diff --git a/docs/source/en/api/pipelines/overview.mdx b/docs/source/en/api/pipelines/overview.mdx
index 411f56ce58..baed333fbd 100644
--- a/docs/source/en/api/pipelines/overview.mdx
+++ b/docs/source/en/api/pipelines/overview.mdx
@@ -46,7 +46,7 @@ available a colab notebook to directly try them out.
|---|---|:---:|:---:|
| [alt_diffusion](./alt_diffusion) | [**AltDiffusion**](https://arxiv.org/abs/2211.06679) | Image-to-Image Text-Guided Generation | -
| [audio_diffusion](./audio_diffusion) | [**Audio Diffusion**](https://github.com/teticio/audio_diffusion.git) | Unconditional Audio Generation |
-| [controlnet](./api/pipelines/stable_diffusion/controlnet) | [**ControlNet with Stable Diffusion**](https://arxiv.org/abs/2302.05543) | Image-to-Image Text-Guided Generation | [](https://colab.research.google.com/drive/1AiR7Q-sBqO88NCyswpfiuwXZc7DfMyKA?usp=sharing)
+| [controlnet](./api/pipelines/stable_diffusion/controlnet) | [**ControlNet with Stable Diffusion**](https://arxiv.org/abs/2302.05543) | Image-to-Image Text-Guided Generation | [
| [cycle_diffusion](./cycle_diffusion) | [**Cycle Diffusion**](https://arxiv.org/abs/2210.05559) | Image-to-Image Text-Guided Generation |
| [dance_diffusion](./dance_diffusion) | [**Dance Diffusion**](https://github.com/williamberman/diffusers.git) | Unconditional Audio Generation |
| [ddpm](./ddpm) | [**Denoising Diffusion Probabilistic Models**](https://arxiv.org/abs/2006.11239) | Unconditional Image Generation |
diff --git a/docs/source/en/api/pipelines/stable_diffusion/controlnet.mdx b/docs/source/en/api/pipelines/stable_diffusion/controlnet.mdx
index f636d79ba5..b536ccfe86 100644
--- a/docs/source/en/api/pipelines/stable_diffusion/controlnet.mdx
+++ b/docs/source/en/api/pipelines/stable_diffusion/controlnet.mdx
@@ -33,7 +33,7 @@ Resources:
| Pipeline | Tasks | Demo
|---|---|:---:|
-| [StableDiffusionControlNetPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_controlnet.py) | *Text-to-Image Generation with ControlNet Conditioning* | [Colab Example](https://colab.research.google.com/drive/1AiR7Q-sBqO88NCyswpfiuwXZc7DfMyKA?usp=sharing) |
+| [StableDiffusionControlNetPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_controlnet.py) | *Text-to-Image Generation with ControlNet Conditioning* | [Colab Example](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/controlnet.ipynb)
## Usage example
@@ -65,6 +65,12 @@ First, we need to install opencv:
pip install opencv-contrib-python
```
+Next, let's also install all required Hugging Face libraries:
+
+```
+pip install diffusers transformers git+https://github.com/huggingface/accelerate.git
+```
+
Then we can retrieve the canny edges of the image.
```python
@@ -145,9 +151,9 @@ All checkpoints can be found under the authors' namespace [lllyasviel](https://h
|[lllyasviel/sd-controlnet-hed](https://huggingface.co/lllyasviel/sd-controlnet-hed)
*Trained with HED edge detection (soft edge)* |A monochrome image with white soft edges on a black background.| |
| |
|[lllyasviel/sd-controlnet-mlsd](https://huggingface.co/lllyasviel/sd-controlnet-mlsd)
|
|[lllyasviel/sd-controlnet-mlsd](https://huggingface.co/lllyasviel/sd-controlnet-mlsd)
*Trained with M-LSD line detection* |A monochrome image composed only of white straight lines on a black background.| |
| |
|[lllyasviel/sd-controlnet-normal](https://huggingface.co/lllyasviel/sd-controlnet-normal)
|
|[lllyasviel/sd-controlnet-normal](https://huggingface.co/lllyasviel/sd-controlnet-normal)
