diff --git a/docs/source/en/_toctree.yml b/docs/source/en/_toctree.yml
index 3e9e83e651..0c05f0ef7f 100644
--- a/docs/source/en/_toctree.yml
+++ b/docs/source/en/_toctree.yml
@@ -19,6 +19,8 @@
title: Train a diffusion model
- local: tutorials/using_peft_for_inference
title: Inference with PEFT
+ - local: tutorials/fast_diffusion
+ title: Accelerate inference of text-to-image diffusion models
title: Tutorials
- sections:
- sections:
@@ -264,10 +266,6 @@
title: ControlNet
- local: api/pipelines/controlnet_sdxl
title: ControlNet with Stable Diffusion XL
- - local: api/pipelines/controlnetxs
- title: ControlNet-XS
- - local: api/pipelines/controlnetxs_sdxl
- title: ControlNet-XS with Stable Diffusion XL
- local: api/pipelines/dance_diffusion
title: Dance Diffusion
- local: api/pipelines/ddim
diff --git a/docs/source/en/api/pipelines/amused.md b/docs/source/en/api/pipelines/amused.md
index cb86938021..615c3c870d 100644
--- a/docs/source/en/api/pipelines/amused.md
+++ b/docs/source/en/api/pipelines/amused.md
@@ -18,12 +18,24 @@ Amused is a vqvae token based transformer that can generate an image in fewer fo
| Model | Params |
|-------|--------|
-| [amused-256](https://huggingface.co/huggingface/amused-256) | 603M |
-| [amused-512](https://huggingface.co/huggingface/amused-512) | 608M |
+| [amused-256](https://huggingface.co/amused/amused-256) | 603M |
+| [amused-512](https://huggingface.co/amused/amused-512) | 608M |
## AmusedPipeline
[[autodoc]] AmusedPipeline
+ - __call__
+ - all
+ - enable_xformers_memory_efficient_attention
+ - disable_xformers_memory_efficient_attention
+
+[[autodoc]] AmusedImg2ImgPipeline
+ - __call__
+ - all
+ - enable_xformers_memory_efficient_attention
+ - disable_xformers_memory_efficient_attention
+
+[[autodoc]] AmusedInpaintPipeline
- __call__
- all
- enable_xformers_memory_efficient_attention
diff --git a/docs/source/en/api/pipelines/animatediff.md b/docs/source/en/api/pipelines/animatediff.md
index 422d345b90..fb38687e88 100644
--- a/docs/source/en/api/pipelines/animatediff.md
+++ b/docs/source/en/api/pipelines/animatediff.md
@@ -38,16 +38,21 @@ The following example demonstrates how to use a *MotionAdapter* checkpoint with
```python
import torch
-from diffusers import MotionAdapter, AnimateDiffPipeline, DDIMScheduler
+from diffusers import AnimateDiffPipeline, DDIMScheduler, MotionAdapter
from diffusers.utils import export_to_gif
# Load the motion adapter
-adapter = MotionAdapter.from_pretrained("guoyww/animatediff-motion-adapter-v1-5-2")
+adapter = MotionAdapter.from_pretrained("guoyww/animatediff-motion-adapter-v1-5-2", torch_dtype=torch.float16)
# load SD 1.5 based finetuned model
model_id = "SG161222/Realistic_Vision_V5.1_noVAE"
-pipe = AnimateDiffPipeline.from_pretrained(model_id, motion_adapter=adapter)
+pipe = AnimateDiffPipeline.from_pretrained(model_id, motion_adapter=adapter, torch_dtype=torch.float16)
scheduler = DDIMScheduler.from_pretrained(
- model_id, subfolder="scheduler", clip_sample=False, timestep_spacing="linspace", steps_offset=1
+ model_id,
+ subfolder="scheduler",
+ clip_sample=False,
+ timestep_spacing="linspace",
+ beta_schedule="linear",
+ steps_offset=1,
)
pipe.scheduler = scheduler
@@ -70,6 +75,7 @@ output = pipe(
)
frames = output.frames[0]
export_to_gif(frames, "animation.gif")
+
```
Here are some sample outputs:
@@ -88,7 +94,7 @@ Here are some sample outputs:
-AnimateDiff tends to work better with finetuned Stable Diffusion models. If you plan on using a scheduler that can clip samples, make sure to disable it by setting `clip_sample=False` in the scheduler as this can also have an adverse effect on generated samples.
+AnimateDiff tends to work better with finetuned Stable Diffusion models. If you plan on using a scheduler that can clip samples, make sure to disable it by setting `clip_sample=False` in the scheduler as this can also have an adverse effect on generated samples. Additionally, the AnimateDiff checkpoints can be sensitive to the beta schedule of the scheduler. We recommend setting this to `linear`.
@@ -98,18 +104,25 @@ Motion LoRAs are a collection of LoRAs that work with the `guoyww/animatediff-mo
```python
import torch
-from diffusers import MotionAdapter, AnimateDiffPipeline, DDIMScheduler
+from diffusers import AnimateDiffPipeline, DDIMScheduler, MotionAdapter
from diffusers.utils import export_to_gif
# Load the motion adapter
-adapter = MotionAdapter.from_pretrained("guoyww/animatediff-motion-adapter-v1-5-2")
+adapter = MotionAdapter.from_pretrained("guoyww/animatediff-motion-adapter-v1-5-2", torch_dtype=torch.float16)
# load SD 1.5 based finetuned model
model_id = "SG161222/Realistic_Vision_V5.1_noVAE"
-pipe = AnimateDiffPipeline.from_pretrained(model_id, motion_adapter=adapter)
-pipe.load_lora_weights("guoyww/animatediff-motion-lora-zoom-out", adapter_name="zoom-out")
+pipe = AnimateDiffPipeline.from_pretrained(model_id, motion_adapter=adapter, torch_dtype=torch.float16)
+pipe.load_lora_weights(
+ "guoyww/animatediff-motion-lora-zoom-out", adapter_name="zoom-out"
+)
scheduler = DDIMScheduler.from_pretrained(
- model_id, subfolder="scheduler", clip_sample=False, timestep_spacing="linspace", steps_offset=1
+ model_id,
+ subfolder="scheduler",
+ clip_sample=False,
+ beta_schedule="linear",
+ timestep_spacing="linspace",
+ steps_offset=1,
)
pipe.scheduler = scheduler
@@ -132,6 +145,7 @@ output = pipe(
)
frames = output.frames[0]
export_to_gif(frames, "animation.gif")
+
```
diff --git a/docs/source/en/training/t2i_adapters.md b/docs/source/en/training/t2i_adapters.md
index 0f65ad8ed3..03f4537cb2 100644
--- a/docs/source/en/training/t2i_adapters.md
+++ b/docs/source/en/training/t2i_adapters.md
@@ -12,7 +12,7 @@ specific language governing permissions and limitations under the License.
# T2I-Adapter
-[T2I-Adapter]((https://hf.co/papers/2302.08453)) is a lightweight adapter model that provides an additional conditioning input image (line art, canny, sketch, depth, pose) to better control image generation. It is similar to a ControlNet, but it is a lot smaller (~77M parameters and ~300MB file size) because its only inserts weights into the UNet instead of copying and training it.
+[T2I-Adapter](https://hf.co/papers/2302.08453) is a lightweight adapter model that provides an additional conditioning input image (line art, canny, sketch, depth, pose) to better control image generation. It is similar to a ControlNet, but it is a lot smaller (~77M parameters and ~300MB file size) because its only inserts weights into the UNet instead of copying and training it.
The T2I-Adapter is only available for training with the Stable Diffusion XL (SDXL) model.
diff --git a/docs/source/en/tutorials/fast_diffusion.md b/docs/source/en/tutorials/fast_diffusion.md
new file mode 100644
index 0000000000..cc83fdd997
--- /dev/null
+++ b/docs/source/en/tutorials/fast_diffusion.md
@@ -0,0 +1,318 @@
+
+
+# Accelerate inference of text-to-image diffusion models
+
+Diffusion models are known to be slower than their counter parts, GANs, because of the iterative and sequential reverse diffusion process. Recent works try to address limitation with:
+
+* progressive timestep distillation (such as [LCM LoRA](../using-diffusers/inference_with_lcm_lora.md))
+* model compression (such as [SSD-1B](https://huggingface.co/segmind/SSD-1B))
+* reusing adjacent features of the denoiser (such as [DeepCache](https://github.com/horseee/DeepCache))
+
+In this tutorial, we focus on leveraging the power of PyTorch 2 to accelerate the inference latency of text-to-image diffusion pipeline, instead. We will use [Stable Diffusion XL (SDXL)](../using-diffusers/sdxl.md) as a case study, but the techniques we will discuss should extend to other text-to-image diffusion pipelines.
+
+## Setup
+
+Make sure you're on the latest version of `diffusers`:
+
+```bash
+pip install -U diffusers
+```
+
+Then upgrade the other required libraries too:
+
+```bash
+pip install -U transformers accelerate peft
+```
+
+To benefit from the fastest kernels, use PyTorch nightly. You can find the installation instructions [here](https://pytorch.org/).
+
+To report the numbers shown below, we used an 80GB 400W A100 with its clock rate set to the maximum.
+
+_This tutorial doesn't present the benchmarking code and focuses on how to perform the optimizations, instead. For the full benchmarking code, refer to: [https://github.com/huggingface/diffusion-fast](https://github.com/huggingface/diffusion-fast)._
+
+## Baseline
+
+Let's start with a baseline. Disable the use of a reduced precision and [`scaled_dot_product_attention`](../optimization/torch2.0.md):
+
+```python
+from diffusers import StableDiffusionXLPipeline
+
+# Load the pipeline in full-precision and place its model components on CUDA.
+pipe = StableDiffusionXLPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-xl-base-1.0"
+).to("cuda")
+
+# Run the attention ops without efficiency.
+pipe.unet.set_default_attn_processor()
+pipe.vae.set_default_attn_processor()
+
+prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
+image = pipe(prompt, num_inference_steps=30).images[0]
+```
+
+This takes 7.36 seconds:
+
+
+
+
+
+
+
+## Running inference in bfloat16
+
+Enable the first optimization: use a reduced precision to run the inference.
+
+```python
+from diffusers import StableDiffusionXLPipeline
+import torch
+
+pipe = StableDiffusionXLPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.bfloat16
+).to("cuda")
+
+# Run the attention ops without efficiency.
+pipe.unet.set_default_attn_processor()
+pipe.vae.set_default_attn_processor()
+
+prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
+image = pipe(prompt, num_inference_steps=30).images[0]
+```
+
+bfloat16 reduces the latency from 7.36 seconds to 4.63 seconds:
+
+
+
+
+
+
+
+**Why bfloat16?**
+
+* Using a reduced numerical precision (such as float16, bfloat16) to run inference doesn’t affect the generation quality but significantly improves latency.
+* The benefits of using the bfloat16 numerical precision as compared to float16 are hardware-dependent. Modern generations of GPUs tend to favor bfloat16.
+* Furthermore, in our experiments, we bfloat16 to be much more resilient when used with quantization in comparison to float16.
+
+We have a [dedicated guide](../optimization/fp16.md) for running inference in a reduced precision.
+
+## Running attention efficiently
+
+Attention blocks are intensive to run. But with PyTorch's [`scaled_dot_product_attention`](../optimization/torch2.0.md), we can run them efficiently.
+
+```python
+from diffusers import StableDiffusionXLPipeline
+import torch
+
+pipe = StableDiffusionXLPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.bfloat16
+).to("cuda")
+
+prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
+image = pipe(prompt, num_inference_steps=30).images[0]
+```
+
+`scaled_dot_product_attention` improves the latency from 4.63 seconds to 3.31 seconds.
+
+
+
+
+
+
+
+## Use faster kernels with torch.compile
+
+Compile the UNet and the VAE to benefit from the faster kernels. First, configure a few compiler flags:
+
+```python
+from diffusers import StableDiffusionXLPipeline
+import torch
+
+torch._inductor.config.conv_1x1_as_mm = True
+torch._inductor.config.coordinate_descent_tuning = True
+torch._inductor.config.epilogue_fusion = False
+torch._inductor.config.coordinate_descent_check_all_directions = True
+```
+
+For the full list of compiler flags, refer to [this file](https://github.com/pytorch/pytorch/blob/main/torch/_inductor/config.py).
+
+It is also important to change the memory layout of the UNet and the VAE to “channels_last” when compiling them. This ensures maximum speed:
+
+```python
+pipe.unet.to(memory_format=torch.channels_last)
+pipe.vae.to(memory_format=torch.channels_last)
+```
+
+Then, compile and perform inference:
+
+```python
+# Compile the UNet and VAE.
+pipe.unet = torch.compile(pipe.unet, mode="max-autotune", fullgraph=True)
+pipe.vae.decode = torch.compile(pipe.vae.decode, mode="max-autotune", fullgraph=True)
+
+prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
+
+# First call to `pipe` will be slow, subsequent ones will be faster.
+image = pipe(prompt, num_inference_steps=30).images[0]
+```
+
+`torch.compile` offers different backends and modes. As we’re aiming for maximum inference speed, we opt for the inductor backend using the “max-autotune”. “max-autotune” uses CUDA graphs and optimizes the compilation graph specifically for latency. Specifying fullgraph to be True ensures that there are no graph breaks in the underlying model, ensuring the fullest potential of `torch.compile`.
+
+Using SDPA attention and compiling both the UNet and VAE reduces the latency from 3.31 seconds to 2.54 seconds.
+
+
+
+
+
+
+
+## Combine the projection matrices of attention
+
+Both the UNet and the VAE used in SDXL make use of Transformer-like blocks. A Transformer block consists of attention blocks and feed-forward blocks.
+
+In an attention block, the input is projected into three sub-spaces using three different projection matrices – Q, K, and V. In the naive implementation, these projections are performed separately on the input. But we can horizontally combine the projection matrices into a single matrix and perform the projection in one shot. This increases the size of the matmuls of the input projections and improves the impact of quantization (to be discussed next).
+
+Enabling this kind of computation in Diffusers just takes a single line of code:
+
+```python
+pipe.fuse_qkv_projections()
+```
+
+It provides a minor boost from 2.54 seconds to 2.52 seconds.
+
+
+
+
+
+
+
+
+
+Support for `fuse_qkv_projections()` is limited and experimental. As such, it's not available for many non-SD pipelines such as [Kandinsky](../using-diffusers/kandinsky.md). You can refer to [this PR](https://github.com/huggingface/diffusers/pull/6179) to get an idea about how to support this kind of computation.
+
+
+
+## Dynamic quantization
+
+Aapply [dynamic int8 quantization](https://pytorch.org/tutorials/recipes/recipes/dynamic_quantization.html) to both the UNet and the VAE. This is because quantization adds additional conversion overhead to the model that is hopefully made up for by faster matmuls (dynamic quantization). If the matmuls are too small, these techniques may degrade performance.
+
+
+
+Through experimentation, we found that certain linear layers in the UNet and the VAE don’t benefit from dynamic int8 quantization. You can check out the full code for filtering those layers [here](https://github.com/huggingface/diffusion-fast/blob/0f169640b1db106fe6a479f78c1ed3bfaeba3386/utils/pipeline_utils.py#L16) (referred to as `dynamic_quant_filter_fn` below).
+
+
+
+You will leverage the ultra-lightweight pure PyTorch library [torchao](https://github.com/pytorch-labs/ao) to use its user-friendly APIs for quantization.
+
+First, configure all the compiler tags:
+
+```python
+from diffusers import StableDiffusionXLPipeline
+import torch
+
+# Notice the two new flags at the end.
+torch._inductor.config.conv_1x1_as_mm = True
+torch._inductor.config.coordinate_descent_tuning = True
+torch._inductor.config.epilogue_fusion = False
+torch._inductor.config.coordinate_descent_check_all_directions = True
+torch._inductor.config.force_fuse_int_mm_with_mul = True
+torch._inductor.config.use_mixed_mm = True
+```
+
+Define the filtering functions:
+
+```python
+def dynamic_quant_filter_fn(mod, *args):
+ return (
+ isinstance(mod, torch.nn.Linear)
+ and mod.in_features > 16
+ and (mod.in_features, mod.out_features)
+ not in [
+ (1280, 640),
+ (1920, 1280),
+ (1920, 640),
+ (2048, 1280),
+ (2048, 2560),
+ (2560, 1280),
+ (256, 128),
+ (2816, 1280),
+ (320, 640),
+ (512, 1536),
+ (512, 256),
+ (512, 512),
+ (640, 1280),
+ (640, 1920),
+ (640, 320),
+ (640, 5120),
+ (640, 640),
+ (960, 320),
+ (960, 640),
+ ]
+ )
+
+
+def conv_filter_fn(mod, *args):
+ return (
+ isinstance(mod, torch.nn.Conv2d) and mod.kernel_size == (1, 1) and 128 in [mod.in_channels, mod.out_channels]
+ )
+```
+
+Then apply all the optimizations discussed so far:
+
+```python
+# SDPA + bfloat16.
+pipe = StableDiffusionXLPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.bfloat16
+).to("cuda")
+
+# Combine attention projection matrices.
+pipe.fuse_qkv_projections()
+
+# Change the memory layout.
+pipe.unet.to(memory_format=torch.channels_last)
+pipe.vae.to(memory_format=torch.channels_last)
+```
+
+Since this quantization support is limited to linear layers only, we also turn suitable pointwise convolution layers into linear layers to maximize the benefit.
+
+```python
+from torchao import swap_conv2d_1x1_to_linear
+
+swap_conv2d_1x1_to_linear(pipe.unet, conv_filter_fn)
+swap_conv2d_1x1_to_linear(pipe.vae, conv_filter_fn)
+```
+
+Apply dynamic quantization:
+
+```python
+from torchao import apply_dynamic_quant
+
+apply_dynamic_quant(pipe.unet, dynamic_quant_filter_fn)
+apply_dynamic_quant(pipe.vae, dynamic_quant_filter_fn)
+```
+
+Finally, compile and perform inference:
+
+```python
+pipe.unet = torch.compile(pipe.unet, mode="max-autotune", fullgraph=True)
+pipe.vae.decode = torch.compile(pipe.vae.decode, mode="max-autotune", fullgraph=True)
+
+prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
+image = pipe(prompt, num_inference_steps=30).images[0]
+```
+
+Applying dynamic quantization improves the latency from 2.52 seconds to 2.43 seconds.
+
+
+
+
+
+
\ No newline at end of file
diff --git a/docs/source/en/tutorials/using_peft_for_inference.md b/docs/source/en/tutorials/using_peft_for_inference.md
index 6f317a7610..35b36b0ab2 100644
--- a/docs/source/en/tutorials/using_peft_for_inference.md
+++ b/docs/source/en/tutorials/using_peft_for_inference.md
@@ -183,3 +183,26 @@ image = pipe(prompt, num_inference_steps=30, generator=torch.manual_seed(0)).ima
# Gets the Unet back to the original state
pipe.unfuse_lora()
```
+
+You can also fuse some adapters using `adapter_names` for faster generation:
+
+```py
+pipe.load_lora_weights("nerijs/pixel-art-xl", weight_name="pixel-art-xl.safetensors", adapter_name="pixel")
+pipe.load_lora_weights("CiroN2022/toy-face", weight_name="toy_face_sdxl.safetensors", adapter_name="toy")
+
+pipe.set_adapters(["pixel"], adapter_weights=[0.5, 1.0])
+# Fuses the LoRAs into the Unet
+pipe.fuse_lora(adapter_names=["pixel"])
+
+prompt = "a hacker with a hoodie, pixel art"
+image = pipe(prompt, num_inference_steps=30, generator=torch.manual_seed(0)).images[0]
+
+# Gets the Unet back to the original state
+pipe.unfuse_lora()
+
+# Fuse all adapters
+pipe.fuse_lora(adapter_names=["pixel", "toy"])
+
+prompt = "toy_face of a hacker with a hoodie, pixel art"
+image = pipe(prompt, num_inference_steps=30, generator=torch.manual_seed(0)).images[0]
+```
diff --git a/docs/source/en/using-diffusers/callback.md b/docs/source/en/using-diffusers/callback.md
index 690d86c17a..ab6fb3779b 100644
--- a/docs/source/en/using-diffusers/callback.md
+++ b/docs/source/en/using-diffusers/callback.md
@@ -63,3 +63,42 @@ With callbacks, you can implement features such as dynamic CFG without having to
🤗 Diffusers currently only supports `callback_on_step_end`, but feel free to open a [feature request](https://github.com/huggingface/diffusers/issues/new/choose) if you have a cool use-case and require a callback function with a different execution point!
+
+
+## Using Callbacks to interrupt the Diffusion Process
+
+The following Pipelines support interrupting the diffusion process via callback
+
+- [StableDiffusionPipeline](../api/pipelines/stable_diffusion/overview.md)
+- [StableDiffusionImg2ImgPipeline](..api/pipelines/stable_diffusion/img2img.md)
+- [StableDiffusionInpaintPipeline](..api/pipelines/stable_diffusion/inpaint.md)
+- [StableDiffusionXLPipeline](../api/pipelines/stable_diffusion/stable_diffusion_xl.md)
+- [StableDiffusionXLImg2ImgPipeline](../api/pipelines/stable_diffusion/stable_diffusion_xl.md)
+- [StableDiffusionXLInpaintPipeline](../api/pipelines/stable_diffusion/stable_diffusion_xl.md)
+
+Interrupting the diffusion process is particularly useful when building UIs that work with Diffusers because it allows users to stop the generation process if they're unhappy with the intermediate results. You can incorporate this into your pipeline with a callback.
+
+This callback function should take the following arguments: `pipe`, `i`, `t`, and `callback_kwargs` (this must be returned). Set the pipeline's `_interrupt` attribute to `True` to stop the diffusion process after a certain number of steps. You are also free to implement your own custom stopping logic inside the callback.
+
+In this example, the diffusion process is stopped after 10 steps even though `num_inference_steps` is set to 50.
+
+```python
+from diffusers import StableDiffusionPipeline
+
+pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
+pipe.enable_model_cpu_offload()
+num_inference_steps = 50
+
+def interrupt_callback(pipe, i, t, callback_kwargs):
+ stop_idx = 10
+ if i == stop_idx:
+ pipe._interrupt = True
+
+ return callback_kwargs
+
+pipe(
+ "A photo of a cat",
+ num_inference_steps=num_inference_steps,
+ callback_on_step_end=interrupt_callback,
+)
+```
diff --git a/docs/source/en/using-diffusers/svd.md b/docs/source/en/using-diffusers/svd.md
index 7fd29284cb..8b9beb0b2f 100644
--- a/docs/source/en/using-diffusers/svd.md
+++ b/docs/source/en/using-diffusers/svd.md
@@ -44,7 +44,7 @@ pipe = StableVideoDiffusionPipeline.from_pretrained(
pipe.enable_model_cpu_offload()
# Load the conditioning image
-image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/svd/rocket.png?download=true")
+image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/svd/rocket.png")
image = image.resize((1024, 576))
generator = torch.manual_seed(42)
@@ -58,6 +58,11 @@ export_to_video(frames, "generated.mp4", fps=7)
+| **Source Image** | **Video** |
+|:------------:|:-----:|
+|  |  |
+
+
Since generating videos is more memory intensive we can use the `decode_chunk_size` argument to control how many frames are decoded at once. This will reduce the memory usage. It's recommended to tweak this value based on your GPU memory.
Setting `decode_chunk_size=1` will decode one frame at a time and will use the least amount of memory but the video might have some flickering.
@@ -120,7 +125,7 @@ pipe = StableVideoDiffusionPipeline.from_pretrained(
pipe.enable_model_cpu_offload()
# Load the conditioning image
-image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/svd/rocket.png?download=true")
+image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/svd/rocket.png")
image = image.resize((1024, 576))
generator = torch.manual_seed(42)
@@ -128,7 +133,5 @@ frames = pipe(image, decode_chunk_size=8, generator=generator, motion_bucket_id=
export_to_video(frames, "generated.mp4", fps=7)
```
-
+
diff --git a/examples/advanced_diffusion_training/train_dreambooth_lora_sdxl_advanced.py b/examples/advanced_diffusion_training/train_dreambooth_lora_sdxl_advanced.py
index ad37363b7d..a02f8772e2 100644
--- a/examples/advanced_diffusion_training/train_dreambooth_lora_sdxl_advanced.py
+++ b/examples/advanced_diffusion_training/train_dreambooth_lora_sdxl_advanced.py
@@ -161,6 +161,8 @@ tags:
base_model: {base_model}
instance_prompt: {instance_prompt}
license: openrail++
+widget:
+ - text: '{validation_prompt if validation_prompt else instance_prompt}'
---
"""
diff --git a/examples/amused/README.md b/examples/amused/README.md
index 517c2d382f..1b118ca2cb 100644
--- a/examples/amused/README.md
+++ b/examples/amused/README.md
@@ -29,7 +29,7 @@ accelerate launch train_amused.py \
--train_batch_size \
--gradient_accumulation_steps \
--learning_rate 1e-4 \
- --pretrained_model_name_or_path huggingface/amused-256 \
+ --pretrained_model_name_or_path amused/amused-256 \
--instance_data_dataset 'm1guelpf/nouns' \
--image_key image \
--prompt_key text \
@@ -70,7 +70,7 @@ accelerate launch train_amused.py \
--gradient_accumulation_steps \
--learning_rate 2e-5 \
--use_8bit_adam \
- --pretrained_model_name_or_path huggingface/amused-256 \
+ --pretrained_model_name_or_path amused/amused-256 \
--instance_data_dataset 'm1guelpf/nouns' \
--image_key image \
--prompt_key text \
@@ -109,7 +109,7 @@ accelerate launch train_amused.py \
--gradient_accumulation_steps \
--learning_rate 8e-4 \
--use_lora \
- --pretrained_model_name_or_path huggingface/amused-256 \
+ --pretrained_model_name_or_path amused/amused-256 \
--instance_data_dataset 'm1guelpf/nouns' \
--image_key image \
--prompt_key text \
@@ -155,7 +155,7 @@ accelerate launch train_amused.py \
--train_batch_size \
--gradient_accumulation_steps \
--learning_rate 8e-5 \
- --pretrained_model_name_or_path huggingface/amused-512 \
+ --pretrained_model_name_or_path amused/amused-512 \
--instance_data_dataset 'monadical-labs/minecraft-preview' \
--prompt_prefix 'minecraft ' \
--image_key image \
@@ -191,7 +191,7 @@ accelerate launch train_amused.py \
--train_batch_size \
--gradient_accumulation_steps \
--learning_rate 5e-6 \
- --pretrained_model_name_or_path huggingface/amused-512 \
+ --pretrained_model_name_or_path amused/amused-512 \
--instance_data_dataset 'monadical-labs/minecraft-preview' \
--prompt_prefix 'minecraft ' \
--image_key image \
@@ -228,7 +228,7 @@ accelerate launch train_amused.py \
--gradient_accumulation_steps \
--learning_rate 1e-4 \
--use_lora \
- --pretrained_model_name_or_path huggingface/amused-512 \
+ --pretrained_model_name_or_path amused/amused-512 \
--instance_data_dataset 'monadical-labs/minecraft-preview' \
--prompt_prefix 'minecraft ' \
--image_key image \
@@ -276,7 +276,7 @@ accelerate launch train_amused.py \
--mixed_precision fp16 \
--report_to wandb \
--use_lora \
- --pretrained_model_name_or_path huggingface/amused-256 \
+ --pretrained_model_name_or_path amused/amused-256 \
--train_batch_size 1 \
--lr_scheduler constant \
--learning_rate 4e-4 \
@@ -308,7 +308,7 @@ accelerate launch train_amused.py \
--mixed_precision fp16 \
--report_to wandb \
--use_lora \
- --pretrained_model_name_or_path huggingface/amused-512 \
+ --pretrained_model_name_or_path amused/amused-512 \
--train_batch_size 1 \
--lr_scheduler constant \
--learning_rate 1e-3 \
diff --git a/examples/community/stable_diffusion_tensorrt_img2img.py b/examples/community/stable_diffusion_tensorrt_img2img.py
index e6e5e9db71..ebb2603cbd 100755
--- a/examples/community/stable_diffusion_tensorrt_img2img.py
+++ b/examples/community/stable_diffusion_tensorrt_img2img.py
@@ -50,6 +50,7 @@ from diffusers.pipelines.stable_diffusion import (
StableDiffusionPipelineOutput,
StableDiffusionSafetyChecker,
)
+from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img import retrieve_latents
from diffusers.schedulers import DDIMScheduler
from diffusers.utils import logging
@@ -608,7 +609,7 @@ class TorchVAEEncoder(torch.nn.Module):
self.vae_encoder = model
def forward(self, x):
- return self.vae_encoder.encode(x).latent_dist.sample()
+ return retrieve_latents(self.vae_encoder.encode(x))
class VAEEncoder(BaseModel):
@@ -1004,7 +1005,7 @@ class TensorRTStableDiffusionImg2ImgPipeline(StableDiffusionImg2ImgPipeline):
"""
self.generator = generator
self.denoising_steps = num_inference_steps
- self.guidance_scale = guidance_scale
+ self._guidance_scale = guidance_scale
# Pre-compute latent input scales and linear multistep coefficients
self.scheduler.set_timesteps(self.denoising_steps, device=self.torch_device)
diff --git a/examples/consistency_distillation/README.md b/examples/consistency_distillation/README.md
index d1c8741471..b8e88c741e 100644
--- a/examples/consistency_distillation/README.md
+++ b/examples/consistency_distillation/README.md
@@ -94,7 +94,7 @@ accelerate launch train_lcm_distill_lora_sd_wds.py \
--mixed_precision=fp16 \
--resolution=512 \
--lora_rank=64 \
- --learning_rate=1e-6 --loss_type="huber" --adam_weight_decay=0.0 \
+ --learning_rate=1e-4 --loss_type="huber" --adam_weight_decay=0.0 \
--max_train_steps=1000 \
--max_train_samples=4000000 \
--dataloader_num_workers=8 \
diff --git a/examples/consistency_distillation/README_sdxl.md b/examples/consistency_distillation/README_sdxl.md
index 4d2177669a..d3abaa4ce1 100644
--- a/examples/consistency_distillation/README_sdxl.md
+++ b/examples/consistency_distillation/README_sdxl.md
@@ -96,7 +96,7 @@ accelerate launch train_lcm_distill_lora_sdxl_wds.py \
--mixed_precision=fp16 \
--resolution=1024 \
--lora_rank=64 \
- --learning_rate=1e-6 --loss_type="huber" --use_fix_crop_and_size --adam_weight_decay=0.0 \
+ --learning_rate=1e-4 --loss_type="huber" --use_fix_crop_and_size --adam_weight_decay=0.0 \
--max_train_steps=1000 \
--max_train_samples=4000000 \
--dataloader_num_workers=8 \
@@ -111,4 +111,38 @@ accelerate launch train_lcm_distill_lora_sdxl_wds.py \
--report_to=wandb \
--seed=453645634 \
--push_to_hub \
-```
\ No newline at end of file
+```
+
+We provide another version for LCM LoRA SDXL that follows best practices of `peft` and leverages the `datasets` library for quick experimentation. The script doesn't load two UNets unlike `train_lcm_distill_lora_sdxl_wds.py` which reduces the memory requirements quite a bit.
+
+Below is an example training command that trains an LCM LoRA on the [Pokemons dataset](https://huggingface.co/datasets/lambdalabs/pokemon-blip-captions):
+
+```bash
+export MODEL_NAME="stabilityai/stable-diffusion-xl-base-1.0"
+export DATASET_NAME="lambdalabs/pokemon-blip-captions"
+export VAE_PATH="madebyollin/sdxl-vae-fp16-fix"
+
+accelerate launch train_lcm_distill_lora_sdxl.py \
+ --pretrained_teacher_model=${MODEL_NAME} \
+ --pretrained_vae_model_name_or_path=${VAE_PATH} \
+ --output_dir="pokemons-lora-lcm-sdxl" \
+ --mixed_precision="fp16" \
+ --dataset_name=$DATASET_NAME \
+ --resolution=1024 \
+ --train_batch_size=24 \
+ --gradient_accumulation_steps=1 \
+ --gradient_checkpointing \
+ --use_8bit_adam \
+ --lora_rank=64 \
+ --learning_rate=1e-4 \
+ --report_to="wandb" \
+ --lr_scheduler="constant" \
+ --lr_warmup_steps=0 \
+ --max_train_steps=3000 \
+ --checkpointing_steps=500 \
+ --validation_steps=50 \
+ --seed="0" \
+ --report_to="wandb" \
+ --push_to_hub
+```
+
diff --git a/examples/consistency_distillation/test_lcm_lora.py b/examples/consistency_distillation/test_lcm_lora.py
new file mode 100644
index 0000000000..88a3f1158f
--- /dev/null
+++ b/examples/consistency_distillation/test_lcm_lora.py
@@ -0,0 +1,112 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import logging
+import os
+import sys
+import tempfile
+
+import safetensors
+
+
+sys.path.append("..")
+from test_examples_utils import ExamplesTestsAccelerate, run_command # noqa: E402
+
+
+logging.basicConfig(level=logging.DEBUG)
+
+logger = logging.getLogger()
+stream_handler = logging.StreamHandler(sys.stdout)
+logger.addHandler(stream_handler)
+
+
+class TextToImageLCM(ExamplesTestsAccelerate):
+ def test_text_to_image_lcm_lora_sdxl(self):
+ with tempfile.TemporaryDirectory() as tmpdir:
+ test_args = f"""
+ examples/consistency_distillation/train_lcm_distill_lora_sdxl.py
+ --pretrained_teacher_model hf-internal-testing/tiny-stable-diffusion-xl-pipe
+ --dataset_name hf-internal-testing/dummy_image_text_data
+ --resolution 64
+ --lora_rank 4
+ --train_batch_size 1
+ --gradient_accumulation_steps 1
+ --max_train_steps 2
+ --learning_rate 5.0e-04
+ --scale_lr
+ --lr_scheduler constant
+ --lr_warmup_steps 0
+ --output_dir {tmpdir}
+ """.split()
+
+ run_command(self._launch_args + test_args)
+ # save_pretrained smoke test
+ self.assertTrue(os.path.isfile(os.path.join(tmpdir, "pytorch_lora_weights.safetensors")))
+
+ # make sure the state_dict has the correct naming in the parameters.
+ lora_state_dict = safetensors.torch.load_file(os.path.join(tmpdir, "pytorch_lora_weights.safetensors"))
+ is_lora = all("lora" in k for k in lora_state_dict.keys())
+ self.assertTrue(is_lora)
+
+ def test_text_to_image_lcm_lora_sdxl_checkpointing(self):
+ with tempfile.TemporaryDirectory() as tmpdir:
+ test_args = f"""
+ examples/consistency_distillation/train_lcm_distill_lora_sdxl.py
+ --pretrained_teacher_model hf-internal-testing/tiny-stable-diffusion-xl-pipe
+ --dataset_name hf-internal-testing/dummy_image_text_data
+ --resolution 64
+ --lora_rank 4
+ --train_batch_size 1
+ --gradient_accumulation_steps 1
+ --max_train_steps 7
+ --checkpointing_steps 2
+ --learning_rate 5.0e-04
+ --scale_lr
+ --lr_scheduler constant
+ --lr_warmup_steps 0
+ --output_dir {tmpdir}
+ """.split()
+
+ run_command(self._launch_args + test_args)
+
+ self.assertEqual(
+ {x for x in os.listdir(tmpdir) if "checkpoint" in x},
+ {"checkpoint-2", "checkpoint-4", "checkpoint-6"},
+ )
+
+ test_args = f"""
+ examples/consistency_distillation/train_lcm_distill_lora_sdxl.py
+ --pretrained_teacher_model hf-internal-testing/tiny-stable-diffusion-xl-pipe
+ --dataset_name hf-internal-testing/dummy_image_text_data
+ --resolution 64
+ --lora_rank 4
+ --train_batch_size 1
+ --gradient_accumulation_steps 1
+ --max_train_steps 9
+ --checkpointing_steps 2
+ --resume_from_checkpoint latest
+ --learning_rate 5.0e-04
+ --scale_lr
+ --lr_scheduler constant
+ --lr_warmup_steps 0
+ --output_dir {tmpdir}
+ """.split()
+
+ run_command(self._launch_args + test_args)
+
+ self.assertEqual(
+ {x for x in os.listdir(tmpdir) if "checkpoint" in x},
+ {"checkpoint-2", "checkpoint-4", "checkpoint-6", "checkpoint-8"},
+ )
diff --git a/examples/consistency_distillation/train_lcm_distill_lora_sdxl.py b/examples/consistency_distillation/train_lcm_distill_lora_sdxl.py
new file mode 100644
index 0000000000..2733eb146c
--- /dev/null
+++ b/examples/consistency_distillation/train_lcm_distill_lora_sdxl.py
@@ -0,0 +1,1358 @@
+#!/usr/bin/env python
+# coding=utf-8
+# Copyright 2023 The LCM team and the HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+
+import argparse
+import copy
+import functools
+import gc
+import logging
+import math
+import os
+import random
+import shutil
+from pathlib import Path
+
+import accelerate
+import numpy as np
+import torch
+import torch.nn.functional as F
+import torch.utils.checkpoint
+import transformers
+from accelerate import Accelerator
+from accelerate.logging import get_logger
+from accelerate.utils import ProjectConfiguration, set_seed
+from datasets import load_dataset
+from huggingface_hub import create_repo, upload_folder
+from packaging import version
+from peft import LoraConfig, get_peft_model_state_dict
+from torchvision import transforms
+from torchvision.transforms.functional import crop
+from tqdm.auto import tqdm
+from transformers import AutoTokenizer, PretrainedConfig
+
+import diffusers
+from diffusers import (
+ AutoencoderKL,
+ DDPMScheduler,
+ LCMScheduler,
+ StableDiffusionXLPipeline,
+ UNet2DConditionModel,
+)
+from diffusers.optimization import get_scheduler
+from diffusers.utils import check_min_version, is_wandb_available
+from diffusers.utils.import_utils import is_xformers_available
+
+
+if is_wandb_available():
+ import wandb
+
+# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
+check_min_version("0.24.0.dev0")
+
+logger = get_logger(__name__)
+
+DATASET_NAME_MAPPING = {
+ "lambdalabs/pokemon-blip-captions": ("image", "text"),
+}
+
+
+class DDIMSolver:
+ def __init__(self, alpha_cumprods, timesteps=1000, ddim_timesteps=50):
+ # DDIM sampling parameters
+ step_ratio = timesteps // ddim_timesteps
+
+ self.ddim_timesteps = (np.arange(1, ddim_timesteps + 1) * step_ratio).round().astype(np.int64) - 1
+ self.ddim_alpha_cumprods = alpha_cumprods[self.ddim_timesteps]
+ self.ddim_alpha_cumprods_prev = np.asarray(
+ [alpha_cumprods[0]] + alpha_cumprods[self.ddim_timesteps[:-1]].tolist()
+ )
+ # convert to torch tensors
+ self.ddim_timesteps = torch.from_numpy(self.ddim_timesteps).long()
+ self.ddim_alpha_cumprods = torch.from_numpy(self.ddim_alpha_cumprods)
+ self.ddim_alpha_cumprods_prev = torch.from_numpy(self.ddim_alpha_cumprods_prev)
+
+ def to(self, device):
+ self.ddim_timesteps = self.ddim_timesteps.to(device)
+ self.ddim_alpha_cumprods = self.ddim_alpha_cumprods.to(device)
+ self.ddim_alpha_cumprods_prev = self.ddim_alpha_cumprods_prev.to(device)
+ return self
+
+ def ddim_step(self, pred_x0, pred_noise, timestep_index):
+ alpha_cumprod_prev = extract_into_tensor(self.ddim_alpha_cumprods_prev, timestep_index, pred_x0.shape)
+ dir_xt = (1.0 - alpha_cumprod_prev).sqrt() * pred_noise
+ x_prev = alpha_cumprod_prev.sqrt() * pred_x0 + dir_xt
+ return x_prev
+
+
+def log_validation(vae, args, accelerator, weight_dtype, step, unet=None, is_final_validation=False):
+ logger.info("Running validation... ")
+
+ pipeline = StableDiffusionXLPipeline.from_pretrained(
+ args.pretrained_teacher_model,
+ vae=vae,
+ scheduler=LCMScheduler.from_pretrained(args.pretrained_teacher_model, subfolder="scheduler"),
+ revision=args.revision,
+ torch_dtype=weight_dtype,
+ ).to(accelerator.device)
+ pipeline.set_progress_bar_config(disable=True)
+
+ to_load = None
+ if not is_final_validation:
+ if unet is None:
+ raise ValueError("Must provide a `unet` when doing intermediate validation.")
