __name__ == "__main__":
shift_terminal=0.1,
)
- pipe = LTXPipeline(
- scheduler=scheduler,
- vae=vae,
- text_encoder=text_encoder,
- tokenizer=tokenizer,
- transformer=transformer,
- )
-
- pipe.save_pretrained(args.output_path, safe_serialization=True, variant=variant, max_shard_size="5GB")
+ if args.version in ["0.9.0", "0.9.1", "0.9.5"]:
+ pipe = LTXPipeline(
+ scheduler=scheduler,
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ transformer=transformer,
+ )
+ pipe.save_pretrained(
+ output_path.as_posix(), safe_serialization=True, variant=variant, max_shard_size="5GB"
+ )
+ elif args.version in ["0.9.7"]:
+ pipe = LTXConditionPipeline(
+ scheduler=scheduler,
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ transformer=transformer,
+ )
+ pipe_upsample = LTXLatentUpsamplePipeline(
+ vae=vae,
+ latent_upsampler=latent_upsampler,
+ )
+ pipe.save_pretrained(
+ (output_path / "ltx_pipeline").as_posix(),
+ safe_serialization=True,
+ variant=variant,
+ max_shard_size="5GB",
+ )
+ pipe_upsample.save_pretrained(
+ (output_path / "ltx_upsample_pipeline").as_posix(),
+ safe_serialization=True,
+ variant=variant,
+ max_shard_size="5GB",
+ )
+ else:
+ raise ValueError(f"Unsupported version: {args.version}")
diff --git a/src/diffusers/__init__.py b/src/diffusers/__init__.py
index 9e172dc3e7..8c4ae36c56 100644
--- a/src/diffusers/__init__.py
+++ b/src/diffusers/__init__.py
@@ -420,6 +420,7 @@ else:
"LEditsPPPipelineStableDiffusionXL",
"LTXConditionPipeline",
"LTXImageToVideoPipeline",
+ "LTXLatentUpsamplePipeline",
"LTXPipeline",
"Lumina2Pipeline",
"Lumina2Text2ImgPipeline",
@@ -440,6 +441,7 @@ else:
"SanaControlNetPipeline",
"SanaPAGPipeline",
"SanaPipeline",
+ "SanaSprintImg2ImgPipeline",
"SanaSprintPipeline",
"SemanticStableDiffusionPipeline",
"ShapEImg2ImgPipeline",
@@ -520,6 +522,8 @@ else:
"VersatileDiffusionPipeline",
"VersatileDiffusionTextToImagePipeline",
"VideoToVideoSDPipeline",
+ "VisualClozeGenerationPipeline",
+ "VisualClozePipeline",
"VQDiffusionPipeline",
"WanImageToVideoPipeline",
"WanPipeline",
@@ -1001,6 +1005,7 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
LEditsPPPipelineStableDiffusionXL,
LTXConditionPipeline,
LTXImageToVideoPipeline,
+ LTXLatentUpsamplePipeline,
LTXPipeline,
Lumina2Pipeline,
Lumina2Text2ImgPipeline,
@@ -1021,6 +1026,7 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
SanaControlNetPipeline,
SanaPAGPipeline,
SanaPipeline,
+ SanaSprintImg2ImgPipeline,
SanaSprintPipeline,
SemanticStableDiffusionPipeline,
ShapEImg2ImgPipeline,
@@ -1100,6 +1106,8 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
VersatileDiffusionPipeline,
VersatileDiffusionTextToImagePipeline,
VideoToVideoSDPipeline,
+ VisualClozeGenerationPipeline,
+ VisualClozePipeline,
VQDiffusionPipeline,
WanImageToVideoPipeline,
WanPipeline,
diff --git a/src/diffusers/experimental/README.md b/src/diffusers/experimental/README.md
index 81a9de81c7..77594b14db 100644
--- a/src/diffusers/experimental/README.md
+++ b/src/diffusers/experimental/README.md
@@ -2,4 +2,4 @@
We are adding experimental code to support novel applications and usages of the Diffusers library.
Currently, the following experiments are supported:
-* Reinforcement learning via an implementation of the [Diffuser](https://arxiv.org/abs/2205.09991) model.
\ No newline at end of file
+* Reinforcement learning via an implementation of the [Diffuser](https://huggingface.co/papers/2205.09991) model.
\ No newline at end of file
diff --git a/src/diffusers/hooks/faster_cache.py b/src/diffusers/hooks/faster_cache.py
index 6346353464..35b176e930 100644
--- a/src/diffusers/hooks/faster_cache.py
+++ b/src/diffusers/hooks/faster_cache.py
@@ -146,7 +146,7 @@ class FasterCacheConfig:
alpha_low_frequency: float = 1.1
alpha_high_frequency: float = 1.1
- # n as described in CFG-Cache explanation in the paper - dependant on the model
+ # n as described in CFG-Cache explanation in the paper - dependent on the model
unconditional_batch_skip_range: int = 5
unconditional_batch_timestep_skip_range: Tuple[int, int] = (-1, 641)
diff --git a/src/diffusers/hooks/group_offloading.py b/src/diffusers/hooks/group_offloading.py
index 7a8970aeed..565f8f1ff8 100644
--- a/src/diffusers/hooks/group_offloading.py
+++ b/src/diffusers/hooks/group_offloading.py
@@ -113,6 +113,7 @@ class ModuleGroup:
finally:
pinned_dict = None
+ @torch.compiler.disable()
def onload_(self):
r"""Onloads the group of modules to the onload_device."""
torch_accelerator_module = (
@@ -165,6 +166,7 @@ class ModuleGroup:
if self.record_stream:
buffer.data.record_stream(current_stream)
+ @torch.compiler.disable()
def offload_(self):
r"""Offloads the group of modules to the offload_device."""
diff --git a/src/diffusers/hooks/hooks.py b/src/diffusers/hooks/hooks.py
index 3b2e4ed91c..2f3f613573 100644
--- a/src/diffusers/hooks/hooks.py
+++ b/src/diffusers/hooks/hooks.py
@@ -45,7 +45,7 @@ class ModelHook:
def deinitalize_hook(self, module: torch.nn.Module) -> torch.nn.Module:
r"""
- Hook that is executed when a model is deinitalized.
+ Hook that is executed when a model is deinitialized.
Args:
module (`torch.nn.Module`):
diff --git a/src/diffusers/hooks/layerwise_casting.py b/src/diffusers/hooks/layerwise_casting.py
index c0105ab934..5c99cb7448 100644
--- a/src/diffusers/hooks/layerwise_casting.py
+++ b/src/diffusers/hooks/layerwise_casting.py
@@ -62,7 +62,7 @@ class LayerwiseCastingHook(ModelHook):
def deinitalize_hook(self, module: torch.nn.Module):
raise NotImplementedError(
- "LayerwiseCastingHook does not support deinitalization. A model once enabled with layerwise casting will "
+ "LayerwiseCastingHook does not support deinitialization. A model once enabled with layerwise casting will "
"have casted its weights to a lower precision dtype for storage. Casting this back to the original dtype "
"will lead to precision loss, which might have an impact on the model's generation quality. The model should "
"be re-initialized and loaded in the original dtype."
diff --git a/src/diffusers/loaders/lora_base.py b/src/diffusers/loaders/lora_base.py
index 1377807b3e..32d7c773d2 100644
--- a/src/diffusers/loaders/lora_base.py
+++ b/src/diffusers/loaders/lora_base.py
@@ -299,8 +299,8 @@ def _best_guess_weight_name(
targeted_files = list(filter(lambda x: x.endswith(LORA_WEIGHT_NAME_SAFE), targeted_files))
if len(targeted_files) > 1:
- raise ValueError(
- f"Provided path contains more than one weights file in the {file_extension} format. Either specify `weight_name` in `load_lora_weights` or make sure there's only one `.safetensors` or `.bin` file in {pretrained_model_name_or_path_or_dict}."
+ logger.warning(
+ f"Provided path contains more than one weights file in the {file_extension} format. `{targeted_files[0]}` is going to be loaded, for precise control, specify a `weight_name` in `load_lora_weights`."
)
weight_name = targeted_files[0]
return weight_name
@@ -465,7 +465,7 @@ class LoraBaseMixin:
"""Utility class for handling LoRAs."""
_lora_loadable_modules = []
- num_fused_loras = 0
+ _merged_adapters = set()
def load_lora_weights(self, **kwargs):
raise NotImplementedError("`load_lora_weights()` is not implemented.")
@@ -592,6 +592,9 @@ class LoraBaseMixin:
if len(components) == 0:
raise ValueError("`components` cannot be an empty list.")
+ # Need to retrieve the names as `adapter_names` can be None. So we cannot directly use it
+ # in `self._merged_adapters = self._merged_adapters | merged_adapter_names`.
+ merged_adapter_names = set()
for fuse_component in components:
if fuse_component not in self._lora_loadable_modules:
raise ValueError(f"{fuse_component} is not found in {self._lora_loadable_modules=}.")
@@ -601,13 +604,19 @@ class LoraBaseMixin:
# check if diffusers model
if issubclass(model.__class__, ModelMixin):
model.fuse_lora(lora_scale, safe_fusing=safe_fusing, adapter_names=adapter_names)
+ for module in model.modules():
+ if isinstance(module, BaseTunerLayer):
+ merged_adapter_names.update(set(module.merged_adapters))
# handle transformers models.
if issubclass(model.__class__, PreTrainedModel):
fuse_text_encoder_lora(
model, lora_scale=lora_scale, safe_fusing=safe_fusing, adapter_names=adapter_names
)
+ for module in model.modules():
+ if isinstance(module, BaseTunerLayer):
+ merged_adapter_names.update(set(module.merged_adapters))
- self.num_fused_loras += 1
+ self._merged_adapters = self._merged_adapters | merged_adapter_names
def unfuse_lora(self, components: List[str] = [], **kwargs):
r"""
@@ -661,9 +670,18 @@ class LoraBaseMixin:
if issubclass(model.__class__, (ModelMixin, PreTrainedModel)):
for module in model.modules():
if isinstance(module, BaseTunerLayer):
+ for adapter in set(module.merged_adapters):
+ if adapter and adapter in self._merged_adapters:
+ self._merged_adapters = self._merged_adapters - {adapter}
module.unmerge()
- self.num_fused_loras -= 1
+ @property
+ def num_fused_loras(self):
+ return len(self._merged_adapters)
+
+ @property
+ def fused_loras(self):
+ return self._merged_adapters
def set_adapters(
self,
diff --git a/src/diffusers/loaders/lora_conversion_utils.py b/src/diffusers/loaders/lora_conversion_utils.py
index d5fa7dcfc3..5b12c3aca8 100644
--- a/src/diffusers/loaders/lora_conversion_utils.py
+++ b/src/diffusers/loaders/lora_conversion_utils.py
@@ -1596,48 +1596,131 @@ def _convert_non_diffusers_wan_lora_to_diffusers(state_dict):
converted_state_dict = {}
original_state_dict = {k[len("diffusion_model.") :]: v for k, v in state_dict.items()}
- num_blocks = len({k.split("blocks.")[1].split(".")[0] for k in original_state_dict})
+ num_blocks = len({k.split("blocks.")[1].split(".")[0] for k in original_state_dict if "blocks." in k})
is_i2v_lora = any("k_img" in k for k in original_state_dict) and any("v_img" in k for k in original_state_dict)
+ lora_down_key = "lora_A" if any("lora_A" in k for k in original_state_dict) else "lora_down"
+ lora_up_key = "lora_B" if any("lora_B" in k for k in original_state_dict) else "lora_up"
+
+ diff_keys = [k for k in original_state_dict if k.endswith((".diff_b", ".diff"))]
+ if diff_keys:
+ for diff_k in diff_keys:
+ param = original_state_dict[diff_k]
+ all_zero = torch.all(param == 0).item()
+ if all_zero:
+ logger.debug(f"Removed {diff_k} key from the state dict as it's all zeros.")
+ original_state_dict.pop(diff_k)
+
+ # For the `diff_b` keys, we treat them as lora_bias.
+ # https://huggingface.co/docs/peft/main/en/package_reference/lora#peft.LoraConfig.lora_bias
for i in range(num_blocks):
# Self-attention
for o, c in zip(["q", "k", "v", "o"], ["to_q", "to_k", "to_v", "to_out.0"]):
converted_state_dict[f"blocks.{i}.attn1.{c}.lora_A.weight"] = original_state_dict.pop(
- f"blocks.{i}.self_attn.{o}.lora_A.weight"
+ f"blocks.{i}.self_attn.{o}.{lora_down_key}.weight"
)
converted_state_dict[f"blocks.{i}.attn1.{c}.lora_B.weight"] = original_state_dict.pop(
- f"blocks.{i}.self_attn.{o}.lora_B.weight"
+ f"blocks.{i}.self_attn.{o}.{lora_up_key}.weight"
)
+ if f"blocks.{i}.self_attn.{o}.diff_b" in original_state_dict:
+ converted_state_dict[f"blocks.{i}.attn1.{c}.lora_B.bias"] = original_state_dict.pop(
+ f"blocks.{i}.self_attn.{o}.diff_b"
+ )
# Cross-attention
for o, c in zip(["q", "k", "v", "o"], ["to_q", "to_k", "to_v", "to_out.0"]):
converted_state_dict[f"blocks.{i}.attn2.{c}.lora_A.weight"] = original_state_dict.pop(
- f"blocks.{i}.cross_attn.{o}.lora_A.weight"
+ f"blocks.{i}.cross_attn.{o}.{lora_down_key}.weight"
)
converted_state_dict[f"blocks.{i}.attn2.{c}.lora_B.weight"] = original_state_dict.pop(
- f"blocks.{i}.cross_attn.{o}.lora_B.weight"
+ f"blocks.{i}.cross_attn.{o}.{lora_up_key}.weight"
)
+ if f"blocks.{i}.cross_attn.{o}.diff_b" in original_state_dict:
+ converted_state_dict[f"blocks.{i}.attn2.{c}.lora_B.bias"] = original_state_dict.pop(
+ f"blocks.{i}.cross_attn.{o}.diff_b"
+ )
if is_i2v_lora:
for o, c in zip(["k_img", "v_img"], ["add_k_proj", "add_v_proj"]):
converted_state_dict[f"blocks.{i}.attn2.{c}.lora_A.weight"] = original_state_dict.pop(
- f"blocks.{i}.cross_attn.{o}.lora_A.weight"
+ f"blocks.{i}.cross_attn.{o}.{lora_down_key}.weight"
)
converted_state_dict[f"blocks.{i}.attn2.{c}.lora_B.weight"] = original_state_dict.pop(
- f"blocks.{i}.cross_attn.{o}.lora_B.weight"
+ f"blocks.{i}.cross_attn.{o}.{lora_up_key}.weight"
)
+ if f"blocks.{i}.cross_attn.{o}.diff_b" in original_state_dict:
+ converted_state_dict[f"blocks.{i}.attn2.{c}.lora_B.bias"] = original_state_dict.pop(
+ f"blocks.{i}.cross_attn.{o}.diff_b"
+ )
# FFN
for o, c in zip(["ffn.0", "ffn.2"], ["net.0.proj", "net.2"]):
converted_state_dict[f"blocks.{i}.ffn.{c}.lora_A.weight"] = original_state_dict.pop(
- f"blocks.{i}.{o}.lora_A.weight"
+ f"blocks.{i}.{o}.{lora_down_key}.weight"
)
converted_state_dict[f"blocks.{i}.ffn.{c}.lora_B.weight"] = original_state_dict.pop(
- f"blocks.{i}.{o}.lora_B.weight"
+ f"blocks.{i}.{o}.{lora_up_key}.weight"
)
+ if f"blocks.{i}.{o}.diff_b" in original_state_dict:
+ converted_state_dict[f"blocks.{i}.ffn.{c}.lora_B.bias"] = original_state_dict.pop(
+ f"blocks.{i}.{o}.diff_b"
+ )
+
+ # Remaining.
+ if original_state_dict:
+ if any("time_projection" in k for k in original_state_dict):
+ converted_state_dict["condition_embedder.time_proj.lora_A.weight"] = original_state_dict.pop(
+ f"time_projection.1.{lora_down_key}.weight"
+ )
+ converted_state_dict["condition_embedder.time_proj.lora_B.weight"] = original_state_dict.pop(
+ f"time_projection.1.{lora_up_key}.weight"
+ )
+ if "time_projection.1.diff_b" in original_state_dict:
+ converted_state_dict["condition_embedder.time_proj.lora_B.bias"] = original_state_dict.pop(
+ "time_projection.1.diff_b"
+ )
+
+ if any("head.head" in k for k in state_dict):
+ converted_state_dict["proj_out.lora_A.weight"] = original_state_dict.pop(
+ f"head.head.{lora_down_key}.weight"
+ )
+ converted_state_dict["proj_out.lora_B.weight"] = original_state_dict.pop(f"head.head.{lora_up_key}.weight")
+ if "head.head.diff_b" in original_state_dict:
+ converted_state_dict["proj_out.lora_B.bias"] = original_state_dict.pop("head.head.diff_b")
+
+ for text_time in ["text_embedding", "time_embedding"]:
+ if any(text_time in k for k in original_state_dict):
+ for b_n in [0, 2]:
+ diffusers_b_n = 1 if b_n == 0 else 2
+ diffusers_name = (
+ "condition_embedder.text_embedder"
+ if text_time == "text_embedding"
+ else "condition_embedder.time_embedder"
+ )
+ if any(f"{text_time}.{b_n}" in k for k in original_state_dict):
+ converted_state_dict[f"{diffusers_name}.linear_{diffusers_b_n}.lora_A.weight"] = (
+ original_state_dict.pop(f"{text_time}.{b_n}.{lora_down_key}.weight")
+ )
+ converted_state_dict[f"{diffusers_name}.linear_{diffusers_b_n}.lora_B.weight"] = (
+ original_state_dict.pop(f"{text_time}.{b_n}.{lora_up_key}.weight")
+ )
+ if f"{text_time}.{b_n}.diff_b" in original_state_dict:
+ converted_state_dict[f"{diffusers_name}.linear_{diffusers_b_n}.lora_B.bias"] = (
+ original_state_dict.pop(f"{text_time}.{b_n}.diff_b")
+ )
if len(original_state_dict) > 0:
- raise ValueError(f"`state_dict` should be empty at this point but has {original_state_dict.keys()=}")
+ diff = all(".diff" in k for k in original_state_dict)
+ if diff:
+ diff_keys = {k for k in original_state_dict if k.endswith(".diff")}
+ if not all("lora" not in k for k in diff_keys):
+ raise ValueError
+ logger.info(
+ "The remaining `state_dict` contains `diff` keys which we do not handle yet. If you see performance issues, please file an issue: "
+ "https://github.com/huggingface/diffusers//issues/new"
+ )
+ else:
+ raise ValueError(f"`state_dict` should be empty at this point but has {original_state_dict.keys()=}")
for key in list(converted_state_dict.keys()):
converted_state_dict[f"transformer.{key}"] = converted_state_dict.pop(key)
@@ -1704,3 +1787,19 @@ def _convert_musubi_wan_lora_to_diffusers(state_dict):
converted_state_dict[f"transformer.{key}"] = converted_state_dict.pop(key)
return converted_state_dict
+
+
+def _convert_non_diffusers_hidream_lora_to_diffusers(state_dict, non_diffusers_prefix="diffusion_model"):
+ if not all(k.startswith(non_diffusers_prefix) for k in state_dict):
+ raise ValueError("Invalid LoRA state dict for HiDream.")
+ converted_state_dict = {k.removeprefix(f"{non_diffusers_prefix}."): v for k, v in state_dict.items()}
+ converted_state_dict = {f"transformer.{k}": v for k, v in converted_state_dict.items()}
+ return converted_state_dict
+
+
+def _convert_non_diffusers_ltxv_lora_to_diffusers(state_dict, non_diffusers_prefix="diffusion_model"):
+ if not all(k.startswith(f"{non_diffusers_prefix}.") for k in state_dict):
+ raise ValueError("Invalid LoRA state dict for LTX-Video.")
+ converted_state_dict = {k.removeprefix(f"{non_diffusers_prefix}."): v for k, v in state_dict.items()}
+ converted_state_dict = {f"transformer.{k}": v for k, v in converted_state_dict.items()}
+ return converted_state_dict
diff --git a/src/diffusers/loaders/lora_pipeline.py b/src/diffusers/loaders/lora_pipeline.py
index 810ec8adb1..6092eeff0a 100644
--- a/src/diffusers/loaders/lora_pipeline.py
+++ b/src/diffusers/loaders/lora_pipeline.py
@@ -43,7 +43,9 @@ from .lora_conversion_utils import (
_convert_hunyuan_video_lora_to_diffusers,
_convert_kohya_flux_lora_to_diffusers,
_convert_musubi_wan_lora_to_diffusers,
+ _convert_non_diffusers_hidream_lora_to_diffusers,
_convert_non_diffusers_lora_to_diffusers,
+ _convert_non_diffusers_ltxv_lora_to_diffusers,
_convert_non_diffusers_lumina2_lora_to_diffusers,
_convert_non_diffusers_wan_lora_to_diffusers,
_convert_xlabs_flux_lora_to_diffusers,
@@ -2543,14 +2545,13 @@ class FluxLoraLoaderMixin(LoraBaseMixin):
if unexpected_modules:
logger.debug(f"Found unexpected modules: {unexpected_modules}. These will be ignored.")
- is_peft_loaded = getattr(transformer, "peft_config", None) is not None
for k in lora_module_names:
if k in unexpected_modules:
continue
base_param_name = (
f"{k.replace(prefix, '')}.base_layer.weight"
- if is_peft_loaded and f"{k.replace(prefix, '')}.base_layer.weight" in transformer_state_dict
+ if f"{k.replace(prefix, '')}.base_layer.weight" in transformer_state_dict
else f"{k.replace(prefix, '')}.weight"
)
base_weight_param = transformer_state_dict[base_param_name]
@@ -3417,7 +3418,6 @@ class LTXVideoLoraLoaderMixin(LoraBaseMixin):
@classmethod
@validate_hf_hub_args
- # Copied from diffusers.loaders.lora_pipeline.CogVideoXLoraLoaderMixin.lora_state_dict
def lora_state_dict(
cls,
pretrained_model_name_or_path_or_dict: Union[str, Dict[str, torch.Tensor]],
@@ -3511,6 +3511,10 @@ class LTXVideoLoraLoaderMixin(LoraBaseMixin):
logger.warning(warn_msg)
state_dict = {k: v for k, v in state_dict.items() if "dora_scale" not in k}
+ is_non_diffusers_format = any(k.startswith("diffusion_model.") for k in state_dict)
+ if is_non_diffusers_format:
+ state_dict = _convert_non_diffusers_ltxv_lora_to_diffusers(state_dict)
+
return state_dict
# Copied from diffusers.loaders.lora_pipeline.CogVideoXLoraLoaderMixin.load_lora_weights
@@ -4808,22 +4812,43 @@ class WanLoraLoaderMixin(LoraBaseMixin):
if transformer.config.image_dim is None:
return state_dict
+ target_device = transformer.device
+
if any(k.startswith("transformer.blocks.") for k in state_dict):
- num_blocks = len({k.split("blocks.")[1].split(".")[0] for k in state_dict})
+ num_blocks = len({k.split("blocks.")[1].split(".")[0] for k in state_dict if "blocks." in k})
is_i2v_lora = any("add_k_proj" in k for k in state_dict) and any("add_v_proj" in k for k in state_dict)
+ has_bias = any(".lora_B.bias" in k for k in state_dict)
if is_i2v_lora:
return state_dict
for i in range(num_blocks):
for o, c in zip(["k_img", "v_img"], ["add_k_proj", "add_v_proj"]):
+ # These keys should exist if the block `i` was part of the T2V LoRA.
+ ref_key_lora_A = f"transformer.blocks.{i}.attn2.to_k.lora_A.weight"
+ ref_key_lora_B = f"transformer.blocks.{i}.attn2.to_k.lora_B.weight"
+
+ if ref_key_lora_A not in state_dict or ref_key_lora_B not in state_dict:
+ continue
+
state_dict[f"transformer.blocks.{i}.attn2.{c}.lora_A.weight"] = torch.zeros_like(
- state_dict[f"transformer.blocks.{i}.attn2.to_k.lora_A.weight"]
+ state_dict[f"transformer.blocks.{i}.attn2.to_k.lora_A.weight"], device=target_device
)
state_dict[f"transformer.blocks.{i}.attn2.{c}.lora_B.weight"] = torch.zeros_like(
- state_dict[f"transformer.blocks.{i}.attn2.to_k.lora_B.weight"]
+ state_dict[f"transformer.blocks.{i}.attn2.to_k.lora_B.weight"], device=target_device
)
+ # If the original LoRA had biases (indicated by has_bias)
+ # AND the specific reference bias key exists for this block.
+
+ ref_key_lora_B_bias = f"transformer.blocks.{i}.attn2.to_k.lora_B.bias"
+ if has_bias and ref_key_lora_B_bias in state_dict:
+ ref_lora_B_bias_tensor = state_dict[ref_key_lora_B_bias]
+ state_dict[f"transformer.blocks.{i}.attn2.{c}.lora_B.bias"] = torch.zeros_like(
+ ref_lora_B_bias_tensor,
+ device=target_device,
+ )
+
return state_dict
def load_lora_weights(
@@ -5371,7 +5396,6 @@ class HiDreamImageLoraLoaderMixin(LoraBaseMixin):
@classmethod
@validate_hf_hub_args
- # Copied from diffusers.loaders.lora_pipeline.CogVideoXLoraLoaderMixin.lora_state_dict
def lora_state_dict(
cls,
pretrained_model_name_or_path_or_dict: Union[str, Dict[str, torch.Tensor]],
@@ -5465,6 +5489,10 @@ class HiDreamImageLoraLoaderMixin(LoraBaseMixin):
logger.warning(warn_msg)
state_dict = {k: v for k, v in state_dict.items() if "dora_scale" not in k}
+ is_non_diffusers_format = any("diffusion_model" in k for k in state_dict)
+ if is_non_diffusers_format:
+ state_dict = _convert_non_diffusers_hidream_lora_to_diffusers(state_dict)
+
return state_dict
# Copied from diffusers.loaders.lora_pipeline.CogVideoXLoraLoaderMixin.load_lora_weights
diff --git a/src/diffusers/loaders/peft.py b/src/diffusers/loaders/peft.py
index b7da4fb746..ff71b0c5c7 100644
--- a/src/diffusers/loaders/peft.py
+++ b/src/diffusers/loaders/peft.py
@@ -57,6 +57,7 @@ _SET_ADAPTER_SCALE_FN_MAPPING = {
"WanTransformer3DModel": lambda model_cls, weights: weights,
"CogView4Transformer2DModel": lambda model_cls, weights: weights,
"HiDreamImageTransformer2DModel": lambda model_cls, weights: weights,
+ "HunyuanVideoFramepackTransformer3DModel": lambda model_cls, weights: weights,
}
@@ -250,7 +251,7 @@ class PeftAdapterMixin:
rank = {}
for key, val in state_dict.items():
- # Cannot figure out rank from lora layers that don't have atleast 2 dimensions.
+ # Cannot figure out rank from lora layers that don't have at least 2 dimensions.
# Bias layers in LoRA only have a single dimension
if "lora_B" in key and val.ndim > 1:
# Check out https://github.com/huggingface/peft/pull/2419 for the `^` symbol.
diff --git a/src/diffusers/loaders/single_file_model.py b/src/diffusers/loaders/single_file_model.py
index a2f27b765a..6919c4949d 100644
--- a/src/diffusers/loaders/single_file_model.py
+++ b/src/diffusers/loaders/single_file_model.py
@@ -31,6 +31,7 @@ from .single_file_utils import (
convert_autoencoder_dc_checkpoint_to_diffusers,
convert_controlnet_checkpoint,
convert_flux_transformer_checkpoint_to_diffusers,
+ convert_hidream_transformer_to_diffusers,
convert_hunyuan_video_transformer_to_diffusers,
convert_ldm_unet_checkpoint,
convert_ldm_vae_checkpoint,
@@ -133,6 +134,10 @@ SINGLE_FILE_LOADABLE_CLASSES = {
"checkpoint_mapping_fn": convert_wan_vae_to_diffusers,
"default_subfolder": "vae",
},
+ "HiDreamImageTransformer2DModel": {
+ "checkpoint_mapping_fn": convert_hidream_transformer_to_diffusers,
+ "default_subfolder": "transformer",
+ },
}
@@ -187,9 +192,8 @@ class FromOriginalModelMixin:
original_config (`str`, *optional*):
Dict or path to a yaml file containing the configuration for the model in its original format.
If a dict is provided, it will be used to initialize the model configuration.
- torch_dtype (`str` or `torch.dtype`, *optional*):
- Override the default `torch.dtype` and load the model with another dtype. If `"auto"` is passed, the
- dtype is automatically derived from the model's weights.
+ torch_dtype (`torch.dtype`, *optional*):
+ Override the default `torch.dtype` and load the model with another dtype.
force_download (`bool`, *optional*, defaults to `False`):
Whether or not to force the (re-)download of the model weights and configuration files, overriding the
cached versions if they exist.
diff --git a/src/diffusers/loaders/single_file_utils.py b/src/diffusers/loaders/single_file_utils.py
index 3a2855df2d..0f762b949d 100644
--- a/src/diffusers/loaders/single_file_utils.py
+++ b/src/diffusers/loaders/single_file_utils.py
@@ -126,6 +126,7 @@ CHECKPOINT_KEY_NAMES = {
],
"wan": ["model.diffusion_model.head.modulation", "head.modulation"],
"wan_vae": "decoder.middle.0.residual.0.gamma",
+ "hidream": "double_stream_blocks.0.block.adaLN_modulation.1.bias",
}
DIFFUSERS_DEFAULT_PIPELINE_PATHS = {
@@ -178,6 +179,7 @@ DIFFUSERS_DEFAULT_PIPELINE_PATHS = {
"ltx-video": {"pretrained_model_name_or_path": "diffusers/LTX-Video-0.9.0"},
"ltx-video-0.9.1": {"pretrained_model_name_or_path": "diffusers/LTX-Video-0.9.1"},
"ltx-video-0.9.5": {"pretrained_model_name_or_path": "Lightricks/LTX-Video-0.9.5"},
+ "ltx-video-0.9.7": {"pretrained_model_name_or_path": "Lightricks/LTX-Video-0.9.7-dev"},
"autoencoder-dc-f128c512": {"pretrained_model_name_or_path": "mit-han-lab/dc-ae-f128c512-mix-1.0-diffusers"},
"autoencoder-dc-f64c128": {"pretrained_model_name_or_path": "mit-han-lab/dc-ae-f64c128-mix-1.0-diffusers"},
"autoencoder-dc-f32c32": {"pretrained_model_name_or_path": "mit-han-lab/dc-ae-f32c32-mix-1.0-diffusers"},
@@ -190,6 +192,7 @@ DIFFUSERS_DEFAULT_PIPELINE_PATHS = {
"wan-t2v-1.3B": {"pretrained_model_name_or_path": "Wan-AI/Wan2.1-T2V-1.3B-Diffusers"},
"wan-t2v-14B": {"pretrained_model_name_or_path": "Wan-AI/Wan2.1-T2V-14B-Diffusers"},
"wan-i2v-14B": {"pretrained_model_name_or_path": "Wan-AI/Wan2.1-I2V-14B-480P-Diffusers"},
+ "hidream": {"pretrained_model_name_or_path": "HiDream-ai/HiDream-I1-Dev"},
}
# Use to configure model sample size when original config is provided
@@ -642,7 +645,10 @@ def infer_diffusers_model_type(checkpoint):
model_type = "flux-schnell"
elif any(key in checkpoint for key in CHECKPOINT_KEY_NAMES["ltx-video"]):
- if checkpoint["vae.encoder.conv_out.conv.weight"].shape[1] == 2048:
+ has_vae = "vae.encoder.conv_in.conv.bias" in checkpoint
+ if any(key.endswith("transformer_blocks.47.scale_shift_table") for key in checkpoint):
+ model_type = "ltx-video-0.9.7"
+ elif has_vae and checkpoint["vae.encoder.conv_out.conv.weight"].shape[1] == 2048:
model_type = "ltx-video-0.9.5"
elif "vae.decoder.last_time_embedder.timestep_embedder.linear_1.weight" in checkpoint:
model_type = "ltx-video-0.9.1"
@@ -701,6 +707,8 @@ def infer_diffusers_model_type(checkpoint):
elif CHECKPOINT_KEY_NAMES["wan_vae"] in checkpoint:
# All Wan models use the same VAE so we can use the same default model repo to fetch the config
model_type = "wan-t2v-14B"
+ elif CHECKPOINT_KEY_NAMES["hidream"] in checkpoint:
+ model_type = "hidream"
else:
model_type = "v1"
@@ -3293,3 +3301,12 @@ def convert_wan_vae_to_diffusers(checkpoint, **kwargs):
converted_state_dict[key] = value
return converted_state_dict
+
+
+def convert_hidream_transformer_to_diffusers(checkpoint, **kwargs):
+ keys = list(checkpoint.keys())
+ for k in keys:
+ if "model.diffusion_model." in k:
+ checkpoint[k.replace("model.diffusion_model.", "")] = checkpoint.pop(k)
+
+ return checkpoint
diff --git a/src/diffusers/models/activations.py b/src/diffusers/models/activations.py
index 42e65d898c..68f4d1d594 100644
--- a/src/diffusers/models/activations.py
+++ b/src/diffusers/models/activations.py
@@ -92,7 +92,7 @@ class GELU(nn.Module):
class GEGLU(nn.Module):
r"""
- A [variant](https://arxiv.org/abs/2002.05202) of the gated linear unit activation function.
+ A [variant](https://huggingface.co/papers/2002.05202) of the gated linear unit activation function.
Parameters:
dim_in (`int`): The number of channels in the input.
@@ -125,8 +125,8 @@ class GEGLU(nn.Module):
class SwiGLU(nn.Module):
r"""
- A [variant](https://arxiv.org/abs/2002.05202) of the gated linear unit activation function. It's similar to `GEGLU`
- but uses SiLU / Swish instead of GeLU.
+ A [variant](https://huggingface.co/papers/2002.05202) of the gated linear unit activation function. It's similar to
+ `GEGLU` but uses SiLU / Swish instead of GeLU.
Parameters:
dim_in (`int`): The number of channels in the input.
@@ -149,7 +149,7 @@ class SwiGLU(nn.Module):
class ApproximateGELU(nn.Module):
r"""
The approximate form of the Gaussian Error Linear Unit (GELU). For more details, see section 2 of this
- [paper](https://arxiv.org/abs/1606.08415).
+ [paper](https://huggingface.co/papers/1606.08415).
Parameters:
dim_in (`int`): The number of channels in the input.
diff --git a/src/diffusers/models/adapter.py b/src/diffusers/models/adapter.py
index 677a991f05..e475fe6bee 100644
--- a/src/diffusers/models/adapter.py
+++ b/src/diffusers/models/adapter.py
@@ -161,9 +161,8 @@ class MultiAdapter(ModelMixin):
pretrained_model_path (`os.PathLike`):
A path to a *directory* containing model weights saved using
[`~diffusers.models.adapter.MultiAdapter.save_pretrained`], e.g., `./my_model_directory/adapter`.
- torch_dtype (`str` or `torch.dtype`, *optional*):
- Override the default `torch.dtype` and load the model under this dtype. If `"auto"` is passed the dtype
- will be automatically derived from the model's weights.
+ torch_dtype (`torch.dtype`, *optional*):
+ Override the default `torch.dtype` and load the model under this dtype.
output_loading_info(`bool`, *optional*, defaults to `False`):
Whether or not to also return a dictionary containing missing keys, unexpected keys and error messages.
device_map (`str` or `Dict[str, Union[int, str, torch.device]]`, *optional*):
diff --git a/src/diffusers/models/attention.py b/src/diffusers/models/attention.py
index 93b11c2b43..21e3390584 100644
--- a/src/diffusers/models/attention.py
+++ b/src/diffusers/models/attention.py
@@ -90,7 +90,7 @@ class JointTransformerBlock(nn.Module):
r"""
A Transformer block following the MMDiT architecture, introduced in Stable Diffusion 3.
- Reference: https://arxiv.org/abs/2403.03206
+ Reference: https://huggingface.co/papers/2403.03206
Parameters:
dim (`int`): The number of channels in the input and output.
@@ -892,8 +892,8 @@ class FreeNoiseTransformerBlock(nn.Module):
The number of frames to be skipped before starting to process a new batch of `context_length` frames.
weighting_scheme (`str`, defaults to `"pyramid"`):
The weighting scheme to use for weighting averaging of processed latent frames. As described in the
- Equation 9. of the [FreeNoise](https://arxiv.org/abs/2310.15169) paper, "pyramid" is the default setting
- used.
+ Equation 9. of the [FreeNoise](https://huggingface.co/papers/2310.15169) paper, "pyramid" is the default
+ setting used.
"""
def __init__(
diff --git a/src/diffusers/models/attention_flax.py b/src/diffusers/models/attention_flax.py
index 246f3afaf5..8e7d65b95e 100644
--- a/src/diffusers/models/attention_flax.py
+++ b/src/diffusers/models/attention_flax.py
@@ -75,7 +75,7 @@ def jax_memory_efficient_attention(
query, key, value, precision=jax.lax.Precision.HIGHEST, query_chunk_size: int = 1024, key_chunk_size: int = 4096
):
r"""
- Flax Memory-efficient multi-head dot product attention. https://arxiv.org/abs/2112.05682v2
+ Flax Memory-efficient multi-head dot product attention. https://huggingface.co/papers/2112.05682v2
https://github.com/AminRezaei0x443/memory-efficient-attention
Args:
@@ -121,7 +121,7 @@ def jax_memory_efficient_attention(
class FlaxAttention(nn.Module):
r"""
- A Flax multi-head attention module as described in: https://arxiv.org/abs/1706.03762
+ A Flax multi-head attention module as described in: https://huggingface.co/papers/1706.03762
Parameters:
query_dim (:obj:`int`):
@@ -133,7 +133,7 @@ class FlaxAttention(nn.Module):
dropout (:obj:`float`, *optional*, defaults to 0.0):
Dropout rate
use_memory_efficient_attention (`bool`, *optional*, defaults to `False`):
- enable memory efficient attention https://arxiv.org/abs/2112.05682
+ enable memory efficient attention https://huggingface.co/papers/2112.05682
split_head_dim (`bool`, *optional*, defaults to `False`):
Whether to split the head dimension into a new axis for the self-attention computation. In most cases,
enabling this flag should speed up the computation for Stable Diffusion 2.x and Stable Diffusion XL.
@@ -244,7 +244,7 @@ class FlaxAttention(nn.Module):
class FlaxBasicTransformerBlock(nn.Module):
r"""
A Flax transformer block layer with `GLU` (Gated Linear Unit) activation function as described in:
- https://arxiv.org/abs/1706.03762
+ https://huggingface.co/papers/1706.03762
Parameters:
@@ -261,7 +261,7 @@ class FlaxBasicTransformerBlock(nn.Module):
dtype (:obj:`jnp.dtype`, *optional*, defaults to jnp.float32):
Parameters `dtype`
use_memory_efficient_attention (`bool`, *optional*, defaults to `False`):
- enable memory efficient attention https://arxiv.org/abs/2112.05682
+ enable memory efficient attention https://huggingface.co/papers/2112.05682
split_head_dim (`bool`, *optional*, defaults to `False`):
Whether to split the head dimension into a new axis for the self-attention computation. In most cases,
enabling this flag should speed up the computation for Stable Diffusion 2.x and Stable Diffusion XL.
@@ -328,7 +328,7 @@ class FlaxBasicTransformerBlock(nn.Module):
class FlaxTransformer2DModel(nn.Module):
r"""
A Spatial Transformer layer with Gated Linear Unit (GLU) activation function as described in:
- https://arxiv.org/pdf/1506.02025.pdf
+ https://huggingface.co/papers/1506.02025
Parameters:
@@ -347,7 +347,7 @@ class FlaxTransformer2DModel(nn.Module):
dtype (:obj:`jnp.dtype`, *optional*, defaults to jnp.float32):
Parameters `dtype`
use_memory_efficient_attention (`bool`, *optional*, defaults to `False`):
- enable memory efficient attention https://arxiv.org/abs/2112.05682
+ enable memory efficient attention https://huggingface.co/papers/2112.05682
split_head_dim (`bool`, *optional*, defaults to `False`):
Whether to split the head dimension into a new axis for the self-attention computation. In most cases,
enabling this flag should speed up the computation for Stable Diffusion 2.x and Stable Diffusion XL.
@@ -436,7 +436,7 @@ class FlaxFeedForward(nn.Module):
Flax module that encapsulates two Linear layers separated by a non-linearity. It is the counterpart of PyTorch's
[`FeedForward`] class, with the following simplifications:
- The activation function is currently hardcoded to a gated linear unit from:
- https://arxiv.org/abs/2002.05202
+ https://huggingface.co/papers/2002.05202
- `dim_out` is equal to `dim`.
- The number of hidden dimensions is hardcoded to `dim * 4` in [`FlaxGELU`].
@@ -468,7 +468,7 @@ class FlaxFeedForward(nn.Module):
class FlaxGEGLU(nn.Module):
r"""
Flax implementation of a Linear layer followed by the variant of the gated linear unit activation function from
- https://arxiv.org/abs/2002.05202.
+ https://huggingface.co/papers/2002.05202.
Parameters:
dim (:obj:`int`):
diff --git a/src/diffusers/models/attention_processor.py b/src/diffusers/models/attention_processor.py
index c7945d3c52..23ae05e2ab 100755
--- a/src/diffusers/models/attention_processor.py
+++ b/src/diffusers/models/attention_processor.py
@@ -3972,7 +3972,7 @@ class PAGHunyuanAttnProcessor2_0:
r"""
Processor for implementing scaled dot-product attention (enabled by default if you're using PyTorch 2.0). This is
used in the HunyuanDiT model. It applies a normalization layer and rotary embedding on query and key vector. This
- variant of the processor employs [Pertubed Attention Guidance](https://arxiv.org/abs/2403.17377).
+ variant of the processor employs [Pertubed Attention Guidance](https://huggingface.co/papers/2403.17377).
"""
def __init__(self):
@@ -4095,7 +4095,7 @@ class PAGCFGHunyuanAttnProcessor2_0:
r"""
Processor for implementing scaled dot-product attention (enabled by default if you're using PyTorch 2.0). This is
used in the HunyuanDiT model. It applies a normalization layer and rotary embedding on query and key vector. This
- variant of the processor employs [Pertubed Attention Guidance](https://arxiv.org/abs/2403.17377).
+ variant of the processor employs [Pertubed Attention Guidance](https://huggingface.co/papers/2403.17377).
"""
def __init__(self):
@@ -4828,7 +4828,7 @@ class SlicedAttnAddedKVProcessor:
class SpatialNorm(nn.Module):
"""
- Spatially conditioned normalization as defined in https://arxiv.org/abs/2209.09002.
+ Spatially conditioned normalization as defined in https://huggingface.co/papers/2209.09002.
Args:
f_channels (`int`):
@@ -5693,7 +5693,7 @@ class SD3IPAdapterJointAttnProcessor2_0(torch.nn.Module):
class PAGIdentitySelfAttnProcessor2_0:
r"""
Processor for implementing PAG using scaled dot-product attention (enabled by default if you're using PyTorch 2.0).
- PAG reference: https://arxiv.org/abs/2403.17377
+ PAG reference: https://huggingface.co/papers/2403.17377
"""
def __init__(self):
@@ -5792,7 +5792,7 @@ class PAGIdentitySelfAttnProcessor2_0:
class PAGCFGIdentitySelfAttnProcessor2_0:
r"""
Processor for implementing PAG using scaled dot-product attention (enabled by default if you're using PyTorch 2.0).
- PAG reference: https://arxiv.org/abs/2403.17377
+ PAG reference: https://huggingface.co/papers/2403.17377
"""
def __init__(self):
diff --git a/src/diffusers/models/auto_model.py b/src/diffusers/models/auto_model.py
index 1b742463aa..96785ce6f5 100644
--- a/src/diffusers/models/auto_model.py
+++ b/src/diffusers/models/auto_model.py
@@ -12,13 +12,16 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-import importlib
import os
from typing import Optional, Union
from huggingface_hub.utils import validate_hf_hub_args
from ..configuration_utils import ConfigMixin
+from ..utils import logging
+
+
+logger = logging.get_logger(__name__)
class AutoModel(ConfigMixin):
@@ -52,9 +55,8 @@ class AutoModel(ConfigMixin):
cache_dir (`Union[str, os.PathLike]`, *optional*):
Path to a directory where a downloaded pretrained model configuration is cached if the standard cache
is not used.
- torch_dtype (`str` or `torch.dtype`, *optional*):
- Override the default `torch.dtype` and load the model with another dtype. If `"auto"` is passed, the
- dtype is automatically derived from the model's weights.
+ torch_dtype (`torch.dtype`, *optional*):
+ Override the default `torch.dtype` and load the model with another dtype.
force_download (`bool`, *optional*, defaults to `False`):
Whether or not to force the (re-)download of the model weights and configuration files, overriding the
cached versions if they exist.
@@ -153,15 +155,50 @@ class AutoModel(ConfigMixin):
"token": token,
"local_files_only": local_files_only,
"revision": revision,
- "subfolder": subfolder,
}
- config = cls.load_config(pretrained_model_or_path, **load_config_kwargs)
- orig_class_name = config["_class_name"]
+ library = None
+ orig_class_name = None
- library = importlib.import_module("diffusers")
+ # Always attempt to fetch model_index.json first
+ try:
+ cls.config_name = "model_index.json"
+ config = cls.load_config(pretrained_model_or_path, **load_config_kwargs)
+
+ if subfolder is not None and subfolder in config:
+ library, orig_class_name = config[subfolder]
+ load_config_kwargs.update({"subfolder": subfolder})
+
+ except EnvironmentError as e:
+ logger.debug(e)
+
+ # Unable to load from model_index.json so fallback to loading from config
+ if library is None and orig_class_name is None:
+ cls.config_name = "config.json"
+ config = cls.load_config(pretrained_model_or_path, subfolder=subfolder, **load_config_kwargs)
+
+ if "_class_name" in config:
+ # If we find a class name in the config, we can try to load the model as a diffusers model
+ orig_class_name = config["_class_name"]
+ library = "diffusers"
+ load_config_kwargs.update({"subfolder": subfolder})
+ elif "model_type" in config:
+ orig_class_name = "AutoModel"
+ library = "transformers"
+ load_config_kwargs.update({"subfolder": "" if subfolder is None else subfolder})
+ else:
+ raise ValueError(f"Couldn't find model associated with the config file at {pretrained_model_or_path}.")
+
+ from ..pipelines.pipeline_loading_utils import ALL_IMPORTABLE_CLASSES, get_class_obj_and_candidates
+
+ model_cls, _ = get_class_obj_and_candidates(
+ library_name=library,
+ class_name=orig_class_name,
+ importable_classes=ALL_IMPORTABLE_CLASSES,
+ pipelines=None,
+ is_pipeline_module=False,
+ )
- model_cls = getattr(library, orig_class_name, None)
if model_cls is None:
raise ValueError(f"AutoModel can't find a model linked to {orig_class_name}.")
diff --git a/src/diffusers/models/autoencoders/autoencoder_asym_kl.py b/src/diffusers/models/autoencoders/autoencoder_asym_kl.py
index c643dcc72a..d65111a127 100644
--- a/src/diffusers/models/autoencoders/autoencoder_asym_kl.py
+++ b/src/diffusers/models/autoencoders/autoencoder_asym_kl.py
@@ -25,8 +25,8 @@ from .vae import DecoderOutput, DiagonalGaussianDistribution, Encoder, MaskCondi
class AsymmetricAutoencoderKL(ModelMixin, ConfigMixin):
r"""
- Designing a Better Asymmetric VQGAN for StableDiffusion https://arxiv.org/abs/2306.04632 . A VAE model with KL loss
- for encoding images into latents and decoding latent representations into images.
+ Designing a Better Asymmetric VQGAN for StableDiffusion https://huggingface.co/papers/2306.04632 . A VAE model with
+ KL loss for encoding images into latents and decoding latent representations into images.
This model inherits from [`ModelMixin`]. Check the superclass documentation for it's generic methods implemented
for all models (such as downloading or saving).
@@ -57,7 +57,7 @@ class AsymmetricAutoencoderKL(ModelMixin, ConfigMixin):
model. The latents are scaled with the formula `z = z * scaling_factor` before being passed to the
diffusion model. When decoding, the latents are scaled back to the original scale with the formula: `z = 1
/ scaling_factor * z`. For more details, refer to sections 4.3.2 and D.1 of the [High-Resolution Image
- Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752) paper.
+ Synthesis with Latent Diffusion Models](https://huggingface.co/papers/2112.10752) paper.
"""
_skip_layerwise_casting_patterns = ["decoder"]
diff --git a/src/diffusers/models/autoencoders/autoencoder_dc.py b/src/diffusers/models/autoencoders/autoencoder_dc.py
index 9146aa5c7c..8be5abd007 100644
--- a/src/diffusers/models/autoencoders/autoencoder_dc.py
+++ b/src/diffusers/models/autoencoders/autoencoder_dc.py
@@ -379,8 +379,8 @@ class Decoder(nn.Module):
class AutoencoderDC(ModelMixin, ConfigMixin, FromOriginalModelMixin):
r"""
- An Autoencoder model introduced in [DCAE](https://arxiv.org/abs/2410.10733) and used in
- [SANA](https://arxiv.org/abs/2410.10629).
+ An Autoencoder model introduced in [DCAE](https://huggingface.co/papers/2410.10733) and used in
+ [SANA](https://huggingface.co/papers/2410.10629).
This model inherits from [`ModelMixin`]. Check the superclass documentation for it's generic methods implemented
for all models (such as downloading or saving).
diff --git a/src/diffusers/models/autoencoders/autoencoder_kl.py b/src/diffusers/models/autoencoders/autoencoder_kl.py
index 357df0c310..8c86908c76 100644
--- a/src/diffusers/models/autoencoders/autoencoder_kl.py
+++ b/src/diffusers/models/autoencoders/autoencoder_kl.py
@@ -60,11 +60,11 @@ class AutoencoderKL(ModelMixin, ConfigMixin, FromOriginalModelMixin, PeftAdapter
model. The latents are scaled with the formula `z = z * scaling_factor` before being passed to the
diffusion model. When decoding, the latents are scaled back to the original scale with the formula: `z = 1
/ scaling_factor * z`. For more details, refer to sections 4.3.2 and D.1 of the [High-Resolution Image
- Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752) paper.
+ Synthesis with Latent Diffusion Models](https://huggingface.co/papers/2112.10752) paper.
force_upcast (`bool`, *optional*, default to `True`):
If enabled it will force the VAE to run in float32 for high image resolution pipelines, such as SD-XL. VAE
- can be fine-tuned / trained to a lower range without loosing too much precision in which case
- `force_upcast` can be set to `False` - see: https://huggingface.co/madebyollin/sdxl-vae-fp16-fix
+ can be fine-tuned / trained to a lower range without losing too much precision in which case `force_upcast`
+ can be set to `False` - see: https://huggingface.co/madebyollin/sdxl-vae-fp16-fix
mid_block_add_attention (`bool`, *optional*, default to `True`):
If enabled, the mid_block of the Encoder and Decoder will have attention blocks. If set to false, the
mid_block will only have resnet blocks
diff --git a/src/diffusers/models/autoencoders/autoencoder_kl_allegro.py b/src/diffusers/models/autoencoders/autoencoder_kl_allegro.py
index a76277366c..c25b158cfc 100644
--- a/src/diffusers/models/autoencoders/autoencoder_kl_allegro.py
+++ b/src/diffusers/models/autoencoders/autoencoder_kl_allegro.py
@@ -712,11 +712,11 @@ class AutoencoderKLAllegro(ModelMixin, ConfigMixin):
model. The latents are scaled with the formula `z = z * scaling_factor` before being passed to the
diffusion model. When decoding, the latents are scaled back to the original scale with the formula: `z = 1
/ scaling_factor * z`. For more details, refer to sections 4.3.2 and D.1 of the [High-Resolution Image
- Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752) paper.
+ Synthesis with Latent Diffusion Models](https://huggingface.co/papers/2112.10752) paper.
force_upcast (`bool`, default to `True`):
If enabled it will force the VAE to run in float32 for high image resolution pipelines, such as SD-XL. VAE
- can be fine-tuned / trained to a lower range without loosing too much precision in which case
- `force_upcast` can be set to `False` - see: https://huggingface.co/madebyollin/sdxl-vae-fp16-fix
+ can be fine-tuned / trained to a lower range without losing too much precision in which case `force_upcast`
+ can be set to `False` - see: https://huggingface.co/madebyollin/sdxl-vae-fp16-fix
"""
_supports_gradient_checkpointing = True
diff --git a/src/diffusers/models/autoencoders/autoencoder_kl_cogvideox.py b/src/diffusers/models/autoencoders/autoencoder_kl_cogvideox.py
index e2b2639689..f76d9e91d4 100644
--- a/src/diffusers/models/autoencoders/autoencoder_kl_cogvideox.py
+++ b/src/diffusers/models/autoencoders/autoencoder_kl_cogvideox.py
@@ -148,8 +148,8 @@ class CogVideoXCausalConv3d(nn.Module):
class CogVideoXSpatialNorm3D(nn.Module):
r"""
- Spatially conditioned normalization as defined in https://arxiv.org/abs/2209.09002. This implementation is specific
- to 3D-video like data.
+ Spatially conditioned normalization as defined in https://huggingface.co/papers/2209.09002. This implementation is
+ specific to 3D-video like data.
CogVideoXSafeConv3d is used instead of nn.Conv3d to avoid OOM in CogVideoX Model.
@@ -980,11 +980,11 @@ class AutoencoderKLCogVideoX(ModelMixin, ConfigMixin, FromOriginalModelMixin):
model. The latents are scaled with the formula `z = z * scaling_factor` before being passed to the
diffusion model. When decoding, the latents are scaled back to the original scale with the formula: `z = 1
/ scaling_factor * z`. For more details, refer to sections 4.3.2 and D.1 of the [High-Resolution Image
- Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752) paper.
+ Synthesis with Latent Diffusion Models](https://huggingface.co/papers/2112.10752) paper.
force_upcast (`bool`, *optional*, default to `True`):
If enabled it will force the VAE to run in float32 for high image resolution pipelines, such as SD-XL. VAE
- can be fine-tuned / trained to a lower range without loosing too much precision in which case
- `force_upcast` can be set to `False` - see: https://huggingface.co/madebyollin/sdxl-vae-fp16-fix
+ can be fine-tuned / trained to a lower range without losing too much precision in which case `force_upcast`
+ can be set to `False` - see: https://huggingface.co/madebyollin/sdxl-vae-fp16-fix
"""
_supports_gradient_checkpointing = True
diff --git a/src/diffusers/models/autoencoders/autoencoder_kl_cosmos.py b/src/diffusers/models/autoencoders/autoencoder_kl_cosmos.py
index 522d8f243e..1d12e2f659 100644
--- a/src/diffusers/models/autoencoders/autoencoder_kl_cosmos.py
+++ b/src/diffusers/models/autoencoders/autoencoder_kl_cosmos.py
@@ -902,8 +902,8 @@ class AutoencoderKLCosmos(ModelMixin, ConfigMixin):
model. The latents are scaled with the formula `z = z * scaling_factor` before being passed to the
diffusion model. When decoding, the latents are scaled back to the original scale with the formula: `z = 1
/ scaling_factor * z`. For more details, refer to sections 4.3.2 and D.1 of the [High-Resolution Image
- Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752) paper. Not applicable in Cosmos,
- but we default to 1.0 for consistency.
+ Synthesis with Latent Diffusion Models](https://huggingface.co/papers/2112.10752) paper. Not applicable in
+ Cosmos, but we default to 1.0 for consistency.
spatial_compression_ratio (`int`, defaults to `8`):
The spatial compression ratio to apply in the VAE. The number of downsample blocks is determined using
this.
diff --git a/src/diffusers/models/autoencoders/autoencoder_kl_ltx.py b/src/diffusers/models/autoencoders/autoencoder_kl_ltx.py
index e5766ef7c3..eed071e29c 100644
--- a/src/diffusers/models/autoencoders/autoencoder_kl_ltx.py
+++ b/src/diffusers/models/autoencoders/autoencoder_kl_ltx.py
@@ -1067,7 +1067,7 @@ class AutoencoderKLLTXVideo(ModelMixin, ConfigMixin, FromOriginalModelMixin):
model. The latents are scaled with the formula `z = z * scaling_factor` before being passed to the
diffusion model. When decoding, the latents are scaled back to the original scale with the formula: `z = 1
/ scaling_factor * z`. For more details, refer to sections 4.3.2 and D.1 of the [High-Resolution Image
- Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752) paper.
+ Synthesis with Latent Diffusion Models](https://huggingface.co/papers/2112.10752) paper.
encoder_causal (`bool`, defaults to `True`):
Whether the encoder should behave causally (future frames depend only on past frames) or not.
decoder_causal (`bool`, defaults to `False`):
diff --git a/src/diffusers/models/autoencoders/autoencoder_kl_magvit.py b/src/diffusers/models/autoencoders/autoencoder_kl_magvit.py
index fc9c9ba404..43294a901f 100644
--- a/src/diffusers/models/autoencoders/autoencoder_kl_magvit.py
+++ b/src/diffusers/models/autoencoders/autoencoder_kl_magvit.py
@@ -428,7 +428,7 @@ class EasyAnimateMidBlock3d(nn.Module):
class EasyAnimateEncoder(nn.Module):
r"""
- Causal encoder for 3D video-like data used in [EasyAnimate](https://arxiv.org/abs/2405.18991).
+ Causal encoder for 3D video-like data used in [EasyAnimate](https://huggingface.co/papers/2405.18991).
"""
_supports_gradient_checkpointing = True
@@ -544,7 +544,7 @@ class EasyAnimateEncoder(nn.Module):
class EasyAnimateDecoder(nn.Module):
r"""
- Causal decoder for 3D video-like data used in [EasyAnimate](https://arxiv.org/abs/2405.18991).
+ Causal decoder for 3D video-like data used in [EasyAnimate](https://huggingface.co/papers/2405.18991).
"""
_supports_gradient_checkpointing = True
@@ -666,7 +666,7 @@ class EasyAnimateDecoder(nn.Module):
class AutoencoderKLMagvit(ModelMixin, ConfigMixin):
r"""
A VAE model with KL loss for encoding images into latents and decoding latent representations into images. This
- model is used in [EasyAnimate](https://arxiv.org/abs/2405.18991).
+ model is used in [EasyAnimate](https://huggingface.co/papers/2405.18991).
This model inherits from [`ModelMixin`]. Check the superclass documentation for it's generic methods implemented
for all models (such as downloading or saving).
diff --git a/src/diffusers/models/autoencoders/autoencoder_kl_mochi.py b/src/diffusers/models/autoencoders/autoencoder_kl_mochi.py
index edf270f66e..719d107f32 100644
--- a/src/diffusers/models/autoencoders/autoencoder_kl_mochi.py
+++ b/src/diffusers/models/autoencoders/autoencoder_kl_mochi.py
@@ -677,7 +677,7 @@ class AutoencoderKLMochi(ModelMixin, ConfigMixin):
model. The latents are scaled with the formula `z = z * scaling_factor` before being passed to the
diffusion model. When decoding, the latents are scaled back to the original scale with the formula: `z = 1
/ scaling_factor * z`. For more details, refer to sections 4.3.2 and D.1 of the [High-Resolution Image
- Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752) paper.
+ Synthesis with Latent Diffusion Models](https://huggingface.co/papers/2112.10752) paper.
"""
_supports_gradient_checkpointing = True
diff --git a/src/diffusers/models/autoencoders/autoencoder_kl_temporal_decoder.py b/src/diffusers/models/autoencoders/autoencoder_kl_temporal_decoder.py
index 5a72cd3951..fb6a7de19d 100644
--- a/src/diffusers/models/autoencoders/autoencoder_kl_temporal_decoder.py
+++ b/src/diffusers/models/autoencoders/autoencoder_kl_temporal_decoder.py
@@ -158,11 +158,11 @@ class AutoencoderKLTemporalDecoder(ModelMixin, ConfigMixin):
model. The latents are scaled with the formula `z = z * scaling_factor` before being passed to the
diffusion model. When decoding, the latents are scaled back to the original scale with the formula: `z = 1
/ scaling_factor * z`. For more details, refer to sections 4.3.2 and D.1 of the [High-Resolution Image
- Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752) paper.
+ Synthesis with Latent Diffusion Models](https://huggingface.co/papers/2112.10752) paper.
force_upcast (`bool`, *optional*, default to `True`):
If enabled it will force the VAE to run in float32 for high image resolution pipelines, such as SD-XL. VAE
- can be fine-tuned / trained to a lower range without loosing too much precision in which case
- `force_upcast` can be set to `False` - see: https://huggingface.co/madebyollin/sdxl-vae-fp16-fix
+ can be fine-tuned / trained to a lower range without losing too much precision in which case `force_upcast`
+ can be set to `False` - see: https://huggingface.co/madebyollin/sdxl-vae-fp16-fix
"""
_supports_gradient_checkpointing = True
diff --git a/src/diffusers/models/autoencoders/autoencoder_tiny.py b/src/diffusers/models/autoencoders/autoencoder_tiny.py
index 7ed727c55c..8f2673af85 100644
--- a/src/diffusers/models/autoencoders/autoencoder_tiny.py
+++ b/src/diffusers/models/autoencoders/autoencoder_tiny.py
@@ -83,8 +83,8 @@ class AutoencoderTiny(ModelMixin, ConfigMixin):
model. The latents are scaled with the formula `z = z * scaling_factor` before being passed to the
diffusion model. When decoding, the latents are scaled back to the original scale with the formula: `z = 1
/ scaling_factor * z`. For more details, refer to sections 4.3.2 and D.1 of the [High-Resolution Image
- Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752) paper. For this Autoencoder,
- however, no such scaling factor was used, hence the value of 1.0 as the default.
+ Synthesis with Latent Diffusion Models](https://huggingface.co/papers/2112.10752) paper. For this
+ Autoencoder, however, no such scaling factor was used, hence the value of 1.0 as the default.
force_upcast (`bool`, *optional*, default to `False`):
If enabled it will force the VAE to run in float32 for high image resolution pipelines, such as SD-XL. VAE
can be fine-tuned / trained to a lower range without losing too much precision, in which case
diff --git a/src/diffusers/models/autoencoders/vq_model.py b/src/diffusers/models/autoencoders/vq_model.py
index 84215389bf..46e4c2c32c 100644
--- a/src/diffusers/models/autoencoders/vq_model.py
+++ b/src/diffusers/models/autoencoders/vq_model.py
@@ -66,7 +66,7 @@ class VQModel(ModelMixin, ConfigMixin):
model. The latents are scaled with the formula `z = z * scaling_factor` before being passed to the
diffusion model. When decoding, the latents are scaled back to the original scale with the formula: `z = 1
/ scaling_factor * z`. For more details, refer to sections 4.3.2 and D.1 of the [High-Resolution Image
- Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752) paper.
+ Synthesis with Latent Diffusion Models](https://huggingface.co/papers/2112.10752) paper.
norm_type (`str`, *optional*, defaults to `"group"`):
Type of normalization layer to use. Can be one of `"group"` or `"spatial"`.
"""
diff --git a/src/diffusers/models/controlnets/controlnet.py b/src/diffusers/models/controlnets/controlnet.py
index 7a6ca886ca..0f66082e10 100644
--- a/src/diffusers/models/controlnets/controlnet.py
+++ b/src/diffusers/models/controlnets/controlnet.py
@@ -63,8 +63,8 @@ class ControlNetOutput(BaseOutput):
class ControlNetConditioningEmbedding(nn.Module):
"""
- Quoting from https://arxiv.org/abs/2302.05543: "Stable Diffusion uses a pre-processing method similar to VQ-GAN
- [11] to convert the entire dataset of 512 × 512 images into smaller 64 × 64 “latent images” for stabilized
+ Quoting from https://huggingface.co/papers/2302.05543: "Stable Diffusion uses a pre-processing method similar to
+ VQ-GAN [11] to convert the entire dataset of 512 × 512 images into smaller 64 × 64 “latent images” for stabilized
training. This requires ControlNets to convert image-based conditions to 64 × 64 feature space to match the
convolution size. We use a tiny network E(·) of four convolution layers with 4 × 4 kernels and 2 × 2 strides
(activated by ReLU, channels are 16, 32, 64, 128, initialized with Gaussian weights, trained jointly with the full
diff --git a/src/diffusers/models/controlnets/controlnet_hunyuan.py b/src/diffusers/models/controlnets/controlnet_hunyuan.py
index fade44def4..4f0113860d 100644
--- a/src/diffusers/models/controlnets/controlnet_hunyuan.py
+++ b/src/diffusers/models/controlnets/controlnet_hunyuan.py
@@ -103,7 +103,7 @@ class HunyuanDiT2DControlNetModel(ModelMixin, ConfigMixin):
activation_fn=activation_fn,
ff_inner_dim=int(self.inner_dim * mlp_ratio),
cross_attention_dim=cross_attention_dim,
- qk_norm=True, # See http://arxiv.org/abs/2302.05442 for details.
+ qk_norm=True, # See https://huggingface.co/papers/2302.05442 for details.
skip=False, # always False as it is the first half of the model
)
for layer in range(transformer_num_layers // 2 - 1)
diff --git a/src/diffusers/models/controlnets/controlnet_sparsectrl.py b/src/diffusers/models/controlnets/controlnet_sparsectrl.py
index 25348ce606..8dbaf08ee5 100644
--- a/src/diffusers/models/controlnets/controlnet_sparsectrl.py
+++ b/src/diffusers/models/controlnets/controlnet_sparsectrl.py
@@ -96,7 +96,7 @@ class SparseControlNetConditioningEmbedding(nn.Module):
class SparseControlNetModel(ModelMixin, ConfigMixin, FromOriginalModelMixin):
"""
A SparseControlNet model as described in [SparseCtrl: Adding Sparse Controls to Text-to-Video Diffusion
- Models](https://arxiv.org/abs/2311.16933).
+ Models](https://huggingface.co/papers/2311.16933).
Args:
in_channels (`int`, defaults to 4):
diff --git a/src/diffusers/models/controlnets/controlnet_xs.py b/src/diffusers/models/controlnets/controlnet_xs.py
index 9248f934bc..b6c97e3279 100644
--- a/src/diffusers/models/controlnets/controlnet_xs.py
+++ b/src/diffusers/models/controlnets/controlnet_xs.py
@@ -942,7 +942,7 @@ class UNetControlNetXSModel(ModelMixin, ConfigMixin):
# Copied from diffusers.models.unets.unet_2d_condition.UNet2DConditionModel.enable_freeu
def enable_freeu(self, s1: float, s2: float, b1: float, b2: float):
- r"""Enables the FreeU mechanism from https://arxiv.org/abs/2309.11497.
+ r"""Enables the FreeU mechanism from https://huggingface.co/papers/2309.11497.
The suffixes after the scaling factors represent the stage blocks where they are being applied.
diff --git a/src/diffusers/models/controlnets/multicontrolnet.py b/src/diffusers/models/controlnets/multicontrolnet.py
index cb022212de..87a9522949 100644
--- a/src/diffusers/models/controlnets/multicontrolnet.py
+++ b/src/diffusers/models/controlnets/multicontrolnet.py
@@ -130,9 +130,8 @@ class MultiControlNetModel(ModelMixin):
A path to a *directory* containing model weights saved using
[`~models.controlnets.multicontrolnet.MultiControlNetModel.save_pretrained`], e.g.,
`./my_model_directory/controlnet`.
- torch_dtype (`str` or `torch.dtype`, *optional*):
- Override the default `torch.dtype` and load the model under this dtype. If `"auto"` is passed the dtype
- will be automatically derived from the model's weights.
+ torch_dtype (`torch.dtype`, *optional*):
+ Override the default `torch.dtype` and load the model under this dtype.
output_loading_info(`bool`, *optional*, defaults to `False`):
Whether or not to also return a dictionary containing missing keys, unexpected keys and error messages.
device_map (`str` or `Dict[str, Union[int, str, torch.device]]`, *optional*):
diff --git a/src/diffusers/models/controlnets/multicontrolnet_union.py b/src/diffusers/models/controlnets/multicontrolnet_union.py
index 40cfa6a884..d5506dc186 100644
--- a/src/diffusers/models/controlnets/multicontrolnet_union.py
+++ b/src/diffusers/models/controlnets/multicontrolnet_union.py
@@ -143,9 +143,8 @@ class MultiControlNetUnionModel(ModelMixin):
A path to a *directory* containing model weights saved using
[`~models.controlnets.multicontrolnet.MultiControlNetUnionModel.save_pretrained`], e.g.,
`./my_model_directory/controlnet`.
- torch_dtype (`str` or `torch.dtype`, *optional*):
- Override the default `torch.dtype` and load the model under this dtype. If `"auto"` is passed the dtype
- will be automatically derived from the model's weights.
+ torch_dtype (`torch.dtype`, *optional*):
+ Override the default `torch.dtype` and load the model under this dtype.
output_loading_info(`bool`, *optional*, defaults to `False`):
Whether or not to also return a dictionary containing missing keys, unexpected keys and error messages.
device_map (`str` or `Dict[str, Union[int, str, torch.device]]`, *optional*):
diff --git a/src/diffusers/models/embeddings.py b/src/diffusers/models/embeddings.py
index b52813ece4..c25e9997e3 100644
--- a/src/diffusers/models/embeddings.py
+++ b/src/diffusers/models/embeddings.py
@@ -1401,7 +1401,7 @@ class ImagePositionalEmbeddings(nn.Module):
Converts latent image classes into vector embeddings. Sums the vector embeddings with positional embeddings for the
height and width of the latent space.
- For more details, see figure 10 of the dall-e paper: https://arxiv.org/abs/2102.12092
+ For more details, see figure 10 of the dall-e paper: https://huggingface.co/papers/2102.12092
For VQ-diffusion:
diff --git a/src/diffusers/models/embeddings_flax.py b/src/diffusers/models/embeddings_flax.py
index 92b5a6c358..1f64741979 100644
--- a/src/diffusers/models/embeddings_flax.py
+++ b/src/diffusers/models/embeddings_flax.py
@@ -89,7 +89,7 @@ class FlaxTimestepEmbedding(nn.Module):
class FlaxTimesteps(nn.Module):
r"""
- Wrapper Module for sinusoidal Time step Embeddings as described in https://arxiv.org/abs/2006.11239
+ Wrapper Module for sinusoidal Time step Embeddings as described in https://huggingface.co/papers/2006.11239
Args:
dim (`int`, *optional*, defaults to `32`):
diff --git a/src/diffusers/models/modeling_utils.py b/src/diffusers/models/modeling_utils.py
index 2a22bc09ad..55ce0cf79f 100644
--- a/src/diffusers/models/modeling_utils.py
+++ b/src/diffusers/models/modeling_utils.py
@@ -787,9 +787,8 @@ class ModelMixin(torch.nn.Module, PushToHubMixin):
cache_dir (`Union[str, os.PathLike]`, *optional*):
Path to a directory where a downloaded pretrained model configuration is cached if the standard cache
is not used.
- torch_dtype (`str` or `torch.dtype`, *optional*):
- Override the default `torch.dtype` and load the model with another dtype. If `"auto"` is passed, the
- dtype is automatically derived from the model's weights.
+ torch_dtype (`torch.dtype`, *optional*):
+ Override the default `torch.dtype` and load the model with another dtype.
force_download (`bool`, *optional*, defaults to `False`):
Whether or not to force the (re-)download of the model weights and configuration files, overriding the
cached versions if they exist.
diff --git a/src/diffusers/models/normalization.py b/src/diffusers/models/normalization.py
index 962ce435bd..4a512c5cb1 100644
--- a/src/diffusers/models/normalization.py
+++ b/src/diffusers/models/normalization.py
@@ -237,7 +237,7 @@ class AdaLayerNormSingle(nn.Module):
r"""
Norm layer adaptive layer norm single (adaLN-single).
- As proposed in PixArt-Alpha (see: https://arxiv.org/abs/2310.00426; Section 2.3).
+ As proposed in PixArt-Alpha (see: https://huggingface.co/papers/2310.00426; Section 2.3).
Parameters:
embedding_dim (`int`): The size of each embedding vector.
@@ -510,7 +510,7 @@ else:
class RMSNorm(nn.Module):
r"""
- RMS Norm as introduced in https://arxiv.org/abs/1910.07467 by Zhang et al.
+ RMS Norm as introduced in https://huggingface.co/papers/1910.07467 by Zhang et al.
Args:
dim (`int`): Number of dimensions to use for `weights`. Only effective when `elementwise_affine` is True.
@@ -600,7 +600,7 @@ class MochiRMSNorm(nn.Module):
class GlobalResponseNorm(nn.Module):
r"""
- Global response normalization as introduced in ConvNeXt-v2 (https://arxiv.org/abs/2301.00808).
+ Global response normalization as introduced in ConvNeXt-v2 (https://huggingface.co/papers/2301.00808).
Args:
dim (`int`): Number of dimensions to use for the `gamma` and `beta`.
diff --git a/src/diffusers/models/transformers/auraflow_transformer_2d.py b/src/diffusers/models/transformers/auraflow_transformer_2d.py
index 6a2ea8b8b8..c02cf7fb17 100644
--- a/src/diffusers/models/transformers/auraflow_transformer_2d.py
+++ b/src/diffusers/models/transformers/auraflow_transformer_2d.py
@@ -359,7 +359,7 @@ class AuraFlowTransformer2DModel(ModelMixin, ConfigMixin, PeftAdapterMixin, From
self.norm_out = AuraFlowPreFinalBlock(self.inner_dim, self.inner_dim)
self.proj_out = nn.Linear(self.inner_dim, patch_size * patch_size * self.out_channels, bias=False)
- # https://arxiv.org/abs/2309.16588
+ # https://huggingface.co/papers/2309.16588
# prevents artifacts in the attention maps
self.register_tokens = nn.Parameter(torch.randn(1, 8, self.inner_dim) * 0.02)
diff --git a/src/diffusers/models/transformers/dit_transformer_2d.py b/src/diffusers/models/transformers/dit_transformer_2d.py
index cdc0738050..7980ac6715 100644
--- a/src/diffusers/models/transformers/dit_transformer_2d.py
+++ b/src/diffusers/models/transformers/dit_transformer_2d.py
@@ -30,7 +30,7 @@ logger = logging.get_logger(__name__) # pylint: disable=invalid-name
class DiTTransformer2DModel(ModelMixin, ConfigMixin):
r"""
- A 2D Transformer model as introduced in DiT (https://arxiv.org/abs/2212.09748).
+ A 2D Transformer model as introduced in DiT (https://huggingface.co/papers/2212.09748).
Parameters:
num_attention_heads (int, optional, defaults to 16): The number of heads to use for multi-head attention.
diff --git a/src/diffusers/models/transformers/hunyuan_transformer_2d.py b/src/diffusers/models/transformers/hunyuan_transformer_2d.py
index 550cc6d9d1..41d4aebb68 100644
--- a/src/diffusers/models/transformers/hunyuan_transformer_2d.py
+++ b/src/diffusers/models/transformers/hunyuan_transformer_2d.py
@@ -308,7 +308,7 @@ class HunyuanDiT2DModel(ModelMixin, ConfigMixin):
activation_fn=activation_fn,
ff_inner_dim=int(self.inner_dim * mlp_ratio),
cross_attention_dim=cross_attention_dim,
- qk_norm=True, # See http://arxiv.org/abs/2302.05442 for details.
+ qk_norm=True, # See https://huggingface.co/papers/2302.05442 for details.
skip=layer > num_layers // 2,
)
for layer in range(num_layers)
diff --git a/src/diffusers/models/transformers/latte_transformer_3d.py b/src/diffusers/models/transformers/latte_transformer_3d.py
index 4f413ea6a5..affb8376c0 100644
--- a/src/diffusers/models/transformers/latte_transformer_3d.py
+++ b/src/diffusers/models/transformers/latte_transformer_3d.py
@@ -30,7 +30,7 @@ class LatteTransformer3DModel(ModelMixin, ConfigMixin, CacheMixin):
_supports_gradient_checkpointing = True
"""
- A 3D Transformer model for video-like data, paper: https://arxiv.org/abs/2401.03048, official code:
+ A 3D Transformer model for video-like data, paper: https://huggingface.co/papers/2401.03048, official code:
https://github.com/Vchitect/Latte
Parameters:
diff --git a/src/diffusers/models/transformers/pixart_transformer_2d.py b/src/diffusers/models/transformers/pixart_transformer_2d.py
index 8e290074a0..61f5d6dafe 100644
--- a/src/diffusers/models/transformers/pixart_transformer_2d.py
+++ b/src/diffusers/models/transformers/pixart_transformer_2d.py
@@ -31,8 +31,8 @@ logger = logging.get_logger(__name__) # pylint: disable=invalid-name
class PixArtTransformer2DModel(ModelMixin, ConfigMixin):
r"""
- A 2D Transformer model as introduced in PixArt family of models (https://arxiv.org/abs/2310.00426,
- https://arxiv.org/abs/2403.04692).
+ A 2D Transformer model as introduced in PixArt family of models (https://huggingface.co/papers/2310.00426,
+ https://huggingface.co/papers/2403.04692).
Parameters:
num_attention_heads (int, optional, defaults to 16): The number of heads to use for multi-head attention.
diff --git a/src/diffusers/models/transformers/prior_transformer.py b/src/diffusers/models/transformers/prior_transformer.py
index 24d4e4d3d7..565da0da8b 100644
--- a/src/diffusers/models/transformers/prior_transformer.py
+++ b/src/diffusers/models/transformers/prior_transformer.py
@@ -61,7 +61,7 @@ class PriorTransformer(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin, Pef
added_emb_type (`str`, *optional*, defaults to `prd`): Additional embeddings to condition the model.
Choose from `prd` or `None`. if choose `prd`, it will prepend a token indicating the (quantized) dot
product between the text embedding and image embedding as proposed in the unclip paper
- https://arxiv.org/abs/2204.06125 If it is `None`, no additional embeddings will be prepended.
+ https://huggingface.co/papers/2204.06125 If it is `None`, no additional embeddings will be prepended.
time_embed_dim (`int, *optional*, defaults to None): The dimension of timestep embeddings.
If None, will be set to `num_attention_heads * attention_head_dim`
embedding_proj_dim (`int`, *optional*, default to None):
diff --git a/src/diffusers/models/transformers/t5_film_transformer.py b/src/diffusers/models/transformers/t5_film_transformer.py
index 1dea37a259..d5a146cd25 100644
--- a/src/diffusers/models/transformers/t5_film_transformer.py
+++ b/src/diffusers/models/transformers/t5_film_transformer.py
@@ -390,7 +390,7 @@ class T5LayerNorm(nn.Module):
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
# T5 uses a layer_norm which only scales and doesn't shift, which is also known as Root Mean
- # Square Layer Normalization https://arxiv.org/abs/1910.07467 thus variance is calculated
+ # Square Layer Normalization https://huggingface.co/papers/1910.07467 thus variance is calculated
# w/o mean and there is no bias. Additionally we want to make sure that the accumulation for
# half-precision inputs is done in fp32
@@ -407,7 +407,7 @@ class T5LayerNorm(nn.Module):
class NewGELUActivation(nn.Module):
"""
Implementation of the GELU activation function currently in Google BERT repo (identical to OpenAI GPT). Also see
- the Gaussian Error Linear Units paper: https://arxiv.org/abs/1606.08415
+ the Gaussian Error Linear Units paper: https://huggingface.co/papers/1606.08415
"""
def forward(self, input: torch.Tensor) -> torch.Tensor:
diff --git a/src/diffusers/models/transformers/transformer_flux.py b/src/diffusers/models/transformers/transformer_flux.py
index 33556bf661..7684b60d40 100644
--- a/src/diffusers/models/transformers/transformer_flux.py
+++ b/src/diffusers/models/transformers/transformer_flux.py
@@ -447,8 +447,6 @@ class FluxTransformer2DModel(
timestep = timestep.to(hidden_states.dtype) * 1000
if guidance is not None:
guidance = guidance.to(hidden_states.dtype) * 1000
- else:
- guidance = None
temb = (
self.time_text_embed(timestep, pooled_projections)
diff --git a/src/diffusers/models/transformers/transformer_hidream_image.py b/src/diffusers/models/transformers/transformer_hidream_image.py
index 06f47fcbaf..77902dcf58 100644
--- a/src/diffusers/models/transformers/transformer_hidream_image.py
+++ b/src/diffusers/models/transformers/transformer_hidream_image.py
@@ -5,7 +5,7 @@ import torch.nn as nn
import torch.nn.functional as F
from ...configuration_utils import ConfigMixin, register_to_config
-from ...loaders import PeftAdapterMixin
+from ...loaders import FromOriginalModelMixin, PeftAdapterMixin
from ...models.modeling_outputs import Transformer2DModelOutput
from ...models.modeling_utils import ModelMixin
from ...utils import USE_PEFT_BACKEND, deprecate, logging, scale_lora_layers, unscale_lora_layers
@@ -602,7 +602,7 @@ class HiDreamBlock(nn.Module):
)
-class HiDreamImageTransformer2DModel(ModelMixin, ConfigMixin, PeftAdapterMixin):
+class HiDreamImageTransformer2DModel(ModelMixin, ConfigMixin, PeftAdapterMixin, FromOriginalModelMixin):
_supports_gradient_checkpointing = True
_no_split_modules = ["HiDreamImageTransformerBlock", "HiDreamImageSingleTransformerBlock"]
diff --git a/src/diffusers/models/transformers/transformer_hunyuan_video_framepack.py b/src/diffusers/models/transformers/transformer_hunyuan_video_framepack.py
index 58b8115694..c2eb7fd2a7 100644
--- a/src/diffusers/models/transformers/transformer_hunyuan_video_framepack.py
+++ b/src/diffusers/models/transformers/transformer_hunyuan_video_framepack.py
@@ -152,9 +152,19 @@ class HunyuanVideoFramepackTransformer3DModel(
# 1. Latent and condition embedders
self.x_embedder = HunyuanVideoPatchEmbed((patch_size_t, patch_size, patch_size), in_channels, inner_dim)
+
+ # Framepack history projection embedder
+ self.clean_x_embedder = None
+ if has_clean_x_embedder:
+ self.clean_x_embedder = HunyuanVideoHistoryPatchEmbed(in_channels, inner_dim)
+
self.context_embedder = HunyuanVideoTokenRefiner(
text_embed_dim, num_attention_heads, attention_head_dim, num_layers=num_refiner_layers
)
+
+ # Framepack image-conditioning embedder
+ self.image_projection = FramepackClipVisionProjection(image_proj_dim, inner_dim) if has_image_proj else None
+
self.time_text_embed = HunyuanVideoConditionEmbedding(
inner_dim, pooled_projection_dim, guidance_embeds, image_condition_type
)
@@ -186,14 +196,7 @@ class HunyuanVideoFramepackTransformer3DModel(
self.norm_out = AdaLayerNormContinuous(inner_dim, inner_dim, elementwise_affine=False, eps=1e-6)
self.proj_out = nn.Linear(inner_dim, patch_size_t * patch_size * patch_size * out_channels)
- # Framepack specific modules
- self.image_projection = FramepackClipVisionProjection(image_proj_dim, inner_dim) if has_image_proj else None
-
- self.clean_x_embedder = None
- if has_clean_x_embedder:
- self.clean_x_embedder = HunyuanVideoHistoryPatchEmbed(in_channels, inner_dim)
-
- self.use_gradient_checkpointing = False
+ self.gradient_checkpointing = False
def forward(
self,
diff --git a/src/diffusers/models/transformers/transformer_omnigen.py b/src/diffusers/models/transformers/transformer_omnigen.py
index 8d5d1b3f8f..f0df588e85 100644
--- a/src/diffusers/models/transformers/transformer_omnigen.py
+++ b/src/diffusers/models/transformers/transformer_omnigen.py
@@ -283,7 +283,7 @@ class OmniGenBlock(nn.Module):
class OmniGenTransformer2DModel(ModelMixin, ConfigMixin):
"""
- The Transformer model introduced in OmniGen (https://arxiv.org/pdf/2409.11340).
+ The Transformer model introduced in OmniGen (https://huggingface.co/papers/2409.11340).
Parameters:
in_channels (`int`, defaults to `4`):
diff --git a/src/diffusers/models/transformers/transformer_wan.py b/src/diffusers/models/transformers/transformer_wan.py
index c78d72dc4a..baa0ede418 100644
--- a/src/diffusers/models/transformers/transformer_wan.py
+++ b/src/diffusers/models/transformers/transformer_wan.py
@@ -72,7 +72,8 @@ class WanAttnProcessor2_0:
if rotary_emb is not None:
def apply_rotary_emb(hidden_states: torch.Tensor, freqs: torch.Tensor):
- x_rotated = torch.view_as_complex(hidden_states.to(torch.float64).unflatten(3, (-1, 2)))
+ dtype = torch.float32 if hidden_states.device.type == "mps" else torch.float64
+ x_rotated = torch.view_as_complex(hidden_states.to(dtype).unflatten(3, (-1, 2)))
x_out = torch.view_as_real(x_rotated * freqs).flatten(3, 4)
return x_out.type_as(hidden_states)
@@ -190,9 +191,10 @@ class WanRotaryPosEmbed(nn.Module):
t_dim = attention_head_dim - h_dim - w_dim
freqs = []
+ freqs_dtype = torch.float32 if torch.backends.mps.is_available() else torch.float64
for dim in [t_dim, h_dim, w_dim]:
freq = get_1d_rotary_pos_embed(
- dim, max_seq_len, theta, use_real=False, repeat_interleave_real=False, freqs_dtype=torch.float64
+ dim, max_seq_len, theta, use_real=False, repeat_interleave_real=False, freqs_dtype=freqs_dtype
)
freqs.append(freq)
self.freqs = torch.cat(freqs, dim=1)
diff --git a/src/diffusers/models/unets/unet_2d_blocks_flax.py b/src/diffusers/models/unets/unet_2d_blocks_flax.py
index a4585dbc88..fbc20cf95a 100644
--- a/src/diffusers/models/unets/unet_2d_blocks_flax.py
+++ b/src/diffusers/models/unets/unet_2d_blocks_flax.py
@@ -22,7 +22,7 @@ from ..resnet_flax import FlaxDownsample2D, FlaxResnetBlock2D, FlaxUpsample2D
class FlaxCrossAttnDownBlock2D(nn.Module):
r"""
Cross Attention 2D Downsizing block - original architecture from Unet transformers:
- https://arxiv.org/abs/2103.06104
+ https://huggingface.co/papers/2103.06104
Parameters:
in_channels (:obj:`int`):
@@ -38,7 +38,7 @@ class FlaxCrossAttnDownBlock2D(nn.Module):
add_downsample (:obj:`bool`, *optional*, defaults to `True`):
Whether to add downsampling layer before each final output
use_memory_efficient_attention (`bool`, *optional*, defaults to `False`):
- enable memory efficient attention https://arxiv.org/abs/2112.05682
+ enable memory efficient attention https://huggingface.co/papers/2112.05682
split_head_dim (`bool`, *optional*, defaults to `False`):
Whether to split the head dimension into a new axis for the self-attention computation. In most cases,
enabling this flag should speed up the computation for Stable Diffusion 2.x and Stable Diffusion XL.
@@ -169,7 +169,7 @@ class FlaxDownBlock2D(nn.Module):
class FlaxCrossAttnUpBlock2D(nn.Module):
r"""
Cross Attention 2D Upsampling block - original architecture from Unet transformers:
- https://arxiv.org/abs/2103.06104
+ https://huggingface.co/papers/2103.06104
Parameters:
in_channels (:obj:`int`):
@@ -185,7 +185,7 @@ class FlaxCrossAttnUpBlock2D(nn.Module):
add_upsample (:obj:`bool`, *optional*, defaults to `True`):
Whether to add upsampling layer before each final output
use_memory_efficient_attention (`bool`, *optional*, defaults to `False`):
- enable memory efficient attention https://arxiv.org/abs/2112.05682
+ enable memory efficient attention https://huggingface.co/papers/2112.05682
split_head_dim (`bool`, *optional*, defaults to `False`):
Whether to split the head dimension into a new axis for the self-attention computation. In most cases,
enabling this flag should speed up the computation for Stable Diffusion 2.x and Stable Diffusion XL.
@@ -324,7 +324,8 @@ class FlaxUpBlock2D(nn.Module):
class FlaxUNetMidBlock2DCrossAttn(nn.Module):
r"""
- Cross Attention 2D Mid-level block - original architecture from Unet transformers: https://arxiv.org/abs/2103.06104
+ Cross Attention 2D Mid-level block - original architecture from Unet transformers:
+ https://huggingface.co/papers/2103.06104
Parameters:
in_channels (:obj:`int`):
@@ -336,7 +337,7 @@ class FlaxUNetMidBlock2DCrossAttn(nn.Module):
num_attention_heads (:obj:`int`, *optional*, defaults to 1):
Number of attention heads of each spatial transformer block
use_memory_efficient_attention (`bool`, *optional*, defaults to `False`):
- enable memory efficient attention https://arxiv.org/abs/2112.05682
+ enable memory efficient attention https://huggingface.co/papers/2112.05682
split_head_dim (`bool`, *optional*, defaults to `False`):
Whether to split the head dimension into a new axis for the self-attention computation. In most cases,
enabling this flag should speed up the computation for Stable Diffusion 2.x and Stable Diffusion XL.
diff --git a/src/diffusers/models/unets/unet_2d_condition.py b/src/diffusers/models/unets/unet_2d_condition.py
index 5674d8ba26..34094eb77a 100644
--- a/src/diffusers/models/unets/unet_2d_condition.py
+++ b/src/diffusers/models/unets/unet_2d_condition.py
@@ -835,7 +835,7 @@ class UNet2DConditionModel(
fn_recursive_set_attention_slice(module, reversed_slice_size)
def enable_freeu(self, s1: float, s2: float, b1: float, b2: float):
- r"""Enables the FreeU mechanism from https://arxiv.org/abs/2309.11497.
+ r"""Enables the FreeU mechanism from https://huggingface.co/papers/2309.11497.
The suffixes after the scaling factors represent the stage blocks where they are being applied.
diff --git a/src/diffusers/models/unets/unet_2d_condition_flax.py b/src/diffusers/models/unets/unet_2d_condition_flax.py
index edbbcbaeda..42be355909 100644
--- a/src/diffusers/models/unets/unet_2d_condition_flax.py
+++ b/src/diffusers/models/unets/unet_2d_condition_flax.py
@@ -94,7 +94,7 @@ class FlaxUNet2DConditionModel(nn.Module, FlaxModelMixin, ConfigMixin):
Whether to flip the sin to cos in the time embedding.
freq_shift (`int`, *optional*, defaults to 0): The frequency shift to apply to the time embedding.
use_memory_efficient_attention (`bool`, *optional*, defaults to `False`):
- Enable memory efficient attention as described [here](https://arxiv.org/abs/2112.05682).
+ Enable memory efficient attention as described [here](https://huggingface.co/papers/2112.05682).
split_head_dim (`bool`, *optional*, defaults to `False`):
Whether to split the head dimension into a new axis for the self-attention computation. In most cases,
enabling this flag should speed up the computation for Stable Diffusion 2.x and Stable Diffusion XL.
diff --git a/src/diffusers/models/unets/unet_3d_condition.py b/src/diffusers/models/unets/unet_3d_condition.py
index a148cf6cbe..c5ac14a3d1 100644
--- a/src/diffusers/models/unets/unet_3d_condition.py
+++ b/src/diffusers/models/unets/unet_3d_condition.py
@@ -470,7 +470,7 @@ class UNet3DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin)
# Copied from diffusers.models.unets.unet_2d_condition.UNet2DConditionModel.enable_freeu
def enable_freeu(self, s1, s2, b1, b2):
- r"""Enables the FreeU mechanism from https://arxiv.org/abs/2309.11497.
+ r"""Enables the FreeU mechanism from https://huggingface.co/papers/2309.11497.
The suffixes after the scaling factors represent the stage blocks where they are being applied.
diff --git a/src/diffusers/models/unets/unet_i2vgen_xl.py b/src/diffusers/models/unets/unet_i2vgen_xl.py
index 58fa30e497..ef80bed9d5 100644
--- a/src/diffusers/models/unets/unet_i2vgen_xl.py
+++ b/src/diffusers/models/unets/unet_i2vgen_xl.py
@@ -434,7 +434,7 @@ class I2VGenXLUNet(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin):
# Copied from diffusers.models.unets.unet_2d_condition.UNet2DConditionModel.enable_freeu
def enable_freeu(self, s1, s2, b1, b2):
- r"""Enables the FreeU mechanism from https://arxiv.org/abs/2309.11497.
+ r"""Enables the FreeU mechanism from https://huggingface.co/papers/2309.11497.
The suffixes after the scaling factors represent the stage blocks where they are being applied.
diff --git a/src/diffusers/models/unets/unet_motion_model.py b/src/diffusers/models/unets/unet_motion_model.py
index bd83024c9b..1a2c252db7 100644
--- a/src/diffusers/models/unets/unet_motion_model.py
+++ b/src/diffusers/models/unets/unet_motion_model.py
@@ -1873,7 +1873,7 @@ class UNetMotionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin, Peft
# Copied from diffusers.models.unets.unet_2d_condition.UNet2DConditionModel.enable_freeu
def enable_freeu(self, s1: float, s2: float, b1: float, b2: float) -> None:
- r"""Enables the FreeU mechanism from https://arxiv.org/abs/2309.11497.
+ r"""Enables the FreeU mechanism from https://huggingface.co/papers/2309.11497.
The suffixes after the scaling factors represent the stage blocks where they are being applied.
diff --git a/src/diffusers/models/vae_flax.py b/src/diffusers/models/vae_flax.py
index 5027f4230e..80f7583df4 100644
--- a/src/diffusers/models/vae_flax.py
+++ b/src/diffusers/models/vae_flax.py
@@ -769,7 +769,7 @@ class FlaxAutoencoderKL(nn.Module, FlaxModelMixin, ConfigMixin):
model. The latents are scaled with the formula `z = z * scaling_factor` before being passed to the
diffusion model. When decoding, the latents are scaled back to the original scale with the formula: `z = 1
/ scaling_factor * z`. For more details, refer to sections 4.3.2 and D.1 of the [High-Resolution Image
- Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752) paper.
+ Synthesis with Latent Diffusion Models](https://huggingface.co/papers/2112.10752) paper.
dtype (`jnp.dtype`, *optional*, defaults to `jnp.float32`):
The `dtype` of the parameters.
"""
diff --git a/src/diffusers/pipelines/README.md b/src/diffusers/pipelines/README.md
index b2954c0743..b0a8a54b14 100644
--- a/src/diffusers/pipelines/README.md
+++ b/src/diffusers/pipelines/README.md
@@ -16,7 +16,7 @@ or created independently from each other.
To that end, we strive to offer all open-sourced, state-of-the-art diffusion system under a unified API.
More specifically, we strive to provide pipelines that
-- 1. can load the officially published weights and yield 1-to-1 the same outputs as the original implementation according to the corresponding paper (*e.g.* [LDMTextToImagePipeline](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines/latent_diffusion), uses the officially released weights of [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752)),
+- 1. can load the officially published weights and yield 1-to-1 the same outputs as the original implementation according to the corresponding paper (*e.g.* [LDMTextToImagePipeline](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines/latent_diffusion), uses the officially released weights of [High-Resolution Image Synthesis with Latent Diffusion Models](https://huggingface.co/papers/2112.10752)),
- 2. have a simple user interface to run the model in inference (see the [Pipelines API](#pipelines-api) section),
- 3. are easy to understand with code that is self-explanatory and can be read along-side the official paper (see [Pipelines summary](#pipelines-summary)),
- 4. can easily be contributed by the community (see the [Contribution](#contribution) section).
