 +
+ + Figure from DDPM paper (https://arxiv.org/abs/2006.11239). +
+
+
+ Figure from DDPM paper (https://arxiv.org/abs/2006.11239).
+
+ **Schedulers**: Algorithm class for both **inference** and **training**. The class provides functionality to compute previous image according to alpha, beta schedule as well as predict noise for training. *Examples*: [DDPM](https://arxiv.org/abs/2006.11239), [DDIM](https://arxiv.org/abs/2010.02502), [PNDM](https://arxiv.org/abs/2202.09778), [DEIS](https://arxiv.org/abs/2204.13902) - - +
+  +
+
+ Sampling and training algorithms. Figure from DDPM paper (https://arxiv.org/abs/2006.11239).
+
+ **Diffusion Pipeline**: End-to-end pipeline that includes multiple diffusion models, possible text encoders, ... *Examples*: GLIDE, Latent-Diffusion, Imagen, DALL-E 2 -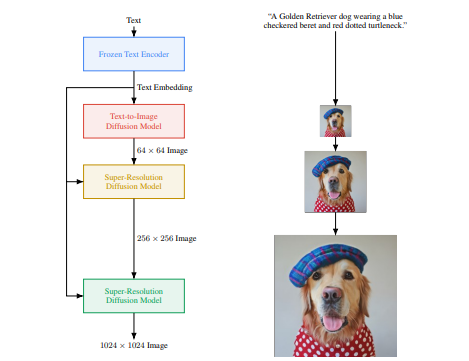 - +
+  +
+
+ Figure from ImageGen (https://imagen.research.google/).
+
+ ## Philosophy - Readability and clarity is prefered over highly optimized code. A strong importance is put on providing readable, intuitive and elementary code design. *E.g.*, the provided [schedulers](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers) are separated from the provided [models](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models) and provide well-commented code that can be read alongside the original paper. @@ -173,6 +185,10 @@ image_pil = PIL.Image.fromarray(image_processed[0]) image_pil.save("test.png") ``` +#### **Examples for other modalities:** + +[Diffuser](https://diffusion-planning.github.io/) for planning in reinforcement learning: [](https://colab.research.google.com/drive/1TmBmlYeKUZSkUZoJqfBmaicVTKx6nN1R?usp=sharing) + ### 2. `diffusers` as a collection of popular Diffusion systems (GLIDE, Dalle, ...) For more examples see [pipelines](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines). diff --git a/src/diffusers/modeling_utils.py b/src/diffusers/modeling_utils.py index 2dd1b9980a..40660d3f4a 100644 --- a/src/diffusers/modeling_utils.py +++ b/src/diffusers/modeling_utils.py @@ -490,7 +490,7 @@ class ModelMixin(torch.nn.Module): raise RuntimeError(f"Error(s) in loading state_dict for {model.__class__.__name__}:\n\t{error_msg}") if len(unexpected_keys) > 0: - logger.warninging( + logger.warning( f"Some weights of the model checkpoint at {pretrained_model_name_or_path} were not used when" f" initializing {model.__class__.__name__}: {unexpected_keys}\n- This IS expected if you are" f" initializing {model.__class__.__name__} from the checkpoint of a model trained on another task or" @@ -502,7 +502,7 @@ class ModelMixin(torch.nn.Module): else: logger.info(f"All model checkpoint weights were used when initializing {model.__class__.__name__}.\n") if len(missing_keys) > 0: - logger.warninging( + logger.warning( f"Some weights of {model.__class__.__name__} were not initialized from the model checkpoint at" f" {pretrained_model_name_or_path} and are newly initialized: {missing_keys}\nYou should probably" " TRAIN this model on a down-stream task to be able to use it for predictions and inference." @@ -521,7 +521,7 @@ class ModelMixin(torch.nn.Module): for key, shape1, shape2 in mismatched_keys ] ) - logger.warninging( + logger.warning( f"Some weights of {model.__class__.__name__} were not initialized from the model checkpoint at" f" {pretrained_model_name_or_path} and are newly initialized because the shapes did not" f" match:\n{mismatched_warning}\nYou should probably TRAIN this model on a down-stream task to be able" diff --git a/tests/test_modeling_utils.py b/tests/test_modeling_utils.py index 3a2a5c36b2..44f611b51c 100755 --- a/tests/test_modeling_utils.py +++ b/tests/test_modeling_utils.py @@ -18,6 +18,7 @@ import inspect import tempfile import unittest import numpy as np +import pytest import torch @@ -32,6 +33,7 @@ from diffusers import ( LatentDiffusion, PNDMScheduler, UNetModel, + GLIDESuperResUNetModel ) from diffusers.configuration_utils import ConfigMixin from diffusers.pipeline_utils import DiffusionPipeline @@ -94,7 +96,7 @@ class ModelTesterMixin: with tempfile.TemporaryDirectory() as tmpdirname: model.save_pretrained(tmpdirname) - new_model = UNetModel.from_pretrained(tmpdirname) + new_model = self.model_class.from_pretrained(tmpdirname) new_model.to(torch_device) with torch.no_grad(): @@ -178,7 +180,7 @@ class ModelTesterMixin: model.to(torch_device) model.train() output = model(**inputs_dict) - noise = torch.randn(inputs_dict["x"].shape).to(torch_device) + noise = torch.randn((inputs_dict["x"].shape[0], ) + self.get_output_shape).to(torch_device) loss = torch.nn.functional.mse_loss(output, noise) loss.backward() @@ -196,6 +198,14 @@ class UnetModelTests(ModelTesterMixin, unittest.TestCase): time_step = torch.tensor([10]).to(torch_device) return {"x": noise, "timesteps": time_step} + + @property + def get_input_shape(self): + return (3, 32, 32) + + @property + def get_output_shape(self): + return (3, 32, 32) def prepare_init_args_and_inputs_for_common(self): init_dict = { @@ -227,7 +237,6 @@ class UnetModelTests(ModelTesterMixin, unittest.TestCase): torch.cuda.manual_seed_all(0) noise = torch.randn(1, model.config.in_channels, model.config.resolution, model.config.resolution) - print(noise.shape) time_step = torch.tensor([10]) with torch.no_grad(): @@ -240,6 +249,98 @@ class UnetModelTests(ModelTesterMixin, unittest.TestCase): print(output_slice) self.assertTrue(torch.allclose(output_slice, expected_output_slice, atol=1e-3)) +class GLIDESuperResUNetTests(ModelTesterMixin, unittest.TestCase): + model_class = GLIDESuperResUNetModel + + @property + def dummy_input(self): + batch_size = 4 + num_channels = 6 + sizes = (32, 32) + low_res_size = (4, 4) + + torch_device = "cpu" + + noise = torch.randn((batch_size, num_channels // 2) + sizes).to(torch_device) + low_res = torch.randn((batch_size, 3) + low_res_size).to(torch_device) + time_step = torch.tensor([10] * noise.shape[0], device=torch_device) + + return {"x": noise, "timesteps": time_step, "low_res": low_res} + + @property + def get_input_shape(self): + return (3, 32, 32) + + @property + def get_output_shape(self): + return (6, 32, 32) + + def prepare_init_args_and_inputs_for_common(self): + init_dict = { + "attention_resolutions": (2,), + "channel_mult": (1,2), + "in_channels": 6, + "out_channels": 6, + "model_channels": 32, + "num_head_channels": 8, + "num_heads_upsample": 1, + "num_res_blocks": 2, + "resblock_updown": True, + "resolution": 32, + "use_scale_shift_norm": True + } + inputs_dict = self.dummy_input + return init_dict, inputs_dict + + def test_output(self): + init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common() + model = self.model_class(**init_dict) + model.to(torch_device) + model.eval() + + with torch.no_grad(): + output = model(**inputs_dict) + + output, _ = torch.split(output, 3, dim=1) + + self.assertIsNotNone(output) + expected_shape = inputs_dict["x"].shape + self.assertEqual(output.shape, expected_shape, "Input and output shapes do not match") + + def test_from_pretrained_hub(self): + model, loading_info = GLIDESuperResUNetModel.from_pretrained("fusing/glide-super-res-dummy", output_loading_info=True) + self.assertIsNotNone(model) + self.assertEqual(len(loading_info["missing_keys"]), 0) + + model.to(torch_device) + image = model(**self.dummy_input) + + assert image is not None, "Make sure output is not None" + + # TODO (patil-suraj): Check why GLIDESuperResUNetModel always outputs zero + @unittest.skip("GLIDESuperResUNetModel always outputs zero") + def test_output_pretrained(self): + model = GLIDESuperResUNetModel.from_pretrained("fusing/glide-super-res-dummy") + model.eval() + + torch.manual_seed(0) + if torch.cuda.is_available(): + torch.cuda.manual_seed_all(0) + + noise = torch.randn(1, 3, 32, 32) + low_res = torch.randn(1, 3, 4, 4) + time_step = torch.tensor([42] * noise.shape[0]) + + with torch.no_grad(): + output = model(noise, time_step, low_res) + + output, _ = torch.split(output, 3, dim=1) + output_slice = output[0, -1, -3:, -3:].flatten() + # fmt: off + expected_output_slice = torch.tensor([ 0.2891, -0.1899, 0.2595, -0.6214, 0.0968, -0.2622, 0.4688, 0.1311, 0.0053]) + # fmt: on + print(output_slice) + self.assertTrue(torch.allclose(output_slice, expected_output_slice, atol=1e-3)) class PipelineTesterMixin(unittest.TestCase):