+ unet = accelerator.unwrap_model(unet)
+ state_dict = get_peft_model_state_dict(unet)
+ to_load = state_dict
+ else:
+ to_load = args.output_dir
+
+ pipeline.load_lora_weights(to_load)
+ pipeline.fuse_lora()
+
+ if args.enable_xformers_memory_efficient_attention:
+ pipeline.enable_xformers_memory_efficient_attention()
+
+ if args.seed is None:
+ generator = None
+ else:
+ generator = torch.Generator(device=accelerator.device).manual_seed(args.seed)
+
+ validation_prompts = [
+ "cute sundar pichai character",
+ "robotic cat with wings",
+ "a photo of yoda",
+ "a cute creature with blue eyes",
+ ]
+
+ image_logs = []
+
+ for _, prompt in enumerate(validation_prompts):
+ images = []
+ with torch.autocast("cuda", dtype=weight_dtype):
+ images = pipeline(
+ prompt=prompt,
+ num_inference_steps=4,
+ num_images_per_prompt=4,
+ generator=generator,
+ guidance_scale=0.0,
+ ).images
+ image_logs.append({"validation_prompt": prompt, "images": images})
+
+ for tracker in accelerator.trackers:
+ if tracker.name == "tensorboard":
+ for log in image_logs:
+ images = log["images"]
+ validation_prompt = log["validation_prompt"]
+ formatted_images = []
+ for image in images:
+ formatted_images.append(np.asarray(image))
+
+ formatted_images = np.stack(formatted_images)
+
+ tracker.writer.add_images(validation_prompt, formatted_images, step, dataformats="NHWC")
+ elif tracker.name == "wandb":
+ formatted_images = []
+
+ for log in image_logs:
+ images = log["images"]
+ validation_prompt = log["validation_prompt"]
+ for image in images:
+ image = wandb.Image(image, caption=validation_prompt)
+ formatted_images.append(image)
+ logger_name = "test" if is_final_validation else "validation"
+ tracker.log({logger_name: formatted_images})
+ else:
+ logger.warn(f"image logging not implemented for {tracker.name}")
+
+ del pipeline
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ return image_logs
+
+
+def append_dims(x, target_dims):
+ """Appends dimensions to the end of a tensor until it has target_dims dimensions."""
+ dims_to_append = target_dims - x.ndim
+ if dims_to_append < 0:
+ raise ValueError(f"input has {x.ndim} dims but target_dims is {target_dims}, which is less")
+ return x[(...,) + (None,) * dims_to_append]
+
+
+# From LCMScheduler.get_scalings_for_boundary_condition_discrete
+def scalings_for_boundary_conditions(timestep, sigma_data=0.5, timestep_scaling=10.0):
+ c_skip = sigma_data**2 / ((timestep / 0.1) ** 2 + sigma_data**2)
+ c_out = (timestep / 0.1) / ((timestep / 0.1) ** 2 + sigma_data**2) ** 0.5
+ return c_skip, c_out
+
+
+# Compare LCMScheduler.step, Step 4
+def get_predicted_original_sample(model_output, timesteps, sample, prediction_type, alphas, sigmas):
+ alphas = extract_into_tensor(alphas, timesteps, sample.shape)
+ sigmas = extract_into_tensor(sigmas, timesteps, sample.shape)
+ if prediction_type == "epsilon":
+ pred_x_0 = (sample - sigmas * model_output) / alphas
+ elif prediction_type == "sample":
+ pred_x_0 = model_output
+ elif prediction_type == "v_prediction":
+ pred_x_0 = alphas * sample - sigmas * model_output
+ else:
+ raise ValueError(
+ f"Prediction type {prediction_type} is not supported; currently, `epsilon`, `sample`, and `v_prediction`"
+ f" are supported."
+ )
+
+ return pred_x_0
+
+
+# Based on step 4 in DDIMScheduler.step
+def get_predicted_noise(model_output, timesteps, sample, prediction_type, alphas, sigmas):
+ alphas = extract_into_tensor(alphas, timesteps, sample.shape)
+ sigmas = extract_into_tensor(sigmas, timesteps, sample.shape)
+ if prediction_type == "epsilon":
+ pred_epsilon = model_output
+ elif prediction_type == "sample":
+ pred_epsilon = (sample - alphas * model_output) / sigmas
+ elif prediction_type == "v_prediction":
+ pred_epsilon = alphas * model_output + sigmas * sample
+ else:
+ raise ValueError(
+ f"Prediction type {prediction_type} is not supported; currently, `epsilon`, `sample`, and `v_prediction`"
+ f" are supported."
+ )
+
+ return pred_epsilon
+
+
+def extract_into_tensor(a, t, x_shape):
+ b, *_ = t.shape
+ out = a.gather(-1, t)
+ return out.reshape(b, *((1,) * (len(x_shape) - 1)))
+
+
+def import_model_class_from_model_name_or_path(
+ pretrained_model_name_or_path: str, revision: str, subfolder: str = "text_encoder"
+):
+ text_encoder_config = PretrainedConfig.from_pretrained(
+ pretrained_model_name_or_path, subfolder=subfolder, revision=revision
+ )
+ model_class = text_encoder_config.architectures[0]
+
+ if model_class == "CLIPTextModel":
+ from transformers import CLIPTextModel
+
+ return CLIPTextModel
+ elif model_class == "CLIPTextModelWithProjection":
+ from transformers import CLIPTextModelWithProjection
+
+ return CLIPTextModelWithProjection
+ else:
+ raise ValueError(f"{model_class} is not supported.")
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Simple example of a training script.")
+ # ----------Model Checkpoint Loading Arguments----------
+ parser.add_argument(
+ "--pretrained_teacher_model",
+ type=str,
+ default=None,
+ required=True,
+ help="Path to pretrained LDM teacher model or model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--pretrained_vae_model_name_or_path",
+ type=str,
+ default=None,
+ help="Path to pretrained VAE model with better numerical stability. More details: https://github.com/huggingface/diffusers/pull/4038.",
+ )
+ parser.add_argument(
+ "--teacher_revision",
+ type=str,
+ default=None,
+ required=False,
+ help="Revision of pretrained LDM teacher model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--revision",
+ type=str,
+ default=None,
+ required=False,
+ help="Revision of pretrained LDM model identifier from huggingface.co/models.",
+ )
+ # ----------Training Arguments----------
+ # ----General Training Arguments----
+ parser.add_argument(
+ "--output_dir",
+ type=str,
+ default="lcm-xl-distilled",
+ help="The output directory where the model predictions and checkpoints will be written.",
+ )
+ parser.add_argument(
+ "--cache_dir",
+ type=str,
+ default=None,
+ help="The directory where the downloaded models and datasets will be stored.",
+ )
+ parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
+ # ----Logging----
+ parser.add_argument(
+ "--logging_dir",
+ type=str,
+ default="logs",
+ help=(
+ "[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
+ " *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
+ ),
+ )
+ parser.add_argument(
+ "--report_to",
+ type=str,
+ default="tensorboard",
+ help=(
+ 'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
+ ' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
+ ),
+ )
+ # ----Checkpointing----
+ parser.add_argument(
+ "--checkpointing_steps",
+ type=int,
+ default=500,
+ help=(
+ "Save a checkpoint of the training state every X updates. These checkpoints are only suitable for resuming"
+ " training using `--resume_from_checkpoint`."
+ ),
+ )
+ parser.add_argument(
+ "--checkpoints_total_limit",
+ type=int,
+ default=None,
+ help=("Max number of checkpoints to store."),
+ )
+ parser.add_argument(
+ "--resume_from_checkpoint",
+ type=str,
+ default=None,
+ help=(
+ "Whether training should be resumed from a previous checkpoint. Use a path saved by"
+ ' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
+ ),
+ )
+ # ----Image Processing----
+ parser.add_argument(
+ "--dataset_name",
+ type=str,
+ default=None,
+ help=(
+ "The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private,"
+ " dataset). It can also be a path pointing to a local copy of a dataset in your filesystem,"
+ " or to a folder containing files that 🤗 Datasets can understand."
+ ),
+ )
+ parser.add_argument(
+ "--dataset_config_name",
+ type=str,
+ default=None,
+ help="The config of the Dataset, leave as None if there's only one config.",
+ )
+ parser.add_argument(
+ "--train_data_dir",
+ type=str,
+ default=None,
+ help=(
+ "A folder containing the training data. Folder contents must follow the structure described in"
+ " https://huggingface.co/docs/datasets/image_dataset#imagefolder. In particular, a `metadata.jsonl` file"
+ " must exist to provide the captions for the images. Ignored if `dataset_name` is specified."
+ ),
+ )
+ parser.add_argument(
+ "--image_column", type=str, default="image", help="The column of the dataset containing an image."
+ )
+ parser.add_argument(
+ "--caption_column",
+ type=str,
+ default="text",
+ help="The column of the dataset containing a caption or a list of captions.",
+ )
+ parser.add_argument(
+ "--resolution",
+ type=int,
+ default=1024,
+ help=(
+ "The resolution for input images, all the images in the train/validation dataset will be resized to this"
+ " resolution"
+ ),
+ )
+ parser.add_argument(
+ "--center_crop",
+ default=False,
+ action="store_true",
+ help=(
+ "Whether to center crop the input images to the resolution. If not set, the images will be randomly"
+ " cropped. The images will be resized to the resolution first before cropping."
+ ),
+ )
+ parser.add_argument(
+ "--random_flip",
+ action="store_true",
+ help="whether to randomly flip images horizontally",
+ )
+ parser.add_argument(
+ "--encode_batch_size",
+ type=int,
+ default=8,
+ help="Batch size to use for VAE encoding of the images for efficient processing.",
+ )
+ # ----Dataloader----
+ parser.add_argument(
+ "--dataloader_num_workers",
+ type=int,
+ default=0,
+ help=(
+ "Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
+ ),
+ )
+ # ----Batch Size and Training Steps----
+ parser.add_argument(
+ "--train_batch_size", type=int, default=16, help="Batch size (per device) for the training dataloader."
+ )
+ parser.add_argument("--num_train_epochs", type=int, default=100)
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=None,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--max_train_samples",
+ type=int,
+ default=None,
+ help=(
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ ),
+ )
+ # ----Learning Rate----
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=1e-6,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument(
+ "--scale_lr",
+ action="store_true",
+ default=False,
+ help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
+ )
+ parser.add_argument(
+ "--lr_scheduler",
+ type=str,
+ default="constant",
+ help=(
+ 'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
+ ' "constant", "constant_with_warmup"]'
+ ),
+ )
+ parser.add_argument(
+ "--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ # ----Optimizer (Adam)----
+ parser.add_argument(
+ "--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
+ )
+ parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
+ parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
+ parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
+ # ----Diffusion Training Arguments----
+ # ----Latent Consistency Distillation (LCD) Specific Arguments----
+ parser.add_argument(
+ "--w_min",
+ type=float,
+ default=3.0,
+ required=False,
+ help=(
+ "The minimum guidance scale value for guidance scale sampling. Note that we are using the Imagen CFG"
+ " formulation rather than the LCM formulation, which means all guidance scales have 1 added to them as"
+ " compared to the original paper."
+ ),
+ )
+ parser.add_argument(
+ "--w_max",
+ type=float,
+ default=15.0,
+ required=False,
+ help=(
+ "The maximum guidance scale value for guidance scale sampling. Note that we are using the Imagen CFG"
+ " formulation rather than the LCM formulation, which means all guidance scales have 1 added to them as"
+ " compared to the original paper."
+ ),
+ )
+ parser.add_argument(
+ "--num_ddim_timesteps",
+ type=int,
+ default=50,
+ help="The number of timesteps to use for DDIM sampling.",
+ )
+ parser.add_argument(
+ "--loss_type",
+ type=str,
+ default="l2",
+ choices=["l2", "huber"],
+ help="The type of loss to use for the LCD loss.",
+ )
+ parser.add_argument(
+ "--huber_c",
+ type=float,
+ default=0.001,
+ help="The huber loss parameter. Only used if `--loss_type=huber`.",
+ )
+ parser.add_argument(
+ "--lora_rank",
+ type=int,
+ default=64,
+ help="The rank of the LoRA projection matrix.",
+ )
+ # ----Mixed Precision----
+ parser.add_argument(
+ "--mixed_precision",
+ type=str,
+ default=None,
+ choices=["no", "fp16", "bf16"],
+ help=(
+ "Whether to use mixed precision. Choose between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
+ " 1.10.and an Nvidia Ampere GPU. Default to the value of accelerate config of the current system or the"
+ " flag passed with the `accelerate.launch` command. Use this argument to override the accelerate config."
+ ),
+ )
+ parser.add_argument(
+ "--allow_tf32",
+ action="store_true",
+ help=(
+ "Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
+ " https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
+ ),
+ )
+ # ----Training Optimizations----
+ parser.add_argument(
+ "--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
+ )
+ parser.add_argument(
+ "--gradient_checkpointing",
+ action="store_true",
+ help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
+ )
+ # ----Distributed Training----
+ parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
+ # ----------Validation Arguments----------
+ parser.add_argument(
+ "--validation_steps",
+ type=int,
+ default=200,
+ help="Run validation every X steps.",
+ )
+ # ----------Huggingface Hub Arguments-----------
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--hub_model_id",
+ type=str,
+ default=None,
+ help="The name of the repository to keep in sync with the local `output_dir`.",
+ )
+ # ----------Accelerate Arguments----------
+ parser.add_argument(
+ "--tracker_project_name",
+ type=str,
+ default="text2image-fine-tune",
+ help=(
+ "The `project_name` argument passed to Accelerator.init_trackers for"
+ " more information see https://huggingface.co/docs/accelerate/v0.17.0/en/package_reference/accelerator#accelerate.Accelerator"
+ ),
+ )
+
+ args = parser.parse_args()
+ env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
+ if env_local_rank != -1 and env_local_rank != args.local_rank:
+ args.local_rank = env_local_rank
+
+ return args
+
+
+# Adapted from pipelines.StableDiffusionXLPipeline.encode_prompt
+def encode_prompt(prompt_batch, text_encoders, tokenizers, is_train=True):
+ prompt_embeds_list = []
+
+ captions = []
+ for caption in prompt_batch:
+ if isinstance(caption, str):
+ captions.append(caption)
+ elif isinstance(caption, (list, np.ndarray)):
+ # take a random caption if there are multiple
+ captions.append(random.choice(caption) if is_train else caption[0])
+
+ with torch.no_grad():
+ for tokenizer, text_encoder in zip(tokenizers, text_encoders):
+ text_inputs = tokenizer(
+ captions,
+ padding="max_length",
+ max_length=tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ prompt_embeds = text_encoder(
+ text_input_ids.to(text_encoder.device),
+ output_hidden_states=True,
+ )
+
+ # We are only ALWAYS interested in the pooled output of the final text encoder
+ pooled_prompt_embeds = prompt_embeds[0]
+ prompt_embeds = prompt_embeds.hidden_states[-2]
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ prompt_embeds = prompt_embeds.view(bs_embed, seq_len, -1)
+ prompt_embeds_list.append(prompt_embeds)
+
+ prompt_embeds = torch.concat(prompt_embeds_list, dim=-1)
+ pooled_prompt_embeds = pooled_prompt_embeds.view(bs_embed, -1)
+ return prompt_embeds, pooled_prompt_embeds
+
+
+def main(args):
+ logging_dir = Path(args.output_dir, args.logging_dir)
+
+ accelerator_project_config = ProjectConfiguration(project_dir=args.output_dir, logging_dir=logging_dir)
+
+ accelerator = Accelerator(
+ gradient_accumulation_steps=args.gradient_accumulation_steps,
+ mixed_precision=args.mixed_precision,
+ log_with=args.report_to,
+ project_config=accelerator_project_config,
+ split_batches=True, # It's important to set this to True when using webdataset to get the right number of steps for lr scheduling. If set to False, the number of steps will be devide by the number of processes assuming batches are multiplied by the number of processes
+ )
+
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ logger.info(accelerator.state, main_process_only=False)
+ if accelerator.is_local_main_process:
+ transformers.utils.logging.set_verbosity_warning()
+ diffusers.utils.logging.set_verbosity_info()
+ else:
+ transformers.utils.logging.set_verbosity_error()
+ diffusers.utils.logging.set_verbosity_error()
+
+ # If passed along, set the training seed now.
+ if args.seed is not None:
+ set_seed(args.seed)
+
+ # Handle the repository creation
+ if accelerator.is_main_process:
+ if args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+
+ if args.push_to_hub:
+ repo_id = create_repo(
+ repo_id=args.hub_model_id or Path(args.output_dir).name,
+ exist_ok=True,
+ token=args.hub_token,
+ private=True,
+ ).repo_id
+
+ # 1. Create the noise scheduler and the desired noise schedule.
+ noise_scheduler = DDPMScheduler.from_pretrained(
+ args.pretrained_teacher_model, subfolder="scheduler", revision=args.teacher_revision
+ )
+
+ # DDPMScheduler calculates the alpha and sigma noise schedules (based on the alpha bars) for us
+ alpha_schedule = torch.sqrt(noise_scheduler.alphas_cumprod)
+ sigma_schedule = torch.sqrt(1 - noise_scheduler.alphas_cumprod)
+ # Initialize the DDIM ODE solver for distillation.
+ solver = DDIMSolver(
+ noise_scheduler.alphas_cumprod.numpy(),
+ timesteps=noise_scheduler.config.num_train_timesteps,
+ ddim_timesteps=args.num_ddim_timesteps,
+ )
+
+ # 2. Load tokenizers from SDXL checkpoint.
+ tokenizer_one = AutoTokenizer.from_pretrained(
+ args.pretrained_teacher_model, subfolder="tokenizer", revision=args.teacher_revision, use_fast=False
+ )
+ tokenizer_two = AutoTokenizer.from_pretrained(
+ args.pretrained_teacher_model, subfolder="tokenizer_2", revision=args.teacher_revision, use_fast=False
+ )
+
+ # 3. Load text encoders from SDXL checkpoint.
+ # import correct text encoder classes
+ text_encoder_cls_one = import_model_class_from_model_name_or_path(
+ args.pretrained_teacher_model, args.teacher_revision
+ )
+ text_encoder_cls_two = import_model_class_from_model_name_or_path(
+ args.pretrained_teacher_model, args.teacher_revision, subfolder="text_encoder_2"
+ )
+
+ text_encoder_one = text_encoder_cls_one.from_pretrained(
+ args.pretrained_teacher_model, subfolder="text_encoder", revision=args.teacher_revision
+ )
+ text_encoder_two = text_encoder_cls_two.from_pretrained(
+ args.pretrained_teacher_model, subfolder="text_encoder_2", revision=args.teacher_revision
+ )
+
+ # 4. Load VAE from SDXL checkpoint (or more stable VAE)
+ vae_path = (
+ args.pretrained_teacher_model
+ if args.pretrained_vae_model_name_or_path is None
+ else args.pretrained_vae_model_name_or_path
+ )
+ vae = AutoencoderKL.from_pretrained(
+ vae_path,
+ subfolder="vae" if args.pretrained_vae_model_name_or_path is None else None,
+ revision=args.teacher_revision,
+ )
+
+ # 6. Freeze teacher vae, text_encoders.
+ vae.requires_grad_(False)
+ text_encoder_one.requires_grad_(False)
+ text_encoder_two.requires_grad_(False)
+
+ # 7. Create online student U-Net.
+ unet = UNet2DConditionModel.from_pretrained(
+ args.pretrained_teacher_model, subfolder="unet", revision=args.teacher_revision
+ )
+ unet.requires_grad_(False)
+
+ # Check that all trainable models are in full precision
+ low_precision_error_string = (
+ " Please make sure to always have all model weights in full float32 precision when starting training - even if"
+ " doing mixed precision training, copy of the weights should still be float32."
+ )
+
+ if accelerator.unwrap_model(unet).dtype != torch.float32:
+ raise ValueError(
+ f"Controlnet loaded as datatype {accelerator.unwrap_model(unet).dtype}. {low_precision_error_string}"
+ )
+
+ # 8. Handle mixed precision and device placement
+ # For mixed precision training we cast all non-trainable weigths to half-precision
+ # as these weights are only used for inference, keeping weights in full precision is not required.
+ weight_dtype = torch.float32
+ if accelerator.mixed_precision == "fp16":
+ weight_dtype = torch.float16
+ elif accelerator.mixed_precision == "bf16":
+ weight_dtype = torch.bfloat16
+
+ # Move unet, vae and text_encoder to device and cast to weight_dtype
+ # The VAE is in float32 to avoid NaN losses.
+ unet.to(accelerator.device, dtype=weight_dtype)
+ if args.pretrained_vae_model_name_or_path is None:
+ vae.to(accelerator.device, dtype=torch.float32)
+ else:
+ vae.to(accelerator.device, dtype=weight_dtype)
+ text_encoder_one.to(accelerator.device, dtype=weight_dtype)
+ text_encoder_two.to(accelerator.device, dtype=weight_dtype)
+
+ # 9. Add LoRA to the student U-Net, only the LoRA projection matrix will be updated by the optimizer.
+ lora_config = LoraConfig(
+ r=args.lora_rank,
+ lora_alpha=args.lora_rank,
+ target_modules=[
+ "to_q",
+ "to_k",
+ "to_v",
+ "to_out.0",
+ "proj_in",
+ "proj_out",
+ "ff.net.0.proj",
+ "ff.net.2",
+ "conv1",
+ "conv2",
+ "conv_shortcut",
+ "downsamplers.0.conv",
+ "upsamplers.0.conv",
+ "time_emb_proj",
+ ],
+ )
+ unet.add_adapter(lora_config)
+
+ # Make sure the trainable params are in float32.
+ if args.mixed_precision == "fp16":
+ for param in unet.parameters():
+ # only upcast trainable parameters (LoRA) into fp32
+ if param.requires_grad:
+ param.data = param.to(torch.float32)
+
+ # Also move the alpha and sigma noise schedules to accelerator.device.
+ alpha_schedule = alpha_schedule.to(accelerator.device)
+ sigma_schedule = sigma_schedule.to(accelerator.device)
+ solver = solver.to(accelerator.device)
+
+ # 10. Handle saving and loading of checkpoints
+ # `accelerate` 0.16.0 will have better support for customized saving
+ if version.parse(accelerate.__version__) >= version.parse("0.16.0"):
+ # create custom saving & loading hooks so that `accelerator.save_state(...)` serializes in a nice format
+ def save_model_hook(models, weights, output_dir):
+ if accelerator.is_main_process:
+ unet_ = accelerator.unwrap_model(unet)
+ # also save the checkpoints in native `diffusers` format so that it can be easily
+ # be independently loaded via `load_lora_weights()`.
+ state_dict = get_peft_model_state_dict(unet_)
+ StableDiffusionXLPipeline.save_lora_weights(output_dir, unet_lora_layers=state_dict)
+
+ for _, model in enumerate(models):
+ # make sure to pop weight so that corresponding model is not saved again
+ weights.pop()
+
+ def load_model_hook(models, input_dir):
+ # load the LoRA into the model
+ unet_ = accelerator.unwrap_model(unet)
+ lora_state_dict, network_alphas = StableDiffusionXLPipeline.lora_state_dict(input_dir)
+ StableDiffusionXLPipeline.load_lora_into_unet(lora_state_dict, network_alphas=network_alphas, unet=unet_)
+
+ for _ in range(len(models)):
+ # pop models so that they are not loaded again
+ models.pop()
+
+ accelerator.register_save_state_pre_hook(save_model_hook)
+ accelerator.register_load_state_pre_hook(load_model_hook)
+
+ # 11. Enable optimizations
+ if args.enable_xformers_memory_efficient_attention:
+ if is_xformers_available():
+ import xformers
+
+ xformers_version = version.parse(xformers.__version__)
+ if xformers_version == version.parse("0.0.16"):
+ logger.warn(
+ "xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
+ )
+ unet.enable_xformers_memory_efficient_attention()
+ else:
+ raise ValueError("xformers is not available. Make sure it is installed correctly")
+
+ # Enable TF32 for faster training on Ampere GPUs,
+ # cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
+ if args.allow_tf32:
+ torch.backends.cuda.matmul.allow_tf32 = True
+
+ if args.gradient_checkpointing:
+ unet.enable_gradient_checkpointing()
+
+ # Use 8-bit Adam for lower memory usage or to fine-tune the model in 16GB GPUs
+ if args.use_8bit_adam:
+ try:
+ import bitsandbytes as bnb
+ except ImportError:
+ raise ImportError(
+ "To use 8-bit Adam, please install the bitsandbytes library: `pip install bitsandbytes`."
+ )
+
+ optimizer_class = bnb.optim.AdamW8bit
+ else:
+ optimizer_class = torch.optim.AdamW
+
+ # 12. Optimizer creation
+ params_to_optimize = filter(lambda p: p.requires_grad, unet.parameters())
+ optimizer = optimizer_class(
+ params_to_optimize,
+ lr=args.learning_rate,
+ betas=(args.adam_beta1, args.adam_beta2),
+ weight_decay=args.adam_weight_decay,
+ eps=args.adam_epsilon,
+ )
+
+ # 13. Dataset creation and data processing
+ # In distributed training, the load_dataset function guarantees that only one local process can concurrently
+ # download the dataset.
+ if args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ dataset = load_dataset(
+ args.dataset_name,
+ args.dataset_config_name,
+ cache_dir=args.cache_dir,
+ )
+ else:
+ data_files = {}
+ if args.train_data_dir is not None:
+ data_files["train"] = os.path.join(args.train_data_dir, "**")
+ dataset = load_dataset(
+ "imagefolder",
+ data_files=data_files,
+ cache_dir=args.cache_dir,
+ )
+ # See more about loading custom images at
+ # https://huggingface.co/docs/datasets/v2.4.0/en/image_load#imagefolder
+
+ # Preprocessing the datasets.
+ column_names = dataset["train"].column_names
+
+ # Get the column names for input/target.
+ dataset_columns = DATASET_NAME_MAPPING.get(args.dataset_name, None)
+ if args.image_column is None:
+ image_column = dataset_columns[0] if dataset_columns is not None else column_names[0]
+ else:
+ image_column = args.image_column
+ if image_column not in column_names:
+ raise ValueError(
+ f"--image_column' value '{args.image_column}' needs to be one of: {', '.join(column_names)}"
+ )
+ if args.caption_column is None:
+ caption_column = dataset_columns[1] if dataset_columns is not None else column_names[1]
+ else:
+ caption_column = args.caption_column
+ if caption_column not in column_names:
+ raise ValueError(
+ f"--caption_column' value '{args.caption_column}' needs to be one of: {', '.join(column_names)}"
+ )
+
+ # Preprocessing the datasets.
+ train_resize = transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR)
+ train_crop = transforms.CenterCrop(args.resolution) if args.center_crop else transforms.RandomCrop(args.resolution)
+ train_flip = transforms.RandomHorizontalFlip(p=1.0)
+ train_transforms = transforms.Compose([transforms.ToTensor(), transforms.Normalize([0.5], [0.5])])
+
+ def preprocess_train(examples):
+ images = [image.convert("RGB") for image in examples[image_column]]
+ # image aug
+ original_sizes = []
+ all_images = []
+ crop_top_lefts = []
+ for image in images:
+ original_sizes.append((image.height, image.width))
+ image = train_resize(image)
+ if args.center_crop:
+ y1 = max(0, int(round((image.height - args.resolution) / 2.0)))
+ x1 = max(0, int(round((image.width - args.resolution) / 2.0)))
+ image = train_crop(image)
+ else:
+ y1, x1, h, w = train_crop.get_params(image, (args.resolution, args.resolution))
+ image = crop(image, y1, x1, h, w)
+ if args.random_flip and random.random() < 0.5:
+ # flip
+ x1 = image.width - x1
+ image = train_flip(image)
+ crop_top_left = (y1, x1)
+ crop_top_lefts.append(crop_top_left)
+ image = train_transforms(image)
+ all_images.append(image)
+
+ examples["original_sizes"] = original_sizes
+ examples["crop_top_lefts"] = crop_top_lefts
+ examples["pixel_values"] = all_images
+ examples["captions"] = list(examples[caption_column])
+ return examples
+
+ with accelerator.main_process_first():
+ if args.max_train_samples is not None:
+ dataset["train"] = dataset["train"].shuffle(seed=args.seed).select(range(args.max_train_samples))
+ # Set the training transforms
+ train_dataset = dataset["train"].with_transform(preprocess_train)
+
+ def collate_fn(examples):
+ pixel_values = torch.stack([example["pixel_values"] for example in examples])
+ pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()
+ original_sizes = [example["original_sizes"] for example in examples]
+ crop_top_lefts = [example["crop_top_lefts"] for example in examples]
+ captions = [example["captions"] for example in examples]
+
+ return {
+ "pixel_values": pixel_values,
+ "captions": captions,
+ "original_sizes": original_sizes,
+ "crop_top_lefts": crop_top_lefts,
+ }
+
+ # DataLoaders creation:
+ train_dataloader = torch.utils.data.DataLoader(
+ train_dataset,
+ shuffle=True,
+ collate_fn=collate_fn,
+ batch_size=args.train_batch_size,
+ num_workers=args.dataloader_num_workers,
+ )
+
+ # 14. Embeddings for the UNet.
+ # Adapted from pipeline.StableDiffusionXLPipeline._get_add_time_ids
+ def compute_embeddings(prompt_batch, original_sizes, crop_coords, text_encoders, tokenizers, is_train=True):
+ def compute_time_ids(original_size, crops_coords_top_left):
+ target_size = (args.resolution, args.resolution)
+ add_time_ids = list(original_size + crops_coords_top_left + target_size)
+ add_time_ids = torch.tensor([add_time_ids])
+ add_time_ids = add_time_ids.to(accelerator.device, dtype=weight_dtype)
+ return add_time_ids
+
+ prompt_embeds, pooled_prompt_embeds = encode_prompt(prompt_batch, text_encoders, tokenizers, is_train)
+ add_text_embeds = pooled_prompt_embeds
+
+ add_time_ids = torch.cat([compute_time_ids(s, c) for s, c in zip(original_sizes, crop_coords)])
+
+ prompt_embeds = prompt_embeds.to(accelerator.device)
+ add_text_embeds = add_text_embeds.to(accelerator.device)
+ unet_added_cond_kwargs = {"text_embeds": add_text_embeds, "time_ids": add_time_ids}
+
+ return {"prompt_embeds": prompt_embeds, **unet_added_cond_kwargs}
+
+ text_encoders = [text_encoder_one, text_encoder_two]
+ tokenizers = [tokenizer_one, tokenizer_two]
+
+ compute_embeddings_fn = functools.partial(compute_embeddings, text_encoders=text_encoders, tokenizers=tokenizers)
+
+ # 15. LR Scheduler creation
+ # Scheduler and math around the number of training steps.
+ overrode_max_train_steps = False
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ overrode_max_train_steps = True
+
+ if args.scale_lr:
+ args.learning_rate = (
+ args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
+ )
+
+ lr_scheduler = get_scheduler(
+ args.lr_scheduler,
+ optimizer=optimizer,
+ num_warmup_steps=args.lr_warmup_steps * accelerator.num_processes,
+ num_training_steps=args.max_train_steps * accelerator.num_processes,
+ )
+
+ # 16. Prepare for training
+ # Prepare everything with our `accelerator`.
+ unet, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
+ unet, optimizer, train_dataloader, lr_scheduler
+ )
+
+ # We need to recalculate our total training steps as the size of the training dataloader may have changed.
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if overrode_max_train_steps:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ # Afterwards we recalculate our number of training epochs
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ # We need to initialize the trackers we use, and also store our configuration.
+ # The trackers initializes automatically on the main process.
+ if accelerator.is_main_process:
+ tracker_config = dict(vars(args))
+ accelerator.init_trackers(args.tracker_project_name, config=tracker_config)
+
+ # 17. Train!
+ total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+ global_step = 0
+ first_epoch = 0
+
+ # Potentially load in the weights and states from a previous save
+ if args.resume_from_checkpoint:
+ if args.resume_from_checkpoint != "latest":
+ path = os.path.basename(args.resume_from_checkpoint)
+ else:
+ # Get the most recent checkpoint
+ dirs = os.listdir(args.output_dir)
+ dirs = [d for d in dirs if d.startswith("checkpoint")]
+ dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
+ path = dirs[-1] if len(dirs) > 0 else None
+
+ if path is None:
+ accelerator.print(
+ f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
+ )
+ args.resume_from_checkpoint = None
+ initial_global_step = 0
+ else:
+ accelerator.print(f"Resuming from checkpoint {path}")
+ accelerator.load_state(os.path.join(args.output_dir, path))
+ global_step = int(path.split("-")[1])
+
+ initial_global_step = global_step
+ first_epoch = global_step // num_update_steps_per_epoch
+ else:
+ initial_global_step = 0
+
+ progress_bar = tqdm(
+ range(0, args.max_train_steps),
+ initial=initial_global_step,
+ desc="Steps",
+ # Only show the progress bar once on each machine.
+ disable=not accelerator.is_local_main_process,
+ )
+
+ unet.train()
+ for epoch in range(first_epoch, args.num_train_epochs):
+ for step, batch in enumerate(train_dataloader):
+ with accelerator.accumulate(unet):
+ # 1. Load and process the image and text conditioning
+ pixel_values, text, orig_size, crop_coords = (
+ batch["pixel_values"],
+ batch["captions"],
+ batch["original_sizes"],
+ batch["crop_top_lefts"],
+ )
+
+ encoded_text = compute_embeddings_fn(text, orig_size, crop_coords)
+
+ # encode pixel values with batch size of at most 8
+ pixel_values = pixel_values.to(dtype=vae.dtype)
+ latents = []
+ for i in range(0, pixel_values.shape[0], args.encode_batch_size):
+ latents.append(vae.encode(pixel_values[i : i + args.encode_batch_size]).latent_dist.sample())
+ latents = torch.cat(latents, dim=0)
+
+ latents = latents * vae.config.scaling_factor
+ if args.pretrained_vae_model_name_or_path is None:
+ latents = latents.to(weight_dtype)
+
+ # 2. Sample a random timestep for each image t_n from the ODE solver timesteps without bias.
+ # For the DDIM solver, the timestep schedule is [T - 1, T - k - 1, T - 2 * k - 1, ...]
+ bsz = latents.shape[0]
+ topk = noise_scheduler.config.num_train_timesteps // args.num_ddim_timesteps
+ index = torch.randint(0, args.num_ddim_timesteps, (bsz,), device=latents.device).long()
+ start_timesteps = solver.ddim_timesteps[index]
+ timesteps = start_timesteps - topk
+ timesteps = torch.where(timesteps < 0, torch.zeros_like(timesteps), timesteps)
+
+ # 3. Get boundary scalings for start_timesteps and (end) timesteps.