@@ -33,17 +33,17 @@ available a colab notebook to directly try them out.
| Pipeline | Source | Tasks | Colab
|-------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------|:---:|:---:|
| [dance diffusion](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/dance_diffusion) | [**Dance Diffusion**](https://github.com/Harmonai-org/sample-generator) | *Unconditional Audio Generation* |
-| [ddpm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/ddpm) | [**Denoising Diffusion Probabilistic Models**](https://arxiv.org/abs/2006.11239) | *Unconditional Image Generation* |
-| [ddim](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/ddim) | [**Denoising Diffusion Implicit Models**](https://arxiv.org/abs/2010.02502) | *Unconditional Image Generation* | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb)
-| [latent_diffusion](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/latent_diffusion) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752) | *Text-to-Image Generation* |
-| [latent_diffusion_uncond](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/latent_diffusion_uncond) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752) | *Unconditional Image Generation* |
-| [pndm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pndm) | [**Pseudo Numerical Methods for Diffusion Models on Manifolds**](https://arxiv.org/abs/2202.09778) | *Unconditional Image Generation* |
+| [ddpm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/ddpm) | [**Denoising Diffusion Probabilistic Models**](https://huggingface.co/papers/2006.11239) | *Unconditional Image Generation* |
+| [ddim](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/ddim) | [**Denoising Diffusion Implicit Models**](https://huggingface.co/papers/2010.02502) | *Unconditional Image Generation* | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb)
+| [latent_diffusion](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/latent_diffusion) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://huggingface.co/papers/2112.10752) | *Text-to-Image Generation* |
+| [latent_diffusion_uncond](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/latent_diffusion_uncond) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://huggingface.co/papers/2112.10752) | *Unconditional Image Generation* |
+| [pndm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pndm) | [**Pseudo Numerical Methods for Diffusion Models on Manifolds**](https://huggingface.co/papers/2202.09778) | *Unconditional Image Generation* |
| [score_sde_ve](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/score_sde_ve) | [**Score-Based Generative Modeling through Stochastic Differential Equations**](https://openreview.net/forum?id=PxTIG12RRHS) | *Unconditional Image Generation* |
| [score_sde_vp](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/score_sde_vp) | [**Score-Based Generative Modeling through Stochastic Differential Equations**](https://openreview.net/forum?id=PxTIG12RRHS) | *Unconditional Image Generation* |
| [stable_diffusion](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | *Text-to-Image Generation* | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_diffusion.ipynb)
| [stable_diffusion](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | *Image-to-Image Text-Guided Generation* | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/image_2_image_using_diffusers.ipynb)
| [stable_diffusion](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | *Text-Guided Image Inpainting* | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/in_painting_with_stable_diffusion_using_diffusers.ipynb)
-| [stochastic_karras_ve](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stochastic_karras_ve) | [**Elucidating the Design Space of Diffusion-Based Generative Models**](https://arxiv.org/abs/2206.00364) | *Unconditional Image Generation* |
+| [stochastic_karras_ve](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stochastic_karras_ve) | [**Elucidating the Design Space of Diffusion-Based Generative Models**](https://huggingface.co/papers/2206.00364) | *Unconditional Image Generation* |
**Note**: Pipelines are simple examples of how to play around with the diffusion systems as described in the corresponding papers.
However, most of them can be adapted to use different scheduler components or even different model components. Some pipeline examples are shown in the [Examples](#examples) below.
diff --git a/src/diffusers/pipelines/__init__.py b/src/diffusers/pipelines/__init__.py
index 90ff30279f..b00530a669 100644
--- a/src/diffusers/pipelines/__init__.py
+++ b/src/diffusers/pipelines/__init__.py
@@ -268,7 +268,12 @@ else:
]
)
_import_structure["latte"] = ["LattePipeline"]
- _import_structure["ltx"] = ["LTXPipeline", "LTXImageToVideoPipeline", "LTXConditionPipeline"]
+ _import_structure["ltx"] = [
+ "LTXPipeline",
+ "LTXImageToVideoPipeline",
+ "LTXConditionPipeline",
+ "LTXLatentUpsamplePipeline",
+ ]
_import_structure["lumina"] = ["LuminaPipeline", "LuminaText2ImgPipeline"]
_import_structure["lumina2"] = ["Lumina2Pipeline", "Lumina2Text2ImgPipeline"]
_import_structure["marigold"].extend(
@@ -281,10 +286,16 @@ else:
_import_structure["mochi"] = ["MochiPipeline"]
_import_structure["musicldm"] = ["MusicLDMPipeline"]
_import_structure["omnigen"] = ["OmniGenPipeline"]
+ _import_structure["visualcloze"] = ["VisualClozePipeline", "VisualClozeGenerationPipeline"]
_import_structure["paint_by_example"] = ["PaintByExamplePipeline"]
_import_structure["pia"] = ["PIAPipeline"]
_import_structure["pixart_alpha"] = ["PixArtAlphaPipeline", "PixArtSigmaPipeline"]
- _import_structure["sana"] = ["SanaPipeline", "SanaSprintPipeline", "SanaControlNetPipeline"]
+ _import_structure["sana"] = [
+ "SanaPipeline",
+ "SanaSprintPipeline",
+ "SanaControlNetPipeline",
+ "SanaSprintImg2ImgPipeline",
+ ]
_import_structure["semantic_stable_diffusion"] = ["SemanticStableDiffusionPipeline"]
_import_structure["shap_e"] = ["ShapEImg2ImgPipeline", "ShapEPipeline"]
_import_structure["stable_audio"] = [
@@ -636,7 +647,7 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
LEditsPPPipelineStableDiffusion,
LEditsPPPipelineStableDiffusionXL,
)
- from .ltx import LTXConditionPipeline, LTXImageToVideoPipeline, LTXPipeline
+ from .ltx import LTXConditionPipeline, LTXImageToVideoPipeline, LTXLatentUpsamplePipeline, LTXPipeline
from .lumina import LuminaPipeline, LuminaText2ImgPipeline
from .lumina2 import Lumina2Pipeline, Lumina2Text2ImgPipeline
from .marigold import (
@@ -669,7 +680,7 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
from .paint_by_example import PaintByExamplePipeline
from .pia import PIAPipeline
from .pixart_alpha import PixArtAlphaPipeline, PixArtSigmaPipeline
- from .sana import SanaControlNetPipeline, SanaPipeline, SanaSprintPipeline
+ from .sana import SanaControlNetPipeline, SanaPipeline, SanaSprintImg2ImgPipeline, SanaSprintPipeline
from .semantic_stable_diffusion import SemanticStableDiffusionPipeline
from .shap_e import ShapEImg2ImgPipeline, ShapEPipeline
from .stable_audio import StableAudioPipeline, StableAudioProjectionModel
@@ -727,6 +738,7 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
UniDiffuserPipeline,
UniDiffuserTextDecoder,
)
+ from .visualcloze import VisualClozeGenerationPipeline, VisualClozePipeline
from .wan import WanImageToVideoPipeline, WanPipeline, WanVideoToVideoPipeline
from .wuerstchen import (
WuerstchenCombinedPipeline,
diff --git a/src/diffusers/pipelines/allegro/pipeline_allegro.py b/src/diffusers/pipelines/allegro/pipeline_allegro.py
index 1fc1c0901a..bb0b23164a 100644
--- a/src/diffusers/pipelines/allegro/pipeline_allegro.py
+++ b/src/diffusers/pipelines/allegro/pipeline_allegro.py
@@ -351,7 +351,7 @@ class AllegroPipeline(DiffusionPipeline):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -738,11 +738,11 @@ class AllegroPipeline(DiffusionPipeline):
Custom timesteps to use for the denoising process. If not defined, equal spaced `num_inference_steps`
timesteps are used. Must be in descending order.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate videos that are closely linked to the text `prompt`,
- usually at the expense of lower video quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate videos that are closely linked to
+ the text `prompt`, usually at the expense of lower video quality.
num_videos_per_prompt (`int`, *optional*, defaults to 1):
The number of videos to generate per prompt.
num_frames: (`int`, *optional*, defaults to 88):
@@ -752,8 +752,8 @@ class AllegroPipeline(DiffusionPipeline):
width (`int`, *optional*, defaults to self.unet.config.sample_size):
The width in pixels of the generated video.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
@@ -833,7 +833,7 @@ class AllegroPipeline(DiffusionPipeline):
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/amused/pipeline_amused.py b/src/diffusers/pipelines/amused/pipeline_amused.py
index f0948ede9b..bb33bd578f 100644
--- a/src/diffusers/pipelines/amused/pipeline_amused.py
+++ b/src/diffusers/pipelines/amused/pipeline_amused.py
@@ -160,10 +160,10 @@ class AmusedPipeline(DiffusionPipeline):
micro_conditioning_aesthetic_score (`int`, *optional*, defaults to 6):
The targeted aesthetic score according to the laion aesthetic classifier. See
https://laion.ai/blog/laion-aesthetics/ and the micro-conditioning section of
- https://arxiv.org/abs/2307.01952.
+ https://huggingface.co/papers/2307.01952.
micro_conditioning_crop_coord (`Tuple[int]`, *optional*, defaults to (0, 0)):
The targeted height, width crop coordinates. See the micro-conditioning section of
- https://arxiv.org/abs/2307.01952.
+ https://huggingface.co/papers/2307.01952.
temperature (`Union[int, Tuple[int, int], List[int]]`, *optional*, defaults to (2, 0)):
Configures the temperature scheduler on `self.scheduler` see `AmusedScheduler#set_timesteps`.
diff --git a/src/diffusers/pipelines/amused/pipeline_amused_img2img.py b/src/diffusers/pipelines/amused/pipeline_amused_img2img.py
index 7ac05b39c3..cfb706c5c8 100644
--- a/src/diffusers/pipelines/amused/pipeline_amused_img2img.py
+++ b/src/diffusers/pipelines/amused/pipeline_amused_img2img.py
@@ -179,10 +179,10 @@ class AmusedImg2ImgPipeline(DiffusionPipeline):
micro_conditioning_aesthetic_score (`int`, *optional*, defaults to 6):
The targeted aesthetic score according to the laion aesthetic classifier. See
https://laion.ai/blog/laion-aesthetics/ and the micro-conditioning section of
- https://arxiv.org/abs/2307.01952.
+ https://huggingface.co/papers/2307.01952.
micro_conditioning_crop_coord (`Tuple[int]`, *optional*, defaults to (0, 0)):
The targeted height, width crop coordinates. See the micro-conditioning section of
- https://arxiv.org/abs/2307.01952.
+ https://huggingface.co/papers/2307.01952.
temperature (`Union[int, Tuple[int, int], List[int]]`, *optional*, defaults to (2, 0)):
Configures the temperature scheduler on `self.scheduler` see `AmusedScheduler#set_timesteps`.
diff --git a/src/diffusers/pipelines/amused/pipeline_amused_inpaint.py b/src/diffusers/pipelines/amused/pipeline_amused_inpaint.py
index d908c32745..8148c9bba7 100644
--- a/src/diffusers/pipelines/amused/pipeline_amused_inpaint.py
+++ b/src/diffusers/pipelines/amused/pipeline_amused_inpaint.py
@@ -203,10 +203,10 @@ class AmusedInpaintPipeline(DiffusionPipeline):
micro_conditioning_aesthetic_score (`int`, *optional*, defaults to 6):
The targeted aesthetic score according to the laion aesthetic classifier. See
https://laion.ai/blog/laion-aesthetics/ and the micro-conditioning section of
- https://arxiv.org/abs/2307.01952.
+ https://huggingface.co/papers/2307.01952.
micro_conditioning_crop_coord (`Tuple[int]`, *optional*, defaults to (0, 0)):
The targeted height, width crop coordinates. See the micro-conditioning section of
- https://arxiv.org/abs/2307.01952.
+ https://huggingface.co/papers/2307.01952.
temperature (`Union[int, Tuple[int, int], List[int]]`, *optional*, defaults to (2, 0)):
Configures the temperature scheduler on `self.scheduler` see `AmusedScheduler#set_timesteps`.
diff --git a/src/diffusers/pipelines/animatediff/pipeline_animatediff.py b/src/diffusers/pipelines/animatediff/pipeline_animatediff.py
index d3ad5cc13c..d9742d161e 100644
--- a/src/diffusers/pipelines/animatediff/pipeline_animatediff.py
+++ b/src/diffusers/pipelines/animatediff/pipeline_animatediff.py
@@ -428,7 +428,7 @@ class AnimateDiffPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -514,7 +514,7 @@ class AnimateDiffPipeline(
def prepare_latents(
self, batch_size, num_channels_latents, num_frames, height, width, dtype, device, generator, latents=None
):
- # If FreeNoise is enabled, generate latents as described in Equation (7) of [FreeNoise](https://arxiv.org/abs/2310.15169)
+ # If FreeNoise is enabled, generate latents as described in Equation (7) of [FreeNoise](https://huggingface.co/papers/2310.15169)
if self.free_noise_enabled:
latents = self._prepare_latents_free_noise(
batch_size, num_channels_latents, num_frames, height, width, dtype, device, generator, latents
@@ -552,7 +552,7 @@ class AnimateDiffPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -621,8 +621,8 @@ class AnimateDiffPipeline(
The prompt or prompts to guide what to not include in image generation. If not defined, you need to
pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
diff --git a/src/diffusers/pipelines/animatediff/pipeline_animatediff_controlnet.py b/src/diffusers/pipelines/animatediff/pipeline_animatediff_controlnet.py
index db54639864..430d8bc198 100644
--- a/src/diffusers/pipelines/animatediff/pipeline_animatediff_controlnet.py
+++ b/src/diffusers/pipelines/animatediff/pipeline_animatediff_controlnet.py
@@ -472,7 +472,7 @@ class AnimateDiffControlNetPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -630,7 +630,7 @@ class AnimateDiffControlNetPipeline(
def prepare_latents(
self, batch_size, num_channels_latents, num_frames, height, width, dtype, device, generator, latents=None
):
- # If FreeNoise is enabled, generate latents as described in Equation (7) of [FreeNoise](https://arxiv.org/abs/2310.15169)
+ # If FreeNoise is enabled, generate latents as described in Equation (7) of [FreeNoise](https://huggingface.co/papers/2310.15169)
if self.free_noise_enabled:
latents = self._prepare_latents_free_noise(
batch_size, num_channels_latents, num_frames, height, width, dtype, device, generator, latents
@@ -700,7 +700,7 @@ class AnimateDiffControlNetPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -772,8 +772,8 @@ class AnimateDiffControlNetPipeline(
The prompt or prompts to guide what to not include in image generation. If not defined, you need to
pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
diff --git a/src/diffusers/pipelines/animatediff/pipeline_animatediff_sdxl.py b/src/diffusers/pipelines/animatediff/pipeline_animatediff_sdxl.py
index 958eb5fb51..dc4a38cc2a 100644
--- a/src/diffusers/pipelines/animatediff/pipeline_animatediff_sdxl.py
+++ b/src/diffusers/pipelines/animatediff/pipeline_animatediff_sdxl.py
@@ -125,7 +125,7 @@ def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
r"""
Rescales `noise_cfg` tensor based on `guidance_rescale` to improve image quality and fix overexposure. Based on
Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891).
Args:
noise_cfg (`torch.Tensor`):
@@ -652,7 +652,7 @@ class AnimateDiffSDXLPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -844,7 +844,7 @@ class AnimateDiffSDXLPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -948,11 +948,11 @@ class AnimateDiffSDXLPipeline(
"Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output)
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower video quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower video quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the video generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
@@ -963,8 +963,8 @@ class AnimateDiffSDXLPipeline(
num_videos_per_prompt (`int`, *optional*, defaults to 1):
The number of videos to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
@@ -1003,9 +1003,10 @@ class AnimateDiffSDXLPipeline(
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
- [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
- Guidance rescale factor should fix overexposure when using zero terminal SNR.
+ Flawed](https://huggingface.co/papers/2305.08891) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are
+ Flawed](https://huggingface.co/papers/2305.08891). Guidance rescale factor should fix overexposure when
+ using zero terminal SNR.
original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
`original_size` defaults to `(height, width)` if not specified. Part of SDXL's micro-conditioning as
@@ -1252,7 +1253,7 @@ class AnimateDiffSDXLPipeline(
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(
noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale
)
diff --git a/src/diffusers/pipelines/animatediff/pipeline_animatediff_sparsectrl.py b/src/diffusers/pipelines/animatediff/pipeline_animatediff_sparsectrl.py
index 8c51fddcd5..43d76dd589 100644
--- a/src/diffusers/pipelines/animatediff/pipeline_animatediff_sparsectrl.py
+++ b/src/diffusers/pipelines/animatediff/pipeline_animatediff_sparsectrl.py
@@ -140,7 +140,7 @@ class AnimateDiffSparseControlNetPipeline(
):
r"""
Pipeline for controlled text-to-video generation using the method described in [SparseCtrl: Adding Sparse Controls
- to Text-to-Video Diffusion Models](https://arxiv.org/abs/2311.16933).
+ to Text-to-Video Diffusion Models](https://huggingface.co/papers/2311.16933).
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods
implemented for all pipelines (downloading, saving, running on a particular device, etc.).
@@ -475,7 +475,7 @@ class AnimateDiffSparseControlNetPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -695,7 +695,7 @@ class AnimateDiffSparseControlNetPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -762,8 +762,8 @@ class AnimateDiffSparseControlNetPipeline(
The prompt or prompts to guide what to not include in image generation. If not defined, you need to
pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
diff --git a/src/diffusers/pipelines/animatediff/pipeline_animatediff_video2video.py b/src/diffusers/pipelines/animatediff/pipeline_animatediff_video2video.py
index 1163970552..e9d8081965 100644
--- a/src/diffusers/pipelines/animatediff/pipeline_animatediff_video2video.py
+++ b/src/diffusers/pipelines/animatediff/pipeline_animatediff_video2video.py
@@ -539,7 +539,7 @@ class AnimateDiffVideoToVideoPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -725,7 +725,7 @@ class AnimateDiffVideoToVideoPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -805,8 +805,8 @@ class AnimateDiffVideoToVideoPipeline(
The prompt or prompts to guide what to not include in image generation. If not defined, you need to
pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
diff --git a/src/diffusers/pipelines/animatediff/pipeline_animatediff_video2video_controlnet.py b/src/diffusers/pipelines/animatediff/pipeline_animatediff_video2video_controlnet.py
index ce97409493..92e3e32097 100644
--- a/src/diffusers/pipelines/animatediff/pipeline_animatediff_video2video_controlnet.py
+++ b/src/diffusers/pipelines/animatediff/pipeline_animatediff_video2video_controlnet.py
@@ -571,7 +571,7 @@ class AnimateDiffVideoToVideoControlNetPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -890,7 +890,7 @@ class AnimateDiffVideoToVideoControlNetPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -975,8 +975,8 @@ class AnimateDiffVideoToVideoControlNetPipeline(
The prompt or prompts to guide what to not include in image generation. If not defined, you need to
pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
diff --git a/src/diffusers/pipelines/audioldm/pipeline_audioldm.py b/src/diffusers/pipelines/audioldm/pipeline_audioldm.py
index 14c6d44fc5..73fa44bad1 100644
--- a/src/diffusers/pipelines/audioldm/pipeline_audioldm.py
+++ b/src/diffusers/pipelines/audioldm/pipeline_audioldm.py
@@ -261,7 +261,7 @@ class AudioLDMPipeline(DiffusionPipeline, StableDiffusionMixin):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -397,8 +397,8 @@ class AudioLDMPipeline(DiffusionPipeline, StableDiffusionMixin):
num_waveforms_per_prompt (`int`, *optional*, defaults to 1):
The number of waveforms to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -472,7 +472,7 @@ class AudioLDMPipeline(DiffusionPipeline, StableDiffusionMixin):
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/audioldm2/pipeline_audioldm2.py b/src/diffusers/pipelines/audioldm2/pipeline_audioldm2.py
index eeabf0d248..dd70fb82ff 100644
--- a/src/diffusers/pipelines/audioldm2/pipeline_audioldm2.py
+++ b/src/diffusers/pipelines/audioldm2/pipeline_audioldm2.py
@@ -713,7 +713,7 @@ class AudioLDM2Pipeline(DiffusionPipeline):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -900,8 +900,8 @@ class AudioLDM2Pipeline(DiffusionPipeline):
generated waveforms based on their cosine similarity with the text input in the joint text-audio
embedding space.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -999,7 +999,7 @@ class AudioLDM2Pipeline(DiffusionPipeline):
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/aura_flow/pipeline_aura_flow.py b/src/diffusers/pipelines/aura_flow/pipeline_aura_flow.py
index 7c98b3b71c..bdf9440eb9 100644
--- a/src/diffusers/pipelines/aura_flow/pipeline_aura_flow.py
+++ b/src/diffusers/pipelines/aura_flow/pipeline_aura_flow.py
@@ -484,11 +484,11 @@ class AuraFlowPipeline(DiffusionPipeline, AuraFlowLoraLoaderMixin):
Custom sigmas used to override the timestep spacing strategy of the scheduler. If `sigmas` is passed,
`num_inference_steps` and `timesteps` must be `None`.
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
@@ -567,7 +567,7 @@ class AuraFlowPipeline(DiffusionPipeline, AuraFlowLoraLoaderMixin):
lora_scale = self.attention_kwargs.get("scale", None) if self.attention_kwargs is not None else None
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/auto_pipeline.py b/src/diffusers/pipelines/auto_pipeline.py
index 6a5f6098b6..ed8ad79ca7 100644
--- a/src/diffusers/pipelines/auto_pipeline.py
+++ b/src/diffusers/pipelines/auto_pipeline.py
@@ -322,9 +322,8 @@ class AutoPipelineForText2Image(ConfigMixin):
- A path to a *directory* (for example `./my_pipeline_directory/`) containing pipeline weights
saved using
[`~DiffusionPipeline.save_pretrained`].
- torch_dtype (`str` or `torch.dtype`, *optional*):
- Override the default `torch.dtype` and load the model with another dtype. If "auto" is passed, the
- dtype is automatically derived from the model's weights.
+ torch_dtype (`torch.dtype`, *optional*):
+ Override the default `torch.dtype` and load the model with another dtype.
force_download (`bool`, *optional*, defaults to `False`):
Whether or not to force the (re-)download of the model weights and configuration files, overriding the
cached versions if they exist.
@@ -619,8 +618,7 @@ class AutoPipelineForImage2Image(ConfigMixin):
saved using
[`~DiffusionPipeline.save_pretrained`].
torch_dtype (`str` or `torch.dtype`, *optional*):
- Override the default `torch.dtype` and load the model with another dtype. If "auto" is passed, the
- dtype is automatically derived from the model's weights.
+ Override the default `torch.dtype` and load the model with another dtype.
force_download (`bool`, *optional*, defaults to `False`):
Whether or not to force the (re-)download of the model weights and configuration files, overriding the
cached versions if they exist.
@@ -930,8 +928,7 @@ class AutoPipelineForInpainting(ConfigMixin):
saved using
[`~DiffusionPipeline.save_pretrained`].
torch_dtype (`str` or `torch.dtype`, *optional*):
- Override the default `torch.dtype` and load the model with another dtype. If "auto" is passed, the
- dtype is automatically derived from the model's weights.
+ Override the default `torch.dtype` and load the model with another dtype.
force_download (`bool`, *optional*, defaults to `False`):
Whether or not to force the (re-)download of the model weights and configuration files, overriding the
cached versions if they exist.
diff --git a/src/diffusers/pipelines/blip_diffusion/pipeline_blip_diffusion.py b/src/diffusers/pipelines/blip_diffusion/pipeline_blip_diffusion.py
index ee9615e828..28c7058c4e 100644
--- a/src/diffusers/pipelines/blip_diffusion/pipeline_blip_diffusion.py
+++ b/src/diffusers/pipelines/blip_diffusion/pipeline_blip_diffusion.py
@@ -229,11 +229,11 @@ class BlipDiffusionPipeline(DiffusionPipeline):
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by random sampling.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
height (`int`, *optional*, defaults to 512):
The height of the generated image.
width (`int`, *optional*, defaults to 512):
diff --git a/src/diffusers/pipelines/cogvideo/pipeline_cogvideox.py b/src/diffusers/pipelines/cogvideo/pipeline_cogvideox.py
index 99ae9025cd..3f37b4cae9 100644
--- a/src/diffusers/pipelines/cogvideo/pipeline_cogvideox.py
+++ b/src/diffusers/pipelines/cogvideo/pipeline_cogvideox.py
@@ -359,7 +359,7 @@ class CogVideoXPipeline(DiffusionPipeline, CogVideoXLoraLoaderMixin):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -558,11 +558,11 @@ class CogVideoXPipeline(DiffusionPipeline, CogVideoXLoraLoaderMixin):
in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
passed will be used. Must be in descending order.
guidance_scale (`float`, *optional*, defaults to 7.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_videos_per_prompt (`int`, *optional*, defaults to 1):
The number of videos to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
@@ -645,7 +645,7 @@ class CogVideoXPipeline(DiffusionPipeline, CogVideoXLoraLoaderMixin):
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/cogvideo/pipeline_cogvideox_fun_control.py b/src/diffusers/pipelines/cogvideo/pipeline_cogvideox_fun_control.py
index e37574ec9c..e2f072a659 100644
--- a/src/diffusers/pipelines/cogvideo/pipeline_cogvideox_fun_control.py
+++ b/src/diffusers/pipelines/cogvideo/pipeline_cogvideox_fun_control.py
@@ -398,7 +398,7 @@ class CogVideoXFunControlPipeline(DiffusionPipeline, CogVideoXLoraLoaderMixin):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -603,11 +603,11 @@ class CogVideoXFunControlPipeline(DiffusionPipeline, CogVideoXLoraLoaderMixin):
in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
passed will be used. Must be in descending order.
guidance_scale (`float`, *optional*, defaults to 6.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_videos_per_prompt (`int`, *optional*, defaults to 1):
The number of videos to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
@@ -698,7 +698,7 @@ class CogVideoXFunControlPipeline(DiffusionPipeline, CogVideoXLoraLoaderMixin):
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/cogvideo/pipeline_cogvideox_image2video.py b/src/diffusers/pipelines/cogvideo/pipeline_cogvideox_image2video.py
index 59d7c4cad5..1246a950c6 100644
--- a/src/diffusers/pipelines/cogvideo/pipeline_cogvideox_image2video.py
+++ b/src/diffusers/pipelines/cogvideo/pipeline_cogvideox_image2video.py
@@ -442,7 +442,7 @@ class CogVideoXImageToVideoPipeline(DiffusionPipeline, CogVideoXLoraLoaderMixin)
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -658,11 +658,11 @@ class CogVideoXImageToVideoPipeline(DiffusionPipeline, CogVideoXLoraLoaderMixin)
in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
passed will be used. Must be in descending order.
guidance_scale (`float`, *optional*, defaults to 7.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_videos_per_prompt (`int`, *optional*, defaults to 1):
The number of videos to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
@@ -747,7 +747,7 @@ class CogVideoXImageToVideoPipeline(DiffusionPipeline, CogVideoXLoraLoaderMixin)
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/cogvideo/pipeline_cogvideox_video2video.py b/src/diffusers/pipelines/cogvideo/pipeline_cogvideox_video2video.py
index c4dc7e574f..d4c79af890 100644
--- a/src/diffusers/pipelines/cogvideo/pipeline_cogvideox_video2video.py
+++ b/src/diffusers/pipelines/cogvideo/pipeline_cogvideox_video2video.py
@@ -418,7 +418,7 @@ class CogVideoXVideoToVideoPipeline(DiffusionPipeline, CogVideoXLoraLoaderMixin)
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -628,11 +628,11 @@ class CogVideoXVideoToVideoPipeline(DiffusionPipeline, CogVideoXLoraLoaderMixin)
strength (`float`, *optional*, defaults to 0.8):
Higher strength leads to more differences between original video and generated video.
guidance_scale (`float`, *optional*, defaults to 7.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_videos_per_prompt (`int`, *optional*, defaults to 1):
The number of videos to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
@@ -718,7 +718,7 @@ class CogVideoXVideoToVideoPipeline(DiffusionPipeline, CogVideoXLoraLoaderMixin)
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/cogview3/pipeline_cogview3plus.py b/src/diffusers/pipelines/cogview3/pipeline_cogview3plus.py
index 0cd3943fbc..c2c552abab 100644
--- a/src/diffusers/pipelines/cogview3/pipeline_cogview3plus.py
+++ b/src/diffusers/pipelines/cogview3/pipeline_cogview3plus.py
@@ -319,7 +319,7 @@ class CogView3PlusPipeline(DiffusionPipeline):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -390,7 +390,7 @@ class CogView3PlusPipeline(DiffusionPipeline):
return self._guidance_scale
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -453,11 +453,11 @@ class CogView3PlusPipeline(DiffusionPipeline):
in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
passed will be used. Must be in descending order.
guidance_scale (`float`, *optional*, defaults to `5.0`):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to `1`):
The number of images to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
@@ -547,7 +547,7 @@ class CogView3PlusPipeline(DiffusionPipeline):
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/cogview4/pipeline_cogview4.py b/src/diffusers/pipelines/cogview4/pipeline_cogview4.py
index 8550fa94f9..8071d05f22 100644
--- a/src/diffusers/pipelines/cogview4/pipeline_cogview4.py
+++ b/src/diffusers/pipelines/cogview4/pipeline_cogview4.py
@@ -377,7 +377,7 @@ class CogView4Pipeline(DiffusionPipeline, CogView4LoraLoaderMixin):
return self._guidance_scale
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -453,11 +453,11 @@ class CogView4Pipeline(DiffusionPipeline, CogView4LoraLoaderMixin):
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, *optional*, defaults to `5.0`):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to `1`):
The number of images to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
diff --git a/src/diffusers/pipelines/cogview4/pipeline_cogview4_control.py b/src/diffusers/pipelines/cogview4/pipeline_cogview4_control.py
index 7613bc3d0f..c20c9a0879 100644
--- a/src/diffusers/pipelines/cogview4/pipeline_cogview4_control.py
+++ b/src/diffusers/pipelines/cogview4/pipeline_cogview4_control.py
@@ -409,7 +409,7 @@ class CogView4ControlPipeline(DiffusionPipeline):
return self._guidance_scale
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -486,11 +486,11 @@ class CogView4ControlPipeline(DiffusionPipeline):
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, *optional*, defaults to `5.0`):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to `1`):
The number of images to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
diff --git a/src/diffusers/pipelines/consisid/consisid_utils.py b/src/diffusers/pipelines/consisid/consisid_utils.py
index 874b3d7614..23811a4986 100644
--- a/src/diffusers/pipelines/consisid/consisid_utils.py
+++ b/src/diffusers/pipelines/consisid/consisid_utils.py
@@ -166,7 +166,7 @@ def process_face_embeddings(
raise RuntimeError("facexlib align face fail")
align_face = face_helper_1.cropped_faces[0] # (512, 512, 3) # RGB
- # incase insightface didn't detect face
+ # in case insightface didn't detect face
if id_ante_embedding is None:
logger.warning("Failed to detect face using insightface. Extracting embedding with align face")
id_ante_embedding = face_helper_2.get_feat(align_face)
diff --git a/src/diffusers/pipelines/consisid/pipeline_consisid.py b/src/diffusers/pipelines/consisid/pipeline_consisid.py
index 8abe24e807..67598d0edf 100644
--- a/src/diffusers/pipelines/consisid/pipeline_consisid.py
+++ b/src/diffusers/pipelines/consisid/pipeline_consisid.py
@@ -540,7 +540,7 @@ class ConsisIDPipeline(DiffusionPipeline, CogVideoXLoraLoaderMixin):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -715,11 +715,11 @@ class ConsisIDPipeline(DiffusionPipeline, CogVideoXLoraLoaderMixin):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 6):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
use_dynamic_cfg (`bool`, *optional*, defaults to `False`):
If True, dynamically adjusts the guidance scale during inference. This allows the model to use a
progressive guidance scale, improving the balance between text-guided generation and image quality over
@@ -821,7 +821,7 @@ class ConsisIDPipeline(DiffusionPipeline, CogVideoXLoraLoaderMixin):
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/controlnet/pipeline_controlnet.py b/src/diffusers/pipelines/controlnet/pipeline_controlnet.py
index a5e38278cd..e14c51ab94 100644
--- a/src/diffusers/pipelines/controlnet/pipeline_controlnet.py
+++ b/src/diffusers/pipelines/controlnet/pipeline_controlnet.py
@@ -579,7 +579,7 @@ class StableDiffusionControlNetPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -886,7 +886,7 @@ class StableDiffusionControlNetPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -979,8 +979,8 @@ class StableDiffusionControlNetPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
diff --git a/src/diffusers/pipelines/controlnet/pipeline_controlnet_blip_diffusion.py b/src/diffusers/pipelines/controlnet/pipeline_controlnet_blip_diffusion.py
index c73dd9824f..0a9145eeeb 100644
--- a/src/diffusers/pipelines/controlnet/pipeline_controlnet_blip_diffusion.py
+++ b/src/diffusers/pipelines/controlnet/pipeline_controlnet_blip_diffusion.py
@@ -280,11 +280,11 @@ class BlipDiffusionControlNetPipeline(DiffusionPipeline):
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by random sampling.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
height (`int`, *optional*, defaults to 512):
The height of the generated image.
width (`int`, *optional*, defaults to 512):
diff --git a/src/diffusers/pipelines/controlnet/pipeline_controlnet_img2img.py b/src/diffusers/pipelines/controlnet/pipeline_controlnet_img2img.py
index be2874f48e..2102b34d5f 100644
--- a/src/diffusers/pipelines/controlnet/pipeline_controlnet_img2img.py
+++ b/src/diffusers/pipelines/controlnet/pipeline_controlnet_img2img.py
@@ -557,7 +557,7 @@ class StableDiffusionControlNetImg2ImgPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -884,7 +884,7 @@ class StableDiffusionControlNetImg2ImgPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -977,8 +977,8 @@ class StableDiffusionControlNetImg2ImgPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
diff --git a/src/diffusers/pipelines/controlnet/pipeline_controlnet_inpaint.py b/src/diffusers/pipelines/controlnet/pipeline_controlnet_inpaint.py
index 2c63aedd96..3fc1206ba5 100644
--- a/src/diffusers/pipelines/controlnet/pipeline_controlnet_inpaint.py
+++ b/src/diffusers/pipelines/controlnet/pipeline_controlnet_inpaint.py
@@ -566,7 +566,7 @@ class StableDiffusionControlNetInpaintPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -976,7 +976,7 @@ class StableDiffusionControlNetInpaintPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1089,8 +1089,8 @@ class StableDiffusionControlNetInpaintPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
diff --git a/src/diffusers/pipelines/controlnet/pipeline_controlnet_inpaint_sd_xl.py b/src/diffusers/pipelines/controlnet/pipeline_controlnet_inpaint_sd_xl.py
index 5907b41f4e..51ddd99714 100644
--- a/src/diffusers/pipelines/controlnet/pipeline_controlnet_inpaint_sd_xl.py
+++ b/src/diffusers/pipelines/controlnet/pipeline_controlnet_inpaint_sd_xl.py
@@ -149,7 +149,7 @@ def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
r"""
Rescales `noise_cfg` tensor based on `guidance_rescale` to improve image quality and fix overexposure. Based on
Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891).
Args:
noise_cfg (`torch.Tensor`):
@@ -605,7 +605,7 @@ class StableDiffusionXLControlNetInpaintPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -1157,7 +1157,7 @@ class StableDiffusionXLControlNetInpaintPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1283,11 +1283,11 @@ class StableDiffusionXLControlNetInpaintPipeline(
forms a part of a "Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output).
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
@@ -1318,8 +1318,8 @@ class StableDiffusionXLControlNetInpaintPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
@@ -1806,7 +1806,7 @@ class StableDiffusionXLControlNetInpaintPipeline(
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/src/diffusers/pipelines/controlnet/pipeline_controlnet_sd_xl.py b/src/diffusers/pipelines/controlnet/pipeline_controlnet_sd_xl.py
index 77d496cf83..8aa47fd427 100644
--- a/src/diffusers/pipelines/controlnet/pipeline_controlnet_sd_xl.py
+++ b/src/diffusers/pipelines/controlnet/pipeline_controlnet_sd_xl.py
@@ -613,7 +613,7 @@ class StableDiffusionXLControlNetPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -985,7 +985,7 @@ class StableDiffusionXLControlNetPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1108,8 +1108,8 @@ class StableDiffusionXLControlNetPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
diff --git a/src/diffusers/pipelines/controlnet/pipeline_controlnet_sd_xl_img2img.py b/src/diffusers/pipelines/controlnet/pipeline_controlnet_sd_xl_img2img.py
index 04f069e12e..52e76a2204 100644
--- a/src/diffusers/pipelines/controlnet/pipeline_controlnet_sd_xl_img2img.py
+++ b/src/diffusers/pipelines/controlnet/pipeline_controlnet_sd_xl_img2img.py
@@ -607,7 +607,7 @@ class StableDiffusionXLControlNetImg2ImgPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -1069,7 +1069,7 @@ class StableDiffusionXLControlNetImg2ImgPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1174,11 +1174,11 @@ class StableDiffusionXLControlNetImg2ImgPipeline(
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
@@ -1189,8 +1189,8 @@ class StableDiffusionXLControlNetImg2ImgPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
diff --git a/src/diffusers/pipelines/controlnet/pipeline_controlnet_union_inpaint_sd_xl.py b/src/diffusers/pipelines/controlnet/pipeline_controlnet_union_inpaint_sd_xl.py
index 8aae9ee7a2..fc160573ba 100644
--- a/src/diffusers/pipelines/controlnet/pipeline_controlnet_union_inpaint_sd_xl.py
+++ b/src/diffusers/pipelines/controlnet/pipeline_controlnet_union_inpaint_sd_xl.py
@@ -134,7 +134,7 @@ def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
r"""
Rescales `noise_cfg` tensor based on `guidance_rescale` to improve image quality and fix overexposure. Based on
Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891).
Args:
noise_cfg (`torch.Tensor`):
@@ -587,7 +587,7 @@ class StableDiffusionXLControlNetUnionInpaintPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -1091,7 +1091,7 @@ class StableDiffusionXLControlNetUnionInpaintPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1215,11 +1215,11 @@ class StableDiffusionXLControlNetUnionInpaintPipeline(
forms a part of a "Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output).
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
@@ -1250,8 +1250,8 @@ class StableDiffusionXLControlNetUnionInpaintPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
@@ -1715,7 +1715,7 @@ class StableDiffusionXLControlNetUnionInpaintPipeline(
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/src/diffusers/pipelines/controlnet/pipeline_controlnet_union_sd_xl.py b/src/diffusers/pipelines/controlnet/pipeline_controlnet_union_sd_xl.py
index ca931c221e..19d8f014bf 100644
--- a/src/diffusers/pipelines/controlnet/pipeline_controlnet_union_sd_xl.py
+++ b/src/diffusers/pipelines/controlnet/pipeline_controlnet_union_sd_xl.py
@@ -603,7 +603,7 @@ class StableDiffusionXLControlNetUnionPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -960,7 +960,7 @@ class StableDiffusionXLControlNetUnionPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1082,8 +1082,8 @@ class StableDiffusionXLControlNetUnionPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
diff --git a/src/diffusers/pipelines/controlnet/pipeline_controlnet_union_sd_xl_img2img.py b/src/diffusers/pipelines/controlnet/pipeline_controlnet_union_sd_xl_img2img.py
index 87398395d9..bd98b79750 100644
--- a/src/diffusers/pipelines/controlnet/pipeline_controlnet_union_sd_xl_img2img.py
+++ b/src/diffusers/pipelines/controlnet/pipeline_controlnet_union_sd_xl_img2img.py
@@ -616,7 +616,7 @@ class StableDiffusionXLControlNetUnionImg2ImgPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -1024,7 +1024,7 @@ class StableDiffusionXLControlNetUnionImg2ImgPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1129,11 +1129,11 @@ class StableDiffusionXLControlNetUnionImg2ImgPipeline(
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
@@ -1144,8 +1144,8 @@ class StableDiffusionXLControlNetUnionImg2ImgPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
diff --git a/src/diffusers/pipelines/controlnet_hunyuandit/pipeline_hunyuandit_controlnet.py b/src/diffusers/pipelines/controlnet_hunyuandit/pipeline_hunyuandit_controlnet.py
index 5ee712b5f1..12ae176567 100644
--- a/src/diffusers/pipelines/controlnet_hunyuandit/pipeline_hunyuandit_controlnet.py
+++ b/src/diffusers/pipelines/controlnet_hunyuandit/pipeline_hunyuandit_controlnet.py
@@ -144,7 +144,7 @@ def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
r"""
Rescales `noise_cfg` tensor based on `guidance_rescale` to improve image quality and fix overexposure. Based on
Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891).
Args:
noise_cfg (`torch.Tensor`):
@@ -463,7 +463,7 @@ class HunyuanDiTControlNetPipeline(DiffusionPipeline):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -621,7 +621,7 @@ class HunyuanDiTControlNetPipeline(DiffusionPipeline):
return self._guidance_rescale
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -709,8 +709,8 @@ class HunyuanDiTControlNetPipeline(DiffusionPipeline):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -746,7 +746,7 @@ class HunyuanDiTControlNetPipeline(DiffusionPipeline):
inputs will be passed.
guidance_rescale (`float`, *optional*, defaults to 0.0):
Rescale the noise_cfg according to `guidance_rescale`. Based on findings of [Common Diffusion Noise
- Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Schedules and Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
original_size (`Tuple[int, int]`, *optional*, defaults to `(1024, 1024)`):
The original size of the image. Used to calculate the time ids.
target_size (`Tuple[int, int]`, *optional*):
@@ -1009,7 +1009,7 @@ class HunyuanDiTControlNetPipeline(DiffusionPipeline):
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/src/diffusers/pipelines/controlnet_sd3/pipeline_stable_diffusion_3_controlnet.py b/src/diffusers/pipelines/controlnet_sd3/pipeline_stable_diffusion_3_controlnet.py
index 7f7acd882b..f4b1f22571 100644
--- a/src/diffusers/pipelines/controlnet_sd3/pipeline_stable_diffusion_3_controlnet.py
+++ b/src/diffusers/pipelines/controlnet_sd3/pipeline_stable_diffusion_3_controlnet.py
@@ -719,7 +719,7 @@ class StableDiffusion3ControlNetPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -877,11 +877,11 @@ class StableDiffusion3ControlNetPipeline(
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
control_guidance_start (`float` or `List[float]`, *optional*, defaults to 0.0):
The percentage of total steps at which the ControlNet starts applying.
control_guidance_end (`float` or `List[float]`, *optional*, defaults to 1.0):
diff --git a/src/diffusers/pipelines/controlnet_sd3/pipeline_stable_diffusion_3_controlnet_inpainting.py b/src/diffusers/pipelines/controlnet_sd3/pipeline_stable_diffusion_3_controlnet_inpainting.py
index cb35f67fa1..5498cb5bc5 100644
--- a/src/diffusers/pipelines/controlnet_sd3/pipeline_stable_diffusion_3_controlnet_inpainting.py
+++ b/src/diffusers/pipelines/controlnet_sd3/pipeline_stable_diffusion_3_controlnet_inpainting.py
@@ -769,7 +769,7 @@ class StableDiffusion3ControlNetInpaintingPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -928,11 +928,11 @@ class StableDiffusion3ControlNetInpaintingPipeline(
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
control_guidance_start (`float` or `List[float]`, *optional*, defaults to 0.0):
The percentage of total steps at which the ControlNet starts applying.
control_guidance_end (`float` or `List[float]`, *optional*, defaults to 1.0):
diff --git a/src/diffusers/pipelines/controlnet_xs/pipeline_controlnet_xs.py b/src/diffusers/pipelines/controlnet_xs/pipeline_controlnet_xs.py
index 8792961e31..ecc7cd4ad7 100644
--- a/src/diffusers/pipelines/controlnet_xs/pipeline_controlnet_xs.py
+++ b/src/diffusers/pipelines/controlnet_xs/pipeline_controlnet_xs.py
@@ -440,7 +440,7 @@ class StableDiffusionControlNetXSPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -697,8 +697,8 @@ class StableDiffusionControlNetXSPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -783,7 +783,7 @@ class StableDiffusionControlNetXSPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/controlnet_xs/pipeline_controlnet_xs_sd_xl.py b/src/diffusers/pipelines/controlnet_xs/pipeline_controlnet_xs_sd_xl.py
index 1d36038d3a..479426d749 100644
--- a/src/diffusers/pipelines/controlnet_xs/pipeline_controlnet_xs_sd_xl.py
+++ b/src/diffusers/pipelines/controlnet_xs/pipeline_controlnet_xs_sd_xl.py
@@ -463,7 +463,7 @@ class StableDiffusionXLControlNetXSPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -803,8 +803,8 @@ class StableDiffusionXLControlNetXSPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -927,7 +927,7 @@ class StableDiffusionXLControlNetXSPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/cosmos/pipeline_cosmos_text2world.py b/src/diffusers/pipelines/cosmos/pipeline_cosmos_text2world.py
index cf8b84f995..ede8be7e69 100644
--- a/src/diffusers/pipelines/cosmos/pipeline_cosmos_text2world.py
+++ b/src/diffusers/pipelines/cosmos/pipeline_cosmos_text2world.py
@@ -432,10 +432,10 @@ class CosmosTextToWorldPipeline(DiffusionPipeline):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, defaults to `6.0`):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`.
fps (`int`, defaults to `30`):
The frames per second of the generated video.
num_videos_per_prompt (`int`, *optional*, defaults to 1):
diff --git a/src/diffusers/pipelines/cosmos/pipeline_cosmos_video2world.py b/src/diffusers/pipelines/cosmos/pipeline_cosmos_video2world.py
index 2f4f91905b..309f76301f 100644
--- a/src/diffusers/pipelines/cosmos/pipeline_cosmos_video2world.py
+++ b/src/diffusers/pipelines/cosmos/pipeline_cosmos_video2world.py
@@ -547,10 +547,10 @@ class CosmosVideoToWorldPipeline(DiffusionPipeline):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, defaults to `6.0`):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`.
fps (`int`, defaults to `30`):
The frames per second of the generated video.
num_videos_per_prompt (`int`, *optional*, defaults to 1):
diff --git a/src/diffusers/pipelines/ddim/pipeline_ddim.py b/src/diffusers/pipelines/ddim/pipeline_ddim.py
index 1fd8ce4e65..d81f121eb0 100644
--- a/src/diffusers/pipelines/ddim/pipeline_ddim.py
+++ b/src/diffusers/pipelines/ddim/pipeline_ddim.py
@@ -77,9 +77,9 @@ class DDIMPipeline(DiffusionPipeline):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers. A value of `0` corresponds to
- DDIM and `1` corresponds to DDPM.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers. A value of `0`
+ corresponds to DDIM and `1` corresponds to DDPM.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
diff --git a/src/diffusers/pipelines/deepfloyd_if/pipeline_if.py b/src/diffusers/pipelines/deepfloyd_if/pipeline_if.py
index 4c39381231..8fa31f8504 100644
--- a/src/diffusers/pipelines/deepfloyd_if/pipeline_if.py
+++ b/src/diffusers/pipelines/deepfloyd_if/pipeline_if.py
@@ -336,7 +336,7 @@ class IFPipeline(DiffusionPipeline, StableDiffusionLoraLoaderMixin):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -581,11 +581,11 @@ class IFPipeline(DiffusionPipeline, StableDiffusionLoraLoaderMixin):
Custom timesteps to use for the denoising process. If not defined, equal spaced `num_inference_steps`
timesteps are used. Must be in descending order.
guidance_scale (`float`, *optional*, defaults to 7.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
@@ -597,8 +597,8 @@ class IFPipeline(DiffusionPipeline, StableDiffusionLoraLoaderMixin):
width (`int`, *optional*, defaults to self.unet.config.sample_size):
The width in pixels of the generated image.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
@@ -655,7 +655,7 @@ class IFPipeline(DiffusionPipeline, StableDiffusionLoraLoaderMixin):
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/deepfloyd_if/pipeline_if_img2img.py b/src/diffusers/pipelines/deepfloyd_if/pipeline_if_img2img.py
index 80f94aa5c7..507927faf6 100644
--- a/src/diffusers/pipelines/deepfloyd_if/pipeline_if_img2img.py
+++ b/src/diffusers/pipelines/deepfloyd_if/pipeline_if_img2img.py
@@ -361,7 +361,7 @@ class IFImg2ImgPipeline(DiffusionPipeline, StableDiffusionLoraLoaderMixin):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -706,11 +706,11 @@ class IFImg2ImgPipeline(DiffusionPipeline, StableDiffusionLoraLoaderMixin):
Custom timesteps to use for the denoising process. If not defined, equal spaced `num_inference_steps`
timesteps are used. Must be in descending order.
guidance_scale (`float`, *optional*, defaults to 10.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
@@ -718,8 +718,8 @@ class IFImg2ImgPipeline(DiffusionPipeline, StableDiffusionLoraLoaderMixin):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
@@ -775,7 +775,7 @@ class IFImg2ImgPipeline(DiffusionPipeline, StableDiffusionLoraLoaderMixin):
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/deepfloyd_if/pipeline_if_img2img_superresolution.py b/src/diffusers/pipelines/deepfloyd_if/pipeline_if_img2img_superresolution.py
index 160849cd4e..9bc15c3c6f 100644
--- a/src/diffusers/pipelines/deepfloyd_if/pipeline_if_img2img_superresolution.py
+++ b/src/diffusers/pipelines/deepfloyd_if/pipeline_if_img2img_superresolution.py
@@ -514,7 +514,7 @@ class IFImg2ImgSuperResolutionPipeline(DiffusionPipeline, StableDiffusionLoraLoa
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -793,11 +793,11 @@ class IFImg2ImgSuperResolutionPipeline(DiffusionPipeline, StableDiffusionLoraLoa
Custom timesteps to use for the denoising process. If not defined, equal spaced `num_inference_steps`
timesteps are used. Must be in descending order.
guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
@@ -805,8 +805,8 @@ class IFImg2ImgSuperResolutionPipeline(DiffusionPipeline, StableDiffusionLoraLoa
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
@@ -870,7 +870,7 @@ class IFImg2ImgSuperResolutionPipeline(DiffusionPipeline, StableDiffusionLoraLoa
# 2. Define call parameters
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/deepfloyd_if/pipeline_if_inpainting.py b/src/diffusers/pipelines/deepfloyd_if/pipeline_if_inpainting.py
index 36559c2e17..9d6cf62020 100644
--- a/src/diffusers/pipelines/deepfloyd_if/pipeline_if_inpainting.py
+++ b/src/diffusers/pipelines/deepfloyd_if/pipeline_if_inpainting.py
@@ -365,7 +365,7 @@ class IFInpaintingPipeline(DiffusionPipeline, StableDiffusionLoraLoaderMixin):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -806,11 +806,11 @@ class IFInpaintingPipeline(DiffusionPipeline, StableDiffusionLoraLoaderMixin):
Custom timesteps to use for the denoising process. If not defined, equal spaced `num_inference_steps`
timesteps are used. Must be in descending order.
guidance_scale (`float`, *optional*, defaults to 7.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
@@ -818,8 +818,8 @@ class IFInpaintingPipeline(DiffusionPipeline, StableDiffusionLoraLoaderMixin):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
@@ -882,7 +882,7 @@ class IFInpaintingPipeline(DiffusionPipeline, StableDiffusionLoraLoaderMixin):
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/deepfloyd_if/pipeline_if_inpainting_superresolution.py b/src/diffusers/pipelines/deepfloyd_if/pipeline_if_inpainting_superresolution.py
index 3c71bd96f1..0122c164d8 100644
--- a/src/diffusers/pipelines/deepfloyd_if/pipeline_if_inpainting_superresolution.py
+++ b/src/diffusers/pipelines/deepfloyd_if/pipeline_if_inpainting_superresolution.py
@@ -516,7 +516,7 @@ class IFInpaintingSuperResolutionPipeline(DiffusionPipeline, StableDiffusionLora
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -889,11 +889,11 @@ class IFInpaintingSuperResolutionPipeline(DiffusionPipeline, StableDiffusionLora
Custom timesteps to use for the denoising process. If not defined, equal spaced `num_inference_steps`
timesteps are used. Must be in descending order.
guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
@@ -901,8 +901,8 @@ class IFInpaintingSuperResolutionPipeline(DiffusionPipeline, StableDiffusionLora
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
@@ -967,7 +967,7 @@ class IFInpaintingSuperResolutionPipeline(DiffusionPipeline, StableDiffusionLora
# 2. Define call parameters
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/deepfloyd_if/pipeline_if_superresolution.py b/src/diffusers/pipelines/deepfloyd_if/pipeline_if_superresolution.py
index 849c683190..ffa60575fe 100644
--- a/src/diffusers/pipelines/deepfloyd_if/pipeline_if_superresolution.py
+++ b/src/diffusers/pipelines/deepfloyd_if/pipeline_if_superresolution.py
@@ -472,7 +472,7 @@ class IFSuperResolutionPipeline(DiffusionPipeline, StableDiffusionLoraLoaderMixi
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -656,11 +656,11 @@ class IFSuperResolutionPipeline(DiffusionPipeline, StableDiffusionLoraLoaderMixi
Custom timesteps to use for the denoising process. If not defined, equal spaced `num_inference_steps`
timesteps are used. Must be in descending order.
guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
@@ -668,8 +668,8 @@ class IFSuperResolutionPipeline(DiffusionPipeline, StableDiffusionLoraLoaderMixi
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
@@ -739,7 +739,7 @@ class IFSuperResolutionPipeline(DiffusionPipeline, StableDiffusionLoraLoaderMixi
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/deprecated/alt_diffusion/pipeline_alt_diffusion.py b/src/diffusers/pipelines/deprecated/alt_diffusion/pipeline_alt_diffusion.py
index 48c0aa4f6d..de20688937 100644
--- a/src/diffusers/pipelines/deprecated/alt_diffusion/pipeline_alt_diffusion.py
+++ b/src/diffusers/pipelines/deprecated/alt_diffusion/pipeline_alt_diffusion.py
@@ -68,7 +68,7 @@ def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
r"""
Rescales `noise_cfg` tensor based on `guidance_rescale` to improve image quality and fix overexposure. Based on
Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891).
Args:
noise_cfg (`torch.Tensor`):
@@ -557,7 +557,7 @@ class AltDiffusionPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -686,7 +686,7 @@ class AltDiffusionPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -754,8 +754,8 @@ class AltDiffusionPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -780,7 +780,7 @@ class AltDiffusionPipeline(
[`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf). Guidance rescale factor should fix overexposure when
+ Flawed](https://huggingface.co/papers/2305.08891). Guidance rescale factor should fix overexposure when
using zero terminal SNR.
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
@@ -942,7 +942,7 @@ class AltDiffusionPipeline(
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/src/diffusers/pipelines/deprecated/alt_diffusion/pipeline_alt_diffusion_img2img.py b/src/diffusers/pipelines/deprecated/alt_diffusion/pipeline_alt_diffusion_img2img.py
index fa70689d79..f690983813 100644
--- a/src/diffusers/pipelines/deprecated/alt_diffusion/pipeline_alt_diffusion_img2img.py
+++ b/src/diffusers/pipelines/deprecated/alt_diffusion/pipeline_alt_diffusion_img2img.py
@@ -585,7 +585,7 @@ class AltDiffusionImg2ImgPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -754,7 +754,7 @@ class AltDiffusionImg2ImgPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -828,8 +828,8 @@ class AltDiffusionImg2ImgPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
diff --git a/src/diffusers/pipelines/deprecated/audio_diffusion/pipeline_audio_diffusion.py b/src/diffusers/pipelines/deprecated/audio_diffusion/pipeline_audio_diffusion.py
index 47044e050a..d9302253c5 100644
--- a/src/diffusers/pipelines/deprecated/audio_diffusion/pipeline_audio_diffusion.py
+++ b/src/diffusers/pipelines/deprecated/audio_diffusion/pipeline_audio_diffusion.py
@@ -115,8 +115,8 @@ class AudioDiffusionPipeline(DiffusionPipeline):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) used to denoise.
None
eta (`float`):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
noise (`torch.Tensor`):
A noise tensor of shape `(batch_size, 1, height, width)` or `None`.
encoding (`torch.Tensor`):
diff --git a/src/diffusers/pipelines/deprecated/pndm/pipeline_pndm.py b/src/diffusers/pipelines/deprecated/pndm/pipeline_pndm.py
index ef78af1940..aa42d2bfcc 100644
--- a/src/diffusers/pipelines/deprecated/pndm/pipeline_pndm.py
+++ b/src/diffusers/pipelines/deprecated/pndm/pipeline_pndm.py
@@ -95,7 +95,7 @@ class PNDMPipeline(DiffusionPipeline):
returned where the first element is a list with the generated images.
"""
# For more information on the sampling method you can take a look at Algorithm 2 of
- # the official paper: https://arxiv.org/pdf/2202.09778.pdf
+ # the official paper: https://huggingface.co/papers/2202.09778
# Sample gaussian noise to begin loop
image = randn_tensor(
diff --git a/src/diffusers/pipelines/deprecated/repaint/pipeline_repaint.py b/src/diffusers/pipelines/deprecated/repaint/pipeline_repaint.py
index 843528a532..f6e9e5f769 100644
--- a/src/diffusers/pipelines/deprecated/repaint/pipeline_repaint.py
+++ b/src/diffusers/pipelines/deprecated/repaint/pipeline_repaint.py
@@ -124,10 +124,11 @@ class RePaintPipeline(DiffusionPipeline):
DDIM and 1.0 is the DDPM scheduler.
jump_length (`int`, *optional*, defaults to 10):
The number of steps taken forward in time before going backward in time for a single jump ("j" in
- RePaint paper). Take a look at Figure 9 and 10 in the [paper](https://arxiv.org/pdf/2201.09865.pdf).
+ RePaint paper). Take a look at Figure 9 and 10 in the
+ [paper](https://huggingface.co/papers/2201.09865).
jump_n_sample (`int`, *optional*, defaults to 10):
The number of times to make a forward time jump for a given chosen time sample. Take a look at Figure 9
- and 10 in the [paper](https://arxiv.org/pdf/2201.09865.pdf).
+ and 10 in the [paper](https://huggingface.co/papers/2201.09865).
generator (`torch.Generator`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
diff --git a/src/diffusers/pipelines/deprecated/stable_diffusion_variants/pipeline_cycle_diffusion.py b/src/diffusers/pipelines/deprecated/stable_diffusion_variants/pipeline_cycle_diffusion.py
index 1752540e8f..53e575ce0d 100644
--- a/src/diffusers/pipelines/deprecated/stable_diffusion_variants/pipeline_cycle_diffusion.py
+++ b/src/diffusers/pipelines/deprecated/stable_diffusion_variants/pipeline_cycle_diffusion.py
@@ -115,7 +115,7 @@ def compute_noise(scheduler, prev_latents, latents, timestep, noise_pred, eta):
beta_prod_t = 1 - alpha_prod_t
# 3. compute predicted original sample from predicted noise also called
- # "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # "predicted x_0" of formula (12) from https://huggingface.co/papers/2010.02502
pred_original_sample = (latents - beta_prod_t ** (0.5) * noise_pred) / alpha_prod_t ** (0.5)
# 4. Clip "predicted x_0"
@@ -127,7 +127,7 @@ def compute_noise(scheduler, prev_latents, latents, timestep, noise_pred, eta):
variance = scheduler._get_variance(timestep, prev_timestep)
std_dev_t = eta * variance ** (0.5)
- # 6. compute "direction pointing to x_t" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # 6. compute "direction pointing to x_t" of formula (12) from https://huggingface.co/papers/2010.02502
pred_sample_direction = (1 - alpha_prod_t_prev - std_dev_t**2) ** (0.5) * noise_pred
noise = (prev_latents - (alpha_prod_t_prev ** (0.5) * pred_original_sample + pred_sample_direction)) / (
@@ -522,7 +522,7 @@ class CycleDiffusionPipeline(DiffusionPipeline, TextualInversionLoaderMixin, Sta
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -678,8 +678,8 @@ class CycleDiffusionPipeline(DiffusionPipeline, TextualInversionLoaderMixin, Sta
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -790,7 +790,7 @@ class CycleDiffusionPipeline(DiffusionPipeline, TextualInversionLoaderMixin, Sta
batch_size = 1 if isinstance(prompt, str) else len(prompt)
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/deprecated/stable_diffusion_variants/pipeline_onnx_stable_diffusion_inpaint_legacy.py b/src/diffusers/pipelines/deprecated/stable_diffusion_variants/pipeline_onnx_stable_diffusion_inpaint_legacy.py
index e9553a8d99..2d9eaa493f 100644
--- a/src/diffusers/pipelines/deprecated/stable_diffusion_variants/pipeline_onnx_stable_diffusion_inpaint_legacy.py
+++ b/src/diffusers/pipelines/deprecated/stable_diffusion_variants/pipeline_onnx_stable_diffusion_inpaint_legacy.py
@@ -337,19 +337,19 @@ class OnnxStableDiffusionInpaintPipelineLegacy(DiffusionPipeline):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference. This parameter will be modulated by `strength`.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (?) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (?) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`np.random.RandomState`, *optional*):
A np.random.RandomState to make generation deterministic.
prompt_embeds (`np.ndarray`, *optional*):
@@ -404,7 +404,7 @@ class OnnxStableDiffusionInpaintPipelineLegacy(DiffusionPipeline):
image = preprocess(image)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
@@ -455,7 +455,7 @@ class OnnxStableDiffusionInpaintPipelineLegacy(DiffusionPipeline):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (?) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to ? in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to ? in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
diff --git a/src/diffusers/pipelines/deprecated/stable_diffusion_variants/pipeline_stable_diffusion_inpaint_legacy.py b/src/diffusers/pipelines/deprecated/stable_diffusion_variants/pipeline_stable_diffusion_inpaint_legacy.py
index f9c9c37c48..7dfa92aa8d 100644
--- a/src/diffusers/pipelines/deprecated/stable_diffusion_variants/pipeline_stable_diffusion_inpaint_legacy.py
+++ b/src/diffusers/pipelines/deprecated/stable_diffusion_variants/pipeline_stable_diffusion_inpaint_legacy.py
@@ -468,7 +468,7 @@ class StableDiffusionInpaintPipelineLegacy(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -605,11 +605,11 @@ class StableDiffusionInpaintPipelineLegacy(
The reference number of denoising steps. More denoising steps usually lead to a higher quality image at
the expense of slower inference. This parameter will be modulated by `strength`, as explained above.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds`. instead. Ignored when not using guidance (i.e., ignored if `guidance_scale`
@@ -620,8 +620,8 @@ class StableDiffusionInpaintPipelineLegacy(
Use predicted noise instead of random noise when constructing noisy versions of the original image in
the reverse diffusion process
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
@@ -672,7 +672,7 @@ class StableDiffusionInpaintPipelineLegacy(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/deprecated/stable_diffusion_variants/pipeline_stable_diffusion_model_editing.py b/src/diffusers/pipelines/deprecated/stable_diffusion_variants/pipeline_stable_diffusion_model_editing.py
index d0e3d208f9..953f3b0aa7 100644
--- a/src/diffusers/pipelines/deprecated/stable_diffusion_variants/pipeline_stable_diffusion_model_editing.py
+++ b/src/diffusers/pipelines/deprecated/stable_diffusion_variants/pipeline_stable_diffusion_model_editing.py
@@ -402,7 +402,7 @@ class StableDiffusionModelEditingPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -500,7 +500,8 @@ class StableDiffusionModelEditingPipeline(
restart_params: bool = True,
):
r"""
- Apply model editing via closed-form solution (see Eq. 5 in the TIME [paper](https://arxiv.org/abs/2303.08084)).
+ Apply model editing via closed-form solution (see Eq. 5 in the TIME
+ [paper](https://huggingface.co/papers/2303.08084)).
Args:
source_prompt (`str`):
@@ -654,8 +655,8 @@ class StableDiffusionModelEditingPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -732,7 +733,7 @@ class StableDiffusionModelEditingPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/deprecated/stable_diffusion_variants/pipeline_stable_diffusion_paradigms.py b/src/diffusers/pipelines/deprecated/stable_diffusion_variants/pipeline_stable_diffusion_paradigms.py
index d486a32f6a..e9b121e760 100644
--- a/src/diffusers/pipelines/deprecated/stable_diffusion_variants/pipeline_stable_diffusion_paradigms.py
+++ b/src/diffusers/pipelines/deprecated/stable_diffusion_variants/pipeline_stable_diffusion_paradigms.py
@@ -385,7 +385,7 @@ class StableDiffusionParadigmsPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -537,8 +537,8 @@ class StableDiffusionParadigmsPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -599,7 +599,7 @@ class StableDiffusionParadigmsPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/deprecated/stable_diffusion_variants/pipeline_stable_diffusion_pix2pix_zero.py b/src/diffusers/pipelines/deprecated/stable_diffusion_variants/pipeline_stable_diffusion_pix2pix_zero.py
index 509f256209..b3662579ac 100644
--- a/src/diffusers/pipelines/deprecated/stable_diffusion_variants/pipeline_stable_diffusion_pix2pix_zero.py
+++ b/src/diffusers/pipelines/deprecated/stable_diffusion_variants/pipeline_stable_diffusion_pix2pix_zero.py
@@ -616,7 +616,7 @@ class StableDiffusionPix2PixZeroPipeline(DiffusionPipeline, StableDiffusionMixin
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -848,10 +848,10 @@ class StableDiffusionPix2PixZeroPipeline(DiffusionPipeline, StableDiffusionMixin
instead.
source_embeds (`torch.Tensor`):
Source concept embeddings. Generation of the embeddings as per the [original
- paper](https://arxiv.org/abs/2302.03027). Used in discovering the edit direction.
+ paper](https://huggingface.co/papers/2302.03027). Used in discovering the edit direction.
target_embeds (`torch.Tensor`):
Target concept embeddings. Generation of the embeddings as per the [original
- paper](https://arxiv.org/abs/2302.03027). Used in discovering the edit direction.
+ paper](https://huggingface.co/papers/2302.03027). Used in discovering the edit direction.
height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
@@ -860,11 +860,11 @@ class StableDiffusionPix2PixZeroPipeline(DiffusionPipeline, StableDiffusionMixin
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
@@ -872,8 +872,8 @@ class StableDiffusionPix2PixZeroPipeline(DiffusionPipeline, StableDiffusionMixin
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
@@ -939,7 +939,7 @@ class StableDiffusionPix2PixZeroPipeline(DiffusionPipeline, StableDiffusionMixin
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
@@ -1140,11 +1140,11 @@ class StableDiffusionPix2PixZeroPipeline(DiffusionPipeline, StableDiffusionMixin
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 1):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
@@ -1199,7 +1199,7 @@ class StableDiffusionPix2PixZeroPipeline(DiffusionPipeline, StableDiffusionMixin
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/deprecated/versatile_diffusion/modeling_text_unet.py b/src/diffusers/pipelines/deprecated/versatile_diffusion/modeling_text_unet.py
index 7dd8182dfe..eda950998d 100644
--- a/src/diffusers/pipelines/deprecated/versatile_diffusion/modeling_text_unet.py
+++ b/src/diffusers/pipelines/deprecated/versatile_diffusion/modeling_text_unet.py
@@ -964,7 +964,7 @@ class UNetFlatConditionModel(ModelMixin, ConfigMixin):
fn_recursive_set_attention_slice(module, reversed_slice_size)
def enable_freeu(self, s1, s2, b1, b2):
- r"""Enables the FreeU mechanism from https://arxiv.org/abs/2309.11497.
+ r"""Enables the FreeU mechanism from https://huggingface.co/papers/2309.11497.
The suffixes after the scaling factors represent the stage blocks where they are being applied.
diff --git a/src/diffusers/pipelines/deprecated/versatile_diffusion/pipeline_versatile_diffusion.py b/src/diffusers/pipelines/deprecated/versatile_diffusion/pipeline_versatile_diffusion.py
index 4fb437958a..61582853b0 100644
--- a/src/diffusers/pipelines/deprecated/versatile_diffusion/pipeline_versatile_diffusion.py
+++ b/src/diffusers/pipelines/deprecated/versatile_diffusion/pipeline_versatile_diffusion.py
@@ -118,8 +118,8 @@ class VersatileDiffusionPipeline(DiffusionPipeline):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -230,8 +230,8 @@ class VersatileDiffusionPipeline(DiffusionPipeline):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -339,8 +339,8 @@ class VersatileDiffusionPipeline(DiffusionPipeline):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
diff --git a/src/diffusers/pipelines/deprecated/versatile_diffusion/pipeline_versatile_diffusion_dual_guided.py b/src/diffusers/pipelines/deprecated/versatile_diffusion/pipeline_versatile_diffusion_dual_guided.py
index 0065279bc0..478fe7b661 100644
--- a/src/diffusers/pipelines/deprecated/versatile_diffusion/pipeline_versatile_diffusion_dual_guided.py
+++ b/src/diffusers/pipelines/deprecated/versatile_diffusion/pipeline_versatile_diffusion_dual_guided.py
@@ -315,7 +315,7 @@ class VersatileDiffusionDualGuidedPipeline(DiffusionPipeline):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -424,8 +424,8 @@ class VersatileDiffusionDualGuidedPipeline(DiffusionPipeline):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -493,7 +493,7 @@ class VersatileDiffusionDualGuidedPipeline(DiffusionPipeline):
batch_size = len(prompt)
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/deprecated/versatile_diffusion/pipeline_versatile_diffusion_image_variation.py b/src/diffusers/pipelines/deprecated/versatile_diffusion/pipeline_versatile_diffusion_image_variation.py
index 7dfc7e9618..9828f1b60d 100644
--- a/src/diffusers/pipelines/deprecated/versatile_diffusion/pipeline_versatile_diffusion_image_variation.py
+++ b/src/diffusers/pipelines/deprecated/versatile_diffusion/pipeline_versatile_diffusion_image_variation.py
@@ -175,7 +175,7 @@ class VersatileDiffusionImageVariationPipeline(DiffusionPipeline):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -276,8 +276,8 @@ class VersatileDiffusionImageVariationPipeline(DiffusionPipeline):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -338,7 +338,7 @@ class VersatileDiffusionImageVariationPipeline(DiffusionPipeline):
batch_size = 1 if isinstance(image, PIL.Image.Image) else len(image)
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/deprecated/versatile_diffusion/pipeline_versatile_diffusion_text_to_image.py b/src/diffusers/pipelines/deprecated/versatile_diffusion/pipeline_versatile_diffusion_text_to_image.py
index 1d6771793f..928675ee2c 100644
--- a/src/diffusers/pipelines/deprecated/versatile_diffusion/pipeline_versatile_diffusion_text_to_image.py
+++ b/src/diffusers/pipelines/deprecated/versatile_diffusion/pipeline_versatile_diffusion_text_to_image.py
@@ -232,7 +232,7 @@ class VersatileDiffusionTextToImagePipeline(DiffusionPipeline):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -362,8 +362,8 @@ class VersatileDiffusionTextToImagePipeline(DiffusionPipeline):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -416,7 +416,7 @@ class VersatileDiffusionTextToImagePipeline(DiffusionPipeline):
batch_size = 1 if isinstance(prompt, str) else len(prompt)
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/easyanimate/pipeline_easyanimate.py b/src/diffusers/pipelines/easyanimate/pipeline_easyanimate.py
index 25975b04f3..92239c0d32 100755
--- a/src/diffusers/pipelines/easyanimate/pipeline_easyanimate.py
+++ b/src/diffusers/pipelines/easyanimate/pipeline_easyanimate.py
@@ -101,7 +101,7 @@ def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
r"""
Rescales `noise_cfg` tensor based on `guidance_rescale` to improve image quality and fix overexposure. Based on
Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891).
Args:
noise_cfg (`torch.Tensor`):
@@ -404,7 +404,7 @@ class EasyAnimatePipeline(DiffusionPipeline):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -507,7 +507,7 @@ class EasyAnimatePipeline(DiffusionPipeline):
return self._guidance_rescale
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -732,7 +732,7 @@ class EasyAnimatePipeline(DiffusionPipeline):
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/src/diffusers/pipelines/easyanimate/pipeline_easyanimate_control.py b/src/diffusers/pipelines/easyanimate/pipeline_easyanimate_control.py
index 1d2c508675..f74a11f87d 100755
--- a/src/diffusers/pipelines/easyanimate/pipeline_easyanimate_control.py
+++ b/src/diffusers/pipelines/easyanimate/pipeline_easyanimate_control.py
@@ -177,7 +177,7 @@ def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
r"""
Rescales `noise_cfg` tensor based on `guidance_rescale` to improve image quality and fix overexposure. Based on
Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891).
Args:
noise_cfg (`torch.Tensor`):
@@ -515,7 +515,7 @@ class EasyAnimateControlPipeline(DiffusionPipeline):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -653,7 +653,7 @@ class EasyAnimateControlPipeline(DiffusionPipeline):
return self._guidance_rescale
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -956,7 +956,7 @@ class EasyAnimateControlPipeline(DiffusionPipeline):
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/src/diffusers/pipelines/easyanimate/pipeline_easyanimate_inpaint.py b/src/diffusers/pipelines/easyanimate/pipeline_easyanimate_inpaint.py
index aaec454cc7..b16ef92d8e 100755
--- a/src/diffusers/pipelines/easyanimate/pipeline_easyanimate_inpaint.py
+++ b/src/diffusers/pipelines/easyanimate/pipeline_easyanimate_inpaint.py
@@ -199,7 +199,7 @@ def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
r"""
Rescales `noise_cfg` tensor based on `guidance_rescale` to improve image quality and fix overexposure. Based on
Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891).
Args:
noise_cfg (`torch.Tensor`):
@@ -557,7 +557,7 @@ class EasyAnimateInpaintPipeline(DiffusionPipeline):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -771,7 +771,7 @@ class EasyAnimateInpaintPipeline(DiffusionPipeline):
return self._guidance_rescale
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -849,7 +849,7 @@ class EasyAnimateInpaintPipeline(DiffusionPipeline):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- A parameter defined in the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies to the
+ A parameter defined in the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only applies to the
[`~schedulers.DDIMScheduler`] and is ignored in other schedulers. It adjusts noise level during the
inference process.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
@@ -883,7 +883,8 @@ class EasyAnimateInpaintPipeline(DiffusionPipeline):
inputs will be passed, facilitating enhanced logging or monitoring of the generation process.
guidance_rescale (`float`, *optional*, defaults to 0.0):
Rescale parameter for adjusting noise configuration based on guidance rescale. Based on findings from
- [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ [Common Diffusion Noise Schedules and Sample Steps are
+ Flawed](https://huggingface.co/papers/2305.08891).
strength (`float`, *optional*, defaults to 1.0):
Affects the overall styling or quality of the generated output. Values closer to 1 usually provide
direct adherence to prompts.
@@ -1180,7 +1181,7 @@ class EasyAnimateInpaintPipeline(DiffusionPipeline):
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/src/diffusers/pipelines/flux/pipeline_flux.py b/src/diffusers/pipelines/flux/pipeline_flux.py
index a7266c3a56..6dbcd5c6db 100644
--- a/src/diffusers/pipelines/flux/pipeline_flux.py
+++ b/src/diffusers/pipelines/flux/pipeline_flux.py
@@ -687,11 +687,11 @@ class FluxPipeline(
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, *optional*, defaults to 3.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
@@ -700,7 +700,7 @@ class FluxPipeline(
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
- tensor will ge generated by sampling using the supplied random `generator`.
+ tensor will be generated by sampling using the supplied random `generator`.
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
diff --git a/src/diffusers/pipelines/flux/pipeline_flux_control.py b/src/diffusers/pipelines/flux/pipeline_flux_control.py
index 113b0dd729..83181a68d5 100644
--- a/src/diffusers/pipelines/flux/pipeline_flux_control.py
+++ b/src/diffusers/pipelines/flux/pipeline_flux_control.py
@@ -661,11 +661,11 @@ class FluxControlPipeline(
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, *optional*, defaults to 3.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
diff --git a/src/diffusers/pipelines/flux/pipeline_flux_control_img2img.py b/src/diffusers/pipelines/flux/pipeline_flux_control_img2img.py
index c269be15a4..cb4d139f5d 100644
--- a/src/diffusers/pipelines/flux/pipeline_flux_control_img2img.py
+++ b/src/diffusers/pipelines/flux/pipeline_flux_control_img2img.py
@@ -699,11 +699,11 @@ class FluxControlImg2ImgPipeline(DiffusionPipeline, FluxLoraLoaderMixin, FromSin
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, *optional*, defaults to 7.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
diff --git a/src/diffusers/pipelines/flux/pipeline_flux_control_inpaint.py b/src/diffusers/pipelines/flux/pipeline_flux_control_inpaint.py
index af7e8b53fa..c326baab1c 100644
--- a/src/diffusers/pipelines/flux/pipeline_flux_control_inpaint.py
+++ b/src/diffusers/pipelines/flux/pipeline_flux_control_inpaint.py
@@ -857,11 +857,11 @@ class FluxControlInpaintPipeline(
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, *optional*, defaults to 7.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
diff --git a/src/diffusers/pipelines/flux/pipeline_flux_controlnet.py b/src/diffusers/pipelines/flux/pipeline_flux_controlnet.py
index f3f1d90204..2132f79bc1 100644
--- a/src/diffusers/pipelines/flux/pipeline_flux_controlnet.py
+++ b/src/diffusers/pipelines/flux/pipeline_flux_controlnet.py
@@ -733,11 +733,11 @@ class FluxControlNetPipeline(DiffusionPipeline, FluxLoraLoaderMixin, FromSingleF
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, *optional*, defaults to 7.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
control_guidance_start (`float` or `List[float]`, *optional*, defaults to 0.0):
The percentage of total steps at which the ControlNet starts applying.
control_guidance_end (`float` or `List[float]`, *optional*, defaults to 1.0):
diff --git a/src/diffusers/pipelines/flux/pipeline_flux_controlnet_image_to_image.py b/src/diffusers/pipelines/flux/pipeline_flux_controlnet_image_to_image.py
index cd9508c00d..52e15de53b 100644
--- a/src/diffusers/pipelines/flux/pipeline_flux_controlnet_image_to_image.py
+++ b/src/diffusers/pipelines/flux/pipeline_flux_controlnet_image_to_image.py
@@ -687,7 +687,8 @@ class FluxControlNetImg2ImgPipeline(DiffusionPipeline, FluxLoraLoaderMixin, From
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, *optional*, defaults to 7.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598).
control_mode (`int` or `List[int]`, *optional*):
The mode for the ControlNet. If multiple ControlNets are used, this should be a list.
controlnet_conditioning_scale (`float` or `List[float]`, *optional*, defaults to 1.0):
diff --git a/src/diffusers/pipelines/flux/pipeline_flux_controlnet_inpainting.py b/src/diffusers/pipelines/flux/pipeline_flux_controlnet_inpainting.py
index 64cc8e13f3..d1e874d0b8 100644
--- a/src/diffusers/pipelines/flux/pipeline_flux_controlnet_inpainting.py
+++ b/src/diffusers/pipelines/flux/pipeline_flux_controlnet_inpainting.py
@@ -801,7 +801,8 @@ class FluxControlNetInpaintPipeline(DiffusionPipeline, FluxLoraLoaderMixin, From
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, *optional*, defaults to 7.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598).
control_guidance_start (`float` or `List[float]`, *optional*, defaults to 0.0):
The percentage of total steps at which the ControlNet starts applying.
control_guidance_end (`float` or `List[float]`, *optional*, defaults to 1.0):
diff --git a/src/diffusers/pipelines/flux/pipeline_flux_fill.py b/src/diffusers/pipelines/flux/pipeline_flux_fill.py
index 546a225aa9..3c3e92c7d2 100644
--- a/src/diffusers/pipelines/flux/pipeline_flux_fill.py
+++ b/src/diffusers/pipelines/flux/pipeline_flux_fill.py
@@ -794,11 +794,11 @@ class FluxFillPipeline(
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, *optional*, defaults to 30.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
diff --git a/src/diffusers/pipelines/flux/pipeline_flux_img2img.py b/src/diffusers/pipelines/flux/pipeline_flux_img2img.py
index 64cd6ac45f..400574d55d 100644
--- a/src/diffusers/pipelines/flux/pipeline_flux_img2img.py
+++ b/src/diffusers/pipelines/flux/pipeline_flux_img2img.py
@@ -607,6 +607,39 @@ class FluxImg2ImgPipeline(DiffusionPipeline, FluxLoraLoaderMixin, FromSingleFile
return latents
+ # Copied from diffusers.pipelines.flux.pipeline_flux.FluxPipeline.enable_vae_slicing
+ def enable_vae_slicing(self):
+ r"""
+ Enable sliced VAE decoding. When this option is enabled, the VAE will split the input tensor in slices to
+ compute decoding in several steps. This is useful to save some memory and allow larger batch sizes.
+ """
+ self.vae.enable_slicing()
+
+ # Copied from diffusers.pipelines.flux.pipeline_flux.FluxPipeline.disable_vae_slicing
+ def disable_vae_slicing(self):
+ r"""
+ Disable sliced VAE decoding. If `enable_vae_slicing` was previously enabled, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_slicing()
+
+ # Copied from diffusers.pipelines.flux.pipeline_flux.FluxPipeline.enable_vae_tiling
+ def enable_vae_tiling(self):
+ r"""
+ Enable tiled VAE decoding. When this option is enabled, the VAE will split the input tensor into tiles to
+ compute decoding and encoding in several steps. This is useful for saving a large amount of memory and to allow
+ processing larger images.
+ """
+ self.vae.enable_tiling()
+
+ # Copied from diffusers.pipelines.flux.pipeline_flux.FluxPipeline.disable_vae_tiling
+ def disable_vae_tiling(self):
+ r"""
+ Disable tiled VAE decoding. If `enable_vae_tiling` was previously enabled, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_tiling()
+
def prepare_latents(
self,
image,
@@ -741,11 +774,11 @@ class FluxImg2ImgPipeline(DiffusionPipeline, FluxLoraLoaderMixin, FromSingleFile
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, *optional*, defaults to 7.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
diff --git a/src/diffusers/pipelines/flux/pipeline_flux_inpaint.py b/src/diffusers/pipelines/flux/pipeline_flux_inpaint.py
index ecd5a8967b..a67eb5d0d6 100644
--- a/src/diffusers/pipelines/flux/pipeline_flux_inpaint.py
+++ b/src/diffusers/pipelines/flux/pipeline_flux_inpaint.py
@@ -860,11 +860,11 @@ class FluxInpaintPipeline(DiffusionPipeline, FluxLoraLoaderMixin, FluxIPAdapterM
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, *optional*, defaults to 7.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
diff --git a/src/diffusers/pipelines/free_init_utils.py b/src/diffusers/pipelines/free_init_utils.py
index 1fb67592ca..bfa7fed2a7 100644
--- a/src/diffusers/pipelines/free_init_utils.py
+++ b/src/diffusers/pipelines/free_init_utils.py
@@ -33,7 +33,7 @@ class FreeInitMixin:
spatial_stop_frequency: float = 0.25,
temporal_stop_frequency: float = 0.25,
):
- """Enables the FreeInit mechanism as in https://arxiv.org/abs/2312.07537.
+ """Enables the FreeInit mechanism as in https://huggingface.co/papers/2312.07537.
This implementation has been adapted from the [official repository](https://github.com/TianxingWu/FreeInit).
diff --git a/src/diffusers/pipelines/free_noise_utils.py b/src/diffusers/pipelines/free_noise_utils.py
index 4a65008183..3151266f97 100644
--- a/src/diffusers/pipelines/free_noise_utils.py
+++ b/src/diffusers/pipelines/free_noise_utils.py
@@ -143,7 +143,7 @@ class SplitInferenceModule(nn.Module):
class AnimateDiffFreeNoiseMixin:
- r"""Mixin class for [FreeNoise](https://arxiv.org/abs/2310.15169)."""
+ r"""Mixin class for [FreeNoise](https://huggingface.co/papers/2310.15169)."""
def _enable_free_noise_in_block(self, block: Union[CrossAttnDownBlockMotion, DownBlockMotion, UpBlockMotion]):
r"""Helper function to enable FreeNoise in transformer blocks."""
diff --git a/src/diffusers/pipelines/hidream_image/pipeline_hidream_image.py b/src/diffusers/pipelines/hidream_image/pipeline_hidream_image.py
index 6fe74cbd9a..20f54bda1a 100644
--- a/src/diffusers/pipelines/hidream_image/pipeline_hidream_image.py
+++ b/src/diffusers/pipelines/hidream_image/pipeline_hidream_image.py
@@ -36,11 +36,11 @@ EXAMPLE_DOC_STRING = """
Examples:
```py
>>> import torch
- >>> from transformers import PreTrainedTokenizerFast, LlamaForCausalLM
- >>> from diffusers import UniPCMultistepScheduler, HiDreamImagePipeline
+ >>> from transformers import AutoTokenizer, LlamaForCausalLM
+ >>> from diffusers import HiDreamImagePipeline
- >>> tokenizer_4 = PreTrainedTokenizerFast.from_pretrained("meta-llama/Meta-Llama-3.1-8B-Instruct")
+ >>> tokenizer_4 = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3.1-8B-Instruct")
>>> text_encoder_4 = LlamaForCausalLM.from_pretrained(
... "meta-llama/Meta-Llama-3.1-8B-Instruct",
... output_hidden_states=True,
@@ -749,11 +749,11 @@ class HiDreamImagePipeline(DiffusionPipeline, HiDreamImageLoraLoaderMixin):
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, *optional*, defaults to 3.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `true_cfg_scale` is
diff --git a/src/diffusers/pipelines/hunyuan_video/pipeline_hunyuan_skyreels_image2video.py b/src/diffusers/pipelines/hunyuan_video/pipeline_hunyuan_skyreels_image2video.py
index 297d2a9c93..36fe450fb9 100644
--- a/src/diffusers/pipelines/hunyuan_video/pipeline_hunyuan_skyreels_image2video.py
+++ b/src/diffusers/pipelines/hunyuan_video/pipeline_hunyuan_skyreels_image2video.py
@@ -575,13 +575,13 @@ class HunyuanSkyreelsImageToVideoPipeline(DiffusionPipeline, HunyuanVideoLoraLoa
true_cfg_scale (`float`, *optional*, defaults to 1.0):
When > 1.0 and a provided `negative_prompt`, enables true classifier-free guidance.
guidance_scale (`float`, defaults to `6.0`):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality. Note that the only available HunyuanVideo model is
- CFG-distilled, which means that traditional guidance between unconditional and conditional latent is
- not applied.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality. Note that the only available
+ HunyuanVideo model is CFG-distilled, which means that traditional guidance between unconditional and
+ conditional latent is not applied.
num_videos_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
diff --git a/src/diffusers/pipelines/hunyuan_video/pipeline_hunyuan_video.py b/src/diffusers/pipelines/hunyuan_video/pipeline_hunyuan_video.py
index 3cb91b3782..9c6ba3bce3 100644
--- a/src/diffusers/pipelines/hunyuan_video/pipeline_hunyuan_video.py
+++ b/src/diffusers/pipelines/hunyuan_video/pipeline_hunyuan_video.py
@@ -531,13 +531,13 @@ class HunyuanVideoPipeline(DiffusionPipeline, HunyuanVideoLoraLoaderMixin):
true_cfg_scale (`float`, *optional*, defaults to 1.0):
When > 1.0 and a provided `negative_prompt`, enables true classifier-free guidance.
guidance_scale (`float`, defaults to `6.0`):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality. Note that the only available HunyuanVideo model is
- CFG-distilled, which means that traditional guidance between unconditional and conditional latent is
- not applied.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality. Note that the only available
+ HunyuanVideo model is CFG-distilled, which means that traditional guidance between unconditional and
+ conditional latent is not applied.
num_videos_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
diff --git a/src/diffusers/pipelines/hunyuan_video/pipeline_hunyuan_video_framepack.py b/src/diffusers/pipelines/hunyuan_video/pipeline_hunyuan_video_framepack.py
index 43db740c6d..40d6534655 100644
--- a/src/diffusers/pipelines/hunyuan_video/pipeline_hunyuan_video_framepack.py
+++ b/src/diffusers/pipelines/hunyuan_video/pipeline_hunyuan_video_framepack.py
@@ -14,6 +14,7 @@
import inspect
import math
+from enum import Enum
from typing import Any, Callable, Dict, List, Optional, Tuple, Union
import numpy as np
@@ -91,6 +92,7 @@ EXAMPLE_DOC_STRING = """
... num_inference_steps=30,
... guidance_scale=9.0,
... generator=torch.Generator().manual_seed(0),
+ ... sampling_type="inverted_anti_drifting",
... ).frames[0]
>>> export_to_video(output, "output.mp4", fps=30)
```
@@ -138,6 +140,7 @@ EXAMPLE_DOC_STRING = """
... num_inference_steps=30,
... guidance_scale=9.0,
... generator=torch.Generator().manual_seed(0),
+ ... sampling_type="inverted_anti_drifting",
... ).frames[0]
>>> export_to_video(output, "output.mp4", fps=30)
```
@@ -232,6 +235,11 @@ def retrieve_timesteps(
return timesteps, num_inference_steps
+class FramepackSamplingType(str, Enum):
+ VANILLA = "vanilla"
+ INVERTED_ANTI_DRIFTING = "inverted_anti_drifting"
+
+
class HunyuanVideoFramepackPipeline(DiffusionPipeline, HunyuanVideoLoraLoaderMixin):
r"""
Pipeline for text-to-video generation using HunyuanVideo.
@@ -455,6 +463,11 @@ class HunyuanVideoFramepackPipeline(DiffusionPipeline, HunyuanVideoLoraLoaderMix
prompt_embeds=None,
callback_on_step_end_tensor_inputs=None,
prompt_template=None,
+ image=None,
+ image_latents=None,
+ last_image=None,
+ last_image_latents=None,
+ sampling_type=None,
):
if height % 16 != 0 or width % 16 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 16 but are {height} and {width}.")
@@ -493,6 +506,21 @@ class HunyuanVideoFramepackPipeline(DiffusionPipeline, HunyuanVideoLoraLoaderMix
f"`prompt_template` has to contain a key `template` but only found {prompt_template.keys()}"
)
+ sampling_types = [x.value for x in FramepackSamplingType.__members__.values()]
+ if sampling_type not in sampling_types:
+ raise ValueError(f"`sampling_type` has to be one of '{sampling_types}' but is '{sampling_type}'")
+
+ if image is not None and image_latents is not None:
+ raise ValueError("Only one of `image` or `image_latents` can be passed.")
+ if last_image is not None and last_image_latents is not None:
+ raise ValueError("Only one of `last_image` or `last_image_latents` can be passed.")
+ if sampling_type != FramepackSamplingType.INVERTED_ANTI_DRIFTING and (
+ last_image is not None or last_image_latents is not None
+ ):
+ raise ValueError(
+ 'Only `"inverted_anti_drifting"` inference type supports `last_image` or `last_image_latents`.'
+ )
+
def prepare_latents(
self,
batch_size: int = 1,
@@ -623,6 +651,7 @@ class HunyuanVideoFramepackPipeline(DiffusionPipeline, HunyuanVideoLoraLoaderMix
callback_on_step_end_tensor_inputs: List[str] = ["latents"],
prompt_template: Dict[str, Any] = DEFAULT_PROMPT_TEMPLATE,
max_sequence_length: int = 256,
+ sampling_type: FramepackSamplingType = FramepackSamplingType.INVERTED_ANTI_DRIFTING,
):
r"""
The call function to the pipeline for generation.
@@ -662,13 +691,13 @@ class HunyuanVideoFramepackPipeline(DiffusionPipeline, HunyuanVideoLoraLoaderMix
true_cfg_scale (`float`, *optional*, defaults to 1.0):
When > 1.0 and a provided `negative_prompt`, enables true classifier-free guidance.
guidance_scale (`float`, defaults to `6.0`):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality. Note that the only available HunyuanVideo model is
- CFG-distilled, which means that traditional guidance between unconditional and conditional latent is
- not applied.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality. Note that the only available
+ HunyuanVideo model is CFG-distilled, which means that traditional guidance between unconditional and
+ conditional latent is not applied.
num_videos_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
@@ -735,6 +764,11 @@ class HunyuanVideoFramepackPipeline(DiffusionPipeline, HunyuanVideoLoraLoaderMix
prompt_embeds,
callback_on_step_end_tensor_inputs,
prompt_template,
+ image,
+ image_latents,
+ last_image,
+ last_image_latents,
+ sampling_type,
)
has_neg_prompt = negative_prompt is not None or (
@@ -806,18 +840,6 @@ class HunyuanVideoFramepackPipeline(DiffusionPipeline, HunyuanVideoLoraLoaderMix
num_channels_latents = self.transformer.config.in_channels
window_num_frames = (latent_window_size - 1) * self.vae_scale_factor_temporal + 1
num_latent_sections = max(1, (num_frames + window_num_frames - 1) // window_num_frames)
- # Specific to the released checkpoint: https://huggingface.co/lllyasviel/FramePackI2V_HY
- # TODO: find a more generic way in future if there are more checkpoints
- history_sizes = [1, 2, 16]
- history_latents = torch.zeros(
- batch_size,
- num_channels_latents,
- sum(history_sizes),
- height // self.vae_scale_factor_spatial,
- width // self.vae_scale_factor_spatial,
- device=device,
- dtype=torch.float32,
- )
history_video = None
total_generated_latent_frames = 0
@@ -829,38 +851,92 @@ class HunyuanVideoFramepackPipeline(DiffusionPipeline, HunyuanVideoLoraLoaderMix
last_image, dtype=torch.float32, device=device, generator=generator
)
- latent_paddings = list(reversed(range(num_latent_sections)))
- if num_latent_sections > 4:
- latent_paddings = [3] + [2] * (num_latent_sections - 3) + [1, 0]
+ # Specific to the released checkpoints:
+ # - https://huggingface.co/lllyasviel/FramePackI2V_HY
+ # - https://huggingface.co/lllyasviel/FramePack_F1_I2V_HY_20250503
+ # TODO: find a more generic way in future if there are more checkpoints
+ if sampling_type == FramepackSamplingType.INVERTED_ANTI_DRIFTING:
+ history_sizes = [1, 2, 16]
+ history_latents = torch.zeros(
+ batch_size,
+ num_channels_latents,
+ sum(history_sizes),
+ height // self.vae_scale_factor_spatial,
+ width // self.vae_scale_factor_spatial,
+ device=device,
+ dtype=torch.float32,
+ )
+
+ elif sampling_type == FramepackSamplingType.VANILLA:
+ history_sizes = [16, 2, 1]
+ history_latents = torch.zeros(
+ batch_size,
+ num_channels_latents,
+ sum(history_sizes),
+ height // self.vae_scale_factor_spatial,
+ width // self.vae_scale_factor_spatial,
+ device=device,
+ dtype=torch.float32,
+ )
+ history_latents = torch.cat([history_latents, image_latents], dim=2)
+ total_generated_latent_frames += 1
+
+ else:
+ assert False
# 6. Prepare guidance condition
guidance = torch.tensor([guidance_scale] * batch_size, dtype=transformer_dtype, device=device) * 1000.0
# 7. Denoising loop
for k in range(num_latent_sections):
- is_first_section = k == 0
- is_last_section = k == num_latent_sections - 1
- latent_padding_size = latent_paddings[k] * latent_window_size
+ if sampling_type == FramepackSamplingType.INVERTED_ANTI_DRIFTING:
+ latent_paddings = list(reversed(range(num_latent_sections)))
+ if num_latent_sections > 4:
+ latent_paddings = [3] + [2] * (num_latent_sections - 3) + [1, 0]
- indices = torch.arange(0, sum([1, latent_padding_size, latent_window_size, *history_sizes]))
- (
- indices_prefix,
- indices_padding,
- indices_latents,
- indices_postfix,
- indices_latents_history_2x,
- indices_latents_history_4x,
- ) = indices.split([1, latent_padding_size, latent_window_size, *history_sizes], dim=0)
- # Inverted anti-drifting sampling: Figure 2(c) in the paper
- indices_clean_latents = torch.cat([indices_prefix, indices_postfix], dim=0)
+ is_first_section = k == 0
+ is_last_section = k == num_latent_sections - 1
+ latent_padding_size = latent_paddings[k] * latent_window_size
- latents_prefix = image_latents
- latents_postfix, latents_history_2x, latents_history_4x = history_latents[
- :, :, : sum(history_sizes)
- ].split(history_sizes, dim=2)
- if last_image is not None and is_first_section:
- latents_postfix = last_image_latents
- latents_clean = torch.cat([latents_prefix, latents_postfix], dim=2)
+ indices = torch.arange(0, sum([1, latent_padding_size, latent_window_size, *history_sizes]))
+ (
+ indices_prefix,
+ indices_padding,
+ indices_latents,
+ indices_latents_history_1x,
+ indices_latents_history_2x,
+ indices_latents_history_4x,
+ ) = indices.split([1, latent_padding_size, latent_window_size, *history_sizes], dim=0)
+ # Inverted anti-drifting sampling: Figure 2(c) in the paper
+ indices_clean_latents = torch.cat([indices_prefix, indices_latents_history_1x], dim=0)
+
+ latents_prefix = image_latents
+ latents_history_1x, latents_history_2x, latents_history_4x = history_latents[
+ :, :, : sum(history_sizes)
+ ].split(history_sizes, dim=2)
+ if last_image is not None and is_first_section:
+ latents_history_1x = last_image_latents
+ latents_clean = torch.cat([latents_prefix, latents_history_1x], dim=2)
+
+ elif sampling_type == FramepackSamplingType.VANILLA:
+ indices = torch.arange(0, sum([1, *history_sizes, latent_window_size]))
+ (
+ indices_prefix,
+ indices_latents_history_4x,
+ indices_latents_history_2x,
+ indices_latents_history_1x,
+ indices_latents,
+ ) = indices.split([1, *history_sizes, latent_window_size], dim=0)
+ indices_clean_latents = torch.cat([indices_prefix, indices_latents_history_1x], dim=0)
+
+ latents_prefix = image_latents
+ latents_history_4x, latents_history_2x, latents_history_1x = history_latents[
+ :, :, -sum(history_sizes) :
+ ].split(history_sizes, dim=2)
+ latents_clean = torch.cat([latents_prefix, latents_history_1x], dim=2)
+
+ else:
+ assert False
latents = self.prepare_latents(
batch_size,
@@ -960,13 +1036,26 @@ class HunyuanVideoFramepackPipeline(DiffusionPipeline, HunyuanVideoLoraLoaderMix
if XLA_AVAILABLE:
xm.mark_step()
- if is_last_section:
- latents = torch.cat([image_latents, latents], dim=2)
+ if sampling_type == FramepackSamplingType.INVERTED_ANTI_DRIFTING:
+ if is_last_section:
+ latents = torch.cat([image_latents, latents], dim=2)
+ total_generated_latent_frames += latents.shape[2]
+ history_latents = torch.cat([latents, history_latents], dim=2)
+ real_history_latents = history_latents[:, :, :total_generated_latent_frames]
+ section_latent_frames = (
+ (latent_window_size * 2 + 1) if is_last_section else (latent_window_size * 2)
+ )
+ index_slice = (slice(None), slice(None), slice(0, section_latent_frames))
- total_generated_latent_frames += latents.shape[2]
- history_latents = torch.cat([latents, history_latents], dim=2)
+ elif sampling_type == FramepackSamplingType.VANILLA:
+ total_generated_latent_frames += latents.shape[2]
+ history_latents = torch.cat([history_latents, latents], dim=2)
+ real_history_latents = history_latents[:, :, -total_generated_latent_frames:]
+ section_latent_frames = latent_window_size * 2
+ index_slice = (slice(None), slice(None), slice(-section_latent_frames, None))
- real_history_latents = history_latents[:, :, :total_generated_latent_frames]
+ else:
+ assert False
if history_video is None:
if not output_type == "latent":
@@ -976,16 +1065,18 @@ class HunyuanVideoFramepackPipeline(DiffusionPipeline, HunyuanVideoLoraLoaderMix
history_video = [real_history_latents]
else:
if not output_type == "latent":
- section_latent_frames = (
- (latent_window_size * 2 + 1) if is_last_section else (latent_window_size * 2)
- )
overlapped_frames = (latent_window_size - 1) * self.vae_scale_factor_temporal + 1
current_latents = (
- real_history_latents[:, :, :section_latent_frames].to(vae_dtype)
- / self.vae.config.scaling_factor
+ real_history_latents[index_slice].to(vae_dtype) / self.vae.config.scaling_factor
)
current_video = self.vae.decode(current_latents, return_dict=False)[0]
- history_video = self._soft_append(current_video, history_video, overlapped_frames)
+
+ if sampling_type == FramepackSamplingType.INVERTED_ANTI_DRIFTING:
+ history_video = self._soft_append(current_video, history_video, overlapped_frames)
+ elif sampling_type == FramepackSamplingType.VANILLA:
+ history_video = self._soft_append(history_video, current_video, overlapped_frames)
+ else:
+ assert False
else:
history_video.append(real_history_latents)
diff --git a/src/diffusers/pipelines/hunyuan_video/pipeline_hunyuan_video_image2video.py b/src/diffusers/pipelines/hunyuan_video/pipeline_hunyuan_video_image2video.py
index 18a0e970c6..4171760803 100644
--- a/src/diffusers/pipelines/hunyuan_video/pipeline_hunyuan_video_image2video.py
+++ b/src/diffusers/pipelines/hunyuan_video/pipeline_hunyuan_video_image2video.py
@@ -711,13 +711,13 @@ class HunyuanVideoImageToVideoPipeline(DiffusionPipeline, HunyuanVideoLoraLoader
true_cfg_scale (`float`, *optional*, defaults to 1.0):
When > 1.0 and a provided `negative_prompt`, enables true classifier-free guidance.
guidance_scale (`float`, defaults to `1.0`):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality. Note that the only available HunyuanVideo model is
- CFG-distilled, which means that traditional guidance between unconditional and conditional latent is
- not applied.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality. Note that the only available
+ HunyuanVideo model is CFG-distilled, which means that traditional guidance between unconditional and
+ conditional latent is not applied.
num_videos_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
diff --git a/src/diffusers/pipelines/hunyuandit/pipeline_hunyuandit.py b/src/diffusers/pipelines/hunyuandit/pipeline_hunyuandit.py
index febf2b0392..4626bd507c 100644
--- a/src/diffusers/pipelines/hunyuandit/pipeline_hunyuandit.py
+++ b/src/diffusers/pipelines/hunyuandit/pipeline_hunyuandit.py
@@ -128,7 +128,7 @@ def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
r"""
Rescales `noise_cfg` tensor based on `guidance_rescale` to improve image quality and fix overexposure. Based on
Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891).