*Trained with normal map* |A [normal mapped](https://en.wikipedia.org/wiki/Normal_mapping) image.| |
| |
-|[lllyasviel/sd-controlnet_openpose](https://huggingface.co/lllyasviel/sd-controlnet_openpose)
|
-|[lllyasviel/sd-controlnet_openpose](https://huggingface.co/lllyasviel/sd-controlnet_openpose)
*Trained with OpenPose bone image* |A [OpenPose bone](https://github.com/CMU-Perceptual-Computing-Lab/openpose) image.|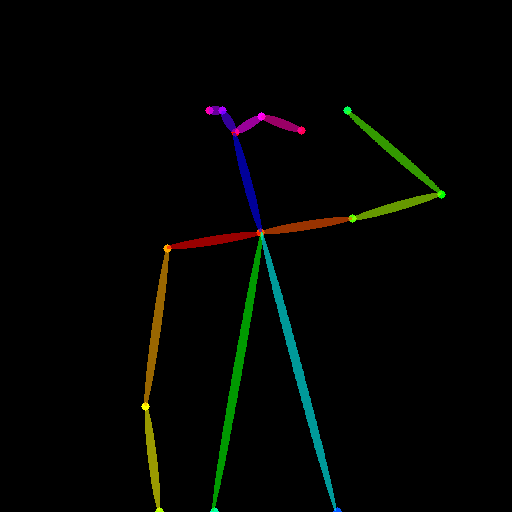 |
| |
-|[lllyasviel/sd-controlnet_scribble](https://huggingface.co/lllyasviel/sd-controlnet_scribble)
|
-|[lllyasviel/sd-controlnet_scribble](https://huggingface.co/lllyasviel/sd-controlnet_scribble)
*Trained with human scribbles* |A hand-drawn monochrome image with white outlines on a black background.| |
| |
-|[lllyasviel/sd-controlnet_seg](https://huggingface.co/lllyasviel/sd-controlnet_seg)
|
-|[lllyasviel/sd-controlnet_seg](https://huggingface.co/lllyasviel/sd-controlnet_seg)
*Trained with semantic segmentation* |An [ADE20K](https://groups.csail.mit.edu/vision/datasets/ADE20K/)'s segmentation protocol image.| |
| |
+|[lllyasviel/sd-controlnet-openpose](https://huggingface.co/lllyasviel/sd-controlnet_openpose)
|
+|[lllyasviel/sd-controlnet-openpose](https://huggingface.co/lllyasviel/sd-controlnet_openpose)
*Trained with OpenPose bone image* |A [OpenPose bone](https://github.com/CMU-Perceptual-Computing-Lab/openpose) image.|||
+|[lllyasviel/sd-controlnet-scribble](https://huggingface.co/lllyasviel/sd-controlnet_scribble)
*Trained with human scribbles* |A hand-drawn monochrome image with white outlines on a black background.|| |
+|[lllyasviel/sd-controlnet-seg](https://huggingface.co/lllyasviel/sd-controlnet_seg)
*Trained with semantic segmentation* |An [ADE20K](https://groups.csail.mit.edu/vision/datasets/ADE20K/)'s segmentation protocol image.|| |
[[autodoc]] StableDiffusionControlNetPipeline
- all
diff --git a/docs/source/en/index.mdx b/docs/source/en/index.mdx
index 5471d9235c..11c093d36a 100644
--- a/docs/source/en/index.mdx
+++ b/docs/source/en/index.mdx
@@ -36,7 +36,7 @@ available a colab notebook to directly try them out.
|---|---|:---:|:---:|
| [alt_diffusion](./api/pipelines/alt_diffusion) | [**AltDiffusion**](https://arxiv.org/abs/2211.06679) | Image-to-Image Text-Guided Generation |
| [audio_diffusion](./api/pipelines/audio_diffusion) | [**Audio Diffusion**](https://github.com/teticio/audio-diffusion.git) | Unconditional Audio Generation | [](https://colab.research.google.com/github/teticio/audio-diffusion/blob/master/notebooks/audio_diffusion_pipeline.ipynb)
-| [controlnet](./api/pipelines/stable_diffusion/controlnet) | [**ControlNet with Stable Diffusion**](https://arxiv.org/abs/2302.05543) | Image-to-Image Text-Guided Generation | [](https://colab.research.google.com/drive/1AiR7Q-sBqO88NCyswpfiuwXZc7DfMyKA?usp=sharing)
+| [controlnet](./api/pipelines/stable_diffusion/controlnet) | [**ControlNet with Stable Diffusion**](https://arxiv.org/abs/2302.05543) | Image-to-Image Text-Guided Generation | [
| [cycle_diffusion](./api/pipelines/cycle_diffusion) | [**Cycle Diffusion**](https://arxiv.org/abs/2210.05559) | Image-to-Image Text-Guided Generation |
| [dance_diffusion](./api/pipelines/dance_diffusion) | [**Dance Diffusion**](https://github.com/williamberman/diffusers.git) | Unconditional Audio Generation |
| [ddpm](./api/pipelines/ddpm) | [**Denoising Diffusion Probabilistic Models**](https://arxiv.org/abs/2006.11239) | Unconditional Image Generation |

 |
| |
| |
| |
| |
|