+ c_skip_start, c_out_start = scalings_for_boundary_conditions(start_timesteps)
+ c_skip_start, c_out_start = [append_dims(x, latents.ndim) for x in [c_skip_start, c_out_start]]
+ c_skip, c_out = scalings_for_boundary_conditions(timesteps)
+ c_skip, c_out = [append_dims(x, latents.ndim) for x in [c_skip, c_out]]
+
+ # 4. Sample noise from the prior and add it to the latents according to the noise magnitude at each
+ # timestep (this is the forward diffusion process) [z_{t_{n + k}} in Algorithm 1]
+ noise = torch.randn_like(latents)
+ noisy_model_input = noise_scheduler.add_noise(latents, noise, start_timesteps)
+
+ # 5. Sample a random guidance scale w from U[w_min, w_max]
+ # Note that for LCM-LoRA distillation it is not necessary to use a guidance scale embedding
+ w = (args.w_max - args.w_min) * torch.rand((bsz,)) + args.w_min
+ w = w.reshape(bsz, 1, 1, 1)
+ w = w.to(device=latents.device, dtype=latents.dtype)
+
+ # 6. Prepare prompt embeds and unet_added_conditions
+ prompt_embeds = encoded_text.pop("prompt_embeds")
+
+ # 7. Get online LCM prediction on z_{t_{n + k}} (noisy_model_input), w, c, t_{n + k} (start_timesteps)
+ noise_pred = unet(
+ noisy_model_input,
+ start_timesteps,
+ encoder_hidden_states=prompt_embeds,
+ added_cond_kwargs=encoded_text,
+ ).sample
+ pred_x_0 = get_predicted_original_sample(
+ noise_pred,
+ start_timesteps,
+ noisy_model_input,
+ noise_scheduler.config.prediction_type,
+ alpha_schedule,
+ sigma_schedule,
+ )
+ model_pred = c_skip_start * noisy_model_input + c_out_start * pred_x_0
+
+ # 8. Compute the conditional and unconditional teacher model predictions to get CFG estimates of the
+ # predicted noise eps_0 and predicted original sample x_0, then run the ODE solver using these
+ # estimates to predict the data point in the augmented PF-ODE trajectory corresponding to the next ODE
+ # solver timestep.
+
+ # With the adapters disabled, the `unet` is the regular teacher model.
+ unet.disable_adapters()
+ with torch.no_grad():
+ # 1. Get teacher model prediction on noisy_model_input z_{t_{n + k}} and conditional embedding c
+ cond_teacher_output = unet(
+ noisy_model_input,
+ start_timesteps,
+ encoder_hidden_states=prompt_embeds,
+ added_cond_kwargs={k: v.to(weight_dtype) for k, v in encoded_text.items()},
+ ).sample
+ cond_pred_x0 = get_predicted_original_sample(
+ cond_teacher_output,
+ start_timesteps,
+ noisy_model_input,
+ noise_scheduler.config.prediction_type,
+ alpha_schedule,
+ sigma_schedule,
+ )
+ cond_pred_noise = get_predicted_noise(
+ cond_teacher_output,
+ start_timesteps,
+ noisy_model_input,
+ noise_scheduler.config.prediction_type,
+ alpha_schedule,
+ sigma_schedule,
+ )
+
+ # 2. Get teacher model prediction on noisy_model_input z_{t_{n + k}} and unconditional embedding 0
+ uncond_prompt_embeds = torch.zeros_like(prompt_embeds)
+ uncond_pooled_prompt_embeds = torch.zeros_like(encoded_text["text_embeds"])
+ uncond_added_conditions = copy.deepcopy(encoded_text)
+ uncond_added_conditions["text_embeds"] = uncond_pooled_prompt_embeds
+ uncond_teacher_output = unet(
+ noisy_model_input,
+ start_timesteps,
+ encoder_hidden_states=uncond_prompt_embeds.to(weight_dtype),
+ added_cond_kwargs={k: v.to(weight_dtype) for k, v in uncond_added_conditions.items()},
+ ).sample
+ uncond_pred_x0 = get_predicted_original_sample(
+ uncond_teacher_output,
+ start_timesteps,
+ noisy_model_input,
+ noise_scheduler.config.prediction_type,
+ alpha_schedule,
+ sigma_schedule,
+ )
+ uncond_pred_noise = get_predicted_noise(
+ uncond_teacher_output,
+ start_timesteps,
+ noisy_model_input,
+ noise_scheduler.config.prediction_type,
+ alpha_schedule,
+ sigma_schedule,
+ )
+
+ # 3. Calculate the CFG estimate of x_0 (pred_x0) and eps_0 (pred_noise)
+ # Note that this uses the LCM paper's CFG formulation rather than the Imagen CFG formulation
+ pred_x0 = cond_pred_x0 + w * (cond_pred_x0 - uncond_pred_x0)
+ pred_noise = cond_pred_noise + w * (cond_pred_noise - uncond_pred_noise)
+ # 4. Run one step of the ODE solver to estimate the next point x_prev on the
+ # augmented PF-ODE trajectory (solving backward in time)
+ # Note that the DDIM step depends on both the predicted x_0 and source noise eps_0.
+ x_prev = solver.ddim_step(pred_x0, pred_noise, index).to(unet.dtype)
+
+ # re-enable unet adapters to turn the `unet` into a student unet.
+ unet.enable_adapters()
+
+ # 9. Get target LCM prediction on x_prev, w, c, t_n (timesteps)
+ # Note that we do not use a separate target network for LCM-LoRA distillation.
+ with torch.no_grad():
+ target_noise_pred = unet(
+ x_prev,
+ timesteps,
+ encoder_hidden_states=prompt_embeds,
+ added_cond_kwargs={k: v.to(weight_dtype) for k, v in encoded_text.items()},
+ ).sample
+ pred_x_0 = get_predicted_original_sample(
+ target_noise_pred,
+ timesteps,
+ x_prev,
+ noise_scheduler.config.prediction_type,
+ alpha_schedule,
+ sigma_schedule,
+ )
+ target = c_skip * x_prev + c_out * pred_x_0
+
+ # 10. Calculate loss
+ if args.loss_type == "l2":
+ loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
+ elif args.loss_type == "huber":
+ loss = torch.mean(
+ torch.sqrt((model_pred.float() - target.float()) ** 2 + args.huber_c**2) - args.huber_c
+ )
+
+ # 11. Backpropagate on the online student model (`unet`) (only LoRA)
+ accelerator.backward(loss)
+ if accelerator.sync_gradients:
+ accelerator.clip_grad_norm_(params_to_optimize, args.max_grad_norm)
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad(set_to_none=True)
+
+ # Checks if the accelerator has performed an optimization step behind the scenes
+ if accelerator.sync_gradients:
+ progress_bar.update(1)
+ global_step += 1
+
+ if accelerator.is_main_process:
+ if global_step % args.checkpointing_steps == 0:
+ # _before_ saving state, check if this save would set us over the `checkpoints_total_limit`
+ if args.checkpoints_total_limit is not None:
+ checkpoints = os.listdir(args.output_dir)
+ checkpoints = [d for d in checkpoints if d.startswith("checkpoint")]
+ checkpoints = sorted(checkpoints, key=lambda x: int(x.split("-")[1]))
+
+ # before we save the new checkpoint, we need to have at _most_ `checkpoints_total_limit - 1` checkpoints
+ if len(checkpoints) >= args.checkpoints_total_limit:
+ num_to_remove = len(checkpoints) - args.checkpoints_total_limit + 1
+ removing_checkpoints = checkpoints[0:num_to_remove]
+
+ logger.info(
+ f"{len(checkpoints)} checkpoints already exist, removing {len(removing_checkpoints)} checkpoints"
+ )
+ logger.info(f"removing checkpoints: {', '.join(removing_checkpoints)}")
+
+ for removing_checkpoint in removing_checkpoints:
+ removing_checkpoint = os.path.join(args.output_dir, removing_checkpoint)
+ shutil.rmtree(removing_checkpoint)
+
+ save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
+ accelerator.save_state(save_path)
+ logger.info(f"Saved state to {save_path}")
+
+ if global_step % args.validation_steps == 0:
+ log_validation(
+ vae, args, accelerator, weight_dtype, global_step, unet=unet, is_final_validation=False
+ )
+
+ logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
+ progress_bar.set_postfix(**logs)
+ accelerator.log(logs, step=global_step)
+
+ if global_step >= args.max_train_steps:
+ break
+
+ # Create the pipeline using using the trained modules and save it.
+ accelerator.wait_for_everyone()
+ if accelerator.is_main_process:
+ unet = accelerator.unwrap_model(unet)
+ unet_lora_state_dict = get_peft_model_state_dict(unet)
+ StableDiffusionXLPipeline.save_lora_weights(args.output_dir, unet_lora_layers=unet_lora_state_dict)
+
+ if args.push_to_hub:
+ upload_folder(
+ repo_id=repo_id,
+ folder_path=args.output_dir,
+ commit_message="End of training",
+ ignore_patterns=["step_*", "epoch_*"],
+ )
+
+ del unet
+ torch.cuda.empty_cache()
+
+ # Final inference.
+ if args.validation_steps is not None:
+ log_validation(vae, args, accelerator, weight_dtype, step=global_step, unet=None, is_final_validation=True)
+
+ accelerator.end_training()
+
+
+if __name__ == "__main__":
+ args = parse_args()
+ main(args)
diff --git a/examples/controlnet/test_controlnet.py b/examples/controlnet/test_controlnet.py
index e62d095ada..e1adafe6be 100644
--- a/examples/controlnet/test_controlnet.py
+++ b/examples/controlnet/test_controlnet.py
@@ -65,7 +65,7 @@ class ControlNet(ExamplesTestsAccelerate):
--train_batch_size=1
--gradient_accumulation_steps=1
--controlnet_model_name_or_path=hf-internal-testing/tiny-controlnet
- --max_train_steps=9
+ --max_train_steps=6
--checkpointing_steps=2
""".split()
@@ -73,7 +73,7 @@ class ControlNet(ExamplesTestsAccelerate):
self.assertEqual(
{x for x in os.listdir(tmpdir) if "checkpoint" in x},
- {"checkpoint-2", "checkpoint-4", "checkpoint-6", "checkpoint-8"},
+ {"checkpoint-2", "checkpoint-4", "checkpoint-6"},
)
resume_run_args = f"""
@@ -85,18 +85,15 @@ class ControlNet(ExamplesTestsAccelerate):
--train_batch_size=1
--gradient_accumulation_steps=1
--controlnet_model_name_or_path=hf-internal-testing/tiny-controlnet
- --max_train_steps=11
+ --max_train_steps=8
--checkpointing_steps=2
- --resume_from_checkpoint=checkpoint-8
- --checkpoints_total_limit=3
+ --resume_from_checkpoint=checkpoint-6
+ --checkpoints_total_limit=2
""".split()
run_command(self._launch_args + resume_run_args)
- self.assertEqual(
- {x for x in os.listdir(tmpdir) if "checkpoint" in x},
- {"checkpoint-8", "checkpoint-10", "checkpoint-12"},
- )
+ self.assertEqual({x for x in os.listdir(tmpdir) if "checkpoint" in x}, {"checkpoint-6", "checkpoint-8"})
class ControlNetSDXL(ExamplesTestsAccelerate):
@@ -111,7 +108,7 @@ class ControlNetSDXL(ExamplesTestsAccelerate):
--train_batch_size=1
--gradient_accumulation_steps=1
--controlnet_model_name_or_path=hf-internal-testing/tiny-controlnet-sdxl
- --max_train_steps=9
+ --max_train_steps=4
--checkpointing_steps=2
""".split()
diff --git a/examples/custom_diffusion/test_custom_diffusion.py b/examples/custom_diffusion/test_custom_diffusion.py
index 78f24c5172..da4355d5ac 100644
--- a/examples/custom_diffusion/test_custom_diffusion.py
+++ b/examples/custom_diffusion/test_custom_diffusion.py
@@ -76,10 +76,7 @@ class CustomDiffusion(ExamplesTestsAccelerate):
run_command(self._launch_args + test_args)
- self.assertEqual(
- {x for x in os.listdir(tmpdir) if "checkpoint" in x},
- {"checkpoint-4", "checkpoint-6"},
- )
+ self.assertEqual({x for x in os.listdir(tmpdir) if "checkpoint" in x}, {"checkpoint-4", "checkpoint-6"})
def test_custom_diffusion_checkpointing_checkpoints_total_limit_removes_multiple_checkpoints(self):
with tempfile.TemporaryDirectory() as tmpdir:
@@ -93,7 +90,7 @@ class CustomDiffusion(ExamplesTestsAccelerate):
--train_batch_size=1
--modifier_token=
--dataloader_num_workers=0
- --max_train_steps=9
+ --max_train_steps=4
--checkpointing_steps=2
--no_safe_serialization
""".split()
@@ -102,7 +99,7 @@ class CustomDiffusion(ExamplesTestsAccelerate):
self.assertEqual(
{x for x in os.listdir(tmpdir) if "checkpoint" in x},
- {"checkpoint-2", "checkpoint-4", "checkpoint-6", "checkpoint-8"},
+ {"checkpoint-2", "checkpoint-4"},
)
resume_run_args = f"""
@@ -115,16 +112,13 @@ class CustomDiffusion(ExamplesTestsAccelerate):
--train_batch_size=1
--modifier_token=
--dataloader_num_workers=0
- --max_train_steps=11
+ --max_train_steps=8
--checkpointing_steps=2
- --resume_from_checkpoint=checkpoint-8
- --checkpoints_total_limit=3
+ --resume_from_checkpoint=checkpoint-4
+ --checkpoints_total_limit=2
--no_safe_serialization
""".split()
run_command(self._launch_args + resume_run_args)
- self.assertEqual(
- {x for x in os.listdir(tmpdir) if "checkpoint" in x},
- {"checkpoint-6", "checkpoint-8", "checkpoint-10"},
- )
+ self.assertEqual({x for x in os.listdir(tmpdir) if "checkpoint" in x}, {"checkpoint-6", "checkpoint-8"})
diff --git a/examples/dreambooth/test_dreambooth.py b/examples/dreambooth/test_dreambooth.py
index 0c6c2a0623..ce2f3215bc 100644
--- a/examples/dreambooth/test_dreambooth.py
+++ b/examples/dreambooth/test_dreambooth.py
@@ -89,7 +89,7 @@ class DreamBooth(ExamplesTestsAccelerate):
with tempfile.TemporaryDirectory() as tmpdir:
# Run training script with checkpointing
- # max_train_steps == 5, checkpointing_steps == 2
+ # max_train_steps == 4, checkpointing_steps == 2
# Should create checkpoints at steps 2, 4
initial_run_args = f"""
@@ -100,7 +100,7 @@ class DreamBooth(ExamplesTestsAccelerate):
--resolution 64
--train_batch_size 1
--gradient_accumulation_steps 1
- --max_train_steps 5
+ --max_train_steps 4
--learning_rate 5.0e-04
--scale_lr
--lr_scheduler constant
@@ -114,7 +114,7 @@ class DreamBooth(ExamplesTestsAccelerate):
# check can run the original fully trained output pipeline
pipe = DiffusionPipeline.from_pretrained(tmpdir, safety_checker=None)
- pipe(instance_prompt, num_inference_steps=2)
+ pipe(instance_prompt, num_inference_steps=1)
# check checkpoint directories exist
self.assertTrue(os.path.isdir(os.path.join(tmpdir, "checkpoint-2")))
@@ -123,7 +123,7 @@ class DreamBooth(ExamplesTestsAccelerate):
# check can run an intermediate checkpoint
unet = UNet2DConditionModel.from_pretrained(tmpdir, subfolder="checkpoint-2/unet")
pipe = DiffusionPipeline.from_pretrained(pretrained_model_name_or_path, unet=unet, safety_checker=None)
- pipe(instance_prompt, num_inference_steps=2)
+ pipe(instance_prompt, num_inference_steps=1)
# Remove checkpoint 2 so that we can check only later checkpoints exist after resuming
shutil.rmtree(os.path.join(tmpdir, "checkpoint-2"))
@@ -138,7 +138,7 @@ class DreamBooth(ExamplesTestsAccelerate):
--resolution 64
--train_batch_size 1
--gradient_accumulation_steps 1
- --max_train_steps 7
+ --max_train_steps 6
--learning_rate 5.0e-04
--scale_lr
--lr_scheduler constant
@@ -153,7 +153,7 @@ class DreamBooth(ExamplesTestsAccelerate):
# check can run new fully trained pipeline
pipe = DiffusionPipeline.from_pretrained(tmpdir, safety_checker=None)
- pipe(instance_prompt, num_inference_steps=2)
+ pipe(instance_prompt, num_inference_steps=1)
# check old checkpoints do not exist
self.assertFalse(os.path.isdir(os.path.join(tmpdir, "checkpoint-2")))
@@ -196,7 +196,7 @@ class DreamBooth(ExamplesTestsAccelerate):
--resolution=64
--train_batch_size=1
--gradient_accumulation_steps=1
- --max_train_steps=9
+ --max_train_steps=4
--checkpointing_steps=2
""".split()
@@ -204,7 +204,7 @@ class DreamBooth(ExamplesTestsAccelerate):
self.assertEqual(
{x for x in os.listdir(tmpdir) if "checkpoint" in x},
- {"checkpoint-2", "checkpoint-4", "checkpoint-6", "checkpoint-8"},
+ {"checkpoint-2", "checkpoint-4"},
)
resume_run_args = f"""
@@ -216,15 +216,12 @@ class DreamBooth(ExamplesTestsAccelerate):
--resolution=64
--train_batch_size=1
--gradient_accumulation_steps=1
- --max_train_steps=11
+ --max_train_steps=8
--checkpointing_steps=2
- --resume_from_checkpoint=checkpoint-8
- --checkpoints_total_limit=3
+ --resume_from_checkpoint=checkpoint-4
+ --checkpoints_total_limit=2
""".split()
run_command(self._launch_args + resume_run_args)
- self.assertEqual(
- {x for x in os.listdir(tmpdir) if "checkpoint" in x},
- {"checkpoint-6", "checkpoint-8", "checkpoint-10"},
- )
+ self.assertEqual({x for x in os.listdir(tmpdir) if "checkpoint" in x}, {"checkpoint-6", "checkpoint-8"})
diff --git a/examples/dreambooth/test_dreambooth_lora.py b/examples/dreambooth/test_dreambooth_lora.py
index fc43269f73..496ce22f81 100644
--- a/examples/dreambooth/test_dreambooth_lora.py
+++ b/examples/dreambooth/test_dreambooth_lora.py
@@ -135,16 +135,13 @@ class DreamBoothLoRA(ExamplesTestsAccelerate):
--resolution=64
--train_batch_size=1
--gradient_accumulation_steps=1
- --max_train_steps=9
+ --max_train_steps=4
--checkpointing_steps=2
""".split()
run_command(self._launch_args + test_args)
- self.assertEqual(
- {x for x in os.listdir(tmpdir) if "checkpoint" in x},
- {"checkpoint-2", "checkpoint-4", "checkpoint-6", "checkpoint-8"},
- )
+ self.assertEqual({x for x in os.listdir(tmpdir) if "checkpoint" in x}, {"checkpoint-2", "checkpoint-4"})
resume_run_args = f"""
examples/dreambooth/train_dreambooth_lora.py
@@ -155,18 +152,15 @@ class DreamBoothLoRA(ExamplesTestsAccelerate):
--resolution=64
--train_batch_size=1
--gradient_accumulation_steps=1
- --max_train_steps=11
+ --max_train_steps=8
--checkpointing_steps=2
- --resume_from_checkpoint=checkpoint-8
- --checkpoints_total_limit=3
+ --resume_from_checkpoint=checkpoint-4
+ --checkpoints_total_limit=2
""".split()
run_command(self._launch_args + resume_run_args)
- self.assertEqual(
- {x for x in os.listdir(tmpdir) if "checkpoint" in x},
- {"checkpoint-6", "checkpoint-8", "checkpoint-10"},
- )
+ self.assertEqual({x for x in os.listdir(tmpdir) if "checkpoint" in x}, {"checkpoint-6", "checkpoint-8"})
def test_dreambooth_lora_if_model(self):
with tempfile.TemporaryDirectory() as tmpdir:
@@ -328,7 +322,7 @@ class DreamBoothLoRASDXL(ExamplesTestsAccelerate):
--resolution 64
--train_batch_size 1
--gradient_accumulation_steps 1
- --max_train_steps 7
+ --max_train_steps 6
--checkpointing_steps=2
--checkpoints_total_limit=2
--learning_rate 5.0e-04
@@ -342,14 +336,11 @@ class DreamBoothLoRASDXL(ExamplesTestsAccelerate):
pipe = DiffusionPipeline.from_pretrained(pipeline_path)
pipe.load_lora_weights(tmpdir)
- pipe("a prompt", num_inference_steps=2)
+ pipe("a prompt", num_inference_steps=1)
# check checkpoint directories exist
- self.assertEqual(
- {x for x in os.listdir(tmpdir) if "checkpoint" in x},
- # checkpoint-2 should have been deleted
- {"checkpoint-4", "checkpoint-6"},
- )
+ # checkpoint-2 should have been deleted
+ self.assertEqual({x for x in os.listdir(tmpdir) if "checkpoint" in x}, {"checkpoint-4", "checkpoint-6"})
def test_dreambooth_lora_sdxl_text_encoder_checkpointing_checkpoints_total_limit(self):
pipeline_path = "hf-internal-testing/tiny-stable-diffusion-xl-pipe"
diff --git a/examples/dreambooth/train_dreambooth_lora.py b/examples/dreambooth/train_dreambooth_lora.py
index 55ef2bbeb8..67132d6d88 100644
--- a/examples/dreambooth/train_dreambooth_lora.py
+++ b/examples/dreambooth/train_dreambooth_lora.py
@@ -827,6 +827,7 @@ def main(args):
# now we will add new LoRA weights to the attention layers
unet_lora_config = LoraConfig(
r=args.rank,
+ lora_alpha=args.rank,
init_lora_weights="gaussian",
target_modules=["to_k", "to_q", "to_v", "to_out.0", "add_k_proj", "add_v_proj"],
)
@@ -835,7 +836,10 @@ def main(args):
# The text encoder comes from 🤗 transformers, we will also attach adapters to it.
if args.train_text_encoder:
text_lora_config = LoraConfig(
- r=args.rank, init_lora_weights="gaussian", target_modules=["q_proj", "k_proj", "v_proj", "out_proj"]
+ r=args.rank,
+ lora_alpha=args.rank,
+ init_lora_weights="gaussian",
+ target_modules=["q_proj", "k_proj", "v_proj", "out_proj"],
)
text_encoder.add_adapter(text_lora_config)
diff --git a/examples/dreambooth/train_dreambooth_lora_sdxl.py b/examples/dreambooth/train_dreambooth_lora_sdxl.py
index 9992292e30..aa6e7d21aa 100644
--- a/examples/dreambooth/train_dreambooth_lora_sdxl.py
+++ b/examples/dreambooth/train_dreambooth_lora_sdxl.py
@@ -54,7 +54,7 @@ from diffusers import (
from diffusers.loaders import LoraLoaderMixin
from diffusers.optimization import get_scheduler
from diffusers.training_utils import compute_snr
-from diffusers.utils import check_min_version, is_wandb_available
+from diffusers.utils import check_min_version, convert_state_dict_to_diffusers, is_wandb_available
from diffusers.utils.import_utils import is_xformers_available
@@ -978,7 +978,10 @@ def main(args):
# now we will add new LoRA weights to the attention layers
unet_lora_config = LoraConfig(
- r=args.rank, init_lora_weights="gaussian", target_modules=["to_k", "to_q", "to_v", "to_out.0"]
+ r=args.rank,
+ lora_alpha=args.rank,
+ init_lora_weights="gaussian",
+ target_modules=["to_k", "to_q", "to_v", "to_out.0"],
)
unet.add_adapter(unet_lora_config)
@@ -986,7 +989,10 @@ def main(args):
# So, instead, we monkey-patch the forward calls of its attention-blocks.
if args.train_text_encoder:
text_lora_config = LoraConfig(
- r=args.rank, init_lora_weights="gaussian", target_modules=["q_proj", "k_proj", "v_proj", "out_proj"]
+ r=args.rank,
+ lora_alpha=args.rank,
+ init_lora_weights="gaussian",
+ target_modules=["q_proj", "k_proj", "v_proj", "out_proj"],
)
text_encoder_one.add_adapter(text_lora_config)
text_encoder_two.add_adapter(text_lora_config)
@@ -1013,11 +1019,15 @@ def main(args):
for model in models:
if isinstance(model, type(accelerator.unwrap_model(unet))):
- unet_lora_layers_to_save = get_peft_model_state_dict(model)
+ unet_lora_layers_to_save = convert_state_dict_to_diffusers(get_peft_model_state_dict(model))
elif isinstance(model, type(accelerator.unwrap_model(text_encoder_one))):
- text_encoder_one_lora_layers_to_save = get_peft_model_state_dict(model)
+ text_encoder_one_lora_layers_to_save = convert_state_dict_to_diffusers(
+ get_peft_model_state_dict(model)
+ )
elif isinstance(model, type(accelerator.unwrap_model(text_encoder_two))):
- text_encoder_two_lora_layers_to_save = get_peft_model_state_dict(model)
+ text_encoder_two_lora_layers_to_save = convert_state_dict_to_diffusers(
+ get_peft_model_state_dict(model)
+ )
else:
raise ValueError(f"unexpected save model: {model.__class__}")
@@ -1144,10 +1154,26 @@ def main(args):
optimizer_class = prodigyopt.Prodigy
+ if args.learning_rate <= 0.1:
+ logger.warn(
+ "Learning rate is too low. When using prodigy, it's generally better to set learning rate around 1.0"
+ )
+ if args.train_text_encoder and args.text_encoder_lr:
+ logger.warn(
+ f"Learning rates were provided both for the unet and the text encoder- e.g. text_encoder_lr:"
+ f" {args.text_encoder_lr} and learning_rate: {args.learning_rate}. "
+ f"When using prodigy only learning_rate is used as the initial learning rate."
+ )
+ # changes the learning rate of text_encoder_parameters_one and text_encoder_parameters_two to be
+ # --learning_rate
+ params_to_optimize[1]["lr"] = args.learning_rate
+ params_to_optimize[2]["lr"] = args.learning_rate
+
optimizer = optimizer_class(
params_to_optimize,
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
+ beta3=args.prodigy_beta3,
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
decouple=args.prodigy_decouple,
@@ -1593,13 +1619,17 @@ def main(args):
if accelerator.is_main_process:
unet = accelerator.unwrap_model(unet)
unet = unet.to(torch.float32)
- unet_lora_layers = get_peft_model_state_dict(unet)
+ unet_lora_layers = convert_state_dict_to_diffusers(get_peft_model_state_dict(unet))
if args.train_text_encoder:
text_encoder_one = accelerator.unwrap_model(text_encoder_one)
- text_encoder_lora_layers = get_peft_model_state_dict(text_encoder_one.to(torch.float32))
+ text_encoder_lora_layers = convert_state_dict_to_diffusers(
+ get_peft_model_state_dict(text_encoder_one.to(torch.float32))
+ )
text_encoder_two = accelerator.unwrap_model(text_encoder_two)
- text_encoder_2_lora_layers = get_peft_model_state_dict(text_encoder_two.to(torch.float32))
+ text_encoder_2_lora_layers = convert_state_dict_to_diffusers(
+ get_peft_model_state_dict(text_encoder_two.to(torch.float32))
+ )
else:
text_encoder_lora_layers = None
text_encoder_2_lora_layers = None
diff --git a/examples/instruct_pix2pix/README_sdxl.md b/examples/instruct_pix2pix/README_sdxl.md
index b8c2ffdc81..8eb640eb35 100644
--- a/examples/instruct_pix2pix/README_sdxl.md
+++ b/examples/instruct_pix2pix/README_sdxl.md
@@ -71,7 +71,7 @@ accelerate launch train_instruct_pix2pix_sdxl.py \
We recommend this type of validation as it can be useful for model debugging. Note that you need `wandb` installed to use this. You can install `wandb` by running `pip install wandb`.
- [Here](https://wandb.ai/sayakpaul/instruct-pix2pix/runs/ctr3kovq), you can find an example training run that includes some validation samples and the training hyperparameters.
+ [Here](https://wandb.ai/sayakpaul/instruct-pix2pix-sdxl-new/runs/sw53gxmc), you can find an example training run that includes some validation samples and the training hyperparameters.
***Note: In the original paper, the authors observed that even when the model is trained with an image resolution of 256x256, it generalizes well to bigger resolutions such as 512x512. This is likely because of the larger dataset they used during training.***
diff --git a/examples/instruct_pix2pix/test_instruct_pix2pix.py b/examples/instruct_pix2pix/test_instruct_pix2pix.py
index c4d7500723..b30baf8b1b 100644
--- a/examples/instruct_pix2pix/test_instruct_pix2pix.py
+++ b/examples/instruct_pix2pix/test_instruct_pix2pix.py
@@ -40,7 +40,7 @@ class InstructPix2Pix(ExamplesTestsAccelerate):
--resolution=64
--random_flip
--train_batch_size=1
- --max_train_steps=7
+ --max_train_steps=6
--checkpointing_steps=2
--checkpoints_total_limit=2
--output_dir {tmpdir}
@@ -63,7 +63,7 @@ class InstructPix2Pix(ExamplesTestsAccelerate):
--resolution=64
--random_flip
--train_batch_size=1
- --max_train_steps=9
+ --max_train_steps=4
--checkpointing_steps=2
--output_dir {tmpdir}
--seed=0
@@ -74,7 +74,7 @@ class InstructPix2Pix(ExamplesTestsAccelerate):
# check checkpoint directories exist
self.assertEqual(
{x for x in os.listdir(tmpdir) if "checkpoint" in x},
- {"checkpoint-2", "checkpoint-4", "checkpoint-6", "checkpoint-8"},
+ {"checkpoint-2", "checkpoint-4"},
)
resume_run_args = f"""
@@ -84,12 +84,12 @@ class InstructPix2Pix(ExamplesTestsAccelerate):
--resolution=64
--random_flip
--train_batch_size=1
- --max_train_steps=11
+ --max_train_steps=8
--checkpointing_steps=2
--output_dir {tmpdir}
--seed=0
- --resume_from_checkpoint=checkpoint-8
- --checkpoints_total_limit=3
+ --resume_from_checkpoint=checkpoint-4
+ --checkpoints_total_limit=2
""".split()
run_command(self._launch_args + resume_run_args)
@@ -97,5 +97,5 @@ class InstructPix2Pix(ExamplesTestsAccelerate):
# check checkpoint directories exist
self.assertEqual(
{x for x in os.listdir(tmpdir) if "checkpoint" in x},
- {"checkpoint-6", "checkpoint-8", "checkpoint-10"},
+ {"checkpoint-6", "checkpoint-8"},
)
diff --git a/docs/source/en/api/pipelines/controlnetxs.md b/examples/research_projects/controlnetxs/README.md
similarity index 61%
rename from docs/source/en/api/pipelines/controlnetxs.md
rename to examples/research_projects/controlnetxs/README.md
index 2d4ae7b8ce..72ed91c01d 100644
--- a/docs/source/en/api/pipelines/controlnetxs.md
+++ b/examples/research_projects/controlnetxs/README.md
@@ -1,15 +1,3 @@
-
-
# ControlNet-XS
ControlNet-XS was introduced in [ControlNet-XS](https://vislearn.github.io/ControlNet-XS/) by Denis Zavadski and Carsten Rother. It is based on the observation that the control model in the [original ControlNet](https://huggingface.co/papers/2302.05543) can be made much smaller and still produce good results.
@@ -24,16 +12,5 @@ Here's the overview from the [project page](https://vislearn.github.io/ControlNe
This model was contributed by [UmerHA](https://twitter.com/UmerHAdil). ❤️
-
-Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
-
-
-
-## StableDiffusionControlNetXSPipeline
-[[autodoc]] StableDiffusionControlNetXSPipeline
- - all
- - __call__
-
-## StableDiffusionPipelineOutput
-[[autodoc]] pipelines.stable_diffusion.StableDiffusionPipelineOutput
+> 🧠 Make sure to check out the Schedulers [guide](https://huggingface.co/docs/diffusers/main/en/using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
\ No newline at end of file
diff --git a/docs/source/en/api/pipelines/controlnetxs_sdxl.md b/examples/research_projects/controlnetxs/README_sdxl.md
similarity index 56%
rename from docs/source/en/api/pipelines/controlnetxs_sdxl.md
rename to examples/research_projects/controlnetxs/README_sdxl.md
index 31075c0ef9..d401c1e766 100644
--- a/docs/source/en/api/pipelines/controlnetxs_sdxl.md
+++ b/examples/research_projects/controlnetxs/README_sdxl.md
@@ -1,15 +1,3 @@
-
-
# ControlNet-XS with Stable Diffusion XL
ControlNet-XS was introduced in [ControlNet-XS](https://vislearn.github.io/ControlNet-XS/) by Denis Zavadski and Carsten Rother. It is based on the observation that the control model in the [original ControlNet](https://huggingface.co/papers/2302.05543) can be made much smaller and still produce good results.
@@ -24,22 +12,4 @@ Here's the overview from the [project page](https://vislearn.github.io/ControlNe
This model was contributed by [UmerHA](https://twitter.com/UmerHAdil). ❤️
-
-
-🧪 Many of the SDXL ControlNet checkpoints are experimental, and there is a lot of room for improvement. Feel free to open an [Issue](https://github.com/huggingface/diffusers/issues/new/choose) and leave us feedback on how we can improve!