Args:
noise_cfg (`torch.Tensor`):
@@ -433,7 +433,7 @@ class HunyuanDiTPipeline(DiffusionPipeline):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -555,7 +555,7 @@ class HunyuanDiTPipeline(DiffusionPipeline):
return self._guidance_rescale
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -625,8 +625,8 @@ class HunyuanDiTPipeline(DiffusionPipeline):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -662,7 +662,7 @@ class HunyuanDiTPipeline(DiffusionPipeline):
inputs will be passed.
guidance_rescale (`float`, *optional*, defaults to 0.0):
Rescale the noise_cfg according to `guidance_rescale`. Based on findings of [Common Diffusion Noise
- Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Schedules and Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
original_size (`Tuple[int, int]`, *optional*, defaults to `(1024, 1024)`):
The original size of the image. Used to calculate the time ids.
target_size (`Tuple[int, int]`, *optional*):
@@ -865,7 +865,7 @@ class HunyuanDiTPipeline(DiffusionPipeline):
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/src/diffusers/pipelines/i2vgen_xl/pipeline_i2vgen_xl.py b/src/diffusers/pipelines/i2vgen_xl/pipeline_i2vgen_xl.py
index a00b16d000..e16e34b025 100644
--- a/src/diffusers/pipelines/i2vgen_xl/pipeline_i2vgen_xl.py
+++ b/src/diffusers/pipelines/i2vgen_xl/pipeline_i2vgen_xl.py
@@ -151,7 +151,7 @@ class I2VGenXLPipeline(
return self._guidance_scale
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -384,7 +384,7 @@ class I2VGenXLPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -557,8 +557,8 @@ class I2VGenXLPipeline(
The prompt or prompts to guide what to not include in image generation. If not defined, you need to
pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
eta (`float`, *optional*):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
num_videos_per_prompt (`int`, *optional*):
The number of images to generate per prompt.
decode_chunk_size (`int`, *optional*):
@@ -614,7 +614,7 @@ class I2VGenXLPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
self._guidance_scale = guidance_scale
diff --git a/src/diffusers/pipelines/kandinsky/pipeline_kandinsky.py b/src/diffusers/pipelines/kandinsky/pipeline_kandinsky.py
index b5f4acf5c0..d2f202f014 100644
--- a/src/diffusers/pipelines/kandinsky/pipeline_kandinsky.py
+++ b/src/diffusers/pipelines/kandinsky/pipeline_kandinsky.py
@@ -278,11 +278,11 @@ class KandinskyPipeline(DiffusionPipeline):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
diff --git a/src/diffusers/pipelines/kandinsky/pipeline_kandinsky_combined.py b/src/diffusers/pipelines/kandinsky/pipeline_kandinsky_combined.py
index 5f8db26eef..f6d445a486 100644
--- a/src/diffusers/pipelines/kandinsky/pipeline_kandinsky_combined.py
+++ b/src/diffusers/pipelines/kandinsky/pipeline_kandinsky_combined.py
@@ -251,20 +251,20 @@ class KandinskyCombinedPipeline(DiffusionPipeline):
width (`int`, *optional*, defaults to 512):
The width in pixels of the generated image.
prior_guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
prior_num_inference_steps (`int`, *optional*, defaults to 100):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
@@ -482,20 +482,20 @@ class KandinskyImg2ImgCombinedPipeline(DiffusionPipeline):
be maximum and the denoising process will run for the full number of iterations specified in
`num_inference_steps`. A value of 1, therefore, essentially ignores `image`.
prior_guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
prior_num_inference_steps (`int`, *optional*, defaults to 100):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
@@ -722,20 +722,20 @@ class KandinskyInpaintCombinedPipeline(DiffusionPipeline):
width (`int`, *optional*, defaults to 512):
The width in pixels of the generated image.
prior_guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
prior_num_inference_steps (`int`, *optional*, defaults to 100):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
diff --git a/src/diffusers/pipelines/kandinsky/pipeline_kandinsky_img2img.py b/src/diffusers/pipelines/kandinsky/pipeline_kandinsky_img2img.py
index 0749d80561..1e2f8dad14 100644
--- a/src/diffusers/pipelines/kandinsky/pipeline_kandinsky_img2img.py
+++ b/src/diffusers/pipelines/kandinsky/pipeline_kandinsky_img2img.py
@@ -349,11 +349,11 @@ class KandinskyImg2ImgPipeline(DiffusionPipeline):
be maximum and the denoising process will run for the full number of iterations specified in
`num_inference_steps`. A value of 1, therefore, essentially ignores `image`.
guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
diff --git a/src/diffusers/pipelines/kandinsky/pipeline_kandinsky_inpaint.py b/src/diffusers/pipelines/kandinsky/pipeline_kandinsky_inpaint.py
index a838f5618f..5704648785 100644
--- a/src/diffusers/pipelines/kandinsky/pipeline_kandinsky_inpaint.py
+++ b/src/diffusers/pipelines/kandinsky/pipeline_kandinsky_inpaint.py
@@ -456,11 +456,11 @@ class KandinskyInpaintPipeline(DiffusionPipeline):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
diff --git a/src/diffusers/pipelines/kandinsky/pipeline_kandinsky_prior.py b/src/diffusers/pipelines/kandinsky/pipeline_kandinsky_prior.py
index a348deef8b..64369bc271 100644
--- a/src/diffusers/pipelines/kandinsky/pipeline_kandinsky_prior.py
+++ b/src/diffusers/pipelines/kandinsky/pipeline_kandinsky_prior.py
@@ -220,11 +220,11 @@ class KandinskyPriorPipeline(DiffusionPipeline):
The prompt not to guide the image generation. Ignored when not using guidance (i.e., ignored if
`guidance_scale` is less than `1`).
guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
Examples:
@@ -439,11 +439,11 @@ class KandinskyPriorPipeline(DiffusionPipeline):
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
output_type (`str`, *optional*, defaults to `"pt"`):
The output format of the generate image. Choose between: `"np"` (`np.array`) or `"pt"`
(`torch.Tensor`).
diff --git a/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2.py b/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2.py
index a584674540..4b410271cf 100644
--- a/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2.py
+++ b/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2.py
@@ -162,11 +162,11 @@ class KandinskyV22Pipeline(DiffusionPipeline):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
diff --git a/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2_combined.py b/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2_combined.py
index 68334fef38..2ebd995eb5 100644
--- a/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2_combined.py
+++ b/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2_combined.py
@@ -242,20 +242,20 @@ class KandinskyV22CombinedPipeline(DiffusionPipeline):
width (`int`, *optional*, defaults to 512):
The width in pixels of the generated image.
prior_guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
prior_num_inference_steps (`int`, *optional*, defaults to 100):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
@@ -479,11 +479,11 @@ class KandinskyV22Img2ImgCombinedPipeline(DiffusionPipeline):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
strength (`float`, *optional*, defaults to 0.3):
Conceptually, indicates how much to transform the reference `image`. Must be between 0 and 1. `image`
will be used as a starting point, adding more noise to it the larger the `strength`. The number of
@@ -498,11 +498,11 @@ class KandinskyV22Img2ImgCombinedPipeline(DiffusionPipeline):
width (`int`, *optional*, defaults to 512):
The width in pixels of the generated image.
prior_guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
prior_num_inference_steps (`int`, *optional*, defaults to 100):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
@@ -722,11 +722,11 @@ class KandinskyV22InpaintCombinedPipeline(DiffusionPipeline):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_inference_steps (`int`, *optional*, defaults to 100):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
@@ -735,11 +735,11 @@ class KandinskyV22InpaintCombinedPipeline(DiffusionPipeline):
width (`int`, *optional*, defaults to 512):
The width in pixels of the generated image.
prior_guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
prior_num_inference_steps (`int`, *optional*, defaults to 100):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
diff --git a/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2_controlnet.py b/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2_controlnet.py
index bada59080c..2e3dd136d4 100644
--- a/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2_controlnet.py
+++ b/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2_controlnet.py
@@ -198,11 +198,11 @@ class KandinskyV22ControlnetPipeline(DiffusionPipeline):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
diff --git a/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2_controlnet_img2img.py b/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2_controlnet_img2img.py
index d51f169cc9..9cc61e8c20 100644
--- a/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2_controlnet_img2img.py
+++ b/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2_controlnet_img2img.py
@@ -244,11 +244,11 @@ class KandinskyV22ControlnetImg2ImgPipeline(DiffusionPipeline):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
diff --git a/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2_img2img.py b/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2_img2img.py
index 909c637567..484d1059db 100644
--- a/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2_img2img.py
+++ b/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2_img2img.py
@@ -225,11 +225,11 @@ class KandinskyV22Img2ImgPipeline(DiffusionPipeline):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
diff --git a/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2_inpainting.py b/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2_inpainting.py
index e99aa918ff..98f0812776 100644
--- a/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2_inpainting.py
+++ b/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2_inpainting.py
@@ -343,11 +343,11 @@ class KandinskyV22InpaintPipeline(DiffusionPipeline):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
diff --git a/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2_prior.py b/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2_prior.py
index d05a7fbdb1..68954c2dc8 100644
--- a/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2_prior.py
+++ b/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2_prior.py
@@ -179,11 +179,11 @@ class KandinskyV22PriorPipeline(DiffusionPipeline):
The prompt not to guide the image generation. Ignored when not using guidance (i.e., ignored if
`guidance_scale` is less than `1`).
guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
Examples:
@@ -414,11 +414,11 @@ class KandinskyV22PriorPipeline(DiffusionPipeline):
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
output_type (`str`, *optional*, defaults to `"pt"`):
The output format of the generate image. Choose between: `"np"` (`np.array`) or `"pt"`
(`torch.Tensor`).
diff --git a/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2_prior_emb2emb.py b/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2_prior_emb2emb.py
index 56d326e26e..13ea2ad6af 100644
--- a/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2_prior_emb2emb.py
+++ b/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2_prior_emb2emb.py
@@ -203,11 +203,11 @@ class KandinskyV22PriorEmb2EmbPipeline(DiffusionPipeline):
The prompt not to guide the image generation. Ignored when not using guidance (i.e., ignored if
`guidance_scale` is less than `1`).
guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
Examples:
@@ -441,11 +441,11 @@ class KandinskyV22PriorEmb2EmbPipeline(DiffusionPipeline):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
output_type (`str`, *optional*, defaults to `"pt"`):
The output format of the generate image. Choose between: `"np"` (`np.array`) or `"pt"`
(`torch.Tensor`).
diff --git a/src/diffusers/pipelines/kandinsky3/pipeline_kandinsky3.py b/src/diffusers/pipelines/kandinsky3/pipeline_kandinsky3.py
index 5309f94a53..57cc027044 100644
--- a/src/diffusers/pipelines/kandinsky3/pipeline_kandinsky3.py
+++ b/src/diffusers/pipelines/kandinsky3/pipeline_kandinsky3.py
@@ -368,11 +368,11 @@ class Kandinsky3Pipeline(DiffusionPipeline, StableDiffusionLoraLoaderMixin):
Custom timesteps to use for the denoising process. If not defined, equal spaced `num_inference_steps`
timesteps are used. Must be in descending order.
guidance_scale (`float`, *optional*, defaults to 3.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
@@ -384,8 +384,8 @@ class Kandinsky3Pipeline(DiffusionPipeline, StableDiffusionLoraLoaderMixin):
width (`int`, *optional*, defaults to self.unet.config.sample_size):
The width in pixels of the generated image.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
diff --git a/src/diffusers/pipelines/kandinsky3/pipeline_kandinsky3_img2img.py b/src/diffusers/pipelines/kandinsky3/pipeline_kandinsky3_img2img.py
index f8fa84085c..c7b8022c22 100644
--- a/src/diffusers/pipelines/kandinsky3/pipeline_kandinsky3_img2img.py
+++ b/src/diffusers/pipelines/kandinsky3/pipeline_kandinsky3_img2img.py
@@ -299,7 +299,7 @@ class Kandinsky3Img2ImgPipeline(DiffusionPipeline, StableDiffusionLoraLoaderMixi
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -439,11 +439,11 @@ class Kandinsky3Img2ImgPipeline(DiffusionPipeline, StableDiffusionLoraLoaderMixi
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 3.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
diff --git a/src/diffusers/pipelines/kolors/pipeline_kolors.py b/src/diffusers/pipelines/kolors/pipeline_kolors.py
index 1fc4c02cc4..d55a46c31a 100644
--- a/src/diffusers/pipelines/kolors/pipeline_kolors.py
+++ b/src/diffusers/pipelines/kolors/pipeline_kolors.py
@@ -436,7 +436,7 @@ class KolorsPipeline(DiffusionPipeline, StableDiffusionMixin, StableDiffusionLor
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -633,7 +633,7 @@ class KolorsPipeline(DiffusionPipeline, StableDiffusionMixin, StableDiffusionLor
return self._guidance_scale
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -729,11 +729,11 @@ class KolorsPipeline(DiffusionPipeline, StableDiffusionMixin, StableDiffusionLor
"Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output)
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
@@ -741,8 +741,8 @@ class KolorsPipeline(DiffusionPipeline, StableDiffusionMixin, StableDiffusionLor
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
diff --git a/src/diffusers/pipelines/kolors/pipeline_kolors_img2img.py b/src/diffusers/pipelines/kolors/pipeline_kolors_img2img.py
index df94ec3f0f..4b0f8cdb62 100644
--- a/src/diffusers/pipelines/kolors/pipeline_kolors_img2img.py
+++ b/src/diffusers/pipelines/kolors/pipeline_kolors_img2img.py
@@ -456,7 +456,7 @@ class KolorsImg2ImgPipeline(DiffusionPipeline, StableDiffusionMixin, StableDiffu
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -761,7 +761,7 @@ class KolorsImg2ImgPipeline(DiffusionPipeline, StableDiffusionMixin, StableDiffu
return self._guidance_scale
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -880,11 +880,11 @@ class KolorsImg2ImgPipeline(DiffusionPipeline, StableDiffusionMixin, StableDiffu
"Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output)
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
@@ -892,8 +892,8 @@ class KolorsImg2ImgPipeline(DiffusionPipeline, StableDiffusionMixin, StableDiffu
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
diff --git a/src/diffusers/pipelines/kolors/text_encoder.py b/src/diffusers/pipelines/kolors/text_encoder.py
index 7fd1a2ec0e..2b647335e5 100644
--- a/src/diffusers/pipelines/kolors/text_encoder.py
+++ b/src/diffusers/pipelines/kolors/text_encoder.py
@@ -434,7 +434,7 @@ class MLP(torch.nn.Module):
self.add_bias = config.add_bias_linear
- # Project to 4h. If using swiglu double the output width, see https://arxiv.org/pdf/2002.05202.pdf
+ # Project to 4h. If using swiglu double the output width, see https://huggingface.co/papers/2002.05202
self.dense_h_to_4h = nn.Linear(
config.hidden_size,
config.ffn_hidden_size * 2,
diff --git a/src/diffusers/pipelines/latent_consistency_models/pipeline_latent_consistency_img2img.py b/src/diffusers/pipelines/latent_consistency_models/pipeline_latent_consistency_img2img.py
index 1c59ca7d6d..f1e48665bc 100644
--- a/src/diffusers/pipelines/latent_consistency_models/pipeline_latent_consistency_img2img.py
+++ b/src/diffusers/pipelines/latent_consistency_models/pipeline_latent_consistency_img2img.py
@@ -607,7 +607,7 @@ class LatentConsistencyModelImg2ImgPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
diff --git a/src/diffusers/pipelines/latent_consistency_models/pipeline_latent_consistency_text2img.py b/src/diffusers/pipelines/latent_consistency_models/pipeline_latent_consistency_text2img.py
index a3d9917d33..b829e27f94 100644
--- a/src/diffusers/pipelines/latent_consistency_models/pipeline_latent_consistency_text2img.py
+++ b/src/diffusers/pipelines/latent_consistency_models/pipeline_latent_consistency_text2img.py
@@ -548,7 +548,7 @@ class LatentConsistencyModelPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
diff --git a/src/diffusers/pipelines/latent_diffusion/pipeline_latent_diffusion_superresolution.py b/src/diffusers/pipelines/latent_diffusion/pipeline_latent_diffusion_superresolution.py
index 879722e6a0..273e97f1ec 100644
--- a/src/diffusers/pipelines/latent_diffusion/pipeline_latent_diffusion_superresolution.py
+++ b/src/diffusers/pipelines/latent_diffusion/pipeline_latent_diffusion_superresolution.py
@@ -95,8 +95,8 @@ class LDMSuperResolutionPipeline(DiffusionPipeline):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -166,7 +166,7 @@ class LDMSuperResolutionPipeline(DiffusionPipeline):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature.
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_kwargs = {}
diff --git a/src/diffusers/pipelines/latte/pipeline_latte.py b/src/diffusers/pipelines/latte/pipeline_latte.py
index 977e648d85..05b97e56f2 100644
--- a/src/diffusers/pipelines/latte/pipeline_latte.py
+++ b/src/diffusers/pipelines/latte/pipeline_latte.py
@@ -356,7 +356,7 @@ class LattePipeline(DiffusionPipeline):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -592,7 +592,7 @@ class LattePipeline(DiffusionPipeline):
return self._guidance_scale
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -657,11 +657,11 @@ class LattePipeline(DiffusionPipeline):
Custom timesteps to use for the denoising process. If not defined, equal spaced `num_inference_steps`
timesteps are used. Must be in descending order.
guidance_scale (`float`, *optional*, defaults to 7.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate videos that are closely linked to the text `prompt`,
- usually at the expense of lower video quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate videos that are closely linked to
+ the text `prompt`, usually at the expense of lower video quality.
video_length (`int`, *optional*, defaults to 16):
The number of video frames that are generated. Defaults to 16 frames which at 8 frames per seconds
num_images_per_prompt (`int`, *optional*, defaults to 1):
@@ -671,8 +671,8 @@ class LattePipeline(DiffusionPipeline):
width (`int`, *optional*, defaults to self.unet.config.sample_size):
The width in pixels of the generated video.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
@@ -747,7 +747,7 @@ class LattePipeline(DiffusionPipeline):
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/ledits_pp/pipeline_leditspp_stable_diffusion.py b/src/diffusers/pipelines/ledits_pp/pipeline_leditspp_stable_diffusion.py
index 37fe35278c..341ccabaa1 100644
--- a/src/diffusers/pipelines/ledits_pp/pipeline_leditspp_stable_diffusion.py
+++ b/src/diffusers/pipelines/ledits_pp/pipeline_leditspp_stable_diffusion.py
@@ -244,7 +244,7 @@ def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
r"""
Rescales `noise_cfg` tensor based on `guidance_rescale` to improve image quality and fix overexposure. Based on
Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891).
Args:
noise_cfg (`torch.Tensor`):
@@ -439,7 +439,7 @@ class LEditsPPPipelineStableDiffusion(
def prepare_extra_step_kwargs(self, eta, generator=None):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -808,7 +808,7 @@ class LEditsPPPipelineStableDiffusion(
edit_guidance_scale (`float` or `List[float]`, *optional*, defaults to 5):
Guidance scale for guiding the image generation. If provided as list values should correspond to
`editing_prompt`. `edit_guidance_scale` is defined as `s_e` of equation 12 of [LEDITS++
- Paper](https://arxiv.org/abs/2301.12247).
+ Paper](https://huggingface.co/papers/2301.12247).
edit_warmup_steps (`float` or `List[float]`, *optional*, defaults to 10):
Number of diffusion steps (for each prompt) for which guidance will not be applied.
edit_cooldown_steps (`float` or `List[float]`, *optional*, defaults to `None`):
@@ -816,7 +816,7 @@ class LEditsPPPipelineStableDiffusion(
edit_threshold (`float` or `List[float]`, *optional*, defaults to 0.9):
Masking threshold of guidance. Threshold should be proportional to the image region that is modified.
'edit_threshold' is defined as 'λ' of equation 12 of [LEDITS++
- Paper](https://arxiv.org/abs/2301.12247).
+ Paper](https://huggingface.co/papers/2301.12247).
user_mask (`torch.Tensor`, *optional*):
User-provided mask for even better control over the editing process. This is helpful when LEDITS++'s
implicit masks do not meet user preferences.
@@ -826,11 +826,11 @@ class LEditsPPPipelineStableDiffusion(
use_cross_attn_mask (`bool`, defaults to `False`):
Whether cross-attention masks are used. Cross-attention masks are always used when use_intersect_mask
is set to true. Cross-attention masks are defined as 'M^1' of equation 12 of [LEDITS++
- paper](https://arxiv.org/pdf/2311.16711.pdf).
+ paper](https://huggingface.co/papers/2311.16711).
use_intersect_mask (`bool`, defaults to `True`):
Whether the masking term is calculated as intersection of cross-attention masks and masks derived from
the noise estimate. Cross-attention mask are defined as 'M^1' and masks derived from the noise estimate
- are defined as 'M^2' of equation 12 of [LEDITS++ paper](https://arxiv.org/pdf/2311.16711.pdf).
+ are defined as 'M^2' of equation 12 of [LEDITS++ paper](https://huggingface.co/papers/2311.16711).
attn_store_steps (`List[int]`, *optional*):
Steps for which the attention maps are stored in the AttentionStore. Just for visualization purposes.
store_averaged_over_steps (`bool`, defaults to `True`):
@@ -841,7 +841,7 @@ class LEditsPPPipelineStableDiffusion(
[`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf). Guidance rescale factor should fix overexposure when
+ Flawed](https://huggingface.co/papers/2305.08891). Guidance rescale factor should fix overexposure when
using zero terminal SNR.
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
@@ -1191,7 +1191,7 @@ class LEditsPPPipelineStableDiffusion(
noise_pred = noise_pred_uncond + noise_guidance_edit
if enable_edit_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(
noise_pred,
noise_pred_edit_concepts.mean(dim=0, keepdim=False),
@@ -1268,8 +1268,8 @@ class LEditsPPPipelineStableDiffusion(
):
r"""
The function to the pipeline for image inversion as described by the [LEDITS++
- Paper](https://arxiv.org/abs/2301.12247). If the scheduler is set to [`~schedulers.DDIMScheduler`] the
- inversion proposed by [edit-friendly DPDM](https://arxiv.org/abs/2304.06140) will be performed instead.
+ Paper](https://huggingface.co/papers/2301.12247). If the scheduler is set to [`~schedulers.DDIMScheduler`] the
+ inversion proposed by [edit-friendly DPDM](https://huggingface.co/papers/2304.06140) will be performed instead.
Args:
image (`PipelineImageInput`):
@@ -1443,7 +1443,7 @@ def compute_noise_ddim(scheduler, prev_latents, latents, timestep, noise_pred, e
beta_prod_t = 1 - alpha_prod_t
# 3. compute predicted original sample from predicted noise also called
- # "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # "predicted x_0" of formula (12) from https://huggingface.co/papers/2010.02502
pred_original_sample = (latents - beta_prod_t ** (0.5) * noise_pred) / alpha_prod_t ** (0.5)
# 4. Clip "predicted x_0"
@@ -1455,7 +1455,7 @@ def compute_noise_ddim(scheduler, prev_latents, latents, timestep, noise_pred, e
variance = scheduler._get_variance(timestep, prev_timestep)
std_dev_t = eta * variance ** (0.5)
- # 6. compute "direction pointing to x_t" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # 6. compute "direction pointing to x_t" of formula (12) from https://huggingface.co/papers/2010.02502
pred_sample_direction = (1 - alpha_prod_t_prev - std_dev_t**2) ** (0.5) * noise_pred
# modified so that updated xtm1 is returned as well (to avoid error accumulation)
diff --git a/src/diffusers/pipelines/ledits_pp/pipeline_leditspp_stable_diffusion_xl.py b/src/diffusers/pipelines/ledits_pp/pipeline_leditspp_stable_diffusion_xl.py
index a062b5ae6d..ac64844f6f 100644
--- a/src/diffusers/pipelines/ledits_pp/pipeline_leditspp_stable_diffusion_xl.py
+++ b/src/diffusers/pipelines/ledits_pp/pipeline_leditspp_stable_diffusion_xl.py
@@ -622,7 +622,7 @@ class LEditsPPPipelineStableDiffusionXL(
def prepare_extra_step_kwargs(self, eta, generator=None):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -747,7 +747,7 @@ class LEditsPPPipelineStableDiffusionXL(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -901,9 +901,10 @@ class LEditsPPPipelineStableDiffusionXL(
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.7):
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
- [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
- Guidance rescale factor should fix overexposure when using zero terminal SNR.
+ Flawed](https://huggingface.co/papers/2305.08891) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are
+ Flawed](https://huggingface.co/papers/2305.08891). Guidance rescale factor should fix overexposure when
+ using zero terminal SNR.
crops_coords_top_left (`Tuple[int]`, *optional*, defaults to (0, 0)):
`crops_coords_top_left` can be used to generate an image that appears to be "cropped" from the position
`crops_coords_top_left` downwards. Favorable, well-centered images are usually achieved by setting
@@ -929,7 +930,7 @@ class LEditsPPPipelineStableDiffusionXL(
edit_guidance_scale (`float` or `List[float]`, *optional*, defaults to 5):
Guidance scale for guiding the image generation. If provided as list values should correspond to
`editing_prompt`. `edit_guidance_scale` is defined as `s_e` of equation 12 of [LEDITS++
- Paper](https://arxiv.org/abs/2301.12247).
+ Paper](https://huggingface.co/papers/2301.12247).
edit_warmup_steps (`float` or `List[float]`, *optional*, defaults to 10):
Number of diffusion steps (for each prompt) for which guidance is not applied.
edit_cooldown_steps (`float` or `List[float]`, *optional*, defaults to `None`):
@@ -937,18 +938,18 @@ class LEditsPPPipelineStableDiffusionXL(
edit_threshold (`float` or `List[float]`, *optional*, defaults to 0.9):
Masking threshold of guidance. Threshold should be proportional to the image region that is modified.
'edit_threshold' is defined as 'λ' of equation 12 of [LEDITS++
- Paper](https://arxiv.org/abs/2301.12247).
+ Paper](https://huggingface.co/papers/2301.12247).
sem_guidance (`List[torch.Tensor]`, *optional*):
List of pre-generated guidance vectors to be applied at generation. Length of the list has to
correspond to `num_inference_steps`.
use_cross_attn_mask:
Whether cross-attention masks are used. Cross-attention masks are always used when use_intersect_mask
is set to true. Cross-attention masks are defined as 'M^1' of equation 12 of [LEDITS++
- paper](https://arxiv.org/pdf/2311.16711.pdf).
+ paper](https://huggingface.co/papers/2311.16711).
use_intersect_mask:
Whether the masking term is calculated as intersection of cross-attention masks and masks derived from
the noise estimate. Cross-attention mask are defined as 'M^1' and masks derived from the noise estimate
- are defined as 'M^2' of equation 12 of [LEDITS++ paper](https://arxiv.org/pdf/2311.16711.pdf).
+ are defined as 'M^2' of equation 12 of [LEDITS++ paper](https://huggingface.co/papers/2311.16711).
user_mask:
User-provided mask for even better control over the editing process. This is helpful when LEDITS++'s
implicit masks do not meet user preferences.
@@ -1350,7 +1351,7 @@ class LEditsPPPipelineStableDiffusionXL(
# compute the previous noisy sample x_t -> x_t-1
if enable_edit_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(
noise_pred,
noise_pred_edit_concepts.mean(dim=0, keepdim=False),
@@ -1478,8 +1479,8 @@ class LEditsPPPipelineStableDiffusionXL(
):
r"""
The function to the pipeline for image inversion as described by the [LEDITS++
- Paper](https://arxiv.org/abs/2301.12247). If the scheduler is set to [`~schedulers.DDIMScheduler`] the
- inversion proposed by [edit-friendly DPDM](https://arxiv.org/abs/2304.06140) will be performed instead.
+ Paper](https://huggingface.co/papers/2301.12247). If the scheduler is set to [`~schedulers.DDIMScheduler`] the
+ inversion proposed by [edit-friendly DPDM](https://huggingface.co/papers/2304.06140) will be performed instead.
Args:
image (`PipelineImageInput`):
@@ -1691,7 +1692,7 @@ def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
r"""
Rescales `noise_cfg` tensor based on `guidance_rescale` to improve image quality and fix overexposure. Based on
Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891).
Args:
noise_cfg (`torch.Tensor`):
@@ -1727,7 +1728,7 @@ def compute_noise_ddim(scheduler, prev_latents, latents, timestep, noise_pred, e
beta_prod_t = 1 - alpha_prod_t
# 3. compute predicted original sample from predicted noise also called
- # "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # "predicted x_0" of formula (12) from https://huggingface.co/papers/2010.02502
pred_original_sample = (latents - beta_prod_t ** (0.5) * noise_pred) / alpha_prod_t ** (0.5)
# 4. Clip "predicted x_0"
@@ -1739,7 +1740,7 @@ def compute_noise_ddim(scheduler, prev_latents, latents, timestep, noise_pred, e
variance = scheduler._get_variance(timestep, prev_timestep)
std_dev_t = eta * variance ** (0.5)
- # 6. compute "direction pointing to x_t" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # 6. compute "direction pointing to x_t" of formula (12) from https://huggingface.co/papers/2010.02502
pred_sample_direction = (1 - alpha_prod_t_prev - std_dev_t**2) ** (0.5) * noise_pred
# modified so that updated xtm1 is returned as well (to avoid error accumulation)
diff --git a/src/diffusers/pipelines/ltx/__init__.py b/src/diffusers/pipelines/ltx/__init__.py
index 199e730d9b..6001867916 100644
--- a/src/diffusers/pipelines/ltx/__init__.py
+++ b/src/diffusers/pipelines/ltx/__init__.py
@@ -22,9 +22,11 @@ except OptionalDependencyNotAvailable:
_dummy_objects.update(get_objects_from_module(dummy_torch_and_transformers_objects))
else:
+ _import_structure["modeling_latent_upsampler"] = ["LTXLatentUpsamplerModel"]
_import_structure["pipeline_ltx"] = ["LTXPipeline"]
_import_structure["pipeline_ltx_condition"] = ["LTXConditionPipeline"]
_import_structure["pipeline_ltx_image2video"] = ["LTXImageToVideoPipeline"]
+ _import_structure["pipeline_ltx_latent_upsample"] = ["LTXLatentUpsamplePipeline"]
if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
try:
@@ -34,9 +36,11 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
except OptionalDependencyNotAvailable:
from ...utils.dummy_torch_and_transformers_objects import *
else:
+ from .modeling_latent_upsampler import LTXLatentUpsamplerModel
from .pipeline_ltx import LTXPipeline
from .pipeline_ltx_condition import LTXConditionPipeline
from .pipeline_ltx_image2video import LTXImageToVideoPipeline
+ from .pipeline_ltx_latent_upsample import LTXLatentUpsamplePipeline
else:
import sys
diff --git a/src/diffusers/pipelines/ltx/modeling_latent_upsampler.py b/src/diffusers/pipelines/ltx/modeling_latent_upsampler.py
new file mode 100644
index 0000000000..6dce792a2b
--- /dev/null
+++ b/src/diffusers/pipelines/ltx/modeling_latent_upsampler.py
@@ -0,0 +1,188 @@
+# Copyright 2025 Lightricks and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from typing import Optional
+
+import torch
+
+from ...configuration_utils import ConfigMixin, register_to_config
+from ...models.modeling_utils import ModelMixin
+
+
+class ResBlock(torch.nn.Module):
+ def __init__(self, channels: int, mid_channels: Optional[int] = None, dims: int = 3):
+ super().__init__()
+ if mid_channels is None:
+ mid_channels = channels
+
+ Conv = torch.nn.Conv2d if dims == 2 else torch.nn.Conv3d
+
+ self.conv1 = Conv(channels, mid_channels, kernel_size=3, padding=1)
+ self.norm1 = torch.nn.GroupNorm(32, mid_channels)
+ self.conv2 = Conv(mid_channels, channels, kernel_size=3, padding=1)
+ self.norm2 = torch.nn.GroupNorm(32, channels)
+ self.activation = torch.nn.SiLU()
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ residual = hidden_states
+ hidden_states = self.conv1(hidden_states)
+ hidden_states = self.norm1(hidden_states)
+ hidden_states = self.activation(hidden_states)
+ hidden_states = self.conv2(hidden_states)
+ hidden_states = self.norm2(hidden_states)
+ hidden_states = self.activation(hidden_states + residual)
+ return hidden_states
+
+
+class PixelShuffleND(torch.nn.Module):
+ def __init__(self, dims, upscale_factors=(2, 2, 2)):
+ super().__init__()
+
+ self.dims = dims
+ self.upscale_factors = upscale_factors
+
+ if dims not in [1, 2, 3]:
+ raise ValueError("dims must be 1, 2, or 3")
+
+ def forward(self, x):
+ if self.dims == 3:
+ # spatiotemporal: b (c p1 p2 p3) d h w -> b c (d p1) (h p2) (w p3)
+ return (
+ x.unflatten(1, (-1, *self.upscale_factors[:3]))
+ .permute(0, 1, 5, 2, 6, 3, 7, 4)
+ .flatten(6, 7)
+ .flatten(4, 5)
+ .flatten(2, 3)
+ )
+ elif self.dims == 2:
+ # spatial: b (c p1 p2) h w -> b c (h p1) (w p2)
+ return (
+ x.unflatten(1, (-1, *self.upscale_factors[:2])).permute(0, 1, 4, 2, 5, 3).flatten(4, 5).flatten(2, 3)
+ )
+ elif self.dims == 1:
+ # temporal: b (c p1) f h w -> b c (f p1) h w
+ return x.unflatten(1, (-1, *self.upscale_factors[:1])).permute(0, 1, 3, 2, 4, 5).flatten(2, 3)
+
+
+class LTXLatentUpsamplerModel(ModelMixin, ConfigMixin):
+ """
+ Model to spatially upsample VAE latents.
+
+ Args:
+ in_channels (`int`, defaults to `128`):
+ Number of channels in the input latent
+ mid_channels (`int`, defaults to `512`):
+ Number of channels in the middle layers
+ num_blocks_per_stage (`int`, defaults to `4`):
+ Number of ResBlocks to use in each stage (pre/post upsampling)
+ dims (`int`, defaults to `3`):
+ Number of dimensions for convolutions (2 or 3)
+ spatial_upsample (`bool`, defaults to `True`):
+ Whether to spatially upsample the latent
+ temporal_upsample (`bool`, defaults to `False`):
+ Whether to temporally upsample the latent
+ """
+
+ @register_to_config
+ def __init__(
+ self,
+ in_channels: int = 128,
+ mid_channels: int = 512,
+ num_blocks_per_stage: int = 4,
+ dims: int = 3,
+ spatial_upsample: bool = True,
+ temporal_upsample: bool = False,
+ ):
+ super().__init__()
+
+ self.in_channels = in_channels
+ self.mid_channels = mid_channels
+ self.num_blocks_per_stage = num_blocks_per_stage
+ self.dims = dims
+ self.spatial_upsample = spatial_upsample
+ self.temporal_upsample = temporal_upsample
+
+ ConvNd = torch.nn.Conv2d if dims == 2 else torch.nn.Conv3d
+
+ self.initial_conv = ConvNd(in_channels, mid_channels, kernel_size=3, padding=1)
+ self.initial_norm = torch.nn.GroupNorm(32, mid_channels)
+ self.initial_activation = torch.nn.SiLU()
+
+ self.res_blocks = torch.nn.ModuleList([ResBlock(mid_channels, dims=dims) for _ in range(num_blocks_per_stage)])
+
+ if spatial_upsample and temporal_upsample:
+ self.upsampler = torch.nn.Sequential(
+ torch.nn.Conv3d(mid_channels, 8 * mid_channels, kernel_size=3, padding=1),
+ PixelShuffleND(3),
+ )
+ elif spatial_upsample:
+ self.upsampler = torch.nn.Sequential(
+ torch.nn.Conv2d(mid_channels, 4 * mid_channels, kernel_size=3, padding=1),
+ PixelShuffleND(2),
+ )
+ elif temporal_upsample:
+ self.upsampler = torch.nn.Sequential(
+ torch.nn.Conv3d(mid_channels, 2 * mid_channels, kernel_size=3, padding=1),
+ PixelShuffleND(1),
+ )
+ else:
+ raise ValueError("Either spatial_upsample or temporal_upsample must be True")
+
+ self.post_upsample_res_blocks = torch.nn.ModuleList(
+ [ResBlock(mid_channels, dims=dims) for _ in range(num_blocks_per_stage)]
+ )
+
+ self.final_conv = ConvNd(mid_channels, in_channels, kernel_size=3, padding=1)
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ batch_size, num_channels, num_frames, height, width = hidden_states.shape
+
+ if self.dims == 2:
+ hidden_states = hidden_states.permute(0, 2, 1, 3, 4).flatten(0, 1)
+ hidden_states = self.initial_conv(hidden_states)
+ hidden_states = self.initial_norm(hidden_states)
+ hidden_states = self.initial_activation(hidden_states)
+
+ for block in self.res_blocks:
+ hidden_states = block(hidden_states)
+
+ hidden_states = self.upsampler(hidden_states)
+
+ for block in self.post_upsample_res_blocks:
+ hidden_states = block(hidden_states)
+
+ hidden_states = self.final_conv(hidden_states)
+ hidden_states = hidden_states.unflatten(0, (batch_size, -1)).permute(0, 2, 1, 3, 4)
+ else:
+ hidden_states = self.initial_conv(hidden_states)
+ hidden_states = self.initial_norm(hidden_states)
+ hidden_states = self.initial_activation(hidden_states)
+
+ for block in self.res_blocks:
+ hidden_states = block(hidden_states)
+
+ if self.temporal_upsample:
+ hidden_states = self.upsampler(hidden_states)
+ hidden_states = hidden_states[:, :, 1:, :, :]
+ else:
+ hidden_states = hidden_states.permute(0, 2, 1, 3, 4).flatten(0, 1)
+ hidden_states = self.upsampler(hidden_states)
+ hidden_states = hidden_states.unflatten(0, (batch_size, -1)).permute(0, 2, 1, 3, 4)
+
+ for block in self.post_upsample_res_blocks:
+ hidden_states = block(hidden_states)
+
+ hidden_states = self.final_conv(hidden_states)
+
+ return hidden_states
diff --git a/src/diffusers/pipelines/ltx/pipeline_ltx.py b/src/diffusers/pipelines/ltx/pipeline_ltx.py
index 6f3faed8ff..7f669ef50e 100644
--- a/src/diffusers/pipelines/ltx/pipeline_ltx.py
+++ b/src/diffusers/pipelines/ltx/pipeline_ltx.py
@@ -140,6 +140,33 @@ def retrieve_timesteps(
return timesteps, num_inference_steps
+# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.rescale_noise_cfg
+def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
+ r"""
+ Rescales `noise_cfg` tensor based on `guidance_rescale` to improve image quality and fix overexposure. Based on
+ Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
+ Flawed](https://huggingface.co/papers/2305.08891).
+
+ Args:
+ noise_cfg (`torch.Tensor`):
+ The predicted noise tensor for the guided diffusion process.
+ noise_pred_text (`torch.Tensor`):
+ The predicted noise tensor for the text-guided diffusion process.
+ guidance_rescale (`float`, *optional*, defaults to 0.0):
+ A rescale factor applied to the noise predictions.
+
+ Returns:
+ noise_cfg (`torch.Tensor`): The rescaled noise prediction tensor.
+ """
+ std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
+ std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
+ # rescale the results from guidance (fixes overexposure)
+ noise_pred_rescaled = noise_cfg * (std_text / std_cfg)
+ # mix with the original results from guidance by factor guidance_rescale to avoid "plain looking" images
+ noise_cfg = guidance_rescale * noise_pred_rescaled + (1 - guidance_rescale) * noise_cfg
+ return noise_cfg
+
+
class LTXPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLoraLoaderMixin):
r"""
Pipeline for text-to-video generation.
@@ -481,6 +508,10 @@ class LTXPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLoraLoaderMixi
def guidance_scale(self):
return self._guidance_scale
+ @property
+ def guidance_rescale(self):
+ return self._guidance_rescale
+
@property
def do_classifier_free_guidance(self):
return self._guidance_scale > 1.0
@@ -514,6 +545,7 @@ class LTXPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLoraLoaderMixi
num_inference_steps: int = 50,
timesteps: List[int] = None,
guidance_scale: float = 3,
+ guidance_rescale: float = 0.0,
num_videos_per_prompt: Optional[int] = 1,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.Tensor] = None,
@@ -551,11 +583,16 @@ class LTXPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLoraLoaderMixi
in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
passed will be used. Must be in descending order.
guidance_scale (`float`, defaults to `3 `):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
+ guidance_rescale (`float`, *optional*, defaults to 0.0):
+ Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
+ Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Guidance rescale factor should fix overexposure when using zero terminal SNR.
num_videos_per_prompt (`int`, *optional*, defaults to 1):
The number of videos to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
@@ -624,6 +661,7 @@ class LTXPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLoraLoaderMixi
)
self._guidance_scale = guidance_scale
+ self._guidance_rescale = guidance_rescale
self._attention_kwargs = attention_kwargs
self._interrupt = False
self._current_timestep = None
@@ -737,6 +775,12 @@ class LTXPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLoraLoaderMixi
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
+ if self.guidance_rescale > 0:
+ # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ noise_pred = rescale_noise_cfg(
+ noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale
+ )
+
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, return_dict=False)[0]
@@ -789,6 +833,7 @@ class LTXPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLoraLoaderMixi
]
latents = (1 - decode_noise_scale) * latents + decode_noise_scale * noise
+ latents = latents.to(self.vae.dtype)
video = self.vae.decode(latents, timestep, return_dict=False)[0]
video = self.video_processor.postprocess_video(video, output_type=output_type)
diff --git a/src/diffusers/pipelines/ltx/pipeline_ltx_condition.py b/src/diffusers/pipelines/ltx/pipeline_ltx_condition.py
index dcfdfaf232..4724880658 100644
--- a/src/diffusers/pipelines/ltx/pipeline_ltx_condition.py
+++ b/src/diffusers/pipelines/ltx/pipeline_ltx_condition.py
@@ -222,6 +222,33 @@ def retrieve_latents(
raise AttributeError("Could not access latents of provided encoder_output")
+# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.rescale_noise_cfg
+def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
+ r"""
+ Rescales `noise_cfg` tensor based on `guidance_rescale` to improve image quality and fix overexposure. Based on
+ Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
+ Flawed](https://huggingface.co/papers/2305.08891).
+
+ Args:
+ noise_cfg (`torch.Tensor`):
+ The predicted noise tensor for the guided diffusion process.
+ noise_pred_text (`torch.Tensor`):
+ The predicted noise tensor for the text-guided diffusion process.
+ guidance_rescale (`float`, *optional*, defaults to 0.0):
+ A rescale factor applied to the noise predictions.
+
+ Returns:
+ noise_cfg (`torch.Tensor`): The rescaled noise prediction tensor.
+ """
+ std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
+ std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
+ # rescale the results from guidance (fixes overexposure)
+ noise_pred_rescaled = noise_cfg * (std_text / std_cfg)
+ # mix with the original results from guidance by factor guidance_rescale to avoid "plain looking" images
+ noise_cfg = guidance_rescale * noise_pred_rescaled + (1 - guidance_rescale) * noise_cfg
+ return noise_cfg
+
+
class LTXConditionPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLoraLoaderMixin):
r"""
Pipeline for text/image/video-to-video generation.
@@ -430,6 +457,7 @@ class LTXConditionPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLoraL
video,
frame_index,
strength,
+ denoise_strength,
height,
width,
callback_on_step_end_tensor_inputs=None,
@@ -497,6 +525,9 @@ class LTXConditionPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLoraL
elif isinstance(video, list) and isinstance(strength, list) and len(video) != len(strength):
raise ValueError("If `conditions` is not provided, `video` and `strength` must be of the same length.")
+ if denoise_strength < 0 or denoise_strength > 1:
+ raise ValueError(f"The value of strength should in [0.0, 1.0] but is {denoise_strength}")
+
@staticmethod
def _prepare_video_ids(
batch_size: int,
@@ -649,6 +680,8 @@ class LTXConditionPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLoraL
width: int = 704,
num_frames: int = 161,
num_prefix_latent_frames: int = 2,
+ sigma: Optional[torch.Tensor] = None,
+ latents: Optional[torch.Tensor] = None,
generator: Optional[torch.Generator] = None,
device: Optional[torch.device] = None,
dtype: Optional[torch.dtype] = None,
@@ -658,7 +691,18 @@ class LTXConditionPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLoraL
latent_width = width // self.vae_spatial_compression_ratio
shape = (batch_size, num_channels_latents, num_latent_frames, latent_height, latent_width)
- latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+
+ noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ if latents is not None and sigma is not None:
+ if latents.shape != shape:
+ raise ValueError(
+ f"Latents shape {latents.shape} does not match expected shape {shape}. Please check the input."
+ )
+ latents = latents.to(device=device, dtype=dtype)
+ sigma = sigma.to(device=device, dtype=dtype)
+ latents = sigma * noise + (1 - sigma) * latents
+ else:
+ latents = noise
if len(conditions) > 0:
condition_latent_frames_mask = torch.zeros(
@@ -766,10 +810,21 @@ class LTXConditionPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLoraL
return latents, conditioning_mask, video_ids, extra_conditioning_num_latents
+ def get_timesteps(self, sigmas, timesteps, num_inference_steps, strength):
+ num_steps = min(int(num_inference_steps * strength), num_inference_steps)
+ start_index = max(num_inference_steps - num_steps, 0)
+ sigmas = sigmas[start_index:]
+ timesteps = timesteps[start_index:]
+ return sigmas, timesteps, num_inference_steps - start_index
+
@property
def guidance_scale(self):
return self._guidance_scale
+ @property
+ def guidance_rescale(self):
+ return self._guidance_rescale
+
@property
def do_classifier_free_guidance(self):
return self._guidance_scale > 1.0
@@ -799,6 +854,7 @@ class LTXConditionPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLoraL
video: List[PipelineImageInput] = None,
frame_index: Union[int, List[int]] = 0,
strength: Union[float, List[float]] = 1.0,
+ denoise_strength: float = 1.0,
prompt: Union[str, List[str]] = None,
negative_prompt: Optional[Union[str, List[str]]] = None,
height: int = 512,
@@ -808,6 +864,7 @@ class LTXConditionPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLoraL
num_inference_steps: int = 50,
timesteps: List[int] = None,
guidance_scale: float = 3,
+ guidance_rescale: float = 0.0,
image_cond_noise_scale: float = 0.15,
num_videos_per_prompt: Optional[int] = 1,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
@@ -842,6 +899,10 @@ class LTXConditionPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLoraL
generation. If not provided, one has to pass `conditions`.
strength (`float` or `List[float]`, *optional*):
The strength or strengths of the conditioning effect. If not provided, one has to pass `conditions`.
+ denoise_strength (`float`, defaults to `1.0`):
+ The strength of the noise added to the latents for editing. Higher strength leads to more noise added
+ to the latents, therefore leading to more differences between original video and generated video. This
+ is useful for video-to-video editing.
prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
instead.
@@ -859,11 +920,16 @@ class LTXConditionPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLoraL
in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
passed will be used. Must be in descending order.
guidance_scale (`float`, defaults to `3 `):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
+ guidance_rescale (`float`, *optional*, defaults to 0.0):
+ Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
+ Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Guidance rescale factor should fix overexposure when using zero terminal SNR.
num_videos_per_prompt (`int`, *optional*, defaults to 1):
The number of videos to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
@@ -918,8 +984,6 @@ class LTXConditionPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLoraL
if isinstance(callback_on_step_end, (PipelineCallback, MultiPipelineCallbacks)):
callback_on_step_end_tensor_inputs = callback_on_step_end.tensor_inputs
- if latents is not None:
- raise ValueError("Passing latents is not yet supported.")
# 1. Check inputs. Raise error if not correct
self.check_inputs(
@@ -929,6 +993,7 @@ class LTXConditionPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLoraL
video=video,
frame_index=frame_index,
strength=strength,
+ denoise_strength=denoise_strength,
height=height,
width=width,
callback_on_step_end_tensor_inputs=callback_on_step_end_tensor_inputs,
@@ -939,6 +1004,7 @@ class LTXConditionPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLoraL
)
self._guidance_scale = guidance_scale
+ self._guidance_rescale = guidance_rescale
self._attention_kwargs = attention_kwargs
self._interrupt = False
self._current_timestep = None
@@ -977,8 +1043,9 @@ class LTXConditionPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLoraL
strength = [strength] * num_conditions
device = self._execution_device
+ vae_dtype = self.vae.dtype
- # 3. Prepare text embeddings
+ # 3. Prepare text embeddings & conditioning image/video
(
prompt_embeds,
prompt_attention_mask,
@@ -1000,8 +1067,6 @@ class LTXConditionPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLoraL
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds], dim=0)
prompt_attention_mask = torch.cat([negative_prompt_attention_mask, prompt_attention_mask], dim=0)
- vae_dtype = self.vae.dtype
-
conditioning_tensors = []
is_conditioning_image_or_video = image is not None or video is not None
if is_conditioning_image_or_video:
@@ -1032,7 +1097,27 @@ class LTXConditionPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLoraL
)
conditioning_tensors.append(condition_tensor)
- # 4. Prepare latent variables
+ # 4. Prepare timesteps
+ latent_num_frames = (num_frames - 1) // self.vae_temporal_compression_ratio + 1
+ latent_height = height // self.vae_spatial_compression_ratio
+ latent_width = width // self.vae_spatial_compression_ratio
+ if timesteps is None:
+ sigmas = linear_quadratic_schedule(num_inference_steps)
+ timesteps = sigmas * 1000
+ timesteps, num_inference_steps = retrieve_timesteps(self.scheduler, num_inference_steps, device, timesteps)
+ sigmas = self.scheduler.sigmas
+ num_warmup_steps = max(len(timesteps) - num_inference_steps * self.scheduler.order, 0)
+
+ latent_sigma = None
+ if denoise_strength < 1:
+ sigmas, timesteps, num_inference_steps = self.get_timesteps(
+ sigmas, timesteps, num_inference_steps, denoise_strength
+ )
+ latent_sigma = sigmas[:1].repeat(batch_size * num_videos_per_prompt)
+
+ self._num_timesteps = len(timesteps)
+
+ # 5. Prepare latent variables
num_channels_latents = self.transformer.config.in_channels
latents, conditioning_mask, video_coords, extra_conditioning_num_latents = self.prepare_latents(
conditioning_tensors,
@@ -1043,6 +1128,8 @@ class LTXConditionPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLoraL
height=height,
width=width,
num_frames=num_frames,
+ sigma=latent_sigma,
+ latents=latents,
generator=generator,
device=device,
dtype=torch.float32,
@@ -1056,21 +1143,6 @@ class LTXConditionPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLoraL
if self.do_classifier_free_guidance:
video_coords = torch.cat([video_coords, video_coords], dim=0)
- # 5. Prepare timesteps
- latent_num_frames = (num_frames - 1) // self.vae_temporal_compression_ratio + 1
- latent_height = height // self.vae_spatial_compression_ratio
- latent_width = width // self.vae_spatial_compression_ratio
- sigmas = linear_quadratic_schedule(num_inference_steps)
- timesteps = sigmas * 1000
- timesteps, num_inference_steps = retrieve_timesteps(
- self.scheduler,
- num_inference_steps,
- device,
- timesteps=timesteps,
- )
- num_warmup_steps = max(len(timesteps) - num_inference_steps * self.scheduler.order, 0)
- self._num_timesteps = len(timesteps)
-
# 6. Denoising loop
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
@@ -1120,6 +1192,12 @@ class LTXConditionPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLoraL
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
timestep, _ = timestep.chunk(2)
+ if self.guidance_rescale > 0:
+ # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ noise_pred = rescale_noise_cfg(
+ noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale
+ )
+
denoised_latents = self.scheduler.step(
-noise_pred, t, latents, per_token_timesteps=timestep, return_dict=False
)[0]
@@ -1168,7 +1246,7 @@ class LTXConditionPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLoraL
if not self.vae.config.timestep_conditioning:
timestep = None
else:
- noise = torch.randn(latents.shape, generator=generator, device=device, dtype=latents.dtype)
+ noise = randn_tensor(latents.shape, generator=generator, device=device, dtype=latents.dtype)
if not isinstance(decode_timestep, list):
decode_timestep = [decode_timestep] * batch_size
if decode_noise_scale is None:
diff --git a/src/diffusers/pipelines/ltx/pipeline_ltx_image2video.py b/src/diffusers/pipelines/ltx/pipeline_ltx_image2video.py
index 1ae67967c6..94bb63b4a4 100644
--- a/src/diffusers/pipelines/ltx/pipeline_ltx_image2video.py
+++ b/src/diffusers/pipelines/ltx/pipeline_ltx_image2video.py
@@ -159,6 +159,33 @@ def retrieve_latents(
raise AttributeError("Could not access latents of provided encoder_output")
+# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.rescale_noise_cfg
+def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
+ r"""
+ Rescales `noise_cfg` tensor based on `guidance_rescale` to improve image quality and fix overexposure. Based on
+ Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
+ Flawed](https://huggingface.co/papers/2305.08891).
+
+ Args:
+ noise_cfg (`torch.Tensor`):
+ The predicted noise tensor for the guided diffusion process.
+ noise_pred_text (`torch.Tensor`):
+ The predicted noise tensor for the text-guided diffusion process.
+ guidance_rescale (`float`, *optional*, defaults to 0.0):
+ A rescale factor applied to the noise predictions.
+
+ Returns:
+ noise_cfg (`torch.Tensor`): The rescaled noise prediction tensor.
+ """
+ std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
+ std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
+ # rescale the results from guidance (fixes overexposure)
+ noise_pred_rescaled = noise_cfg * (std_text / std_cfg)
+ # mix with the original results from guidance by factor guidance_rescale to avoid "plain looking" images
+ noise_cfg = guidance_rescale * noise_pred_rescaled + (1 - guidance_rescale) * noise_cfg
+ return noise_cfg
+
+
class LTXImageToVideoPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLoraLoaderMixin):
r"""
Pipeline for image-to-video generation.
@@ -542,6 +569,10 @@ class LTXImageToVideoPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLo
def guidance_scale(self):
return self._guidance_scale
+ @property
+ def guidance_rescale(self):
+ return self._guidance_rescale
+
@property
def do_classifier_free_guidance(self):
return self._guidance_scale > 1.0
@@ -576,6 +607,7 @@ class LTXImageToVideoPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLo
num_inference_steps: int = 50,
timesteps: List[int] = None,
guidance_scale: float = 3,
+ guidance_rescale: float = 0.0,
num_videos_per_prompt: Optional[int] = 1,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.Tensor] = None,
@@ -615,11 +647,16 @@ class LTXImageToVideoPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLo
in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
passed will be used. Must be in descending order.
guidance_scale (`float`, defaults to `3 `):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
+ guidance_rescale (`float`, *optional*, defaults to 0.0):
+ Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
+ Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Guidance rescale factor should fix overexposure when using zero terminal SNR.
num_videos_per_prompt (`int`, *optional*, defaults to 1):
The number of videos to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
@@ -688,6 +725,7 @@ class LTXImageToVideoPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLo
)
self._guidance_scale = guidance_scale
+ self._guidance_rescale = guidance_rescale
self._attention_kwargs = attention_kwargs
self._interrupt = False
self._current_timestep = None
@@ -811,6 +849,12 @@ class LTXImageToVideoPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLo
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
timestep, _ = timestep.chunk(2)
+ if self.guidance_rescale > 0:
+ # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ noise_pred = rescale_noise_cfg(
+ noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale
+ )
+
# compute the previous noisy sample x_t -> x_t-1
noise_pred = self._unpack_latents(
noise_pred,
diff --git a/src/diffusers/pipelines/ltx/pipeline_ltx_latent_upsample.py b/src/diffusers/pipelines/ltx/pipeline_ltx_latent_upsample.py
new file mode 100644
index 0000000000..49cf94e25d
--- /dev/null
+++ b/src/diffusers/pipelines/ltx/pipeline_ltx_latent_upsample.py
@@ -0,0 +1,275 @@
+# Copyright 2025 Lightricks and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from typing import List, Optional, Union
+
+import torch
+
+from ...image_processor import PipelineImageInput
+from ...models import AutoencoderKLLTXVideo
+from ...utils import get_logger
+from ...utils.torch_utils import randn_tensor
+from ...video_processor import VideoProcessor
+from ..pipeline_utils import DiffusionPipeline
+from .modeling_latent_upsampler import LTXLatentUpsamplerModel
+from .pipeline_output import LTXPipelineOutput
+
+
+logger = get_logger(__name__) # pylint: disable=invalid-name
+
+
+# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.retrieve_latents
+def retrieve_latents(
+ encoder_output: torch.Tensor, generator: Optional[torch.Generator] = None, sample_mode: str = "sample"
+):
+ if hasattr(encoder_output, "latent_dist") and sample_mode == "sample":
+ return encoder_output.latent_dist.sample(generator)
+ elif hasattr(encoder_output, "latent_dist") and sample_mode == "argmax":
+ return encoder_output.latent_dist.mode()
+ elif hasattr(encoder_output, "latents"):
+ return encoder_output.latents
+ else:
+ raise AttributeError("Could not access latents of provided encoder_output")
+
+
+class LTXLatentUpsamplePipeline(DiffusionPipeline):
+ def __init__(
+ self,
+ vae: AutoencoderKLLTXVideo,
+ latent_upsampler: LTXLatentUpsamplerModel,
+ ) -> None:
+ super().__init__()
+
+ self.register_modules(vae=vae, latent_upsampler=latent_upsampler)
+
+ self.vae_spatial_compression_ratio = (
+ self.vae.spatial_compression_ratio if getattr(self, "vae", None) is not None else 32
+ )
+ self.vae_temporal_compression_ratio = (
+ self.vae.temporal_compression_ratio if getattr(self, "vae", None) is not None else 8
+ )
+ self.video_processor = VideoProcessor(vae_scale_factor=self.vae_spatial_compression_ratio)
+
+ def prepare_latents(
+ self,
+ video: Optional[torch.Tensor] = None,
+ batch_size: int = 1,
+ dtype: Optional[torch.dtype] = None,
+ device: Optional[torch.device] = None,
+ generator: Optional[torch.Generator] = None,
+ latents: Optional[torch.Tensor] = None,
+ ) -> torch.Tensor:
+ if latents is not None:
+ return latents.to(device=device, dtype=dtype)
+
+ video = video.to(device=device, dtype=self.vae.dtype)
+ if isinstance(generator, list):
+ if len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ init_latents = [
+ retrieve_latents(self.vae.encode(video[i].unsqueeze(0)), generator[i]) for i in range(batch_size)
+ ]
+ else:
+ init_latents = [retrieve_latents(self.vae.encode(vid.unsqueeze(0)), generator) for vid in video]
+
+ init_latents = torch.cat(init_latents, dim=0).to(dtype)
+ init_latents = self._normalize_latents(init_latents, self.vae.latents_mean, self.vae.latents_std)
+ return init_latents
+
+ def adain_filter_latent(self, latents: torch.Tensor, reference_latents: torch.Tensor, factor: float = 1.0):
+ """
+ Applies Adaptive Instance Normalization (AdaIN) to a latent tensor based on statistics from a reference latent
+ tensor.
+
+ Args:
+ latent (`torch.Tensor`):
+ Input latents to normalize
+ reference_latents (`torch.Tensor`):
+ The reference latents providing style statistics.
+ factor (`float`):
+ Blending factor between original and transformed latent. Range: -10.0 to 10.0, Default: 1.0
+
+ Returns:
+ torch.Tensor: The transformed latent tensor
+ """
+ result = latents.clone()
+
+ for i in range(latents.size(0)):
+ for c in range(latents.size(1)):
+ r_sd, r_mean = torch.std_mean(reference_latents[i, c], dim=None) # index by original dim order
+ i_sd, i_mean = torch.std_mean(result[i, c], dim=None)
+
+ result[i, c] = ((result[i, c] - i_mean) / i_sd) * r_sd + r_mean
+
+ result = torch.lerp(latents, result, factor)
+ return result
+
+ @staticmethod
+ # Copied from diffusers.pipelines.ltx.pipeline_ltx.LTXPipeline._normalize_latents
+ def _normalize_latents(
+ latents: torch.Tensor, latents_mean: torch.Tensor, latents_std: torch.Tensor, scaling_factor: float = 1.0
+ ) -> torch.Tensor:
+ # Normalize latents across the channel dimension [B, C, F, H, W]
+ latents_mean = latents_mean.view(1, -1, 1, 1, 1).to(latents.device, latents.dtype)
+ latents_std = latents_std.view(1, -1, 1, 1, 1).to(latents.device, latents.dtype)
+ latents = (latents - latents_mean) * scaling_factor / latents_std
+ return latents
+
+ @staticmethod
+ # Copied from diffusers.pipelines.ltx.pipeline_ltx.LTXPipeline._denormalize_latents
+ def _denormalize_latents(
+ latents: torch.Tensor, latents_mean: torch.Tensor, latents_std: torch.Tensor, scaling_factor: float = 1.0
+ ) -> torch.Tensor:
+ # Denormalize latents across the channel dimension [B, C, F, H, W]
+ latents_mean = latents_mean.view(1, -1, 1, 1, 1).to(latents.device, latents.dtype)
+ latents_std = latents_std.view(1, -1, 1, 1, 1).to(latents.device, latents.dtype)
+ latents = latents * latents_std / scaling_factor + latents_mean
+ return latents
+
+ def enable_vae_slicing(self):
+ r"""
+ Enable sliced VAE decoding. When this option is enabled, the VAE will split the input tensor in slices to
+ compute decoding in several steps. This is useful to save some memory and allow larger batch sizes.
+ """
+ self.vae.enable_slicing()
+
+ def disable_vae_slicing(self):
+ r"""
+ Disable sliced VAE decoding. If `enable_vae_slicing` was previously enabled, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_slicing()
+
+ def enable_vae_tiling(self):
+ r"""
+ Enable tiled VAE decoding. When this option is enabled, the VAE will split the input tensor into tiles to
+ compute decoding and encoding in several steps. This is useful for saving a large amount of memory and to allow
+ processing larger images.
+ """
+ self.vae.enable_tiling()
+
+ def disable_vae_tiling(self):
+ r"""
+ Disable tiled VAE decoding. If `enable_vae_tiling` was previously enabled, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_tiling()
+
+ def check_inputs(self, video, height, width, latents):
+ if height % self.vae_spatial_compression_ratio != 0 or width % self.vae_spatial_compression_ratio != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 32 but are {height} and {width}.")
+
+ if video is not None and latents is not None:
+ raise ValueError("Only one of `video` or `latents` can be provided.")
+ if video is None and latents is None:
+ raise ValueError("One of `video` or `latents` has to be provided.")
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ video: Optional[List[PipelineImageInput]] = None,
+ height: int = 512,
+ width: int = 704,
+ latents: Optional[torch.Tensor] = None,
+ decode_timestep: Union[float, List[float]] = 0.0,
+ decode_noise_scale: Optional[Union[float, List[float]]] = None,
+ adain_factor: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ ):
+ self.check_inputs(
+ video=video,
+ height=height,
+ width=width,
+ latents=latents,
+ )
+
+ if video is not None:
+ # Batched video input is not yet tested/supported. TODO: take a look later
+ batch_size = 1
+ else:
+ batch_size = latents.shape[0]
+ device = self._execution_device
+
+ if video is not None:
+ num_frames = len(video)
+ if num_frames % self.vae_temporal_compression_ratio != 1:
+ num_frames = (
+ num_frames // self.vae_temporal_compression_ratio * self.vae_temporal_compression_ratio + 1
+ )
+ video = video[:num_frames]
+ logger.warning(
+ f"Video length expected to be of the form `k * {self.vae_temporal_compression_ratio} + 1` but is {len(video)}. Truncating to {num_frames} frames."
+ )
+ video = self.video_processor.preprocess_video(video, height=height, width=width)
+ video = video.to(device=device, dtype=torch.float32)
+
+ latents = self.prepare_latents(
+ video=video,
+ batch_size=batch_size,
+ dtype=torch.float32,
+ device=device,
+ generator=generator,
+ latents=latents,
+ )
+
+ latents = self._denormalize_latents(
+ latents, self.vae.latents_mean, self.vae.latents_std, self.vae.config.scaling_factor
+ )
+ latents = latents.to(self.latent_upsampler.dtype)
+ latents_upsampled = self.latent_upsampler(latents)
+
+ if adain_factor > 0.0:
+ latents = self.adain_filter_latent(latents_upsampled, latents, adain_factor)
+ else:
+ latents = latents_upsampled
+
+ if output_type == "latent":
+ latents = self._normalize_latents(
+ latents, self.vae.latents_mean, self.vae.latents_std, self.vae.config.scaling_factor
+ )
+ video = latents
+ else:
+ if not self.vae.config.timestep_conditioning:
+ timestep = None
+ else:
+ noise = randn_tensor(latents.shape, generator=generator, device=device, dtype=latents.dtype)
+ if not isinstance(decode_timestep, list):
+ decode_timestep = [decode_timestep] * batch_size
+ if decode_noise_scale is None:
+ decode_noise_scale = decode_timestep
+ elif not isinstance(decode_noise_scale, list):
+ decode_noise_scale = [decode_noise_scale] * batch_size
+
+ timestep = torch.tensor(decode_timestep, device=device, dtype=latents.dtype)
+ decode_noise_scale = torch.tensor(decode_noise_scale, device=device, dtype=latents.dtype)[
+ :, None, None, None, None
+ ]
+ latents = (1 - decode_noise_scale) * latents + decode_noise_scale * noise
+
+ video = self.vae.decode(latents, timestep, return_dict=False)[0]
+ video = self.video_processor.postprocess_video(video, output_type=output_type)
+
+ # Offload all models
+ self.maybe_free_model_hooks()
+
+ if not return_dict:
+ return (video,)
+
+ return LTXPipelineOutput(frames=video)
diff --git a/src/diffusers/pipelines/lumina/pipeline_lumina.py b/src/diffusers/pipelines/lumina/pipeline_lumina.py
index 22ff926afa..e10f637151 100644
--- a/src/diffusers/pipelines/lumina/pipeline_lumina.py
+++ b/src/diffusers/pipelines/lumina/pipeline_lumina.py
@@ -372,7 +372,7 @@ class LuminaPipeline(DiffusionPipeline):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -619,7 +619,7 @@ class LuminaPipeline(DiffusionPipeline):
return self._guidance_scale
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -677,11 +677,11 @@ class LuminaPipeline(DiffusionPipeline):
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
height (`int`, *optional*, defaults to self.unet.config.sample_size):
@@ -689,8 +689,8 @@ class LuminaPipeline(DiffusionPipeline):
width (`int`, *optional*, defaults to self.unet.config.sample_size):
The width in pixels of the generated image.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
@@ -771,7 +771,7 @@ class LuminaPipeline(DiffusionPipeline):
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
@@ -848,7 +848,7 @@ class LuminaPipeline(DiffusionPipeline):
# prepare image_rotary_emb for positional encoding
# dynamic scaling_factor for different resolution.
# NOTE: For `Time-aware` denosing mechanism from Lumina-Next
- # https://arxiv.org/abs/2406.18583, Sec 2.3
+ # https://huggingface.co/papers/2406.18583, Sec 2.3
# NOTE: We should compute different image_rotary_emb with different timestep.
if current_timestep[0] < scaling_watershed:
linear_factor = scaling_factor
diff --git a/src/diffusers/pipelines/lumina2/pipeline_lumina2.py b/src/diffusers/pipelines/lumina2/pipeline_lumina2.py
index e0905a2f13..1d9a1a8b22 100644
--- a/src/diffusers/pipelines/lumina2/pipeline_lumina2.py
+++ b/src/diffusers/pipelines/lumina2/pipeline_lumina2.py
@@ -342,7 +342,7 @@ class Lumina2Pipeline(DiffusionPipeline, Lumina2LoraLoaderMixin):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -487,7 +487,7 @@ class Lumina2Pipeline(DiffusionPipeline, Lumina2LoraLoaderMixin):
return self._attention_kwargs
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -544,11 +544,11 @@ class Lumina2Pipeline(DiffusionPipeline, Lumina2LoraLoaderMixin):
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
height (`int`, *optional*, defaults to self.unet.config.sample_size):
@@ -556,8 +556,8 @@ class Lumina2Pipeline(DiffusionPipeline, Lumina2LoraLoaderMixin):
width (`int`, *optional*, defaults to self.unet.config.sample_size):
The width in pixels of the generated image.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
diff --git a/src/diffusers/pipelines/mochi/pipeline_mochi.py b/src/diffusers/pipelines/mochi/pipeline_mochi.py
index d1f88b02c5..355fd80b60 100644
--- a/src/diffusers/pipelines/mochi/pipeline_mochi.py
+++ b/src/diffusers/pipelines/mochi/pipeline_mochi.py
@@ -521,11 +521,11 @@ class MochiPipeline(DiffusionPipeline, Mochi1LoraLoaderMixin):
in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
passed will be used. Must be in descending order.
guidance_scale (`float`, defaults to `4.5`):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_videos_per_prompt (`int`, *optional*, defaults to 1):
The number of videos to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
diff --git a/src/diffusers/pipelines/musicldm/pipeline_musicldm.py b/src/diffusers/pipelines/musicldm/pipeline_musicldm.py
index 73837af7d4..d28864298d 100644
--- a/src/diffusers/pipelines/musicldm/pipeline_musicldm.py
+++ b/src/diffusers/pipelines/musicldm/pipeline_musicldm.py
@@ -297,7 +297,7 @@ class MusicLDMPipeline(DiffusionPipeline, StableDiffusionMixin):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -472,8 +472,8 @@ class MusicLDMPipeline(DiffusionPipeline, StableDiffusionMixin):
and the input text. This scoring ranks the generated waveforms based on their cosine similarity to text
input in the joint text-audio embedding space.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -548,7 +548,7 @@ class MusicLDMPipeline(DiffusionPipeline, StableDiffusionMixin):
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/omnigen/pipeline_omnigen.py b/src/diffusers/pipelines/omnigen/pipeline_omnigen.py
index eb564b841e..1d15ea9cae 100644
--- a/src/diffusers/pipelines/omnigen/pipeline_omnigen.py
+++ b/src/diffusers/pipelines/omnigen/pipeline_omnigen.py
@@ -120,7 +120,7 @@ class OmniGenPipeline(
r"""
The OmniGen pipeline for multimodal-to-image generation.
- Reference: https://arxiv.org/pdf/2409.11340
+ Reference: https://huggingface.co/papers/2409.11340
Args:
transformer ([`OmniGenTransformer2DModel`]):
@@ -346,13 +346,13 @@ class OmniGenPipeline(
in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
passed will be used. Must be in descending order.
guidance_scale (`float`, *optional*, defaults to 2.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
img_guidance_scale (`float`, *optional*, defaults to 1.6):
- Defined as equation 3 in [Instrucpix2pix](https://arxiv.org/pdf/2211.09800).
+ Defined as equation 3 in [Instrucpix2pix](https://huggingface.co/papers/2211.09800).
use_input_image_size_as_output (bool, defaults to False):
whether to use the input image size as the output image size, which can be used for single-image input,
e.g., image editing task
diff --git a/src/diffusers/pipelines/omnigen/processor_omnigen.py b/src/diffusers/pipelines/omnigen/processor_omnigen.py
index 40fac01f8f..6e8c1a7e4a 100644
--- a/src/diffusers/pipelines/omnigen/processor_omnigen.py
+++ b/src/diffusers/pipelines/omnigen/processor_omnigen.py
@@ -198,7 +198,7 @@ class OmniGenCollator:
def create_mask(self, attention_mask, num_tokens_for_output_images):
"""
OmniGen applies causal attention to each element in the sequence, but applies bidirectional attention within
- each image sequence References: [OmniGen](https://arxiv.org/pdf/2409.11340)
+ each image sequence References: [OmniGen](https://huggingface.co/papers/2409.11340)
"""
extended_mask = []
padding_images = []
diff --git a/src/diffusers/pipelines/pag/pag_utils.py b/src/diffusers/pipelines/pag/pag_utils.py
index 4cd2fe4cb7..74993ccf16 100644
--- a/src/diffusers/pipelines/pag/pag_utils.py
+++ b/src/diffusers/pipelines/pag/pag_utils.py
@@ -31,7 +31,7 @@ logger = logging.get_logger(__name__) # pylint: disable=invalid-name
class PAGMixin:
- r"""Mixin class for [Pertubed Attention Guidance](https://arxiv.org/abs/2403.17377v1)."""
+ r"""Mixin class for [Pertubed Attention Guidance](https://huggingface.co/papers/2403.17377v1)."""
def _set_pag_attn_processor(self, pag_applied_layers, do_classifier_free_guidance):
r"""
diff --git a/src/diffusers/pipelines/pag/pipeline_pag_controlnet_sd.py b/src/diffusers/pipelines/pag/pipeline_pag_controlnet_sd.py
index bc90073cba..2058687629 100644
--- a/src/diffusers/pipelines/pag/pipeline_pag_controlnet_sd.py
+++ b/src/diffusers/pipelines/pag/pipeline_pag_controlnet_sd.py
@@ -541,7 +541,7 @@ class StableDiffusionControlNetPAGPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -843,7 +843,7 @@ class StableDiffusionControlNetPAGPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -933,8 +933,8 @@ class StableDiffusionControlNetPAGPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
diff --git a/src/diffusers/pipelines/pag/pipeline_pag_controlnet_sd_inpaint.py b/src/diffusers/pipelines/pag/pipeline_pag_controlnet_sd_inpaint.py
index 6d89f16765..f8a58a6654 100644
--- a/src/diffusers/pipelines/pag/pipeline_pag_controlnet_sd_inpaint.py
+++ b/src/diffusers/pipelines/pag/pipeline_pag_controlnet_sd_inpaint.py
@@ -520,7 +520,7 @@ class StableDiffusionControlNetPAGInpaintPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -955,7 +955,7 @@ class StableDiffusionControlNetPAGInpaintPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1064,8 +1064,8 @@ class StableDiffusionControlNetPAGInpaintPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
diff --git a/src/diffusers/pipelines/pag/pipeline_pag_controlnet_sd_xl.py b/src/diffusers/pipelines/pag/pipeline_pag_controlnet_sd_xl.py
index 83540885bf..259b8939ce 100644
--- a/src/diffusers/pipelines/pag/pipeline_pag_controlnet_sd_xl.py
+++ b/src/diffusers/pipelines/pag/pipeline_pag_controlnet_sd_xl.py
@@ -619,7 +619,7 @@ class StableDiffusionXLControlNetPAGPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -992,7 +992,7 @@ class StableDiffusionXLControlNetPAGPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1111,8 +1111,8 @@ class StableDiffusionXLControlNetPAGPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
diff --git a/src/diffusers/pipelines/pag/pipeline_pag_controlnet_sd_xl_img2img.py b/src/diffusers/pipelines/pag/pipeline_pag_controlnet_sd_xl_img2img.py
index 71245a75e2..dc20ea95cd 100644
--- a/src/diffusers/pipelines/pag/pipeline_pag_controlnet_sd_xl_img2img.py
+++ b/src/diffusers/pipelines/pag/pipeline_pag_controlnet_sd_xl_img2img.py
@@ -611,7 +611,7 @@ class StableDiffusionXLControlNetPAGImg2ImgPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -1074,7 +1074,7 @@ class StableDiffusionXLControlNetPAGImg2ImgPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1176,11 +1176,11 @@ class StableDiffusionXLControlNetPAGImg2ImgPipeline(
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
@@ -1191,8 +1191,8 @@ class StableDiffusionXLControlNetPAGImg2ImgPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
diff --git a/src/diffusers/pipelines/pag/pipeline_pag_hunyuandit.py b/src/diffusers/pipelines/pag/pipeline_pag_hunyuandit.py
index a6a8deb588..dc0241000a 100644
--- a/src/diffusers/pipelines/pag/pipeline_pag_hunyuandit.py
+++ b/src/diffusers/pipelines/pag/pipeline_pag_hunyuandit.py
@@ -131,7 +131,7 @@ def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
r"""
Rescales `noise_cfg` tensor based on `guidance_rescale` to improve image quality and fix overexposure. Based on
Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891).
Args:
noise_cfg (`torch.Tensor`):
@@ -443,7 +443,7 @@ class HunyuanDiTPAGPipeline(DiffusionPipeline, PAGMixin):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -566,7 +566,7 @@ class HunyuanDiTPAGPipeline(DiffusionPipeline, PAGMixin):
return self._guidance_rescale
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -638,8 +638,8 @@ class HunyuanDiTPAGPipeline(DiffusionPipeline, PAGMixin):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -675,7 +675,7 @@ class HunyuanDiTPAGPipeline(DiffusionPipeline, PAGMixin):
inputs will be passed.
guidance_rescale (`float`, *optional*, defaults to 0.0):
Rescale the noise_cfg according to `guidance_rescale`. Based on findings of [Common Diffusion Noise
- Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Schedules and Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
original_size (`Tuple[int, int]`, *optional*, defaults to `(1024, 1024)`):
The original size of the image. Used to calculate the time ids.
target_size (`Tuple[int, int]`, *optional*):
@@ -915,7 +915,7 @@ class HunyuanDiTPAGPipeline(DiffusionPipeline, PAGMixin):
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/src/diffusers/pipelines/pag/pipeline_pag_kolors.py b/src/diffusers/pipelines/pag/pipeline_pag_kolors.py
index 62f634312a..903d754fbf 100644
--- a/src/diffusers/pipelines/pag/pipeline_pag_kolors.py
+++ b/src/diffusers/pipelines/pag/pipeline_pag_kolors.py
@@ -453,7 +453,7 @@ class KolorsPAGPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -651,7 +651,7 @@ class KolorsPAGPipeline(
return self._guidance_scale
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -749,11 +749,11 @@ class KolorsPAGPipeline(
"Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output)
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
@@ -761,8 +761,8 @@ class KolorsPAGPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
diff --git a/src/diffusers/pipelines/pag/pipeline_pag_pixart_sigma.py b/src/diffusers/pipelines/pag/pipeline_pag_pixart_sigma.py
index 71ee5879d0..75c061dcee 100644
--- a/src/diffusers/pipelines/pag/pipeline_pag_pixart_sigma.py
+++ b/src/diffusers/pipelines/pag/pipeline_pag_pixart_sigma.py
@@ -326,7 +326,7 @@ class PixArtSigmaPAGPipeline(DiffusionPipeline, PAGMixin):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -624,11 +624,11 @@ class PixArtSigmaPAGPipeline(DiffusionPipeline, PAGMixin):
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, *optional*, defaults to 4.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
height (`int`, *optional*, defaults to self.unet.config.sample_size):
@@ -636,8 +636,8 @@ class PixArtSigmaPAGPipeline(DiffusionPipeline, PAGMixin):
width (`int`, *optional*, defaults to self.unet.config.sample_size):
The width in pixels of the generated image.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
@@ -729,7 +729,7 @@ class PixArtSigmaPAGPipeline(DiffusionPipeline, PAGMixin):
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/pag/pipeline_pag_sana.py b/src/diffusers/pipelines/pag/pipeline_pag_sana.py
index a233f70136..02ede6c3d6 100644
--- a/src/diffusers/pipelines/pag/pipeline_pag_sana.py
+++ b/src/diffusers/pipelines/pag/pipeline_pag_sana.py
@@ -363,7 +363,7 @@ class SanaPAGPipeline(DiffusionPipeline, PAGMixin):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -683,11 +683,11 @@ class SanaPAGPipeline(DiffusionPipeline, PAGMixin):
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, *optional*, defaults to 4.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
height (`int`, *optional*, defaults to self.unet.config.sample_size):
@@ -695,8 +695,8 @@ class SanaPAGPipeline(DiffusionPipeline, PAGMixin):
width (`int`, *optional*, defaults to self.unet.config.sample_size):
The width in pixels of the generated image.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
diff --git a/src/diffusers/pipelines/pag/pipeline_pag_sd.py b/src/diffusers/pipelines/pag/pipeline_pag_sd.py
index fc7dc3a83f..839ecb67bc 100644
--- a/src/diffusers/pipelines/pag/pipeline_pag_sd.py
+++ b/src/diffusers/pipelines/pag/pipeline_pag_sd.py
@@ -72,7 +72,7 @@ def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
r"""
Rescales `noise_cfg` tensor based on `guidance_rescale` to improve image quality and fix overexposure. Based on
Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891).
Args:
noise_cfg (`torch.Tensor`):
@@ -573,7 +573,7 @@ class StableDiffusionPAGPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -724,7 +724,7 @@ class StableDiffusionPAGPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -802,8 +802,8 @@ class StableDiffusionPAGPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -833,7 +833,7 @@ class StableDiffusionPAGPipeline(
[`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf). Guidance rescale factor should fix overexposure when
+ Flawed](https://huggingface.co/papers/2305.08891). Guidance rescale factor should fix overexposure when
using zero terminal SNR.
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
@@ -1027,7 +1027,7 @@ class StableDiffusionPAGPipeline(
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/src/diffusers/pipelines/pag/pipeline_pag_sd_3.py b/src/diffusers/pipelines/pag/pipeline_pag_sd_3.py
index fde3e500a5..38cc72fb8e 100644
--- a/src/diffusers/pipelines/pag/pipeline_pag_sd_3.py
+++ b/src/diffusers/pipelines/pag/pipeline_pag_sd_3.py
@@ -663,7 +663,7 @@ class StableDiffusion3PAGPipeline(DiffusionPipeline, SD3LoraLoaderMixin, FromSin
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -738,11 +738,11 @@ class StableDiffusion3PAGPipeline(DiffusionPipeline, SD3LoraLoaderMixin, FromSin
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, *optional*, defaults to 7.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
diff --git a/src/diffusers/pipelines/pag/pipeline_pag_sd_3_img2img.py b/src/diffusers/pipelines/pag/pipeline_pag_sd_3_img2img.py
index d64582a26f..0575c8a67c 100644
--- a/src/diffusers/pipelines/pag/pipeline_pag_sd_3_img2img.py
+++ b/src/diffusers/pipelines/pag/pipeline_pag_sd_3_img2img.py
@@ -714,7 +714,7 @@ class StableDiffusion3PAGImg2ImgPipeline(DiffusionPipeline, SD3LoraLoaderMixin,
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -799,11 +799,11 @@ class StableDiffusion3PAGImg2ImgPipeline(DiffusionPipeline, SD3LoraLoaderMixin,
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, *optional*, defaults to 7.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
diff --git a/src/diffusers/pipelines/pag/pipeline_pag_sd_animatediff.py b/src/diffusers/pipelines/pag/pipeline_pag_sd_animatediff.py
index d3a015e569..22cf88515c 100644
--- a/src/diffusers/pipelines/pag/pipeline_pag_sd_animatediff.py
+++ b/src/diffusers/pipelines/pag/pipeline_pag_sd_animatediff.py
@@ -438,7 +438,7 @@ class AnimateDiffPAGPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -520,7 +520,7 @@ class AnimateDiffPAGPipeline(
def prepare_latents(
self, batch_size, num_channels_latents, num_frames, height, width, dtype, device, generator, latents=None
):
- # If FreeNoise is enabled, generate latents as described in Equation (7) of [FreeNoise](https://arxiv.org/abs/2310.15169)
+ # If FreeNoise is enabled, generate latents as described in Equation (7) of [FreeNoise](https://huggingface.co/papers/2310.15169)
if self.free_noise_enabled:
latents = self._prepare_latents_free_noise(
batch_size, num_channels_latents, num_frames, height, width, dtype, device, generator, latents
@@ -558,7 +558,7 @@ class AnimateDiffPAGPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -624,8 +624,8 @@ class AnimateDiffPAGPipeline(
The prompt or prompts to guide what to not include in image generation. If not defined, you need to
pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
diff --git a/src/diffusers/pipelines/pag/pipeline_pag_sd_img2img.py b/src/diffusers/pipelines/pag/pipeline_pag_sd_img2img.py
index d91c02b607..5c0d65fbbd 100644
--- a/src/diffusers/pipelines/pag/pipeline_pag_sd_img2img.py
+++ b/src/diffusers/pipelines/pag/pipeline_pag_sd_img2img.py
@@ -568,7 +568,7 @@ class StableDiffusionPAGImg2ImgPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -761,7 +761,7 @@ class StableDiffusionPAGImg2ImgPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -847,8 +847,8 @@ class StableDiffusionPAGImg2ImgPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
diff --git a/src/diffusers/pipelines/pag/pipeline_pag_sd_inpaint.py b/src/diffusers/pipelines/pag/pipeline_pag_sd_inpaint.py
index db652989cf..c5d89bf285 100644
--- a/src/diffusers/pipelines/pag/pipeline_pag_sd_inpaint.py
+++ b/src/diffusers/pipelines/pag/pipeline_pag_sd_inpaint.py
@@ -99,7 +99,7 @@ def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
r"""
Rescales `noise_cfg` tensor based on `guidance_rescale` to improve image quality and fix overexposure. Based on
Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891).
Args:
noise_cfg (`torch.Tensor`):
@@ -603,7 +603,7 @@ class StableDiffusionPAGInpaintPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -889,7 +889,7 @@ class StableDiffusionPAGInpaintPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -972,8 +972,8 @@ class StableDiffusionPAGInpaintPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -1003,7 +1003,7 @@ class StableDiffusionPAGInpaintPipeline(
[`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf). Guidance rescale factor should fix overexposure when
+ Flawed](https://huggingface.co/papers/2305.08891). Guidance rescale factor should fix overexposure when
using zero terminal SNR.
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
@@ -1294,7 +1294,7 @@ class StableDiffusionPAGInpaintPipeline(
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/src/diffusers/pipelines/pag/pipeline_pag_sd_xl.py b/src/diffusers/pipelines/pag/pipeline_pag_sd_xl.py
index 856f6a3e78..2b7a8cb86f 100644
--- a/src/diffusers/pipelines/pag/pipeline_pag_sd_xl.py
+++ b/src/diffusers/pipelines/pag/pipeline_pag_sd_xl.py
@@ -91,7 +91,7 @@ def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
r"""
Rescales `noise_cfg` tensor based on `guidance_rescale` to improve image quality and fix overexposure. Based on
Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891).
Args:
noise_cfg (`torch.Tensor`):
@@ -607,7 +607,7 @@ class StableDiffusionXLPAGPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -823,7 +823,7 @@ class StableDiffusionXLPAGPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -925,11 +925,11 @@ class StableDiffusionXLPAGPipeline(
"Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output)
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
@@ -940,8 +940,8 @@ class StableDiffusionXLPAGPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
@@ -981,9 +981,10 @@ class StableDiffusionXLPAGPipeline(
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
- [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
- Guidance rescale factor should fix overexposure when using zero terminal SNR.
+ Flawed](https://huggingface.co/papers/2305.08891) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are
+ Flawed](https://huggingface.co/papers/2305.08891). Guidance rescale factor should fix overexposure when
+ using zero terminal SNR.
original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
`original_size` defaults to `(height, width)` if not specified. Part of SDXL's micro-conditioning as
@@ -1266,7 +1267,7 @@ class StableDiffusionXLPAGPipeline(
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/src/diffusers/pipelines/pag/pipeline_pag_sd_xl_img2img.py b/src/diffusers/pipelines/pag/pipeline_pag_sd_xl_img2img.py
index 93dcca0ea9..92eb45a72e 100644
--- a/src/diffusers/pipelines/pag/pipeline_pag_sd_xl_img2img.py
+++ b/src/diffusers/pipelines/pag/pipeline_pag_sd_xl_img2img.py
@@ -95,7 +95,7 @@ def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
r"""
Rescales `noise_cfg` tensor based on `guidance_rescale` to improve image quality and fix overexposure. Based on
Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891).
Args:
noise_cfg (`torch.Tensor`):
@@ -553,7 +553,7 @@ class StableDiffusionXLPAGImg2ImgPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -970,7 +970,7 @@ class StableDiffusionXLPAGImg2ImgPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1088,11 +1088,11 @@ class StableDiffusionXLPAGImg2ImgPipeline(
forms a part of a "Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refine Image
Quality**](https://huggingface.co/docs/diffusers/using-diffusers/sdxl#refine-image-quality).
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
@@ -1103,8 +1103,8 @@ class StableDiffusionXLPAGImg2ImgPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
@@ -1144,9 +1144,10 @@ class StableDiffusionXLPAGImg2ImgPipeline(
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
- [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
- Guidance rescale factor should fix overexposure when using zero terminal SNR.
+ Flawed](https://huggingface.co/papers/2305.08891) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are
+ Flawed](https://huggingface.co/papers/2305.08891). Guidance rescale factor should fix overexposure when
+ using zero terminal SNR.
original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
`original_size` defaults to `(height, width)` if not specified. Part of SDXL's micro-conditioning as
@@ -1461,7 +1462,7 @@ class StableDiffusionXLPAGImg2ImgPipeline(
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/src/diffusers/pipelines/pag/pipeline_pag_sd_xl_inpaint.py b/src/diffusers/pipelines/pag/pipeline_pag_sd_xl_inpaint.py
index 8b06bdc9c9..d1301feb8a 100644
--- a/src/diffusers/pipelines/pag/pipeline_pag_sd_xl_inpaint.py
+++ b/src/diffusers/pipelines/pag/pipeline_pag_sd_xl_inpaint.py
@@ -108,7 +108,7 @@ def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
r"""
Rescales `noise_cfg` tensor based on `guidance_rescale` to improve image quality and fix overexposure. Based on
Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891).
Args:
noise_cfg (`torch.Tensor`):
@@ -643,7 +643,7 @@ class StableDiffusionXLPAGInpaintPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -1061,7 +1061,7 @@ class StableDiffusionXLPAGInpaintPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1208,11 +1208,11 @@ class StableDiffusionXLPAGInpaintPipeline(
forms a part of a "Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output).
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
@@ -1243,8 +1243,8 @@ class StableDiffusionXLPAGInpaintPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
@@ -1673,7 +1673,7 @@ class StableDiffusionXLPAGInpaintPipeline(
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/src/diffusers/pipelines/paint_by_example/pipeline_paint_by_example.py b/src/diffusers/pipelines/paint_by_example/pipeline_paint_by_example.py
index 288f269a65..3e18fd0419 100644
--- a/src/diffusers/pipelines/paint_by_example/pipeline_paint_by_example.py
+++ b/src/diffusers/pipelines/paint_by_example/pipeline_paint_by_example.py
@@ -239,7 +239,7 @@ class PaintByExamplePipeline(DiffusionPipeline, StableDiffusionMixin):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -447,8 +447,8 @@ class PaintByExamplePipeline(DiffusionPipeline, StableDiffusionMixin):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -521,7 +521,7 @@ class PaintByExamplePipeline(DiffusionPipeline, StableDiffusionMixin):
batch_size = image.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/pia/pipeline_pia.py b/src/diffusers/pipelines/pia/pipeline_pia.py
index df8499ab90..44d6c3a4b2 100644
--- a/src/diffusers/pipelines/pia/pipeline_pia.py
+++ b/src/diffusers/pipelines/pia/pipeline_pia.py
@@ -432,7 +432,7 @@ class PIAPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -653,7 +653,7 @@ class PIAPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -723,8 +723,8 @@ class PIAPipeline(
The prompt or prompts to guide what to not include in image generation. If not defined, you need to
pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
diff --git a/src/diffusers/pipelines/pipeline_flax_utils.py b/src/diffusers/pipelines/pipeline_flax_utils.py
index 54ab7d19e3..7c5ac89602 100644
--- a/src/diffusers/pipelines/pipeline_flax_utils.py
+++ b/src/diffusers/pipelines/pipeline_flax_utils.py
@@ -248,9 +248,8 @@ class FlaxDiffusionPipeline(ConfigMixin, PushToHubMixin):
pretrained pipeline hosted on the Hub.
- A path to a *directory* (for example `./my_model_directory`) containing the model weights saved
using [`~FlaxDiffusionPipeline.save_pretrained`].
- dtype (`str` or `jnp.dtype`, *optional*):
- Override the default `jnp.dtype` and load the model under this dtype. If `"auto"`, the dtype is
- automatically derived from the model's weights.
+ dtype (`jnp.dtype`, *optional*):
+ Override the default `jnp.dtype` and load the model under this dtype.
force_download (`bool`, *optional*, defaults to `False`):
Whether or not to force the (re-)download of the model weights and configuration files, overriding the
cached versions if they exist.
diff --git a/src/diffusers/pipelines/pipeline_loading_utils.py b/src/diffusers/pipelines/pipeline_loading_utils.py
index 9788d758e9..7132e9521f 100644
--- a/src/diffusers/pipelines/pipeline_loading_utils.py
+++ b/src/diffusers/pipelines/pipeline_loading_utils.py
@@ -92,7 +92,7 @@ for library in LOADABLE_CLASSES:
ALL_IMPORTABLE_CLASSES.update(LOADABLE_CLASSES[library])
-def is_safetensors_compatible(filenames, passed_components=None, folder_names=None) -> bool:
+def is_safetensors_compatible(filenames, passed_components=None, folder_names=None, variant=None) -> bool:
"""
Checking for safetensors compatibility:
- The model is safetensors compatible only if there is a safetensors file for each model component present in
@@ -103,6 +103,31 @@ def is_safetensors_compatible(filenames, passed_components=None, folder_names=No
- For models from the transformers library, the filename changes from "pytorch_model" to "model", and the ".bin"
extension is replaced with ".safetensors"
"""
+ weight_names = [
+ WEIGHTS_NAME,
+ SAFETENSORS_WEIGHTS_NAME,
+ FLAX_WEIGHTS_NAME,
+ ONNX_WEIGHTS_NAME,
+ ONNX_EXTERNAL_WEIGHTS_NAME,
+ ]
+
+ if is_transformers_available():
+ weight_names += [TRANSFORMERS_WEIGHTS_NAME, TRANSFORMERS_SAFE_WEIGHTS_NAME, TRANSFORMERS_FLAX_WEIGHTS_NAME]
+
+ # model_pytorch, diffusion_model_pytorch, ...