-
-
-
-
-
-Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
-
-
-
-## StableDiffusionXLControlNetXSPipeline
-[[autodoc]] StableDiffusionXLControlNetXSPipeline
- - all
- - __call__
-
-## StableDiffusionPipelineOutput
-[[autodoc]] pipelines.stable_diffusion.StableDiffusionPipelineOutput
+> 🧠 Make sure to check out the Schedulers [guide](https://huggingface.co/docs/diffusers/main/en/using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
\ No newline at end of file
diff --git a/src/diffusers/models/controlnetxs.py b/examples/research_projects/controlnetxs/controlnetxs.py
similarity index 98%
rename from src/diffusers/models/controlnetxs.py
rename to examples/research_projects/controlnetxs/controlnetxs.py
index 41fe624b9b..c6419b44da 100644
--- a/src/diffusers/models/controlnetxs.py
+++ b/examples/research_projects/controlnetxs/controlnetxs.py
@@ -21,13 +21,12 @@ from torch import nn
from torch.nn import functional as F
from torch.nn.modules.normalization import GroupNorm
-from ..configuration_utils import ConfigMixin, register_to_config
-from ..utils import BaseOutput, logging
-from .attention_processor import USE_PEFT_BACKEND, AttentionProcessor
-from .autoencoders import AutoencoderKL
-from .lora import LoRACompatibleConv
-from .modeling_utils import ModelMixin
-from .unet_2d_blocks import (
+from diffusers.configuration_utils import ConfigMixin, register_to_config
+from diffusers.models.attention_processor import USE_PEFT_BACKEND, AttentionProcessor
+from diffusers.models.autoencoders import AutoencoderKL
+from diffusers.models.lora import LoRACompatibleConv
+from diffusers.models.modeling_utils import ModelMixin
+from diffusers.models.unet_2d_blocks import (
CrossAttnDownBlock2D,
CrossAttnUpBlock2D,
DownBlock2D,
@@ -37,7 +36,8 @@ from .unet_2d_blocks import (
UpBlock2D,
Upsample2D,
)
-from .unet_2d_condition import UNet2DConditionModel
+from diffusers.models.unet_2d_condition import UNet2DConditionModel
+from diffusers.utils import BaseOutput, logging
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
diff --git a/examples/research_projects/controlnetxs/infer_sd_controlnetxs.py b/examples/research_projects/controlnetxs/infer_sd_controlnetxs.py
new file mode 100644
index 0000000000..722b282a32
--- /dev/null
+++ b/examples/research_projects/controlnetxs/infer_sd_controlnetxs.py
@@ -0,0 +1,58 @@
+# !pip install opencv-python transformers accelerate
+import argparse
+
+import cv2
+import numpy as np
+import torch
+from controlnetxs import ControlNetXSModel
+from PIL import Image
+from pipeline_controlnet_xs import StableDiffusionControlNetXSPipeline
+
+from diffusers.utils import load_image
+
+
+parser = argparse.ArgumentParser()
+parser.add_argument(
+ "--prompt", type=str, default="aerial view, a futuristic research complex in a bright foggy jungle, hard lighting"
+)
+parser.add_argument("--negative_prompt", type=str, default="low quality, bad quality, sketches")
+parser.add_argument("--controlnet_conditioning_scale", type=float, default=0.7)
+parser.add_argument(
+ "--image_path",
+ type=str,
+ default="https://hf.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/hf-logo.png",
+)
+parser.add_argument("--num_inference_steps", type=int, default=50)
+
+args = parser.parse_args()
+
+prompt = args.prompt
+negative_prompt = args.negative_prompt
+# download an image
+image = load_image(args.image_path)
+
+# initialize the models and pipeline
+controlnet_conditioning_scale = args.controlnet_conditioning_scale
+controlnet = ControlNetXSModel.from_pretrained("UmerHA/ConrolNetXS-SD2.1-canny", torch_dtype=torch.float16)
+pipe = StableDiffusionControlNetXSPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-2-1", controlnet=controlnet, torch_dtype=torch.float16
+)
+pipe.enable_model_cpu_offload()
+
+# get canny image
+image = np.array(image)
+image = cv2.Canny(image, 100, 200)
+image = image[:, :, None]
+image = np.concatenate([image, image, image], axis=2)
+canny_image = Image.fromarray(image)
+
+num_inference_steps = args.num_inference_steps
+
+# generate image
+image = pipe(
+ prompt,
+ controlnet_conditioning_scale=controlnet_conditioning_scale,
+ image=canny_image,
+ num_inference_steps=num_inference_steps,
+).images[0]
+image.save("cnxs_sd.canny.png")
diff --git a/examples/research_projects/controlnetxs/infer_sdxl_controlnetxs.py b/examples/research_projects/controlnetxs/infer_sdxl_controlnetxs.py
new file mode 100644
index 0000000000..e5b8cfd882
--- /dev/null
+++ b/examples/research_projects/controlnetxs/infer_sdxl_controlnetxs.py
@@ -0,0 +1,57 @@
+# !pip install opencv-python transformers accelerate
+import argparse
+
+import cv2
+import numpy as np
+import torch
+from controlnetxs import ControlNetXSModel
+from PIL import Image
+from pipeline_controlnet_xs import StableDiffusionControlNetXSPipeline
+
+from diffusers.utils import load_image
+
+
+parser = argparse.ArgumentParser()
+parser.add_argument(
+ "--prompt", type=str, default="aerial view, a futuristic research complex in a bright foggy jungle, hard lighting"
+)
+parser.add_argument("--negative_prompt", type=str, default="low quality, bad quality, sketches")
+parser.add_argument("--controlnet_conditioning_scale", type=float, default=0.7)
+parser.add_argument(
+ "--image_path",
+ type=str,
+ default="https://hf.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/hf-logo.png",
+)
+parser.add_argument("--num_inference_steps", type=int, default=50)
+
+args = parser.parse_args()
+
+prompt = args.prompt
+negative_prompt = args.negative_prompt
+# download an image
+image = load_image(args.image_path)
+# initialize the models and pipeline
+controlnet_conditioning_scale = args.controlnet_conditioning_scale
+controlnet = ControlNetXSModel.from_pretrained("UmerHA/ConrolNetXS-SDXL-canny", torch_dtype=torch.float16)
+pipe = StableDiffusionControlNetXSPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-xl-base-1.0", controlnet=controlnet, torch_dtype=torch.float16
+)
+pipe.enable_model_cpu_offload()
+
+# get canny image
+image = np.array(image)
+image = cv2.Canny(image, 100, 200)
+image = image[:, :, None]
+image = np.concatenate([image, image, image], axis=2)
+canny_image = Image.fromarray(image)
+
+num_inference_steps = args.num_inference_steps
+
+# generate image
+image = pipe(
+ prompt,
+ controlnet_conditioning_scale=controlnet_conditioning_scale,
+ image=canny_image,
+ num_inference_steps=num_inference_steps,
+).images[0]
+image.save("cnxs_sdxl.canny.png")
diff --git a/src/diffusers/pipelines/controlnet_xs/pipeline_controlnet_xs.py b/examples/research_projects/controlnetxs/pipeline_controlnet_xs.py
similarity index 94%
rename from src/diffusers/pipelines/controlnet_xs/pipeline_controlnet_xs.py
rename to examples/research_projects/controlnetxs/pipeline_controlnet_xs.py
index bf3ac50505..8e95306da5 100644
--- a/src/diffusers/pipelines/controlnet_xs/pipeline_controlnet_xs.py
+++ b/examples/research_projects/controlnetxs/pipeline_controlnet_xs.py
@@ -19,74 +19,30 @@ import numpy as np
import PIL.Image
import torch
import torch.nn.functional as F
+from controlnetxs import ControlNetXSModel
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
-from ...image_processor import PipelineImageInput, VaeImageProcessor
-from ...loaders import FromSingleFileMixin, LoraLoaderMixin, TextualInversionLoaderMixin
-from ...models import AutoencoderKL, ControlNetXSModel, UNet2DConditionModel
-from ...models.lora import adjust_lora_scale_text_encoder
-from ...schedulers import KarrasDiffusionSchedulers
-from ...utils import (
+from diffusers.image_processor import PipelineImageInput, VaeImageProcessor
+from diffusers.loaders import FromSingleFileMixin, LoraLoaderMixin, TextualInversionLoaderMixin
+from diffusers.models import AutoencoderKL, UNet2DConditionModel
+from diffusers.models.lora import adjust_lora_scale_text_encoder
+from diffusers.pipelines.pipeline_utils import DiffusionPipeline
+from diffusers.pipelines.stable_diffusion.pipeline_output import StableDiffusionPipelineOutput
+from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
+from diffusers.schedulers import KarrasDiffusionSchedulers
+from diffusers.utils import (
USE_PEFT_BACKEND,
deprecate,
logging,
- replace_example_docstring,
scale_lora_layers,
unscale_lora_layers,
)
-from ...utils.torch_utils import is_compiled_module, is_torch_version, randn_tensor
-from ..pipeline_utils import DiffusionPipeline
-from ..stable_diffusion.pipeline_output import StableDiffusionPipelineOutput
-from ..stable_diffusion.safety_checker import StableDiffusionSafetyChecker
+from diffusers.utils.torch_utils import is_compiled_module, is_torch_version, randn_tensor
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
-EXAMPLE_DOC_STRING = """
- Examples:
- ```py
- >>> # !pip install opencv-python transformers accelerate
- >>> from diffusers import StableDiffusionControlNetXSPipeline, ControlNetXSModel
- >>> from diffusers.utils import load_image
- >>> import numpy as np
- >>> import torch
-
- >>> import cv2
- >>> from PIL import Image
-
- >>> prompt = "aerial view, a futuristic research complex in a bright foggy jungle, hard lighting"
- >>> negative_prompt = "low quality, bad quality, sketches"
-
- >>> # download an image
- >>> image = load_image(
- ... "https://hf.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/hf-logo.png"
- ... )
-
- >>> # initialize the models and pipeline
- >>> controlnet_conditioning_scale = 0.5
- >>> controlnet = ControlNetXSModel.from_pretrained(
- ... "UmerHA/ConrolNetXS-SD2.1-canny", torch_dtype=torch.float16
- ... )
- >>> pipe = StableDiffusionControlNetXSPipeline.from_pretrained(
- ... "stabilityai/stable-diffusion-2-1", controlnet=controlnet, torch_dtype=torch.float16
- ... )
- >>> pipe.enable_model_cpu_offload()
-
- >>> # get canny image
- >>> image = np.array(image)
- >>> image = cv2.Canny(image, 100, 200)
- >>> image = image[:, :, None]
- >>> image = np.concatenate([image, image, image], axis=2)
- >>> canny_image = Image.fromarray(image)
- >>> # generate image
- >>> image = pipe(
- ... prompt, controlnet_conditioning_scale=controlnet_conditioning_scale, image=canny_image
- ... ).images[0]
- ```
-"""
-
-
class StableDiffusionControlNetXSPipeline(
DiffusionPipeline, TextualInversionLoaderMixin, LoraLoaderMixin, FromSingleFileMixin
):
@@ -669,7 +625,6 @@ class StableDiffusionControlNetXSPipeline(
self.unet.disable_freeu()
@torch.no_grad()
- @replace_example_docstring(EXAMPLE_DOC_STRING)
def __call__(
self,
prompt: Union[str, List[str]] = None,
diff --git a/src/diffusers/pipelines/controlnet_xs/pipeline_controlnet_xs_sd_xl.py b/examples/research_projects/controlnetxs/pipeline_controlnet_xs_sd_xl.py
similarity index 95%
rename from src/diffusers/pipelines/controlnet_xs/pipeline_controlnet_xs_sd_xl.py
rename to examples/research_projects/controlnetxs/pipeline_controlnet_xs_sd_xl.py
index 58f0f544a5..be888d7e11 100644
--- a/src/diffusers/pipelines/controlnet_xs/pipeline_controlnet_xs_sd_xl.py
+++ b/examples/research_projects/controlnetxs/pipeline_controlnet_xs_sd_xl.py
@@ -21,76 +21,36 @@ import torch
import torch.nn.functional as F
from transformers import CLIPTextModel, CLIPTextModelWithProjection, CLIPTokenizer
-from diffusers.utils.import_utils import is_invisible_watermark_available
-
-from ...image_processor import PipelineImageInput, VaeImageProcessor
-from ...loaders import FromSingleFileMixin, StableDiffusionXLLoraLoaderMixin, TextualInversionLoaderMixin
-from ...models import AutoencoderKL, ControlNetXSModel, UNet2DConditionModel
-from ...models.attention_processor import (
+from diffusers.image_processor import PipelineImageInput, VaeImageProcessor
+from diffusers.loaders import FromSingleFileMixin, StableDiffusionXLLoraLoaderMixin, TextualInversionLoaderMixin
+from diffusers.models import AutoencoderKL, ControlNetXSModel, UNet2DConditionModel
+from diffusers.models.attention_processor import (
AttnProcessor2_0,
LoRAAttnProcessor2_0,
LoRAXFormersAttnProcessor,
XFormersAttnProcessor,
)
-from ...models.lora import adjust_lora_scale_text_encoder
-from ...schedulers import KarrasDiffusionSchedulers
-from ...utils import USE_PEFT_BACKEND, logging, replace_example_docstring, scale_lora_layers, unscale_lora_layers
-from ...utils.torch_utils import is_compiled_module, is_torch_version, randn_tensor
-from ..pipeline_utils import DiffusionPipeline
-from ..stable_diffusion_xl.pipeline_output import StableDiffusionXLPipelineOutput
+from diffusers.models.lora import adjust_lora_scale_text_encoder
+from diffusers.pipelines.pipeline_utils import DiffusionPipeline
+from diffusers.pipelines.stable_diffusion_xl.pipeline_output import StableDiffusionXLPipelineOutput
+from diffusers.schedulers import KarrasDiffusionSchedulers
+from diffusers.utils import (
+ USE_PEFT_BACKEND,
+ logging,
+ scale_lora_layers,
+ unscale_lora_layers,
+)
+from diffusers.utils.import_utils import is_invisible_watermark_available
+from diffusers.utils.torch_utils import is_compiled_module, is_torch_version, randn_tensor
if is_invisible_watermark_available():
- from ..stable_diffusion_xl.watermark import StableDiffusionXLWatermarker
+ from diffusers.pipelines.stable_diffusion_xl.watermark import StableDiffusionXLWatermarker
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
-EXAMPLE_DOC_STRING = """
- Examples:
- ```py
- >>> # !pip install opencv-python transformers accelerate
- >>> from diffusers import StableDiffusionXLControlNetXSPipeline, ControlNetXSModel, AutoencoderKL
- >>> from diffusers.utils import load_image
- >>> import numpy as np
- >>> import torch
-
- >>> import cv2
- >>> from PIL import Image
-
- >>> prompt = "aerial view, a futuristic research complex in a bright foggy jungle, hard lighting"
- >>> negative_prompt = "low quality, bad quality, sketches"
-
- >>> # download an image
- >>> image = load_image(
- ... "https://hf.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/hf-logo.png"
- ... )
-
- >>> # initialize the models and pipeline
- >>> controlnet_conditioning_scale = 0.5 # recommended for good generalization
- >>> controlnet = ControlNetXSModel.from_pretrained("UmerHA/ConrolNetXS-SDXL-canny", torch_dtype=torch.float16)
- >>> vae = AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16)
- >>> pipe = StableDiffusionXLControlNetXSPipeline.from_pretrained(
- ... "stabilityai/stable-diffusion-xl-base-1.0", controlnet=controlnet, vae=vae, torch_dtype=torch.float16
- ... )
- >>> pipe.enable_model_cpu_offload()
-
- >>> # get canny image
- >>> image = np.array(image)
- >>> image = cv2.Canny(image, 100, 200)
- >>> image = image[:, :, None]
- >>> image = np.concatenate([image, image, image], axis=2)
- >>> canny_image = Image.fromarray(image)
-
- >>> # generate image
- >>> image = pipe(
- ... prompt, controlnet_conditioning_scale=controlnet_conditioning_scale, image=canny_image
- ... ).images[0]
- ```
-"""
-
-
class StableDiffusionXLControlNetXSPipeline(
DiffusionPipeline, TextualInversionLoaderMixin, StableDiffusionXLLoraLoaderMixin, FromSingleFileMixin
):
@@ -730,7 +690,6 @@ class StableDiffusionXLControlNetXSPipeline(
self.unet.disable_freeu()
@torch.no_grad()
- @replace_example_docstring(EXAMPLE_DOC_STRING)
def __call__(
self,
prompt: Union[str, List[str]] = None,
diff --git a/examples/text_to_image/test_text_to_image.py b/examples/text_to_image/test_text_to_image.py
index 308a038b55..814c13cf48 100644
--- a/examples/text_to_image/test_text_to_image.py
+++ b/examples/text_to_image/test_text_to_image.py
@@ -64,7 +64,7 @@ class TextToImage(ExamplesTestsAccelerate):
with tempfile.TemporaryDirectory() as tmpdir:
# Run training script with checkpointing
- # max_train_steps == 5, checkpointing_steps == 2
+ # max_train_steps == 4, checkpointing_steps == 2
# Should create checkpoints at steps 2, 4
initial_run_args = f"""
@@ -76,7 +76,7 @@ class TextToImage(ExamplesTestsAccelerate):
--random_flip
--train_batch_size 1
--gradient_accumulation_steps 1
- --max_train_steps 5
+ --max_train_steps 4
--learning_rate 5.0e-04
--scale_lr
--lr_scheduler constant
@@ -89,7 +89,7 @@ class TextToImage(ExamplesTestsAccelerate):
run_command(self._launch_args + initial_run_args)
pipe = DiffusionPipeline.from_pretrained(tmpdir, safety_checker=None)
- pipe(prompt, num_inference_steps=2)
+ pipe(prompt, num_inference_steps=1)
# check checkpoint directories exist
self.assertEqual(
@@ -100,12 +100,12 @@ class TextToImage(ExamplesTestsAccelerate):
# check can run an intermediate checkpoint
unet = UNet2DConditionModel.from_pretrained(tmpdir, subfolder="checkpoint-2/unet")
pipe = DiffusionPipeline.from_pretrained(pretrained_model_name_or_path, unet=unet, safety_checker=None)
- pipe(prompt, num_inference_steps=2)
+ pipe(prompt, num_inference_steps=1)
# Remove checkpoint 2 so that we can check only later checkpoints exist after resuming
shutil.rmtree(os.path.join(tmpdir, "checkpoint-2"))
- # Run training script for 7 total steps resuming from checkpoint 4
+ # Run training script for 2 total steps resuming from checkpoint 4
resume_run_args = f"""
examples/text_to_image/train_text_to_image.py
@@ -116,13 +116,13 @@ class TextToImage(ExamplesTestsAccelerate):
--random_flip
--train_batch_size 1
--gradient_accumulation_steps 1
- --max_train_steps 7
+ --max_train_steps 2
--learning_rate 5.0e-04
--scale_lr
--lr_scheduler constant
--lr_warmup_steps 0
--output_dir {tmpdir}
- --checkpointing_steps=2
+ --checkpointing_steps=1
--resume_from_checkpoint=checkpoint-4
--seed=0
""".split()
@@ -131,16 +131,13 @@ class TextToImage(ExamplesTestsAccelerate):
# check can run new fully trained pipeline
pipe = DiffusionPipeline.from_pretrained(tmpdir, safety_checker=None)
- pipe(prompt, num_inference_steps=2)
+ pipe(prompt, num_inference_steps=1)
+ # no checkpoint-2 -> check old checkpoints do not exist
+ # check new checkpoints exist
self.assertEqual(
{x for x in os.listdir(tmpdir) if "checkpoint" in x},
- {
- # no checkpoint-2 -> check old checkpoints do not exist
- # check new checkpoints exist
- "checkpoint-4",
- "checkpoint-6",
- },
+ {"checkpoint-4", "checkpoint-5"},
)
def test_text_to_image_checkpointing_use_ema(self):
@@ -149,7 +146,7 @@ class TextToImage(ExamplesTestsAccelerate):
with tempfile.TemporaryDirectory() as tmpdir:
# Run training script with checkpointing
- # max_train_steps == 5, checkpointing_steps == 2
+ # max_train_steps == 4, checkpointing_steps == 2
# Should create checkpoints at steps 2, 4
initial_run_args = f"""
@@ -161,7 +158,7 @@ class TextToImage(ExamplesTestsAccelerate):
--random_flip
--train_batch_size 1
--gradient_accumulation_steps 1
- --max_train_steps 5
+ --max_train_steps 4
--learning_rate 5.0e-04
--scale_lr
--lr_scheduler constant
@@ -186,12 +183,12 @@ class TextToImage(ExamplesTestsAccelerate):
# check can run an intermediate checkpoint
unet = UNet2DConditionModel.from_pretrained(tmpdir, subfolder="checkpoint-2/unet")
pipe = DiffusionPipeline.from_pretrained(pretrained_model_name_or_path, unet=unet, safety_checker=None)
- pipe(prompt, num_inference_steps=2)
+ pipe(prompt, num_inference_steps=1)
# Remove checkpoint 2 so that we can check only later checkpoints exist after resuming
shutil.rmtree(os.path.join(tmpdir, "checkpoint-2"))
- # Run training script for 7 total steps resuming from checkpoint 4
+ # Run training script for 2 total steps resuming from checkpoint 4
resume_run_args = f"""
examples/text_to_image/train_text_to_image.py
@@ -202,13 +199,13 @@ class TextToImage(ExamplesTestsAccelerate):
--random_flip
--train_batch_size 1
--gradient_accumulation_steps 1
- --max_train_steps 7
+ --max_train_steps 2
--learning_rate 5.0e-04
--scale_lr
--lr_scheduler constant
--lr_warmup_steps 0
--output_dir {tmpdir}
- --checkpointing_steps=2
+ --checkpointing_steps=1
--resume_from_checkpoint=checkpoint-4
--use_ema
--seed=0
@@ -218,16 +215,13 @@ class TextToImage(ExamplesTestsAccelerate):
# check can run new fully trained pipeline
pipe = DiffusionPipeline.from_pretrained(tmpdir, safety_checker=None)
- pipe(prompt, num_inference_steps=2)
+ pipe(prompt, num_inference_steps=1)
+ # no checkpoint-2 -> check old checkpoints do not exist
+ # check new checkpoints exist
self.assertEqual(
{x for x in os.listdir(tmpdir) if "checkpoint" in x},
- {
- # no checkpoint-2 -> check old checkpoints do not exist
- # check new checkpoints exist
- "checkpoint-4",
- "checkpoint-6",
- },
+ {"checkpoint-4", "checkpoint-5"},
)
def test_text_to_image_checkpointing_checkpoints_total_limit(self):
@@ -236,7 +230,7 @@ class TextToImage(ExamplesTestsAccelerate):
with tempfile.TemporaryDirectory() as tmpdir:
# Run training script with checkpointing
- # max_train_steps == 7, checkpointing_steps == 2, checkpoints_total_limit == 2
+ # max_train_steps == 6, checkpointing_steps == 2, checkpoints_total_limit == 2
# Should create checkpoints at steps 2, 4, 6
# with checkpoint at step 2 deleted
@@ -249,7 +243,7 @@ class TextToImage(ExamplesTestsAccelerate):
--random_flip
--train_batch_size 1
--gradient_accumulation_steps 1
- --max_train_steps 7
+ --max_train_steps 6
--learning_rate 5.0e-04
--scale_lr
--lr_scheduler constant
@@ -263,14 +257,11 @@ class TextToImage(ExamplesTestsAccelerate):
run_command(self._launch_args + initial_run_args)
pipe = DiffusionPipeline.from_pretrained(tmpdir, safety_checker=None)
- pipe(prompt, num_inference_steps=2)
+ pipe(prompt, num_inference_steps=1)
# check checkpoint directories exist
- self.assertEqual(
- {x for x in os.listdir(tmpdir) if "checkpoint" in x},
- # checkpoint-2 should have been deleted
- {"checkpoint-4", "checkpoint-6"},
- )
+ # checkpoint-2 should have been deleted
+ self.assertEqual({x for x in os.listdir(tmpdir) if "checkpoint" in x}, {"checkpoint-4", "checkpoint-6"})
def test_text_to_image_checkpointing_checkpoints_total_limit_removes_multiple_checkpoints(self):
pretrained_model_name_or_path = "hf-internal-testing/tiny-stable-diffusion-pipe"
@@ -278,8 +269,8 @@ class TextToImage(ExamplesTestsAccelerate):
with tempfile.TemporaryDirectory() as tmpdir:
# Run training script with checkpointing
- # max_train_steps == 9, checkpointing_steps == 2
- # Should create checkpoints at steps 2, 4, 6, 8
+ # max_train_steps == 4, checkpointing_steps == 2
+ # Should create checkpoints at steps 2, 4
initial_run_args = f"""
examples/text_to_image/train_text_to_image.py
@@ -290,7 +281,7 @@ class TextToImage(ExamplesTestsAccelerate):
--random_flip
--train_batch_size 1
--gradient_accumulation_steps 1
- --max_train_steps 9
+ --max_train_steps 4
--learning_rate 5.0e-04
--scale_lr
--lr_scheduler constant
@@ -303,15 +294,15 @@ class TextToImage(ExamplesTestsAccelerate):
run_command(self._launch_args + initial_run_args)
pipe = DiffusionPipeline.from_pretrained(tmpdir, safety_checker=None)
- pipe(prompt, num_inference_steps=2)
+ pipe(prompt, num_inference_steps=1)
# check checkpoint directories exist
self.assertEqual(
{x for x in os.listdir(tmpdir) if "checkpoint" in x},
- {"checkpoint-2", "checkpoint-4", "checkpoint-6", "checkpoint-8"},
+ {"checkpoint-2", "checkpoint-4"},
)
- # resume and we should try to checkpoint at 10, where we'll have to remove
+ # resume and we should try to checkpoint at 6, where we'll have to remove
# checkpoint-2 and checkpoint-4 instead of just a single previous checkpoint
resume_run_args = f"""
@@ -323,27 +314,27 @@ class TextToImage(ExamplesTestsAccelerate):
--random_flip
--train_batch_size 1
--gradient_accumulation_steps 1
- --max_train_steps 11
+ --max_train_steps 8
--learning_rate 5.0e-04
--scale_lr
--lr_scheduler constant
--lr_warmup_steps 0
--output_dir {tmpdir}
--checkpointing_steps=2
- --resume_from_checkpoint=checkpoint-8
- --checkpoints_total_limit=3
+ --resume_from_checkpoint=checkpoint-4
+ --checkpoints_total_limit=2
--seed=0
""".split()
run_command(self._launch_args + resume_run_args)
pipe = DiffusionPipeline.from_pretrained(tmpdir, safety_checker=None)
- pipe(prompt, num_inference_steps=2)
+ pipe(prompt, num_inference_steps=1)
# check checkpoint directories exist
self.assertEqual(
{x for x in os.listdir(tmpdir) if "checkpoint" in x},
- {"checkpoint-6", "checkpoint-8", "checkpoint-10"},
+ {"checkpoint-6", "checkpoint-8"},
)
diff --git a/examples/text_to_image/test_text_to_image_lora.py b/examples/text_to_image/test_text_to_image_lora.py
index 83cbb78b2d..4daee834d0 100644
--- a/examples/text_to_image/test_text_to_image_lora.py
+++ b/examples/text_to_image/test_text_to_image_lora.py
@@ -41,7 +41,7 @@ class TextToImageLoRA(ExamplesTestsAccelerate):
with tempfile.TemporaryDirectory() as tmpdir:
# Run training script with checkpointing
- # max_train_steps == 7, checkpointing_steps == 2, checkpoints_total_limit == 2
+ # max_train_steps == 6, checkpointing_steps == 2, checkpoints_total_limit == 2
# Should create checkpoints at steps 2, 4, 6
# with checkpoint at step 2 deleted
@@ -52,7 +52,7 @@ class TextToImageLoRA(ExamplesTestsAccelerate):
--resolution 64
--train_batch_size 1
--gradient_accumulation_steps 1
- --max_train_steps 7
+ --max_train_steps 6
--learning_rate 5.0e-04
--scale_lr
--lr_scheduler constant
@@ -66,14 +66,11 @@ class TextToImageLoRA(ExamplesTestsAccelerate):
pipe = DiffusionPipeline.from_pretrained(pipeline_path)
pipe.load_lora_weights(tmpdir)
- pipe(prompt, num_inference_steps=2)
+ pipe(prompt, num_inference_steps=1)
# check checkpoint directories exist
- self.assertEqual(
- {x for x in os.listdir(tmpdir) if "checkpoint" in x},
- # checkpoint-2 should have been deleted
- {"checkpoint-4", "checkpoint-6"},
- )
+ # checkpoint-2 should have been deleted
+ self.assertEqual({x for x in os.listdir(tmpdir) if "checkpoint" in x}, {"checkpoint-4", "checkpoint-6"})
def test_text_to_image_lora_checkpointing_checkpoints_total_limit(self):
pretrained_model_name_or_path = "hf-internal-testing/tiny-stable-diffusion-pipe"
@@ -81,7 +78,7 @@ class TextToImageLoRA(ExamplesTestsAccelerate):
with tempfile.TemporaryDirectory() as tmpdir:
# Run training script with checkpointing
- # max_train_steps == 7, checkpointing_steps == 2, checkpoints_total_limit == 2
+ # max_train_steps == 6, checkpointing_steps == 2, checkpoints_total_limit == 2
# Should create checkpoints at steps 2, 4, 6
# with checkpoint at step 2 deleted
@@ -94,7 +91,7 @@ class TextToImageLoRA(ExamplesTestsAccelerate):
--random_flip
--train_batch_size 1
--gradient_accumulation_steps 1
- --max_train_steps 7
+ --max_train_steps 6
--learning_rate 5.0e-04
--scale_lr
--lr_scheduler constant
@@ -112,14 +109,11 @@ class TextToImageLoRA(ExamplesTestsAccelerate):
"hf-internal-testing/tiny-stable-diffusion-pipe", safety_checker=None
)
pipe.load_lora_weights(tmpdir)
- pipe(prompt, num_inference_steps=2)
+ pipe(prompt, num_inference_steps=1)
# check checkpoint directories exist
- self.assertEqual(
- {x for x in os.listdir(tmpdir) if "checkpoint" in x},
- # checkpoint-2 should have been deleted
- {"checkpoint-4", "checkpoint-6"},
- )
+ # checkpoint-2 should have been deleted
+ self.assertEqual({x for x in os.listdir(tmpdir) if "checkpoint" in x}, {"checkpoint-4", "checkpoint-6"})
def test_text_to_image_lora_checkpointing_checkpoints_total_limit_removes_multiple_checkpoints(self):
pretrained_model_name_or_path = "hf-internal-testing/tiny-stable-diffusion-pipe"
@@ -127,8 +121,8 @@ class TextToImageLoRA(ExamplesTestsAccelerate):
with tempfile.TemporaryDirectory() as tmpdir:
# Run training script with checkpointing
- # max_train_steps == 9, checkpointing_steps == 2
- # Should create checkpoints at steps 2, 4, 6, 8
+ # max_train_steps == 4, checkpointing_steps == 2
+ # Should create checkpoints at steps 2, 4
initial_run_args = f"""
examples/text_to_image/train_text_to_image_lora.py
@@ -139,7 +133,7 @@ class TextToImageLoRA(ExamplesTestsAccelerate):
--random_flip
--train_batch_size 1
--gradient_accumulation_steps 1
- --max_train_steps 9
+ --max_train_steps 4
--learning_rate 5.0e-04
--scale_lr
--lr_scheduler constant
@@ -156,15 +150,15 @@ class TextToImageLoRA(ExamplesTestsAccelerate):
"hf-internal-testing/tiny-stable-diffusion-pipe", safety_checker=None
)
pipe.load_lora_weights(tmpdir)
- pipe(prompt, num_inference_steps=2)
+ pipe(prompt, num_inference_steps=1)
# check checkpoint directories exist
self.assertEqual(
{x for x in os.listdir(tmpdir) if "checkpoint" in x},
- {"checkpoint-2", "checkpoint-4", "checkpoint-6", "checkpoint-8"},
+ {"checkpoint-2", "checkpoint-4"},
)
- # resume and we should try to checkpoint at 10, where we'll have to remove
+ # resume and we should try to checkpoint at 6, where we'll have to remove
# checkpoint-2 and checkpoint-4 instead of just a single previous checkpoint
resume_run_args = f"""
@@ -176,15 +170,15 @@ class TextToImageLoRA(ExamplesTestsAccelerate):
--random_flip
--train_batch_size 1
--gradient_accumulation_steps 1
- --max_train_steps 11
+ --max_train_steps 8
--learning_rate 5.0e-04
--scale_lr
--lr_scheduler constant
--lr_warmup_steps 0
--output_dir {tmpdir}
--checkpointing_steps=2
- --resume_from_checkpoint=checkpoint-8
- --checkpoints_total_limit=3
+ --resume_from_checkpoint=checkpoint-4
+ --checkpoints_total_limit=2
--seed=0
--num_validation_images=0
""".split()
@@ -195,12 +189,12 @@ class TextToImageLoRA(ExamplesTestsAccelerate):
"hf-internal-testing/tiny-stable-diffusion-pipe", safety_checker=None
)
pipe.load_lora_weights(tmpdir)
- pipe(prompt, num_inference_steps=2)
+ pipe(prompt, num_inference_steps=1)
# check checkpoint directories exist
self.assertEqual(
{x for x in os.listdir(tmpdir) if "checkpoint" in x},
- {"checkpoint-6", "checkpoint-8", "checkpoint-10"},
+ {"checkpoint-6", "checkpoint-8"},
)
@@ -272,7 +266,7 @@ class TextToImageLoRASDXL(ExamplesTestsAccelerate):
with tempfile.TemporaryDirectory() as tmpdir:
# Run training script with checkpointing
- # max_train_steps == 7, checkpointing_steps == 2, checkpoints_total_limit == 2
+ # max_train_steps == 6, checkpointing_steps == 2, checkpoints_total_limit == 2
# Should create checkpoints at steps 2, 4, 6
# with checkpoint at step 2 deleted
@@ -283,7 +277,7 @@ class TextToImageLoRASDXL(ExamplesTestsAccelerate):
--resolution 64
--train_batch_size 1
--gradient_accumulation_steps 1
- --max_train_steps 7
+ --max_train_steps 6
--learning_rate 5.0e-04
--scale_lr
--lr_scheduler constant
@@ -298,11 +292,8 @@ class TextToImageLoRASDXL(ExamplesTestsAccelerate):
pipe = DiffusionPipeline.from_pretrained(pipeline_path)
pipe.load_lora_weights(tmpdir)
- pipe(prompt, num_inference_steps=2)
+ pipe(prompt, num_inference_steps=1)
# check checkpoint directories exist
- self.assertEqual(
- {x for x in os.listdir(tmpdir) if "checkpoint" in x},
- # checkpoint-2 should have been deleted
- {"checkpoint-4", "checkpoint-6"},
- )
+ # checkpoint-2 should have been deleted
+ self.assertEqual({x for x in os.listdir(tmpdir) if "checkpoint" in x}, {"checkpoint-4", "checkpoint-6"})
diff --git a/examples/text_to_image/train_text_to_image_lora.py b/examples/text_to_image/train_text_to_image_lora.py
index c8efbddd0b..2efbaf298d 100644
--- a/examples/text_to_image/train_text_to_image_lora.py
+++ b/examples/text_to_image/train_text_to_image_lora.py
@@ -452,7 +452,10 @@ def main():
param.requires_grad_(False)
unet_lora_config = LoraConfig(
- r=args.rank, init_lora_weights="gaussian", target_modules=["to_k", "to_q", "to_v", "to_out.0"]
+ r=args.rank,
+ lora_alpha=args.rank,
+ init_lora_weights="gaussian",
+ target_modules=["to_k", "to_q", "to_v", "to_out.0"],
)
# Move unet, vae and text_encoder to device and cast to weight_dtype
@@ -844,10 +847,11 @@ def main():
if args.seed is not None:
generator = generator.manual_seed(args.seed)
images = []
- for _ in range(args.num_validation_images):
- images.append(
- pipeline(args.validation_prompt, num_inference_steps=30, generator=generator).images[0]
- )
+ with torch.cuda.amp.autocast():
+ for _ in range(args.num_validation_images):
+ images.append(
+ pipeline(args.validation_prompt, num_inference_steps=30, generator=generator).images[0]
+ )
for tracker in accelerator.trackers:
if tracker.name == "tensorboard":
@@ -913,8 +917,11 @@ def main():
if args.seed is not None:
generator = generator.manual_seed(args.seed)
images = []
- for _ in range(args.num_validation_images):
- images.append(pipeline(args.validation_prompt, num_inference_steps=30, generator=generator).images[0])
+ with torch.cuda.amp.autocast():
+ for _ in range(args.num_validation_images):
+ images.append(
+ pipeline(args.validation_prompt, num_inference_steps=30, generator=generator).images[0]
+ )
for tracker in accelerator.trackers:
if len(images) != 0:
diff --git a/examples/text_to_image/train_text_to_image_lora_sdxl.py b/examples/text_to_image/train_text_to_image_lora_sdxl.py
index be17c13c28..d95fcbbba0 100644
--- a/examples/text_to_image/train_text_to_image_lora_sdxl.py
+++ b/examples/text_to_image/train_text_to_image_lora_sdxl.py
@@ -609,7 +609,10 @@ def main(args):
# now we will add new LoRA weights to the attention layers
# Set correct lora layers
unet_lora_config = LoraConfig(
- r=args.rank, init_lora_weights="gaussian", target_modules=["to_k", "to_q", "to_v", "to_out.0"]
+ r=args.rank,
+ lora_alpha=args.rank,
+ init_lora_weights="gaussian",
+ target_modules=["to_k", "to_q", "to_v", "to_out.0"],
)
unet.add_adapter(unet_lora_config)
@@ -618,7 +621,10 @@ def main(args):
if args.train_text_encoder:
# ensure that dtype is float32, even if rest of the model that isn't trained is loaded in fp16
text_lora_config = LoraConfig(
- r=args.rank, init_lora_weights="gaussian", target_modules=["q_proj", "k_proj", "v_proj", "out_proj"]
+ r=args.rank,
+ lora_alpha=args.rank,
+ init_lora_weights="gaussian",
+ target_modules=["q_proj", "k_proj", "v_proj", "out_proj"],
)
text_encoder_one.add_adapter(text_lora_config)
text_encoder_two.add_adapter(text_lora_config)
diff --git a/examples/textual_inversion/test_textual_inversion.py b/examples/textual_inversion/test_textual_inversion.py
index a5d7bcb65d..ba9cabd9aa 100644
--- a/examples/textual_inversion/test_textual_inversion.py
+++ b/examples/textual_inversion/test_textual_inversion.py
@@ -40,8 +40,6 @@ class TextualInversion(ExamplesTestsAccelerate):
--learnable_property object
--placeholder_token
--initializer_token a
- --validation_prompt
- --validation_steps 1
--save_steps 1
--num_vectors 2
--resolution 64
@@ -68,8 +66,6 @@ class TextualInversion(ExamplesTestsAccelerate):
--learnable_property object
--placeholder_token
--initializer_token a
- --validation_prompt
- --validation_steps 1
--save_steps 1
--num_vectors 2
--resolution 64
@@ -102,14 +98,12 @@ class TextualInversion(ExamplesTestsAccelerate):
--learnable_property object
--placeholder_token
--initializer_token a
- --validation_prompt
- --validation_steps 1
--save_steps 1
--num_vectors 2
--resolution 64
--train_batch_size 1
--gradient_accumulation_steps 1
- --max_train_steps 3
+ --max_train_steps 2
--learning_rate 5.0e-04
--scale_lr
--lr_scheduler constant
@@ -123,7 +117,7 @@ class TextualInversion(ExamplesTestsAccelerate):
# check checkpoint directories exist
self.assertEqual(
{x for x in os.listdir(tmpdir) if "checkpoint" in x},
- {"checkpoint-1", "checkpoint-2", "checkpoint-3"},
+ {"checkpoint-1", "checkpoint-2"},
)
resume_run_args = f"""
@@ -133,21 +127,19 @@ class TextualInversion(ExamplesTestsAccelerate):
--learnable_property object
--placeholder_token
--initializer_token a
- --validation_prompt
- --validation_steps 1
--save_steps 1
--num_vectors 2
--resolution 64
--train_batch_size 1
--gradient_accumulation_steps 1
- --max_train_steps 4
+ --max_train_steps 2
--learning_rate 5.0e-04
--scale_lr
--lr_scheduler constant
--lr_warmup_steps 0
--output_dir {tmpdir}
--checkpointing_steps=1
- --resume_from_checkpoint=checkpoint-3
+ --resume_from_checkpoint=checkpoint-2
--checkpoints_total_limit=2
""".split()
@@ -156,5 +148,5 @@ class TextualInversion(ExamplesTestsAccelerate):
# check checkpoint directories exist
self.assertEqual(
{x for x in os.listdir(tmpdir) if "checkpoint" in x},
- {"checkpoint-3", "checkpoint-4"},
+ {"checkpoint-2", "checkpoint-3"},
)
diff --git a/examples/unconditional_image_generation/test_unconditional.py b/examples/unconditional_image_generation/test_unconditional.py
index b7e19abe9f..49e11f33d4 100644
--- a/examples/unconditional_image_generation/test_unconditional.py
+++ b/examples/unconditional_image_generation/test_unconditional.py
@@ -90,10 +90,10 @@ class Unconditional(ExamplesTestsAccelerate):
--train_batch_size 1
--num_epochs 1
--gradient_accumulation_steps 1
- --ddpm_num_inference_steps 2
+ --ddpm_num_inference_steps 1
--learning_rate 1e-3
--lr_warmup_steps 5
- --checkpointing_steps=1
+ --checkpointing_steps=2
""".split()
run_command(self._launch_args + initial_run_args)
@@ -101,7 +101,7 @@ class Unconditional(ExamplesTestsAccelerate):
# check checkpoint directories exist
self.assertEqual(
{x for x in os.listdir(tmpdir) if "checkpoint" in x},
- {"checkpoint-1", "checkpoint-2", "checkpoint-3", "checkpoint-4", "checkpoint-5", "checkpoint-6"},
+ {"checkpoint-2", "checkpoint-4", "checkpoint-6"},
)
resume_run_args = f"""
@@ -113,12 +113,12 @@ class Unconditional(ExamplesTestsAccelerate):
--train_batch_size 1
--num_epochs 2
--gradient_accumulation_steps 1
- --ddpm_num_inference_steps 2
+ --ddpm_num_inference_steps 1
--learning_rate 1e-3
--lr_warmup_steps 5
--resume_from_checkpoint=checkpoint-6
--checkpointing_steps=2
- --checkpoints_total_limit=3
+ --checkpoints_total_limit=2
""".split()
run_command(self._launch_args + resume_run_args)
@@ -126,5 +126,5 @@ class Unconditional(ExamplesTestsAccelerate):
# check checkpoint directories exist
self.assertEqual(
{x for x in os.listdir(tmpdir) if "checkpoint" in x},
- {"checkpoint-8", "checkpoint-10", "checkpoint-12"},
+ {"checkpoint-10", "checkpoint-12"},
)
diff --git a/examples/wuerstchen/text_to_image/train_text_to_image_lora_prior.py b/examples/wuerstchen/text_to_image/train_text_to_image_lora_prior.py
index 1e67f05abe..f1f6b32152 100644
--- a/examples/wuerstchen/text_to_image/train_text_to_image_lora_prior.py
+++ b/examples/wuerstchen/text_to_image/train_text_to_image_lora_prior.py
@@ -527,9 +527,17 @@ def main():
# lora attn processor
prior_lora_config = LoraConfig(
- r=args.rank, target_modules=["to_k", "to_q", "to_v", "to_out.0", "add_k_proj", "add_v_proj"]
+ r=args.rank,
+ lora_alpha=args.rank,
+ target_modules=["to_k", "to_q", "to_v", "to_out.0", "add_k_proj", "add_v_proj"],
)
+ # Add adapter and make sure the trainable params are in float32.