+ weight_prefixes = [w.split(".")[0] for w in weight_names]
+ # .bin, .safetensors, ...
+ weight_suffixs = [w.split(".")[-1] for w in weight_names]
+ # -00001-of-00002
+ transformers_index_format = r"\d{5}-of-\d{5}"
+ # `diffusion_pytorch_model.bin` as well as `model-00001-of-00002.safetensors`
+ variant_file_re = re.compile(
+ rf"({'|'.join(weight_prefixes)})\.({variant}|{variant}-{transformers_index_format})\.({'|'.join(weight_suffixs)})$"
+ )
+ non_variant_file_re = re.compile(
+ rf"({'|'.join(weight_prefixes)})(-{transformers_index_format})?\.({'|'.join(weight_suffixs)})$"
+ )
+
passed_components = passed_components or []
if folder_names:
filenames = {f for f in filenames if os.path.split(f)[0] in folder_names}
@@ -121,15 +146,29 @@ def is_safetensors_compatible(filenames, passed_components=None, folder_names=No
components[component].append(component_filename)
# If there are no component folders check the main directory for safetensors files
+ filtered_filenames = set()
if not components:
- return any(".safetensors" in filename for filename in filenames)
+ if variant is not None:
+ filtered_filenames = filter_with_regex(filenames, variant_file_re)
+
+ # If no variant filenames exist check if non-variant files are available
+ if not filtered_filenames:
+ filtered_filenames = filter_with_regex(filenames, non_variant_file_re)
+ return any(".safetensors" in filename for filename in filtered_filenames)
# iterate over all files of a component
# check if safetensor files exist for that component
- # if variant is provided check if the variant of the safetensors exists
for component, component_filenames in components.items():
matches = []
- for component_filename in component_filenames:
+ filtered_component_filenames = set()
+ # if variant is provided check if the variant of the safetensors exists
+ if variant is not None:
+ filtered_component_filenames = filter_with_regex(component_filenames, variant_file_re)
+
+ # if variant safetensor files do not exist check for non-variants
+ if not filtered_component_filenames:
+ filtered_component_filenames = filter_with_regex(component_filenames, non_variant_file_re)
+ for component_filename in filtered_component_filenames:
filename, extension = os.path.splitext(component_filename)
match_exists = extension == ".safetensors"
@@ -159,6 +198,10 @@ def filter_model_files(filenames):
return [f for f in filenames if any(f.endswith(extension) for extension in allowed_extensions)]
+def filter_with_regex(filenames, pattern_re):
+ return {f for f in filenames if pattern_re.match(f.split("/")[-1]) is not None}
+
+
def variant_compatible_siblings(filenames, variant=None, ignore_patterns=None) -> Union[List[os.PathLike], str]:
weight_names = [
WEIGHTS_NAME,
@@ -207,9 +250,6 @@ def variant_compatible_siblings(filenames, variant=None, ignore_patterns=None) -
# interested in the extension name
return {f for f in filenames if not any(f.endswith(pat.lstrip("*.")) for pat in ignore_patterns)}
- def filter_with_regex(filenames, pattern_re):
- return {f for f in filenames if pattern_re.match(f.split("/")[-1]) is not None}
-
# Group files by component
components = {}
for filename in filenames:
@@ -335,14 +375,14 @@ def get_class_obj_and_candidates(
library_name, class_name, importable_classes, pipelines, is_pipeline_module, component_name=None, cache_dir=None
):
"""Simple helper method to retrieve class object of module as well as potential parent class objects"""
- component_folder = os.path.join(cache_dir, component_name)
+ component_folder = os.path.join(cache_dir, component_name) if component_name and cache_dir else None
if is_pipeline_module:
pipeline_module = getattr(pipelines, library_name)
class_obj = getattr(pipeline_module, class_name)
class_candidates = dict.fromkeys(importable_classes.keys(), class_obj)
- elif os.path.isfile(os.path.join(component_folder, library_name + ".py")):
+ elif component_folder and os.path.isfile(os.path.join(component_folder, library_name + ".py")):
# load custom component
class_obj = get_class_from_dynamic_module(
component_folder, module_file=library_name + ".py", class_name=class_name
@@ -675,8 +715,10 @@ def load_sub_model(
use_safetensors: bool,
dduf_entries: Optional[Dict[str, DDUFEntry]],
provider_options: Any,
+ quantization_config: Optional[Any] = None,
):
"""Helper method to load the module `name` from `library_name` and `class_name`"""
+ from ..quantizers import PipelineQuantizationConfig
# retrieve class candidates
@@ -769,6 +811,17 @@ def load_sub_model(
else:
loading_kwargs["low_cpu_mem_usage"] = False
+ if (
+ quantization_config is not None
+ and isinstance(quantization_config, PipelineQuantizationConfig)
+ and issubclass(class_obj, torch.nn.Module)
+ ):
+ model_quant_config = quantization_config._resolve_quant_config(
+ is_diffusers=is_diffusers_model, module_name=name
+ )
+ if model_quant_config is not None:
+ loading_kwargs["quantization_config"] = model_quant_config
+
# check if the module is in a subdirectory
if dduf_entries:
loading_kwargs["dduf_entries"] = dduf_entries
@@ -984,7 +1037,7 @@ def _get_ignore_patterns(
use_safetensors
and not allow_pickle
and not is_safetensors_compatible(
- model_filenames, passed_components=passed_components, folder_names=model_folder_names
+ model_filenames, passed_components=passed_components, folder_names=model_folder_names, variant=variant
)
):
raise EnvironmentError(
@@ -995,7 +1048,7 @@ def _get_ignore_patterns(
ignore_patterns = ["*.bin", "*.safetensors", "*.onnx", "*.pb"]
elif use_safetensors and is_safetensors_compatible(
- model_filenames, passed_components=passed_components, folder_names=model_folder_names
+ model_filenames, passed_components=passed_components, folder_names=model_folder_names, variant=variant
):
ignore_patterns = ["*.bin", "*.msgpack"]
diff --git a/src/diffusers/pipelines/pipeline_utils.py b/src/diffusers/pipelines/pipeline_utils.py
index 3be3e46ca4..8184573b02 100644
--- a/src/diffusers/pipelines/pipeline_utils.py
+++ b/src/diffusers/pipelines/pipeline_utils.py
@@ -47,6 +47,7 @@ from ..configuration_utils import ConfigMixin
from ..models import AutoencoderKL
from ..models.attention_processor import FusedAttnProcessor2_0
from ..models.modeling_utils import _LOW_CPU_MEM_USAGE_DEFAULT, ModelMixin
+from ..quantizers import PipelineQuantizationConfig
from ..quantizers.bitsandbytes.utils import _check_bnb_status
from ..schedulers.scheduling_utils import SCHEDULER_CONFIG_NAME
from ..utils import (
@@ -572,12 +573,12 @@ class DiffusionPipeline(ConfigMixin, PushToHubMixin):
saved using
[`~DiffusionPipeline.save_pretrained`].
- A path to a *directory* (for example `./my_pipeline_directory/`) containing a dduf file
- torch_dtype (`str` or `torch.dtype` or `dict[str, Union[str, torch.dtype]]`, *optional*):
- Override the default `torch.dtype` and load the model with another dtype. If "auto" is passed, the
- dtype is automatically derived from the model's weights. To load submodels with different dtype pass a
- `dict` (for example `{'transformer': torch.bfloat16, 'vae': torch.float16}`). Set the default dtype for
- unspecified components with `default` (for example `{'transformer': torch.bfloat16, 'default':
- torch.float16}`). If a component is not specified and no default is set, `torch.float32` is used.
+ torch_dtype (`torch.dtype` or `dict[str, Union[str, torch.dtype]]`, *optional*):
+ Override the default `torch.dtype` and load the model with another dtype. To load submodels with
+ different dtype pass a `dict` (for example `{'transformer': torch.bfloat16, 'vae': torch.float16}`).
+ Set the default dtype for unspecified components with `default` (for example `{'transformer':
+ torch.bfloat16, 'default': torch.float16}`). If a component is not specified and no default is set,
+ `torch.float32` is used.
custom_pipeline (`str`, *optional*):
@@ -725,6 +726,7 @@ class DiffusionPipeline(ConfigMixin, PushToHubMixin):
use_safetensors = kwargs.pop("use_safetensors", None)
use_onnx = kwargs.pop("use_onnx", None)
load_connected_pipeline = kwargs.pop("load_connected_pipeline", False)
+ quantization_config = kwargs.pop("quantization_config", None)
if torch_dtype is not None and not isinstance(torch_dtype, dict) and not isinstance(torch_dtype, torch.dtype):
torch_dtype = torch.float32
@@ -741,6 +743,9 @@ class DiffusionPipeline(ConfigMixin, PushToHubMixin):
" install accelerate\n```\n."
)
+ if quantization_config is not None and not isinstance(quantization_config, PipelineQuantizationConfig):
+ raise ValueError("`quantization_config` must be an instance of `PipelineQuantizationConfig`.")
+
if low_cpu_mem_usage is True and not is_torch_version(">=", "1.9.0"):
raise NotImplementedError(
"Low memory initialization requires torch >= 1.9.0. Please either update your PyTorch version or set"
@@ -1001,6 +1006,7 @@ class DiffusionPipeline(ConfigMixin, PushToHubMixin):
use_safetensors=use_safetensors,
dduf_entries=dduf_entries,
provider_options=provider_options,
+ quantization_config=quantization_config,
)
logger.info(
f"Loaded {name} as {class_name} from `{name}` subfolder of {pretrained_model_name_or_path}."
@@ -1659,6 +1665,8 @@ class DiffusionPipeline(ConfigMixin, PushToHubMixin):
signature_types[k] = (v.annotation,)
elif get_origin(v.annotation) == Union:
signature_types[k] = get_args(v.annotation)
+ elif get_origin(v.annotation) in [List, Dict, list, dict]:
+ signature_types[k] = (v.annotation,)
else:
logger.warning(f"cannot get type annotation for Parameter {k} of {cls}.")
return signature_types
@@ -2021,7 +2029,7 @@ class StableDiffusionMixin:
self.vae.disable_tiling()
def enable_freeu(self, s1: float, s2: float, b1: float, b2: float):
- r"""Enables the FreeU mechanism as in https://arxiv.org/abs/2309.11497.
+ r"""Enables the FreeU mechanism as in https://huggingface.co/papers/2309.11497.
The suffixes after the scaling factors represent the stages where they are being applied.
diff --git a/src/diffusers/pipelines/pixart_alpha/pipeline_pixart_alpha.py b/src/diffusers/pipelines/pixart_alpha/pipeline_pixart_alpha.py
index 79e007fea3..5a7be1ab6d 100644
--- a/src/diffusers/pipelines/pixart_alpha/pipeline_pixart_alpha.py
+++ b/src/diffusers/pipelines/pixart_alpha/pipeline_pixart_alpha.py
@@ -437,7 +437,7 @@ class PixArtAlphaPipeline(DiffusionPipeline):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -733,11 +733,11 @@ class PixArtAlphaPipeline(DiffusionPipeline):
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, *optional*, defaults to 4.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
height (`int`, *optional*, defaults to self.unet.config.sample_size):
@@ -745,8 +745,8 @@ class PixArtAlphaPipeline(DiffusionPipeline):
width (`int`, *optional*, defaults to self.unet.config.sample_size):
The width in pixels of the generated image.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
@@ -832,7 +832,7 @@ class PixArtAlphaPipeline(DiffusionPipeline):
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/pixart_alpha/pipeline_pixart_sigma.py b/src/diffusers/pipelines/pixart_alpha/pipeline_pixart_sigma.py
index 14f4bdcce8..6324490fc9 100644
--- a/src/diffusers/pipelines/pixart_alpha/pipeline_pixart_sigma.py
+++ b/src/diffusers/pipelines/pixart_alpha/pipeline_pixart_sigma.py
@@ -363,7 +363,7 @@ class PixArtSigmaPipeline(DiffusionPipeline):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -660,11 +660,11 @@ class PixArtSigmaPipeline(DiffusionPipeline):
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, *optional*, defaults to 4.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
height (`int`, *optional*, defaults to self.unet.config.sample_size):
@@ -672,8 +672,8 @@ class PixArtSigmaPipeline(DiffusionPipeline):
width (`int`, *optional*, defaults to self.unet.config.sample_size):
The width in pixels of the generated image.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
@@ -758,7 +758,7 @@ class PixArtSigmaPipeline(DiffusionPipeline):
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/sana/__init__.py b/src/diffusers/pipelines/sana/__init__.py
index 5f188ca508..91684f35f1 100644
--- a/src/diffusers/pipelines/sana/__init__.py
+++ b/src/diffusers/pipelines/sana/__init__.py
@@ -25,6 +25,7 @@ else:
_import_structure["pipeline_sana"] = ["SanaPipeline"]
_import_structure["pipeline_sana_controlnet"] = ["SanaControlNetPipeline"]
_import_structure["pipeline_sana_sprint"] = ["SanaSprintPipeline"]
+ _import_structure["pipeline_sana_sprint_img2img"] = ["SanaSprintImg2ImgPipeline"]
if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
try:
@@ -37,6 +38,7 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
from .pipeline_sana import SanaPipeline
from .pipeline_sana_controlnet import SanaControlNetPipeline
from .pipeline_sana_sprint import SanaSprintPipeline
+ from .pipeline_sana_sprint_img2img import SanaSprintImg2ImgPipeline
else:
import sys
diff --git a/src/diffusers/pipelines/sana/pipeline_sana.py b/src/diffusers/pipelines/sana/pipeline_sana.py
index 34b84a89e6..6c2c1fb0a8 100644
--- a/src/diffusers/pipelines/sana/pipeline_sana.py
+++ b/src/diffusers/pipelines/sana/pipeline_sana.py
@@ -440,7 +440,7 @@ class SanaPipeline(DiffusionPipeline, SanaLoraLoaderMixin):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -761,11 +761,11 @@ class SanaPipeline(DiffusionPipeline, SanaLoraLoaderMixin):
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, *optional*, defaults to 4.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
height (`int`, *optional*, defaults to self.unet.config.sample_size):
@@ -773,8 +773,8 @@ class SanaPipeline(DiffusionPipeline, SanaLoraLoaderMixin):
width (`int`, *optional*, defaults to self.unet.config.sample_size):
The width in pixels of the generated image.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
diff --git a/src/diffusers/pipelines/sana/pipeline_sana_controlnet.py b/src/diffusers/pipelines/sana/pipeline_sana_controlnet.py
index a7c7d027fb..593e0895e4 100644
--- a/src/diffusers/pipelines/sana/pipeline_sana_controlnet.py
+++ b/src/diffusers/pipelines/sana/pipeline_sana_controlnet.py
@@ -455,7 +455,7 @@ class SanaControlNetPipeline(DiffusionPipeline, SanaLoraLoaderMixin):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -812,11 +812,11 @@ class SanaControlNetPipeline(DiffusionPipeline, SanaLoraLoaderMixin):
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, *optional*, defaults to 4.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
control_image (`torch.Tensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.Tensor]`, `List[PIL.Image.Image]`, `List[np.ndarray]`,:
`List[List[torch.Tensor]]`, `List[List[np.ndarray]]` or `List[List[PIL.Image.Image]]`):
The ControlNet input condition to provide guidance to the `unet` for generation. If the type is
@@ -836,8 +836,8 @@ class SanaControlNetPipeline(DiffusionPipeline, SanaLoraLoaderMixin):
width (`int`, *optional*, defaults to self.unet.config.sample_size):
The width in pixels of the generated image.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
diff --git a/src/diffusers/pipelines/sana/pipeline_sana_sprint.py b/src/diffusers/pipelines/sana/pipeline_sana_sprint.py
index 03b306b539..46edbf7c33 100644
--- a/src/diffusers/pipelines/sana/pipeline_sana_sprint.py
+++ b/src/diffusers/pipelines/sana/pipeline_sana_sprint.py
@@ -347,7 +347,7 @@ class SanaSprintPipeline(DiffusionPipeline, SanaLoraLoaderMixin):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -643,11 +643,11 @@ class SanaSprintPipeline(DiffusionPipeline, SanaLoraLoaderMixin):
in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
passed will be used. Must be in descending order.
guidance_scale (`float`, *optional*, defaults to 4.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
height (`int`, *optional*, defaults to self.unet.config.sample_size):
@@ -655,8 +655,8 @@ class SanaSprintPipeline(DiffusionPipeline, SanaLoraLoaderMixin):
width (`int`, *optional*, defaults to self.unet.config.sample_size):
The width in pixels of the generated image.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
diff --git a/src/diffusers/pipelines/sana/pipeline_sana_sprint_img2img.py b/src/diffusers/pipelines/sana/pipeline_sana_sprint_img2img.py
new file mode 100644
index 0000000000..f71b980ffc
--- /dev/null
+++ b/src/diffusers/pipelines/sana/pipeline_sana_sprint_img2img.py
@@ -0,0 +1,975 @@
+# Copyright 2024 PixArt-Sigma Authors and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import html
+import inspect
+import re
+import urllib.parse as ul
+import warnings
+from typing import Any, Callable, Dict, List, Optional, Tuple, Union
+
+import torch
+import torch.nn.functional as F
+from transformers import Gemma2PreTrainedModel, GemmaTokenizer, GemmaTokenizerFast
+
+from ...callbacks import MultiPipelineCallbacks, PipelineCallback
+from ...image_processor import PipelineImageInput, PixArtImageProcessor
+from ...loaders import SanaLoraLoaderMixin
+from ...models import AutoencoderDC, SanaTransformer2DModel
+from ...schedulers import DPMSolverMultistepScheduler
+from ...utils import (
+ BACKENDS_MAPPING,
+ USE_PEFT_BACKEND,
+ is_bs4_available,
+ is_ftfy_available,
+ is_torch_xla_available,
+ logging,
+ replace_example_docstring,
+ scale_lora_layers,
+ unscale_lora_layers,
+)
+from ...utils.torch_utils import randn_tensor
+from ..pipeline_utils import DiffusionPipeline
+from ..pixart_alpha.pipeline_pixart_alpha import ASPECT_RATIO_1024_BIN
+from .pipeline_output import SanaPipelineOutput
+
+
+if is_torch_xla_available():
+ import torch_xla.core.xla_model as xm
+
+ XLA_AVAILABLE = True
+else:
+ XLA_AVAILABLE = False
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+if is_bs4_available():
+ from bs4 import BeautifulSoup
+
+if is_ftfy_available():
+ import ftfy
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> import torch
+ >>> from diffusers import SanaSprintImg2ImgPipeline
+ >>> from diffusers.utils.loading_utils import load_image
+
+ >>> pipe = SanaSprintImg2ImgPipeline.from_pretrained(
+ ... "Efficient-Large-Model/Sana_Sprint_1.6B_1024px_diffusers", torch_dtype=torch.bfloat16
+ ... )
+ >>> pipe.to("cuda")
+
+ >>> image = load_image(
+ ... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/penguin.png"
+ ... )
+
+
+ >>> image = pipe(prompt="a cute pink bear", image=image, strength=0.5, height=832, width=480).images[0]
+ >>> image[0].save("output.png")
+ ```
+"""
+
+
+# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.retrieve_timesteps
+def retrieve_timesteps(
+ scheduler,
+ num_inference_steps: Optional[int] = None,
+ device: Optional[Union[str, torch.device]] = None,
+ timesteps: Optional[List[int]] = None,
+ sigmas: Optional[List[float]] = None,
+ **kwargs,
+):
+ r"""
+ Calls the scheduler's `set_timesteps` method and retrieves timesteps from the scheduler after the call. Handles
+ custom timesteps. Any kwargs will be supplied to `scheduler.set_timesteps`.
+
+ Args:
+ scheduler (`SchedulerMixin`):
+ The scheduler to get timesteps from.
+ num_inference_steps (`int`):
+ The number of diffusion steps used when generating samples with a pre-trained model. If used, `timesteps`
+ must be `None`.
+ device (`str` or `torch.device`, *optional*):
+ The device to which the timesteps should be moved to. If `None`, the timesteps are not moved.
+ timesteps (`List[int]`, *optional*):
+ Custom timesteps used to override the timestep spacing strategy of the scheduler. If `timesteps` is passed,
+ `num_inference_steps` and `sigmas` must be `None`.
+ sigmas (`List[float]`, *optional*):
+ Custom sigmas used to override the timestep spacing strategy of the scheduler. If `sigmas` is passed,
+ `num_inference_steps` and `timesteps` must be `None`.
+
+ Returns:
+ `Tuple[torch.Tensor, int]`: A tuple where the first element is the timestep schedule from the scheduler and the
+ second element is the number of inference steps.
+ """
+ if timesteps is not None and sigmas is not None:
+ raise ValueError("Only one of `timesteps` or `sigmas` can be passed. Please choose one to set custom values")
+ if timesteps is not None:
+ accepts_timesteps = "timesteps" in set(inspect.signature(scheduler.set_timesteps).parameters.keys())
+ if not accepts_timesteps:
+ raise ValueError(
+ f"The current scheduler class {scheduler.__class__}'s `set_timesteps` does not support custom"
+ f" timestep schedules. Please check whether you are using the correct scheduler."
+ )
+ scheduler.set_timesteps(timesteps=timesteps, device=device, **kwargs)
+ timesteps = scheduler.timesteps
+ num_inference_steps = len(timesteps)
+ elif sigmas is not None:
+ accept_sigmas = "sigmas" in set(inspect.signature(scheduler.set_timesteps).parameters.keys())
+ if not accept_sigmas:
+ raise ValueError(
+ f"The current scheduler class {scheduler.__class__}'s `set_timesteps` does not support custom"
+ f" sigmas schedules. Please check whether you are using the correct scheduler."
+ )
+ scheduler.set_timesteps(sigmas=sigmas, device=device, **kwargs)
+ timesteps = scheduler.timesteps
+ num_inference_steps = len(timesteps)
+ else:
+ scheduler.set_timesteps(num_inference_steps, device=device, **kwargs)
+ timesteps = scheduler.timesteps
+ return timesteps, num_inference_steps
+
+
+class SanaSprintImg2ImgPipeline(DiffusionPipeline, SanaLoraLoaderMixin):
+ r"""
+ Pipeline for text-to-image generation using [SANA-Sprint](https://huggingface.co/papers/2503.09641).
+ """
+
+ # fmt: off
+ bad_punct_regex = re.compile(
+ r"[" + "#®•©™&@·º½¾¿¡§~" + r"\)" + r"\(" + r"\]" + r"\[" + r"\}" + r"\{" + r"\|" + "\\" + r"\/" + r"\*" + r"]{1,}")
+ # fmt: on
+
+ model_cpu_offload_seq = "text_encoder->transformer->vae"
+ _callback_tensor_inputs = ["latents", "prompt_embeds"]
+
+ def __init__(
+ self,
+ tokenizer: Union[GemmaTokenizer, GemmaTokenizerFast],
+ text_encoder: Gemma2PreTrainedModel,
+ vae: AutoencoderDC,
+ transformer: SanaTransformer2DModel,
+ scheduler: DPMSolverMultistepScheduler,
+ ):
+ super().__init__()
+
+ self.register_modules(
+ tokenizer=tokenizer, text_encoder=text_encoder, vae=vae, transformer=transformer, scheduler=scheduler
+ )
+
+ self.vae_scale_factor = (
+ 2 ** (len(self.vae.config.encoder_block_out_channels) - 1)
+ if hasattr(self, "vae") and self.vae is not None
+ else 32
+ )
+ self.image_processor = PixArtImageProcessor(vae_scale_factor=self.vae_scale_factor)
+
+ # Copied from diffusers.pipelines.sana.pipeline_sana.SanaPipeline.enable_vae_slicing
+ def enable_vae_slicing(self):
+ r"""
+ Enable sliced VAE decoding. When this option is enabled, the VAE will split the input tensor in slices to
+ compute decoding in several steps. This is useful to save some memory and allow larger batch sizes.
+ """
+ self.vae.enable_slicing()
+
+ # Copied from diffusers.pipelines.sana.pipeline_sana.SanaPipeline.disable_vae_slicing
+ def disable_vae_slicing(self):
+ r"""
+ Disable sliced VAE decoding. If `enable_vae_slicing` was previously enabled, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_slicing()
+
+ # Copied from diffusers.pipelines.sana.pipeline_sana.SanaPipeline.enable_vae_tiling
+ def enable_vae_tiling(self):
+ r"""
+ Enable tiled VAE decoding. When this option is enabled, the VAE will split the input tensor into tiles to
+ compute decoding and encoding in several steps. This is useful for saving a large amount of memory and to allow
+ processing larger images.
+ """
+ self.vae.enable_tiling()
+
+ def disable_vae_tiling(self):
+ r"""
+ Disable tiled VAE decoding. If `enable_vae_tiling` was previously enabled, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_tiling()
+
+ # Copied from diffusers.pipelines.sana.pipeline_sana.SanaPipeline._get_gemma_prompt_embeds
+ def _get_gemma_prompt_embeds(
+ self,
+ prompt: Union[str, List[str]],
+ device: torch.device,
+ dtype: torch.dtype,
+ clean_caption: bool = False,
+ max_sequence_length: int = 300,
+ complex_human_instruction: Optional[List[str]] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ device: (`torch.device`, *optional*):
+ torch device to place the resulting embeddings on
+ clean_caption (`bool`, defaults to `False`):
+ If `True`, the function will preprocess and clean the provided caption before encoding.
+ max_sequence_length (`int`, defaults to 300): Maximum sequence length to use for the prompt.
+ complex_human_instruction (`list[str]`, defaults to `complex_human_instruction`):
+ If `complex_human_instruction` is not empty, the function will use the complex Human instruction for
+ the prompt.
+ """
+ prompt = [prompt] if isinstance(prompt, str) else prompt
+
+ if getattr(self, "tokenizer", None) is not None:
+ self.tokenizer.padding_side = "right"
+
+ prompt = self._text_preprocessing(prompt, clean_caption=clean_caption)
+
+ # prepare complex human instruction
+ if not complex_human_instruction:
+ max_length_all = max_sequence_length
+ else:
+ chi_prompt = "\n".join(complex_human_instruction)
+ prompt = [chi_prompt + p for p in prompt]
+ num_chi_prompt_tokens = len(self.tokenizer.encode(chi_prompt))
+ max_length_all = num_chi_prompt_tokens + max_sequence_length - 2
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=max_length_all,
+ truncation=True,
+ add_special_tokens=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+
+ prompt_attention_mask = text_inputs.attention_mask
+ prompt_attention_mask = prompt_attention_mask.to(device)
+
+ prompt_embeds = self.text_encoder(text_input_ids.to(device), attention_mask=prompt_attention_mask)
+ prompt_embeds = prompt_embeds[0].to(dtype=dtype, device=device)
+
+ return prompt_embeds, prompt_attention_mask
+
+ # Copied from diffusers.pipelines.sana.pipeline_sana_sprint.SanaSprintPipeline.encode_prompt
+ def encode_prompt(
+ self,
+ prompt: Union[str, List[str]],
+ num_images_per_prompt: int = 1,
+ device: Optional[torch.device] = None,
+ prompt_embeds: Optional[torch.Tensor] = None,
+ prompt_attention_mask: Optional[torch.Tensor] = None,
+ clean_caption: bool = False,
+ max_sequence_length: int = 300,
+ complex_human_instruction: Optional[List[str]] = None,
+ lora_scale: Optional[float] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ number of images that should be generated per prompt
+ device: (`torch.device`, *optional*):
+ torch device to place the resulting embeddings on
+ prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ clean_caption (`bool`, defaults to `False`):
+ If `True`, the function will preprocess and clean the provided caption before encoding.
+ max_sequence_length (`int`, defaults to 300): Maximum sequence length to use for the prompt.
+ complex_human_instruction (`list[str]`, defaults to `complex_human_instruction`):
+ If `complex_human_instruction` is not empty, the function will use the complex Human instruction for
+ the prompt.
+ """
+
+ if device is None:
+ device = self._execution_device
+
+ if self.text_encoder is not None:
+ dtype = self.text_encoder.dtype
+ else:
+ dtype = None
+
+ # set lora scale so that monkey patched LoRA
+ # function of text encoder can correctly access it
+ if lora_scale is not None and isinstance(self, SanaLoraLoaderMixin):
+ self._lora_scale = lora_scale
+
+ # dynamically adjust the LoRA scale
+ if self.text_encoder is not None and USE_PEFT_BACKEND:
+ scale_lora_layers(self.text_encoder, lora_scale)
+
+ if getattr(self, "tokenizer", None) is not None:
+ self.tokenizer.padding_side = "right"
+
+ # See Section 3.1. of the paper.
+ max_length = max_sequence_length
+ select_index = [0] + list(range(-max_length + 1, 0))
+
+ if prompt_embeds is None:
+ prompt_embeds, prompt_attention_mask = self._get_gemma_prompt_embeds(
+ prompt=prompt,
+ device=device,
+ dtype=dtype,
+ clean_caption=clean_caption,
+ max_sequence_length=max_sequence_length,
+ complex_human_instruction=complex_human_instruction,
+ )
+
+ prompt_embeds = prompt_embeds[:, select_index]
+ prompt_attention_mask = prompt_attention_mask[:, select_index]
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings and attention mask for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+ prompt_attention_mask = prompt_attention_mask.view(bs_embed, -1)
+ prompt_attention_mask = prompt_attention_mask.repeat(num_images_per_prompt, 1)
+
+ if self.text_encoder is not None:
+ if isinstance(self, SanaLoraLoaderMixin) and USE_PEFT_BACKEND:
+ # Retrieve the original scale by scaling back the LoRA layers
+ unscale_lora_layers(self.text_encoder, lora_scale)
+
+ return prompt_embeds, prompt_attention_mask
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ # Copied from diffusers.pipelines.stable_diffusion_3.pipeline_stable_diffusion_3_img2img.StableDiffusion3Img2ImgPipeline.get_timesteps
+ def get_timesteps(self, num_inference_steps, strength, device):
+ # get the original timestep using init_timestep
+ init_timestep = min(num_inference_steps * strength, num_inference_steps)
+
+ t_start = int(max(num_inference_steps - init_timestep, 0))
+ timesteps = self.scheduler.timesteps[t_start * self.scheduler.order :]
+ if hasattr(self.scheduler, "set_begin_index"):
+ self.scheduler.set_begin_index(t_start * self.scheduler.order)
+
+ return timesteps, num_inference_steps - t_start
+
+ def check_inputs(
+ self,
+ prompt,
+ strength,
+ height,
+ width,
+ num_inference_steps,
+ timesteps,
+ max_timesteps,
+ intermediate_timesteps,
+ callback_on_step_end_tensor_inputs=None,
+ prompt_embeds=None,
+ prompt_attention_mask=None,
+ ):
+ if strength < 0 or strength > 1:
+ raise ValueError(f"The value of strength should in [0.0, 1.0] but is {strength}")
+
+ if height % 32 != 0 or width % 32 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 32 but are {height} and {width}.")
+
+ if callback_on_step_end_tensor_inputs is not None and not all(
+ k in self._callback_tensor_inputs for k in callback_on_step_end_tensor_inputs
+ ):
+ raise ValueError(
+ f"`callback_on_step_end_tensor_inputs` has to be in {self._callback_tensor_inputs}, but found {[k for k in callback_on_step_end_tensor_inputs if k not in self._callback_tensor_inputs]}"
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if prompt_embeds is not None and prompt_attention_mask is None:
+ raise ValueError("Must provide `prompt_attention_mask` when specifying `prompt_embeds`.")
+
+ if timesteps is not None and len(timesteps) != num_inference_steps + 1:
+ raise ValueError("If providing custom timesteps, `timesteps` must be of length `num_inference_steps + 1`.")
+
+ if timesteps is not None and max_timesteps is not None:
+ raise ValueError("If providing custom timesteps, `max_timesteps` should not be provided.")
+
+ if timesteps is None and max_timesteps is None:
+ raise ValueError("Should provide either `timesteps` or `max_timesteps`.")
+
+ if intermediate_timesteps is not None and num_inference_steps != 2:
+ raise ValueError("Intermediate timesteps for SCM is not supported when num_inference_steps != 2.")
+
+ # Copied from diffusers.pipelines.deepfloyd_if.pipeline_if.IFPipeline._text_preprocessing
+ def _text_preprocessing(self, text, clean_caption=False):
+ if clean_caption and not is_bs4_available():
+ logger.warning(BACKENDS_MAPPING["bs4"][-1].format("Setting `clean_caption=True`"))
+ logger.warning("Setting `clean_caption` to False...")
+ clean_caption = False
+
+ if clean_caption and not is_ftfy_available():
+ logger.warning(BACKENDS_MAPPING["ftfy"][-1].format("Setting `clean_caption=True`"))
+ logger.warning("Setting `clean_caption` to False...")
+ clean_caption = False
+
+ if not isinstance(text, (tuple, list)):
+ text = [text]
+
+ def process(text: str):
+ if clean_caption:
+ text = self._clean_caption(text)
+ text = self._clean_caption(text)
+ else:
+ text = text.lower().strip()
+ return text
+
+ return [process(t) for t in text]
+
+ # Copied from diffusers.pipelines.deepfloyd_if.pipeline_if.IFPipeline._clean_caption
+ def _clean_caption(self, caption):
+ caption = str(caption)
+ caption = ul.unquote_plus(caption)
+ caption = caption.strip().lower()
+ caption = re.sub("", "person", caption)
+ # urls:
+ caption = re.sub(
+ r"\b((?:https?:(?:\/{1,3}|[a-zA-Z0-9%])|[a-zA-Z0-9.\-]+[.](?:com|co|ru|net|org|edu|gov|it)[\w/-]*\b\/?(?!@)))", # noqa
+ "",
+ caption,
+ ) # regex for urls
+ caption = re.sub(
+ r"\b((?:www:(?:\/{1,3}|[a-zA-Z0-9%])|[a-zA-Z0-9.\-]+[.](?:com|co|ru|net|org|edu|gov|it)[\w/-]*\b\/?(?!@)))", # noqa
+ "",
+ caption,
+ ) # regex for urls
+ # html:
+ caption = BeautifulSoup(caption, features="html.parser").text
+
+ # @
+ caption = re.sub(r"@[\w\d]+\b", "", caption)
+
+ # 31C0—31EF CJK Strokes
+ # 31F0—31FF Katakana Phonetic Extensions
+ # 3200—32FF Enclosed CJK Letters and Months
+ # 3300—33FF CJK Compatibility
+ # 3400—4DBF CJK Unified Ideographs Extension A
+ # 4DC0—4DFF Yijing Hexagram Symbols
+ # 4E00—9FFF CJK Unified Ideographs
+ caption = re.sub(r"[\u31c0-\u31ef]+", "", caption)
+ caption = re.sub(r"[\u31f0-\u31ff]+", "", caption)
+ caption = re.sub(r"[\u3200-\u32ff]+", "", caption)
+ caption = re.sub(r"[\u3300-\u33ff]+", "", caption)
+ caption = re.sub(r"[\u3400-\u4dbf]+", "", caption)
+ caption = re.sub(r"[\u4dc0-\u4dff]+", "", caption)
+ caption = re.sub(r"[\u4e00-\u9fff]+", "", caption)
+ #######################################################
+
+ # все виды тире / all types of dash --> "-"
+ caption = re.sub(
+ r"[\u002D\u058A\u05BE\u1400\u1806\u2010-\u2015\u2E17\u2E1A\u2E3A\u2E3B\u2E40\u301C\u3030\u30A0\uFE31\uFE32\uFE58\uFE63\uFF0D]+", # noqa
+ "-",
+ caption,
+ )
+
+ # кавычки к одному стандарту
+ caption = re.sub(r"[`´«»“”¨]", '"', caption)
+ caption = re.sub(r"[‘’]", "'", caption)
+
+ # "
+ caption = re.sub(r""?", "", caption)
+ # &
+ caption = re.sub(r"&", "", caption)
+
+ # ip addresses:
+ caption = re.sub(r"\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}", " ", caption)
+
+ # article ids:
+ caption = re.sub(r"\d:\d\d\s+$", "", caption)
+
+ # \n
+ caption = re.sub(r"\\n", " ", caption)
+
+ # "#123"
+ caption = re.sub(r"#\d{1,3}\b", "", caption)
+ # "#12345.."
+ caption = re.sub(r"#\d{5,}\b", "", caption)
+ # "123456.."
+ caption = re.sub(r"\b\d{6,}\b", "", caption)
+ # filenames:
+ caption = re.sub(r"[\S]+\.(?:png|jpg|jpeg|bmp|webp|eps|pdf|apk|mp4)", "", caption)
+
+ #
+ caption = re.sub(r"[\"\']{2,}", r'"', caption) # """AUSVERKAUFT"""
+ caption = re.sub(r"[\.]{2,}", r" ", caption) # """AUSVERKAUFT"""
+
+ caption = re.sub(self.bad_punct_regex, r" ", caption) # ***AUSVERKAUFT***, #AUSVERKAUFT
+ caption = re.sub(r"\s+\.\s+", r" ", caption) # " . "
+
+ # this-is-my-cute-cat / this_is_my_cute_cat
+ regex2 = re.compile(r"(?:\-|\_)")
+ if len(re.findall(regex2, caption)) > 3:
+ caption = re.sub(regex2, " ", caption)
+
+ caption = ftfy.fix_text(caption)
+ caption = html.unescape(html.unescape(caption))
+
+ caption = re.sub(r"\b[a-zA-Z]{1,3}\d{3,15}\b", "", caption) # jc6640
+ caption = re.sub(r"\b[a-zA-Z]+\d+[a-zA-Z]+\b", "", caption) # jc6640vc
+ caption = re.sub(r"\b\d+[a-zA-Z]+\d+\b", "", caption) # 6640vc231
+
+ caption = re.sub(r"(worldwide\s+)?(free\s+)?shipping", "", caption)
+ caption = re.sub(r"(free\s)?download(\sfree)?", "", caption)
+ caption = re.sub(r"\bclick\b\s(?:for|on)\s\w+", "", caption)
+ caption = re.sub(r"\b(?:png|jpg|jpeg|bmp|webp|eps|pdf|apk|mp4)(\simage[s]?)?", "", caption)
+ caption = re.sub(r"\bpage\s+\d+\b", "", caption)
+
+ caption = re.sub(r"\b\d*[a-zA-Z]+\d+[a-zA-Z]+\d+[a-zA-Z\d]*\b", r" ", caption) # j2d1a2a...
+
+ caption = re.sub(r"\b\d+\.?\d*[xх×]\d+\.?\d*\b", "", caption)
+
+ caption = re.sub(r"\b\s+\:\s+", r": ", caption)
+ caption = re.sub(r"(\D[,\./])\b", r"\1 ", caption)
+ caption = re.sub(r"\s+", " ", caption)
+
+ caption.strip()
+
+ caption = re.sub(r"^[\"\']([\w\W]+)[\"\']$", r"\1", caption)
+ caption = re.sub(r"^[\'\_,\-\:;]", r"", caption)
+ caption = re.sub(r"[\'\_,\-\:\-\+]$", r"", caption)
+ caption = re.sub(r"^\.\S+$", "", caption)
+
+ return caption.strip()
+
+ def prepare_image(
+ self,
+ image: PipelineImageInput,
+ width: int,
+ height: int,
+ device: torch.device,
+ dtype: torch.dtype,
+ ):
+ if isinstance(image, torch.Tensor):
+ if image.ndim == 3:
+ image = image.unsqueeze(0)
+ # Resize if current dimensions do not match target dimensions.
+ if image.shape[2] != height or image.shape[3] != width:
+ image = F.interpolate(image, size=(height, width), mode="bilinear", align_corners=False)
+
+ image = self.image_processor.preprocess(image, height=height, width=width)
+
+ else:
+ image = self.image_processor.preprocess(image, height=height, width=width)
+
+ image = image.to(device=device, dtype=dtype)
+
+ return image
+
+ def prepare_latents(
+ self, image, timestep, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None
+ ):
+ if latents is not None:
+ return latents.to(device=device, dtype=dtype)
+
+ shape = (
+ batch_size,
+ num_channels_latents,
+ int(height) // self.vae_scale_factor,
+ int(width) // self.vae_scale_factor,
+ )
+
+ if image.shape[1] != num_channels_latents:
+ image = self.vae.encode(image).latent
+ image_latents = image * self.vae.config.scaling_factor * self.scheduler.config.sigma_data
+ else:
+ image_latents = image
+ if batch_size > image_latents.shape[0] and batch_size % image_latents.shape[0] == 0:
+ # expand init_latents for batch_size
+ additional_image_per_prompt = batch_size // image_latents.shape[0]
+ image_latents = torch.cat([image_latents] * additional_image_per_prompt, dim=0)
+ elif batch_size > image_latents.shape[0] and batch_size % image_latents.shape[0] != 0:
+ raise ValueError(
+ f"Cannot duplicate `image` of batch size {image_latents.shape[0]} to {batch_size} text prompts."
+ )
+ else:
+ image_latents = torch.cat([image_latents], dim=0)
+
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ # adapt from https://github.com/huggingface/diffusers/blob/c36f8487df35895421c15f351c7d360bd680[…]/examples/research_projects/sana/train_sana_sprint_diffusers.py
+ noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype) * self.scheduler.config.sigma_data
+ latents = torch.cos(timestep) * image_latents + torch.sin(timestep) * noise
+ return latents
+
+ @property
+ def guidance_scale(self):
+ return self._guidance_scale
+
+ @property
+ def attention_kwargs(self):
+ return self._attention_kwargs
+
+ @property
+ def num_timesteps(self):
+ return self._num_timesteps
+
+ @property
+ def interrupt(self):
+ return self._interrupt
+
+ @torch.no_grad()
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ num_inference_steps: int = 2,
+ timesteps: List[int] = None,
+ max_timesteps: float = 1.57080,
+ intermediate_timesteps: float = 1.3,
+ guidance_scale: float = 4.5,
+ image: PipelineImageInput = None,
+ strength: float = 0.6,
+ num_images_per_prompt: Optional[int] = 1,
+ height: int = 1024,
+ width: int = 1024,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.Tensor] = None,
+ prompt_embeds: Optional[torch.Tensor] = None,
+ prompt_attention_mask: Optional[torch.Tensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ clean_caption: bool = False,
+ use_resolution_binning: bool = True,
+ attention_kwargs: Optional[Dict[str, Any]] = None,
+ callback_on_step_end: Optional[Callable[[int, int, Dict], None]] = None,
+ callback_on_step_end_tensor_inputs: List[str] = ["latents"],
+ max_sequence_length: int = 300,
+ complex_human_instruction: List[str] = [
+ "Given a user prompt, generate an 'Enhanced prompt' that provides detailed visual descriptions suitable for image generation. Evaluate the level of detail in the user prompt:",
+ "- If the prompt is simple, focus on adding specifics about colors, shapes, sizes, textures, and spatial relationships to create vivid and concrete scenes.",
+ "- If the prompt is already detailed, refine and enhance the existing details slightly without overcomplicating.",
+ "Here are examples of how to transform or refine prompts:",
+ "- User Prompt: A cat sleeping -> Enhanced: A small, fluffy white cat curled up in a round shape, sleeping peacefully on a warm sunny windowsill, surrounded by pots of blooming red flowers.",
+ "- User Prompt: A busy city street -> Enhanced: A bustling city street scene at dusk, featuring glowing street lamps, a diverse crowd of people in colorful clothing, and a double-decker bus passing by towering glass skyscrapers.",
+ "Please generate only the enhanced description for the prompt below and avoid including any additional commentary or evaluations:",
+ "User Prompt: ",
+ ],
+ ) -> Union[SanaPipelineOutput, Tuple]:
+ """
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ num_inference_steps (`int`, *optional*, defaults to 20):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ max_timesteps (`float`, *optional*, defaults to 1.57080):
+ The maximum timestep value used in the SCM scheduler.
+ intermediate_timesteps (`float`, *optional*, defaults to 1.3):
+ The intermediate timestep value used in SCM scheduler (only used when num_inference_steps=2).
+ timesteps (`List[int]`, *optional*):
+ Custom timesteps to use for the denoising process with schedulers which support a `timesteps` argument
+ in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
+ passed will be used. Must be in descending order.
+ guidance_scale (`float`, *optional*, defaults to 4.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ height (`int`, *optional*, defaults to self.unet.config.sample_size):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.unet.config.sample_size):
+ The width in pixels of the generated image.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.Tensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.Tensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ prompt_attention_mask (`torch.Tensor`, *optional*): Pre-generated attention mask for text embeddings.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.IFPipelineOutput`] instead of a plain tuple.
+ attention_kwargs:
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
+ clean_caption (`bool`, *optional*, defaults to `True`):
+ Whether or not to clean the caption before creating embeddings. Requires `beautifulsoup4` and `ftfy` to
+ be installed. If the dependencies are not installed, the embeddings will be created from the raw
+ prompt.
+ use_resolution_binning (`bool` defaults to `True`):
+ If set to `True`, the requested height and width are first mapped to the closest resolutions using
+ `ASPECT_RATIO_1024_BIN`. After the produced latents are decoded into images, they are resized back to
+ the requested resolution. Useful for generating non-square images.
+ callback_on_step_end (`Callable`, *optional*):
+ A function that calls at the end of each denoising steps during the inference. The function is called
+ with the following arguments: `callback_on_step_end(self: DiffusionPipeline, step: int, timestep: int,
+ callback_kwargs: Dict)`. `callback_kwargs` will include a list of all tensors as specified by
+ `callback_on_step_end_tensor_inputs`.
+ callback_on_step_end_tensor_inputs (`List`, *optional*):
+ The list of tensor inputs for the `callback_on_step_end` function. The tensors specified in the list
+ will be passed as `callback_kwargs` argument. You will only be able to include variables listed in the
+ `._callback_tensor_inputs` attribute of your pipeline class.
+ max_sequence_length (`int` defaults to `300`):
+ Maximum sequence length to use with the `prompt`.
+ complex_human_instruction (`List[str]`, *optional*):
+ Instructions for complex human attention:
+ https://github.com/NVlabs/Sana/blob/main/configs/sana_app_config/Sana_1600M_app.yaml#L55.
+
+ Examples:
+
+ Returns:
+ [`~pipelines.sana.pipeline_output.SanaPipelineOutput`] or `tuple`:
+ If `return_dict` is `True`, [`~pipelines.sana.pipeline_output.SanaPipelineOutput`] is returned,
+ otherwise a `tuple` is returned where the first element is a list with the generated images
+ """
+
+ if isinstance(callback_on_step_end, (PipelineCallback, MultiPipelineCallbacks)):
+ callback_on_step_end_tensor_inputs = callback_on_step_end.tensor_inputs
+
+ # 1. Check inputs. Raise error if not correct
+ if use_resolution_binning:
+ if self.transformer.config.sample_size == 32:
+ aspect_ratio_bin = ASPECT_RATIO_1024_BIN
+ else:
+ raise ValueError("Invalid sample size")
+ orig_height, orig_width = height, width
+ height, width = self.image_processor.classify_height_width_bin(height, width, ratios=aspect_ratio_bin)
+
+ self.check_inputs(
+ prompt=prompt,
+ strength=strength,
+ height=height,
+ width=width,
+ num_inference_steps=num_inference_steps,
+ timesteps=timesteps,
+ max_timesteps=max_timesteps,
+ intermediate_timesteps=intermediate_timesteps,
+ callback_on_step_end_tensor_inputs=callback_on_step_end_tensor_inputs,
+ prompt_embeds=prompt_embeds,
+ prompt_attention_mask=prompt_attention_mask,
+ )
+
+ self._guidance_scale = guidance_scale
+ self._attention_kwargs = attention_kwargs
+ self._interrupt = False
+
+ # 2. Default height and width to transformer
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+ lora_scale = self.attention_kwargs.get("scale", None) if self.attention_kwargs is not None else None
+
+ # 2. Preprocess image
+ init_image = self.prepare_image(image, width, height, device, self.vae.dtype)
+
+ # 3. Encode input prompt
+ (
+ prompt_embeds,
+ prompt_attention_mask,
+ ) = self.encode_prompt(
+ prompt,
+ num_images_per_prompt=num_images_per_prompt,
+ device=device,
+ prompt_embeds=prompt_embeds,
+ prompt_attention_mask=prompt_attention_mask,
+ clean_caption=clean_caption,
+ max_sequence_length=max_sequence_length,
+ complex_human_instruction=complex_human_instruction,
+ lora_scale=lora_scale,
+ )
+
+ # 5. Prepare timesteps
+ timesteps, num_inference_steps = retrieve_timesteps(
+ self.scheduler,
+ num_inference_steps,
+ device,
+ timesteps,
+ sigmas=None,
+ max_timesteps=max_timesteps,
+ intermediate_timesteps=intermediate_timesteps,
+ )
+ if hasattr(self.scheduler, "set_begin_index"):
+ self.scheduler.set_begin_index(0)
+
+ timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, strength, device)
+ if num_inference_steps < 1:
+ raise ValueError(
+ f"After adjusting the num_inference_steps by strength parameter: {strength}, the number of pipeline"
+ f"steps is {num_inference_steps} which is < 1 and not appropriate for this pipeline."
+ )
+ latent_timestep = timesteps[:1]
+
+ # 5. Prepare latents.
+ latent_channels = self.transformer.config.in_channels
+ latents = self.prepare_latents(
+ init_image,
+ latent_timestep,
+ batch_size * num_images_per_prompt,
+ latent_channels,
+ height,
+ width,
+ torch.float32,
+ device,
+ generator,
+ latents,
+ )
+
+ # I think this is redundant given the scaling in prepare_latents
+ # latents = latents * self.scheduler.config.sigma_data
+
+ guidance = torch.full([1], guidance_scale, device=device, dtype=torch.float32)
+ guidance = guidance.expand(latents.shape[0]).to(prompt_embeds.dtype)
+ guidance = guidance * self.transformer.config.guidance_embeds_scale
+
+ # 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 7. Denoising loop
+ timesteps = timesteps[:-1]
+ num_warmup_steps = max(len(timesteps) - num_inference_steps * self.scheduler.order, 0)
+ self._num_timesteps = len(timesteps)
+
+ transformer_dtype = self.transformer.dtype
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ if self.interrupt:
+ continue
+
+ # broadcast to batch dimension in a way that's compatible with ONNX/Core ML
+ timestep = t.expand(latents.shape[0])
+ latents_model_input = latents / self.scheduler.config.sigma_data
+
+ scm_timestep = torch.sin(timestep) / (torch.cos(timestep) + torch.sin(timestep))
+
+ scm_timestep_expanded = scm_timestep.view(-1, 1, 1, 1)
+ latent_model_input = latents_model_input * torch.sqrt(
+ scm_timestep_expanded**2 + (1 - scm_timestep_expanded) ** 2
+ )
+
+ # predict noise model_output
+ noise_pred = self.transformer(
+ latent_model_input.to(dtype=transformer_dtype),
+ encoder_hidden_states=prompt_embeds.to(dtype=transformer_dtype),
+ encoder_attention_mask=prompt_attention_mask,
+ guidance=guidance,
+ timestep=scm_timestep,
+ return_dict=False,
+ attention_kwargs=self.attention_kwargs,
+ )[0]
+
+ noise_pred = (
+ (1 - 2 * scm_timestep_expanded) * latent_model_input
+ + (1 - 2 * scm_timestep_expanded + 2 * scm_timestep_expanded**2) * noise_pred
+ ) / torch.sqrt(scm_timestep_expanded**2 + (1 - scm_timestep_expanded) ** 2)
+ noise_pred = noise_pred.float() * self.scheduler.config.sigma_data
+
+ # compute previous image: x_t -> x_t-1
+ latents, denoised = self.scheduler.step(
+ noise_pred, timestep, latents, **extra_step_kwargs, return_dict=False
+ )
+
+ if callback_on_step_end is not None:
+ callback_kwargs = {}
+ for k in callback_on_step_end_tensor_inputs:
+ callback_kwargs[k] = locals()[k]
+ callback_outputs = callback_on_step_end(self, i, t, callback_kwargs)
+
+ latents = callback_outputs.pop("latents", latents)
+ prompt_embeds = callback_outputs.pop("prompt_embeds", prompt_embeds)
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+
+ if XLA_AVAILABLE:
+ xm.mark_step()
+
+ latents = denoised / self.scheduler.config.sigma_data
+ if output_type == "latent":
+ image = latents
+ else:
+ latents = latents.to(self.vae.dtype)
+ try:
+ image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
+ except torch.cuda.OutOfMemoryError as e:
+ warnings.warn(
+ f"{e}. \n"
+ f"Try to use VAE tiling for large images. For example: \n"
+ f"pipe.vae.enable_tiling(tile_sample_min_width=512, tile_sample_min_height=512)"
+ )
+ if use_resolution_binning:
+ image = self.image_processor.resize_and_crop_tensor(image, orig_width, orig_height)
+
+ if not output_type == "latent":
+ image = self.image_processor.postprocess(image, output_type=output_type)
+
+ # Offload all models
+ self.maybe_free_model_hooks()
+
+ if not return_dict:
+ return (image,)
+
+ return SanaPipelineOutput(images=image)
diff --git a/src/diffusers/pipelines/semantic_stable_diffusion/pipeline_semantic_stable_diffusion.py b/src/diffusers/pipelines/semantic_stable_diffusion/pipeline_semantic_stable_diffusion.py
index a8c3742593..d3779f9c8b 100644
--- a/src/diffusers/pipelines/semantic_stable_diffusion/pipeline_semantic_stable_diffusion.py
+++ b/src/diffusers/pipelines/semantic_stable_diffusion/pipeline_semantic_stable_diffusion.py
@@ -129,7 +129,7 @@ class SemanticStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -270,8 +270,8 @@ class SemanticStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -451,7 +451,7 @@ class SemanticStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMixin):
edit_concepts = edit_concepts.view(bs_embed_edit * num_images_per_prompt, seq_len_edit, -1)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
diff --git a/src/diffusers/pipelines/shap_e/renderer.py b/src/diffusers/pipelines/shap_e/renderer.py
index 00f873115f..68948d7ac3 100644
--- a/src/diffusers/pipelines/shap_e/renderer.py
+++ b/src/diffusers/pipelines/shap_e/renderer.py
@@ -54,7 +54,7 @@ def posenc_nerf(x: torch.Tensor, min_deg: int = 0, max_deg: int = 15) -> torch.T
"""
Concatenate x and its positional encodings, following NeRF.
- Reference: https://arxiv.org/pdf/2210.04628.pdf
+ Reference: https://huggingface.co/papers/2210.04628
"""
if min_deg == max_deg:
return x
diff --git a/src/diffusers/pipelines/stable_audio/pipeline_stable_audio.py b/src/diffusers/pipelines/stable_audio/pipeline_stable_audio.py
index 1b87c02df0..366c39dc3f 100644
--- a/src/diffusers/pipelines/stable_audio/pipeline_stable_audio.py
+++ b/src/diffusers/pipelines/stable_audio/pipeline_stable_audio.py
@@ -306,7 +306,7 @@ class StableAudioPipeline(DiffusionPipeline):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -526,8 +526,8 @@ class StableAudioPipeline(DiffusionPipeline):
num_waveforms_per_prompt (`int`, *optional*, defaults to 1):
The number of waveforms to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -616,7 +616,7 @@ class StableAudioPipeline(DiffusionPipeline):
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/stable_cascade/pipeline_stable_cascade.py b/src/diffusers/pipelines/stable_cascade/pipeline_stable_cascade.py
index fce8efdd3c..ba1d78f5b3 100644
--- a/src/diffusers/pipelines/stable_cascade/pipeline_stable_cascade.py
+++ b/src/diffusers/pipelines/stable_cascade/pipeline_stable_cascade.py
@@ -332,11 +332,11 @@ class StableCascadeDecoderPipeline(DiffusionPipeline):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 0.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `decoder_guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting
- `decoder_guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely
- linked to the text `prompt`, usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `decoder_guidance_scale` is defined as `w` of
+ equation 2. of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by
+ setting `decoder_guidance_scale > 1`. Higher guidance scale encourages to generate images that are
+ closely linked to the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `decoder_guidance_scale` is less than `1`).
diff --git a/src/diffusers/pipelines/stable_cascade/pipeline_stable_cascade_combined.py b/src/diffusers/pipelines/stable_cascade/pipeline_stable_cascade_combined.py
index 28a74ab837..a7c273fbe1 100644
--- a/src/diffusers/pipelines/stable_cascade/pipeline_stable_cascade_combined.py
+++ b/src/diffusers/pipelines/stable_cascade/pipeline_stable_cascade_combined.py
@@ -212,11 +212,11 @@ class StableCascadeCombinedPipeline(DiffusionPipeline):
width (`int`, *optional*, defaults to 512):
The width in pixels of the generated image.
prior_guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `prior_guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting
- `prior_guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked
- to the text `prompt`, usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `prior_guidance_scale` is defined as `w` of
+ equation 2. of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by
+ setting `prior_guidance_scale > 1`. Higher guidance scale encourages to generate images that are
+ closely linked to the text `prompt`, usually at the expense of lower image quality.
prior_num_inference_steps (`Union[int, Dict[float, int]]`, *optional*, defaults to 60):
The number of prior denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference. For more specific timestep spacing, you can pass customized
@@ -226,11 +226,11 @@ class StableCascadeCombinedPipeline(DiffusionPipeline):
the expense of slower inference. For more specific timestep spacing, you can pass customized
`timesteps`
decoder_guidance_scale (`float`, *optional*, defaults to 0.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
diff --git a/src/diffusers/pipelines/stable_cascade/pipeline_stable_cascade_prior.py b/src/diffusers/pipelines/stable_cascade/pipeline_stable_cascade_prior.py
index f08e38e7ce..46c811643d 100644
--- a/src/diffusers/pipelines/stable_cascade/pipeline_stable_cascade_prior.py
+++ b/src/diffusers/pipelines/stable_cascade/pipeline_stable_cascade_prior.py
@@ -409,11 +409,11 @@ class StableCascadePriorPipeline(DiffusionPipeline):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 8.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `decoder_guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting
- `decoder_guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely
- linked to the text `prompt`, usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `decoder_guidance_scale` is defined as `w` of
+ equation 2. of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by
+ setting `decoder_guidance_scale > 1`. Higher guidance scale encourages to generate images that are
+ closely linked to the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `decoder_guidance_scale` is less than `1`).
diff --git a/src/diffusers/pipelines/stable_diffusion/README.md b/src/diffusers/pipelines/stable_diffusion/README.md
index 5b229fddad..2dc538f858 100644
--- a/src/diffusers/pipelines/stable_diffusion/README.md
+++ b/src/diffusers/pipelines/stable_diffusion/README.md
@@ -10,7 +10,7 @@ The summary of the model is the following:
## Tips:
-- Stable Diffusion has the same architecture as [Latent Diffusion](https://arxiv.org/abs/2112.10752) but uses a frozen CLIP Text Encoder instead of training the text encoder jointly with the diffusion model.
+- Stable Diffusion has the same architecture as [Latent Diffusion](https://huggingface.co/papers/2112.10752) but uses a frozen CLIP Text Encoder instead of training the text encoder jointly with the diffusion model.
- An in-detail explanation of the Stable Diffusion model can be found under [Stable Diffusion with 🧨 Diffusers](https://huggingface.co/blog/stable_diffusion).
- If you don't want to rely on the Hugging Face Hub and having to pass a authentication token, you can
download the weights with `git lfs install; git clone https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5` and instead pass the local path to the cloned folder to `from_pretrained` as shown below.
diff --git a/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion.py b/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion.py
index 9917276e0a..86a216508b 100644
--- a/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion.py
+++ b/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion.py
@@ -294,11 +294,11 @@ class OnnxStableDiffusionPipeline(DiffusionPipeline):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds`. instead. Ignored when not using guidance (i.e., ignored if `guidance_scale`
@@ -306,8 +306,8 @@ class OnnxStableDiffusionPipeline(DiffusionPipeline):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`np.random.RandomState`, *optional*):
One or a list of [numpy generator(s)](TODO) to make generation deterministic.
latents (`np.ndarray`, *optional*):
@@ -359,7 +359,7 @@ class OnnxStableDiffusionPipeline(DiffusionPipeline):
generator = np.random
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
@@ -387,7 +387,7 @@ class OnnxStableDiffusionPipeline(DiffusionPipeline):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
diff --git a/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_img2img.py b/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_img2img.py
index 92c82d61b8..dd0997d0d2 100644
--- a/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_img2img.py
+++ b/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_img2img.py
@@ -348,19 +348,19 @@ class OnnxStableDiffusionImg2ImgPipeline(DiffusionPipeline):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference. This parameter will be modulated by `strength`.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`np.random.RandomState`, *optional*):
A np.random.RandomState to make generation deterministic.
prompt_embeds (`np.ndarray`, *optional*):
@@ -414,7 +414,7 @@ class OnnxStableDiffusionImg2ImgPipeline(DiffusionPipeline):
image = preprocess(image).cpu().numpy()
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
@@ -470,7 +470,7 @@ class OnnxStableDiffusionImg2ImgPipeline(DiffusionPipeline):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
diff --git a/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_inpaint.py b/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_inpaint.py
index f2e1d87be8..07620b0fef 100644
--- a/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_inpaint.py
+++ b/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_inpaint.py
@@ -360,19 +360,19 @@ class OnnxStableDiffusionInpaintPipeline(DiffusionPipeline):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`np.random.RandomState`, *optional*):
A np.random.RandomState to make generation deterministic.
latents (`np.ndarray`, *optional*):
@@ -427,7 +427,7 @@ class OnnxStableDiffusionInpaintPipeline(DiffusionPipeline):
self.scheduler.set_timesteps(num_inference_steps)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
@@ -487,7 +487,7 @@ class OnnxStableDiffusionInpaintPipeline(DiffusionPipeline):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
diff --git a/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_upscale.py b/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_upscale.py
index ef84cdd38b..46a3c3735a 100644
--- a/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_upscale.py
+++ b/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_upscale.py
@@ -378,11 +378,11 @@ class OnnxStableDiffusionUpscalePipeline(DiffusionPipeline):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference. This parameter will be modulated by `strength`.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
noise_level (`float`, defaults to 0.2):
Deteremines the amount of noise to add to the initial image before performing upscaling.
negative_prompt (`str` or `List[str]`, *optional*):
@@ -391,8 +391,8 @@ class OnnxStableDiffusionUpscalePipeline(DiffusionPipeline):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`np.random.RandomState`, *optional*):
A np.random.RandomState to make generation deterministic.
latents (`torch.Tensor`, *optional*):
@@ -450,7 +450,7 @@ class OnnxStableDiffusionUpscalePipeline(DiffusionPipeline):
generator = np.random
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py b/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py
index 6e93c34929..6445c4cdeb 100644
--- a/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py
+++ b/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py
@@ -70,7 +70,7 @@ def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
r"""
Rescales `noise_cfg` tensor based on `guidance_rescale` to improve image quality and fix overexposure. Based on
Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891).
Args:
noise_cfg (`torch.Tensor`):
@@ -608,7 +608,7 @@ class StableDiffusionPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -757,7 +757,7 @@ class StableDiffusionPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -836,8 +836,8 @@ class StableDiffusionPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -867,7 +867,7 @@ class StableDiffusionPipeline(
[`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf). Guidance rescale factor should fix overexposure when
+ Flawed](https://huggingface.co/papers/2305.08891). Guidance rescale factor should fix overexposure when
using zero terminal SNR.
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
@@ -1053,7 +1053,7 @@ class StableDiffusionPipeline(
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_depth2img.py b/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_depth2img.py
index f158c41cac..ffdba66ae5 100644
--- a/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_depth2img.py
+++ b/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_depth2img.py
@@ -414,7 +414,7 @@ class StableDiffusionDepth2ImgPipeline(DiffusionPipeline, TextualInversionLoader
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -617,7 +617,7 @@ class StableDiffusionDepth2ImgPipeline(DiffusionPipeline, TextualInversionLoader
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -684,8 +684,8 @@ class StableDiffusionDepth2ImgPipeline(DiffusionPipeline, TextualInversionLoader
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
diff --git a/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_image_variation.py b/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_image_variation.py
index e0268065a4..b2d28eaff6 100644
--- a/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_image_variation.py
+++ b/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_image_variation.py
@@ -197,7 +197,7 @@ class StableDiffusionImageVariationPipeline(DiffusionPipeline, StableDiffusionMi
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -293,8 +293,8 @@ class StableDiffusionImageVariationPipeline(DiffusionPipeline, StableDiffusionMi
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -359,7 +359,7 @@ class StableDiffusionImageVariationPipeline(DiffusionPipeline, StableDiffusionMi
batch_size = image.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_img2img.py b/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_img2img.py
index 901dcd6db0..e217d7c1d7 100644
--- a/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_img2img.py
+++ b/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_img2img.py
@@ -639,7 +639,7 @@ class StableDiffusionImg2ImgPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -837,7 +837,7 @@ class StableDiffusionImg2ImgPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -922,8 +922,8 @@ class StableDiffusionImg2ImgPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
diff --git a/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_inpaint.py b/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_inpaint.py
index 0f7be1a1bb..12beb373dc 100644
--- a/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_inpaint.py
+++ b/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_inpaint.py
@@ -581,7 +581,7 @@ class StableDiffusionInpaintPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -859,7 +859,7 @@ class StableDiffusionInpaintPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -968,8 +968,8 @@ class StableDiffusionInpaintPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
diff --git a/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_instruct_pix2pix.py b/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_instruct_pix2pix.py
index e0748943ff..bd0595ce8b 100644
--- a/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_instruct_pix2pix.py
+++ b/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_instruct_pix2pix.py
@@ -221,8 +221,8 @@ class StableDiffusionInstructPix2PixPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -742,7 +742,7 @@ class StableDiffusionInstructPix2PixPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -910,7 +910,7 @@ class StableDiffusionInstructPix2PixPipeline(
return self._num_timesteps
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
diff --git a/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_latent_upscale.py b/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_latent_upscale.py
index 42db88b030..c25df30b25 100644
--- a/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_latent_upscale.py
+++ b/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_latent_upscale.py
@@ -433,8 +433,8 @@ class StableDiffusionLatentUpscalePipeline(DiffusionPipeline, StableDiffusionMix
The prompt or prompts to guide what to not include in image generation. If not defined, you need to
pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -516,7 +516,7 @@ class StableDiffusionLatentUpscalePipeline(DiffusionPipeline, StableDiffusionMix
batch_size = prompt_embeds.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_upscale.py b/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_upscale.py
index f9b6dcbf5a..ff7a061cc5 100644
--- a/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_upscale.py
+++ b/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_upscale.py
@@ -404,7 +404,7 @@ class StableDiffusionUpscalePipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -587,8 +587,8 @@ class StableDiffusionUpscalePipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -677,7 +677,7 @@ class StableDiffusionUpscalePipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/stable_diffusion/pipeline_stable_unclip.py b/src/diffusers/pipelines/stable_diffusion/pipeline_stable_unclip.py
index be01e0acbf..a5fed55eb2 100644
--- a/src/diffusers/pipelines/stable_diffusion/pipeline_stable_unclip.py
+++ b/src/diffusers/pipelines/stable_diffusion/pipeline_stable_unclip.py
@@ -492,7 +492,7 @@ class StableUnCLIPPipeline(
def prepare_prior_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the prior_scheduler step, since not all prior_schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other prior_schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.prior_scheduler.step).parameters.keys())
@@ -510,7 +510,7 @@ class StableUnCLIPPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -693,8 +693,8 @@ class StableUnCLIPPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -774,7 +774,7 @@ class StableUnCLIPPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
prior_do_classifier_free_guidance = prior_guidance_scale > 1.0
@@ -842,7 +842,7 @@ class StableUnCLIPPipeline(
# done prior
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/stable_diffusion/pipeline_stable_unclip_img2img.py b/src/diffusers/pipelines/stable_diffusion/pipeline_stable_unclip_img2img.py
index eac9945ff3..2acf8d7e6e 100644
--- a/src/diffusers/pipelines/stable_diffusion/pipeline_stable_unclip_img2img.py
+++ b/src/diffusers/pipelines/stable_diffusion/pipeline_stable_unclip_img2img.py
@@ -454,7 +454,7 @@ class StableUnCLIPImg2ImgPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -674,8 +674,8 @@ class StableUnCLIPImg2ImgPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -753,7 +753,7 @@ class StableUnCLIPImg2ImgPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/stable_diffusion_3/pipeline_stable_diffusion_3.py b/src/diffusers/pipelines/stable_diffusion_3/pipeline_stable_diffusion_3.py
index 4618d384cb..48382fad33 100644
--- a/src/diffusers/pipelines/stable_diffusion_3/pipeline_stable_diffusion_3.py
+++ b/src/diffusers/pipelines/stable_diffusion_3/pipeline_stable_diffusion_3.py
@@ -673,7 +673,7 @@ class StableDiffusion3Pipeline(DiffusionPipeline, SD3LoraLoaderMixin, FromSingle
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -830,11 +830,11 @@ class StableDiffusion3Pipeline(DiffusionPipeline, SD3LoraLoaderMixin, FromSingle
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, *optional*, defaults to 7.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
diff --git a/src/diffusers/pipelines/stable_diffusion_3/pipeline_stable_diffusion_3_img2img.py b/src/diffusers/pipelines/stable_diffusion_3/pipeline_stable_diffusion_3_img2img.py
index 19bdc9792e..d6af3cf899 100644
--- a/src/diffusers/pipelines/stable_diffusion_3/pipeline_stable_diffusion_3_img2img.py
+++ b/src/diffusers/pipelines/stable_diffusion_3/pipeline_stable_diffusion_3_img2img.py
@@ -734,7 +734,7 @@ class StableDiffusion3Img2ImgPipeline(DiffusionPipeline, SD3LoraLoaderMixin, Fro
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -886,11 +886,11 @@ class StableDiffusion3Img2ImgPipeline(DiffusionPipeline, SD3LoraLoaderMixin, Fro
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, *optional*, defaults to 7.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
diff --git a/src/diffusers/pipelines/stable_diffusion_3/pipeline_stable_diffusion_3_inpaint.py b/src/diffusers/pipelines/stable_diffusion_3/pipeline_stable_diffusion_3_inpaint.py
index cac305a87f..62b39c31d8 100644
--- a/src/diffusers/pipelines/stable_diffusion_3/pipeline_stable_diffusion_3_inpaint.py
+++ b/src/diffusers/pipelines/stable_diffusion_3/pipeline_stable_diffusion_3_inpaint.py
@@ -822,7 +822,7 @@ class StableDiffusion3InpaintPipeline(DiffusionPipeline, SD3LoraLoaderMixin, Fro
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1010,11 +1010,11 @@ class StableDiffusion3InpaintPipeline(DiffusionPipeline, SD3LoraLoaderMixin, Fro
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, *optional*, defaults to 7.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
diff --git a/src/diffusers/pipelines/stable_diffusion_attend_and_excite/pipeline_stable_diffusion_attend_and_excite.py b/src/diffusers/pipelines/stable_diffusion_attend_and_excite/pipeline_stable_diffusion_attend_and_excite.py
index 2c972284a1..893039316b 100644
--- a/src/diffusers/pipelines/stable_diffusion_attend_and_excite/pipeline_stable_diffusion_attend_and_excite.py
+++ b/src/diffusers/pipelines/stable_diffusion_attend_and_excite/pipeline_stable_diffusion_attend_and_excite.py
@@ -502,7 +502,7 @@ class StableDiffusionAttendAndExcitePipeline(DiffusionPipeline, StableDiffusionM
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -794,8 +794,8 @@ class StableDiffusionAttendAndExcitePipeline(DiffusionPipeline, StableDiffusionM
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -873,7 +873,7 @@ class StableDiffusionAttendAndExcitePipeline(DiffusionPipeline, StableDiffusionM
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/stable_diffusion_diffedit/pipeline_stable_diffusion_diffedit.py b/src/diffusers/pipelines/stable_diffusion_diffedit/pipeline_stable_diffusion_diffedit.py
index 4b999662a6..0343a1aa6f 100644
--- a/src/diffusers/pipelines/stable_diffusion_diffedit/pipeline_stable_diffusion_diffedit.py
+++ b/src/diffusers/pipelines/stable_diffusion_diffedit/pipeline_stable_diffusion_diffedit.py
@@ -618,7 +618,7 @@ class StableDiffusionDiffEditPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -969,7 +969,7 @@ class StableDiffusionDiffEditPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
@@ -1176,7 +1176,7 @@ class StableDiffusionDiffEditPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
@@ -1349,8 +1349,8 @@ class StableDiffusionDiffEditPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -1422,7 +1422,7 @@ class StableDiffusionDiffEditPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/stable_diffusion_gligen/pipeline_stable_diffusion_gligen.py b/src/diffusers/pipelines/stable_diffusion_gligen/pipeline_stable_diffusion_gligen.py
index 4bbb93e44a..14bac0fafc 100644
--- a/src/diffusers/pipelines/stable_diffusion_gligen/pipeline_stable_diffusion_gligen.py
+++ b/src/diffusers/pipelines/stable_diffusion_gligen/pipeline_stable_diffusion_gligen.py
@@ -415,7 +415,7 @@ class StableDiffusionGLIGENPipeline(DiffusionPipeline, StableDiffusionMixin):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -589,7 +589,7 @@ class StableDiffusionGLIGENPipeline(DiffusionPipeline, StableDiffusionMixin):
`gligen_phrases`. Otherwise, it is treated as a generation task on a blank input image.
gligen_scheduled_sampling_beta (`float`, defaults to 0.3):
Scheduled Sampling factor from [GLIGEN: Open-Set Grounded Text-to-Image
- Generation](https://arxiv.org/pdf/2301.07093.pdf). Scheduled Sampling factor is only varied for
+ Generation](https://huggingface.co/papers/2301.07093). Scheduled Sampling factor is only varied for
scheduled sampling during inference for improved quality and controllability.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide what to not include in image generation. If not defined, you need to
@@ -597,8 +597,8 @@ class StableDiffusionGLIGENPipeline(DiffusionPipeline, StableDiffusionMixin):
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -628,7 +628,7 @@ class StableDiffusionGLIGENPipeline(DiffusionPipeline, StableDiffusionMixin):
[`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf). Guidance rescale factor should fix overexposure when
+ Flawed](https://huggingface.co/papers/2305.08891). Guidance rescale factor should fix overexposure when
using zero terminal SNR.
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
@@ -669,7 +669,7 @@ class StableDiffusionGLIGENPipeline(DiffusionPipeline, StableDiffusionMixin):
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/stable_diffusion_gligen/pipeline_stable_diffusion_gligen_text_image.py b/src/diffusers/pipelines/stable_diffusion_gligen/pipeline_stable_diffusion_gligen_text_image.py
index ac9b8ce19c..f61a8ac231 100644
--- a/src/diffusers/pipelines/stable_diffusion_gligen/pipeline_stable_diffusion_gligen_text_image.py
+++ b/src/diffusers/pipelines/stable_diffusion_gligen/pipeline_stable_diffusion_gligen_text_image.py
@@ -447,7 +447,7 @@ class StableDiffusionGLIGENTextImagePipeline(DiffusionPipeline, StableDiffusionM
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -775,7 +775,7 @@ class StableDiffusionGLIGENTextImagePipeline(DiffusionPipeline, StableDiffusionM
`gligen_phrases`. Otherwise, it is treated as a generation task on a blank input image.
gligen_scheduled_sampling_beta (`float`, defaults to 0.3):
Scheduled Sampling factor from [GLIGEN: Open-Set Grounded Text-to-Image
- Generation](https://arxiv.org/pdf/2301.07093.pdf). Scheduled Sampling factor is only varied for
+ Generation](https://huggingface.co/papers/2301.07093). Scheduled Sampling factor is only varied for
scheduled sampling during inference for improved quality and controllability.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide what to not include in image generation. If not defined, you need to
@@ -783,8 +783,8 @@ class StableDiffusionGLIGENTextImagePipeline(DiffusionPipeline, StableDiffusionM
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -854,7 +854,7 @@ class StableDiffusionGLIGENTextImagePipeline(DiffusionPipeline, StableDiffusionM
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/stable_diffusion_k_diffusion/pipeline_stable_diffusion_k_diffusion.py b/src/diffusers/pipelines/stable_diffusion_k_diffusion/pipeline_stable_diffusion_k_diffusion.py
index 1ca1fd2ded..85c67f08ff 100755
--- a/src/diffusers/pipelines/stable_diffusion_k_diffusion/pipeline_stable_diffusion_k_diffusion.py
+++ b/src/diffusers/pipelines/stable_diffusion_k_diffusion/pipeline_stable_diffusion_k_diffusion.py
@@ -513,11 +513,11 @@ class StableDiffusionKDiffusionPipeline(
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds`. instead. Ignored when not using guidance (i.e., ignored if `guidance_scale`
@@ -525,8 +525,8 @@ class StableDiffusionKDiffusionPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
@@ -588,7 +588,7 @@ class StableDiffusionKDiffusionPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = True
if guidance_scale <= 1.0:
diff --git a/src/diffusers/pipelines/stable_diffusion_k_diffusion/pipeline_stable_diffusion_xl_k_diffusion.py b/src/diffusers/pipelines/stable_diffusion_k_diffusion/pipeline_stable_diffusion_xl_k_diffusion.py
index c7c5bd9cff..ead6de6943 100644
--- a/src/diffusers/pipelines/stable_diffusion_k_diffusion/pipeline_stable_diffusion_xl_k_diffusion.py
+++ b/src/diffusers/pipelines/stable_diffusion_k_diffusion/pipeline_stable_diffusion_xl_k_diffusion.py
@@ -568,7 +568,7 @@ class StableDiffusionXLKDiffusionPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -629,11 +629,11 @@ class StableDiffusionXLKDiffusionPipeline(
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
diff --git a/src/diffusers/pipelines/stable_diffusion_ldm3d/pipeline_stable_diffusion_ldm3d.py b/src/diffusers/pipelines/stable_diffusion_ldm3d/pipeline_stable_diffusion_ldm3d.py
index 702f3eda58..b6a214b0c4 100644
--- a/src/diffusers/pipelines/stable_diffusion_ldm3d/pipeline_stable_diffusion_ldm3d.py
+++ b/src/diffusers/pipelines/stable_diffusion_ldm3d/pipeline_stable_diffusion_ldm3d.py
@@ -73,7 +73,7 @@ def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
r"""
Rescales `noise_cfg` tensor based on `guidance_rescale` to improve image quality and fix overexposure. Based on
Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891).
Args:
noise_cfg (`torch.Tensor`):
@@ -573,7 +573,7 @@ class StableDiffusionLDM3DPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -723,7 +723,7 @@ class StableDiffusionLDM3DPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -800,8 +800,8 @@ class StableDiffusionLDM3DPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -988,7 +988,7 @@ class StableDiffusionLDM3DPipeline(
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/src/diffusers/pipelines/stable_diffusion_panorama/pipeline_stable_diffusion_panorama.py b/src/diffusers/pipelines/stable_diffusion_panorama/pipeline_stable_diffusion_panorama.py
index ccee6d47b4..f3c887ed0b 100644
--- a/src/diffusers/pipelines/stable_diffusion_panorama/pipeline_stable_diffusion_panorama.py
+++ b/src/diffusers/pipelines/stable_diffusion_panorama/pipeline_stable_diffusion_panorama.py
@@ -73,7 +73,7 @@ def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
r"""
Rescales `noise_cfg` tensor based on `guidance_rescale` to improve image quality and fix overexposure. Based on
Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891).
Args:
noise_cfg (`torch.Tensor`):
@@ -587,7 +587,7 @@ class StableDiffusionPanoramaPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -735,8 +735,8 @@ class StableDiffusionPanoramaPipeline(
) -> List[Tuple[int, int, int, int]]:
"""
Generates a list of views based on the given parameters. Here, we define the mappings F_i (see Eq. 7 in the
- MultiDiffusion paper https://arxiv.org/abs/2302.08113). If panorama's height/width < window_size, num_blocks of
- height/width should return 1.
+ MultiDiffusion paper https://huggingface.co/papers/2302.08113). If panorama's height/width < window_size,
+ num_blocks of height/width should return 1.
Args:
panorama_height (int): The height of the panorama.
@@ -854,8 +854,8 @@ class StableDiffusionPanoramaPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -962,7 +962,7 @@ class StableDiffusionPanoramaPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
@@ -1054,7 +1054,7 @@ class StableDiffusionPanoramaPipeline(
# Here, we iterate through different spatial crops of the latents and denoise them. These
# denoised (latent) crops are then averaged to produce the final latent
# for the current timestep via MultiDiffusion. Please see Sec. 4.1 in the
- # MultiDiffusion paper for more details: https://arxiv.org/abs/2302.08113
+ # MultiDiffusion paper for more details: https://huggingface.co/papers/2302.08113
# Batch views denoise
for j, batch_view in enumerate(views_batch):
vb_size = len(batch_view)
@@ -1113,7 +1113,7 @@ class StableDiffusionPanoramaPipeline(
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(
noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale
)
@@ -1144,7 +1144,7 @@ class StableDiffusionPanoramaPipeline(
value[:, :, h_start:h_end, w_start:w_end] += latents_view_denoised
count[:, :, h_start:h_end, w_start:w_end] += 1
- # take the MultiDiffusion step. Eq. 5 in MultiDiffusion paper: https://arxiv.org/abs/2302.08113
+ # take the MultiDiffusion step. Eq. 5 in MultiDiffusion paper: https://huggingface.co/papers/2302.08113
latents = torch.where(count > 0, value / count, value)
if callback_on_step_end is not None:
diff --git a/src/diffusers/pipelines/stable_diffusion_safe/pipeline_stable_diffusion_safe.py b/src/diffusers/pipelines/stable_diffusion_safe/pipeline_stable_diffusion_safe.py
index deae82eb88..5b9695f78e 100644
--- a/src/diffusers/pipelines/stable_diffusion_safe/pipeline_stable_diffusion_safe.py
+++ b/src/diffusers/pipelines/stable_diffusion_safe/pipeline_stable_diffusion_safe.py
@@ -358,7 +358,7 @@ class StableDiffusionPipelineSafe(DiffusionPipeline, StableDiffusionMixin, IPAda
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -561,8 +561,8 @@ class StableDiffusionPipelineSafe(DiffusionPipeline, StableDiffusionMixin, IPAda
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -632,7 +632,7 @@ class StableDiffusionPipelineSafe(DiffusionPipeline, StableDiffusionMixin, IPAda
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/stable_diffusion_sag/pipeline_stable_diffusion_sag.py b/src/diffusers/pipelines/stable_diffusion_sag/pipeline_stable_diffusion_sag.py
index e96422073b..2a808dd946 100644
--- a/src/diffusers/pipelines/stable_diffusion_sag/pipeline_stable_diffusion_sag.py
+++ b/src/diffusers/pipelines/stable_diffusion_sag/pipeline_stable_diffusion_sag.py
@@ -106,7 +106,7 @@ class CrossAttnStoreProcessor:
return hidden_states
-# Modified to get self-attention guidance scale in this paper (https://arxiv.org/pdf/2210.00939.pdf) as an input
+# Modified to get self-attention guidance scale in this paper (https://huggingface.co/papers/2210.00939) as an input
class StableDiffusionSAGPipeline(DiffusionPipeline, StableDiffusionMixin, TextualInversionLoaderMixin, IPAdapterMixin):
r"""
Pipeline for text-to-image generation using Stable Diffusion.
@@ -476,7 +476,7 @@ class StableDiffusionSAGPipeline(DiffusionPipeline, StableDiffusionMixin, Textua
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -616,8 +616,8 @@ class StableDiffusionSAGPipeline(DiffusionPipeline, StableDiffusionMixin, Textua
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -681,11 +681,11 @@ class StableDiffusionSAGPipeline(DiffusionPipeline, StableDiffusionMixin, Textua
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# and `sag_scale` is` `s` of equation (16)
- # of the self-attention guidance paper: https://arxiv.org/pdf/2210.00939.pdf
+ # of the self-attention guidance paper: https://huggingface.co/papers/2210.00939
# `sag_scale = 0` means no self-attention guidance
do_self_attention_guidance = sag_scale > 0.0
@@ -802,7 +802,7 @@ class StableDiffusionSAGPipeline(DiffusionPipeline, StableDiffusionMixin, Textua
if do_self_attention_guidance:
# classifier-free guidance produces two chunks of attention map
# and we only use unconditional one according to equation (25)
- # in https://arxiv.org/pdf/2210.00939.pdf
+ # in https://huggingface.co/papers/2210.00939
if do_classifier_free_guidance:
# DDIM-like prediction of x0
pred_x0 = self.pred_x0(latents, noise_pred_uncond, t)
@@ -876,7 +876,7 @@ class StableDiffusionSAGPipeline(DiffusionPipeline, StableDiffusionMixin, Textua
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
def sag_masking(self, original_latents, attn_map, map_size, t, eps):
- # Same masking process as in SAG paper: https://arxiv.org/pdf/2210.00939.pdf
+ # Same masking process as in SAG paper: https://huggingface.co/papers/2210.00939
bh, hw1, hw2 = attn_map.shape
b, latent_channel, latent_h, latent_w = original_latents.shape
h = self.unet.config.attention_head_dim
diff --git a/src/diffusers/pipelines/stable_diffusion_xl/pipeline_stable_diffusion_xl.py b/src/diffusers/pipelines/stable_diffusion_xl/pipeline_stable_diffusion_xl.py
index 9c69fe65fb..737caac515 100644
--- a/src/diffusers/pipelines/stable_diffusion_xl/pipeline_stable_diffusion_xl.py
+++ b/src/diffusers/pipelines/stable_diffusion_xl/pipeline_stable_diffusion_xl.py
@@ -90,7 +90,7 @@ def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
r"""
Rescales `noise_cfg` tensor based on `guidance_rescale` to improve image quality and fix overexposure. Based on
Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891).
Args:
noise_cfg (`torch.Tensor`):
@@ -598,7 +598,7 @@ class StableDiffusionXLPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -811,7 +811,7 @@ class StableDiffusionXLPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -914,11 +914,11 @@ class StableDiffusionXLPipeline(
"Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output)
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
@@ -929,8 +929,8 @@ class StableDiffusionXLPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
@@ -970,9 +970,10 @@ class StableDiffusionXLPipeline(
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
- [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
- Guidance rescale factor should fix overexposure when using zero terminal SNR.
+ Flawed](https://huggingface.co/papers/2305.08891) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are
+ Flawed](https://huggingface.co/papers/2305.08891). Guidance rescale factor should fix overexposure when
+ using zero terminal SNR.
original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
`original_size` defaults to `(height, width)` if not specified. Part of SDXL's micro-conditioning as
@@ -1229,7 +1230,7 @@ class StableDiffusionXLPipeline(
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/src/diffusers/pipelines/stable_diffusion_xl/pipeline_stable_diffusion_xl_img2img.py b/src/diffusers/pipelines/stable_diffusion_xl/pipeline_stable_diffusion_xl_img2img.py
index 08d0b44d61..dfbbdaeac5 100644
--- a/src/diffusers/pipelines/stable_diffusion_xl/pipeline_stable_diffusion_xl_img2img.py
+++ b/src/diffusers/pipelines/stable_diffusion_xl/pipeline_stable_diffusion_xl_img2img.py
@@ -93,7 +93,7 @@ def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
r"""
Rescales `noise_cfg` tensor based on `guidance_rescale` to improve image quality and fix overexposure. Based on
Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891).
Args:
noise_cfg (`torch.Tensor`):
@@ -544,7 +544,7 @@ class StableDiffusionXLImg2ImgPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -957,7 +957,7 @@ class StableDiffusionXLImg2ImgPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1074,11 +1074,11 @@ class StableDiffusionXLImg2ImgPipeline(
forms a part of a "Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refine Image
Quality**](https://huggingface.co/docs/diffusers/using-diffusers/sdxl#refine-image-quality).
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
@@ -1089,8 +1089,8 @@ class StableDiffusionXLImg2ImgPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
@@ -1130,9 +1130,10 @@ class StableDiffusionXLImg2ImgPipeline(
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
- [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
- Guidance rescale factor should fix overexposure when using zero terminal SNR.
+ Flawed](https://huggingface.co/papers/2305.08891) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are
+ Flawed](https://huggingface.co/papers/2305.08891). Guidance rescale factor should fix overexposure when
+ using zero terminal SNR.
original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
`original_size` defaults to `(height, width)` if not specified. Part of SDXL's micro-conditioning as
@@ -1420,7 +1421,7 @@ class StableDiffusionXLImg2ImgPipeline(
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/src/diffusers/pipelines/stable_diffusion_xl/pipeline_stable_diffusion_xl_inpaint.py b/src/diffusers/pipelines/stable_diffusion_xl/pipeline_stable_diffusion_xl_inpaint.py
index 835c0af800..81984371b6 100644
--- a/src/diffusers/pipelines/stable_diffusion_xl/pipeline_stable_diffusion_xl_inpaint.py
+++ b/src/diffusers/pipelines/stable_diffusion_xl/pipeline_stable_diffusion_xl_inpaint.py
@@ -104,7 +104,7 @@ def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
r"""
Rescales `noise_cfg` tensor based on `guidance_rescale` to improve image quality and fix overexposure. Based on
Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891).
Args:
noise_cfg (`torch.Tensor`):
@@ -648,7 +648,7 @@ class StableDiffusionXLInpaintPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -1062,7 +1062,7 @@ class StableDiffusionXLInpaintPipeline(
return self._clip_skip
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -1208,11 +1208,11 @@ class StableDiffusionXLInpaintPipeline(
forms a part of a "Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output).
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
@@ -1243,8 +1243,8 @@ class StableDiffusionXLInpaintPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
@@ -1638,7 +1638,7 @@ class StableDiffusionXLInpaintPipeline(
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/src/diffusers/pipelines/stable_diffusion_xl/pipeline_stable_diffusion_xl_instruct_pix2pix.py b/src/diffusers/pipelines/stable_diffusion_xl/pipeline_stable_diffusion_xl_instruct_pix2pix.py
index aaffe8efa7..8d7d70c641 100644
--- a/src/diffusers/pipelines/stable_diffusion_xl/pipeline_stable_diffusion_xl_instruct_pix2pix.py
+++ b/src/diffusers/pipelines/stable_diffusion_xl/pipeline_stable_diffusion_xl_instruct_pix2pix.py
@@ -104,7 +104,7 @@ def retrieve_latents(
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
- Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
+ Sample Steps are Flawed](https://huggingface.co/papers/2305.08891). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
@@ -427,7 +427,7 @@ class StableDiffusionXLInstructPix2PixPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -667,11 +667,11 @@ class StableDiffusionXLInstructPix2PixPipeline(
"Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output)
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
image_guidance_scale (`float`, *optional*, defaults to 1.5):
Image guidance scale is to push the generated image towards the initial image `image`. Image guidance
scale is enabled by setting `image_guidance_scale > 1`. Higher image guidance scale encourages to
@@ -687,8 +687,8 @@ class StableDiffusionXLInstructPix2PixPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
@@ -728,9 +728,10 @@ class StableDiffusionXLInstructPix2PixPipeline(
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
- [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
- Guidance rescale factor should fix overexposure when using zero terminal SNR.
+ Flawed](https://huggingface.co/papers/2305.08891) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are
+ Flawed](https://huggingface.co/papers/2305.08891). Guidance rescale factor should fix overexposure when
+ using zero terminal SNR.
original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
`original_size` defaults to `(height, width)` if not specified. Part of SDXL's micro-conditioning as
@@ -785,7 +786,7 @@ class StableDiffusionXLInstructPix2PixPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0 and image_guidance_scale >= 1.0
@@ -928,7 +929,7 @@ class StableDiffusionXLInstructPix2PixPipeline(
)
if do_classifier_free_guidance and guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/src/diffusers/pipelines/stable_video_diffusion/pipeline_stable_video_diffusion.py b/src/diffusers/pipelines/stable_video_diffusion/pipeline_stable_video_diffusion.py
index 8c1af7863e..827f031b7d 100644
--- a/src/diffusers/pipelines/stable_video_diffusion/pipeline_stable_video_diffusion.py
+++ b/src/diffusers/pipelines/stable_video_diffusion/pipeline_stable_video_diffusion.py
@@ -369,7 +369,7 @@ class StableVideoDiffusionPipeline(DiffusionPipeline):
return self._guidance_scale
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -495,7 +495,7 @@ class StableVideoDiffusionPipeline(DiffusionPipeline):
batch_size = image.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
self._guidance_scale = max_guidance_scale
diff --git a/src/diffusers/pipelines/t2i_adapter/pipeline_stable_diffusion_adapter.py b/src/diffusers/pipelines/t2i_adapter/pipeline_stable_diffusion_adapter.py
index 85b157d8ef..87784d8ee3 100644
--- a/src/diffusers/pipelines/t2i_adapter/pipeline_stable_diffusion_adapter.py
+++ b/src/diffusers/pipelines/t2i_adapter/pipeline_stable_diffusion_adapter.py
@@ -191,7 +191,7 @@ def retrieve_timesteps(
class StableDiffusionAdapterPipeline(DiffusionPipeline, StableDiffusionMixin, FromSingleFileMixin):
r"""
Pipeline for text-to-image generation using Stable Diffusion augmented with T2I-Adapter
- https://arxiv.org/abs/2302.08453
+ https://huggingface.co/papers/2302.08453
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
@@ -521,7 +521,7 @@ class StableDiffusionAdapterPipeline(DiffusionPipeline, StableDiffusionMixin, Fr
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -680,7 +680,7 @@ class StableDiffusionAdapterPipeline(DiffusionPipeline, StableDiffusionMixin, Fr
return self._guidance_scale
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -740,11 +740,11 @@ class StableDiffusionAdapterPipeline(DiffusionPipeline, StableDiffusionMixin, Fr
their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
will be used.
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds`. instead. If not defined, one has to pass `negative_prompt_embeds`. instead.
@@ -752,8 +752,8 @@ class StableDiffusionAdapterPipeline(DiffusionPipeline, StableDiffusionMixin, Fr
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
diff --git a/src/diffusers/pipelines/t2i_adapter/pipeline_stable_diffusion_xl_adapter.py b/src/diffusers/pipelines/t2i_adapter/pipeline_stable_diffusion_xl_adapter.py
index d5382517ca..901790c2af 100644
--- a/src/diffusers/pipelines/t2i_adapter/pipeline_stable_diffusion_xl_adapter.py
+++ b/src/diffusers/pipelines/t2i_adapter/pipeline_stable_diffusion_xl_adapter.py
@@ -131,7 +131,7 @@ def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
r"""
Rescales `noise_cfg` tensor based on `guidance_rescale` to improve image quality and fix overexposure. Based on
Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891).
Args:
noise_cfg (`torch.Tensor`):
@@ -223,7 +223,7 @@ class StableDiffusionXLAdapterPipeline(
):
r"""
Pipeline for text-to-image generation using Stable Diffusion augmented with T2I-Adapter
- https://arxiv.org/abs/2302.08453
+ https://huggingface.co/papers/2302.08453
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
@@ -624,7 +624,7 @@ class StableDiffusionXLAdapterPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -859,7 +859,7 @@ class StableDiffusionXLAdapterPipeline(
return self._guidance_scale
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
@property
def do_classifier_free_guidance(self):
@@ -948,11 +948,11 @@ class StableDiffusionXLAdapterPipeline(
"Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output)
guidance_scale (`float`, *optional*, defaults to 5.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
@@ -963,8 +963,8 @@ class StableDiffusionXLAdapterPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
@@ -1010,9 +1010,10 @@ class StableDiffusionXLAdapterPipeline(
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
- [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
- Guidance rescale factor should fix overexposure when using zero terminal SNR.
+ Flawed](https://huggingface.co/papers/2305.08891) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are
+ Flawed](https://huggingface.co/papers/2305.08891). Guidance rescale factor should fix overexposure when
+ using zero terminal SNR.
original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
`original_size` defaults to `(height, width)` if not specified. Part of SDXL's micro-conditioning as
@@ -1266,7 +1267,7 @@ class StableDiffusionXLAdapterPipeline(
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if self.do_classifier_free_guidance and guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
diff --git a/src/diffusers/pipelines/text_to_video_synthesis/pipeline_text_to_video_synth.py b/src/diffusers/pipelines/text_to_video_synthesis/pipeline_text_to_video_synth.py
index 5c63d66e31..4e41ce9900 100644
--- a/src/diffusers/pipelines/text_to_video_synthesis/pipeline_text_to_video_synth.py
+++ b/src/diffusers/pipelines/text_to_video_synthesis/pipeline_text_to_video_synth.py
@@ -349,7 +349,7 @@ class TextToVideoSDPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -489,8 +489,8 @@ class TextToVideoSDPipeline(
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -550,7 +550,7 @@ class TextToVideoSDPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/text_to_video_synthesis/pipeline_text_to_video_synth_img2img.py b/src/diffusers/pipelines/text_to_video_synthesis/pipeline_text_to_video_synth_img2img.py
index 006c7a79ce..37a830891b 100644
--- a/src/diffusers/pipelines/text_to_video_synthesis/pipeline_text_to_video_synth_img2img.py
+++ b/src/diffusers/pipelines/text_to_video_synthesis/pipeline_text_to_video_synth_img2img.py
@@ -385,7 +385,7 @@ class VideoToVideoSDPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -553,8 +553,8 @@ class VideoToVideoSDPipeline(
The prompt or prompts to guide what to not include in video generation. If not defined, you need to
pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -609,7 +609,7 @@ class VideoToVideoSDPipeline(
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/text_to_video_synthesis/pipeline_text_to_video_zero.py b/src/diffusers/pipelines/text_to_video_synthesis/pipeline_text_to_video_zero.py
index df85f470a8..7a8db4a8e5 100644
--- a/src/diffusers/pipelines/text_to_video_synthesis/pipeline_text_to_video_zero.py
+++ b/src/diffusers/pipelines/text_to_video_synthesis/pipeline_text_to_video_zero.py
@@ -588,8 +588,8 @@ class TextToVideoZeroPipeline(
num_videos_per_prompt (`int`, *optional*, defaults to 1):
The number of videos to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -610,17 +610,17 @@ class TextToVideoZeroPipeline(
The frequency at which the `callback` function is called. If not specified, the callback is called at
every step.
motion_field_strength_x (`float`, *optional*, defaults to 12):
- Strength of motion in generated video along x-axis. See the [paper](https://arxiv.org/abs/2303.13439),
- Sect. 3.3.1.