prior.add_adapter(prior_lora_config)
+ if args.mixed_precision == "fp16":
+ for param in prior.parameters():
+ # only upcast trainable parameters (LoRA) into fp32
+ if param.requires_grad:
+ param.data = param.to(torch.float32)
# create custom saving & loading hooks so that `accelerator.save_state(...)` serializes in a nice format
def save_model_hook(models, weights, output_dir):
diff --git a/scripts/convert_animatediff_motion_lora_to_diffusers.py b/scripts/convert_animatediff_motion_lora_to_diffusers.py
new file mode 100644
index 0000000000..509a734579
--- /dev/null
+++ b/scripts/convert_animatediff_motion_lora_to_diffusers.py
@@ -0,0 +1,51 @@
+import argparse
+
+import torch
+from safetensors.torch import save_file
+
+
+def convert_motion_module(original_state_dict):
+ converted_state_dict = {}
+ for k, v in original_state_dict.items():
+ if "pos_encoder" in k:
+ continue
+
+ else:
+ converted_state_dict[
+ k.replace(".norms.0", ".norm1")
+ .replace(".norms.1", ".norm2")
+ .replace(".ff_norm", ".norm3")
+ .replace(".attention_blocks.0", ".attn1")
+ .replace(".attention_blocks.1", ".attn2")
+ .replace(".temporal_transformer", "")
+ ] = v
+
+ return converted_state_dict
+
+
+def get_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--ckpt_path", type=str, required=True)
+ parser.add_argument("--output_path", type=str, required=True)
+
+ return parser.parse_args()
+
+
+if __name__ == "__main__":
+ args = get_args()
+
+ state_dict = torch.load(args.ckpt_path, map_location="cpu")
+
+ if "state_dict" in state_dict.keys():
+ state_dict = state_dict["state_dict"]
+
+ conv_state_dict = convert_motion_module(state_dict)
+
+ # convert to new format
+ output_dict = {}
+ for module_name, params in conv_state_dict.items():
+ if type(params) is not torch.Tensor:
+ continue
+ output_dict.update({f"unet.{module_name}": params})
+
+ save_file(output_dict, f"{args.output_path}/diffusion_pytorch_model.safetensors")
diff --git a/scripts/convert_animatediff_motion_module_to_diffusers.py b/scripts/convert_animatediff_motion_module_to_diffusers.py
new file mode 100644
index 0000000000..9c5d236fd7
--- /dev/null
+++ b/scripts/convert_animatediff_motion_module_to_diffusers.py
@@ -0,0 +1,51 @@
+import argparse
+
+import torch
+
+from diffusers import MotionAdapter
+
+
+def convert_motion_module(original_state_dict):
+ converted_state_dict = {}
+ for k, v in original_state_dict.items():
+ if "pos_encoder" in k:
+ continue
+
+ else:
+ converted_state_dict[
+ k.replace(".norms.0", ".norm1")
+ .replace(".norms.1", ".norm2")
+ .replace(".ff_norm", ".norm3")
+ .replace(".attention_blocks.0", ".attn1")
+ .replace(".attention_blocks.1", ".attn2")
+ .replace(".temporal_transformer", "")
+ ] = v
+
+ return converted_state_dict
+
+
+def get_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--ckpt_path", type=str, required=True)
+ parser.add_argument("--output_path", type=str, required=True)
+ parser.add_argument("--use_motion_mid_block", action="store_true")
+ parser.add_argument("--motion_max_seq_length", type=int, default=32)
+
+ return parser.parse_args()
+
+
+if __name__ == "__main__":
+ args = get_args()
+
+ state_dict = torch.load(args.ckpt_path, map_location="cpu")
+ if "state_dict" in state_dict.keys():
+ state_dict = state_dict["state_dict"]
+
+ conv_state_dict = convert_motion_module(state_dict)
+ adapter = MotionAdapter(
+ use_motion_mid_block=args.use_motion_mid_block, motion_max_seq_length=args.motion_max_seq_length
+ )
+ # skip loading position embeddings
+ adapter.load_state_dict(conv_state_dict, strict=False)
+ adapter.save_pretrained(args.output_path)
+ adapter.save_pretrained(args.output_path, variant="fp16", torch_dtype=torch.float16)
diff --git a/src/diffusers/__init__.py b/src/diffusers/__init__.py
index 10c5b0f465..180b210953 100644
--- a/src/diffusers/__init__.py
+++ b/src/diffusers/__init__.py
@@ -80,7 +80,6 @@ else:
"AutoencoderTiny",
"ConsistencyDecoderVAE",
"ControlNetModel",
- "ControlNetXSModel",
"Kandinsky3UNet",
"ModelMixin",
"MotionAdapter",
@@ -256,7 +255,6 @@ else:
"StableDiffusionControlNetImg2ImgPipeline",
"StableDiffusionControlNetInpaintPipeline",
"StableDiffusionControlNetPipeline",
- "StableDiffusionControlNetXSPipeline",
"StableDiffusionDepth2ImgPipeline",
"StableDiffusionDiffEditPipeline",
"StableDiffusionGLIGENPipeline",
@@ -280,7 +278,6 @@ else:
"StableDiffusionXLControlNetImg2ImgPipeline",
"StableDiffusionXLControlNetInpaintPipeline",
"StableDiffusionXLControlNetPipeline",
- "StableDiffusionXLControlNetXSPipeline",
"StableDiffusionXLImg2ImgPipeline",
"StableDiffusionXLInpaintPipeline",
"StableDiffusionXLInstructPix2PixPipeline",
@@ -462,7 +459,6 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
AutoencoderTiny,
ConsistencyDecoderVAE,
ControlNetModel,
- ControlNetXSModel,
Kandinsky3UNet,
ModelMixin,
MotionAdapter,
@@ -617,7 +613,6 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
StableDiffusionControlNetImg2ImgPipeline,
StableDiffusionControlNetInpaintPipeline,
StableDiffusionControlNetPipeline,
- StableDiffusionControlNetXSPipeline,
StableDiffusionDepth2ImgPipeline,
StableDiffusionDiffEditPipeline,
StableDiffusionGLIGENPipeline,
@@ -641,7 +636,6 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
StableDiffusionXLControlNetImg2ImgPipeline,
StableDiffusionXLControlNetInpaintPipeline,
StableDiffusionXLControlNetPipeline,
- StableDiffusionXLControlNetXSPipeline,
StableDiffusionXLImg2ImgPipeline,
StableDiffusionXLInpaintPipeline,
StableDiffusionXLInstructPix2PixPipeline,
diff --git a/src/diffusers/image_processor.py b/src/diffusers/image_processor.py
index ab96384fe9..447440f07c 100644
--- a/src/diffusers/image_processor.py
+++ b/src/diffusers/image_processor.py
@@ -18,7 +18,7 @@ from typing import List, Optional, Tuple, Union
import numpy as np
import PIL.Image
import torch
-from PIL import Image
+from PIL import Image, ImageFilter, ImageOps
from .configuration_utils import ConfigMixin, register_to_config
from .utils import CONFIG_NAME, PIL_INTERPOLATION, deprecate
@@ -166,6 +166,244 @@ class VaeImageProcessor(ConfigMixin):
return image
+ @staticmethod
+ def blur(image: PIL.Image.Image, blur_factor: int = 4) -> PIL.Image.Image:
+ """
+ Blurs an image.
+ """
+ image = image.filter(ImageFilter.GaussianBlur(blur_factor))
+
+ return image
+
+ @staticmethod
+ def get_crop_region(mask_image: PIL.Image.Image, width: int, height: int, pad=0):
+ """
+ Finds a rectangular region that contains all masked ares in an image, and expands region to match the aspect ratio of the original image;
+ for example, if user drew mask in a 128x32 region, and the dimensions for processing are 512x512, the region will be expanded to 128x128.
+
+ Args:
+ mask_image (PIL.Image.Image): Mask image.
+ width (int): Width of the image to be processed.
+ height (int): Height of the image to be processed.
+ pad (int, optional): Padding to be added to the crop region. Defaults to 0.
+
+ Returns:
+ tuple: (x1, y1, x2, y2) represent a rectangular region that contains all masked ares in an image and matches the original aspect ratio.
+ """
+
+ mask_image = mask_image.convert("L")
+ mask = np.array(mask_image)
+
+ # 1. find a rectangular region that contains all masked ares in an image
+ h, w = mask.shape
+ crop_left = 0
+ for i in range(w):
+ if not (mask[:, i] == 0).all():
+ break
+ crop_left += 1
+
+ crop_right = 0
+ for i in reversed(range(w)):
+ if not (mask[:, i] == 0).all():
+ break
+ crop_right += 1
+
+ crop_top = 0
+ for i in range(h):
+ if not (mask[i] == 0).all():
+ break
+ crop_top += 1
+
+ crop_bottom = 0
+ for i in reversed(range(h)):
+ if not (mask[i] == 0).all():
+ break
+ crop_bottom += 1
+
+ # 2. add padding to the crop region
+ x1, y1, x2, y2 = (
+ int(max(crop_left - pad, 0)),
+ int(max(crop_top - pad, 0)),
+ int(min(w - crop_right + pad, w)),
+ int(min(h - crop_bottom + pad, h)),
+ )
+
+ # 3. expands crop region to match the aspect ratio of the image to be processed
+ ratio_crop_region = (x2 - x1) / (y2 - y1)
+ ratio_processing = width / height
+
+ if ratio_crop_region > ratio_processing:
+ desired_height = (x2 - x1) / ratio_processing
+ desired_height_diff = int(desired_height - (y2 - y1))
+ y1 -= desired_height_diff // 2
+ y2 += desired_height_diff - desired_height_diff // 2
+ if y2 >= mask_image.height:
+ diff = y2 - mask_image.height
+ y2 -= diff
+ y1 -= diff
+ if y1 < 0:
+ y2 -= y1
+ y1 -= y1
+ if y2 >= mask_image.height:
+ y2 = mask_image.height
+ else:
+ desired_width = (y2 - y1) * ratio_processing
+ desired_width_diff = int(desired_width - (x2 - x1))
+ x1 -= desired_width_diff // 2
+ x2 += desired_width_diff - desired_width_diff // 2
+ if x2 >= mask_image.width:
+ diff = x2 - mask_image.width
+ x2 -= diff
+ x1 -= diff
+ if x1 < 0:
+ x2 -= x1
+ x1 -= x1
+ if x2 >= mask_image.width:
+ x2 = mask_image.width
+
+ return x1, y1, x2, y2
+
+ def _resize_and_fill(
+ self,
+ image: PIL.Image.Image,
+ width: int,
+ height: int,
+ ) -> PIL.Image.Image:
+ """
+ Resize the image to fit within the specified width and height, maintaining the aspect ratio, and then center the image within the dimensions, filling empty with data from image.
+
+ Args:
+ image: The image to resize.
+ width: The width to resize the image to.
+ height: The height to resize the image to.
+ """
+
+ ratio = width / height
+ src_ratio = image.width / image.height
+
+ src_w = width if ratio < src_ratio else image.width * height // image.height
+ src_h = height if ratio >= src_ratio else image.height * width // image.width
+
+ resized = image.resize((src_w, src_h), resample=PIL_INTERPOLATION["lanczos"])
+ res = Image.new("RGB", (width, height))
+ res.paste(resized, box=(width // 2 - src_w // 2, height // 2 - src_h // 2))
+
+ if ratio < src_ratio:
+ fill_height = height // 2 - src_h // 2
+ if fill_height > 0:
+ res.paste(resized.resize((width, fill_height), box=(0, 0, width, 0)), box=(0, 0))
+ res.paste(
+ resized.resize((width, fill_height), box=(0, resized.height, width, resized.height)),
+ box=(0, fill_height + src_h),
+ )
+ elif ratio > src_ratio:
+ fill_width = width // 2 - src_w // 2
+ if fill_width > 0:
+ res.paste(resized.resize((fill_width, height), box=(0, 0, 0, height)), box=(0, 0))
+ res.paste(
+ resized.resize((fill_width, height), box=(resized.width, 0, resized.width, height)),
+ box=(fill_width + src_w, 0),
+ )
+
+ return res
+
+ def _resize_and_crop(
+ self,
+ image: PIL.Image.Image,
+ width: int,
+ height: int,
+ ) -> PIL.Image.Image:
+ """
+ Resize the image to fit within the specified width and height, maintaining the aspect ratio, and then center the image within the dimensions, cropping the excess.
+
+ Args:
+ image: The image to resize.
+ width: The width to resize the image to.
+ height: The height to resize the image to.
+ """
+ ratio = width / height
+ src_ratio = image.width / image.height
+
+ src_w = width if ratio > src_ratio else image.width * height // image.height
+ src_h = height if ratio <= src_ratio else image.height * width // image.width
+
+ resized = image.resize((src_w, src_h), resample=PIL_INTERPOLATION["lanczos"])
+ res = Image.new("RGB", (width, height))
+ res.paste(resized, box=(width // 2 - src_w // 2, height // 2 - src_h // 2))
+ return res
+
+ def resize(
+ self,
+ image: Union[PIL.Image.Image, np.ndarray, torch.Tensor],
+ height: int,
+ width: int,
+ resize_mode: str = "default", # "defalt", "fill", "crop"
+ ) -> Union[PIL.Image.Image, np.ndarray, torch.Tensor]:
+ """
+ Resize image.
+
+ Args:
+ image (`PIL.Image.Image`, `np.ndarray` or `torch.Tensor`):
+ The image input, can be a PIL image, numpy array or pytorch tensor.
+ height (`int`):
+ The height to resize to.
+ width (`int`):
+ The width to resize to.
+ resize_mode (`str`, *optional*, defaults to `default`):
+ The resize mode to use, can be one of `default` or `fill`. If `default`, will resize the image to fit
+ within the specified width and height, and it may not maintaining the original aspect ratio.
+ If `fill`, will resize the image to fit within the specified width and height, maintaining the aspect ratio, and then center the image
+ within the dimensions, filling empty with data from image.
+ If `crop`, will resize the image to fit within the specified width and height, maintaining the aspect ratio, and then center the image
+ within the dimensions, cropping the excess.
+ Note that resize_mode `fill` and `crop` are only supported for PIL image input.
+
+ Returns:
+ `PIL.Image.Image`, `np.ndarray` or `torch.Tensor`:
+ The resized image.
+ """
+ if resize_mode != "default" and not isinstance(image, PIL.Image.Image):
+ raise ValueError(f"Only PIL image input is supported for resize_mode {resize_mode}")
+ if isinstance(image, PIL.Image.Image):
+ if resize_mode == "default":
+ image = image.resize((width, height), resample=PIL_INTERPOLATION[self.config.resample])
+ elif resize_mode == "fill":
+ image = self._resize_and_fill(image, width, height)
+ elif resize_mode == "crop":
+ image = self._resize_and_crop(image, width, height)
+ else:
+ raise ValueError(f"resize_mode {resize_mode} is not supported")
+
+ elif isinstance(image, torch.Tensor):
+ image = torch.nn.functional.interpolate(
+ image,
+ size=(height, width),
+ )
+ elif isinstance(image, np.ndarray):
+ image = self.numpy_to_pt(image)
+ image = torch.nn.functional.interpolate(
+ image,
+ size=(height, width),
+ )
+ image = self.pt_to_numpy(image)
+ return image
+
+ def binarize(self, image: PIL.Image.Image) -> PIL.Image.Image:
+ """
+ Create a mask.
+
+ Args:
+ image (`PIL.Image.Image`):
+ The image input, should be a PIL image.
+
+ Returns:
+ `PIL.Image.Image`:
+ The binarized image. Values less than 0.5 are set to 0, values greater than 0.5 are set to 1.
+ """
+ image[image < 0.5] = 0
+ image[image >= 0.5] = 1
+ return image
+
def get_default_height_width(
self,
image: Union[PIL.Image.Image, np.ndarray, torch.Tensor],
@@ -209,67 +447,34 @@ class VaeImageProcessor(ConfigMixin):
return height, width
- def resize(
- self,
- image: Union[PIL.Image.Image, np.ndarray, torch.Tensor],
- height: Optional[int] = None,
- width: Optional[int] = None,
- ) -> Union[PIL.Image.Image, np.ndarray, torch.Tensor]:
- """
- Resize image.
-
- Args:
- image (`PIL.Image.Image`, `np.ndarray` or `torch.Tensor`):
- The image input, can be a PIL image, numpy array or pytorch tensor.
- height (`int`, *optional*, defaults to `None`):
- The height to resize to.
- width (`int`, *optional*`, defaults to `None`):
- The width to resize to.
-
- Returns:
- `PIL.Image.Image`, `np.ndarray` or `torch.Tensor`:
- The resized image.
- """
- if isinstance(image, PIL.Image.Image):
- image = image.resize((width, height), resample=PIL_INTERPOLATION[self.config.resample])
- elif isinstance(image, torch.Tensor):
- image = torch.nn.functional.interpolate(
- image,
- size=(height, width),
- )
- elif isinstance(image, np.ndarray):
- image = self.numpy_to_pt(image)
- image = torch.nn.functional.interpolate(
- image,
- size=(height, width),
- )
- image = self.pt_to_numpy(image)
- return image
-
- def binarize(self, image: PIL.Image.Image) -> PIL.Image.Image:
- """
- Create a mask.
-
- Args:
- image (`PIL.Image.Image`):
- The image input, should be a PIL image.
-
- Returns:
- `PIL.Image.Image`:
- The binarized image. Values less than 0.5 are set to 0, values greater than 0.5 are set to 1.
- """
- image[image < 0.5] = 0
- image[image >= 0.5] = 1
- return image
-
def preprocess(
self,
- image: Union[torch.FloatTensor, PIL.Image.Image, np.ndarray],
+ image: PipelineImageInput,
height: Optional[int] = None,
width: Optional[int] = None,
+ resize_mode: str = "default", # "defalt", "fill", "crop"
+ crops_coords: Optional[Tuple[int, int, int, int]] = None,
) -> torch.Tensor:
"""
- Preprocess the image input. Accepted formats are PIL images, NumPy arrays or PyTorch tensors.
+ Preprocess the image input.
+
+ Args:
+ image (`pipeline_image_input`):
+ The image input, accepted formats are PIL images, NumPy arrays, PyTorch tensors; Also accept list of supported formats.
+ height (`int`, *optional*, defaults to `None`):
+ The height in preprocessed image. If `None`, will use the `get_default_height_width()` to get default height.
+ width (`int`, *optional*`, defaults to `None`):
+ The width in preprocessed. If `None`, will use get_default_height_width()` to get the default width.
+ resize_mode (`str`, *optional*, defaults to `default`):
+ The resize mode, can be one of `default` or `fill`. If `default`, will resize the image to fit
+ within the specified width and height, and it may not maintaining the original aspect ratio.
+ If `fill`, will resize the image to fit within the specified width and height, maintaining the aspect ratio, and then center the image
+ within the dimensions, filling empty with data from image.
+ If `crop`, will resize the image to fit within the specified width and height, maintaining the aspect ratio, and then center the image
+ within the dimensions, cropping the excess.
+ Note that resize_mode `fill` and `crop` are only supported for PIL image input.
+ crops_coords (`List[Tuple[int, int, int, int]]`, *optional*, defaults to `None`):
+ The crop coordinates for each image in the batch. If `None`, will not crop the image.
"""
supported_formats = (PIL.Image.Image, np.ndarray, torch.Tensor)
@@ -299,13 +504,15 @@ class VaeImageProcessor(ConfigMixin):
)
if isinstance(image[0], PIL.Image.Image):
+ if crops_coords is not None:
+ image = [i.crop(crops_coords) for i in image]
+ if self.config.do_resize:
+ height, width = self.get_default_height_width(image[0], height, width)
+ image = [self.resize(i, height, width, resize_mode=resize_mode) for i in image]
if self.config.do_convert_rgb:
image = [self.convert_to_rgb(i) for i in image]
elif self.config.do_convert_grayscale:
image = [self.convert_to_grayscale(i) for i in image]
- if self.config.do_resize:
- height, width = self.get_default_height_width(image[0], height, width)
- image = [self.resize(i, height, width) for i in image]
image = self.pil_to_numpy(image) # to np
image = self.numpy_to_pt(image) # to pt
@@ -406,6 +613,39 @@ class VaeImageProcessor(ConfigMixin):
if output_type == "pil":
return self.numpy_to_pil(image)
+ def apply_overlay(
+ self,
+ mask: PIL.Image.Image,
+ init_image: PIL.Image.Image,
+ image: PIL.Image.Image,
+ crop_coords: Optional[Tuple[int, int, int, int]] = None,
+ ) -> PIL.Image.Image:
+ """
+ overlay the inpaint output to the original image
+ """
+
+ width, height = image.width, image.height
+
+ init_image = self.resize(init_image, width=width, height=height)
+ mask = self.resize(mask, width=width, height=height)
+
+ init_image_masked = PIL.Image.new("RGBa", (width, height))
+ init_image_masked.paste(init_image.convert("RGBA").convert("RGBa"), mask=ImageOps.invert(mask.convert("L")))
+ init_image_masked = init_image_masked.convert("RGBA")
+
+ if crop_coords is not None:
+ x, y, w, h = crop_coords
+ base_image = PIL.Image.new("RGBA", (width, height))
+ image = self.resize(image, height=h, width=w, resize_mode="crop")
+ base_image.paste(image, (x, y))
+ image = base_image.convert("RGB")
+
+ image = image.convert("RGBA")
+ image.alpha_composite(init_image_masked)
+ image = image.convert("RGB")
+
+ return image
+
class VaeImageProcessorLDM3D(VaeImageProcessor):
"""
diff --git a/src/diffusers/loaders/ip_adapter.py b/src/diffusers/loaders/ip_adapter.py
index 158bde4363..3df0492380 100644
--- a/src/diffusers/loaders/ip_adapter.py
+++ b/src/diffusers/loaders/ip_adapter.py
@@ -149,9 +149,11 @@ class IPAdapterMixin:
self.feature_extractor = CLIPImageProcessor()
# load ip-adapter into unet
- self.unet._load_ip_adapter_weights(state_dict)
+ unet = getattr(self, self.unet_name) if not hasattr(self, "unet") else self.unet
+ unet._load_ip_adapter_weights(state_dict)
def set_ip_adapter_scale(self, scale):
- for attn_processor in self.unet.attn_processors.values():
+ unet = getattr(self, self.unet_name) if not hasattr(self, "unet") else self.unet
+ for attn_processor in unet.attn_processors.values():
if isinstance(attn_processor, (IPAdapterAttnProcessor, IPAdapterAttnProcessor2_0)):
attn_processor.scale = scale
diff --git a/src/diffusers/loaders/lora.py b/src/diffusers/loaders/lora.py
index fc50c52e41..bbd01a9950 100644
--- a/src/diffusers/loaders/lora.py
+++ b/src/diffusers/loaders/lora.py
@@ -11,6 +11,7 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
+import inspect
import os
from contextlib import nullcontext
from typing import Callable, Dict, List, Optional, Union
@@ -912,10 +913,10 @@ class LoraLoaderMixin:
)
if unet_lora_layers:
- state_dict.update(pack_weights(unet_lora_layers, "unet"))
+ state_dict.update(pack_weights(unet_lora_layers, cls.unet_name))
if text_encoder_lora_layers:
- state_dict.update(pack_weights(text_encoder_lora_layers, "text_encoder"))
+ state_dict.update(pack_weights(text_encoder_lora_layers, cls.text_encoder_name))
if transformer_lora_layers:
state_dict.update(pack_weights(transformer_lora_layers, "transformer"))
@@ -975,6 +976,8 @@ class LoraLoaderMixin:
>>> ...
```
"""
+ unet = getattr(self, self.unet_name) if not hasattr(self, "unet") else self.unet
+
if not USE_PEFT_BACKEND:
if version.parse(__version__) > version.parse("0.23"):
logger.warn(
@@ -982,13 +985,13 @@ class LoraLoaderMixin:
"you can use `pipe.enable_lora()` or `pipe.disable_lora()`. After installing the latest version of PEFT."
)
- for _, module in self.unet.named_modules():
+ for _, module in unet.named_modules():
if hasattr(module, "set_lora_layer"):
module.set_lora_layer(None)
else:
- recurse_remove_peft_layers(self.unet)
- if hasattr(self.unet, "peft_config"):
- del self.unet.peft_config
+ recurse_remove_peft_layers(unet)
+ if hasattr(unet, "peft_config"):
+ del unet.peft_config
# Safe to call the following regardless of LoRA.
self._remove_text_encoder_monkey_patch()
@@ -999,6 +1002,7 @@ class LoraLoaderMixin:
fuse_text_encoder: bool = True,
lora_scale: float = 1.0,
safe_fusing: bool = False,
+ adapter_names: Optional[List[str]] = None,
):
r"""
Fuses the LoRA parameters into the original parameters of the corresponding blocks.
@@ -1018,6 +1022,21 @@ class LoraLoaderMixin:
Controls how much to influence the outputs with the LoRA parameters.
safe_fusing (`bool`, defaults to `False`):
Whether to check fused weights for NaN values before fusing and if values are NaN not fusing them.
+ adapter_names (`List[str]`, *optional*):
+ Adapter names to be used for fusing. If nothing is passed, all active adapters will be fused.
+
+ Example:
+
+ ```py
+ from diffusers import DiffusionPipeline
+ import torch
+
+ pipeline = DiffusionPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16
+ ).to("cuda")
+ pipeline.load_lora_weights("nerijs/pixel-art-xl", weight_name="pixel-art-xl.safetensors", adapter_name="pixel")
+ pipeline.fuse_lora(lora_scale=0.7)
+ ```
"""
if fuse_unet or fuse_text_encoder:
self.num_fused_loras += 1
@@ -1027,24 +1046,44 @@ class LoraLoaderMixin:
)
if fuse_unet:
- self.unet.fuse_lora(lora_scale, safe_fusing=safe_fusing)
+ unet = getattr(self, self.unet_name) if not hasattr(self, "unet") else self.unet
+ unet.fuse_lora(lora_scale, safe_fusing=safe_fusing, adapter_names=adapter_names)
if USE_PEFT_BACKEND:
from peft.tuners.tuners_utils import BaseTunerLayer
- def fuse_text_encoder_lora(text_encoder, lora_scale=1.0, safe_fusing=False):
- # TODO(Patrick, Younes): enable "safe" fusing
+ def fuse_text_encoder_lora(text_encoder, lora_scale=1.0, safe_fusing=False, adapter_names=None):
+ merge_kwargs = {"safe_merge": safe_fusing}
+
for module in text_encoder.modules():
if isinstance(module, BaseTunerLayer):
if lora_scale != 1.0:
module.scale_layer(lora_scale)
- module.merge()
+ # For BC with previous PEFT versions, we need to check the signature
+ # of the `merge` method to see if it supports the `adapter_names` argument.
+ supported_merge_kwargs = list(inspect.signature(module.merge).parameters)
+ if "adapter_names" in supported_merge_kwargs:
+ merge_kwargs["adapter_names"] = adapter_names
+ elif "adapter_names" not in supported_merge_kwargs and adapter_names is not None:
+ raise ValueError(
+ "The `adapter_names` argument is not supported with your PEFT version. "
+ "Please upgrade to the latest version of PEFT. `pip install -U peft`"
+ )
+
+ module.merge(**merge_kwargs)
else:
deprecate("fuse_text_encoder_lora", "0.27", LORA_DEPRECATION_MESSAGE)
- def fuse_text_encoder_lora(text_encoder, lora_scale=1.0, safe_fusing=False):
+ def fuse_text_encoder_lora(text_encoder, lora_scale=1.0, safe_fusing=False, **kwargs):
+ if "adapter_names" in kwargs and kwargs["adapter_names"] is not None:
+ raise ValueError(
+ "The `adapter_names` argument is not supported in your environment. Please switch to PEFT "
+ "backend to use this argument by installing latest PEFT and transformers."
+ " `pip install -U peft transformers`"
+ )
+
for _, attn_module in text_encoder_attn_modules(text_encoder):
if isinstance(attn_module.q_proj, PatchedLoraProjection):
attn_module.q_proj._fuse_lora(lora_scale, safe_fusing)
@@ -1059,9 +1098,9 @@ class LoraLoaderMixin:
if fuse_text_encoder:
if hasattr(self, "text_encoder"):
- fuse_text_encoder_lora(self.text_encoder, lora_scale, safe_fusing)
+ fuse_text_encoder_lora(self.text_encoder, lora_scale, safe_fusing, adapter_names=adapter_names)
if hasattr(self, "text_encoder_2"):
- fuse_text_encoder_lora(self.text_encoder_2, lora_scale, safe_fusing)
+ fuse_text_encoder_lora(self.text_encoder_2, lora_scale, safe_fusing, adapter_names=adapter_names)
def unfuse_lora(self, unfuse_unet: bool = True, unfuse_text_encoder: bool = True):
r"""
@@ -1080,13 +1119,14 @@ class LoraLoaderMixin:
Whether to unfuse the text encoder LoRA parameters. If the text encoder wasn't monkey-patched with the
LoRA parameters then it won't have any effect.
"""
+ unet = getattr(self, self.unet_name) if not hasattr(self, "unet") else self.unet
if unfuse_unet:
if not USE_PEFT_BACKEND:
- self.unet.unfuse_lora()
+ unet.unfuse_lora()
else:
from peft.tuners.tuners_utils import BaseTunerLayer
- for module in self.unet.modules():
+ for module in unet.modules():
if isinstance(module, BaseTunerLayer):
module.unmerge()
@@ -1202,8 +1242,9 @@ class LoraLoaderMixin:
adapter_names: Union[List[str], str],
adapter_weights: Optional[List[float]] = None,
):
+ unet = getattr(self, self.unet_name) if not hasattr(self, "unet") else self.unet
# Handle the UNET
- self.unet.set_adapters(adapter_names, adapter_weights)
+ unet.set_adapters(adapter_names, adapter_weights)
# Handle the Text Encoder
if hasattr(self, "text_encoder"):
@@ -1216,7 +1257,8 @@ class LoraLoaderMixin:
raise ValueError("PEFT backend is required for this method.")
# Disable unet adapters
- self.unet.disable_lora()
+ unet = getattr(self, self.unet_name) if not hasattr(self, "unet") else self.unet
+ unet.disable_lora()
# Disable text encoder adapters
if hasattr(self, "text_encoder"):
@@ -1229,7 +1271,8 @@ class LoraLoaderMixin:
raise ValueError("PEFT backend is required for this method.")
# Enable unet adapters
- self.unet.enable_lora()
+ unet = getattr(self, self.unet_name) if not hasattr(self, "unet") else self.unet
+ unet.enable_lora()
# Enable text encoder adapters
if hasattr(self, "text_encoder"):
@@ -1251,7 +1294,8 @@ class LoraLoaderMixin:
adapter_names = [adapter_names]
# Delete unet adapters
- self.unet.delete_adapters(adapter_names)
+ unet = getattr(self, self.unet_name) if not hasattr(self, "unet") else self.unet
+ unet.delete_adapters(adapter_names)
for adapter_name in adapter_names:
# Delete text encoder adapters
@@ -1284,8 +1328,8 @@ class LoraLoaderMixin:
from peft.tuners.tuners_utils import BaseTunerLayer
active_adapters = []
-
- for module in self.unet.modules():
+ unet = getattr(self, self.unet_name) if not hasattr(self, "unet") else self.unet
+ for module in unet.modules():
if isinstance(module, BaseTunerLayer):
active_adapters = module.active_adapters
break
@@ -1309,8 +1353,9 @@ class LoraLoaderMixin:
if hasattr(self, "text_encoder_2") and hasattr(self.text_encoder_2, "peft_config"):
set_adapters["text_encoder_2"] = list(self.text_encoder_2.peft_config.keys())
- if hasattr(self, "unet") and hasattr(self.unet, "peft_config"):
- set_adapters["unet"] = list(self.unet.peft_config.keys())
+ unet = getattr(self, self.unet_name) if not hasattr(self, "unet") else self.unet
+ if hasattr(self, self.unet_name) and hasattr(unet, "peft_config"):
+ set_adapters[self.unet_name] = list(self.unet.peft_config.keys())
return set_adapters
@@ -1331,7 +1376,8 @@ class LoraLoaderMixin:
from peft.tuners.tuners_utils import BaseTunerLayer
# Handle the UNET
- for unet_module in self.unet.modules():
+ unet = getattr(self, self.unet_name) if not hasattr(self, "unet") else self.unet
+ for unet_module in unet.modules():
if isinstance(unet_module, BaseTunerLayer):
for adapter_name in adapter_names:
unet_module.lora_A[adapter_name].to(device)
diff --git a/src/diffusers/loaders/unet.py b/src/diffusers/loaders/unet.py
index 7dec43571b..5d4c7429e4 100644
--- a/src/diffusers/loaders/unet.py
+++ b/src/diffusers/loaders/unet.py
@@ -11,9 +11,11 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
+import inspect
import os
from collections import defaultdict
from contextlib import nullcontext
+from functools import partial
from typing import Callable, Dict, List, Optional, Union
import safetensors
@@ -504,22 +506,43 @@ class UNet2DConditionLoadersMixin:
save_function(state_dict, os.path.join(save_directory, weight_name))
logger.info(f"Model weights saved in {os.path.join(save_directory, weight_name)}")
- def fuse_lora(self, lora_scale=1.0, safe_fusing=False):
+ def fuse_lora(self, lora_scale=1.0, safe_fusing=False, adapter_names=None):
self.lora_scale = lora_scale
self._safe_fusing = safe_fusing
- self.apply(self._fuse_lora_apply)
+ self.apply(partial(self._fuse_lora_apply, adapter_names=adapter_names))
- def _fuse_lora_apply(self, module):
+ def _fuse_lora_apply(self, module, adapter_names=None):
if not USE_PEFT_BACKEND:
if hasattr(module, "_fuse_lora"):
module._fuse_lora(self.lora_scale, self._safe_fusing)
+
+ if adapter_names is not None:
+ raise ValueError(
+ "The `adapter_names` argument is not supported in your environment. Please switch"
+ " to PEFT backend to use this argument by installing latest PEFT and transformers."
+ " `pip install -U peft transformers`"
+ )
else:
from peft.tuners.tuners_utils import BaseTunerLayer
+ merge_kwargs = {"safe_merge": self._safe_fusing}
+
if isinstance(module, BaseTunerLayer):
if self.lora_scale != 1.0:
module.scale_layer(self.lora_scale)
- module.merge(safe_merge=self._safe_fusing)
+
+ # For BC with prevous PEFT versions, we need to check the signature
+ # of the `merge` method to see if it supports the `adapter_names` argument.