+ Strength of motion in generated video along x-axis. See the
+ [paper](https://huggingface.co/papers/2303.13439), Sect. 3.3.1.
motion_field_strength_y (`float`, *optional*, defaults to 12):
- Strength of motion in generated video along y-axis. See the [paper](https://arxiv.org/abs/2303.13439),
- Sect. 3.3.1.
+ Strength of motion in generated video along y-axis. See the
+ [paper](https://huggingface.co/papers/2303.13439), Sect. 3.3.1.
t0 (`int`, *optional*, defaults to 44):
Timestep t0. Should be in the range [0, num_inference_steps - 1]. See the
- [paper](https://arxiv.org/abs/2303.13439), Sect. 3.3.1.
+ [paper](https://huggingface.co/papers/2303.13439), Sect. 3.3.1.
t1 (`int`, *optional*, defaults to 47):
Timestep t0. Should be in the range [t0 + 1, num_inference_steps - 1]. See the
- [paper](https://arxiv.org/abs/2303.13439), Sect. 3.3.1.
+ [paper](https://huggingface.co/papers/2303.13439), Sect. 3.3.1.
frame_ids (`List[int]`, *optional*):
Indexes of the frames that are being generated. This is used when generating longer videos
chunk-by-chunk.
@@ -663,7 +663,7 @@ class TextToVideoZeroPipeline(
batch_size = 1 if isinstance(prompt, str) else len(prompt)
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
@@ -797,7 +797,7 @@ class TextToVideoZeroPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
diff --git a/src/diffusers/pipelines/text_to_video_synthesis/pipeline_text_to_video_zero_sdxl.py b/src/diffusers/pipelines/text_to_video_synthesis/pipeline_text_to_video_zero_sdxl.py
index 339d5b3a60..d38e65ec97 100644
--- a/src/diffusers/pipelines/text_to_video_synthesis/pipeline_text_to_video_zero_sdxl.py
+++ b/src/diffusers/pipelines/text_to_video_synthesis/pipeline_text_to_video_zero_sdxl.py
@@ -323,7 +323,7 @@ def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
r"""
Rescales `noise_cfg` tensor based on `guidance_rescale` to improve image quality and fix overexposure. Based on
Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf).
+ Flawed](https://huggingface.co/papers/2305.08891).
Args:
noise_cfg (`torch.Tensor`):
@@ -439,7 +439,7 @@ class TextToVideoZeroSDXLPipeline(
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -929,7 +929,7 @@ class TextToVideoZeroSDXLPipeline(
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if do_classifier_free_guidance and guidance_rescale > 0.0:
- # Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
+ # Based on 3.4. in https://huggingface.co/papers/2305.08891
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
@@ -1009,11 +1009,11 @@ class TextToVideoZeroSDXLPipeline(
"Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output)
guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
@@ -1024,8 +1024,8 @@ class TextToVideoZeroSDXLPipeline(
num_videos_per_prompt (`int`, *optional*, defaults to 1):
The number of videos to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
+ Corresponds to parameter eta (η) in the DDIM paper: https://huggingface.co/papers/2010.02502. Only
+ applies to [`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
@@ -1051,11 +1051,11 @@ class TextToVideoZeroSDXLPipeline(
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
motion_field_strength_x (`float`, *optional*, defaults to 12):
- Strength of motion in generated video along x-axis. See the [paper](https://arxiv.org/abs/2303.13439),
- Sect. 3.3.1.
+ Strength of motion in generated video along x-axis. See the
+ [paper](https://huggingface.co/papers/2303.13439), Sect. 3.3.1.
motion_field_strength_y (`float`, *optional*, defaults to 12):
- Strength of motion in generated video along y-axis. See the [paper](https://arxiv.org/abs/2303.13439),
- Sect. 3.3.1.
+ Strength of motion in generated video along y-axis. See the
+ [paper](https://huggingface.co/papers/2303.13439), Sect. 3.3.1.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
@@ -1074,9 +1074,10 @@ class TextToVideoZeroSDXLPipeline(
[diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
guidance_rescale (`float`, *optional*, defaults to 0.7):
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
- Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
- [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
- Guidance rescale factor should fix overexposure when using zero terminal SNR.
+ Flawed](https://huggingface.co/papers/2305.08891) `guidance_scale` is defined as `φ` in equation 16. of
+ [Common Diffusion Noise Schedules and Sample Steps are
+ Flawed](https://huggingface.co/papers/2305.08891). Guidance rescale factor should fix overexposure when
+ using zero terminal SNR.
original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
`original_size` defaults to `(width, height)` if not specified. Part of SDXL's micro-conditioning as
@@ -1093,10 +1094,10 @@ class TextToVideoZeroSDXLPipeline(
section 2.2 of [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
t0 (`int`, *optional*, defaults to 44):
Timestep t0. Should be in the range [0, num_inference_steps - 1]. See the
- [paper](https://arxiv.org/abs/2303.13439), Sect. 3.3.1.
+ [paper](https://huggingface.co/papers/2303.13439), Sect. 3.3.1.
t1 (`int`, *optional*, defaults to 47):
Timestep t0. Should be in the range [t0 + 1, num_inference_steps - 1]. See the
- [paper](https://arxiv.org/abs/2303.13439), Sect. 3.3.1.
+ [paper](https://huggingface.co/papers/2303.13439), Sect. 3.3.1.
Returns:
[`~pipelines.text_to_video_synthesis.pipeline_text_to_video_zero.TextToVideoSDXLPipelineOutput`] or
@@ -1153,7 +1154,7 @@ class TextToVideoZeroSDXLPipeline(
)
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/unclip/text_proj.py b/src/diffusers/pipelines/unclip/text_proj.py
index 5a86d0c08a..e66829716d 100644
--- a/src/diffusers/pipelines/unclip/text_proj.py
+++ b/src/diffusers/pipelines/unclip/text_proj.py
@@ -24,7 +24,7 @@ class UnCLIPTextProjModel(ModelMixin, ConfigMixin):
Utility class for CLIP embeddings. Used to combine the image and text embeddings into a format usable by the
decoder.
- For more details, see the original paper: https://arxiv.org/abs/2204.06125 section 2.1
+ For more details, see the original paper: https://huggingface.co/papers/2204.06125 section 2.1
"""
@register_to_config
diff --git a/src/diffusers/pipelines/unidiffuser/modeling_text_decoder.py b/src/diffusers/pipelines/unidiffuser/modeling_text_decoder.py
index 29f99f3fc7..0ddcbf7357 100644
--- a/src/diffusers/pipelines/unidiffuser/modeling_text_decoder.py
+++ b/src/diffusers/pipelines/unidiffuser/modeling_text_decoder.py
@@ -13,7 +13,7 @@ from ...models import ModelMixin
# Modified from ClipCaptionModel in https://github.com/thu-ml/unidiffuser/blob/main/libs/caption_decoder.py
class UniDiffuserTextDecoder(ModelMixin, ConfigMixin, ModuleUtilsMixin):
"""
- Text decoder model for a image-text [UniDiffuser](https://arxiv.org/pdf/2303.06555.pdf) model. This is used to
+ Text decoder model for a image-text [UniDiffuser](https://huggingface.co/papers/2303.06555) model. This is used to
generate text from the UniDiffuser image-text embedding.
Parameters:
diff --git a/src/diffusers/pipelines/unidiffuser/modeling_uvit.py b/src/diffusers/pipelines/unidiffuser/modeling_uvit.py
index 1e285a9670..2a04ec2e40 100644
--- a/src/diffusers/pipelines/unidiffuser/modeling_uvit.py
+++ b/src/diffusers/pipelines/unidiffuser/modeling_uvit.py
@@ -832,7 +832,7 @@ class UTransformer2DModel(ModelMixin, ConfigMixin):
class UniDiffuserModel(ModelMixin, ConfigMixin):
"""
- Transformer model for a image-text [UniDiffuser](https://arxiv.org/pdf/2303.06555.pdf) model. This is a
+ Transformer model for a image-text [UniDiffuser](https://huggingface.co/papers/2303.06555) model. This is a
modification of [`UTransformer2DModel`] with input and output heads for the VAE-embedded latent image, the
CLIP-embedded image, and the CLIP-embedded prompt (see paper for more details).
diff --git a/src/diffusers/pipelines/unidiffuser/pipeline_unidiffuser.py b/src/diffusers/pipelines/unidiffuser/pipeline_unidiffuser.py
index 865dba75b7..49d301a5cf 100644
--- a/src/diffusers/pipelines/unidiffuser/pipeline_unidiffuser.py
+++ b/src/diffusers/pipelines/unidiffuser/pipeline_unidiffuser.py
@@ -153,7 +153,7 @@ class UniDiffuserPipeline(DiffusionPipeline):
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # eta corresponds to η in DDIM paper: https://huggingface.co/papers/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
@@ -1154,8 +1154,8 @@ class UniDiffuserPipeline(DiffusionPipeline):
`text` mode. If the mode is joint and both `num_images_per_prompt` and `num_prompts_per_image` are
supplied, `min(num_images_per_prompt, num_prompts_per_image)` samples are generated.
eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
+ Corresponds to parameter eta (η) from the [DDIM](https://huggingface.co/papers/2010.02502) paper. Only
+ applies to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
@@ -1243,7 +1243,7 @@ class UniDiffuserPipeline(DiffusionPipeline):
reduce_text_emb_dim = self.text_intermediate_dim < self.text_encoder_hidden_size or self.mode != "text2img"
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # of the Imagen paper: https://huggingface.co/papers/2205.11487 . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
# Note that this differs from the formulation in the unidiffusers paper!
do_classifier_free_guidance = guidance_scale > 1.0
diff --git a/src/diffusers/pipelines/visualcloze/__init__.py b/src/diffusers/pipelines/visualcloze/__init__.py
new file mode 100644
index 0000000000..ab765a1bba
--- /dev/null
+++ b/src/diffusers/pipelines/visualcloze/__init__.py
@@ -0,0 +1,52 @@
+from typing import TYPE_CHECKING
+
+from ...utils import (
+ DIFFUSERS_SLOW_IMPORT,
+ OptionalDependencyNotAvailable,
+ _LazyModule,
+ get_objects_from_module,
+ is_torch_available,
+ is_transformers_available,
+)
+
+
+_dummy_objects = {}
+_import_structure = {}
+
+
+try:
+ if not (is_transformers_available() and is_torch_available()):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ...utils import dummy_torch_and_transformers_objects # noqa F403
+
+ _dummy_objects.update(get_objects_from_module(dummy_torch_and_transformers_objects))
+else:
+ _import_structure["pipeline_visualcloze_combined"] = ["VisualClozePipeline"]
+ _import_structure["pipeline_visualcloze_generation"] = ["VisualClozeGenerationPipeline"]
+
+
+if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
+ try:
+ if not (is_transformers_available() and is_torch_available()):
+ raise OptionalDependencyNotAvailable()
+
+ except OptionalDependencyNotAvailable:
+ from ...utils.dummy_torch_and_transformers_objects import *
+ else:
+ from .pipeline_visualcloze_combined import VisualClozePipeline
+ from .pipeline_visualcloze_generation import VisualClozeGenerationPipeline
+
+
+else:
+ import sys
+
+ sys.modules[__name__] = _LazyModule(
+ __name__,
+ globals()["__file__"],
+ _import_structure,
+ module_spec=__spec__,
+ )
+
+ for name, value in _dummy_objects.items():
+ setattr(sys.modules[__name__], name, value)
diff --git a/src/diffusers/pipelines/visualcloze/pipeline_visualcloze_combined.py b/src/diffusers/pipelines/visualcloze/pipeline_visualcloze_combined.py
new file mode 100644
index 0000000000..68130baad7
--- /dev/null
+++ b/src/diffusers/pipelines/visualcloze/pipeline_visualcloze_combined.py
@@ -0,0 +1,444 @@
+# Copyright 2025 VisualCloze team and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from typing import Any, Callable, Dict, List, Optional, Union
+
+import torch
+from PIL import Image
+from transformers import CLIPTextModel, CLIPTokenizer, T5EncoderModel, T5TokenizerFast
+
+from ...loaders import FluxLoraLoaderMixin, FromSingleFileMixin, TextualInversionLoaderMixin
+from ...models.autoencoders import AutoencoderKL
+from ...models.transformers import FluxTransformer2DModel
+from ...schedulers import FlowMatchEulerDiscreteScheduler
+from ...utils import (
+ is_torch_xla_available,
+ logging,
+ replace_example_docstring,
+)
+from ..flux.pipeline_flux_fill import FluxFillPipeline as VisualClozeUpsamplingPipeline
+from ..flux.pipeline_output import FluxPipelineOutput
+from ..pipeline_utils import DiffusionPipeline
+from .pipeline_visualcloze_generation import VisualClozeGenerationPipeline
+
+
+if is_torch_xla_available():
+ XLA_AVAILABLE = True
+else:
+ XLA_AVAILABLE = False
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```python
+ >>> import torch
+ >>> from diffusers import VisualClozePipeline
+ >>> from diffusers.utils import load_image
+
+ >>> image_paths = [
+ ... # in-context examples
+ ... [
+ ... load_image(
+ ... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/visualcloze/visualcloze_mask2image_incontext-example-1_mask.jpg"
+ ... ),
+ ... load_image(
+ ... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/visualcloze/visualcloze_mask2image_incontext-example-1_image.jpg"
+ ... ),
+ ... ],
+ ... # query with the target image
+ ... [
+ ... load_image(
+ ... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/visualcloze/visualcloze_mask2image_query_mask.jpg"
+ ... ),
+ ... None, # No image needed for the target image
+ ... ],
+ ... ]
+ >>> task_prompt = "In each row, a logical task is demonstrated to achieve [IMAGE2] an aesthetically pleasing photograph based on [IMAGE1] sam 2-generated masks with rich color coding."
+ >>> content_prompt = "Majestic photo of a golden eagle perched on a rocky outcrop in a mountainous landscape. The eagle is positioned in the right foreground, facing left, with its sharp beak and keen eyes prominently visible. Its plumage is a mix of dark brown and golden hues, with intricate feather details. The background features a soft-focus view of snow-capped mountains under a cloudy sky, creating a serene and grandiose atmosphere. The foreground includes rugged rocks and patches of green moss. Photorealistic, medium depth of field, soft natural lighting, cool color palette, high contrast, sharp focus on the eagle, blurred background, tranquil, majestic, wildlife photography."
+ >>> pipe = VisualClozePipeline.from_pretrained(
+ ... "VisualCloze/VisualClozePipeline-384", resolution=384, torch_dtype=torch.bfloat16
+ ... )
+ >>> pipe.to("cuda")
+
+ >>> image = pipe(
+ ... task_prompt=task_prompt,
+ ... content_prompt=content_prompt,
+ ... image=image_paths,
+ ... upsampling_width=1344,
+ ... upsampling_height=768,
+ ... upsampling_strength=0.4,
+ ... guidance_scale=30,
+ ... num_inference_steps=30,
+ ... max_sequence_length=512,
+ ... generator=torch.Generator("cpu").manual_seed(0),
+ ... ).images[0][0]
+ >>> image.save("visualcloze.png")
+ ```
+"""
+
+
+class VisualClozePipeline(
+ DiffusionPipeline,
+ FluxLoraLoaderMixin,
+ FromSingleFileMixin,
+ TextualInversionLoaderMixin,
+):
+ r"""
+ The VisualCloze pipeline for image generation with visual context. Reference:
+ https://github.com/lzyhha/VisualCloze/tree/main. This pipeline is designed to generate images based on visual
+ in-context examples.
+
+ Args:
+ transformer ([`FluxTransformer2DModel`]):
+ Conditional Transformer (MMDiT) architecture to denoise the encoded image latents.
+ scheduler ([`FlowMatchEulerDiscreteScheduler`]):
+ A scheduler to be used in combination with `transformer` to denoise the encoded image latents.
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ text_encoder_2 ([`T5EncoderModel`]):
+ [T5](https://huggingface.co/docs/transformers/en/model_doc/t5#transformers.T5EncoderModel), specifically
+ the [google/t5-v1_1-xxl](https://huggingface.co/google/t5-v1_1-xxl) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/en/model_doc/clip#transformers.CLIPTokenizer).
+ tokenizer_2 (`T5TokenizerFast`):
+ Second Tokenizer of class
+ [T5TokenizerFast](https://huggingface.co/docs/transformers/en/model_doc/t5#transformers.T5TokenizerFast).
+ resolution (`int`, *optional*, defaults to 384):
+ The resolution of each image when concatenating images from the query and in-context examples.
+ """
+
+ model_cpu_offload_seq = "text_encoder->text_encoder_2->transformer->vae"
+ _optional_components = []
+ _callback_tensor_inputs = ["latents", "prompt_embeds"]
+
+ def __init__(
+ self,
+ scheduler: FlowMatchEulerDiscreteScheduler,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ text_encoder_2: T5EncoderModel,
+ tokenizer_2: T5TokenizerFast,
+ transformer: FluxTransformer2DModel,
+ resolution: int = 384,
+ ):
+ super().__init__()
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ text_encoder_2=text_encoder_2,
+ tokenizer=tokenizer,
+ tokenizer_2=tokenizer_2,
+ transformer=transformer,
+ scheduler=scheduler,
+ )
+
+ self.generation_pipe = VisualClozeGenerationPipeline(
+ vae=vae,
+ text_encoder=text_encoder,
+ text_encoder_2=text_encoder_2,
+ tokenizer=tokenizer,
+ tokenizer_2=tokenizer_2,
+ transformer=transformer,
+ scheduler=scheduler,
+ resolution=resolution,
+ )
+ self.upsampling_pipe = VisualClozeUpsamplingPipeline(
+ vae=vae,
+ text_encoder=text_encoder,
+ text_encoder_2=text_encoder_2,
+ tokenizer=tokenizer,
+ tokenizer_2=tokenizer_2,
+ transformer=transformer,
+ scheduler=scheduler,
+ )
+
+ def check_inputs(
+ self,
+ image,
+ task_prompt,
+ content_prompt,
+ upsampling_height,
+ upsampling_width,
+ strength,
+ prompt_embeds=None,
+ pooled_prompt_embeds=None,
+ callback_on_step_end_tensor_inputs=None,
+ max_sequence_length=None,
+ ):
+ if strength < 0 or strength > 1:
+ raise ValueError(f"The value of strength should in [0.0, 1.0] but is {strength}")
+
+ if upsampling_height is not None and upsampling_height % (self.vae_scale_factor * 2) != 0:
+ logger.warning(
+ f"`upsampling_height`has to be divisible by {self.vae_scale_factor * 2} but are {upsampling_height}. Dimensions will be resized accordingly"
+ )
+ if upsampling_width is not None and upsampling_width % (self.vae_scale_factor * 2) != 0:
+ logger.warning(
+ f"`upsampling_width` have to be divisible by {self.vae_scale_factor * 2} but are {upsampling_width}. Dimensions will be resized accordingly"
+ )
+
+ if callback_on_step_end_tensor_inputs is not None and not all(
+ k in self._callback_tensor_inputs for k in callback_on_step_end_tensor_inputs
+ ):
+ raise ValueError(
+ f"`callback_on_step_end_tensor_inputs` has to be in {self._callback_tensor_inputs}, but found {[k for k in callback_on_step_end_tensor_inputs if k not in self._callback_tensor_inputs]}"
+ )
+
+ # Validate prompt inputs
+ if (task_prompt is not None or content_prompt is not None) and prompt_embeds is not None:
+ raise ValueError("Cannot provide both text `task_prompt` + `content_prompt` and `prompt_embeds`. ")
+
+ if task_prompt is None and content_prompt is None and prompt_embeds is None:
+ raise ValueError("Must provide either `task_prompt` + `content_prompt` or pre-computed `prompt_embeds`. ")
+
+ # Validate prompt types and consistency
+ if task_prompt is None:
+ raise ValueError("`task_prompt` is missing.")
+
+ if task_prompt is not None and not isinstance(task_prompt, (str, list)):
+ raise ValueError(f"`task_prompt` must be str or list, got {type(task_prompt)}")
+
+ if content_prompt is not None and not isinstance(content_prompt, (str, list)):
+ raise ValueError(f"`content_prompt` must be str or list, got {type(content_prompt)}")
+
+ if isinstance(task_prompt, list) or isinstance(content_prompt, list):
+ if not isinstance(task_prompt, list) or not isinstance(content_prompt, list):
+ raise ValueError(
+ f"`task_prompt` and `content_prompt` must both be lists, or both be of type str or None, "
+ f"got {type(task_prompt)} and {type(content_prompt)}"
+ )
+ if len(content_prompt) != len(task_prompt):
+ raise ValueError("`task_prompt` and `content_prompt` must have the same length whe they are lists.")
+
+ for sample in image:
+ if not isinstance(sample, list) or not isinstance(sample[0], list):
+ raise ValueError("Each sample in the batch must have a 2D list of images.")
+ if len({len(row) for row in sample}) != 1:
+ raise ValueError("Each in-context example and query should contain the same number of images.")
+ if not any(img is None for img in sample[-1]):
+ raise ValueError("There are no targets in the query, which should be represented as None.")
+ for row in sample[:-1]:
+ if any(img is None for img in row):
+ raise ValueError("Images are missing in in-context examples.")
+
+ # Validate embeddings
+ if prompt_embeds is not None and pooled_prompt_embeds is None:
+ raise ValueError(
+ "If `prompt_embeds` are provided, `pooled_prompt_embeds` also have to be passed. Make sure to generate `pooled_prompt_embeds` from the same text encoder that was used to generate `prompt_embeds`."
+ )
+
+ # Validate sequence length
+ if max_sequence_length is not None and max_sequence_length > 512:
+ raise ValueError(f"max_sequence_length cannot exceed 512, got {max_sequence_length}")
+
+ @torch.no_grad()
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ task_prompt: Union[str, List[str]] = None,
+ content_prompt: Union[str, List[str]] = None,
+ image: Optional[torch.FloatTensor] = None,
+ upsampling_height: Optional[int] = None,
+ upsampling_width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ sigmas: Optional[List[float]] = None,
+ guidance_scale: float = 30.0,
+ num_images_per_prompt: Optional[int] = 1,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ joint_attention_kwargs: Optional[Dict[str, Any]] = None,
+ callback_on_step_end: Optional[Callable[[int, int, Dict], None]] = None,
+ callback_on_step_end_tensor_inputs: List[str] = ["latents"],
+ max_sequence_length: int = 512,
+ upsampling_strength: float = 1.0,
+ ):
+ r"""
+ Function invoked when calling the VisualCloze pipeline for generation.
+
+ Args:
+ task_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to define the task intention.
+ content_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to define the content or caption of the target image to be generated.
+ image (`torch.Tensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.Tensor]`, `List[PIL.Image.Image]`, or `List[np.ndarray]`):
+ `Image`, numpy array or tensor representing an image batch to be used as the starting point. For both
+ numpy array and pytorch tensor, the expected value range is between `[0, 1]` If it's a tensor or a list
+ or tensors, the expected shape should be `(B, C, H, W)` or `(C, H, W)`. If it is a numpy array or a
+ list of arrays, the expected shape should be `(B, H, W, C)` or `(H, W, C)`.
+ upsampling_height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image (i.e., output image) after upsampling via SDEdit. By
+ default, the image is upsampled by a factor of three, and the base resolution is determined by the
+ resolution parameter of the pipeline. When only one of `upsampling_height` or `upsampling_width` is
+ specified, the other will be automatically set based on the aspect ratio.
+ upsampling_width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image (i.e., output image) after upsampling via SDEdit. By
+ default, the image is upsampled by a factor of three, and the base resolution is determined by the
+ resolution parameter of the pipeline. When only one of `upsampling_height` or `upsampling_width` is
+ specified, the other will be automatically set based on the aspect ratio.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ sigmas (`List[float]`, *optional*):
+ Custom sigmas to use for the denoising process with schedulers which support a `sigmas` argument in
+ their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
+ will be used.
+ guidance_scale (`float`, *optional*, defaults to 30.0):
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
+ If not provided, pooled text embeddings will be generated from `prompt` input argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.flux.FluxPipelineOutput`] instead of a plain tuple.
+ joint_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
+ callback_on_step_end (`Callable`, *optional*):
+ A function that calls at the end of each denoising steps during the inference. The function is called
+ with the following arguments: `callback_on_step_end(self: DiffusionPipeline, step: int, timestep: int,
+ callback_kwargs: Dict)`. `callback_kwargs` will include a list of all tensors as specified by
+ `callback_on_step_end_tensor_inputs`.
+ callback_on_step_end_tensor_inputs (`List`, *optional*):
+ The list of tensor inputs for the `callback_on_step_end` function. The tensors specified in the list
+ will be passed as `callback_kwargs` argument. You will only be able to include variables listed in the
+ `._callback_tensor_inputs` attribute of your pipeline class.
+ max_sequence_length (`int` defaults to 512): Maximum sequence length to use with the `prompt`.
+ upsampling_strength (`float`, *optional*, defaults to 1.0):
+ Indicates extent to transform the reference `image` when upsampling the results. Must be between 0 and
+ 1. The generated image is used as a starting point and more noise is added the higher the
+ `upsampling_strength`. The number of denoising steps depends on the amount of noise initially added.
+ When `upsampling_strength` is 1, added noise is maximum and the denoising process runs for the full
+ number of iterations specified in `num_inference_steps`. A value of 0 skips the upsampling step and
+ output the results at the resolution of `self.resolution`.
+
+ Examples:
+
+ Returns:
+ [`~pipelines.flux.FluxPipelineOutput`] or `tuple`: [`~pipelines.flux.FluxPipelineOutput`] if `return_dict`
+ is True, otherwise a `tuple`. When returning a tuple, the first element is a list with the generated
+ images.
+ """
+
+ generation_output = self.generation_pipe(
+ task_prompt=task_prompt,
+ content_prompt=content_prompt,
+ image=image,
+ num_inference_steps=num_inference_steps,
+ sigmas=sigmas,
+ guidance_scale=guidance_scale,
+ num_images_per_prompt=num_images_per_prompt,
+ generator=generator,
+ latents=latents,
+ prompt_embeds=prompt_embeds,
+ pooled_prompt_embeds=pooled_prompt_embeds,
+ joint_attention_kwargs=joint_attention_kwargs,
+ callback_on_step_end=callback_on_step_end,
+ callback_on_step_end_tensor_inputs=callback_on_step_end_tensor_inputs,
+ max_sequence_length=max_sequence_length,
+ output_type=output_type if upsampling_strength == 0 else "pil",
+ )
+ if upsampling_strength == 0:
+ if not return_dict:
+ return (generation_output,)
+
+ return FluxPipelineOutput(images=generation_output)
+
+ # Upsampling the generated images
+ # 1. Prepare the input images and prompts
+ if not isinstance(content_prompt, (list)):
+ content_prompt = [content_prompt]
+ n_target_per_sample = []
+ upsampling_image = []
+ upsampling_mask = []
+ upsampling_prompt = []
+ upsampling_generator = generator if isinstance(generator, (torch.Generator,)) else []
+ for i in range(len(generation_output.images)):
+ n_target_per_sample.append(len(generation_output.images[i]))
+ for image in generation_output.images[i]:
+ upsampling_image.append(image)
+ upsampling_mask.append(Image.new("RGB", image.size, (255, 255, 255)))
+ upsampling_prompt.append(
+ content_prompt[i % len(content_prompt)] if content_prompt[i % len(content_prompt)] else ""
+ )
+ if not isinstance(generator, (torch.Generator,)):
+ upsampling_generator.append(generator[i % len(content_prompt)])
+
+ # 2. Apply the denosing loop
+ upsampling_output = self.upsampling_pipe(
+ prompt=upsampling_prompt,
+ image=upsampling_image,
+ mask_image=upsampling_mask,
+ height=upsampling_height,
+ width=upsampling_width,
+ strength=upsampling_strength,
+ num_inference_steps=num_inference_steps,
+ sigmas=sigmas,
+ guidance_scale=guidance_scale,
+ generator=upsampling_generator,
+ output_type=output_type,
+ joint_attention_kwargs=joint_attention_kwargs,
+ callback_on_step_end=callback_on_step_end,
+ callback_on_step_end_tensor_inputs=callback_on_step_end_tensor_inputs,
+ max_sequence_length=max_sequence_length,
+ )
+ image = upsampling_output.images
+
+ output = []
+ if output_type == "pil":
+ # Each sample in the batch may have multiple output images. When returning as PIL images,
+ # these images cannot be concatenated. Therefore, for each sample,
+ # a list is used to represent all the output images.
+ output = []
+ start = 0
+ for n in n_target_per_sample:
+ output.append(image[start : start + n])
+ start += n
+ else:
+ output = image
+
+ if not return_dict:
+ return (output,)
+
+ return FluxPipelineOutput(images=output)
diff --git a/src/diffusers/pipelines/visualcloze/pipeline_visualcloze_generation.py b/src/diffusers/pipelines/visualcloze/pipeline_visualcloze_generation.py
new file mode 100644
index 0000000000..e7a1d4a4b2
--- /dev/null
+++ b/src/diffusers/pipelines/visualcloze/pipeline_visualcloze_generation.py
@@ -0,0 +1,952 @@
+# Copyright 2025 VisualCloze team and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from typing import Any, Callable, Dict, List, Optional, Union
+
+import numpy as np
+import torch
+from transformers import CLIPTextModel, CLIPTokenizer, T5EncoderModel, T5TokenizerFast
+
+from ...loaders import FluxLoraLoaderMixin, FromSingleFileMixin, TextualInversionLoaderMixin
+from ...models.autoencoders import AutoencoderKL
+from ...models.transformers import FluxTransformer2DModel
+from ...schedulers import FlowMatchEulerDiscreteScheduler
+from ...utils import (
+ USE_PEFT_BACKEND,
+ is_torch_xla_available,
+ logging,
+ replace_example_docstring,
+ scale_lora_layers,
+ unscale_lora_layers,
+)
+from ...utils.torch_utils import randn_tensor
+from ..flux.pipeline_flux_fill import calculate_shift, retrieve_latents, retrieve_timesteps
+from ..flux.pipeline_output import FluxPipelineOutput
+from ..pipeline_utils import DiffusionPipeline
+from .visualcloze_utils import VisualClozeProcessor
+
+
+if is_torch_xla_available():
+ import torch_xla.core.xla_model as xm
+
+ XLA_AVAILABLE = True
+else:
+ XLA_AVAILABLE = False
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```python
+ >>> import torch
+ >>> from diffusers import VisualClozeGenerationPipeline, FluxFillPipeline as VisualClozeUpsamplingPipeline
+ >>> from diffusers.utils import load_image
+ >>> from PIL import Image
+
+ >>> image_paths = [
+ ... # in-context examples
+ ... [
+ ... load_image(
+ ... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/visualcloze/visualcloze_mask2image_incontext-example-1_mask.jpg"
+ ... ),
+ ... load_image(
+ ... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/visualcloze/visualcloze_mask2image_incontext-example-1_image.jpg"
+ ... ),
+ ... ],
+ ... # query with the target image
+ ... [
+ ... load_image(
+ ... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/visualcloze/visualcloze_mask2image_query_mask.jpg"
+ ... ),
+ ... None, # No image needed for the target image
+ ... ],
+ ... ]
+ >>> task_prompt = "In each row, a logical task is demonstrated to achieve [IMAGE2] an aesthetically pleasing photograph based on [IMAGE1] sam 2-generated masks with rich color coding."
+ >>> content_prompt = "Majestic photo of a golden eagle perched on a rocky outcrop in a mountainous landscape. The eagle is positioned in the right foreground, facing left, with its sharp beak and keen eyes prominently visible. Its plumage is a mix of dark brown and golden hues, with intricate feather details. The background features a soft-focus view of snow-capped mountains under a cloudy sky, creating a serene and grandiose atmosphere. The foreground includes rugged rocks and patches of green moss. Photorealistic, medium depth of field, soft natural lighting, cool color palette, high contrast, sharp focus on the eagle, blurred background, tranquil, majestic, wildlife photography."
+ >>> pipe = VisualClozeGenerationPipeline.from_pretrained(
+ ... "VisualCloze/VisualClozePipeline-384", resolution=384, torch_dtype=torch.bfloat16
+ ... )
+ >>> pipe.to("cuda")
+
+ >>> image = pipe(
+ ... task_prompt=task_prompt,
+ ... content_prompt=content_prompt,
+ ... image=image_paths,
+ ... guidance_scale=30,
+ ... num_inference_steps=30,
+ ... max_sequence_length=512,
+ ... generator=torch.Generator("cpu").manual_seed(0),
+ ... ).images[0][0]
+
+ >>> # optional, upsampling the generated image
+ >>> pipe_upsample = VisualClozeUpsamplingPipeline.from_pipe(pipe)
+ >>> pipe_upsample.to("cuda")
+
+ >>> mask_image = Image.new("RGB", image.size, (255, 255, 255))
+
+ >>> image = pipe_upsample(
+ ... image=image,
+ ... mask_image=mask_image,
+ ... prompt=content_prompt,
+ ... width=1344,
+ ... height=768,
+ ... strength=0.4,
+ ... guidance_scale=30,
+ ... num_inference_steps=30,
+ ... max_sequence_length=512,
+ ... generator=torch.Generator("cpu").manual_seed(0),
+ ... ).images[0]
+
+ >>> image.save("visualcloze.png")
+ ```
+"""
+
+
+class VisualClozeGenerationPipeline(
+ DiffusionPipeline,
+ FluxLoraLoaderMixin,
+ FromSingleFileMixin,
+ TextualInversionLoaderMixin,
+):
+ r"""
+ The VisualCloze pipeline for image generation with visual context. Reference:
+ https://github.com/lzyhha/VisualCloze/tree/main This pipeline is designed to generate images based on visual
+ in-context examples.
+
+ Args:
+ transformer ([`FluxTransformer2DModel`]):
+ Conditional Transformer (MMDiT) architecture to denoise the encoded image latents.
+ scheduler ([`FlowMatchEulerDiscreteScheduler`]):
+ A scheduler to be used in combination with `transformer` to denoise the encoded image latents.
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ text_encoder_2 ([`T5EncoderModel`]):
+ [T5](https://huggingface.co/docs/transformers/en/model_doc/t5#transformers.T5EncoderModel), specifically
+ the [google/t5-v1_1-xxl](https://huggingface.co/google/t5-v1_1-xxl) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/en/model_doc/clip#transformers.CLIPTokenizer).
+ tokenizer_2 (`T5TokenizerFast`):
+ Second Tokenizer of class
+ [T5TokenizerFast](https://huggingface.co/docs/transformers/en/model_doc/t5#transformers.T5TokenizerFast).
+ resolution (`int`, *optional*, defaults to 384):
+ The resolution of each image when concatenating images from the query and in-context examples.
+ """
+
+ model_cpu_offload_seq = "text_encoder->text_encoder_2->transformer->vae"
+ _optional_components = []
+ _callback_tensor_inputs = ["latents", "prompt_embeds"]
+
+ def __init__(
+ self,
+ scheduler: FlowMatchEulerDiscreteScheduler,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ text_encoder_2: T5EncoderModel,
+ tokenizer_2: T5TokenizerFast,
+ transformer: FluxTransformer2DModel,
+ resolution: int = 384,
+ ):
+ super().__init__()
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ text_encoder_2=text_encoder_2,
+ tokenizer=tokenizer,
+ tokenizer_2=tokenizer_2,
+ transformer=transformer,
+ scheduler=scheduler,
+ )
+ self.resolution = resolution
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1) if getattr(self, "vae", None) else 8
+ # Flux latents are turned into 2x2 patches and packed. This means the latent width and height has to be divisible
+ # by the patch size. So the vae scale factor is multiplied by the patch size to account for this
+ self.latent_channels = self.vae.config.latent_channels if getattr(self, "vae", None) else 16
+ self.image_processor = VisualClozeProcessor(
+ vae_scale_factor=self.vae_scale_factor * 2, vae_latent_channels=self.latent_channels, resolution=resolution
+ )
+ self.tokenizer_max_length = (
+ self.tokenizer.model_max_length if hasattr(self, "tokenizer") and self.tokenizer is not None else 77
+ )
+ self.default_sample_size = 128
+
+ # Copied from diffusers.pipelines.flux.pipeline_flux.FluxPipeline._get_t5_prompt_embeds
+ def _get_t5_prompt_embeds(
+ self,
+ prompt: Union[str, List[str]] = None,
+ num_images_per_prompt: int = 1,
+ max_sequence_length: int = 512,
+ device: Optional[torch.device] = None,
+ dtype: Optional[torch.dtype] = None,
+ ):
+ device = device or self._execution_device
+ dtype = dtype or self.text_encoder.dtype
+
+ prompt = [prompt] if isinstance(prompt, str) else prompt
+ batch_size = len(prompt)
+
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, self.tokenizer_2)
+
+ text_inputs = self.tokenizer_2(
+ prompt,
+ padding="max_length",
+ max_length=max_sequence_length,
+ truncation=True,
+ return_length=False,
+ return_overflowing_tokens=False,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer_2(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(text_input_ids, untruncated_ids):
+ removed_text = self.tokenizer_2.batch_decode(untruncated_ids[:, self.tokenizer_max_length - 1 : -1])
+ logger.warning(
+ "The following part of your input was truncated because `max_sequence_length` is set to "
+ f" {max_sequence_length} tokens: {removed_text}"
+ )
+
+ prompt_embeds = self.text_encoder_2(text_input_ids.to(device), output_hidden_states=False)[0]
+
+ dtype = self.text_encoder_2.dtype
+ prompt_embeds = prompt_embeds.to(dtype=dtype, device=device)
+
+ _, seq_len, _ = prompt_embeds.shape
+
+ # duplicate text embeddings and attention mask for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ return prompt_embeds
+
+ # Copied from diffusers.pipelines.flux.pipeline_flux.FluxPipeline._get_clip_prompt_embeds
+ def _get_clip_prompt_embeds(
+ self,
+ prompt: Union[str, List[str]],
+ num_images_per_prompt: int = 1,
+ device: Optional[torch.device] = None,
+ ):
+ device = device or self._execution_device
+
+ prompt = [prompt] if isinstance(prompt, str) else prompt
+ batch_size = len(prompt)
+
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer_max_length,
+ truncation=True,
+ return_overflowing_tokens=False,
+ return_length=False,
+ return_tensors="pt",
+ )
+
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(text_input_ids, untruncated_ids):
+ removed_text = self.tokenizer.batch_decode(untruncated_ids[:, self.tokenizer_max_length - 1 : -1])
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer_max_length} tokens: {removed_text}"
+ )
+ prompt_embeds = self.text_encoder(text_input_ids.to(device), output_hidden_states=False)
+
+ # Use pooled output of CLIPTextModel
+ prompt_embeds = prompt_embeds.pooler_output
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt)
+ prompt_embeds = prompt_embeds.view(batch_size * num_images_per_prompt, -1)
+
+ return prompt_embeds
+
+ # Modified from diffusers.pipelines.flux.pipeline_flux.FluxPipeline.encode_prompt
+ def encode_prompt(
+ self,
+ layout_prompt: Union[str, List[str]],
+ task_prompt: Union[str, List[str]],
+ content_prompt: Union[str, List[str]],
+ device: Optional[torch.device] = None,
+ num_images_per_prompt: int = 1,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ max_sequence_length: int = 512,
+ lora_scale: Optional[float] = None,
+ ):
+ r"""
+
+ Args:
+ layout_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to define the number of in-context examples and the number of images involved in
+ the task.
+ task_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to define the task intention.
+ content_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to define the content or caption of the target image to be generated.
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
+ If not provided, pooled text embeddings will be generated from `prompt` input argument.
+ lora_scale (`float`, *optional*):
+ A lora scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
+ """
+ device = device or self._execution_device
+
+ # set lora scale so that monkey patched LoRA
+ # function of text encoder can correctly access it
+ if lora_scale is not None and isinstance(self, FluxLoraLoaderMixin):
+ self._lora_scale = lora_scale
+
+ # dynamically adjust the LoRA scale
+ if self.text_encoder is not None and USE_PEFT_BACKEND:
+ scale_lora_layers(self.text_encoder, lora_scale)
+ if self.text_encoder_2 is not None and USE_PEFT_BACKEND:
+ scale_lora_layers(self.text_encoder_2, lora_scale)
+
+ if isinstance(layout_prompt, str):
+ layout_prompt = [layout_prompt]
+ task_prompt = [task_prompt]
+ content_prompt = [content_prompt]
+
+ def _preprocess(prompt, content=False):
+ if prompt is not None:
+ return f"The last image of the last row depicts: {prompt}" if content else prompt
+ else:
+ return ""
+
+ prompt = [
+ f"{_preprocess(layout_prompt[i])} {_preprocess(task_prompt[i])} {_preprocess(content_prompt[i], content=True)}".strip()
+ for i in range(len(layout_prompt))
+ ]
+ pooled_prompt_embeds = self._get_clip_prompt_embeds(
+ prompt=prompt,
+ device=device,
+ num_images_per_prompt=num_images_per_prompt,
+ )
+ prompt_embeds = self._get_t5_prompt_embeds(
+ prompt=prompt,
+ num_images_per_prompt=num_images_per_prompt,
+ max_sequence_length=max_sequence_length,
+ device=device,
+ )
+
+ if self.text_encoder is not None:
+ if isinstance(self, FluxLoraLoaderMixin) and USE_PEFT_BACKEND:
+ # Retrieve the original scale by scaling back the LoRA layers
+ unscale_lora_layers(self.text_encoder, lora_scale)
+
+ if self.text_encoder_2 is not None:
+ if isinstance(self, FluxLoraLoaderMixin) and USE_PEFT_BACKEND:
+ # Retrieve the original scale by scaling back the LoRA layers
+ unscale_lora_layers(self.text_encoder_2, lora_scale)
+
+ dtype = self.text_encoder.dtype if self.text_encoder is not None else self.transformer.dtype
+ text_ids = torch.zeros(prompt_embeds.shape[1], 3).to(device=device, dtype=dtype)
+
+ return prompt_embeds, pooled_prompt_embeds, text_ids
+
+ # Copied from diffusers.pipelines.stable_diffusion_3.pipeline_stable_diffusion_3_inpaint.StableDiffusion3InpaintPipeline._encode_vae_image
+ def _encode_vae_image(self, image: torch.Tensor, generator: torch.Generator):
+ if isinstance(generator, list):
+ image_latents = [
+ retrieve_latents(self.vae.encode(image[i : i + 1]), generator=generator[i])
+ for i in range(image.shape[0])
+ ]
+ image_latents = torch.cat(image_latents, dim=0)
+ else:
+ image_latents = retrieve_latents(self.vae.encode(image), generator=generator)
+
+ image_latents = (image_latents - self.vae.config.shift_factor) * self.vae.config.scaling_factor
+
+ return image_latents
+
+ # Copied from diffusers.pipelines.stable_diffusion_3.pipeline_stable_diffusion_3_img2img.StableDiffusion3Img2ImgPipeline.get_timesteps
+ def get_timesteps(self, num_inference_steps, strength, device):
+ # get the original timestep using init_timestep
+ init_timestep = min(num_inference_steps * strength, num_inference_steps)
+
+ t_start = int(max(num_inference_steps - init_timestep, 0))
+ timesteps = self.scheduler.timesteps[t_start * self.scheduler.order :]
+ if hasattr(self.scheduler, "set_begin_index"):
+ self.scheduler.set_begin_index(t_start * self.scheduler.order)
+
+ return timesteps, num_inference_steps - t_start
+
+ def check_inputs(
+ self,
+ image,
+ task_prompt,
+ content_prompt,
+ prompt_embeds=None,
+ pooled_prompt_embeds=None,
+ callback_on_step_end_tensor_inputs=None,
+ max_sequence_length=None,
+ ):
+ if callback_on_step_end_tensor_inputs is not None and not all(
+ k in self._callback_tensor_inputs for k in callback_on_step_end_tensor_inputs
+ ):
+ raise ValueError(
+ f"`callback_on_step_end_tensor_inputs` has to be in {self._callback_tensor_inputs}, but found {[k for k in callback_on_step_end_tensor_inputs if k not in self._callback_tensor_inputs]}"
+ )
+
+ # Validate prompt inputs
+ if (task_prompt is not None or content_prompt is not None) and prompt_embeds is not None:
+ raise ValueError("Cannot provide both text `task_prompt` + `content_prompt` and `prompt_embeds`. ")
+
+ if task_prompt is None and content_prompt is None and prompt_embeds is None:
+ raise ValueError("Must provide either `task_prompt` + `content_prompt` or pre-computed `prompt_embeds`. ")
+
+ # Validate prompt types and consistency
+ if task_prompt is None:
+ raise ValueError("`task_prompt` is missing.")
+
+ if task_prompt is not None and not isinstance(task_prompt, (str, list)):
+ raise ValueError(f"`task_prompt` must be str or list, got {type(task_prompt)}")
+
+ if content_prompt is not None and not isinstance(content_prompt, (str, list)):
+ raise ValueError(f"`content_prompt` must be str or list, got {type(content_prompt)}")
+
+ if isinstance(task_prompt, list) or isinstance(content_prompt, list):
+ if not isinstance(task_prompt, list) or not isinstance(content_prompt, list):
+ raise ValueError(
+ f"`task_prompt` and `content_prompt` must both be lists, or both be of type str or None, "
+ f"got {type(task_prompt)} and {type(content_prompt)}"
+ )
+ if len(content_prompt) != len(task_prompt):
+ raise ValueError("`task_prompt` and `content_prompt` must have the same length whe they are lists.")
+
+ for sample in image:
+ if not isinstance(sample, list) or not isinstance(sample[0], list):
+ raise ValueError("Each sample in the batch must have a 2D list of images.")
+ if len({len(row) for row in sample}) != 1:
+ raise ValueError("Each in-context example and query should contain the same number of images.")
+ if not any(img is None for img in sample[-1]):
+ raise ValueError("There are no targets in the query, which should be represented as None.")
+ for row in sample[:-1]:
+ if any(img is None for img in row):
+ raise ValueError("Images are missing in in-context examples.")
+
+ # Validate embeddings
+ if prompt_embeds is not None and pooled_prompt_embeds is None:
+ raise ValueError(
+ "If `prompt_embeds` are provided, `pooled_prompt_embeds` also have to be passed. Make sure to generate `pooled_prompt_embeds` from the same text encoder that was used to generate `prompt_embeds`."
+ )
+
+ # Validate sequence length
+ if max_sequence_length is not None and max_sequence_length > 512:
+ raise ValueError(f"max_sequence_length cannot exceed 512, got {max_sequence_length}")
+
+ @staticmethod
+ def _prepare_latent_image_ids(image, vae_scale_factor, device, dtype):
+ latent_image_ids = []
+
+ for idx, img in enumerate(image, start=1):
+ img = img.squeeze(0)
+ channels, height, width = img.shape
+
+ num_patches_h = height // vae_scale_factor // 2
+ num_patches_w = width // vae_scale_factor // 2
+
+ patch_ids = torch.zeros(num_patches_h, num_patches_w, 3, device=device, dtype=dtype)
+ patch_ids[..., 0] = idx
+ patch_ids[..., 1] = torch.arange(num_patches_h, device=device, dtype=dtype)[:, None]
+ patch_ids[..., 2] = torch.arange(num_patches_w, device=device, dtype=dtype)[None, :]
+
+ patch_ids = patch_ids.reshape(-1, 3)
+ latent_image_ids.append(patch_ids)
+
+ return torch.cat(latent_image_ids, dim=0)
+
+ @staticmethod
+ # Copied from diffusers.pipelines.flux.pipeline_flux.FluxPipeline._pack_latents
+ def _pack_latents(latents, batch_size, num_channels_latents, height, width):
+ latents = latents.view(batch_size, num_channels_latents, height // 2, 2, width // 2, 2)
+ latents = latents.permute(0, 2, 4, 1, 3, 5)
+ latents = latents.reshape(batch_size, (height // 2) * (width // 2), num_channels_latents * 4)
+
+ return latents
+
+ @staticmethod
+ def _unpack_latents(latents, sizes, vae_scale_factor):
+ batch_size, num_patches, channels = latents.shape
+
+ start = 0
+ unpacked_latents = []
+ for i in range(len(sizes)):
+ cur_size = sizes[i]
+ height = cur_size[0][0] // vae_scale_factor
+ width = sum([size[1] for size in cur_size]) // vae_scale_factor
+
+ end = start + (height * width) // 4
+
+ cur_latents = latents[:, start:end]
+ cur_latents = cur_latents.view(batch_size, height // 2, width // 2, channels // 4, 2, 2)
+ cur_latents = cur_latents.permute(0, 3, 1, 4, 2, 5)
+ cur_latents = cur_latents.reshape(batch_size, channels // (2 * 2), height, width)
+
+ unpacked_latents.append(cur_latents)
+
+ start = end
+
+ return unpacked_latents
+
+ def enable_vae_slicing(self):
+ r"""
+ Enable sliced VAE decoding. When this option is enabled, the VAE will split the input tensor in slices to
+ compute decoding in several steps. This is useful to save some memory and allow larger batch sizes.
+ """
+ self.vae.enable_slicing()
+
+ def disable_vae_slicing(self):
+ r"""
+ Disable sliced VAE decoding. If `enable_vae_slicing` was previously enabled, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_slicing()
+
+ def enable_vae_tiling(self):
+ r"""
+ Enable tiled VAE decoding. When this option is enabled, the VAE will split the input tensor into tiles to
+ compute decoding and encoding in several steps. This is useful for saving a large amount of memory and to allow
+ processing larger images.
+ """
+ self.vae.enable_tiling()
+
+ def disable_vae_tiling(self):
+ r"""
+ Disable tiled VAE decoding. If `enable_vae_tiling` was previously enabled, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_tiling()
+
+ def _prepare_latents(self, image, mask, gen, vae_scale_factor, device, dtype):
+ """Helper function to prepare latents for a single batch."""
+ # Concatenate images and masks along width dimension
+ image = [torch.cat(img, dim=3).to(device=device, dtype=dtype) for img in image]
+ mask = [torch.cat(m, dim=3).to(device=device, dtype=dtype) for m in mask]
+
+ # Generate latent image IDs
+ latent_image_ids = self._prepare_latent_image_ids(image, vae_scale_factor, device, dtype)
+
+ # For initial encoding, use actual images
+ image_latent = [self._encode_vae_image(img, gen) for img in image]
+ masked_image_latent = [img.clone() for img in image_latent]
+
+ for i in range(len(image_latent)):
+ # Rearrange latents and masks for patch processing
+ num_channels_latents, height, width = image_latent[i].shape[1:]
+ image_latent[i] = self._pack_latents(image_latent[i], 1, num_channels_latents, height, width)
+ masked_image_latent[i] = self._pack_latents(masked_image_latent[i], 1, num_channels_latents, height, width)
+
+ # Rearrange masks for patch processing
+ num_channels_latents, height, width = mask[i].shape[1:]
+ mask[i] = mask[i].view(
+ 1,
+ num_channels_latents,
+ height // vae_scale_factor,
+ vae_scale_factor,
+ width // vae_scale_factor,
+ vae_scale_factor,
+ )
+ mask[i] = mask[i].permute(0, 1, 3, 5, 2, 4)
+ mask[i] = mask[i].reshape(
+ 1,
+ num_channels_latents * (vae_scale_factor**2),
+ height // vae_scale_factor,
+ width // vae_scale_factor,
+ )
+ mask[i] = self._pack_latents(
+ mask[i],
+ 1,
+ num_channels_latents * (vae_scale_factor**2),
+ height // vae_scale_factor,
+ width // vae_scale_factor,
+ )
+
+ # Concatenate along batch dimension
+ image_latent = torch.cat(image_latent, dim=1)
+ masked_image_latent = torch.cat(masked_image_latent, dim=1)
+ mask = torch.cat(mask, dim=1)
+
+ return image_latent, masked_image_latent, mask, latent_image_ids
+
+ def prepare_latents(
+ self,
+ input_image,
+ input_mask,
+ timestep,
+ batch_size,
+ dtype,
+ device,
+ generator,
+ vae_scale_factor,
+ ):
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ # Process each batch
+ masked_image_latents = []
+ image_latents = []
+ masks = []
+ latent_image_ids = []
+
+ for i in range(len(input_image)):
+ _image_latent, _masked_image_latent, _mask, _latent_image_ids = self._prepare_latents(
+ input_image[i],
+ input_mask[i],
+ generator if isinstance(generator, torch.Generator) else generator[i],
+ vae_scale_factor,
+ device,
+ dtype,
+ )
+ masked_image_latents.append(_masked_image_latent)
+ image_latents.append(_image_latent)
+ masks.append(_mask)
+ latent_image_ids.append(_latent_image_ids)
+
+ # Concatenate all batches
+ masked_image_latents = torch.cat(masked_image_latents, dim=0)
+ image_latents = torch.cat(image_latents, dim=0)
+ masks = torch.cat(masks, dim=0)
+
+ # Handle batch size expansion
+ if batch_size > masked_image_latents.shape[0]:
+ if batch_size % masked_image_latents.shape[0] == 0:
+ # Expand batches by repeating
+ additional_image_per_prompt = batch_size // masked_image_latents.shape[0]
+ masked_image_latents = torch.cat([masked_image_latents] * additional_image_per_prompt, dim=0)
+ image_latents = torch.cat([image_latents] * additional_image_per_prompt, dim=0)
+ masks = torch.cat([masks] * additional_image_per_prompt, dim=0)
+ else:
+ raise ValueError(
+ f"Cannot expand batch size from {masked_image_latents.shape[0]} to {batch_size}. "
+ "Batch sizes must be multiples of each other."
+ )
+
+ # Add noise to latents
+ noises = randn_tensor(image_latents.shape, generator=generator, device=device, dtype=dtype)
+ latents = self.scheduler.scale_noise(image_latents, timestep, noises).to(dtype=dtype)
+
+ # Combine masked latents with masks
+ masked_image_latents = torch.cat((masked_image_latents, masks), dim=-1).to(dtype=dtype)
+
+ return latents, masked_image_latents, latent_image_ids[0]
+
+ @property
+ def guidance_scale(self):
+ return self._guidance_scale
+
+ @property
+ def joint_attention_kwargs(self):
+ return self._joint_attention_kwargs
+
+ @property
+ def num_timesteps(self):
+ return self._num_timesteps
+
+ @property
+ def interrupt(self):
+ return self._interrupt
+
+ @torch.no_grad()
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ task_prompt: Union[str, List[str]] = None,
+ content_prompt: Union[str, List[str]] = None,
+ image: Optional[torch.FloatTensor] = None,
+ num_inference_steps: int = 50,
+ sigmas: Optional[List[float]] = None,
+ guidance_scale: float = 30.0,
+ num_images_per_prompt: Optional[int] = 1,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ joint_attention_kwargs: Optional[Dict[str, Any]] = None,
+ callback_on_step_end: Optional[Callable[[int, int, Dict], None]] = None,
+ callback_on_step_end_tensor_inputs: List[str] = ["latents"],
+ max_sequence_length: int = 512,
+ ):
+ r"""
+ Function invoked when calling the VisualCloze pipeline for generation.
+
+ Args:
+ task_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to define the task intention.
+ content_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to define the content or caption of the target image to be generated.
+ image (`torch.Tensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.Tensor]`, `List[PIL.Image.Image]`, or `List[np.ndarray]`):
+ `Image`, numpy array or tensor representing an image batch to be used as the starting point. For both
+ numpy array and pytorch tensor, the expected value range is between `[0, 1]` If it's a tensor or a list
+ or tensors, the expected shape should be `(B, C, H, W)` or `(C, H, W)`. If it is a numpy array or a
+ list of arrays, the expected shape should be `(B, H, W, C)` or `(H, W, C)`.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ sigmas (`List[float]`, *optional*):
+ Custom sigmas to use for the denoising process with schedulers which support a `sigmas` argument in
+ their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is passed
+ will be used.
+ guidance_scale (`float`, *optional*, defaults to 30.0):
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
+ If not provided, pooled text embeddings will be generated from `prompt` input argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.flux.FluxPipelineOutput`] instead of a plain tuple.
+ joint_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
+ callback_on_step_end (`Callable`, *optional*):
+ A function that calls at the end of each denoising steps during the inference. The function is called
+ with the following arguments: `callback_on_step_end(self: DiffusionPipeline, step: int, timestep: int,
+ callback_kwargs: Dict)`. `callback_kwargs` will include a list of all tensors as specified by
+ `callback_on_step_end_tensor_inputs`.
+ callback_on_step_end_tensor_inputs (`List`, *optional*):
+ The list of tensor inputs for the `callback_on_step_end` function. The tensors specified in the list
+ will be passed as `callback_kwargs` argument. You will only be able to include variables listed in the
+ `._callback_tensor_inputs` attribute of your pipeline class.
+ max_sequence_length (`int` defaults to 512): Maximum sequence length to use with the `prompt`.
+
+ Examples:
+
+ Returns:
+ [`~pipelines.flux.FluxPipelineOutput`] or `tuple`: [`~pipelines.flux.FluxPipelineOutput`] if `return_dict`
+ is True, otherwise a `tuple`. When returning a tuple, the first element is a list with the generated
+ images.
+ """
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ image,
+ task_prompt,
+ content_prompt,
+ prompt_embeds=prompt_embeds,
+ pooled_prompt_embeds=pooled_prompt_embeds,
+ callback_on_step_end_tensor_inputs=callback_on_step_end_tensor_inputs,
+ max_sequence_length=max_sequence_length,
+ )
+
+ self._guidance_scale = guidance_scale
+ self._joint_attention_kwargs = joint_attention_kwargs
+ self._interrupt = False
+
+ processor_output = self.image_processor.preprocess(
+ task_prompt, content_prompt, image, vae_scale_factor=self.vae_scale_factor
+ )
+
+ # 2. Define call parameters
+ if processor_output["task_prompt"] is not None and isinstance(processor_output["task_prompt"], str):
+ batch_size = 1
+ elif processor_output["task_prompt"] is not None and isinstance(processor_output["task_prompt"], list):
+ batch_size = len(processor_output["task_prompt"])
+
+ device = self._execution_device
+
+ # 3. Prepare prompt embeddings
+ lora_scale = (
+ self.joint_attention_kwargs.get("scale", None) if self.joint_attention_kwargs is not None else None
+ )
+ prompt_embeds, pooled_prompt_embeds, text_ids = self.encode_prompt(
+ layout_prompt=processor_output["layout_prompt"],
+ task_prompt=processor_output["task_prompt"],
+ content_prompt=processor_output["content_prompt"],
+ prompt_embeds=prompt_embeds,
+ pooled_prompt_embeds=pooled_prompt_embeds,
+ device=device,
+ num_images_per_prompt=num_images_per_prompt,
+ max_sequence_length=max_sequence_length,
+ lora_scale=lora_scale,
+ )
+
+ # 4. Prepare timesteps
+ # Calculate sequence length and shift factor
+ image_seq_len = sum(
+ (size[0] // self.vae_scale_factor // 2) * (size[1] // self.vae_scale_factor // 2)
+ for sample in processor_output["image_size"][0]
+ for size in sample
+ )
+
+ # Calculate noise schedule parameters
+ mu = calculate_shift(
+ image_seq_len,
+ self.scheduler.config.get("base_image_seq_len", 256),
+ self.scheduler.config.get("max_image_seq_len", 4096),
+ self.scheduler.config.get("base_shift", 0.5),
+ self.scheduler.config.get("max_shift", 1.15),
+ )
+
+ # Get timesteps
+ sigmas = np.linspace(1.0, 1 / num_inference_steps, num_inference_steps) if sigmas is None else sigmas
+ timesteps, num_inference_steps = retrieve_timesteps(
+ self.scheduler,
+ num_inference_steps,
+ device,
+ sigmas=sigmas,
+ mu=mu,
+ )
+ timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, 1.0, device)
+
+ # 5. Prepare latent variables
+ latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt)
+ latents, masked_image_latents, latent_image_ids = self.prepare_latents(
+ processor_output["init_image"],
+ processor_output["mask"],
+ latent_timestep,
+ batch_size * num_images_per_prompt,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ vae_scale_factor=self.vae_scale_factor,
+ )
+
+ # Calculate warmup steps
+ num_warmup_steps = max(len(timesteps) - num_inference_steps * self.scheduler.order, 0)
+ self._num_timesteps = len(timesteps)
+
+ # Prepare guidance
+ if self.transformer.config.guidance_embeds:
+ guidance = torch.full([1], guidance_scale, device=device, dtype=torch.float32)
+ guidance = guidance.expand(latents.shape[0])
+ else:
+ guidance = None
+
+ # 6. Denoising loop
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ if self.interrupt:
+ continue
+
+ # Broadcast to batch dimension in a way that's compatible with ONNX/Core ML
+ timestep = t.expand(latents.shape[0]).to(latents.dtype)
+ latent_model_input = torch.cat((latents, masked_image_latents), dim=2)
+
+ noise_pred = self.transformer(
+ hidden_states=latent_model_input,
+ timestep=timestep / 1000,
+ guidance=guidance,
+ pooled_projections=pooled_prompt_embeds,
+ encoder_hidden_states=prompt_embeds,
+ txt_ids=text_ids,
+ img_ids=latent_image_ids,
+ joint_attention_kwargs=self.joint_attention_kwargs,
+ return_dict=False,
+ )[0]
+
+ # Compute the previous noisy sample x_t -> x_t-1
+ latents_dtype = latents.dtype
+ latents = self.scheduler.step(noise_pred, t, latents, return_dict=False)[0]
+
+ if latents.dtype != latents_dtype:
+ if torch.backends.mps.is_available():
+ # Some platforms (eg. apple mps) misbehave due to a pytorch bug: https://github.com/pytorch/pytorch/pull/99272
+ latents = latents.to(latents_dtype)
+
+ if callback_on_step_end is not None:
+ callback_kwargs = {}
+ for k in callback_on_step_end_tensor_inputs:
+ callback_kwargs[k] = locals()[k]
+ callback_outputs = callback_on_step_end(self, i, t, callback_kwargs)
+
+ latents = callback_outputs.pop("latents", latents)
+ prompt_embeds = callback_outputs.pop("prompt_embeds", prompt_embeds)
+
+ # Call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+
+ # XLA optimization
+ if XLA_AVAILABLE:
+ xm.mark_step()
+
+ # 7. Post-process the image
+ # Crop the target image
+ # Since the generated image is a concatenation of the conditional and target regions,
+ # we need to extract only the target regions based on their positions
+ image = []
+ if output_type == "latent":
+ image = latents
+ else:
+ for b in range(len(latents)):
+ cur_image_size = processor_output["image_size"][b % batch_size]
+ cur_target_position = processor_output["target_position"][b % batch_size]
+ cur_latent = self._unpack_latents(latents[b].unsqueeze(0), cur_image_size, self.vae_scale_factor)[-1]
+ cur_latent = (cur_latent / self.vae.config.scaling_factor) + self.vae.config.shift_factor
+ cur_image = self.vae.decode(cur_latent, return_dict=False)[0]
+ cur_image = self.image_processor.postprocess(cur_image, output_type=output_type)[0]
+
+ start = 0
+ cropped = []
+ for i, size in enumerate(cur_image_size[-1]):
+ if cur_target_position[i]:
+ if output_type == "pil":
+ cropped.append(cur_image.crop((start, 0, start + size[1], size[0])))
+ else:
+ cropped.append(cur_image[0 : size[0], start : start + size[1]])
+ start += size[1]
+ image.append(cropped)
+ if output_type != "pil":
+ image = np.concatenate([arr[None] for sub_image in image for arr in sub_image], axis=0)
+
+ # Offload all models
+ self.maybe_free_model_hooks()
+
+ if not return_dict:
+ return (image,)
+
+ return FluxPipelineOutput(images=image)
diff --git a/src/diffusers/pipelines/visualcloze/visualcloze_utils.py b/src/diffusers/pipelines/visualcloze/visualcloze_utils.py
new file mode 100644
index 0000000000..5d221bc1e8
--- /dev/null
+++ b/src/diffusers/pipelines/visualcloze/visualcloze_utils.py
@@ -0,0 +1,251 @@
+# Copyright 2025 VisualCloze team and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from typing import Dict, List, Optional, Tuple, Union
+
+import torch
+from PIL import Image
+
+from ...image_processor import VaeImageProcessor
+
+
+class VisualClozeProcessor(VaeImageProcessor):
+ """
+ Image processor for the VisualCloze pipeline.
+
+ This processor handles the preprocessing of images for visual cloze tasks, including resizing, normalization, and
+ mask generation.
+
+ Args:
+ resolution (int, optional):
+ Target resolution for processing images. Each image will be resized to this resolution before being
+ concatenated to avoid the out-of-memory error. Defaults to 384.
+ *args: Additional arguments passed to [~image_processor.VaeImageProcessor]
+ **kwargs: Additional keyword arguments passed to [~image_processor.VaeImageProcessor]
+ """
+
+ def __init__(self, *args, resolution: int = 384, **kwargs):
+ super().__init__(*args, **kwargs)
+ self.resolution = resolution
+
+ def preprocess_image(
+ self, input_images: List[List[Optional[Image.Image]]], vae_scale_factor: int
+ ) -> Tuple[List[List[torch.Tensor]], List[List[List[int]]], List[int]]:
+ """
+ Preprocesses input images for the VisualCloze pipeline.
+
+ This function handles the preprocessing of input images by:
+ 1. Resizing and cropping images to maintain consistent dimensions
+ 2. Converting images to the Tensor format for the VAE
+ 3. Normalizing pixel values
+ 4. Tracking image sizes and positions of target images
+
+ Args:
+ input_images (List[List[Optional[Image.Image]]]):
+ A nested list of PIL Images where:
+ - Outer list represents different samples, including in-context examples and the query
+ - Inner list contains images for the task
+ - In the last row, condition images are provided and the target images are placed as None
+ vae_scale_factor (int):
+ The scale factor used by the VAE for resizing images
+
+ Returns:
+ Tuple containing:
+ - List[List[torch.Tensor]]: Preprocessed images in tensor format
+ - List[List[List[int]]]: Dimensions of each processed image [height, width]
+ - List[int]: Target positions indicating which images are to be generated
+ """
+ n_samples, n_task_images = len(input_images), len(input_images[0])
+ divisible = 2 * vae_scale_factor
+
+ processed_images: List[List[Image.Image]] = [[] for _ in range(n_samples)]
+ resize_size: List[Optional[Tuple[int, int]]] = [None for _ in range(n_samples)]
+ target_position: List[int] = []
+
+ # Process each sample
+ for i in range(n_samples):
+ # Determine size from first non-None image
+ for j in range(n_task_images):
+ if input_images[i][j] is not None:
+ aspect_ratio = input_images[i][j].width / input_images[i][j].height
+ target_area = self.resolution * self.resolution
+ new_h = int((target_area / aspect_ratio) ** 0.5)
+ new_w = int(new_h * aspect_ratio)
+
+ new_w = max(new_w // divisible, 1) * divisible
+ new_h = max(new_h // divisible, 1) * divisible
+ resize_size[i] = (new_w, new_h)
+ break
+
+ # Process all images in the sample
+ for j in range(n_task_images):
+ if input_images[i][j] is not None:
+ target = self._resize_and_crop(input_images[i][j], resize_size[i][0], resize_size[i][1])
+ processed_images[i].append(target)
+ if i == n_samples - 1:
+ target_position.append(0)
+ else:
+ blank = Image.new("RGB", resize_size[i] or (self.resolution, self.resolution), (0, 0, 0))
+ processed_images[i].append(blank)
+ if i == n_samples - 1:
+ target_position.append(1)
+
+ # Ensure consistent width for multiple target images when there are multiple target images
+ if len(target_position) > 1 and sum(target_position) > 1:
+ new_w = resize_size[n_samples - 1][0] or 384
+ for i in range(len(processed_images)):
+ for j in range(len(processed_images[i])):
+ if processed_images[i][j] is not None:
+ new_h = int(processed_images[i][j].height * (new_w / processed_images[i][j].width))
+ new_w = int(new_w / 16) * 16
+ new_h = int(new_h / 16) * 16
+ processed_images[i][j] = self.height(processed_images[i][j], new_h, new_w)
+
+ # Convert to tensors and normalize
+ image_sizes = []
+ for i in range(len(processed_images)):
+ image_sizes.append([[img.height, img.width] for img in processed_images[i]])
+ for j, image in enumerate(processed_images[i]):
+ image = self.pil_to_numpy(image)
+ image = self.numpy_to_pt(image)
+ image = self.normalize(image)
+ processed_images[i][j] = image
+
+ return processed_images, image_sizes, target_position
+
+ def preprocess_mask(
+ self, input_images: List[List[Image.Image]], target_position: List[int]
+ ) -> List[List[torch.Tensor]]:
+ """
+ Generate masks for the VisualCloze pipeline.
+
+ Args:
+ input_images (List[List[Image.Image]]):
+ Processed images from preprocess_image
+ target_position (List[int]):
+ Binary list marking the positions of target images (1 for target, 0 for condition)
+
+ Returns:
+ List[List[torch.Tensor]]:
+ A nested list of mask tensors (1 for target positions, 0 for condition images)
+ """
+ mask = []
+ for i, row in enumerate(input_images):
+ if i == len(input_images) - 1: # Query row
+ row_masks = [
+ torch.full((1, 1, row[0].shape[2], row[0].shape[3]), fill_value=m) for m in target_position
+ ]
+ else: # In-context examples
+ row_masks = [
+ torch.full((1, 1, row[0].shape[2], row[0].shape[3]), fill_value=0) for _ in target_position
+ ]
+ mask.append(row_masks)
+ return mask
+
+ def preprocess_image_upsampling(
+ self,
+ input_images: List[List[Image.Image]],
+ height: int,
+ width: int,
+ ) -> Tuple[List[List[Image.Image]], List[List[List[int]]]]:
+ """Process images for the upsampling stage in the VisualCloze pipeline.
+
+ Args:
+ input_images: Input image to process
+ height: Target height
+ width: Target width
+
+ Returns:
+ Tuple of processed image and its size
+ """
+ image = self.resize(input_images[0][0], height, width)
+ image = self.pil_to_numpy(image) # to np
+ image = self.numpy_to_pt(image) # to pt
+ image = self.normalize(image)
+
+ input_images[0][0] = image
+ image_sizes = [[[height, width]]]
+ return input_images, image_sizes
+
+ def preprocess_mask_upsampling(self, input_images: List[List[Image.Image]]) -> List[List[torch.Tensor]]:
+ return [[torch.ones((1, 1, input_images[0][0].shape[2], input_images[0][0].shape[3]))]]
+
+ def get_layout_prompt(self, size: Tuple[int, int]) -> str:
+ layout_instruction = (
+ f"A grid layout with {size[0]} rows and {size[1]} columns, displaying {size[0] * size[1]} images arranged side by side.",
+ )
+ return layout_instruction
+
+ def preprocess(
+ self,
+ task_prompt: Union[str, List[str]],
+ content_prompt: Union[str, List[str]],
+ input_images: Optional[List[List[List[Optional[str]]]]] = None,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ upsampling: bool = False,
+ vae_scale_factor: int = 16,
+ ) -> Dict:
+ """Process visual cloze inputs.
+
+ Args:
+ task_prompt: Task description(s)
+ content_prompt: Content description(s)
+ input_images: List of images or None for the target images
+ height: Optional target height for upsampling stage
+ width: Optional target width for upsampling stage
+ upsampling: Whether this is in the upsampling processing stage
+
+ Returns:
+ Dictionary containing processed images, masks, prompts and metadata
+ """
+ if isinstance(task_prompt, str):
+ task_prompt = [task_prompt]
+ content_prompt = [content_prompt]
+ input_images = [input_images]
+
+ output = {
+ "init_image": [],
+ "mask": [],
+ "task_prompt": task_prompt if not upsampling else [None for _ in range(len(task_prompt))],
+ "content_prompt": content_prompt,
+ "layout_prompt": [],
+ "target_position": [],
+ "image_size": [],
+ }
+ for i in range(len(task_prompt)):
+ if upsampling:
+ layout_prompt = None
+ else:
+ layout_prompt = self.get_layout_prompt((len(input_images[i]), len(input_images[i][0])))
+
+ if upsampling:
+ cur_processed_images, cur_image_size = self.preprocess_image_upsampling(
+ input_images[i], height=height, width=width
+ )
+ cur_mask = self.preprocess_mask_upsampling(cur_processed_images)
+ else:
+ cur_processed_images, cur_image_size, cur_target_position = self.preprocess_image(
+ input_images[i], vae_scale_factor=vae_scale_factor
+ )
+ cur_mask = self.preprocess_mask(cur_processed_images, cur_target_position)
+
+ output["target_position"].append(cur_target_position)
+
+ output["image_size"].append(cur_image_size)
+ output["init_image"].append(cur_processed_images)
+ output["mask"].append(cur_mask)
+ output["layout_prompt"].append(layout_prompt)
+
+ return output
diff --git a/src/diffusers/pipelines/wan/pipeline_wan.py b/src/diffusers/pipelines/wan/pipeline_wan.py
index 572995530f..3c0ac30bb6 100644
--- a/src/diffusers/pipelines/wan/pipeline_wan.py
+++ b/src/diffusers/pipelines/wan/pipeline_wan.py
@@ -400,11 +400,11 @@ class WanPipeline(DiffusionPipeline, WanLoraLoaderMixin):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, defaults to `5.0`):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_videos_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
diff --git a/src/diffusers/pipelines/wan/pipeline_wan_i2v.py b/src/diffusers/pipelines/wan/pipeline_wan_i2v.py
index b3e1222a46..77f0e4d56a 100644
--- a/src/diffusers/pipelines/wan/pipeline_wan_i2v.py
+++ b/src/diffusers/pipelines/wan/pipeline_wan_i2v.py
@@ -522,11 +522,11 @@ class WanImageToVideoPipeline(DiffusionPipeline, WanLoraLoaderMixin):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, defaults to `5.0`):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_videos_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
diff --git a/src/diffusers/pipelines/wan/pipeline_wan_video2video.py b/src/diffusers/pipelines/wan/pipeline_wan_video2video.py
index b2b1516239..1844f1b49b 100644
--- a/src/diffusers/pipelines/wan/pipeline_wan_video2video.py
+++ b/src/diffusers/pipelines/wan/pipeline_wan_video2video.py
@@ -525,11 +525,11 @@ class WanVideoToVideoPipeline(DiffusionPipeline, WanLoraLoaderMixin):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, defaults to `5.0`):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
num_videos_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
diff --git a/src/diffusers/pipelines/wuerstchen/pipeline_wuerstchen.py b/src/diffusers/pipelines/wuerstchen/pipeline_wuerstchen.py
index edc01f0d5c..f4092ca885 100644
--- a/src/diffusers/pipelines/wuerstchen/pipeline_wuerstchen.py
+++ b/src/diffusers/pipelines/wuerstchen/pipeline_wuerstchen.py
@@ -247,11 +247,11 @@ class WuerstchenDecoderPipeline(DiffusionPipeline):
Custom timesteps to use for the denoising process. If not defined, equal spaced `num_inference_steps`
timesteps are used. Must be in descending order.
guidance_scale (`float`, *optional*, defaults to 0.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `decoder_guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting
- `decoder_guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely
- linked to the text `prompt`, usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `decoder_guidance_scale` is defined as `w` of
+ equation 2. of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by
+ setting `decoder_guidance_scale > 1`. Higher guidance scale encourages to generate images that are
+ closely linked to the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `decoder_guidance_scale` is less than `1`).
diff --git a/src/diffusers/pipelines/wuerstchen/pipeline_wuerstchen_combined.py b/src/diffusers/pipelines/wuerstchen/pipeline_wuerstchen_combined.py
index 7819c8c0a0..e4756efbac 100644
--- a/src/diffusers/pipelines/wuerstchen/pipeline_wuerstchen_combined.py
+++ b/src/diffusers/pipelines/wuerstchen/pipeline_wuerstchen_combined.py
@@ -190,11 +190,11 @@ class WuerstchenCombinedPipeline(DiffusionPipeline):
width (`int`, *optional*, defaults to 512):
The width in pixels of the generated image.
prior_guidance_scale (`float`, *optional*, defaults to 4.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `prior_guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting
- `prior_guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked
- to the text `prompt`, usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `prior_guidance_scale` is defined as `w` of
+ equation 2. of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by
+ setting `prior_guidance_scale > 1`. Higher guidance scale encourages to generate images that are
+ closely linked to the text `prompt`, usually at the expense of lower image quality.
prior_num_inference_steps (`Union[int, Dict[float, int]]`, *optional*, defaults to 60):
The number of prior denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference. For more specific timestep spacing, you can pass customized
@@ -210,11 +210,11 @@ class WuerstchenCombinedPipeline(DiffusionPipeline):
Custom timesteps to use for the denoising process for the decoder. If not defined, equal spaced
`num_inference_steps` timesteps are used. Must be in descending order.
decoder_guidance_scale (`float`, *optional*, defaults to 0.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `guidance_scale` is defined as `w` of equation 2.
+ of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
diff --git a/src/diffusers/pipelines/wuerstchen/pipeline_wuerstchen_prior.py b/src/diffusers/pipelines/wuerstchen/pipeline_wuerstchen_prior.py
index 8f6ba41972..ca9f81747d 100644
--- a/src/diffusers/pipelines/wuerstchen/pipeline_wuerstchen_prior.py
+++ b/src/diffusers/pipelines/wuerstchen/pipeline_wuerstchen_prior.py
@@ -325,11 +325,11 @@ class WuerstchenPriorPipeline(DiffusionPipeline, StableDiffusionLoraLoaderMixin)
Custom timesteps to use for the denoising process. If not defined, equal spaced `num_inference_steps`
timesteps are used. Must be in descending order.
guidance_scale (`float`, *optional*, defaults to 8.0):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `decoder_guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting
- `decoder_guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely
- linked to the text `prompt`, usually at the expense of lower image quality.
+ Guidance scale as defined in [Classifier-Free Diffusion
+ Guidance](https://huggingface.co/papers/2207.12598). `decoder_guidance_scale` is defined as `w` of
+ equation 2. of [Imagen Paper](https://huggingface.co/papers/2205.11487). Guidance scale is enabled by
+ setting `decoder_guidance_scale > 1`. Higher guidance scale encourages to generate images that are
+ closely linked to the text `prompt`, usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `decoder_guidance_scale` is less than `1`).
diff --git a/src/diffusers/quantizers/__init__.py b/src/diffusers/quantizers/__init__.py
index 4c8483a3d6..bd9e2303c9 100644
--- a/src/diffusers/quantizers/__init__.py
+++ b/src/diffusers/quantizers/__init__.py
@@ -12,5 +12,183 @@
# See the License for the specific language governing permissions and
# limitations under the License.
+import inspect
+from typing import Dict, List, Optional, Union
+
+from ..utils import is_transformers_available, logging
from .auto import DiffusersAutoQuantizer
from .base import DiffusersQuantizer
+from .quantization_config import QuantizationConfigMixin as DiffQuantConfigMixin
+
+
+try:
+ from transformers.utils.quantization_config import QuantizationConfigMixin as TransformersQuantConfigMixin
+except ImportError:
+
+ class TransformersQuantConfigMixin:
+ pass
+
+
+logger = logging.get_logger(__name__)
+
+
+class PipelineQuantizationConfig:
+ """
+ Configuration class to be used when applying quantization on-the-fly to [`~DiffusionPipeline.from_pretrained`].
+
+ Args:
+ quant_backend (`str`): Quantization backend to be used. When using this option, we assume that the backend
+ is available to both `diffusers` and `transformers`.
+ quant_kwargs (`dict`): Params to initialize the quantization backend class.
+ components_to_quantize (`list`): Components of a pipeline to be quantized.
+ quant_mapping (`dict`): Mapping defining the quantization specs to be used for the pipeline
+ components. When using this argument, users are not expected to provide `quant_backend`, `quant_kawargs`,
+ and `components_to_quantize`.
+ """
+
+ def __init__(
+ self,
+ quant_backend: str = None,
+ quant_kwargs: Dict[str, Union[str, float, int, dict]] = None,
+ components_to_quantize: Optional[List[str]] = None,
+ quant_mapping: Dict[str, Union[DiffQuantConfigMixin, "TransformersQuantConfigMixin"]] = None,
+ ):
+ self.quant_backend = quant_backend
+ # Initialize kwargs to be {} to set to the defaults.
+ self.quant_kwargs = quant_kwargs or {}
+ self.components_to_quantize = components_to_quantize
+ self.quant_mapping = quant_mapping
+
+ self.post_init()
+
+ def post_init(self):
+ quant_mapping = self.quant_mapping
+ self.is_granular = True if quant_mapping is not None else False
+
+ self._validate_init_args()
+
+ def _validate_init_args(self):
+ if self.quant_backend and self.quant_mapping:
+ raise ValueError("Both `quant_backend` and `quant_mapping` cannot be specified at the same time.")
+
+ if not self.quant_mapping and not self.quant_backend:
+ raise ValueError("Must provide a `quant_backend` when not providing a `quant_mapping`.")
+
+ if not self.quant_kwargs and not self.quant_mapping:
+ raise ValueError("Both `quant_kwargs` and `quant_mapping` cannot be None.")
+
+ if self.quant_backend is not None:
+ self._validate_init_kwargs_in_backends()
+
+ if self.quant_mapping is not None:
+ self._validate_quant_mapping_args()
+
+ def _validate_init_kwargs_in_backends(self):
+ quant_backend = self.quant_backend
+
+ self._check_backend_availability(quant_backend)
+
+ quant_config_mapping_transformers, quant_config_mapping_diffusers = self._get_quant_config_list()
+
+ if quant_config_mapping_transformers is not None:
+ init_kwargs_transformers = inspect.signature(quant_config_mapping_transformers[quant_backend].__init__)
+ init_kwargs_transformers = {name for name in init_kwargs_transformers.parameters if name != "self"}
+ else:
+ init_kwargs_transformers = None
+
+ init_kwargs_diffusers = inspect.signature(quant_config_mapping_diffusers[quant_backend].__init__)
+ init_kwargs_diffusers = {name for name in init_kwargs_diffusers.parameters if name != "self"}
+
+ if init_kwargs_transformers != init_kwargs_diffusers:
+ raise ValueError(
+ "The signatures of the __init__ methods of the quantization config classes in `diffusers` and `transformers` don't match. "
+ f"Please provide a `quant_mapping` instead, in the {self.__class__.__name__} class. Refer to [the docs](https://huggingface.co/docs/diffusers/main/en/quantization/overview#pipeline-level-quantization) to learn more about how "
+ "this mapping would look like."
+ )
+
+ def _validate_quant_mapping_args(self):
+ quant_mapping = self.quant_mapping
+ transformers_map, diffusers_map = self._get_quant_config_list()
+
+ available_transformers = list(transformers_map.values()) if transformers_map else None
+ available_diffusers = list(diffusers_map.values())
+
+ for module_name, config in quant_mapping.items():
+ if any(isinstance(config, cfg) for cfg in available_diffusers):
+ continue
+
+ if available_transformers and any(isinstance(config, cfg) for cfg in available_transformers):
+ continue
+
+ if available_transformers:
+ raise ValueError(
+ f"Provided config for module_name={module_name} could not be found. "
+ f"Available diffusers configs: {available_diffusers}; "
+ f"Available transformers configs: {available_transformers}."
+ )
+ else:
+ raise ValueError(
+ f"Provided config for module_name={module_name} could not be found. "
+ f"Available diffusers configs: {available_diffusers}."
+ )
+
+ def _check_backend_availability(self, quant_backend: str):
+ quant_config_mapping_transformers, quant_config_mapping_diffusers = self._get_quant_config_list()
+
+ available_backends_transformers = (
+ list(quant_config_mapping_transformers.keys()) if quant_config_mapping_transformers else None
+ )
+ available_backends_diffusers = list(quant_config_mapping_diffusers.keys())
+
+ if (
+ available_backends_transformers and quant_backend not in available_backends_transformers
+ ) or quant_backend not in quant_config_mapping_diffusers:
+ error_message = f"Provided quant_backend={quant_backend} was not found."
+ if available_backends_transformers:
+ error_message += f"\nAvailable ones (transformers): {available_backends_transformers}."
+ error_message += f"\nAvailable ones (diffusers): {available_backends_diffusers}."
+ raise ValueError(error_message)
+
+ def _resolve_quant_config(self, is_diffusers: bool = True, module_name: str = None):
+ quant_config_mapping_transformers, quant_config_mapping_diffusers = self._get_quant_config_list()
+
+ quant_mapping = self.quant_mapping
+ components_to_quantize = self.components_to_quantize
+
+ # Granular case
+ if self.is_granular and module_name in quant_mapping:
+ logger.debug(f"Initializing quantization config class for {module_name}.")
+ config = quant_mapping[module_name]
+ return config
+
+ # Global config case
+ else:
+ should_quantize = False
+ # Only quantize the modules requested for.
+ if components_to_quantize and module_name in components_to_quantize:
+ should_quantize = True
+ # No specification for `components_to_quantize` means all modules should be quantized.
+ elif not self.is_granular and not components_to_quantize:
+ should_quantize = True
+
+ if should_quantize:
+ logger.debug(f"Initializing quantization config class for {module_name}.")
+ mapping_to_use = quant_config_mapping_diffusers if is_diffusers else quant_config_mapping_transformers
+ quant_config_cls = mapping_to_use[self.quant_backend]
+ quant_kwargs = self.quant_kwargs
+ return quant_config_cls(**quant_kwargs)
+
+ # Fallback: no applicable configuration found.
+ return None
+
+ def _get_quant_config_list(self):
+ if is_transformers_available():
+ from transformers.quantizers.auto import (
+ AUTO_QUANTIZATION_CONFIG_MAPPING as quant_config_mapping_transformers,
+ )
+ else:
+ quant_config_mapping_transformers = None
+
+ from ..quantizers.auto import AUTO_QUANTIZATION_CONFIG_MAPPING as quant_config_mapping_diffusers
+
+ return quant_config_mapping_transformers, quant_config_mapping_diffusers
diff --git a/src/diffusers/quantizers/bitsandbytes/utils.py b/src/diffusers/quantizers/bitsandbytes/utils.py
index 9943c1a511..429aabb8fa 100644
--- a/src/diffusers/quantizers/bitsandbytes/utils.py
+++ b/src/diffusers/quantizers/bitsandbytes/utils.py
@@ -121,8 +121,9 @@ def replace_with_bnb_linear(model, modules_to_not_convert=None, current_key_name
References:
* `bnb.nn.Linear8bit`: [LLM.int8(): 8-bit Matrix Multiplication for Transformers at
- Scale](https://arxiv.org/abs/2208.07339)
- * `bnb.nn.Linear4bit`: [QLoRA: Efficient Finetuning of Quantized LLMs](https://arxiv.org/abs/2305.14314)
+ Scale](https://huggingface.co/papers/2208.07339)
+ * `bnb.nn.Linear4bit`: [QLoRA: Efficient Finetuning of Quantized
+ LLMs](https://huggingface.co/papers/2305.14314)
Parameters:
model (`torch.nn.Module`):
diff --git a/src/diffusers/quantizers/gguf/utils.py b/src/diffusers/quantizers/gguf/utils.py
index de82dcab07..531fd61273 100644
--- a/src/diffusers/quantizers/gguf/utils.py
+++ b/src/diffusers/quantizers/gguf/utils.py
@@ -408,6 +408,18 @@ class GGUFParameter(torch.nn.Parameter):
def as_tensor(self):
return torch.Tensor._make_subclass(torch.Tensor, self, self.requires_grad)
+ @staticmethod
+ def _extract_quant_type(args):
+ # When converting from original format checkpoints we often use splits, cats etc on tensors
+ # this method ensures that the returned tensor type from those operations remains GGUFParameter
+ # so that we preserve quant_type information
+ for arg in args:
+ if isinstance(arg, list) and isinstance(arg[0], GGUFParameter):
+ return arg[0].quant_type
+ if isinstance(arg, GGUFParameter):
+ return arg.quant_type
+ return None
+
@classmethod
def __torch_function__(cls, func, types, args=(), kwargs=None):
if kwargs is None:
@@ -415,22 +427,13 @@ class GGUFParameter(torch.nn.Parameter):
result = super().__torch_function__(func, types, args, kwargs)
- # When converting from original format checkpoints we often use splits, cats etc on tensors
- # this method ensures that the returned tensor type from those operations remains GGUFParameter
- # so that we preserve quant_type information
- quant_type = None
- for arg in args:
- if isinstance(arg, list) and isinstance(arg[0], GGUFParameter):
- quant_type = arg[0].quant_type
- break
- if isinstance(arg, GGUFParameter):
- quant_type = arg.quant_type
- break
if isinstance(result, torch.Tensor):
+ quant_type = cls._extract_quant_type(args)
return cls(result, quant_type=quant_type)
# Handle tuples and lists
- elif isinstance(result, (tuple, list)):
+ elif type(result) in (list, tuple):
# Preserve the original type (tuple or list)
+ quant_type = cls._extract_quant_type(args)
wrapped = [cls(x, quant_type=quant_type) if isinstance(x, torch.Tensor) else x for x in result]
return type(result)(wrapped)
else:
diff --git a/src/diffusers/quantizers/quantization_config.py b/src/diffusers/quantizers/quantization_config.py
index 3d1056c53a..328e707a08 100644
--- a/src/diffusers/quantizers/quantization_config.py
+++ b/src/diffusers/quantizers/quantization_config.py
@@ -75,7 +75,7 @@ class QuantizationConfigMixin:
Args:
config_dict (`Dict[str, Any]`):
Dictionary that will be used to instantiate the configuration object.
- return_unused_kwargs (`bool`,*optional*, defaults to `False`):
+ return_unused_kwargs (`bool`, *optional*, defaults to `False`):
Whether or not to return a list of unused keyword arguments. Used for `from_pretrained` method in
`PreTrainedModel`.
kwargs (`Dict[str, Any]`):
@@ -192,10 +192,10 @@ class BitsAndBytesConfig(QuantizationConfigMixin):
`bitsandbytes`.
llm_int8_threshold (`float`, *optional*, defaults to 6.0):
This corresponds to the outlier threshold for outlier detection as described in `LLM.int8() : 8-bit Matrix
- Multiplication for Transformers at Scale` paper: https://arxiv.org/abs/2208.07339 Any hidden states value
- that is above this threshold will be considered an outlier and the operation on those values will be done
- in fp16. Values are usually normally distributed, that is, most values are in the range [-3.5, 3.5], but
- there are some exceptional systematic outliers that are very differently distributed for large models.
+ Multiplication for Transformers at Scale` paper: https://huggingface.co/papers/2208.07339 Any hidden states
+ value that is above this threshold will be considered an outlier and the operation on those values will be
+ done in fp16. Values are usually normally distributed, that is, most values are in the range [-3.5, 3.5],
+ but there are some exceptional systematic outliers that are very differently distributed for large models.
These outliers are often in the interval [-60, -6] or [6, 60]. Int8 quantization works well for values of
magnitude ~5, but beyond that, there is a significant performance penalty. A good default threshold is 6,
but a lower threshold might be needed for more unstable models (small models, fine-tuning).
diff --git a/src/diffusers/schedulers/deprecated/scheduling_karras_ve.py b/src/diffusers/schedulers/deprecated/scheduling_karras_ve.py
index f5f9bd256c..57fd7e6687 100644
--- a/src/diffusers/schedulers/deprecated/scheduling_karras_ve.py
+++ b/src/diffusers/schedulers/deprecated/scheduling_karras_ve.py
@@ -55,8 +55,9 @@ class KarrasVeScheduler(SchedulerMixin, ConfigMixin):
- For more details on the parameters, see [Appendix E](https://arxiv.org/abs/2206.00364). The grid search values used
- to find the optimal `{s_noise, s_churn, s_min, s_max}` for a specific model are described in Table 5 of the paper.
+ For more details on the parameters, see [Appendix E](https://huggingface.co/papers/2206.00364). The grid search
+ values used to find the optimal `{s_noise, s_churn, s_min, s_max}` for a specific model are described in Table 5 of
+ the paper.
diff --git a/src/diffusers/schedulers/scheduling_cosine_dpmsolver_multistep.py b/src/diffusers/schedulers/scheduling_cosine_dpmsolver_multistep.py
index d276220b66..0eca18f044 100644
--- a/src/diffusers/schedulers/scheduling_cosine_dpmsolver_multistep.py
+++ b/src/diffusers/schedulers/scheduling_cosine_dpmsolver_multistep.py
@@ -30,7 +30,7 @@ class CosineDPMSolverMultistepScheduler(SchedulerMixin, ConfigMixin):
Implements a variant of `DPMSolverMultistepScheduler` with cosine schedule, proposed by Nichol and Dhariwal (2021).
This scheduler was used in Stable Audio Open [1].
- [1] Evans, Parker, et al. "Stable Audio Open" https://arxiv.org/abs/2407.14358
+ [1] Evans, Parker, et al. "Stable Audio Open" https://huggingface.co/papers/2407.14358
This model inherits from [`SchedulerMixin`] and [`ConfigMixin`]. Check the superclass documentation for the generic
methods the library implements for all schedulers such as loading and saving.
@@ -44,8 +44,8 @@ class CosineDPMSolverMultistepScheduler(SchedulerMixin, ConfigMixin):
The standard deviation of the data distribution. This is set to 1.0 in Stable Audio Open [1].
sigma_schedule (`str`, *optional*, defaults to `exponential`):
Sigma schedule to compute the `sigmas`. By default, we the schedule introduced in the EDM paper
- (https://arxiv.org/abs/2206.00364). Other acceptable value is "exponential". The exponential schedule was
- incorporated in this model: https://huggingface.co/stabilityai/cosxl.
+ (https://huggingface.co/papers/2206.00364). Other acceptable value is "exponential". The exponential
+ schedule was incorporated in this model: https://huggingface.co/stabilityai/cosxl.
num_train_timesteps (`int`, defaults to 1000):
The number of diffusion steps to train the model.
solver_order (`int`, defaults to 2):
diff --git a/src/diffusers/schedulers/scheduling_ddim.py b/src/diffusers/schedulers/scheduling_ddim.py
index 13c9b3b4a5..6d7ff396ce 100644
--- a/src/diffusers/schedulers/scheduling_ddim.py
+++ b/src/diffusers/schedulers/scheduling_ddim.py
@@ -94,7 +94,7 @@ def betas_for_alpha_bar(
def rescale_zero_terminal_snr(betas):
"""
- Rescales betas to have zero terminal SNR Based on https://arxiv.org/pdf/2305.08891.pdf (Algorithm 1)
+ Rescales betas to have zero terminal SNR Based on https://huggingface.co/papers/2305.08891 (Algorithm 1)
Args:
@@ -269,7 +269,7 @@ class DDIMScheduler(SchedulerMixin, ConfigMixin):
pixels from saturation at each step. We find that dynamic thresholding results in significantly better
photorealism as well as better image-text alignment, especially when using very large guidance weights."
- https://arxiv.org/abs/2205.11487
+ https://huggingface.co/papers/2205.11487
"""
dtype = sample.dtype
batch_size, channels, *remaining_dims = sample.shape
@@ -312,7 +312,7 @@ class DDIMScheduler(SchedulerMixin, ConfigMixin):
self.num_inference_steps = num_inference_steps
- # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://arxiv.org/abs/2305.08891
+ # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://huggingface.co/papers/2305.08891
if self.config.timestep_spacing == "linspace":
timesteps = (
np.linspace(0, self.config.num_train_timesteps - 1, num_inference_steps)
@@ -387,7 +387,7 @@ class DDIMScheduler(SchedulerMixin, ConfigMixin):
"Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
)
- # See formulas (12) and (16) of DDIM paper https://arxiv.org/pdf/2010.02502.pdf
+ # See formulas (12) and (16) of DDIM paper https://huggingface.co/papers/2010.02502
# Ideally, read DDIM paper in-detail understanding
# Notation ( ->
@@ -408,7 +408,7 @@ class DDIMScheduler(SchedulerMixin, ConfigMixin):
beta_prod_t = 1 - alpha_prod_t
# 3. compute predicted original sample from predicted noise also called
- # "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # "predicted x_0" of formula (12) from https://huggingface.co/papers/2010.02502
if self.config.prediction_type == "epsilon":
pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
pred_epsilon = model_output
@@ -441,10 +441,10 @@ class DDIMScheduler(SchedulerMixin, ConfigMixin):
# the pred_epsilon is always re-derived from the clipped x_0 in Glide
pred_epsilon = (sample - alpha_prod_t ** (0.5) * pred_original_sample) / beta_prod_t ** (0.5)
- # 6. compute "direction pointing to x_t" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # 6. compute "direction pointing to x_t" of formula (12) from https://huggingface.co/papers/2010.02502
pred_sample_direction = (1 - alpha_prod_t_prev - std_dev_t**2) ** (0.5) * pred_epsilon
- # 7. compute x_t without "random noise" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # 7. compute x_t without "random noise" of formula (12) from https://huggingface.co/papers/2010.02502
prev_sample = alpha_prod_t_prev ** (0.5) * pred_original_sample + pred_sample_direction
if eta > 0:
diff --git a/src/diffusers/schedulers/scheduling_ddim_cogvideox.py b/src/diffusers/schedulers/scheduling_ddim_cogvideox.py
index 5c13175293..d82de8b43f 100644
--- a/src/diffusers/schedulers/scheduling_ddim_cogvideox.py
+++ b/src/diffusers/schedulers/scheduling_ddim_cogvideox.py
@@ -94,7 +94,7 @@ def betas_for_alpha_bar(
def rescale_zero_terminal_snr(alphas_cumprod):
"""
- Rescales betas to have zero terminal SNR Based on https://arxiv.org/pdf/2305.08891.pdf (Algorithm 1)
+ Rescales betas to have zero terminal SNR Based on https://huggingface.co/papers/2305.08891 (Algorithm 1)
Args:
@@ -275,7 +275,7 @@ class CogVideoXDDIMScheduler(SchedulerMixin, ConfigMixin):
self.num_inference_steps = num_inference_steps
- # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://arxiv.org/abs/2305.08891
+ # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://huggingface.co/papers/2305.08891
if self.config.timestep_spacing == "linspace":
timesteps = (
np.linspace(0, self.config.num_train_timesteps - 1, num_inference_steps)
@@ -350,7 +350,7 @@ class CogVideoXDDIMScheduler(SchedulerMixin, ConfigMixin):
"Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
)
- # See formulas (12) and (16) of DDIM paper https://arxiv.org/pdf/2010.02502.pdf
+ # See formulas (12) and (16) of DDIM paper https://huggingface.co/papers/2010.02502
# Ideally, read DDIM paper in-detail understanding
# Notation ( ->
@@ -371,7 +371,7 @@ class CogVideoXDDIMScheduler(SchedulerMixin, ConfigMixin):
beta_prod_t = 1 - alpha_prod_t
# 3. compute predicted original sample from predicted noise also called
- # "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # "predicted x_0" of formula (12) from https://huggingface.co/papers/2010.02502
# To make style tests pass, commented out `pred_epsilon` as it is an unused variable
if self.config.prediction_type == "epsilon":
pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
diff --git a/src/diffusers/schedulers/scheduling_ddim_flax.py b/src/diffusers/schedulers/scheduling_ddim_flax.py
index 23c71a6145..6ccf35628b 100644
--- a/src/diffusers/schedulers/scheduling_ddim_flax.py
+++ b/src/diffusers/schedulers/scheduling_ddim_flax.py
@@ -73,7 +73,7 @@ class FlaxDDIMScheduler(FlaxSchedulerMixin, ConfigMixin):
[`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
[`~SchedulerMixin.from_pretrained`] functions.
- For more details, see the original paper: https://arxiv.org/abs/2010.02502
+ For more details, see the original paper: https://huggingface.co/papers/2010.02502
Args:
num_train_timesteps (`int`): number of diffusion steps used to train the model.
@@ -230,7 +230,7 @@ class FlaxDDIMScheduler(FlaxSchedulerMixin, ConfigMixin):
"Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
)
- # See formulas (12) and (16) of DDIM paper https://arxiv.org/pdf/2010.02502.pdf
+ # See formulas (12) and (16) of DDIM paper https://huggingface.co/papers/2010.02502
# Ideally, read DDIM paper in-detail understanding
# Notation ( ->
@@ -254,7 +254,7 @@ class FlaxDDIMScheduler(FlaxSchedulerMixin, ConfigMixin):
beta_prod_t = 1 - alpha_prod_t
# 3. compute predicted original sample from predicted noise also called
- # "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # "predicted x_0" of formula (12) from https://huggingface.co/papers/2010.02502
if self.config.prediction_type == "epsilon":
pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
pred_epsilon = model_output
@@ -281,10 +281,10 @@ class FlaxDDIMScheduler(FlaxSchedulerMixin, ConfigMixin):
variance = self._get_variance(state, timestep, prev_timestep)
std_dev_t = eta * variance ** (0.5)
- # 5. compute "direction pointing to x_t" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # 5. compute "direction pointing to x_t" of formula (12) from https://huggingface.co/papers/2010.02502
pred_sample_direction = (1 - alpha_prod_t_prev - std_dev_t**2) ** (0.5) * pred_epsilon
- # 6. compute x_t without "random noise" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # 6. compute x_t without "random noise" of formula (12) from https://huggingface.co/papers/2010.02502
prev_sample = alpha_prod_t_prev ** (0.5) * pred_original_sample + pred_sample_direction
if not return_dict:
diff --git a/src/diffusers/schedulers/scheduling_ddim_inverse.py b/src/diffusers/schedulers/scheduling_ddim_inverse.py
index d9d9ae683a..b0caf630da 100644
--- a/src/diffusers/schedulers/scheduling_ddim_inverse.py
+++ b/src/diffusers/schedulers/scheduling_ddim_inverse.py
@@ -93,7 +93,7 @@ def betas_for_alpha_bar(
# Copied from diffusers.schedulers.scheduling_ddim.rescale_zero_terminal_snr
def rescale_zero_terminal_snr(betas):
"""
- Rescales betas to have zero terminal SNR Based on https://arxiv.org/pdf/2305.08891.pdf (Algorithm 1)
+ Rescales betas to have zero terminal SNR Based on https://huggingface.co/papers/2305.08891 (Algorithm 1)
Args:
@@ -266,7 +266,7 @@ class DDIMInverseScheduler(SchedulerMixin, ConfigMixin):
self.num_inference_steps = num_inference_steps
- # "leading" and "trailing" corresponds to annotation of Table 2. of https://arxiv.org/abs/2305.08891
+ # "leading" and "trailing" corresponds to annotation of Table 2. of https://huggingface.co/papers/2305.08891
if self.config.timestep_spacing == "leading":
step_ratio = self.config.num_train_timesteps // self.num_inference_steps
# creates integer timesteps by multiplying by ratio
@@ -338,7 +338,7 @@ class DDIMInverseScheduler(SchedulerMixin, ConfigMixin):
beta_prod_t = 1 - alpha_prod_t
# 3. compute predicted original sample from predicted noise also called
- # "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # "predicted x_0" of formula (12) from https://huggingface.co/papers/2010.02502
if self.config.prediction_type == "epsilon":
pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
pred_epsilon = model_output
@@ -360,10 +360,10 @@ class DDIMInverseScheduler(SchedulerMixin, ConfigMixin):
-self.config.clip_sample_range, self.config.clip_sample_range
)
- # 5. compute "direction pointing to x_t" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # 5. compute "direction pointing to x_t" of formula (12) from https://huggingface.co/papers/2010.02502
pred_sample_direction = (1 - alpha_prod_t_prev) ** (0.5) * pred_epsilon
- # 6. compute x_t without "random noise" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # 6. compute x_t without "random noise" of formula (12) from https://huggingface.co/papers/2010.02502
prev_sample = alpha_prod_t_prev ** (0.5) * pred_original_sample + pred_sample_direction
if not return_dict:
diff --git a/src/diffusers/schedulers/scheduling_ddim_parallel.py b/src/diffusers/schedulers/scheduling_ddim_parallel.py
index 64412709ae..54404a3306 100644
--- a/src/diffusers/schedulers/scheduling_ddim_parallel.py
+++ b/src/diffusers/schedulers/scheduling_ddim_parallel.py
@@ -95,7 +95,7 @@ def betas_for_alpha_bar(
# Copied from diffusers.schedulers.scheduling_ddim.rescale_zero_terminal_snr
def rescale_zero_terminal_snr(betas):
"""
- Rescales betas to have zero terminal SNR Based on https://arxiv.org/pdf/2305.08891.pdf (Algorithm 1)
+ Rescales betas to have zero terminal SNR Based on https://huggingface.co/papers/2305.08891 (Algorithm 1)
Args:
@@ -139,7 +139,7 @@ class DDIMParallelScheduler(SchedulerMixin, ConfigMixin):
[`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
[`~SchedulerMixin.from_pretrained`] functions.
- For more details, see the original paper: https://arxiv.org/abs/2010.02502
+ For more details, see the original paper: https://huggingface.co/papers/2010.02502
Args:
num_train_timesteps (`int`): number of diffusion steps used to train the model.
@@ -165,21 +165,21 @@ class DDIMParallelScheduler(SchedulerMixin, ConfigMixin):
process), `sample` (directly predicting the noisy sample`) or `v_prediction` (see section 2.4
https://imagen.research.google/video/paper.pdf)
thresholding (`bool`, default `False`):
- whether to use the "dynamic thresholding" method (introduced by Imagen, https://arxiv.org/abs/2205.11487).
- Note that the thresholding method is unsuitable for latent-space diffusion models (such as
- stable-diffusion).
+ whether to use the "dynamic thresholding" method (introduced by Imagen,
+ https://huggingface.co/papers/2205.11487). Note that the thresholding method is unsuitable for latent-space
+ diffusion models (such as stable-diffusion).
dynamic_thresholding_ratio (`float`, default `0.995`):
the ratio for the dynamic thresholding method. Default is `0.995`, the same as Imagen
- (https://arxiv.org/abs/2205.11487). Valid only when `thresholding=True`.
+ (https://huggingface.co/papers/2205.11487). Valid only when `thresholding=True`.
sample_max_value (`float`, default `1.0`):
the threshold value for dynamic thresholding. Valid only when `thresholding=True`.
timestep_spacing (`str`, default `"leading"`):
The way the timesteps should be scaled. Refer to Table 2. of [Common Diffusion Noise Schedules and Sample
- Steps are Flawed](https://arxiv.org/abs/2305.08891) for more information.
+ Steps are Flawed](https://huggingface.co/papers/2305.08891) for more information.
rescale_betas_zero_snr (`bool`, default `False`):
- whether to rescale the betas to have zero terminal SNR (proposed by https://arxiv.org/pdf/2305.08891.pdf).
- This can enable the model to generate very bright and dark samples instead of limiting it to samples with
- medium brightness. Loosely related to
+ whether to rescale the betas to have zero terminal SNR (proposed by
+ https://huggingface.co/papers/2305.08891). This can enable the model to generate very bright and dark
+ samples instead of limiting it to samples with medium brightness. Loosely related to
[`--offset_noise`](https://github.com/huggingface/diffusers/blob/74fd735eb073eb1d774b1ab4154a0876eb82f055/examples/dreambooth/train_dreambooth.py#L506).
"""
@@ -291,7 +291,7 @@ class DDIMParallelScheduler(SchedulerMixin, ConfigMixin):
pixels from saturation at each step. We find that dynamic thresholding results in significantly better
photorealism as well as better image-text alignment, especially when using very large guidance weights."
- https://arxiv.org/abs/2205.11487
+ https://huggingface.co/papers/2205.11487
"""
dtype = sample.dtype
batch_size, channels, *remaining_dims = sample.shape
@@ -335,7 +335,7 @@ class DDIMParallelScheduler(SchedulerMixin, ConfigMixin):
self.num_inference_steps = num_inference_steps
- # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://arxiv.org/abs/2305.08891
+ # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://huggingface.co/papers/2305.08891
if self.config.timestep_spacing == "linspace":
timesteps = (
np.linspace(0, self.config.num_train_timesteps - 1, num_inference_steps)
@@ -390,7 +390,7 @@ class DDIMParallelScheduler(SchedulerMixin, ConfigMixin):
generator: random number generator.
variance_noise (`torch.Tensor`): instead of generating noise for the variance using `generator`, we
can directly provide the noise for the variance itself. This is useful for methods such as
- CycleDiffusion. (https://arxiv.org/abs/2210.05559)
+ CycleDiffusion. (https://huggingface.co/papers/2210.05559)
return_dict (`bool`): option for returning tuple rather than DDIMParallelSchedulerOutput class
Returns:
@@ -404,7 +404,7 @@ class DDIMParallelScheduler(SchedulerMixin, ConfigMixin):
"Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
)
- # See formulas (12) and (16) of DDIM paper https://arxiv.org/pdf/2010.02502.pdf
+ # See formulas (12) and (16) of DDIM paper https://huggingface.co/papers/2010.02502
# Ideally, read DDIM paper in-detail understanding
# Notation ( ->
@@ -425,7 +425,7 @@ class DDIMParallelScheduler(SchedulerMixin, ConfigMixin):
beta_prod_t = 1 - alpha_prod_t
# 3. compute predicted original sample from predicted noise also called
- # "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # "predicted x_0" of formula (12) from https://huggingface.co/papers/2010.02502
if self.config.prediction_type == "epsilon":
pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
pred_epsilon = model_output
@@ -458,10 +458,10 @@ class DDIMParallelScheduler(SchedulerMixin, ConfigMixin):
# the pred_epsilon is always re-derived from the clipped x_0 in Glide
pred_epsilon = (sample - alpha_prod_t ** (0.5) * pred_original_sample) / beta_prod_t ** (0.5)
- # 6. compute "direction pointing to x_t" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # 6. compute "direction pointing to x_t" of formula (12) from https://huggingface.co/papers/2010.02502
pred_sample_direction = (1 - alpha_prod_t_prev - std_dev_t**2) ** (0.5) * pred_epsilon
- # 7. compute x_t without "random noise" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # 7. compute x_t without "random noise" of formula (12) from https://huggingface.co/papers/2010.02502
prev_sample = alpha_prod_t_prev ** (0.5) * pred_original_sample + pred_sample_direction
if eta > 0:
@@ -526,7 +526,7 @@ class DDIMParallelScheduler(SchedulerMixin, ConfigMixin):
assert eta == 0.0
- # See formulas (12) and (16) of DDIM paper https://arxiv.org/pdf/2010.02502.pdf
+ # See formulas (12) and (16) of DDIM paper https://huggingface.co/papers/2010.02502
# Ideally, read DDIM paper in-detail understanding
# Notation ( ->
@@ -554,7 +554,7 @@ class DDIMParallelScheduler(SchedulerMixin, ConfigMixin):
beta_prod_t = 1 - alpha_prod_t
# 3. compute predicted original sample from predicted noise also called
- # "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # "predicted x_0" of formula (12) from https://huggingface.co/papers/2010.02502
if self.config.prediction_type == "epsilon":
pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
pred_epsilon = model_output
@@ -587,10 +587,10 @@ class DDIMParallelScheduler(SchedulerMixin, ConfigMixin):
# the pred_epsilon is always re-derived from the clipped x_0 in Glide
pred_epsilon = (sample - alpha_prod_t ** (0.5) * pred_original_sample) / beta_prod_t ** (0.5)
- # 6. compute "direction pointing to x_t" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # 6. compute "direction pointing to x_t" of formula (12) from https://huggingface.co/papers/2010.02502
pred_sample_direction = (1 - alpha_prod_t_prev - std_dev_t**2) ** (0.5) * pred_epsilon
- # 7. compute x_t without "random noise" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # 7. compute x_t without "random noise" of formula (12) from https://huggingface.co/papers/2010.02502
prev_sample = alpha_prod_t_prev ** (0.5) * pred_original_sample + pred_sample_direction
return prev_sample
diff --git a/src/diffusers/schedulers/scheduling_ddpm.py b/src/diffusers/schedulers/scheduling_ddpm.py
index f9eb9c365a..4f99cf4ce5 100644
--- a/src/diffusers/schedulers/scheduling_ddpm.py
+++ b/src/diffusers/schedulers/scheduling_ddpm.py
@@ -92,7 +92,7 @@ def betas_for_alpha_bar(
# Copied from diffusers.schedulers.scheduling_ddim.rescale_zero_terminal_snr
def rescale_zero_terminal_snr(betas):
"""
- Rescales betas to have zero terminal SNR Based on https://arxiv.org/pdf/2305.08891.pdf (Algorithm 1)
+ Rescales betas to have zero terminal SNR Based on https://huggingface.co/papers/2305.08891 (Algorithm 1)
Args:
@@ -295,7 +295,7 @@ class DDPMScheduler(SchedulerMixin, ConfigMixin):
self.num_inference_steps = num_inference_steps
self.custom_timesteps = False
- # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://arxiv.org/abs/2305.08891
+ # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://huggingface.co/papers/2305.08891
if self.config.timestep_spacing == "linspace":
timesteps = (
np.linspace(0, self.config.num_train_timesteps - 1, num_inference_steps)
@@ -329,7 +329,7 @@ class DDPMScheduler(SchedulerMixin, ConfigMixin):
alpha_prod_t_prev = self.alphas_cumprod[prev_t] if prev_t >= 0 else self.one
current_beta_t = 1 - alpha_prod_t / alpha_prod_t_prev
- # For t > 0, compute predicted variance βt (see formula (6) and (7) from https://arxiv.org/pdf/2006.11239.pdf)
+ # For t > 0, compute predicted variance βt (see formula (6) and (7) from https://huggingface.co/papers/2006.11239)
# and sample from it to get previous sample
# x_{t-1} ~ N(pred_prev_sample, variance) == add variance to pred_sample
variance = (1 - alpha_prod_t_prev) / (1 - alpha_prod_t) * current_beta_t
@@ -343,7 +343,7 @@ class DDPMScheduler(SchedulerMixin, ConfigMixin):
# hacks - were probably added for training stability
if variance_type == "fixed_small":
variance = variance
- # for rl-diffuser https://arxiv.org/abs/2205.09991
+ # for rl-diffuser https://huggingface.co/papers/2205.09991
elif variance_type == "fixed_small_log":
variance = torch.log(variance)
variance = torch.exp(0.5 * variance)
@@ -370,7 +370,7 @@ class DDPMScheduler(SchedulerMixin, ConfigMixin):
pixels from saturation at each step. We find that dynamic thresholding results in significantly better
photorealism as well as better image-text alignment, especially when using very large guidance weights."
- https://arxiv.org/abs/2205.11487
+ https://huggingface.co/papers/2205.11487
"""
dtype = sample.dtype
batch_size, channels, *remaining_dims = sample.shape
@@ -443,7 +443,7 @@ class DDPMScheduler(SchedulerMixin, ConfigMixin):
current_beta_t = 1 - current_alpha_t
# 2. compute predicted original sample from predicted noise also called
- # "predicted x_0" of formula (15) from https://arxiv.org/pdf/2006.11239.pdf
+ # "predicted x_0" of formula (15) from https://huggingface.co/papers/2006.11239
if self.config.prediction_type == "epsilon":
pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
elif self.config.prediction_type == "sample":
@@ -465,12 +465,12 @@ class DDPMScheduler(SchedulerMixin, ConfigMixin):
)
# 4. Compute coefficients for pred_original_sample x_0 and current sample x_t
- # See formula (7) from https://arxiv.org/pdf/2006.11239.pdf
+ # See formula (7) from https://huggingface.co/papers/2006.11239
pred_original_sample_coeff = (alpha_prod_t_prev ** (0.5) * current_beta_t) / beta_prod_t
current_sample_coeff = current_alpha_t ** (0.5) * beta_prod_t_prev / beta_prod_t
# 5. Compute predicted previous sample µ_t
- # See formula (7) from https://arxiv.org/pdf/2006.11239.pdf
+ # See formula (7) from https://huggingface.co/papers/2006.11239
pred_prev_sample = pred_original_sample_coeff * pred_original_sample + current_sample_coeff * sample
# 6. Add noise
diff --git a/src/diffusers/schedulers/scheduling_ddpm_flax.py b/src/diffusers/schedulers/scheduling_ddpm_flax.py
index d06a171159..a81ad4168d 100644
--- a/src/diffusers/schedulers/scheduling_ddpm_flax.py
+++ b/src/diffusers/schedulers/scheduling_ddpm_flax.py
@@ -61,7 +61,7 @@ class FlaxDDPMScheduler(FlaxSchedulerMixin, ConfigMixin):
[`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
[`~SchedulerMixin.from_pretrained`] functions.
- For more details, see the original paper: https://arxiv.org/abs/2006.11239
+ For more details, see the original paper: https://huggingface.co/papers/2006.11239
Args:
num_train_timesteps (`int`): number of diffusion steps used to train the model.
@@ -163,7 +163,7 @@ class FlaxDDPMScheduler(FlaxSchedulerMixin, ConfigMixin):
alpha_prod_t = state.common.alphas_cumprod[t]
alpha_prod_t_prev = jnp.where(t > 0, state.common.alphas_cumprod[t - 1], jnp.array(1.0, dtype=self.dtype))
- # For t > 0, compute predicted variance βt (see formula (6) and (7) from https://arxiv.org/pdf/2006.11239.pdf)
+ # For t > 0, compute predicted variance βt (see formula (6) and (7) from https://huggingface.co/papers/2006.11239)
# and sample from it to get previous sample
# x_{t-1} ~ N(pred_prev_sample, variance) == add variance to pred_sample
variance = (1 - alpha_prod_t_prev) / (1 - alpha_prod_t) * state.common.betas[t]
@@ -174,7 +174,7 @@ class FlaxDDPMScheduler(FlaxSchedulerMixin, ConfigMixin):
# hacks - were probably added for training stability
if variance_type == "fixed_small":
variance = jnp.clip(variance, a_min=1e-20)
- # for rl-diffuser https://arxiv.org/abs/2205.09991
+ # for rl-diffuser https://huggingface.co/papers/2205.09991
elif variance_type == "fixed_small_log":
variance = jnp.log(jnp.clip(variance, a_min=1e-20))
elif variance_type == "fixed_large":
@@ -240,7 +240,7 @@ class FlaxDDPMScheduler(FlaxSchedulerMixin, ConfigMixin):
beta_prod_t_prev = 1 - alpha_prod_t_prev
# 2. compute predicted original sample from predicted noise also called
- # "predicted x_0" of formula (15) from https://arxiv.org/pdf/2006.11239.pdf
+ # "predicted x_0" of formula (15) from https://huggingface.co/papers/2006.11239
if self.config.prediction_type == "epsilon":
pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
elif self.config.prediction_type == "sample":
@@ -258,12 +258,12 @@ class FlaxDDPMScheduler(FlaxSchedulerMixin, ConfigMixin):
pred_original_sample = jnp.clip(pred_original_sample, -1, 1)
# 4. Compute coefficients for pred_original_sample x_0 and current sample x_t
- # See formula (7) from https://arxiv.org/pdf/2006.11239.pdf
+ # See formula (7) from https://huggingface.co/papers/2006.11239
pred_original_sample_coeff = (alpha_prod_t_prev ** (0.5) * state.common.betas[t]) / beta_prod_t
current_sample_coeff = state.common.alphas[t] ** (0.5) * beta_prod_t_prev / beta_prod_t
# 5. Compute predicted previous sample µ_t
- # See formula (7) from https://arxiv.org/pdf/2006.11239.pdf
+ # See formula (7) from https://huggingface.co/papers/2006.11239
pred_prev_sample = pred_original_sample_coeff * pred_original_sample + current_sample_coeff * sample
# 6. Add noise
diff --git a/src/diffusers/schedulers/scheduling_ddpm_parallel.py b/src/diffusers/schedulers/scheduling_ddpm_parallel.py
index 64195be141..cc5d55c0b6 100644
--- a/src/diffusers/schedulers/scheduling_ddpm_parallel.py
+++ b/src/diffusers/schedulers/scheduling_ddpm_parallel.py
@@ -94,7 +94,7 @@ def betas_for_alpha_bar(
# Copied from diffusers.schedulers.scheduling_ddim.rescale_zero_terminal_snr
def rescale_zero_terminal_snr(betas):
"""
- Rescales betas to have zero terminal SNR Based on https://arxiv.org/pdf/2305.08891.pdf (Algorithm 1)
+ Rescales betas to have zero terminal SNR Based on https://huggingface.co/papers/2305.08891 (Algorithm 1)
Args:
@@ -138,7 +138,7 @@ class DDPMParallelScheduler(SchedulerMixin, ConfigMixin):
[`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
[`~SchedulerMixin.from_pretrained`] functions.
- For more details, see the original paper: https://arxiv.org/abs/2006.11239
+ For more details, see the original paper: https://huggingface.co/papers/2006.11239
Args:
num_train_timesteps (`int`): number of diffusion steps used to train the model.
@@ -161,17 +161,17 @@ class DDPMParallelScheduler(SchedulerMixin, ConfigMixin):
process), `sample` (directly predicting the noisy sample`) or `v_prediction` (see section 2.4
https://imagen.research.google/video/paper.pdf)
thresholding (`bool`, default `False`):
- whether to use the "dynamic thresholding" method (introduced by Imagen, https://arxiv.org/abs/2205.11487).
- Note that the thresholding method is unsuitable for latent-space diffusion models (such as
- stable-diffusion).
+ whether to use the "dynamic thresholding" method (introduced by Imagen,
+ https://huggingface.co/papers/2205.11487). Note that the thresholding method is unsuitable for latent-space
+ diffusion models (such as stable-diffusion).
dynamic_thresholding_ratio (`float`, default `0.995`):
the ratio for the dynamic thresholding method. Default is `0.995`, the same as Imagen
- (https://arxiv.org/abs/2205.11487). Valid only when `thresholding=True`.
+ (https://huggingface.co/papers/2205.11487). Valid only when `thresholding=True`.
sample_max_value (`float`, default `1.0`):
the threshold value for dynamic thresholding. Valid only when `thresholding=True`.
timestep_spacing (`str`, default `"leading"`):
The way the timesteps should be scaled. Refer to Table 2. of [Common Diffusion Noise Schedules and Sample
- Steps are Flawed](https://arxiv.org/abs/2305.08891) for more information.
+ Steps are Flawed](https://huggingface.co/papers/2305.08891) for more information.
steps_offset (`int`, default `0`):
An offset added to the inference steps, as required by some model families.
rescale_betas_zero_snr (`bool`, defaults to `False`):
@@ -305,7 +305,7 @@ class DDPMParallelScheduler(SchedulerMixin, ConfigMixin):
self.num_inference_steps = num_inference_steps
self.custom_timesteps = False
- # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://arxiv.org/abs/2305.08891
+ # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://huggingface.co/papers/2305.08891
if self.config.timestep_spacing == "linspace":
timesteps = (
np.linspace(0, self.config.num_train_timesteps - 1, num_inference_steps)
@@ -340,7 +340,7 @@ class DDPMParallelScheduler(SchedulerMixin, ConfigMixin):
alpha_prod_t_prev = self.alphas_cumprod[prev_t] if prev_t >= 0 else self.one
current_beta_t = 1 - alpha_prod_t / alpha_prod_t_prev
- # For t > 0, compute predicted variance βt (see formula (6) and (7) from https://arxiv.org/pdf/2006.11239.pdf)
+ # For t > 0, compute predicted variance βt (see formula (6) and (7) from https://huggingface.co/papers/2006.11239)
# and sample from it to get previous sample
# x_{t-1} ~ N(pred_prev_sample, variance) == add variance to pred_sample
variance = (1 - alpha_prod_t_prev) / (1 - alpha_prod_t) * current_beta_t
@@ -354,7 +354,7 @@ class DDPMParallelScheduler(SchedulerMixin, ConfigMixin):
# hacks - were probably added for training stability
if variance_type == "fixed_small":
variance = variance
- # for rl-diffuser https://arxiv.org/abs/2205.09991
+ # for rl-diffuser https://huggingface.co/papers/2205.09991
elif variance_type == "fixed_small_log":
variance = torch.log(variance)
variance = torch.exp(0.5 * variance)
@@ -382,7 +382,7 @@ class DDPMParallelScheduler(SchedulerMixin, ConfigMixin):
pixels from saturation at each step. We find that dynamic thresholding results in significantly better
photorealism as well as better image-text alignment, especially when using very large guidance weights."
- https://arxiv.org/abs/2205.11487
+ https://huggingface.co/papers/2205.11487
"""
dtype = sample.dtype
batch_size, channels, *remaining_dims = sample.shape
@@ -451,7 +451,7 @@ class DDPMParallelScheduler(SchedulerMixin, ConfigMixin):
current_beta_t = 1 - current_alpha_t
# 2. compute predicted original sample from predicted noise also called
- # "predicted x_0" of formula (15) from https://arxiv.org/pdf/2006.11239.pdf
+ # "predicted x_0" of formula (15) from https://huggingface.co/papers/2006.11239
if self.config.prediction_type == "epsilon":
pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
elif self.config.prediction_type == "sample":
@@ -473,12 +473,12 @@ class DDPMParallelScheduler(SchedulerMixin, ConfigMixin):
)
# 4. Compute coefficients for pred_original_sample x_0 and current sample x_t
- # See formula (7) from https://arxiv.org/pdf/2006.11239.pdf
+ # See formula (7) from https://huggingface.co/papers/2006.11239
pred_original_sample_coeff = (alpha_prod_t_prev ** (0.5) * current_beta_t) / beta_prod_t
current_sample_coeff = current_alpha_t ** (0.5) * beta_prod_t_prev / beta_prod_t
# 5. Compute predicted previous sample µ_t
- # See formula (7) from https://arxiv.org/pdf/2006.11239.pdf
+ # See formula (7) from https://huggingface.co/papers/2006.11239
pred_prev_sample = pred_original_sample_coeff * pred_original_sample + current_sample_coeff * sample
# 6. Add noise
@@ -554,7 +554,7 @@ class DDPMParallelScheduler(SchedulerMixin, ConfigMixin):
current_beta_t = 1 - current_alpha_t
# 2. compute predicted original sample from predicted noise also called
- # "predicted x_0" of formula (15) from https://arxiv.org/pdf/2006.11239.pdf
+ # "predicted x_0" of formula (15) from https://huggingface.co/papers/2006.11239
if self.config.prediction_type == "epsilon":
pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
elif self.config.prediction_type == "sample":
@@ -576,12 +576,12 @@ class DDPMParallelScheduler(SchedulerMixin, ConfigMixin):
)
# 4. Compute coefficients for pred_original_sample x_0 and current sample x_t
- # See formula (7) from https://arxiv.org/pdf/2006.11239.pdf
+ # See formula (7) from https://huggingface.co/papers/2006.11239
pred_original_sample_coeff = (alpha_prod_t_prev ** (0.5) * current_beta_t) / beta_prod_t
current_sample_coeff = current_alpha_t ** (0.5) * beta_prod_t_prev / beta_prod_t
# 5. Compute predicted previous sample µ_t
- # See formula (7) from https://arxiv.org/pdf/2006.11239.pdf
+ # See formula (7) from https://huggingface.co/papers/2006.11239
pred_prev_sample = pred_original_sample_coeff * pred_original_sample + current_sample_coeff * sample
return pred_prev_sample
diff --git a/src/diffusers/schedulers/scheduling_ddpm_wuerstchen.py b/src/diffusers/schedulers/scheduling_ddpm_wuerstchen.py
index 71b5669b05..a7f607c5ef 100644
--- a/src/diffusers/schedulers/scheduling_ddpm_wuerstchen.py
+++ b/src/diffusers/schedulers/scheduling_ddpm_wuerstchen.py
@@ -95,7 +95,7 @@ class DDPMWuerstchenScheduler(SchedulerMixin, ConfigMixin):
[`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
[`~SchedulerMixin.from_pretrained`] functions.
- For more details, see the original paper: https://arxiv.org/abs/2006.11239
+ For more details, see the original paper: https://huggingface.co/papers/2006.11239
Args:
scaler (`float`): ....
diff --git a/src/diffusers/schedulers/scheduling_deis_multistep.py b/src/diffusers/schedulers/scheduling_deis_multistep.py
index af9a7f79e3..962dd339da 100644
--- a/src/diffusers/schedulers/scheduling_deis_multistep.py
+++ b/src/diffusers/schedulers/scheduling_deis_multistep.py
@@ -12,7 +12,7 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-# DISCLAIMER: check https://arxiv.org/abs/2204.13902 and https://github.com/qsh-zh/deis for more info
+# DISCLAIMER: check https://huggingface.co/papers/2204.13902 and https://github.com/qsh-zh/deis for more info
# The codebase is modified based on https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_dpmsolver_multistep.py
import math
@@ -242,7 +242,7 @@ class DEISMultistepScheduler(SchedulerMixin, ConfigMixin):
device (`str` or `torch.device`, *optional*):
The device to which the timesteps should be moved to. If `None`, the timesteps are not moved.
"""
- # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://arxiv.org/abs/2305.08891
+ # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://huggingface.co/papers/2305.08891
if self.config.timestep_spacing == "linspace":
timesteps = (
np.linspace(0, self.config.num_train_timesteps - 1, num_inference_steps + 1)
@@ -319,7 +319,7 @@ class DEISMultistepScheduler(SchedulerMixin, ConfigMixin):
pixels from saturation at each step. We find that dynamic thresholding results in significantly better
photorealism as well as better image-text alignment, especially when using very large guidance weights."
- https://arxiv.org/abs/2205.11487
+ https://huggingface.co/papers/2205.11487
"""
dtype = sample.dtype
batch_size, channels, *remaining_dims = sample.shape
diff --git a/src/diffusers/schedulers/scheduling_dpm_cogvideox.py b/src/diffusers/schedulers/scheduling_dpm_cogvideox.py
index 1a2c7be711..ed15f04bd1 100644
--- a/src/diffusers/schedulers/scheduling_dpm_cogvideox.py
+++ b/src/diffusers/schedulers/scheduling_dpm_cogvideox.py
@@ -95,7 +95,7 @@ def betas_for_alpha_bar(
def rescale_zero_terminal_snr(alphas_cumprod):
"""
- Rescales betas to have zero terminal SNR Based on https://arxiv.org/pdf/2305.08891.pdf (Algorithm 1)
+ Rescales betas to have zero terminal SNR Based on https://huggingface.co/papers/2305.08891 (Algorithm 1)
Args:
@@ -276,7 +276,7 @@ class CogVideoXDPMScheduler(SchedulerMixin, ConfigMixin):
self.num_inference_steps = num_inference_steps
- # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://arxiv.org/abs/2305.08891
+ # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://huggingface.co/papers/2305.08891
if self.config.timestep_spacing == "linspace":
timesteps = (
np.linspace(0, self.config.num_train_timesteps - 1, num_inference_steps)
@@ -377,7 +377,7 @@ class CogVideoXDPMScheduler(SchedulerMixin, ConfigMixin):
"Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
)
- # See formulas (12) and (16) of DDIM paper https://arxiv.org/pdf/2010.02502.pdf
+ # See formulas (12) and (16) of DDIM paper https://huggingface.co/papers/2010.02502
# Ideally, read DDIM paper in-detail understanding
# Notation ( ->
@@ -399,7 +399,7 @@ class CogVideoXDPMScheduler(SchedulerMixin, ConfigMixin):
beta_prod_t = 1 - alpha_prod_t
# 3. compute predicted original sample from predicted noise also called
- # "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # "predicted x_0" of formula (12) from https://huggingface.co/papers/2010.02502
# To make style tests pass, commented out `pred_epsilon` as it is an unused variable
if self.config.prediction_type == "epsilon":
pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
diff --git a/src/diffusers/schedulers/scheduling_dpmsolver_multistep.py b/src/diffusers/schedulers/scheduling_dpmsolver_multistep.py
index 4c59d060cf..33a5ccdf22 100644
--- a/src/diffusers/schedulers/scheduling_dpmsolver_multistep.py
+++ b/src/diffusers/schedulers/scheduling_dpmsolver_multistep.py
@@ -78,7 +78,7 @@ def betas_for_alpha_bar(
# Copied from diffusers.schedulers.scheduling_ddim.rescale_zero_terminal_snr
def rescale_zero_terminal_snr(betas):
"""
- Rescales betas to have zero terminal SNR Based on https://arxiv.org/pdf/2305.08891.pdf (Algorithm 1)
+ Rescales betas to have zero terminal SNR Based on https://huggingface.co/papers/2305.08891 (Algorithm 1)
Args:
@@ -366,7 +366,7 @@ class DPMSolverMultistepScheduler(SchedulerMixin, ConfigMixin):
clipped_idx = torch.searchsorted(torch.flip(self.lambda_t, [0]), self.config.lambda_min_clipped)
last_timestep = ((self.config.num_train_timesteps - clipped_idx).numpy()).item()
- # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://arxiv.org/abs/2305.08891
+ # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://huggingface.co/papers/2305.08891
if self.config.timestep_spacing == "linspace":
timesteps = (
np.linspace(0, last_timestep - 1, num_inference_steps + 1)
@@ -460,7 +460,7 @@ class DPMSolverMultistepScheduler(SchedulerMixin, ConfigMixin):
pixels from saturation at each step. We find that dynamic thresholding results in significantly better
photorealism as well as better image-text alignment, especially when using very large guidance weights."
- https://arxiv.org/abs/2205.11487
+ https://huggingface.co/papers/2205.11487
"""
dtype = sample.dtype
batch_size, channels, *remaining_dims = sample.shape
@@ -845,7 +845,7 @@ class DPMSolverMultistepScheduler(SchedulerMixin, ConfigMixin):
r0 = h_0 / h
D0, D1 = m0, (1.0 / r0) * (m0 - m1)
if self.config.algorithm_type == "dpmsolver++":
- # See https://arxiv.org/abs/2211.01095 for detailed derivations
+ # See https://huggingface.co/papers/2211.01095 for detailed derivations
if self.config.solver_type == "midpoint":
x_t = (
(sigma_t / sigma_s0) * sample
@@ -859,7 +859,7 @@ class DPMSolverMultistepScheduler(SchedulerMixin, ConfigMixin):
+ (alpha_t * ((torch.exp(-h) - 1.0) / h + 1.0)) * D1
)
elif self.config.algorithm_type == "dpmsolver":
- # See https://arxiv.org/abs/2206.00927 for detailed derivations
+ # See https://huggingface.co/papers/2206.00927 for detailed derivations
if self.config.solver_type == "midpoint":
x_t = (
(alpha_t / alpha_s0) * sample
@@ -975,7 +975,7 @@ class DPMSolverMultistepScheduler(SchedulerMixin, ConfigMixin):
D1 = D1_0 + (r0 / (r0 + r1)) * (D1_0 - D1_1)
D2 = (1.0 / (r0 + r1)) * (D1_0 - D1_1)
if self.config.algorithm_type == "dpmsolver++":
- # See https://arxiv.org/abs/2206.00927 for detailed derivations
+ # See https://huggingface.co/papers/2206.00927 for detailed derivations
x_t = (
(sigma_t / sigma_s0) * sample
- (alpha_t * (torch.exp(-h) - 1.0)) * D0
@@ -983,7 +983,7 @@ class DPMSolverMultistepScheduler(SchedulerMixin, ConfigMixin):
- (alpha_t * ((torch.exp(-h) - 1.0 + h) / h**2 - 0.5)) * D2
)
elif self.config.algorithm_type == "dpmsolver":
- # See https://arxiv.org/abs/2206.00927 for detailed derivations
+ # See https://huggingface.co/papers/2206.00927 for detailed derivations
x_t = (
(alpha_t / alpha_s0) * sample
- (sigma_t * (torch.exp(h) - 1.0)) * D0
diff --git a/src/diffusers/schedulers/scheduling_dpmsolver_multistep_flax.py b/src/diffusers/schedulers/scheduling_dpmsolver_multistep_flax.py
index 3f48066455..10458431de 100644
--- a/src/diffusers/schedulers/scheduling_dpmsolver_multistep_flax.py
+++ b/src/diffusers/schedulers/scheduling_dpmsolver_multistep_flax.py
@@ -80,14 +80,15 @@ class FlaxDPMSolverMultistepScheduler(FlaxSchedulerMixin, ConfigMixin):
the convergence order guarantee. Empirically, sampling by DPM-Solver with only 20 steps can generate high-quality
samples, and it can generate quite good samples even in only 10 steps.
- For more details, see the original paper: https://arxiv.org/abs/2206.00927 and https://arxiv.org/abs/2211.01095
+ For more details, see the original paper: https://huggingface.co/papers/2206.00927 and
+ https://huggingface.co/papers/2211.01095
Currently, we support the multistep DPM-Solver for both noise prediction models and data prediction models. We
recommend to use `solver_order=2` for guided sampling, and `solver_order=3` for unconditional sampling.
- We also support the "dynamic thresholding" method in Imagen (https://arxiv.org/abs/2205.11487). For pixel-space
- diffusion models, you can set both `algorithm_type="dpmsolver++"` and `thresholding=True` to use the dynamic
- thresholding. Note that the thresholding method is unsuitable for latent-space diffusion models (such as
+ We also support the "dynamic thresholding" method in Imagen (https://huggingface.co/papers/2205.11487). For
+ pixel-space diffusion models, you can set both `algorithm_type="dpmsolver++"` and `thresholding=True` to use the
+ dynamic thresholding. Note that the thresholding method is unsuitable for latent-space diffusion models (such as
stable-diffusion).
[`~ConfigMixin`] takes care of storing all config attributes that are passed in the scheduler's `__init__`
@@ -95,7 +96,8 @@ class FlaxDPMSolverMultistepScheduler(FlaxSchedulerMixin, ConfigMixin):
[`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
[`~SchedulerMixin.from_pretrained`] functions.
- For more details, see the original paper: https://arxiv.org/abs/2206.00927 and https://arxiv.org/abs/2211.01095
+ For more details, see the original paper: https://huggingface.co/papers/2206.00927 and
+ https://huggingface.co/papers/2211.01095
Args:
num_train_timesteps (`int`): number of diffusion steps used to train the model.
@@ -113,21 +115,21 @@ class FlaxDPMSolverMultistepScheduler(FlaxSchedulerMixin, ConfigMixin):
indicates whether the model predicts the noise (epsilon), or the data / `x0`. One of `epsilon`, `sample`,
or `v-prediction`.
thresholding (`bool`, default `False`):
- whether to use the "dynamic thresholding" method (introduced by Imagen, https://arxiv.org/abs/2205.11487).
- For pixel-space diffusion models, you can set both `algorithm_type=dpmsolver++` and `thresholding=True` to
- use the dynamic thresholding. Note that the thresholding method is unsuitable for latent-space diffusion
- models (such as stable-diffusion).
+ whether to use the "dynamic thresholding" method (introduced by Imagen,
+ https://huggingface.co/papers/2205.11487). For pixel-space diffusion models, you can set both
+ `algorithm_type=dpmsolver++` and `thresholding=True` to use the dynamic thresholding. Note that the
+ thresholding method is unsuitable for latent-space diffusion models (such as stable-diffusion).
dynamic_thresholding_ratio (`float`, default `0.995`):
the ratio for the dynamic thresholding method. Default is `0.995`, the same as Imagen
- (https://arxiv.org/abs/2205.11487).
+ (https://huggingface.co/papers/2205.11487).
sample_max_value (`float`, default `1.0`):
the threshold value for dynamic thresholding. Valid only when `thresholding=True` and
`algorithm_type="dpmsolver++`.
algorithm_type (`str`, default `dpmsolver++`):
the algorithm type for the solver. Either `dpmsolver` or `dpmsolver++`. The `dpmsolver` type implements the
- algorithms in https://arxiv.org/abs/2206.00927, and the `dpmsolver++` type implements the algorithms in
- https://arxiv.org/abs/2211.01095. We recommend to use `dpmsolver++` with `solver_order=2` for guided
- sampling (e.g. stable-diffusion).
+ algorithms in https://huggingface.co/papers/2206.00927, and the `dpmsolver++` type implements the
+ algorithms in https://huggingface.co/papers/2211.01095. We recommend to use `dpmsolver++` with
+ `solver_order=2` for guided sampling (e.g. stable-diffusion).
solver_type (`str`, default `midpoint`):
the solver type for the second-order solver. Either `midpoint` or `heun`. The solver type slightly affects
the sample quality, especially for small number of steps. We empirically find that `midpoint` solvers are
@@ -297,7 +299,7 @@ class FlaxDPMSolverMultistepScheduler(FlaxSchedulerMixin, ConfigMixin):
)
if self.config.thresholding:
- # Dynamic thresholding in https://arxiv.org/abs/2205.11487
+ # Dynamic thresholding in https://huggingface.co/papers/2205.11487
dynamic_max_val = jnp.percentile(
jnp.abs(x0_pred), self.config.dynamic_thresholding_ratio, axis=tuple(range(1, x0_pred.ndim))
)
@@ -335,7 +337,7 @@ class FlaxDPMSolverMultistepScheduler(FlaxSchedulerMixin, ConfigMixin):
"""
One step for the first-order DPM-Solver (equivalent to DDIM).
- See https://arxiv.org/abs/2206.00927 for the detailed derivation.
+ See https://huggingface.co/papers/2206.00927 for the detailed derivation.
Args:
model_output (`jnp.ndarray`): direct output from learned diffusion model.
@@ -390,7 +392,7 @@ class FlaxDPMSolverMultistepScheduler(FlaxSchedulerMixin, ConfigMixin):
r0 = h_0 / h
D0, D1 = m0, (1.0 / r0) * (m0 - m1)
if self.config.algorithm_type == "dpmsolver++":
- # See https://arxiv.org/abs/2211.01095 for detailed derivations
+ # See https://huggingface.co/papers/2211.01095 for detailed derivations
if self.config.solver_type == "midpoint":
x_t = (
(sigma_t / sigma_s0) * sample
@@ -404,7 +406,7 @@ class FlaxDPMSolverMultistepScheduler(FlaxSchedulerMixin, ConfigMixin):
+ (alpha_t * ((jnp.exp(-h) - 1.0) / h + 1.0)) * D1
)
elif self.config.algorithm_type == "dpmsolver":
- # See https://arxiv.org/abs/2206.00927 for detailed derivations
+ # See https://huggingface.co/papers/2206.00927 for detailed derivations
if self.config.solver_type == "midpoint":
x_t = (
(alpha_t / alpha_s0) * sample
@@ -458,7 +460,7 @@ class FlaxDPMSolverMultistepScheduler(FlaxSchedulerMixin, ConfigMixin):
D1 = D1_0 + (r0 / (r0 + r1)) * (D1_0 - D1_1)
D2 = (1.0 / (r0 + r1)) * (D1_0 - D1_1)
if self.config.algorithm_type == "dpmsolver++":
- # See https://arxiv.org/abs/2206.00927 for detailed derivations
+ # See https://huggingface.co/papers/2206.00927 for detailed derivations
x_t = (
(sigma_t / sigma_s0) * sample
- (alpha_t * (jnp.exp(-h) - 1.0)) * D0
@@ -466,7 +468,7 @@ class FlaxDPMSolverMultistepScheduler(FlaxSchedulerMixin, ConfigMixin):
- (alpha_t * ((jnp.exp(-h) - 1.0 + h) / h**2 - 0.5)) * D2
)
elif self.config.algorithm_type == "dpmsolver":
- # See https://arxiv.org/abs/2206.00927 for detailed derivations
+ # See https://huggingface.co/papers/2206.00927 for detailed derivations
x_t = (
(alpha_t / alpha_s0) * sample
- (sigma_t * (jnp.exp(h) - 1.0)) * D0
diff --git a/src/diffusers/schedulers/scheduling_dpmsolver_multistep_inverse.py b/src/diffusers/schedulers/scheduling_dpmsolver_multistep_inverse.py
index 011294c6f2..29da9fb0d5 100644
--- a/src/diffusers/schedulers/scheduling_dpmsolver_multistep_inverse.py
+++ b/src/diffusers/schedulers/scheduling_dpmsolver_multistep_inverse.py
@@ -257,7 +257,7 @@ class DPMSolverMultistepInverseScheduler(SchedulerMixin, ConfigMixin):
clipped_idx = torch.searchsorted(torch.flip(self.lambda_t, [0]), self.config.lambda_min_clipped).item()
self.noisiest_timestep = self.config.num_train_timesteps - 1 - clipped_idx
- # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://arxiv.org/abs/2305.08891
+ # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://huggingface.co/papers/2305.08891
if self.config.timestep_spacing == "linspace":
timesteps = (
np.linspace(0, self.noisiest_timestep, num_inference_steps + 1).round()[:-1].copy().astype(np.int64)
@@ -338,7 +338,7 @@ class DPMSolverMultistepInverseScheduler(SchedulerMixin, ConfigMixin):
pixels from saturation at each step. We find that dynamic thresholding results in significantly better
photorealism as well as better image-text alignment, especially when using very large guidance weights."
- https://arxiv.org/abs/2205.11487
+ https://huggingface.co/papers/2205.11487
"""
dtype = sample.dtype
batch_size, channels, *remaining_dims = sample.shape
@@ -714,7 +714,7 @@ class DPMSolverMultistepInverseScheduler(SchedulerMixin, ConfigMixin):
r0 = h_0 / h
D0, D1 = m0, (1.0 / r0) * (m0 - m1)
if self.config.algorithm_type == "dpmsolver++":
- # See https://arxiv.org/abs/2211.01095 for detailed derivations
+ # See https://huggingface.co/papers/2211.01095 for detailed derivations
if self.config.solver_type == "midpoint":
x_t = (
(sigma_t / sigma_s0) * sample
@@ -728,7 +728,7 @@ class DPMSolverMultistepInverseScheduler(SchedulerMixin, ConfigMixin):
+ (alpha_t * ((torch.exp(-h) - 1.0) / h + 1.0)) * D1
)
elif self.config.algorithm_type == "dpmsolver":
- # See https://arxiv.org/abs/2206.00927 for detailed derivations
+ # See https://huggingface.co/papers/2206.00927 for detailed derivations
if self.config.solver_type == "midpoint":
x_t = (
(alpha_t / alpha_s0) * sample
@@ -845,7 +845,7 @@ class DPMSolverMultistepInverseScheduler(SchedulerMixin, ConfigMixin):
D1 = D1_0 + (r0 / (r0 + r1)) * (D1_0 - D1_1)
D2 = (1.0 / (r0 + r1)) * (D1_0 - D1_1)
if self.config.algorithm_type == "dpmsolver++":
- # See https://arxiv.org/abs/2206.00927 for detailed derivations
+ # See https://huggingface.co/papers/2206.00927 for detailed derivations
x_t = (
(sigma_t / sigma_s0) * sample
- (alpha_t * (torch.exp(-h) - 1.0)) * D0
@@ -853,7 +853,7 @@ class DPMSolverMultistepInverseScheduler(SchedulerMixin, ConfigMixin):
- (alpha_t * ((torch.exp(-h) - 1.0 + h) / h**2 - 0.5)) * D2
)
elif self.config.algorithm_type == "dpmsolver":
- # See https://arxiv.org/abs/2206.00927 for detailed derivations
+ # See https://huggingface.co/papers/2206.00927 for detailed derivations
x_t = (
(alpha_t / alpha_s0) * sample
- (sigma_t * (torch.exp(h) - 1.0)) * D0
diff --git a/src/diffusers/schedulers/scheduling_dpmsolver_sde.py b/src/diffusers/schedulers/scheduling_dpmsolver_sde.py
index 6c9cb975fe..685ad6fd8c 100644
--- a/src/diffusers/schedulers/scheduling_dpmsolver_sde.py
+++ b/src/diffusers/schedulers/scheduling_dpmsolver_sde.py
@@ -352,7 +352,7 @@ class DPMSolverSDEScheduler(SchedulerMixin, ConfigMixin):
num_train_timesteps = num_train_timesteps or self.config.num_train_timesteps
- # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://arxiv.org/abs/2305.08891
+ # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://huggingface.co/papers/2305.08891
if self.config.timestep_spacing == "linspace":
timesteps = np.linspace(0, num_train_timesteps - 1, num_inference_steps, dtype=float)[::-1].copy()
elif self.config.timestep_spacing == "leading":
diff --git a/src/diffusers/schedulers/scheduling_dpmsolver_singlestep.py b/src/diffusers/schedulers/scheduling_dpmsolver_singlestep.py
index dd28af3607..39efca7842 100644
--- a/src/diffusers/schedulers/scheduling_dpmsolver_singlestep.py
+++ b/src/diffusers/schedulers/scheduling_dpmsolver_singlestep.py
@@ -410,7 +410,7 @@ class DPMSolverSinglestepScheduler(SchedulerMixin, ConfigMixin):
pixels from saturation at each step. We find that dynamic thresholding results in significantly better
photorealism as well as better image-text alignment, especially when using very large guidance weights."
- https://arxiv.org/abs/2205.11487
+ https://huggingface.co/papers/2205.11487
"""
dtype = sample.dtype
batch_size, channels, *remaining_dims = sample.shape
@@ -780,7 +780,7 @@ class DPMSolverSinglestepScheduler(SchedulerMixin, ConfigMixin):
r0 = h_0 / h
D0, D1 = m1, (1.0 / r0) * (m0 - m1)
if self.config.algorithm_type == "dpmsolver++":
- # See https://arxiv.org/abs/2211.01095 for detailed derivations
+ # See https://huggingface.co/papers/2211.01095 for detailed derivations
if self.config.solver_type == "midpoint":
x_t = (
(sigma_t / sigma_s1) * sample
@@ -794,7 +794,7 @@ class DPMSolverSinglestepScheduler(SchedulerMixin, ConfigMixin):
+ (alpha_t * ((torch.exp(-h) - 1.0) / h + 1.0)) * D1
)
elif self.config.algorithm_type == "dpmsolver":
- # See https://arxiv.org/abs/2206.00927 for detailed derivations
+ # See https://huggingface.co/papers/2206.00927 for detailed derivations
if self.config.solver_type == "midpoint":
x_t = (
(alpha_t / alpha_s1) * sample
@@ -899,7 +899,7 @@ class DPMSolverSinglestepScheduler(SchedulerMixin, ConfigMixin):
D1 = (r0 * D1_0 - r1 * D1_1) / (r0 - r1)
D2 = 2.0 * (D1_1 - D1_0) / (r0 - r1)
if self.config.algorithm_type == "dpmsolver++":
- # See https://arxiv.org/abs/2206.00927 for detailed derivations
+ # See https://huggingface.co/papers/2206.00927 for detailed derivations
if self.config.solver_type == "midpoint":
x_t = (
(sigma_t / sigma_s2) * sample
@@ -914,7 +914,7 @@ class DPMSolverSinglestepScheduler(SchedulerMixin, ConfigMixin):
- (alpha_t * ((torch.exp(-h) - 1.0 + h) / h**2 - 0.5)) * D2
)
elif self.config.algorithm_type == "dpmsolver":
- # See https://arxiv.org/abs/2206.00927 for detailed derivations
+ # See https://huggingface.co/papers/2206.00927 for detailed derivations
if self.config.solver_type == "midpoint":
x_t = (
(alpha_t / alpha_s2) * sample
diff --git a/src/diffusers/schedulers/scheduling_edm_dpmsolver_multistep.py b/src/diffusers/schedulers/scheduling_edm_dpmsolver_multistep.py
index 702c328f59..3e85bde5be 100644
--- a/src/diffusers/schedulers/scheduling_edm_dpmsolver_multistep.py
+++ b/src/diffusers/schedulers/scheduling_edm_dpmsolver_multistep.py
@@ -31,7 +31,7 @@ class EDMDPMSolverMultistepScheduler(SchedulerMixin, ConfigMixin):
`EDMDPMSolverMultistepScheduler` is a fast dedicated high-order solver for diffusion ODEs.
[1] Karras, Tero, et al. "Elucidating the Design Space of Diffusion-Based Generative Models."
- https://arxiv.org/abs/2206.00364
+ https://huggingface.co/papers/2206.00364
This model inherits from [`SchedulerMixin`] and [`ConfigMixin`]. Check the superclass documentation for the generic
methods the library implements for all schedulers such as loading and saving.
@@ -47,8 +47,8 @@ class EDMDPMSolverMultistepScheduler(SchedulerMixin, ConfigMixin):
The standard deviation of the data distribution. This is set to 0.5 in the EDM paper [1].
sigma_schedule (`str`, *optional*, defaults to `karras`):
Sigma schedule to compute the `sigmas`. By default, we the schedule introduced in the EDM paper
- (https://arxiv.org/abs/2206.00364). Other acceptable value is "exponential". The exponential schedule was
- incorporated in this model: https://huggingface.co/stabilityai/cosxl.
+ (https://huggingface.co/papers/2206.00364). Other acceptable value is "exponential". The exponential
+ schedule was incorporated in this model: https://huggingface.co/stabilityai/cosxl.
num_train_timesteps (`int`, defaults to 1000):
The number of diffusion steps to train the model.
solver_order (`int`, defaults to 2):
@@ -305,7 +305,7 @@ class EDMDPMSolverMultistepScheduler(SchedulerMixin, ConfigMixin):
pixels from saturation at each step. We find that dynamic thresholding results in significantly better
photorealism as well as better image-text alignment, especially when using very large guidance weights."
- https://arxiv.org/abs/2205.11487
+ https://huggingface.co/papers/2205.11487
"""
dtype = sample.dtype
batch_size, channels, *remaining_dims = sample.shape
@@ -472,7 +472,7 @@ class EDMDPMSolverMultistepScheduler(SchedulerMixin, ConfigMixin):
r0 = h_0 / h
D0, D1 = m0, (1.0 / r0) * (m0 - m1)
if self.config.algorithm_type == "dpmsolver++":
- # See https://arxiv.org/abs/2211.01095 for detailed derivations
+ # See https://huggingface.co/papers/2211.01095 for detailed derivations
if self.config.solver_type == "midpoint":
x_t = (
(sigma_t / sigma_s0) * sample
@@ -548,7 +548,7 @@ class EDMDPMSolverMultistepScheduler(SchedulerMixin, ConfigMixin):
D1 = D1_0 + (r0 / (r0 + r1)) * (D1_0 - D1_1)
D2 = (1.0 / (r0 + r1)) * (D1_0 - D1_1)
if self.config.algorithm_type == "dpmsolver++":
- # See https://arxiv.org/abs/2206.00927 for detailed derivations
+ # See https://huggingface.co/papers/2206.00927 for detailed derivations
x_t = (
(sigma_t / sigma_s0) * sample
- (alpha_t * (torch.exp(-h) - 1.0)) * D0
diff --git a/src/diffusers/schedulers/scheduling_edm_euler.py b/src/diffusers/schedulers/scheduling_edm_euler.py
index cd95fdf481..d5c89306e8 100644
--- a/src/diffusers/schedulers/scheduling_edm_euler.py
+++ b/src/diffusers/schedulers/scheduling_edm_euler.py
@@ -51,7 +51,7 @@ class EDMEulerScheduler(SchedulerMixin, ConfigMixin):
Implements the Euler scheduler in EDM formulation as presented in Karras et al. 2022 [1].
[1] Karras, Tero, et al. "Elucidating the Design Space of Diffusion-Based Generative Models."
- https://arxiv.org/abs/2206.00364
+ https://huggingface.co/papers/2206.00364
This model inherits from [`SchedulerMixin`] and [`ConfigMixin`]. Check the superclass documentation for the generic
methods the library implements for all schedulers such as loading and saving.
@@ -67,8 +67,8 @@ class EDMEulerScheduler(SchedulerMixin, ConfigMixin):
The standard deviation of the data distribution. This is set to 0.5 in the EDM paper [1].
sigma_schedule (`str`, *optional*, defaults to `karras`):
Sigma schedule to compute the `sigmas`. By default, we the schedule introduced in the EDM paper
- (https://arxiv.org/abs/2206.00364). Other acceptable value is "exponential". The exponential schedule was
- incorporated in this model: https://huggingface.co/stabilityai/cosxl.
+ (https://huggingface.co/papers/2206.00364). Other acceptable value is "exponential". The exponential
+ schedule was incorporated in this model: https://huggingface.co/stabilityai/cosxl.
num_train_timesteps (`int`, defaults to 1000):
The number of diffusion steps to train the model.
prediction_type (`str`, defaults to `epsilon`, *optional*):
diff --git a/src/diffusers/schedulers/scheduling_euler_ancestral_discrete.py b/src/diffusers/schedulers/scheduling_euler_ancestral_discrete.py
index 4df43a160c..0b6f8b817c 100644
--- a/src/diffusers/schedulers/scheduling_euler_ancestral_discrete.py
+++ b/src/diffusers/schedulers/scheduling_euler_ancestral_discrete.py
@@ -95,7 +95,7 @@ def betas_for_alpha_bar(
# Copied from diffusers.schedulers.scheduling_ddim.rescale_zero_terminal_snr
def rescale_zero_terminal_snr(betas):
"""
- Rescales betas to have zero terminal SNR Based on https://arxiv.org/pdf/2305.08891.pdf (Algorithm 1)
+ Rescales betas to have zero terminal SNR Based on https://huggingface.co/papers/2305.08891 (Algorithm 1)
Args:
@@ -286,7 +286,7 @@ class EulerAncestralDiscreteScheduler(SchedulerMixin, ConfigMixin):
"""
self.num_inference_steps = num_inference_steps
- # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://arxiv.org/abs/2305.08891
+ # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://huggingface.co/papers/2305.08891
if self.config.timestep_spacing == "linspace":
timesteps = np.linspace(0, self.config.num_train_timesteps - 1, num_inference_steps, dtype=np.float32)[
::-1
diff --git a/src/diffusers/schedulers/scheduling_euler_discrete.py b/src/diffusers/schedulers/scheduling_euler_discrete.py
index 56757f3ca1..1bade69726 100644
--- a/src/diffusers/schedulers/scheduling_euler_discrete.py
+++ b/src/diffusers/schedulers/scheduling_euler_discrete.py
@@ -98,7 +98,7 @@ def betas_for_alpha_bar(
# Copied from diffusers.schedulers.scheduling_ddim.rescale_zero_terminal_snr
def rescale_zero_terminal_snr(betas):
"""
- Rescales betas to have zero terminal SNR Based on https://arxiv.org/pdf/2305.08891.pdf (Algorithm 1)
+ Rescales betas to have zero terminal SNR Based on https://huggingface.co/papers/2305.08891 (Algorithm 1)
Args:
@@ -376,7 +376,7 @@ class EulerDiscreteScheduler(SchedulerMixin, ConfigMixin):
if timesteps is not None:
timesteps = np.array(timesteps).astype(np.float32)
else:
- # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://arxiv.org/abs/2305.08891
+ # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://huggingface.co/papers/2305.08891
if self.config.timestep_spacing == "linspace":
timesteps = np.linspace(
0, self.config.num_train_timesteps - 1, num_inference_steps, dtype=np.float32
diff --git a/src/diffusers/schedulers/scheduling_euler_discrete_flax.py b/src/diffusers/schedulers/scheduling_euler_discrete_flax.py
index 55b0c2460a..b2b7d6e8c3 100644
--- a/src/diffusers/schedulers/scheduling_euler_discrete_flax.py
+++ b/src/diffusers/schedulers/scheduling_euler_discrete_flax.py
@@ -52,8 +52,8 @@ class FlaxEulerDiscreteSchedulerOutput(FlaxSchedulerOutput):
class FlaxEulerDiscreteScheduler(FlaxSchedulerMixin, ConfigMixin):
"""
- Euler scheduler (Algorithm 2) from Karras et al. (2022) https://arxiv.org/abs/2206.00364. . Based on the original
- k-diffusion implementation by Katherine Crowson:
+ Euler scheduler (Algorithm 2) from Karras et al. (2022) https://huggingface.co/papers/2206.00364. . Based on the
+ original k-diffusion implementation by Katherine Crowson:
https://github.com/crowsonkb/k-diffusion/blob/481677d114f6ea445aa009cf5bd7a9cdee909e47/k_diffusion/sampling.py#L51
diff --git a/src/diffusers/schedulers/scheduling_heun_discrete.py b/src/diffusers/schedulers/scheduling_heun_discrete.py
index cb6cb9e795..26a2beab6e 100644
--- a/src/diffusers/schedulers/scheduling_heun_discrete.py
+++ b/src/diffusers/schedulers/scheduling_heun_discrete.py
@@ -301,7 +301,7 @@ class HeunDiscreteScheduler(SchedulerMixin, ConfigMixin):
if timesteps is not None:
timesteps = np.array(timesteps, dtype=np.float32)
else:
- # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://arxiv.org/abs/2305.08891
+ # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://huggingface.co/papers/2305.08891
if self.config.timestep_spacing == "linspace":
timesteps = np.linspace(0, num_train_timesteps - 1, num_inference_steps, dtype=np.float32)[::-1].copy()
elif self.config.timestep_spacing == "leading":
diff --git a/src/diffusers/schedulers/scheduling_ipndm.py b/src/diffusers/schedulers/scheduling_ipndm.py
index 28f349ae21..426e7f8cc5 100644
--- a/src/diffusers/schedulers/scheduling_ipndm.py
+++ b/src/diffusers/schedulers/scheduling_ipndm.py
@@ -49,7 +49,7 @@ class IPNDMScheduler(SchedulerMixin, ConfigMixin):
self.init_noise_sigma = 1.0
# For now we only support F-PNDM, i.e. the runge-kutta method
- # For more information on the algorithm please take a look at the paper: https://arxiv.org/pdf/2202.09778.pdf
+ # For more information on the algorithm please take a look at the paper: https://huggingface.co/papers/2202.09778
# mainly at formula (9), (12), (13) and the Algorithm 2.
self.pndm_order = 4
diff --git a/src/diffusers/schedulers/scheduling_k_dpm_2_ancestral_discrete.py b/src/diffusers/schedulers/scheduling_k_dpm_2_ancestral_discrete.py
index 4b388b4d75..2085be82da 100644
--- a/src/diffusers/schedulers/scheduling_k_dpm_2_ancestral_discrete.py
+++ b/src/diffusers/schedulers/scheduling_k_dpm_2_ancestral_discrete.py
@@ -260,7 +260,7 @@ class KDPM2AncestralDiscreteScheduler(SchedulerMixin, ConfigMixin):
num_train_timesteps = num_train_timesteps or self.config.num_train_timesteps
- # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://arxiv.org/abs/2305.08891
+ # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://huggingface.co/papers/2305.08891
if self.config.timestep_spacing == "linspace":
timesteps = np.linspace(0, num_train_timesteps - 1, num_inference_steps, dtype=np.float32)[::-1].copy()
elif self.config.timestep_spacing == "leading":
diff --git a/src/diffusers/schedulers/scheduling_k_dpm_2_discrete.py b/src/diffusers/schedulers/scheduling_k_dpm_2_discrete.py
index a2e564e70a..db7f19c3b4 100644
--- a/src/diffusers/schedulers/scheduling_k_dpm_2_discrete.py
+++ b/src/diffusers/schedulers/scheduling_k_dpm_2_discrete.py
@@ -260,7 +260,7 @@ class KDPM2DiscreteScheduler(SchedulerMixin, ConfigMixin):
num_train_timesteps = num_train_timesteps or self.config.num_train_timesteps
- # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://arxiv.org/abs/2305.08891
+ # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://huggingface.co/papers/2305.08891
if self.config.timestep_spacing == "linspace":
timesteps = np.linspace(0, num_train_timesteps - 1, num_inference_steps, dtype=np.float32)[::-1].copy()
elif self.config.timestep_spacing == "leading":
diff --git a/src/diffusers/schedulers/scheduling_karras_ve_flax.py b/src/diffusers/schedulers/scheduling_karras_ve_flax.py
index 0d387b53ac..f68f89d433 100644
--- a/src/diffusers/schedulers/scheduling_karras_ve_flax.py
+++ b/src/diffusers/schedulers/scheduling_karras_ve_flax.py
@@ -63,8 +63,8 @@ class FlaxKarrasVeScheduler(FlaxSchedulerMixin, ConfigMixin):
the VE column of Table 1 from [1] for reference.
[1] Karras, Tero, et al. "Elucidating the Design Space of Diffusion-Based Generative Models."
- https://arxiv.org/abs/2206.00364 [2] Song, Yang, et al. "Score-based generative modeling through stochastic
- differential equations." https://arxiv.org/abs/2011.13456
+ https://huggingface.co/papers/2206.00364 [2] Song, Yang, et al. "Score-based generative modeling through stochastic
+ differential equations." https://huggingface.co/papers/2011.13456
[`~ConfigMixin`] takes care of storing all config attributes that are passed in the scheduler's `__init__`
function, such as `num_train_timesteps`. They can be accessed via `scheduler.config.num_train_timesteps`.
@@ -72,8 +72,8 @@ class FlaxKarrasVeScheduler(FlaxSchedulerMixin, ConfigMixin):
[`~SchedulerMixin.from_pretrained`] functions.
For more details on the parameters, see the original paper's Appendix E.: "Elucidating the Design Space of
- Diffusion-Based Generative Models." https://arxiv.org/abs/2206.00364. The grid search values used to find the
- optimal {s_noise, s_churn, s_min, s_max} for a specific model are described in Table 5 of the paper.
+ Diffusion-Based Generative Models." https://huggingface.co/papers/2206.00364. The grid search values used to find
+ the optimal {s_noise, s_churn, s_min, s_max} for a specific model are described in Table 5 of the paper.
Args:
sigma_min (`float`): minimum noise magnitude
diff --git a/src/diffusers/schedulers/scheduling_lcm.py b/src/diffusers/schedulers/scheduling_lcm.py
index 2a0cce7bf1..58735441bc 100644
--- a/src/diffusers/schedulers/scheduling_lcm.py
+++ b/src/diffusers/schedulers/scheduling_lcm.py
@@ -97,7 +97,7 @@ def betas_for_alpha_bar(
# Copied from diffusers.schedulers.scheduling_ddim.rescale_zero_terminal_snr
def rescale_zero_terminal_snr(betas: torch.Tensor) -> torch.Tensor:
"""
- Rescales betas to have zero terminal SNR Based on https://arxiv.org/pdf/2305.08891.pdf (Algorithm 1)
+ Rescales betas to have zero terminal SNR Based on https://huggingface.co/papers/2305.08891 (Algorithm 1)
Args:
@@ -321,7 +321,7 @@ class LCMScheduler(SchedulerMixin, ConfigMixin):
pixels from saturation at each step. We find that dynamic thresholding results in significantly better
photorealism as well as better image-text alignment, especially when using very large guidance weights."
- https://arxiv.org/abs/2205.11487
+ https://huggingface.co/papers/2205.11487
"""
dtype = sample.dtype
batch_size, channels, *remaining_dims = sample.shape
diff --git a/src/diffusers/schedulers/scheduling_lms_discrete.py b/src/diffusers/schedulers/scheduling_lms_discrete.py
index bcf9d9b59e..3f4c6140ae 100644
--- a/src/diffusers/schedulers/scheduling_lms_discrete.py
+++ b/src/diffusers/schedulers/scheduling_lms_discrete.py
@@ -272,7 +272,7 @@ class LMSDiscreteScheduler(SchedulerMixin, ConfigMixin):
"""
self.num_inference_steps = num_inference_steps
- # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://arxiv.org/abs/2305.08891
+ # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://huggingface.co/papers/2305.08891
if self.config.timestep_spacing == "linspace":
timesteps = np.linspace(0, self.config.num_train_timesteps - 1, num_inference_steps, dtype=np.float32)[
::-1
diff --git a/src/diffusers/schedulers/scheduling_pndm.py b/src/diffusers/schedulers/scheduling_pndm.py
index a05e71c3c2..7a732cffc0 100644
--- a/src/diffusers/schedulers/scheduling_pndm.py
+++ b/src/diffusers/schedulers/scheduling_pndm.py
@@ -146,7 +146,7 @@ class PNDMScheduler(SchedulerMixin, ConfigMixin):
self.init_noise_sigma = 1.0
# For now we only support F-PNDM, i.e. the runge-kutta method
- # For more information on the algorithm please take a look at the paper: https://arxiv.org/pdf/2202.09778.pdf
+ # For more information on the algorithm please take a look at the paper: https://huggingface.co/papers/2202.09778
# mainly at formula (9), (12), (13) and the Algorithm 2.
self.pndm_order = 4
@@ -175,7 +175,7 @@ class PNDMScheduler(SchedulerMixin, ConfigMixin):
"""
self.num_inference_steps = num_inference_steps
- # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://arxiv.org/abs/2305.08891
+ # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://huggingface.co/papers/2305.08891
if self.config.timestep_spacing == "linspace":
self._timesteps = (
np.linspace(0, self.config.num_train_timesteps - 1, num_inference_steps).round().astype(np.int64)
@@ -403,7 +403,7 @@ class PNDMScheduler(SchedulerMixin, ConfigMixin):
return sample
def _get_prev_sample(self, sample, timestep, prev_timestep, model_output):
- # See formula (9) of PNDM paper https://arxiv.org/pdf/2202.09778.pdf
+ # See formula (9) of PNDM paper https://huggingface.co/papers/2202.09778
# this function computes x_(t−δ) using the formula of (9)
# Note that x_t needs to be added to both sides of the equation
diff --git a/src/diffusers/schedulers/scheduling_pndm_flax.py b/src/diffusers/schedulers/scheduling_pndm_flax.py
index 3ac3ba5ca1..59c92eae5d 100644
--- a/src/diffusers/schedulers/scheduling_pndm_flax.py
+++ b/src/diffusers/schedulers/scheduling_pndm_flax.py
@@ -80,7 +80,7 @@ class FlaxPNDMScheduler(FlaxSchedulerMixin, ConfigMixin):
[`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
[`~SchedulerMixin.from_pretrained`] functions.
- For more details, see the original paper: https://arxiv.org/abs/2202.09778
+ For more details, see the original paper: https://huggingface.co/papers/2202.09778
Args:
num_train_timesteps (`int`): number of diffusion steps used to train the model.
@@ -134,7 +134,7 @@ class FlaxPNDMScheduler(FlaxSchedulerMixin, ConfigMixin):
self.dtype = dtype
# For now we only support F-PNDM, i.e. the runge-kutta method
- # For more information on the algorithm please take a look at the paper: https://arxiv.org/pdf/2202.09778.pdf
+ # For more information on the algorithm please take a look at the paper: https://huggingface.co/papers/2202.09778
# mainly at formula (9), (12), (13) and the Algorithm 2.
self.pndm_order = 4
@@ -452,7 +452,7 @@ class FlaxPNDMScheduler(FlaxSchedulerMixin, ConfigMixin):
return (prev_sample, state)
def _get_prev_sample(self, state: PNDMSchedulerState, sample, timestep, prev_timestep, model_output):
- # See formula (9) of PNDM paper https://arxiv.org/pdf/2202.09778.pdf
+ # See formula (9) of PNDM paper https://huggingface.co/papers/2202.09778
# this function computes x_(t−δ) using the formula of (9)
# Note that x_t needs to be added to both sides of the equation
diff --git a/src/diffusers/schedulers/scheduling_repaint.py b/src/diffusers/schedulers/scheduling_repaint.py
index a14797b42f..7dae0337fa 100644
--- a/src/diffusers/schedulers/scheduling_repaint.py
+++ b/src/diffusers/schedulers/scheduling_repaint.py
@@ -233,10 +233,10 @@ class RePaintScheduler(SchedulerMixin, ConfigMixin):
beta_prod_t_prev = 1 - alpha_prod_t_prev
# For t > 0, compute predicted variance βt (see formula (6) and (7) from
- # https://arxiv.org/pdf/2006.11239.pdf) and sample from it to get
+ # https://huggingface.co/papers/2006.11239) and sample from it to get
# previous sample x_{t-1} ~ N(pred_prev_sample, variance) == add
# variance to pred_sample
- # Is equivalent to formula (16) in https://arxiv.org/pdf/2010.02502.pdf
+ # Is equivalent to formula (16) in https://huggingface.co/papers/2010.02502
# without eta.
# variance = (1 - alpha_prod_t_prev) / (1 - alpha_prod_t) * self.betas[t]
variance = (beta_prod_t_prev / beta_prod_t) * (1 - alpha_prod_t / alpha_prod_t_prev)
@@ -288,7 +288,7 @@ class RePaintScheduler(SchedulerMixin, ConfigMixin):
beta_prod_t = 1 - alpha_prod_t
# 2. compute predicted original sample from predicted noise also called
- # "predicted x_0" of formula (15) from https://arxiv.org/pdf/2006.11239.pdf
+ # "predicted x_0" of formula (15) from https://huggingface.co/papers/2006.11239
pred_original_sample = (sample - beta_prod_t**0.5 * model_output) / alpha_prod_t**0.5
# 3. Clip "predicted x_0"
@@ -312,20 +312,20 @@ class RePaintScheduler(SchedulerMixin, ConfigMixin):
variance = std_dev_t * noise
# 6. compute "direction pointing to x_t" of formula (12)
- # from https://arxiv.org/pdf/2010.02502.pdf
+ # from https://huggingface.co/papers/2010.02502
pred_sample_direction = (1 - alpha_prod_t_prev - std_dev_t**2) ** 0.5 * model_output
- # 7. compute x_{t-1} of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ # 7. compute x_{t-1} of formula (12) from https://huggingface.co/papers/2010.02502
prev_unknown_part = alpha_prod_t_prev**0.5 * pred_original_sample + pred_sample_direction + variance
- # 8. Algorithm 1 Line 5 https://arxiv.org/pdf/2201.09865.pdf
+ # 8. Algorithm 1 Line 5 https://huggingface.co/papers/2201.09865
# The computation reported in Algorithm 1 Line 5 is incorrect. Line 5 refers to formula (8a) of the same paper,
# which tells to sample from a Gaussian distribution with mean "(alpha_prod_t_prev**0.5) * original_image"
# and variance "(1 - alpha_prod_t_prev)". This means that the standard Gaussian distribution "noise" should be
# scaled by the square root of the variance (as it is done here), however Algorithm 1 Line 5 tells to scale by the variance.
prev_known_part = (alpha_prod_t_prev**0.5) * original_image + ((1 - alpha_prod_t_prev) ** 0.5) * noise
- # 9. Algorithm 1 Line 8 https://arxiv.org/pdf/2201.09865.pdf
+ # 9. Algorithm 1 Line 8 https://huggingface.co/papers/2201.09865
pred_prev_sample = mask * prev_known_part + (1.0 - mask) * prev_unknown_part
if not return_dict:
@@ -348,7 +348,7 @@ class RePaintScheduler(SchedulerMixin, ConfigMixin):
else:
noise = randn_tensor(sample.shape, generator=generator, device=sample.device, dtype=sample.dtype)
- # 10. Algorithm 1 Line 10 https://arxiv.org/pdf/2201.09865.pdf
+ # 10. Algorithm 1 Line 10 https://huggingface.co/papers/2201.09865
sample = (1 - beta) ** 0.5 * sample + beta**0.5 * noise
return sample
diff --git a/src/diffusers/schedulers/scheduling_sasolver.py b/src/diffusers/schedulers/scheduling_sasolver.py
index c741955699..6a48859a44 100644
--- a/src/diffusers/schedulers/scheduling_sasolver.py
+++ b/src/diffusers/schedulers/scheduling_sasolver.py
@@ -12,7 +12,7 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-# DISCLAIMER: check https://arxiv.org/abs/2309.05019
+# DISCLAIMER: check https://huggingface.co/papers/2309.05019
# The codebase is modified based on https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_dpmsolver_multistep.py
import math
@@ -109,7 +109,7 @@ class SASolverScheduler(SchedulerMixin, ConfigMixin):
Stochasticity during the sampling. Default in init is `lambda t: 1 if t >= 200 and t <= 800 else 0`.
SA-Solver will sample from vanilla diffusion ODE if tau_func is set to `lambda t: 0`. SA-Solver will sample
from vanilla diffusion SDE if tau_func is set to `lambda t: 1`. For more details, please check
- https://arxiv.org/abs/2309.05019
+ https://huggingface.co/papers/2309.05019
thresholding (`bool`, defaults to `False`):
Whether to use the "dynamic thresholding" method. This is unsuitable for latent-space diffusion models such
as Stable Diffusion.
@@ -273,7 +273,7 @@ class SASolverScheduler(SchedulerMixin, ConfigMixin):
clipped_idx = torch.searchsorted(torch.flip(self.lambda_t, [0]), self.config.lambda_min_clipped)
last_timestep = ((self.config.num_train_timesteps - clipped_idx).numpy()).item()
- # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://arxiv.org/abs/2305.08891
+ # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://huggingface.co/papers/2305.08891
if self.config.timestep_spacing == "linspace":
timesteps = (
np.linspace(0, last_timestep - 1, num_inference_steps + 1).round()[::-1][:-1].copy().astype(np.int64)
@@ -348,7 +348,7 @@ class SASolverScheduler(SchedulerMixin, ConfigMixin):
pixels from saturation at each step. We find that dynamic thresholding results in significantly better
photorealism as well as better image-text alignment, especially when using very large guidance weights."
- https://arxiv.org/abs/2205.11487
+ https://huggingface.co/papers/2205.11487
"""
dtype = sample.dtype
batch_size, channels, *remaining_dims = sample.shape
diff --git a/src/diffusers/schedulers/scheduling_sde_ve_flax.py b/src/diffusers/schedulers/scheduling_sde_ve_flax.py
index 0a8d45d4ac..db7f8beb4c 100644
--- a/src/diffusers/schedulers/scheduling_sde_ve_flax.py
+++ b/src/diffusers/schedulers/scheduling_sde_ve_flax.py
@@ -61,7 +61,7 @@ class FlaxScoreSdeVeScheduler(FlaxSchedulerMixin, ConfigMixin):
"""
The variance exploding stochastic differential equation (SDE) scheduler.
- For more information, see the original paper: https://arxiv.org/abs/2011.13456
+ For more information, see the original paper: https://huggingface.co/papers/2011.13456
[`~ConfigMixin`] takes care of storing all config attributes that are passed in the scheduler's `__init__`
function, such as `num_train_timesteps`. They can be accessed via `scheduler.config.num_train_timesteps`.
diff --git a/src/diffusers/schedulers/scheduling_tcd.py b/src/diffusers/schedulers/scheduling_tcd.py
index 77770ab206..6a27323aeb 100644
--- a/src/diffusers/schedulers/scheduling_tcd.py
+++ b/src/diffusers/schedulers/scheduling_tcd.py
@@ -96,7 +96,7 @@ def betas_for_alpha_bar(
# Copied from diffusers.schedulers.scheduling_ddim.rescale_zero_terminal_snr
def rescale_zero_terminal_snr(betas: torch.Tensor) -> torch.Tensor:
"""
- Rescales betas to have zero terminal SNR Based on https://arxiv.org/pdf/2305.08891.pdf (Algorithm 1)
+ Rescales betas to have zero terminal SNR Based on https://huggingface.co/papers/2305.08891 (Algorithm 1)
Args:
@@ -334,7 +334,7 @@ class TCDScheduler(SchedulerMixin, ConfigMixin):
pixels from saturation at each step. We find that dynamic thresholding results in significantly better
photorealism as well as better image-text alignment, especially when using very large guidance weights."
- https://arxiv.org/abs/2205.11487
+ https://huggingface.co/papers/2205.11487
"""
dtype = sample.dtype
batch_size, channels, *remaining_dims = sample.shape
diff --git a/src/diffusers/schedulers/scheduling_unclip.py b/src/diffusers/schedulers/scheduling_unclip.py
index 22a53b0e73..46c855c9c1 100644
--- a/src/diffusers/schedulers/scheduling_unclip.py
+++ b/src/diffusers/schedulers/scheduling_unclip.py
@@ -191,7 +191,7 @@ class UnCLIPScheduler(SchedulerMixin, ConfigMixin):
else:
beta = 1 - alpha_prod_t / alpha_prod_t_prev
- # For t > 0, compute predicted variance βt (see formula (6) and (7) from https://arxiv.org/pdf/2006.11239.pdf)
+ # For t > 0, compute predicted variance βt (see formula (6) and (7) from https://huggingface.co/papers/2006.11239)
# and sample from it to get previous sample
# x_{t-1} ~ N(pred_prev_sample, variance) == add variance to pred_sample
variance = beta_prod_t_prev / beta_prod_t * beta
@@ -266,7 +266,7 @@ class UnCLIPScheduler(SchedulerMixin, ConfigMixin):
alpha = 1 - beta
# 2. compute predicted original sample from predicted noise also called
- # "predicted x_0" of formula (15) from https://arxiv.org/pdf/2006.11239.pdf
+ # "predicted x_0" of formula (15) from https://huggingface.co/papers/2006.11239
if self.config.prediction_type == "epsilon":
pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
elif self.config.prediction_type == "sample":
@@ -284,12 +284,12 @@ class UnCLIPScheduler(SchedulerMixin, ConfigMixin):
)
# 4. Compute coefficients for pred_original_sample x_0 and current sample x_t
- # See formula (7) from https://arxiv.org/pdf/2006.11239.pdf
+ # See formula (7) from https://huggingface.co/papers/2006.11239
pred_original_sample_coeff = (alpha_prod_t_prev ** (0.5) * beta) / beta_prod_t
current_sample_coeff = alpha ** (0.5) * beta_prod_t_prev / beta_prod_t
# 5. Compute predicted previous sample µ_t
- # See formula (7) from https://arxiv.org/pdf/2006.11239.pdf
+ # See formula (7) from https://huggingface.co/papers/2006.11239
pred_prev_sample = pred_original_sample_coeff * pred_original_sample + current_sample_coeff * sample
# 6. Add noise
diff --git a/src/diffusers/schedulers/scheduling_unipc_multistep.py b/src/diffusers/schedulers/scheduling_unipc_multistep.py
index d7f795dff8..b456667492 100644
--- a/src/diffusers/schedulers/scheduling_unipc_multistep.py
+++ b/src/diffusers/schedulers/scheduling_unipc_multistep.py
@@ -12,7 +12,7 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-# DISCLAIMER: check https://arxiv.org/abs/2302.04867 and https://github.com/wl-zhao/UniPC for more info
+# DISCLAIMER: check https://huggingface.co/papers/2302.04867 and https://github.com/wl-zhao/UniPC for more info
# The codebase is modified based on https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_dpmsolver_multistep.py
import math
@@ -78,7 +78,7 @@ def betas_for_alpha_bar(
# Copied from diffusers.schedulers.scheduling_ddim.rescale_zero_terminal_snr
def rescale_zero_terminal_snr(betas):
"""
- Rescales betas to have zero terminal SNR Based on https://arxiv.org/pdf/2305.08891.pdf (Algorithm 1)
+ Rescales betas to have zero terminal SNR Based on https://huggingface.co/papers/2305.08891 (Algorithm 1)
Args:
@@ -308,7 +308,7 @@ class UniPCMultistepScheduler(SchedulerMixin, ConfigMixin):
device (`str` or `torch.device`, *optional*):
The device to which the timesteps should be moved to. If `None`, the timesteps are not moved.
"""
- # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://arxiv.org/abs/2305.08891
+ # "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://huggingface.co/papers/2305.08891
if self.config.timestep_spacing == "linspace":
timesteps = (
np.linspace(0, self.config.num_train_timesteps - 1, num_inference_steps + 1)
@@ -429,7 +429,7 @@ class UniPCMultistepScheduler(SchedulerMixin, ConfigMixin):
pixels from saturation at each step. We find that dynamic thresholding results in significantly better
photorealism as well as better image-text alignment, especially when using very large guidance weights."
- https://arxiv.org/abs/2205.11487
+ https://huggingface.co/papers/2205.11487
"""
dtype = sample.dtype
batch_size, channels, *remaining_dims = sample.shape
diff --git a/src/diffusers/training_utils.py b/src/diffusers/training_utils.py
index b98c4e33f8..43bf0010d7 100644
--- a/src/diffusers/training_utils.py
+++ b/src/diffusers/training_utils.py
@@ -149,9 +149,9 @@ def compute_dream_and_update_latents(
dream_detail_preservation: float = 1.0,
) -> Tuple[Optional[torch.Tensor], Optional[torch.Tensor]]:
"""
- Implements "DREAM (Diffusion Rectification and Estimation-Adaptive Models)" from http://arxiv.org/abs/2312.00210.
- DREAM helps align training with sampling to help training be more efficient and accurate at the cost of an extra
- forward step without gradients.
+ Implements "DREAM (Diffusion Rectification and Estimation-Adaptive Models)" from
+ https://huggingface.co/papers/2312.00210. DREAM helps align training with sampling to help training be more
+ efficient and accurate at the cost of an extra forward step without gradients.
Args:
`unet`: The state unet to use to make a prediction.
@@ -261,7 +261,7 @@ def compute_density_for_timestep_sampling(
Courtesy: This was contributed by Rafie Walker in https://github.com/huggingface/diffusers/pull/8528.
- SD3 paper reference: https://arxiv.org/abs/2403.03206v1.
+ SD3 paper reference: https://huggingface.co/papers/2403.03206v1.
"""
if weighting_scheme == "logit_normal":
u = torch.normal(mean=logit_mean, std=logit_std, size=(batch_size,), device=device, generator=generator)
@@ -280,7 +280,7 @@ def compute_loss_weighting_for_sd3(weighting_scheme: str, sigmas=None):
Courtesy: This was contributed by Rafie Walker in https://github.com/huggingface/diffusers/pull/8528.
- SD3 paper reference: https://arxiv.org/abs/2403.03206v1.
+ SD3 paper reference: https://huggingface.co/papers/2403.03206v1.
"""
if weighting_scheme == "sigma_sqrt":
weighting = (sigmas**-2.0).float()
diff --git a/src/diffusers/utils/dummy_torch_and_transformers_objects.py b/src/diffusers/utils/dummy_torch_and_transformers_objects.py
index c36c758d87..159d81add3 100644
--- a/src/diffusers/utils/dummy_torch_and_transformers_objects.py
+++ b/src/diffusers/utils/dummy_torch_and_transformers_objects.py
@@ -1307,6 +1307,21 @@ class LTXImageToVideoPipeline(metaclass=DummyObject):
requires_backends(cls, ["torch", "transformers"])
+class LTXLatentUpsamplePipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
class LTXPipeline(metaclass=DummyObject):
_backends = ["torch", "transformers"]
@@ -1607,6 +1622,21 @@ class SanaPipeline(metaclass=DummyObject):
requires_backends(cls, ["torch", "transformers"])
+class SanaSprintImg2ImgPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
class SanaSprintPipeline(metaclass=DummyObject):
_backends = ["torch", "transformers"]
@@ -2792,6 +2822,36 @@ class VideoToVideoSDPipeline(metaclass=DummyObject):
requires_backends(cls, ["torch", "transformers"])
+class VisualClozeGenerationPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class VisualClozePipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
class VQDiffusionPipeline(metaclass=DummyObject):
_backends = ["torch", "transformers"]
diff --git a/src/diffusers/utils/testing_utils.py b/src/diffusers/utils/testing_utils.py
index 7a524e76f1..e19a9f83fd 100644
--- a/src/diffusers/utils/testing_utils.py
+++ b/src/diffusers/utils/testing_utils.py
@@ -38,6 +38,7 @@ from .import_utils import (
is_note_seq_available,
is_onnx_available,
is_opencv_available,
+ is_optimum_quanto_available,
is_peft_available,
is_timm_available,
is_torch_available,
@@ -486,6 +487,13 @@ def require_bitsandbytes(test_case):
return unittest.skipUnless(is_bitsandbytes_available(), "test requires bitsandbytes")(test_case)
+def require_quanto(test_case):
+ """
+ Decorator marking a test that requires quanto. These tests are skipped when quanto isn't installed.
+ """
+ return unittest.skipUnless(is_optimum_quanto_available(), "test requires quanto")(test_case)
+
+
def require_accelerate(test_case):
"""
Decorator marking a test that requires accelerate. These tests are skipped when accelerate isn't installed.
@@ -627,10 +635,10 @@ def load_numpy(arry: Union[str, np.ndarray], local_path: Optional[str] = None) -
return arry
-def load_pt(url: str, map_location: str):
+def load_pt(url: str, map_location: Optional[str] = None, weights_only: Optional[bool] = True):
response = requests.get(url, timeout=DIFFUSERS_REQUEST_TIMEOUT)
response.raise_for_status()
- arry = torch.load(BytesIO(response.content), map_location=map_location)
+ arry = torch.load(BytesIO(response.content), map_location=map_location, weights_only=weights_only)
return arry
@@ -1204,8 +1212,8 @@ def _device_agnostic_dispatch(device: str, dispatch_table: Dict[str, Callable],
# Some device agnostic functions return values. Need to guard against 'None' instead at
# user level
- if fn is None:
- return None
+ if not callable(fn):
+ return fn
return fn(*args, **kwargs)
diff --git a/src/diffusers/utils/torch_utils.py b/src/diffusers/utils/torch_utils.py
index 19c076a4a6..bb5674092d 100644
--- a/src/diffusers/utils/torch_utils.py
+++ b/src/diffusers/utils/torch_utils.py
@@ -18,7 +18,7 @@ PyTorch utilities: Utilities related to PyTorch
from typing import List, Optional, Tuple, Union
from . import logging
-from .import_utils import is_torch_available, is_torch_version
+from .import_utils import is_torch_available, is_torch_npu_available, is_torch_version
if is_torch_available():
@@ -38,7 +38,7 @@ except (ImportError, ModuleNotFoundError):
def randn_tensor(
shape: Union[Tuple, List],
generator: Optional[Union[List["torch.Generator"], "torch.Generator"]] = None,
- device: Optional["torch.device"] = None,
+ device: Optional[Union[str, "torch.device"]] = None,
dtype: Optional["torch.dtype"] = None,
layout: Optional["torch.layout"] = None,
):
@@ -47,6 +47,8 @@ def randn_tensor(
is always created on the CPU.
"""
# device on which tensor is created defaults to device
+ if isinstance(device, str):
+ device = torch.device(device)
rand_device = device
batch_size = shape[0]
@@ -91,7 +93,7 @@ def is_compiled_module(module) -> bool:
def fourier_filter(x_in: "torch.Tensor", threshold: int, scale: int) -> "torch.Tensor":
- """Fourier filter as introduced in FreeU (https://arxiv.org/abs/2309.11497).
+ """Fourier filter as introduced in FreeU (https://huggingface.co/papers/2309.11497).