+ supported_merge_kwargs = list(inspect.signature(module.merge).parameters)
+ if "adapter_names" in supported_merge_kwargs:
+ merge_kwargs["adapter_names"] = adapter_names
+ elif "adapter_names" not in supported_merge_kwargs and adapter_names is not None:
+ raise ValueError(
+ "The `adapter_names` argument is not supported with your PEFT version. Please upgrade"
+ " to the latest version of PEFT. `pip install -U peft`"
+ )
+
+ module.merge(**merge_kwargs)
def unfuse_lora(self):
self.apply(self._unfuse_lora_apply)
diff --git a/src/diffusers/models/__init__.py b/src/diffusers/models/__init__.py
index 6e7fe72bc9..36dbe14c50 100644
--- a/src/diffusers/models/__init__.py
+++ b/src/diffusers/models/__init__.py
@@ -32,7 +32,6 @@ if is_torch_available():
_import_structure["autoencoders.autoencoder_tiny"] = ["AutoencoderTiny"]
_import_structure["autoencoders.consistency_decoder_vae"] = ["ConsistencyDecoderVAE"]
_import_structure["controlnet"] = ["ControlNetModel"]
- _import_structure["controlnetxs"] = ["ControlNetXSModel"]
_import_structure["dual_transformer_2d"] = ["DualTransformer2DModel"]
_import_structure["embeddings"] = ["ImageProjection"]
_import_structure["modeling_utils"] = ["ModelMixin"]
@@ -67,7 +66,6 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
ConsistencyDecoderVAE,
)
from .controlnet import ControlNetModel
- from .controlnetxs import ControlNetXSModel
from .dual_transformer_2d import DualTransformer2DModel
from .embeddings import ImageProjection
from .modeling_utils import ModelMixin
diff --git a/src/diffusers/pipelines/__init__.py b/src/diffusers/pipelines/__init__.py
index 3bf67dfc1c..2b456f4c3d 100644
--- a/src/diffusers/pipelines/__init__.py
+++ b/src/diffusers/pipelines/__init__.py
@@ -128,12 +128,6 @@ else:
"StableDiffusionXLControlNetPipeline",
]
)
- _import_structure["controlnet_xs"].extend(
- [
- "StableDiffusionControlNetXSPipeline",
- "StableDiffusionXLControlNetXSPipeline",
- ]
- )
_import_structure["deepfloyd_if"] = [
"IFImg2ImgPipeline",
"IFImg2ImgSuperResolutionPipeline",
@@ -361,10 +355,6 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
StableDiffusionXLControlNetInpaintPipeline,
StableDiffusionXLControlNetPipeline,
)
- from .controlnet_xs import (
- StableDiffusionControlNetXSPipeline,
- StableDiffusionXLControlNetXSPipeline,
- )
from .deepfloyd_if import (
IFImg2ImgPipeline,
IFImg2ImgSuperResolutionPipeline,
diff --git a/src/diffusers/pipelines/amused/pipeline_amused.py b/src/diffusers/pipelines/amused/pipeline_amused.py
index e93569c230..a2efbfe6e5 100644
--- a/src/diffusers/pipelines/amused/pipeline_amused.py
+++ b/src/diffusers/pipelines/amused/pipeline_amused.py
@@ -31,7 +31,7 @@ EXAMPLE_DOC_STRING = """
>>> from diffusers import AmusedPipeline
>>> pipe = AmusedPipeline.from_pretrained(
- ... "huggingface/amused-512", variant="fp16", torch_dtype=torch.float16
+ ... "amused/amused-512", variant="fp16", torch_dtype=torch.float16
... )
>>> pipe = pipe.to("cuda")
diff --git a/src/diffusers/pipelines/amused/pipeline_amused_img2img.py b/src/diffusers/pipelines/amused/pipeline_amused_img2img.py
index 694b7c2229..ad63b63d28 100644
--- a/src/diffusers/pipelines/amused/pipeline_amused_img2img.py
+++ b/src/diffusers/pipelines/amused/pipeline_amused_img2img.py
@@ -32,7 +32,7 @@ EXAMPLE_DOC_STRING = """
>>> from diffusers.utils import load_image
>>> pipe = AmusedImg2ImgPipeline.from_pretrained(
- ... "huggingface/amused-512", variant="fp16", torch_dtype=torch.float16
+ ... "amused/amused-512", variant="fp16", torch_dtype=torch.float16
... )
>>> pipe = pipe.to("cuda")
diff --git a/src/diffusers/pipelines/amused/pipeline_amused_inpaint.py b/src/diffusers/pipelines/amused/pipeline_amused_inpaint.py
index a4c5644c96..cdb272c617 100644
--- a/src/diffusers/pipelines/amused/pipeline_amused_inpaint.py
+++ b/src/diffusers/pipelines/amused/pipeline_amused_inpaint.py
@@ -33,7 +33,7 @@ EXAMPLE_DOC_STRING = """
>>> from diffusers.utils import load_image
>>> pipe = AmusedInpaintPipeline.from_pretrained(
- ... "huggingface/amused-512", variant="fp16", torch_dtype=torch.float16
+ ... "amused/amused-512", variant="fp16", torch_dtype=torch.float16
... )
>>> pipe = pipe.to("cuda")
diff --git a/src/diffusers/pipelines/animatediff/pipeline_animatediff.py b/src/diffusers/pipelines/animatediff/pipeline_animatediff.py
index 0dab722e51..b0fe790c22 100644
--- a/src/diffusers/pipelines/animatediff/pipeline_animatediff.py
+++ b/src/diffusers/pipelines/animatediff/pipeline_animatediff.py
@@ -33,7 +33,14 @@ from ...schedulers import (
LMSDiscreteScheduler,
PNDMScheduler,
)
-from ...utils import USE_PEFT_BACKEND, BaseOutput, logging, scale_lora_layers, unscale_lora_layers
+from ...utils import (
+ USE_PEFT_BACKEND,
+ BaseOutput,
+ logging,
+ replace_example_docstring,
+ scale_lora_layers,
+ unscale_lora_layers,
+)
from ...utils.torch_utils import randn_tensor
from ..pipeline_utils import DiffusionPipeline
@@ -47,7 +54,7 @@ EXAMPLE_DOC_STRING = """
>>> from diffusers import MotionAdapter, AnimateDiffPipeline, DDIMScheduler
>>> from diffusers.utils import export_to_gif
- >>> adapter = MotionAdapter.from_pretrained("diffusers/motion-adapter")
+ >>> adapter = MotionAdapter.from_pretrained("guoyww/animatediff-motion-adapter-v1-5-2")
>>> pipe = AnimateDiffPipeline.from_pretrained("frankjoshua/toonyou_beta6", motion_adapter=adapter)
>>> pipe.scheduler = DDIMScheduler(beta_schedule="linear", steps_offset=1, clip_sample=False)
>>> output = pipe(prompt="A corgi walking in the park")
@@ -533,6 +540,7 @@ class AnimateDiffPipeline(DiffusionPipeline, TextualInversionLoaderMixin, IPAdap
return latents
@torch.no_grad()
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
def __call__(
self,
prompt: Union[str, List[str]] = None,
diff --git a/src/diffusers/pipelines/controlnet/pipeline_controlnet.py b/src/diffusers/pipelines/controlnet/pipeline_controlnet.py
index d7168bec82..6bdc281ef8 100644
--- a/src/diffusers/pipelines/controlnet/pipeline_controlnet.py
+++ b/src/diffusers/pipelines/controlnet/pipeline_controlnet.py
@@ -633,7 +633,7 @@ class StableDiffusionControlNetPipeline(
# When `image` is a nested list:
# (e.g. [[canny_image_1, pose_image_1], [canny_image_2, pose_image_2]])
elif any(isinstance(i, list) for i in image):
- raise ValueError("A single batch of multiple conditionings are supported at the moment.")
+ raise ValueError("A single batch of multiple conditionings is not supported at the moment.")
elif len(image) != len(self.controlnet.nets):
raise ValueError(
f"For multiple controlnets: `image` must have the same length as the number of controlnets, but got {len(image)} images and {len(self.controlnet.nets)} ControlNets."
@@ -659,7 +659,7 @@ class StableDiffusionControlNetPipeline(
):
if isinstance(controlnet_conditioning_scale, list):
if any(isinstance(i, list) for i in controlnet_conditioning_scale):
- raise ValueError("A single batch of multiple conditionings are supported at the moment.")
+ raise ValueError("A single batch of multiple conditionings is not supported at the moment.")
elif isinstance(controlnet_conditioning_scale, list) and len(controlnet_conditioning_scale) != len(
self.controlnet.nets
):
diff --git a/src/diffusers/pipelines/controlnet_xs/__init__.py b/src/diffusers/pipelines/controlnet_xs/__init__.py
deleted file mode 100644
index 978278b184..0000000000
--- a/src/diffusers/pipelines/controlnet_xs/__init__.py
+++ /dev/null
@@ -1,68 +0,0 @@
-from typing import TYPE_CHECKING
-
-from ...utils import (
- DIFFUSERS_SLOW_IMPORT,
- OptionalDependencyNotAvailable,
- _LazyModule,
- get_objects_from_module,
- is_flax_available,
- is_torch_available,
- is_transformers_available,
-)
-
-
-_dummy_objects = {}
-_import_structure = {}
-
-try:
- if not (is_transformers_available() and is_torch_available()):
- raise OptionalDependencyNotAvailable()
-except OptionalDependencyNotAvailable:
- from ...utils import dummy_torch_and_transformers_objects # noqa F403
-
- _dummy_objects.update(get_objects_from_module(dummy_torch_and_transformers_objects))
-else:
- _import_structure["pipeline_controlnet_xs"] = ["StableDiffusionControlNetXSPipeline"]
- _import_structure["pipeline_controlnet_xs_sd_xl"] = ["StableDiffusionXLControlNetXSPipeline"]
-try:
- if not (is_transformers_available() and is_flax_available()):
- raise OptionalDependencyNotAvailable()
-except OptionalDependencyNotAvailable:
- from ...utils import dummy_flax_and_transformers_objects # noqa F403
-
- _dummy_objects.update(get_objects_from_module(dummy_flax_and_transformers_objects))
-else:
- pass # _import_structure["pipeline_flax_controlnet"] = ["FlaxStableDiffusionControlNetPipeline"]
-
-
-if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
- try:
- if not (is_transformers_available() and is_torch_available()):
- raise OptionalDependencyNotAvailable()
-
- except OptionalDependencyNotAvailable:
- from ...utils.dummy_torch_and_transformers_objects import *
- else:
- from .pipeline_controlnet_xs import StableDiffusionControlNetXSPipeline
- from .pipeline_controlnet_xs_sd_xl import StableDiffusionXLControlNetXSPipeline
-
- try:
- if not (is_transformers_available() and is_flax_available()):
- raise OptionalDependencyNotAvailable()
- except OptionalDependencyNotAvailable:
- from ...utils.dummy_flax_and_transformers_objects import * # noqa F403
- else:
- pass # from .pipeline_flax_controlnet import FlaxStableDiffusionControlNetPipeline
-
-
-else:
- import sys
-
- sys.modules[__name__] = _LazyModule(
- __name__,
- globals()["__file__"],
- _import_structure,
- module_spec=__spec__,
- )
- for name, value in _dummy_objects.items():
- setattr(sys.modules[__name__], name, value)
diff --git a/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py b/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py
index b05d0b17dd..dc4ad60ce0 100644
--- a/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py
+++ b/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py
@@ -768,6 +768,10 @@ class StableDiffusionPipeline(
def num_timesteps(self):
return self._num_timesteps
+ @property
+ def interrupt(self):
+ return self._interrupt
+
@torch.no_grad()
@replace_example_docstring(EXAMPLE_DOC_STRING)
def __call__(
@@ -909,6 +913,7 @@ class StableDiffusionPipeline(
self._guidance_rescale = guidance_rescale
self._clip_skip = clip_skip
self._cross_attention_kwargs = cross_attention_kwargs
+ self._interrupt = False
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
@@ -986,6 +991,9 @@ class StableDiffusionPipeline(
self._num_timesteps = len(timesteps)
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
+ if self.interrupt:
+ continue
+
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if self.do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
diff --git a/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_img2img.py b/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_img2img.py
index d2538749f3..45dbd1128d 100644
--- a/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_img2img.py
+++ b/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_img2img.py
@@ -832,6 +832,10 @@ class StableDiffusionImg2ImgPipeline(
def num_timesteps(self):
return self._num_timesteps
+ @property
+ def interrupt(self):
+ return self._interrupt
+
@torch.no_grad()
@replace_example_docstring(EXAMPLE_DOC_STRING)
def __call__(
@@ -963,6 +967,7 @@ class StableDiffusionImg2ImgPipeline(
self._guidance_scale = guidance_scale
self._clip_skip = clip_skip
self._cross_attention_kwargs = cross_attention_kwargs
+ self._interrupt = False
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
@@ -1041,6 +1046,9 @@ class StableDiffusionImg2ImgPipeline(
self._num_timesteps = len(timesteps)
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
+ if self.interrupt:
+ continue
+
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if self.do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
diff --git a/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_inpaint.py b/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_inpaint.py
index bc6c65f4a6..58af756849 100644
--- a/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_inpaint.py
+++ b/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_inpaint.py
@@ -636,6 +636,8 @@ class StableDiffusionInpaintPipeline(
def check_inputs(
self,
prompt,
+ image,
+ mask_image,
height,
width,
strength,
@@ -644,6 +646,7 @@ class StableDiffusionInpaintPipeline(
prompt_embeds=None,
negative_prompt_embeds=None,
callback_on_step_end_tensor_inputs=None,
+ padding_mask_crop=None,
):
if strength < 0 or strength > 1:
raise ValueError(f"The value of strength should in [0.0, 1.0] but is {strength}")
@@ -689,6 +692,21 @@ class StableDiffusionInpaintPipeline(
f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
f" {negative_prompt_embeds.shape}."
)
+ if padding_mask_crop is not None:
+ if self.unet.config.in_channels != 4:
+ raise ValueError(
+ f"The UNet should have 4 input channels for inpainting mask crop, but has"
+ f" {self.unet.config.in_channels} input channels."
+ )
+ if not isinstance(image, PIL.Image.Image):
+ raise ValueError(
+ f"The image should be a PIL image when inpainting mask crop, but is of type" f" {type(image)}."
+ )
+ if not isinstance(mask_image, PIL.Image.Image):
+ raise ValueError(
+ f"The mask image should be a PIL image when inpainting mask crop, but is of type"
+ f" {type(mask_image)}."
+ )
def prepare_latents(
self,
@@ -958,6 +976,10 @@ class StableDiffusionInpaintPipeline(
def num_timesteps(self):
return self._num_timesteps
+ @property
+ def interrupt(self):
+ return self._interrupt
+
@torch.no_grad()
def __call__(
self,
@@ -967,6 +989,7 @@ class StableDiffusionInpaintPipeline(
masked_image_latents: torch.FloatTensor = None,
height: Optional[int] = None,
width: Optional[int] = None,
+ padding_mask_crop: Optional[int] = None,
strength: float = 1.0,
num_inference_steps: int = 50,
timesteps: List[int] = None,
@@ -1011,6 +1034,12 @@ class StableDiffusionInpaintPipeline(
The height in pixels of the generated image.
width (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
The width in pixels of the generated image.
+ padding_mask_crop (`int`, *optional*, defaults to `None`):
+ The size of margin in the crop to be applied to the image and masking. If `None`, no crop is applied to image and mask_image. If
+ `padding_mask_crop` is not `None`, it will first find a rectangular region with the same aspect ration of the image and
+ contains all masked area, and then expand that area based on `padding_mask_crop`. The image and mask_image will then be cropped based on
+ the expanded area before resizing to the original image size for inpainting. This is useful when the masked area is small while the image is large
+ and contain information inreleant for inpainging, such as background.
strength (`float`, *optional*, defaults to 1.0):
Indicates extent to transform the reference `image`. Must be between 0 and 1. `image` is used as a
starting point and more noise is added the higher the `strength`. The number of denoising steps depends
@@ -1131,6 +1160,8 @@ class StableDiffusionInpaintPipeline(
# 1. Check inputs
self.check_inputs(
prompt,
+ image,
+ mask_image,
height,
width,
strength,
@@ -1139,11 +1170,13 @@ class StableDiffusionInpaintPipeline(
prompt_embeds,
negative_prompt_embeds,
callback_on_step_end_tensor_inputs,
+ padding_mask_crop,
)
self._guidance_scale = guidance_scale
self._clip_skip = clip_skip
self._cross_attention_kwargs = cross_attention_kwargs
+ self._interrupt = False
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
@@ -1202,7 +1235,17 @@ class StableDiffusionInpaintPipeline(
# 5. Preprocess mask and image
- init_image = self.image_processor.preprocess(image, height=height, width=width)
+ if padding_mask_crop is not None:
+ crops_coords = self.mask_processor.get_crop_region(mask_image, width, height, pad=padding_mask_crop)
+ resize_mode = "fill"
+ else:
+ crops_coords = None
+ resize_mode = "default"
+
+ original_image = image
+ init_image = self.image_processor.preprocess(
+ image, height=height, width=width, crops_coords=crops_coords, resize_mode=resize_mode
+ )
init_image = init_image.to(dtype=torch.float32)
# 6. Prepare latent variables
@@ -1232,7 +1275,9 @@ class StableDiffusionInpaintPipeline(
latents, noise = latents_outputs
# 7. Prepare mask latent variables
- mask_condition = self.mask_processor.preprocess(mask_image, height=height, width=width)
+ mask_condition = self.mask_processor.preprocess(
+ mask_image, height=height, width=width, resize_mode=resize_mode, crops_coords=crops_coords
+ )
if masked_image_latents is None:
masked_image = init_image * (mask_condition < 0.5)
@@ -1288,6 +1333,9 @@ class StableDiffusionInpaintPipeline(
self._num_timesteps = len(timesteps)
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
+ if self.interrupt:
+ continue
+
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if self.do_classifier_free_guidance else latents
@@ -1372,6 +1420,9 @@ class StableDiffusionInpaintPipeline(
image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
+ if padding_mask_crop is not None:
+ image = [self.image_processor.apply_overlay(mask_image, original_image, i, crops_coords) for i in image]
+
# Offload all models
self.maybe_free_model_hooks()
diff --git a/src/diffusers/pipelines/stable_diffusion_xl/pipeline_stable_diffusion_xl.py b/src/diffusers/pipelines/stable_diffusion_xl/pipeline_stable_diffusion_xl.py
index 569668a168..f9bafc9733 100644
--- a/src/diffusers/pipelines/stable_diffusion_xl/pipeline_stable_diffusion_xl.py
+++ b/src/diffusers/pipelines/stable_diffusion_xl/pipeline_stable_diffusion_xl.py
@@ -849,6 +849,10 @@ class StableDiffusionXLPipeline(
def num_timesteps(self):
return self._num_timesteps
+ @property
+ def interrupt(self):
+ return self._interrupt
+
@torch.no_grad()
@replace_example_docstring(EXAMPLE_DOC_STRING)
def __call__(
@@ -1067,6 +1071,7 @@ class StableDiffusionXLPipeline(
self._clip_skip = clip_skip
self._cross_attention_kwargs = cross_attention_kwargs
self._denoising_end = denoising_end
+ self._interrupt = False
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
@@ -1196,6 +1201,9 @@ class StableDiffusionXLPipeline(
self._num_timesteps = len(timesteps)
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
+ if self.interrupt:
+ continue
+
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if self.do_classifier_free_guidance else latents
diff --git a/src/diffusers/pipelines/stable_diffusion_xl/pipeline_stable_diffusion_xl_img2img.py b/src/diffusers/pipelines/stable_diffusion_xl/pipeline_stable_diffusion_xl_img2img.py
index 4f75ce6878..1c22affba1 100644
--- a/src/diffusers/pipelines/stable_diffusion_xl/pipeline_stable_diffusion_xl_img2img.py
+++ b/src/diffusers/pipelines/stable_diffusion_xl/pipeline_stable_diffusion_xl_img2img.py
@@ -990,6 +990,10 @@ class StableDiffusionXLImg2ImgPipeline(
def num_timesteps(self):
return self._num_timesteps
+ @property
+ def interrupt(self):
+ return self._interrupt
+
@torch.no_grad()
@replace_example_docstring(EXAMPLE_DOC_STRING)
def __call__(
@@ -1221,6 +1225,7 @@ class StableDiffusionXLImg2ImgPipeline(
self._cross_attention_kwargs = cross_attention_kwargs
self._denoising_end = denoising_end
self._denoising_start = denoising_start
+ self._interrupt = False
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
@@ -1376,6 +1381,9 @@ class StableDiffusionXLImg2ImgPipeline(
self._num_timesteps = len(timesteps)
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
+ if self.interrupt:
+ continue
+
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if self.do_classifier_free_guidance else latents
diff --git a/src/diffusers/pipelines/stable_diffusion_xl/pipeline_stable_diffusion_xl_inpaint.py b/src/diffusers/pipelines/stable_diffusion_xl/pipeline_stable_diffusion_xl_inpaint.py
index 751823ea4b..2f02a213b8 100644
--- a/src/diffusers/pipelines/stable_diffusion_xl/pipeline_stable_diffusion_xl_inpaint.py
+++ b/src/diffusers/pipelines/stable_diffusion_xl/pipeline_stable_diffusion_xl_inpaint.py
@@ -1210,6 +1210,10 @@ class StableDiffusionXLInpaintPipeline(
def num_timesteps(self):
return self._num_timesteps
+ @property
+ def interrupt(self):
+ return self._interrupt
+
@torch.no_grad()
@replace_example_docstring(EXAMPLE_DOC_STRING)
def __call__(
@@ -1462,6 +1466,7 @@ class StableDiffusionXLInpaintPipeline(
self._cross_attention_kwargs = cross_attention_kwargs
self._denoising_end = denoising_end
self._denoising_start = denoising_start
+ self._interrupt = False
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
@@ -1684,6 +1689,8 @@ class StableDiffusionXLInpaintPipeline(
self._num_timesteps = len(timesteps)
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
+ if self.interrupt:
+ continue
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if self.do_classifier_free_guidance else latents
diff --git a/src/diffusers/schedulers/scheduling_ddim_inverse.py b/src/diffusers/schedulers/scheduling_ddim_inverse.py
index ea2d4945bd..f1fe6a6861 100644
--- a/src/diffusers/schedulers/scheduling_ddim_inverse.py
+++ b/src/diffusers/schedulers/scheduling_ddim_inverse.py
@@ -293,9 +293,6 @@ class DDIMInverseScheduler(SchedulerMixin, ConfigMixin):
model_output: torch.FloatTensor,
timestep: int,
sample: torch.FloatTensor,
- eta: float = 0.0,
- use_clipped_model_output: bool = False,
- variance_noise: Optional[torch.FloatTensor] = None,
return_dict: bool = True,
) -> Union[DDIMSchedulerOutput, Tuple]:
"""
@@ -332,7 +329,7 @@ class DDIMInverseScheduler(SchedulerMixin, ConfigMixin):
# 1. get previous step value (=t+1)
prev_timestep = timestep
timestep = min(
- timestep - self.config.num_train_timesteps // self.num_inference_steps, self.num_train_timesteps - 1
+ timestep - self.config.num_train_timesteps // self.num_inference_steps, self.config.num_train_timesteps - 1
)
# 2. compute alphas, betas
diff --git a/src/diffusers/schedulers/scheduling_ddpm.py b/src/diffusers/schedulers/scheduling_ddpm.py
index c4a3eb4357..868cf1c2d8 100644
--- a/src/diffusers/schedulers/scheduling_ddpm.py
+++ b/src/diffusers/schedulers/scheduling_ddpm.py
@@ -89,6 +89,43 @@ def betas_for_alpha_bar(
return torch.tensor(betas, dtype=torch.float32)
+# Copied from diffusers.schedulers.scheduling_ddim.rescale_zero_terminal_snr
+def rescale_zero_terminal_snr(betas):
+ """
+ Rescales betas to have zero terminal SNR Based on https://arxiv.org/pdf/2305.08891.pdf (Algorithm 1)
+
+
+ Args:
+ betas (`torch.FloatTensor`):
+ the betas that the scheduler is being initialized with.
+
+ Returns:
+ `torch.FloatTensor`: rescaled betas with zero terminal SNR
+ """
+ # Convert betas to alphas_bar_sqrt
+ alphas = 1.0 - betas
+ alphas_cumprod = torch.cumprod(alphas, dim=0)
+ alphas_bar_sqrt = alphas_cumprod.sqrt()
+
+ # Store old values.
+ alphas_bar_sqrt_0 = alphas_bar_sqrt[0].clone()
+ alphas_bar_sqrt_T = alphas_bar_sqrt[-1].clone()
+
+ # Shift so the last timestep is zero.
+ alphas_bar_sqrt -= alphas_bar_sqrt_T
+
+ # Scale so the first timestep is back to the old value.
+ alphas_bar_sqrt *= alphas_bar_sqrt_0 / (alphas_bar_sqrt_0 - alphas_bar_sqrt_T)
+
+ # Convert alphas_bar_sqrt to betas
+ alphas_bar = alphas_bar_sqrt**2 # Revert sqrt
+ alphas = alphas_bar[1:] / alphas_bar[:-1] # Revert cumprod
+ alphas = torch.cat([alphas_bar[0:1], alphas])
+ betas = 1 - alphas
+
+ return betas
+
+
class DDPMScheduler(SchedulerMixin, ConfigMixin):
"""
`DDPMScheduler` explores the connections between denoising score matching and Langevin dynamics sampling.
@@ -131,6 +168,10 @@ class DDPMScheduler(SchedulerMixin, ConfigMixin):
An offset added to the inference steps. You can use a combination of `offset=1` and
`set_alpha_to_one=False` to make the last step use step 0 for the previous alpha product like in Stable
Diffusion.
+ rescale_betas_zero_snr (`bool`, defaults to `False`):
+ Whether to rescale the betas to have zero terminal SNR. This enables the model to generate very bright and
+ dark samples instead of limiting it to samples with medium brightness. Loosely related to
+ [`--offset_noise`](https://github.com/huggingface/diffusers/blob/74fd735eb073eb1d774b1ab4154a0876eb82f055/examples/dreambooth/train_dreambooth.py#L506).
"""
_compatibles = [e.name for e in KarrasDiffusionSchedulers]
@@ -153,6 +194,7 @@ class DDPMScheduler(SchedulerMixin, ConfigMixin):
sample_max_value: float = 1.0,
timestep_spacing: str = "leading",
steps_offset: int = 0,
+ rescale_betas_zero_snr: int = False,
):
if trained_betas is not None:
self.betas = torch.tensor(trained_betas, dtype=torch.float32)
@@ -171,6 +213,10 @@ class DDPMScheduler(SchedulerMixin, ConfigMixin):
else:
raise NotImplementedError(f"{beta_schedule} does is not implemented for {self.__class__}")
+ # Rescale for zero SNR
+ if rescale_betas_zero_snr:
+ self.betas = rescale_zero_terminal_snr(self.betas)
+
self.alphas = 1.0 - self.betas
self.alphas_cumprod = torch.cumprod(self.alphas, dim=0)
self.one = torch.tensor(1.0)
diff --git a/src/diffusers/schedulers/scheduling_ddpm_parallel.py b/src/diffusers/schedulers/scheduling_ddpm_parallel.py
index 6f2bebfb5a..9a84bfdf28 100644
--- a/src/diffusers/schedulers/scheduling_ddpm_parallel.py
+++ b/src/diffusers/schedulers/scheduling_ddpm_parallel.py
@@ -91,6 +91,43 @@ def betas_for_alpha_bar(
return torch.tensor(betas, dtype=torch.float32)
+# Copied from diffusers.schedulers.scheduling_ddim.rescale_zero_terminal_snr
+def rescale_zero_terminal_snr(betas):
+ """
+ Rescales betas to have zero terminal SNR Based on https://arxiv.org/pdf/2305.08891.pdf (Algorithm 1)
+
+
+ Args:
+ betas (`torch.FloatTensor`):
+ the betas that the scheduler is being initialized with.
+
+ Returns:
+ `torch.FloatTensor`: rescaled betas with zero terminal SNR
+ """
+ # Convert betas to alphas_bar_sqrt
+ alphas = 1.0 - betas
+ alphas_cumprod = torch.cumprod(alphas, dim=0)
+ alphas_bar_sqrt = alphas_cumprod.sqrt()
+
+ # Store old values.
+ alphas_bar_sqrt_0 = alphas_bar_sqrt[0].clone()
+ alphas_bar_sqrt_T = alphas_bar_sqrt[-1].clone()
+
+ # Shift so the last timestep is zero.
+ alphas_bar_sqrt -= alphas_bar_sqrt_T
+
+ # Scale so the first timestep is back to the old value.
+ alphas_bar_sqrt *= alphas_bar_sqrt_0 / (alphas_bar_sqrt_0 - alphas_bar_sqrt_T)
+
+ # Convert alphas_bar_sqrt to betas
+ alphas_bar = alphas_bar_sqrt**2 # Revert sqrt
+ alphas = alphas_bar[1:] / alphas_bar[:-1] # Revert cumprod
+ alphas = torch.cat([alphas_bar[0:1], alphas])
+ betas = 1 - alphas
+
+ return betas
+
+
class DDPMParallelScheduler(SchedulerMixin, ConfigMixin):
"""
Denoising diffusion probabilistic models (DDPMs) explores the connections between denoising score matching and
@@ -139,6 +176,10 @@ class DDPMParallelScheduler(SchedulerMixin, ConfigMixin):
an offset added to the inference steps. You can use a combination of `offset=1` and
`set_alpha_to_one=False`, to make the last step use step 0 for the previous alpha product, as done in
stable diffusion.
+ rescale_betas_zero_snr (`bool`, defaults to `False`):
+ Whether to rescale the betas to have zero terminal SNR. This enables the model to generate very bright and
+ dark samples instead of limiting it to samples with medium brightness. Loosely related to
+ [`--offset_noise`](https://github.com/huggingface/diffusers/blob/74fd735eb073eb1d774b1ab4154a0876eb82f055/examples/dreambooth/train_dreambooth.py#L506).
"""
_compatibles = [e.name for e in KarrasDiffusionSchedulers]
@@ -163,6 +204,7 @@ class DDPMParallelScheduler(SchedulerMixin, ConfigMixin):
sample_max_value: float = 1.0,
timestep_spacing: str = "leading",
steps_offset: int = 0,
+ rescale_betas_zero_snr: int = False,
):
if trained_betas is not None:
self.betas = torch.tensor(trained_betas, dtype=torch.float32)
@@ -181,6 +223,10 @@ class DDPMParallelScheduler(SchedulerMixin, ConfigMixin):
else:
raise NotImplementedError(f"{beta_schedule} does is not implemented for {self.__class__}")
+ # Rescale for zero SNR
+ if rescale_betas_zero_snr:
+ self.betas = rescale_zero_terminal_snr(self.betas)
+
self.alphas = 1.0 - self.betas
self.alphas_cumprod = torch.cumprod(self.alphas, dim=0)
self.one = torch.tensor(1.0)
diff --git a/src/diffusers/utils/dummy_pt_objects.py b/src/diffusers/utils/dummy_pt_objects.py
index 5bd2f493ce..d306a3575b 100644
--- a/src/diffusers/utils/dummy_pt_objects.py
+++ b/src/diffusers/utils/dummy_pt_objects.py
@@ -92,21 +92,6 @@ class ControlNetModel(metaclass=DummyObject):
requires_backends(cls, ["torch"])
-class ControlNetXSModel(metaclass=DummyObject):
- _backends = ["torch"]
-
- def __init__(self, *args, **kwargs):
- requires_backends(self, ["torch"])
-
- @classmethod
- def from_config(cls, *args, **kwargs):
- requires_backends(cls, ["torch"])
-
- @classmethod
- def from_pretrained(cls, *args, **kwargs):
- requires_backends(cls, ["torch"])
-
-
class Kandinsky3UNet(metaclass=DummyObject):
_backends = ["torch"]
diff --git a/src/diffusers/utils/dummy_torch_and_transformers_objects.py b/src/diffusers/utils/dummy_torch_and_transformers_objects.py
index ae6c6c9160..2eb9599658 100644
--- a/src/diffusers/utils/dummy_torch_and_transformers_objects.py
+++ b/src/diffusers/utils/dummy_torch_and_transformers_objects.py
@@ -782,21 +782,6 @@ class StableDiffusionControlNetPipeline(metaclass=DummyObject):
requires_backends(cls, ["torch", "transformers"])
-class StableDiffusionControlNetXSPipeline(metaclass=DummyObject):
- _backends = ["torch", "transformers"]
-
- def __init__(self, *args, **kwargs):
- requires_backends(self, ["torch", "transformers"])
-
- @classmethod
- def from_config(cls, *args, **kwargs):
- requires_backends(cls, ["torch", "transformers"])
-
- @classmethod
- def from_pretrained(cls, *args, **kwargs):
- requires_backends(cls, ["torch", "transformers"])
-
-
class StableDiffusionDepth2ImgPipeline(metaclass=DummyObject):
_backends = ["torch", "transformers"]
@@ -1142,21 +1127,6 @@ class StableDiffusionXLControlNetPipeline(metaclass=DummyObject):
requires_backends(cls, ["torch", "transformers"])
-class StableDiffusionXLControlNetXSPipeline(metaclass=DummyObject):
- _backends = ["torch", "transformers"]
-
- def __init__(self, *args, **kwargs):
- requires_backends(self, ["torch", "transformers"])
-
- @classmethod
- def from_config(cls, *args, **kwargs):
- requires_backends(cls, ["torch", "transformers"])
-
- @classmethod
- def from_pretrained(cls, *args, **kwargs):
- requires_backends(cls, ["torch", "transformers"])
-
-
class StableDiffusionXLImg2ImgPipeline(metaclass=DummyObject):
_backends = ["torch", "transformers"]
diff --git a/src/diffusers/utils/state_dict_utils.py b/src/diffusers/utils/state_dict_utils.py
index 777c611f71..6c163034e7 100644
--- a/src/diffusers/utils/state_dict_utils.py
+++ b/src/diffusers/utils/state_dict_utils.py
@@ -79,6 +79,14 @@ PEFT_TO_DIFFUSERS = {
".v_proj.lora_A": ".v_proj.lora_linear_layer.down",
".out_proj.lora_B": ".out_proj.lora_linear_layer.up",
".out_proj.lora_A": ".out_proj.lora_linear_layer.down",
+ "to_k.lora_A": "to_k.lora.down",
+ "to_k.lora_B": "to_k.lora.up",
+ "to_q.lora_A": "to_q.lora.down",
+ "to_q.lora_B": "to_q.lora.up",
+ "to_v.lora_A": "to_v.lora.down",
+ "to_v.lora_B": "to_v.lora.up",
+ "to_out.0.lora_A": "to_out.0.lora.down",
+ "to_out.0.lora_B": "to_out.0.lora.up",
}
DIFFUSERS_OLD_TO_DIFFUSERS = {
diff --git a/src/diffusers/utils/testing_utils.py b/src/diffusers/utils/testing_utils.py
index 606980f8a3..df1a4fc420 100644
--- a/src/diffusers/utils/testing_utils.py
+++ b/src/diffusers/utils/testing_utils.py
@@ -300,6 +300,23 @@ def require_peft_backend(test_case):
return unittest.skipUnless(USE_PEFT_BACKEND, "test requires PEFT backend")(test_case)
+def require_peft_version_greater(peft_version):
+ """
+ Decorator marking a test that requires PEFT backend with a specific version, this would require some specific
+ versions of PEFT and transformers.