This version of the method comes from here:
https://github.com/huggingface/diffusers/pull/5164#issuecomment-1732638706
@@ -164,6 +166,8 @@ def get_torch_cuda_device_capability():
def get_device():
if torch.cuda.is_available():
return "cuda"
+ elif is_torch_npu_available():
+ return "npu"
elif hasattr(torch, "xpu") and torch.xpu.is_available():
return "xpu"
else:
diff --git a/tests/hooks/test_group_offloading.py b/tests/hooks/test_group_offloading.py
index 37c5c9451b..1e115dcaa9 100644
--- a/tests/hooks/test_group_offloading.py
+++ b/tests/hooks/test_group_offloading.py
@@ -22,7 +22,13 @@ from diffusers.models import ModelMixin
from diffusers.pipelines.pipeline_utils import DiffusionPipeline
from diffusers.utils import get_logger
from diffusers.utils.import_utils import compare_versions
-from diffusers.utils.testing_utils import require_torch_gpu, torch_device
+from diffusers.utils.testing_utils import (
+ backend_empty_cache,
+ backend_max_memory_allocated,
+ backend_reset_peak_memory_stats,
+ require_torch_accelerator,
+ torch_device,
+)
class DummyBlock(torch.nn.Module):
@@ -107,7 +113,7 @@ class DummyPipeline(DiffusionPipeline):
return x
-@require_torch_gpu
+@require_torch_accelerator
class GroupOffloadTests(unittest.TestCase):
in_features = 64
hidden_features = 256
@@ -125,8 +131,8 @@ class GroupOffloadTests(unittest.TestCase):
del self.model
del self.input
gc.collect()
- torch.cuda.empty_cache()
- torch.cuda.reset_peak_memory_stats()
+ backend_empty_cache(torch_device)
+ backend_reset_peak_memory_stats(torch_device)
def get_model(self):
torch.manual_seed(0)
@@ -141,8 +147,8 @@ class GroupOffloadTests(unittest.TestCase):
@torch.no_grad()
def run_forward(model):
gc.collect()
- torch.cuda.empty_cache()
- torch.cuda.reset_peak_memory_stats()
+ backend_empty_cache(torch_device)
+ backend_reset_peak_memory_stats(torch_device)
self.assertTrue(
all(
module._diffusers_hook.get_hook("group_offloading") is not None
@@ -152,7 +158,7 @@ class GroupOffloadTests(unittest.TestCase):
)
model.eval()
output = model(self.input)[0].cpu()
- max_memory_allocated = torch.cuda.max_memory_allocated()
+ max_memory_allocated = backend_max_memory_allocated(torch_device)
return output, max_memory_allocated
self.model.to(torch_device)
@@ -187,10 +193,10 @@ class GroupOffloadTests(unittest.TestCase):
self.assertTrue(torch.allclose(output_without_group_offloading, output_with_group_offloading5, atol=1e-5))
# Memory assertions - offloading should reduce memory usage
- self.assertTrue(mem4 <= mem5 < mem2 < mem3 < mem1 < mem_baseline)
+ self.assertTrue(mem4 <= mem5 < mem2 <= mem3 < mem1 < mem_baseline)
- def test_warning_logged_if_group_offloaded_module_moved_to_cuda(self):
- if torch.device(torch_device).type != "cuda":
+ def test_warning_logged_if_group_offloaded_module_moved_to_accelerator(self):
+ if torch.device(torch_device).type not in ["cuda", "xpu"]:
return
self.model.enable_group_offload(torch_device, offload_type="block_level", num_blocks_per_group=3)
logger = get_logger("diffusers.models.modeling_utils")
@@ -199,8 +205,8 @@ class GroupOffloadTests(unittest.TestCase):
self.model.to(torch_device)
self.assertIn(f"The module '{self.model.__class__.__name__}' is group offloaded", cm.output[0])
- def test_warning_logged_if_group_offloaded_pipe_moved_to_cuda(self):
- if torch.device(torch_device).type != "cuda":
+ def test_warning_logged_if_group_offloaded_pipe_moved_to_accelerator(self):
+ if torch.device(torch_device).type not in ["cuda", "xpu"]:
return
pipe = DummyPipeline(self.model)
self.model.enable_group_offload(torch_device, offload_type="block_level", num_blocks_per_group=3)
@@ -210,19 +216,20 @@ class GroupOffloadTests(unittest.TestCase):
pipe.to(torch_device)
self.assertIn(f"The module '{self.model.__class__.__name__}' is group offloaded", cm.output[0])
- def test_error_raised_if_streams_used_and_no_cuda_device(self):
- original_is_available = torch.cuda.is_available
- torch.cuda.is_available = lambda: False
+ def test_error_raised_if_streams_used_and_no_accelerator_device(self):
+ torch_accelerator_module = getattr(torch, torch_device, torch.cuda)
+ original_is_available = torch_accelerator_module.is_available
+ torch_accelerator_module.is_available = lambda: False
with self.assertRaises(ValueError):
self.model.enable_group_offload(
- onload_device=torch.device("cuda"), offload_type="leaf_level", use_stream=True
+ onload_device=torch.device(torch_device), offload_type="leaf_level", use_stream=True
)
- torch.cuda.is_available = original_is_available
+ torch_accelerator_module.is_available = original_is_available
def test_error_raised_if_supports_group_offloading_false(self):
self.model._supports_group_offloading = False
with self.assertRaisesRegex(ValueError, "does not support group offloading"):
- self.model.enable_group_offload(onload_device=torch.device("cuda"))
+ self.model.enable_group_offload(onload_device=torch.device(torch_device))
def test_error_raised_if_model_offloading_applied_on_group_offloaded_module(self):
pipe = DummyPipeline(self.model)
@@ -249,7 +256,7 @@ class GroupOffloadTests(unittest.TestCase):
pipe.model.enable_group_offload(torch_device, offload_type="block_level", num_blocks_per_group=3)
def test_block_level_stream_with_invocation_order_different_from_initialization_order(self):
- if torch.device(torch_device).type != "cuda":
+ if torch.device(torch_device).type not in ["cuda", "xpu"]:
return
model = DummyModelWithMultipleBlocks(
in_features=self.in_features,
diff --git a/tests/lora/test_lora_layers_cogvideox.py b/tests/lora/test_lora_layers_cogvideox.py
index dc2695452c..26dcdb1f4f 100644
--- a/tests/lora/test_lora_layers_cogvideox.py
+++ b/tests/lora/test_lora_layers_cogvideox.py
@@ -124,6 +124,9 @@ class CogVideoXLoRATests(unittest.TestCase, PeftLoraLoaderMixinTests):
def test_simple_inference_with_text_denoiser_lora_unfused(self):
super().test_simple_inference_with_text_denoiser_lora_unfused(expected_atol=9e-3)
+ def test_lora_scale_kwargs_match_fusion(self):
+ super().test_lora_scale_kwargs_match_fusion(expected_atol=9e-3, expected_rtol=9e-3)
+
@unittest.skip("Not supported in CogVideoX.")
def test_simple_inference_with_text_denoiser_block_scale(self):
pass
diff --git a/tests/lora/test_lora_layers_sdxl.py b/tests/lora/test_lora_layers_sdxl.py
index 0a31f214a3..22d3ecbde8 100644
--- a/tests/lora/test_lora_layers_sdxl.py
+++ b/tests/lora/test_lora_layers_sdxl.py
@@ -117,6 +117,40 @@ class StableDiffusionXLLoRATests(PeftLoraLoaderMixinTests, unittest.TestCase):
def test_multiple_wrong_adapter_name_raises_error(self):
super().test_multiple_wrong_adapter_name_raises_error()
+ def test_simple_inference_with_text_denoiser_lora_unfused(self):
+ if torch.cuda.is_available():
+ expected_atol = 9e-2
+ expected_rtol = 9e-2
+ else:
+ expected_atol = 1e-3
+ expected_rtol = 1e-3
+
+ super().test_simple_inference_with_text_denoiser_lora_unfused(
+ expected_atol=expected_atol, expected_rtol=expected_rtol
+ )
+
+ def test_simple_inference_with_text_lora_denoiser_fused_multi(self):
+ if torch.cuda.is_available():
+ expected_atol = 9e-2
+ expected_rtol = 9e-2
+ else:
+ expected_atol = 1e-3
+ expected_rtol = 1e-3
+
+ super().test_simple_inference_with_text_lora_denoiser_fused_multi(
+ expected_atol=expected_atol, expected_rtol=expected_rtol
+ )
+
+ def test_lora_scale_kwargs_match_fusion(self):
+ if torch.cuda.is_available():
+ expected_atol = 9e-2
+ expected_rtol = 9e-2
+ else:
+ expected_atol = 1e-3
+ expected_rtol = 1e-3
+
+ super().test_lora_scale_kwargs_match_fusion(expected_atol=expected_atol, expected_rtol=expected_rtol)
+
@slow
@nightly
diff --git a/tests/lora/utils.py b/tests/lora/utils.py
index 87a8fddfa5..7c89f5a47d 100644
--- a/tests/lora/utils.py
+++ b/tests/lora/utils.py
@@ -80,6 +80,18 @@ def initialize_dummy_state_dict(state_dict):
POSSIBLE_ATTENTION_KWARGS_NAMES = ["cross_attention_kwargs", "joint_attention_kwargs", "attention_kwargs"]
+def determine_attention_kwargs_name(pipeline_class):
+ call_signature_keys = inspect.signature(pipeline_class.__call__).parameters.keys()
+
+ # TODO(diffusers): Discuss a common naming convention across library for 1.0.0 release
+ for possible_attention_kwargs in POSSIBLE_ATTENTION_KWARGS_NAMES:
+ if possible_attention_kwargs in call_signature_keys:
+ attention_kwargs_name = possible_attention_kwargs
+ break
+ assert attention_kwargs_name is not None
+ return attention_kwargs_name
+
+
@require_peft_backend
class PeftLoraLoaderMixinTests:
pipeline_class = None
@@ -442,14 +454,7 @@ class PeftLoraLoaderMixinTests:
Tests a simple inference with lora attached on the text encoder + scale argument
and makes sure it works as expected
"""
- call_signature_keys = inspect.signature(self.pipeline_class.__call__).parameters.keys()
-
- # TODO(diffusers): Discuss a common naming convention across library for 1.0.0 release
- for possible_attention_kwargs in POSSIBLE_ATTENTION_KWARGS_NAMES:
- if possible_attention_kwargs in call_signature_keys:
- attention_kwargs_name = possible_attention_kwargs
- break
- assert attention_kwargs_name is not None
+ attention_kwargs_name = determine_attention_kwargs_name(self.pipeline_class)
for scheduler_cls in self.scheduler_classes:
components, text_lora_config, _ = self.get_dummy_components(scheduler_cls)
@@ -740,12 +745,7 @@ class PeftLoraLoaderMixinTests:
Tests a simple inference with lora attached on the text encoder + Unet + scale argument
and makes sure it works as expected
"""
- call_signature_keys = inspect.signature(self.pipeline_class.__call__).parameters.keys()
- for possible_attention_kwargs in POSSIBLE_ATTENTION_KWARGS_NAMES:
- if possible_attention_kwargs in call_signature_keys:
- attention_kwargs_name = possible_attention_kwargs
- break
- assert attention_kwargs_name is not None
+ attention_kwargs_name = determine_attention_kwargs_name(self.pipeline_class)
for scheduler_cls in self.scheduler_classes:
components, text_lora_config, denoiser_lora_config = self.get_dummy_components(scheduler_cls)
@@ -878,9 +878,11 @@ class PeftLoraLoaderMixinTests:
pipe, denoiser = self.check_if_adapters_added_correctly(pipe, text_lora_config, denoiser_lora_config)
pipe.fuse_lora(components=self.pipeline_class._lora_loadable_modules)
+ self.assertTrue(pipe.num_fused_loras == 1, f"{pipe.num_fused_loras=}, {pipe.fused_loras=}")
output_fused_lora = pipe(**inputs, generator=torch.manual_seed(0))[0]
pipe.unfuse_lora(components=self.pipeline_class._lora_loadable_modules)
+ self.assertTrue(pipe.num_fused_loras == 0, f"{pipe.num_fused_loras=}, {pipe.fused_loras=}")
output_unfused_lora = pipe(**inputs, generator=torch.manual_seed(0))[0]
# unloading should remove the LoRA layers
@@ -1090,7 +1092,7 @@ class PeftLoraLoaderMixinTests:
def test_simple_inference_with_text_denoiser_multi_adapter_block_lora(self):
"""
Tests a simple inference with lora attached to text encoder and unet, attaches
- multiple adapters and set differnt weights for different blocks (i.e. block lora)
+ multiple adapters and set different weights for different blocks (i.e. block lora)
"""
for scheduler_cls in self.scheduler_classes:
components, text_lora_config, denoiser_lora_config = self.get_dummy_components(scheduler_cls)
@@ -1608,26 +1610,21 @@ class PeftLoraLoaderMixinTests:
self.assertTrue(
check_if_lora_correctly_set(pipe.text_encoder), "Lora not correctly set in text encoder"
)
+ pipe.text_encoder.add_adapter(text_lora_config, "adapter-2")
denoiser = pipe.transformer if self.unet_kwargs is None else pipe.unet
denoiser.add_adapter(denoiser_lora_config, "adapter-1")
-
- # Attach a second adapter
- if "text_encoder" in self.pipeline_class._lora_loadable_modules:
- pipe.text_encoder.add_adapter(text_lora_config, "adapter-2")
-
- denoiser.add_adapter(denoiser_lora_config, "adapter-2")
-
self.assertTrue(check_if_lora_correctly_set(denoiser), "Lora not correctly set in denoiser.")
+ denoiser.add_adapter(denoiser_lora_config, "adapter-2")
if self.has_two_text_encoders or self.has_three_text_encoders:
lora_loadable_components = self.pipeline_class._lora_loadable_modules
if "text_encoder_2" in lora_loadable_components:
pipe.text_encoder_2.add_adapter(text_lora_config, "adapter-1")
- pipe.text_encoder_2.add_adapter(text_lora_config, "adapter-2")
self.assertTrue(
check_if_lora_correctly_set(pipe.text_encoder_2), "Lora not correctly set in text encoder 2"
)
+ pipe.text_encoder_2.add_adapter(text_lora_config, "adapter-2")
# set them to multi-adapter inference mode
pipe.set_adapters(["adapter-1", "adapter-2"])
@@ -1637,8 +1634,9 @@ class PeftLoraLoaderMixinTests:
outputs_lora_1 = pipe(**inputs, generator=torch.manual_seed(0))[0]
pipe.fuse_lora(components=self.pipeline_class._lora_loadable_modules, adapter_names=["adapter-1"])
+ self.assertTrue(pipe.num_fused_loras == 1, f"{pipe.num_fused_loras=}, {pipe.fused_loras=}")
- # Fusing should still keep the LoRA layers so outpout should remain the same
+ # Fusing should still keep the LoRA layers so output should remain the same
outputs_lora_1_fused = pipe(**inputs, generator=torch.manual_seed(0))[0]
self.assertTrue(
@@ -1647,9 +1645,23 @@ class PeftLoraLoaderMixinTests:
)
pipe.unfuse_lora(components=self.pipeline_class._lora_loadable_modules)
+ self.assertTrue(pipe.num_fused_loras == 0, f"{pipe.num_fused_loras=}, {pipe.fused_loras=}")
+
+ if "text_encoder" in self.pipeline_class._lora_loadable_modules:
+ self.assertTrue(check_if_lora_correctly_set(pipe.text_encoder), "Unfuse should still keep LoRA layers")
+
+ self.assertTrue(check_if_lora_correctly_set(denoiser), "Unfuse should still keep LoRA layers")
+
+ if self.has_two_text_encoders or self.has_three_text_encoders:
+ if "text_encoder_2" in self.pipeline_class._lora_loadable_modules:
+ self.assertTrue(
+ check_if_lora_correctly_set(pipe.text_encoder_2), "Unfuse should still keep LoRA layers"
+ )
+
pipe.fuse_lora(
components=self.pipeline_class._lora_loadable_modules, adapter_names=["adapter-2", "adapter-1"]
)
+ self.assertTrue(pipe.num_fused_loras == 2, f"{pipe.num_fused_loras=}, {pipe.fused_loras=}")
# Fusing should still keep the LoRA layers
output_all_lora_fused = pipe(**inputs, generator=torch.manual_seed(0))[0]
@@ -1657,6 +1669,63 @@ class PeftLoraLoaderMixinTests:
np.allclose(output_all_lora_fused, outputs_all_lora, atol=expected_atol, rtol=expected_rtol),
"Fused lora should not change the output",
)
+ pipe.unfuse_lora(components=self.pipeline_class._lora_loadable_modules)
+ self.assertTrue(pipe.num_fused_loras == 0, f"{pipe.num_fused_loras=}, {pipe.fused_loras=}")
+
+ def test_lora_scale_kwargs_match_fusion(self, expected_atol: float = 1e-3, expected_rtol: float = 1e-3):
+ attention_kwargs_name = determine_attention_kwargs_name(self.pipeline_class)
+
+ for lora_scale in [1.0, 0.8]:
+ for scheduler_cls in self.scheduler_classes:
+ components, text_lora_config, denoiser_lora_config = self.get_dummy_components(scheduler_cls)
+ pipe = self.pipeline_class(**components)
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ _, _, inputs = self.get_dummy_inputs(with_generator=False)
+
+ output_no_lora = pipe(**inputs, generator=torch.manual_seed(0))[0]
+ self.assertTrue(output_no_lora.shape == self.output_shape)
+
+ if "text_encoder" in self.pipeline_class._lora_loadable_modules:
+ pipe.text_encoder.add_adapter(text_lora_config, "adapter-1")
+ self.assertTrue(
+ check_if_lora_correctly_set(pipe.text_encoder), "Lora not correctly set in text encoder"
+ )
+
+ denoiser = pipe.transformer if self.unet_kwargs is None else pipe.unet
+ denoiser.add_adapter(denoiser_lora_config, "adapter-1")
+ self.assertTrue(check_if_lora_correctly_set(denoiser), "Lora not correctly set in denoiser.")
+
+ if self.has_two_text_encoders or self.has_three_text_encoders:
+ lora_loadable_components = self.pipeline_class._lora_loadable_modules
+ if "text_encoder_2" in lora_loadable_components:
+ pipe.text_encoder_2.add_adapter(text_lora_config, "adapter-1")
+ self.assertTrue(
+ check_if_lora_correctly_set(pipe.text_encoder_2),
+ "Lora not correctly set in text encoder 2",
+ )
+
+ pipe.set_adapters(["adapter-1"])
+ attention_kwargs = {attention_kwargs_name: {"scale": lora_scale}}
+ outputs_lora_1 = pipe(**inputs, generator=torch.manual_seed(0), **attention_kwargs)[0]
+
+ pipe.fuse_lora(
+ components=self.pipeline_class._lora_loadable_modules,
+ adapter_names=["adapter-1"],
+ lora_scale=lora_scale,
+ )
+ self.assertTrue(pipe.num_fused_loras == 1, f"{pipe.num_fused_loras=}, {pipe.fused_loras=}")
+
+ outputs_lora_1_fused = pipe(**inputs, generator=torch.manual_seed(0))[0]
+
+ self.assertTrue(
+ np.allclose(outputs_lora_1, outputs_lora_1_fused, atol=expected_atol, rtol=expected_rtol),
+ "Fused lora should not change the output",
+ )
+ self.assertFalse(
+ np.allclose(output_no_lora, outputs_lora_1, atol=expected_atol, rtol=expected_rtol),
+ "LoRA should change the output",
+ )
@require_peft_version_greater(peft_version="0.9.0")
def test_simple_inference_with_dora(self):
@@ -1838,12 +1907,7 @@ class PeftLoraLoaderMixinTests:
def test_set_adapters_match_attention_kwargs(self):
"""Test to check if outputs after `set_adapters()` and attention kwargs match."""
- call_signature_keys = inspect.signature(self.pipeline_class.__call__).parameters.keys()
- for possible_attention_kwargs in POSSIBLE_ATTENTION_KWARGS_NAMES:
- if possible_attention_kwargs in call_signature_keys:
- attention_kwargs_name = possible_attention_kwargs
- break
- assert attention_kwargs_name is not None
+ attention_kwargs_name = determine_attention_kwargs_name(self.pipeline_class)
for scheduler_cls in self.scheduler_classes:
components, text_lora_config, denoiser_lora_config = self.get_dummy_components(scheduler_cls)
@@ -2149,3 +2213,51 @@ class PeftLoraLoaderMixinTests:
_, _, inputs = self.get_dummy_inputs(with_generator=False)
pipe(**inputs, generator=torch.manual_seed(0))[0]
+
+ def test_inference_load_delete_load_adapters(self):
+ "Tests if `load_lora_weights()` -> `delete_adapters()` -> `load_lora_weights()` works."
+ for scheduler_cls in self.scheduler_classes:
+ components, text_lora_config, denoiser_lora_config = self.get_dummy_components(scheduler_cls)
+ pipe = self.pipeline_class(**components)
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ _, _, inputs = self.get_dummy_inputs(with_generator=False)
+
+ output_no_lora = pipe(**inputs, generator=torch.manual_seed(0))[0]
+
+ if "text_encoder" in self.pipeline_class._lora_loadable_modules:
+ pipe.text_encoder.add_adapter(text_lora_config)
+ self.assertTrue(
+ check_if_lora_correctly_set(pipe.text_encoder), "Lora not correctly set in text encoder"
+ )
+
+ denoiser = pipe.transformer if self.unet_kwargs is None else pipe.unet
+ denoiser.add_adapter(denoiser_lora_config)
+ self.assertTrue(check_if_lora_correctly_set(denoiser), "Lora not correctly set in denoiser.")
+
+ if self.has_two_text_encoders or self.has_three_text_encoders:
+ lora_loadable_components = self.pipeline_class._lora_loadable_modules
+ if "text_encoder_2" in lora_loadable_components:
+ pipe.text_encoder_2.add_adapter(text_lora_config)
+ self.assertTrue(
+ check_if_lora_correctly_set(pipe.text_encoder_2), "Lora not correctly set in text encoder 2"
+ )
+
+ output_adapter_1 = pipe(**inputs, generator=torch.manual_seed(0))[0]
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ modules_to_save = self._get_modules_to_save(pipe, has_denoiser=True)
+ lora_state_dicts = self._get_lora_state_dicts(modules_to_save)
+ self.pipeline_class.save_lora_weights(save_directory=tmpdirname, **lora_state_dicts)
+ self.assertTrue(os.path.isfile(os.path.join(tmpdirname, "pytorch_lora_weights.safetensors")))
+
+ # First, delete adapter and compare.
+ pipe.delete_adapters(pipe.get_active_adapters()[0])
+ output_no_adapter = pipe(**inputs, generator=torch.manual_seed(0))[0]
+ self.assertFalse(np.allclose(output_adapter_1, output_no_adapter, atol=1e-3, rtol=1e-3))
+ self.assertTrue(np.allclose(output_no_lora, output_no_adapter, atol=1e-3, rtol=1e-3))
+
+ # Then load adapter and compare.
+ pipe.load_lora_weights(tmpdirname)
+ output_lora_loaded = pipe(**inputs, generator=torch.manual_seed(0))[0]
+ self.assertTrue(np.allclose(output_adapter_1, output_lora_loaded, atol=1e-3, rtol=1e-3))
diff --git a/tests/models/test_modeling_common.py b/tests/models/test_modeling_common.py
index 57431d8b16..8de26212a2 100644
--- a/tests/models/test_modeling_common.py
+++ b/tests/models/test_modeling_common.py
@@ -62,7 +62,6 @@ from diffusers.utils.testing_utils import (
backend_max_memory_allocated,
backend_reset_peak_memory_stats,
backend_synchronize,
- floats_tensor,
get_python_version,
is_torch_compile,
numpy_cosine_similarity_distance,
@@ -1581,6 +1580,34 @@ class ModelTesterMixin:
self.assertTrue(torch.allclose(output_without_group_offloading, output_with_group_offloading3, atol=1e-5))
self.assertTrue(torch.allclose(output_without_group_offloading, output_with_group_offloading4, atol=1e-5))
+ @parameterized.expand([(False, "block_level"), (True, "leaf_level")])
+ @require_torch_accelerator
+ @torch.no_grad()
+ def test_group_offloading_with_layerwise_casting(self, record_stream, offload_type):
+ torch.manual_seed(0)
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+ model = self.model_class(**init_dict)
+
+ if not getattr(model, "_supports_group_offloading", True):
+ return
+
+ model.to(torch_device)
+ model.eval()
+ _ = model(**inputs_dict)[0]
+
+ torch.manual_seed(0)
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+ storage_dtype, compute_dtype = torch.float16, torch.float32
+ inputs_dict = cast_maybe_tensor_dtype(inputs_dict, torch.float32, compute_dtype)
+ model = self.model_class(**init_dict)
+ model.eval()
+ additional_kwargs = {} if offload_type == "leaf_level" else {"num_blocks_per_group": 1}
+ model.enable_group_offload(
+ torch_device, offload_type=offload_type, use_stream=True, record_stream=record_stream, **additional_kwargs
+ )
+ model.enable_layerwise_casting(storage_dtype=storage_dtype, compute_dtype=compute_dtype)
+ _ = model(**inputs_dict)[0]
+
def test_auto_model(self, expected_max_diff=5e-5):
if self.forward_requires_fresh_args:
model = self.model_class(**self.init_dict)
@@ -1721,14 +1748,14 @@ class TorchCompileTesterMixin:
def setUp(self):
# clean up the VRAM before each test
super().setUp()
- torch._dynamo.reset()
+ torch.compiler.reset()
gc.collect()
backend_empty_cache(torch_device)
def tearDown(self):
# clean up the VRAM after each test in case of CUDA runtime errors
super().tearDown()
- torch._dynamo.reset()
+ torch.compiler.reset()
gc.collect()
backend_empty_cache(torch_device)
@@ -1737,13 +1764,17 @@ class TorchCompileTesterMixin:
@is_torch_compile
@slow
def test_torch_compile_recompilation_and_graph_break(self):
- torch._dynamo.reset()
+ torch.compiler.reset()
init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
model = self.model_class(**init_dict).to(torch_device)
model = torch.compile(model, fullgraph=True)
- with torch._dynamo.config.patch(error_on_recompile=True), torch.no_grad():
+ with (
+ torch._inductor.utils.fresh_inductor_cache(),
+ torch._dynamo.config.patch(error_on_recompile=True),
+ torch.no_grad(),
+ ):
_ = model(**inputs_dict)
_ = model(**inputs_dict)
@@ -1754,7 +1785,7 @@ class TorchCompileTesterMixin:
@require_peft_backend
@require_peft_version_greater("0.14.0")
@is_torch_compile
-class TestLoraHotSwappingForModel(unittest.TestCase):
+class LoraHotSwappingForModelTesterMixin:
"""Test that hotswapping does not result in recompilation on the model directly.
We're not extensively testing the hotswapping functionality since it is implemented in PEFT and is extensively
@@ -1771,52 +1802,28 @@ class TestLoraHotSwappingForModel(unittest.TestCase):
# It is critical that the dynamo cache is reset for each test. Otherwise, if the test re-uses the same model,
# there will be recompilation errors, as torch caches the model when run in the same process.
super().tearDown()
- torch._dynamo.reset()
+ torch.compiler.reset()
gc.collect()
backend_empty_cache(torch_device)
- def get_small_unet(self):
- # from diffusers UNet2DConditionModelTests
- torch.manual_seed(0)
- init_dict = {
- "block_out_channels": (4, 8),
- "norm_num_groups": 4,
- "down_block_types": ("CrossAttnDownBlock2D", "DownBlock2D"),
- "up_block_types": ("UpBlock2D", "CrossAttnUpBlock2D"),
- "cross_attention_dim": 8,
- "attention_head_dim": 2,
- "out_channels": 4,
- "in_channels": 4,
- "layers_per_block": 1,
- "sample_size": 16,
- }
- model = UNet2DConditionModel(**init_dict)
- return model.to(torch_device)
-
- def get_unet_lora_config(self, lora_rank, lora_alpha, target_modules):
+ def get_lora_config(self, lora_rank, lora_alpha, target_modules):
# from diffusers test_models_unet_2d_condition.py
from peft import LoraConfig
- unet_lora_config = LoraConfig(
+ lora_config = LoraConfig(
r=lora_rank,
lora_alpha=lora_alpha,
target_modules=target_modules,
init_lora_weights=False,
use_dora=False,
)
- return unet_lora_config
+ return lora_config
- def get_dummy_input(self):
- # from UNet2DConditionModelTests
- batch_size = 4
- num_channels = 4
- sizes = (16, 16)
-
- noise = floats_tensor((batch_size, num_channels) + sizes).to(torch_device)
- time_step = torch.tensor([10]).to(torch_device)
- encoder_hidden_states = floats_tensor((batch_size, 4, 8)).to(torch_device)
-
- return {"sample": noise, "timestep": time_step, "encoder_hidden_states": encoder_hidden_states}
+ def get_linear_module_name_other_than_attn(self, model):
+ linear_names = [
+ name for name, module in model.named_modules() if isinstance(module, nn.Linear) and "to_" not in name
+ ]
+ return linear_names[0]
def check_model_hotswap(self, do_compile, rank0, rank1, target_modules0, target_modules1=None):
"""
@@ -1834,23 +1841,27 @@ class TestLoraHotSwappingForModel(unittest.TestCase):
fine.
"""
# create 2 adapters with different ranks and alphas
- dummy_input = self.get_dummy_input()
+ torch.manual_seed(0)
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+ model = self.model_class(**init_dict).to(torch_device)
+
alpha0, alpha1 = rank0, rank1
max_rank = max([rank0, rank1])
if target_modules1 is None:
target_modules1 = target_modules0[:]
- lora_config0 = self.get_unet_lora_config(rank0, alpha0, target_modules0)
- lora_config1 = self.get_unet_lora_config(rank1, alpha1, target_modules1)
+ lora_config0 = self.get_lora_config(rank0, alpha0, target_modules0)
+ lora_config1 = self.get_lora_config(rank1, alpha1, target_modules1)
- unet = self.get_small_unet()
- unet.add_adapter(lora_config0, adapter_name="adapter0")
+ model.add_adapter(lora_config0, adapter_name="adapter0")
with torch.inference_mode():
- output0_before = unet(**dummy_input)["sample"]
+ torch.manual_seed(0)
+ output0_before = model(**inputs_dict)["sample"]
- unet.add_adapter(lora_config1, adapter_name="adapter1")
- unet.set_adapter("adapter1")
+ model.add_adapter(lora_config1, adapter_name="adapter1")
+ model.set_adapter("adapter1")
with torch.inference_mode():
- output1_before = unet(**dummy_input)["sample"]
+ torch.manual_seed(0)
+ output1_before = model(**inputs_dict)["sample"]
# sanity checks:
tol = 5e-3
@@ -1860,40 +1871,43 @@ class TestLoraHotSwappingForModel(unittest.TestCase):
with tempfile.TemporaryDirectory() as tmp_dirname:
# save the adapter checkpoints
- unet.save_lora_adapter(os.path.join(tmp_dirname, "0"), safe_serialization=True, adapter_name="adapter0")
- unet.save_lora_adapter(os.path.join(tmp_dirname, "1"), safe_serialization=True, adapter_name="adapter1")
- del unet
+ model.save_lora_adapter(os.path.join(tmp_dirname, "0"), safe_serialization=True, adapter_name="adapter0")
+ model.save_lora_adapter(os.path.join(tmp_dirname, "1"), safe_serialization=True, adapter_name="adapter1")
+ del model
# load the first adapter
- unet = self.get_small_unet()
+ torch.manual_seed(0)
+ init_dict, _ = self.prepare_init_args_and_inputs_for_common()
+ model = self.model_class(**init_dict).to(torch_device)
+
if do_compile or (rank0 != rank1):
# no need to prepare if the model is not compiled or if the ranks are identical
- unet.enable_lora_hotswap(target_rank=max_rank)
+ model.enable_lora_hotswap(target_rank=max_rank)
file_name0 = os.path.join(os.path.join(tmp_dirname, "0"), "pytorch_lora_weights.safetensors")
file_name1 = os.path.join(os.path.join(tmp_dirname, "1"), "pytorch_lora_weights.safetensors")
- unet.load_lora_adapter(file_name0, safe_serialization=True, adapter_name="adapter0", prefix=None)
+ model.load_lora_adapter(file_name0, safe_serialization=True, adapter_name="adapter0", prefix=None)
if do_compile:
- unet = torch.compile(unet, mode="reduce-overhead")
+ model = torch.compile(model, mode="reduce-overhead")
with torch.inference_mode():
- output0_after = unet(**dummy_input)["sample"]
+ output0_after = model(**inputs_dict)["sample"]
assert torch.allclose(output0_before, output0_after, atol=tol, rtol=tol)
# hotswap the 2nd adapter
- unet.load_lora_adapter(file_name1, adapter_name="adapter0", hotswap=True, prefix=None)
+ model.load_lora_adapter(file_name1, adapter_name="adapter0", hotswap=True, prefix=None)
# we need to call forward to potentially trigger recompilation
with torch.inference_mode():
- output1_after = unet(**dummy_input)["sample"]
+ output1_after = model(**inputs_dict)["sample"]
assert torch.allclose(output1_before, output1_after, atol=tol, rtol=tol)
# check error when not passing valid adapter name
name = "does-not-exist"
msg = f"Trying to hotswap LoRA adapter '{name}' but there is no existing adapter by that name"
with self.assertRaisesRegex(ValueError, msg):
- unet.load_lora_adapter(file_name1, adapter_name=name, hotswap=True, prefix=None)
+ model.load_lora_adapter(file_name1, adapter_name=name, hotswap=True, prefix=None)
@parameterized.expand([(11, 11), (7, 13), (13, 7)]) # important to test small to large and vice versa
def test_hotswapping_model(self, rank0, rank1):
@@ -1905,64 +1919,92 @@ class TestLoraHotSwappingForModel(unittest.TestCase):
def test_hotswapping_compiled_model_linear(self, rank0, rank1):
# It's important to add this context to raise an error on recompilation
target_modules = ["to_q", "to_k", "to_v", "to_out.0"]
- with torch._dynamo.config.patch(error_on_recompile=True):
+ with torch._dynamo.config.patch(error_on_recompile=True), torch._inductor.utils.fresh_inductor_cache():
self.check_model_hotswap(do_compile=True, rank0=rank0, rank1=rank1, target_modules0=target_modules)
@parameterized.expand([(11, 11), (7, 13), (13, 7)]) # important to test small to large and vice versa
def test_hotswapping_compiled_model_conv2d(self, rank0, rank1):
+ if "unet" not in self.model_class.__name__.lower():
+ return
+
# It's important to add this context to raise an error on recompilation
target_modules = ["conv", "conv1", "conv2"]
- with torch._dynamo.config.patch(error_on_recompile=True):
+ with torch._dynamo.config.patch(error_on_recompile=True), torch._inductor.utils.fresh_inductor_cache():
self.check_model_hotswap(do_compile=True, rank0=rank0, rank1=rank1, target_modules0=target_modules)
@parameterized.expand([(11, 11), (7, 13), (13, 7)]) # important to test small to large and vice versa
def test_hotswapping_compiled_model_both_linear_and_conv2d(self, rank0, rank1):
+ if "unet" not in self.model_class.__name__.lower():
+ return
+
# It's important to add this context to raise an error on recompilation
target_modules = ["to_q", "conv"]
+ with torch._dynamo.config.patch(error_on_recompile=True), torch._inductor.utils.fresh_inductor_cache():
+ self.check_model_hotswap(do_compile=True, rank0=rank0, rank1=rank1, target_modules0=target_modules)
+
+ @parameterized.expand([(11, 11), (7, 13), (13, 7)]) # important to test small to large and vice versa
+ def test_hotswapping_compiled_model_both_linear_and_other(self, rank0, rank1):
+ # In `test_hotswapping_compiled_model_both_linear_and_conv2d()`, we check if we can do hotswapping
+ # with `torch.compile()` for models that have both linear and conv layers. In this test, we check
+ # if we can target a linear layer from the transformer blocks and another linear layer from non-attention
+ # block.
+ target_modules = ["to_q"]
+ init_dict, _ = self.prepare_init_args_and_inputs_for_common()
+ model = self.model_class(**init_dict)
+
+ target_modules.append(self.get_linear_module_name_other_than_attn(model))
+ del model
+
+ # It's important to add this context to raise an error on recompilation
with torch._dynamo.config.patch(error_on_recompile=True):
self.check_model_hotswap(do_compile=True, rank0=rank0, rank1=rank1, target_modules0=target_modules)
def test_enable_lora_hotswap_called_after_adapter_added_raises(self):
# ensure that enable_lora_hotswap is called before loading the first adapter
- lora_config = self.get_unet_lora_config(8, 8, target_modules=["to_q"])
- unet = self.get_small_unet()
- unet.add_adapter(lora_config)
+ lora_config = self.get_lora_config(8, 8, target_modules=["to_q"])
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+ model = self.model_class(**init_dict).to(torch_device)
+ model.add_adapter(lora_config)
+
msg = re.escape("Call `enable_lora_hotswap` before loading the first adapter.")
with self.assertRaisesRegex(RuntimeError, msg):
- unet.enable_lora_hotswap(target_rank=32)
+ model.enable_lora_hotswap(target_rank=32)
def test_enable_lora_hotswap_called_after_adapter_added_warning(self):
# ensure that enable_lora_hotswap is called before loading the first adapter
from diffusers.loaders.peft import logger
- lora_config = self.get_unet_lora_config(8, 8, target_modules=["to_q"])
- unet = self.get_small_unet()
- unet.add_adapter(lora_config)
+ lora_config = self.get_lora_config(8, 8, target_modules=["to_q"])
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+ model = self.model_class(**init_dict).to(torch_device)
+ model.add_adapter(lora_config)
msg = (
"It is recommended to call `enable_lora_hotswap` before loading the first adapter to avoid recompilation."
)
with self.assertLogs(logger=logger, level="WARNING") as cm:
- unet.enable_lora_hotswap(target_rank=32, check_compiled="warn")
+ model.enable_lora_hotswap(target_rank=32, check_compiled="warn")
assert any(msg in log for log in cm.output)
def test_enable_lora_hotswap_called_after_adapter_added_ignore(self):
# check possibility to ignore the error/warning
- lora_config = self.get_unet_lora_config(8, 8, target_modules=["to_q"])
- unet = self.get_small_unet()
- unet.add_adapter(lora_config)
+ lora_config = self.get_lora_config(8, 8, target_modules=["to_q"])
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+ model = self.model_class(**init_dict).to(torch_device)
+ model.add_adapter(lora_config)
with warnings.catch_warnings(record=True) as w:
warnings.simplefilter("always") # Capture all warnings
- unet.enable_lora_hotswap(target_rank=32, check_compiled="warn")
+ model.enable_lora_hotswap(target_rank=32, check_compiled="warn")
self.assertEqual(len(w), 0, f"Expected no warnings, but got: {[str(warn.message) for warn in w]}")
def test_enable_lora_hotswap_wrong_check_compiled_argument_raises(self):
# check that wrong argument value raises an error
- lora_config = self.get_unet_lora_config(8, 8, target_modules=["to_q"])
- unet = self.get_small_unet()
- unet.add_adapter(lora_config)
+ lora_config = self.get_lora_config(8, 8, target_modules=["to_q"])
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+ model = self.model_class(**init_dict).to(torch_device)
+ model.add_adapter(lora_config)
msg = re.escape("check_compiles should be one of 'error', 'warn', or 'ignore', got 'wrong-argument' instead.")
with self.assertRaisesRegex(ValueError, msg):
- unet.enable_lora_hotswap(target_rank=32, check_compiled="wrong-argument")
+ model.enable_lora_hotswap(target_rank=32, check_compiled="wrong-argument")
def test_hotswap_second_adapter_targets_more_layers_raises(self):
# check the error and log
diff --git a/tests/models/test_models_auto.py b/tests/models/test_models_auto.py
new file mode 100644
index 0000000000..a70754343f
--- /dev/null
+++ b/tests/models/test_models_auto.py
@@ -0,0 +1,32 @@
+import unittest
+from unittest.mock import patch
+
+from transformers import CLIPTextModel, LongformerModel
+
+from diffusers.models import AutoModel, UNet2DConditionModel
+
+
+class TestAutoModel(unittest.TestCase):
+ @patch(
+ "diffusers.models.AutoModel.load_config",
+ side_effect=[EnvironmentError("File not found"), {"_class_name": "UNet2DConditionModel"}],
+ )
+ def test_load_from_config_diffusers_with_subfolder(self, mock_load_config):
+ model = AutoModel.from_pretrained("hf-internal-testing/tiny-stable-diffusion-torch", subfolder="unet")
+ assert isinstance(model, UNet2DConditionModel)
+
+ @patch(
+ "diffusers.models.AutoModel.load_config",
+ side_effect=[EnvironmentError("File not found"), {"model_type": "clip_text_model"}],
+ )
+ def test_load_from_config_transformers_with_subfolder(self, mock_load_config):
+ model = AutoModel.from_pretrained("hf-internal-testing/tiny-stable-diffusion-torch", subfolder="text_encoder")
+ assert isinstance(model, CLIPTextModel)
+
+ def test_load_from_config_without_subfolder(self):
+ model = AutoModel.from_pretrained("hf-internal-testing/tiny-random-longformer")
+ assert isinstance(model, LongformerModel)
+
+ def test_load_from_model_index(self):
+ model = AutoModel.from_pretrained("hf-internal-testing/tiny-stable-diffusion-torch", subfolder="text_encoder")
+ assert isinstance(model, CLIPTextModel)
diff --git a/tests/models/transformers/test_models_transformer_flux.py b/tests/models/transformers/test_models_transformer_flux.py
index f767d2196e..2a61d66135 100644
--- a/tests/models/transformers/test_models_transformer_flux.py
+++ b/tests/models/transformers/test_models_transformer_flux.py
@@ -22,7 +22,7 @@ from diffusers.models.attention_processor import FluxIPAdapterJointAttnProcessor
from diffusers.models.embeddings import ImageProjection
from diffusers.utils.testing_utils import enable_full_determinism, torch_device
-from ..test_modeling_common import ModelTesterMixin, TorchCompileTesterMixin
+from ..test_modeling_common import LoraHotSwappingForModelTesterMixin, ModelTesterMixin, TorchCompileTesterMixin
enable_full_determinism()
@@ -78,7 +78,9 @@ def create_flux_ip_adapter_state_dict(model):
return ip_state_dict
-class FluxTransformerTests(ModelTesterMixin, TorchCompileTesterMixin, unittest.TestCase):
+class FluxTransformerTests(
+ ModelTesterMixin, TorchCompileTesterMixin, LoraHotSwappingForModelTesterMixin, unittest.TestCase
+):
model_class = FluxTransformer2DModel
main_input_name = "hidden_states"
# We override the items here because the transformer under consideration is small.
diff --git a/tests/models/transformers/test_models_transformer_hidream.py b/tests/models/transformers/test_models_transformer_hidream.py
new file mode 100644
index 0000000000..fa0fa5123a
--- /dev/null
+++ b/tests/models/transformers/test_models_transformer_hidream.py
@@ -0,0 +1,96 @@
+# coding=utf-8
+# Copyright 2025 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import unittest
+
+import torch
+
+from diffusers import HiDreamImageTransformer2DModel
+from diffusers.utils.testing_utils import (
+ enable_full_determinism,
+ torch_device,
+)
+
+from ..test_modeling_common import ModelTesterMixin
+
+
+enable_full_determinism()
+
+
+class HiDreamTransformerTests(ModelTesterMixin, unittest.TestCase):
+ model_class = HiDreamImageTransformer2DModel
+ main_input_name = "hidden_states"
+ model_split_percents = [0.8, 0.8, 0.9]
+
+ @property
+ def dummy_input(self):
+ batch_size = 2
+ num_channels = 4
+ height = width = 32
+ embedding_dim_t5, embedding_dim_llama, embedding_dim_pooled = 8, 4, 8
+ sequence_length = 8
+
+ hidden_states = torch.randn((batch_size, num_channels, height, width)).to(torch_device)
+ encoder_hidden_states_t5 = torch.randn((batch_size, sequence_length, embedding_dim_t5)).to(torch_device)
+ encoder_hidden_states_llama3 = torch.randn((batch_size, batch_size, sequence_length, embedding_dim_llama)).to(
+ torch_device
+ )
+ pooled_embeds = torch.randn((batch_size, embedding_dim_pooled)).to(torch_device)
+ timesteps = torch.randint(0, 1000, size=(batch_size,)).to(torch_device)
+
+ return {
+ "hidden_states": hidden_states,
+ "encoder_hidden_states_t5": encoder_hidden_states_t5,
+ "encoder_hidden_states_llama3": encoder_hidden_states_llama3,
+ "pooled_embeds": pooled_embeds,
+ "timesteps": timesteps,
+ }
+
+ @property
+ def input_shape(self):
+ return (4, 32, 32)
+
+ @property
+ def output_shape(self):
+ return (4, 32, 32)
+
+ def prepare_init_args_and_inputs_for_common(self):
+ init_dict = {
+ "patch_size": 2,
+ "in_channels": 4,
+ "out_channels": 4,
+ "num_layers": 1,
+ "num_single_layers": 1,
+ "attention_head_dim": 8,
+ "num_attention_heads": 4,
+ "caption_channels": [8, 4],
+ "text_emb_dim": 8,
+ "num_routed_experts": 2,
+ "num_activated_experts": 2,
+ "axes_dims_rope": (4, 2, 2),
+ "max_resolution": (32, 32),
+ "llama_layers": (0, 1),
+ "force_inference_output": True, # TODO: as we don't implement MoE loss in training tests.
+ }
+ inputs_dict = self.dummy_input
+ return init_dict, inputs_dict
+
+ @unittest.skip("HiDreamImageTransformer2DModel uses a dedicated attention processor. This test doesn't apply")
+ def test_set_attn_processor_for_determinism(self):
+ pass
+
+ def test_gradient_checkpointing_is_applied(self):
+ expected_set = {"HiDreamImageTransformer2DModel"}
+ super().test_gradient_checkpointing_is_applied(expected_set=expected_set)
diff --git a/tests/models/transformers/test_models_transformer_hunyuan_video.py b/tests/models/transformers/test_models_transformer_hunyuan_video.py
index 0a91735216..5c83d22ab6 100644
--- a/tests/models/transformers/test_models_transformer_hunyuan_video.py
+++ b/tests/models/transformers/test_models_transformer_hunyuan_video.py
@@ -19,20 +19,16 @@ import torch
from diffusers import HunyuanVideoTransformer3DModel
from diffusers.utils.testing_utils import (
enable_full_determinism,
- is_torch_compile,
- require_torch_2,
- require_torch_gpu,
- slow,
torch_device,
)
-from ..test_modeling_common import ModelTesterMixin
+from ..test_modeling_common import ModelTesterMixin, TorchCompileTesterMixin
enable_full_determinism()
-class HunyuanVideoTransformer3DTests(ModelTesterMixin, unittest.TestCase):
+class HunyuanVideoTransformer3DTests(ModelTesterMixin, TorchCompileTesterMixin, unittest.TestCase):
model_class = HunyuanVideoTransformer3DModel
main_input_name = "hidden_states"
uses_custom_attn_processor = True
@@ -96,23 +92,8 @@ class HunyuanVideoTransformer3DTests(ModelTesterMixin, unittest.TestCase):
expected_set = {"HunyuanVideoTransformer3DModel"}
super().test_gradient_checkpointing_is_applied(expected_set=expected_set)
- @require_torch_gpu
- @require_torch_2
- @is_torch_compile
- @slow
- def test_torch_compile_recompilation_and_graph_break(self):
- torch._dynamo.reset()
- init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
- model = self.model_class(**init_dict).to(torch_device)
- model = torch.compile(model, fullgraph=True)
-
- with torch._dynamo.config.patch(error_on_recompile=True), torch.no_grad():
- _ = model(**inputs_dict)
- _ = model(**inputs_dict)
-
-
-class HunyuanSkyreelsImageToVideoTransformer3DTests(ModelTesterMixin, unittest.TestCase):
+class HunyuanSkyreelsImageToVideoTransformer3DTests(ModelTesterMixin, TorchCompileTesterMixin, unittest.TestCase):
model_class = HunyuanVideoTransformer3DModel
main_input_name = "hidden_states"
uses_custom_attn_processor = True
@@ -179,23 +160,8 @@ class HunyuanSkyreelsImageToVideoTransformer3DTests(ModelTesterMixin, unittest.T
expected_set = {"HunyuanVideoTransformer3DModel"}
super().test_gradient_checkpointing_is_applied(expected_set=expected_set)
- @require_torch_gpu
- @require_torch_2
- @is_torch_compile
- @slow
- def test_torch_compile_recompilation_and_graph_break(self):
- torch._dynamo.reset()
- init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
- model = self.model_class(**init_dict).to(torch_device)
- model = torch.compile(model, fullgraph=True)
-
- with torch._dynamo.config.patch(error_on_recompile=True), torch.no_grad():
- _ = model(**inputs_dict)
- _ = model(**inputs_dict)
-
-
-class HunyuanVideoImageToVideoTransformer3DTests(ModelTesterMixin, unittest.TestCase):
+class HunyuanVideoImageToVideoTransformer3DTests(ModelTesterMixin, TorchCompileTesterMixin, unittest.TestCase):
model_class = HunyuanVideoTransformer3DModel
main_input_name = "hidden_states"
uses_custom_attn_processor = True
@@ -260,23 +226,10 @@ class HunyuanVideoImageToVideoTransformer3DTests(ModelTesterMixin, unittest.Test
expected_set = {"HunyuanVideoTransformer3DModel"}
super().test_gradient_checkpointing_is_applied(expected_set=expected_set)
- @require_torch_gpu
- @require_torch_2
- @is_torch_compile
- @slow
- def test_torch_compile_recompilation_and_graph_break(self):
- torch._dynamo.reset()
- init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
- model = self.model_class(**init_dict).to(torch_device)
- model = torch.compile(model, fullgraph=True)
-
- with torch._dynamo.config.patch(error_on_recompile=True), torch.no_grad():
- _ = model(**inputs_dict)
- _ = model(**inputs_dict)
-
-
-class HunyuanVideoTokenReplaceImageToVideoTransformer3DTests(ModelTesterMixin, unittest.TestCase):
+class HunyuanVideoTokenReplaceImageToVideoTransformer3DTests(
+ ModelTesterMixin, TorchCompileTesterMixin, unittest.TestCase
+):
model_class = HunyuanVideoTransformer3DModel
main_input_name = "hidden_states"
uses_custom_attn_processor = True
@@ -342,18 +295,3 @@ class HunyuanVideoTokenReplaceImageToVideoTransformer3DTests(ModelTesterMixin, u
def test_gradient_checkpointing_is_applied(self):
expected_set = {"HunyuanVideoTransformer3DModel"}
super().test_gradient_checkpointing_is_applied(expected_set=expected_set)
-
- @require_torch_gpu
- @require_torch_2
- @is_torch_compile
- @slow
- def test_torch_compile_recompilation_and_graph_break(self):
- torch._dynamo.reset()
- init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
-
- model = self.model_class(**init_dict).to(torch_device)
- model = torch.compile(model, fullgraph=True)
-
- with torch._dynamo.config.patch(error_on_recompile=True), torch.no_grad():
- _ = model(**inputs_dict)
- _ = model(**inputs_dict)
diff --git a/tests/models/transformers/test_models_transformer_hunyuan_video_framepack.py b/tests/models/transformers/test_models_transformer_hunyuan_video_framepack.py
new file mode 100644
index 0000000000..5f485b210f
--- /dev/null
+++ b/tests/models/transformers/test_models_transformer_hunyuan_video_framepack.py
@@ -0,0 +1,116 @@
+# Copyright 2024 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import unittest
+
+import torch
+
+from diffusers import HunyuanVideoFramepackTransformer3DModel
+from diffusers.utils.testing_utils import (
+ enable_full_determinism,
+ torch_device,
+)
+
+from ..test_modeling_common import ModelTesterMixin
+
+
+enable_full_determinism()
+
+
+class HunyuanVideoTransformer3DTests(ModelTesterMixin, unittest.TestCase):
+ model_class = HunyuanVideoFramepackTransformer3DModel
+ main_input_name = "hidden_states"
+ uses_custom_attn_processor = True
+ model_split_percents = [0.5, 0.7, 0.9]
+
+ @property
+ def dummy_input(self):
+ batch_size = 1
+ num_channels = 4
+ num_frames = 3
+ height = 4
+ width = 4
+ text_encoder_embedding_dim = 16
+ image_encoder_embedding_dim = 16
+ pooled_projection_dim = 8
+ sequence_length = 12
+
+ hidden_states = torch.randn((batch_size, num_channels, num_frames, height, width)).to(torch_device)
+ encoder_hidden_states = torch.randn((batch_size, sequence_length, text_encoder_embedding_dim)).to(torch_device)
+ pooled_projections = torch.randn((batch_size, pooled_projection_dim)).to(torch_device)
+ encoder_attention_mask = torch.ones((batch_size, sequence_length)).to(torch_device)
+ image_embeds = torch.randn((batch_size, sequence_length, image_encoder_embedding_dim)).to(torch_device)
+ indices_latents = torch.ones((3,)).to(torch_device)
+ latents_clean = torch.randn((batch_size, num_channels, num_frames - 1, height, width)).to(torch_device)
+ indices_latents_clean = torch.ones((num_frames - 1,)).to(torch_device)
+ latents_history_2x = torch.randn((batch_size, num_channels, num_frames - 1, height, width)).to(torch_device)
+ indices_latents_history_2x = torch.ones((num_frames - 1,)).to(torch_device)
+ latents_history_4x = torch.randn((batch_size, num_channels, (num_frames - 1) * 4, height, width)).to(
+ torch_device
+ )
+ indices_latents_history_4x = torch.ones(((num_frames - 1) * 4,)).to(torch_device)
+ timestep = torch.randint(0, 1000, size=(batch_size,)).to(torch_device)
+ guidance = torch.randint(0, 1000, size=(batch_size,)).to(torch_device)
+
+ return {
+ "hidden_states": hidden_states,
+ "timestep": timestep,
+ "encoder_hidden_states": encoder_hidden_states,
+ "pooled_projections": pooled_projections,
+ "encoder_attention_mask": encoder_attention_mask,
+ "guidance": guidance,
+ "image_embeds": image_embeds,
+ "indices_latents": indices_latents,
+ "latents_clean": latents_clean,
+ "indices_latents_clean": indices_latents_clean,
+ "latents_history_2x": latents_history_2x,
+ "indices_latents_history_2x": indices_latents_history_2x,
+ "latents_history_4x": latents_history_4x,
+ "indices_latents_history_4x": indices_latents_history_4x,
+ }
+
+ @property
+ def input_shape(self):
+ return (4, 3, 4, 4)
+
+ @property
+ def output_shape(self):
+ return (4, 3, 4, 4)
+
+ def prepare_init_args_and_inputs_for_common(self):
+ init_dict = {
+ "in_channels": 4,
+ "out_channels": 4,
+ "num_attention_heads": 2,
+ "attention_head_dim": 10,
+ "num_layers": 1,
+ "num_single_layers": 1,
+ "num_refiner_layers": 1,
+ "patch_size": 2,
+ "patch_size_t": 1,
+ "guidance_embeds": True,
+ "text_embed_dim": 16,
+ "pooled_projection_dim": 8,
+ "rope_axes_dim": (2, 4, 4),
+ "image_condition_type": None,
+ "has_image_proj": True,
+ "image_proj_dim": 16,
+ "has_clean_x_embedder": True,
+ }
+ inputs_dict = self.dummy_input
+ return init_dict, inputs_dict
+
+ def test_gradient_checkpointing_is_applied(self):
+ expected_set = {"HunyuanVideoFramepackTransformer3DModel"}
+ super().test_gradient_checkpointing_is_applied(expected_set=expected_set)
diff --git a/tests/models/transformers/test_models_transformer_ltx.py b/tests/models/transformers/test_models_transformer_ltx.py
index 128bf04155..8649ce97a5 100644
--- a/tests/models/transformers/test_models_transformer_ltx.py
+++ b/tests/models/transformers/test_models_transformer_ltx.py
@@ -20,13 +20,13 @@ import torch
from diffusers import LTXVideoTransformer3DModel
from diffusers.utils.testing_utils import enable_full_determinism, torch_device
-from ..test_modeling_common import ModelTesterMixin
+from ..test_modeling_common import ModelTesterMixin, TorchCompileTesterMixin
enable_full_determinism()
-class LTXTransformerTests(ModelTesterMixin, unittest.TestCase):
+class LTXTransformerTests(ModelTesterMixin, TorchCompileTesterMixin, unittest.TestCase):
model_class = LTXVideoTransformer3DModel
main_input_name = "hidden_states"
uses_custom_attn_processor = True
diff --git a/tests/models/transformers/test_models_transformer_wan.py b/tests/models/transformers/test_models_transformer_wan.py
index 8270c2ee21..4eadb89236 100644
--- a/tests/models/transformers/test_models_transformer_wan.py
+++ b/tests/models/transformers/test_models_transformer_wan.py
@@ -19,20 +19,16 @@ import torch
from diffusers import WanTransformer3DModel
from diffusers.utils.testing_utils import (
enable_full_determinism,
- is_torch_compile,
- require_torch_2,
- require_torch_gpu,
- slow,
torch_device,
)
-from ..test_modeling_common import ModelTesterMixin
+from ..test_modeling_common import ModelTesterMixin, TorchCompileTesterMixin
enable_full_determinism()
-class WanTransformer3DTests(ModelTesterMixin, unittest.TestCase):
+class WanTransformer3DTests(ModelTesterMixin, TorchCompileTesterMixin, unittest.TestCase):
model_class = WanTransformer3DModel
main_input_name = "hidden_states"
uses_custom_attn_processor = True
@@ -86,18 +82,3 @@ class WanTransformer3DTests(ModelTesterMixin, unittest.TestCase):
def test_gradient_checkpointing_is_applied(self):
expected_set = {"WanTransformer3DModel"}
super().test_gradient_checkpointing_is_applied(expected_set=expected_set)
-
- @require_torch_gpu
- @require_torch_2
- @is_torch_compile
- @slow
- def test_torch_compile_recompilation_and_graph_break(self):
- torch._dynamo.reset()
- init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
-
- model = self.model_class(**init_dict).to(torch_device)
- model = torch.compile(model, fullgraph=True)
-
- with torch._dynamo.config.patch(error_on_recompile=True), torch.no_grad():
- _ = model(**inputs_dict)
- _ = model(**inputs_dict)
diff --git a/tests/models/unets/test_models_unet_2d_condition.py b/tests/models/unets/test_models_unet_2d_condition.py
index d01a0b4935..24d944bbf9 100644
--- a/tests/models/unets/test_models_unet_2d_condition.py
+++ b/tests/models/unets/test_models_unet_2d_condition.py
@@ -53,7 +53,12 @@ from diffusers.utils.testing_utils import (
torch_device,
)
-from ..test_modeling_common import ModelTesterMixin, UNetTesterMixin
+from ..test_modeling_common import (
+ LoraHotSwappingForModelTesterMixin,
+ ModelTesterMixin,
+ TorchCompileTesterMixin,
+ UNetTesterMixin,
+)
if is_peft_available():
@@ -350,7 +355,9 @@ def create_custom_diffusion_layers(model, mock_weights: bool = True):
return custom_diffusion_attn_procs
-class UNet2DConditionModelTests(ModelTesterMixin, UNetTesterMixin, unittest.TestCase):
+class UNet2DConditionModelTests(
+ ModelTesterMixin, TorchCompileTesterMixin, LoraHotSwappingForModelTesterMixin, UNetTesterMixin, unittest.TestCase
+):
model_class = UNet2DConditionModel
main_input_name = "sample"
# We override the items here because the unet under consideration is small.
diff --git a/tests/pipelines/cogvideo/test_cogvideox_image2video.py b/tests/pipelines/cogvideo/test_cogvideox_image2video.py
index ec4e51bd1b..c2e7d0cdbf 100644
--- a/tests/pipelines/cogvideo/test_cogvideox_image2video.py
+++ b/tests/pipelines/cogvideo/test_cogvideox_image2video.py
@@ -270,7 +270,7 @@ class CogVideoXImageToVideoPipelineFastTests(PipelineTesterMixin, unittest.TestC
generator_device = "cpu"
components = self.get_dummy_components()
- # The reason to modify it this way is because I2V Transformer limits the generation to resolutions used during initalization.
+ # The reason to modify it this way is because I2V Transformer limits the generation to resolutions used during initialization.
# This limitation comes from using learned positional embeddings which cannot be generated on-the-fly like sincos or RoPE embeddings.
# See the if-statement on "self.use_learned_positional_embeddings" in diffusers/models/embeddings.py
components["transformer"] = CogVideoXTransformer3DModel.from_config(
diff --git a/tests/pipelines/consisid/test_consisid.py b/tests/pipelines/consisid/test_consisid.py
index a39c17bb4f..9e158b6b06 100644
--- a/tests/pipelines/consisid/test_consisid.py
+++ b/tests/pipelines/consisid/test_consisid.py
@@ -24,9 +24,10 @@ from transformers import AutoTokenizer, T5EncoderModel
from diffusers import AutoencoderKLCogVideoX, ConsisIDPipeline, ConsisIDTransformer3DModel, DDIMScheduler
from diffusers.utils import load_image
from diffusers.utils.testing_utils import (
+ backend_empty_cache,
enable_full_determinism,
numpy_cosine_similarity_distance,
- require_torch_gpu,
+ require_torch_accelerator,
slow,
torch_device,
)
@@ -279,7 +280,7 @@ class ConsisIDPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
generator_device = "cpu"
components = self.get_dummy_components()
- # The reason to modify it this way is because ConsisID Transformer limits the generation to resolutions used during initalization.
+ # The reason to modify it this way is because ConsisID Transformer limits the generation to resolutions used during initialization.
# This limitation comes from using learned positional embeddings which cannot be generated on-the-fly like sincos or RoPE embeddings.
# See the if-statement on "self.use_learned_positional_embeddings" in diffusers/models/embeddings.py
components["transformer"] = ConsisIDTransformer3DModel.from_config(
@@ -316,19 +317,19 @@ class ConsisIDPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
@slow
-@require_torch_gpu
+@require_torch_accelerator
class ConsisIDPipelineIntegrationTests(unittest.TestCase):
prompt = "A painting of a squirrel eating a burger."
def setUp(self):
super().setUp()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def tearDown(self):
super().tearDown()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def test_consisid(self):
generator = torch.Generator("cpu").manual_seed(0)
@@ -338,8 +339,8 @@ class ConsisIDPipelineIntegrationTests(unittest.TestCase):
prompt = self.prompt
image = load_image("https://github.com/PKU-YuanGroup/ConsisID/blob/main/asserts/example_images/2.png?raw=true")
- id_vit_hidden = [torch.ones([1, 2, 2])] * 1
- id_cond = torch.ones(1, 2)
+ id_vit_hidden = [torch.ones([1, 577, 1024])] * 5
+ id_cond = torch.ones(1, 1280)
videos = pipe(
image=image,
@@ -357,5 +358,5 @@ class ConsisIDPipelineIntegrationTests(unittest.TestCase):
video = videos[0]
expected_video = torch.randn(1, 16, 480, 720, 3).numpy()
- max_diff = numpy_cosine_similarity_distance(video, expected_video)
+ max_diff = numpy_cosine_similarity_distance(video.cpu(), expected_video)
assert max_diff < 1e-3, f"Max diff is too high. got {video}"
diff --git a/tests/pipelines/controlnet/test_controlnet.py b/tests/pipelines/controlnet/test_controlnet.py
index bb21c9ac8d..a2951a8b46 100644
--- a/tests/pipelines/controlnet/test_controlnet.py
+++ b/tests/pipelines/controlnet/test_controlnet.py
@@ -15,7 +15,6 @@
import gc
import tempfile
-import traceback
import unittest
import numpy as np
@@ -39,13 +38,9 @@ from diffusers.utils.testing_utils import (
backend_reset_max_memory_allocated,
backend_reset_peak_memory_stats,
enable_full_determinism,
- get_python_version,
- is_torch_compile,
load_image,
load_numpy,
- require_torch_2,
require_torch_accelerator,
- run_test_in_subprocess,
slow,
torch_device,
)
@@ -68,52 +63,6 @@ from ..test_pipelines_common import (
enable_full_determinism()
-# Will be run via run_test_in_subprocess
-def _test_stable_diffusion_compile(in_queue, out_queue, timeout):
- error = None
- try:
- _ = in_queue.get(timeout=timeout)
-
- controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny")
-
- pipe = StableDiffusionControlNetPipeline.from_pretrained(
- "stable-diffusion-v1-5/stable-diffusion-v1-5", safety_checker=None, controlnet=controlnet
- )
- pipe.to(torch_device)
- pipe.set_progress_bar_config(disable=None)
-
- pipe.unet.to(memory_format=torch.channels_last)
- pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
-
- pipe.controlnet.to(memory_format=torch.channels_last)
- pipe.controlnet = torch.compile(pipe.controlnet, mode="reduce-overhead", fullgraph=True)
-
- generator = torch.Generator(device="cpu").manual_seed(0)
- prompt = "bird"
- image = load_image(
- "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/bird_canny.png"
- ).resize((512, 512))
-
- output = pipe(prompt, image, num_inference_steps=10, generator=generator, output_type="np")
- image = output.images[0]
-
- assert image.shape == (512, 512, 3)
-
- expected_image = load_numpy(
- "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/bird_canny_out_full.npy"
- )
- expected_image = np.resize(expected_image, (512, 512, 3))
-
- assert np.abs(expected_image - image).max() < 1.0
-
- except Exception:
- error = f"{traceback.format_exc()}"
-
- results = {"error": error}
- out_queue.put(results, timeout=timeout)
- out_queue.join()
-
-
class ControlNetPipelineFastTests(
IPAdapterTesterMixin,
PipelineLatentTesterMixin,
@@ -1053,15 +1002,6 @@ class ControlNetPipelineSlowTests(unittest.TestCase):
expected_slice = np.array([0.1655, 0.1721, 0.1623, 0.1685, 0.1711, 0.1646, 0.1651, 0.1631, 0.1494])
assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
- @is_torch_compile
- @require_torch_2
- @unittest.skipIf(
- get_python_version == (3, 12),
- reason="Torch Dynamo isn't yet supported for Python 3.12.",
- )
- def test_stable_diffusion_compile(self):
- run_test_in_subprocess(test_case=self, target_func=_test_stable_diffusion_compile, inputs=None)
-
def test_v11_shuffle_global_pool_conditions(self):
controlnet = ControlNetModel.from_pretrained("lllyasviel/control_v11e_sd15_shuffle")
diff --git a/tests/pipelines/controlnet_xs/test_controlnetxs.py b/tests/pipelines/controlnet_xs/test_controlnetxs.py
index 74af4b6775..6f8422797c 100644
--- a/tests/pipelines/controlnet_xs/test_controlnetxs.py
+++ b/tests/pipelines/controlnet_xs/test_controlnetxs.py
@@ -14,7 +14,6 @@
# limitations under the License.
import gc
-import traceback
import unittest
import numpy as np
@@ -36,13 +35,9 @@ from diffusers.utils.import_utils import is_xformers_available
from diffusers.utils.testing_utils import (
backend_empty_cache,
enable_full_determinism,
- is_torch_compile,
load_image,
- load_numpy,
require_accelerator,
- require_torch_2,
require_torch_accelerator,
- run_test_in_subprocess,
slow,
torch_device,
)
@@ -78,53 +73,6 @@ def to_np(tensor):
return tensor
-# Will be run via run_test_in_subprocess
-def _test_stable_diffusion_compile(in_queue, out_queue, timeout):
- error = None
- try:
- _ = in_queue.get(timeout=timeout)
-
- controlnet = ControlNetXSAdapter.from_pretrained(
- "UmerHA/Testing-ConrolNetXS-SD2.1-canny", torch_dtype=torch.float16
- )
- pipe = StableDiffusionControlNetXSPipeline.from_pretrained(
- "stabilityai/stable-diffusion-2-1-base",
- controlnet=controlnet,
- safety_checker=None,
- torch_dtype=torch.float16,
- )
- pipe.to(torch_device)
- pipe.set_progress_bar_config(disable=None)
-
- pipe.unet.to(memory_format=torch.channels_last)
- pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
-
- generator = torch.Generator(device="cpu").manual_seed(0)
- prompt = "bird"
- image = load_image(
- "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/bird_canny.png"
- ).resize((512, 512))
-
- output = pipe(prompt, image, num_inference_steps=10, generator=generator, output_type="np")
- image = output.images[0]
-
- assert image.shape == (512, 512, 3)
-
- expected_image = load_numpy(
- "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/bird_canny_out_full.npy"
- )
- expected_image = np.resize(expected_image, (512, 512, 3))
-
- assert np.abs(expected_image - image).max() < 1.0
-
- except Exception:
- error = f"{traceback.format_exc()}"
-
- results = {"error": error}
- out_queue.put(results, timeout=timeout)
- out_queue.join()
-
-
class ControlNetXSPipelineFastTests(
PipelineLatentTesterMixin,
PipelineKarrasSchedulerTesterMixin,
@@ -402,8 +350,3 @@ class ControlNetXSPipelineSlowTests(unittest.TestCase):
original_image = image[-3:, -3:, -1].flatten()
expected_image = np.array([0.4844, 0.4937, 0.4956, 0.4663, 0.5039, 0.5044, 0.4565, 0.4883, 0.4941])
assert np.allclose(original_image, expected_image, atol=1e-04)
-
- @is_torch_compile
- @require_torch_2
- def test_stable_diffusion_compile(self):
- run_test_in_subprocess(test_case=self, target_func=_test_stable_diffusion_compile, inputs=None)
diff --git a/tests/pipelines/dance_diffusion/test_dance_diffusion.py b/tests/pipelines/dance_diffusion/test_dance_diffusion.py
index 1f60c0b421..881946e6a0 100644
--- a/tests/pipelines/dance_diffusion/test_dance_diffusion.py
+++ b/tests/pipelines/dance_diffusion/test_dance_diffusion.py
@@ -20,7 +20,14 @@ import numpy as np
import torch
from diffusers import DanceDiffusionPipeline, IPNDMScheduler, UNet1DModel
-from diffusers.utils.testing_utils import enable_full_determinism, nightly, require_torch_gpu, skip_mps, torch_device
+from diffusers.utils.testing_utils import (
+ backend_empty_cache,
+ enable_full_determinism,
+ nightly,
+ require_torch_accelerator,
+ skip_mps,
+ torch_device,
+)
from ..pipeline_params import UNCONDITIONAL_AUDIO_GENERATION_BATCH_PARAMS, UNCONDITIONAL_AUDIO_GENERATION_PARAMS
from ..test_pipelines_common import PipelineTesterMixin
@@ -116,19 +123,19 @@ class DanceDiffusionPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
@nightly
-@require_torch_gpu
+@require_torch_accelerator
class PipelineIntegrationTests(unittest.TestCase):
def setUp(self):
# clean up the VRAM before each test
super().setUp()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def tearDown(self):
# clean up the VRAM after each test
super().tearDown()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def test_dance_diffusion(self):
device = torch_device
diff --git a/tests/pipelines/dit/test_dit.py b/tests/pipelines/dit/test_dit.py
index 18732c0058..65f39db078 100644
--- a/tests/pipelines/dit/test_dit.py
+++ b/tests/pipelines/dit/test_dit.py
@@ -21,7 +21,15 @@ import torch
from diffusers import AutoencoderKL, DDIMScheduler, DiTPipeline, DiTTransformer2DModel, DPMSolverMultistepScheduler
from diffusers.utils import is_xformers_available
-from diffusers.utils.testing_utils import enable_full_determinism, load_numpy, nightly, require_torch_gpu, torch_device
+from diffusers.utils.testing_utils import (
+ backend_empty_cache,
+ enable_full_determinism,
+ load_numpy,
+ nightly,
+ numpy_cosine_similarity_distance,
+ require_torch_accelerator,
+ torch_device,
+)
from ..pipeline_params import (
CLASS_CONDITIONED_IMAGE_GENERATION_BATCH_PARAMS,
@@ -107,23 +115,23 @@ class DiTPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
@nightly
-@require_torch_gpu
+@require_torch_accelerator
class DiTPipelineIntegrationTests(unittest.TestCase):
def setUp(self):
super().setUp()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def tearDown(self):
super().tearDown()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def test_dit_256(self):
generator = torch.manual_seed(0)
pipe = DiTPipeline.from_pretrained("facebook/DiT-XL-2-256")
- pipe.to("cuda")
+ pipe.to(torch_device)
words = ["vase", "umbrella", "white shark", "white wolf"]
ids = pipe.get_label_ids(words)
@@ -139,7 +147,7 @@ class DiTPipelineIntegrationTests(unittest.TestCase):
def test_dit_512(self):
pipe = DiTPipeline.from_pretrained("facebook/DiT-XL-2-512")
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
- pipe.to("cuda")
+ pipe.to(torch_device)
words = ["vase", "umbrella"]
ids = pipe.get_label_ids(words)
@@ -152,4 +160,7 @@ class DiTPipelineIntegrationTests(unittest.TestCase):
f"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/dit/{word}_512.npy"
)
- assert np.abs((expected_image - image).max()) < 1e-1
+ expected_slice = expected_image.flatten()
+ output_slice = image.flatten()
+
+ assert numpy_cosine_similarity_distance(expected_slice, output_slice) < 1e-2
diff --git a/tests/pipelines/easyanimate/test_easyanimate.py b/tests/pipelines/easyanimate/test_easyanimate.py
index 13d5c2f49b..161734a166 100644
--- a/tests/pipelines/easyanimate/test_easyanimate.py
+++ b/tests/pipelines/easyanimate/test_easyanimate.py
@@ -27,9 +27,10 @@ from diffusers import (
FlowMatchEulerDiscreteScheduler,
)
from diffusers.utils.testing_utils import (
+ backend_empty_cache,
enable_full_determinism,
numpy_cosine_similarity_distance,
- require_torch_gpu,
+ require_torch_accelerator,
slow,
torch_device,
)
@@ -256,19 +257,19 @@ class EasyAnimatePipelineFastTests(PipelineTesterMixin, unittest.TestCase):
@slow
-@require_torch_gpu
+@require_torch_accelerator
class EasyAnimatePipelineIntegrationTests(unittest.TestCase):
prompt = "A painting of a squirrel eating a burger."
def setUp(self):
super().setUp()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def tearDown(self):
super().tearDown()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def test_EasyAnimate(self):
generator = torch.Generator("cpu").manual_seed(0)
diff --git a/tests/pipelines/kandinsky2_2/test_kandinsky_controlnet.py b/tests/pipelines/kandinsky2_2/test_kandinsky_controlnet.py
index 10a95d6177..6454152b7a 100644
--- a/tests/pipelines/kandinsky2_2/test_kandinsky_controlnet.py
+++ b/tests/pipelines/kandinsky2_2/test_kandinsky_controlnet.py
@@ -28,13 +28,15 @@ from diffusers import (
VQModel,
)
from diffusers.utils.testing_utils import (
+ backend_empty_cache,
enable_full_determinism,
floats_tensor,
load_image,
load_numpy,
nightly,
numpy_cosine_similarity_distance,
- require_torch_gpu,
+ require_torch_accelerator,
+ torch_device,
)
from ..test_pipelines_common import PipelineTesterMixin
@@ -226,19 +228,19 @@ class KandinskyV22ControlnetPipelineFastTests(PipelineTesterMixin, unittest.Test
@nightly
-@require_torch_gpu
+@require_torch_accelerator
class KandinskyV22ControlnetPipelineIntegrationTests(unittest.TestCase):
def setUp(self):
# clean up the VRAM before each test
super().setUp()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def tearDown(self):
# clean up the VRAM after each test
super().tearDown()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def test_kandinsky_controlnet(self):
expected_image = load_numpy(
diff --git a/tests/pipelines/kandinsky2_2/test_kandinsky_controlnet_img2img.py b/tests/pipelines/kandinsky2_2/test_kandinsky_controlnet_img2img.py
index 58fbbecc05..c99b7b738a 100644
--- a/tests/pipelines/kandinsky2_2/test_kandinsky_controlnet_img2img.py
+++ b/tests/pipelines/kandinsky2_2/test_kandinsky_controlnet_img2img.py
@@ -29,13 +29,15 @@ from diffusers import (
VQModel,
)
from diffusers.utils.testing_utils import (
+ backend_empty_cache,
enable_full_determinism,
floats_tensor,
load_image,
load_numpy,
nightly,
numpy_cosine_similarity_distance,
- require_torch_gpu,
+ require_torch_accelerator,
+ torch_device,
)
from ..test_pipelines_common import PipelineTesterMixin
@@ -233,19 +235,19 @@ class KandinskyV22ControlnetImg2ImgPipelineFastTests(PipelineTesterMixin, unitte
@nightly
-@require_torch_gpu
+@require_torch_accelerator
class KandinskyV22ControlnetImg2ImgPipelineIntegrationTests(unittest.TestCase):
def setUp(self):
# clean up the VRAM before each test
super().setUp()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def tearDown(self):
# clean up the VRAM after each test
super().tearDown()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def test_kandinsky_controlnet_img2img(self):
expected_image = load_numpy(
@@ -309,4 +311,4 @@ class KandinskyV22ControlnetImg2ImgPipelineIntegrationTests(unittest.TestCase):
assert image.shape == (512, 512, 3)
max_diff = numpy_cosine_similarity_distance(expected_image.flatten(), image.flatten())
- assert max_diff < 1e-4
+ assert max_diff < 5e-4
diff --git a/tests/pipelines/kolors/test_kolors_img2img.py b/tests/pipelines/kolors/test_kolors_img2img.py
index 89da95753a..f3caed704a 100644
--- a/tests/pipelines/kolors/test_kolors_img2img.py
+++ b/tests/pipelines/kolors/test_kolors_img2img.py
@@ -155,6 +155,6 @@ class KolorsPipelineImg2ImgFastTests(PipelineTesterMixin, unittest.TestCase):
def test_float16_inference(self):
super().test_float16_inference(expected_max_diff=7e-2)
- @unittest.skip("Test not supported because kolors img2img doesn't take pooled embeds as inputs unline kolors t2i.")
+ @unittest.skip("Test not supported because kolors img2img doesn't take pooled embeds as inputs unlike kolors t2i.")
def test_encode_prompt_works_in_isolation(self):
pass
diff --git a/tests/pipelines/latent_diffusion/test_latent_diffusion.py b/tests/pipelines/latent_diffusion/test_latent_diffusion.py
index e751240e43..245116d5fa 100644
--- a/tests/pipelines/latent_diffusion/test_latent_diffusion.py
+++ b/tests/pipelines/latent_diffusion/test_latent_diffusion.py
@@ -22,10 +22,11 @@ from transformers import CLIPTextConfig, CLIPTextModel, CLIPTokenizer
from diffusers import AutoencoderKL, DDIMScheduler, LDMTextToImagePipeline, UNet2DConditionModel
from diffusers.utils.testing_utils import (
+ backend_empty_cache,
enable_full_determinism,
load_numpy,
nightly,
- require_torch_gpu,
+ require_torch_accelerator,
torch_device,
)
@@ -136,17 +137,17 @@ class LDMTextToImagePipelineFastTests(PipelineTesterMixin, unittest.TestCase):
@nightly
-@require_torch_gpu
+@require_torch_accelerator
class LDMTextToImagePipelineSlowTests(unittest.TestCase):
def setUp(self):
super().setUp()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def tearDown(self):
super().tearDown()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def get_inputs(self, device, dtype=torch.float32, seed=0):
generator = torch.manual_seed(seed)
@@ -177,17 +178,17 @@ class LDMTextToImagePipelineSlowTests(unittest.TestCase):
@nightly
-@require_torch_gpu
+@require_torch_accelerator
class LDMTextToImagePipelineNightlyTests(unittest.TestCase):
def setUp(self):
super().setUp()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def tearDown(self):
super().tearDown()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def get_inputs(self, device, dtype=torch.float32, seed=0):
generator = torch.manual_seed(seed)
diff --git a/tests/pipelines/ltx/test_ltx_image2video.py b/tests/pipelines/ltx/test_ltx_image2video.py
index 1c3e018a8a..6c425a2e3f 100644
--- a/tests/pipelines/ltx/test_ltx_image2video.py
+++ b/tests/pipelines/ltx/test_ltx_image2video.py
@@ -109,7 +109,7 @@ class LTXImageToVideoPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
else:
generator = torch.Generator(device=device).manual_seed(seed)
- image = torch.randn((1, 3, 32, 32), generator=generator, device=device)
+ image = torch.rand((1, 3, 32, 32), generator=generator, device=device)
inputs = {
"image": image,
@@ -142,7 +142,7 @@ class LTXImageToVideoPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
self.assertEqual(generated_video.shape, (9, 3, 32, 32))
expected_video = torch.randn(9, 3, 32, 32)
- max_diff = np.abs(generated_video - expected_video).max()
+ max_diff = torch.amax(torch.abs(generated_video - expected_video))
self.assertLessEqual(max_diff, 1e10)
def test_callback_inputs(self):
diff --git a/tests/pipelines/ltx/test_ltx_latent_upsample.py b/tests/pipelines/ltx/test_ltx_latent_upsample.py
new file mode 100644
index 0000000000..f9ddb12186
--- /dev/null
+++ b/tests/pipelines/ltx/test_ltx_latent_upsample.py
@@ -0,0 +1,159 @@
+# Copyright 2025 The HuggingFace Team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import unittest
+
+import numpy as np
+import torch
+
+from diffusers import AutoencoderKLLTXVideo, LTXLatentUpsamplePipeline
+from diffusers.pipelines.ltx.modeling_latent_upsampler import LTXLatentUpsamplerModel
+from diffusers.utils.testing_utils import enable_full_determinism
+
+from ..test_pipelines_common import PipelineTesterMixin, to_np
+
+
+enable_full_determinism()
+
+
+class LTXLatentUpsamplePipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = LTXLatentUpsamplePipeline
+ params = {"video", "generator"}
+ batch_params = {"video", "generator"}
+ required_optional_params = frozenset(["generator", "latents", "return_dict"])
+ test_xformers_attention = False
+ supports_dduf = False
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ vae = AutoencoderKLLTXVideo(
+ in_channels=3,
+ out_channels=3,
+ latent_channels=8,
+ block_out_channels=(8, 8, 8, 8),
+ decoder_block_out_channels=(8, 8, 8, 8),
+ layers_per_block=(1, 1, 1, 1, 1),
+ decoder_layers_per_block=(1, 1, 1, 1, 1),
+ spatio_temporal_scaling=(True, True, False, False),
+ decoder_spatio_temporal_scaling=(True, True, False, False),
+ decoder_inject_noise=(False, False, False, False, False),
+ upsample_residual=(False, False, False, False),
+ upsample_factor=(1, 1, 1, 1),
+ timestep_conditioning=False,
+ patch_size=1,
+ patch_size_t=1,
+ encoder_causal=True,
+ decoder_causal=False,
+ )
+ vae.use_framewise_encoding = False
+ vae.use_framewise_decoding = False
+
+ torch.manual_seed(0)
+ latent_upsampler = LTXLatentUpsamplerModel(
+ in_channels=8,
+ mid_channels=32,
+ num_blocks_per_stage=1,
+ dims=3,
+ spatial_upsample=True,
+ temporal_upsample=False,
+ )
+
+ components = {
+ "vae": vae,
+ "latent_upsampler": latent_upsampler,
+ }
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+
+ video = torch.randn((5, 3, 32, 32), generator=generator, device=device)
+
+ inputs = {
+ "video": video,
+ "generator": generator,
+ "height": 16,
+ "width": 16,
+ "output_type": "pt",
+ }
+
+ return inputs
+
+ def test_inference(self):
+ device = "cpu"
+
+ components = self.get_dummy_components()
+ pipe = self.pipeline_class(**components)
+ pipe.to(device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ video = pipe(**inputs).frames
+ generated_video = video[0]
+
+ self.assertEqual(generated_video.shape, (5, 3, 32, 32))
+ expected_video = torch.randn(5, 3, 32, 32)
+ max_diff = np.abs(generated_video - expected_video).max()
+ self.assertLessEqual(max_diff, 1e10)
+
+ def test_vae_tiling(self, expected_diff_max: float = 0.25):
+ generator_device = "cpu"
+ components = self.get_dummy_components()
+
+ pipe = self.pipeline_class(**components)
+ pipe.to("cpu")
+ pipe.set_progress_bar_config(disable=None)
+
+ # Without tiling
+ inputs = self.get_dummy_inputs(generator_device)
+ inputs["height"] = inputs["width"] = 128
+ output_without_tiling = pipe(**inputs)[0]
+
+ # With tiling
+ pipe.vae.enable_tiling(
+ tile_sample_min_height=96,
+ tile_sample_min_width=96,
+ tile_sample_stride_height=64,
+ tile_sample_stride_width=64,
+ )
+ inputs = self.get_dummy_inputs(generator_device)
+ inputs["height"] = inputs["width"] = 128
+ output_with_tiling = pipe(**inputs)[0]
+
+ self.assertLess(
+ (to_np(output_without_tiling) - to_np(output_with_tiling)).max(),
+ expected_diff_max,
+ "VAE tiling should not affect the inference results",
+ )
+
+ @unittest.skip("Test is not applicable.")
+ def test_callback_inputs(self):
+ pass
+
+ @unittest.skip("Test is not applicable.")
+ def test_attention_slicing_forward_pass(
+ self, test_max_difference=True, test_mean_pixel_difference=True, expected_max_diff=1e-3
+ ):
+ pass
+
+ @unittest.skip("Test is not applicable.")
+ def test_inference_batch_consistent(self):
+ pass
+
+ @unittest.skip("Test is not applicable.")
+ def test_inference_batch_single_identical(self):
+ pass
diff --git a/tests/pipelines/mochi/test_mochi.py b/tests/pipelines/mochi/test_mochi.py
index ea2d015af5..55b0efbe60 100644
--- a/tests/pipelines/mochi/test_mochi.py
+++ b/tests/pipelines/mochi/test_mochi.py
@@ -27,8 +27,8 @@ from diffusers.utils.testing_utils import (
enable_full_determinism,
nightly,
numpy_cosine_similarity_distance,
- require_big_gpu_with_torch_cuda,
- require_torch_gpu,
+ require_big_accelerator,
+ require_torch_accelerator,
torch_device,
)
@@ -266,9 +266,9 @@ class MochiPipelineFastTests(PipelineTesterMixin, FasterCacheTesterMixin, unitte
@nightly
-@require_torch_gpu
-@require_big_gpu_with_torch_cuda
-@pytest.mark.big_gpu_with_torch_cuda
+@require_torch_accelerator
+@require_big_accelerator
+@pytest.mark.big_accelerator
class MochiPipelineIntegrationTests(unittest.TestCase):
prompt = "A painting of a squirrel eating a burger."
@@ -302,5 +302,5 @@ class MochiPipelineIntegrationTests(unittest.TestCase):
video = videos[0]
expected_video = torch.randn(1, 19, 480, 848, 3).numpy()
- max_diff = numpy_cosine_similarity_distance(video, expected_video)
+ max_diff = numpy_cosine_similarity_distance(video.cpu(), expected_video)
assert max_diff < 1e-3, f"Max diff is too high. got {video}"
diff --git a/tests/pipelines/musicldm/test_musicldm.py b/tests/pipelines/musicldm/test_musicldm.py
index bdd536b6ff..7f553e919c 100644
--- a/tests/pipelines/musicldm/test_musicldm.py
+++ b/tests/pipelines/musicldm/test_musicldm.py
@@ -39,7 +39,13 @@ from diffusers import (
UNet2DConditionModel,
)
from diffusers.utils import is_xformers_available
-from diffusers.utils.testing_utils import enable_full_determinism, nightly, require_torch_gpu, torch_device
+from diffusers.utils.testing_utils import (
+ backend_empty_cache,
+ enable_full_determinism,
+ nightly,
+ require_torch_accelerator,
+ torch_device,
+)
from ..pipeline_params import TEXT_TO_AUDIO_BATCH_PARAMS, TEXT_TO_AUDIO_PARAMS
from ..test_pipelines_common import PipelineTesterMixin
@@ -408,17 +414,17 @@ class MusicLDMPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
@nightly
-@require_torch_gpu
+@require_torch_accelerator
class MusicLDMPipelineNightlyTests(unittest.TestCase):
def setUp(self):
super().setUp()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def tearDown(self):
super().tearDown()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def get_inputs(self, device, generator_device="cpu", dtype=torch.float32, seed=0):
generator = torch.Generator(device=generator_device).manual_seed(seed)
diff --git a/tests/pipelines/omnigen/test_pipeline_omnigen.py b/tests/pipelines/omnigen/test_pipeline_omnigen.py
index 2f9c4d4e3f..e8f84eb913 100644
--- a/tests/pipelines/omnigen/test_pipeline_omnigen.py
+++ b/tests/pipelines/omnigen/test_pipeline_omnigen.py
@@ -7,8 +7,10 @@ from transformers import AutoTokenizer
from diffusers import AutoencoderKL, FlowMatchEulerDiscreteScheduler, OmniGenPipeline, OmniGenTransformer2DModel
from diffusers.utils.testing_utils import (
+ Expectations,
+ backend_empty_cache,
numpy_cosine_similarity_distance,
- require_torch_gpu,
+ require_torch_accelerator,
slow,
torch_device,
)
@@ -87,7 +89,7 @@ class OmniGenPipelineFastTests(unittest.TestCase, PipelineTesterMixin):
@slow
-@require_torch_gpu
+@require_torch_accelerator
class OmniGenPipelineSlowTests(unittest.TestCase):
pipeline_class = OmniGenPipeline
repo_id = "shitao/OmniGen-v1-diffusers"
@@ -95,12 +97,12 @@ class OmniGenPipelineSlowTests(unittest.TestCase):
def setUp(self):
super().setUp()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def tearDown(self):
super().tearDown()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def get_inputs(self, device, seed=0):
if str(device).startswith("mps"):
@@ -125,21 +127,56 @@ class OmniGenPipelineSlowTests(unittest.TestCase):
image = pipe(**inputs).images[0]
image_slice = image[0, :10, :10]
- expected_slice = np.array(
- [
- [0.1783447, 0.16772744, 0.14339337],
- [0.17066911, 0.15521264, 0.13757327],
- [0.17072496, 0.15531206, 0.13524258],
- [0.16746324, 0.1564025, 0.13794944],
- [0.16490817, 0.15258026, 0.13697758],
- [0.16971767, 0.15826806, 0.13928896],
- [0.16782972, 0.15547255, 0.13783783],
- [0.16464645, 0.15281534, 0.13522372],
- [0.16535294, 0.15301755, 0.13526791],
- [0.16365296, 0.15092957, 0.13443318],
- ],
- dtype=np.float32,
+ expected_slices = Expectations(
+ {
+ ("xpu", 3): np.array(
+ [
+ [0.05859375, 0.05859375, 0.04492188],
+ [0.04882812, 0.04101562, 0.03320312],
+ [0.04882812, 0.04296875, 0.03125],
+ [0.04296875, 0.0390625, 0.03320312],
+ [0.04296875, 0.03710938, 0.03125],
+ [0.04492188, 0.0390625, 0.03320312],
+ [0.04296875, 0.03710938, 0.03125],
+ [0.04101562, 0.03710938, 0.02734375],
+ [0.04101562, 0.03515625, 0.02734375],
+ [0.04101562, 0.03515625, 0.02929688],
+ ],
+ dtype=np.float32,
+ ),
+ ("cuda", 7): np.array(
+ [
+ [0.1783447, 0.16772744, 0.14339337],
+ [0.17066911, 0.15521264, 0.13757327],
+ [0.17072496, 0.15531206, 0.13524258],
+ [0.16746324, 0.1564025, 0.13794944],
+ [0.16490817, 0.15258026, 0.13697758],
+ [0.16971767, 0.15826806, 0.13928896],
+ [0.16782972, 0.15547255, 0.13783783],
+ [0.16464645, 0.15281534, 0.13522372],
+ [0.16535294, 0.15301755, 0.13526791],
+ [0.16365296, 0.15092957, 0.13443318],
+ ],
+ dtype=np.float32,
+ ),
+ ("cuda", 8): np.array(
+ [
+ [0.0546875, 0.05664062, 0.04296875],
+ [0.046875, 0.04101562, 0.03320312],
+ [0.05078125, 0.04296875, 0.03125],
+ [0.04296875, 0.04101562, 0.03320312],
+ [0.0390625, 0.03710938, 0.02929688],
+ [0.04296875, 0.03710938, 0.03125],
+ [0.0390625, 0.03710938, 0.02929688],
+ [0.0390625, 0.03710938, 0.02734375],
+ [0.0390625, 0.03320312, 0.02734375],
+ [0.0390625, 0.03320312, 0.02734375],
+ ],
+ dtype=np.float32,
+ ),
+ }
)
+ expected_slice = expected_slices.get_expectation()
max_diff = numpy_cosine_similarity_distance(expected_slice.flatten(), image_slice.flatten())
diff --git a/tests/pipelines/pag/test_pag_pixart_sigma.py b/tests/pipelines/pag/test_pag_pixart_sigma.py
index 624b578443..c79f5ee821 100644
--- a/tests/pipelines/pag/test_pag_pixart_sigma.py
+++ b/tests/pipelines/pag/test_pag_pixart_sigma.py
@@ -254,7 +254,7 @@ class PixArtSigmaPAGPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
assert_mean_pixel_difference(to_np(output_with_slicing1[0]), to_np(output_without_slicing[0]))
assert_mean_pixel_difference(to_np(output_with_slicing2[0]), to_np(output_without_slicing[0]))
- # Because we have `pag_applied_layers` we cannot direcly apply
+ # Because we have `pag_applied_layers` we cannot directly apply
# `set_default_attn_processor`
def test_dict_tuple_outputs_equivalent(self, expected_slice=None, expected_max_difference=1e-4):
components = self.get_dummy_components()
diff --git a/tests/pipelines/paint_by_example/test_paint_by_example.py b/tests/pipelines/paint_by_example/test_paint_by_example.py
index 6b668de276..4192bc71ca 100644
--- a/tests/pipelines/paint_by_example/test_paint_by_example.py
+++ b/tests/pipelines/paint_by_example/test_paint_by_example.py
@@ -25,11 +25,12 @@ from transformers import CLIPImageProcessor, CLIPVisionConfig
from diffusers import AutoencoderKL, PaintByExamplePipeline, PNDMScheduler, UNet2DConditionModel
from diffusers.pipelines.paint_by_example import PaintByExampleImageEncoder
from diffusers.utils.testing_utils import (
+ backend_empty_cache,
enable_full_determinism,
floats_tensor,
load_image,
nightly,
- require_torch_gpu,
+ require_torch_accelerator,
torch_device,
)
@@ -174,19 +175,19 @@ class PaintByExamplePipelineFastTests(PipelineTesterMixin, unittest.TestCase):
@nightly
-@require_torch_gpu
+@require_torch_accelerator
class PaintByExamplePipelineIntegrationTests(unittest.TestCase):
def setUp(self):
# clean up the VRAM before each test
super().setUp()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def tearDown(self):
# clean up the VRAM after each test
super().tearDown()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def test_paint_by_example(self):
# make sure here that pndm scheduler skips prk
diff --git a/tests/pipelines/sana/test_sana_sprint_img2img.py b/tests/pipelines/sana/test_sana_sprint_img2img.py
new file mode 100644
index 0000000000..a0c90126ad
--- /dev/null
+++ b/tests/pipelines/sana/test_sana_sprint_img2img.py
@@ -0,0 +1,313 @@
+# Copyright 2024 The HuggingFace Team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+import unittest
+
+import numpy as np
+import torch
+from transformers import Gemma2Config, Gemma2Model, GemmaTokenizer
+
+from diffusers import AutoencoderDC, SanaSprintImg2ImgPipeline, SanaTransformer2DModel, SCMScheduler
+from diffusers.utils.testing_utils import (
+ enable_full_determinism,
+ torch_device,
+)
+
+from ..pipeline_params import (
+ IMAGE_TO_IMAGE_IMAGE_PARAMS,
+ TEXT_GUIDED_IMAGE_VARIATION_BATCH_PARAMS,
+ TEXT_GUIDED_IMAGE_VARIATION_PARAMS,
+)
+from ..test_pipelines_common import PipelineTesterMixin, to_np
+
+
+enable_full_determinism()
+
+
+class SanaSprintImg2ImgPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = SanaSprintImg2ImgPipeline
+ params = TEXT_GUIDED_IMAGE_VARIATION_PARAMS - {
+ "negative_prompt",
+ "negative_prompt_embeds",
+ }
+ batch_params = TEXT_GUIDED_IMAGE_VARIATION_BATCH_PARAMS - {"negative_prompt"}
+ image_params = IMAGE_TO_IMAGE_IMAGE_PARAMS
+ image_latents_params = IMAGE_TO_IMAGE_IMAGE_PARAMS
+ required_optional_params = frozenset(
+ [
+ "num_inference_steps",
+ "generator",
+ "latents",
+ "return_dict",
+ "callback_on_step_end",
+ "callback_on_step_end_tensor_inputs",
+ ]
+ )
+ test_xformers_attention = False
+ test_layerwise_casting = True
+ test_group_offloading = True
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ transformer = SanaTransformer2DModel(
+ patch_size=1,
+ in_channels=4,
+ out_channels=4,
+ num_layers=1,
+ num_attention_heads=2,
+ attention_head_dim=4,
+ num_cross_attention_heads=2,
+ cross_attention_head_dim=4,
+ cross_attention_dim=8,
+ caption_channels=8,
+ sample_size=32,
+ qk_norm="rms_norm_across_heads",
+ guidance_embeds=True,
+ )
+
+ torch.manual_seed(0)
+ vae = AutoencoderDC(
+ in_channels=3,
+ latent_channels=4,
+ attention_head_dim=2,
+ encoder_block_types=(
+ "ResBlock",
+ "EfficientViTBlock",
+ ),
+ decoder_block_types=(
+ "ResBlock",
+ "EfficientViTBlock",
+ ),
+ encoder_block_out_channels=(8, 8),
+ decoder_block_out_channels=(8, 8),
+ encoder_qkv_multiscales=((), (5,)),
+ decoder_qkv_multiscales=((), (5,)),
+ encoder_layers_per_block=(1, 1),
+ decoder_layers_per_block=[1, 1],
+ downsample_block_type="conv",
+ upsample_block_type="interpolate",
+ decoder_norm_types="rms_norm",
+ decoder_act_fns="silu",
+ scaling_factor=0.41407,
+ )
+
+ torch.manual_seed(0)
+ scheduler = SCMScheduler()
+
+ torch.manual_seed(0)
+ text_encoder_config = Gemma2Config(
+ head_dim=16,
+ hidden_size=8,
+ initializer_range=0.02,
+ intermediate_size=64,
+ max_position_embeddings=8192,
+ model_type="gemma2",
+ num_attention_heads=2,
+ num_hidden_layers=1,
+ num_key_value_heads=2,
+ vocab_size=8,
+ attn_implementation="eager",
+ )
+ text_encoder = Gemma2Model(text_encoder_config)
+ tokenizer = GemmaTokenizer.from_pretrained("hf-internal-testing/dummy-gemma")
+
+ components = {
+ "transformer": transformer,
+ "vae": vae,
+ "scheduler": scheduler,
+ "text_encoder": text_encoder,
+ "tokenizer": tokenizer,
+ }
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+ image = torch.randn(1, 3, 32, 32, generator=generator)
+ inputs = {
+ "prompt": "",
+ "image": image,
+ "strength": 0.5,
+ "generator": generator,
+ "num_inference_steps": 2,
+ "guidance_scale": 6.0,
+ "height": 32,
+ "width": 32,
+ "max_sequence_length": 16,
+ "output_type": "pt",
+ "complex_human_instruction": None,
+ }
+ return inputs
+
+ def test_inference(self):
+ device = "cpu"
+
+ components = self.get_dummy_components()
+ pipe = self.pipeline_class(**components)
+ pipe.to(device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ image = pipe(**inputs)[0]
+ generated_image = image[0]
+
+ self.assertEqual(generated_image.shape, (3, 32, 32))
+ expected_image = torch.randn(3, 32, 32)
+ max_diff = np.abs(generated_image - expected_image).max()
+ self.assertLessEqual(max_diff, 1e10)
+
+ def test_callback_inputs(self):
+ sig = inspect.signature(self.pipeline_class.__call__)
+ has_callback_tensor_inputs = "callback_on_step_end_tensor_inputs" in sig.parameters
+ has_callback_step_end = "callback_on_step_end" in sig.parameters
+
+ if not (has_callback_tensor_inputs and has_callback_step_end):
+ return
+
+ components = self.get_dummy_components()
+ pipe = self.pipeline_class(**components)
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ self.assertTrue(
+ hasattr(pipe, "_callback_tensor_inputs"),
+ f" {self.pipeline_class} should have `_callback_tensor_inputs` that defines a list of tensor variables its callback function can use as inputs",
+ )
+
+ def callback_inputs_subset(pipe, i, t, callback_kwargs):
+ # iterate over callback args
+ for tensor_name, tensor_value in callback_kwargs.items():
+ # check that we're only passing in allowed tensor inputs
+ assert tensor_name in pipe._callback_tensor_inputs
+
+ return callback_kwargs
+
+ def callback_inputs_all(pipe, i, t, callback_kwargs):
+ for tensor_name in pipe._callback_tensor_inputs:
+ assert tensor_name in callback_kwargs
+
+ # iterate over callback args
+ for tensor_name, tensor_value in callback_kwargs.items():
+ # check that we're only passing in allowed tensor inputs
+ assert tensor_name in pipe._callback_tensor_inputs
+
+ return callback_kwargs
+
+ inputs = self.get_dummy_inputs(torch_device)
+
+ # Test passing in a subset
+ inputs["callback_on_step_end"] = callback_inputs_subset
+ inputs["callback_on_step_end_tensor_inputs"] = ["latents"]
+ output = pipe(**inputs)[0]
+
+ # Test passing in a everything
+ inputs["callback_on_step_end"] = callback_inputs_all
+ inputs["callback_on_step_end_tensor_inputs"] = pipe._callback_tensor_inputs
+ output = pipe(**inputs)[0]
+
+ def callback_inputs_change_tensor(pipe, i, t, callback_kwargs):
+ is_last = i == (pipe.num_timesteps - 1)
+ if is_last:
+ callback_kwargs["latents"] = torch.zeros_like(callback_kwargs["latents"])
+ return callback_kwargs
+
+ inputs["callback_on_step_end"] = callback_inputs_change_tensor
+ inputs["callback_on_step_end_tensor_inputs"] = pipe._callback_tensor_inputs
+ output = pipe(**inputs)[0]
+ assert output.abs().sum() < 1e10
+
+ def test_attention_slicing_forward_pass(
+ self, test_max_difference=True, test_mean_pixel_difference=True, expected_max_diff=1e-3
+ ):
+ if not self.test_attention_slicing:
+ return
+
+ components = self.get_dummy_components()
+ pipe = self.pipeline_class(**components)
+ for component in pipe.components.values():
+ if hasattr(component, "set_default_attn_processor"):
+ component.set_default_attn_processor()
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ generator_device = "cpu"
+ inputs = self.get_dummy_inputs(generator_device)
+ output_without_slicing = pipe(**inputs)[0]
+
+ pipe.enable_attention_slicing(slice_size=1)
+ inputs = self.get_dummy_inputs(generator_device)
+ output_with_slicing1 = pipe(**inputs)[0]
+
+ pipe.enable_attention_slicing(slice_size=2)
+ inputs = self.get_dummy_inputs(generator_device)
+ output_with_slicing2 = pipe(**inputs)[0]
+
+ if test_max_difference:
+ max_diff1 = np.abs(to_np(output_with_slicing1) - to_np(output_without_slicing)).max()
+ max_diff2 = np.abs(to_np(output_with_slicing2) - to_np(output_without_slicing)).max()
+ self.assertLess(
+ max(max_diff1, max_diff2),
+ expected_max_diff,
+ "Attention slicing should not affect the inference results",
+ )
+
+ @unittest.skip("vae tiling resulted in a small margin over the expected max diff, so skipping this test for now")
+ def test_vae_tiling(self, expected_diff_max: float = 0.2):
+ generator_device = "cpu"
+ components = self.get_dummy_components()
+
+ pipe = self.pipeline_class(**components)
+ pipe.to("cpu")
+ pipe.set_progress_bar_config(disable=None)
+
+ # Without tiling
+ inputs = self.get_dummy_inputs(generator_device)
+ inputs["height"] = inputs["width"] = 128
+ output_without_tiling = pipe(**inputs)[0]
+
+ # With tiling
+ pipe.vae.enable_tiling(
+ tile_sample_min_height=96,
+ tile_sample_min_width=96,
+ tile_sample_stride_height=64,
+ tile_sample_stride_width=64,
+ )
+ inputs = self.get_dummy_inputs(generator_device)
+ inputs["height"] = inputs["width"] = 128
+ output_with_tiling = pipe(**inputs)[0]
+
+ self.assertLess(
+ (to_np(output_without_tiling) - to_np(output_with_tiling)).max(),
+ expected_diff_max,
+ "VAE tiling should not affect the inference results",
+ )
+
+ # TODO(aryan): Create a dummy gemma model with smol vocab size
+ @unittest.skip(
+ "A very small vocab size is used for fast tests. So, any kind of prompt other than the empty default used in other tests will lead to a embedding lookup error. This test uses a long prompt that causes the error."
+ )
+ def test_inference_batch_consistent(self):
+ pass
+
+ @unittest.skip(
+ "A very small vocab size is used for fast tests. So, any kind of prompt other than the empty default used in other tests will lead to a embedding lookup error. This test uses a long prompt that causes the error."
+ )
+ def test_inference_batch_single_identical(self):
+ pass
+
+ def test_float16_inference(self):
+ # Requires higher tolerance as model seems very sensitive to dtype
+ super().test_float16_inference(expected_max_diff=0.08)
diff --git a/tests/pipelines/shap_e/test_shap_e.py b/tests/pipelines/shap_e/test_shap_e.py
index 6cf643fe47..638de7e8cc 100644
--- a/tests/pipelines/shap_e/test_shap_e.py
+++ b/tests/pipelines/shap_e/test_shap_e.py
@@ -21,7 +21,13 @@ from transformers import CLIPTextConfig, CLIPTextModelWithProjection, CLIPTokeni
from diffusers import HeunDiscreteScheduler, PriorTransformer, ShapEPipeline
from diffusers.pipelines.shap_e import ShapERenderer
-from diffusers.utils.testing_utils import load_numpy, nightly, require_torch_gpu, torch_device
+from diffusers.utils.testing_utils import (
+ backend_empty_cache,
+ load_numpy,
+ nightly,
+ require_torch_accelerator,
+ torch_device,
+)
from ..test_pipelines_common import PipelineTesterMixin, assert_mean_pixel_difference
@@ -222,19 +228,19 @@ class ShapEPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
@nightly
-@require_torch_gpu
+@require_torch_accelerator
class ShapEPipelineIntegrationTests(unittest.TestCase):
def setUp(self):
# clean up the VRAM before each test
super().setUp()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def tearDown(self):
# clean up the VRAM after each test
super().tearDown()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def test_shap_e(self):
expected_image = load_numpy(
diff --git a/tests/pipelines/shap_e/test_shap_e_img2img.py b/tests/pipelines/shap_e/test_shap_e_img2img.py
index 72eee3e35e..ed0a4d47b6 100644
--- a/tests/pipelines/shap_e/test_shap_e_img2img.py
+++ b/tests/pipelines/shap_e/test_shap_e_img2img.py
@@ -23,11 +23,12 @@ from transformers import CLIPImageProcessor, CLIPVisionConfig, CLIPVisionModel
from diffusers import HeunDiscreteScheduler, PriorTransformer, ShapEImg2ImgPipeline
from diffusers.pipelines.shap_e import ShapERenderer
from diffusers.utils.testing_utils import (
+ backend_empty_cache,
floats_tensor,
load_image,
load_numpy,
nightly,
- require_torch_gpu,
+ require_torch_accelerator,
torch_device,
)
@@ -250,19 +251,19 @@ class ShapEImg2ImgPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
@nightly
-@require_torch_gpu
+@require_torch_accelerator
class ShapEImg2ImgPipelineIntegrationTests(unittest.TestCase):
def setUp(self):
# clean up the VRAM before each test
super().setUp()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def tearDown(self):
# clean up the VRAM after each test
super().tearDown()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def test_shap_e_img2img(self):
input_image = load_image(
diff --git a/tests/pipelines/stable_audio/test_stable_audio.py b/tests/pipelines/stable_audio/test_stable_audio.py
index 01df82056c..f8f4803ccf 100644
--- a/tests/pipelines/stable_audio/test_stable_audio.py
+++ b/tests/pipelines/stable_audio/test_stable_audio.py
@@ -32,7 +32,14 @@ from diffusers import (
StableAudioProjectionModel,
)
from diffusers.utils import is_xformers_available
-from diffusers.utils.testing_utils import enable_full_determinism, nightly, require_torch_gpu, torch_device
+from diffusers.utils.testing_utils import (
+ Expectations,
+ backend_empty_cache,
+ enable_full_determinism,
+ nightly,
+ require_torch_accelerator,
+ torch_device,
+)
from ..pipeline_params import TEXT_TO_AUDIO_BATCH_PARAMS
from ..test_pipelines_common import PipelineTesterMixin
@@ -419,17 +426,17 @@ class StableAudioPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
@nightly
-@require_torch_gpu
+@require_torch_accelerator
class StableAudioPipelineIntegrationTests(unittest.TestCase):
def setUp(self):
super().setUp()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def tearDown(self):
super().tearDown()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def get_inputs(self, device, generator_device="cpu", dtype=torch.float32, seed=0):
generator = torch.Generator(device=generator_device).manual_seed(seed)
@@ -459,9 +466,15 @@ class StableAudioPipelineIntegrationTests(unittest.TestCase):
# check the portion of the generated audio with the largest dynamic range (reduces flakiness)
audio_slice = audio[0, 447590:447600]
# fmt: off
- expected_slice = np.array(
- [-0.0278, 0.1096, 0.1877, 0.3178, 0.5329, 0.6990, 0.6972, 0.6186, 0.5608, 0.5060]
+ expected_slices = Expectations(
+ {
+ ("xpu", 3): np.array([-0.0285, 0.1083, 0.1863, 0.3165, 0.5312, 0.6971, 0.6958, 0.6177, 0.5598, 0.5048]),
+ ("cuda", 7): np.array([-0.0278, 0.1096, 0.1877, 0.3178, 0.5329, 0.6990, 0.6972, 0.6186, 0.5608, 0.5060]),
+ ("cuda", 8): np.array([-0.0285, 0.1082, 0.1862, 0.3163, 0.5306, 0.6964, 0.6953, 0.6172, 0.5593, 0.5044]),
+ }
)
- # fmt: one
+ # fmt: on
+
+ expected_slice = expected_slices.get_expectation()
max_diff = np.abs(expected_slice - audio_slice.detach().cpu().numpy()).max()
assert max_diff < 1.5e-3
diff --git a/tests/pipelines/stable_cascade/test_stable_cascade_decoder.py b/tests/pipelines/stable_cascade/test_stable_cascade_decoder.py
index afcd8fca71..2b51e59f6b 100644
--- a/tests/pipelines/stable_cascade/test_stable_cascade_decoder.py
+++ b/tests/pipelines/stable_cascade/test_stable_cascade_decoder.py
@@ -304,7 +304,8 @@ class StableCascadeDecoderPipelineIntegrationTests(unittest.TestCase):
generator = torch.Generator(device="cpu").manual_seed(0)
image_embedding = load_pt(
- "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/stable_cascade/image_embedding.pt"
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/stable_cascade/image_embedding.pt",
+ map_location=torch_device,
)
image = pipe(
@@ -320,4 +321,4 @@ class StableCascadeDecoderPipelineIntegrationTests(unittest.TestCase):
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/stable_cascade/stable_cascade_decoder_image.npy"
)
max_diff = numpy_cosine_similarity_distance(image.flatten(), expected_image.flatten())
- assert max_diff < 1e-4
+ assert max_diff < 2e-4
diff --git a/tests/pipelines/stable_diffusion/test_stable_diffusion.py b/tests/pipelines/stable_diffusion/test_stable_diffusion.py
index 3b5c7a24b4..2c6739c8ef 100644
--- a/tests/pipelines/stable_diffusion/test_stable_diffusion.py
+++ b/tests/pipelines/stable_diffusion/test_stable_diffusion.py
@@ -17,7 +17,6 @@
import gc
import tempfile
import time
-import traceback
import unittest
import numpy as np
@@ -49,16 +48,12 @@ from diffusers.utils.testing_utils import (
backend_reset_max_memory_allocated,
backend_reset_peak_memory_stats,
enable_full_determinism,
- is_torch_compile,
- load_image,
load_numpy,
nightly,
numpy_cosine_similarity_distance,
require_accelerate_version_greater,
- require_torch_2,
require_torch_accelerator,
require_torch_multi_accelerator,
- run_test_in_subprocess,
skip_mps,
slow,
torch_device,
@@ -81,39 +76,6 @@ from ..test_pipelines_common import (
enable_full_determinism()
-# Will be run via run_test_in_subprocess
-def _test_stable_diffusion_compile(in_queue, out_queue, timeout):
- error = None
- try:
- inputs = in_queue.get(timeout=timeout)
- torch_device = inputs.pop("torch_device")
- seed = inputs.pop("seed")
- inputs["generator"] = torch.Generator(device=torch_device).manual_seed(seed)
-
- sd_pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", safety_checker=None)
- sd_pipe.scheduler = DDIMScheduler.from_config(sd_pipe.scheduler.config)
- sd_pipe = sd_pipe.to(torch_device)
-
- sd_pipe.unet.to(memory_format=torch.channels_last)
- sd_pipe.unet = torch.compile(sd_pipe.unet, mode="reduce-overhead", fullgraph=True)
-
- sd_pipe.set_progress_bar_config(disable=None)
-
- image = sd_pipe(**inputs).images
- image_slice = image[0, -3:, -3:, -1].flatten()
-
- assert image.shape == (1, 512, 512, 3)
- expected_slice = np.array([0.38019, 0.28647, 0.27321, 0.40377, 0.38290, 0.35446, 0.39218, 0.38165, 0.42239])
-
- assert np.abs(image_slice - expected_slice).max() < 5e-3
- except Exception:
- error = f"{traceback.format_exc()}"
-
- results = {"error": error}
- out_queue.put(results, timeout=timeout)
- out_queue.join()
-
-
class StableDiffusionPipelineFastTests(
IPAdapterTesterMixin,
PipelineLatentTesterMixin,
@@ -1224,40 +1186,6 @@ class StableDiffusionPipelineSlowTests(unittest.TestCase):
max_diff = np.abs(expected_image - image).max()
assert max_diff < 8e-1
- @is_torch_compile
- @require_torch_2
- def test_stable_diffusion_compile(self):
- seed = 0
- inputs = self.get_inputs(torch_device, seed=seed)
- # Can't pickle a Generator object
- del inputs["generator"]
- inputs["torch_device"] = torch_device
- inputs["seed"] = seed
- run_test_in_subprocess(test_case=self, target_func=_test_stable_diffusion_compile, inputs=inputs)
-
- def test_stable_diffusion_lcm(self):
- unet = UNet2DConditionModel.from_pretrained("SimianLuo/LCM_Dreamshaper_v7", subfolder="unet")
- sd_pipe = StableDiffusionPipeline.from_pretrained("Lykon/dreamshaper-7", unet=unet).to(torch_device)
- sd_pipe.scheduler = LCMScheduler.from_config(sd_pipe.scheduler.config)
- sd_pipe.set_progress_bar_config(disable=None)
-
- inputs = self.get_inputs(torch_device)
- inputs["num_inference_steps"] = 6
- inputs["output_type"] = "pil"
-
- image = sd_pipe(**inputs).images[0]
-
- expected_image = load_image(
- "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/lcm_full/stable_diffusion_lcm.png"
- )
-
- image = sd_pipe.image_processor.pil_to_numpy(image)
- expected_image = sd_pipe.image_processor.pil_to_numpy(expected_image)
-
- max_diff = numpy_cosine_similarity_distance(image.flatten(), expected_image.flatten())
-
- assert max_diff < 1e-2
-
@slow
@require_torch_accelerator
diff --git a/tests/pipelines/stable_diffusion/test_stable_diffusion_img2img.py b/tests/pipelines/stable_diffusion/test_stable_diffusion_img2img.py
index 82b01a7486..094e98d09e 100644
--- a/tests/pipelines/stable_diffusion/test_stable_diffusion_img2img.py
+++ b/tests/pipelines/stable_diffusion/test_stable_diffusion_img2img.py
@@ -15,7 +15,6 @@
import gc
import random
-import traceback
import unittest
import numpy as np
@@ -41,13 +40,10 @@ from diffusers.utils.testing_utils import (
backend_reset_peak_memory_stats,
enable_full_determinism,
floats_tensor,
- is_torch_compile,
load_image,
load_numpy,
nightly,
- require_torch_2,
require_torch_accelerator,
- run_test_in_subprocess,
skip_mps,
slow,
torch_device,
@@ -70,38 +66,6 @@ from ..test_pipelines_common import (
enable_full_determinism()
-# Will be run via run_test_in_subprocess
-def _test_img2img_compile(in_queue, out_queue, timeout):
- error = None
- try:
- inputs = in_queue.get(timeout=timeout)
- torch_device = inputs.pop("torch_device")
- seed = inputs.pop("seed")
- inputs["generator"] = torch.Generator(device=torch_device).manual_seed(seed)
-
- pipe = StableDiffusionImg2ImgPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", safety_checker=None)
- pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
- pipe.unet.set_default_attn_processor()
- pipe.to(torch_device)
- pipe.set_progress_bar_config(disable=None)
- pipe.unet.to(memory_format=torch.channels_last)
- pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
-
- image = pipe(**inputs).images
- image_slice = image[0, -3:, -3:, -1].flatten()
-
- assert image.shape == (1, 512, 768, 3)
- expected_slice = np.array([0.0606, 0.0570, 0.0805, 0.0579, 0.0628, 0.0623, 0.0843, 0.1115, 0.0806])
-
- assert np.abs(expected_slice - image_slice).max() < 1e-3
- except Exception:
- error = f"{traceback.format_exc()}"
-
- results = {"error": error}
- out_queue.put(results, timeout=timeout)
- out_queue.join()
-
-
class StableDiffusionImg2ImgPipelineFastTests(
IPAdapterTesterMixin,
PipelineLatentTesterMixin,
@@ -654,17 +618,6 @@ class StableDiffusionImg2ImgPipelineSlowTests(unittest.TestCase):
assert out.nsfw_content_detected[0], f"Safety checker should work for prompt: {inputs['prompt']}"
assert np.abs(out.images[0]).sum() < 1e-5 # should be all zeros
- @is_torch_compile
- @require_torch_2
- def test_img2img_compile(self):
- seed = 0
- inputs = self.get_inputs(torch_device, seed=seed)
- # Can't pickle a Generator object
- del inputs["generator"]
- inputs["torch_device"] = torch_device
- inputs["seed"] = seed
- run_test_in_subprocess(test_case=self, target_func=_test_img2img_compile, inputs=inputs)
-
@nightly
@require_torch_accelerator
diff --git a/tests/pipelines/stable_diffusion/test_stable_diffusion_inpaint.py b/tests/pipelines/stable_diffusion/test_stable_diffusion_inpaint.py
index e028b40178..8456994d6f 100644
--- a/tests/pipelines/stable_diffusion/test_stable_diffusion_inpaint.py
+++ b/tests/pipelines/stable_diffusion/test_stable_diffusion_inpaint.py
@@ -15,7 +15,6 @@
import gc
import random
-import traceback
import unittest
import numpy as np
@@ -44,13 +43,10 @@ from diffusers.utils.testing_utils import (
backend_reset_peak_memory_stats,
enable_full_determinism,
floats_tensor,
- is_torch_compile,
load_image,
load_numpy,
nightly,
- require_torch_2,
require_torch_accelerator,
- run_test_in_subprocess,
slow,
torch_device,
)
@@ -71,40 +67,6 @@ from ..test_pipelines_common import (
enable_full_determinism()
-# Will be run via run_test_in_subprocess
-def _test_inpaint_compile(in_queue, out_queue, timeout):
- error = None
- try:
- inputs = in_queue.get(timeout=timeout)
- torch_device = inputs.pop("torch_device")
- seed = inputs.pop("seed")
- inputs["generator"] = torch.Generator(device=torch_device).manual_seed(seed)
-
- pipe = StableDiffusionInpaintPipeline.from_pretrained(
- "botp/stable-diffusion-v1-5-inpainting", safety_checker=None
- )
- pipe.unet.set_default_attn_processor()
- pipe.scheduler = PNDMScheduler.from_config(pipe.scheduler.config)
- pipe.to(torch_device)
- pipe.set_progress_bar_config(disable=None)
-
- pipe.unet.to(memory_format=torch.channels_last)
- pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
-
- image = pipe(**inputs).images
- image_slice = image[0, 253:256, 253:256, -1].flatten()
-
- assert image.shape == (1, 512, 512, 3)
- expected_slice = np.array([0.0689, 0.0699, 0.0790, 0.0536, 0.0470, 0.0488, 0.041, 0.0508, 0.04179])
- assert np.abs(expected_slice - image_slice).max() < 3e-3
- except Exception:
- error = f"{traceback.format_exc()}"
-
- results = {"error": error}
- out_queue.put(results, timeout=timeout)
- out_queue.join()
-
-
class StableDiffusionInpaintPipelineFastTests(
IPAdapterTesterMixin,
PipelineLatentTesterMixin,
@@ -727,17 +689,6 @@ class StableDiffusionInpaintPipelineSlowTests(unittest.TestCase):
# make sure that less than 2.2 GB is allocated
assert mem_bytes < 2.2 * 10**9
- @is_torch_compile
- @require_torch_2
- def test_inpaint_compile(self):
- seed = 0
- inputs = self.get_inputs(torch_device, seed=seed)
- # Can't pickle a Generator object
- del inputs["generator"]
- inputs["torch_device"] = torch_device
- inputs["seed"] = seed
- run_test_in_subprocess(test_case=self, target_func=_test_inpaint_compile, inputs=inputs)
-
def test_stable_diffusion_inpaint_pil_input_resolution_test(self):
pipe = StableDiffusionInpaintPipeline.from_pretrained(
"botp/stable-diffusion-v1-5-inpainting", safety_checker=None
@@ -964,11 +915,6 @@ class StableDiffusionInpaintPipelineAsymmetricAutoencoderKLSlowTests(unittest.Te
# make sure that less than 2.45 GB is allocated
assert mem_bytes < 2.45 * 10**9
- @is_torch_compile
- @require_torch_2
- def test_inpaint_compile(self):
- pass
-
def test_stable_diffusion_inpaint_pil_input_resolution_test(self):
vae = AsymmetricAutoencoderKL.from_pretrained(
"cross-attention/asymmetric-autoencoder-kl-x-1-5",
diff --git a/tests/pipelines/stable_diffusion_k_diffusion/test_stable_diffusion_k_diffusion.py b/tests/pipelines/stable_diffusion_k_diffusion/test_stable_diffusion_k_diffusion.py
index fe78f0ec3c..33a44c0fcd 100644
--- a/tests/pipelines/stable_diffusion_k_diffusion/test_stable_diffusion_k_diffusion.py
+++ b/tests/pipelines/stable_diffusion_k_diffusion/test_stable_diffusion_k_diffusion.py
@@ -20,26 +20,32 @@ import numpy as np
import torch
from diffusers import StableDiffusionKDiffusionPipeline
-from diffusers.utils.testing_utils import enable_full_determinism, nightly, require_torch_gpu, torch_device
+from diffusers.utils.testing_utils import (
+ backend_empty_cache,
+ enable_full_determinism,
+ nightly,
+ require_torch_accelerator,
+ torch_device,
+)
enable_full_determinism()
@nightly
-@require_torch_gpu
+@require_torch_accelerator
class StableDiffusionPipelineIntegrationTests(unittest.TestCase):
def setUp(self):
# clean up the VRAM before each test
super().setUp()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def tearDown(self):
# clean up the VRAM after each test
super().tearDown()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def test_stable_diffusion_1(self):
sd_pipe = StableDiffusionKDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
diff --git a/tests/pipelines/stable_diffusion_ldm3d/test_stable_diffusion_ldm3d.py b/tests/pipelines/stable_diffusion_ldm3d/test_stable_diffusion_ldm3d.py
index 8f07d02aad..2c4ae94ede 100644
--- a/tests/pipelines/stable_diffusion_ldm3d/test_stable_diffusion_ldm3d.py
+++ b/tests/pipelines/stable_diffusion_ldm3d/test_stable_diffusion_ldm3d.py
@@ -28,7 +28,13 @@ from diffusers import (
StableDiffusionLDM3DPipeline,
UNet2DConditionModel,
)
-from diffusers.utils.testing_utils import enable_full_determinism, nightly, require_torch_gpu, torch_device
+from diffusers.utils.testing_utils import (
+ backend_empty_cache,
+ enable_full_determinism,
+ nightly,
+ require_torch_accelerator,
+ torch_device,
+)
from ..pipeline_params import TEXT_TO_IMAGE_BATCH_PARAMS, TEXT_TO_IMAGE_IMAGE_PARAMS, TEXT_TO_IMAGE_PARAMS
@@ -205,17 +211,17 @@ class StableDiffusionLDM3DPipelineFastTests(unittest.TestCase):
@nightly
-@require_torch_gpu
+@require_torch_accelerator
class StableDiffusionLDM3DPipelineSlowTests(unittest.TestCase):
def setUp(self):
super().setUp()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def tearDown(self):
super().tearDown()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def get_inputs(self, device, generator_device="cpu", dtype=torch.float32, seed=0):
generator = torch.Generator(device=generator_device).manual_seed(seed)
@@ -256,17 +262,17 @@ class StableDiffusionLDM3DPipelineSlowTests(unittest.TestCase):
@nightly
-@require_torch_gpu
+@require_torch_accelerator
class StableDiffusionPipelineNightlyTests(unittest.TestCase):
def setUp(self):
super().setUp()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def tearDown(self):
super().tearDown()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def get_inputs(self, device, generator_device="cpu", dtype=torch.float32, seed=0):
generator = torch.Generator(device=generator_device).manual_seed(seed)
diff --git a/tests/pipelines/stable_diffusion_sag/test_stable_diffusion_sag.py b/tests/pipelines/stable_diffusion_sag/test_stable_diffusion_sag.py
index bd1ba268d2..ebdd17c46f 100644
--- a/tests/pipelines/stable_diffusion_sag/test_stable_diffusion_sag.py
+++ b/tests/pipelines/stable_diffusion_sag/test_stable_diffusion_sag.py
@@ -29,7 +29,13 @@ from diffusers import (
StableDiffusionSAGPipeline,
UNet2DConditionModel,
)
-from diffusers.utils.testing_utils import enable_full_determinism, nightly, require_torch_gpu, torch_device
+from diffusers.utils.testing_utils import (
+ backend_empty_cache,
+ enable_full_determinism,
+ nightly,
+ require_torch_accelerator,
+ torch_device,
+)
from ..pipeline_params import TEXT_TO_IMAGE_BATCH_PARAMS, TEXT_TO_IMAGE_IMAGE_PARAMS, TEXT_TO_IMAGE_PARAMS
from ..test_pipelines_common import (
@@ -162,19 +168,19 @@ class StableDiffusionSAGPipelineFastTests(
@nightly
-@require_torch_gpu
+@require_torch_accelerator
class StableDiffusionPipelineIntegrationTests(unittest.TestCase):
def setUp(self):
# clean up the VRAM before each test
super().setUp()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def tearDown(self):
# clean up the VRAM after each test
super().tearDown()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def test_stable_diffusion_1(self):
sag_pipe = StableDiffusionSAGPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
diff --git a/tests/pipelines/stable_unclip/test_stable_unclip.py b/tests/pipelines/stable_unclip/test_stable_unclip.py
index 8cf103dffd..e3cbb1891b 100644
--- a/tests/pipelines/stable_unclip/test_stable_unclip.py
+++ b/tests/pipelines/stable_unclip/test_stable_unclip.py
@@ -13,7 +13,17 @@ from diffusers import (
UNet2DConditionModel,
)
from diffusers.pipelines.stable_diffusion.stable_unclip_image_normalizer import StableUnCLIPImageNormalizer
-from diffusers.utils.testing_utils import enable_full_determinism, load_numpy, nightly, require_torch_gpu, torch_device
+from diffusers.utils.testing_utils import (
+ backend_empty_cache,
+ backend_max_memory_allocated,
+ backend_reset_max_memory_allocated,
+ backend_reset_peak_memory_stats,
+ enable_full_determinism,
+ load_numpy,
+ nightly,
+ require_torch_accelerator,
+ torch_device,
+)
from ..pipeline_params import TEXT_TO_IMAGE_BATCH_PARAMS, TEXT_TO_IMAGE_IMAGE_PARAMS, TEXT_TO_IMAGE_PARAMS
from ..test_pipelines_common import (
@@ -190,19 +200,19 @@ class StableUnCLIPPipelineFastTests(
@nightly
-@require_torch_gpu
+@require_torch_accelerator
class StableUnCLIPPipelineIntegrationTests(unittest.TestCase):
def setUp(self):
# clean up the VRAM before each test
super().setUp()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def tearDown(self):
# clean up the VRAM after each test
super().tearDown()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def test_stable_unclip(self):
expected_image = load_numpy(
@@ -217,7 +227,7 @@ class StableUnCLIPPipelineIntegrationTests(unittest.TestCase):
pipe.enable_sequential_cpu_offload()
generator = torch.Generator(device="cpu").manual_seed(0)
- output = pipe("anime turle", generator=generator, output_type="np")
+ output = pipe("anime turtle", generator=generator, output_type="np")
image = output.images[0]
@@ -226,9 +236,9 @@ class StableUnCLIPPipelineIntegrationTests(unittest.TestCase):
assert_mean_pixel_difference(image, expected_image)
def test_stable_unclip_pipeline_with_sequential_cpu_offloading(self):
- torch.cuda.empty_cache()
- torch.cuda.reset_max_memory_allocated()
- torch.cuda.reset_peak_memory_stats()
+ backend_empty_cache(torch_device)
+ backend_reset_max_memory_allocated(torch_device)
+ backend_reset_peak_memory_stats(torch_device)
pipe = StableUnCLIPPipeline.from_pretrained("fusing/stable-unclip-2-1-l", torch_dtype=torch.float16)
pipe.set_progress_bar_config(disable=None)
@@ -242,6 +252,6 @@ class StableUnCLIPPipelineIntegrationTests(unittest.TestCase):
output_type="np",
)
- mem_bytes = torch.cuda.max_memory_allocated()
+ mem_bytes = backend_max_memory_allocated(torch_device)
# make sure that less than 7 GB is allocated
assert mem_bytes < 7 * 10**9
diff --git a/tests/pipelines/stable_unclip/test_stable_unclip_img2img.py b/tests/pipelines/stable_unclip/test_stable_unclip_img2img.py
index 176b6954d6..8ca5723ce6 100644
--- a/tests/pipelines/stable_unclip/test_stable_unclip_img2img.py
+++ b/tests/pipelines/stable_unclip/test_stable_unclip_img2img.py
@@ -18,12 +18,16 @@ from diffusers.pipelines.pipeline_utils import DiffusionPipeline
from diffusers.pipelines.stable_diffusion.stable_unclip_image_normalizer import StableUnCLIPImageNormalizer
from diffusers.utils.import_utils import is_xformers_available
from diffusers.utils.testing_utils import (
+ backend_empty_cache,
+ backend_max_memory_allocated,
+ backend_reset_max_memory_allocated,
+ backend_reset_peak_memory_stats,
enable_full_determinism,
floats_tensor,
load_image,
load_numpy,
nightly,
- require_torch_gpu,
+ require_torch_accelerator,
skip_mps,
torch_device,
)
@@ -213,19 +217,19 @@ class StableUnCLIPImg2ImgPipelineFastTests(
@nightly
-@require_torch_gpu
+@require_torch_accelerator
class StableUnCLIPImg2ImgPipelineIntegrationTests(unittest.TestCase):
def setUp(self):
# clean up the VRAM before each test
super().setUp()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def tearDown(self):
# clean up the VRAM after each test
super().tearDown()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def test_stable_unclip_l_img2img(self):
input_image = load_image(
@@ -246,7 +250,7 @@ class StableUnCLIPImg2ImgPipelineIntegrationTests(unittest.TestCase):
pipe.enable_sequential_cpu_offload()
generator = torch.Generator(device="cpu").manual_seed(0)
- output = pipe(input_image, "anime turle", generator=generator, output_type="np")
+ output = pipe(input_image, "anime turtle", generator=generator, output_type="np")
image = output.images[0]
@@ -273,7 +277,7 @@ class StableUnCLIPImg2ImgPipelineIntegrationTests(unittest.TestCase):
pipe.enable_sequential_cpu_offload()
generator = torch.Generator(device="cpu").manual_seed(0)
- output = pipe(input_image, "anime turle", generator=generator, output_type="np")
+ output = pipe(input_image, "anime turtle", generator=generator, output_type="np")
image = output.images[0]
@@ -286,9 +290,9 @@ class StableUnCLIPImg2ImgPipelineIntegrationTests(unittest.TestCase):
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/stable_unclip/turtle.png"
)
- torch.cuda.empty_cache()
- torch.cuda.reset_max_memory_allocated()
- torch.cuda.reset_peak_memory_stats()
+ backend_empty_cache(torch_device)
+ backend_reset_max_memory_allocated(torch_device)
+ backend_reset_peak_memory_stats(torch_device)
pipe = StableUnCLIPImg2ImgPipeline.from_pretrained(
"fusing/stable-unclip-2-1-h-img2img", torch_dtype=torch.float16
@@ -304,6 +308,6 @@ class StableUnCLIPImg2ImgPipelineIntegrationTests(unittest.TestCase):
output_type="np",
)
- mem_bytes = torch.cuda.max_memory_allocated()
+ mem_bytes = backend_max_memory_allocated(torch_device)
# make sure that less than 7 GB is allocated
assert mem_bytes < 7 * 10**9
diff --git a/tests/pipelines/test_pipeline_utils.py b/tests/pipelines/test_pipeline_utils.py
index 423c2b8ab1..f49ad282f3 100644
--- a/tests/pipelines/test_pipeline_utils.py
+++ b/tests/pipelines/test_pipeline_utils.py
@@ -19,7 +19,7 @@ from diffusers import (
UNet2DConditionModel,
)
from diffusers.pipelines.pipeline_loading_utils import is_safetensors_compatible, variant_compatible_siblings
-from diffusers.utils.testing_utils import require_torch_gpu, torch_device
+from diffusers.utils.testing_utils import require_torch_accelerator, torch_device
class IsSafetensorsCompatibleTests(unittest.TestCase):
@@ -87,21 +87,24 @@ class IsSafetensorsCompatibleTests(unittest.TestCase):
"unet/diffusion_pytorch_model.fp16.bin",
"unet/diffusion_pytorch_model.fp16.safetensors",
]
- self.assertTrue(is_safetensors_compatible(filenames))
+ self.assertFalse(is_safetensors_compatible(filenames))
+ self.assertTrue(is_safetensors_compatible(filenames, variant="fp16"))
def test_diffusers_model_is_compatible_variant(self):
filenames = [
"unet/diffusion_pytorch_model.fp16.bin",
"unet/diffusion_pytorch_model.fp16.safetensors",
]
- self.assertTrue(is_safetensors_compatible(filenames))
+ self.assertFalse(is_safetensors_compatible(filenames))
+ self.assertTrue(is_safetensors_compatible(filenames, variant="fp16"))
def test_diffusers_model_is_compatible_variant_mixed(self):
filenames = [
"unet/diffusion_pytorch_model.bin",
"unet/diffusion_pytorch_model.fp16.safetensors",
]
- self.assertTrue(is_safetensors_compatible(filenames))
+ self.assertFalse(is_safetensors_compatible(filenames))
+ self.assertTrue(is_safetensors_compatible(filenames, variant="fp16"))
def test_diffusers_model_is_not_compatible_variant(self):
filenames = [
@@ -121,7 +124,8 @@ class IsSafetensorsCompatibleTests(unittest.TestCase):
"text_encoder/pytorch_model.fp16.bin",
"text_encoder/model.fp16.safetensors",
]
- self.assertTrue(is_safetensors_compatible(filenames))
+ self.assertFalse(is_safetensors_compatible(filenames))
+ self.assertTrue(is_safetensors_compatible(filenames, variant="fp16"))
def test_transformer_model_is_not_compatible_variant(self):
filenames = [
@@ -145,7 +149,8 @@ class IsSafetensorsCompatibleTests(unittest.TestCase):
"unet/diffusion_pytorch_model.fp16.bin",
"unet/diffusion_pytorch_model.fp16.safetensors",
]
- self.assertTrue(is_safetensors_compatible(filenames, folder_names={"vae", "unet"}))
+ self.assertFalse(is_safetensors_compatible(filenames, folder_names={"vae", "unet"}))
+ self.assertTrue(is_safetensors_compatible(filenames, folder_names={"vae", "unet"}, variant="fp16"))
def test_transformer_model_is_not_compatible_variant_extra_folder(self):
filenames = [
@@ -173,7 +178,8 @@ class IsSafetensorsCompatibleTests(unittest.TestCase):
"text_encoder/model.fp16-00001-of-00002.safetensors",
"text_encoder/model.fp16-00001-of-00002.safetensors",
]
- self.assertTrue(is_safetensors_compatible(filenames))
+ self.assertFalse(is_safetensors_compatible(filenames))
+ self.assertTrue(is_safetensors_compatible(filenames, variant="fp16"))
def test_diffusers_is_compatible_sharded(self):
filenames = [
@@ -189,13 +195,15 @@ class IsSafetensorsCompatibleTests(unittest.TestCase):
"unet/diffusion_pytorch_model.fp16-00001-of-00002.safetensors",
"unet/diffusion_pytorch_model.fp16-00001-of-00002.safetensors",
]
- self.assertTrue(is_safetensors_compatible(filenames))
+ self.assertFalse(is_safetensors_compatible(filenames))
+ self.assertTrue(is_safetensors_compatible(filenames, variant="fp16"))
def test_diffusers_is_compatible_only_variants(self):
filenames = [
"unet/diffusion_pytorch_model.fp16.safetensors",
]
- self.assertTrue(is_safetensors_compatible(filenames))
+ self.assertFalse(is_safetensors_compatible(filenames))
+ self.assertTrue(is_safetensors_compatible(filenames, variant="fp16"))
def test_diffusers_is_compatible_no_components(self):
filenames = [
@@ -209,6 +217,20 @@ class IsSafetensorsCompatibleTests(unittest.TestCase):
]
self.assertFalse(is_safetensors_compatible(filenames))
+ def test_is_compatible_mixed_variants(self):
+ filenames = [
+ "unet/diffusion_pytorch_model.fp16.safetensors",
+ "vae/diffusion_pytorch_model.safetensors",
+ ]
+ self.assertTrue(is_safetensors_compatible(filenames, variant="fp16"))
+
+ def test_is_compatible_variant_and_non_safetensors(self):
+ filenames = [
+ "unet/diffusion_pytorch_model.fp16.safetensors",
+ "vae/diffusion_pytorch_model.bin",
+ ]
+ self.assertFalse(is_safetensors_compatible(filenames, variant="fp16"))
+
class VariantCompatibleSiblingsTest(unittest.TestCase):
def test_only_non_variants_downloaded(self):
@@ -828,9 +850,9 @@ class ProgressBarTests(unittest.TestCase):
self.assertTrue(stderr.getvalue() == "", "Progress bar should be disabled")
-@require_torch_gpu
+@require_torch_accelerator
class PipelineDeviceAndDtypeStabilityTests(unittest.TestCase):
- expected_pipe_device = torch.device("cuda:0")
+ expected_pipe_device = torch.device(f"{torch_device}:0")
expected_pipe_dtype = torch.float64
def get_dummy_components_image_generation(self):
@@ -899,8 +921,8 @@ class PipelineDeviceAndDtypeStabilityTests(unittest.TestCase):
pipe.to(device=torch_device, dtype=torch.float32)
pipe.unet.to(device="cpu")
- pipe.vae.to(device="cuda")
- pipe.text_encoder.to(device="cuda:0")
+ pipe.vae.to(device=torch_device)
+ pipe.text_encoder.to(device=f"{torch_device}:0")
pipe_device = pipe.device
diff --git a/tests/pipelines/test_pipelines.py b/tests/pipelines/test_pipelines.py
index caa7755904..f1d9d244e5 100644
--- a/tests/pipelines/test_pipelines.py
+++ b/tests/pipelines/test_pipelines.py
@@ -588,20 +588,17 @@ class DownloadTests(unittest.TestCase):
logger = logging.get_logger("diffusers.pipelines.pipeline_utils")
deprecated_warning_msg = "Warning: The repository contains sharded checkpoints for variant"
- for is_local in [True, False]:
- with CaptureLogger(logger) as cap_logger:
- with tempfile.TemporaryDirectory() as tmpdirname:
- local_repo_id = repo_id
- if is_local:
- local_repo_id = snapshot_download(repo_id, cache_dir=tmpdirname)
+ with CaptureLogger(logger) as cap_logger:
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ local_repo_id = snapshot_download(repo_id, cache_dir=tmpdirname)
- _ = DiffusionPipeline.from_pretrained(
- local_repo_id,
- safety_checker=None,
- variant="fp16",
- use_safetensors=True,
- )
- assert deprecated_warning_msg in str(cap_logger), "Deprecation warning not found in logs"
+ _ = DiffusionPipeline.from_pretrained(
+ local_repo_id,
+ safety_checker=None,
+ variant="fp16",
+ use_safetensors=True,
+ )
+ assert deprecated_warning_msg in str(cap_logger), "Deprecation warning not found in logs"
def test_download_safetensors_only_variant_exists_for_model(self):
variant = None
@@ -616,7 +613,7 @@ class DownloadTests(unittest.TestCase):
variant=variant,
use_safetensors=use_safetensors,
)
- assert "Error no file name" in str(error_context.exception)
+ assert "Could not find the necessary `safetensors` weights" in str(error_context.exception)
# text encoder has fp16 variants so we can load it
with tempfile.TemporaryDirectory() as tmpdirname:
@@ -675,7 +672,7 @@ class DownloadTests(unittest.TestCase):
use_safetensors=use_safetensors,
)
- assert "Error no file name" in str(error_context.exception)
+ assert "Could not find the necessary `safetensors` weights" in str(error_context.exception)
def test_download_bin_variant_does_not_exist_for_model(self):
variant = "no_ema"
@@ -1997,7 +1994,9 @@ class PipelineSlowTests(unittest.TestCase):
reason="Torch Dynamo isn't yet supported for Python 3.12.",
)
def test_from_save_pretrained_dynamo(self):
- run_test_in_subprocess(test_case=self, target_func=_test_from_save_pretrained_dynamo, inputs=None)
+ torch.compiler.rest()
+ with torch._inductor.utils.fresh_inductor_cache():
+ run_test_in_subprocess(test_case=self, target_func=_test_from_save_pretrained_dynamo, inputs=None)
def test_from_pretrained_hub(self):
model_path = "google/ddpm-cifar10-32"
@@ -2209,7 +2208,7 @@ class TestLoraHotSwappingForPipeline(unittest.TestCase):
# It is critical that the dynamo cache is reset for each test. Otherwise, if the test re-uses the same model,
# there will be recompilation errors, as torch caches the model when run in the same process.
super().tearDown()
- torch._dynamo.reset()
+ torch.compiler.reset()
gc.collect()
backend_empty_cache(torch_device)
@@ -2334,21 +2333,21 @@ class TestLoraHotSwappingForPipeline(unittest.TestCase):
def test_hotswapping_compiled_pipline_linear(self, rank0, rank1):
# It's important to add this context to raise an error on recompilation
target_modules = ["to_q", "to_k", "to_v", "to_out.0"]
- with torch._dynamo.config.patch(error_on_recompile=True):
+ with torch._dynamo.config.patch(error_on_recompile=True), torch._inductor.utils.fresh_inductor_cache():
self.check_pipeline_hotswap(do_compile=True, rank0=rank0, rank1=rank1, target_modules0=target_modules)
@parameterized.expand([(11, 11), (7, 13), (13, 7)]) # important to test small to large and vice versa
def test_hotswapping_compiled_pipline_conv2d(self, rank0, rank1):
# It's important to add this context to raise an error on recompilation
target_modules = ["conv", "conv1", "conv2"]
- with torch._dynamo.config.patch(error_on_recompile=True):
+ with torch._dynamo.config.patch(error_on_recompile=True), torch._inductor.utils.fresh_inductor_cache():
self.check_pipeline_hotswap(do_compile=True, rank0=rank0, rank1=rank1, target_modules0=target_modules)
@parameterized.expand([(11, 11), (7, 13), (13, 7)]) # important to test small to large and vice versa
def test_hotswapping_compiled_pipline_both_linear_and_conv2d(self, rank0, rank1):
# It's important to add this context to raise an error on recompilation
target_modules = ["to_q", "conv"]
- with torch._dynamo.config.patch(error_on_recompile=True):
+ with torch._dynamo.config.patch(error_on_recompile=True), torch._inductor.utils.fresh_inductor_cache():
self.check_pipeline_hotswap(do_compile=True, rank0=rank0, rank1=rank1, target_modules0=target_modules)
def test_enable_lora_hotswap_called_after_adapter_added_raises(self):
diff --git a/tests/pipelines/test_pipelines_common.py b/tests/pipelines/test_pipelines_common.py
index af3a832d31..53273c273f 100644
--- a/tests/pipelines/test_pipelines_common.py
+++ b/tests/pipelines/test_pipelines_common.py
@@ -1111,14 +1111,14 @@ class PipelineTesterMixin:
def setUp(self):
# clean up the VRAM before each test
super().setUp()
- torch._dynamo.reset()
+ torch.compiler.reset()
gc.collect()
backend_empty_cache(torch_device)
def tearDown(self):
# clean up the VRAM after each test in case of CUDA runtime errors
super().tearDown()
- torch._dynamo.reset()
+ torch.compiler.reset()
gc.collect()
backend_empty_cache(torch_device)
@@ -2096,11 +2096,11 @@ class PipelineTesterMixin:
with torch.no_grad():
encoded_prompt_outputs = pipe_with_just_text_encoder.encode_prompt(**encode_prompt_inputs)
- # Programatically determine the reutrn names of `encode_prompt.`
- ast_vistor = ReturnNameVisitor()
- encode_prompt_tree = ast_vistor.get_ast_tree(cls=self.pipeline_class)
- ast_vistor.visit(encode_prompt_tree)
- prompt_embed_kwargs = ast_vistor.return_names
+ # Programmatically determine the return names of `encode_prompt.`
+ ast_visitor = ReturnNameVisitor()
+ encode_prompt_tree = ast_visitor.get_ast_tree(cls=self.pipeline_class)
+ ast_visitor.visit(encode_prompt_tree)
+ prompt_embed_kwargs = ast_visitor.return_names
prompt_embeds_kwargs = dict(zip(prompt_embed_kwargs, encoded_prompt_outputs))
# Pack the outputs of `encode_prompt`.
diff --git a/tests/pipelines/text_to_video_synthesis/test_text_to_video_zero.py b/tests/pipelines/text_to_video_synthesis/test_text_to_video_zero.py
index f1bf6ee522..3146414646 100644
--- a/tests/pipelines/text_to_video_synthesis/test_text_to_video_zero.py
+++ b/tests/pipelines/text_to_video_synthesis/test_text_to_video_zero.py
@@ -19,37 +19,44 @@ import unittest
import torch
from diffusers import DDIMScheduler, TextToVideoZeroPipeline
-from diffusers.utils.testing_utils import load_pt, nightly, require_torch_gpu
+from diffusers.utils.testing_utils import (
+ backend_empty_cache,
+ load_pt,
+ nightly,
+ require_torch_accelerator,
+ torch_device,
+)
from ..test_pipelines_common import assert_mean_pixel_difference
@nightly
-@require_torch_gpu
+@require_torch_accelerator
class TextToVideoZeroPipelineSlowTests(unittest.TestCase):
def setUp(self):
# clean up the VRAM before each test
super().setUp()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def tearDown(self):
# clean up the VRAM after each test
super().tearDown()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def test_full_model(self):
model_id = "stable-diffusion-v1-5/stable-diffusion-v1-5"
- pipe = TextToVideoZeroPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
+ pipe = TextToVideoZeroPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to(torch_device)
pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
- generator = torch.Generator(device="cuda").manual_seed(0)
+ generator = torch.Generator(device="cpu").manual_seed(0)
prompt = "A bear is playing a guitar on Times Square"
result = pipe(prompt=prompt, generator=generator).images
expected_result = load_pt(
- "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/text-to-video/A bear is playing a guitar on Times Square.pt"
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/text-to-video/A bear is playing a guitar on Times Square.pt",
+ weights_only=False,
)
assert_mean_pixel_difference(result, expected_result)
diff --git a/tests/pipelines/text_to_video_synthesis/test_text_to_video_zero_sdxl.py b/tests/pipelines/text_to_video_synthesis/test_text_to_video_zero_sdxl.py
index db24767b60..827e83243b 100644
--- a/tests/pipelines/text_to_video_synthesis/test_text_to_video_zero_sdxl.py
+++ b/tests/pipelines/text_to_video_synthesis/test_text_to_video_zero_sdxl.py
@@ -24,11 +24,11 @@ from transformers import CLIPTextConfig, CLIPTextModel, CLIPTextModelWithProject
from diffusers import AutoencoderKL, DDIMScheduler, TextToVideoZeroSDXLPipeline, UNet2DConditionModel
from diffusers.utils.testing_utils import (
+ backend_empty_cache,
enable_full_determinism,
nightly,
require_accelerate_version_greater,
- require_accelerator,
- require_torch_gpu,
+ require_torch_accelerator,
torch_device,
)
@@ -220,7 +220,7 @@ class TextToVideoZeroSDXLPipelineFastTests(PipelineTesterMixin, PipelineFromPipe
self.assertLess(max_diff, expected_max_difference)
@unittest.skipIf(torch_device not in ["cuda", "xpu"], reason="float16 requires CUDA or XPU")
- @require_accelerator
+ @require_torch_accelerator
def test_float16_inference(self, expected_max_diff=5e-2):
components = self.get_dummy_components()
for name, module in components.items():
@@ -262,7 +262,7 @@ class TextToVideoZeroSDXLPipelineFastTests(PipelineTesterMixin, PipelineFromPipe
def test_inference_batch_single_identical(self):
pass
- @require_accelerator
+ @require_torch_accelerator
@require_accelerate_version_greater("0.17.0")
def test_model_cpu_offload_forward_pass(self, expected_max_diff=2e-4):
components = self.get_dummy_components()
@@ -285,7 +285,7 @@ class TextToVideoZeroSDXLPipelineFastTests(PipelineTesterMixin, PipelineFromPipe
pass
@unittest.skipIf(torch_device not in ["cuda", "xpu"], reason="float16 requires CUDA or XPU")
- @require_accelerator
+ @require_torch_accelerator
def test_save_load_float16(self, expected_max_diff=1e-2):
components = self.get_dummy_components()
for name, module in components.items():
@@ -337,7 +337,7 @@ class TextToVideoZeroSDXLPipelineFastTests(PipelineTesterMixin, PipelineFromPipe
def test_sequential_cpu_offload_forward_pass(self):
pass
- @require_accelerator
+ @require_torch_accelerator
def test_to_device(self):
components = self.get_dummy_components()
pipe = self.pipeline_class(**components)
@@ -365,19 +365,19 @@ class TextToVideoZeroSDXLPipelineFastTests(PipelineTesterMixin, PipelineFromPipe
@nightly
-@require_torch_gpu
+@require_torch_accelerator
class TextToVideoZeroSDXLPipelineSlowTests(unittest.TestCase):
def setUp(self):
# clean up the VRAM before each test
super().setUp()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def tearDown(self):
# clean up the VRAM after each test
super().tearDown()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def test_full_model(self):
model_id = "stabilityai/stable-diffusion-xl-base-1.0"
diff --git a/tests/pipelines/unclip/test_unclip.py b/tests/pipelines/unclip/test_unclip.py
index 834d97f30d..64f3d9de24 100644
--- a/tests/pipelines/unclip/test_unclip.py
+++ b/tests/pipelines/unclip/test_unclip.py
@@ -23,10 +23,14 @@ from transformers import CLIPTextConfig, CLIPTextModelWithProjection, CLIPTokeni
from diffusers import PriorTransformer, UnCLIPPipeline, UnCLIPScheduler, UNet2DConditionModel, UNet2DModel
from diffusers.pipelines.unclip.text_proj import UnCLIPTextProjModel
from diffusers.utils.testing_utils import (
+ backend_empty_cache,
+ backend_max_memory_allocated,
+ backend_reset_max_memory_allocated,
+ backend_reset_peak_memory_stats,
enable_full_determinism,
load_numpy,
nightly,
- require_torch_gpu,
+ require_torch_accelerator,
skip_mps,
torch_device,
)
@@ -426,13 +430,13 @@ class UnCLIPPipelineCPUIntegrationTests(unittest.TestCase):
# clean up the VRAM before each test
super().setUp()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def tearDown(self):
# clean up the VRAM after each test
super().tearDown()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def test_unclip_karlo_cpu_fp32(self):
expected_image = load_numpy(
@@ -458,19 +462,19 @@ class UnCLIPPipelineCPUIntegrationTests(unittest.TestCase):
@nightly
-@require_torch_gpu
+@require_torch_accelerator
class UnCLIPPipelineIntegrationTests(unittest.TestCase):
def setUp(self):
# clean up the VRAM before each test
super().setUp()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def tearDown(self):
# clean up the VRAM after each test
super().tearDown()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def test_unclip_karlo(self):
expected_image = load_numpy(
@@ -496,9 +500,9 @@ class UnCLIPPipelineIntegrationTests(unittest.TestCase):
assert_mean_pixel_difference(image, expected_image)
def test_unclip_pipeline_with_sequential_cpu_offloading(self):
- torch.cuda.empty_cache()
- torch.cuda.reset_max_memory_allocated()
- torch.cuda.reset_peak_memory_stats()
+ backend_empty_cache(torch_device)
+ backend_reset_max_memory_allocated(torch_device)
+ backend_reset_peak_memory_stats(torch_device)
pipe = UnCLIPPipeline.from_pretrained("kakaobrain/karlo-v1-alpha", torch_dtype=torch.float16)
pipe.set_progress_bar_config(disable=None)
@@ -514,6 +518,6 @@ class UnCLIPPipelineIntegrationTests(unittest.TestCase):
output_type="np",
)
- mem_bytes = torch.cuda.max_memory_allocated()
+ mem_bytes = backend_max_memory_allocated(torch_device)
# make sure that less than 7 GB is allocated
assert mem_bytes < 7 * 10**9
diff --git a/tests/pipelines/unclip/test_unclip_image_variation.py b/tests/pipelines/unclip/test_unclip_image_variation.py
index e402629fe1..3aa3c1b115 100644
--- a/tests/pipelines/unclip/test_unclip_image_variation.py
+++ b/tests/pipelines/unclip/test_unclip_image_variation.py
@@ -37,12 +37,13 @@ from diffusers import (
)
from diffusers.pipelines.unclip.text_proj import UnCLIPTextProjModel
from diffusers.utils.testing_utils import (
+ backend_empty_cache,
enable_full_determinism,
floats_tensor,
load_image,
load_numpy,
nightly,
- require_torch_gpu,
+ require_torch_accelerator,
skip_mps,
torch_device,
)
@@ -496,19 +497,19 @@ class UnCLIPImageVariationPipelineFastTests(PipelineTesterMixin, unittest.TestCa
@nightly
-@require_torch_gpu
+@require_torch_accelerator
class UnCLIPImageVariationPipelineIntegrationTests(unittest.TestCase):
def setUp(self):
# clean up the VRAM before each test
super().setUp()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def tearDown(self):
# clean up the VRAM after each test
super().tearDown()
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def test_unclip_image_variation_karlo(self):
input_image = load_image(
diff --git a/tests/pipelines/unidiffuser/test_unidiffuser.py b/tests/pipelines/unidiffuser/test_unidiffuser.py
index b1216a091c..dccb1a8500 100644
--- a/tests/pipelines/unidiffuser/test_unidiffuser.py
+++ b/tests/pipelines/unidiffuser/test_unidiffuser.py
@@ -1,6 +1,5 @@
import gc
import random
-import traceback
import unittest
import numpy as np
@@ -27,9 +26,7 @@ from diffusers.utils.testing_utils import (
floats_tensor,
load_image,
nightly,
- require_torch_2,
require_torch_accelerator,
- run_test_in_subprocess,
torch_device,
)
from diffusers.utils.torch_utils import randn_tensor
@@ -45,38 +42,6 @@ from ..test_pipelines_common import PipelineKarrasSchedulerTesterMixin, Pipeline
enable_full_determinism()
-# Will be run via run_test_in_subprocess
-def _test_unidiffuser_compile(in_queue, out_queue, timeout):
- error = None
- try:
- inputs = in_queue.get(timeout=timeout)
- torch_device = inputs.pop("torch_device")
- seed = inputs.pop("seed")
- inputs["generator"] = torch.Generator(device=torch_device).manual_seed(seed)
-
- pipe = UniDiffuserPipeline.from_pretrained("thu-ml/unidiffuser-v1")
- # pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
- pipe = pipe.to(torch_device)
-
- pipe.unet.to(memory_format=torch.channels_last)
- pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
-
- pipe.set_progress_bar_config(disable=None)
-
- image = pipe(**inputs).images
- image_slice = image[0, -3:, -3:, -1].flatten()
-
- assert image.shape == (1, 512, 512, 3)
- expected_slice = np.array([0.2402, 0.2375, 0.2285, 0.2378, 0.2407, 0.2263, 0.2354, 0.2307, 0.2520])
- assert np.abs(image_slice - expected_slice).max() < 1e-1
- except Exception:
- error = f"{traceback.format_exc()}"
-
- results = {"error": error}
- out_queue.put(results, timeout=timeout)
- out_queue.join()
-
-
class UniDiffuserPipelineFastTests(
PipelineTesterMixin, PipelineLatentTesterMixin, PipelineKarrasSchedulerTesterMixin, unittest.TestCase
):
@@ -690,19 +655,6 @@ class UniDiffuserPipelineSlowTests(unittest.TestCase):
expected_text_prefix = "An astronaut"
assert text[0][: len(expected_text_prefix)] == expected_text_prefix
- @unittest.skip(reason="Skip torch.compile test to speed up the slow test suite.")
- @require_torch_2
- def test_unidiffuser_compile(self, seed=0):
- inputs = self.get_inputs(torch_device, seed=seed, generate_latents=True)
- # Delete prompt and image for joint inference.
- del inputs["prompt"]
- del inputs["image"]
- # Can't pickle a Generator object
- del inputs["generator"]
- inputs["torch_device"] = torch_device
- inputs["seed"] = seed
- run_test_in_subprocess(test_case=self, target_func=_test_unidiffuser_compile, inputs=inputs)
-
@nightly
@require_torch_accelerator
diff --git a/tests/pipelines/visualcloze/__init__.py b/tests/pipelines/visualcloze/__init__.py
new file mode 100644
index 0000000000..e69de29bb2
diff --git a/tests/pipelines/visualcloze/test_pipeline_visualcloze_combined.py b/tests/pipelines/visualcloze/test_pipeline_visualcloze_combined.py
new file mode 100644
index 0000000000..7e2aa25709
--- /dev/null
+++ b/tests/pipelines/visualcloze/test_pipeline_visualcloze_combined.py
@@ -0,0 +1,344 @@
+import random
+import tempfile
+import unittest
+
+import numpy as np
+import torch
+from PIL import Image
+from transformers import AutoTokenizer, CLIPTextConfig, CLIPTextModel, CLIPTokenizer, T5EncoderModel
+
+import diffusers
+from diffusers import AutoencoderKL, FlowMatchEulerDiscreteScheduler, FluxTransformer2DModel, VisualClozePipeline
+from diffusers.utils import logging
+from diffusers.utils.testing_utils import (
+ CaptureLogger,
+ enable_full_determinism,
+ floats_tensor,
+ require_accelerator,
+ torch_device,
+)
+
+from ..test_pipelines_common import PipelineTesterMixin, to_np
+
+
+enable_full_determinism()
+
+
+class VisualClozePipelineFastTests(unittest.TestCase, PipelineTesterMixin):
+ pipeline_class = VisualClozePipeline
+ params = frozenset(
+ [
+ "task_prompt",
+ "content_prompt",
+ "upsampling_height",
+ "upsampling_width",
+ "guidance_scale",
+ "prompt_embeds",
+ "pooled_prompt_embeds",
+ "upsampling_strength",
+ ]
+ )
+ batch_params = frozenset(["task_prompt", "content_prompt", "image"])
+ test_xformers_attention = False
+ test_layerwise_casting = True
+ test_group_offloading = True
+
+ supports_dduf = False
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ transformer = FluxTransformer2DModel(
+ patch_size=1,
+ in_channels=12,
+ out_channels=4,
+ num_layers=1,
+ num_single_layers=1,
+ attention_head_dim=6,
+ num_attention_heads=2,
+ joint_attention_dim=32,
+ pooled_projection_dim=32,
+ axes_dims_rope=[2, 2, 2],
+ )
+ clip_text_encoder_config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ hidden_act="gelu",
+ projection_dim=32,
+ )
+
+ torch.manual_seed(0)
+ text_encoder = CLIPTextModel(clip_text_encoder_config)
+
+ torch.manual_seed(0)
+ text_encoder_2 = T5EncoderModel.from_pretrained("hf-internal-testing/tiny-random-t5")
+
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+ tokenizer_2 = AutoTokenizer.from_pretrained("hf-internal-testing/tiny-random-t5")
+
+ torch.manual_seed(0)
+ vae = AutoencoderKL(
+ sample_size=32,
+ in_channels=3,
+ out_channels=3,
+ block_out_channels=(4,),
+ layers_per_block=1,
+ latent_channels=1,
+ norm_num_groups=1,
+ use_quant_conv=False,
+ use_post_quant_conv=False,
+ shift_factor=0.0609,
+ scaling_factor=1.5035,
+ )
+
+ scheduler = FlowMatchEulerDiscreteScheduler()
+
+ return {
+ "scheduler": scheduler,
+ "text_encoder": text_encoder,
+ "text_encoder_2": text_encoder_2,
+ "tokenizer": tokenizer,
+ "tokenizer_2": tokenizer_2,
+ "transformer": transformer,
+ "vae": vae,
+ "resolution": 32,
+ }
+
+ def get_dummy_inputs(self, device, seed=0):
+ # Create example images to simulate the input format required by VisualCloze
+ context_image = [
+ Image.fromarray(floats_tensor((32, 32, 3), rng=random.Random(seed), scale=255).numpy().astype(np.uint8))
+ for _ in range(2)
+ ]
+ query_image = [
+ Image.fromarray(
+ floats_tensor((32, 32, 3), rng=random.Random(seed + 1), scale=255).numpy().astype(np.uint8)
+ ),
+ None,
+ ]
+
+ # Create an image list that conforms to the VisualCloze input format
+ image = [
+ context_image, # In-Context example
+ query_image, # Query image
+ ]
+
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device="cpu").manual_seed(seed)
+
+ inputs = {
+ "task_prompt": "Each row outlines a logical process, starting from [IMAGE1] gray-based depth map with detailed object contours, to achieve [IMAGE2] an image with flawless clarity.",
+ "content_prompt": "A beautiful landscape with mountains and a lake",
+ "image": image,
+ "generator": generator,
+ "num_inference_steps": 2,
+ "guidance_scale": 5.0,
+ "upsampling_height": 32,
+ "upsampling_width": 32,
+ "max_sequence_length": 77,
+ "output_type": "np",
+ "upsampling_strength": 0.4,
+ }
+ return inputs
+
+ def test_visualcloze_different_prompts(self):
+ pipe = self.pipeline_class(**self.get_dummy_components()).to(torch_device)
+
+ inputs = self.get_dummy_inputs(torch_device)
+ output_same_prompt = pipe(**inputs).images[0]
+
+ inputs = self.get_dummy_inputs(torch_device)
+ inputs["task_prompt"] = "A different task to perform."
+ output_different_prompts = pipe(**inputs).images[0]
+
+ max_diff = np.abs(output_same_prompt - output_different_prompts).max()
+
+ # Outputs should be different
+ assert max_diff > 1e-6
+
+ def test_visualcloze_image_output_shape(self):
+ pipe = self.pipeline_class(**self.get_dummy_components()).to(torch_device)
+ inputs = self.get_dummy_inputs(torch_device)
+
+ height_width_pairs = [(32, 32), (72, 57)]
+ for height, width in height_width_pairs:
+ expected_height = height - height % (pipe.generation_pipe.vae_scale_factor * 2)
+ expected_width = width - width % (pipe.generation_pipe.vae_scale_factor * 2)
+
+ inputs.update({"upsampling_height": height, "upsampling_width": width})
+ image = pipe(**inputs).images[0]
+ output_height, output_width, _ = image.shape
+ assert (output_height, output_width) == (expected_height, expected_width)
+
+ def test_inference_batch_single_identical(self):
+ self._test_inference_batch_single_identical(expected_max_diff=1e-3)
+
+ def test_upsampling_strength(self, expected_min_diff=1e-1):
+ pipe = self.pipeline_class(**self.get_dummy_components()).to(torch_device)
+ inputs = self.get_dummy_inputs(torch_device)
+
+ # Test different upsampling strengths
+ inputs["upsampling_strength"] = 0.2
+ output_no_upsampling = pipe(**inputs).images[0]
+
+ inputs["upsampling_strength"] = 0.8
+ output_full_upsampling = pipe(**inputs).images[0]
+
+ # Different upsampling strengths should produce different outputs
+ max_diff = np.abs(output_no_upsampling - output_full_upsampling).max()
+ assert max_diff > expected_min_diff
+
+ def test_different_task_prompts(self, expected_min_diff=1e-1):
+ pipe = self.pipeline_class(**self.get_dummy_components()).to(torch_device)
+ inputs = self.get_dummy_inputs(torch_device)
+
+ output_original = pipe(**inputs).images[0]
+
+ inputs["task_prompt"] = "A different task description for image generation"
+ output_different_task = pipe(**inputs).images[0]
+
+ # Different task prompts should produce different outputs
+ max_diff = np.abs(output_original - output_different_task).max()
+ assert max_diff > expected_min_diff
+
+ @unittest.skip(
+ "Test not applicable because the pipeline being tested is a wrapper pipeline. CFG tests should be done on the inner pipelines."
+ )
+ def test_callback_cfg(self):
+ pass
+
+ def test_save_load_local(self, expected_max_difference=5e-4):
+ components = self.get_dummy_components()
+ pipe = self.pipeline_class(**components)
+ for component in pipe.components.values():
+ if hasattr(component, "set_default_attn_processor"):
+ component.set_default_attn_processor()
+
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(torch_device)
+ output = pipe(**inputs)[0]
+
+ logger = logging.get_logger("diffusers.pipelines.pipeline_utils")
+ logger.setLevel(diffusers.logging.INFO)
+
+ with tempfile.TemporaryDirectory() as tmpdir:
+ pipe.save_pretrained(tmpdir, safe_serialization=False)
+
+ with CaptureLogger(logger) as cap_logger:
+ # NOTE: Resolution must be set to 32 for loading otherwise will lead to OOM on CI hardware
+ # This attribute is not serialized in the config of the pipeline
+ pipe_loaded = self.pipeline_class.from_pretrained(tmpdir, resolution=32)
+
+ for component in pipe_loaded.components.values():
+ if hasattr(component, "set_default_attn_processor"):
+ component.set_default_attn_processor()
+
+ for name in pipe_loaded.components.keys():
+ if name not in pipe_loaded._optional_components:
+ assert name in str(cap_logger)
+
+ pipe_loaded.to(torch_device)
+ pipe_loaded.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(torch_device)
+ output_loaded = pipe_loaded(**inputs)[0]
+
+ max_diff = np.abs(to_np(output) - to_np(output_loaded)).max()
+ self.assertLess(max_diff, expected_max_difference)
+
+ def test_save_load_optional_components(self, expected_max_difference=1e-4):
+ if not hasattr(self.pipeline_class, "_optional_components"):
+ return
+ components = self.get_dummy_components()
+ pipe = self.pipeline_class(**components)
+ for component in pipe.components.values():
+ if hasattr(component, "set_default_attn_processor"):
+ component.set_default_attn_processor()
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ # set all optional components to None
+ for optional_component in pipe._optional_components:
+ setattr(pipe, optional_component, None)
+
+ generator_device = "cpu"
+ inputs = self.get_dummy_inputs(generator_device)
+ torch.manual_seed(0)
+ output = pipe(**inputs)[0]
+
+ with tempfile.TemporaryDirectory() as tmpdir:
+ pipe.save_pretrained(tmpdir, safe_serialization=False)
+ # NOTE: Resolution must be set to 32 for loading otherwise will lead to OOM on CI hardware
+ # This attribute is not serialized in the config of the pipeline
+ pipe_loaded = self.pipeline_class.from_pretrained(tmpdir, resolution=32)
+ for component in pipe_loaded.components.values():
+ if hasattr(component, "set_default_attn_processor"):
+ component.set_default_attn_processor()
+ pipe_loaded.to(torch_device)
+ pipe_loaded.set_progress_bar_config(disable=None)
+
+ for optional_component in pipe._optional_components:
+ self.assertTrue(
+ getattr(pipe_loaded, optional_component) is None,
+ f"`{optional_component}` did not stay set to None after loading.",
+ )
+
+ inputs = self.get_dummy_inputs(generator_device)
+ torch.manual_seed(0)
+ output_loaded = pipe_loaded(**inputs)[0]
+
+ max_diff = np.abs(to_np(output) - to_np(output_loaded)).max()
+ self.assertLess(max_diff, expected_max_difference)
+
+ @unittest.skipIf(torch_device not in ["cuda", "xpu"], reason="float16 requires CUDA or XPU")
+ @require_accelerator
+ def test_save_load_float16(self, expected_max_diff=1e-2):
+ components = self.get_dummy_components()
+ for name, module in components.items():
+ if hasattr(module, "half"):
+ components[name] = module.to(torch_device).half()
+
+ pipe = self.pipeline_class(**components)
+ for component in pipe.components.values():
+ if hasattr(component, "set_default_attn_processor"):
+ component.set_default_attn_processor()
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(torch_device)
+ output = pipe(**inputs)[0]
+
+ with tempfile.TemporaryDirectory() as tmpdir:
+ pipe.save_pretrained(tmpdir)
+ # NOTE: Resolution must be set to 32 for loading otherwise will lead to OOM on CI hardware
+ # This attribute is not serialized in the config of the pipeline
+ pipe_loaded = self.pipeline_class.from_pretrained(tmpdir, torch_dtype=torch.float16, resolution=32)
+ for component in pipe_loaded.components.values():
+ if hasattr(component, "set_default_attn_processor"):
+ component.set_default_attn_processor()
+ pipe_loaded.to(torch_device)
+ pipe_loaded.set_progress_bar_config(disable=None)
+
+ for name, component in pipe_loaded.components.items():
+ if hasattr(component, "dtype"):
+ self.assertTrue(
+ component.dtype == torch.float16,
+ f"`{name}.dtype` switched from `float16` to {component.dtype} after loading.",
+ )
+
+ inputs = self.get_dummy_inputs(torch_device)
+ output_loaded = pipe_loaded(**inputs)[0]
+ max_diff = np.abs(to_np(output) - to_np(output_loaded)).max()
+ self.assertLess(
+ max_diff, expected_max_diff, "The output of the fp16 pipeline changed after saving and loading."
+ )
diff --git a/tests/pipelines/visualcloze/test_pipeline_visualcloze_generation.py b/tests/pipelines/visualcloze/test_pipeline_visualcloze_generation.py
new file mode 100644
index 0000000000..0cd714af17
--- /dev/null
+++ b/tests/pipelines/visualcloze/test_pipeline_visualcloze_generation.py
@@ -0,0 +1,312 @@
+import random
+import tempfile
+import unittest
+
+import numpy as np
+import torch
+from PIL import Image
+from transformers import AutoTokenizer, CLIPTextConfig, CLIPTextModel, CLIPTokenizer, T5EncoderModel
+
+import diffusers
+from diffusers import (
+ AutoencoderKL,
+ FlowMatchEulerDiscreteScheduler,
+ FluxTransformer2DModel,
+ VisualClozeGenerationPipeline,
+)
+from diffusers.utils import logging
+from diffusers.utils.testing_utils import (
+ CaptureLogger,
+ enable_full_determinism,
+ floats_tensor,
+ require_accelerator,
+ torch_device,
+)
+
+from ..test_pipelines_common import PipelineTesterMixin, to_np
+
+
+enable_full_determinism()
+
+
+class VisualClozeGenerationPipelineFastTests(unittest.TestCase, PipelineTesterMixin):
+ pipeline_class = VisualClozeGenerationPipeline
+ params = frozenset(
+ [
+ "task_prompt",
+ "content_prompt",
+ "guidance_scale",
+ "prompt_embeds",
+ "pooled_prompt_embeds",
+ ]
+ )
+ batch_params = frozenset(["task_prompt", "content_prompt", "image"])
+ test_xformers_attention = False
+ test_layerwise_casting = True
+ test_group_offloading = True
+
+ supports_dduf = False
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ transformer = FluxTransformer2DModel(
+ patch_size=1,
+ in_channels=12,
+ out_channels=4,
+ num_layers=1,
+ num_single_layers=1,
+ attention_head_dim=6,
+ num_attention_heads=2,
+ joint_attention_dim=32,
+ pooled_projection_dim=32,
+ axes_dims_rope=[2, 2, 2],
+ )
+ clip_text_encoder_config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ hidden_act="gelu",
+ projection_dim=32,
+ )
+
+ torch.manual_seed(0)
+ text_encoder = CLIPTextModel(clip_text_encoder_config)
+
+ torch.manual_seed(0)
+ text_encoder_2 = T5EncoderModel.from_pretrained("hf-internal-testing/tiny-random-t5")
+
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+ tokenizer_2 = AutoTokenizer.from_pretrained("hf-internal-testing/tiny-random-t5")
+
+ torch.manual_seed(0)
+ vae = AutoencoderKL(
+ sample_size=32,
+ in_channels=3,
+ out_channels=3,
+ block_out_channels=(4,),
+ layers_per_block=1,
+ latent_channels=1,
+ norm_num_groups=1,
+ use_quant_conv=False,
+ use_post_quant_conv=False,
+ shift_factor=0.0609,
+ scaling_factor=1.5035,
+ )
+
+ scheduler = FlowMatchEulerDiscreteScheduler()
+
+ return {
+ "scheduler": scheduler,
+ "text_encoder": text_encoder,
+ "text_encoder_2": text_encoder_2,
+ "tokenizer": tokenizer,
+ "tokenizer_2": tokenizer_2,
+ "transformer": transformer,
+ "vae": vae,
+ "resolution": 32,
+ }
+
+ def get_dummy_inputs(self, device, seed=0):
+ # Create example images to simulate the input format required by VisualCloze
+ context_image = [
+ Image.fromarray(floats_tensor((32, 32, 3), rng=random.Random(seed), scale=255).numpy().astype(np.uint8))
+ for _ in range(2)
+ ]
+ query_image = [
+ Image.fromarray(
+ floats_tensor((32, 32, 3), rng=random.Random(seed + 1), scale=255).numpy().astype(np.uint8)
+ ),
+ None,
+ ]
+
+ # Create an image list that conforms to the VisualCloze input format
+ image = [
+ context_image, # In-Context example
+ query_image, # Query image
+ ]
+
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device="cpu").manual_seed(seed)
+
+ inputs = {
+ "task_prompt": "Each row outlines a logical process, starting from [IMAGE1] gray-based depth map with detailed object contours, to achieve [IMAGE2] an image with flawless clarity.",
+ "content_prompt": "A beautiful landscape with mountains and a lake",
+ "image": image,
+ "generator": generator,
+ "num_inference_steps": 2,
+ "guidance_scale": 5.0,
+ "max_sequence_length": 77,
+ "output_type": "np",
+ }
+ return inputs
+
+ def test_visualcloze_different_prompts(self):
+ pipe = self.pipeline_class(**self.get_dummy_components()).to(torch_device)
+
+ inputs = self.get_dummy_inputs(torch_device)
+ output_same_prompt = pipe(**inputs).images[0]
+
+ inputs = self.get_dummy_inputs(torch_device)
+ inputs["task_prompt"] = "A different task to perform."
+ output_different_prompts = pipe(**inputs).images[0]
+
+ max_diff = np.abs(output_same_prompt - output_different_prompts).max()
+
+ # Outputs should be different
+ assert max_diff > 1e-6
+
+ def test_inference_batch_single_identical(self):
+ self._test_inference_batch_single_identical(expected_max_diff=1e-3)
+
+ def test_different_task_prompts(self, expected_min_diff=1e-1):
+ pipe = self.pipeline_class(**self.get_dummy_components()).to(torch_device)
+ inputs = self.get_dummy_inputs(torch_device)
+
+ output_original = pipe(**inputs).images[0]
+
+ inputs["task_prompt"] = "A different task description for image generation"
+ output_different_task = pipe(**inputs).images[0]
+
+ # Different task prompts should produce different outputs
+ max_diff = np.abs(output_original - output_different_task).max()
+ assert max_diff > expected_min_diff
+
+ def test_save_load_local(self, expected_max_difference=5e-4):
+ components = self.get_dummy_components()
+ pipe = self.pipeline_class(**components)
+ for component in pipe.components.values():
+ if hasattr(component, "set_default_attn_processor"):
+ component.set_default_attn_processor()
+
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(torch_device)
+ output = pipe(**inputs)[0]
+
+ logger = logging.get_logger("diffusers.pipelines.pipeline_utils")
+ logger.setLevel(diffusers.logging.INFO)
+
+ with tempfile.TemporaryDirectory() as tmpdir:
+ pipe.save_pretrained(tmpdir, safe_serialization=False)
+
+ with CaptureLogger(logger) as cap_logger:
+ # NOTE: Resolution must be set to 32 for loading otherwise will lead to OOM on CI hardware
+ # This attribute is not serialized in the config of the pipeline
+ pipe_loaded = self.pipeline_class.from_pretrained(tmpdir, resolution=32)
+
+ for component in pipe_loaded.components.values():
+ if hasattr(component, "set_default_attn_processor"):
+ component.set_default_attn_processor()
+
+ for name in pipe_loaded.components.keys():
+ if name not in pipe_loaded._optional_components:
+ assert name in str(cap_logger)
+
+ pipe_loaded.to(torch_device)
+ pipe_loaded.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(torch_device)
+ output_loaded = pipe_loaded(**inputs)[0]
+
+ max_diff = np.abs(to_np(output) - to_np(output_loaded)).max()
+ self.assertLess(max_diff, expected_max_difference)
+
+ def test_save_load_optional_components(self, expected_max_difference=1e-4):
+ if not hasattr(self.pipeline_class, "_optional_components"):
+ return
+ components = self.get_dummy_components()
+ pipe = self.pipeline_class(**components)
+ for component in pipe.components.values():
+ if hasattr(component, "set_default_attn_processor"):
+ component.set_default_attn_processor()
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ # set all optional components to None
+ for optional_component in pipe._optional_components:
+ setattr(pipe, optional_component, None)
+
+ generator_device = "cpu"
+ inputs = self.get_dummy_inputs(generator_device)
+ torch.manual_seed(0)
+ output = pipe(**inputs)[0]
+
+ with tempfile.TemporaryDirectory() as tmpdir:
+ pipe.save_pretrained(tmpdir, safe_serialization=False)
+ # NOTE: Resolution must be set to 32 for loading otherwise will lead to OOM on CI hardware
+ # This attribute is not serialized in the config of the pipeline
+ pipe_loaded = self.pipeline_class.from_pretrained(tmpdir, resolution=32)
+ for component in pipe_loaded.components.values():
+ if hasattr(component, "set_default_attn_processor"):
+ component.set_default_attn_processor()
+ pipe_loaded.to(torch_device)
+ pipe_loaded.set_progress_bar_config(disable=None)
+
+ for optional_component in pipe._optional_components:
+ self.assertTrue(
+ getattr(pipe_loaded, optional_component) is None,
+ f"`{optional_component}` did not stay set to None after loading.",
+ )
+
+ inputs = self.get_dummy_inputs(generator_device)
+ torch.manual_seed(0)
+ output_loaded = pipe_loaded(**inputs)[0]
+
+ max_diff = np.abs(to_np(output) - to_np(output_loaded)).max()
+ self.assertLess(max_diff, expected_max_difference)
+
+ @unittest.skipIf(torch_device not in ["cuda", "xpu"], reason="float16 requires CUDA or XPU")
+ @require_accelerator
+ def test_save_load_float16(self, expected_max_diff=1e-2):
+ components = self.get_dummy_components()
+ for name, module in components.items():
+ if hasattr(module, "half"):
+ components[name] = module.to(torch_device).half()
+
+ pipe = self.pipeline_class(**components)
+ for component in pipe.components.values():
+ if hasattr(component, "set_default_attn_processor"):
+ component.set_default_attn_processor()
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(torch_device)
+ output = pipe(**inputs)[0]
+
+ with tempfile.TemporaryDirectory() as tmpdir:
+ pipe.save_pretrained(tmpdir)
+ # NOTE: Resolution must be set to 32 for loading otherwise will lead to OOM on CI hardware
+ # This attribute is not serialized in the config of the pipeline
+ pipe_loaded = self.pipeline_class.from_pretrained(tmpdir, torch_dtype=torch.float16, resolution=32)
+ for component in pipe_loaded.components.values():
+ if hasattr(component, "set_default_attn_processor"):
+ component.set_default_attn_processor()
+ pipe_loaded.to(torch_device)
+ pipe_loaded.set_progress_bar_config(disable=None)
+
+ for name, component in pipe_loaded.components.items():
+ if hasattr(component, "dtype"):
+ self.assertTrue(
+ component.dtype == torch.float16,
+ f"`{name}.dtype` switched from `float16` to {component.dtype} after loading.",
+ )
+
+ inputs = self.get_dummy_inputs(torch_device)
+ output_loaded = pipe_loaded(**inputs)[0]
+ max_diff = np.abs(to_np(output) - to_np(output_loaded)).max()
+ self.assertLess(
+ max_diff, expected_max_diff, "The output of the fp16 pipeline changed after saving and loading."
+ )
+
+ @unittest.skip("Skipped due to missing layout_prompt. Needs further investigation.")
+ def test_encode_prompt_works_in_isolation(self, extra_required_param_value_dict=None, atol=0.0001, rtol=0.0001):
+ pass
diff --git a/tests/quantization/bnb/test_4bit.py b/tests/quantization/bnb/test_4bit.py
index 096ee4c344..bd5584296a 100644
--- a/tests/quantization/bnb/test_4bit.py
+++ b/tests/quantization/bnb/test_4bit.py
@@ -205,7 +205,7 @@ class BnB4BitBasicTests(Base4bitTests):
def test_original_dtype(self):
r"""
- A simple test to check if the model succesfully stores the original dtype
+ A simple test to check if the model successfully stores the original dtype
"""
self.assertTrue("_pre_quantization_dtype" in self.model_4bit.config)
self.assertFalse("_pre_quantization_dtype" in self.model_fp16.config)
@@ -389,7 +389,7 @@ class BnB4BitBasicTests(Base4bitTests):
class BnB4BitTrainingTests(Base4bitTests):
def setUp(self):
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
@@ -657,7 +657,7 @@ class SlowBnb4BitTests(Base4bitTests):
class SlowBnb4BitFluxTests(Base4bitTests):
def setUp(self) -> None:
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
model_id = "hf-internal-testing/flux.1-dev-nf4-pkg"
t5_4bit = T5EncoderModel.from_pretrained(model_id, subfolder="text_encoder_2")
@@ -674,7 +674,7 @@ class SlowBnb4BitFluxTests(Base4bitTests):
del self.pipeline_4bit
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def test_quality(self):
# keep the resolution and max tokens to a lower number for faster execution.
@@ -722,7 +722,7 @@ class SlowBnb4BitFluxTests(Base4bitTests):
class SlowBnb4BitFluxControlWithLoraTests(Base4bitTests):
def setUp(self) -> None:
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
self.pipeline_4bit = FluxControlPipeline.from_pretrained("eramth/flux-4bit", torch_dtype=torch.float16)
self.pipeline_4bit.enable_model_cpu_offload()
@@ -731,7 +731,7 @@ class SlowBnb4BitFluxControlWithLoraTests(Base4bitTests):
del self.pipeline_4bit
gc.collect()
- torch.cuda.empty_cache()
+ backend_empty_cache(torch_device)
def test_lora_loading(self):
self.pipeline_4bit.load_lora_weights("black-forest-labs/FLUX.1-Canny-dev-lora")
diff --git a/tests/quantization/bnb/test_mixed_int8.py b/tests/quantization/bnb/test_mixed_int8.py
index a8aff679b5..f987097799 100644
--- a/tests/quantization/bnb/test_mixed_int8.py
+++ b/tests/quantization/bnb/test_mixed_int8.py
@@ -195,7 +195,7 @@ class BnB8bitBasicTests(Base8bitTests):
def test_original_dtype(self):
r"""
- A simple test to check if the model succesfully stores the original dtype
+ A simple test to check if the model successfully stores the original dtype
"""
self.assertTrue("_pre_quantization_dtype" in self.model_8bit.config)
self.assertFalse("_pre_quantization_dtype" in self.model_fp16.config)
diff --git a/tests/quantization/gguf/test_gguf.py b/tests/quantization/gguf/test_gguf.py
index 9f54ecf6c6..ae3900459d 100644
--- a/tests/quantization/gguf/test_gguf.py
+++ b/tests/quantization/gguf/test_gguf.py
@@ -12,6 +12,7 @@ from diffusers import (
FluxPipeline,
FluxTransformer2DModel,
GGUFQuantizationConfig,
+ HiDreamImageTransformer2DModel,
SD3Transformer2DModel,
StableDiffusion3Pipeline,
)
@@ -549,3 +550,30 @@ class FluxControlLoRAGGUFTests(unittest.TestCase):
max_diff = numpy_cosine_similarity_distance(expected_slice, out_slice)
self.assertTrue(max_diff < 1e-3)
+
+
+class HiDreamGGUFSingleFileTests(GGUFSingleFileTesterMixin, unittest.TestCase):
+ ckpt_path = "https://huggingface.co/city96/HiDream-I1-Dev-gguf/blob/main/hidream-i1-dev-Q2_K.gguf"
+ torch_dtype = torch.bfloat16
+ model_cls = HiDreamImageTransformer2DModel
+ expected_memory_use_in_gb = 8
+
+ def get_dummy_inputs(self):
+ return {
+ "hidden_states": torch.randn((1, 16, 128, 128), generator=torch.Generator("cpu").manual_seed(0)).to(
+ torch_device, self.torch_dtype
+ ),
+ "encoder_hidden_states_t5": torch.randn(
+ (1, 128, 4096),
+ generator=torch.Generator("cpu").manual_seed(0),
+ ).to(torch_device, self.torch_dtype),
+ "encoder_hidden_states_llama3": torch.randn(
+ (32, 1, 128, 4096),
+ generator=torch.Generator("cpu").manual_seed(0),
+ ).to(torch_device, self.torch_dtype),
+ "pooled_embeds": torch.randn(
+ (1, 2048),
+ generator=torch.Generator("cpu").manual_seed(0),
+ ).to(torch_device, self.torch_dtype),
+ "timesteps": torch.tensor([1]).to(torch_device, self.torch_dtype),
+ }
diff --git a/tests/quantization/test_pipeline_level_quantization.py b/tests/quantization/test_pipeline_level_quantization.py
new file mode 100644
index 0000000000..b82b2889d7
--- /dev/null
+++ b/tests/quantization/test_pipeline_level_quantization.py
@@ -0,0 +1,190 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Team Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a clone of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import tempfile
+import unittest
+
+import torch
+
+from diffusers import DiffusionPipeline, QuantoConfig
+from diffusers.quantizers import PipelineQuantizationConfig
+from diffusers.utils.testing_utils import (
+ is_transformers_available,
+ require_accelerate,
+ require_bitsandbytes_version_greater,
+ require_quanto,
+ require_torch,
+ require_torch_accelerator,
+ slow,
+ torch_device,
+)
+
+
+if is_transformers_available():
+ from transformers import BitsAndBytesConfig as TranBitsAndBytesConfig
+else:
+ TranBitsAndBytesConfig = None
+
+
+@require_bitsandbytes_version_greater("0.43.2")
+@require_quanto
+@require_accelerate
+@require_torch
+@require_torch_accelerator
+@slow
+class PipelineQuantizationTests(unittest.TestCase):
+ model_name = "hf-internal-testing/tiny-flux-pipe"
+ prompt = "a beautiful sunset amidst the mountains."
+ num_inference_steps = 10
+ seed = 0
+
+ def test_quant_config_set_correctly_through_kwargs(self):
+ components_to_quantize = ["transformer", "text_encoder_2"]
+ quant_config = PipelineQuantizationConfig(
+ quant_backend="bitsandbytes_4bit",
+ quant_kwargs={
+ "load_in_4bit": True,
+ "bnb_4bit_quant_type": "nf4",
+ "bnb_4bit_compute_dtype": torch.bfloat16,
+ },
+ components_to_quantize=components_to_quantize,
+ )
+ pipe = DiffusionPipeline.from_pretrained(
+ self.model_name,
+ quantization_config=quant_config,
+ torch_dtype=torch.bfloat16,
+ ).to(torch_device)
+ for name, component in pipe.components.items():
+ if name in components_to_quantize:
+ self.assertTrue(getattr(component.config, "quantization_config", None) is not None)
+ quantization_config = component.config.quantization_config
+ self.assertTrue(quantization_config.load_in_4bit)
+ self.assertTrue(quantization_config.quant_method == "bitsandbytes")
+
+ _ = pipe(self.prompt, num_inference_steps=self.num_inference_steps)
+
+ def test_quant_config_set_correctly_through_granular(self):
+ quant_config = PipelineQuantizationConfig(
+ quant_mapping={
+ "transformer": QuantoConfig(weights_dtype="int8"),
+ "text_encoder_2": TranBitsAndBytesConfig(load_in_4bit=True, compute_dtype=torch.bfloat16),
+ }
+ )
+ components_to_quantize = list(quant_config.quant_mapping.keys())
+ pipe = DiffusionPipeline.from_pretrained(
+ self.model_name,
+ quantization_config=quant_config,
+ torch_dtype=torch.bfloat16,
+ ).to(torch_device)
+ for name, component in pipe.components.items():
+ if name in components_to_quantize:
+ self.assertTrue(getattr(component.config, "quantization_config", None) is not None)
+ quantization_config = component.config.quantization_config
+
+ if name == "text_encoder_2":
+ self.assertTrue(quantization_config.load_in_4bit)
+ self.assertTrue(quantization_config.quant_method == "bitsandbytes")
+ else:
+ self.assertTrue(quantization_config.quant_method == "quanto")
+
+ _ = pipe(self.prompt, num_inference_steps=self.num_inference_steps)
+
+ def test_raises_error_for_invalid_config(self):
+ with self.assertRaises(ValueError) as err_context:
+ _ = PipelineQuantizationConfig(
+ quant_mapping={
+ "transformer": QuantoConfig(weights_dtype="int8"),
+ "text_encoder_2": TranBitsAndBytesConfig(load_in_4bit=True, compute_dtype=torch.bfloat16),
+ },
+ quant_backend="bitsandbytes_4bit",
+ )
+
+ self.assertTrue(
+ str(err_context.exception)
+ == "Both `quant_backend` and `quant_mapping` cannot be specified at the same time."
+ )
+
+ def test_validation_for_kwargs(self):
+ components_to_quantize = ["transformer", "text_encoder_2"]
+ with self.assertRaises(ValueError) as err_context:
+ _ = PipelineQuantizationConfig(
+ quant_backend="quanto",
+ quant_kwargs={"weights_dtype": "int8"},
+ components_to_quantize=components_to_quantize,
+ )
+
+ self.assertTrue(
+ "The signatures of the __init__ methods of the quantization config classes" in str(err_context.exception)
+ )
+
+ def test_raises_error_for_wrong_config_class(self):
+ quant_config = {
+ "transformer": QuantoConfig(weights_dtype="int8"),
+ "text_encoder_2": TranBitsAndBytesConfig(load_in_4bit=True, compute_dtype=torch.bfloat16),
+ }
+ with self.assertRaises(ValueError) as err_context:
+ _ = DiffusionPipeline.from_pretrained(
+ self.model_name,
+ quantization_config=quant_config,
+ torch_dtype=torch.bfloat16,
+ )
+ self.assertTrue(
+ str(err_context.exception) == "`quantization_config` must be an instance of `PipelineQuantizationConfig`."
+ )
+
+ def test_validation_for_mapping(self):
+ with self.assertRaises(ValueError) as err_context:
+ _ = PipelineQuantizationConfig(
+ quant_mapping={
+ "transformer": DiffusionPipeline(),
+ "text_encoder_2": TranBitsAndBytesConfig(load_in_4bit=True, compute_dtype=torch.bfloat16),
+ }
+ )
+
+ self.assertTrue("Provided config for module_name=transformer could not be found" in str(err_context.exception))
+
+ def test_saving_loading(self):
+ quant_config = PipelineQuantizationConfig(
+ quant_mapping={
+ "transformer": QuantoConfig(weights_dtype="int8"),
+ "text_encoder_2": TranBitsAndBytesConfig(load_in_4bit=True, compute_dtype=torch.bfloat16),
+ }
+ )
+ components_to_quantize = list(quant_config.quant_mapping.keys())
+ pipe = DiffusionPipeline.from_pretrained(
+ self.model_name,
+ quantization_config=quant_config,
+ torch_dtype=torch.bfloat16,
+ ).to(torch_device)
+
+ pipe_inputs = {"prompt": self.prompt, "num_inference_steps": self.num_inference_steps, "output_type": "latent"}
+ output_1 = pipe(**pipe_inputs, generator=torch.manual_seed(self.seed)).images
+
+ with tempfile.TemporaryDirectory() as tmpdir:
+ pipe.save_pretrained(tmpdir)
+ loaded_pipe = DiffusionPipeline.from_pretrained(tmpdir, torch_dtype=torch.bfloat16).to(torch_device)
+ for name, component in loaded_pipe.components.items():
+ if name in components_to_quantize:
+ self.assertTrue(getattr(component.config, "quantization_config", None) is not None)
+ quantization_config = component.config.quantization_config
+
+ if name == "text_encoder_2":
+ self.assertTrue(quantization_config.load_in_4bit)
+ self.assertTrue(quantization_config.quant_method == "bitsandbytes")
+ else:
+ self.assertTrue(quantization_config.quant_method == "quanto")
+
+ output_2 = loaded_pipe(**pipe_inputs, generator=torch.manual_seed(self.seed)).images
+
+ self.assertTrue(torch.allclose(output_1, output_2))
diff --git a/tests/single_file/test_model_autoencoder_dc_single_file.py b/tests/single_file/test_model_autoencoder_dc_single_file.py
index 31b2eb6e36..27348fa7b2 100644
--- a/tests/single_file/test_model_autoencoder_dc_single_file.py
+++ b/tests/single_file/test_model_autoencoder_dc_single_file.py
@@ -95,7 +95,7 @@ class AutoencoderDCSingleFileTests(unittest.TestCase):
# `in` variant checkpoints require passing in a `config` parameter
# in order to set the scaling factor correctly.
# `in` and `mix` variants have the same keys and we cannot automatically infer a scaling factor.
- # We default to using teh `mix` config
+ # We default to using the `mix` config
repo_id = "mit-han-lab/dc-ae-f128c512-in-1.0-diffusers"
ckpt_path = "https://huggingface.co/mit-han-lab/dc-ae-f128c512-in-1.0/blob/main/model.safetensors"
diff --git a/utils/custom_init_isort.py b/utils/custom_init_isort.py
index 791df0e786..cc3bccb9bd 100644
--- a/utils/custom_init_isort.py
+++ b/utils/custom_init_isort.py
@@ -252,7 +252,7 @@ def sort_imports(file: str, check_only: bool = True):
code, start_prompt="_import_structure = {", end_prompt="if TYPE_CHECKING:"
)
- # We ignore block 0 (everything untils start_prompt) and the last block (everything after end_prompt).
+ # We ignore block 0 (everything until start_prompt) and the last block (everything after end_prompt).
for block_idx in range(1, len(main_blocks) - 1):
# Check if the block contains some `_import_structure`s thingy to sort.
block = main_blocks[block_idx]
diff --git a/utils/print_env.py b/utils/print_env.py
index 0a1cfbef13..2d2acb59d5 100644
--- a/utils/print_env.py
+++ b/utils/print_env.py
@@ -34,13 +34,24 @@ try:
print("Torch version:", torch.__version__)
print("Cuda available:", torch.cuda.is_available())
- print("Cuda version:", torch.version.cuda)
- print("CuDNN version:", torch.backends.cudnn.version())
- print("Number of GPUs available:", torch.cuda.device_count())
if torch.cuda.is_available():
+ print("Cuda version:", torch.version.cuda)
+ print("CuDNN version:", torch.backends.cudnn.version())
+ print("Number of GPUs available:", torch.cuda.device_count())
device_properties = torch.cuda.get_device_properties(0)
total_memory = device_properties.total_memory / (1024**3)
print(f"CUDA memory: {total_memory} GB")
+
+ print("XPU available:", hasattr(torch, "xpu") and torch.xpu.is_available())
+ if hasattr(torch, "xpu") and torch.xpu.is_available():
+ print("XPU model:", torch.xpu.get_device_properties(0).name)
+ print("XPU compiler version:", torch.version.xpu)
+ print("Number of XPUs available:", torch.xpu.device_count())
+ device_properties = torch.xpu.get_device_properties(0)
+ total_memory = device_properties.total_memory / (1024**3)
+ print(f"XPU memory: {total_memory} GB")
+
+
except ImportError:
print("Torch version:", None)