+ """
+
+ def decorator(test_case):
+ correct_peft_version = is_peft_available() and version.parse(
+ version.parse(importlib.metadata.version("peft")).base_version
+ ) > version.parse(peft_version)
+ return unittest.skipUnless(
+ correct_peft_version, f"test requires PEFT backend with the version greater than {peft_version}"
+ )(test_case)
+
+ return decorator
+
+
def deprecate_after_peft_backend(test_case):
"""
Decorator marking a test that will be skipped after PEFT backend
diff --git a/tests/lora/test_lora_layers_peft.py b/tests/lora/test_lora_layers_peft.py
index f6cd2a714a..c139e0d6ea 100644
--- a/tests/lora/test_lora_layers_peft.py
+++ b/tests/lora/test_lora_layers_peft.py
@@ -50,6 +50,7 @@ from diffusers.utils.testing_utils import (
nightly,
numpy_cosine_similarity_distance,
require_peft_backend,
+ require_peft_version_greater,
require_torch_gpu,
slow,
torch_device,
@@ -111,12 +112,16 @@ class PeftLoraLoaderMixinTests:
def get_dummy_components(self, scheduler_cls=None):
scheduler_cls = self.scheduler_cls if scheduler_cls is None else LCMScheduler
+ rank = 4
torch.manual_seed(0)
unet = UNet2DConditionModel(**self.unet_kwargs)
+
scheduler = scheduler_cls(**self.scheduler_kwargs)
+
torch.manual_seed(0)
vae = AutoencoderKL(**self.vae_kwargs)
+
text_encoder = CLIPTextModel.from_pretrained("peft-internal-testing/tiny-clip-text-2")
tokenizer = CLIPTokenizer.from_pretrained("peft-internal-testing/tiny-clip-text-2")
@@ -125,11 +130,14 @@ class PeftLoraLoaderMixinTests:
tokenizer_2 = CLIPTokenizer.from_pretrained("peft-internal-testing/tiny-clip-text-2")
text_lora_config = LoraConfig(
- r=4, lora_alpha=4, target_modules=["q_proj", "k_proj", "v_proj", "out_proj"], init_lora_weights=False
+ r=rank,
+ lora_alpha=rank,
+ target_modules=["q_proj", "k_proj", "v_proj", "out_proj"],
+ init_lora_weights=False,
)
unet_lora_config = LoraConfig(
- r=4, lora_alpha=4, target_modules=["to_q", "to_k", "to_v", "to_out.0"], init_lora_weights=False
+ r=rank, lora_alpha=rank, target_modules=["to_q", "to_k", "to_v", "to_out.0"], init_lora_weights=False
)
unet_lora_attn_procs, unet_lora_layers = create_unet_lora_layers(unet)
@@ -1098,6 +1106,68 @@ class PeftLoraLoaderMixinTests:
{"unet": ["adapter-1", "adapter-2", "adapter-3"], "text_encoder": ["adapter-1", "adapter-2"]},
)
+ @require_peft_version_greater(peft_version="0.6.2")
+ def test_simple_inference_with_text_lora_unet_fused_multi(self):
+ """
+ Tests a simple inference with lora attached into text encoder + fuses the lora weights into base model
+ and makes sure it works as expected - with unet and multi-adapter case
+ """
+ for scheduler_cls in [DDIMScheduler, LCMScheduler]:
+ components, _, text_lora_config, unet_lora_config = self.get_dummy_components(scheduler_cls)
+ pipe = self.pipeline_class(**components)
+ pipe = pipe.to(self.torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ _, _, inputs = self.get_dummy_inputs(with_generator=False)
+
+ output_no_lora = pipe(**inputs, generator=torch.manual_seed(0)).images
+ self.assertTrue(output_no_lora.shape == (1, 64, 64, 3))
+
+ pipe.text_encoder.add_adapter(text_lora_config, "adapter-1")
+ pipe.unet.add_adapter(unet_lora_config, "adapter-1")
+
+ # Attach a second adapter
+ pipe.text_encoder.add_adapter(text_lora_config, "adapter-2")
+ pipe.unet.add_adapter(unet_lora_config, "adapter-2")
+
+ self.assertTrue(
+ self.check_if_lora_correctly_set(pipe.text_encoder), "Lora not correctly set in text encoder"
+ )
+ self.assertTrue(self.check_if_lora_correctly_set(pipe.unet), "Lora not correctly set in Unet")
+
+ if self.has_two_text_encoders:
+ pipe.text_encoder_2.add_adapter(text_lora_config, "adapter-1")
+ pipe.text_encoder_2.add_adapter(text_lora_config, "adapter-2")
+ self.assertTrue(
+ self.check_if_lora_correctly_set(pipe.text_encoder_2), "Lora not correctly set in text encoder 2"
+ )
+
+ # set them to multi-adapter inference mode
+ pipe.set_adapters(["adapter-1", "adapter-2"])
+ ouputs_all_lora = pipe(**inputs, generator=torch.manual_seed(0)).images
+
+ pipe.set_adapters(["adapter-1"])
+ ouputs_lora_1 = pipe(**inputs, generator=torch.manual_seed(0)).images
+
+ pipe.fuse_lora(adapter_names=["adapter-1"])
+
+ # Fusing should still keep the LoRA layers so outpout should remain the same
+ outputs_lora_1_fused = pipe(**inputs, generator=torch.manual_seed(0)).images
+
+ self.assertTrue(
+ np.allclose(ouputs_lora_1, outputs_lora_1_fused, atol=1e-3, rtol=1e-3),
+ "Fused lora should not change the output",
+ )
+
+ pipe.unfuse_lora()
+ pipe.fuse_lora(adapter_names=["adapter-2", "adapter-1"])
+
+ # Fusing should still keep the LoRA layers
+ output_all_lora_fused = pipe(**inputs, generator=torch.manual_seed(0)).images
+ self.assertTrue(
+ np.allclose(output_all_lora_fused, ouputs_all_lora, atol=1e-3, rtol=1e-3),
+ "Fused lora should not change the output",
+ )
+
@unittest.skip("This is failing for now - need to investigate")
def test_simple_inference_with_text_unet_lora_unfused_torch_compile(self):
"""
@@ -1398,6 +1468,35 @@ class StableDiffusionXLLoRATests(PeftLoraLoaderMixinTests, unittest.TestCase):
@slow
@require_torch_gpu
class LoraIntegrationTests(PeftLoraLoaderMixinTests, unittest.TestCase):
+ pipeline_class = StableDiffusionPipeline
+ scheduler_cls = DDIMScheduler
+ scheduler_kwargs = {
+ "beta_start": 0.00085,
+ "beta_end": 0.012,
+ "beta_schedule": "scaled_linear",
+ "clip_sample": False,
+ "set_alpha_to_one": False,
+ "steps_offset": 1,
+ }
+ unet_kwargs = {
+ "block_out_channels": (32, 64),
+ "layers_per_block": 2,
+ "sample_size": 32,
+ "in_channels": 4,
+ "out_channels": 4,
+ "down_block_types": ("DownBlock2D", "CrossAttnDownBlock2D"),
+ "up_block_types": ("CrossAttnUpBlock2D", "UpBlock2D"),
+ "cross_attention_dim": 32,
+ }
+ vae_kwargs = {
+ "block_out_channels": [32, 64],
+ "in_channels": 3,
+ "out_channels": 3,
+ "down_block_types": ["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ "up_block_types": ["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ "latent_channels": 4,
+ }
+
def tearDown(self):
import gc
@@ -1651,6 +1750,42 @@ class LoraIntegrationTests(PeftLoraLoaderMixinTests, unittest.TestCase):
@slow
@require_torch_gpu
class LoraSDXLIntegrationTests(PeftLoraLoaderMixinTests, unittest.TestCase):
+ has_two_text_encoders = True
+ pipeline_class = StableDiffusionXLPipeline
+ scheduler_cls = EulerDiscreteScheduler
+ scheduler_kwargs = {
+ "beta_start": 0.00085,
+ "beta_end": 0.012,
+ "beta_schedule": "scaled_linear",
+ "timestep_spacing": "leading",
+ "steps_offset": 1,
+ }
+ unet_kwargs = {
+ "block_out_channels": (32, 64),
+ "layers_per_block": 2,
+ "sample_size": 32,
+ "in_channels": 4,
+ "out_channels": 4,
+ "down_block_types": ("DownBlock2D", "CrossAttnDownBlock2D"),
+ "up_block_types": ("CrossAttnUpBlock2D", "UpBlock2D"),
+ "attention_head_dim": (2, 4),
+ "use_linear_projection": True,
+ "addition_embed_type": "text_time",
+ "addition_time_embed_dim": 8,
+ "transformer_layers_per_block": (1, 2),
+ "projection_class_embeddings_input_dim": 80, # 6 * 8 + 32
+ "cross_attention_dim": 64,
+ }
+ vae_kwargs = {
+ "block_out_channels": [32, 64],
+ "in_channels": 3,
+ "out_channels": 3,
+ "down_block_types": ["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ "up_block_types": ["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ "latent_channels": 4,
+ "sample_size": 128,
+ }
+
def tearDown(self):
import gc
@@ -1877,7 +2012,9 @@ class LoraSDXLIntegrationTests(PeftLoraLoaderMixinTests, unittest.TestCase):
).images
images_without_fusion = images.flatten()
- self.assertTrue(np.allclose(images_with_fusion, images_without_fusion, atol=1e-3))
+ max_diff = numpy_cosine_similarity_distance(images_with_fusion, images_without_fusion)
+ assert max_diff < 1e-4
+
release_memory(pipe)
def test_sdxl_1_0_lora_unfusion_effectivity(self):
diff --git a/tests/pipelines/amused/test_amused.py b/tests/pipelines/amused/test_amused.py
index 38159cf2ac..55be4000c0 100644
--- a/tests/pipelines/amused/test_amused.py
+++ b/tests/pipelines/amused/test_amused.py
@@ -133,7 +133,7 @@ class AmusedPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
@require_torch_gpu
class AmusedPipelineSlowTests(unittest.TestCase):
def test_amused_256(self):
- pipe = AmusedPipeline.from_pretrained("huggingface/amused-256")
+ pipe = AmusedPipeline.from_pretrained("amused/amused-256")
pipe.to(torch_device)
image = pipe("dog", generator=torch.Generator().manual_seed(0), num_inference_steps=2, output_type="np").images
@@ -145,7 +145,7 @@ class AmusedPipelineSlowTests(unittest.TestCase):
assert np.abs(image_slice - expected_slice).max() < 3e-3
def test_amused_256_fp16(self):
- pipe = AmusedPipeline.from_pretrained("huggingface/amused-256", variant="fp16", torch_dtype=torch.float16)
+ pipe = AmusedPipeline.from_pretrained("amused/amused-256", variant="fp16", torch_dtype=torch.float16)
pipe.to(torch_device)
image = pipe("dog", generator=torch.Generator().manual_seed(0), num_inference_steps=2, output_type="np").images
@@ -157,7 +157,7 @@ class AmusedPipelineSlowTests(unittest.TestCase):
assert np.abs(image_slice - expected_slice).max() < 7e-3
def test_amused_512(self):
- pipe = AmusedPipeline.from_pretrained("huggingface/amused-512")
+ pipe = AmusedPipeline.from_pretrained("amused/amused-512")
pipe.to(torch_device)
image = pipe("dog", generator=torch.Generator().manual_seed(0), num_inference_steps=2, output_type="np").images
@@ -169,7 +169,7 @@ class AmusedPipelineSlowTests(unittest.TestCase):
assert np.abs(image_slice - expected_slice).max() < 3e-3
def test_amused_512_fp16(self):
- pipe = AmusedPipeline.from_pretrained("huggingface/amused-512", variant="fp16", torch_dtype=torch.float16)
+ pipe = AmusedPipeline.from_pretrained("amused/amused-512", variant="fp16", torch_dtype=torch.float16)
pipe.to(torch_device)
image = pipe("dog", generator=torch.Generator().manual_seed(0), num_inference_steps=2, output_type="np").images
diff --git a/tests/pipelines/amused/test_amused_img2img.py b/tests/pipelines/amused/test_amused_img2img.py
index dcd29ae88e..a7b4b01414 100644
--- a/tests/pipelines/amused/test_amused_img2img.py
+++ b/tests/pipelines/amused/test_amused_img2img.py
@@ -137,7 +137,7 @@ class AmusedImg2ImgPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
@require_torch_gpu
class AmusedImg2ImgPipelineSlowTests(unittest.TestCase):
def test_amused_256(self):
- pipe = AmusedImg2ImgPipeline.from_pretrained("huggingface/amused-256")
+ pipe = AmusedImg2ImgPipeline.from_pretrained("amused/amused-256")
pipe.to(torch_device)
image = (
@@ -162,9 +162,7 @@ class AmusedImg2ImgPipelineSlowTests(unittest.TestCase):
assert np.abs(image_slice - expected_slice).max() < 1e-2
def test_amused_256_fp16(self):
- pipe = AmusedImg2ImgPipeline.from_pretrained(
- "huggingface/amused-256", torch_dtype=torch.float16, variant="fp16"
- )
+ pipe = AmusedImg2ImgPipeline.from_pretrained("amused/amused-256", torch_dtype=torch.float16, variant="fp16")
pipe.to(torch_device)
image = (
@@ -189,7 +187,7 @@ class AmusedImg2ImgPipelineSlowTests(unittest.TestCase):
assert np.abs(image_slice - expected_slice).max() < 1e-2
def test_amused_512(self):
- pipe = AmusedImg2ImgPipeline.from_pretrained("huggingface/amused-512")
+ pipe = AmusedImg2ImgPipeline.from_pretrained("amused/amused-512")
pipe.to(torch_device)
image = (
@@ -213,9 +211,7 @@ class AmusedImg2ImgPipelineSlowTests(unittest.TestCase):
assert np.abs(image_slice - expected_slice).max() < 0.1
def test_amused_512_fp16(self):
- pipe = AmusedImg2ImgPipeline.from_pretrained(
- "huggingface/amused-512", variant="fp16", torch_dtype=torch.float16
- )
+ pipe = AmusedImg2ImgPipeline.from_pretrained("amused/amused-512", variant="fp16", torch_dtype=torch.float16)
pipe.to(torch_device)
image = (
diff --git a/tests/pipelines/amused/test_amused_inpaint.py b/tests/pipelines/amused/test_amused_inpaint.py
index 014485d7b9..658736b12f 100644
--- a/tests/pipelines/amused/test_amused_inpaint.py
+++ b/tests/pipelines/amused/test_amused_inpaint.py
@@ -141,7 +141,7 @@ class AmusedInpaintPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
@require_torch_gpu
class AmusedInpaintPipelineSlowTests(unittest.TestCase):
def test_amused_256(self):
- pipe = AmusedInpaintPipeline.from_pretrained("huggingface/amused-256")
+ pipe = AmusedInpaintPipeline.from_pretrained("amused/amused-256")
pipe.to(torch_device)
image = (
@@ -174,9 +174,7 @@ class AmusedInpaintPipelineSlowTests(unittest.TestCase):
assert np.abs(image_slice - expected_slice).max() < 0.1
def test_amused_256_fp16(self):
- pipe = AmusedInpaintPipeline.from_pretrained(
- "huggingface/amused-256", variant="fp16", torch_dtype=torch.float16
- )
+ pipe = AmusedInpaintPipeline.from_pretrained("amused/amused-256", variant="fp16", torch_dtype=torch.float16)
pipe.to(torch_device)
image = (
@@ -209,7 +207,7 @@ class AmusedInpaintPipelineSlowTests(unittest.TestCase):
assert np.abs(image_slice - expected_slice).max() < 0.1
def test_amused_512(self):
- pipe = AmusedInpaintPipeline.from_pretrained("huggingface/amused-512")
+ pipe = AmusedInpaintPipeline.from_pretrained("amused/amused-512")
pipe.to(torch_device)
image = (
@@ -242,9 +240,7 @@ class AmusedInpaintPipelineSlowTests(unittest.TestCase):
assert np.abs(image_slice - expected_slice).max() < 0.05
def test_amused_512_fp16(self):
- pipe = AmusedInpaintPipeline.from_pretrained(
- "huggingface/amused-512", variant="fp16", torch_dtype=torch.float16
- )
+ pipe = AmusedInpaintPipeline.from_pretrained("amused/amused-512", variant="fp16", torch_dtype=torch.float16)
pipe.to(torch_device)
image = (
diff --git a/tests/pipelines/controlnetxs/__init__.py b/tests/pipelines/controlnetxs/__init__.py
deleted file mode 100644
index e69de29bb2..0000000000
diff --git a/tests/pipelines/controlnetxs/test_controlnetxs.py b/tests/pipelines/controlnetxs/test_controlnetxs.py
deleted file mode 100644
index 1f184e5bb1..0000000000
--- a/tests/pipelines/controlnetxs/test_controlnetxs.py
+++ /dev/null
@@ -1,311 +0,0 @@
-# coding=utf-8
-# Copyright 2023 HuggingFace Inc.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import gc
-import traceback
-import unittest
-
-import numpy as np
-import torch
-from transformers import CLIPTextConfig, CLIPTextModel, CLIPTokenizer
-
-from diffusers import (
- AutoencoderKL,
- ControlNetXSModel,
- DDIMScheduler,
- LCMScheduler,
- StableDiffusionControlNetXSPipeline,
- UNet2DConditionModel,
-)
-from diffusers.utils.import_utils import is_xformers_available
-from diffusers.utils.testing_utils import (
- enable_full_determinism,
- load_image,
- load_numpy,
- numpy_cosine_similarity_distance,
- require_python39_or_higher,
- require_torch_2,
- require_torch_gpu,
- run_test_in_subprocess,
- slow,
- torch_device,
-)
-from diffusers.utils.torch_utils import randn_tensor
-
-from ..pipeline_params import (
- IMAGE_TO_IMAGE_IMAGE_PARAMS,
- TEXT_TO_IMAGE_BATCH_PARAMS,
- TEXT_TO_IMAGE_IMAGE_PARAMS,
- TEXT_TO_IMAGE_PARAMS,
-)
-from ..test_pipelines_common import (
- PipelineKarrasSchedulerTesterMixin,
- PipelineLatentTesterMixin,
- PipelineTesterMixin,
-)
-
-
-enable_full_determinism()
-
-
-# Will be run via run_test_in_subprocess
-def _test_stable_diffusion_compile(in_queue, out_queue, timeout):
- error = None
- try:
- _ = in_queue.get(timeout=timeout)
-
- controlnet = ControlNetXSModel.from_pretrained("UmerHA/ConrolNetXS-SD2.1-canny")
-
- pipe = StableDiffusionControlNetXSPipeline.from_pretrained(
- "stabilityai/stable-diffusion-2-1", safety_checker=None, controlnet=controlnet
- )
- pipe.to("cuda")
- pipe.set_progress_bar_config(disable=None)
-
- pipe.unet.to(memory_format=torch.channels_last)
- pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
-
- pipe.controlnet.to(memory_format=torch.channels_last)
- pipe.controlnet = torch.compile(pipe.controlnet, mode="reduce-overhead", fullgraph=True)
-
- generator = torch.Generator(device="cpu").manual_seed(0)
- prompt = "bird"
- image = load_image(
- "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/bird_canny.png"
- ).resize((512, 512))
-
- output = pipe(prompt, image, num_inference_steps=10, generator=generator, output_type="np")
- image = output.images[0]
-
- assert image.shape == (512, 512, 3)
-
- expected_image = load_numpy(
- "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/bird_canny_out_full.npy"
- )
- expected_image = np.resize(expected_image, (512, 512, 3))
-
- assert np.abs(expected_image - image).max() < 1.0
-
- except Exception:
- error = f"{traceback.format_exc()}"
-
- results = {"error": error}
- out_queue.put(results, timeout=timeout)
- out_queue.join()
-
-
-class ControlNetXSPipelineFastTests(
- PipelineLatentTesterMixin, PipelineKarrasSchedulerTesterMixin, PipelineTesterMixin, unittest.TestCase
-):
- pipeline_class = StableDiffusionControlNetXSPipeline
- params = TEXT_TO_IMAGE_PARAMS
- batch_params = TEXT_TO_IMAGE_BATCH_PARAMS
- image_params = IMAGE_TO_IMAGE_IMAGE_PARAMS
- image_latents_params = TEXT_TO_IMAGE_IMAGE_PARAMS
-
- def get_dummy_components(self, time_cond_proj_dim=None):
- torch.manual_seed(0)
- unet = UNet2DConditionModel(
- block_out_channels=(4, 8),
- layers_per_block=2,
- sample_size=32,
- in_channels=4,
- out_channels=4,
- down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
- up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
- cross_attention_dim=32,
- norm_num_groups=1,
- time_cond_proj_dim=time_cond_proj_dim,
- )
- torch.manual_seed(0)
- controlnet = ControlNetXSModel.from_unet(
- unet=unet,
- time_embedding_mix=0.95,
- learn_embedding=True,
- size_ratio=0.5,
- conditioning_embedding_out_channels=(16, 32),
- num_attention_heads=2,
- )
- torch.manual_seed(0)
- scheduler = DDIMScheduler(
- beta_start=0.00085,
- beta_end=0.012,
- beta_schedule="scaled_linear",
- clip_sample=False,
- set_alpha_to_one=False,
- )
- torch.manual_seed(0)
- vae = AutoencoderKL(
- block_out_channels=[4, 8],
- in_channels=3,
- out_channels=3,
- down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
- up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
- latent_channels=4,
- norm_num_groups=2,
- )
- torch.manual_seed(0)
- text_encoder_config = CLIPTextConfig(
- bos_token_id=0,
- eos_token_id=2,
- hidden_size=32,
- intermediate_size=37,
- layer_norm_eps=1e-05,
- num_attention_heads=4,
- num_hidden_layers=5,
- pad_token_id=1,
- vocab_size=1000,
- )
- text_encoder = CLIPTextModel(text_encoder_config)
- tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
-
- components = {
- "unet": unet,
- "controlnet": controlnet,
- "scheduler": scheduler,
- "vae": vae,
- "text_encoder": text_encoder,
- "tokenizer": tokenizer,
- "safety_checker": None,
- "feature_extractor": None,
- }
- return components
-
- def get_dummy_inputs(self, device, seed=0):
- if str(device).startswith("mps"):
- generator = torch.manual_seed(seed)
- else:
- generator = torch.Generator(device=device).manual_seed(seed)
-
- controlnet_embedder_scale_factor = 2
- image = randn_tensor(
- (1, 3, 32 * controlnet_embedder_scale_factor, 32 * controlnet_embedder_scale_factor),
- generator=generator,
- device=torch.device(device),
- )
-
- inputs = {
- "prompt": "A painting of a squirrel eating a burger",
- "generator": generator,
- "num_inference_steps": 2,
- "guidance_scale": 6.0,
- "output_type": "numpy",
- "image": image,
- }
-
- return inputs
-
- def test_attention_slicing_forward_pass(self):
- return self._test_attention_slicing_forward_pass(expected_max_diff=2e-3)
-
- @unittest.skipIf(
- torch_device != "cuda" or not is_xformers_available(),
- reason="XFormers attention is only available with CUDA and `xformers` installed",
- )
- def test_xformers_attention_forwardGenerator_pass(self):
- self._test_xformers_attention_forwardGenerator_pass(expected_max_diff=2e-3)
-
- def test_inference_batch_single_identical(self):
- self._test_inference_batch_single_identical(expected_max_diff=2e-3)
-
- def test_controlnet_lcm(self):
- device = "cpu" # ensure determinism for the device-dependent torch.Generator
-
- components = self.get_dummy_components(time_cond_proj_dim=256)
- sd_pipe = StableDiffusionControlNetXSPipeline(**components)
- sd_pipe.scheduler = LCMScheduler.from_config(sd_pipe.scheduler.config)
- sd_pipe = sd_pipe.to(torch_device)
- sd_pipe.set_progress_bar_config(disable=None)
-
- inputs = self.get_dummy_inputs(device)
- output = sd_pipe(**inputs)
- image = output.images
-
- image_slice = image[0, -3:, -3:, -1]
-
- assert image.shape == (1, 64, 64, 3)
- expected_slice = np.array(
- [0.52700454, 0.3930534, 0.25509018, 0.7132304, 0.53696585, 0.46568912, 0.7095368, 0.7059624, 0.4744786]
- )
-
- assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
-
-
-@slow
-@require_torch_gpu
-class ControlNetXSPipelineSlowTests(unittest.TestCase):
- def tearDown(self):
- super().tearDown()
- gc.collect()
- torch.cuda.empty_cache()
-
- def test_canny(self):
- controlnet = ControlNetXSModel.from_pretrained("UmerHA/ConrolNetXS-SD2.1-canny")
-
- pipe = StableDiffusionControlNetXSPipeline.from_pretrained(
- "stabilityai/stable-diffusion-2-1", safety_checker=None, controlnet=controlnet
- )
- pipe.enable_model_cpu_offload()
- pipe.set_progress_bar_config(disable=None)
-
- generator = torch.Generator(device="cpu").manual_seed(0)
- prompt = "bird"
- image = load_image(
- "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/bird_canny.png"
- )
-
- output = pipe(prompt, image, generator=generator, output_type="np", num_inference_steps=3)
-
- image = output.images[0]
-
- assert image.shape == (768, 512, 3)
-
- original_image = image[-3:, -3:, -1].flatten()
- expected_image = np.array([0.1274, 0.1401, 0.147, 0.1185, 0.1555, 0.1492, 0.1565, 0.1474, 0.1701])
-
- max_diff = numpy_cosine_similarity_distance(original_image, expected_image)
- assert max_diff < 1e-4
-
- def test_depth(self):
- controlnet = ControlNetXSModel.from_pretrained("UmerHA/ConrolNetXS-SD2.1-depth")
-
- pipe = StableDiffusionControlNetXSPipeline.from_pretrained(
- "stabilityai/stable-diffusion-2-1", safety_checker=None, controlnet=controlnet
- )
- pipe.enable_model_cpu_offload()
- pipe.set_progress_bar_config(disable=None)
-
- generator = torch.Generator(device="cpu").manual_seed(0)
- prompt = "Stormtrooper's lecture"
- image = load_image(
- "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/stormtrooper_depth.png"
- )
-
- output = pipe(prompt, image, generator=generator, output_type="np", num_inference_steps=3)
-
- image = output.images[0]
-
- assert image.shape == (512, 512, 3)
-
- original_image = image[-3:, -3:, -1].flatten()
- expected_image = np.array([0.1098, 0.1025, 0.1211, 0.1129, 0.1165, 0.1262, 0.1185, 0.1261, 0.1703])
-
- max_diff = numpy_cosine_similarity_distance(original_image, expected_image)
- assert max_diff < 1e-4
-
- @require_python39_or_higher
- @require_torch_2
- def test_stable_diffusion_compile(self):
- run_test_in_subprocess(test_case=self, target_func=_test_stable_diffusion_compile, inputs=None)
diff --git a/tests/pipelines/controlnetxs/test_controlnetxs_sdxl.py b/tests/pipelines/controlnetxs/test_controlnetxs_sdxl.py
deleted file mode 100644
index dbdc532a6f..0000000000
--- a/tests/pipelines/controlnetxs/test_controlnetxs_sdxl.py
+++ /dev/null
@@ -1,362 +0,0 @@
-# coding=utf-8
-# Copyright 2023 HuggingFace Inc.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import gc
-import unittest
-
-import numpy as np
-import torch
-from transformers import CLIPTextConfig, CLIPTextModel, CLIPTextModelWithProjection, CLIPTokenizer
-
-from diffusers import (
- AutoencoderKL,
- ControlNetXSModel,
- EulerDiscreteScheduler,
- StableDiffusionXLControlNetXSPipeline,
- UNet2DConditionModel,
-)
-from diffusers.utils.import_utils import is_xformers_available
-from diffusers.utils.testing_utils import enable_full_determinism, load_image, require_torch_gpu, slow, torch_device
-from diffusers.utils.torch_utils import randn_tensor
-
-from ..pipeline_params import (
- IMAGE_TO_IMAGE_IMAGE_PARAMS,
- TEXT_TO_IMAGE_BATCH_PARAMS,
- TEXT_TO_IMAGE_IMAGE_PARAMS,
- TEXT_TO_IMAGE_PARAMS,
-)
-from ..test_pipelines_common import (
- PipelineKarrasSchedulerTesterMixin,
- PipelineLatentTesterMixin,
- PipelineTesterMixin,
- SDXLOptionalComponentsTesterMixin,
-)
-
-
-enable_full_determinism()
-
-
-class StableDiffusionXLControlNetXSPipelineFastTests(
- PipelineLatentTesterMixin,
- PipelineKarrasSchedulerTesterMixin,
- PipelineTesterMixin,
- SDXLOptionalComponentsTesterMixin,
- unittest.TestCase,
-):
- pipeline_class = StableDiffusionXLControlNetXSPipeline
- params = TEXT_TO_IMAGE_PARAMS
- batch_params = TEXT_TO_IMAGE_BATCH_PARAMS
- image_params = IMAGE_TO_IMAGE_IMAGE_PARAMS
- image_latents_params = TEXT_TO_IMAGE_IMAGE_PARAMS
-
- def get_dummy_components(self):
- torch.manual_seed(0)
- unet = UNet2DConditionModel(
- block_out_channels=(32, 64),
- layers_per_block=2,
- sample_size=32,
- in_channels=4,
- out_channels=4,
- down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
- up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
- # SD2-specific config below
- attention_head_dim=(2, 4),
- use_linear_projection=True,
- addition_embed_type="text_time",
- addition_time_embed_dim=8,
- transformer_layers_per_block=(1, 2),
- projection_class_embeddings_input_dim=80, # 6 * 8 + 32
- cross_attention_dim=64,
- )
- torch.manual_seed(0)
- controlnet = ControlNetXSModel.from_unet(
- unet,
- time_embedding_mix=0.95,
- learn_embedding=True,
- size_ratio=0.5,
- conditioning_embedding_out_channels=(16, 32),
- )
- torch.manual_seed(0)
- scheduler = EulerDiscreteScheduler(
- beta_start=0.00085,
- beta_end=0.012,
- steps_offset=1,
- beta_schedule="scaled_linear",
- timestep_spacing="leading",
- )
- torch.manual_seed(0)
- vae = AutoencoderKL(
- block_out_channels=[32, 64],
- in_channels=3,
- out_channels=3,
- down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
- up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
- latent_channels=4,
- )
- torch.manual_seed(0)
- text_encoder_config = CLIPTextConfig(
- bos_token_id=0,
- eos_token_id=2,
- hidden_size=32,
- intermediate_size=37,
- layer_norm_eps=1e-05,
- num_attention_heads=4,
- num_hidden_layers=5,
- pad_token_id=1,
- vocab_size=1000,
- # SD2-specific config below
- hidden_act="gelu",
- projection_dim=32,
- )
- text_encoder = CLIPTextModel(text_encoder_config)
- tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
-
- text_encoder_2 = CLIPTextModelWithProjection(text_encoder_config)
- tokenizer_2 = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
-
- components = {
- "unet": unet,
- "controlnet": controlnet,
- "scheduler": scheduler,
- "vae": vae,
- "text_encoder": text_encoder,
- "tokenizer": tokenizer,
- "text_encoder_2": text_encoder_2,
- "tokenizer_2": tokenizer_2,
- }
- return components
-
- # copied from test_controlnet_sdxl.py
- def get_dummy_inputs(self, device, seed=0):
- if str(device).startswith("mps"):
- generator = torch.manual_seed(seed)
- else:
- generator = torch.Generator(device=device).manual_seed(seed)
-
- controlnet_embedder_scale_factor = 2
- image = randn_tensor(
- (1, 3, 32 * controlnet_embedder_scale_factor, 32 * controlnet_embedder_scale_factor),
- generator=generator,
- device=torch.device(device),
- )
-
- inputs = {
- "prompt": "A painting of a squirrel eating a burger",
- "generator": generator,
- "num_inference_steps": 2,
- "guidance_scale": 6.0,
- "output_type": "np",
- "image": image,
- }
-
- return inputs
-
- # copied from test_controlnet_sdxl.py
- def test_attention_slicing_forward_pass(self):
- return self._test_attention_slicing_forward_pass(expected_max_diff=2e-3)
-
- # copied from test_controlnet_sdxl.py
- @unittest.skipIf(
- torch_device != "cuda" or not is_xformers_available(),
- reason="XFormers attention is only available with CUDA and `xformers` installed",
- )
- def test_xformers_attention_forwardGenerator_pass(self):
- self._test_xformers_attention_forwardGenerator_pass(expected_max_diff=2e-3)
-
- # copied from test_controlnet_sdxl.py
- def test_inference_batch_single_identical(self):
- self._test_inference_batch_single_identical(expected_max_diff=2e-3)
-
- # copied from test_controlnet_sdxl.py
- def test_save_load_optional_components(self):
- self._test_save_load_optional_components()
-
- # copied from test_controlnet_sdxl.py
- @require_torch_gpu
- def test_stable_diffusion_xl_offloads(self):
- pipes = []
- components = self.get_dummy_components()
- sd_pipe = self.pipeline_class(**components).to(torch_device)
- pipes.append(sd_pipe)
-
- components = self.get_dummy_components()
- sd_pipe = self.pipeline_class(**components)
- sd_pipe.enable_model_cpu_offload()
- pipes.append(sd_pipe)
-
- components = self.get_dummy_components()
- sd_pipe = self.pipeline_class(**components)
- sd_pipe.enable_sequential_cpu_offload()
- pipes.append(sd_pipe)
-
- image_slices = []
- for pipe in pipes:
- pipe.unet.set_default_attn_processor()
-
- inputs = self.get_dummy_inputs(torch_device)
- image = pipe(**inputs).images
-
- image_slices.append(image[0, -3:, -3:, -1].flatten())
-
- assert np.abs(image_slices[0] - image_slices[1]).max() < 1e-3
- assert np.abs(image_slices[0] - image_slices[2]).max() < 1e-3
-
- # copied from test_controlnet_sdxl.py
- def test_stable_diffusion_xl_multi_prompts(self):
- components = self.get_dummy_components()
- sd_pipe = self.pipeline_class(**components).to(torch_device)
-
- # forward with single prompt
- inputs = self.get_dummy_inputs(torch_device)
- output = sd_pipe(**inputs)
- image_slice_1 = output.images[0, -3:, -3:, -1]
-
- # forward with same prompt duplicated
- inputs = self.get_dummy_inputs(torch_device)
- inputs["prompt_2"] = inputs["prompt"]
- output = sd_pipe(**inputs)
- image_slice_2 = output.images[0, -3:, -3:, -1]
-
- # ensure the results are equal
- assert np.abs(image_slice_1.flatten() - image_slice_2.flatten()).max() < 1e-4
-
- # forward with different prompt
- inputs = self.get_dummy_inputs(torch_device)
- inputs["prompt_2"] = "different prompt"
- output = sd_pipe(**inputs)
- image_slice_3 = output.images[0, -3:, -3:, -1]
-
- # ensure the results are not equal
- assert np.abs(image_slice_1.flatten() - image_slice_3.flatten()).max() > 1e-4
-
- # manually set a negative_prompt
- inputs = self.get_dummy_inputs(torch_device)
- inputs["negative_prompt"] = "negative prompt"
- output = sd_pipe(**inputs)
- image_slice_1 = output.images[0, -3:, -3:, -1]
-
- # forward with same negative_prompt duplicated
- inputs = self.get_dummy_inputs(torch_device)
- inputs["negative_prompt"] = "negative prompt"
- inputs["negative_prompt_2"] = inputs["negative_prompt"]
- output = sd_pipe(**inputs)
- image_slice_2 = output.images[0, -3:, -3:, -1]
-
- # ensure the results are equal
- assert np.abs(image_slice_1.flatten() - image_slice_2.flatten()).max() < 1e-4
-
- # forward with different negative_prompt
- inputs = self.get_dummy_inputs(torch_device)
- inputs["negative_prompt"] = "negative prompt"
- inputs["negative_prompt_2"] = "different negative prompt"
- output = sd_pipe(**inputs)
- image_slice_3 = output.images[0, -3:, -3:, -1]
-
- # ensure the results are not equal
- assert np.abs(image_slice_1.flatten() - image_slice_3.flatten()).max() > 1e-4
-
- # copied from test_stable_diffusion_xl.py
- def test_stable_diffusion_xl_prompt_embeds(self):
- components = self.get_dummy_components()
- sd_pipe = self.pipeline_class(**components)
- sd_pipe = sd_pipe.to(torch_device)
- sd_pipe = sd_pipe.to(torch_device)
- sd_pipe.set_progress_bar_config(disable=None)
-
- # forward without prompt embeds
- inputs = self.get_dummy_inputs(torch_device)
- inputs["prompt"] = 2 * [inputs["prompt"]]
- inputs["num_images_per_prompt"] = 2
-
- output = sd_pipe(**inputs)
- image_slice_1 = output.images[0, -3:, -3:, -1]
-
- # forward with prompt embeds
- inputs = self.get_dummy_inputs(torch_device)
- prompt = 2 * [inputs.pop("prompt")]
-
- (
- prompt_embeds,
- negative_prompt_embeds,
- pooled_prompt_embeds,
- negative_pooled_prompt_embeds,
- ) = sd_pipe.encode_prompt(prompt)
-
- output = sd_pipe(
- **inputs,
- prompt_embeds=prompt_embeds,
- negative_prompt_embeds=negative_prompt_embeds,
- pooled_prompt_embeds=pooled_prompt_embeds,
- negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
- )
- image_slice_2 = output.images[0, -3:, -3:, -1]
-
- # make sure that it's equal
- assert np.abs(image_slice_1.flatten() - image_slice_2.flatten()).max() < 1.1e-4
-
-
-@slow
-@require_torch_gpu
-class ControlNetSDXLPipelineXSSlowTests(unittest.TestCase):
- def tearDown(self):
- super().tearDown()
- gc.collect()
- torch.cuda.empty_cache()
-
- def test_canny(self):
- controlnet = ControlNetXSModel.from_pretrained("UmerHA/ConrolNetXS-SDXL-canny")
-
- pipe = StableDiffusionXLControlNetXSPipeline.from_pretrained(
- "stabilityai/stable-diffusion-xl-base-1.0", controlnet=controlnet
- )
- pipe.enable_sequential_cpu_offload()
- pipe.set_progress_bar_config(disable=None)
-
- generator = torch.Generator(device="cpu").manual_seed(0)
- prompt = "bird"
- image = load_image(
- "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/bird_canny.png"
- )
-
- images = pipe(prompt, image=image, generator=generator, output_type="np", num_inference_steps=3).images
-
- assert images[0].shape == (768, 512, 3)
-
- original_image = images[0, -3:, -3:, -1].flatten()
- expected_image = np.array([0.4359, 0.4335, 0.4609, 0.4515, 0.4669, 0.4494, 0.452, 0.4493, 0.4382])
- assert np.allclose(original_image, expected_image, atol=1e-04)
-
- def test_depth(self):
- controlnet = ControlNetXSModel.from_pretrained("UmerHA/ConrolNetXS-SDXL-depth")
-
- pipe = StableDiffusionXLControlNetXSPipeline.from_pretrained(
- "stabilityai/stable-diffusion-xl-base-1.0", controlnet=controlnet
- )
- pipe.enable_sequential_cpu_offload()
- pipe.set_progress_bar_config(disable=None)
-
- generator = torch.Generator(device="cpu").manual_seed(0)
- prompt = "Stormtrooper's lecture"
- image = load_image(
- "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/stormtrooper_depth.png"
- )
-
- images = pipe(prompt, image=image, generator=generator, output_type="np", num_inference_steps=3).images
-
- assert images[0].shape == (512, 512, 3)
-
- original_image = images[0, -3:, -3:, -1].flatten()
- expected_image = np.array([0.4411, 0.3617, 0.2654, 0.266, 0.3449, 0.3898, 0.3745, 0.353, 0.326])
- assert np.allclose(original_image, expected_image, atol=1e-04)
diff --git a/tests/pipelines/stable_diffusion/test_stable_diffusion.py b/tests/pipelines/stable_diffusion/test_stable_diffusion.py
index ac105d22fa..8854b482de 100644
--- a/tests/pipelines/stable_diffusion/test_stable_diffusion.py
+++ b/tests/pipelines/stable_diffusion/test_stable_diffusion.py
@@ -692,6 +692,58 @@ class StableDiffusionPipelineFastTests(
original_image_slice, image_slice_disabled, atol=1e-2, rtol=1e-2
), "Original outputs should match when fused QKV projections are disabled."
+ def test_pipeline_interrupt(self):
+ components = self.get_dummy_components()
+ sd_pipe = StableDiffusionPipeline(**components)
+ sd_pipe = sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ prompt = "hey"
+ num_inference_steps = 3
+
+ # store intermediate latents from the generation process
+ class PipelineState:
+ def __init__(self):
+ self.state = []
+
+ def apply(self, pipe, i, t, callback_kwargs):
+ self.state.append(callback_kwargs["latents"])
+ return callback_kwargs
+
+ pipe_state = PipelineState()
+ sd_pipe(
+ prompt,
+ num_inference_steps=num_inference_steps,
+ output_type="np",
+ generator=torch.Generator("cpu").manual_seed(0),
+ callback_on_step_end=pipe_state.apply,
+ ).images
+
+ # interrupt generation at step index
+ interrupt_step_idx = 1
+
+ def callback_on_step_end(pipe, i, t, callback_kwargs):
+ if i == interrupt_step_idx:
+ pipe._interrupt = True
+
+ return callback_kwargs
+
+ output_interrupted = sd_pipe(
+ prompt,
+ num_inference_steps=num_inference_steps,
+ output_type="latent",
+ generator=torch.Generator("cpu").manual_seed(0),
+ callback_on_step_end=callback_on_step_end,
+ ).images
+
+ # fetch intermediate latents at the interrupted step
+ # from the completed generation process
+ intermediate_latent = pipe_state.state[interrupt_step_idx]
+
+ # compare the intermediate latent to the output of the interrupted process
+ # they should be the same
+ assert torch.allclose(intermediate_latent, output_interrupted, atol=1e-4)
+
@slow
@require_torch_gpu
diff --git a/tests/pipelines/stable_diffusion/test_stable_diffusion_img2img.py b/tests/pipelines/stable_diffusion/test_stable_diffusion_img2img.py
index fb56d868f1..cd69b56e02 100644
--- a/tests/pipelines/stable_diffusion/test_stable_diffusion_img2img.py
+++ b/tests/pipelines/stable_diffusion/test_stable_diffusion_img2img.py
@@ -320,6 +320,62 @@ class StableDiffusionImg2ImgPipelineFastTests(
def test_float16_inference(self):
super().test_float16_inference(expected_max_diff=5e-1)
+ def test_pipeline_interrupt(self):
+ components = self.get_dummy_components()
+ sd_pipe = StableDiffusionImg2ImgPipeline(**components)
+ sd_pipe = sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(torch_device)
+
+ prompt = "hey"
+ num_inference_steps = 3
+
+ # store intermediate latents from the generation process
+ class PipelineState:
+ def __init__(self):
+ self.state = []
+
+ def apply(self, pipe, i, t, callback_kwargs):
+ self.state.append(callback_kwargs["latents"])
+ return callback_kwargs
+
+ pipe_state = PipelineState()
+ sd_pipe(
+ prompt,
+ image=inputs["image"],
+ num_inference_steps=num_inference_steps,
+ output_type="np",
+ generator=torch.Generator("cpu").manual_seed(0),
+ callback_on_step_end=pipe_state.apply,
+ ).images
+
+ # interrupt generation at step index
+ interrupt_step_idx = 1
+
+ def callback_on_step_end(pipe, i, t, callback_kwargs):
+ if i == interrupt_step_idx:
+ pipe._interrupt = True
+
+ return callback_kwargs
+
+ output_interrupted = sd_pipe(
+ prompt,
+ image=inputs["image"],
+ num_inference_steps=num_inference_steps,
+ output_type="latent",
+ generator=torch.Generator("cpu").manual_seed(0),
+ callback_on_step_end=callback_on_step_end,
+ ).images
+
+ # fetch intermediate latents at the interrupted step
+ # from the completed generation process
+ intermediate_latent = pipe_state.state[interrupt_step_idx]
+
+ # compare the intermediate latent to the output of the interrupted process
+ # they should be the same
+ assert torch.allclose(intermediate_latent, output_interrupted, atol=1e-4)
+
@slow
@require_torch_gpu
diff --git a/tests/pipelines/stable_diffusion/test_stable_diffusion_inpaint.py b/tests/pipelines/stable_diffusion/test_stable_diffusion_inpaint.py
index a69edb8696..fe664b21e2 100644
--- a/tests/pipelines/stable_diffusion/test_stable_diffusion_inpaint.py
+++ b/tests/pipelines/stable_diffusion/test_stable_diffusion_inpaint.py
@@ -319,6 +319,64 @@ class StableDiffusionInpaintPipelineFastTests(
out_1 = sd_pipe(**inputs).images
assert np.abs(out_0 - out_1).max() < 1e-2
+ def test_pipeline_interrupt(self):
+ components = self.get_dummy_components()
+ sd_pipe = StableDiffusionInpaintPipeline(**components)
+ sd_pipe = sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(torch_device)
+
+ prompt = "hey"
+ num_inference_steps = 3
+
+ # store intermediate latents from the generation process
+ class PipelineState:
+ def __init__(self):
+ self.state = []
+
+ def apply(self, pipe, i, t, callback_kwargs):
+ self.state.append(callback_kwargs["latents"])
+ return callback_kwargs
+
+ pipe_state = PipelineState()
+ sd_pipe(
+ prompt,
+ image=inputs["image"],
+ mask_image=inputs["mask_image"],
+ num_inference_steps=num_inference_steps,
+ output_type="np",
+ generator=torch.Generator("cpu").manual_seed(0),
+ callback_on_step_end=pipe_state.apply,
+ ).images
+
+ # interrupt generation at step index
+ interrupt_step_idx = 1
+
+ def callback_on_step_end(pipe, i, t, callback_kwargs):
+ if i == interrupt_step_idx:
+ pipe._interrupt = True
+
+ return callback_kwargs
+
+ output_interrupted = sd_pipe(
+ prompt,
+ image=inputs["image"],
+ mask_image=inputs["mask_image"],
+ num_inference_steps=num_inference_steps,
+ output_type="latent",
+ generator=torch.Generator("cpu").manual_seed(0),
+ callback_on_step_end=callback_on_step_end,
+ ).images
+
+ # fetch intermediate latents at the interrupted step
+ # from the completed generation process
+ intermediate_latent = pipe_state.state[interrupt_step_idx]
+
+ # compare the intermediate latent to the output of the interrupted process
+ # they should be the same
+ assert torch.allclose(intermediate_latent, output_interrupted, atol=1e-4)
+
class StableDiffusionSimpleInpaintPipelineFastTests(StableDiffusionInpaintPipelineFastTests):
pipeline_class = StableDiffusionInpaintPipeline
diff --git a/tests/pipelines/stable_diffusion_xl/test_stable_diffusion_xl.py b/tests/pipelines/stable_diffusion_xl/test_stable_diffusion_xl.py
index 280030d94b..80bff3663a 100644
--- a/tests/pipelines/stable_diffusion_xl/test_stable_diffusion_xl.py
+++ b/tests/pipelines/stable_diffusion_xl/test_stable_diffusion_xl.py
@@ -969,6 +969,58 @@ class StableDiffusionXLPipelineFastTests(
original_image_slice, image_slice_disabled, atol=1e-2, rtol=1e-2
), "Original outputs should match when fused QKV projections are disabled."
+ def test_pipeline_interrupt(self):
+ components = self.get_dummy_components()
+ sd_pipe = StableDiffusionXLPipeline(**components)
+ sd_pipe = sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ prompt = "hey"
+ num_inference_steps = 3
+
+ # store intermediate latents from the generation process
+ class PipelineState:
+ def __init__(self):
+ self.state = []
+
+ def apply(self, pipe, i, t, callback_kwargs):
+ self.state.append(callback_kwargs["latents"])
+ return callback_kwargs
+
+ pipe_state = PipelineState()
+ sd_pipe(
+ prompt,
+ num_inference_steps=num_inference_steps,
+ output_type="np",
+ generator=torch.Generator("cpu").manual_seed(0),
+ callback_on_step_end=pipe_state.apply,
+ ).images
+
+ # interrupt generation at step index
+ interrupt_step_idx = 1
+
+ def callback_on_step_end(pipe, i, t, callback_kwargs):
+ if i == interrupt_step_idx:
+ pipe._interrupt = True
+
+ return callback_kwargs
+
+ output_interrupted = sd_pipe(
+ prompt,
+ num_inference_steps=num_inference_steps,
+ output_type="latent",
+ generator=torch.Generator("cpu").manual_seed(0),
+ callback_on_step_end=callback_on_step_end,
+ ).images
+
+ # fetch intermediate latents at the interrupted step
+ # from the completed generation process
+ intermediate_latent = pipe_state.state[interrupt_step_idx]
+
+ # compare the intermediate latent to the output of the interrupted process
+ # they should be the same
+ assert torch.allclose(intermediate_latent, output_interrupted, atol=1e-4)
+
@slow
class StableDiffusionXLPipelineIntegrationTests(unittest.TestCase):
diff --git a/tests/pipelines/stable_diffusion_xl/test_stable_diffusion_xl_img2img.py b/tests/pipelines/stable_diffusion_xl/test_stable_diffusion_xl_img2img.py
index 7cad3fff0a..0a7d4d0de4 100644
--- a/tests/pipelines/stable_diffusion_xl/test_stable_diffusion_xl_img2img.py
+++ b/tests/pipelines/stable_diffusion_xl/test_stable_diffusion_xl_img2img.py
@@ -439,6 +439,64 @@ class StableDiffusionXLImg2ImgPipelineFastTests(PipelineLatentTesterMixin, Pipel
> 1e-4
)
+ def test_pipeline_interrupt(self):
+ components = self.get_dummy_components()
+ sd_pipe = StableDiffusionXLImg2ImgPipeline(**components)
+ sd_pipe = sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(torch_device)
+
+ prompt = "hey"
+ num_inference_steps = 5
+
+ # store intermediate latents from the generation process
+ class PipelineState:
+ def __init__(self):
+ self.state = []
+
+ def apply(self, pipe, i, t, callback_kwargs):
+ self.state.append(callback_kwargs["latents"])
+ return callback_kwargs
+
+ pipe_state = PipelineState()
+ sd_pipe(
+ prompt,
+ image=inputs["image"],
+ strength=0.8,
+ num_inference_steps=num_inference_steps,
+ output_type="np",
+ generator=torch.Generator("cpu").manual_seed(0),
+ callback_on_step_end=pipe_state.apply,
+ ).images
+
+ # interrupt generation at step index
+ interrupt_step_idx = 1
+
+ def callback_on_step_end(pipe, i, t, callback_kwargs):
+ if i == interrupt_step_idx:
+ pipe._interrupt = True
+
+ return callback_kwargs
+
+ output_interrupted = sd_pipe(
+ prompt,
+ image=inputs["image"],
+ strength=0.8,
+ num_inference_steps=num_inference_steps,
+ output_type="latent",
+ generator=torch.Generator("cpu").manual_seed(0),
+ callback_on_step_end=callback_on_step_end,
+ ).images
+
+ # fetch intermediate latents at the interrupted step
+ # from the completed generation process
+ intermediate_latent = pipe_state.state[interrupt_step_idx]
+
+ # compare the intermediate latent to the output of the interrupted process
+ # they should be the same
+ assert torch.allclose(intermediate_latent, output_interrupted, atol=1e-4)
+
class StableDiffusionXLImg2ImgRefinerOnlyPipelineFastTests(
PipelineLatentTesterMixin, PipelineTesterMixin, SDXLOptionalComponentsTesterMixin, unittest.TestCase
diff --git a/tests/pipelines/stable_diffusion_xl/test_stable_diffusion_xl_inpaint.py b/tests/pipelines/stable_diffusion_xl/test_stable_diffusion_xl_inpaint.py
index 4a2798b3ed..27fb224fb0 100644
--- a/tests/pipelines/stable_diffusion_xl/test_stable_diffusion_xl_inpaint.py
+++ b/tests/pipelines/stable_diffusion_xl/test_stable_diffusion_xl_inpaint.py
@@ -746,3 +746,63 @@ class StableDiffusionXLInpaintPipelineFastTests(PipelineLatentTesterMixin, Pipel
image_slice1 = images[0, -3:, -3:, -1]
image_slice2 = images[1, -3:, -3:, -1]
assert np.abs(image_slice1.flatten() - image_slice2.flatten()).max() > 1e-2
+
+ def test_pipeline_interrupt(self):
+ components = self.get_dummy_components()
+ sd_pipe = StableDiffusionXLInpaintPipeline(**components)
+ sd_pipe = sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(torch_device)
+
+ prompt = "hey"
+ num_inference_steps = 5
+
+ # store intermediate latents from the generation process
+ class PipelineState:
+ def __init__(self):
+ self.state = []
+
+ def apply(self, pipe, i, t, callback_kwargs):
+ self.state.append(callback_kwargs["latents"])
+ return callback_kwargs
+
+ pipe_state = PipelineState()
+ sd_pipe(
+ prompt,
+ image=inputs["image"],
+ mask_image=inputs["mask_image"],
+ strength=0.8,
+ num_inference_steps=num_inference_steps,
+ output_type="np",
+ generator=torch.Generator("cpu").manual_seed(0),
+ callback_on_step_end=pipe_state.apply,
+ ).images
+
+ # interrupt generation at step index
+ interrupt_step_idx = 1
+
+ def callback_on_step_end(pipe, i, t, callback_kwargs):
+ if i == interrupt_step_idx:
+ pipe._interrupt = True
+
+ return callback_kwargs
+
+ output_interrupted = sd_pipe(
+ prompt,
+ image=inputs["image"],
+ mask_image=inputs["mask_image"],
+ strength=0.8,
+ num_inference_steps=num_inference_steps,
+ output_type="latent",
+ generator=torch.Generator("cpu").manual_seed(0),
+ callback_on_step_end=callback_on_step_end,
+ ).images
+
+ # fetch intermediate latents at the interrupted step
+ # from the completed generation process
+ intermediate_latent = pipe_state.state[interrupt_step_idx]
+
+ # compare the intermediate latent to the output of the interrupted process
+ # they should be the same
+ assert torch.allclose(intermediate_latent, output_interrupted, atol=1e-4)
diff --git a/tests/schedulers/test_scheduler_ddim_inverse.py b/tests/schedulers/test_scheduler_ddim_inverse.py
index ab6596b98b..696f57644a 100644
--- a/tests/schedulers/test_scheduler_ddim_inverse.py
+++ b/tests/schedulers/test_scheduler_ddim_inverse.py
@@ -7,7 +7,7 @@ from .test_schedulers import SchedulerCommonTest
class DDIMInverseSchedulerTest(SchedulerCommonTest):
scheduler_classes = (DDIMInverseScheduler,)
- forward_default_kwargs = (("eta", 0.0), ("num_inference_steps", 50))
+ forward_default_kwargs = (("num_inference_steps", 50),)
def get_scheduler_config(self, **kwargs):
config = {
@@ -26,7 +26,7 @@ class DDIMInverseSchedulerTest(SchedulerCommonTest):
scheduler_config = self.get_scheduler_config(**config)
scheduler = scheduler_class(**scheduler_config)
- num_inference_steps, eta = 10, 0.0
+ num_inference_steps = 10
model = self.dummy_model()
sample = self.dummy_sample_deter
@@ -35,7 +35,7 @@ class DDIMInverseSchedulerTest(SchedulerCommonTest):
for t in scheduler.timesteps:
residual = model(sample, t)
- sample = scheduler.step(residual, t, sample, eta).prev_sample
+ sample = scheduler.step(residual, t, sample).prev_sample
return sample
diff --git a/tests/schedulers/test_scheduler_ddpm.py b/tests/schedulers/test_scheduler_ddpm.py
index 4e2a3c74d8..056b5d8335 100644
--- a/tests/schedulers/test_scheduler_ddpm.py
+++ b/tests/schedulers/test_scheduler_ddpm.py
@@ -68,6 +68,10 @@ class DDPMSchedulerTest(SchedulerCommonTest):
assert torch.sum(torch.abs(scheduler._get_variance(487) - 0.00979)) < 1e-5
assert torch.sum(torch.abs(scheduler._get_variance(999) - 0.02)) < 1e-5
+ def test_rescale_betas_zero_snr(self):
+ for rescale_betas_zero_snr in [True, False]:
+ self.check_over_configs(rescale_betas_zero_snr=rescale_betas_zero_snr)
+
def test_full_loop_no_noise(self):
scheduler_class = self.scheduler_classes[0]
scheduler_config = self.get_scheduler_config()
diff --git a/tests/schedulers/test_scheduler_ddpm_parallel.py b/tests/schedulers/test_scheduler_ddpm_parallel.py
index b25f7151e1..4c33c090b0 100644
--- a/tests/schedulers/test_scheduler_ddpm_parallel.py
+++ b/tests/schedulers/test_scheduler_ddpm_parallel.py
@@ -82,6 +82,10 @@ class DDPMParallelSchedulerTest(SchedulerCommonTest):
assert torch.sum(torch.abs(scheduler._get_variance(487) - 0.00979)) < 1e-5
assert torch.sum(torch.abs(scheduler._get_variance(999) - 0.02)) < 1e-5
+ def test_rescale_betas_zero_snr(self):
+ for rescale_betas_zero_snr in [True, False]:
+ self.check_over_configs(rescale_betas_zero_snr=rescale_betas_zero_snr)
+
def test_batch_step_no_noise(self):
scheduler_class = self.scheduler_classes[0]
scheduler_config = self.get_scheduler_config()
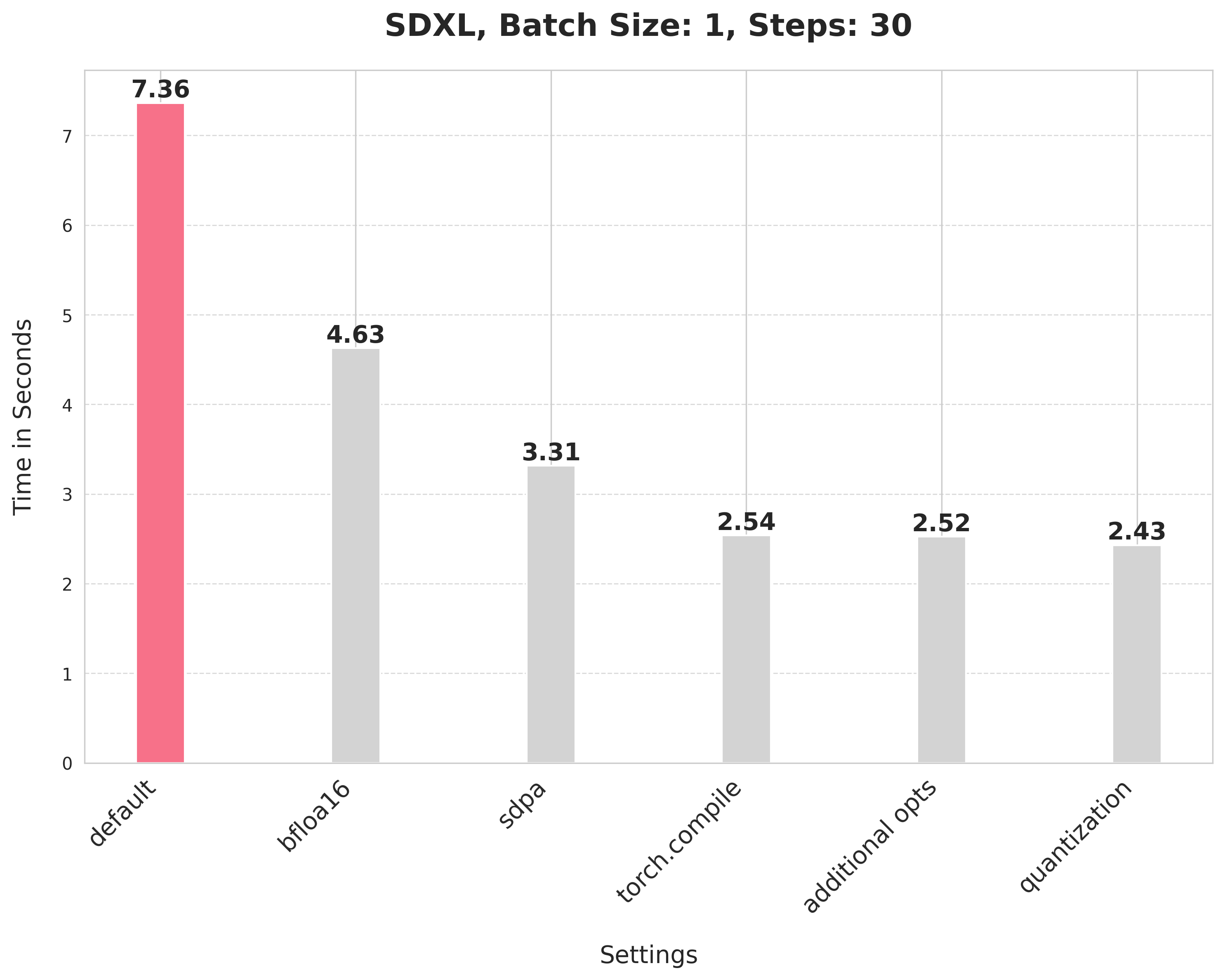 +
+
+
+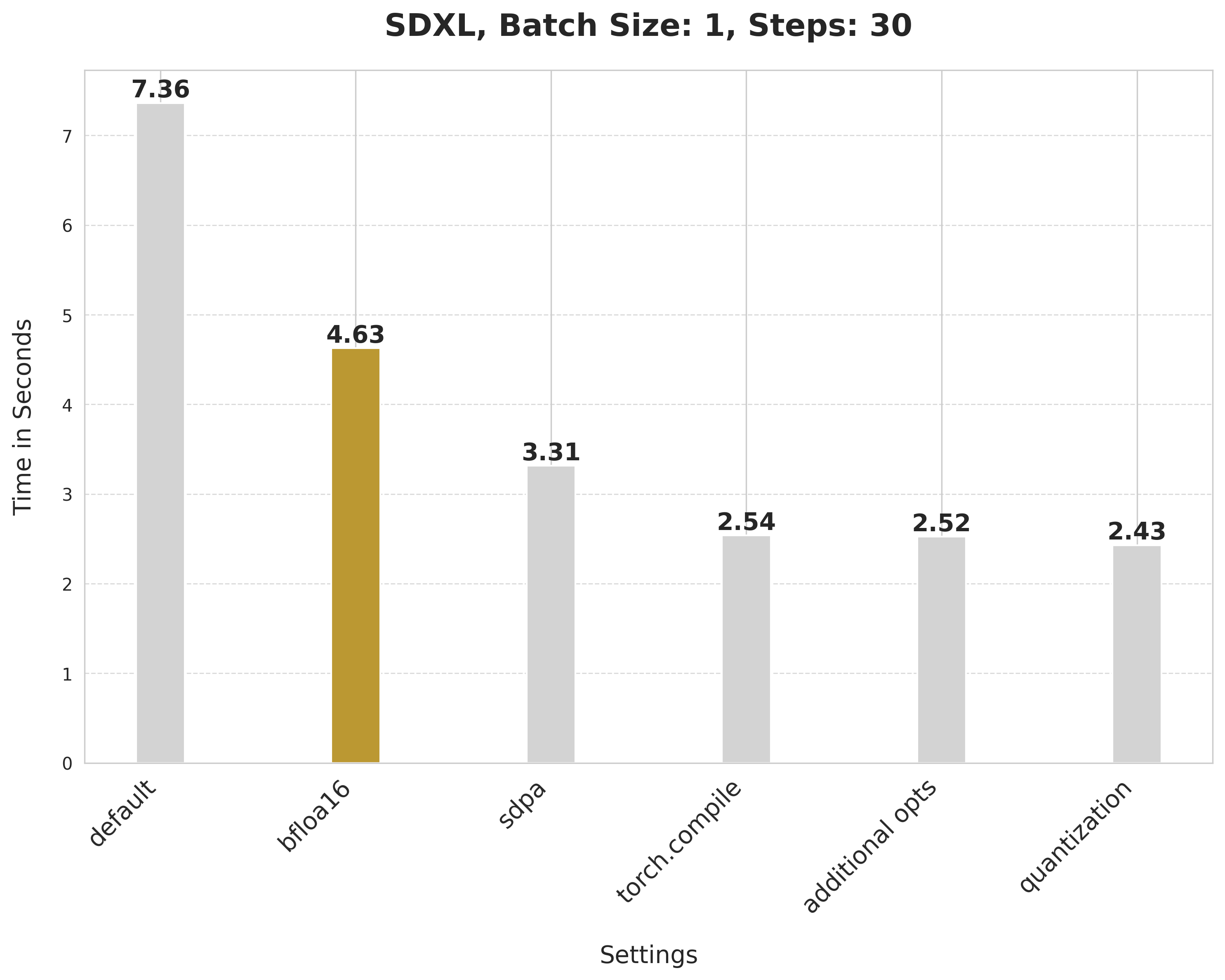 +
+
+
+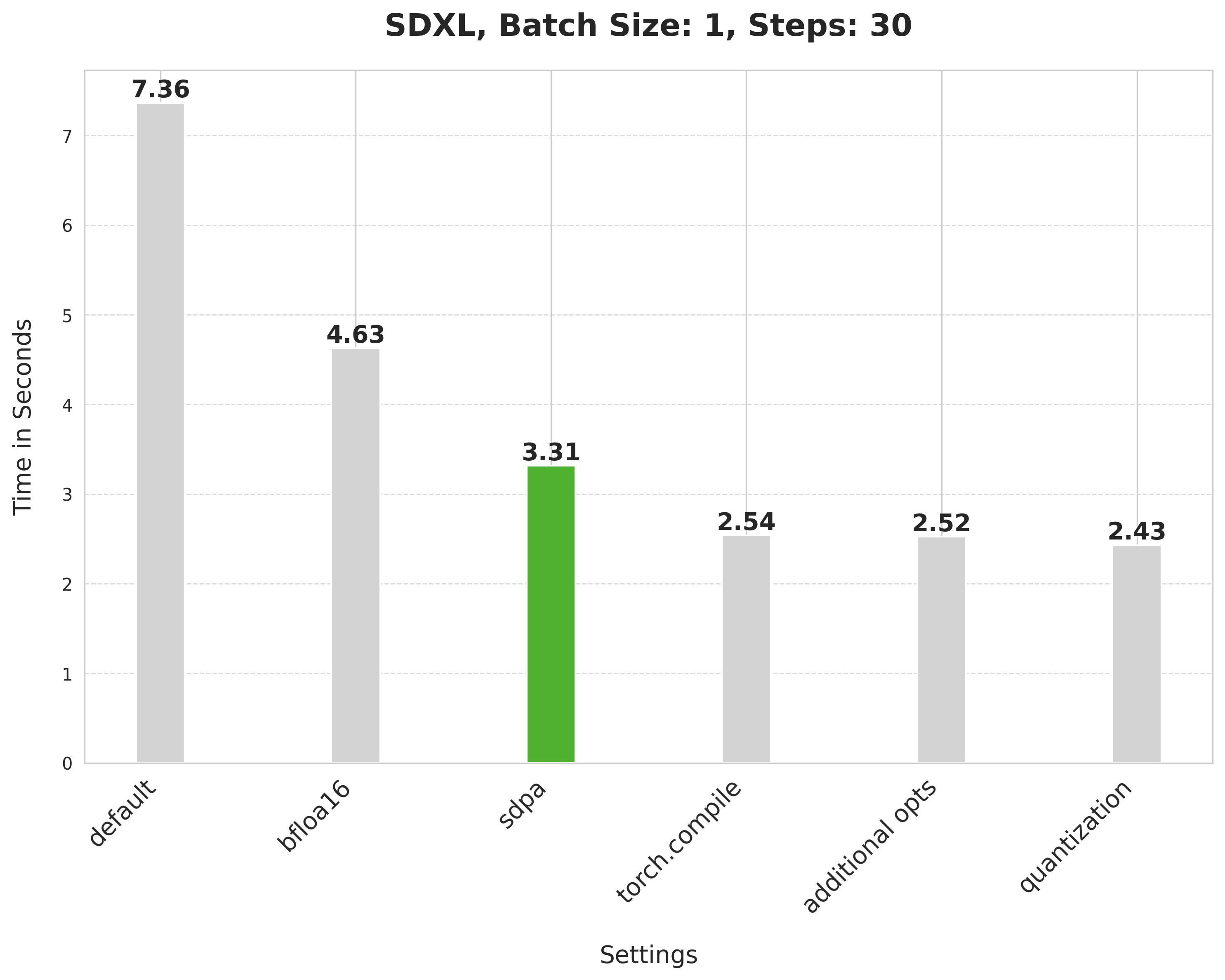 +
+
+
+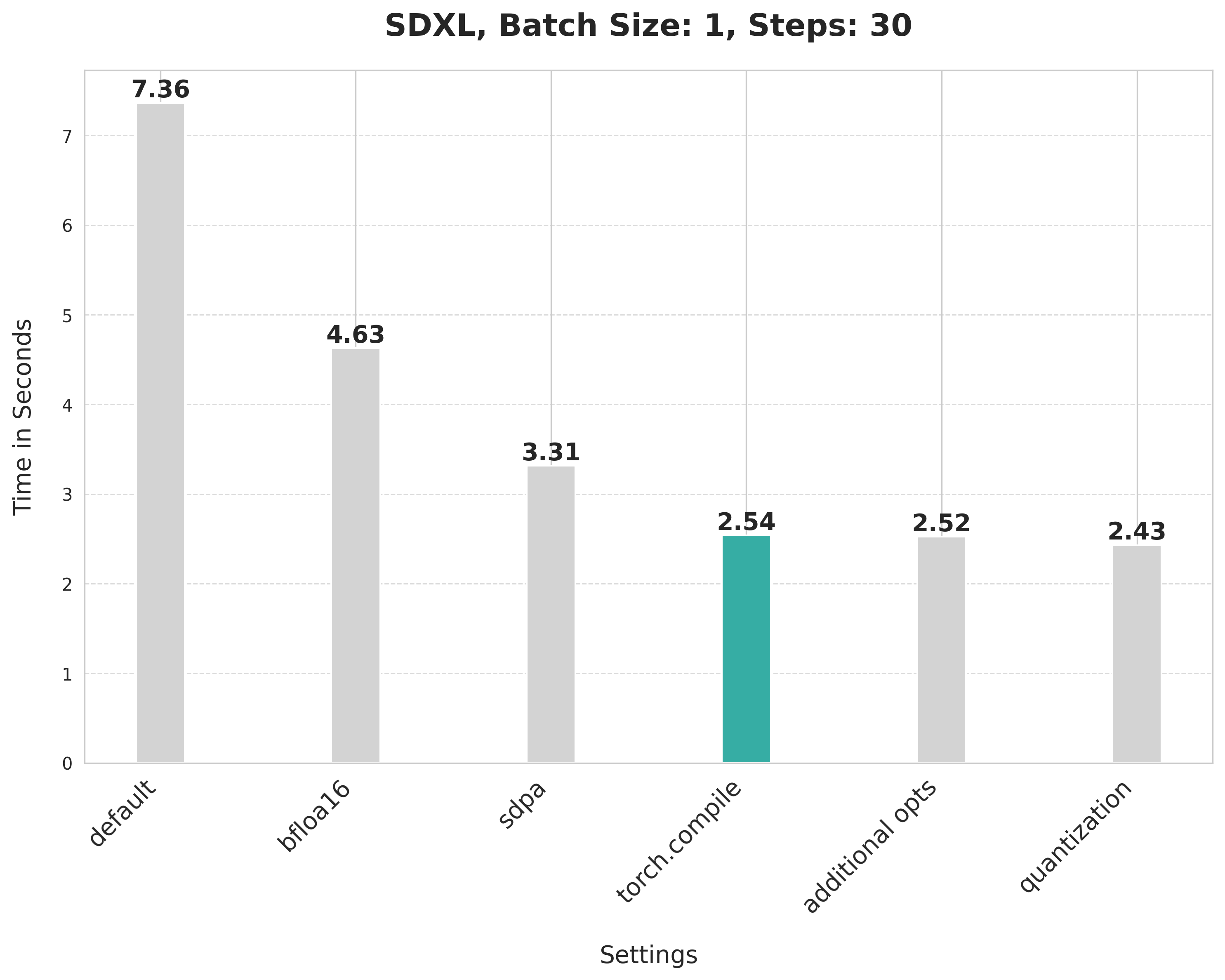 +
+
+
+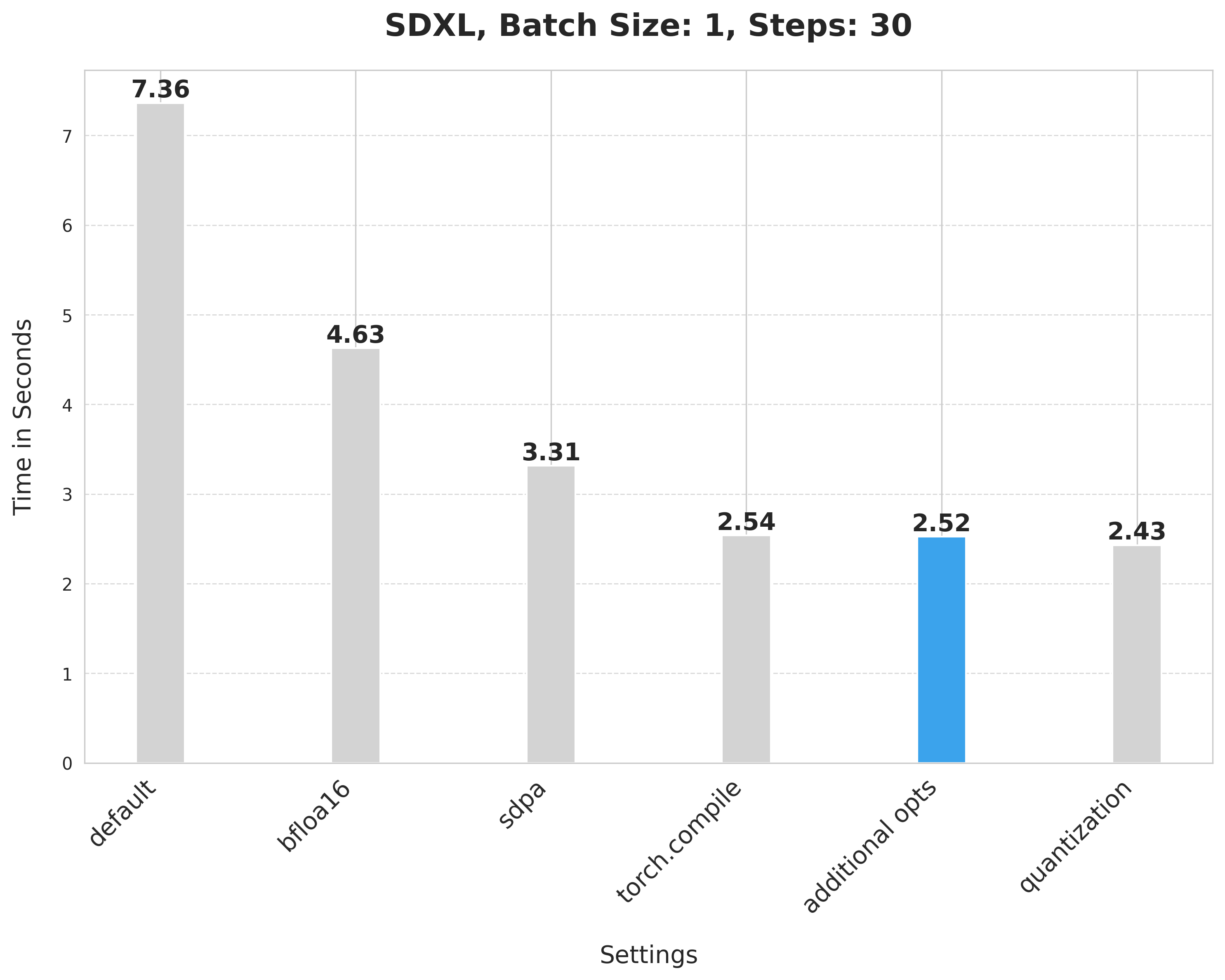 +
+
+
+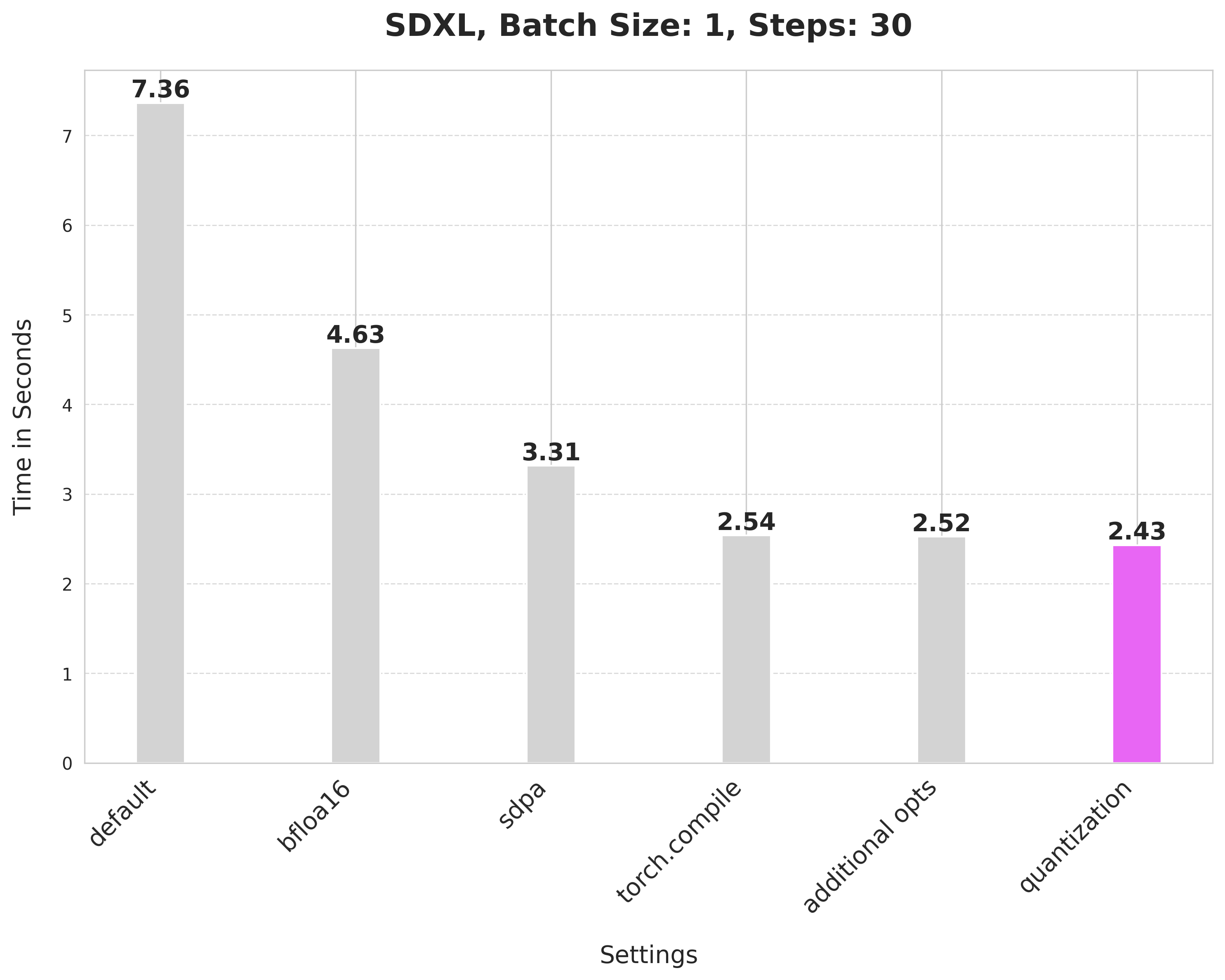 +
+
+
+